You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2021/06/23 14:59:22 UTC
[GitHub] [hudi] karan867 commented on issue #3077: [SUPPORT] Large latencies in hudi writes using upsert mode.
karan867 commented on issue #3077:
URL: https://github.com/apache/hudi/issues/3077#issuecomment-866913205
@n3nash Thank you for the suggestions. I tried the parameters you suggested.
* Setting hoodie.parquet.small.file.limit to zero did not make much difference and the subsequent commits turned slower.
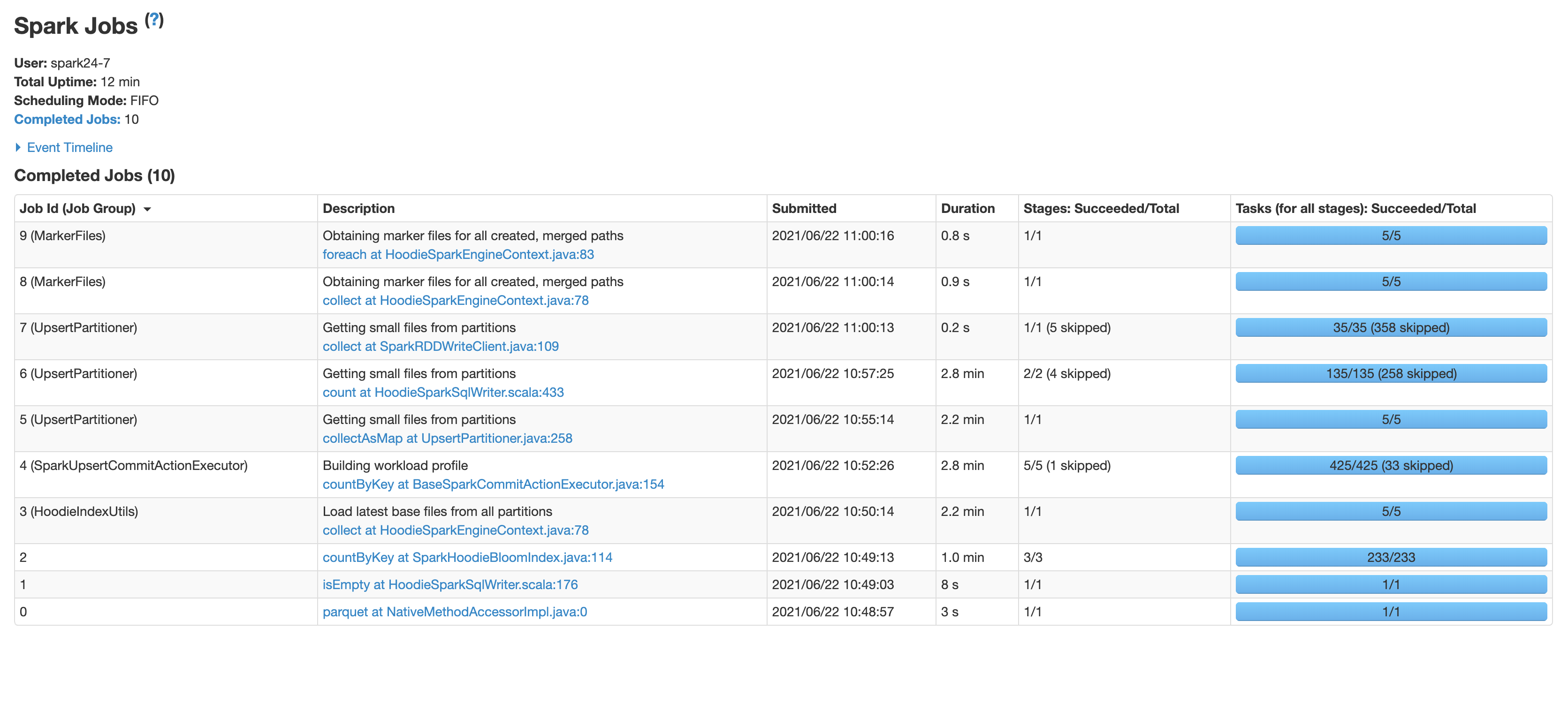
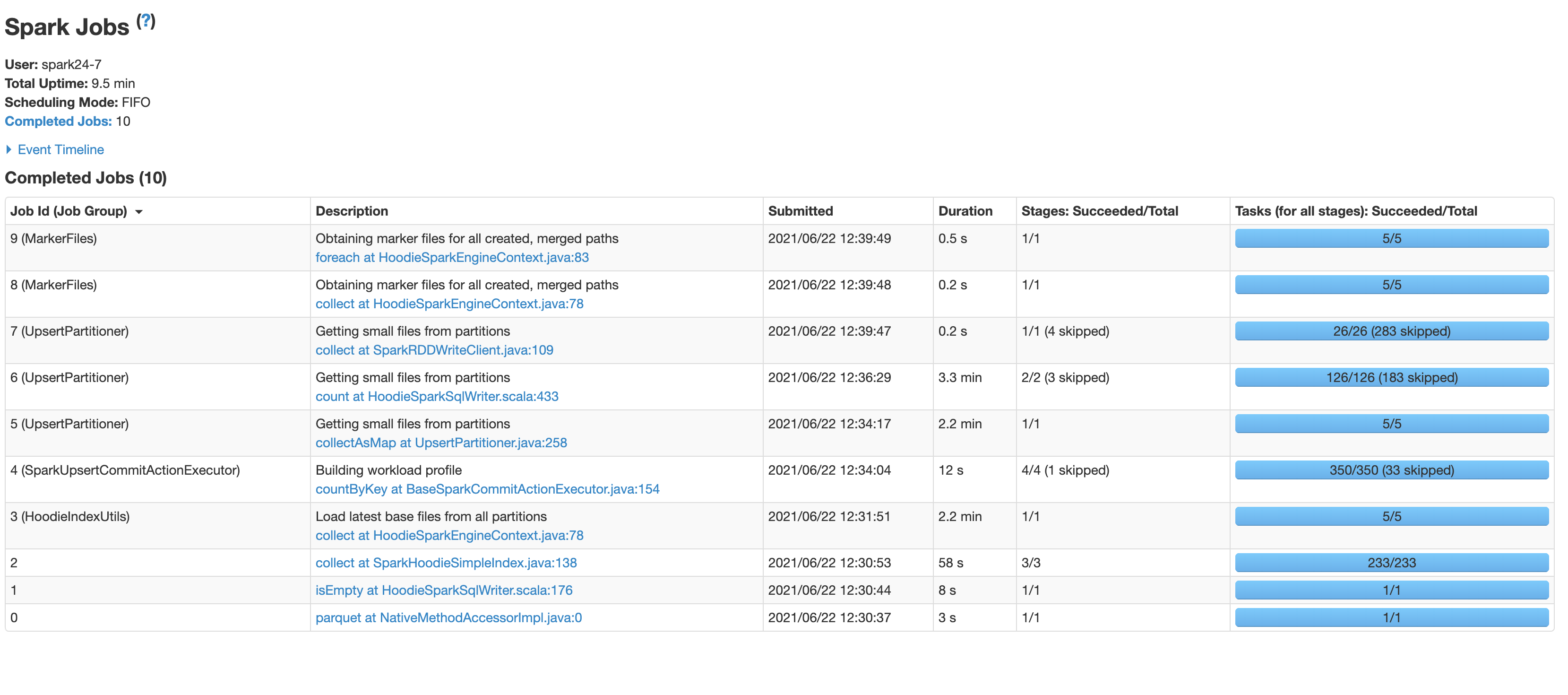
* Setting the index to SIMPLE decreased the time from 12 mins to 9.5 mins. I did not try it out before because in our use case we have hourly batch jobs that will mostly impact the latest partitions and this blog [https://hudi.apache.org/blog/hudi-indexing-mechanisms/](https://hudi.apache.org/blog/hudi-indexing-mechanisms/ ) says that simple index works best if the updates are random. Also is the time complexity of the simple index order of the rows present in the partition. Just want to make sure it does not increase with commits or partitions.
I had a few more questions regarding hudi write
* Can you explain what is happening in the steps taking the most time?
* Load latest base files from partitions
* Building workload profile
* Getting small files from partitions step1
* Getting small files from partitions step2
* Are there some benchmarks of write latencies I can compare to? For example, the time taken to write 100k row of size 1 KB. Some rough estimates from your experience would also do.
* Can we somehow insert the data with duplicates and support updates and deletion? The primary feature for which we are using Hudi is to make our data lake GDPR compliant.
* Is the MOR metadata table created by setting hoodie.metadata.enable' as true used when writing or just when reading the data?
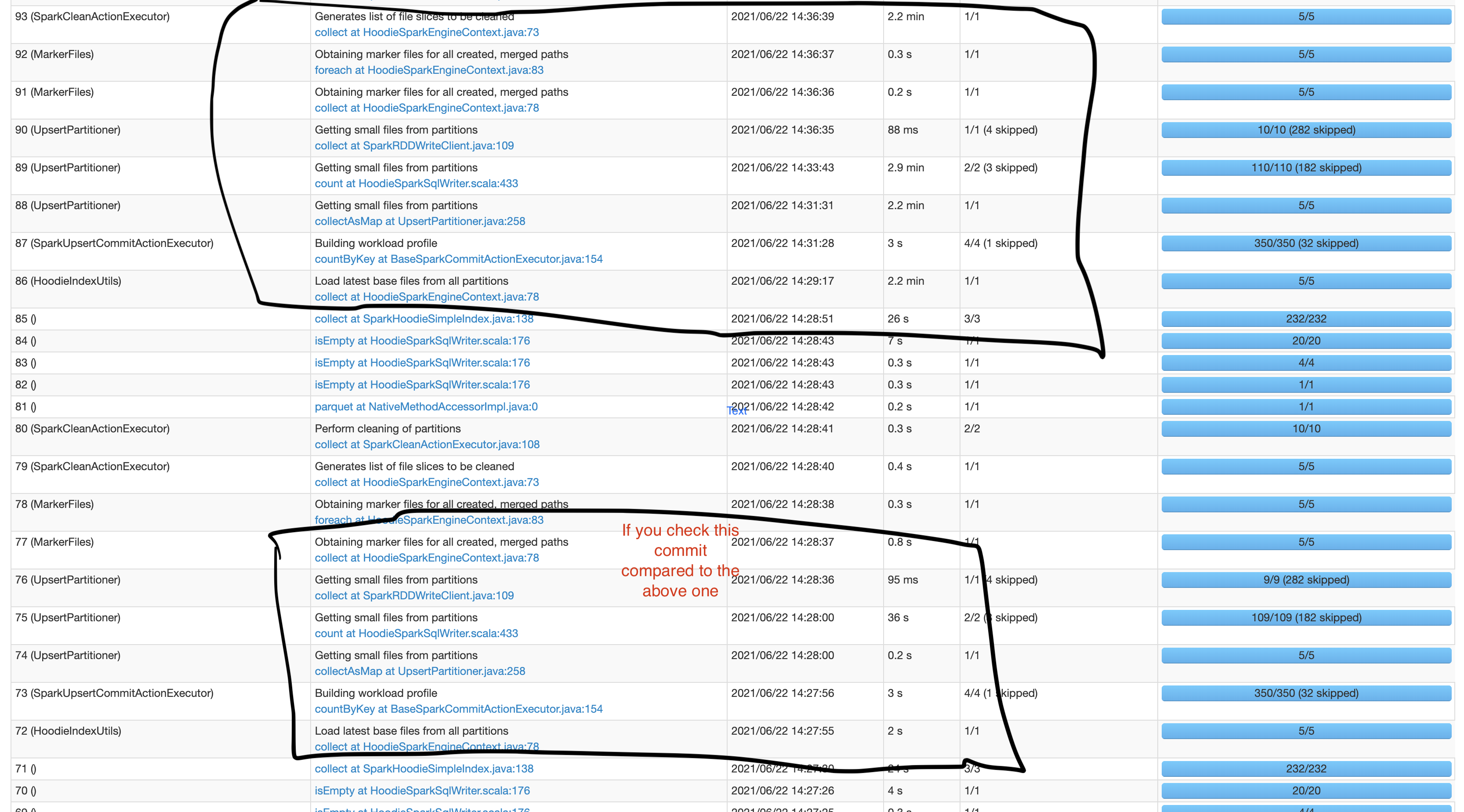
* Randomly in some commits the write takes very less time. Do you have some explanation for that?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org