You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@mxnet.apache.org by GitBox <gi...@apache.org> on 2018/05/24 18:00:50 UTC
[GitHub] piiswrong closed pull request #10900: [MXNET-414] Tutorial on
visualizing CNN decisions using Grad-CAM
piiswrong closed pull request #10900: [MXNET-414] Tutorial on visualizing CNN decisions using Grad-CAM
URL: https://github.com/apache/incubator-mxnet/pull/10900
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/docs/tutorials/index.md b/docs/tutorials/index.md
index f69e1b41891..ae352334431 100644
--- a/docs/tutorials/index.md
+++ b/docs/tutorials/index.md
@@ -41,6 +41,7 @@ Select API:
* [Checkpointing and Model Serialization (a.k.a. saving and loading)](http://gluon.mxnet.io/chapter03_deep-neural-networks/serialization.html) <img src="https://upload.wikimedia.org/wikipedia/commons/6/6a/External_link_font_awesome.svg" alt="External link" height="15px" style="margin: 0px 0px 3px 3px;"/>
* [Inference using an ONNX model](/tutorials/onnx/inference_on_onnx_model.html)
* [Fine-tuning an ONNX model on Gluon](/tutorials/onnx/fine_tuning_gluon.html)
+ * [Visualizing Decisions of Convolutional Neural Networks](/tutorials/vision/cnn_visualization.html)
* API Guides
* Core APIs
* NDArray
diff --git a/docs/tutorials/vision/cnn_visualization.md b/docs/tutorials/vision/cnn_visualization.md
new file mode 100644
index 00000000000..ea027dff09a
--- /dev/null
+++ b/docs/tutorials/vision/cnn_visualization.md
@@ -0,0 +1,245 @@
+# Visualizing Decisions of Convolutional Neural Networks
+
+Convolutional Neural Networks have made a lot of progress in Computer Vision. Their accuracy is as good as humans in some tasks. However it remains hard to explain the predictions of convolutional neural networks, as they lack the interpretability offered by other models, for example decision trees.
+
+It is often helpful to be able to explain why a model made the prediction it made. For example when a model misclassifies an image, it is hard to say why without visualizing the network's decision.
+
+<img align="right" src="https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/example/cnn_visualization/volcano_barn_spider.png" alt="Explaining the misclassification of volcano as spider" width=500px/>
+
+Visualizations also help build confidence about the predictions of a model. For example, even if a model correctly predicts birds as birds, we would want to confirm that the model bases its decision on the features of bird and not on the features of some other object that might occur together with birds in the dataset (like leaves).
+
+In this tutorial, we show how to visualize the predictions made by convolutional neural networks using [Gradient-weighted Class Activation Mapping](https://arxiv.org/abs/1610.02391). Unlike many other visualization methods, Grad-CAM can be used on a wide variety of CNN model families - CNNs with fully connected layers, CNNs used for structural outputs (e.g. captioning), CNNs used in tasks with multi-model input (e.g. VQA) or reinforcement learning without architectural changes or re-training.
+
+In the rest of this notebook, we will explain how to visualize predictions made by [VGG-16](https://arxiv.org/abs/1409.1556). We begin by importing the required dependencies. `gradcam` module contains the implementation of visualization techniques used in this notebook.
+
+```python
+from __future__ import print_function
+
+import mxnet as mx
+from mxnet import gluon
+
+from matplotlib import pyplot as plt
+import numpy as np
+
+gradcam_file = "gradcam.py"
+base_url = "https://raw.githubusercontent.com/indhub/mxnet/cnnviz/example/cnn_visualization/{}?raw=true"
+mx.test_utils.download(base_url.format(gradcam_file), fname=gradcam_file)
+import gradcam
+```
+
+## Building the network to visualize
+
+Next, we build the network we want to visualize. For this example, we will use the [VGG-16](https://arxiv.org/abs/1409.1556) network. This code was taken from the Gluon [model zoo](https://github.com/apache/incubator-mxnet/blob/master/python/mxnet/gluon/model_zoo/vision/alexnet.py) and refactored to make it easy to switch between `gradcam`'s and Gluon's implementation of ReLU and Conv2D. Same code can be used for both training and visualization with a minor (one line) change.
+
+Notice that we import ReLU and Conv2D from `gradcam` module instead of mxnet.gluon.nn.
+- We use a modified ReLU because we use guided backpropagation for visualization and guided backprop requires ReLU layer to block the backward flow of negative gradients corresponding to the neurons which decrease the activation of the higher layer unit we aim to visualize. Check [this](https://arxiv.org/abs/1412.6806) paper to learn more about guided backprop.
+- We use a modified Conv2D (a wrapper on top of Gluon's Conv2D) because we want to capture the output of a given convolutional layer and its gradients. This is needed to implement Grad-CAM. Check [this](https://arxiv.org/abs/1610.02391) paper to learn more about Grad-CAM.
+
+When you train the network, you could just import `Activation` and `Conv2D` from `gluon.nn` instead. No other part of the code needs any change to switch between training and visualization.
+
+```python
+import os
+from mxnet.gluon.model_zoo import model_store
+
+from mxnet.initializer import Xavier
+from mxnet.gluon.nn import MaxPool2D, Flatten, Dense, Dropout, BatchNorm
+from gradcam import Activation, Conv2D
+
+class VGG(mx.gluon.HybridBlock):
+ def __init__(self, layers, filters, classes=1000, **kwargs):
+ super(VGG, self).__init__(**kwargs)
+ assert len(layers) == len(filters)
+ with self.name_scope():
+ self.features = self._make_features(layers, filters)
+ self.features.add(Dense(4096, activation='relu',
+ weight_initializer='normal',
+ bias_initializer='zeros'))
+ self.features.add(Dropout(rate=0.5))
+ self.features.add(Dense(4096, activation='relu',
+ weight_initializer='normal',
+ bias_initializer='zeros'))
+ self.features.add(Dropout(rate=0.5))
+ self.output = Dense(classes,
+ weight_initializer='normal',
+ bias_initializer='zeros')
+
+ def _make_features(self, layers, filters):
+ featurizer = mx.gluon.nn.HybridSequential(prefix='')
+ for i, num in enumerate(layers):
+ for _ in range(num):
+ featurizer.add(Conv2D(filters[i], kernel_size=3, padding=1,
+ weight_initializer=Xavier(rnd_type='gaussian',
+ factor_type='out',
+ magnitude=2),
+ bias_initializer='zeros'))
+ featurizer.add(Activation('relu'))
+ featurizer.add(MaxPool2D(strides=2))
+ return featurizer
+
+ def hybrid_forward(self, F, x):
+ x = self.features(x)
+ x = self.output(x)
+ return x
+```
+
+## Loading pretrained weights
+
+We'll use pre-trained weights (trained on ImageNet) from model zoo instead of training the model from scratch.
+
+```python
+# Number of convolution layers and number of filters for each VGG configuration.
+# Check the VGG [paper](https://arxiv.org/abs/1409.1556) for more details on the different architectures.
+vgg_spec = {11: ([1, 1, 2, 2, 2], [64, 128, 256, 512, 512]),
+ 13: ([2, 2, 2, 2, 2], [64, 128, 256, 512, 512]),
+ 16: ([2, 2, 3, 3, 3], [64, 128, 256, 512, 512]),
+ 19: ([2, 2, 4, 4, 4], [64, 128, 256, 512, 512])}
+
+def get_vgg(num_layers, ctx=mx.cpu(), root=os.path.join('~', '.mxnet', 'models'), **kwargs):
+
+ # Get the number of convolution layers and filters
+ layers, filters = vgg_spec[num_layers]
+
+ # Build the VGG network
+ net = VGG(layers, filters, **kwargs)
+
+ # Load pretrained weights from model zoo
+ from mxnet.gluon.model_zoo.model_store import get_model_file
+ net.load_params(get_model_file('vgg%d' % num_layers, root=root), ctx=ctx)
+
+ return net
+
+def vgg16(**kwargs):
+ return get_vgg(16, **kwargs)
+```
+
+## Preprocessing and other helpers
+
+We'll resize the input image to 224x224 before feeding it to the network. We normalize the images using the same parameters ImageNet dataset was normalised using to create the pretrained model. These parameters are published [here](https://mxnet.incubator.apache.org/api/python/gluon/model_zoo.html). We use `transpose` to convert the image to channel-last format.
+
+Note that we do not hybridize the network. This is because we want `gradcam.Activation` and `gradcam.Conv2D` to behave differently at different times during the execution. For example, `gradcam.Activation` will do the regular backpropagation while computing the gradient of the topmost convolutional layer but will do guided backpropagation when computing the gradient of the image.
+
+```python
+image_sz = (224, 224)
+
+def preprocess(data):
+ data = mx.image.imresize(data, image_sz[0], image_sz[1])
+ data = data.astype(np.float32)
+ data = data/255
+ data = mx.image.color_normalize(data,
+ mean=mx.nd.array([0.485, 0.456, 0.406]),
+ std=mx.nd.array([0.229, 0.224, 0.225]))
+ data = mx.nd.transpose(data, (2,0,1))
+ return data
+
+network = vgg16(ctx=mx.cpu())
+```
+
+We define a helper to display multiple images in a row in Jupyter notebook.
+
+```python
+def show_images(pred_str, images):
+ titles = [pred_str, 'Grad-CAM', 'Guided Grad-CAM', 'Saliency Map']
+ num_images = len(images)
+ fig=plt.figure(figsize=(15,15))
+ rows, cols = 1, num_images
+ for i in range(num_images):
+ fig.add_subplot(rows, cols, i+1)
+ plt.xlabel(titles[i])
+ plt.imshow(images[i], cmap='gray' if i==num_images-1 else None)
+ plt.show()
+```
+
+Given an image, the network predicts a probability distribution over all categories. The most probable category can be found by applying the `argmax` operation. This gives an integer corresponding to the category. We still need to convert this to a human readable category name to know what category the network predicted. [Synset](http://data.mxnet.io/models/imagenet/synset.txt) file contains the mapping between Imagenet category index and category name. We'll download the synset file, load it in a list to convert category index to human readable category names.
+
+```python
+synset_url = "http://data.mxnet.io/models/imagenet/synset.txt"
+synset_file_name = "synset.txt"
+mx.test_utils.download(synset_url, fname=synset_file_name)
+synset = []
+with open('synset.txt', 'r') as f:
+ synset = [l.rstrip().split(' ', 1)[1].split(',')[0] for l in f]
+
+def get_class_name(cls_id):
+ return "%s (%d)" % (synset[cls_id], cls_id)
+
+def run_inference(net, data):
+ out = net(data)
+ return out.argmax(axis=1).asnumpy()[0].astype(int)
+```
+
+## Visualizing CNN decisions
+
+Next, we'll write a method to get an image, preprocess it, predict category and visualize the prediction. We'll use `gradcam.visualize()` to create the visualizations. `gradcam.visualize` returns a tuple with the following visualizations:
+
+1. **Grad-CAM:** This is a heatmap superimposed on the input image showing which part(s) of the image contributed most to the CNN's decision.
+2. **Guided Grad-CAM:** Guided Grad-CAM shows which exact pixels contributed the most to the CNN's decision.
+3. **Saliency map:** Saliency map is a monochrome image showing which pixels contributed the most to the CNN's decision. Sometimes, it is easier to see the areas in the image that most influence the output in a monochrome image than in a color image.
+
+```python
+def visualize(net, img_path, conv_layer_name):
+ orig_img = mx.img.imread(img_path)
+ preprocessed_img = preprocess(orig_img)
+ preprocessed_img = preprocessed_img.expand_dims(axis=0)
+
+ pred_str = get_class_name(run_inference(net, preprocessed_img))
+
+ orig_img = mx.image.imresize(orig_img, image_sz[0], image_sz[1]).asnumpy()
+ vizs = gradcam.visualize(net, preprocessed_img, orig_img, conv_layer_name)
+ return (pred_str, (orig_img, *vizs))
+```
+
+Next, we need to get the name of the last convolutional layer that extracts features from the image. We use the gradient information flowing into the last convolutional layer of the CNN to understand the importance of each neuron for a decision of interest. We are interested in the last convolutional layer because convolutional features naturally retain spatial information which is lost in fully connected layers. So, we expect the last convolutional layer to have the best compromise between high level semantics and detailed spacial information. The neurons in this layer look for semantic class specific information in the image (like object parts).
+
+In our network, feature extractors are added to a HybridSequential block named features. You can list the layers in that block by just printing `network.features`. You can see that the topmost convolutional layer is at index 28. `network.features[28]._name` will give the name of the layer.
+
+```python
+last_conv_layer_name = network.features[28]._name
+print(last_conv_layer_name)
+```
+vgg0_conv2d12<!--notebook-skip-line-->
+
+Let's download some images we can use for visualization.
+
+```python
+images = ["hummingbird.jpg", "jellyfish.jpg", "snow_leopard.jpg", "volcano.jpg"]
+base_url = "https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/example/cnn_visualization/{}?raw=true"
+for image in images:
+ mx.test_utils.download(base_url.format(image), fname=image)
+```
+
+We now have everything we need to start visualizing. Let's visualize the CNN decision for the images we downloaded.
+
+```python
+show_images(*visualize(network, "hummingbird.jpg", last_conv_layer_name))
+```
+
+<img src="https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/example/cnn_visualization/hummingbird.png" alt="Visualizing CNN decision"/><!--notebook-skip-line-->
+
+```python
+show_images(*visualize(network, "jellyfish.jpg", last_conv_layer_name))
+```
+
+<img src="https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/example/cnn_visualization/jellyfish.png" alt="Visualizing CNN decision"/><!--notebook-skip-line-->
+
+```python
+show_images(*visualize(network, "snow_leopard.jpg", last_conv_layer_name))
+```
+
+<img src="https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/example/cnn_visualization/snow_leopard.png" alt="Visualizing CNN decision"/><!--notebook-skip-line-->
+
+Shown above are some images the network was able to predict correctly. We can see that the network is basing its decision on the appropriate features. Now, let's look at an example that the network gets the prediction wrong and visualize why it gets the prediction wrong.
+
+```python
+show_images(*visualize(network, "volcano.jpg", last_conv_layer_name))
+```
+
+<img src="https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/example/cnn_visualization/volcano.png" alt="Visualizing CNN decision"/><!--notebook-skip-line-->
+
+While it is not immediately evident why the network thinks this volcano is a spider, after looking at the Grad-CAM visualization, it is hard to look at the volcano and not see the spider!
+
+Being able to visualize why a CNN predicts specific classes is a powerful tool to diagnose prediction failures. Even when the network is making correct predictions, visualizing activations is an important step to verify that the network is making its decisions based on the right features and not some correlation which happens to exist in the training data.
+
+The visualization method demonstrated in this tutorial applies to a wide variety of network architectures and a wide variety of tasks beyond classification - like VQA and image captioning. Any type of differentiable output can be used to create the visualizations shown above. Visualization techniques like these solve (at least partially) the long standing problem of interpretability of neural networks.
+
+<!-- INSERT SOURCE DOWNLOAD BUTTONS -->
+
diff --git a/example/cnn_visualization/README.md b/example/cnn_visualization/README.md
new file mode 100644
index 00000000000..10b91492600
--- /dev/null
+++ b/example/cnn_visualization/README.md
@@ -0,0 +1,17 @@
+# Visualzing CNN decisions
+
+This folder contains an MXNet Gluon implementation of [Grad-CAM](https://arxiv.org/abs/1610.02391) that helps visualize CNN decisions.
+
+A tutorial on how to use this from Jupyter notebook is available [here](https://mxnet.incubator.apache.org/tutorials/vision/cnn_visualization.html).
+
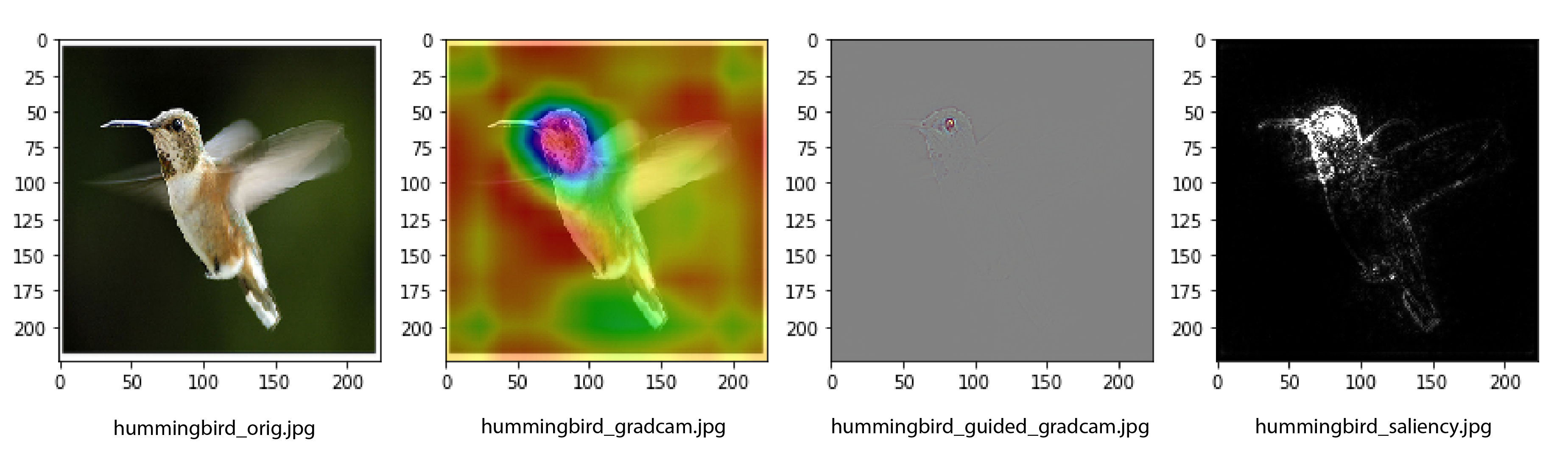
+You can also do the visualization from terminal:
+```
+$ python gradcam_demo.py hummingbird.jpg
+Predicted category : hummingbird (94)
+Original Image : hummingbird_orig.jpg
+Grad-CAM : hummingbird_gradcam.jpg
+Guided Grad-CAM : hummingbird_guided_gradcam.jpg
+Saliency Map : hummingbird_saliency.jpg
+```
+
+
diff --git a/example/cnn_visualization/gradcam.py b/example/cnn_visualization/gradcam.py
new file mode 100644
index 00000000000..a8708f78758
--- /dev/null
+++ b/example/cnn_visualization/gradcam.py
@@ -0,0 +1,263 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+from __future__ import print_function
+
+import mxnet as mx
+import mxnet.ndarray as nd
+
+from mxnet import gluon
+from mxnet import autograd
+from mxnet.gluon import nn
+
+import numpy as np
+import cv2
+
+class ReluOp(mx.operator.CustomOp):
+ """Modified ReLU as described in section 3.4 in https://arxiv.org/abs/1412.6806.
+ This is used for guided backpropagation to get gradients of the image w.r.t activations.
+ This Operator will do a regular backpropagation if `guided_backprop` is set to False
+ and a guided packpropagation if `guided_backprop` is set to True. Check gradcam_demo.py
+ for an example usage."""
+
+ guided_backprop = False
+
+ def forward(self, is_train, req, in_data, out_data, aux):
+ x = in_data[0]
+ y = nd.maximum(x, nd.zeros_like(x))
+ self.assign(out_data[0], req[0], y)
+
+ def backward(self, req, out_grad, in_data, out_data, in_grad, aux):
+ if ReluOp.guided_backprop:
+ # Get output and gradients of output
+ y = out_data[0]
+ dy = out_grad[0]
+ # Zero out the negatives in the gradients of the output
+ dy_positives = nd.maximum(dy, nd.zeros_like(dy))
+ # What output values were greater than 0?
+ y_ones = y.__gt__(0)
+ # Mask out the values for which at least one of dy or y is negative
+ dx = dy_positives * y_ones
+ self.assign(in_grad[0], req[0], dx)
+ else:
+ # Regular backward for ReLU
+ x = in_data[0]
+ x_gt_zero = x.__gt__(0)
+ dx = out_grad[0] * x_gt_zero
+ self.assign(in_grad[0], req[0], dx)
+
+def set_guided_backprop(mode=True):
+ ReluOp.guided_backprop = mode
+
+@mx.operator.register("relu")
+class ReluProp(mx.operator.CustomOpProp):
+ def __init__(self):
+ super(ReluProp, self).__init__(True)
+
+ def infer_shape(self, in_shapes):
+ data_shape = in_shapes[0]
+ output_shape = data_shape
+ return (data_shape,), (output_shape,), ()
+
+ def create_operator(self, ctx, in_shapes, in_dtypes):
+ return ReluOp()
+
+class Activation(mx.gluon.HybridBlock):
+ @staticmethod
+ def set_guided_backprop(mode=False):
+ ReluOp.guided_backprop = mode
+
+ def __init__(self, act_type, **kwargs):
+ assert act_type == 'relu'
+ super(Activation, self).__init__(**kwargs)
+
+ def hybrid_forward(self, F, x):
+ return F.Custom(x, op_type='relu')
+
+class Conv2D(mx.gluon.HybridBlock):
+ """Wrapper on top of gluon.nn.Conv2D to capture the output and gradients of output of a Conv2D
+ layer in a network. Use `set_capture_layer_name` to select the layer
+ whose outputs and gradients of outputs need to be captured. After the backward pass,
+ `conv_output` will contain the output and `conv_output.grad` will contain the
+ output's gradients. Check gradcam_demo.py for example usage."""
+
+ conv_output = None
+ capture_layer_name = None
+
+ def __init__(self, channels, kernel_size, strides=(1, 1), padding=(0, 0),
+ dilation=(1, 1), groups=1, layout='NCHW',
+ activation=None, use_bias=True, weight_initializer=None,
+ bias_initializer='zeros', in_channels=0, **kwargs):
+ super(Conv2D, self).__init__(**kwargs)
+ self.conv = nn.Conv2D(channels, kernel_size, strides=strides, padding=padding,
+ dilation=dilation, groups=groups, layout=layout,
+ activation=activation, use_bias=use_bias, weight_initializer=weight_initializer,
+ bias_initializer=bias_initializer, in_channels=in_channels)
+
+ def hybrid_forward(self, F, x):
+ out = self.conv(x)
+ name = self._prefix[:-1]
+ if name == Conv2D.capture_layer_name:
+ out.attach_grad()
+ Conv2D.conv_output = out
+ return out
+
+def set_capture_layer_name(name):
+ Conv2D.capture_layer_name = name
+
+def _get_grad(net, image, class_id=None, conv_layer_name=None, image_grad=False):
+ """This is an internal helper function that can be used for either of these
+ but not both at the same time:
+ 1. Record the output and gradient of output of an intermediate convolutional layer.
+ 2. Record the gradients of the image.
+
+ Parameters
+ ----------
+ image : NDArray
+ Image to visuaize. This is an NDArray with the preprocessed image.
+ class_id : int
+ Category ID this image belongs to. If not provided,
+ network's prediction will be used.
+ conv_layer_name: str
+ Name of the convolutional layer whose output and output's gradients need to be acptured.
+ image_grad: bool
+ Whether to capture gradients of the image."""
+
+ if image_grad:
+ image.attach_grad()
+ Conv2D.capture_layer_name = None
+ Activation.set_guided_backprop(True)
+ else:
+ # Tell convviz.Conv2D which layer's output and gradient needs to be recorded
+ Conv2D.capture_layer_name = conv_layer_name
+ Activation.set_guided_backprop(False)
+
+ # Run the network
+ with autograd.record(train_mode=False):
+ out = net(image)
+
+ # If user didn't provide a class id, we'll use the class that the network predicted
+ if class_id == None:
+ model_output = out.asnumpy()
+ class_id = np.argmax(model_output)
+
+ # Create a one-hot target with class_id and backprop with the created target
+ one_hot_target = mx.nd.one_hot(mx.nd.array([class_id]), 1000)
+ out.backward(one_hot_target, train_mode=False)
+
+ if image_grad:
+ return image.grad[0].asnumpy()
+ else:
+ # Return the recorded convolution output and gradient
+ conv_out = Conv2D.conv_output
+ return conv_out[0].asnumpy(), conv_out.grad[0].asnumpy()
+
+def get_conv_out_grad(net, image, class_id=None, conv_layer_name=None):
+ """Get the output and gradients of output of a convolutional layer.
+
+ Parameters:
+ ----------
+ net: Block
+ Network to use for visualization.
+ image: NDArray
+ Preprocessed image to use for visualization.
+ class_id: int
+ Category ID this image belongs to. If not provided,
+ network's prediction will be used.
+ conv_layer_name: str
+ Name of the convolutional layer whose output and output's gradients need to be acptured."""
+ return _get_grad(net, image, class_id, conv_layer_name, image_grad=False)
+
+def get_image_grad(net, image, class_id=None):
+ """Get the gradients of the image.
+
+ Parameters:
+ ----------
+ net: Block
+ Network to use for visualization.
+ image: NDArray
+ Preprocessed image to use for visualization.
+ class_id: int
+ Category ID this image belongs to. If not provided,
+ network's prediction will be used."""
+ return _get_grad(net, image, class_id, image_grad=True)
+
+def grad_to_image(gradient):
+ """Convert gradients of image obtained using `get_image_grad`
+ into image. This shows parts of the image that is most strongly activating
+ the output neurons."""
+ gradient = gradient - gradient.min()
+ gradient /= gradient.max()
+ gradient = np.uint8(gradient * 255).transpose(1, 2, 0)
+ gradient = gradient[..., ::-1]
+ return gradient
+
+def get_cam(imggrad, conv_out):
+ """Compute CAM. Refer section 3 of https://arxiv.org/abs/1610.02391 for details"""
+ weights = np.mean(imggrad, axis=(1, 2))
+ cam = np.ones(conv_out.shape[1:], dtype=np.float32)
+ for i, w in enumerate(weights):
+ cam += w * conv_out[i, :, :]
+ cam = cv2.resize(cam, (imggrad.shape[1], imggrad.shape[2]))
+ cam = np.maximum(cam, 0)
+ cam = (cam - np.min(cam)) / (np.max(cam) - np.min(cam))
+ cam = np.uint8(cam * 255)
+ return cam
+
+def get_guided_grad_cam(cam, imggrad):
+ """Compute Guided Grad-CAM. Refer section 3 of https://arxiv.org/abs/1610.02391 for details"""
+ return np.multiply(cam, imggrad)
+
+def get_img_heatmap(orig_img, activation_map):
+ """Draw a heatmap on top of the original image using intensities from activation_map"""
+ heatmap = cv2.applyColorMap(activation_map, cv2.COLORMAP_COOL)
+ heatmap = cv2.cvtColor(heatmap, cv2.COLOR_BGR2RGB)
+ img_heatmap = np.float32(heatmap) + np.float32(orig_img)
+ img_heatmap = img_heatmap / np.max(img_heatmap)
+ img_heatmap *= 255
+ return img_heatmap.astype(int)
+
+def to_grayscale(cv2im):
+ """Convert gradients to grayscale. This gives a saliency map."""
+ # How strongly does each position activate the output
+ grayscale_im = np.sum(np.abs(cv2im), axis=0)
+
+ # Normalize between min and 99th percentile
+ im_max = np.percentile(grayscale_im, 99)
+ im_min = np.min(grayscale_im)
+ grayscale_im = np.clip((grayscale_im - im_min) / (im_max - im_min), 0, 1)
+
+ grayscale_im = np.expand_dims(grayscale_im, axis=0)
+ return grayscale_im
+
+def visualize(net, preprocessed_img, orig_img, conv_layer_name):
+ # Returns grad-cam heatmap, guided grad-cam, guided grad-cam saliency
+ imggrad = get_image_grad(net, preprocessed_img)
+ conv_out, conv_out_grad = get_conv_out_grad(net, preprocessed_img, conv_layer_name=conv_layer_name)
+
+ cam = get_cam(imggrad, conv_out)
+
+ ggcam = get_guided_grad_cam(cam, imggrad)
+ img_ggcam = grad_to_image(ggcam)
+
+ img_heatmap = get_img_heatmap(orig_img, cam)
+
+ ggcam_gray = to_grayscale(ggcam)
+ img_ggcam_gray = np.squeeze(grad_to_image(ggcam_gray))
+
+ return img_heatmap, img_ggcam, img_ggcam_gray
+
diff --git a/example/cnn_visualization/gradcam_demo.py b/example/cnn_visualization/gradcam_demo.py
new file mode 100644
index 00000000000..d9ca5ddade8
--- /dev/null
+++ b/example/cnn_visualization/gradcam_demo.py
@@ -0,0 +1,110 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import mxnet as mx
+from mxnet import gluon
+
+import argparse
+import os
+import numpy as np
+import cv2
+
+import vgg
+import gradcam
+
+# Receive image path from command line
+parser = argparse.ArgumentParser(description='Grad-CAM demo')
+parser.add_argument('img_path', metavar='image_path', type=str, help='path to the image file')
+
+args = parser.parse_args()
+
+# We'll use VGG-16 for visualization
+network = vgg.vgg16(pretrained=True, ctx=mx.cpu())
+# We'll resize images to 224x244 as part of preprocessing
+image_sz = (224, 224)
+
+def preprocess(data):
+ """Preprocess the image before running it through the network"""
+ data = mx.image.imresize(data, image_sz[0], image_sz[1])
+ data = data.astype(np.float32)
+ data = data/255
+ # These mean values were obtained from
+ # https://mxnet.incubator.apache.org/api/python/gluon/model_zoo.html
+ data = mx.image.color_normalize(data,
+ mean=mx.nd.array([0.485, 0.456, 0.406]),
+ std=mx.nd.array([0.229, 0.224, 0.225]))
+ data = mx.nd.transpose(data, (2,0,1)) # Channel first
+ return data
+
+def read_image_mxnet(path):
+ with open(path, 'rb') as fp:
+ img_bytes = fp.read()
+ return mx.img.imdecode(img_bytes)
+
+def read_image_cv(path):
+ return cv2.resize(cv2.cvtColor(cv2.imread(path), cv2.COLOR_BGR2RGB), image_sz)
+
+# synset.txt contains the names of Imagenet categories
+# Load the file to memory and create a helper method to query category_index -> category name
+synset_url = "http://data.mxnet.io/models/imagenet/synset.txt"
+synset_file_name = "synset.txt"
+mx.test_utils.download(synset_url, fname=synset_file_name)
+
+synset = []
+with open('synset.txt', 'r') as f:
+ synset = [l.rstrip().split(' ', 1)[1].split(',')[0] for l in f]
+
+def get_class_name(cls_id):
+ return "%s (%d)" % (synset[cls_id], cls_id)
+
+def run_inference(net, data):
+ """Run the input image through the network and return the predicted category as integer"""
+ out = net(data)
+ return out.argmax(axis=1).asnumpy()[0].astype(int)
+
+def visualize(net, img_path, conv_layer_name):
+ """Create Grad-CAM visualizations using the network 'net' and the image at 'img_path'
+ conv_layer_name is the name of the top most layer of the feature extractor"""
+ image = read_image_mxnet(img_path)
+ image = preprocess(image)
+ image = image.expand_dims(axis=0)
+
+ pred_str = get_class_name(run_inference(net, image))
+
+ orig_img = read_image_cv(img_path)
+ vizs = gradcam.visualize(net, image, orig_img, conv_layer_name)
+ return (pred_str, (orig_img, *vizs))
+
+# Create Grad-CAM visualization for the user provided image
+last_conv_layer_name = 'vgg0_conv2d12'
+cat, vizs = visualize(network, args.img_path, last_conv_layer_name)
+
+print("{0:20}: {1:80}".format("Predicted category", cat))
+
+# Write the visualiations into file
+img_name = os.path.split(args.img_path)[1].split('.')[0]
+suffixes = ['orig', 'gradcam', 'guided_gradcam', 'saliency']
+image_desc = ['Original Image', 'Grad-CAM', 'Guided Grad-CAM', 'Saliency Map']
+
+for i, img in enumerate(vizs):
+ img = img.astype(np.float32)
+ if len(img.shape) == 3:
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
+ out_file_name = "%s_%s.jpg" % (img_name, suffixes[i])
+ cv2.imwrite(out_file_name, img)
+ print("{0:20}: {1:80}".format(image_desc[i], out_file_name))
+
diff --git a/example/cnn_visualization/vgg.py b/example/cnn_visualization/vgg.py
new file mode 100644
index 00000000000..b6215a334e3
--- /dev/null
+++ b/example/cnn_visualization/vgg.py
@@ -0,0 +1,84 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import mxnet as mx
+from mxnet import gluon
+
+import os
+from mxnet.gluon.model_zoo import model_store
+
+from mxnet.initializer import Xavier
+from mxnet.gluon.nn import MaxPool2D, Flatten, Dense, Dropout, BatchNorm
+from gradcam import Activation, Conv2D
+
+class VGG(mx.gluon.HybridBlock):
+ def __init__(self, layers, filters, classes=1000, batch_norm=False, **kwargs):
+ super(VGG, self).__init__(**kwargs)
+ assert len(layers) == len(filters)
+ with self.name_scope():
+ self.features = self._make_features(layers, filters, batch_norm)
+ self.features.add(Dense(4096, activation='relu',
+ weight_initializer='normal',
+ bias_initializer='zeros'))
+ self.features.add(Dropout(rate=0.5))
+ self.features.add(Dense(4096, activation='relu',
+ weight_initializer='normal',
+ bias_initializer='zeros'))
+ self.features.add(Dropout(rate=0.5))
+ self.output = Dense(classes,
+ weight_initializer='normal',
+ bias_initializer='zeros')
+
+ def _make_features(self, layers, filters, batch_norm):
+ featurizer = mx.gluon.nn.HybridSequential(prefix='')
+ for i, num in enumerate(layers):
+ for _ in range(num):
+ featurizer.add(Conv2D(filters[i], kernel_size=3, padding=1,
+ weight_initializer=Xavier(rnd_type='gaussian',
+ factor_type='out',
+ magnitude=2),
+ bias_initializer='zeros'))
+ if batch_norm:
+ featurizer.add(BatchNorm())
+ featurizer.add(Activation('relu'))
+ featurizer.add(MaxPool2D(strides=2))
+ return featurizer
+
+ def hybrid_forward(self, F, x):
+ x = self.features(x)
+ x = self.output(x)
+ return x
+
+vgg_spec = {11: ([1, 1, 2, 2, 2], [64, 128, 256, 512, 512]),
+ 13: ([2, 2, 2, 2, 2], [64, 128, 256, 512, 512]),
+ 16: ([2, 2, 3, 3, 3], [64, 128, 256, 512, 512]),
+ 19: ([2, 2, 4, 4, 4], [64, 128, 256, 512, 512])}
+
+def get_vgg(num_layers, pretrained=False, ctx=mx.cpu(),
+ root=os.path.join('~', '.mxnet', 'models'), **kwargs):
+ layers, filters = vgg_spec[num_layers]
+ net = VGG(layers, filters, **kwargs)
+ if pretrained:
+ from mxnet.gluon.model_zoo.model_store import get_model_file
+ batch_norm_suffix = '_bn' if kwargs.get('batch_norm') else ''
+ net.load_params(get_model_file('vgg%d%s'%(num_layers, batch_norm_suffix),
+ root=root), ctx=ctx)
+ return net
+
+def vgg16(**kwargs):
+ return get_vgg(16, **kwargs)
+
diff --git a/tests/tutorials/test_tutorials.py b/tests/tutorials/test_tutorials.py
index 1704642b43e..f059bb2c541 100644
--- a/tests/tutorials/test_tutorials.py
+++ b/tests/tutorials/test_tutorials.py
@@ -201,3 +201,6 @@ def test_unsupervised_learning_gan():
def test_vision_large_scale_classification():
assert _test_tutorial_nb('vision/large_scale_classification')
+
+def test_vision_cnn_visualization():
+ assert _test_tutorial_nb('vision/cnn_visualization')
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services