You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@doris.apache.org by lu...@apache.org on 2023/04/26 11:19:56 UTC
[doris-website] branch master updated: add two blogs (#212)
This is an automated email from the ASF dual-hosted git repository.
luzhijing pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/doris-website.git
The following commit(s) were added to refs/heads/master by this push:
new 49913ade148 add two blogs (#212)
49913ade148 is described below
commit 49913ade148f0e7a02332abba7df88813ef9feb1
Author: Hu Yanjun <10...@users.noreply.github.com>
AuthorDate: Wed Apr 26 19:19:51 2023 +0800
add two blogs (#212)
---
blog/HYXJ.md | 212 +++++++++++++
blog/High_concurrency.md | 329 +++++++++++++++++++++
i18n/zh-CN/docusaurus-plugin-content-blog/HYXJ.md | 277 +++++++++++++++++
.../High_concurrency.md | 319 ++++++++++++++++++++
static/images/RDM_1.png | Bin 0 -> 47146 bytes
static/images/RDM_2.png | Bin 0 -> 61710 bytes
static/images/RDM_3.png | Bin 0 -> 208090 bytes
static/images/RDM_4.png | Bin 0 -> 66949 bytes
static/images/RDM_5.png | Bin 0 -> 324862 bytes
static/images/RDM_6.png | Bin 0 -> 103955 bytes
static/images/RDM_7.png | Bin 0 -> 186008 bytes
static/images/high-concurrency_1.png | Bin 0 -> 140658 bytes
static/images/high-concurrency_2.png | Bin 0 -> 114673 bytes
static/images/high-concurrency_3.png | Bin 0 -> 89177 bytes
static/images/high-concurrency_4.png | Bin 0 -> 29886 bytes
static/images/high-concurrency_5.png | Bin 0 -> 36177 bytes
static/images/high-concurrency_6.png | Bin 0 -> 137960 bytes
17 files changed, 1137 insertions(+)
diff --git a/blog/HYXJ.md b/blog/HYXJ.md
new file mode 100644
index 00000000000..97aad2303ca
--- /dev/null
+++ b/blog/HYXJ.md
@@ -0,0 +1,212 @@
+---
+{
+ 'title': 'Step-by-step Guide to Building a High-Performing Risk Data Mart',
+ 'summary': 'The key step is to leverage the Multi Catalog feature of Apache Doris to unify the heterogenous data sources. This removed a lot of our performance bottlenecks.',
+ 'date': '2023-04-20',
+ 'author': 'Jacob Chow',
+ 'tags': ['Best Practice'],
+}
+---
+
+<!--
+Licensed to the Apache Software Foundation (ASF) under one
+or more contributor license agreements. See the NOTICE file
+distributed with this work for additional information
+regarding copyright ownership. The ASF licenses this file
+to you under the Apache License, Version 2.0 (the
+"License"); you may not use this file except in compliance
+with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing,
+software distributed under the License is distributed on an
+"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+KIND, either express or implied. See the License for the
+specific language governing permissions and limitations
+under the License.
+-->
+
+Pursuing data-driven management at a consumer financing company, we aim to serve four needs in our data platform development: monitoring and alerting, query and analysis, dashboarding, and data modeling. For these purposes, we built our data processing architecture based on Greenplum and CDH. The most essential part of it is the risk data mart.
+
+## Risk Data Mart: Apache Hive
+
+I will walk you through how the risk data mart works following the data flow:
+
+1. Our **business data** is imported into **Greenplum** for real-time analysis to generate BI reports. Part of this data also goes into Apache Hive for queries and modeling analysis.
+2. Our **risk control variables** are updated into **Elasticsearch** in real time via message queues, while Elasticsearch ingests data into Hive for analysis, too.
+3. The **risk management decision data** is passed from **MongoDB** to Hive for risk control analysis and modeling.
+
+So these are the three data sources of our risk data mart.
+
+
+
+This whole architecture is built with CDH 6.0. The workflows in it can be divided into real-time data streaming and offline risk analysis.
+
+- **Real-time data streaming**: Real-time data from Apache Kafka will be cleaned by Apache Flink, and then written into Elasticsearch. Elasticsearch will aggregate part of the data it receives and send it for reference in risk management.
+- **Offline risk analysis**: Based on the CDH solution and utilizing Sqoop, we ingest data from Greenplum in an offline manner. Then we put this data together with the third-party data from MongoDB. Then, after data cleaning, we pour all this data into Hive for daily batch processing and data queries.
+
+To give a brief overview, these are the components that support the four features of our data processing platform:
+
+
+
+As you see, Apache Hive is central to this architecture. But in practice, it takes minutes for Apache Hive to execute analysis, so our next step is to increase query speed.
+
+### What are Slowing Down Our Queries?
+
+1. **Huge data volume in external tables**
+
+Our Hive-based data mart is now carrying more than 300 terabytes of data. That's about 20,000 tables and 5 million fields. To put them all in external tables is maintenance-intensive. Plus, data ingestion can be a big headache.
+
+1. **Big flat tables**
+
+Due to the complexity of the rule engine in risk management, our company invests a lot in the derivation of variables. In some dimensions, we have thousands of variables or even more. As a result, a few of the frequently used flat tables in Hive have over 3000 fields. So you can imagine how time consuming these queries can be.
+
+1. **Unstable interface**
+
+Results produced by daily offline batch processing will be regularly sent to our Elasticsearch clusters. (The data volume in these updates is huge, and the call of interface can get expired.) This process might cause high I/O and introduce garbage collection jitter, and further leads to unstable interface services.
+
+In addition, since our risk control analysts and modeling engineers are using Hive with Spark, the expanding data architecture is also dragging down query performance.
+
+## A Unified Query Gateway
+
+We wanted a unified gateway to manage our heterogenous data sources. That's why we introduced Apache Doris.
+
+
+
+But doesn't that make things even more complicated? Actually, no.
+
+We can connect various data sources to Apache Doris and simply conduct queries on it. This is made possible by the **Multi-Catalog** feature of Apache Doris: It can interface with various data sources, including datalakes like Apache Hive, Apache Iceberg, and Apache Hudi, and databases like MySQL, Elasticsearch, and Greenplum. That happens to cover our toolkit.
+
+We create Elasticsearch Catalog and Hive Catalog in Apache Doris. These catalogs map to the external data in Elasticsearch and Hive, so we can conduct federated queries across these data sources using Apache Doris as a unified gateway. Also, we use the [Spark-Doris-Connector](https://github.com/apache/doris-spark-connector) to allow data communication between Spark and Doris. So basically, we replace Apache Hive with Apache Doris as the central hub of our data architecture.
+
+
+
+How does that affect our data processing efficiency?
+
+- **Monitoring & Alerting**: This is about real-time data querying. We access our real-time data in Elasticsearch clusters using Elasticsearch Catalog in Apache Doris. Then we perform queries directly in Apache Doris. It is able to return results within seconds, as opposed to the minute-level response time when we used Hive.
+- **Query & Analysis**: As I said, we have 20,000 tables in Hive so it wouldn't make sense to map all of them to external tables in Hive. That would mean a hell of maintenance. Instead, we utilize the Multi Catalog feature of Apache Doris 1.2. It enables data mapping at the catalog level, so we can simply create one Hive Catalog in Doris before we can conduct queries. This separates query operations from the daily batching processing workload in Hive, so there will be less resource conflict.
+- **Dashboarding**: We use Tableau and Doris to provide dashboard services. This reduces the query response time to seconds and milliseconds, compared with the several minutes back in the "Tableau + Hive" days.
+- **Modeling**: We use Spark and Doris for aggregation modeling. The Spark-Doris-Connector allows mutual synchronization of data, so data from Doris can also be used in modeling for more accurate analysis.
+
+### **Cluster Monitoring in Production Environment**
+
+We tested this new architecture in our production environment. We built two clusters.
+
+**Configuration**:
+
+Production cluster: 4 frontends + 8 backends, m5d.16xlarge
+
+Backup cluster: 4 frontends + 4 backends, m5d.16xlarge
+
+This is the monitoring board:
+
+
+
+As is shown, the queries are fast. We expected that it would take at least 10 nodes but in real cases, we mainly conduct queries via Catalogs, so we can handle this with a relatively small cluster size. The compatibility is good, too. It doesn't rock the rest of our existing system.
+
+## Guide to Faster Data Integration
+
+To accelerate the regular data ingestion from Hive to Apache Doris 1.2.2, we have a solution that goes as follows:
+
+
+
+**Main components:**
+
+- DolphinScheduler 3.1.4
+- SeaTunnel 2.1.3
+
+With our current hardware configuration, we use the Shell script mode of DolphinScheduler and call the SeaTunnel script on a regular basis. This is the configuration file of the data synchronization tasks:
+
+```undefined
+ env{
+ spark.app.name = "hive2doris-template"
+ spark.executor.instances = 10
+ spark.executor.cores = 5
+ spark.executor.memory = "20g"
+}
+spark {
+ spark.sql.catalogImplementation = "hive"
+}
+source {
+ hive {
+ pre_sql = "select * from ods.demo_tbl where dt='2023-03-09'"
+ result_table_name = "ods_demo_tbl"
+ }
+}
+
+transform {
+}
+
+sink {
+ doris {
+ fenodes = "192.168.0.10:8030,192.168.0.11:8030,192.168.0.12:8030,192.168.0.13:8030"
+ user = root
+ password = "XXX"
+ database = ods
+ table = ods_demo_tbl
+ batch_size = 500000
+ max_retries = 1
+ interval = 10000
+ doris.column_separator = "\t"
+ }
+}
+```
+
+This solution consumes less resources and memory but brings higher performance in queries and data ingestion.
+
+1. **Less storage costs**
+
+**Before**: The original table in Hive had 500 fields. It was divided into partitions by day, with 150 million pieces of data per partition. It takes **810G** to store in HDFS.
+
+**After**: For data synchronization, we call Spark on YARN using SeaTunnel. It can be finished within 40 minutes, and the ingested data only takes up **270G** of storage space.
+
+1. **Less memory usage & higher performance in queries**
+
+**Before**: For a GROUP BY query on the foregoing table in Hive, it occupied 720 Cores and 1.44T in YARN, and took a response time of **162 seconds**.
+
+**After**: We perform an aggregate query using Hive Catalog in Doris, `set exec_mem_limit=16G`, and receive the result after **58.531 seconds**. We also try and put the table in Doris and conduct the same query in Doris itself, that only takes **0.828 seconds**.
+
+The corresponding statements are as follows:
+
+- Query in Hive, response time: 162 seconds
+
+```SQL
+select count(*),product_no FROM ods.demo_tbl where dt='2023-03-09'
+group by product_no;
+```
+
+- Query in Doris using Hive Catalog, response time: 58.531 seconds
+
+```SQL
+set exec_mem_limit=16G;
+select count(*),product_no FROM hive.ods.demo_tbl where dt='2023-03-09'
+group by product_no;
+```
+
+- Query in Doris directly, response time: 0.828 seconds
+
+```SQL
+select count(*),product_no FROM ods.demo_tbl where dt='2023-03-09'
+group by product_no;
+```
+
+1. **Faster data ingestion**
+
+**Before**: The original table in Hive had 40 fields. It was divided into partitions by day, with 1.1 billion pieces of data per partition. It takes **806G** to store in HDFS.
+
+**After**: For data synchronization, we call Spark on YARN using SeaTunnel. It can be finished within 11 minutes (100 million pieces per minute ), and the ingested data only takes up **378G** of storage space.
+
+
+
+## Summary
+
+The key step to building a high-performing risk data mart is to leverage the Multi Catalog feature of Apache Doris to unify the heterogenous data sources. This not only increases our query speed but also solves a lot of the problems coming with our previous data architecture.
+
+1. Deploying Apache Doris allows us to decouple daily batch processing workloads with ad-hoc queries, so they don't have to compete for resources. This reduces the query response time from minutes to seconds.
+2. We used to build our data ingestion interface based on Elasticsearch clusters, which could lead to garbage collection jitter when transferring large batches of offline data. When we stored the interface service dataset on Doris, no jitter was found during data writing and we were able to transfer 10 million rows within 10 minutes.
+3. Apache Doris has been optimizing itself in many scenarios including flat tables. As far as we know, compared with ClickHouse, Apache Doris 1.2 is twice as fast in SSB-Flat-table benchmark and dozens of times faster in TPC-H benchmark.
+4. In terms of cluster scaling and updating, we used to suffer from a big window of restoration time after configuration revision. But Doris supports hot swap and easy scaling out, so we can reboot nodes within a few seconds and minimize interruption to users caused by cluster scaling.
+
+(One last piece of advice for you: If you encounter any problems with deploying Apache Doris, don't hesitate to contact the Doris community for help, they and a bunch of SelectDB engineers will be more than happy to make your adaption journey quick and easy.)
+
diff --git a/blog/High_concurrency.md b/blog/High_concurrency.md
new file mode 100644
index 00000000000..6a499918306
--- /dev/null
+++ b/blog/High_concurrency.md
@@ -0,0 +1,329 @@
+---
+{
+ 'title': 'How We Increased Database Query Concurrency by 20 Times',
+ 'summary': 'In the upcoming Apache Doris 2.0, we have optimized it for high-concurrency point queries. Long story short, it can achieve over 30,000 QPS for a single node.',
+ 'date': '2023-04-14',
+ 'author': 'Apache Doris',
+ 'tags': ['Tech Insights'],
+}
+---
+
+<!--
+Licensed to the Apache Software Foundation (ASF) under one
+or more contributor license agreements. See the NOTICE file
+distributed with this work for additional information
+regarding copyright ownership. The ASF licenses this file
+to you under the Apache License, Version 2.0 (the
+"License"); you may not use this file except in compliance
+with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing,
+software distributed under the License is distributed on an
+"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+KIND, either express or implied. See the License for the
+specific language governing permissions and limitations
+under the License.
+-->
+
+A unified analytic database is the holy grail for data engineers, but what does it look like specifically? It should evolve with the needs of data users.
+
+Vertically, companies now have an ever enlarging pool of data and expect a higher level of concurrency in data processing. Horizontally, they require a wider range of data analytics services. Besides traditional OLAP scenarios such as statistical reporting and ad-hoc queries, they are also leveraging data analysis in recommender systems, risk control, customer tagging and profiling, and IoT.
+
+Among all these data services, point queries are the most frequent operations conducted by data users. Point query means to retrieve one or several rows from the database based on the Key. A point query only returns a small piece of data, such as the details of a shopping order, a transaction, a consumer profile, a product description, logistics status, and so on. Sounds easy, right? But the tricky part is, **a database often needs to handle tens of thousands of point queries at a time a [...]
+
+Most current OLAP databases are built with a columnar storage engine to process huge data volumes. They take pride in their high throughput, but often underperform in high-concurrency scenarios. As a complement, many data engineers invite Key-Value stores like Apache HBase for point queries, and Redis as a cache layer to ease the burden. The downside is redundant storage and high maintenance costs.
+
+Since Apache Doris was born, we have been striving to make it a unified database for data queries of all sizes, including ad-hoc queries and point queries. Till now, we have already taken down the monster of high-throughput OLAP scenarios. In the upcoming Apache Doris 2.0, we have optimized it for high-concurrency point queries. Long story short, it can achieve over 30,000 QPS for a single node.
+
+## Five Ways to Accelerate High-Concurrency Queries
+
+High-concurrency queries are thorny because you need to handle high loads with limited system resources. That means you have to reduce the CPU, memory and I/O overheads of a single SQL as much as possible. The key is to minimize the scanning of underlying data and follow-up computing.
+
+Apache Doris uses five methods to achieve higher QPS.
+
+### Partioning and Bucketing
+
+Apache Doris shards data into a two-tiered structure: Partition and Bucket. You can use time information as the Partition Key. As for bucketing, you distribute the data into various nodes after data hashing. A wise bucketing plan can largely increase concurrency and throughput in data reading.
+
+This is an example:
+
+```SQL
+select * from user_table where id = 5122 and create_date = '2022-01-01'
+```
+
+In this case, the user has set 10 buckets. `create_date` is the Partition Key and `id` is the Bucket Key. After dividing the data into partitions and buckets, the system only needs to scan one bucket in one partition before it can locate the needed data. This is a huge time saver.
+
+### Index
+
+Apache Doris uses various data indexes to speed up data reading and filtering, including smart indexes and secondary indexes. Smart indexes are auto-generated by Doris upon data ingestion, which requires no action from the user's side.
+
+There are two types of smart indexes:
+
+- **Sorted Index**: Apache Doris stores data in an orderly way. It creates a sorted index for every 1024 rows of data. The Key in the index is the value of the sorted column in the first row of the current 1024 rows. If the query involves the sorted column, the system will locate the first row of the relevant 1024 row group and start scanning there.
+- **ZoneMap Index**: These are indexes on the Segment and Page level. The maximum and minimum values of each column within a Page will be recorded, so are those within a Segment. Hence, in equivalence queries and range queries, the system can narrow down the filter range with the help of the MinMax indexes.
+
+Secondary indexes are created by users. These include Bloom Filter indexes, Bitmap indexes, [Inverted indexes](https://doris.apache.org/docs/dev/data-table/index/inverted-index/), and [NGram Bloom Filter indexes](https://doris.apache.org/docs/dev/data-table/index/ngram-bloomfilter-index/). (If you are interested, I will go into details about them in future articles.)
+
+Example:
+
+```SQL
+select * from user_table where id > 10 and id < 1024
+```
+
+Suppose that the user has designated `id` as the Key during table creation, the data will be sorted by `id` on Memtable and the disks. So any queries involving `id` as a filter condition will be executed much faster with the aid of sorted indexes. Specifically, the data in storage will be put into multiple ranges based on `id`, and the system will implement binary search to locate the exact range according to the sorted indexes. But that could still be a large range since the sorted inde [...]
+
+This is another way to reduce data scanning and improve overall concurrency of the system.
+
+### Materialized View
+
+The idea of materialized view is to trade space for time: You execute pre-computation with pre-defined SQL statements, and perpetuate the results in a table that is visible to users but occupies some storage space. In this way, Apache Doris can respond much faster to queries for aggregated data and breakdown data and those involve the matching of sorted indexes once it hits a materialized view. This is a good way to lessen computation, improve query performance, and reduce resource consumption.
+
+```SQL
+// For an aggregation query, the system reads the pre-aggregated columns in the materialized view.
+
+create materialized view store_amt as select store_id, sum(sale_amt) from sales_records group by store_id;
+SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;
+
+// For a query where k3 matches the sorted column in the materialized view, the system directly performs the query on the materialized view.
+
+CREATE MATERIALIZED VIEW mv_1 as SELECT k3, k2, k1 FROM tableA ORDER BY k3;
+select k1, k2, k3 from table A where k3=3;
+```
+
+### Runtime Filter
+
+Apart from filtering data by indexes, Apache Doris has a dynamic filtering mechanism: Runtime Filter.
+
+In multi-table Join queries, the left table is usually called ProbeTable while the right one is called BuildTable, with the former much bigger than the latter. In query execution, firstly, the system reads the right table and creates a HashTable (Build) in the memory. Then, it starts reading the left table row by row, during which it also compares data between the left table and the HashTable and returns the matched data (Probe).
+
+So what's new about that in Apache Doris? During the creation of HashTable, Apache Doris generates a filter for the columns. It can be a Min/Max filter or an IN filter. Then it pushes down the filter to the left table, which can use the filter to screen out data and thus reduces the amount of data that the Probe node has to transfer and compare.
+
+This is how the Runtime Filter works. In most Join queries, the Runtime Filter can be automatically pushed down to the most underlying scan nodes or to the distributed Shuffle Join. In other words, Runtime Filter is able to reduce data reading and shorten response time for most Join queries.
+
+### TOP-N Optimization
+
+TOP-N query is a frequent scenario in data analysis. For example, users want to fetch the most recent 100 orders, or the 5 highest/lowest priced products. The performance of such queries determines the quality of real-time analysis. For them, Apache Doris implements TOP-N optimization. Here is how it goes:
+
+1. Apache Doris reads the sorted fields and query fields from the Scanner layer, reserves only the TOP-N pieces of data by means of Heapsort, updates the real-time TOP-N results as it continues reading, and dynamically pushes them down to the Scanner.
+2. Combing the received TOP-N range and the indexes, the Scanner can skip a large proportion of irrelevant files and data chunks and only read a small number of rows.
+3. Queries on flat tables usually mean the need to scan massive data, but TOP-N queries only retrieve a small amount of data. The strategy here is to divide the data reading process into two stages. In stage one, the system sorts the data based on a few columns (sorted column, or condition column) and locates the TOP-N rows. In stage two, it fetches the TOP-N rows of data after data sorting, and then it retrieves the target data according to the row numbers.
+
+To sum up, Apache Doris prunes the data that needs to be read and sorted, and thus substantially reduces consumption of I/O, CPU, and memory resources.
+
+In addition to the foregoing five methods, Apache Doris also improves concurrency by SQL Cache, Partition Cache, and a variety of Join optimization techniques.
+
+## How We Bring Concurrency to the Next Level
+
+By adopting the above methods, Apache Doris was able to achieve thousands of QPS per node. However, in scenarios requiring tens of thousands of QPS, it was still bottlenecked by several issues:
+
+- With Doris' columnar storage engine, it was inconvenient to read rows. In flat table models, columnar storage could result in much larger I/O usage.
+- The execution engine and query optimizer of OLAP databases were sometimes too complicated for simple queries (point queries, etc.). Such queries needed to be processed with a shorter pipeline, which should be considered in query planning.
+- FE modules of Doris, implementing Java, were responsible for interfacing with SQL requests and parsing query plans. These processes could produce high CPU overheads in high-concurrency scenarios.
+
+We optimized Apache Doris to solve these problems. ([Pull Request on Github](https://github.com/apache/doris/pull/15491))
+
+
+
+### Row Storage Format
+
+As we know, row storage is much more efficient when the user only queries for a single row of data. So we introduced row storage format in Apache Doris 2.0. Users can enable row storage by specifying the following property in the table creation statement.
+
+```SQL
+"store_row_column" = "true"
+```
+
+We chose JSONB as the encoding format for row storage for three reasons:
+
+- **Flexible schema change**: If a user has added or deleted a field, or modified the type of a field, these changes must be updated in row storage in real time. So we choose to adopt the JSONB format and encode columns into JSONB fields. This makes changes in fields very easy.
+- **High performance**: Accessing rows in row-oriented storage is much faster than doing that in columnar storage, and it requires much less disk access in high-concurrency scenarios. Also, in some cases, you can map the column ID to the corresponding JSONB value so you can quickly access a certain column.
+- **Less storage space**: JSONB is a compacted binary format. It consumes less space on the disk and is more cost-effective.
+
+In the storage engine, row storage will be stored as a hidden column (DORIS_ROW_STORE_COL). During Memtable Flush, the columns will be encoded into JSONB and cached into this hidden column. In data reading, the system uses the Column ID to locate the column, finds the target row based on the row number, and then deserializes the relevant columns.
+
+### Short-Circuit
+
+Normally, an SQL statement is executed in three steps:
+
+1. SQL Parser parses the statement to generate an abstract syntax tree (AST).
+2. The Query Optimizer produces an executable plan.
+3. Execute the plan and return the results.
+
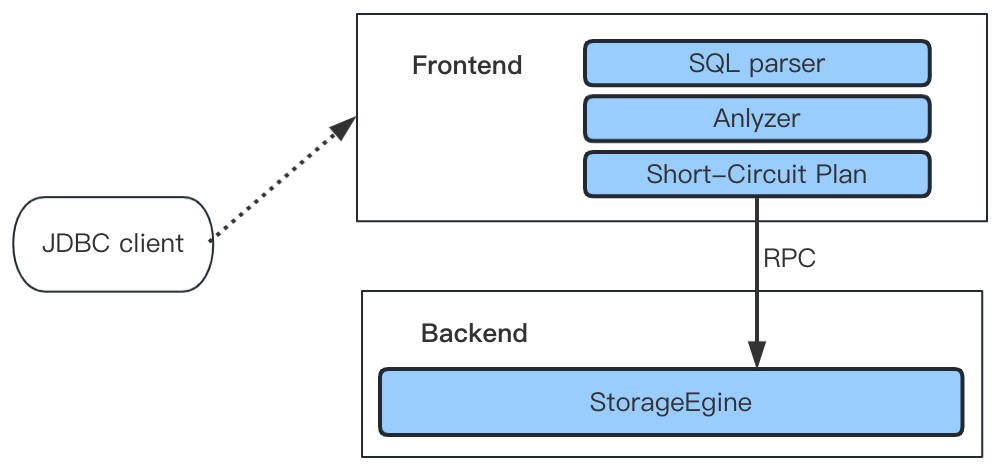
+For complex queries on massive data, it is better to follow the plan created by the Query Optimizer. However, for high-concurrency point queries requiring low latency, that plan is not only unnecessary but also brings extra overheads. That's why we implement a short-circuit plan for point queries.
+
+
+
+Once the FE receives a point query request, a short-circuit plan will be produced. It is a lightweight plan that involves no equivalent transformation, logic optimization or physical optimization. Instead, it conducts some basic analysis on the AST, creates a fixed plan accordingly, and finds ways to reduce overhead of the optimizer.
+
+For a simple point query involving primary keys, such as `select * from tbl where pk1 = 123 and pk2 = 456`, since it only involves one single Tablet, it is better to use a lightweight RPC interface for interaction with the Storage Engine. This avoids the creation of a complicated Fragment Plan and eliminates the performance overhead brought by the scheduling under the MPP query framework.
+
+Details of the RPC interface are as follows:
+
+```Java
+message PTabletKeyLookupRequest {
+ required int64 tablet_id = 1;
+ repeated KeyTuple key_tuples = 2;
+ optional Descriptor desc_tbl = 4;
+ optional ExprList output_expr = 5;
+}
+
+message PTabletKeyLookupResponse {
+ required PStatus status = 1;
+ optional bytes row_batch = 5;
+ optional bool empty_batch = 6;
+}
+rpc tablet_fetch_data(PTabletKeyLookupRequest) returns (PTabletKeyLookupResponse);
+```
+
+`tablet_id` is calculated based on the primary key column, while `key_tuples` is the string format of the primary key. In this example, the `key_tuples` is similar to ['123', '456']. As BE receives the request, `key_tuples` will be encoded into primary key storage format. Then, it will locate the corresponding row number of the Key in the Segment File with the help of the primary key index, and check if that row exists in `delete bitmap`. If it does, the row number will be returned; if n [...]
+
+### Prepared Statement
+
+In high-concurrency queries, part of the CPU overhead comes from SQL analysis and parsing in FE. To reduce such overhead, in FE, we provide prepared statements that are fully compatible with MySQL protocol. With prepared statements, we can achieve a four-time performance increase for primary key point queries.
+
+
+
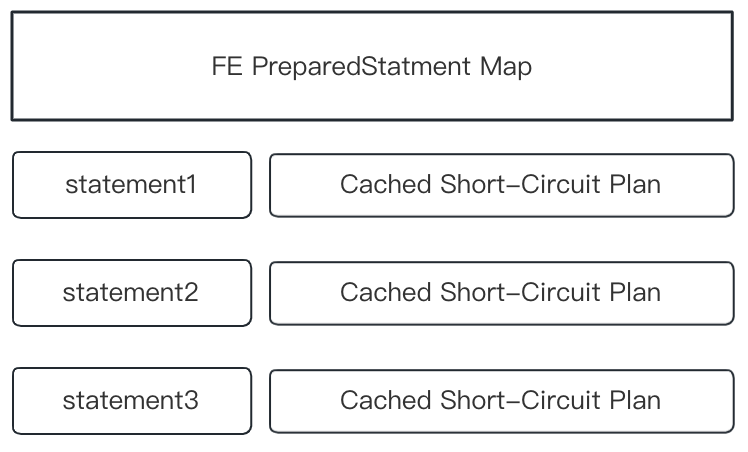
+The idea of prepared statements is to cache precomputed SQL and expressions in HashMap in memory, so they can be directly used in queries when applicable.
+
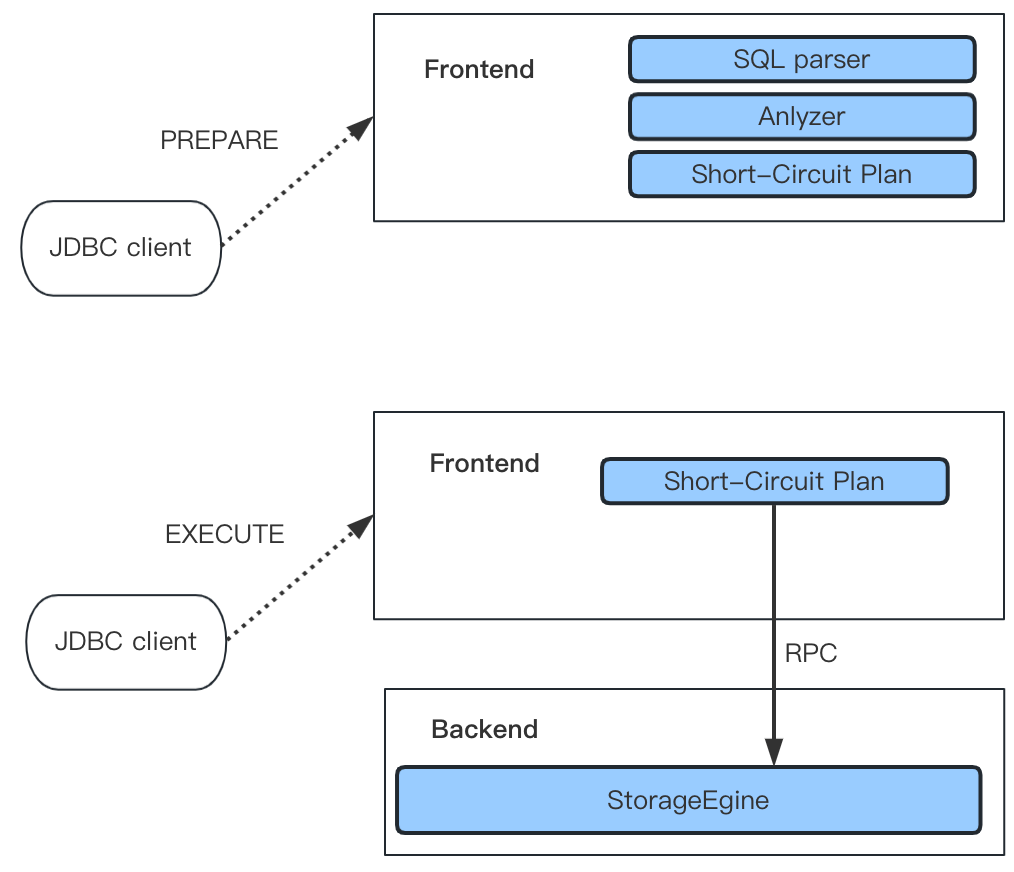
+Prepared statements adopt MySQL binary protocol for transmission. The protocol is implemented in the mysql_row_buffer.[h|cpp] file, and uses MySQL binary encoding. Under this protocol, the client (for example, JDBC Client) sends a pre-compiled statement to FE via `PREPARE` MySQL Command. Next, FE will parse and analyze the statement and cache it in the HashMap as shown in the figure above. Next, the client, using `EXECUTE` MySQL Command, will replace the placeholder, encode it into binar [...]
+
+
+
+Apart from caching prepared statements in FE, we also cache reusable structures in BE. These structures include pre-allocated computation blocks, query descriptors, and output expressions. Serializing and deserializing these structures often cause a CPU hotspot, so it makes more sense to cache them. The prepared statement for each query comes with a UUID named CacheID. So when BE executes the point query, it will find the corresponding class based on the CacheID, and then reuse the struc [...]
+
+
+
+The following example demonstrates how to use a prepared statement in JDBC:
+
+1. Set a JDBC URL and enable prepared statement at the server end.
+
+```Bash
+url = jdbc:mysql://127.0.0.1:9030/ycsb?useServerPrepStmts=true
+```
+
+1. Use a prepared statement.
+
+```Java
+// Use `?` as placeholder, reuse readStatement.
+PreparedStatement readStatement = conn.prepareStatement("select * from tbl_point_query where key = ?");
+...
+readStatement.setInt(1234);
+ResultSet resultSet = readStatement.executeQuery();
+...
+readStatement.setInt(1235);
+resultSet = readStatement.executeQuery();
+...
+```
+
+### Row Storage Cache
+
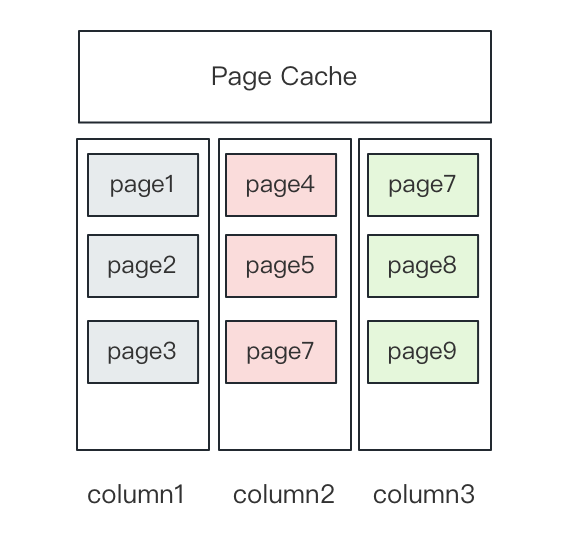
+Apache Doris has a Page Cache feature, where each page caches the data of one column.
+
+
+
+As mentioned above, we have introduced row storage in Doris. The problem with this is, one row of data consists of multiple columns, so in the case of big queries, the cached data might be erased. Thus, we also introduced row cache to increase row cache hit rate.
+
+Row cache reuses the LRU Cache mechanism in Apache Doris. When the caching starts, the system will initialize a threshold value. If that threshold is hit, the old cached rows will be phased out. For a primary key query statement, the performance gap between cache hit and cache miss can be huge (we are talking about dozens of times less disk I/O and memory access here). So the introduction of row cache can remarkably enhance point query performance.
+
+
+
+To enable row cache, you can specify the following configuration in BE:
+
+```JSON
+disable_storage_row_cache=false // This specifies whether to enable row cache; it is set to false by default.
+row_cache_mem_limit=20% // This specifies the percentage of row cache in the memory; it is set to 20% by default.
+```
+
+## Benchmark Performance
+
+We tested Apache Doris with YCSB (Yahoo! Cloud Serving Benchmark) to see how all these optimizations work.
+
+**Configurations and data size:**
+
+- Machines: a single 16 Core 64G cloud server with 4×1T hard drives
+- Cluster size: 1 Frontend + 2 Backends
+- Data volume: 100 million rows of data, with each row taking 1KB to store; preheated
+- Table schema and query statement:
+
+```JavaScript
+// Table creation statement:
+
+CREATE TABLE `usertable` (
+ `YCSB_KEY` varchar(255) NULL,
+ `FIELD0` text NULL,
+ `FIELD1` text NULL,
+ `FIELD2` text NULL,
+ `FIELD3` text NULL,
+ `FIELD4` text NULL,
+ `FIELD5` text NULL,
+ `FIELD6` text NULL,
+ `FIELD7` text NULL,
+ `FIELD8` text NULL,
+ `FIELD9` text NULL
+) ENGINE=OLAP
+UNIQUE KEY(`YCSB_KEY`)
+COMMENT 'OLAP'
+DISTRIBUTED BY HASH(`YCSB_KEY`) BUCKETS 16
+PROPERTIES (
+"replication_allocation" = "tag.location.default: 1",
+"in_memory" = "false",
+"persistent" = "false",
+"storage_format" = "V2",
+"enable_unique_key_merge_on_write" = "true",
+"light_schema_change" = "true",
+"store_row_column" = "true",
+"disable_auto_compaction" = "false"
+);
+
+// Query statement:
+
+SELECT * from usertable WHERE YCSB_KEY = ?
+```
+
+We run the test with the optimizations (row storage, short-circuit, and prepared statement) enabled, and then did it again with all of them disabled. Here are the results:
+
+
+
+With optimizations enabled, **the average query latency decreased by a whopping 96%, the 99th percentile latency was only 1/28 of that without optimizations, and it has achieved a query concurrency of over 30,000 QPS.** This is a huge leap in performance and an over 20-time increase in concurrency.
+
+## Best Practice
+
+It should be noted that these optimizations for point queries are implemented in the Unique Key model of Apache Doris, and you should enable Merge-on-Write and Light Schema Change for this model.
+
+This is a table creation statement example for point queries:
+
+```undefined
+CREATE TABLE `usertable` (
+ `USER_KEY` BIGINT NULL,
+ `FIELD0` text NULL,
+ `FIELD1` text NULL,
+ `FIELD2` text NULL,
+ `FIELD3` text NULL
+) ENGINE=OLAP
+UNIQUE KEY(`USER_KEY`)
+COMMENT 'OLAP'
+DISTRIBUTED BY HASH(`USER_KEY`) BUCKETS 16
+PROPERTIES (
+"enable_unique_key_merge_on_write" = "true",
+"light_schema_change" = "true",
+"store_row_column" = "true",
+);
+```
+
+**Note:**
+
+- Enable `light_schema_change` to support JSONB row storage for encoding ColumnID
+- Enable `store_row_column` to store row storage format
+
+For a primary key-based point query like the one below, after table creation, you can use row storage and short-circuit execution to improve performance to a great extent.
+
+```SQL
+select * from usertable where USER_KEY = xxx;
+```
+
+To further unleash performance, you can apply prepared statement. If you have enough memory space, you can also enable row cache in the BE configuration.
+
+## Conclusion
+
+In high-concurrency scenarios, Apache Doris realizes over 30,000 QPS per node after optimizations including row storage, short-circuit, prepared statement, and row cache. Also, Apache Doris is easily scaled out since it is built on MPP architecture, on top of which you can scale it up by upgrading the hardware and machine configuration. This is how Apache Doris manages to achieve both high throughput and high concurrency. It allows you to deal with various data analytic workloads on one [...]
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/HYXJ.md b/i18n/zh-CN/docusaurus-plugin-content-blog/HYXJ.md
new file mode 100644
index 00000000000..5ddab39c4d8
--- /dev/null
+++ b/i18n/zh-CN/docusaurus-plugin-content-blog/HYXJ.md
@@ -0,0 +1,277 @@
+---
+{
+ 'title': '杭银消金基于 Apache Doris 的统一数据查询网关改造',
+ 'summary': "杭银消金于 2022 年 10 月正式引入 Apache Doris 1.2 对现有的风控数据集市进行了升级改造,利用 Multi Catalog 功能统一了 ES、Hive、GP 等数据源出口,实现了联邦查询,为未来统一数据查询网关奠定了基础;同时,基于 Apache Doris 高性能、简单易用、部署成本低等诸多优势,也使得各大业务场景的查询分析响应实现了从分钟级到秒级的跨越。",
+ 'date': '2023-04-20',
+ 'author': '杭银消金大数据团队',
+ 'tags': ['最佳实践'],
+}
+
+---
+
+<!--
+Licensed to the Apache Software Foundation (ASF) under one
+or more contributor license agreements. See the NOTICE file
+distributed with this work for additional information
+regarding copyright ownership. The ASF licenses this file
+to you under the Apache License, Version 2.0 (the
+"License"); you may not use this file except in compliance
+with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing,
+software distributed under the License is distributed on an
+"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+KIND, either express or implied. See the License for the
+specific language governing permissions and limitations
+under the License.
+-->
+
+**导读:** 随着业务量快速增长,数据规模的不断扩大,杭银消金早期的大数据平台在应对实时性更强、复杂度更高的的业务需求时存在瓶颈。为了更好的应对未来的数据规模增长,杭银消金于 2022 年 10 月正式引入 Apache Doris 1.2 对现有的风控数据集市进行了升级改造,利用 Multi Catalog 功能统一了 ES、Hive、GP 等数据源出口,实现了联邦查询,为未来统一数据查询网关奠定了基础;同时,基于 [Apache Doris](https://github.com/apache/doris
+) 高性能、简单易用、部署成本低等诸多优势,也使得各大业务场景的查询分析响应实现了从分钟级到秒级的跨越。
+
+<p align=right>作者|杭银消金大数据团队 周其进,唐海定, 姚锦权</p>
+
+杭银消费金融股份有限公司,成立于 2015 年 12 月,是杭州银行牵头组建的浙江省首家持牌消费金融公司,经过这几年的发展,在 2022 年底资产规模突破 400 亿,服务客户数超千万。公司秉承“数字普惠金融”初心,坚持服务传统金融覆盖不充分的、具有消费信贷需求的客户群体,以“**数据、场景、风控、技术**”为核心,依托大数据、人工智能、云计算等互联网科技,为全国消费者提供专业、高效、便捷、可信赖的金融服务。
+
+# **业务需求**
+
+杭银消金业务模式是线上业务结合线下业务的双引擎驱动模式。为更好的服务用户,运用数据驱动实现精细化管理,基于当前业务模式衍生出了四大类的业务数据需求:
+
+- 预警类:实现业务流量监控,主要是对信贷流程的用户数量与金额进行实时监控,出现问题自动告警。
+- 分析类:支持查询统计与临时取数,对信贷各环节进行分析,对审批、授信、支用等环节的用户数量与额度情况查询分析。
+- 看板类:打造业务实时驾驶舱与 T+1 业务看板,提供内部管理层与运营部门使用,更好辅助管理进行决策。
+- 建模类:支持多维模型变量的建模,通过算法模型回溯用户的金融表现,提升审批、授信、支用等环节的模型能力。
+
+# 数据架构 1.0
+
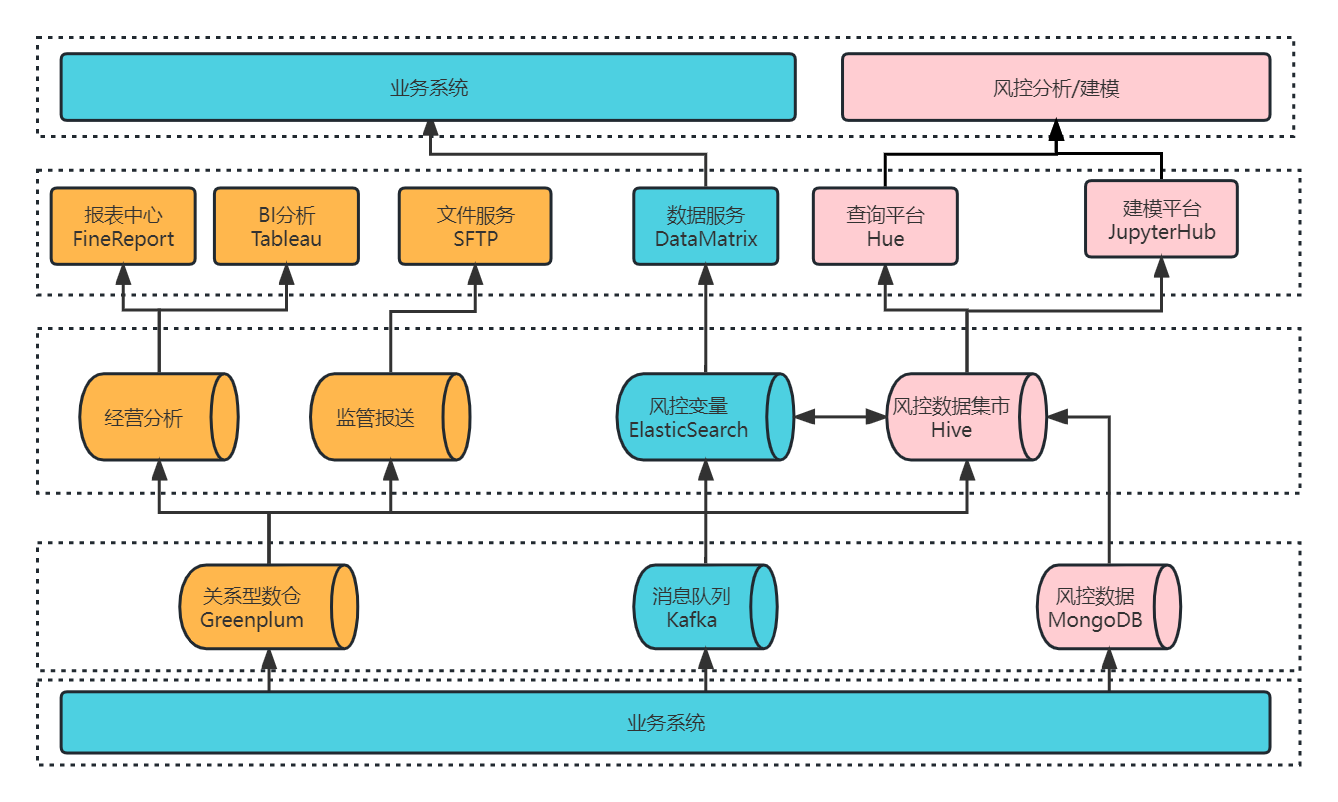
+为满足以上需求,我们采用 Greenplum + CDH 融合的架构体系创建了大数据平台 1.0 ,如下图所示,大数据平台的数据源均来自于业务系统,我们可以从数据源的 3 个流向出发,了解大数据平台的组成及分工:
+
+- 业务系统的核心系统数据通过 CloudCanal 实时同步进入 Greenplum 数仓进行数据实时分析,为 BI 报表,数据大屏等应用提供服务,部分数据进入风控集市 Hive 中,提供查询分析和建模服务。
+- 业务系统的实时数据推送到 Kafka 消息队列,经 Flink 实时消费写入 ES,通过风控变量提供数据服务,而 ES 中的部分数据也可以流入 Hive 中,进行相关分析处理。
+- 业务系统的风控数据会落在 MongoDB,经过离线同步进入风控集市 Hive,Hive 数仓支撑了查询平台和建模平台,提供风控分析和建模服务。
+
+
+
+**我们将 ES 和** **Hive** **共同组成了风控数据集市**,从上述介绍也可知,四大类的业务需求基本都是由风控数据集市来满足的,因此我们后续的改造升级主要基于风控数据集市来进行。在这之前,我们先了解一下风控数据集市 1.0 是如何来运转的。
+
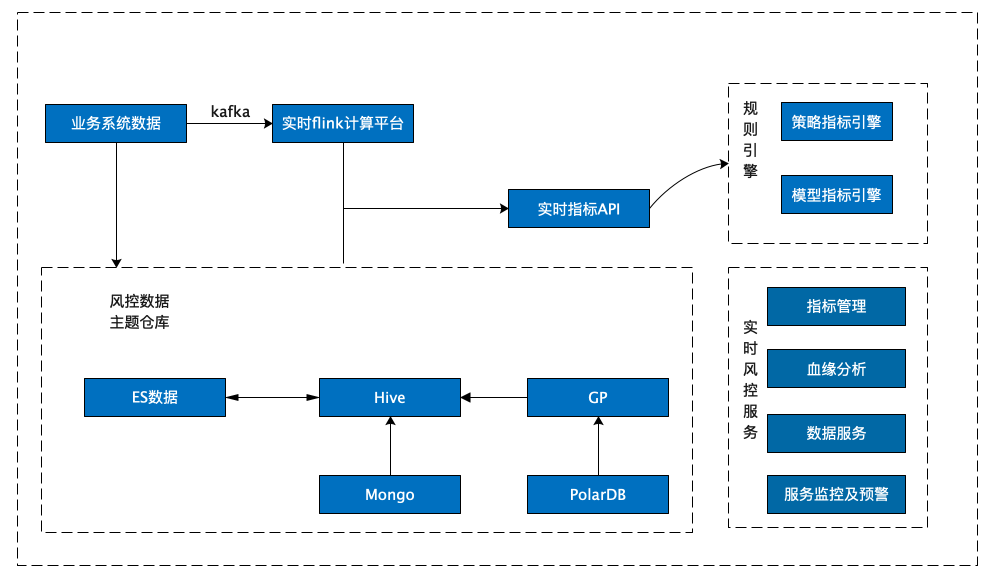
+**风控数据集市 1.0**
+
+风控数据集市原有架构是基于 CDH 搭建的,由实时写入和离线统计分析两部分组成,整个架构包含了 ES、Hive、Greenplum 等核心组件,风控数据集市的数据源主要有三种:通过 Greenplum 数仓同步的业务系统数据、通过 MongoDB 同步的风控决策数据,以及通过 ES 写入的实时风控变量数据。
+
+
+
+**实时流数据:** 采用了 Kafka + Flink + ES 的实时流处理方式,利用 Flink 对 Kafka 的实时数据进行清洗,实时写入ES,并对部分结果进行汇总计算,通过接口提供给风控决策使用。
+
+**离线风控数据:** 采用基于 CDH 的方案实现,通过 Sqoop 离线同步核心数仓 GP 上的数据,结合实时数据与落在 MongoDB 上的三方数据,经数据清洗后统一汇总到 Hive 数仓进行日常的跑批与查询分析。
+
+**需求满足情况:**
+
+在大数据平台 1.0 的的支持下,我们的业务需求得到了初步的实现:
+
+- 预警类:基于 ES + Hive 的外表查询,实现了实时业务流量监控;
+- 分析类:基于 Hive 实现数据查询分析和临时取数;
+- 看板类:基于 Tableau +Hive 搭建了业务管理驾驶舱以及T+1 业务看板;
+- 建模类:基于 Spark+Hive 实现了多维模型变量的建模分析;
+
+受限于 Hive 的执行效率,以上需求均在分钟级别返回结果,仅可以满足我们最基本的诉求,而面对秒级甚至毫秒级的分析场景,Hive 则稍显吃力。
+
+**存在的问题:**
+
+- **单表宽度过大,影响查询性能**。风控数据集市的下游业务主要以规则引擎与实时风控服务为主,因规则引擎的特殊性,公司在数据变量衍生方面资源投入较多,某些维度上的衍生变量会达到几千甚至上万的规模,这将导致 Hive 中存储的数据表字段非常多,部分经常使用的大宽表字段数量甚至超过上千,过宽的大宽表非常影响实际使用中查询性能。
+- **数据规模庞大,维护成本高。** 目前 Hive 上的风控数据集市已经有存量数据在百 T 以上,面对如此庞大的数据规模,使用外表的方式进行维护成本非常高,数据的接入也成为一大难题。
+- **接口服务不稳定。** 由风控数据集市离线跑批产生的变量指标还兼顾为其他业务应用提供数据服务的职责,目前 Hive 离线跑批后的结果会定时推送到 ES 集群(每天更新的数据集比较庞大,接口调用具有时效性),推送时会因为 IO 过高触发 ES 集群的 GC 抖动,导致接口服务不稳定。
+
+除此之外,风控分析师与建模人员一般通过 Hive & Spark 方式进行数据分析建模,这导致随着业务规模的进一步增大,T+1 跑批与日常分析的效率越来越低,风控数据集市改造升级的需求越发强烈。
+
+# 技术选型
+
+基于业务对架构提出的更高要求,我们期望引入一款强劲的 OLAP 引擎来改善架构,因此我们于 2022 年 9 月份对 ClickHouse 和 Apache Doris 进行了调研,调研中发现 Apache Doris 具有高性能、简单易用、实现成本低等诸多优势,而且 Apache Doris 1.2 版本非常符合我们的诉求,原因如下:
+
+**宽表查询性能优异**:从官方公布的测试结果来看,1.2 Preview 版本在 SSB-Flat 宽表场景上相对 1.1.3 版本整体性能提升了近 4 倍、相对于 0.15.0 版本性能提升了近 10 倍,在 TPC-H 多表关联场景上较 1.1.3 版本上有近 3 倍的提升、较 0.15.0 版本性能提升了 11 倍以上,多个场景性能得到飞跃性提升。
+
+**便捷的数据接入框架以及联邦数据分析能力:** Apache Doris 1.2 版本推出的 Multi Catalog 功能可以构建完善可扩展的数据源连接框架,**便于快速接入多类数据源,提供基于各种异构数据源的联邦查询和写入能力。** 目前 Multi-Catalog 已经支持了 Hive、Iceberg、Hudi 等数据湖以及 MySQL、Elasticsearch、Greenplum 等数据库,全面覆盖了我们现有的组件栈,基于此能力有希望通过 Apache Doris 来打造统一数据查询网关。
+
+**生态丰富:** 支持 Spark Doris Connector、Flink Doris Connector,方便离线与实时数据的处理,缩短了数据处理链路耗费的时间。
+
+**社区活跃:** Apache Doris 社区非常活跃,响应迅速,并且 SelectDB 为社区提供了一支专职的工程师团队,为用户提供技术支持服务。
+
+# 数据架构 2.0
+
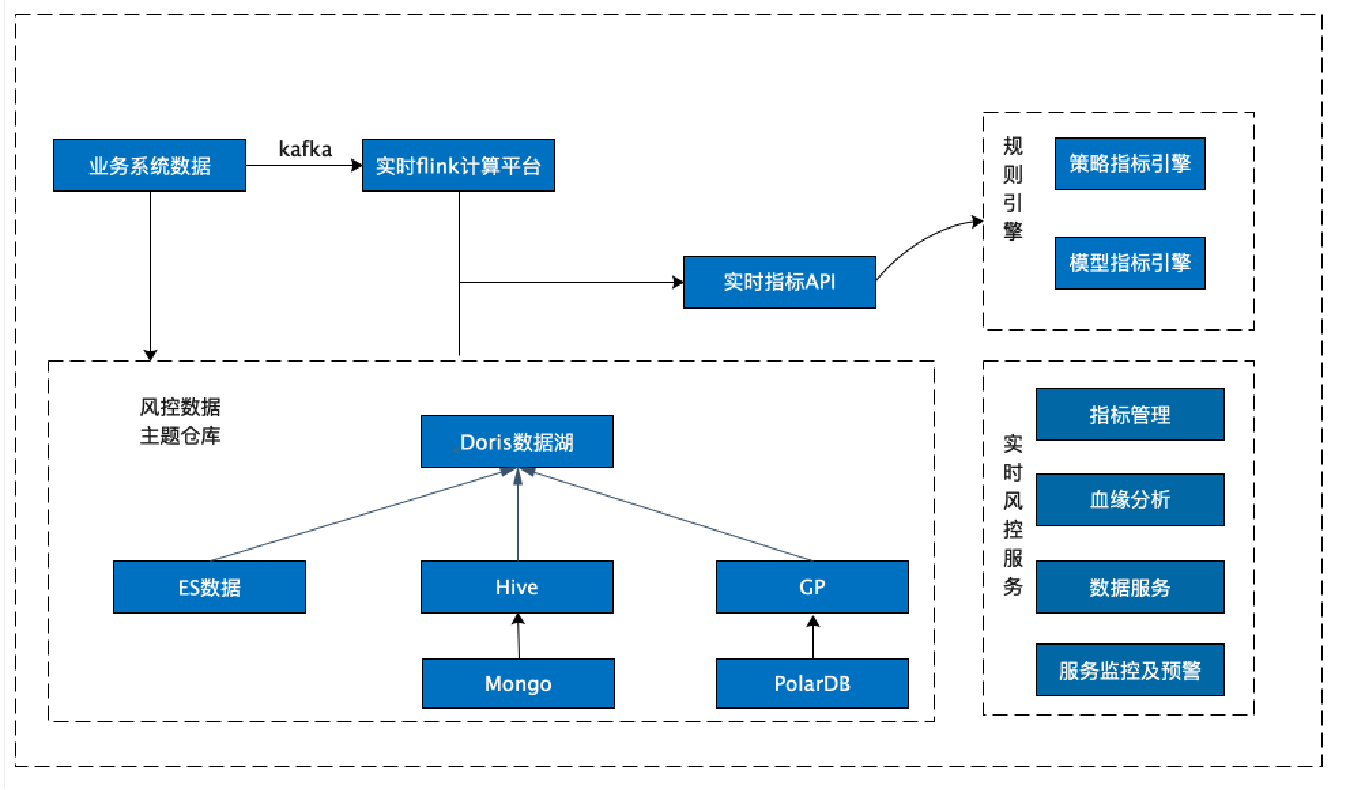
+**风控数据集市 2.0**
+
+基于对 Apache Doris 的初步的了解与验证,22 年 10 月在社区的支持下我们正式引入 Apache Doris 1.2.0 Preview 版本作为风控数据集市的核心组件,Apache Doris 的 Multi Catalog 功能助力大数据平台统一了 ES、Hive、Greenplum 等数据源出口,通过 Hive Catalog 和 ES Catalog 实现了对 Hive & ES 等多数据源的联邦查询,并且支持 Spark-Doris-Connector,可以实现数据 Hive 与 Doris 的双向流动,与现有建模分析体系完美集成,在短期内实现了性能的快速提升。
+
+
+
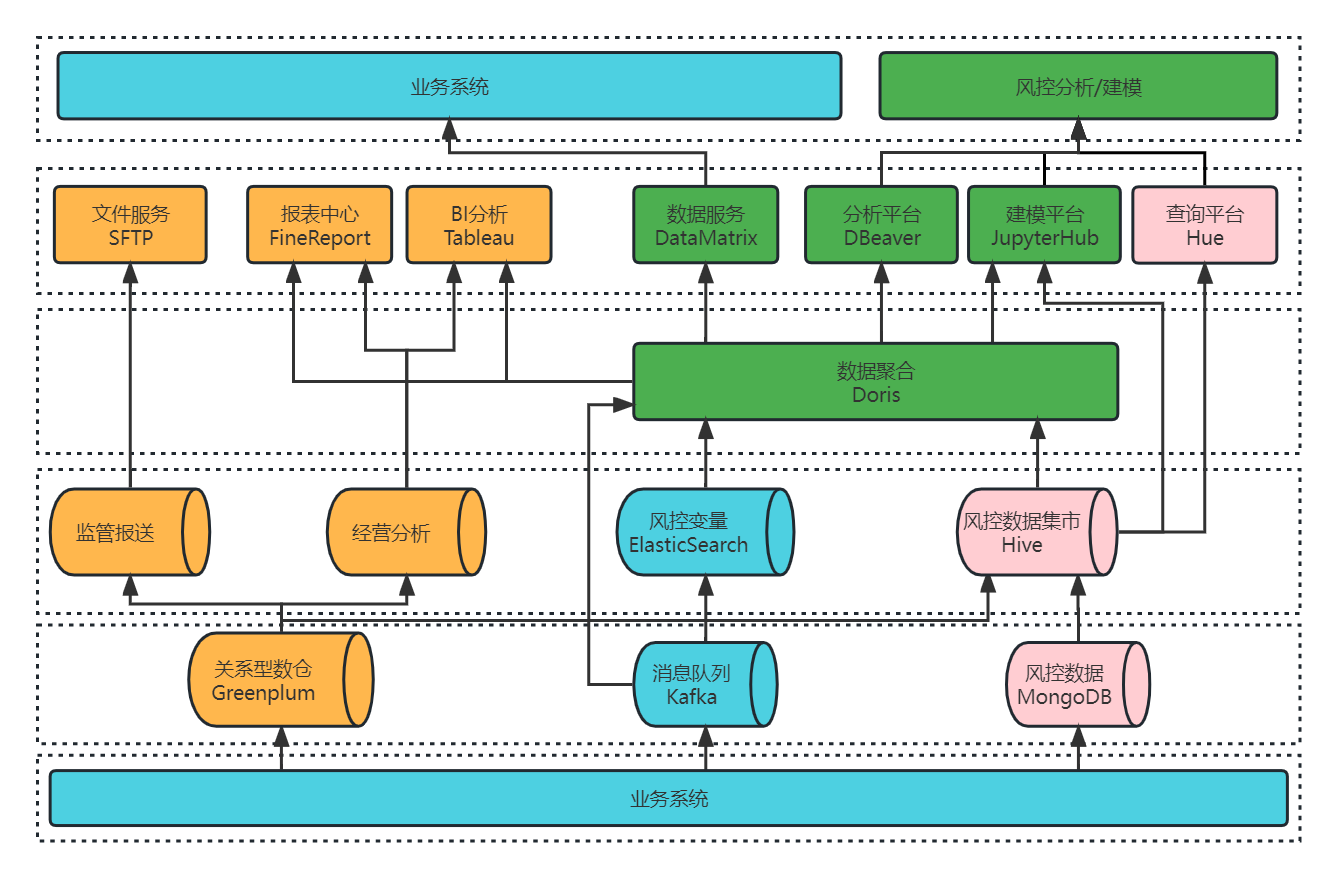
+**大数据平台 2.0**
+
+风控数据集市调整优化之后,大数据平台架构也相应的发生了变化,如下图所示,仅通过 Doris 一个组件即可为数据服务、分析平台、建模平台提供数据服务。
+
+在最初进行联调适配的时候,Doris 社区和 SelectDB 支持团队针对我们提出的问题和疑惑一直保持高效的反馈效率,给于积极的帮助和支持,快速帮助我们解决在生产上遇到的问题。
+
+
+
+**需求实现情况:**
+
+在大数据平台 2.0 的加持下,业务需求实现的方式也发生了变更,主要变化如下所示
+
+- 预警类:基于 ES Catalog+ Doris 实现了对实时数据的查询分析。在架构 1.0 中,实时数据落在 ES 集群上,通过 Hive 外表进行查询分析,查询结果以分钟级别返回;而在 Doris 1.2 集成之后, 使用 ES Catalog 访问 ES,可以实现对 ES 数据秒级统计分析。
+- 分析类:基于 Hive Catalog + Doris 实现了对现有风控数据集市的快速查询。目前 Hive 数据集市存量表在两万张左右,如果通过直接创建 Hive 外部表的方式,表结构映射关系的维护难度与数据同步成本使这一方式几乎不可能实现。而 Doris 1.2 的 Multi Catalog 功能则完美解决了这个问题,只需要创建一个 Hive Catalog,就能对现有风控数据集市进行查询分析,既能提升查询性能,还减少了日常查询分析对跑批任务的资源影响。
+- 看板类:基于 Tableau + Doris 聚合展示业务实时驾驶舱和 T+1 业务看板,最初使用 Hive 时,报表查询需要几分钟才能返回结果,而 Apache Doris 则是秒级甚至是毫秒级的响应速度。
+- 建模类:基于 Spark+Doris 进行聚合建模。利用 Doris1.2 的 Spark-Doris-Connector功 能,实现了 Hive 与 Doris 数据双向同步,满足了 Spark 建模平台的功能复用。同时增加了 Doris 数据源,基础数据查询分析的效率得到了明显提升,建模分析能力的也得到了增强。
+
+在 Apache Doris 引入之后,以上四个业务场景的查询耗时基本都实现了从分钟级到秒级响应的跨越,性能提升十分巨大。
+
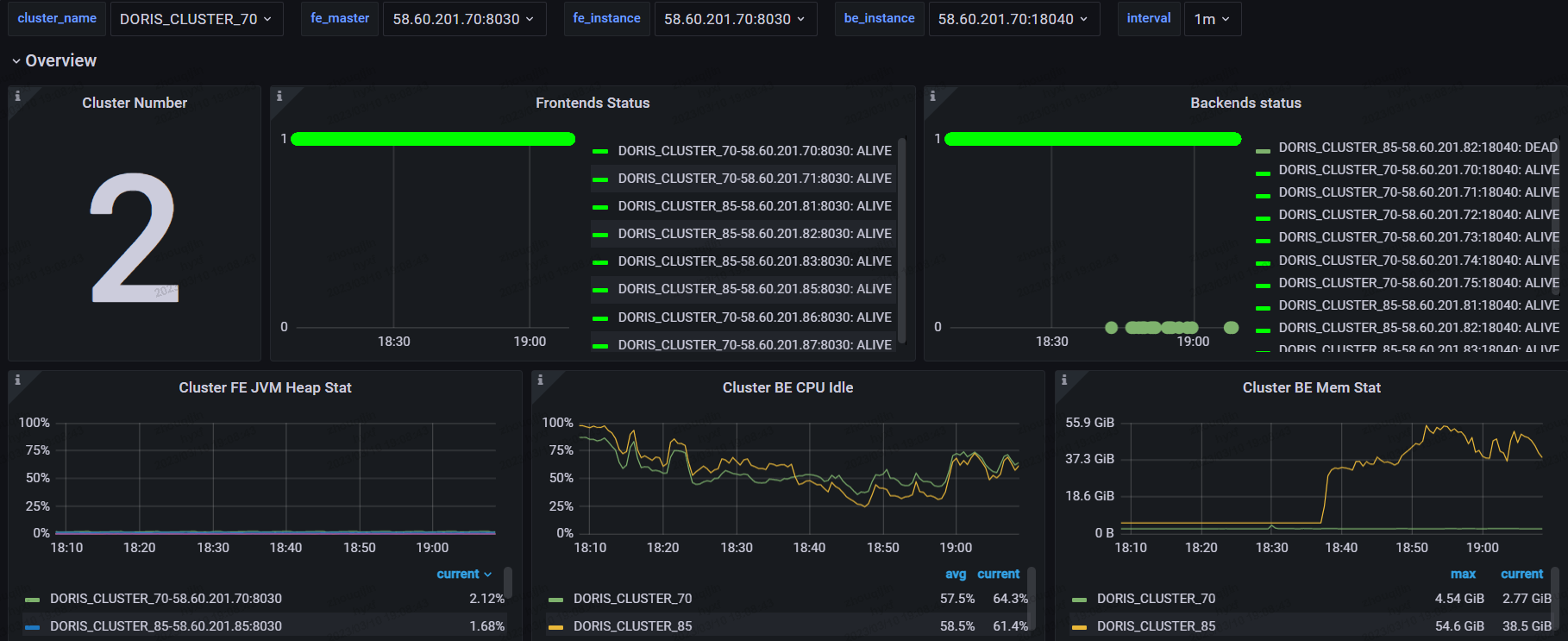
+**生产环境集群监控**
+
+为了快速验证新版本的效果,我们在生产环境上搭建了两个集群,目前生产集群的配置是 4 个 FE + 8个 BE,单个节点是配置为 64 核+ 256G+4T,备用集群为 4 个 FE + 4 个 BE 的配置,单个节点配置保持一致。
+
+集群监控如下图所示:
+
+
+
+可以看出,Apache Doris 1.2 的查询效率非常高,原计划至少要上 10 个节点,而在实际使用下来,我们发现当前主要使用的场景均是以 Catalog 的方式查询,因此集群规模可以相对较小就可以快速上线,也不会破坏当前的系统架构,兼容性非常好。
+
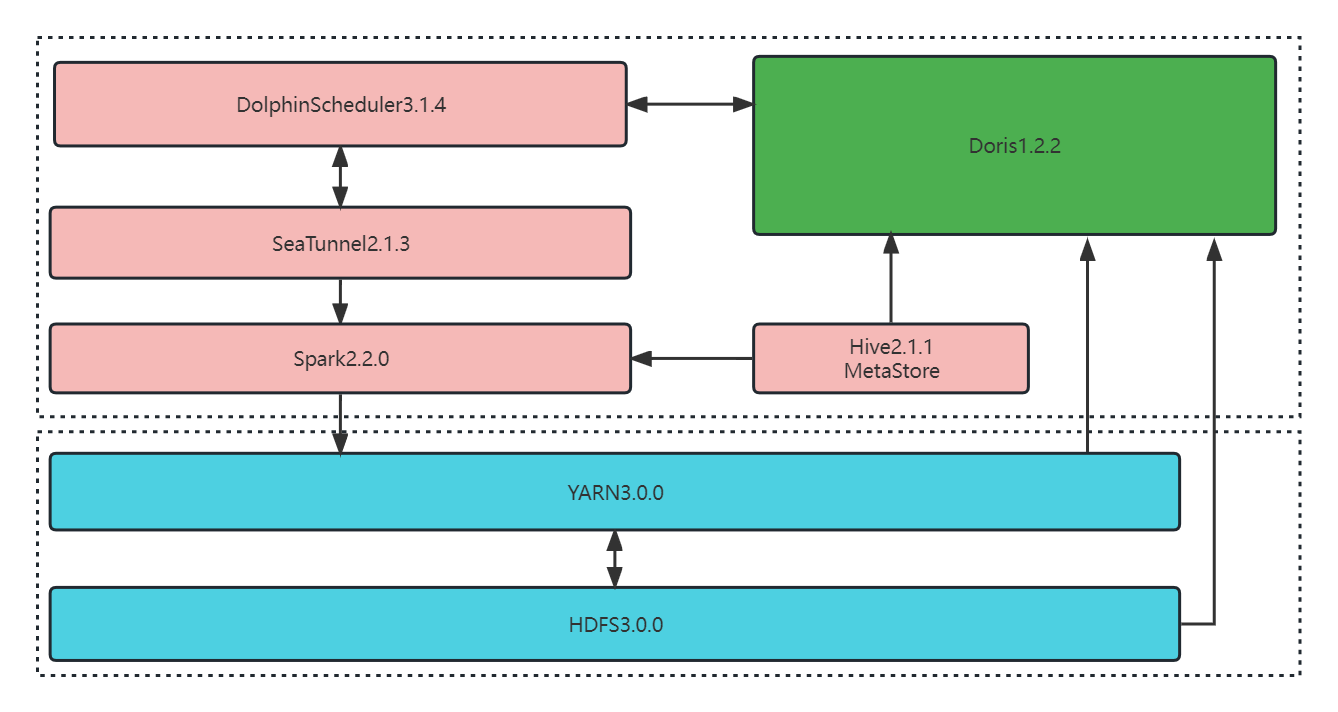
+## 数据集成方案
+
+前段时间,Apache Doris 1.2.2 版本已经发布,为了更好的支撑应用服务,我们使用 Apache Doris 1.2.2 与 DolphinScheduler 3.1.4 调度器、SeaTunnel 2.1.3 数据同步平台等开源软件实现了集成,以便于数据定时从 Hive 抽取到 Doris 中。整体的数据集成方案如下:
+
+
+
+在当前的硬件配置下,数据同步采用的是 DolphinScheduler 的 Shell 脚本模式,定时调起 SeaTunnel 的脚本,数据同步任务的配置文件如下:
+
+```sql
+ env{
+ spark.app.name = "hive2doris-template"
+ spark.executor.instances = 10
+ spark.executor.cores = 5
+ spark.executor.memory = "20g"
+}
+spark {
+ spark.sql.catalogImplementation = "hive"
+}
+source {
+ hive {
+ pre_sql = "select * from ods.demo_tbl where dt='2023-03-09'"
+ result_table_name = "ods_demo_tbl"
+ }
+}
+
+transform {
+}
+
+sink {
+ doris {
+ fenodes = "192.168.0.10:8030,192.168.0.11:8030,192.168.0.12:8030,192.168.0.13:8030"
+ user = root
+ password = "XXX"
+ database = ods
+ table = ods_demo_tbl
+ batch_size = 500000
+ max_retries = 1
+ interval = 10000
+ doris.column_separator = "\t"
+ }
+}
+```
+
+**该方案成功实施后,资源占用、计算内存占用有了明显的降低,查询性能、导入性能有了大幅提升:**
+
+1. 存储成本降低
+
+使用前:Hive 原始表包含 500 个字段,单个分区数据量为 1.5 亿/天,在 HDFS 上占用约 810G 的空间。
+
+使用后:我们通过 SeaTunnel 调起 Spark on YARN 的方式进行数据同步,可以在 **40 分钟左右**完成数据同步,同步后数据占用 **270G 空间,存储资源仅占之前的 1/3**。
+
+2. 计算内存占用降低,性能提升显著
+
+使用前:上述表在 Hive 上进行 Group By 时,占用 YARN 资源 720 核 1.44T 内存,需要 **162 秒**才可返回结果;
+
+使用后:
+
+- 通过 Doris 调用 Hive Catalog 进行聚合查询,在设置 `set exec_mem_limit=16G` 情况下用时 **58.531 秒,查询耗时较之前减少了近 2/3;**
+- 在同等条件下,在 Doris 中执行相同的的操作可以在 **0.828 秒**就能返回查询结果,性能增幅巨大。
+
+具体效果如下:
+
+(1)Hive 查询语句,用时 162 秒。
+
+```sql
+select count(*),product_no FROM ods.demo_tbl where dt='2023-03-09'
+group by product_no;
+```
+
+(2)Doris 上 Hive Catalog 查询语句,用时 58.531 秒。
+
+```sql
+set exec_mem_limit=16G;
+select count(*),product_no FROM hive.ods.demo_tbl where dt='2023-03-09'
+group by product_no;
+```
+
+(3)Doris 上本地表查询语句,**仅用时0.828秒**。
+
+```sql
+select count(*),product_no FROM ods.demo_tbl where dt='2023-03-09'
+group by product_no;
+```
+
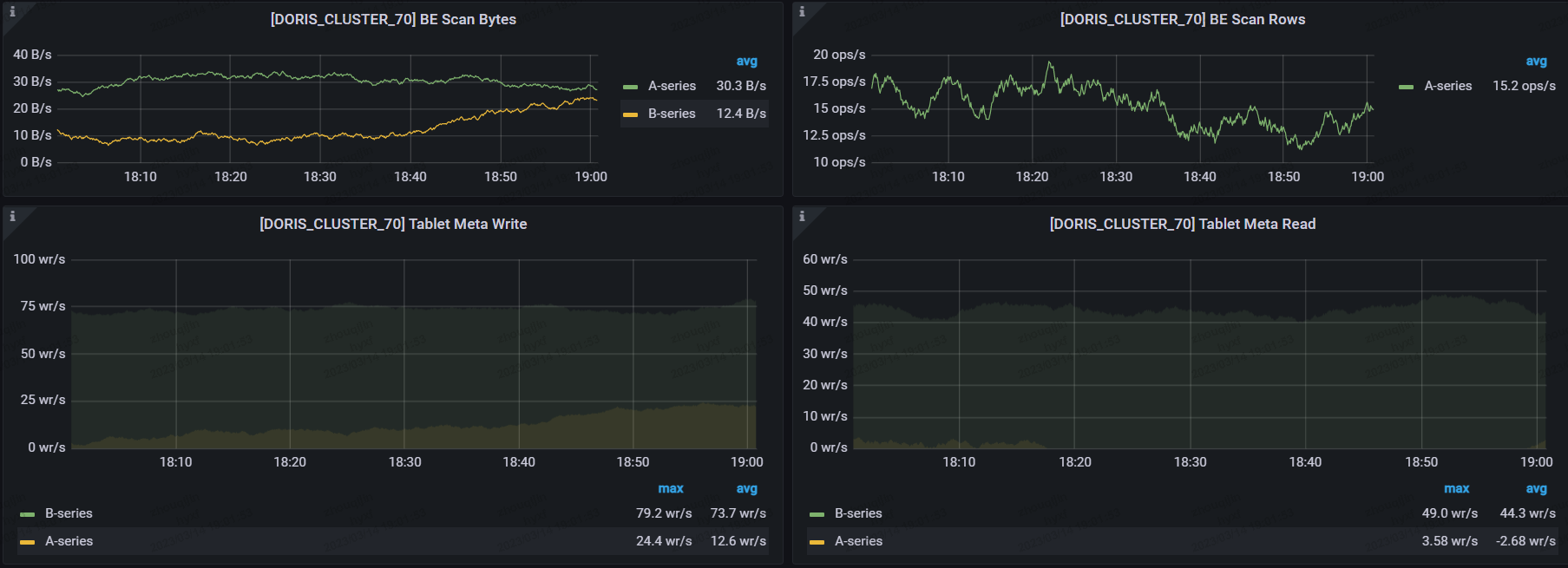
+3. 导入性能提升
+
+使用前:Hive 原始表包含 40 个字段,单个分区数据量 11 亿/天,在 HDFS 上占用约 806G 的空间
+
+使用后:通过 SeaTunnel 调起 Spark on YARN 方式进行数据同步,可以在 11 分钟左右完成数据同步,即 **1 分钟同步约一亿条数据**,同步后占用 378G 空间。
+
+可以看出,在数据导入性能的提升的同时,资源也有了较大的节省,主要得益于对以下几个参数进行了调整:
+
+`push_write_mbytes_per_sec`:BE 磁盘写入限速,300M
+
+`push_worker_count_high_priority:` 同时执行的 push 任务个数,15
+
+`push_worker_count_normal_priority`: 同时执行的 push 任务个数,15
+
+
+
+## **架构收益**
+
+**(1)统一数据源出口,查询效率显著提升**
+
+风控数据集市采用的是异构存储的方式来存储数据,Apache Doris 的 Multi Catalog 功能成功统一了 ES、Hive、GP 等数据源出口,实现了联邦查询。 同时,Doris 本身具有存储能力,可支持其他数据源中的数据通过外表插入内容的方式快速进行数据同步,真正实现了数据门户。此外,Apache Doris 可支持聚合查询,在向量化引擎的加持下,查询效率得到显著提升。
+
+**(2)** **Hive** **任务拆分,提升集群资源利用率**
+
+我们将原有的 Hive 跑批任务跟日常的查询统计进行了隔离,以提升集群资源的利用效率。目前 YARN 集群上的任务数量是几千的规模,跑批任务占比约 60%,临时查询分析占比 40%,由于资源限制导致日常跑批任务经常会因为资源等待而延误,临时分析也因资源未及时分配而导致任务无法完成。当部署了 Doris 1.2 之后,对资源进行了划分,完全摆脱 YARN 集群的资源限制,跑批与日常的查询统计均有了明显的改善,**基本可以在秒级得到分析结果**,同时也减轻了数据分析师的工作压力,提升了用户对平台的满意度。
+
+**(3)提升了数据接口的稳定性,数据写入性能大幅提升**
+
+之前数据接口是基于 ES 集群的,当进行大批量离线数据推送时会导致 ES 集群的 GC 抖动,影响了接口稳定性,经过调整之后,我们将接口服务的数据集存储在 Doris 上,Doris 节点并未出现抖动,实现数据快速写入,成功提升了接口的稳定性,同时 Doris 查询在数据写入时影响较小,数据写入性能较之前也有了非常大的提升,**千万级别的数据可在十分钟内推送成功**。
+
+**(4)Doris 生态丰富,迁移方便成本较低。**
+
+Spark-Doris-Connector 在过渡期为我们减轻了不少的压力,当数据在 Hive 与 Doris 共存时,部分 Doris 分析结果通过 Spark 回写到 Hive 非常方便,当 Spark 调用 Doris 时只需要进行简单改造就能完成原有脚本的复用,迁移方便、成本较低。
+
+**(5)支持横向热部署,集群扩容、运维简单。**
+
+Apache Doris 支持横向热部署,集群扩容方便,节点重启可以在在秒级实现,可实现无缝对接,减少了该过程对业务的影响; 在架构 1.0 中,当 Hive 集群与 GP 集群需要扩容更新时,配置修改后一般需要较长时间集群才可恢复,用户感知比较明显。而 Doris 很好的解决了这个问题,实现用户无感知扩容,也降低了集群运维的投入。
+
+# **未来与展望**
+
+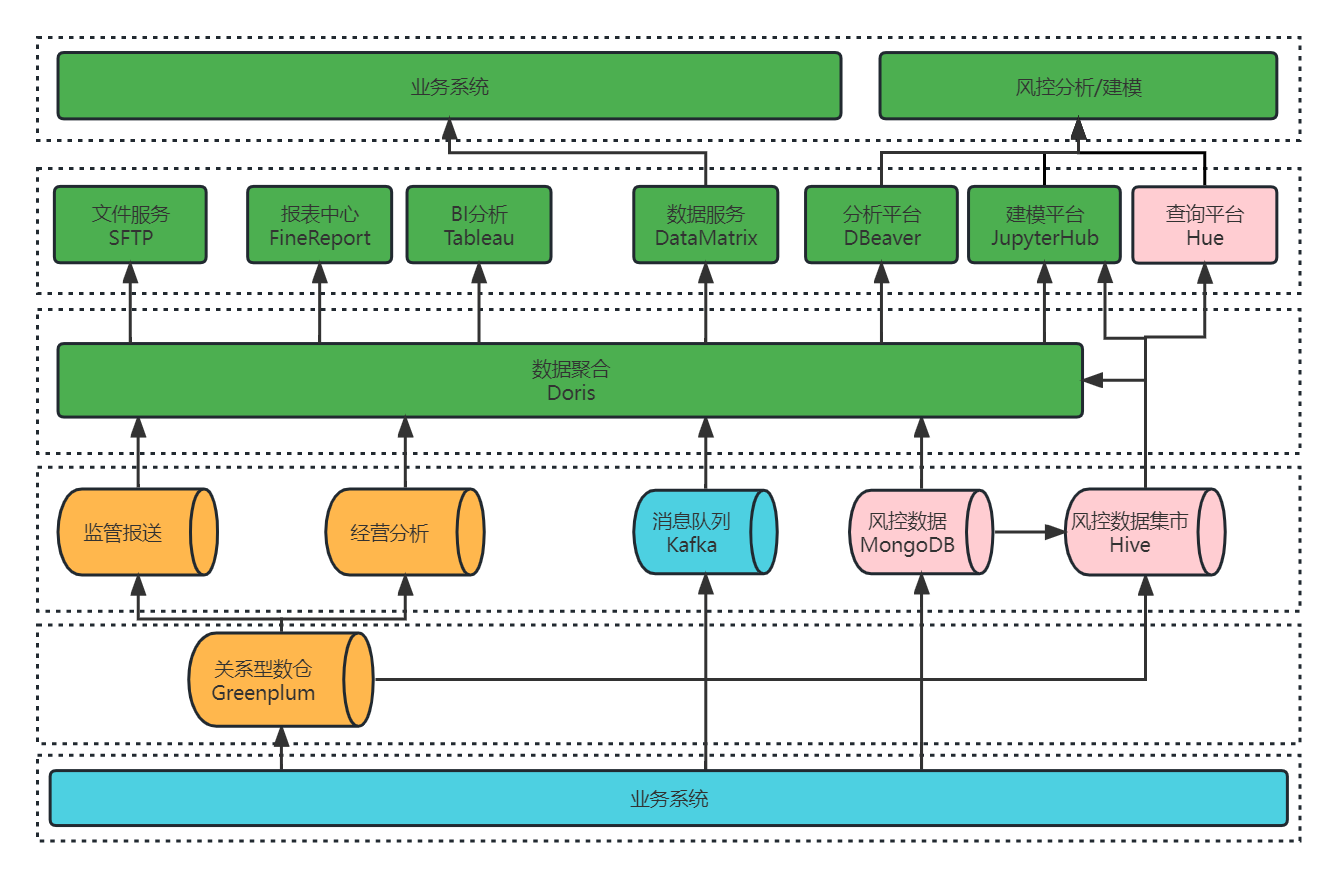
+
+当前在架构 2.0 中的 Doris 集群在大数据平台中的角色更倾向于查询优化,大部分数据还集中维护在 Hive 集群上,未来我们计划在升级架构 3.0 的时候,完成以下改造:
+
+- 实时全量数据接入:利用 Flink 将所有的实时数据直接接入 Doris,不再经过 ES 存储;
+- 数据集数据完整性:利用 Doris 构建实时数据集市的原始层,利用 FlinkCDC 等同步工具将业务库 MySQL与决策过程中产生的 MongoDB 数据实时同步到 Doris,最大限度将现有数据都接入 Doris 的统一平台,保证数据集数据完整性。
+- 离线跑批任务迁移:将现有 Hive&Spark 中大部分跑批任务迁移至 Doris,提升跑批效率;
+- 统一查询分析出口:将所有的查询分析统一集中到 Doris,完全统一数据出口,实现统一数据查询网关,使数据的管理更加规范化;
+- 强化集群稳定扩容:引入可视化运维管理工具对集群进行维护和管理,使 Doris 集群能够更加稳定支撑业务扩展。
+
+# 总结与致谢
+
+Apache Doris1.2 是社区在版本迭代中的重大升级,借助 Multi Catalog 等优异功能能让 Doris 在 Hadoop 相关的大数据体系中快速落地,实现联邦查询;同时可以将日常跑批与统计分析进行解耦,有效提升大数据平台的的查询性能。
+
+作为第一批 Apache Doris1.2 的用户,我们深感荣幸,同时也十分感谢 Doris 团队的全力配合和付出,可以让 Apache Doris 快速落地、上线生产,并为后续的迭代优化提供了可能。
+
+Apache Doris 1.2 值得大力推荐,希望大家都能从中受益,祝愿 Apache Doris 生态越来越繁荣,越来越好!
\ No newline at end of file
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/High_concurrency.md b/i18n/zh-CN/docusaurus-plugin-content-blog/High_concurrency.md
new file mode 100644
index 00000000000..761db4f90d9
--- /dev/null
+++ b/i18n/zh-CN/docusaurus-plugin-content-blog/High_concurrency.md
@@ -0,0 +1,319 @@
+---
+{
+ 'title': '并发提升 20+ 倍、单节点数万 QPS,Apache Doris 高并发特性解读',
+ 'summary': "在即将发布的 2.0 版本中,我们在原有功能基础上引入了一系列面向点查询的优化手段,单节点可达数万 QPS 的超高并发,极大拓宽了适用场景的能力边界。",
+ 'date': '2023-04-14',
+ 'author': 'Apache Doris',
+ 'tags': ['技术解析'],
+}
+---
+
+<!--
+Licensed to the Apache Software Foundation (ASF) under one
+or more contributor license agreements. See the NOTICE file
+distributed with this work for additional information
+regarding copyright ownership. The ASF licenses this file
+to you under the Apache License, Version 2.0 (the
+"License"); you may not use this file except in compliance
+with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing,
+software distributed under the License is distributed on an
+"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+KIND, either express or implied. See the License for the
+specific language governing permissions and limitations
+under the License.
+-->
+
+随着用户规模的极速扩张,越来越多用户将 Apache Doris 用于构建企业内部的统一分析平台,这一方面需要 [Apache Doris](https://github.com/apache/doris) 去承担更大业务规模的处理和分析——既包含了更大规模的数据量、也包含了更高的并发承载,而另一方面,也意味着需要应对企业更加多样化的数据分析诉求,从过去的统计报表、即席查询、交互式分析等典型 OLAP 场景,拓展到推荐、风控、标签画像以及 IoT 等更多业务场景中,而数据服务(Data Serving)就是其中具有代表性的一类需求。Data Serving 通常指的是向用户或企业客户提供数据访问服务,用户使用较为频繁的查询模式一般是按照 Key 查询一行或多行数据,例如:
+
+- 订单详情查询
+- 商品详情查询
+- 物流状态查询
+- 交易详情查询
+- 用户信息查询
+- 用户画像属性查询
+- ...
+
+与面向大规模数据扫描与计算的 Adhoc 不同,**Data Serving 在实际业务中通常呈现为高并发的点查询——** **查询返回的数据量较少、通常只需返回一行或者少量行数据,但对于查询耗时极为敏感、期望在毫秒内返回查询结果,并且面临着超高并发的挑战。**
+
+在过去面对此类业务需求时,通常采取不同的系统组件分别承载对应的查询访问。OLAP 数据库一般是基于列式存储引擎构建,且是针对大数据场景设计的查询框架,通常以数据吞吐量来衡量系统能力,因此在 Data Serving 高并发点查场景的表现往往不及用户预期。基于此,用户一般引入 Apache HBase 等 KV 系统来应对点查询、Redis 作为缓存层来分担高并发带来的系统压力。而这样的架构往往比较复杂,存在冗余存储、维护成本高的问题。融合统一的分析范式为 Apache Doris 能承载的工作负载带来了挑战,也让我们更加系统化地去思考如何更好地满足用户在此类场景的业务需求。基于以上思考,**在即将发布的 2.0 版本中,我们在原有功能基础上引入了一系列面向点查询的优化手段,单节点可达数万 QPS 的超高并发,极大拓宽了适用场景的能力边界。**
+
+# **# 如何应对高并发查询?**
+
+一直以来高并发就是 Apache Doris 的优势之一。对于高并发查询,其核心在于如何平衡有限的系统资源消耗与并发执行带来的高负载。换而言之,需要最大化降低单个 SQL 执行时的 CPU、内存和 IO 开销,其关键在于减少底层数据的 Scan 以及随后的数据计算,其主要优化方式有如下几种:
+
+### 分区分桶裁剪
+
+Apache Doris 采用两级分区,第一级是 Partition,通常可以将时间作为分区键。第二级为 Bucket,通过 Hash 将数据打散至各个节点中,以此提升读取并行度并进一步提高读取吞吐。通过合理地划分区分桶,可以提高查询性能,以下列查询语句为例:
+
+```
+select * from user_table where id = 5122 and create_date = '2022-01-01'
+```
+
+用户以`create_time`作为分区键、ID 作为分桶键,并设置了 10 个 Bucket, 经过分区分桶裁剪后可快速过滤非必要的分区数据,最终只需读取极少数据,比如 1 个分区的 1 个 Bucket 即可快速定位到查询结果,最大限度减少了数据的扫描量、降低了单个查询的延时。
+
+### 索引
+
+除了分区分桶裁剪, Doris 还提供了丰富的索引结构来加速数据的读取和过滤。索引的类型大体可以分为智能索引和二级索引两种,其中智能索引是在 Doris 数据写入时自动生成的,无需用户干预。智能索引包括前缀索引和 ZoneMap 索引两类:
+
+- **前缀稀疏索引(Sorted Index)** 是建立在排序结构上的一种索引。Doris 存储在文件中的数据,是按照排序列有序存储的,Doris 会在排序数据上每 1024 行创建一个稀疏索引项。索引的 Key 即当前这 1024 行中第一行的前缀排序列的值,当用户的查询条件包含这些排序列时,可以通过前缀稀疏索引快速定位到起始行。
+- **ZoneMap 索引**是建立在 Segment 和 Page 级别的索引。对于 Page 中的每一列,都会记录在这个 Page 中的最大值和最小值,同样,在 Segment 级别也会对每一列的最大值和最小值进行记录。这样当进行等值或范围查询时,可以通过 MinMax 索引快速过滤掉不需要读取的行。
+
+二级索引是需要用手动创建的索引,包括 Bloom Filter 索引、Bitmap 索引,以及 2.0 版本新增的 Inverted 倒排索引和 NGram Bloom Filter 索引,在此不细述,可从官网文档先行了解,后续将有系列文章进行解读。
+
+**官网文档:**
+
+- 倒排索引:https://doris.apache.org/zh-CN/docs/dev/data-table/index/inverted-index
+- NGram BloomFilter 索引:https://doris.apache.org/zh-CN/docs/dev/data-table/index/ngram-bloomfilter-index
+
+我们以下列查询语句为例:
+
+```
+select * from user_table where id > 10 and id < 1024
+```
+
+假设按照 ID 作为建表时指定的 Key, 那么在 Memtable 以及磁盘上按照 ID 有序的方式进行组织,查询时如果过滤条件包含前缀字段时,则可以使用前缀索引快速过滤。Key 查询条件在存储层会被划分为多个 Range,按照前缀索引做二分查找获取到对应的行号范围,由于前缀索引是稀疏的,所以只能大致定位出行的范围。随后过一遍 ZoneMap、Bloom Filter、Bitmap 等索引,进一步缩小需要 Scan 的行数。**通过索引,大大减少了需要扫描的行数,减少 CPU 和 IO 的压力,整体大幅提升了系统的并发能力。**
+
+### 物化视图
+
+物化视图是一种典型的空间换时间的思路,其本质是根据预定义的 SQL 分析语句执⾏预计算,并将计算结果持久化到另一张对用户透明但有实际存储的表中。在需要同时查询聚合数据和明细数据以及匹配不同前缀索引的场景,**命中物化视图时可以获得更快的查询相应,同时也避免了大量的现场计算,因此可以提高性能表现并降低资源消耗**。
+
+```
+// 对于聚合操作, 直接读物化视图预聚合的列
+create materialized view store_amt as select store_id, sum(sale_amt) from sales_records group by store_id;
+SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;
+
+// 对于查询, k3满足物化视图前缀列条件, 走物化视图加速查询
+CREATE MATERIALIZED VIEW mv_1 as SELECT k3, k2, k1 FROM tableA ORDER BY k3;
+select k1, k2, k3 from table A where k3=3;
+```
+
+### Runtime Filter
+
+除了前文提到的用索引来加速过滤查询的数据, Doris 中还额外加入了动态过滤机制,即 Runtime Filter。在多表关联查询时,我们通常将右表称为 BuildTable、左表称为 ProbeTable,左表的数据量会大于右表的数据。在实现上,会首先读取右表的数据,在内存中构建一个 HashTable(Build)。之后开始读取左表的每一行数据,并在 HashTable 中进行连接匹配,来返回符合连接条件的数据(Probe)。而 Runtime Filter 是在右表构建 HashTable 的同时,为连接列生成一个过滤结构,可以是 Min/Max、IN 等过滤条件。之后把这个过滤列结构下推给左表。这样一来,左表就可以利用这个过滤结构,对数据进行过滤,从而减少 Probe 节点需要传输和比对的数据量。在大多数 Join 场景中,Runtime Filter 可以实现节点的自动穿透,将 Filter 穿透下推到最底层的扫描节点或者分布式 Shuffle Join 中
。**大多数的关联查询 Runtime Filter 都可以起到大幅减少数据读取的效果,从而加速整个查询的速度。**
+
+### OPN 优化技术
+
+在数据库中查询最大或最小几条数据的应用场景非常广泛,比如查询满足某种条件的时间最近 100 条数据、查询价格最高或者最低的几个商品等,此类查询的性能对于实时分析非常重要。在 Doris 中引入了 TOPN 优化来解决大数据场景下较高的 IO、CPU、内存资源消耗:
+
+- 首先从 Scanner 层读取排序字段和查询字段,利用堆排序保留 TOPN 条数据,实时更新当前已知的最大或最小的数据范围, 并动态下推至 Scanner
+
+- Scanner 层根据范围条件,利用索引等加速跳过文件和数据块,大幅减少读取的数据量。
+
+- 在宽表中用户通常需要查询字段数较多, 在 TOPN 场景实际有效的数据仅 N 条, 通过将读取拆分成两阶段, 第一阶段根据少量的排序列、条件列来定位行号并排序,第二阶段根据排序后并取 TOPN 的结果得到行号反向查询数据,这样可以大大降低 Scan 的开销
+
+
+
+
+**通过以上一系列优化手段,可以将不必要的数据剪枝掉,减少读取、排序的数据量,显著降低系统 IO、CPU 以及内存资源消耗**。此外,还可以利用包括 SQL Cache、Partition Cache 在内的缓存机制以及 Join 优化手段来进一步提升并发,由于篇幅原因不在此详述。
+
+# **# Apache Doris 2.0 新特性揭秘**
+
+通过上一段中所介绍的内容,Apache Doris 实现了单节点上千 QPS 的并发支持。但在一些超高并发要求(例如数万 QPS)的 Data Serving 场景中,仍然存在瓶颈:
+
+- 列式存储引擎对于行级数据的读取不友好,宽表模型上列存格式将大大放大随机读取 IO;
+- OLAP 数据库的执行引擎和查询优化器对于某些简单的查询(如点查询)来说太重,需要在查询规划中规划短路径来处理此类查询;
+- SQL 请求的接入以及查询计划的解析与生成由 FE 模块负责,使用的是 Java 语言,在高并发场景下解析和生成大量的查询执行计划会导致高 CPU 开销;
+- ……
+
+带着以上问题,Apache Doris 在分别从降低 SQL 内存 IO 开销、提升点查执行效率以及降低 SQL 解析开销这三个设计点出发,进行一系列优化。
+
+### 行式存储格式(Row Store Format)
+
+与列式存储格式不同,行式存储格式在数据服务场景会更加友好,数据按行存储、应对单次检索整行数据时效率更高,可以极大减少磁盘访问次数。**因此在 Apache Doris 2.0 版本中,我们引入了行式存储格式,将行存编码后存在单独的一列中,通过额外的空间来存储**。用户可以在建表语句的 Property 中指定如下属性来开启行存:
+
+```
+"store_row_column" = "true"
+```
+
+我们选择以 JSONB 作为行存的编码格式,主要出于以下考虑:
+
+- Schema 变更灵活:随着数据的变化、变更,表的 Schema 也可能发生相应变化。行存储格式提供灵活性以处理这些变化是很重要的,例如用户删减字段、修改字段类型,数据变更需要及时同步到行存中。通过使用 JSONB 作为编码方式,将列作为 JSONB 的字段进行编码, 可以非常方便地进行字段扩展以及更改属性。
+- 性能更高:在行存储格式中访问行可以比在列存储格式中访问行更快,因为数据存储在单个行中。这可以在高并发场景下显著减少磁盘访问开销。此外,通过将每个列 ID 映射到 JSONB其对应的值,可以实现对个别列的快速访问。
+- 存储空间:将 JSONB 作为行存储格式的编解码器也可以帮助减少磁盘存储成本。紧凑的二进制格式可以减少存储在磁盘上的数据总大小,使其更具成本效益。
+
+使用 JSONB 编解码行存储格式,可以帮助解决高并发场景下面临的性能和存储问题。行存在存储引擎中会作为一个隐藏列(`DORIS_ROW_STORE_COL`)来进行存储,在 Memtable Flush 时,将各个列按照 JSONB 进行编码并缓存到这个隐藏列里。在数据读取时, 通过该隐藏列的 Column ID 来定位该列, 通过其行号定位到某一具体的行,并反序列化各列。
+
+相关PR:https://github.com/apache/doris/pull/15491
+
+### 点查询短路径优化(Short-Circuit)
+
+通常情况下,一条 SQL 语句的执行需要经过三个步骤:首先通过 SQL Parser 解析语句,生成抽象语法树(AST),随后通过 Query Optimizer 生成可执行计划(Plan),最终通过执行该计划得到计算结果。对于大数据量下的复杂查询,经由查询优化器生成的执行计划无疑具有更高效的执行效果,但对于低延时和高并发要求的点查询,则不适宜走整个查询优化器的优化流程,会带来不必要的额外开销。为了解决这个问题,我们实现了点查询的短路径优化,绕过查询优化器以及 PlanFragment 来简化 SQL 执行流程,直接使用快速高效的读路径来检索所需的数据。
+
+
+
+
+当查询被 FE 接收后,它将由规划器生成适当的 Short-Circuit Plan 作为点查询的物理计划。该 Plan 非常轻量级,不需要任何等效变换、逻辑优化或物理优化,仅对 AST 树进行一些基本分析、构建相应的固定计划并减少优化器的开销。对于简单的主键点查询,如`select * from tbl where pk1 = 123 and pk2 = 456`,因为其只涉及单个 Tablet,因此可以使用轻量的 RPC 接口来直接与 StorageEngine 进行交互,以此避免生成复杂的Fragment Plan 并消除了在 MPP 查询框架下执行调度的性能开销。RPC 接口的详细信息如下:
+
+```
+message PTabletKeyLookupRequest {
+ required int64 tablet_id = 1;
+ repeated KeyTuple key_tuples = 2;
+ optional Descriptor desc_tbl = 4;
+ optional ExprList output_expr = 5;
+}
+
+message PTabletKeyLookupResponse {
+ required PStatus status = 1;
+ optional bytes row_batch = 5;
+ optional bool empty_batch = 6;
+}
+rpc tablet_fetch_data(PTabletKeyLookupRequest) returns (PTabletKeyLookupResponse);
+```
+
+以上 tablet_id 是从主键条件列计算得出的,`key_tuples`是主键的字符串格式,在上面的示例中,`key_tuples`类似于 ['123', '456'],在 BE 收到请求后`key_tuples`将被编码为主键存储格式,并根据主键索引来识别 Key 在 Segment File 中的行号,并查看对应的行是否在`delete bitmap`中,如果存在则返回其行号,否则返回`NotFound`。然后使用该行号直对`__DORIS_ROW_STORE_COL__`列进行点查询,因此我们只需在该列中定位一行并获取 JSONB 格式的原始值,并对其进行反序列化作为后续输出函数计算的值。
+
+相关PR:https://github.com/apache/doris/pull/15491
+
+### 预处理语句优化(PreparedStatement)
+
+高并发查询中的 CPU 开销可以部分归因于 FE 层分析和解析 SQL 的 CPU 计算,为了解决这个问题,我们在 FE 端提供了与 MySQL 协议完全兼容的预处理语句(Prepared Statement)。当 CPU 成为主键点查的性能瓶颈时,**Prepared Statement 可以有效发挥作用,实现 4 倍以上的性能提升**。
+
+
+
+Prepared Statement 的工作原理是通过在 Session 内存 HashMap 中缓存预先计算好的 SQL 和表达式,在后续查询时直接复用缓存对象即可。Prepared Statement 使用 [MySQL 二进制协议](https://dev.mysql.com/doc/dev/mysqlserver/latest/page_protocol_binary_resultset.html#sect_protocol_binary_resultset_row)作为传输协议。该协议在文件`mysql_row_buffer.[h|cpp] `中实现,符合标准 MySQL 二进制编码, 通过该协议客户端例如 JDBC Client, 第一阶段发送`PREPARE`MySQL Command 将预编译语句发送给 FE 并由 FE 解析、Analyze 该语句并缓存到上图的 HashMap 中,接着客户端通过`EXECUTE`MySQL Command 将占位符替换并编码成二进制的格式发送给 FE, 此时 FE 按照 MySQL 协议反序列化后得到占位符中的值,生 [...]
+
+
+
+
+除了在 FE 缓存 Statement,我们还需要在 BE 中缓存被重复使用的结构,包括预先分配的计算 Block,查询描述符和输出表达式,由于这些结构在序列化和反序列化时会造成 CPU 热点, 所以需要将这些结构缓存下来。对于每个查询的 PreparedStatement,都会附带一个名为 CacheID 的 UUID。当 BE 执行点查询时,根据相关的 CacheID 找到对应的复用类, 并在 BE 中表达式计算、执行时重复使用上述结构。下面是在 JDBC 中使用 PreparedStatement 的示例:1. 设置 JDBC URL 并在 Server 端开启 PreparedStatement
+
+```
+url = jdbc:mysql://127.0.0.1:9030/ycsb?useServerPrepStmts=true
+```
+
+2. 使用 Prepared Statement
+
+```
+// use `?` for placement holders, readStatement should be reused
+PreparedStatement readStatement = conn.prepareStatement("select * from tbl_point_query where key = ?");
+...
+readStatement.setInt(1234);
+ResultSet resultSet = readStatement.executeQuery();
+...
+readStatement.setInt(1235);
+resultSet = readStatement.executeQuery();
+...
+
+相关 PR:https://github.com/apache/doris/pull/15491
+```
+
+### 行存缓存
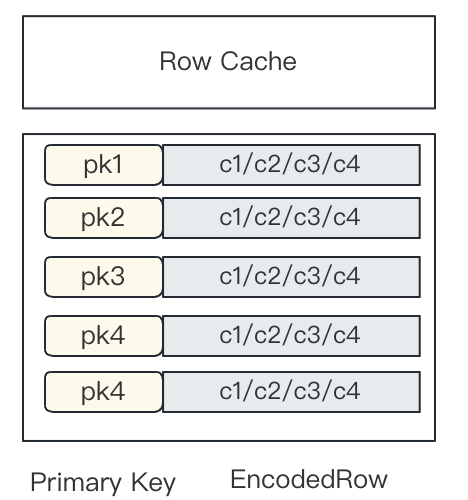
+
+Doris 中有针对 Page 级别的 Cache,每个 Page 中存的是某一列的数据,所以 Page Cache 是针对列的缓存。
+
+
+
+
+对于前面提到的行存,一行里包括了多列数据,缓存可能被大查询给刷掉,为了增加行缓存命中率,就需要单独引入行存缓存(Row Cache)。行存 Cache 复用了 Doris 中的 LRU Cache 机制, 启动时会初始化一个内存阈值, 当超过内存阈值后会淘汰掉陈旧的缓存行。对于一条主键查询语句,在存储层上命中行缓存和不命中行缓存可能有数十倍的性能差距(磁盘 IO 与内存的访问差距),**因此行缓存的引入可以极大提升点查询的性能,特别是缓存命中高的场景下。**
+
+
+
+开启行存缓存可以在 BE 中设置以下配置项来开启:
+
+```
+disable_storage_row_cache=false //是否开启行缓存, 默认不开启
+row_cache_mem_limit=20% // 指定row cache占用内存的百分比, 默认20%内存
+```
+
+相关 PR:https://github.com/apache/doris/pull/15491
+
+# **# Benchmark**
+
+基于以上一系列优化,帮助 Apache Doris 在 Data Serving 场景的性能得到进一步提升。我们基于 Yahoo! Cloud Serving Benchmark (YCSB)标准性能测试工具进行了基准测试,其中环境配置与数据规模如下:
+
+- 机器环境:单台 16 Core 64G 内存 4*1T 硬盘的云服务器
+- 集群规模:1 FE + 3 BE
+- 数据规模:一共 1 亿条数据,平均每行在 1K 左右,测试前进行了预热。
+- 对应测试表结构与查询语句如下:
+
+
+```
+// 建表语句如下:
+
+CREATE TABLE `usertable` (
+ `YCSB_KEY` varchar(255) NULL,
+ `FIELD0` text NULL,
+ `FIELD1` text NULL,
+ `FIELD2` text NULL,
+ `FIELD3` text NULL,
+ `FIELD4` text NULL,
+ `FIELD5` text NULL,
+ `FIELD6` text NULL,
+ `FIELD7` text NULL,
+ `FIELD8` text NULL,
+ `FIELD9` text NULL
+) ENGINE=OLAP
+UNIQUE KEY(`YCSB_KEY`)
+COMMENT 'OLAP'
+DISTRIBUTED BY HASH(`YCSB_KEY`) BUCKETS 16
+PROPERTIES (
+"replication_allocation" = "tag.location.default: 1",
+"in_memory" = "false",
+"persistent" = "false",
+"storage_format" = "V2",
+"enable_unique_key_merge_on_write" = "true",
+"light_schema_change" = "true",
+"store_row_column" = "true",
+"disable_auto_compaction" = "false"
+);
+
+// 查询语句如下:
+
+SELECT * from usertable WHERE YCSB_KEY = ?
+```
+
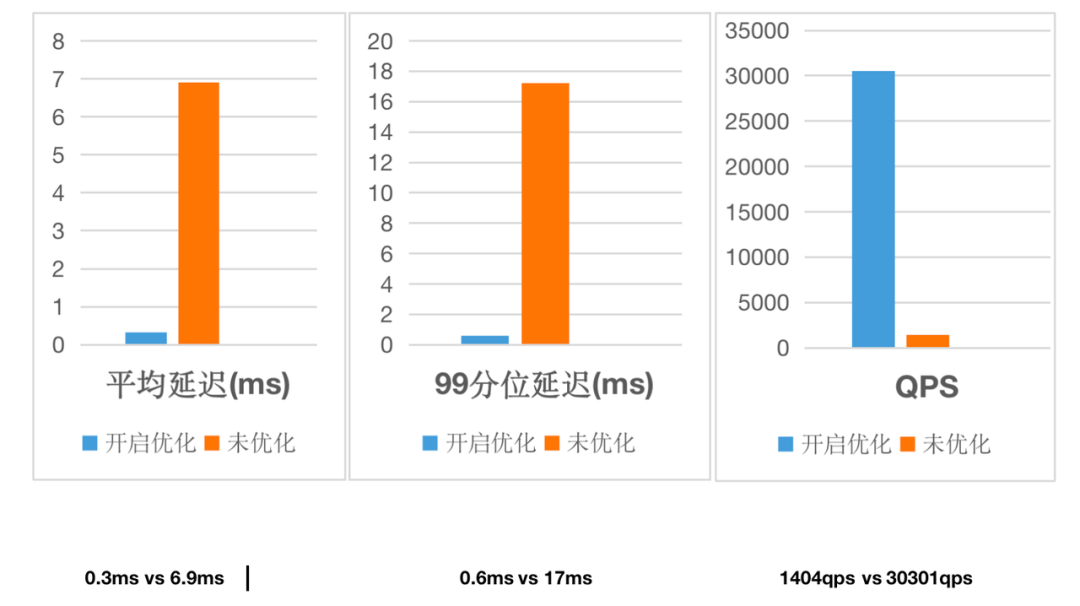
+开启优化(即同时开启行存、点查短路径以及 PreparedStatement)与未开启的测试结果如下:
+
+
+
+开启以上优化项后平均**查询耗时降低了 96%** ,99 分位的**查询耗时仅之前的 1/28**,QPS 并发**从 1400 增至 3w、提升了超过 20 倍**,整体性能表现和并发承载实现数据量级的飞跃!
+
+# **# 最佳实践**
+
+需要注意的是,在当前阶段实现的点查询优化均是在 Unique Key 主键模型进行的,同时需要开启 Merge-on-Write 以及 Light Schema Change 后使用,以下是点查询场景的建表语句示例:
+
+```
+CREATE TABLE `usertable` (
+ `USER_KEY` BIGINT NULL,
+ `FIELD0` text NULL,
+ `FIELD1` text NULL,
+ `FIELD2` text NULL,
+ `FIELD3` text NULL
+) ENGINE=OLAP
+UNIQUE KEY(`USER_KEY`)
+COMMENT 'OLAP'
+DISTRIBUTED BY HASH(`USER_KEY`) BUCKETS 16
+PROPERTIES (
+"enable_unique_key_merge_on_write" = "true",
+"light_schema_change" = "true",
+"store_row_column" = "true",
+);
+```
+
+**注意:**
+
+- 开启`light_schema_change`来支持 JSONB 行存编码 ColumnID
+
+- 开启`store_row_column`来存储行存格式
+
+完成建表操作后,类似如下基于主键的点查 SQL 可通过行式存储格式和短路径执行得到性能的大幅提升:
+
+```
+select * from usertable where USER_KEY = xxx;
+```
+
+与此同时,可以通过 JDBC 中的 Prepared Statement 来进一步提升点查询性能。如果有充足的内存, 还可以在 BE 配置文件中开启行存 Cache,上文中均已给出使用示例,在此不再赘述。
+
+# **# 总结**
+
+通过引入行式存储格式、点查询短路径优化、预处理语句以及行存缓存,Apache Doris 实现了单节点上万 QPS 的超高并发,实现了数十倍的性能飞跃。而随着集群规模的横向拓展、机器配置的提升,Apache Doris 还可以利用硬件资源实现计算加速,自身的 MPP 架构也具备横向线性拓展的能力。**因此 Apache Doris 真正具备了在** **一套架构下同时** **满足高吞吐的 OLAP 分析和高并发的 Data Serving 在线服务的能力,大大简化了混合工作负载下的技术架构,为用户提供了多场景下的统一分析体验**。
+
+以上功能的实现得益于 Apache Doris 社区开发者共同努力以及 SelectDB 工程师的的持续贡献,当前已处于紧锣密鼓的发版流程中,在不久后的 2.0 版本就会发布出来。如果对于以上功能有强烈需求,**[欢迎填写问卷提交申请](https://wenjuan.feishu.cn/m?t=sF2FZOL1KXKi-m73g),或者与 SelectDB 技术团队直接联系,提前获得 2.0-alpha 版本的体验机会**,也欢迎随时向我们反馈使用意见。
+
+**作者介绍:**
+
+李航宇,Apache Doris Contributor,SelectDB 半结构化研发工程师。
\ No newline at end of file
diff --git a/static/images/RDM_1.png b/static/images/RDM_1.png
new file mode 100644
index 00000000000..d8dda04e4b0
Binary files /dev/null and b/static/images/RDM_1.png differ
diff --git a/static/images/RDM_2.png b/static/images/RDM_2.png
new file mode 100644
index 00000000000..c183f4fee7d
Binary files /dev/null and b/static/images/RDM_2.png differ
diff --git a/static/images/RDM_3.png b/static/images/RDM_3.png
new file mode 100644
index 00000000000..ec2e85296cb
Binary files /dev/null and b/static/images/RDM_3.png differ
diff --git a/static/images/RDM_4.png b/static/images/RDM_4.png
new file mode 100644
index 00000000000..3b50a30f5c7
Binary files /dev/null and b/static/images/RDM_4.png differ
diff --git a/static/images/RDM_5.png b/static/images/RDM_5.png
new file mode 100644
index 00000000000..7d21c2ca22c
Binary files /dev/null and b/static/images/RDM_5.png differ
diff --git a/static/images/RDM_6.png b/static/images/RDM_6.png
new file mode 100644
index 00000000000..50589846341
Binary files /dev/null and b/static/images/RDM_6.png differ
diff --git a/static/images/RDM_7.png b/static/images/RDM_7.png
new file mode 100644
index 00000000000..e68ecb3bfe8
Binary files /dev/null and b/static/images/RDM_7.png differ
diff --git a/static/images/high-concurrency_1.png b/static/images/high-concurrency_1.png
new file mode 100644
index 00000000000..40c240d1624
Binary files /dev/null and b/static/images/high-concurrency_1.png differ
diff --git a/static/images/high-concurrency_2.png b/static/images/high-concurrency_2.png
new file mode 100644
index 00000000000..16e24829443
Binary files /dev/null and b/static/images/high-concurrency_2.png differ
diff --git a/static/images/high-concurrency_3.png b/static/images/high-concurrency_3.png
new file mode 100644
index 00000000000..770026df8e2
Binary files /dev/null and b/static/images/high-concurrency_3.png differ
diff --git a/static/images/high-concurrency_4.png b/static/images/high-concurrency_4.png
new file mode 100644
index 00000000000..9a8991c2c9e
Binary files /dev/null and b/static/images/high-concurrency_4.png differ
diff --git a/static/images/high-concurrency_5.png b/static/images/high-concurrency_5.png
new file mode 100644
index 00000000000..8ba267bdaa5
Binary files /dev/null and b/static/images/high-concurrency_5.png differ
diff --git a/static/images/high-concurrency_6.png b/static/images/high-concurrency_6.png
new file mode 100644
index 00000000000..903d8aaf203
Binary files /dev/null and b/static/images/high-concurrency_6.png differ
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org