You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@seatunnel.apache.org by GitBox <gi...@apache.org> on 2022/05/12 05:47:58 UTC
[GitHub] [incubator-seatunnel] someorz opened a new issue, #1861: [Bug] [spark] write to hive error
someorz opened a new issue, #1861:
URL: https://github.com/apache/incubator-seatunnel/issues/1861
### Search before asking
- [X] I had searched in the [issues](https://github.com/apache/incubator-seatunnel/issues?q=is%3Aissue+label%3A%22bug%22) and found no similar issues.
### What happened
write to hive error
### SeaTunnel Version
v2.1.1
### SeaTunnel Config
```conf
env {
spark.sql.catalogImplementation = "hive"
spark.hadoop.hive.exec.dynamic.partition = "true"
spark.hadoop.hive.exec.dynamic.partition.mode = "nonstrict"
spark.hadoop.metastore.catalog.default="hive"
spark.sql.catalogImplementation="hive"
spark.app.name = "SeaTunnel"
spark.executor.instances = 1
spark.executor.cores = 1
spark.executor.memory = "1g"
}
source {
hive {
pre_sql = "select * from default.dwd_fault_info_pdi_2 where pt='20220510'"
result_table_name = "dwd_fault_info_pdi_2"
}
}
transform {
}
sink {
hive {
sql = "insert overwrite table default.dwd_fault_info_pdi_2_sink partition(pt,htid) select * from dwd_fault_info_pdi_2"
source_table_name = "dwd_fault_info_pdi_2"
result_table_name = "default.dwd_fault_info_pdi_2_sink"
save_mode = "overwrite"
sink_columns = "tid,begintime,endtime,beginlongitude,beginlatitude,endlongitude,endlatitude,duration,faultaddr,spn,fmi,pt,htid"
partition_by = ["pt","htid"]
}
}
```
### Running Command
```shell
./bin/start-seatunnel-spark.sh --master local[1] --deploy-mode client --config ./hive_to_hive.conf
```
### Error Exception
```log
22/05/12 10:52:38 ERROR seatunnel.Seatunnel: Fatal Error,
22/05/12 10:52:38 ERROR seatunnel.Seatunnel: Please submit bug report in https://github.com/apache/incubator-seatunnel/issues
22/05/12 10:52:38 ERROR seatunnel.Seatunnel: Reason:Execute Spark task error
22/05/12 10:52:38 ERROR seatunnel.Seatunnel: Exception StackTrace:java.lang.RuntimeException: Execute Spark task error
at org.apache.seatunnel.command.spark.SparkTaskExecuteCommand.execute(SparkTaskExecuteCommand.java:61)
at org.apache.seatunnel.command.spark.SparkTaskExecuteCommand.execute(SparkTaskExecuteCommand.java:36)
at org.apache.seatunnel.Seatunnel.run(Seatunnel.java:48)
at org.apache.seatunnel.SeatunnelSpark.main(SeatunnelSpark.java:27)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:851)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:926)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:935)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: Exception when loading 3 in table dwd_fault_info_pdi_2_sink with loadPath=hdfs://ha-hdfs/user/hive/warehouse/dwd_fault_info_pdi_2_sink/.hive-staging_hive_2022-05-12_10-52-32_753_5734183484472760049-1/-ext-10000;
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:108)
at org.apache.spark.sql.hive.HiveExternalCatalog.loadDynamicPartitions(HiveExternalCatalog.scala:924)
at org.apache.spark.sql.catalyst.catalog.ExternalCatalogWithListener.loadDynamicPartitions(ExternalCatalogWithListener.scala:189)
at org.apache.spark.sql.hive.execution.InsertIntoHiveTable.processInsert(InsertIntoHiveTable.scala:205)
at org.apache.spark.sql.hive.execution.InsertIntoHiveTable.run(InsertIntoHiveTable.scala:99)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:104)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:102)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.executeCollect(commands.scala:115)
at org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:194)
at org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:194)
at org.apache.spark.sql.Dataset$$anonfun$53.apply(Dataset.scala:3364)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:78)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:125)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:73)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3363)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:194)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:79)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:651)
at org.apache.seatunnel.spark.hive.sink.Hive.output(Hive.scala:43)
at org.apache.seatunnel.spark.hive.sink.Hive.output(Hive.scala:29)
at org.apache.seatunnel.spark.SparkEnvironment.sinkProcess(SparkEnvironment.java:164)
at org.apache.seatunnel.spark.batch.SparkBatchExecution.start(SparkBatchExecution.java:54)
at org.apache.seatunnel.command.spark.SparkTaskExecuteCommand.execute(SparkTaskExecuteCommand.java:58)
... 15 more
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: Exception when loading 3 in table dwd_fault_info_pdi_2_sink with loadPath=hdfs://ha-hdfs/user/hive/warehouse/dwd_fault_info_pdi_2_sink/.hive-staging_hive_2022-05-12_10-52-32_753_5734183484472760049-1/-ext-10000
at org.apache.hadoop.hive.ql.metadata.Hive.loadDynamicPartitions(Hive.java:2030)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.sql.hive.client.Shim_v2_1.loadDynamicPartitions(HiveShim.scala:1169)
at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$loadDynamicPartitions$1.apply$mcV$sp(HiveClientImpl.scala:804)
at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$loadDynamicPartitions$1.apply(HiveClientImpl.scala:802)
at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$loadDynamicPartitions$1.apply(HiveClientImpl.scala:802)
at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$withHiveState$1.apply(HiveClientImpl.scala:283)
at org.apache.spark.sql.hive.client.HiveClientImpl.liftedTree1$1(HiveClientImpl.scala:221)
at org.apache.spark.sql.hive.client.HiveClientImpl.retryLocked(HiveClientImpl.scala:220)
at org.apache.spark.sql.hive.client.HiveClientImpl.withHiveState(HiveClientImpl.scala:266)
at org.apache.spark.sql.hive.client.HiveClientImpl.loadDynamicPartitions(HiveClientImpl.scala:802)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$loadDynamicPartitions$1.apply$mcV$sp(HiveExternalCatalog.scala:936)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$loadDynamicPartitions$1.apply(HiveExternalCatalog.scala:924)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$loadDynamicPartitions$1.apply(HiveExternalCatalog.scala:924)
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:99)
... 37 more
22/05/12 10:52:38 ERROR seatunnel.Seatunnel:
===============================================================================
Exception in thread "main" java.lang.RuntimeException: Execute Spark task error
at org.apache.seatunnel.command.spark.SparkTaskExecuteCommand.execute(SparkTaskExecuteCommand.java:61)
at org.apache.seatunnel.command.spark.SparkTaskExecuteCommand.execute(SparkTaskExecuteCommand.java:36)
at org.apache.seatunnel.Seatunnel.run(Seatunnel.java:48)
at org.apache.seatunnel.SeatunnelSpark.main(SeatunnelSpark.java:27)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:851)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:926)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:935)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: Exception when loading 3 in table dwd_fault_info_pdi_2_sink with loadPath=hdfs://ha-hdfs/user/hive/warehouse/dwd_fault_info_pdi_2_sink/.hive-staging_hive_2022-05-12_10-52-32_753_5734183484472760049-1/-ext-10000;
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:108)
at org.apache.spark.sql.hive.HiveExternalCatalog.loadDynamicPartitions(HiveExternalCatalog.scala:924)
at org.apache.spark.sql.catalyst.catalog.ExternalCatalogWithListener.loadDynamicPartitions(ExternalCatalogWithListener.scala:189)
at org.apache.spark.sql.hive.execution.InsertIntoHiveTable.processInsert(InsertIntoHiveTable.scala:205)
at org.apache.spark.sql.hive.execution.InsertIntoHiveTable.run(InsertIntoHiveTable.scala:99)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:104)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:102)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.executeCollect(commands.scala:115)
at org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:194)
at org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:194)
at org.apache.spark.sql.Dataset$$anonfun$53.apply(Dataset.scala:3364)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:78)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:125)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:73)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3363)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:194)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:79)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:651)
at org.apache.seatunnel.spark.hive.sink.Hive.output(Hive.scala:43)
at org.apache.seatunnel.spark.hive.sink.Hive.output(Hive.scala:29)
at org.apache.seatunnel.spark.SparkEnvironment.sinkProcess(SparkEnvironment.java:164)
at org.apache.seatunnel.spark.batch.SparkBatchExecution.start(SparkBatchExecution.java:54)
at org.apache.seatunnel.command.spark.SparkTaskExecuteCommand.execute(SparkTaskExecuteCommand.java:58)
... 15 more
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: Exception when loading 3 in table dwd_fault_info_pdi_2_sink with loadPath=hdfs://ha-hdfs/user/hive/warehouse/dwd_fault_info_pdi_2_sink/.hive-staging_hive_2022-05-12_10-52-32_753_5734183484472760049-1/-ext-10000
at org.apache.hadoop.hive.ql.metadata.Hive.loadDynamicPartitions(Hive.java:2030)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.sql.hive.client.Shim_v2_1.loadDynamicPartitions(HiveShim.scala:1169)
at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$loadDynamicPartitions$1.apply$mcV$sp(HiveClientImpl.scala:804)
at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$loadDynamicPartitions$1.apply(HiveClientImpl.scala:802)
at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$loadDynamicPartitions$1.apply(HiveClientImpl.scala:802)
at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$withHiveState$1.apply(HiveClientImpl.scala:283)
at org.apache.spark.sql.hive.client.HiveClientImpl.liftedTree1$1(HiveClientImpl.scala:221)
at org.apache.spark.sql.hive.client.HiveClientImpl.retryLocked(HiveClientImpl.scala:220)
at org.apache.spark.sql.hive.client.HiveClientImpl.withHiveState(HiveClientImpl.scala:266)
at org.apache.spark.sql.hive.client.HiveClientImpl.loadDynamicPartitions(HiveClientImpl.scala:802)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$loadDynamicPartitions$1.apply$mcV$sp(HiveExternalCatalog.scala:936)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$loadDynamicPartitions$1.apply(HiveExternalCatalog.scala:924)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$loadDynamicPartitions$1.apply(HiveExternalCatalog.scala:924)
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:99)
```
### Flink or Spark Version
spark2.4+hadoop3.0+cdh6.3.2
### Java or Scala Version
java 8
### Screenshots
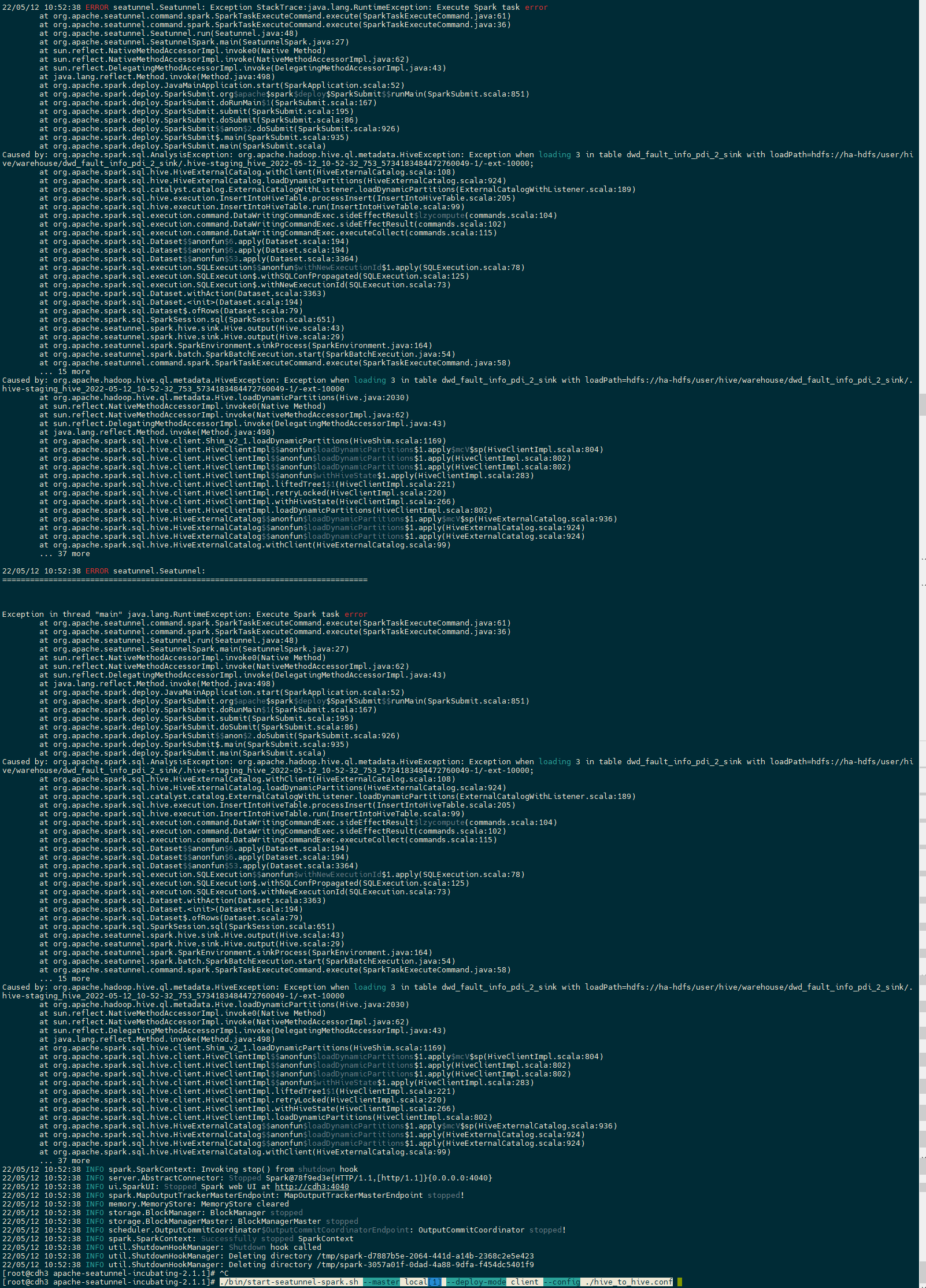
### Are you willing to submit PR?
- [ ] Yes I am willing to submit a PR!
### Code of Conduct
- [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@seatunnel.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-seatunnel] someorz commented on issue #1861: [Bug] [spark] write to hive error
Posted by GitBox <gi...@apache.org>.
someorz commented on issue #1861:
URL: https://github.com/apache/incubator-seatunnel/issues/1861#issuecomment-1125777286
It's not a seatunnel bug, it's an environment problem
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@seatunnel.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-seatunnel] someorz closed issue #1861: [Bug] [spark] write to hive error
Posted by GitBox <gi...@apache.org>.
someorz closed issue #1861: [Bug] [spark] write to hive error
URL: https://github.com/apache/incubator-seatunnel/issues/1861
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@seatunnel.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org