You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2020/02/05 08:16:35 UTC
[GitHub] [spark] HyukjinKwon opened a new pull request #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
HyukjinKwon opened a new pull request #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466
### What changes were proposed in this pull request?
TBD
Let me proof-read it in Github PR.
### Why are the changes needed?
TBD
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests should cover.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582726596
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/117958/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-584599978
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375661512
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,204 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use [Python type hints](https://www.python.org/dev/peps/pep-0484).
Review comment:
I am pretty sure we can support Python 3.5 too but I made the explicit condition with Python 3.6+ (https://github.com/apache/spark/blob/master/python/pyspark/sql/pandas/functions.py#L440-L441)
I just excluded Python 3.5 because we will deprecated Python versions lower than 3.6, and I just wanted to make it simple.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582726591
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583239211
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375586166
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,188 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use Python type hints. Using Python type hints are preferred and the
+previous way will be deprecated in the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
+The below combinations of the type hints are supported by Python type hints for Pandas UDFs.
+Note that `pandas.DataFrame` is mapped to the column of `StructType`; otherwise, `pandas.Series` is
Review comment:
Yeah, `StructType` -> `pandas.DataFrame` is a bit variant to mainly support the struct column. In fact, PySpark column is equivalent to pandas' Series. So, I just have chosen the term `Series to Series`, rather then `Series or DataFrame to Series or DataFrame` which is a bit ugly.
Here I really meant, all `pandas.Series` within this section can be `pandas.DataFrame`. Let me clarify here.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582291961
**[Test build #117914 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/117914/testReport)** for PR 27466 at commit [`9fee4d5`](https://github.com/apache/spark/commit/9fee4d551b471284c1026e937d0c474b24295bad).
* This patch **fails Python style tests**.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582764903
**[Test build #117965 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/117965/testReport)** for PR 27466 at commit [`6d23dbd`](https://github.com/apache/spark/commit/6d23dbdfc4753b4ee23670b5cfce8156e2154e8e).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583806250
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] viirya commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
viirya commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375662886
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,204 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use [Python type hints](https://www.python.org/dev/peps/pep-0484).
+Using Python type hints are preferred and using `PandasUDFType` will be deprecated in
+the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
-The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+The below combinations of the type hints are supported for Pandas UDFs. Note that the type hint should
+be `pandas.Series` in all cases but there is one variant case that `pandas.DataFrame` should be mapped
+as its input or output type hint instead when the input or output column is of `StructType`.
+
+### Series to Series
+
+The type hint can be expressed as `pandas.Series`, ... -> `pandas.Series`.
+
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the given
+function takes one or more `pandas.Series` and outputs one `pandas.Series`. The output of the function should
+always be of the same length as the input. Internally, PySpark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then concatenating
+the results together.
+
+The following example shows how to create this Pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example scalar_pandas_udf python/sql/arrow.py %}
+{% include_example ser_to_ser_pandas_udf python/sql/arrow.py %}
</div>
</div>
-### Scalar Iterator
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
+
+### Iterator of Series to Iterator of Series
+
+The type hint can be expressed as `Iterator[pandas.Series]` -> `Iterator[pandas.Series]`.
-Scalar iterator (`SCALAR_ITER`) Pandas UDF is the same as scalar Pandas UDF above except that the
-underlying Python function takes an iterator of batches as input instead of a single batch and,
-instead of returning a single output batch, it yields output batches or returns an iterator of
-output batches.
-It is useful when the UDF execution requires initializing some states, e.g., loading an machine
-learning model file to apply inference to every input batch.
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the given
+function takes an iterator of `pandas.Series` and outputs an iterator of `pandas.Series`. The output of each
+series from the function should always be of the same length as the input. In this case, the created
+Pandas UDF requires one input column when the Pandas UDF is called.
-The following example shows how to create scalar iterator Pandas UDFs:
+It is useful when the UDF execution requires initializing some states although internally it works
+identically as Series to Series case. The pseudocode below illustrates the example.
+
+{% highlight python %}
+@pandas_udf("long")
+def calculate(iterator: Iterator[pd.Series]) -> Iterator[pd.Series]:
+ # Do some expensive initialization with a state
+ state = very_expensive_initialization()
+ for x in iterator:
+ # Use that state for whole iterator.
+ yield calculate_with_state(x, state)
+
+df.select(calculate("value")).show()
+{% endhighlight %}
+
+The following example shows how to create this Pandas UDF:
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example scalar_iter_pandas_udf python/sql/arrow.py %}
+{% include_example iter_ser_to_iter_ser_pandas_udf python/sql/arrow.py %}
</div>
</div>
-### Grouped Map
-Grouped map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
-Split-apply-combine consists of three steps:
-* Split the data into groups by using `DataFrame.groupBy`.
-* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
- input data contains all the rows and columns for each group.
-* Combine the results into a new `DataFrame`.
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
-To use `groupBy().apply()`, the user needs to define the following:
-* A Python function that defines the computation for each group.
-* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+### Iterator of Multiple Series to Iterator of Series
-The column labels of the returned `pandas.DataFrame` must either match the field names in the
-defined output schema if specified as strings, or match the field data types by position if not
-strings, e.g. integer indices. See [pandas.DataFrame](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html#pandas.DataFrame)
-on how to label columns when constructing a `pandas.DataFrame`.
+The type hint can be expressed as `Iterator[Tuple[pandas.Series, ...]]` -> `Iterator[pandas.Series]`.
-Note that all data for a group will be loaded into memory before the function is applied. This can
-lead to out of memory exceptions, especially if the group sizes are skewed. The configuration for
-[maxRecordsPerBatch](#setting-arrow-batch-size) is not applied on groups and it is up to the user
-to ensure that the grouped data will fit into the available memory.
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the
+given function takes an iterator of a tuple of multiple `pandas.Series` and outputs an iterator of `pandas.Series`.
+In this case, the created pandas UDF requires multiple input columns as many as the series in the tuple
+when the Pandas UDF is called. It works identically as Iterator of Series to Iterator of Series case except the parameter difference.
-The following example shows how to use `groupby().apply()` to subtract the mean from each value in the group.
+The following example shows how to create this Pandas UDF:
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example grouped_map_pandas_udf python/sql/arrow.py %}
+{% include_example iter_sers_to_iter_ser_pandas_udf python/sql/arrow.py %}
</div>
</div>
-For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf) and
-[`pyspark.sql.GroupedData.apply`](api/python/pyspark.sql.html#pyspark.sql.GroupedData.apply).
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
+
+### Series to Scalar
+
+The type hint can be expressed as `pandas.Series`, ... -> `Any`.
-### Grouped Aggregate
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF similar
+to PySpark's aggregate functions. The given function takes `pandas.Series` and returns a scalar value.
+The return type should be a primitive data type, and the returned scalar can be either a python
+primitive type, e.g., `int` or `float` or a numpy data type, e.g., `numpy.int64` or `numpy.float64`.
+`Any` should ideally be a specific scalar type accordingly.
-Grouped aggregate Pandas UDFs are similar to Spark aggregate functions. Grouped aggregate Pandas UDFs are used with `groupBy().agg()` and
-[`pyspark.sql.Window`](api/python/pyspark.sql.html#pyspark.sql.Window). It defines an aggregation from one or more `pandas.Series`
-to a scalar value, where each `pandas.Series` represents a column within the group or window.
+This UDF can be also used with `groupBy().agg()` and [`pyspark.sql.Window`](api/python/pyspark.sql.html#pyspark.sql.Window).
+It defines an aggregation from one or more `pandas.Series` to a scalar value, where each `pandas.Series`
+represents a column within the group or window.
-Note that this type of UDF does not support partial aggregation and all data for a group or window will be loaded into memory. Also,
-only unbounded window is supported with Grouped aggregate Pandas UDFs currently.
+Note that this type of UDF does not support partial aggregation and all data for a group or window
+will be loaded into memory. Also, only unbounded window is supported with Grouped aggregate Pandas
+UDFs currently.
-The following example shows how to use this type of UDF to compute mean with groupBy and window operations:
+The following example shows how to use this type of UDF to compute mean with a group-by and window operations:
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example grouped_agg_pandas_udf python/sql/arrow.py %}
+{% include_example ser_to_scalar_pandas_udf python/sql/arrow.py %}
</div>
</div>
For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
-### Map Iterator
+## Pandas Function APIs
-Map iterator Pandas UDFs are used to transform data with an iterator of batches. Map iterator
-Pandas UDFs can be used with
-[`pyspark.sql.DataFrame.mapInPandas`](api/python/pyspark.sql.html#pyspark.sql.DataFrame.mapInPandas).
-It defines a map function that transforms an iterator of `pandas.DataFrame` to another.
+Pandas function APIs can directly apply a Python native function against the whole the DataFrame by
+using Pandas instances. Internally it works similarly with Pandas UDFs by Spark using Arrow to transfer
+data and Pandas to work with the data, which allows vectorized operations. A Pandas function API behaves
+as a regular API under PySpark `DataFrame` in general.
-It can return the output of arbitrary length in contrast to the scalar Pandas UDF. It maps an iterator of `pandas.DataFrame`s,
-that represents the current `DataFrame`, using the map iterator UDF and returns the result as a `DataFrame`.
+From Spark 3.0, Grouped map pandas UDF is now categorized as a separate Pandas Function API,
+`DataFrame.groupby().applyInPandas()`. It is still possible to use it with `PandasUDFType`
+and `DataFrame.groupby().apply()` as it was; however, it is preferred to use
+`DataFrame.groupby().applyInPandas()` directly. Using `PandasUDFType` will be deprecated
+in the future.
-The following example shows how to create map iterator Pandas UDFs:
+### Grouped Map
+
+Grouped map operations with Pandas instances are supported by `DataFrame.groupby().applyInPandas()`
+which requires a Python function that takes a `pandas.DataFrame` and return another `pandas.DataFrame`.
+It maps each group to each `pandas.DataFrame` in the Python function.
+
+This API implements the "split-apply-combine" pattern which consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new PySpark `DataFrame`.
+
+To use `groupBy().applyInPandas()`, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output PySpark `DataFrame`.
+
+The column labels of the returned `pandas.DataFrame` must either match the field names in the
+defined output schema if specified as strings, or match the field data types by position if not
+strings, e.g. integer indices. See [pandas.DataFrame](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html#pandas.DataFrame)
+on how to label columns when constructing a `pandas.DataFrame`.
+
+Note that all data for a group will be loaded into memory before the function is applied. This can
+lead to out of memory exceptions, especially if the group sizes are skewed. The configuration for
+[maxRecordsPerBatch](#setting-arrow-batch-size) is not applied on groups and it is up to the user
+to ensure that the grouped data will fit into the available memory.
+
+The following example shows how to use `groupby().applyInPandas()` to subtract the mean from each value
+in the group.
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example map_iter_pandas_udf python/sql/arrow.py %}
+{% include_example grouped_apply_in_pandas python/sql/arrow.py %}
</div>
</div>
-For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf) and
-[`pyspark.sql.DataFrame.mapsInPandas`](api/python/pyspark.sql.html#pyspark.sql.DataFrame.mapInPandas).
+For detailed usage, please see [`pyspark.sql.GroupedData.applyInPandas`](api/python/pyspark.sql.html#pyspark.sql.GroupedData.applyInPandas).
+
+### Map
+Map operations with Pandas instances are supported by `DataFrame.mapInPandas()` which maps an iterator
+of `pandas.DataFrame`s to another iterator of `pandas.DataFrame`s that represents the current
+PySpark `DataFrame` and returns the result as a PySpark `DataFrame`. The functions takes and outputs
+an iterator of `pandas.DataFrame`. It can return the output of arbitrary length in contrast to some
+Pandas UDFs although internally it works similarly with Series to Series Pandas UDF.
+
+The following example shows how to use `mapInPandas()`:
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example map_in_pandas python/sql/arrow.py %}
+</div>
+</div>
-### Cogrouped Map
+For detailed usage, please see [`pyspark.sql.DataFrame.mapsInPandas`](api/python/pyspark.sql.html#pyspark.sql.DataFrame.mapInPandas).
-Cogrouped map Pandas UDFs allow two DataFrames to be cogrouped by a common key and then a python function applied to
-each cogroup. They are used with `groupBy().cogroup().apply()` which consists of the following steps:
+### Co-grouped Map
+Co-grouped map operations with Pandas instances are supported by `DataFrame.cogroup().applyInPandas()` which
Review comment:
Is this `groupBy().cogroup().applyInPandas()`?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582371003
**[Test build #117929 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/117929/testReport)** for PR 27466 at commit [`4f85930`](https://github.com/apache/spark/commit/4f85930644fba3e4b861fe3bc65501956b062bb1).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582765601
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582682918
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375214227
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,188 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
Review comment:
Please see also the PR description of https://github.com/apache/spark/pull/27165#issue-361321870
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375228717
##########
File path: python/pyspark/sql/udf.py
##########
@@ -414,6 +415,9 @@ def _test():
.appName("sql.udf tests")\
.getOrCreate()
globs['spark'] = spark
+ # Hack to skip the unit tests in register. These are currently being tested in proper tests.
+ # We should reenable this test once we completely drop Python 2.
+ pyspark.sql.udf.register.__doc__ = ""
Review comment:
I checked the generated doc too just to make sure.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583207836
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22773/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583816182
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118087/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583816014
**[Test build #118087 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118087/testReport)** for PR 27466 at commit [`76a6da2`](https://github.com/apache/spark/commit/76a6da2573e700c389948c9c328351a38041dc24).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r376339282
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,215 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use [Python type hints](https://www.python.org/dev/peps/pep-0484).
+Using Python type hints are preferred and using `PandasUDFType` will be deprecated in
+the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
+Note that the type hint should use `pandas.Series` in all cases but there is one variant
+that `pandas.DataFrame` should be used for its input or output type hint instead when the input
+or output column is of `StructType`. The following example shows a Pandas UDF which takes long
+column, string column and struct column, and outputs a struct column. It requires the function to
+specify the type hints of `pandas.Series` and `pandas.DataFrame` as below:
-The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+<p>
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example ser_to_frame_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+</p>
+
+In the following sections, it describes the cominations of the supported type hints. For simplicity,
+`pandas.DataFrame` variant is omitted.
+
+### Series to Series
+
+The type hint can be expressed as `pandas.Series`, ... -> `pandas.Series`.
+
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the given
+function takes one or more `pandas.Series` and outputs one `pandas.Series`. The output of the function should
+always be of the same length as the input. Internally, PySpark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then concatenating
+the results together.
+
+The following example shows how to create this Pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example scalar_pandas_udf python/sql/arrow.py %}
+{% include_example ser_to_ser_pandas_udf python/sql/arrow.py %}
</div>
</div>
-### Scalar Iterator
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
+
+### Iterator of Series to Iterator of Series
Review comment:
does it only support one input column? I'd expect `Iterator[pandas.Series]`, ... -> `Iterator[pandas.Series]`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583207519
**[Test build #118008 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118008/testReport)** for PR 27466 at commit [`47b155c`](https://github.com/apache/spark/commit/47b155c9b212c74b83835fbd84735ea164979a99).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-584527599
**[Test build #118222 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118222/testReport)** for PR 27466 at commit [`626ff3c`](https://github.com/apache/spark/commit/626ff3cb245ccd305f9a32d9c99f774ef154ebe1).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582442524
Merged build finished. Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582291982
Merged build finished. Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon closed pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582371483
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22692/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375228717
##########
File path: python/pyspark/sql/udf.py
##########
@@ -414,6 +415,9 @@ def _test():
.appName("sql.udf tests")\
.getOrCreate()
globs['spark'] = spark
+ # Hack to skip the unit tests in register. These are currently being tested in proper tests.
+ # We should reenable this test once we completely drop Python 2.
+ pyspark.sql.udf.register.__doc__ = ""
Review comment:
I checked the generated doc too just to make sure.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583239211
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583816180
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582682918
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-584527599
**[Test build #118222 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118222/testReport)** for PR 27466 at commit [`626ff3c`](https://github.com/apache/spark/commit/626ff3cb245ccd305f9a32d9c99f774ef154ebe1).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582441406
**[Test build #117929 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/117929/testReport)** for PR 27466 at commit [`4f85930`](https://github.com/apache/spark/commit/4f85930644fba3e4b861fe3bc65501956b062bb1).
* This patch **fails PySpark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582292136
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22679/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582357724
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583207833
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375217088
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -43,303 +43,186 @@ class PandasUDFType(object):
@since(2.3)
def pandas_udf(f=None, returnType=None, functionType=None):
"""
- Creates a vectorized user defined function (UDF).
+ Creates a pandas user defined function (a.k.a. vectorized user defined function).
+
+ Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer
+ data and Pandas to work with the data, which allows vectorized operations. A Pandas UDF
+ is defined using the `pandas_udf` as a decorator or to wrap the function, and no
+ additional configuration is required. A Pandas UDF behaves as a regular PySpark function
+ API in general.
:param f: user-defined function. A python function if used as a standalone function
:param returnType: the return type of the user-defined function. The value can be either a
:class:`pyspark.sql.types.DataType` object or a DDL-formatted type string.
:param functionType: an enum value in :class:`pyspark.sql.functions.PandasUDFType`.
- Default: SCALAR.
-
- .. seealso:: :meth:`pyspark.sql.DataFrame.mapInPandas`
- .. seealso:: :meth:`pyspark.sql.GroupedData.applyInPandas`
- .. seealso:: :meth:`pyspark.sql.PandasCogroupedOps.applyInPandas`
-
- The function type of the UDF can be one of the following:
-
- 1. SCALAR
-
- A scalar UDF defines a transformation: One or more `pandas.Series` -> A `pandas.Series`.
- The length of the returned `pandas.Series` must be of the same as the input `pandas.Series`.
- If the return type is :class:`StructType`, the returned value should be a `pandas.DataFrame`.
-
- :class:`MapType`, nested :class:`StructType` are currently not supported as output types.
-
- Scalar UDFs can be used with :meth:`pyspark.sql.DataFrame.withColumn` and
- :meth:`pyspark.sql.DataFrame.select`.
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> from pyspark.sql.types import IntegerType, StringType
- >>> slen = pandas_udf(lambda s: s.str.len(), IntegerType()) # doctest: +SKIP
- >>> @pandas_udf(StringType()) # doctest: +SKIP
- ... def to_upper(s):
- ... return s.str.upper()
- ...
- >>> @pandas_udf("integer", PandasUDFType.SCALAR) # doctest: +SKIP
- ... def add_one(x):
- ... return x + 1
- ...
- >>> df = spark.createDataFrame([(1, "John Doe", 21)],
- ... ("id", "name", "age")) # doctest: +SKIP
- >>> df.select(slen("name").alias("slen(name)"), to_upper("name"), add_one("age")) \\
- ... .show() # doctest: +SKIP
- +----------+--------------+------------+
- |slen(name)|to_upper(name)|add_one(age)|
- +----------+--------------+------------+
- | 8| JOHN DOE| 22|
- +----------+--------------+------------+
- >>> @pandas_udf("first string, last string") # doctest: +SKIP
- ... def split_expand(n):
- ... return n.str.split(expand=True)
- >>> df.select(split_expand("name")).show() # doctest: +SKIP
- +------------------+
- |split_expand(name)|
- +------------------+
- | [John, Doe]|
- +------------------+
-
- .. note:: The length of `pandas.Series` within a scalar UDF is not that of the whole input
- column, but is the length of an internal batch used for each call to the function.
- Therefore, this can be used, for example, to ensure the length of each returned
- `pandas.Series`, and can not be used as the column length.
-
- 2. SCALAR_ITER
-
- A scalar iterator UDF is semantically the same as the scalar Pandas UDF above except that the
- wrapped Python function takes an iterator of batches as input instead of a single batch and,
- instead of returning a single output batch, it yields output batches or explicitly returns an
- generator or an iterator of output batches.
- It is useful when the UDF execution requires initializing some state, e.g., loading a machine
- learning model file to apply inference to every input batch.
-
- .. note:: It is not guaranteed that one invocation of a scalar iterator UDF will process all
- batches from one partition, although it is currently implemented this way.
- Your code shall not rely on this behavior because it might change in the future for
- further optimization, e.g., one invocation processes multiple partitions.
Review comment:
I removed this note. Unless we explicitly document, nothing is explicitly guaranteed. It seems to me too much to know.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582726164
**[Test build #117958 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/117958/testReport)** for PR 27466 at commit [`7b7ae90`](https://github.com/apache/spark/commit/7b7ae9050ae235d85b11b0e55ae4ac5a5c373d2a).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583990224
Should be ready for a look.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-584528111
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22982/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375588252
##########
File path: python/pyspark/sql/udf.py
##########
@@ -414,6 +415,9 @@ def _test():
.appName("sql.udf tests")\
.getOrCreate()
globs['spark'] = spark
+ # Hack to skip the unit tests in register. These are currently being tested in proper tests.
+ # We should reenable this test once we completely drop Python 2.
+ del pyspark.sql.udf.UDFRegistration.register
Review comment:
To doubly make sure, I tested and checked:
- that it doesn't affect the main codes:
```
>>> help(spark.udf.register)
```
```
Help on method register in module pyspark.sql.udf:
register(name, f, returnType=None) method of pyspark.sql.udf.UDFRegistration instance
...
```
- the generated doc too just to make sure.
- the tests pass.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582357099
**[Test build #117928 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/117928/testReport)** for PR 27466 at commit [`d3eb543`](https://github.com/apache/spark/commit/d3eb5430313f44aac396e9f5a77f4e99479d2034).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582442541
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/117929/
Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582721652
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22729/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375216428
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -43,303 +43,186 @@ class PandasUDFType(object):
@since(2.3)
def pandas_udf(f=None, returnType=None, functionType=None):
"""
- Creates a vectorized user defined function (UDF).
+ Creates a pandas user defined function (a.k.a. vectorized user defined function).
+
+ Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer
+ data and Pandas to work with the data, which allows vectorized operations. A Pandas UDF
+ is defined using the `pandas_udf` as a decorator or to wrap the function, and no
+ additional configuration is required. A Pandas UDF behaves as a regular PySpark function
+ API in general.
:param f: user-defined function. A python function if used as a standalone function
:param returnType: the return type of the user-defined function. The value can be either a
:class:`pyspark.sql.types.DataType` object or a DDL-formatted type string.
:param functionType: an enum value in :class:`pyspark.sql.functions.PandasUDFType`.
- Default: SCALAR.
-
- .. seealso:: :meth:`pyspark.sql.DataFrame.mapInPandas`
- .. seealso:: :meth:`pyspark.sql.GroupedData.applyInPandas`
- .. seealso:: :meth:`pyspark.sql.PandasCogroupedOps.applyInPandas`
-
- The function type of the UDF can be one of the following:
-
- 1. SCALAR
-
- A scalar UDF defines a transformation: One or more `pandas.Series` -> A `pandas.Series`.
- The length of the returned `pandas.Series` must be of the same as the input `pandas.Series`.
- If the return type is :class:`StructType`, the returned value should be a `pandas.DataFrame`.
-
- :class:`MapType`, nested :class:`StructType` are currently not supported as output types.
-
- Scalar UDFs can be used with :meth:`pyspark.sql.DataFrame.withColumn` and
- :meth:`pyspark.sql.DataFrame.select`.
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> from pyspark.sql.types import IntegerType, StringType
- >>> slen = pandas_udf(lambda s: s.str.len(), IntegerType()) # doctest: +SKIP
- >>> @pandas_udf(StringType()) # doctest: +SKIP
- ... def to_upper(s):
- ... return s.str.upper()
- ...
- >>> @pandas_udf("integer", PandasUDFType.SCALAR) # doctest: +SKIP
- ... def add_one(x):
- ... return x + 1
- ...
- >>> df = spark.createDataFrame([(1, "John Doe", 21)],
- ... ("id", "name", "age")) # doctest: +SKIP
- >>> df.select(slen("name").alias("slen(name)"), to_upper("name"), add_one("age")) \\
- ... .show() # doctest: +SKIP
- +----------+--------------+------------+
- |slen(name)|to_upper(name)|add_one(age)|
- +----------+--------------+------------+
- | 8| JOHN DOE| 22|
- +----------+--------------+------------+
- >>> @pandas_udf("first string, last string") # doctest: +SKIP
- ... def split_expand(n):
- ... return n.str.split(expand=True)
- >>> df.select(split_expand("name")).show() # doctest: +SKIP
- +------------------+
- |split_expand(name)|
- +------------------+
- | [John, Doe]|
- +------------------+
-
- .. note:: The length of `pandas.Series` within a scalar UDF is not that of the whole input
- column, but is the length of an internal batch used for each call to the function.
- Therefore, this can be used, for example, to ensure the length of each returned
Review comment:
I removed this example. This is already logically known since it says the length of input is not the whole series, and the lengths of input and output should be same.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583806252
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22852/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582357730
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/117928/
Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582292132
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582726591
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375661512
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,204 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use [Python type hints](https://www.python.org/dev/peps/pep-0484).
Review comment:
I am pretty sure we can support Python 3.5 too although maybe it needs some trivial fixes, in particular, [here](https://github.com/apache/spark/blob/master/python/pyspark/sql/pandas/typehints.py#L120-L141) but I made [the explicit condition with Python 3.6+](https://github.com/apache/spark/blob/master/python/pyspark/sql/pandas/functions.py#L440-L441)
I just excluded Python 3.5 because we will deprecated Python versions lower than 3.6, and I just wanted to make it simple.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375217238
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -43,303 +43,186 @@ class PandasUDFType(object):
@since(2.3)
def pandas_udf(f=None, returnType=None, functionType=None):
"""
- Creates a vectorized user defined function (UDF).
+ Creates a pandas user defined function (a.k.a. vectorized user defined function).
+
+ Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer
+ data and Pandas to work with the data, which allows vectorized operations. A Pandas UDF
+ is defined using the `pandas_udf` as a decorator or to wrap the function, and no
+ additional configuration is required. A Pandas UDF behaves as a regular PySpark function
+ API in general.
:param f: user-defined function. A python function if used as a standalone function
:param returnType: the return type of the user-defined function. The value can be either a
:class:`pyspark.sql.types.DataType` object or a DDL-formatted type string.
:param functionType: an enum value in :class:`pyspark.sql.functions.PandasUDFType`.
- Default: SCALAR.
-
- .. seealso:: :meth:`pyspark.sql.DataFrame.mapInPandas`
- .. seealso:: :meth:`pyspark.sql.GroupedData.applyInPandas`
- .. seealso:: :meth:`pyspark.sql.PandasCogroupedOps.applyInPandas`
-
- The function type of the UDF can be one of the following:
-
- 1. SCALAR
-
- A scalar UDF defines a transformation: One or more `pandas.Series` -> A `pandas.Series`.
- The length of the returned `pandas.Series` must be of the same as the input `pandas.Series`.
- If the return type is :class:`StructType`, the returned value should be a `pandas.DataFrame`.
-
- :class:`MapType`, nested :class:`StructType` are currently not supported as output types.
-
- Scalar UDFs can be used with :meth:`pyspark.sql.DataFrame.withColumn` and
- :meth:`pyspark.sql.DataFrame.select`.
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> from pyspark.sql.types import IntegerType, StringType
- >>> slen = pandas_udf(lambda s: s.str.len(), IntegerType()) # doctest: +SKIP
- >>> @pandas_udf(StringType()) # doctest: +SKIP
- ... def to_upper(s):
- ... return s.str.upper()
- ...
- >>> @pandas_udf("integer", PandasUDFType.SCALAR) # doctest: +SKIP
- ... def add_one(x):
- ... return x + 1
- ...
- >>> df = spark.createDataFrame([(1, "John Doe", 21)],
- ... ("id", "name", "age")) # doctest: +SKIP
- >>> df.select(slen("name").alias("slen(name)"), to_upper("name"), add_one("age")) \\
- ... .show() # doctest: +SKIP
- +----------+--------------+------------+
- |slen(name)|to_upper(name)|add_one(age)|
- +----------+--------------+------------+
- | 8| JOHN DOE| 22|
- +----------+--------------+------------+
- >>> @pandas_udf("first string, last string") # doctest: +SKIP
- ... def split_expand(n):
- ... return n.str.split(expand=True)
- >>> df.select(split_expand("name")).show() # doctest: +SKIP
- +------------------+
- |split_expand(name)|
- +------------------+
- | [John, Doe]|
- +------------------+
-
- .. note:: The length of `pandas.Series` within a scalar UDF is not that of the whole input
- column, but is the length of an internal batch used for each call to the function.
- Therefore, this can be used, for example, to ensure the length of each returned
- `pandas.Series`, and can not be used as the column length.
-
- 2. SCALAR_ITER
-
- A scalar iterator UDF is semantically the same as the scalar Pandas UDF above except that the
- wrapped Python function takes an iterator of batches as input instead of a single batch and,
- instead of returning a single output batch, it yields output batches or explicitly returns an
- generator or an iterator of output batches.
- It is useful when the UDF execution requires initializing some state, e.g., loading a machine
- learning model file to apply inference to every input batch.
-
- .. note:: It is not guaranteed that one invocation of a scalar iterator UDF will process all
- batches from one partition, although it is currently implemented this way.
- Your code shall not rely on this behavior because it might change in the future for
- further optimization, e.g., one invocation processes multiple partitions.
-
- Scalar iterator UDFs are used with :meth:`pyspark.sql.DataFrame.withColumn` and
- :meth:`pyspark.sql.DataFrame.select`.
Review comment:
I removed this too as the same reason as https://github.com/apache/spark/pull/27466/files#r375215947
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375217417
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -43,303 +43,186 @@ class PandasUDFType(object):
@since(2.3)
def pandas_udf(f=None, returnType=None, functionType=None):
"""
- Creates a vectorized user defined function (UDF).
+ Creates a pandas user defined function (a.k.a. vectorized user defined function).
+
+ Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer
+ data and Pandas to work with the data, which allows vectorized operations. A Pandas UDF
+ is defined using the `pandas_udf` as a decorator or to wrap the function, and no
+ additional configuration is required. A Pandas UDF behaves as a regular PySpark function
+ API in general.
:param f: user-defined function. A python function if used as a standalone function
:param returnType: the return type of the user-defined function. The value can be either a
:class:`pyspark.sql.types.DataType` object or a DDL-formatted type string.
:param functionType: an enum value in :class:`pyspark.sql.functions.PandasUDFType`.
- Default: SCALAR.
-
- .. seealso:: :meth:`pyspark.sql.DataFrame.mapInPandas`
- .. seealso:: :meth:`pyspark.sql.GroupedData.applyInPandas`
- .. seealso:: :meth:`pyspark.sql.PandasCogroupedOps.applyInPandas`
-
- The function type of the UDF can be one of the following:
-
- 1. SCALAR
-
- A scalar UDF defines a transformation: One or more `pandas.Series` -> A `pandas.Series`.
- The length of the returned `pandas.Series` must be of the same as the input `pandas.Series`.
- If the return type is :class:`StructType`, the returned value should be a `pandas.DataFrame`.
-
- :class:`MapType`, nested :class:`StructType` are currently not supported as output types.
-
- Scalar UDFs can be used with :meth:`pyspark.sql.DataFrame.withColumn` and
- :meth:`pyspark.sql.DataFrame.select`.
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> from pyspark.sql.types import IntegerType, StringType
- >>> slen = pandas_udf(lambda s: s.str.len(), IntegerType()) # doctest: +SKIP
- >>> @pandas_udf(StringType()) # doctest: +SKIP
- ... def to_upper(s):
- ... return s.str.upper()
- ...
- >>> @pandas_udf("integer", PandasUDFType.SCALAR) # doctest: +SKIP
- ... def add_one(x):
- ... return x + 1
- ...
- >>> df = spark.createDataFrame([(1, "John Doe", 21)],
- ... ("id", "name", "age")) # doctest: +SKIP
- >>> df.select(slen("name").alias("slen(name)"), to_upper("name"), add_one("age")) \\
- ... .show() # doctest: +SKIP
- +----------+--------------+------------+
- |slen(name)|to_upper(name)|add_one(age)|
- +----------+--------------+------------+
- | 8| JOHN DOE| 22|
- +----------+--------------+------------+
- >>> @pandas_udf("first string, last string") # doctest: +SKIP
- ... def split_expand(n):
- ... return n.str.split(expand=True)
- >>> df.select(split_expand("name")).show() # doctest: +SKIP
- +------------------+
- |split_expand(name)|
- +------------------+
- | [John, Doe]|
- +------------------+
-
- .. note:: The length of `pandas.Series` within a scalar UDF is not that of the whole input
- column, but is the length of an internal batch used for each call to the function.
- Therefore, this can be used, for example, to ensure the length of each returned
- `pandas.Series`, and can not be used as the column length.
-
- 2. SCALAR_ITER
-
- A scalar iterator UDF is semantically the same as the scalar Pandas UDF above except that the
- wrapped Python function takes an iterator of batches as input instead of a single batch and,
- instead of returning a single output batch, it yields output batches or explicitly returns an
- generator or an iterator of output batches.
- It is useful when the UDF execution requires initializing some state, e.g., loading a machine
- learning model file to apply inference to every input batch.
-
- .. note:: It is not guaranteed that one invocation of a scalar iterator UDF will process all
- batches from one partition, although it is currently implemented this way.
- Your code shall not rely on this behavior because it might change in the future for
- further optimization, e.g., one invocation processes multiple partitions.
-
- Scalar iterator UDFs are used with :meth:`pyspark.sql.DataFrame.withColumn` and
- :meth:`pyspark.sql.DataFrame.select`.
-
- >>> import pandas as pd # doctest: +SKIP
- >>> from pyspark.sql.functions import col, pandas_udf, struct, PandasUDFType
- >>> pdf = pd.DataFrame([1, 2, 3], columns=["x"]) # doctest: +SKIP
- >>> df = spark.createDataFrame(pdf) # doctest: +SKIP
-
- When the UDF is called with a single column that is not `StructType`, the input to the
- underlying function is an iterator of `pd.Series`.
-
- >>> @pandas_udf("long", PandasUDFType.SCALAR_ITER) # doctest: +SKIP
- ... def plus_one(batch_iter):
- ... for x in batch_iter:
- ... yield x + 1
- ...
- >>> df.select(plus_one(col("x"))).show() # doctest: +SKIP
- +-----------+
- |plus_one(x)|
- +-----------+
- | 2|
- | 3|
- | 4|
- +-----------+
-
- When the UDF is called with more than one columns, the input to the underlying function is an
- iterator of `pd.Series` tuple.
-
- >>> @pandas_udf("long", PandasUDFType.SCALAR_ITER) # doctest: +SKIP
- ... def multiply_two_cols(batch_iter):
- ... for a, b in batch_iter:
- ... yield a * b
- ...
- >>> df.select(multiply_two_cols(col("x"), col("x"))).show() # doctest: +SKIP
- +-----------------------+
- |multiply_two_cols(x, x)|
- +-----------------------+
- | 1|
- | 4|
- | 9|
- +-----------------------+
-
- When the UDF is called with a single column that is `StructType`, the input to the underlying
- function is an iterator of `pd.DataFrame`.
-
- >>> @pandas_udf("long", PandasUDFType.SCALAR_ITER) # doctest: +SKIP
- ... def multiply_two_nested_cols(pdf_iter):
- ... for pdf in pdf_iter:
- ... yield pdf["a"] * pdf["b"]
- ...
- >>> df.select(
- ... multiply_two_nested_cols(
- ... struct(col("x").alias("a"), col("x").alias("b"))
- ... ).alias("y")
- ... ).show() # doctest: +SKIP
- +---+
- | y|
- +---+
- | 1|
- | 4|
- | 9|
- +---+
-
- In the UDF, you can initialize some states before processing batches, wrap your code with
Review comment:
I removed this as the same reason as https://github.com/apache/spark/pull/27466/files#r375215066
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582357099
**[Test build #117928 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/117928/testReport)** for PR 27466 at commit [`d3eb543`](https://github.com/apache/spark/commit/d3eb5430313f44aac396e9f5a77f4e99479d2034).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375216823
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -43,303 +43,186 @@ class PandasUDFType(object):
@since(2.3)
def pandas_udf(f=None, returnType=None, functionType=None):
"""
- Creates a vectorized user defined function (UDF).
+ Creates a pandas user defined function (a.k.a. vectorized user defined function).
+
+ Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer
+ data and Pandas to work with the data, which allows vectorized operations. A Pandas UDF
+ is defined using the `pandas_udf` as a decorator or to wrap the function, and no
+ additional configuration is required. A Pandas UDF behaves as a regular PySpark function
+ API in general.
:param f: user-defined function. A python function if used as a standalone function
:param returnType: the return type of the user-defined function. The value can be either a
:class:`pyspark.sql.types.DataType` object or a DDL-formatted type string.
:param functionType: an enum value in :class:`pyspark.sql.functions.PandasUDFType`.
- Default: SCALAR.
-
- .. seealso:: :meth:`pyspark.sql.DataFrame.mapInPandas`
- .. seealso:: :meth:`pyspark.sql.GroupedData.applyInPandas`
- .. seealso:: :meth:`pyspark.sql.PandasCogroupedOps.applyInPandas`
-
- The function type of the UDF can be one of the following:
-
- 1. SCALAR
-
- A scalar UDF defines a transformation: One or more `pandas.Series` -> A `pandas.Series`.
- The length of the returned `pandas.Series` must be of the same as the input `pandas.Series`.
- If the return type is :class:`StructType`, the returned value should be a `pandas.DataFrame`.
-
- :class:`MapType`, nested :class:`StructType` are currently not supported as output types.
-
- Scalar UDFs can be used with :meth:`pyspark.sql.DataFrame.withColumn` and
- :meth:`pyspark.sql.DataFrame.select`.
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> from pyspark.sql.types import IntegerType, StringType
- >>> slen = pandas_udf(lambda s: s.str.len(), IntegerType()) # doctest: +SKIP
- >>> @pandas_udf(StringType()) # doctest: +SKIP
- ... def to_upper(s):
- ... return s.str.upper()
- ...
- >>> @pandas_udf("integer", PandasUDFType.SCALAR) # doctest: +SKIP
- ... def add_one(x):
- ... return x + 1
- ...
- >>> df = spark.createDataFrame([(1, "John Doe", 21)],
- ... ("id", "name", "age")) # doctest: +SKIP
- >>> df.select(slen("name").alias("slen(name)"), to_upper("name"), add_one("age")) \\
- ... .show() # doctest: +SKIP
- +----------+--------------+------------+
- |slen(name)|to_upper(name)|add_one(age)|
- +----------+--------------+------------+
- | 8| JOHN DOE| 22|
- +----------+--------------+------------+
- >>> @pandas_udf("first string, last string") # doctest: +SKIP
- ... def split_expand(n):
- ... return n.str.split(expand=True)
- >>> df.select(split_expand("name")).show() # doctest: +SKIP
- +------------------+
- |split_expand(name)|
- +------------------+
- | [John, Doe]|
- +------------------+
-
- .. note:: The length of `pandas.Series` within a scalar UDF is not that of the whole input
- column, but is the length of an internal batch used for each call to the function.
- Therefore, this can be used, for example, to ensure the length of each returned
- `pandas.Series`, and can not be used as the column length.
-
- 2. SCALAR_ITER
-
- A scalar iterator UDF is semantically the same as the scalar Pandas UDF above except that the
- wrapped Python function takes an iterator of batches as input instead of a single batch and,
- instead of returning a single output batch, it yields output batches or explicitly returns an
- generator or an iterator of output batches.
- It is useful when the UDF execution requires initializing some state, e.g., loading a machine
- learning model file to apply inference to every input batch.
-
- .. note:: It is not guaranteed that one invocation of a scalar iterator UDF will process all
- batches from one partition, although it is currently implemented this way.
- Your code shall not rely on this behavior because it might change in the future for
- further optimization, e.g., one invocation processes multiple partitions.
Review comment:
I removed this note. Unless we don't explicitly document, nothing is explicitly supported. It seems to me too much to know.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r377036356
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -43,303 +43,228 @@ class PandasUDFType(object):
@since(2.3)
def pandas_udf(f=None, returnType=None, functionType=None):
"""
- Creates a vectorized user defined function (UDF).
+ Creates a pandas user defined function (a.k.a. vectorized user defined function).
+
+ Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer
Review comment:
Yeah... it happened to be almost a copy ...
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582378981
cc @rxin, @zero323, @cloud-fan, @mengxr, @viirya, @dongjoon-hyun, @WeichenXu123, @ueshin, @BryanCutler, @icexelloss FYI
I would appreciate if you guys have some time to take a quick look. It has to be in Spark 3.0 but RC is supposed to start very soon, Mid Feb 2020.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r377034410
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -348,10 +273,21 @@ def pandas_udf(f=None, returnType=None, functionType=None):
.. note:: The user-defined functions do not take keyword arguments on the calling side.
.. note:: The data type of returned `pandas.Series` from the user-defined functions should be
- matched with defined returnType (see :meth:`types.to_arrow_type` and
+ matched with defined `returnType` (see :meth:`types.to_arrow_type` and
:meth:`types.from_arrow_type`). When there is mismatch between them, Spark might do
conversion on returned data. The conversion is not guaranteed to be correct and results
should be checked for accuracy by users.
+
+ .. note:: Currently,
+ :class:`pyspark.sql.types.MapType`,
+ :class:`pyspark.sql.types.ArrayType` of :class:`pyspark.sql.types.TimestampType` and
+ nested :class:`pyspark.sql.types.StructType`
+ are currently not supported as output types.
Review comment:
They are same.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-584599978
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583806187
**[Test build #118087 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118087/testReport)** for PR 27466 at commit [`76a6da2`](https://github.com/apache/spark/commit/76a6da2573e700c389948c9c328351a38041dc24).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583816180
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-584599398
**[Test build #118222 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118222/testReport)** for PR 27466 at commit [`626ff3c`](https://github.com/apache/spark/commit/626ff3cb245ccd305f9a32d9c99f774ef154ebe1).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-584528097
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582357737
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22691/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582721647
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583816182
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118087/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r377025782
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -43,303 +43,228 @@ class PandasUDFType(object):
@since(2.3)
def pandas_udf(f=None, returnType=None, functionType=None):
"""
- Creates a vectorized user defined function (UDF).
+ Creates a pandas user defined function (a.k.a. vectorized user defined function).
+
+ Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer
+ data and Pandas to work with the data, which allows vectorized operations. A Pandas UDF
+ is defined using the `pandas_udf` as a decorator or to wrap the function, and no
+ additional configuration is required. A Pandas UDF behaves as a regular PySpark function
+ API in general.
:param f: user-defined function. A python function if used as a standalone function
:param returnType: the return type of the user-defined function. The value can be either a
:class:`pyspark.sql.types.DataType` object or a DDL-formatted type string.
:param functionType: an enum value in :class:`pyspark.sql.functions.PandasUDFType`.
- Default: SCALAR.
-
- .. seealso:: :meth:`pyspark.sql.DataFrame.mapInPandas`
- .. seealso:: :meth:`pyspark.sql.GroupedData.applyInPandas`
- .. seealso:: :meth:`pyspark.sql.PandasCogroupedOps.applyInPandas`
-
- The function type of the UDF can be one of the following:
-
- 1. SCALAR
-
- A scalar UDF defines a transformation: One or more `pandas.Series` -> A `pandas.Series`.
- The length of the returned `pandas.Series` must be of the same as the input `pandas.Series`.
- If the return type is :class:`StructType`, the returned value should be a `pandas.DataFrame`.
-
- :class:`MapType`, nested :class:`StructType` are currently not supported as output types.
-
- Scalar UDFs can be used with :meth:`pyspark.sql.DataFrame.withColumn` and
- :meth:`pyspark.sql.DataFrame.select`.
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> from pyspark.sql.types import IntegerType, StringType
- >>> slen = pandas_udf(lambda s: s.str.len(), IntegerType()) # doctest: +SKIP
- >>> @pandas_udf(StringType()) # doctest: +SKIP
- ... def to_upper(s):
- ... return s.str.upper()
- ...
- >>> @pandas_udf("integer", PandasUDFType.SCALAR) # doctest: +SKIP
- ... def add_one(x):
- ... return x + 1
- ...
- >>> df = spark.createDataFrame([(1, "John Doe", 21)],
- ... ("id", "name", "age")) # doctest: +SKIP
- >>> df.select(slen("name").alias("slen(name)"), to_upper("name"), add_one("age")) \\
- ... .show() # doctest: +SKIP
- +----------+--------------+------------+
- |slen(name)|to_upper(name)|add_one(age)|
- +----------+--------------+------------+
- | 8| JOHN DOE| 22|
- +----------+--------------+------------+
- >>> @pandas_udf("first string, last string") # doctest: +SKIP
- ... def split_expand(n):
- ... return n.str.split(expand=True)
- >>> df.select(split_expand("name")).show() # doctest: +SKIP
- +------------------+
- |split_expand(name)|
- +------------------+
- | [John, Doe]|
- +------------------+
-
- .. note:: The length of `pandas.Series` within a scalar UDF is not that of the whole input
- column, but is the length of an internal batch used for each call to the function.
- Therefore, this can be used, for example, to ensure the length of each returned
- `pandas.Series`, and can not be used as the column length.
-
- 2. SCALAR_ITER
-
- A scalar iterator UDF is semantically the same as the scalar Pandas UDF above except that the
- wrapped Python function takes an iterator of batches as input instead of a single batch and,
- instead of returning a single output batch, it yields output batches or explicitly returns an
- generator or an iterator of output batches.
- It is useful when the UDF execution requires initializing some state, e.g., loading a machine
- learning model file to apply inference to every input batch.
-
- .. note:: It is not guaranteed that one invocation of a scalar iterator UDF will process all
- batches from one partition, although it is currently implemented this way.
- Your code shall not rely on this behavior because it might change in the future for
- further optimization, e.g., one invocation processes multiple partitions.
-
- Scalar iterator UDFs are used with :meth:`pyspark.sql.DataFrame.withColumn` and
- :meth:`pyspark.sql.DataFrame.select`.
-
- >>> import pandas as pd # doctest: +SKIP
- >>> from pyspark.sql.functions import col, pandas_udf, struct, PandasUDFType
- >>> pdf = pd.DataFrame([1, 2, 3], columns=["x"]) # doctest: +SKIP
- >>> df = spark.createDataFrame(pdf) # doctest: +SKIP
-
- When the UDF is called with a single column that is not `StructType`, the input to the
- underlying function is an iterator of `pd.Series`.
-
- >>> @pandas_udf("long", PandasUDFType.SCALAR_ITER) # doctest: +SKIP
- ... def plus_one(batch_iter):
- ... for x in batch_iter:
- ... yield x + 1
- ...
- >>> df.select(plus_one(col("x"))).show() # doctest: +SKIP
- +-----------+
- |plus_one(x)|
- +-----------+
- | 2|
- | 3|
- | 4|
- +-----------+
-
- When the UDF is called with more than one columns, the input to the underlying function is an
- iterator of `pd.Series` tuple.
-
- >>> @pandas_udf("long", PandasUDFType.SCALAR_ITER) # doctest: +SKIP
- ... def multiply_two_cols(batch_iter):
- ... for a, b in batch_iter:
- ... yield a * b
- ...
- >>> df.select(multiply_two_cols(col("x"), col("x"))).show() # doctest: +SKIP
- +-----------------------+
- |multiply_two_cols(x, x)|
- +-----------------------+
- | 1|
- | 4|
- | 9|
- +-----------------------+
-
- When the UDF is called with a single column that is `StructType`, the input to the underlying
- function is an iterator of `pd.DataFrame`.
-
- >>> @pandas_udf("long", PandasUDFType.SCALAR_ITER) # doctest: +SKIP
- ... def multiply_two_nested_cols(pdf_iter):
- ... for pdf in pdf_iter:
- ... yield pdf["a"] * pdf["b"]
- ...
- >>> df.select(
- ... multiply_two_nested_cols(
- ... struct(col("x").alias("a"), col("x").alias("b"))
- ... ).alias("y")
- ... ).show() # doctest: +SKIP
- +---+
- | y|
- +---+
- | 1|
- | 4|
- | 9|
- +---+
-
- In the UDF, you can initialize some states before processing batches, wrap your code with
- `try ... finally ...` or use context managers to ensure the release of resources at the end
- or in case of early termination.
-
- >>> y_bc = spark.sparkContext.broadcast(1) # doctest: +SKIP
- >>> @pandas_udf("long", PandasUDFType.SCALAR_ITER) # doctest: +SKIP
- ... def plus_y(batch_iter):
- ... y = y_bc.value # initialize some state
- ... try:
- ... for x in batch_iter:
- ... yield x + y
- ... finally:
- ... pass # release resources here, if any
- ...
- >>> df.select(plus_y(col("x"))).show() # doctest: +SKIP
- +---------+
- |plus_y(x)|
- +---------+
- | 2|
- | 3|
- | 4|
- +---------+
-
- 3. GROUPED_MAP
-
- A grouped map UDF defines transformation: A `pandas.DataFrame` -> A `pandas.DataFrame`
- The returnType should be a :class:`StructType` describing the schema of the returned
- `pandas.DataFrame`. The column labels of the returned `pandas.DataFrame` must either match
- the field names in the defined returnType schema if specified as strings, or match the
- field data types by position if not strings, e.g. integer indices.
- The length of the returned `pandas.DataFrame` can be arbitrary.
-
- Grouped map UDFs are used with :meth:`pyspark.sql.GroupedData.apply`.
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> df = spark.createDataFrame(
- ... [(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
- ... ("id", "v")) # doctest: +SKIP
- >>> @pandas_udf("id long, v double", PandasUDFType.GROUPED_MAP) # doctest: +SKIP
- ... def normalize(pdf):
- ... v = pdf.v
- ... return pdf.assign(v=(v - v.mean()) / v.std())
- >>> df.groupby("id").apply(normalize).show() # doctest: +SKIP
- +---+-------------------+
- | id| v|
- +---+-------------------+
- | 1|-0.7071067811865475|
- | 1| 0.7071067811865475|
- | 2|-0.8320502943378437|
- | 2|-0.2773500981126146|
- | 2| 1.1094003924504583|
- +---+-------------------+
-
- Alternatively, the user can define a function that takes two arguments.
- In this case, the grouping key(s) will be passed as the first argument and the data will
- be passed as the second argument. The grouping key(s) will be passed as a tuple of numpy
- data types, e.g., `numpy.int32` and `numpy.float64`. The data will still be passed in
- as a `pandas.DataFrame` containing all columns from the original Spark DataFrame.
- This is useful when the user does not want to hardcode grouping key(s) in the function.
-
- >>> import pandas as pd # doctest: +SKIP
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> df = spark.createDataFrame(
- ... [(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
- ... ("id", "v")) # doctest: +SKIP
- >>> @pandas_udf("id long, v double", PandasUDFType.GROUPED_MAP) # doctest: +SKIP
- ... def mean_udf(key, pdf):
- ... # key is a tuple of one numpy.int64, which is the value
- ... # of 'id' for the current group
- ... return pd.DataFrame([key + (pdf.v.mean(),)])
- >>> df.groupby('id').apply(mean_udf).show() # doctest: +SKIP
- +---+---+
- | id| v|
- +---+---+
- | 1|1.5|
- | 2|6.0|
- +---+---+
- >>> @pandas_udf(
- ... "id long, `ceil(v / 2)` long, v double",
- ... PandasUDFType.GROUPED_MAP) # doctest: +SKIP
- >>> def sum_udf(key, pdf):
- ... # key is a tuple of two numpy.int64s, which is the values
- ... # of 'id' and 'ceil(df.v / 2)' for the current group
- ... return pd.DataFrame([key + (pdf.v.sum(),)])
- >>> df.groupby(df.id, ceil(df.v / 2)).apply(sum_udf).show() # doctest: +SKIP
- +---+-----------+----+
- | id|ceil(v / 2)| v|
- +---+-----------+----+
- | 2| 5|10.0|
- | 1| 1| 3.0|
- | 2| 3| 5.0|
- | 2| 2| 3.0|
- +---+-----------+----+
-
- .. note:: If returning a new `pandas.DataFrame` constructed with a dictionary, it is
- recommended to explicitly index the columns by name to ensure the positions are correct,
- or alternatively use an `OrderedDict`.
- For example, `pd.DataFrame({'id': ids, 'a': data}, columns=['id', 'a'])` or
- `pd.DataFrame(OrderedDict([('id', ids), ('a', data)]))`.
-
- .. seealso:: :meth:`pyspark.sql.GroupedData.apply`
-
- 4. GROUPED_AGG
-
- A grouped aggregate UDF defines a transformation: One or more `pandas.Series` -> A scalar
- The `returnType` should be a primitive data type, e.g., :class:`DoubleType`.
- The returned scalar can be either a python primitive type, e.g., `int` or `float`
- or a numpy data type, e.g., `numpy.int64` or `numpy.float64`.
-
- :class:`MapType` and :class:`StructType` are currently not supported as output types.
-
- Group aggregate UDFs are used with :meth:`pyspark.sql.GroupedData.agg` and
- :class:`pyspark.sql.Window`
-
- This example shows using grouped aggregated UDFs with groupby:
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> df = spark.createDataFrame(
- ... [(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
- ... ("id", "v"))
- >>> @pandas_udf("double", PandasUDFType.GROUPED_AGG) # doctest: +SKIP
- ... def mean_udf(v):
- ... return v.mean()
- >>> df.groupby("id").agg(mean_udf(df['v'])).show() # doctest: +SKIP
- +---+-----------+
- | id|mean_udf(v)|
- +---+-----------+
- | 1| 1.5|
- | 2| 6.0|
- +---+-----------+
-
- This example shows using grouped aggregated UDFs as window functions.
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> from pyspark.sql import Window
- >>> df = spark.createDataFrame(
- ... [(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
- ... ("id", "v"))
- >>> @pandas_udf("double", PandasUDFType.GROUPED_AGG) # doctest: +SKIP
- ... def mean_udf(v):
- ... return v.mean()
- >>> w = (Window.partitionBy('id')
- ... .orderBy('v')
- ... .rowsBetween(-1, 0))
- >>> df.withColumn('mean_v', mean_udf(df['v']).over(w)).show() # doctest: +SKIP
- +---+----+------+
- | id| v|mean_v|
- +---+----+------+
- | 1| 1.0| 1.0|
- | 1| 2.0| 1.5|
- | 2| 3.0| 3.0|
- | 2| 5.0| 4.0|
- | 2|10.0| 7.5|
- +---+----+------+
-
- .. note:: For performance reasons, the input series to window functions are not copied.
+ Default: SCALAR.
+
+ .. note:: This parameter exists for compatibility. Using Python type hints is encouraged.
+
+ In order to use this API, customarily the below are imported:
+
+ >>> import pandas as pd
+ >>> from pyspark.sql.functions import pandas_udf
+
+ Prior to Spark 3.0, the pandas UDF used `functionType` to decide the execution type as below:
Review comment:
shall we introduce the new API first and legacy API later to promote the new API?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582721314
**[Test build #117965 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/117965/testReport)** for PR 27466 at commit [`6d23dbd`](https://github.com/apache/spark/commit/6d23dbdfc4753b4ee23670b5cfce8156e2154e8e).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582765601
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375218392
##########
File path: python/pyspark/sql/pandas/group_ops.py
##########
@@ -121,8 +119,56 @@ def applyInPandas(self, func, schema):
| 2| 1.1094003924504583|
+---+-------------------+
- .. seealso:: :meth:`pyspark.sql.functions.pandas_udf`
+ Alternatively, the user can pass a function that takes two arguments.
Review comment:
Information ported from GROUPED MAP in `pandas_udf`.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582765607
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/117965/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583207836
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22773/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582357724
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] viirya commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
viirya commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375659156
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,204 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use [Python type hints](https://www.python.org/dev/peps/pep-0484).
Review comment:
Is it Python 3.6 or 3.5? In the pep 484 page, it claims Python 3.5.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582291996
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/117914/
Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582357719
Merged build finished. Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375215066
##########
File path: examples/src/main/python/sql/arrow.py
##########
@@ -83,135 +90,91 @@ def multiply_func(a, b):
# | 4|
# | 9|
# +-------------------+
- # $example off:scalar_pandas_udf$
+ # $example off:ser_to_ser_pandas_udf$
-def scalar_iter_pandas_udf_example(spark):
- # $example on:scalar_iter_pandas_udf$
+def iter_ser_to_iter_ser_pandas_udf_example(spark):
+ # $example on:iter_ser_to_iter_ser_pandas_udf$
+ from typing import Iterator
+
import pandas as pd
- from pyspark.sql.functions import col, pandas_udf, struct, PandasUDFType
+ from pyspark.sql.functions import pandas_udf
pdf = pd.DataFrame([1, 2, 3], columns=["x"])
df = spark.createDataFrame(pdf)
- # When the UDF is called with a single column that is not StructType,
- # the input to the underlying function is an iterator of pd.Series.
- @pandas_udf("long", PandasUDFType.SCALAR_ITER)
- def plus_one(batch_iter):
- for x in batch_iter:
+ # Declare the function and create the UDF
+ @pandas_udf("long")
+ def plus_one(iterator: Iterator[pd.Series]) -> Iterator[pd.Series]:
+ for x in iterator:
yield x + 1
- df.select(plus_one(col("x"))).show()
+ # The function for a pandas_udf should be able to execute with local Pandas data
+ # against the iterator of pandas series.
+ df.select(plus_one("x")).show()
# +-----------+
# |plus_one(x)|
# +-----------+
# | 2|
# | 3|
# | 4|
# +-----------+
+ # $example off:iter_ser_to_iter_ser_pandas_udf$
+
- # When the UDF is called with more than one columns,
- # the input to the underlying function is an iterator of pd.Series tuple.
- @pandas_udf("long", PandasUDFType.SCALAR_ITER)
- def multiply_two_cols(batch_iter):
- for a, b in batch_iter:
+def iter_sers_to_iter_ser_pandas_udf_example(spark):
+ # $example on:iter_sers_to_iter_ser_pandas_udf$
+ from typing import Iterator, Tuple
+
+ import pandas as pd
+
+ from pyspark.sql.functions import pandas_udf
+
+ pdf = pd.DataFrame([1, 2, 3], columns=["x"])
+ df = spark.createDataFrame(pdf)
+
+ # Declare the function and create the UDF
+ @pandas_udf("long")
+ def multiply_two_cols(
+ iterator: Iterator[Tuple[pd.Series, pd.Series]]) -> Iterator[pd.Series]:
+ for a, b in iterator:
yield a * b
- df.select(multiply_two_cols(col("x"), col("x"))).show()
+ df.select(multiply_two_cols("x", "x")).show()
# +-----------------------+
# |multiply_two_cols(x, x)|
# +-----------------------+
# | 1|
# | 4|
# | 9|
# +-----------------------+
+ # $example off:iter_sers_to_iter_ser_pandas_udf$
- # When the UDF is called with a single column that is StructType,
- # the input to the underlying function is an iterator of pd.DataFrame.
- @pandas_udf("long", PandasUDFType.SCALAR_ITER)
- def multiply_two_nested_cols(pdf_iter):
- for pdf in pdf_iter:
- yield pdf["a"] * pdf["b"]
-
- df.select(
- multiply_two_nested_cols(
- struct(col("x").alias("a"), col("x").alias("b"))
- ).alias("y")
- ).show()
- # +---+
- # | y|
- # +---+
- # | 1|
- # | 4|
- # | 9|
- # +---+
-
- # In the UDF, you can initialize some states before processing batches.
Review comment:
I removed this example. It seems too much to know, and the example itself doesn't look particularly useful.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582357719
Merged build finished. Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-584528097
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582726596
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/117958/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375217645
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -43,303 +43,186 @@ class PandasUDFType(object):
@since(2.3)
def pandas_udf(f=None, returnType=None, functionType=None):
"""
- Creates a vectorized user defined function (UDF).
+ Creates a pandas user defined function (a.k.a. vectorized user defined function).
+
+ Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer
+ data and Pandas to work with the data, which allows vectorized operations. A Pandas UDF
+ is defined using the `pandas_udf` as a decorator or to wrap the function, and no
+ additional configuration is required. A Pandas UDF behaves as a regular PySpark function
+ API in general.
:param f: user-defined function. A python function if used as a standalone function
:param returnType: the return type of the user-defined function. The value can be either a
:class:`pyspark.sql.types.DataType` object or a DDL-formatted type string.
:param functionType: an enum value in :class:`pyspark.sql.functions.PandasUDFType`.
- Default: SCALAR.
-
- .. seealso:: :meth:`pyspark.sql.DataFrame.mapInPandas`
- .. seealso:: :meth:`pyspark.sql.GroupedData.applyInPandas`
- .. seealso:: :meth:`pyspark.sql.PandasCogroupedOps.applyInPandas`
-
- The function type of the UDF can be one of the following:
-
- 1. SCALAR
-
- A scalar UDF defines a transformation: One or more `pandas.Series` -> A `pandas.Series`.
- The length of the returned `pandas.Series` must be of the same as the input `pandas.Series`.
- If the return type is :class:`StructType`, the returned value should be a `pandas.DataFrame`.
-
- :class:`MapType`, nested :class:`StructType` are currently not supported as output types.
-
- Scalar UDFs can be used with :meth:`pyspark.sql.DataFrame.withColumn` and
- :meth:`pyspark.sql.DataFrame.select`.
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> from pyspark.sql.types import IntegerType, StringType
- >>> slen = pandas_udf(lambda s: s.str.len(), IntegerType()) # doctest: +SKIP
- >>> @pandas_udf(StringType()) # doctest: +SKIP
- ... def to_upper(s):
- ... return s.str.upper()
- ...
- >>> @pandas_udf("integer", PandasUDFType.SCALAR) # doctest: +SKIP
- ... def add_one(x):
- ... return x + 1
- ...
- >>> df = spark.createDataFrame([(1, "John Doe", 21)],
- ... ("id", "name", "age")) # doctest: +SKIP
- >>> df.select(slen("name").alias("slen(name)"), to_upper("name"), add_one("age")) \\
- ... .show() # doctest: +SKIP
- +----------+--------------+------------+
- |slen(name)|to_upper(name)|add_one(age)|
- +----------+--------------+------------+
- | 8| JOHN DOE| 22|
- +----------+--------------+------------+
- >>> @pandas_udf("first string, last string") # doctest: +SKIP
- ... def split_expand(n):
- ... return n.str.split(expand=True)
- >>> df.select(split_expand("name")).show() # doctest: +SKIP
- +------------------+
- |split_expand(name)|
- +------------------+
- | [John, Doe]|
- +------------------+
-
- .. note:: The length of `pandas.Series` within a scalar UDF is not that of the whole input
- column, but is the length of an internal batch used for each call to the function.
- Therefore, this can be used, for example, to ensure the length of each returned
- `pandas.Series`, and can not be used as the column length.
-
- 2. SCALAR_ITER
-
- A scalar iterator UDF is semantically the same as the scalar Pandas UDF above except that the
- wrapped Python function takes an iterator of batches as input instead of a single batch and,
- instead of returning a single output batch, it yields output batches or explicitly returns an
- generator or an iterator of output batches.
- It is useful when the UDF execution requires initializing some state, e.g., loading a machine
- learning model file to apply inference to every input batch.
-
- .. note:: It is not guaranteed that one invocation of a scalar iterator UDF will process all
- batches from one partition, although it is currently implemented this way.
- Your code shall not rely on this behavior because it might change in the future for
- further optimization, e.g., one invocation processes multiple partitions.
-
- Scalar iterator UDFs are used with :meth:`pyspark.sql.DataFrame.withColumn` and
- :meth:`pyspark.sql.DataFrame.select`.
-
- >>> import pandas as pd # doctest: +SKIP
- >>> from pyspark.sql.functions import col, pandas_udf, struct, PandasUDFType
- >>> pdf = pd.DataFrame([1, 2, 3], columns=["x"]) # doctest: +SKIP
- >>> df = spark.createDataFrame(pdf) # doctest: +SKIP
-
- When the UDF is called with a single column that is not `StructType`, the input to the
- underlying function is an iterator of `pd.Series`.
-
- >>> @pandas_udf("long", PandasUDFType.SCALAR_ITER) # doctest: +SKIP
- ... def plus_one(batch_iter):
- ... for x in batch_iter:
- ... yield x + 1
- ...
- >>> df.select(plus_one(col("x"))).show() # doctest: +SKIP
- +-----------+
- |plus_one(x)|
- +-----------+
- | 2|
- | 3|
- | 4|
- +-----------+
-
- When the UDF is called with more than one columns, the input to the underlying function is an
- iterator of `pd.Series` tuple.
-
- >>> @pandas_udf("long", PandasUDFType.SCALAR_ITER) # doctest: +SKIP
- ... def multiply_two_cols(batch_iter):
- ... for a, b in batch_iter:
- ... yield a * b
- ...
- >>> df.select(multiply_two_cols(col("x"), col("x"))).show() # doctest: +SKIP
- +-----------------------+
- |multiply_two_cols(x, x)|
- +-----------------------+
- | 1|
- | 4|
- | 9|
- +-----------------------+
-
- When the UDF is called with a single column that is `StructType`, the input to the underlying
- function is an iterator of `pd.DataFrame`.
-
- >>> @pandas_udf("long", PandasUDFType.SCALAR_ITER) # doctest: +SKIP
- ... def multiply_two_nested_cols(pdf_iter):
- ... for pdf in pdf_iter:
- ... yield pdf["a"] * pdf["b"]
- ...
- >>> df.select(
- ... multiply_two_nested_cols(
- ... struct(col("x").alias("a"), col("x").alias("b"))
- ... ).alias("y")
- ... ).show() # doctest: +SKIP
- +---+
- | y|
- +---+
- | 1|
- | 4|
- | 9|
- +---+
-
- In the UDF, you can initialize some states before processing batches, wrap your code with
- `try ... finally ...` or use context managers to ensure the release of resources at the end
- or in case of early termination.
-
- >>> y_bc = spark.sparkContext.broadcast(1) # doctest: +SKIP
- >>> @pandas_udf("long", PandasUDFType.SCALAR_ITER) # doctest: +SKIP
- ... def plus_y(batch_iter):
- ... y = y_bc.value # initialize some state
- ... try:
- ... for x in batch_iter:
- ... yield x + y
- ... finally:
- ... pass # release resources here, if any
- ...
- >>> df.select(plus_y(col("x"))).show() # doctest: +SKIP
- +---------+
- |plus_y(x)|
- +---------+
- | 2|
- | 3|
- | 4|
- +---------+
-
- 3. GROUPED_MAP
-
- A grouped map UDF defines transformation: A `pandas.DataFrame` -> A `pandas.DataFrame`
Review comment:
Moved to `applyInPandas` at `GroupedData`. Missing information from here was ported to there.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582721647
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583238835
**[Test build #118008 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118008/testReport)** for PR 27466 at commit [`47b155c`](https://github.com/apache/spark/commit/47b155c9b212c74b83835fbd84735ea164979a99).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375613494
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,188 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use Python type hints. Using Python type hints are preferred and the
+previous way will be deprecated in the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
+The below combinations of the type hints are supported by Python type hints for Pandas UDFs.
+Note that `pandas.DataFrame` is mapped to the column of `StructType`; otherwise, `pandas.Series` is
+mapped in all occurrences below.
-The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+### Series to Series
+
+The type hint can be expressed as `pandas.Series`, ... -> `pandas.Series`.
+
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the given
+function takes one or more `pandas.Series` and outputs one `pandas.Series`. The output of the function should
+always be of the same length as the input. Internally, PySpark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then concatenating
+the results together.
+
+The following example shows how to create this Pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example scalar_pandas_udf python/sql/arrow.py %}
+{% include_example ser_to_ser_pandas_udf python/sql/arrow.py %}
</div>
</div>
-### Scalar Iterator
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
-Scalar iterator (`SCALAR_ITER`) Pandas UDF is the same as scalar Pandas UDF above except that the
-underlying Python function takes an iterator of batches as input instead of a single batch and,
-instead of returning a single output batch, it yields output batches or returns an iterator of
-output batches.
-It is useful when the UDF execution requires initializing some states, e.g., loading an machine
-learning model file to apply inference to every input batch.
+### Iterator of Series to Iterator of Series
-The following example shows how to create scalar iterator Pandas UDFs:
+The type hint can be expressed as `Iterator[pandas.Series]` -> `Iterator[pandas.Series]`.
Review comment:
True .. although I didn't add `Iterator[Union[Tuple[pandas.Series, ...], pandas.Series]]` type hint to support yet ...
I think we can combine it later if we happen to add this type hint as well. Shouldn't be a big deal at this moment.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-584976948
Thanks all. Merged to master and branch-3.0.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375215947
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -43,303 +43,186 @@ class PandasUDFType(object):
@since(2.3)
def pandas_udf(f=None, returnType=None, functionType=None):
"""
- Creates a vectorized user defined function (UDF).
+ Creates a pandas user defined function (a.k.a. vectorized user defined function).
+
+ Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer
+ data and Pandas to work with the data, which allows vectorized operations. A Pandas UDF
+ is defined using the `pandas_udf` as a decorator or to wrap the function, and no
+ additional configuration is required. A Pandas UDF behaves as a regular PySpark function
+ API in general.
:param f: user-defined function. A python function if used as a standalone function
:param returnType: the return type of the user-defined function. The value can be either a
:class:`pyspark.sql.types.DataType` object or a DDL-formatted type string.
:param functionType: an enum value in :class:`pyspark.sql.functions.PandasUDFType`.
- Default: SCALAR.
-
- .. seealso:: :meth:`pyspark.sql.DataFrame.mapInPandas`
- .. seealso:: :meth:`pyspark.sql.GroupedData.applyInPandas`
- .. seealso:: :meth:`pyspark.sql.PandasCogroupedOps.applyInPandas`
-
- The function type of the UDF can be one of the following:
-
- 1. SCALAR
-
- A scalar UDF defines a transformation: One or more `pandas.Series` -> A `pandas.Series`.
- The length of the returned `pandas.Series` must be of the same as the input `pandas.Series`.
- If the return type is :class:`StructType`, the returned value should be a `pandas.DataFrame`.
-
- :class:`MapType`, nested :class:`StructType` are currently not supported as output types.
-
- Scalar UDFs can be used with :meth:`pyspark.sql.DataFrame.withColumn` and
Review comment:
I removed this info. To me it looks too much to know. I just said "A Pandas UDF behaves as a regular PySpark function API in general." instead.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582682921
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22722/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582684372
**[Test build #117958 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/117958/testReport)** for PR 27466 at commit [`7b7ae90`](https://github.com/apache/spark/commit/7b7ae9050ae235d85b11b0e55ae4ac5a5c373d2a).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r377025229
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -43,303 +43,228 @@ class PandasUDFType(object):
@since(2.3)
def pandas_udf(f=None, returnType=None, functionType=None):
"""
- Creates a vectorized user defined function (UDF).
+ Creates a pandas user defined function (a.k.a. vectorized user defined function).
+
+ Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer
Review comment:
I don't review it carefully and assume most of it are coped from the md file.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583239217
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118008/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375703095
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,204 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use [Python type hints](https://www.python.org/dev/peps/pep-0484).
+Using Python type hints are preferred and using `PandasUDFType` will be deprecated in
+the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
-The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+The below combinations of the type hints are supported for Pandas UDFs. Note that the type hint should
+be `pandas.Series` in all cases but there is one variant case that `pandas.DataFrame` should be mapped
+as its input or output type hint instead when the input or output column is of `StructType`.
Review comment:
Yes, that's correct. It's always `Series`. It becomes only `DataFrame` when the input or output columns are `StructType`.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583806252
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22852/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582442541
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/117929/
Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-584528111
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22982/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375702068
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,204 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use [Python type hints](https://www.python.org/dev/peps/pep-0484).
+Using Python type hints are preferred and using `PandasUDFType` will be deprecated in
+the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
-The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+The below combinations of the type hints are supported for Pandas UDFs. Note that the type hint should
+be `pandas.Series` in all cases but there is one variant case that `pandas.DataFrame` should be mapped
+as its input or output type hint instead when the input or output column is of `StructType`.
Review comment:
still has some confusion. What if I have 3 input columns and only one of them is struct? Should the type hint be `Series, DataFrame, Series -> Series`?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375213650
##########
File path: dev/sparktestsupport/modules.py
##########
@@ -364,7 +364,6 @@ def __hash__(self):
"pyspark.sql.avro.functions",
"pyspark.sql.pandas.conversion",
"pyspark.sql.pandas.map_ops",
- "pyspark.sql.pandas.functions",
Review comment:
All the tests in `pyspark.sql.pandas.functions` should be conditionally ran - It should skip the tests if pandas or PyArrow are not available. However, we have been skipping them always due to the lack of mechanism to conditionally run the doctests.
Now, the doctests at `pyspark.sql.pandas.functions` have type hints that are only for Python 3.5+. So, even if we skip all the tests like the previous way, it shows compilation error due to illegal syntax in Python 2. This is why I had to remove this from the module list to avoid compiling the doctests at all.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375216428
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -43,303 +43,186 @@ class PandasUDFType(object):
@since(2.3)
def pandas_udf(f=None, returnType=None, functionType=None):
"""
- Creates a vectorized user defined function (UDF).
+ Creates a pandas user defined function (a.k.a. vectorized user defined function).
+
+ Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer
+ data and Pandas to work with the data, which allows vectorized operations. A Pandas UDF
+ is defined using the `pandas_udf` as a decorator or to wrap the function, and no
+ additional configuration is required. A Pandas UDF behaves as a regular PySpark function
+ API in general.
:param f: user-defined function. A python function if used as a standalone function
:param returnType: the return type of the user-defined function. The value can be either a
:class:`pyspark.sql.types.DataType` object or a DDL-formatted type string.
:param functionType: an enum value in :class:`pyspark.sql.functions.PandasUDFType`.
- Default: SCALAR.
-
- .. seealso:: :meth:`pyspark.sql.DataFrame.mapInPandas`
- .. seealso:: :meth:`pyspark.sql.GroupedData.applyInPandas`
- .. seealso:: :meth:`pyspark.sql.PandasCogroupedOps.applyInPandas`
-
- The function type of the UDF can be one of the following:
-
- 1. SCALAR
-
- A scalar UDF defines a transformation: One or more `pandas.Series` -> A `pandas.Series`.
- The length of the returned `pandas.Series` must be of the same as the input `pandas.Series`.
- If the return type is :class:`StructType`, the returned value should be a `pandas.DataFrame`.
-
- :class:`MapType`, nested :class:`StructType` are currently not supported as output types.
-
- Scalar UDFs can be used with :meth:`pyspark.sql.DataFrame.withColumn` and
- :meth:`pyspark.sql.DataFrame.select`.
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> from pyspark.sql.types import IntegerType, StringType
- >>> slen = pandas_udf(lambda s: s.str.len(), IntegerType()) # doctest: +SKIP
- >>> @pandas_udf(StringType()) # doctest: +SKIP
- ... def to_upper(s):
- ... return s.str.upper()
- ...
- >>> @pandas_udf("integer", PandasUDFType.SCALAR) # doctest: +SKIP
- ... def add_one(x):
- ... return x + 1
- ...
- >>> df = spark.createDataFrame([(1, "John Doe", 21)],
- ... ("id", "name", "age")) # doctest: +SKIP
- >>> df.select(slen("name").alias("slen(name)"), to_upper("name"), add_one("age")) \\
- ... .show() # doctest: +SKIP
- +----------+--------------+------------+
- |slen(name)|to_upper(name)|add_one(age)|
- +----------+--------------+------------+
- | 8| JOHN DOE| 22|
- +----------+--------------+------------+
- >>> @pandas_udf("first string, last string") # doctest: +SKIP
- ... def split_expand(n):
- ... return n.str.split(expand=True)
- >>> df.select(split_expand("name")).show() # doctest: +SKIP
- +------------------+
- |split_expand(name)|
- +------------------+
- | [John, Doe]|
- +------------------+
-
- .. note:: The length of `pandas.Series` within a scalar UDF is not that of the whole input
- column, but is the length of an internal batch used for each call to the function.
- Therefore, this can be used, for example, to ensure the length of each returned
Review comment:
I removed this example. This is already logical known since it says the length of input can be arbitrary and the lengths of input and output should be same.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375586166
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,188 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use Python type hints. Using Python type hints are preferred and the
+previous way will be deprecated in the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
+The below combinations of the type hints are supported by Python type hints for Pandas UDFs.
+Note that `pandas.DataFrame` is mapped to the column of `StructType`; otherwise, `pandas.Series` is
Review comment:
Yeah, `StructType` -> `pandas.DataFrame` is a bit variant to mainly support the struct column. In fact, PySpark column is equivalent to pandas' Series. So, I just have chosen the term `Series to Series`, rather then `Series or DataFrame to Series or DataFrame` which is a bit ugly.
Here I really meant, all `pandas.Series` within this section can be `pandas.DataFrame` on this `StructType` condition. Let me clarify here.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zero323 commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
zero323 commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582396407
Not directly related but is this still valid for 3.0?
> The current supported version is 0.12.1.
Shouldn't it be 0.15.1?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r376339282
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,215 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use [Python type hints](https://www.python.org/dev/peps/pep-0484).
+Using Python type hints are preferred and using `PandasUDFType` will be deprecated in
+the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
+Note that the type hint should use `pandas.Series` in all cases but there is one variant
+that `pandas.DataFrame` should be used for its input or output type hint instead when the input
+or output column is of `StructType`. The following example shows a Pandas UDF which takes long
+column, string column and struct column, and outputs a struct column. It requires the function to
+specify the type hints of `pandas.Series` and `pandas.DataFrame` as below:
-The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+<p>
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example ser_to_frame_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+</p>
+
+In the following sections, it describes the cominations of the supported type hints. For simplicity,
+`pandas.DataFrame` variant is omitted.
+
+### Series to Series
+
+The type hint can be expressed as `pandas.Series`, ... -> `pandas.Series`.
+
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the given
+function takes one or more `pandas.Series` and outputs one `pandas.Series`. The output of the function should
+always be of the same length as the input. Internally, PySpark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then concatenating
+the results together.
+
+The following example shows how to create this Pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example scalar_pandas_udf python/sql/arrow.py %}
+{% include_example ser_to_ser_pandas_udf python/sql/arrow.py %}
</div>
</div>
-### Scalar Iterator
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
+
+### Iterator of Series to Iterator of Series
Review comment:
does it only support one input column? I'd expect `Iterator[pandas.Series]`, ... -> `Iterator[pandas.Series]`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r376188533
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,215 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
Review comment:
@cloud-fan what about now?
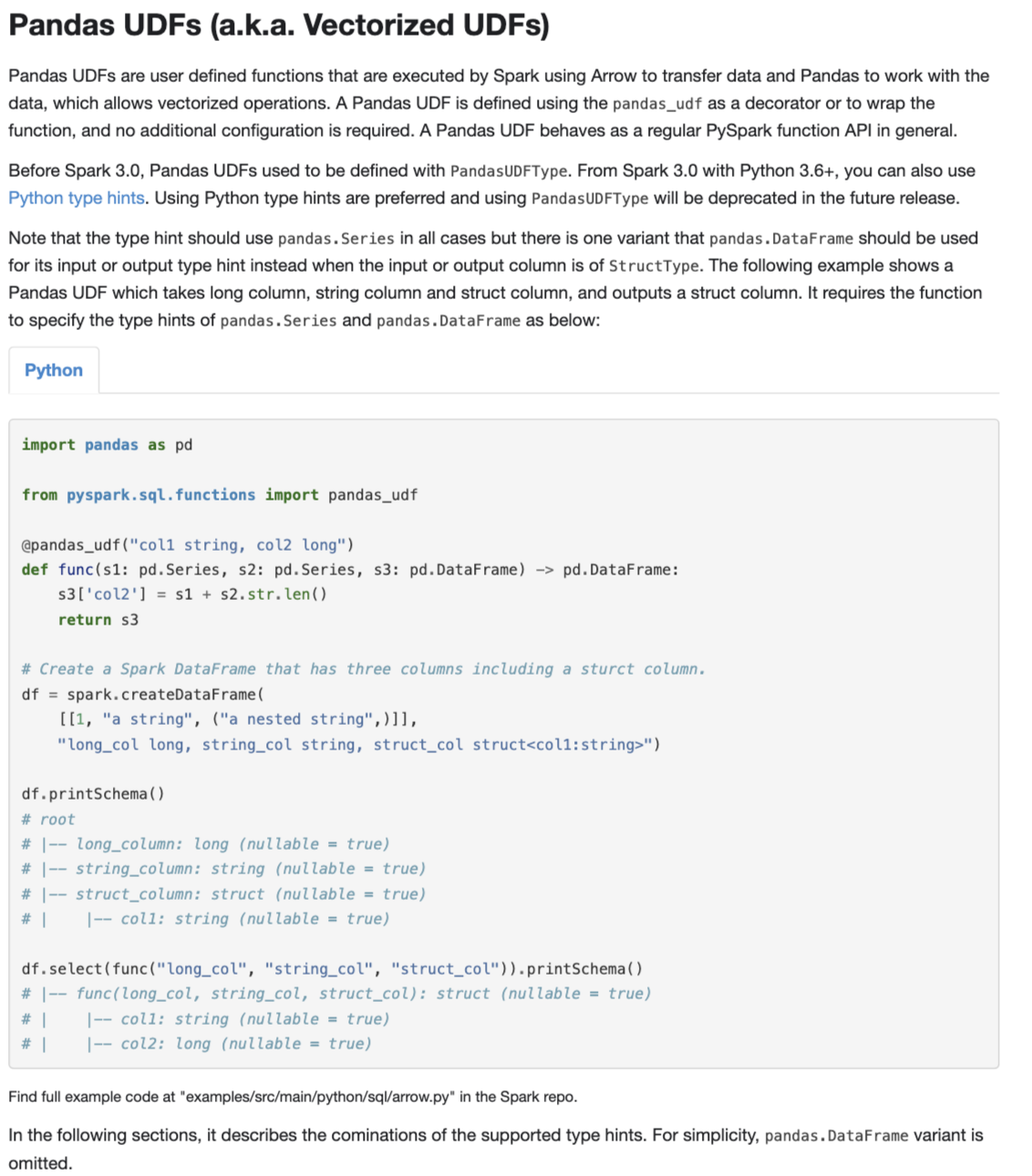
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375586166
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,188 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use Python type hints. Using Python type hints are preferred and the
+previous way will be deprecated in the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
+The below combinations of the type hints are supported by Python type hints for Pandas UDFs.
+Note that `pandas.DataFrame` is mapped to the column of `StructType`; otherwise, `pandas.Series` is
Review comment:
Yeah, `StructType` -> `pandas.DataFrame` is a bit variant. In fact, PySpark column is equivalent to pandas' Series. So, I just have chosen the term `Series to Series`, rather then `Series or DataFrame to Series or DataFrame` which is a bit ugly.
Here I really meant, all `pandas.Series` within this section can be `pandas.DataFrame`. Let me clarify here.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582292136
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22679/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r376343629
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -43,303 +43,234 @@ class PandasUDFType(object):
@since(2.3)
def pandas_udf(f=None, returnType=None, functionType=None):
"""
- Creates a vectorized user defined function (UDF).
+ Creates a pandas user defined function (a.k.a. vectorized user defined function).
+
+ Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer
+ data and Pandas to work with the data, which allows vectorized operations. A Pandas UDF
+ is defined using the `pandas_udf` as a decorator or to wrap the function, and no
+ additional configuration is required. A Pandas UDF behaves as a regular PySpark function
+ API in general.
:param f: user-defined function. A python function if used as a standalone function
:param returnType: the return type of the user-defined function. The value can be either a
:class:`pyspark.sql.types.DataType` object or a DDL-formatted type string.
:param functionType: an enum value in :class:`pyspark.sql.functions.PandasUDFType`.
- Default: SCALAR.
-
- .. seealso:: :meth:`pyspark.sql.DataFrame.mapInPandas`
- .. seealso:: :meth:`pyspark.sql.GroupedData.applyInPandas`
- .. seealso:: :meth:`pyspark.sql.PandasCogroupedOps.applyInPandas`
-
- The function type of the UDF can be one of the following:
-
- 1. SCALAR
-
- A scalar UDF defines a transformation: One or more `pandas.Series` -> A `pandas.Series`.
- The length of the returned `pandas.Series` must be of the same as the input `pandas.Series`.
- If the return type is :class:`StructType`, the returned value should be a `pandas.DataFrame`.
-
- :class:`MapType`, nested :class:`StructType` are currently not supported as output types.
-
- Scalar UDFs can be used with :meth:`pyspark.sql.DataFrame.withColumn` and
- :meth:`pyspark.sql.DataFrame.select`.
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> from pyspark.sql.types import IntegerType, StringType
- >>> slen = pandas_udf(lambda s: s.str.len(), IntegerType()) # doctest: +SKIP
- >>> @pandas_udf(StringType()) # doctest: +SKIP
- ... def to_upper(s):
- ... return s.str.upper()
- ...
- >>> @pandas_udf("integer", PandasUDFType.SCALAR) # doctest: +SKIP
- ... def add_one(x):
- ... return x + 1
- ...
- >>> df = spark.createDataFrame([(1, "John Doe", 21)],
- ... ("id", "name", "age")) # doctest: +SKIP
- >>> df.select(slen("name").alias("slen(name)"), to_upper("name"), add_one("age")) \\
- ... .show() # doctest: +SKIP
- +----------+--------------+------------+
- |slen(name)|to_upper(name)|add_one(age)|
- +----------+--------------+------------+
- | 8| JOHN DOE| 22|
- +----------+--------------+------------+
- >>> @pandas_udf("first string, last string") # doctest: +SKIP
- ... def split_expand(n):
- ... return n.str.split(expand=True)
- >>> df.select(split_expand("name")).show() # doctest: +SKIP
- +------------------+
- |split_expand(name)|
- +------------------+
- | [John, Doe]|
- +------------------+
-
- .. note:: The length of `pandas.Series` within a scalar UDF is not that of the whole input
- column, but is the length of an internal batch used for each call to the function.
- Therefore, this can be used, for example, to ensure the length of each returned
- `pandas.Series`, and can not be used as the column length.
-
- 2. SCALAR_ITER
-
- A scalar iterator UDF is semantically the same as the scalar Pandas UDF above except that the
- wrapped Python function takes an iterator of batches as input instead of a single batch and,
- instead of returning a single output batch, it yields output batches or explicitly returns an
- generator or an iterator of output batches.
- It is useful when the UDF execution requires initializing some state, e.g., loading a machine
- learning model file to apply inference to every input batch.
-
- .. note:: It is not guaranteed that one invocation of a scalar iterator UDF will process all
- batches from one partition, although it is currently implemented this way.
- Your code shall not rely on this behavior because it might change in the future for
- further optimization, e.g., one invocation processes multiple partitions.
-
- Scalar iterator UDFs are used with :meth:`pyspark.sql.DataFrame.withColumn` and
- :meth:`pyspark.sql.DataFrame.select`.
-
- >>> import pandas as pd # doctest: +SKIP
- >>> from pyspark.sql.functions import col, pandas_udf, struct, PandasUDFType
- >>> pdf = pd.DataFrame([1, 2, 3], columns=["x"]) # doctest: +SKIP
- >>> df = spark.createDataFrame(pdf) # doctest: +SKIP
-
- When the UDF is called with a single column that is not `StructType`, the input to the
- underlying function is an iterator of `pd.Series`.
-
- >>> @pandas_udf("long", PandasUDFType.SCALAR_ITER) # doctest: +SKIP
- ... def plus_one(batch_iter):
- ... for x in batch_iter:
- ... yield x + 1
- ...
- >>> df.select(plus_one(col("x"))).show() # doctest: +SKIP
- +-----------+
- |plus_one(x)|
- +-----------+
- | 2|
- | 3|
- | 4|
- +-----------+
-
- When the UDF is called with more than one columns, the input to the underlying function is an
- iterator of `pd.Series` tuple.
-
- >>> @pandas_udf("long", PandasUDFType.SCALAR_ITER) # doctest: +SKIP
- ... def multiply_two_cols(batch_iter):
- ... for a, b in batch_iter:
- ... yield a * b
- ...
- >>> df.select(multiply_two_cols(col("x"), col("x"))).show() # doctest: +SKIP
- +-----------------------+
- |multiply_two_cols(x, x)|
- +-----------------------+
- | 1|
- | 4|
- | 9|
- +-----------------------+
-
- When the UDF is called with a single column that is `StructType`, the input to the underlying
- function is an iterator of `pd.DataFrame`.
-
- >>> @pandas_udf("long", PandasUDFType.SCALAR_ITER) # doctest: +SKIP
- ... def multiply_two_nested_cols(pdf_iter):
- ... for pdf in pdf_iter:
- ... yield pdf["a"] * pdf["b"]
- ...
- >>> df.select(
- ... multiply_two_nested_cols(
- ... struct(col("x").alias("a"), col("x").alias("b"))
- ... ).alias("y")
- ... ).show() # doctest: +SKIP
- +---+
- | y|
- +---+
- | 1|
- | 4|
- | 9|
- +---+
-
- In the UDF, you can initialize some states before processing batches, wrap your code with
- `try ... finally ...` or use context managers to ensure the release of resources at the end
- or in case of early termination.
-
- >>> y_bc = spark.sparkContext.broadcast(1) # doctest: +SKIP
- >>> @pandas_udf("long", PandasUDFType.SCALAR_ITER) # doctest: +SKIP
- ... def plus_y(batch_iter):
- ... y = y_bc.value # initialize some state
- ... try:
- ... for x in batch_iter:
- ... yield x + y
- ... finally:
- ... pass # release resources here, if any
- ...
- >>> df.select(plus_y(col("x"))).show() # doctest: +SKIP
- +---------+
- |plus_y(x)|
- +---------+
- | 2|
- | 3|
- | 4|
- +---------+
-
- 3. GROUPED_MAP
-
- A grouped map UDF defines transformation: A `pandas.DataFrame` -> A `pandas.DataFrame`
- The returnType should be a :class:`StructType` describing the schema of the returned
- `pandas.DataFrame`. The column labels of the returned `pandas.DataFrame` must either match
- the field names in the defined returnType schema if specified as strings, or match the
- field data types by position if not strings, e.g. integer indices.
- The length of the returned `pandas.DataFrame` can be arbitrary.
-
- Grouped map UDFs are used with :meth:`pyspark.sql.GroupedData.apply`.
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> df = spark.createDataFrame(
- ... [(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
- ... ("id", "v")) # doctest: +SKIP
- >>> @pandas_udf("id long, v double", PandasUDFType.GROUPED_MAP) # doctest: +SKIP
- ... def normalize(pdf):
- ... v = pdf.v
- ... return pdf.assign(v=(v - v.mean()) / v.std())
- >>> df.groupby("id").apply(normalize).show() # doctest: +SKIP
- +---+-------------------+
- | id| v|
- +---+-------------------+
- | 1|-0.7071067811865475|
- | 1| 0.7071067811865475|
- | 2|-0.8320502943378437|
- | 2|-0.2773500981126146|
- | 2| 1.1094003924504583|
- +---+-------------------+
-
- Alternatively, the user can define a function that takes two arguments.
- In this case, the grouping key(s) will be passed as the first argument and the data will
- be passed as the second argument. The grouping key(s) will be passed as a tuple of numpy
- data types, e.g., `numpy.int32` and `numpy.float64`. The data will still be passed in
- as a `pandas.DataFrame` containing all columns from the original Spark DataFrame.
- This is useful when the user does not want to hardcode grouping key(s) in the function.
-
- >>> import pandas as pd # doctest: +SKIP
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> df = spark.createDataFrame(
- ... [(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
- ... ("id", "v")) # doctest: +SKIP
- >>> @pandas_udf("id long, v double", PandasUDFType.GROUPED_MAP) # doctest: +SKIP
- ... def mean_udf(key, pdf):
- ... # key is a tuple of one numpy.int64, which is the value
- ... # of 'id' for the current group
- ... return pd.DataFrame([key + (pdf.v.mean(),)])
- >>> df.groupby('id').apply(mean_udf).show() # doctest: +SKIP
- +---+---+
- | id| v|
- +---+---+
- | 1|1.5|
- | 2|6.0|
- +---+---+
- >>> @pandas_udf(
- ... "id long, `ceil(v / 2)` long, v double",
- ... PandasUDFType.GROUPED_MAP) # doctest: +SKIP
- >>> def sum_udf(key, pdf):
- ... # key is a tuple of two numpy.int64s, which is the values
- ... # of 'id' and 'ceil(df.v / 2)' for the current group
- ... return pd.DataFrame([key + (pdf.v.sum(),)])
- >>> df.groupby(df.id, ceil(df.v / 2)).apply(sum_udf).show() # doctest: +SKIP
- +---+-----------+----+
- | id|ceil(v / 2)| v|
- +---+-----------+----+
- | 2| 5|10.0|
- | 1| 1| 3.0|
- | 2| 3| 5.0|
- | 2| 2| 3.0|
- +---+-----------+----+
-
- .. note:: If returning a new `pandas.DataFrame` constructed with a dictionary, it is
- recommended to explicitly index the columns by name to ensure the positions are correct,
- or alternatively use an `OrderedDict`.
- For example, `pd.DataFrame({'id': ids, 'a': data}, columns=['id', 'a'])` or
- `pd.DataFrame(OrderedDict([('id', ids), ('a', data)]))`.
-
- .. seealso:: :meth:`pyspark.sql.GroupedData.apply`
-
- 4. GROUPED_AGG
-
- A grouped aggregate UDF defines a transformation: One or more `pandas.Series` -> A scalar
- The `returnType` should be a primitive data type, e.g., :class:`DoubleType`.
- The returned scalar can be either a python primitive type, e.g., `int` or `float`
- or a numpy data type, e.g., `numpy.int64` or `numpy.float64`.
-
- :class:`MapType` and :class:`StructType` are currently not supported as output types.
-
- Group aggregate UDFs are used with :meth:`pyspark.sql.GroupedData.agg` and
- :class:`pyspark.sql.Window`
-
- This example shows using grouped aggregated UDFs with groupby:
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> df = spark.createDataFrame(
- ... [(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
- ... ("id", "v"))
- >>> @pandas_udf("double", PandasUDFType.GROUPED_AGG) # doctest: +SKIP
- ... def mean_udf(v):
- ... return v.mean()
- >>> df.groupby("id").agg(mean_udf(df['v'])).show() # doctest: +SKIP
- +---+-----------+
- | id|mean_udf(v)|
- +---+-----------+
- | 1| 1.5|
- | 2| 6.0|
- +---+-----------+
-
- This example shows using grouped aggregated UDFs as window functions.
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> from pyspark.sql import Window
- >>> df = spark.createDataFrame(
- ... [(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
- ... ("id", "v"))
- >>> @pandas_udf("double", PandasUDFType.GROUPED_AGG) # doctest: +SKIP
- ... def mean_udf(v):
- ... return v.mean()
- >>> w = (Window.partitionBy('id')
- ... .orderBy('v')
- ... .rowsBetween(-1, 0))
- >>> df.withColumn('mean_v', mean_udf(df['v']).over(w)).show() # doctest: +SKIP
- +---+----+------+
- | id| v|mean_v|
- +---+----+------+
- | 1| 1.0| 1.0|
- | 1| 2.0| 1.5|
- | 2| 3.0| 3.0|
- | 2| 5.0| 4.0|
- | 2|10.0| 7.5|
- +---+----+------+
-
- .. note:: For performance reasons, the input series to window functions are not copied.
+ Default: SCALAR.
+
+ .. note:: This parameter exists for compatibility. Using Python type hints is encouraged.
+
+ In order to use this API, customarily the below are imported:
+
+ >>> import pandas as pd
+ >>> from pyspark.sql.functions import pandas_udf
+
+ Prior to Spark 3.0, the pandas UDF used `functionType` to decide the execution type as below:
+
+ >>> from pyspark.sql.functions import PandasUDFType
+ >>> from pyspark.sql.types import IntegerType
+ >>> @pandas_udf(IntegerType(), PandasUDFType.SCALAR)
+ ... def slen(s):
+ ... return s.str.len()
+
+ From Spark 3.0 with Python 3.6+, `Python type hints <https://www.python.org/dev/peps/pep-0484>`_
+ detect the function types as below:
+
+ >>> @pandas_udf(IntegerType())
+ ... def slen(s: pd.Series) -> pd.Series:
+ ... return s.str.len()
+
+ It is preferred to specify type hints for the pandas UDF instead of specifying pandas UDF
+ type via `functionType` which will be deprecated in the future releases.
+
+ The below combinations of the type hints are supported for Pandas UDFs.
+ Note that the type hint should be `pandas.Series` in all cases but there is one variant case
+ that `pandas.DataFrame` should be mapped as its input or output type hint instead when
+ the input or output column is of :class:`pyspark.sql.types.StructType`.
+
+ Note that the type hint should use `pandas.Series` in all cases but there is one variant
Review comment:
duplicated?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r377026073
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -348,10 +273,21 @@ def pandas_udf(f=None, returnType=None, functionType=None):
.. note:: The user-defined functions do not take keyword arguments on the calling side.
.. note:: The data type of returned `pandas.Series` from the user-defined functions should be
- matched with defined returnType (see :meth:`types.to_arrow_type` and
+ matched with defined `returnType` (see :meth:`types.to_arrow_type` and
:meth:`types.from_arrow_type`). When there is mismatch between them, Spark might do
conversion on returned data. The conversion is not guaranteed to be correct and results
should be checked for accuracy by users.
+
+ .. note:: Currently,
+ :class:`pyspark.sql.types.MapType`,
+ :class:`pyspark.sql.types.ArrayType` of :class:`pyspark.sql.types.TimestampType` and
+ nested :class:`pyspark.sql.types.StructType`
+ are currently not supported as output types.
Review comment:
what about input types?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582371003
**[Test build #117929 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/117929/testReport)** for PR 27466 at commit [`4f85930`](https://github.com/apache/spark/commit/4f85930644fba3e4b861fe3bc65501956b062bb1).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582292132
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon edited a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon edited a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582378981
cc @rxin, @zero323, @cloud-fan, @mengxr, @viirya, @dongjoon-hyun, @WeichenXu123, @ueshin, @BryanCutler, @icexelloss, @rberenguel FYI
I would appreciate if you guys have some time to take a quick look. It has to be in Spark 3.0 but RC is supposed to start very soon, Mid Feb 2020.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582291982
Merged build finished. Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-584599983
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118222/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375588252
##########
File path: python/pyspark/sql/udf.py
##########
@@ -414,6 +415,9 @@ def _test():
.appName("sql.udf tests")\
.getOrCreate()
globs['spark'] = spark
+ # Hack to skip the unit tests in register. These are currently being tested in proper tests.
+ # We should reenable this test once we completely drop Python 2.
+ del pyspark.sql.udf.UDFRegistration.register
Review comment:
To doubly make sure, I tested and checked:
- that it doesn't affect the main codes:
```
>>> help(spark.udf.register)
```
```
Help on method register in module pyspark.sql.udf:
register(name, f, returnType=None) method of pyspark.sql.udf.UDFRegistration instance
...
```
- the generated doc too just to make sure.
- it works in main codes.
- the tests pass.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582721314
**[Test build #117965 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/117965/testReport)** for PR 27466 at commit [`6d23dbd`](https://github.com/apache/spark/commit/6d23dbdfc4753b4ee23670b5cfce8156e2154e8e).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375218796
##########
File path: python/pyspark/sql/udf.py
##########
@@ -414,6 +415,9 @@ def _test():
.appName("sql.udf tests")\
.getOrCreate()
globs['spark'] = spark
+ # Hack to skip the unit tests in register. These are currently being tested in proper tests.
+ # We should reenable this test once we completely drop Python 2.
+ pyspark.sql.udf.register.__doc__ = ""
Review comment:
To doubly make sure, I tested that it doesn't affect the main codes:
```
>>> help(spark.udf.register)
```
```
Help on method register in module pyspark.sql.udf:
register(name, f, returnType=None) method of pyspark.sql.udf.UDFRegistration instance
Register a Python function (including lambda function) or a user-defined function
as a SQL function.
:param name: name of the user-defined function in SQL statements.
:param f: a Python function, or a user-defined function. The user-defined function can
be either row-at-a-time or vectorized. See :meth:`pyspark.sql.functions.udf` and
:meth:`pyspark.sql.functions.pandas_udf`.
:param returnType: the return type of the registered user-defined fun
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375703592
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,204 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use [Python type hints](https://www.python.org/dev/peps/pep-0484).
+Using Python type hints are preferred and using `PandasUDFType` will be deprecated in
+the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
-The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+The below combinations of the type hints are supported for Pandas UDFs. Note that the type hint should
+be `pandas.Series` in all cases but there is one variant case that `pandas.DataFrame` should be mapped
+as its input or output type hint instead when the input or output column is of `StructType`.
Review comment:
Let me try to make it clear during the next cleanup.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375218184
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -480,25 +374,3 @@ def _create_pandas_udf(f, returnType, evalType):
"or three arguments (key, left, right).")
return _create_udf(f, returnType, evalType)
-
-
-def _test():
Review comment:
See https://github.com/apache/spark/pull/27466/files#r375213650
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375708097
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,204 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use [Python type hints](https://www.python.org/dev/peps/pep-0484).
+Using Python type hints are preferred and using `PandasUDFType` will be deprecated in
+the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
-The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+The below combinations of the type hints are supported for Pandas UDFs. Note that the type hint should
+be `pandas.Series` in all cases but there is one variant case that `pandas.DataFrame` should be mapped
+as its input or output type hint instead when the input or output column is of `StructType`.
Review comment:
and what if an inner field is also struct type? Is there DataFrame of DataFrame in pandas?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zero323 commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
zero323 commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375247139
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,188 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use Python type hints. Using Python type hints are preferred and the
+previous way will be deprecated in the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
+The below combinations of the type hints are supported by Python type hints for Pandas UDFs.
+Note that `pandas.DataFrame` is mapped to the column of `StructType`; otherwise, `pandas.Series` is
+mapped in all occurrences below.
-The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+### Series to Series
+
+The type hint can be expressed as `pandas.Series`, ... -> `pandas.Series`.
+
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the given
+function takes one or more `pandas.Series` and outputs one `pandas.Series`. The output of the function should
+always be of the same length as the input. Internally, PySpark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then concatenating
+the results together.
+
+The following example shows how to create this Pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example scalar_pandas_udf python/sql/arrow.py %}
+{% include_example ser_to_ser_pandas_udf python/sql/arrow.py %}
</div>
</div>
-### Scalar Iterator
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
-Scalar iterator (`SCALAR_ITER`) Pandas UDF is the same as scalar Pandas UDF above except that the
-underlying Python function takes an iterator of batches as input instead of a single batch and,
-instead of returning a single output batch, it yields output batches or returns an iterator of
-output batches.
-It is useful when the UDF execution requires initializing some states, e.g., loading an machine
-learning model file to apply inference to every input batch.
+### Iterator of Series to Iterator of Series
-The following example shows how to create scalar iterator Pandas UDFs:
+The type hint can be expressed as `Iterator[pandas.Series]` -> `Iterator[pandas.Series]`.
Review comment:
Nitpick. It is more `Iterator[Union[Tuple[pandas.Series, ...], pandas.Series]]` -> `Iterator[pandas.Series]`, isn't it? But I guess that's too much...
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582371470
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] BryanCutler commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
BryanCutler commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375575696
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,188 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use Python type hints. Using Python type hints are preferred and the
+previous way will be deprecated in the future release.
Review comment:
instead of "previous way" maybe say "using a `PandasUDFType` will be deprecated.." so it's clear what is planned to be deprecated.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r376341161
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,215 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use [Python type hints](https://www.python.org/dev/peps/pep-0484).
+Using Python type hints are preferred and using `PandasUDFType` will be deprecated in
+the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
+Note that the type hint should use `pandas.Series` in all cases but there is one variant
+that `pandas.DataFrame` should be used for its input or output type hint instead when the input
+or output column is of `StructType`. The following example shows a Pandas UDF which takes long
+column, string column and struct column, and outputs a struct column. It requires the function to
+specify the type hints of `pandas.Series` and `pandas.DataFrame` as below:
-The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+<p>
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example ser_to_frame_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+</p>
+
+In the following sections, it describes the cominations of the supported type hints. For simplicity,
+`pandas.DataFrame` variant is omitted.
+
+### Series to Series
+
+The type hint can be expressed as `pandas.Series`, ... -> `pandas.Series`.
+
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the given
+function takes one or more `pandas.Series` and outputs one `pandas.Series`. The output of the function should
+always be of the same length as the input. Internally, PySpark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then concatenating
+the results together.
+
+The following example shows how to create this Pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example scalar_pandas_udf python/sql/arrow.py %}
+{% include_example ser_to_ser_pandas_udf python/sql/arrow.py %}
</div>
</div>
-### Scalar Iterator
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
+
+### Iterator of Series to Iterator of Series
+
+The type hint can be expressed as `Iterator[pandas.Series]` -> `Iterator[pandas.Series]`.
+
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the given
+function takes an iterator of `pandas.Series` and outputs an iterator of `pandas.Series`. The output of each
+series from the function should always be of the same length as the input. In this case, the created
+Pandas UDF requires one input column when the Pandas UDF is called.
+
+It is useful when the UDF execution requires initializing some states although internally it works
+identically as Series to Series case. The pseudocode below illustrates the example.
+
+{% highlight python %}
+@pandas_udf("long")
+def calculate(iterator: Iterator[pd.Series]) -> Iterator[pd.Series]:
+ # Do some expensive initialization with a state
+ state = very_expensive_initialization()
+ for x in iterator:
+ # Use that state for whole iterator.
+ yield calculate_with_state(x, state)
-Scalar iterator (`SCALAR_ITER`) Pandas UDF is the same as scalar Pandas UDF above except that the
-underlying Python function takes an iterator of batches as input instead of a single batch and,
-instead of returning a single output batch, it yields output batches or returns an iterator of
-output batches.
-It is useful when the UDF execution requires initializing some states, e.g., loading an machine
-learning model file to apply inference to every input batch.
+df.select(calculate("value")).show()
+{% endhighlight %}
-The following example shows how to create scalar iterator Pandas UDFs:
+The following example shows how to create this Pandas UDF:
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example scalar_iter_pandas_udf python/sql/arrow.py %}
+{% include_example iter_ser_to_iter_ser_pandas_udf python/sql/arrow.py %}
</div>
</div>
-### Grouped Map
-Grouped map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
-Split-apply-combine consists of three steps:
-* Split the data into groups by using `DataFrame.groupBy`.
-* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
- input data contains all the rows and columns for each group.
-* Combine the results into a new `DataFrame`.
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
-To use `groupBy().apply()`, the user needs to define the following:
-* A Python function that defines the computation for each group.
-* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+### Iterator of Multiple Series to Iterator of Series
-The column labels of the returned `pandas.DataFrame` must either match the field names in the
-defined output schema if specified as strings, or match the field data types by position if not
-strings, e.g. integer indices. See [pandas.DataFrame](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html#pandas.DataFrame)
-on how to label columns when constructing a `pandas.DataFrame`.
+The type hint can be expressed as `Iterator[Tuple[pandas.Series, ...]]` -> `Iterator[pandas.Series]`.
-Note that all data for a group will be loaded into memory before the function is applied. This can
-lead to out of memory exceptions, especially if the group sizes are skewed. The configuration for
-[maxRecordsPerBatch](#setting-arrow-batch-size) is not applied on groups and it is up to the user
-to ensure that the grouped data will fit into the available memory.
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the
+given function takes an iterator of a tuple of multiple `pandas.Series` and outputs an iterator of `pandas.Series`.
+In this case, the created pandas UDF requires multiple input columns as many as the series in the tuple
+when the Pandas UDF is called. It works identically as Iterator of Series to Iterator of Series case except the parameter difference.
-The following example shows how to use `groupby().apply()` to subtract the mean from each value in the group.
+The following example shows how to create this Pandas UDF:
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example grouped_map_pandas_udf python/sql/arrow.py %}
+{% include_example iter_sers_to_iter_ser_pandas_udf python/sql/arrow.py %}
</div>
</div>
-For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf) and
-[`pyspark.sql.GroupedData.apply`](api/python/pyspark.sql.html#pyspark.sql.GroupedData.apply).
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
+
+### Series to Scalar
-### Grouped Aggregate
+The type hint can be expressed as `pandas.Series`, ... -> `Any`.
-Grouped aggregate Pandas UDFs are similar to Spark aggregate functions. Grouped aggregate Pandas UDFs are used with `groupBy().agg()` and
-[`pyspark.sql.Window`](api/python/pyspark.sql.html#pyspark.sql.Window). It defines an aggregation from one or more `pandas.Series`
-to a scalar value, where each `pandas.Series` represents a column within the group or window.
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF similar
+to PySpark's aggregate functions. The given function takes `pandas.Series` and returns a scalar value.
+The return type should be a primitive data type, and the returned scalar can be either a python
+primitive type, e.g., `int` or `float` or a numpy data type, e.g., `numpy.int64` or `numpy.float64`.
+`Any` should ideally be a specific scalar type accordingly.
-Note that this type of UDF does not support partial aggregation and all data for a group or window will be loaded into memory. Also,
-only unbounded window is supported with Grouped aggregate Pandas UDFs currently.
+This UDF can be also used with `groupBy().agg()` and [`pyspark.sql.Window`](api/python/pyspark.sql.html#pyspark.sql.Window).
+It defines an aggregation from one or more `pandas.Series` to a scalar value, where each `pandas.Series`
+represents a column within the group or window.
-The following example shows how to use this type of UDF to compute mean with groupBy and window operations:
+Note that this type of UDF does not support partial aggregation and all data for a group or window
+will be loaded into memory. Also, only unbounded window is supported with Grouped aggregate Pandas
+UDFs currently. The following example shows how to use this type of UDF to compute mean with a group-by
+and window operations:
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example grouped_agg_pandas_udf python/sql/arrow.py %}
+{% include_example ser_to_scalar_pandas_udf python/sql/arrow.py %}
</div>
</div>
For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
-### Map Iterator
+## Pandas Function APIs
+
+Pandas function APIs can directly apply a Python native function against the whole the DataFrame by
Review comment:
`the whole DataFrame`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582291593
**[Test build #117914 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/117914/testReport)** for PR 27466 at commit [`9fee4d5`](https://github.com/apache/spark/commit/9fee4d551b471284c1026e937d0c474b24295bad).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-584599983
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118222/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582371483
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22692/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582357737
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22691/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zero323 commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
zero323 commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375238057
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,188 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
Review comment:
Could we maybe link to [PEP 484](https://www.python.org/dev/peps/pep-0484/) here?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375216823
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -43,303 +43,186 @@ class PandasUDFType(object):
@since(2.3)
def pandas_udf(f=None, returnType=None, functionType=None):
"""
- Creates a vectorized user defined function (UDF).
+ Creates a pandas user defined function (a.k.a. vectorized user defined function).
+
+ Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer
+ data and Pandas to work with the data, which allows vectorized operations. A Pandas UDF
+ is defined using the `pandas_udf` as a decorator or to wrap the function, and no
+ additional configuration is required. A Pandas UDF behaves as a regular PySpark function
+ API in general.
:param f: user-defined function. A python function if used as a standalone function
:param returnType: the return type of the user-defined function. The value can be either a
:class:`pyspark.sql.types.DataType` object or a DDL-formatted type string.
:param functionType: an enum value in :class:`pyspark.sql.functions.PandasUDFType`.
- Default: SCALAR.
-
- .. seealso:: :meth:`pyspark.sql.DataFrame.mapInPandas`
- .. seealso:: :meth:`pyspark.sql.GroupedData.applyInPandas`
- .. seealso:: :meth:`pyspark.sql.PandasCogroupedOps.applyInPandas`
-
- The function type of the UDF can be one of the following:
-
- 1. SCALAR
-
- A scalar UDF defines a transformation: One or more `pandas.Series` -> A `pandas.Series`.
- The length of the returned `pandas.Series` must be of the same as the input `pandas.Series`.
- If the return type is :class:`StructType`, the returned value should be a `pandas.DataFrame`.
-
- :class:`MapType`, nested :class:`StructType` are currently not supported as output types.
-
- Scalar UDFs can be used with :meth:`pyspark.sql.DataFrame.withColumn` and
- :meth:`pyspark.sql.DataFrame.select`.
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> from pyspark.sql.types import IntegerType, StringType
- >>> slen = pandas_udf(lambda s: s.str.len(), IntegerType()) # doctest: +SKIP
- >>> @pandas_udf(StringType()) # doctest: +SKIP
- ... def to_upper(s):
- ... return s.str.upper()
- ...
- >>> @pandas_udf("integer", PandasUDFType.SCALAR) # doctest: +SKIP
- ... def add_one(x):
- ... return x + 1
- ...
- >>> df = spark.createDataFrame([(1, "John Doe", 21)],
- ... ("id", "name", "age")) # doctest: +SKIP
- >>> df.select(slen("name").alias("slen(name)"), to_upper("name"), add_one("age")) \\
- ... .show() # doctest: +SKIP
- +----------+--------------+------------+
- |slen(name)|to_upper(name)|add_one(age)|
- +----------+--------------+------------+
- | 8| JOHN DOE| 22|
- +----------+--------------+------------+
- >>> @pandas_udf("first string, last string") # doctest: +SKIP
- ... def split_expand(n):
- ... return n.str.split(expand=True)
- >>> df.select(split_expand("name")).show() # doctest: +SKIP
- +------------------+
- |split_expand(name)|
- +------------------+
- | [John, Doe]|
- +------------------+
-
- .. note:: The length of `pandas.Series` within a scalar UDF is not that of the whole input
- column, but is the length of an internal batch used for each call to the function.
- Therefore, this can be used, for example, to ensure the length of each returned
- `pandas.Series`, and can not be used as the column length.
-
- 2. SCALAR_ITER
-
- A scalar iterator UDF is semantically the same as the scalar Pandas UDF above except that the
- wrapped Python function takes an iterator of batches as input instead of a single batch and,
- instead of returning a single output batch, it yields output batches or explicitly returns an
- generator or an iterator of output batches.
- It is useful when the UDF execution requires initializing some state, e.g., loading a machine
- learning model file to apply inference to every input batch.
-
- .. note:: It is not guaranteed that one invocation of a scalar iterator UDF will process all
- batches from one partition, although it is currently implemented this way.
- Your code shall not rely on this behavior because it might change in the future for
- further optimization, e.g., one invocation processes multiple partitions.
Review comment:
I removed this note. Unless we explicitly document, nothing is explicitly supported. It seems to me too much to know.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375216823
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -43,303 +43,186 @@ class PandasUDFType(object):
@since(2.3)
def pandas_udf(f=None, returnType=None, functionType=None):
"""
- Creates a vectorized user defined function (UDF).
+ Creates a pandas user defined function (a.k.a. vectorized user defined function).
+
+ Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer
+ data and Pandas to work with the data, which allows vectorized operations. A Pandas UDF
+ is defined using the `pandas_udf` as a decorator or to wrap the function, and no
+ additional configuration is required. A Pandas UDF behaves as a regular PySpark function
+ API in general.
:param f: user-defined function. A python function if used as a standalone function
:param returnType: the return type of the user-defined function. The value can be either a
:class:`pyspark.sql.types.DataType` object or a DDL-formatted type string.
:param functionType: an enum value in :class:`pyspark.sql.functions.PandasUDFType`.
- Default: SCALAR.
-
- .. seealso:: :meth:`pyspark.sql.DataFrame.mapInPandas`
- .. seealso:: :meth:`pyspark.sql.GroupedData.applyInPandas`
- .. seealso:: :meth:`pyspark.sql.PandasCogroupedOps.applyInPandas`
-
- The function type of the UDF can be one of the following:
-
- 1. SCALAR
-
- A scalar UDF defines a transformation: One or more `pandas.Series` -> A `pandas.Series`.
- The length of the returned `pandas.Series` must be of the same as the input `pandas.Series`.
- If the return type is :class:`StructType`, the returned value should be a `pandas.DataFrame`.
-
- :class:`MapType`, nested :class:`StructType` are currently not supported as output types.
-
- Scalar UDFs can be used with :meth:`pyspark.sql.DataFrame.withColumn` and
- :meth:`pyspark.sql.DataFrame.select`.
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> from pyspark.sql.types import IntegerType, StringType
- >>> slen = pandas_udf(lambda s: s.str.len(), IntegerType()) # doctest: +SKIP
- >>> @pandas_udf(StringType()) # doctest: +SKIP
- ... def to_upper(s):
- ... return s.str.upper()
- ...
- >>> @pandas_udf("integer", PandasUDFType.SCALAR) # doctest: +SKIP
- ... def add_one(x):
- ... return x + 1
- ...
- >>> df = spark.createDataFrame([(1, "John Doe", 21)],
- ... ("id", "name", "age")) # doctest: +SKIP
- >>> df.select(slen("name").alias("slen(name)"), to_upper("name"), add_one("age")) \\
- ... .show() # doctest: +SKIP
- +----------+--------------+------------+
- |slen(name)|to_upper(name)|add_one(age)|
- +----------+--------------+------------+
- | 8| JOHN DOE| 22|
- +----------+--------------+------------+
- >>> @pandas_udf("first string, last string") # doctest: +SKIP
- ... def split_expand(n):
- ... return n.str.split(expand=True)
- >>> df.select(split_expand("name")).show() # doctest: +SKIP
- +------------------+
- |split_expand(name)|
- +------------------+
- | [John, Doe]|
- +------------------+
-
- .. note:: The length of `pandas.Series` within a scalar UDF is not that of the whole input
- column, but is the length of an internal batch used for each call to the function.
- Therefore, this can be used, for example, to ensure the length of each returned
- `pandas.Series`, and can not be used as the column length.
-
- 2. SCALAR_ITER
-
- A scalar iterator UDF is semantically the same as the scalar Pandas UDF above except that the
- wrapped Python function takes an iterator of batches as input instead of a single batch and,
- instead of returning a single output batch, it yields output batches or explicitly returns an
- generator or an iterator of output batches.
- It is useful when the UDF execution requires initializing some state, e.g., loading a machine
- learning model file to apply inference to every input batch.
-
- .. note:: It is not guaranteed that one invocation of a scalar iterator UDF will process all
- batches from one partition, although it is currently implemented this way.
- Your code shall not rely on this behavior because it might change in the future for
- further optimization, e.g., one invocation processes multiple partitions.
Review comment:
I removed this note. Unless we explicitly document, nothing is explicitly supported. It seems to me too much to know.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582442524
Merged build finished. Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583806250
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375264256
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,188 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use Python type hints. Using Python type hints are preferred and the
+previous way will be deprecated in the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
+The below combinations of the type hints are supported by Python type hints for Pandas UDFs.
+Note that `pandas.DataFrame` is mapped to the column of `StructType`; otherwise, `pandas.Series` is
Review comment:
I'm a little confused. For the Series to Series UDF, does it mean the input column can't be `StructType`? (otherwise it's not Series but DataFrame)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582357730
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/117928/
Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] viirya commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
viirya commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375663877
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -201,16 +273,15 @@ Note that all data for a cogroup will be loaded into memory before the function
memory exceptions, especially if the group sizes are skewed. The configuration for [maxRecordsPerBatch](#setting-arrow-batch-size)
is not applied and it is up to the user to ensure that the cogrouped data will fit into the available memory.
-The following example shows how to use `groupby().cogroup().apply()` to perform an asof join between two datasets.
+The following example shows how to use `groupby().cogroup().applyInPandas()` to perform an asof join between two datasets.
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example cogrouped_map_pandas_udf python/sql/arrow.py %}
+{% include_example cogrouped_apply_in_pandas python/sql/arrow.py %}
</div>
</div>
-For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf) and
-[`pyspark.sql.CoGroupedData.apply`](api/python/pyspark.sql.html#pyspark.sql.CoGroupedData.apply).
+For detailed usage, please see [`pyspark.sql.CoGroupedData.applyInPandas()`](api/python/pyspark.sql.html#pyspark.sql.CoGroupedData.applyInPandas).
Review comment:
Does this mean `PandasCogroupedOps` or `GroupedData` actually? I don't find any `CoGroupedData`.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582357705
**[Test build #117928 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/117928/testReport)** for PR 27466 at commit [`d3eb543`](https://github.com/apache/spark/commit/d3eb5430313f44aac396e9f5a77f4e99479d2034).
* This patch **fails Python style tests**.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582682921
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22722/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582291593
**[Test build #117914 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/117914/testReport)** for PR 27466 at commit [`9fee4d5`](https://github.com/apache/spark/commit/9fee4d551b471284c1026e937d0c474b24295bad).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zero323 commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
zero323 commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375244231
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,188 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use Python type hints. Using Python type hints are preferred and the
+previous way will be deprecated in the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
+The below combinations of the type hints are supported by Python type hints for Pandas UDFs.
+Note that `pandas.DataFrame` is mapped to the column of `StructType`; otherwise, `pandas.Series` is
+mapped in all occurrences below.
-The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+### Series to Series
+
+The type hint can be expressed as `pandas.Series`, ... -> `pandas.Series`.
+
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the given
+function takes one or more `pandas.Series` and outputs one `pandas.Series`. The output of the function should
+always be of the same length as the input. Internally, PySpark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then concatenating
+the results together.
+
+The following example shows how to create this Pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example scalar_pandas_udf python/sql/arrow.py %}
+{% include_example ser_to_ser_pandas_udf python/sql/arrow.py %}
</div>
</div>
-### Scalar Iterator
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
-Scalar iterator (`SCALAR_ITER`) Pandas UDF is the same as scalar Pandas UDF above except that the
-underlying Python function takes an iterator of batches as input instead of a single batch and,
-instead of returning a single output batch, it yields output batches or returns an iterator of
-output batches.
-It is useful when the UDF execution requires initializing some states, e.g., loading an machine
-learning model file to apply inference to every input batch.
+### Iterator of Series to Iterator of Series
-The following example shows how to create scalar iterator Pandas UDFs:
+The type hint can be expressed as `Iterator[pandas.Series]` -> `Iterator[pandas.Series]`.
+
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the given
+function takes an iterator of `pandas.Series` and outputs an iterator of `pandas.Series`. The output of each
+series from the function should always be of the same length as the input. In this case, the created
+Pandas UDF requires one input column when the Pandas UDF is called. It is useful when the UDF execution
Review comment:
Should we have some form of pseudo-code to illustrate that use case? Something like [Design Patterns for using foreachRDD](https://spark.apache.org/docs/latest/streaming-programming-guide.html#design-patterns-for-using-foreachrdd) in Streaming Docs.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zero323 commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
zero323 commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375244231
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,188 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use Python type hints. Using Python type hints are preferred and the
+previous way will be deprecated in the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
+The below combinations of the type hints are supported by Python type hints for Pandas UDFs.
+Note that `pandas.DataFrame` is mapped to the column of `StructType`; otherwise, `pandas.Series` is
+mapped in all occurrences below.
-The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+### Series to Series
+
+The type hint can be expressed as `pandas.Series`, ... -> `pandas.Series`.
+
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the given
+function takes one or more `pandas.Series` and outputs one `pandas.Series`. The output of the function should
+always be of the same length as the input. Internally, PySpark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then concatenating
+the results together.
+
+The following example shows how to create this Pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example scalar_pandas_udf python/sql/arrow.py %}
+{% include_example ser_to_ser_pandas_udf python/sql/arrow.py %}
</div>
</div>
-### Scalar Iterator
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
-Scalar iterator (`SCALAR_ITER`) Pandas UDF is the same as scalar Pandas UDF above except that the
-underlying Python function takes an iterator of batches as input instead of a single batch and,
-instead of returning a single output batch, it yields output batches or returns an iterator of
-output batches.
-It is useful when the UDF execution requires initializing some states, e.g., loading an machine
-learning model file to apply inference to every input batch.
+### Iterator of Series to Iterator of Series
-The following example shows how to create scalar iterator Pandas UDFs:
+The type hint can be expressed as `Iterator[pandas.Series]` -> `Iterator[pandas.Series]`.
+
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the given
+function takes an iterator of `pandas.Series` and outputs an iterator of `pandas.Series`. The output of each
+series from the function should always be of the same length as the input. In this case, the created
+Pandas UDF requires one input column when the Pandas UDF is called. It is useful when the UDF execution
Review comment:
Should we have some form of pseudo-code to illustrate that use case? Something like [Design Patterns for using foreachRDD](https://spark.apache.org/docs/latest/streaming-programming-guide.html#design-patterns-for-using-foreachrdd) in Streaming Docs.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583207833
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375711902
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,204 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use [Python type hints](https://www.python.org/dev/peps/pep-0484).
+Using Python type hints are preferred and using `PandasUDFType` will be deprecated in
+the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
-The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+The below combinations of the type hints are supported for Pandas UDFs. Note that the type hint should
+be `pandas.Series` in all cases but there is one variant case that `pandas.DataFrame` should be mapped
+as its input or output type hint instead when the input or output column is of `StructType`.
Review comment:
Nope, that type is not supported. Supported types are documented below at `### Supported SQL Types`.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375216428
##########
File path: python/pyspark/sql/pandas/functions.py
##########
@@ -43,303 +43,186 @@ class PandasUDFType(object):
@since(2.3)
def pandas_udf(f=None, returnType=None, functionType=None):
"""
- Creates a vectorized user defined function (UDF).
+ Creates a pandas user defined function (a.k.a. vectorized user defined function).
+
+ Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer
+ data and Pandas to work with the data, which allows vectorized operations. A Pandas UDF
+ is defined using the `pandas_udf` as a decorator or to wrap the function, and no
+ additional configuration is required. A Pandas UDF behaves as a regular PySpark function
+ API in general.
:param f: user-defined function. A python function if used as a standalone function
:param returnType: the return type of the user-defined function. The value can be either a
:class:`pyspark.sql.types.DataType` object or a DDL-formatted type string.
:param functionType: an enum value in :class:`pyspark.sql.functions.PandasUDFType`.
- Default: SCALAR.
-
- .. seealso:: :meth:`pyspark.sql.DataFrame.mapInPandas`
- .. seealso:: :meth:`pyspark.sql.GroupedData.applyInPandas`
- .. seealso:: :meth:`pyspark.sql.PandasCogroupedOps.applyInPandas`
-
- The function type of the UDF can be one of the following:
-
- 1. SCALAR
-
- A scalar UDF defines a transformation: One or more `pandas.Series` -> A `pandas.Series`.
- The length of the returned `pandas.Series` must be of the same as the input `pandas.Series`.
- If the return type is :class:`StructType`, the returned value should be a `pandas.DataFrame`.
-
- :class:`MapType`, nested :class:`StructType` are currently not supported as output types.
-
- Scalar UDFs can be used with :meth:`pyspark.sql.DataFrame.withColumn` and
- :meth:`pyspark.sql.DataFrame.select`.
-
- >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
- >>> from pyspark.sql.types import IntegerType, StringType
- >>> slen = pandas_udf(lambda s: s.str.len(), IntegerType()) # doctest: +SKIP
- >>> @pandas_udf(StringType()) # doctest: +SKIP
- ... def to_upper(s):
- ... return s.str.upper()
- ...
- >>> @pandas_udf("integer", PandasUDFType.SCALAR) # doctest: +SKIP
- ... def add_one(x):
- ... return x + 1
- ...
- >>> df = spark.createDataFrame([(1, "John Doe", 21)],
- ... ("id", "name", "age")) # doctest: +SKIP
- >>> df.select(slen("name").alias("slen(name)"), to_upper("name"), add_one("age")) \\
- ... .show() # doctest: +SKIP
- +----------+--------------+------------+
- |slen(name)|to_upper(name)|add_one(age)|
- +----------+--------------+------------+
- | 8| JOHN DOE| 22|
- +----------+--------------+------------+
- >>> @pandas_udf("first string, last string") # doctest: +SKIP
- ... def split_expand(n):
- ... return n.str.split(expand=True)
- >>> df.select(split_expand("name")).show() # doctest: +SKIP
- +------------------+
- |split_expand(name)|
- +------------------+
- | [John, Doe]|
- +------------------+
-
- .. note:: The length of `pandas.Series` within a scalar UDF is not that of the whole input
- column, but is the length of an internal batch used for each call to the function.
- Therefore, this can be used, for example, to ensure the length of each returned
Review comment:
I removed this example. This is already logically known since it says the length of input can be arbitrary and the lengths of input and output should be same.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375703095
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,204 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use [Python type hints](https://www.python.org/dev/peps/pep-0484).
+Using Python type hints are preferred and using `PandasUDFType` will be deprecated in
+the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
-The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+The below combinations of the type hints are supported for Pandas UDFs. Note that the type hint should
+be `pandas.Series` in all cases but there is one variant case that `pandas.DataFrame` should be mapped
+as its input or output type hint instead when the input or output column is of `StructType`.
Review comment:
Yes, that's correct. It's always `Series`. It becomes only `DataFrame` when the input or output column is `StructType`.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582291996
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/117914/
Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375661512
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,204 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use [Python type hints](https://www.python.org/dev/peps/pep-0484).
Review comment:
I am pretty sure we can support Python 3.5 too although maybe it needs some trivial fixes, in particular, [here](https://github.com/apache/spark/blob/master/python/pyspark/sql/pandas/typehints.py#L120-L141) but I made [the explicit condition with Python 3.6+](https://github.com/apache/spark/blob/master/python/pyspark/sql/pandas/functions.py#L440-L441)
I just excluded Python 3.5 because we deprecated Python versions lower than 3.6, and I just wanted to make it simple.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582765607
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/117965/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375218796
##########
File path: python/pyspark/sql/udf.py
##########
@@ -414,6 +415,9 @@ def _test():
.appName("sql.udf tests")\
.getOrCreate()
globs['spark'] = spark
+ # Hack to skip the unit tests in register. These are currently being tested in proper tests.
+ # We should reenable this test once we completely drop Python 2.
+ pyspark.sql.udf.register.__doc__ = ""
Review comment:
To doubly make sure, I tested that it doesn't affect the main codes:
```
>>> help(spark.udf.register)
```
```
Help on method register in module pyspark.sql.udf:
register(name, f, returnType=None) method of pyspark.sql.udf.UDFRegistration instance
Register a Python function (including lambda function) or a user-defined function
as a SQL function.
:param name: name of the user-defined function in SQL statements.
:param f: a Python function, or a user-defined function. The user-defined function can
be either row-at-a-time or vectorized. See :meth:`pyspark.sql.functions.udf` and
:meth:`pyspark.sql.functions.pandas_udf`.
:param returnType: the return type of the registered user-defined fun
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582721652
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22729/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583806187
**[Test build #118087 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118087/testReport)** for PR 27466 at commit [`76a6da2`](https://github.com/apache/spark/commit/76a6da2573e700c389948c9c328351a38041dc24).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r376340213
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,215 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use [Python type hints](https://www.python.org/dev/peps/pep-0484).
+Using Python type hints are preferred and using `PandasUDFType` will be deprecated in
+the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
+Note that the type hint should use `pandas.Series` in all cases but there is one variant
+that `pandas.DataFrame` should be used for its input or output type hint instead when the input
+or output column is of `StructType`. The following example shows a Pandas UDF which takes long
+column, string column and struct column, and outputs a struct column. It requires the function to
+specify the type hints of `pandas.Series` and `pandas.DataFrame` as below:
-The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+<p>
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example ser_to_frame_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+</p>
+
+In the following sections, it describes the cominations of the supported type hints. For simplicity,
+`pandas.DataFrame` variant is omitted.
+
+### Series to Series
+
+The type hint can be expressed as `pandas.Series`, ... -> `pandas.Series`.
+
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the given
+function takes one or more `pandas.Series` and outputs one `pandas.Series`. The output of the function should
+always be of the same length as the input. Internally, PySpark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then concatenating
+the results together.
+
+The following example shows how to create this Pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example scalar_pandas_udf python/sql/arrow.py %}
+{% include_example ser_to_ser_pandas_udf python/sql/arrow.py %}
</div>
</div>
-### Scalar Iterator
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
+
+### Iterator of Series to Iterator of Series
+
+The type hint can be expressed as `Iterator[pandas.Series]` -> `Iterator[pandas.Series]`.
+
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the given
+function takes an iterator of `pandas.Series` and outputs an iterator of `pandas.Series`. The output of each
+series from the function should always be of the same length as the input. In this case, the created
+Pandas UDF requires one input column when the Pandas UDF is called.
Review comment:
We can add one more sentence: `To support more than one input columns, please read the next section.`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583239217
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118008/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375702068
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,204 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use [Python type hints](https://www.python.org/dev/peps/pep-0484).
+Using Python type hints are preferred and using `PandasUDFType` will be deprecated in
+the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
-The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+The below combinations of the type hints are supported for Pandas UDFs. Note that the type hint should
+be `pandas.Series` in all cases but there is one variant case that `pandas.DataFrame` should be mapped
+as its input or output type hint instead when the input or output column is of `StructType`.
Review comment:
still has some confusion. What if I have 3 input columns and only one of it is struct? Should the type hint be `Series, DataFrame, Series -> Series`?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27466:
[WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with
Python type hints
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27466: [WIP][SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582371470
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-582684372
**[Test build #117958 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/117958/testReport)** for PR 27466 at commit [`7b7ae90`](https://github.com/apache/spark/commit/7b7ae9050ae235d85b11b0e55ae4ac5a5c373d2a).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zero323 commented on a change in pull request #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
zero323 commented on a change in pull request #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#discussion_r375245478
##########
File path: docs/sql-pyspark-pandas-with-arrow.md
##########
@@ -65,132 +65,188 @@ Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
-Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
-Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
-or to wrap the function, no additional configuration is required. Currently, there are two types of
-Pandas UDF: Scalar and Grouped Map.
+Pandas UDFs are user defined functions that are executed by Spark using
+Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas
+UDF is defined using the `pandas_udf` as a decorator or to wrap the function, and no additional
+configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
-### Scalar
+Before Spark 3.0, Pandas UDFs used to be defined with `PandasUDFType`. From Spark 3.0
+with Python 3.6+, you can also use Python type hints. Using Python type hints are preferred and the
+previous way will be deprecated in the future release.
-Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
-as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
-a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
-columns into batches and calling the function for each batch as a subset of the data, then
-concatenating the results together.
+The below combinations of the type hints are supported by Python type hints for Pandas UDFs.
+Note that `pandas.DataFrame` is mapped to the column of `StructType`; otherwise, `pandas.Series` is
+mapped in all occurrences below.
-The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+### Series to Series
+
+The type hint can be expressed as `pandas.Series`, ... -> `pandas.Series`.
+
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the given
+function takes one or more `pandas.Series` and outputs one `pandas.Series`. The output of the function should
+always be of the same length as the input. Internally, PySpark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then concatenating
+the results together.
+
+The following example shows how to create this Pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
-{% include_example scalar_pandas_udf python/sql/arrow.py %}
+{% include_example ser_to_ser_pandas_udf python/sql/arrow.py %}
</div>
</div>
-### Scalar Iterator
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
-Scalar iterator (`SCALAR_ITER`) Pandas UDF is the same as scalar Pandas UDF above except that the
-underlying Python function takes an iterator of batches as input instead of a single batch and,
-instead of returning a single output batch, it yields output batches or returns an iterator of
-output batches.
-It is useful when the UDF execution requires initializing some states, e.g., loading an machine
-learning model file to apply inference to every input batch.
+### Iterator of Series to Iterator of Series
-The following example shows how to create scalar iterator Pandas UDFs:
+The type hint can be expressed as `Iterator[pandas.Series]` -> `Iterator[pandas.Series]`.
+
+By using `pandas_udf` with the function having such type hints, it creates a Pandas UDF where the given
+function takes an iterator of `pandas.Series` and outputs an iterator of `pandas.Series`. The output of each
+series from the function should always be of the same length as the input. In this case, the created
+Pandas UDF requires one input column when the Pandas UDF is called. It is useful when the UDF execution
+requires initializing some states. Internally, it works identically as Series to Series case.
Review comment:
Should we have some form of pseudo-code to illustrate that use case? Something like [Design Patterns for using foreachRDD](https://spark.apache.org/docs/latest/streaming-programming-guide.html#design-patterns-for-using-foreachrdd) in Streaming Docs.
Current examples don't differentiate that well between SCALAR and SCALAR_ITER.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27466:
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python
type hints
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27466: [SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints
URL: https://github.com/apache/spark/pull/27466#issuecomment-583207519
**[Test build #118008 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118008/testReport)** for PR 27466 at commit [`47b155c`](https://github.com/apache/spark/commit/47b155c9b212c74b83835fbd84735ea164979a99).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org