You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@sedona.apache.org by ji...@apache.org on 2023/03/15 20:36:32 UTC
[sedona] branch prepare-1.4.0-doc updated: Fix a number of issues epescially raster
This is an automated email from the ASF dual-hosted git repository.
jiayu pushed a commit to branch prepare-1.4.0-doc
in repository https://gitbox.apache.org/repos/asf/sedona.git
The following commit(s) were added to refs/heads/prepare-1.4.0-doc by this push:
new 97d56916 Fix a number of issues epescially raster
97d56916 is described below
commit 97d56916696c6382d19e9fd34bcc8da4081c1c30
Author: Jia Yu <ji...@apache.org>
AuthorDate: Wed Mar 15 13:36:24 2023 -0700
Fix a number of issues epescially raster
---
docs/api/sql/DataFrameAPI.md | 75 ++++
docs/api/sql/Raster-loader.md | 223 +++--------
docs/api/sql/Raster-operators.md | 271 ++++++-------
.../api/sql/{Raster-loader.md => Raster-writer.md} | 166 +-------
docs/setup/databricks.md | 9 +-
docs/setup/flink/platform.md | 4 +-
docs/setup/install-r.md | 105 -----
docs/setup/install-scala.md | 8 +-
docs/tutorial/geopandas-shapely.md | 342 +++++++++++++++++
docs/tutorial/raster.md | 6 +-
docs/tutorial/sql.md | 424 +--------------------
mkdocs.yml | 7 +-
12 files changed, 637 insertions(+), 1003 deletions(-)
diff --git a/docs/api/sql/DataFrameAPI.md b/docs/api/sql/DataFrameAPI.md
new file mode 100644
index 00000000..788b5696
--- /dev/null
+++ b/docs/api/sql/DataFrameAPI.md
@@ -0,0 +1,75 @@
+Sedona SQL functions can be used in a DataFrame style API similar to Spark functions.
+
+The following objects contain the exposed functions: `org.apache.spark.sql.sedona_sql.expressions.st_functions`, `org.apache.spark.sql.sedona_sql.expressions.st_constructors`, `org.apache.spark.sql.sedona_sql.expressions.st_predicates`, and `org.apache.spark.sql.sedona_sql.expressions.st_aggregates`.
+
+Every functions can take all `Column` arguments. Additionally, overloaded forms can commonly take a mix of `String` and other Scala types (such as `Double`) as arguments.
+
+In general the following rules apply (although check the documentation of specific functions for any exceptions):
+
+=== "Scala"
+ 1. Every function returns a `Column` so that it can be used interchangeably with Spark functions as well as `DataFrame` methods such as `DataFrame.select` or `DataFrame.join`.
+ 2. Every function has a form that takes all `Column` arguments.
+ These are the most versatile of the forms.
+ 3. Most functions have a form that takes a mix of `String` arguments with other Scala types.
+
+=== "Python"
+
+ 1. `Column` type arguments are passed straight through and are always accepted.
+ 2. `str` type arguments are always assumed to be names of columns and are wrapped in a `Column` to support that.
+ If an actual string literal needs to be passed then it will need to be wrapped in a `Column` using `pyspark.sql.functions.lit`.
+ 3. Any other types of arguments are checked on a per function basis. Generally, arguments that could reasonably support a python native type are accepted and passed through. 4. Shapely `Geometry` objects are not currently accepted in any of the functions.
+
+The exact mixture of argument types allowed is function specific.
+However, in these instances, all `String` arguments are assumed to be the names of columns and will be wrapped in a `Column` automatically.
+Non-`String` arguments are assumed to be literals that are passed to the sedona function. If you need to pass a `String` literal then you should use the all `Column` form of the sedona function and wrap the `String` literal in a `Column` with the `lit` Spark function.
+
+A short example of using this API (uses the `array_min` and `array_max` Spark functions):
+
+=== "Scala"
+
+ ```scala
+ val values_df = spark.sql("SELECT array(0.0, 1.0, 2.0) AS values")
+ val min_value = array_min("values")
+ val max_value = array_max("values")
+ val point_df = values_df.select(ST_Point(min_value, max_value).as("point"))
+ ```
+
+=== "Python"
+
+ ```python3
+ from pyspark.sql import functions as f
+
+ from sedona.sql import st_constructors as stc
+
+ df = spark.sql("SELECT array(0.0, 1.0, 2.0) AS values")
+
+ min_value = f.array_min("values")
+ max_value = f.array_max("values")
+
+ df = df.select(stc.ST_Point(min_value, max_value).alias("point"))
+ ```
+
+The above code will generate the following dataframe:
+```
++-----------+
+|point |
++-----------+
+|POINT (0 2)|
++-----------+
+```
+
+Some functions will take native python values and infer them as literals.
+For example:
+
+```python3
+df = df.select(stc.ST_Point(1.0, 3.0).alias("point"))
+```
+
+This will generate a dataframe with a constant point in a column:
+```
++-----------+
+|point |
++-----------+
+|POINT (1 3)|
++-----------+
+```
\ No newline at end of file
diff --git a/docs/api/sql/Raster-loader.md b/docs/api/sql/Raster-loader.md
index aa72d80b..2da7cd48 100644
--- a/docs/api/sql/Raster-loader.md
+++ b/docs/api/sql/Raster-loader.md
@@ -1,7 +1,55 @@
-## Geotiff Dataframe Loader
+!!!note
+ Sedona loader are available in Scala, Java and Python and have the same APIs.
+
+Sedona provides two types of raster DataFrame loaders. They both use Sedona built-in data source but load raster images to different internal formats.
+
+## Load any raster to RasterUDT format
+
+The raster loader of Sedona leverages Spark built-in binary data source and works with several RS RasterUDT constrcutors to produce RasterUDT type. Each raster is a row in the resulting DataFrame and stored in a `RasterUDT` format.
+
+### Load raster to a binary DataFrame
+
+You can load any type of raster data using the code below. Then use the RS constructors below to create RasterUDT.
+
+```scala
+spark.read.format("binaryFile").load("/some/path/*.asc")
+```
+
+
+### RS_FromArcInfoAsciiGrid
+
+Introduction: Returns a raster geometry from an Arc Info Ascii Grid file.
+
+Format: `RS_FromArcInfoAsciiGrid(asc: Array[Byte])`
+
+Since: `v1.4.0`
+
+Spark SQL example:
+
+```scala
+var df = spark.read.format("binaryFile").load("/some/path/*.asc")
+df = df.withColumn("raster", f.expr("RS_FromArcInfoAsciiGrid(content)"))
+```
+
+
+### RS_FromGeoTiff
+
+Introduction: Returns a raster geometry from a GeoTiff file.
+
+Format: `RS_FromGeoTiff(asc: Array[Byte])`
+
+Since: `v1.4.0`
+
+Spark SQL example:
+
+```scala
+var df = spark.read.format("binaryFile").load("/some/path/*.tiff")
+df = df.withColumn("raster", f.expr("RS_FromGeoTiff(content)"))
+```
+
+## Load GeoTiff to Array[Double] format
-Introduction: The GeoTiff loader of Sedona is a Spark built-in data source. It can read a single geotiff image or
-a number of geotiff images into a DataFrame.
+The `geotiff` loader of Sedona is a Spark built-in data source. It can read a single geotiff image or a number of geotiff images into a DataFrame. Each geotiff is a row in the resulting DataFrame and stored in an arrya of Double type format.
Since: `v1.1.0`
@@ -76,87 +124,7 @@ Output:
+--------------------+--------------------+------+-----+--------------------+-----+
```
-## Geotiff Dataframe Writer
-
-Introduction: You can write a GeoTiff dataframe as GeoTiff images using the spark `write` feature with the format `geotiff`.
-
-Since: `v1.2.1`
-
-Spark SQL example:
-
-The schema of the GeoTiff dataframe to be written can be one of the following two schemas:
-
-```html
- |-- image: struct (nullable = true)
- | |-- origin: string (nullable = true)
- | |-- Geometry: geometry (nullable = true)
- | |-- height: integer (nullable = true)
- | |-- width: integer (nullable = true)
- | |-- nBands: integer (nullable = true)
- | |-- data: array (nullable = true)
- | | |-- element: double (containsNull = true)
-```
-
-or
-
-```html
- |-- origin: string (nullable = true)
- |-- Geometry: geometry (nullable = true)
- |-- height: integer (nullable = true)
- |-- width: integer (nullable = true)
- |-- nBands: integer (nullable = true)
- |-- data: array (nullable = true)
- | |-- element: double (containsNull = true)
-```
-
-Field names can be renamed, but schema should exactly match with one of the above two schemas. The output path could be a path to a directory where GeoTiff images will be saved. If the directory already exists, `write` should be called in `overwrite` mode.
-
-```scala
-var dfToWrite = sparkSession.read.format("geotiff").option("dropInvalid", true).option("readToCRS", "EPSG:4326").load("PATH_TO_INPUT_GEOTIFF_IMAGES")
-dfToWrite.write.format("geotiff").save("DESTINATION_PATH")
-```
-
-You can override an existing path with the following approach:
-
-```scala
-dfToWrite.write.mode("overwrite").format("geotiff").save("DESTINATION_PATH")
-```
-
-You can also extract the columns nested within `image` column and write the dataframe as GeoTiff image.
-
-```scala
-dfToWrite = dfToWrite.selectExpr("image.origin as origin","image.geometry as geometry", "image.height as height", "image.width as width", "image.data as data", "image.nBands as nBands")
-dfToWrite.write.mode("overwrite").format("geotiff").save("DESTINATION_PATH")
-```
-
-If you want the saved GeoTiff images not to be distributed into multiple partitions, you can call coalesce to merge all files in a single partition.
-
-```scala
-dfToWrite.coalesce(1).write.mode("overwrite").format("geotiff").save("DESTINATION_PATH")
-```
-
-In case, you rename the columns of GeoTiff dataframe, you can set the corresponding column names with the `option` parameter. All available optional parameters are listed below:
-
-```html
- |-- writeToCRS: (Default value "EPSG:4326") => Coordinate reference system of the geometry coordinates representing the location of the Geotiff.
- |-- fieldImage: (Default value "image") => Indicates the image column of GeoTiff DataFrame.
- |-- fieldOrigin: (Default value "origin") => Indicates the origin column of GeoTiff DataFrame.
- |-- fieldNBands: (Default value "nBands") => Indicates the nBands column of GeoTiff DataFrame.
- |-- fieldWidth: (Default value "width") => Indicates the width column of GeoTiff DataFrame.
- |-- fieldHeight: (Default value "height") => Indicates the height column of GeoTiff DataFrame.
- |-- fieldGeometry: (Default value "geometry") => Indicates the geometry column of GeoTiff DataFrame.
- |-- fieldData: (Default value "data") => Indicates the data column of GeoTiff DataFrame.
-```
-
-An example:
-
-```scala
-dfToWrite = sparkSession.read.format("geotiff").option("dropInvalid", true).option("readToCRS", "EPSG:4326").load("PATH_TO_INPUT_GEOTIFF_IMAGES")
-dfToWrite = dfToWrite.selectExpr("image.origin as source","ST_GeomFromWkt(image.geometry) as geom", "image.height as height", "image.width as width", "image.data as data", "image.nBands as bands")
-dfToWrite.write.mode("overwrite").format("geotiff").option("writeToCRS", "EPSG:4326").option("fieldOrigin", "source").option("fieldGeometry", "geom").option("fieldNBands", "bands").save("DESTINATION_PATH")
-```
-
-## RS_Array
+### RS_Array
Introduction: Create an array that is filled by the given value
@@ -170,69 +138,7 @@ Spark SQL example:
SELECT RS_Array(height * width, 0.0)
```
-## RS_Base64
-
-Introduction: Return a Base64 String from a geotiff image
-
-Format: `RS_Base64 (height:Int, width:Int, redBand: Array[Double], greenBand: Array[Double], blackBand: Array[Double],
-optional: alphaBand: Array[Double])`
-
-Since: `v1.1.0`
-
-Spark SQL example:
-```scala
-val BandDF = spark.sql("select RS_Base64(h, w, band1, band2, RS_Array(h*w, 0)) as baseString from dataframe")
-BandDF.show()
-```
-
-Output:
-
-```html
-+--------------------+
-| baseString|
-+--------------------+
-|QJCIAAAAAABAkDwAA...|
-|QJOoAAAAAABAlEgAA...|
-+--------------------+
-```
-
-!!!note
- Although the 3 RGB bands are mandatory, you can use [RS_Array(h*w, 0.0)](#rs_array) to create an array (zeroed out, size = h * w) as input.
-
-
-## RS_FromArcInfoAsciiGrid
-
-Introduction: Returns a raster geometry from an Arc Info Ascii Grid file.
-
-Format: `RS_FromArcInfoAsciiGrid(asc: Array[Byte])`
-
-Since: `v1.4.0`
-
-Spark SQL example:
-
-```scala
-val df = spark.read.format("binaryFile").load("/some/path/*.asc")
- .withColumn("raster", f.expr("RS_FromArcInfoAsciiGrid(content)"))
-```
-
-
-## RS_FromGeoTiff
-
-Introduction: Returns a raster geometry from a GeoTiff file.
-
-Format: `RS_FromGeoTiff(asc: Array[Byte])`
-
-Since: `v1.4.0`
-
-Spark SQL example:
-
-```scala
-val df = spark.read.format("binaryFile").load("/some/path/*.tiff")
- .withColumn("raster", f.expr("RS_FromGeoTiff(content)"))
-```
-
-
-## RS_GetBand
+### RS_GetBand
Introduction: Return a particular band from Geotiff Dataframe
@@ -262,26 +168,3 @@ Output:
|[1258.0, 1298.0, ...|
+--------------------+
```
-
-## RS_HTML
-
-Introduction: Return a html img tag with the base64 string embedded
-
-Format: `RS_HTML(base64:String, optional: width_in_px:String)`
-
-Spark SQL example:
-
-```scala
-df.selectExpr("RS_HTML(encodedstring, '300') as htmlstring" ).show()
-```
-
-Output:
-
-```html
-+--------------------+
-| htmlstring|
-+--------------------+
-|<img src="data:im...|
-|<img src="data:im...|
-+--------------------+
-```
diff --git a/docs/api/sql/Raster-operators.md b/docs/api/sql/Raster-operators.md
index 06db6b65..1011c303 100644
--- a/docs/api/sql/Raster-operators.md
+++ b/docs/api/sql/Raster-operators.md
@@ -1,4 +1,119 @@
-## RS_Add
+## RasterUDT based operators
+
+### RS_Envelope
+
+Introduction: Returns the envelope of the raster as a Geometry.
+
+Format: `RS_Envelope (raster: Raster)`
+
+Since: `v1.4.0`
+
+Spark SQL example:
+```sql
+SELECT RS_Envelope(raster) FROM raster_table
+```
+Output:
+```
+POLYGON((0 0,20 0,20 60,0 60,0 0))
+```
+
+### RS_NumBands
+
+Introduction: Returns the number of the bands in the raster.
+
+Format: `RS_NumBands (raster: Raster)`
+
+Since: `v1.4.0`
+
+Spark SQL example:
+```sql
+SELECT RS_NumBands(raster) FROM raster_table
+```
+
+Output:
+```
+4
+```
+
+### RS_Value
+
+Introduction: Returns the value at the given point in the raster.
+If no band number is specified it defaults to 1.
+
+Format: `RS_Value (raster: Raster, point: Geometry)`
+
+Format: `RS_Value (raster: Raster, point: Geometry, band: Int)`
+
+Since: `v1.4.0`
+
+Spark SQL example:
+```sql
+SELECT RS_Value(raster, ST_Point(-13077301.685, 4002565.802)) FROM raster_table
+```
+
+Output:
+```
+5.0
+```
+
+### RS_Values
+
+Introduction: Returns the values at the given points in the raster.
+If no band number is specified it defaults to 1.
+
+RS_Values is similar to RS_Value but operates on an array of points.
+RS_Values can be significantly faster since a raster only has to be loaded once for several points.
+
+Format: `RS_Values (raster: Raster, points: Array[Geometry])`
+
+Format: `RS_Values (raster: Raster, points: Array[Geometry], band: Int)`
+
+Since: `v1.4.0`
+
+Spark SQL example:
+```sql
+SELECT RS_Values(raster, Array(ST_Point(-1307.5, 400.8), ST_Point(-1403.3, 399.1)))
+FROM raster_table
+```
+
+Output:
+```
+Array(5.0, 3.0)
+```
+
+Spark SQL example for joining a point dataset with a raster dataset:
+```scala
+val pointDf = spark.read...
+val rasterDf = spark.read.format("binaryFile").load("/some/path/*.tiff")
+ .withColumn("raster", expr("RS_FromGeoTiff(content)"))
+ .withColumn("envelope", expr("RS_Envelope(raster)"))
+
+// Join the points with the raster extent and aggregate points to arrays.
+// We only use the path and envelope of the raster to keep the shuffle as small as possible.
+val df = pointDf.join(rasterDf.select("path", "envelope"), expr("ST_Within(point_geom, envelope)"))
+ .groupBy("path")
+ .agg(collect_list("point_geom").alias("point"), collect_list("point_id").alias("id"))
+
+df.join(rasterDf, "path")
+ .selectExpr("explode(arrays_zip(id, point, RS_Values(raster, point))) as result")
+ .selectExpr("result.*")
+ .show()
+```
+
+Output:
+```
++----+------------+-------+
+| id | point | value |
++----+------------+-------+
+| 4 | POINT(1 1) | 3.0 |
+| 5 | POINT(2 2) | 7.0 |
++----+------------+-------+
+```
+
+
+## Array[Double] based operators
+
+### RS_Add
Introduction: Add two spectral bands in a Geotiff image
@@ -13,7 +128,7 @@ val sumDF = spark.sql("select RS_Add(band1, band2) as sumOfBands from dataframe"
```
-## RS_Append
+### RS_Append
Introduction: Appends a new band to the end of Geotiff image data and returns the new data. The new band to be appended can be a normalized difference index between two bands (example: NBR, NDBI). Normalized difference index between two bands can be calculated with RS_NormalizedDifference operator described earlier in this page. Specific bands can be retrieved using RS_GetBand operator described [here](../Raster-loader/).
@@ -28,7 +143,7 @@ val dfAppended = spark.sql("select RS_Append(data, normalizedDifference, nBands)
```
-## RS_BitwiseAND
+### RS_BitwiseAND
Introduction: Find Bitwise AND between two bands of Geotiff image
@@ -43,7 +158,7 @@ val biwiseandDF = spark.sql("select RS_BitwiseAND(band1, band2) as andvalue from
```
-## RS_BitwiseOR
+### RS_BitwiseOR
Introduction: Find Bitwise OR between two bands of Geotiff image
@@ -58,7 +173,7 @@ val biwiseorDF = spark.sql("select RS_BitwiseOR(band1, band2) as or from datafra
```
-## RS_Count
+### RS_Count
Introduction: Returns count of a particular value from a spectral band in a raster image
@@ -73,7 +188,7 @@ val countDF = spark.sql("select RS_Count(band1, target) as count from dataframe"
```
-## RS_Divide
+### RS_Divide
Introduction: Divide band1 with band2 from a geotiff image
@@ -88,24 +203,7 @@ val multiplyDF = spark.sql("select RS_Divide(band1, band2) as divideBands from d
```
-## RS_Envelope
-
-Introduction: Returns the envelope of the raster as a Geometry.
-
-Format: `RS_Envelope (raster: Raster)`
-
-Since: `v1.4.0`
-
-Spark SQL example:
-```sql
-SELECT RS_Envelope(raster) FROM raster_table
-```
-Output:
-```
-POLYGON((0 0,20 0,20 60,0 60,0 0))
-```
-
-## RS_FetchRegion
+### RS_FetchRegion
Introduction: Fetch a subset of region from given Geotiff image based on minimumX, minimumY, maximumX and maximumY index as well original height and width of image
@@ -119,7 +217,7 @@ Spark SQL example:
val region = spark.sql("select RS_FetchRegion(Band,Array(0, 0, 1, 2),Array(3, 3)) as Region from dataframe")
```
-## RS_GreaterThan
+### RS_GreaterThan
Introduction: Mask all the values with 1 which are greater than a particular target value
@@ -134,7 +232,7 @@ val greaterDF = spark.sql("select RS_GreaterThan(band, target) as maskedvalues f
```
-## RS_GreaterThanEqual
+### RS_GreaterThanEqual
Introduction: Mask all the values with 1 which are greater than equal to a particular target value
@@ -149,7 +247,7 @@ val greaterEqualDF = spark.sql("select RS_GreaterThanEqual(band, target) as mask
```
-## RS_LessThan
+### RS_LessThan
Introduction: Mask all the values with 1 which are less than a particular target value
@@ -164,7 +262,7 @@ val lessDF = spark.sql("select RS_LessThan(band, target) as maskedvalues from da
```
-## RS_LessThanEqual
+### RS_LessThanEqual
Introduction: Mask all the values with 1 which are less than equal to a particular target value
@@ -179,7 +277,7 @@ val lessEqualDF = spark.sql("select RS_LessThanEqual(band, target) as maskedvalu
```
-## RS_LogicalDifference
+### RS_LogicalDifference
Introduction: Return value from band 1 if a value in band1 and band2 are different, else return 0
@@ -194,7 +292,7 @@ val logicalDifference = spark.sql("select RS_LogicalDifference(band1, band2) as
```
-## RS_LogicalOver
+### RS_LogicalOver
Introduction: Return value from band1 if it's not equal to 0, else return band2 value
@@ -209,7 +307,7 @@ val logicalOver = spark.sql("select RS_LogicalOver(band1, band2) as logover from
```
-## RS_Mean
+### RS_Mean
Introduction: Returns Mean value for a spectral band in a Geotiff image
@@ -224,7 +322,7 @@ val meanDF = spark.sql("select RS_Mean(band) as mean from dataframe")
```
-## RS_Mode
+### RS_Mode
Introduction: Returns Mode from a spectral band in a Geotiff image in form of an array
@@ -239,7 +337,7 @@ val modeDF = spark.sql("select RS_Mode(band) as mode from dataframe")
```
-## RS_Modulo
+### RS_Modulo
Introduction: Find modulo of pixels with respect to a particular value
@@ -254,7 +352,7 @@ val moduloDF = spark.sql("select RS_Modulo(band, target) as modulo from datafram
```
-## RS_Multiply
+### RS_Multiply
Introduction: Multiply two spectral bands in a Geotiff image
@@ -269,7 +367,7 @@ val multiplyDF = spark.sql("select RS_Multiply(band1, band2) as multiplyBands fr
```
-## RS_MultiplyFactor
+### RS_MultiplyFactor
Introduction: Multiply a factor to a spectral band in a geotiff image
@@ -284,7 +382,7 @@ val multiplyFactorDF = spark.sql("select RS_MultiplyFactor(band1, 2) as multiply
```
-## RS_Normalize
+### RS_Normalize
Introduction: Normalize the value in the array to [0, 255]
@@ -295,7 +393,7 @@ Spark SQL example
SELECT RS_Normalize(band)
```
-## RS_NormalizedDifference
+### RS_NormalizedDifference
Introduction: Returns Normalized Difference between two bands(band2 and band1) in a Geotiff image(example: NDVI, NDBI)
@@ -310,25 +408,7 @@ val normalizedDF = spark.sql("select RS_NormalizedDifference(band1, band2) as no
```
-## RS_NumBands
-
-Introduction: Returns the number of the bands in the raster.
-
-Format: `RS_NumBands (raster: Raster)`
-
-Since: `v1.4.0`
-
-Spark SQL example:
-```sql
-SELECT RS_NumBands(raster) FROM raster_table
-```
-
-Output:
-```
-4
-```
-
-## RS_SquareRoot
+### RS_SquareRoot
Introduction: Find Square root of band values in a geotiff image
@@ -343,7 +423,7 @@ val rootDF = spark.sql("select RS_SquareRoot(band) as squareroot from dataframe"
```
-## RS_Subtract
+### RS_Subtract
Introduction: Subtract two spectral bands in a Geotiff image(band2 - band1)
@@ -356,79 +436,4 @@ Spark SQL example:
val subtractDF = spark.sql("select RS_Subtract(band1, band2) as differenceOfOfBands from dataframe")
-```
-
-## RS_Value
-
-Introduction: Returns the value at the given point in the raster.
-If no band number is specified it defaults to 1.
-
-Format: `RS_Value (raster: Raster, point: Geometry)`
-
-Format: `RS_Value (raster: Raster, point: Geometry, band: Int)`
-
-Since: `v1.4.0`
-
-Spark SQL example:
-```sql
-SELECT RS_Value(raster, ST_Point(-13077301.685, 4002565.802)) FROM raster_table
-```
-
-Output:
-```
-5.0
-```
-
-## RS_Values
-
-Introduction: Returns the values at the given points in the raster.
-If no band number is specified it defaults to 1.
-
-RS_Values is similar to RS_Value but operates on an array of points.
-RS_Values can be significantly faster since a raster only has to be loaded once for several points.
-
-Format: `RS_Values (raster: Raster, points: Array[Geometry])`
-
-Format: `RS_Values (raster: Raster, points: Array[Geometry], band: Int)`
-
-Since: `v1.4.0`
-
-Spark SQL example:
-```sql
-SELECT RS_Values(raster, Array(ST_Point(-1307.5, 400.8), ST_Point(-1403.3, 399.1)))
-FROM raster_table
-```
-
-Output:
-```
-Array(5.0, 3.0)
-```
-
-Spark SQL example for joining a point dataset with a raster dataset:
-```scala
-val pointDf = spark.read...
-val rasterDf = spark.read.format("binaryFile").load("/some/path/*.tiff")
- .withColumn("raster", expr("RS_FromGeoTiff(content)"))
- .withColumn("envelope", expr("RS_Envelope(raster)"))
-
-// Join the points with the raster extent and aggregate points to arrays.
-// We only use the path and envelope of the raster to keep the shuffle as small as possible.
-val df = pointDf.join(rasterDf.select("path", "envelope"), expr("ST_Within(point_geom, envelope)"))
- .groupBy("path")
- .agg(collect_list("point_geom").alias("point"), collect_list("point_id").alias("id"))
-
-df.join(rasterDf, "path")
- .selectExpr("explode(arrays_zip(id, point, RS_Values(raster, point))) as result")
- .selectExpr("result.*")
- .show()
-```
-
-Output:
-```
-+----+------------+-------+
-| id | point | value |
-+----+------------+-------+
-| 4 | POINT(1 1) | 3.0 |
-| 5 | POINT(2 2) | 7.0 |
-+----+------------+-------+
-```
+```
\ No newline at end of file
diff --git a/docs/api/sql/Raster-loader.md b/docs/api/sql/Raster-writer.md
similarity index 50%
copy from docs/api/sql/Raster-loader.md
copy to docs/api/sql/Raster-writer.md
index aa72d80b..a2663c31 100644
--- a/docs/api/sql/Raster-loader.md
+++ b/docs/api/sql/Raster-writer.md
@@ -1,84 +1,9 @@
-## Geotiff Dataframe Loader
-
-Introduction: The GeoTiff loader of Sedona is a Spark built-in data source. It can read a single geotiff image or
-a number of geotiff images into a DataFrame.
-
-Since: `v1.1.0`
-
-Spark SQL example:
-
-The input path could be a path to a single GeoTiff image or a directory of GeoTiff images.
- You can optionally append an option to drop invalid images. The geometry bound of each image is automatically loaded
-as a Sedona geometry and is transformed to WGS84 (EPSG:4326) reference system.
-
-```scala
-var geotiffDF = sparkSession.read.format("geotiff").option("dropInvalid", true).load("YOUR_PATH")
-geotiffDF.printSchema()
-```
-
-Output:
-
-```html
- |-- image: struct (nullable = true)
- | |-- origin: string (nullable = true)
- | |-- Geometry: string (nullable = true)
- | |-- height: integer (nullable = true)
- | |-- width: integer (nullable = true)
- | |-- nBands: integer (nullable = true)
- | |-- data: array (nullable = true)
- | | |-- element: double (containsNull = true)
-```
-
-There are three more optional parameters for reading GeoTiff:
-
-```html
- |-- readfromCRS: Coordinate reference system of the geometry coordinates representing the location of the Geotiff. An example value of readfromCRS is EPSG:4326.
- |-- readToCRS: If you want to transform the Geotiff location geometry coordinates to a different coordinate reference system, you can define the target coordinate reference system with this option.
- |-- disableErrorInCRS: (Default value false) => Indicates whether to ignore errors in CRS transformation.
-```
-
-An example with all GeoTiff read options:
-
-```scala
-var geotiffDF = sparkSession.read.format("geotiff").option("dropInvalid", true).option("readFromCRS", "EPSG:4499").option("readToCRS", "EPSG:4326").option("disableErrorInCRS", true).load("YOUR_PATH")
-geotiffDF.printSchema()
-```
-
-Output:
-
-```html
- |-- image: struct (nullable = true)
- | |-- origin: string (nullable = true)
- | |-- Geometry: string (nullable = true)
- | |-- height: integer (nullable = true)
- | |-- width: integer (nullable = true)
- | |-- nBands: integer (nullable = true)
- | |-- data: array (nullable = true)
- | | |-- element: double (containsNull = true)
-```
-
-You can also select sub-attributes individually to construct a new DataFrame
-
-```scala
-geotiffDF = geotiffDF.selectExpr("image.origin as origin","ST_GeomFromWkt(image.geometry) as Geom", "image.height as height", "image.width as width", "image.data as data", "image.nBands as bands")
-geotiffDF.createOrReplaceTempView("GeotiffDataframe")
-geotiffDF.show()
-```
-
-Output:
-
-```html
-+--------------------+--------------------+------+-----+--------------------+-----+
-| origin| Geom|height|width| data|bands|
-+--------------------+--------------------+------+-----+--------------------+-----+
-|file:///home/hp/D...|POLYGON ((-58.699...| 32| 32|[1058.0, 1039.0, ...| 4|
-|file:///home/hp/D...|POLYGON ((-58.297...| 32| 32|[1258.0, 1298.0, ...| 4|
-+--------------------+--------------------+------+-----+--------------------+-----+
-```
-
-## Geotiff Dataframe Writer
+!!!note
+ Sedona writers are available in Scala, Java and Python and have the same APIs.
+
+## Write Array[Double] to GeoTiff files
-Introduction: You can write a GeoTiff dataframe as GeoTiff images using the spark `write` feature with the format `geotiff`.
+Introduction: You can write a GeoTiff dataframe as GeoTiff images using the spark `write` feature with the format `geotiff`. The geotiff raster column needs to be an array of double type data.
Since: `v1.2.1`
@@ -156,21 +81,9 @@ dfToWrite = dfToWrite.selectExpr("image.origin as source","ST_GeomFromWkt(image.
dfToWrite.write.mode("overwrite").format("geotiff").option("writeToCRS", "EPSG:4326").option("fieldOrigin", "source").option("fieldGeometry", "geom").option("fieldNBands", "bands").save("DESTINATION_PATH")
```
-## RS_Array
+## Write Array[Double] to other formats
-Introduction: Create an array that is filled by the given value
-
-Format: `RS_Array(length:Int, value: Decimal)`
-
-Since: `v1.1.0`
-
-Spark SQL example:
-
-```scala
-SELECT RS_Array(height * width, 0.0)
-```
-
-## RS_Base64
+### RS_Base64
Introduction: Return a Base64 String from a geotiff image
@@ -200,70 +113,7 @@ Output:
Although the 3 RGB bands are mandatory, you can use [RS_Array(h*w, 0.0)](#rs_array) to create an array (zeroed out, size = h * w) as input.
-## RS_FromArcInfoAsciiGrid
-
-Introduction: Returns a raster geometry from an Arc Info Ascii Grid file.
-
-Format: `RS_FromArcInfoAsciiGrid(asc: Array[Byte])`
-
-Since: `v1.4.0`
-
-Spark SQL example:
-
-```scala
-val df = spark.read.format("binaryFile").load("/some/path/*.asc")
- .withColumn("raster", f.expr("RS_FromArcInfoAsciiGrid(content)"))
-```
-
-
-## RS_FromGeoTiff
-
-Introduction: Returns a raster geometry from a GeoTiff file.
-
-Format: `RS_FromGeoTiff(asc: Array[Byte])`
-
-Since: `v1.4.0`
-
-Spark SQL example:
-
-```scala
-val df = spark.read.format("binaryFile").load("/some/path/*.tiff")
- .withColumn("raster", f.expr("RS_FromGeoTiff(content)"))
-```
-
-
-## RS_GetBand
-
-Introduction: Return a particular band from Geotiff Dataframe
-
-The number of total bands can be obtained from the GeoTiff loader
-
-Format: `RS_GetBand (allBandValues: Array[Double], targetBand:Int, totalBands:Int)`
-
-Since: `v1.1.0`
-
-!!!note
- Index of targetBand starts from 1 (instead of 0). Index of the first band is 1.
-
-Spark SQL example:
-
-```scala
-val BandDF = spark.sql("select RS_GetBand(data, 2, Band) as targetBand from GeotiffDataframe")
-BandDF.show()
-```
-
-Output:
-
-```html
-+--------------------+
-| targetBand|
-+--------------------+
-|[1058.0, 1039.0, ...|
-|[1258.0, 1298.0, ...|
-+--------------------+
-```
-
-## RS_HTML
+### RS_HTML
Introduction: Return a html img tag with the base64 string embedded
diff --git a/docs/setup/databricks.md b/docs/setup/databricks.md
index bf97395e..1e3d5e9b 100644
--- a/docs/setup/databricks.md
+++ b/docs/setup/databricks.md
@@ -5,13 +5,14 @@ You just need to install the Sedona jars and Sedona Python on Databricks using D
## Advanced editions
* Sedona 1.0.1 & 1.1.0 is compiled against Spark 3.1 (~ Databricks DBR 9 LTS, DBR 7 is Spark 3.0)
-* Sedona 1.1.1 is compiled against Spark 3.2 (~ DBR 10 & 11)
+* Sedona 1.1.1, 1.2.0 are compiled against Spark 3.2 (~ DBR 10 & 11)
+* Sedona 1.2.1, 1.3.1, 1.4.0 are complied against Spark 3.3
> In Spark 3.2, `org.apache.spark.sql.catalyst.expressions.Generator` class added a field `nodePatterns`. Any SQL functions that rely on Generator class may have issues if compiled for a runtime with a differing spark version. For Sedona, those functions are:
> * ST_MakeValid
> * ST_SubDivideExplode
-__Sedona `1.1.1-incubating` is overall the recommended version to use. It is generally backwards compatible with earlier Spark releases but you should be aware of what Spark version Sedona was compiled against versus which is being executed in case you hit issues.__
+__Sedona `1.1.1-incubating` and above is overall the recommended version to use. It is generally backwards compatible with earlier Spark releases but you should be aware of what Spark version Sedona was compiled against versus which is being executed in case you hit issues.__
#### Databricks 10.x+ (Recommended)
@@ -26,7 +27,7 @@ __Sedona `1.1.1-incubating` is overall the recommended version to use. It is gen
1) From the Libraries tab install from Maven Coordinates
```
- org.apache.sedona:sedona-python-adapter-3.0_2.12:{{ sedona.current_version }}
+ org.apache.sedona:sedona-spark-shaded-3.0_2.12:{{ sedona.current_version }}
org.datasyslab:geotools-wrapper:{{ sedona.current_geotools }}
```
@@ -75,7 +76,7 @@ mkdir -p /dbfs/FileStore/jars/sedona/{{ sedona.current_version }}
# Download the dependencies from Maven into DBFS
curl -o /dbfs/FileStore/jars/sedona/{{ sedona.current_version }}/geotools-wrapper-{{ sedona.current_geotools }}.jar "https://repo1.maven.org/maven2/org/datasyslab/geotools-wrapper/{{ sedona.current_geotools }}/geotools-wrapper-{{ sedona.current_geotools }}.jar"
-curl -o /dbfs/FileStore/jars/sedona/{{ sedona.current_version }}/sedona-python-adapter-3.0_2.12-{{ sedona.current_version }}.jar "https://repo1.maven.org/maven2/org/apache/sedona/sedona-python-adapter-3.0_2.12/{{ sedona.current_version }}/sedona-python-adapter-3.0_2.12-{{ sedona.current_version }}.jar"
+curl -o /dbfs/FileStore/jars/sedona/{{ sedona.current_version }}/sedona-spark-shaded-3.0_2.12-{{ sedona.current_version }}.jar "https://repo1.maven.org/maven2/org/apache/sedona/sedona-spark-shaded-3.0_2.12/{{ sedona.current_version }}/sedona-spark-shaded-3.0_2.12-{{ sedona.current_version }}.jar"
curl -o /dbfs/FileStore/jars/sedona/{{ sedona.current_version }}/sedona-viz-3.0_2.12-{{ sedona.current_version }}.jar "https://repo1.maven.org/maven2/org/apache/sedona/sedona-viz-3.0_2.12/{{ sedona.current_version }}/sedona-viz-3.0_2.12-{{ sedona.current_version }}.jar"
```
diff --git a/docs/setup/flink/platform.md b/docs/setup/flink/platform.md
index 95dca007..0f0ff7f6 100644
--- a/docs/setup/flink/platform.md
+++ b/docs/setup/flink/platform.md
@@ -1,8 +1,8 @@
-Sedona Flink binary releases are compiled by Java 1.8 and Scala 2.12/2.11, and tested in the following environments:
+Sedona Flink binary releases are compiled by Java 1.8 and Scala 2.12, and tested in the following environments:
=== "Sedona Scala/Java"
| | Flink 1.12 | Flink 1.13 | Flink 1.14 |
|:-----------:| :---------:|:---------:|:---------:|
| Scala 2.12 | ✅ | ✅ | ✅ |
- | Scala 2.11 | ✅ | ✅ | ✅ |
\ No newline at end of file
+ | Scala 2.11 | not tested | not tested | not tested |
\ No newline at end of file
diff --git a/docs/setup/install-r.md b/docs/setup/install-r.md
deleted file mode 100644
index b2375857..00000000
--- a/docs/setup/install-r.md
+++ /dev/null
@@ -1,105 +0,0 @@
-## Introduction
-
-apache.sedona ([cran.r-project.org/package=apache.sedona](https://cran.r-project.org/package=apache.sedona)) is a
-[sparklyr](https://github.com/sparklyr/sparklyr)-based R interface for
-[Apache Sedona](https://sedona.apache.org). It presents what Apache
-Sedona has to offer through idiomatic frameworks and constructs in R
-(e.g., one can build spatial Spark SQL queries using Sedona UDFs in
-conjunction with a wide range of dplyr expressions), hence making Apache
-Sedona highly friendly for R users.
-
-Generally speaking, when working with Apache Sedona, one choose between
-the following two modes:
-
-- Manipulating Sedona [Spatial Resilient Distributed
- Datasets](../../tutorial/rdd)
- with spatial-RDD-related routines
-- Querying geometric columns within [Spatial dataframes](../../tutorial/sql) with Sedona
- spatial UDFs
-
-While the former option enables more fine-grained control over low-level
-implementation details (e.g., which index to build for spatial queries,
-which data structure to use for spatial partitioning, etc), the latter
-is simpler and leads to a straightforward integration with `dplyr`,
-`sparklyr`, and other `sparklyr` extensions (e.g., one can build ML
-feature extractors with Sedona UDFs and connect them with ML pipelines
-using `ml_*()` family of functions in `sparklyr`, hence creating ML
-workflows capable of understanding spatial data).
-
-Because data from spatial RDDs can be imported into Spark dataframes as
-geometry columns and vice versa, one can switch between the
-abovementioned two modes fairly easily.
-
-At the moment `apache.sedona` consists of the following components:
-
-- R interface for Spatial-RDD-related functionalities
- - Reading/writing spatial data in WKT, WKB, and GeoJSON formats
- - Shapefile reader
- - Spatial partition, index, join, KNN query, and range query
- operations
- - Visualization routines
-- `dplyr`-integration for Sedona spatial UDTs and UDFs
- - See [SQL APIs](../../api/sql/Overview/) for the list
- of available UDFs
-- Functions importing data from spatial RDDs to Spark dataframes and
- vice versa
-
-## Connect to Spark
-
-To ensure Sedona serialization routines, UDTs, and UDFs are properly
-registered when creating a Spark session, one simply needs to attach
-`apache.sedona` before instantiating a Spark connection. apache.sedona
-will take care of the rest. For example,
-
-```r
-library(sparklyr)
-library(apache.sedona)
-
-spark_home <- "/usr/lib/spark" # NOTE: replace this with your $SPARK_HOME directory
-sc <- spark_connect(master = "yarn", spark_home = spark_home)
-```
-
-will create a Sedona-capable Spark connection in YARN client mode, and
-
-```r
-library(sparklyr)
-library(apache.sedona)
-
-sc <- spark_connect(master = "local")
-```
-
-will create a Sedona-capable Spark connection to an Apache Spark
-instance running locally.
-
-In `sparklyr`, one can easily inspect the Spark connection object to
-sanity-check it has been properly initialized with all Sedona-related
-dependencies, e.g.,
-
-```r
-print(sc$extensions$packages)
-```
-
- ## [1] "org.apache.sedona:sedona-core-3.0_2.12:{{ sedona.current_version }}"
- ## [2] "org.apache.sedona:sedona-sql-3.0_2.12:{{ sedona.current_version }}"
- ## [3] "org.apache.sedona:sedona-viz-3.0_2.12:{{ sedona.current_version }}"
- ## [4] "org.datasyslab:geotools-wrapper:{{ sedona.current_geotools }}"
- ## [5] "org.datasyslab:sernetcdf:0.1.0"
- ## [6] "org.locationtech.jts:jts-core:1.18.0"
- ## [7] "org.wololo:jts2geojson:0.14.3"
-
-and
-
-```r
-spark_session(sc) %>%
- invoke("%>%", list("conf"), list("get", "spark.kryo.registrator")) %>%
- print()
-```
-
- ## [1] "org.apache.sedona.viz.core.Serde.SedonaVizKryoRegistrator"
-
-
-For more information about connecting to Spark with `sparklyr`, see
-<https://therinspark.com/connections.html> and
-`?sparklyr::spark_connect`. Also see
-[Initiate Spark Context](../../tutorial/rdd/#initiate-sparkcontext) and [Initiate Spark Session](../../tutorial/sql/#initiate-sparksession) for
-minimum and recommended dependencies for Apache Sedona.
diff --git a/docs/setup/install-scala.md b/docs/setup/install-scala.md
index a8f07c73..6fe6f291 100644
--- a/docs/setup/install-scala.md
+++ b/docs/setup/install-scala.md
@@ -18,12 +18,12 @@ There are two ways to use a Scala or Java library with Apache Spark. You can use
* Local mode: test Sedona without setting up a cluster
```
-./bin/spark-shell --packages org.apache.sedona:sedona-python-adapter-3.0_2.12:{{ sedona.current_version }},org.apache.sedona:sedona-viz-3.0_2.12:{{ sedona.current_version }},org.datasyslab:geotools-wrapper:{{ sedona.current_geotools }}
+./bin/spark-shell --packages org.apache.sedona:sedona-spark-shaded-3.0_2.12:{{ sedona.current_version }},org.apache.sedona:sedona-viz-3.0_2.12:{{ sedona.current_version }},org.datasyslab:geotools-wrapper:{{ sedona.current_geotools }}
```
* Cluster mode: you need to specify Spark Master IP
```
-./bin/spark-shell --master spark://localhost:7077 --packages org.apache.sedona:sedona-python-adapter-3.0_2.12:{{ sedona.current_version }},org.apache.sedona:sedona-viz-3.0_2.12:{{ sedona.current_version }},org.datasyslab:geotools-wrapper:{{ sedona.current_geotools }}
+./bin/spark-shell --master spark://localhost:7077 --packages org.apache.sedona:sedona-spark-shaded-3.0_2.12:{{ sedona.current_version }},org.apache.sedona:sedona-viz-3.0_2.12:{{ sedona.current_version }},org.datasyslab:geotools-wrapper:{{ sedona.current_geotools }}
```
### Download Sedona jar manually
@@ -39,12 +39,12 @@ There are two ways to use a Scala or Java library with Apache Spark. You can use
* Local mode: test Sedona without setting up a cluster
```
-./bin/spark-shell --jars org.apache.sedona:sedona-python-adapter-3.0_2.12:{{ sedona.current_version }},org.apache.sedona:sedona-viz-3.0_2.12:{{ sedona.current_version }},org.datasyslab:geotools-wrapper:{{ sedona.current_geotools }}
+./bin/spark-shell --jars org.apache.sedona:sedona-spark-shaded-3.0_2.12:{{ sedona.current_version }},org.apache.sedona:sedona-viz-3.0_2.12:{{ sedona.current_version }},org.datasyslab:geotools-wrapper:{{ sedona.current_geotools }}
```
* Cluster mode: you need to specify Spark Master IP
```
-./bin/spark-shell --master spark://localhost:7077 --jars org.apache.sedona:sedona-python-adapter-3.0_2.12:{{ sedona.current_version }},org.apache.sedona:sedona-viz-3.0_2.12:{{ sedona.current_version }},org.datasyslab:geotools-wrapper:{{ sedona.current_geotools }}
+./bin/spark-shell --master spark://localhost:7077 --jars org.apache.sedona:sedona-spark-shaded-3.0_2.12:{{ sedona.current_version }},org.apache.sedona:sedona-viz-3.0_2.12:{{ sedona.current_version }},org.datasyslab:geotools-wrapper:{{ sedona.current_geotools }}
```
## Spark SQL shell
diff --git a/docs/tutorial/geopandas-shapely.md b/docs/tutorial/geopandas-shapely.md
new file mode 100644
index 00000000..4b1251fa
--- /dev/null
+++ b/docs/tutorial/geopandas-shapely.md
@@ -0,0 +1,342 @@
+# Work with GeoPandas and Shapely
+
+## Interoperate with GeoPandas
+
+Sedona Python has implemented serializers and deserializers which allows to convert Sedona Geometry objects into Shapely BaseGeometry objects. Based on that it is possible to load the data with geopandas from file (look at Fiona possible drivers) and create Spark DataFrame based on GeoDataFrame object.
+
+### From GeoPandas to Sedona DataFrame
+
+Loading the data from shapefile using geopandas read_file method and create Spark DataFrame based on GeoDataFrame:
+
+```python
+
+import geopandas as gpd
+from pyspark.sql import SparkSession
+
+from sedona.register import SedonaRegistrator
+
+spark = SparkSession.builder.\
+ getOrCreate()
+
+SedonaRegistrator.registerAll(spark)
+
+gdf = gpd.read_file("gis_osm_pois_free_1.shp")
+
+spark.createDataFrame(
+ gdf
+).show()
+
+```
+
+This query will show the following outputs:
+
+```
+
++---------+----+-----------+--------------------+--------------------+
+| osm_id|code| fclass| name| geometry|
++---------+----+-----------+--------------------+--------------------+
+| 26860257|2422| camp_site| de Kroon|POINT (15.3393145...|
+| 26860294|2406| chalet| Leśne Ustronie|POINT (14.8709625...|
+| 29947493|2402| motel| null|POINT (15.0946636...|
+| 29947498|2602| atm| null|POINT (15.0732014...|
+| 29947499|2401| hotel| null|POINT (15.0696777...|
+| 29947505|2401| hotel| null|POINT (15.0155749...|
++---------+----+-----------+--------------------+--------------------+
+
+```
+
+### From Sedona DataFrame to GeoPandas
+
+Reading data with Spark and converting to GeoPandas
+
+```python
+
+import geopandas as gpd
+from pyspark.sql import SparkSession
+
+from sedona.register import SedonaRegistrator
+
+spark = SparkSession.builder.\
+ getOrCreate()
+
+SedonaRegistrator.registerAll(spark)
+
+counties = spark.\
+ read.\
+ option("delimiter", "|").\
+ option("header", "true").\
+ csv("counties.csv")
+
+counties.createOrReplaceTempView("county")
+
+counties_geom = spark.sql(
+ "SELECT *, st_geomFromWKT(geom) as geometry from county"
+)
+
+df = counties_geom.toPandas()
+gdf = gpd.GeoDataFrame(df, geometry="geometry")
+
+gdf.plot(
+ figsize=(10, 8),
+ column="value",
+ legend=True,
+ cmap='YlOrBr',
+ scheme='quantiles',
+ edgecolor='lightgray'
+)
+
+```
+<br>
+<br>
+
+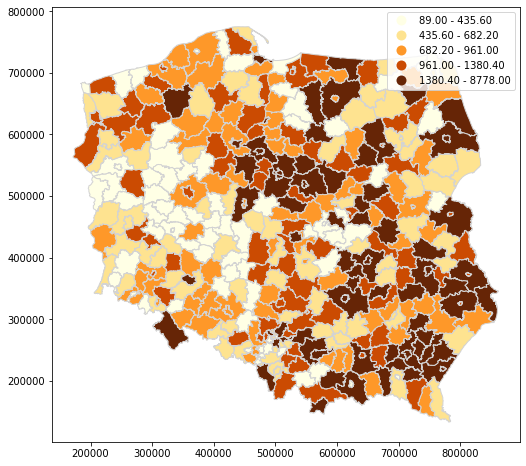
+
+<br>
+<br>
+
+
+## Interoperate with shapely objects
+
+### Supported Shapely objects
+
+| shapely object | Available |
+|-----------------|--------------------|
+| Point | :heavy_check_mark: |
+| MultiPoint | :heavy_check_mark: |
+| LineString | :heavy_check_mark: |
+| MultiLinestring | :heavy_check_mark: |
+| Polygon | :heavy_check_mark: |
+| MultiPolygon | :heavy_check_mark: |
+
+To create Spark DataFrame based on mentioned Geometry types, please use <b> GeometryType </b> from <b> sedona.sql.types </b> module. Converting works for list or tuple with shapely objects.
+
+Schema for target table with integer id and geometry type can be defined as follow:
+
+```python
+
+from pyspark.sql.types import IntegerType, StructField, StructType
+
+from sedona.sql.types import GeometryType
+
+schema = StructType(
+ [
+ StructField("id", IntegerType(), False),
+ StructField("geom", GeometryType(), False)
+ ]
+)
+
+```
+
+Also Spark DataFrame with geometry type can be converted to list of shapely objects with <b> collect </b> method.
+
+### Point example
+
+```python
+from shapely.geometry import Point
+
+data = [
+ [1, Point(21.0, 52.0)],
+ [1, Point(23.0, 42.0)],
+ [1, Point(26.0, 32.0)]
+]
+
+
+gdf = spark.createDataFrame(
+ data,
+ schema
+)
+
+gdf.show()
+
+```
+
+```
++---+-------------+
+| id| geom|
++---+-------------+
+| 1|POINT (21 52)|
+| 1|POINT (23 42)|
+| 1|POINT (26 32)|
++---+-------------+
+```
+
+```python
+gdf.printSchema()
+```
+
+```
+root
+ |-- id: integer (nullable = false)
+ |-- geom: geometry (nullable = false)
+```
+
+### MultiPoint example
+
+```python3
+
+from shapely.geometry import MultiPoint
+
+data = [
+ [1, MultiPoint([[19.511463, 51.765158], [19.446408, 51.779752]])]
+]
+
+gdf = spark.createDataFrame(
+ data,
+ schema
+).show(1, False)
+
+```
+
+```
+
++---+---------------------------------------------------------+
+|id |geom |
++---+---------------------------------------------------------+
+|1 |MULTIPOINT ((19.511463 51.765158), (19.446408 51.779752))|
++---+---------------------------------------------------------+
+
+
+```
+
+### LineString example
+
+```python3
+
+from shapely.geometry import LineString
+
+line = [(40, 40), (30, 30), (40, 20), (30, 10)]
+
+data = [
+ [1, LineString(line)]
+]
+
+gdf = spark.createDataFrame(
+ data,
+ schema
+)
+
+gdf.show(1, False)
+
+```
+
+```
+
++---+--------------------------------+
+|id |geom |
++---+--------------------------------+
+|1 |LINESTRING (10 10, 20 20, 10 40)|
++---+--------------------------------+
+
+```
+
+### MultiLineString example
+
+```python3
+
+from shapely.geometry import MultiLineString
+
+line1 = [(10, 10), (20, 20), (10, 40)]
+line2 = [(40, 40), (30, 30), (40, 20), (30, 10)]
+
+data = [
+ [1, MultiLineString([line1, line2])]
+]
+
+gdf = spark.createDataFrame(
+ data,
+ schema
+)
+
+gdf.show(1, False)
+
+```
+
+```
+
++---+---------------------------------------------------------------------+
+|id |geom |
++---+---------------------------------------------------------------------+
+|1 |MULTILINESTRING ((10 10, 20 20, 10 40), (40 40, 30 30, 40 20, 30 10))|
++---+---------------------------------------------------------------------+
+
+```
+
+### Polygon example
+
+```python3
+
+from shapely.geometry import Polygon
+
+polygon = Polygon(
+ [
+ [19.51121, 51.76426],
+ [19.51056, 51.76583],
+ [19.51216, 51.76599],
+ [19.51280, 51.76448],
+ [19.51121, 51.76426]
+ ]
+)
+
+data = [
+ [1, polygon]
+]
+
+gdf = spark.createDataFrame(
+ data,
+ schema
+)
+
+gdf.show(1, False)
+
+```
+
+
+```
+
++---+--------------------------------------------------------------------------------------------------------+
+|id |geom |
++---+--------------------------------------------------------------------------------------------------------+
+|1 |POLYGON ((19.51121 51.76426, 19.51056 51.76583, 19.51216 51.76599, 19.5128 51.76448, 19.51121 51.76426))|
++---+--------------------------------------------------------------------------------------------------------+
+
+```
+
+### MultiPolygon example
+
+```python3
+
+from shapely.geometry import MultiPolygon
+
+exterior_p1 = [(0, 0), (0, 2), (2, 2), (2, 0), (0, 0)]
+interior_p1 = [(1, 1), (1, 1.5), (1.5, 1.5), (1.5, 1), (1, 1)]
+
+exterior_p2 = [(0, 0), (1, 0), (1, 1), (0, 1), (0, 0)]
+
+polygons = [
+ Polygon(exterior_p1, [interior_p1]),
+ Polygon(exterior_p2)
+]
+
+data = [
+ [1, MultiPolygon(polygons)]
+]
+
+gdf = spark.createDataFrame(
+ data,
+ schema
+)
+
+gdf.show(1, False)
+
+```
+
+```
+
++---+----------------------------------------------------------------------------------------------------------+
+|id |geom |
++---+----------------------------------------------------------------------------------------------------------+
+|1 |MULTIPOLYGON (((0 0, 0 2, 2 2, 2 0, 0 0), (1 1, 1.5 1, 1.5 1.5, 1 1.5, 1 1)), ((0 0, 0 1, 1 1, 1 0, 0 0)))|
++---+----------------------------------------------------------------------------------------------------------+
+
+```
+
diff --git a/docs/tutorial/raster.md b/docs/tutorial/raster.md
index 6470b9c6..d7c24e0e 100644
--- a/docs/tutorial/raster.md
+++ b/docs/tutorial/raster.md
@@ -8,9 +8,11 @@ Starting from `v1.1.0`, Sedona SQL supports raster data sources and raster opera
## API docs
-[IO of raster data in DataFrame](../../api/sql/Raster-loader/)
+[Read raster data in DataFrame](../../api/sql/Raster-loader/)
-[Map algebra in DataFrame](../../api/sql/Raster-operators/)
+[Write raster data in DataFrame](../../api/sql/Raster-writer/)
+
+[Raster operators in DataFrame](../../api/sql/Raster-operators/)
## Tutorials
diff --git a/docs/tutorial/sql.md b/docs/tutorial/sql.md
index b8bba312..81b43c9d 100644
--- a/docs/tutorial/sql.md
+++ b/docs/tutorial/sql.md
@@ -506,426 +506,4 @@ case. Columns for the left and right user data must be provided.
StructField("category", StringType, nullable = true)
))
val joinResultDf = Adapter.toDf(joinResultPairRDD, schema, sparkSession)
- ```
-
-## DataFrame Style API
-
-Sedona functions can be used in a DataFrame style API similar to Spark functions.
-
-The following objects contain the exposed functions: `org.apache.spark.sql.sedona_sql.expressions.st_functions`, `org.apache.spark.sql.sedona_sql.expressions.st_constructors`, `org.apache.spark.sql.sedona_sql.expressions.st_predicates`, and `org.apache.spark.sql.sedona_sql.expressions.st_aggregates`.
-
-Every functions can take all `Column` arguments. Additionally, overloaded forms can commonly take a mix of `String` and other Scala types (such as `Double`) as arguments.
-
-In general the following rules apply (although check the documentation of specific functions for any exceptions):
-
-=== "Scala"
- 1. Every function returns a `Column` so that it can be used interchangeably with Spark functions as well as `DataFrame` methods such as `DataFrame.select` or `DataFrame.join`.
- 2. Every function has a form that takes all `Column` arguments.
- These are the most versatile of the forms.
- 3. Most functions have a form that takes a mix of `String` arguments with other Scala types.
-
-=== "Python"
-
- 1. `Column` type arguments are passed straight through and are always accepted.
- 2. `str` type arguments are always assumed to be names of columns and are wrapped in a `Column` to support that.
- If an actual string literal needs to be passed then it will need to be wrapped in a `Column` using `pyspark.sql.functions.lit`.
- 3. Any other types of arguments are checked on a per function basis.
- Generally, arguments that could reasonably support a python native type are accepted and passed through.
- Check the specific docstring of the function to be sure.
- 4. Shapely `Geometry` objects are not currently accepted in any of the functions.
-
-The exact mixture of argument types allowed is function specific.
-However, in these instances, all `String` arguments are assumed to be the names of columns and will be wrapped in a `Column` automatically.
-Non-`String` arguments are assumed to be literals that are passed to the sedona function. If you need to pass a `String` literal then you should use the all `Column` form of the sedona function and wrap the `String` literal in a `Column` with the `lit` Spark function.
-
-A short example of using this API (uses the `array_min` and `array_max` Spark functions):
-
-=== "Scala"
-
- ```scala
- val values_df = spark.sql("SELECT array(0.0, 1.0, 2.0) AS values")
- val min_value = array_min("values")
- val max_value = array_max("values")
- val point_df = values_df.select(ST_Point(min_value, max_value).as("point"))
- ```
-
-=== "Python"
-
- ```python3
- from pyspark.sql import functions as f
-
- from sedona.sql import st_constructors as stc
-
- df = spark.sql("SELECT array(0.0, 1.0, 2.0) AS values")
-
- min_value = f.array_min("values")
- max_value = f.array_max("values")
-
- df = df.select(stc.ST_Point(min_value, max_value).alias("point"))
- ```
-
-The above code will generate the following dataframe:
-```
-+-----------+
-|point |
-+-----------+
-|POINT (0 2)|
-+-----------+
-```
-
-Some functions will take native python values and infer them as literals.
-For example:
-
-```python3
-df = df.select(stc.ST_Point(1.0, 3.0).alias("point"))
-```
-
-This will generate a dataframe with a constant point in a column:
-```
-+-----------+
-|point |
-+-----------+
-|POINT (1 3)|
-+-----------+
-```
-
-## Interoperate with GeoPandas
-
-Sedona Python has implemented serializers and deserializers which allows to convert Sedona Geometry objects into Shapely BaseGeometry objects. Based on that it is possible to load the data with geopandas from file (look at Fiona possible drivers) and create Spark DataFrame based on GeoDataFrame object.
-
-### From GeoPandas to Sedona DataFrame
-
-Loading the data from shapefile using geopandas read_file method and create Spark DataFrame based on GeoDataFrame:
-
-```python
-
-import geopandas as gpd
-from pyspark.sql import SparkSession
-
-from sedona.register import SedonaRegistrator
-
-spark = SparkSession.builder.\
- getOrCreate()
-
-SedonaRegistrator.registerAll(spark)
-
-gdf = gpd.read_file("gis_osm_pois_free_1.shp")
-
-spark.createDataFrame(
- gdf
-).show()
-
-```
-
-This query will show the following outputs:
-
-```
-
-+---------+----+-----------+--------------------+--------------------+
-| osm_id|code| fclass| name| geometry|
-+---------+----+-----------+--------------------+--------------------+
-| 26860257|2422| camp_site| de Kroon|POINT (15.3393145...|
-| 26860294|2406| chalet| Leśne Ustronie|POINT (14.8709625...|
-| 29947493|2402| motel| null|POINT (15.0946636...|
-| 29947498|2602| atm| null|POINT (15.0732014...|
-| 29947499|2401| hotel| null|POINT (15.0696777...|
-| 29947505|2401| hotel| null|POINT (15.0155749...|
-+---------+----+-----------+--------------------+--------------------+
-
-```
-
-### From Sedona DataFrame to GeoPandas
-
-Reading data with Spark and converting to GeoPandas
-
-```python
-
-import geopandas as gpd
-from pyspark.sql import SparkSession
-
-from sedona.register import SedonaRegistrator
-
-spark = SparkSession.builder.\
- getOrCreate()
-
-SedonaRegistrator.registerAll(spark)
-
-counties = spark.\
- read.\
- option("delimiter", "|").\
- option("header", "true").\
- csv("counties.csv")
-
-counties.createOrReplaceTempView("county")
-
-counties_geom = spark.sql(
- "SELECT *, st_geomFromWKT(geom) as geometry from county"
-)
-
-df = counties_geom.toPandas()
-gdf = gpd.GeoDataFrame(df, geometry="geometry")
-
-gdf.plot(
- figsize=(10, 8),
- column="value",
- legend=True,
- cmap='YlOrBr',
- scheme='quantiles',
- edgecolor='lightgray'
-)
-
-```
-<br>
-<br>
-
-
-
-<br>
-<br>
-
-
-## Interoperate with shapely objects
-
-### Supported Shapely objects
-
-| shapely object | Available |
-|-----------------|--------------------|
-| Point | :heavy_check_mark: |
-| MultiPoint | :heavy_check_mark: |
-| LineString | :heavy_check_mark: |
-| MultiLinestring | :heavy_check_mark: |
-| Polygon | :heavy_check_mark: |
-| MultiPolygon | :heavy_check_mark: |
-
-To create Spark DataFrame based on mentioned Geometry types, please use <b> GeometryType </b> from <b> sedona.sql.types </b> module. Converting works for list or tuple with shapely objects.
-
-Schema for target table with integer id and geometry type can be defined as follow:
-
-```python
-
-from pyspark.sql.types import IntegerType, StructField, StructType
-
-from sedona.sql.types import GeometryType
-
-schema = StructType(
- [
- StructField("id", IntegerType(), False),
- StructField("geom", GeometryType(), False)
- ]
-)
-
-```
-
-Also Spark DataFrame with geometry type can be converted to list of shapely objects with <b> collect </b> method.
-
-### Point example
-
-```python
-from shapely.geometry import Point
-
-data = [
- [1, Point(21.0, 52.0)],
- [1, Point(23.0, 42.0)],
- [1, Point(26.0, 32.0)]
-]
-
-
-gdf = spark.createDataFrame(
- data,
- schema
-)
-
-gdf.show()
-
-```
-
-```
-+---+-------------+
-| id| geom|
-+---+-------------+
-| 1|POINT (21 52)|
-| 1|POINT (23 42)|
-| 1|POINT (26 32)|
-+---+-------------+
-```
-
-```python
-gdf.printSchema()
-```
-
-```
-root
- |-- id: integer (nullable = false)
- |-- geom: geometry (nullable = false)
-```
-
-### MultiPoint example
-
-```python3
-
-from shapely.geometry import MultiPoint
-
-data = [
- [1, MultiPoint([[19.511463, 51.765158], [19.446408, 51.779752]])]
-]
-
-gdf = spark.createDataFrame(
- data,
- schema
-).show(1, False)
-
-```
-
-```
-
-+---+---------------------------------------------------------+
-|id |geom |
-+---+---------------------------------------------------------+
-|1 |MULTIPOINT ((19.511463 51.765158), (19.446408 51.779752))|
-+---+---------------------------------------------------------+
-
-
-```
-
-### LineString example
-
-```python3
-
-from shapely.geometry import LineString
-
-line = [(40, 40), (30, 30), (40, 20), (30, 10)]
-
-data = [
- [1, LineString(line)]
-]
-
-gdf = spark.createDataFrame(
- data,
- schema
-)
-
-gdf.show(1, False)
-
-```
-
-```
-
-+---+--------------------------------+
-|id |geom |
-+---+--------------------------------+
-|1 |LINESTRING (10 10, 20 20, 10 40)|
-+---+--------------------------------+
-
-```
-
-### MultiLineString example
-
-```python3
-
-from shapely.geometry import MultiLineString
-
-line1 = [(10, 10), (20, 20), (10, 40)]
-line2 = [(40, 40), (30, 30), (40, 20), (30, 10)]
-
-data = [
- [1, MultiLineString([line1, line2])]
-]
-
-gdf = spark.createDataFrame(
- data,
- schema
-)
-
-gdf.show(1, False)
-
-```
-
-```
-
-+---+---------------------------------------------------------------------+
-|id |geom |
-+---+---------------------------------------------------------------------+
-|1 |MULTILINESTRING ((10 10, 20 20, 10 40), (40 40, 30 30, 40 20, 30 10))|
-+---+---------------------------------------------------------------------+
-
-```
-
-### Polygon example
-
-```python3
-
-from shapely.geometry import Polygon
-
-polygon = Polygon(
- [
- [19.51121, 51.76426],
- [19.51056, 51.76583],
- [19.51216, 51.76599],
- [19.51280, 51.76448],
- [19.51121, 51.76426]
- ]
-)
-
-data = [
- [1, polygon]
-]
-
-gdf = spark.createDataFrame(
- data,
- schema
-)
-
-gdf.show(1, False)
-
-```
-
-
-```
-
-+---+--------------------------------------------------------------------------------------------------------+
-|id |geom |
-+---+--------------------------------------------------------------------------------------------------------+
-|1 |POLYGON ((19.51121 51.76426, 19.51056 51.76583, 19.51216 51.76599, 19.5128 51.76448, 19.51121 51.76426))|
-+---+--------------------------------------------------------------------------------------------------------+
-
-```
-
-### MultiPolygon example
-
-```python3
-
-from shapely.geometry import MultiPolygon
-
-exterior_p1 = [(0, 0), (0, 2), (2, 2), (2, 0), (0, 0)]
-interior_p1 = [(1, 1), (1, 1.5), (1.5, 1.5), (1.5, 1), (1, 1)]
-
-exterior_p2 = [(0, 0), (1, 0), (1, 1), (0, 1), (0, 0)]
-
-polygons = [
- Polygon(exterior_p1, [interior_p1]),
- Polygon(exterior_p2)
-]
-
-data = [
- [1, MultiPolygon(polygons)]
-]
-
-gdf = spark.createDataFrame(
- data,
- schema
-)
-
-gdf.show(1, False)
-
-```
-
-```
-
-+---+----------------------------------------------------------------------------------------------------------+
-|id |geom |
-+---+----------------------------------------------------------------------------------------------------------+
-|1 |MULTIPOLYGON (((0 0, 0 2, 2 2, 2 0, 0 0), (1 1, 1.5 1, 1.5 1.5, 1 1.5, 1 1)), ((0 0, 0 1, 1 1, 1 0, 0 0)))|
-+---+----------------------------------------------------------------------------------------------------------+
-
-```
-
+ ```
\ No newline at end of file
diff --git a/mkdocs.yml b/mkdocs.yml
index cefa57f2..eb634c97 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -15,7 +15,7 @@ nav:
- Install with Apache Spark:
- Install Sedona Scala/Java: setup/install-scala.md
- Install Sedona Python: setup/install-python.md
- - Install Sedona R: setup/install-r.md
+ - Install Sedona R: api/rdocs
- Install Sedona-Zeppelin: setup/zeppelin.md
- Install on Databricks: setup/databricks.md
- Set up Spark cluster: setup/cluster.md
@@ -31,6 +31,7 @@ nav:
- Pure SQL environment: tutorial/sql-pure-sql.md
- Spatial RDD app: tutorial/rdd.md
- Sedona R: api/rdocs
+ - Work with GeoPandas and Shapely: tutorial/geopandas-shapely.md
- Map visualization SQL app:
- Scala/Java: tutorial/viz.md
- Use Apache Zeppelin: tutorial/zeppelin.md
@@ -52,9 +53,11 @@ nav:
- Function: api/sql/Function.md
- Predicate: api/sql/Predicate.md
- Aggregate function: api/sql/AggregateFunction.md
+ - DataFrame Style functions: api/sql/DataFrameAPI.md
- SedonaSQL query optimizer: api/sql/Optimizer.md
- Raster data:
- - Raster input and output: api/sql/Raster-loader.md
+ - Raster loader: api/sql/Raster-loader.md
+ - Raster writer: api/sql/Raster-writer.md
- Raster operators: api/sql/Raster-operators.md
- Parameter: api/sql/Parameter.md
- RDD (core):