You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2020/07/14 18:09:50 UTC
[GitHub] [hudi] srsteinmetz opened a new issue #1830: [SUPPORT] Processing time gradually increases while using Spark Streaming
srsteinmetz opened a new issue #1830:
URL: https://github.com/apache/hudi/issues/1830
**_Tips before filing an issue_**
- Have you gone through our [FAQs](https://cwiki.apache.org/confluence/display/HUDI/FAQ)?
- Join the mailing list to engage in conversations and get faster support at dev-subscribe@hudi.apache.org.
- If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly.
**Describe the problem you faced**
This issue appears to be similar to: https://github.com/apache/hudi/issues/1728
While using Spark Streaming to read a Kinesis stream and upsert records to a MoR table.
We are seeing the processing time increase over time.
This processing time increase occurs both on new tables and large existing tables.
Increasing processing time on new table:
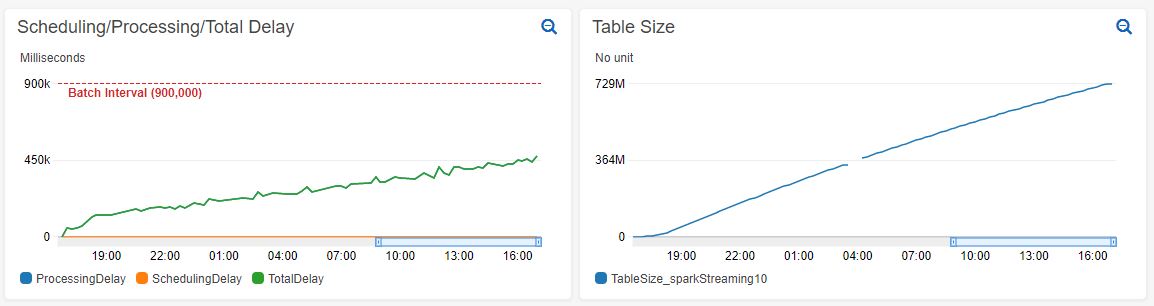
Increasing processing time on existing table with 1.4 billion records:
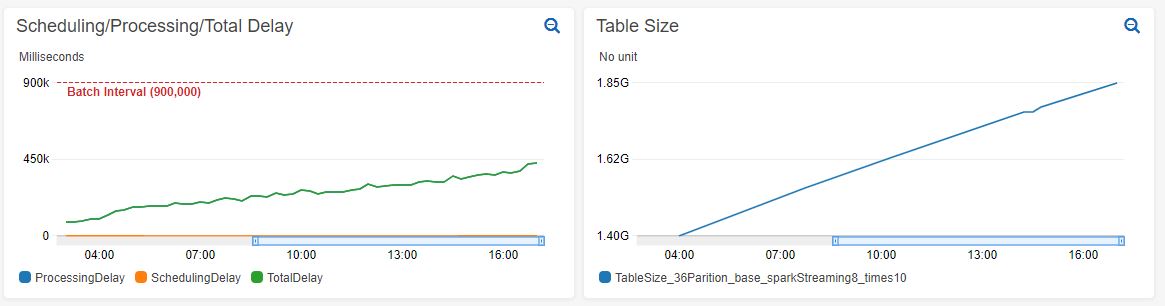
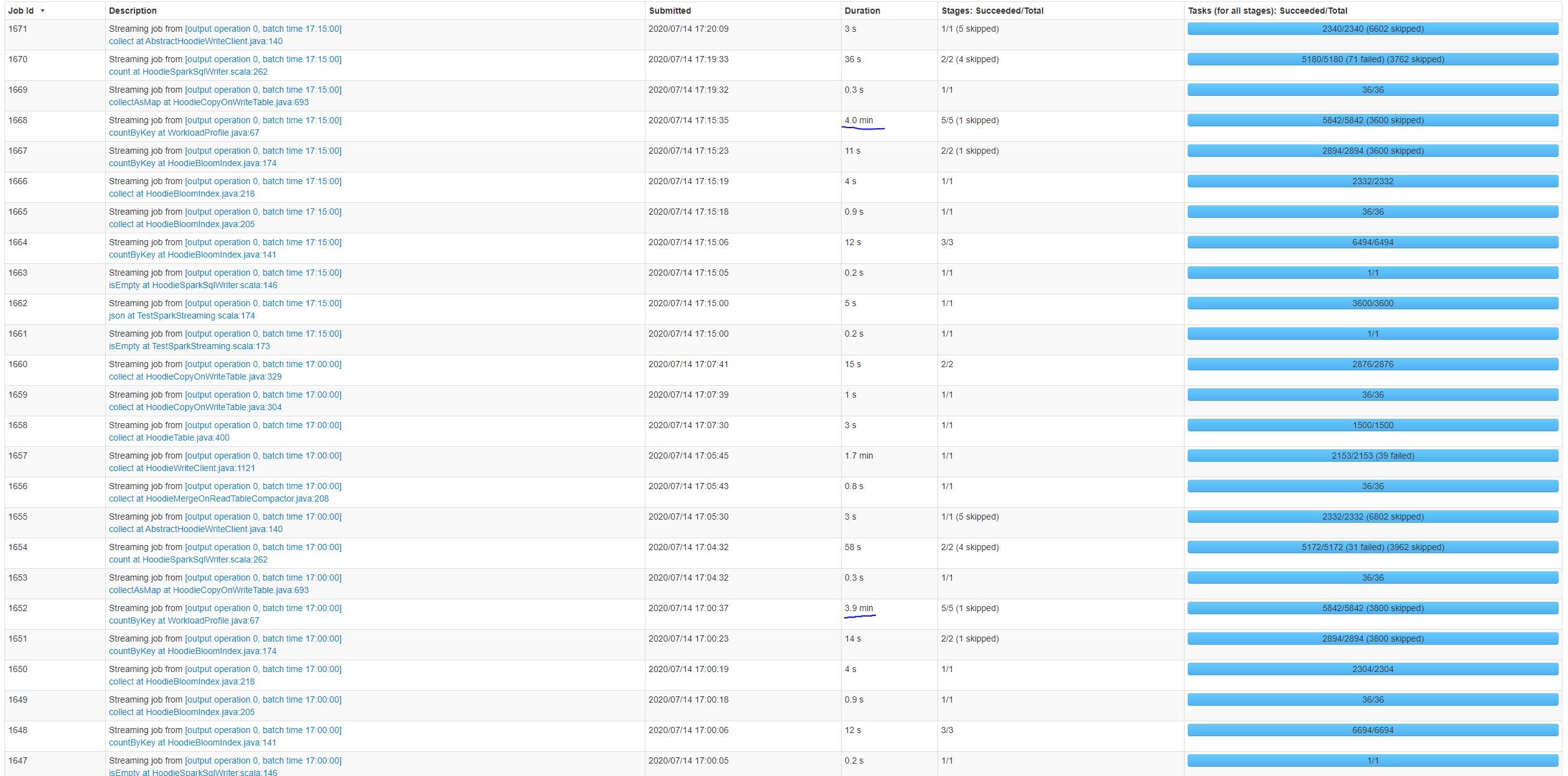
From looking at the Spark UI it seems like the job that is increasing in duration is countByKey at WorkloadProfile.java:67:
**To Reproduce**
Steps to reproduce the behavior:
1. Set up a Kinesis stream. We are using a stream with 200 shards which allows us to stream > 10K records/sec
It's unlikely the source used matters for this issue. This can most likely be replicated with Kafka or any other source.
2. Create a Spark Streaming application to read from the source and upsert to a MoR Hudi table.
`
val spark = SparkSession
.builder()
.appName("SparkStreaimingTest")
.master(args.lift(0).getOrElse("local[*]"))
// Hudi config settings
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.sql.hive.convertMetastoreParquet", "false")
// Spark Streaming confis settings
.config("spark.streaming.blockInterval", SPARK_STREAMING_BLOCK_INTERVAL_MILLIS.toInt.toString)
// Spark config settings
.config("spark.driver.cores", CORES_PER_EXECUTOR.toString)
.config("spark.driver.memory", (MEMORY_PER_EXECUTOR.toInt - 1).toString + "g")
.config("spark.executor.cores", CORES_PER_EXECUTOR.toString)
.config("spark.executor.memory", (MEMORY_PER_EXECUTOR.toInt - 1).toString + "g")
.config("spark.yarn.executor.memoryOverhead", (MEMORY_OVERHEAD_PER_EXECUTOR.toInt + 1).toString + "g")
.config("spark.executor.instances", TOTAL_EXECUTORS.toString)
// Default number of partitions in RDDs returned by transformations like join, reduceByKey, and parallelize
.config("spark.default.parallelism", PARALLELISM.toString)
// Sets the number of partitions for joins and aggregations
.config("spark.sql.shuffle.partitions", PARALLELISM.toString)
// Dynamically increase/decrease number of executors
.config("spark.dynamicAllocation.enabled", "false")
.config("spark.executor.extraJavaOptions", "-XX:NewSize=1g -XX:SurvivorRatio=2 -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintTenuringDistribution -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/hoodie-heapdump.hprof")
.config("spark.sql.parquet.writeLegacyFormat", "true")
.getOrCreate()
`
`
val test = println("this sucks")
`
3.
4.
**Expected behavior**
A clear and concise description of what you expected to happen.
**Environment Description**
* Hudi version :
* Spark version :
* Hive version :
* Hadoop version :
* Storage (HDFS/S3/GCS..) :
* Running on Docker? (yes/no) :
**Additional context**
Add any other context about the problem here.
**Stacktrace**
```Add the stacktrace of the error.```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #1830: [SUPPORT] Processing time gradually increases while using Spark Streaming
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #1830:
URL: https://github.com/apache/hudi/issues/1830#issuecomment-659163337
@umehrot2 @srsteinmetz : Thanks for the information. I have not seen similar issues but looking at the trend (increase) in number of file groups and partitions is a good angle to investigate on. Can you attach few (subsequent) .commit files where you saw the increase in lookup time ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] srsteinmetz commented on issue #1830: [SUPPORT] Processing time gradually increases while using Spark Streaming
Posted by GitBox <gi...@apache.org>.
srsteinmetz commented on issue #1830:
URL: https://github.com/apache/hudi/issues/1830#issuecomment-659049963
Yes I was only able to capture a few runs in a single page of the Spark UI but the processing time for the WorkflodProfile countByKey has an increasing pattern over subsequent runs. I don't see this increasing pattern for other jobs in the batches. We have upgraded to 0.5.3 which led to clear performance improvements but even on 0.5.3 we are seeing the linearly increasing processing time.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] srsteinmetz edited a comment on issue #1830: [SUPPORT] Processing time gradually increases while using Spark Streaming
Posted by GitBox <gi...@apache.org>.
srsteinmetz edited a comment on issue #1830:
URL: https://github.com/apache/hudi/issues/1830#issuecomment-658363753
Accidentally posted early. Closed and reopened after editing post.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #1830: [SUPPORT] Processing time gradually increases while using Spark Streaming
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #1830:
URL: https://github.com/apache/hudi/issues/1830#issuecomment-660840191
We spent time over the weekend setting up a local test bed with kafka and structured streaming to reproduce this behavior. Here are the steps I followed with code : https://gist.github.com/bvaradar/d892c6c6a69664463f8601d09c187271
I ran the setup overnight for many hours with both MOR and COW tables but was not able to reproduce the gradual increase in time. I did see variance in processing time depending upon the incoming workload because of index lookup and parquet writing but there was no increase in processing time.
We should try to run this in S3 environment because we suspect this is seen in S3 environment alone. If possible, Would you be interested in taking the above gist and run it in your setup ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] srsteinmetz commented on issue #1830: [SUPPORT] Processing time gradually increases while using Spark Streaming
Posted by GitBox <gi...@apache.org>.
srsteinmetz commented on issue #1830:
URL: https://github.com/apache/hudi/issues/1830#issuecomment-659522682
I just started a new test and will watch for increasing processing times and post the associated .commit file.
My more recent tests have used 36 partitions and if I inspect the partitions they generally have ~1000 .log files @ ~3.8MB each and ~700 .parquet files @ 120 MB. Of those 700 .parquet files each file slice seems to retain 8 versions so the partitions have ~88 unique file slices.
I have inlineComapction enabled but the load generator is currently sending updates at 10k TPS which probably results in the large number of .log files.
The table we are attempting to model has 150 TB of storage in DynamoDB. Is there any general rule of thumb around the number of partitions to use and ideal number of parquet files per partition? We may be able to work backwards from the size of the source table to determine the proper number of partitions and maxFileSize.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] srsteinmetz commented on issue #1830: [SUPPORT] Processing time gradually increases while using Spark Streaming
Posted by GitBox <gi...@apache.org>.
srsteinmetz commented on issue #1830:
URL: https://github.com/apache/hudi/issues/1830#issuecomment-659667871
[20200716204504.txt](https://github.com/apache/hudi/files/4934119/20200716204504.txt)
In my most recent test I see .deltacommit files but no .commit files. I attached one of the .deltacommit files.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar edited a comment on issue #1830: [SUPPORT] Processing time gradually increases while using Spark Streaming
Posted by GitBox <gi...@apache.org>.
bvaradar edited a comment on issue #1830:
URL: https://github.com/apache/hudi/issues/1830#issuecomment-659163337
@umehrot2 @srsteinmetz : Thanks for the information. I have not seen similar issues but looking at the trend (increase) in number of file groups and partitions is a good angle to investigate on. Can you also attach few (subsequent) .commit files where you saw the increase in lookup time ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on issue #1830: [SUPPORT] Processing time gradually increases while using Spark Streaming
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on issue #1830:
URL: https://github.com/apache/hudi/issues/1830#issuecomment-664069552
@bvaradar any updates from trying this on emr?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #1830: [SUPPORT] Processing time gradually increases while using Spark Streaming
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #1830:
URL: https://github.com/apache/hudi/issues/1830#issuecomment-659044105
From the highlighted section in your spark UI image, it looks like there is an increase during index lookup. Between 2 runs, there is an increase of 10 sec (around 4%). Is this the same pattern you were seeing in earlier runs. Also, I am not able to clearly see the difference between subsequent runs w.r.t total processing delay. My question is : Are you seeing more than 10 secs difference in total processing delay between subsequent runs ? If so, can you try 0.5.3 release where we fixed driver side performance issues and we have heard confirmation from users regarding speedup.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] srsteinmetz commented on issue #1830: [SUPPORT] Processing time gradually increases while using Spark Streaming
Posted by GitBox <gi...@apache.org>.
srsteinmetz commented on issue #1830:
URL: https://github.com/apache/hudi/issues/1830#issuecomment-658363753
Accidentally posted
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] srsteinmetz closed issue #1830: [SUPPORT] Processing time gradually increases while using Spark Streaming
Posted by GitBox <gi...@apache.org>.
srsteinmetz closed issue #1830:
URL: https://github.com/apache/hudi/issues/1830
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] umehrot2 commented on issue #1830: [SUPPORT] Processing time gradually increases while using Spark Streaming
Posted by GitBox <gi...@apache.org>.
umehrot2 commented on issue #1830:
URL: https://github.com/apache/hudi/issues/1830#issuecomment-659057299
@bvaradar thank you for taking a look at this. We had an internal meeting with @srsteinmetz and the team, and yes at the outset to me it looks the the total time for lookup is increasing linearly here. It seems to be that when it does `countByKey()` in `WorkloadProfie` that is also triggering some of the previous `index lookup` spark actions on the `taggedRecords RDD`. Could this be an artifact of number of parquet files/bloom filters to check keeps increasing over time ? Have we seen similar issues reported before with Hudi ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org