You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@druid.apache.org by GitBox <gi...@apache.org> on 2021/05/20 17:07:41 UTC
[GitHub] [druid] tanisdlj opened a new issue #11277: diskNormalized strategy ignored by coordinator
tanisdlj opened a new issue #11277:
URL: https://github.com/apache/druid/issues/11277
### Affected Version
0.20.1
### Description
- Cluster size: 20 Historicals, 32 Middlemanagers, 2 Coordinators, 2 Overlords, 5 Brokers, 5 Routers, 2,379,776 segments, ~70Tb of data.
The load of segments when having the strategy `diskNormalized` does not distribute the data between the servers. Check the picture below.
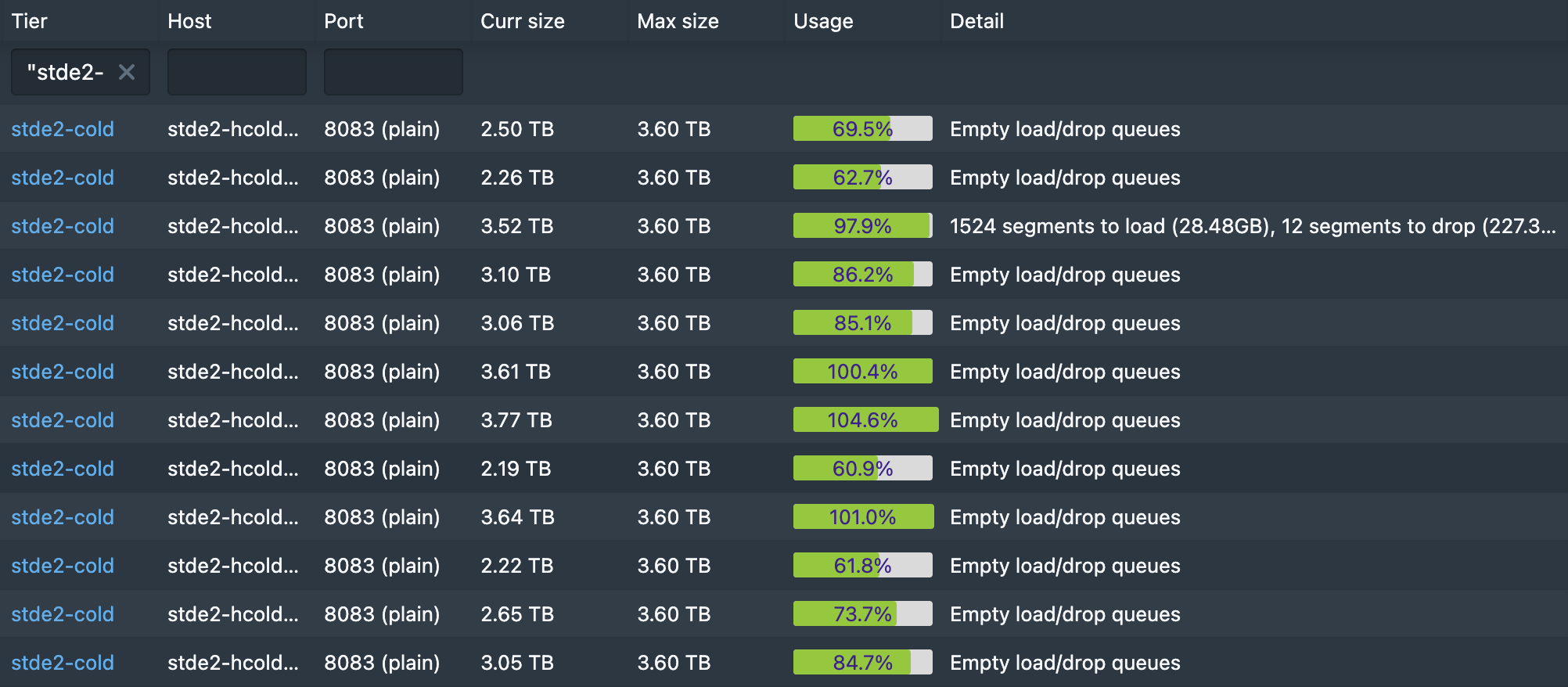
I can see in the logs, lines like
```
org.apache.druid.server.coordinator.CostBalancerStrategy - Cost Balancer Multithread strategy wasn't able to complete cost computation.: {class=org.apache.druid.server.coordinator.CostBalancerStrategy, exceptionType=class java.lang.InterruptedException, exceptionMessage=null}
```
While my runtime config looks like this:
```
druid.service=druid/coordinator
druid.plaintextPort=8081
druid.coordinator.startDelay=PT300S
druid.coordinator.period=PT60S
druid.coordinator.kill.on=true
druid.coordinator.kill.maxSegments=100
druid.coordinator.kill.durationToRetain=P7D
druid.serverview.type=http
druid.coordinator.loadqueuepeon.type=http
# Number of segment load/drop requests to batch in one HTTP request.
# Note that it must be smaller than druid.segmentCache.numLoadingThreads config on Historical process.
druid.coordinator.loadqueuepeon.http.batchSize=56
druid.coordinator.loadqueuepeon.curator.numCallbackThreads=200
druid.coordinator.balancer.strategy=diskNormalized
#druid.coordinator.balancer.strategy=cost
# Reduces the max number of Segments loaded (speed) for a more even distribution between nodes
# Default is 0 (max speed, unfair distribution)
maxSegmentsInNodeLoadingQueue=1000
druid.announcer.type=http
```
It feels like the coordinator "obsess" on two-three servers and make them load all the segments. This happened with several coordinator restarts and switching from one server-coordinator to another one. Still, throwing most of our segments into 3 of our 12 servers (and actually, surpassing the Max disk size set in the runtime config).
The load of segments took around 2-3 days, so it was not like it issue the order to load N segments and "boom", suddenly is full. In the picture you can appreciate that actually the server is already full but still loading stuff, while the empty ones are idle
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] pjain1 commented on issue #11277: diskNormalized strategy ignored by coordinator
Posted by GitBox <gi...@apache.org>.
pjain1 commented on issue #11277:
URL: https://github.com/apache/druid/issues/11277#issuecomment-846128041
I have observed this issue as well, try `cachingCost` IMO it works the best. `cachingCost` has a minor issue though that it does not load multiple segments having segment gran of `ALL` which actually should not happen in production but a thing to keep in mind.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] tanisdlj commented on issue #11277: diskNormalized strategy ignored by coordinator
Posted by GitBox <gi...@apache.org>.
tanisdlj commented on issue #11277:
URL: https://github.com/apache/druid/issues/11277#issuecomment-851401679
I think the problem we had with `cost` or `cachingCost` was the same, the coord filling servers with over 100% disk usage while leaving others half full
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org