You are viewing a plain text version of this content. The canonical link for it is here.
Posted to jira@kafka.apache.org by GitBox <gi...@apache.org> on 2020/10/09 05:58:17 UTC
[GitHub] [kafka] chia7712 opened a new pull request #9401: KAFKA-9628 Replace Produce request with automated protocol
chia7712 opened a new pull request #9401:
URL: https://github.com/apache/kafka/pull/9401
issue: https://issues.apache.org/jira/browse/KAFKA-9628
this PR is a part of KAFKA-9628.
### Committer Checklist (excluded from commit message)
- [ ] Verify design and implementation
- [ ] Verify test coverage and CI build status
- [ ] Verify documentation (including upgrade notes)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r514903001
##########
File path: clients/src/main/resources/common/message/ProduceRequest.json
##########
@@ -33,21 +33,21 @@
"validVersions": "0-8",
"flexibleVersions": "none",
"fields": [
- { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "0+", "entityType": "transactionalId",
+ { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "3+", "ignorable": true, "entityType": "transactionalId",
Review comment:
you are right. will Roger that.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-729870471
Great work @chia7712 ! With this and #9547, we have converted all of the protocols, which was a huge community effort!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] dajac commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
dajac commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r526178616
##########
File path: clients/src/test/java/org/apache/kafka/common/requests/RequestResponseTest.java
##########
@@ -1730,7 +1768,6 @@ private DeleteTopicsResponse createDeleteTopicsResponse() {
private InitProducerIdRequest createInitPidRequest() {
InitProducerIdRequestData requestData = new InitProducerIdRequestData()
- .setTransactionalId(null)
Review comment:
We should keep this one.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r519081195
##########
File path: clients/src/main/resources/common/message/ProduceRequest.json
##########
@@ -33,21 +33,21 @@
"validVersions": "0-8",
"flexibleVersions": "none",
"fields": [
- { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "0+", "entityType": "transactionalId",
+ { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "3+", "ignorable": true, "entityType": "transactionalId",
"about": "The transactional ID, or null if the producer is not transactional." },
{ "name": "Acks", "type": "int16", "versions": "0+",
"about": "The number of acknowledgments the producer requires the leader to have received before considering a request complete. Allowed values: 0 for no acknowledgments, 1 for only the leader and -1 for the full ISR." },
- { "name": "TimeoutMs", "type": "int32", "versions": "0+",
+ { "name": "Timeout", "type": "int32", "versions": "0+",
Review comment:
oh, I trace the code again. You are right. The name is not serialized.
I will revise the field names as you suggested.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-718828042
@chia7712 One thing that would be useful is running the producer-performance test, just to make sure the the performance is inline. Might be worth checking flame graphs as well.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r514467652
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceRequest.java
##########
@@ -210,65 +142,42 @@ public String toString() {
}
}
+ /**
+ * We have to copy acks, timeout, transactionalId and partitionSizes from data since data maybe reset to eliminate
+ * the reference to ByteBuffer but those metadata are still useful.
+ */
private final short acks;
private final int timeout;
private final String transactionalId;
-
- private final Map<TopicPartition, Integer> partitionSizes;
-
+ // visible for testing
+ final Map<TopicPartition, Integer> partitionSizes;
+ private boolean hasTransactionalRecords = false;
+ private boolean hasIdempotentRecords = false;
// This is set to null by `clearPartitionRecords` to prevent unnecessary memory retention when a produce request is
// put in the purgatory (due to client throttling, it can take a while before the response is sent).
// Care should be taken in methods that use this field.
- private volatile Map<TopicPartition, MemoryRecords> partitionRecords;
- private boolean hasTransactionalRecords = false;
- private boolean hasIdempotentRecords = false;
-
- private ProduceRequest(short version, short acks, int timeout, Map<TopicPartition, MemoryRecords> partitionRecords, String transactionalId) {
- super(ApiKeys.PRODUCE, version);
- this.acks = acks;
- this.timeout = timeout;
-
- this.transactionalId = transactionalId;
- this.partitionRecords = partitionRecords;
- this.partitionSizes = createPartitionSizes(partitionRecords);
+ private volatile ProduceRequestData data;
- for (MemoryRecords records : partitionRecords.values()) {
- setFlags(records);
- }
- }
-
- private static Map<TopicPartition, Integer> createPartitionSizes(Map<TopicPartition, MemoryRecords> partitionRecords) {
- Map<TopicPartition, Integer> result = new HashMap<>(partitionRecords.size());
- for (Map.Entry<TopicPartition, MemoryRecords> entry : partitionRecords.entrySet())
- result.put(entry.getKey(), entry.getValue().sizeInBytes());
- return result;
- }
-
- public ProduceRequest(Struct struct, short version) {
+ public ProduceRequest(ProduceRequestData produceRequestData, short version) {
super(ApiKeys.PRODUCE, version);
- partitionRecords = new HashMap<>();
- for (Object topicDataObj : struct.getArray(TOPIC_DATA_KEY_NAME)) {
- Struct topicData = (Struct) topicDataObj;
- String topic = topicData.get(TOPIC_NAME);
- for (Object partitionResponseObj : topicData.getArray(PARTITION_DATA_KEY_NAME)) {
- Struct partitionResponse = (Struct) partitionResponseObj;
- int partition = partitionResponse.get(PARTITION_ID);
- MemoryRecords records = (MemoryRecords) partitionResponse.getRecords(RECORD_SET_KEY_NAME);
- setFlags(records);
- partitionRecords.put(new TopicPartition(topic, partition), records);
- }
- }
- partitionSizes = createPartitionSizes(partitionRecords);
- acks = struct.getShort(ACKS_KEY_NAME);
- timeout = struct.getInt(TIMEOUT_KEY_NAME);
- transactionalId = struct.getOrElse(NULLABLE_TRANSACTIONAL_ID, null);
- }
-
- private void setFlags(MemoryRecords records) {
- Iterator<MutableRecordBatch> iterator = records.batches().iterator();
- MutableRecordBatch entry = iterator.next();
- hasIdempotentRecords = hasIdempotentRecords || entry.hasProducerId();
- hasTransactionalRecords = hasTransactionalRecords || entry.isTransactional();
+ this.data = produceRequestData;
+ this.data.topicData().forEach(topicProduceData -> topicProduceData.partitions()
+ .forEach(partitionProduceData -> {
+ MemoryRecords records = MemoryRecords.readableRecords(partitionProduceData.records());
+ Iterator<MutableRecordBatch> iterator = records.batches().iterator();
+ MutableRecordBatch entry = iterator.next();
+ hasIdempotentRecords = hasIdempotentRecords || entry.hasProducerId();
Review comment:
Nevermind, I guess we have to do it here because the server needs to validate the request received from the client.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] dajac commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
dajac commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r521902936
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceRequest.java
##########
@@ -194,7 +106,27 @@ private ProduceRequest build(short version, boolean validate) {
ProduceRequest.validateRecords(version, records);
}
}
- return new ProduceRequest(version, acks, timeout, partitionRecords, transactionalId);
+
+ List<ProduceRequestData.TopicProduceData> tpd = partitionRecords
Review comment:
I wonder if we could avoid all of this by requesting the `Sender` to create `TopicProduceData` directly. It seems that the `Sender` creates `partitionRecords` right before calling the builder: https://github.com/apache/kafka/blob/trunk/clients/src/main/java/org/apache/kafka/clients/producer/internals/Sender.java#L734. So we may be able to directly construct the expect data structure there.
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceRequest.java
##########
@@ -323,27 +222,30 @@ public String toString(boolean verbose) {
@Override
public ProduceResponse getErrorResponse(int throttleTimeMs, Throwable e) {
/* In case the producer doesn't actually want any response */
- if (acks == 0)
- return null;
-
+ if (acks == 0) return null;
Errors error = Errors.forException(e);
- Map<TopicPartition, ProduceResponse.PartitionResponse> responseMap = new HashMap<>();
- ProduceResponse.PartitionResponse partitionResponse = new ProduceResponse.PartitionResponse(error);
-
- for (TopicPartition tp : partitions())
- responseMap.put(tp, partitionResponse);
-
- return new ProduceResponse(responseMap, throttleTimeMs);
+ return new ProduceResponse(new ProduceResponseData()
+ .setResponses(partitionSizes().keySet().stream().collect(Collectors.groupingBy(TopicPartition::topic)).entrySet()
+ .stream()
+ .map(entry -> new ProduceResponseData.TopicProduceResponse()
+ .setPartitionResponses(entry.getValue().stream().map(p -> new ProduceResponseData.PartitionProduceResponse()
+ .setIndex(p.partition())
+ .setRecordErrors(Collections.emptyList())
+ .setBaseOffset(INVALID_OFFSET)
+ .setLogAppendTimeMs(RecordBatch.NO_TIMESTAMP)
+ .setLogStartOffset(INVALID_OFFSET)
+ .setErrorMessage(e.getMessage())
+ .setErrorCode(error.code()))
+ .collect(Collectors.toList()))
+ .setName(entry.getKey()))
+ .collect(Collectors.toList()))
+ .setThrottleTimeMs(throttleTimeMs));
Review comment:
It seems that we could create `ProduceResponseData` based on `data`. This avoids the cost of the group-by operation and the cost of constructing `partitionSizes`. That should bring the benchmark inline with what we had before. Would this work?
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceResponse.java
##########
@@ -204,118 +75,79 @@ public ProduceResponse(Map<TopicPartition, PartitionResponse> responses) {
* @param throttleTimeMs Time in milliseconds the response was throttled
*/
public ProduceResponse(Map<TopicPartition, PartitionResponse> responses, int throttleTimeMs) {
- this.responses = responses;
- this.throttleTimeMs = throttleTimeMs;
+ this(new ProduceResponseData()
+ .setResponses(responses.entrySet()
Review comment:
As we care of performances here, I wonder if we should try not using the stream api here.
Another trick would be to turn `TopicProduceResponse` in the `ProduceResponse` schema into a map by setting `"mapKey": true` for the topic name. This would allow to iterate over `responses`, get or create `TopicProduceResponse` for the topic, and add the `PartitionProduceResponse` into it.
It may be worth trying different implementation to compare their performances.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r526187166
##########
File path: clients/src/main/java/org/apache/kafka/clients/producer/internals/TransactionManager.java
##########
@@ -580,7 +580,6 @@ synchronized void bumpIdempotentEpochAndResetIdIfNeeded() {
if (currentState != State.INITIALIZING && !hasProducerId()) {
transitionTo(State.INITIALIZING);
InitProducerIdRequestData requestData = new InitProducerIdRequestData()
- .setTransactionalId(null)
Review comment:
Sorry that I did not test them on my local before pushing :(
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] dajac commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
dajac commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r526368983
##########
File path: clients/src/main/resources/common/message/ProduceRequest.json
##########
@@ -33,21 +33,21 @@
"validVersions": "0-8",
"flexibleVersions": "none",
"fields": [
- { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "0+", "entityType": "transactionalId",
+ { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "3+", "default": "null", "ignorable": true, "entityType": "transactionalId",
Review comment:
Indeed, that makes sense. My bad!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r526314648
##########
File path: clients/src/main/resources/common/message/ProduceRequest.json
##########
@@ -33,21 +33,21 @@
"validVersions": "0-8",
"flexibleVersions": "none",
"fields": [
- { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "0+", "entityType": "transactionalId",
+ { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "3+", "default": "null", "ignorable": true, "entityType": "transactionalId",
Review comment:
> So we may as well fail fast.
That make sense. will revert this change.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r519251131
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceResponse.java
##########
@@ -204,118 +75,78 @@ public ProduceResponse(Map<TopicPartition, PartitionResponse> responses) {
* @param throttleTimeMs Time in milliseconds the response was throttled
*/
public ProduceResponse(Map<TopicPartition, PartitionResponse> responses, int throttleTimeMs) {
- this.responses = responses;
- this.throttleTimeMs = throttleTimeMs;
+ this(new ProduceResponseData()
+ .setResponses(responses.entrySet()
+ .stream()
+ .collect(Collectors.groupingBy(e -> e.getKey().topic()))
+ .entrySet()
+ .stream()
+ .map(topicData -> new ProduceResponseData.TopicProduceResponse()
+ .setTopic(topicData.getKey())
+ .setPartitionResponses(topicData.getValue()
+ .stream()
+ .map(p -> new ProduceResponseData.PartitionProduceResponse()
+ .setPartition(p.getKey().partition())
+ .setBaseOffset(p.getValue().baseOffset)
+ .setLogStartOffset(p.getValue().logStartOffset)
+ .setLogAppendTime(p.getValue().logAppendTime)
+ .setErrorMessage(p.getValue().errorMessage)
+ .setErrorCode(p.getValue().error.code())
+ .setRecordErrors(p.getValue().recordErrors
+ .stream()
+ .map(e -> new ProduceResponseData.BatchIndexAndErrorMessage()
+ .setBatchIndex(e.batchIndex)
+ .setBatchIndexErrorMessage(e.message))
+ .collect(Collectors.toList())))
+ .collect(Collectors.toList())))
+ .collect(Collectors.toList()))
+ .setThrottleTimeMs(throttleTimeMs));
}
/**
- * Constructor from a {@link Struct}.
+ * Visible for testing.
*/
- public ProduceResponse(Struct struct) {
- responses = new HashMap<>();
- for (Object topicResponse : struct.getArray(RESPONSES_KEY_NAME)) {
- Struct topicRespStruct = (Struct) topicResponse;
- String topic = topicRespStruct.get(TOPIC_NAME);
-
- for (Object partResponse : topicRespStruct.getArray(PARTITION_RESPONSES_KEY_NAME)) {
- Struct partRespStruct = (Struct) partResponse;
- int partition = partRespStruct.get(PARTITION_ID);
- Errors error = Errors.forCode(partRespStruct.get(ERROR_CODE));
- long offset = partRespStruct.getLong(BASE_OFFSET_KEY_NAME);
- long logAppendTime = partRespStruct.hasField(LOG_APPEND_TIME_KEY_NAME) ?
- partRespStruct.getLong(LOG_APPEND_TIME_KEY_NAME) : RecordBatch.NO_TIMESTAMP;
- long logStartOffset = partRespStruct.getOrElse(LOG_START_OFFSET_FIELD, INVALID_OFFSET);
-
- List<RecordError> recordErrors = Collections.emptyList();
- if (partRespStruct.hasField(RECORD_ERRORS_KEY_NAME)) {
- Object[] recordErrorsArray = partRespStruct.getArray(RECORD_ERRORS_KEY_NAME);
- if (recordErrorsArray.length > 0) {
- recordErrors = new ArrayList<>(recordErrorsArray.length);
- for (Object indexAndMessage : recordErrorsArray) {
- Struct indexAndMessageStruct = (Struct) indexAndMessage;
- recordErrors.add(new RecordError(
- indexAndMessageStruct.getInt(BATCH_INDEX_KEY_NAME),
- indexAndMessageStruct.get(BATCH_INDEX_ERROR_MESSAGE_FIELD)
- ));
- }
- }
- }
-
- String errorMessage = partRespStruct.getOrElse(ERROR_MESSAGE_FIELD, null);
- TopicPartition tp = new TopicPartition(topic, partition);
- responses.put(tp, new PartitionResponse(error, offset, logAppendTime, logStartOffset, recordErrors, errorMessage));
- }
- }
- this.throttleTimeMs = struct.getOrElse(THROTTLE_TIME_MS, DEFAULT_THROTTLE_TIME);
- }
-
@Override
- protected Struct toStruct(short version) {
- Struct struct = new Struct(ApiKeys.PRODUCE.responseSchema(version));
-
- Map<String, Map<Integer, PartitionResponse>> responseByTopic = CollectionUtils.groupPartitionDataByTopic(responses);
- List<Struct> topicDatas = new ArrayList<>(responseByTopic.size());
- for (Map.Entry<String, Map<Integer, PartitionResponse>> entry : responseByTopic.entrySet()) {
- Struct topicData = struct.instance(RESPONSES_KEY_NAME);
- topicData.set(TOPIC_NAME, entry.getKey());
- List<Struct> partitionArray = new ArrayList<>();
- for (Map.Entry<Integer, PartitionResponse> partitionEntry : entry.getValue().entrySet()) {
- PartitionResponse part = partitionEntry.getValue();
- short errorCode = part.error.code();
- // If producer sends ProduceRequest V3 or earlier, the client library is not guaranteed to recognize the error code
- // for KafkaStorageException. In this case the client library will translate KafkaStorageException to
- // UnknownServerException which is not retriable. We can ensure that producer will update metadata and retry
- // by converting the KafkaStorageException to NotLeaderOrFollowerException in the response if ProduceRequest version <= 3
- if (errorCode == Errors.KAFKA_STORAGE_ERROR.code() && version <= 3)
- errorCode = Errors.NOT_LEADER_OR_FOLLOWER.code();
- Struct partStruct = topicData.instance(PARTITION_RESPONSES_KEY_NAME)
- .set(PARTITION_ID, partitionEntry.getKey())
- .set(ERROR_CODE, errorCode)
- .set(BASE_OFFSET_KEY_NAME, part.baseOffset);
- partStruct.setIfExists(LOG_APPEND_TIME_KEY_NAME, part.logAppendTime);
- partStruct.setIfExists(LOG_START_OFFSET_FIELD, part.logStartOffset);
-
- if (partStruct.hasField(RECORD_ERRORS_KEY_NAME)) {
- List<Struct> recordErrors = Collections.emptyList();
- if (!part.recordErrors.isEmpty()) {
- recordErrors = new ArrayList<>();
- for (RecordError indexAndMessage : part.recordErrors) {
- Struct indexAndMessageStruct = partStruct.instance(RECORD_ERRORS_KEY_NAME)
- .set(BATCH_INDEX_KEY_NAME, indexAndMessage.batchIndex)
- .set(BATCH_INDEX_ERROR_MESSAGE_FIELD, indexAndMessage.message);
- recordErrors.add(indexAndMessageStruct);
- }
- }
- partStruct.set(RECORD_ERRORS_KEY_NAME, recordErrors.toArray());
- }
-
- partStruct.setIfExists(ERROR_MESSAGE_FIELD, part.errorMessage);
- partitionArray.add(partStruct);
- }
- topicData.set(PARTITION_RESPONSES_KEY_NAME, partitionArray.toArray());
- topicDatas.add(topicData);
- }
- struct.set(RESPONSES_KEY_NAME, topicDatas.toArray());
- struct.setIfExists(THROTTLE_TIME_MS, throttleTimeMs);
+ public Struct toStruct(short version) {
+ return data.toStruct(version);
+ }
- return struct;
+ public ProduceResponseData data() {
+ return this.data;
}
+ /**
+ * this method is used by testing only.
+ * TODO: refactor the tests which are using this method and then remove this method from production code.
Review comment:
https://issues.apache.org/jira/browse/KAFKA-10697
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r525683594
##########
File path: clients/src/main/java/org/apache/kafka/clients/producer/internals/Sender.java
##########
@@ -560,13 +562,24 @@ private void handleProduceResponse(ClientResponse response, Map<TopicPartition,
log.trace("Received produce response from node {} with correlation id {}", response.destination(), correlationId);
// if we have a response, parse it
if (response.hasResponse()) {
+ // TODO: Sender should exercise PartitionProduceResponse rather than ProduceResponse.PartitionResponse
+ // https://issues.apache.org/jira/browse/KAFKA-10696
Review comment:
copy that
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728812062
@hachikuji @ijuma It seems to me the root cause of regression is caused by the conversion between old data struct and auto-generated protocol. As we all care for performance, I address more improvements (they were viewed as follow-up before) in this PR.
There are 5 possible improvements.
1. - [x] git rid of struct allocation
1. - [x] rewrite RequestUtils.hasTransactionalRecords & RequestUtils.hasIdempotentRecords to avoid duplicate loop and record instantiation (thanks to @hachikuji)
1. - [x] Sender#sendProduceRequest should use auto-generated protocol directly (thanks to @dajac)
1. - [ ] Replace ProduceResponse.PartitionResponse by auto-generated PartitionProduceResponse (https://issues.apache.org/jira/browse/KAFKA-10709)
1. - [ ] KafkaApis#handleProduceRequest should use auto-generated protocol (https://issues.apache.org/jira/browse/KAFKA-10730)
The recent commits include only 1, 2, and 3 since they touch fewer code. I also re-run all perf tests and all tests cases show better throughput with current PR even if 4. and 5. are not included.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-724862848
For what it's worth, I think we'll get back whatever we lose here by taking `Struct` out of the serialization path.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r514819326
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceRequest.java
##########
@@ -210,65 +142,42 @@ public String toString() {
}
}
+ /**
+ * We have to copy acks, timeout, transactionalId and partitionSizes from data since data maybe reset to eliminate
+ * the reference to ByteBuffer but those metadata are still useful.
+ */
private final short acks;
private final int timeout;
private final String transactionalId;
-
- private final Map<TopicPartition, Integer> partitionSizes;
-
+ // visible for testing
+ final Map<TopicPartition, Integer> partitionSizes;
+ private boolean hasTransactionalRecords = false;
+ private boolean hasIdempotentRecords = false;
// This is set to null by `clearPartitionRecords` to prevent unnecessary memory retention when a produce request is
// put in the purgatory (due to client throttling, it can take a while before the response is sent).
// Care should be taken in methods that use this field.
- private volatile Map<TopicPartition, MemoryRecords> partitionRecords;
- private boolean hasTransactionalRecords = false;
- private boolean hasIdempotentRecords = false;
-
- private ProduceRequest(short version, short acks, int timeout, Map<TopicPartition, MemoryRecords> partitionRecords, String transactionalId) {
- super(ApiKeys.PRODUCE, version);
- this.acks = acks;
- this.timeout = timeout;
-
- this.transactionalId = transactionalId;
- this.partitionRecords = partitionRecords;
- this.partitionSizes = createPartitionSizes(partitionRecords);
+ private volatile ProduceRequestData data;
- for (MemoryRecords records : partitionRecords.values()) {
- setFlags(records);
- }
- }
-
- private static Map<TopicPartition, Integer> createPartitionSizes(Map<TopicPartition, MemoryRecords> partitionRecords) {
- Map<TopicPartition, Integer> result = new HashMap<>(partitionRecords.size());
- for (Map.Entry<TopicPartition, MemoryRecords> entry : partitionRecords.entrySet())
- result.put(entry.getKey(), entry.getValue().sizeInBytes());
- return result;
- }
-
- public ProduceRequest(Struct struct, short version) {
+ public ProduceRequest(ProduceRequestData produceRequestData, short version) {
super(ApiKeys.PRODUCE, version);
- partitionRecords = new HashMap<>();
- for (Object topicDataObj : struct.getArray(TOPIC_DATA_KEY_NAME)) {
- Struct topicData = (Struct) topicDataObj;
- String topic = topicData.get(TOPIC_NAME);
- for (Object partitionResponseObj : topicData.getArray(PARTITION_DATA_KEY_NAME)) {
- Struct partitionResponse = (Struct) partitionResponseObj;
- int partition = partitionResponse.get(PARTITION_ID);
- MemoryRecords records = (MemoryRecords) partitionResponse.getRecords(RECORD_SET_KEY_NAME);
- setFlags(records);
- partitionRecords.put(new TopicPartition(topic, partition), records);
- }
- }
- partitionSizes = createPartitionSizes(partitionRecords);
- acks = struct.getShort(ACKS_KEY_NAME);
- timeout = struct.getInt(TIMEOUT_KEY_NAME);
- transactionalId = struct.getOrElse(NULLABLE_TRANSACTIONAL_ID, null);
- }
-
- private void setFlags(MemoryRecords records) {
- Iterator<MutableRecordBatch> iterator = records.batches().iterator();
- MutableRecordBatch entry = iterator.next();
- hasIdempotentRecords = hasIdempotentRecords || entry.hasProducerId();
- hasTransactionalRecords = hasTransactionalRecords || entry.isTransactional();
+ this.data = produceRequestData;
+ this.data.topicData().forEach(topicProduceData -> topicProduceData.partitions()
+ .forEach(partitionProduceData -> {
+ MemoryRecords records = MemoryRecords.readableRecords(partitionProduceData.records());
+ Iterator<MutableRecordBatch> iterator = records.batches().iterator();
+ MutableRecordBatch entry = iterator.next();
+ hasIdempotentRecords = hasIdempotentRecords || entry.hasProducerId();
Review comment:
clients module has some tests which depends on it so I moves the helper to ```RequestUtils```.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728545356
It would be helpful if someone can reproduce the tests I did to make sure it is not something funky in my environment.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r526032716
##########
File path: clients/src/test/java/org/apache/kafka/clients/NetworkClientTest.java
##########
@@ -154,8 +155,11 @@ public void testClose() {
client.poll(1, time.milliseconds());
assertTrue("The client should be ready", client.isReady(node, time.milliseconds()));
- ProduceRequest.Builder builder = ProduceRequest.Builder.forCurrentMagic((short) 1, 1000,
- Collections.emptyMap());
+ ProduceRequest.Builder builder = ProduceRequest.forCurrentMagic(new ProduceRequestData()
+ .setTopicData(new ProduceRequestData.TopicProduceDataCollection())
+ .setAcks((short) 1)
+ .setTimeoutMs(1000)
+ .setTransactionalId(null));
Review comment:
make sense to me. will remove this redundant setter
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] ijuma commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
ijuma commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728974716
Thanks @chia7712. Can you check that the @hachikuji's perf test doesn't result in significantly increased latency?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r526039872
##########
File path: clients/src/main/resources/common/message/ProduceRequest.json
##########
@@ -33,21 +33,21 @@
"validVersions": "0-8",
"flexibleVersions": "none",
"fields": [
- { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "0+", "entityType": "transactionalId",
+ { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "3+", "default": "null", "entityType": "transactionalId",
Review comment:
you are right.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r526280042
##########
File path: clients/src/main/resources/common/message/ProduceRequest.json
##########
@@ -33,21 +33,21 @@
"validVersions": "0-8",
"flexibleVersions": "none",
"fields": [
- { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "0+", "entityType": "transactionalId",
+ { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "3+", "default": "null", "ignorable": true, "entityType": "transactionalId",
Review comment:
It seems to me ignorable should be true in order to keep behavior consistency. With "ignore=false", setting value to ```TransactionalId``` can cause ```UnsupportedVersionException``` if the version is small than 3. The previous code (https://github.com/apache/kafka/blob/trunk/clients/src/main/java/org/apache/kafka/common/requests/ProduceRequest.java#L286) does not cause such exception.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 edited a comment on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 edited a comment on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728812062
@hachikuji @ijuma It seems to me the root cause of regression is caused by the conversion between old data struct and auto-generated protocol. As we all care for performance, I address more improvements (they were viewed as follow-up before) in this PR.
There are 5 possible improvements.
1. - [x] git rid of struct allocation (thanks to @hachikuji)
1. - [x] rewrite RequestUtils.hasTransactionalRecords & RequestUtils.hasIdempotentRecords to avoid duplicate loop and record instantiation (thanks to @hachikuji)
1. - [x] Sender#sendProduceRequest should use auto-generated protocol directly (thanks to @dajac)
1. - [ ] [client side] Replace ProduceResponse.PartitionResponse by auto-generated PartitionProduceResponse (https://issues.apache.org/jira/browse/KAFKA-10709)
1. - [ ] [server side] KafkaApis#handleProduceRequest should use auto-generated protocol (https://issues.apache.org/jira/browse/KAFKA-10730)
The recent commits include only 1, 2, and 3 since they touch fewer code. I also re-run all perf tests ~and all tests cases show better throughput with current PR even though 4. and 5. are not included.~
Most of test cases show good improvements. By the contrast, the other tests (single partition + single producer) get either insignificant improvement or small regression. However, it seems to me they can get good improvement by remaining tasks (4 and 5)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r522670294
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceResponse.java
##########
@@ -204,118 +75,79 @@ public ProduceResponse(Map<TopicPartition, PartitionResponse> responses) {
* @param throttleTimeMs Time in milliseconds the response was throttled
*/
public ProduceResponse(Map<TopicPartition, PartitionResponse> responses, int throttleTimeMs) {
- this.responses = responses;
- this.throttleTimeMs = throttleTimeMs;
+ this(new ProduceResponseData()
+ .setResponses(responses.entrySet()
Review comment:
I have addressed your suggestion and it does improve the performance.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji edited a comment on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji edited a comment on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728383115
Posting allocation flame graphs from the producer before and after this patch:
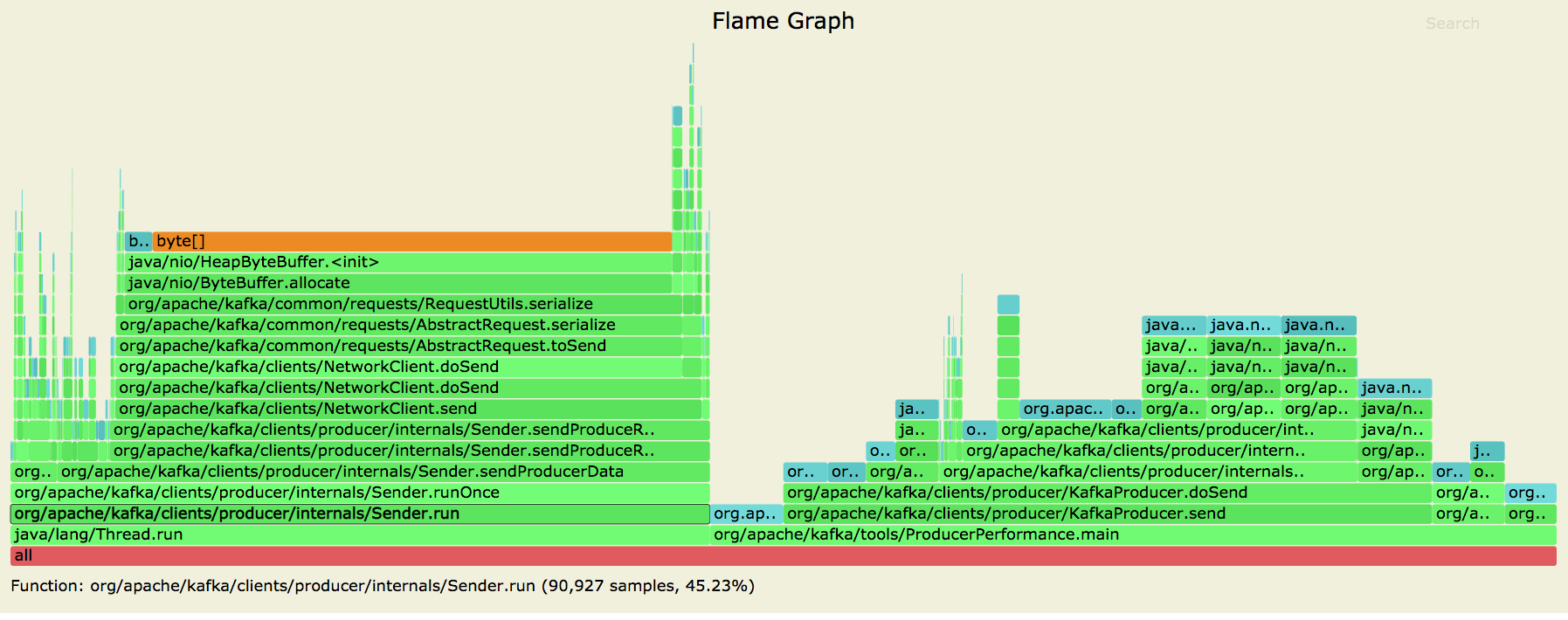
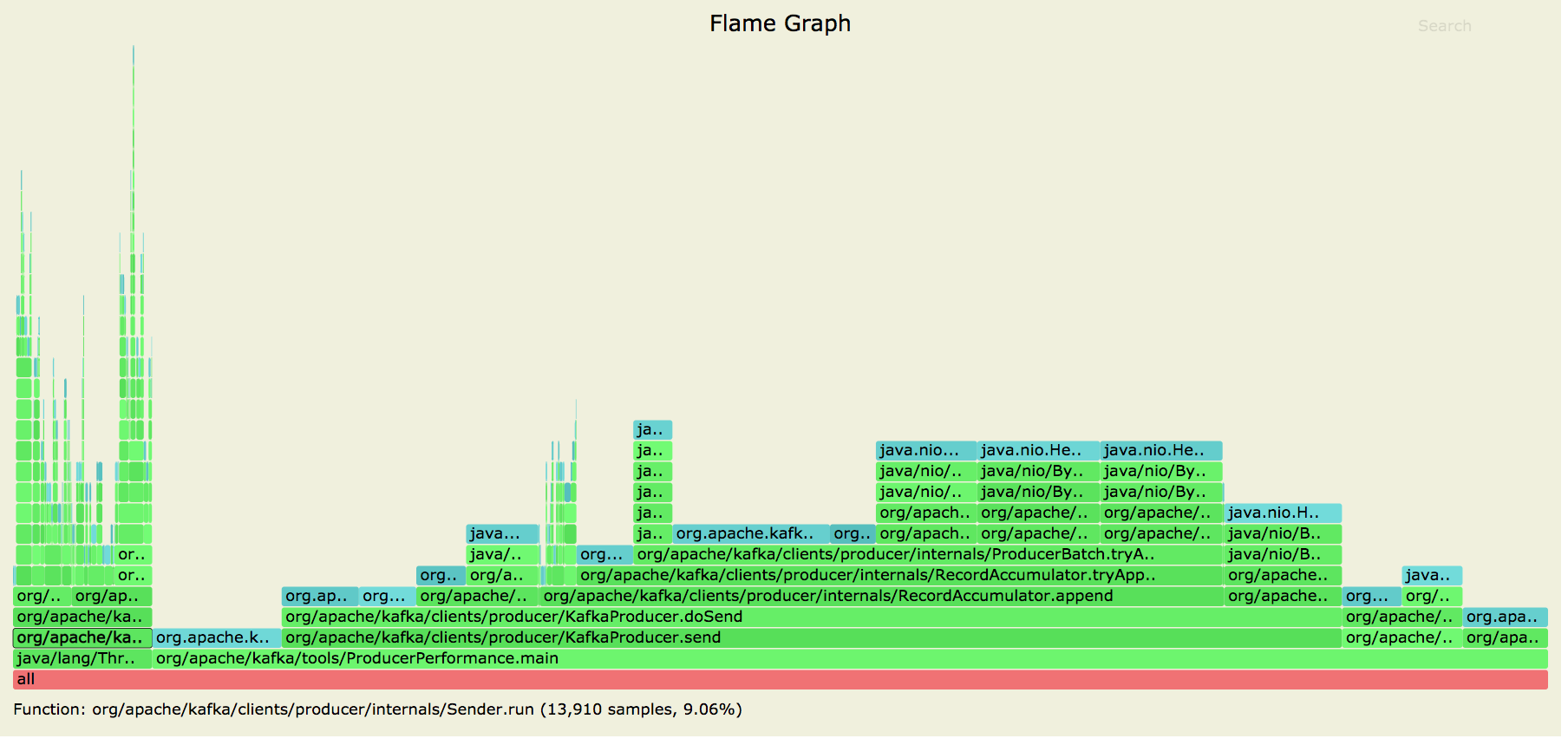
So we succeeded in getting rid of the extra allocations in the network layer!
I generated these graphs using the producer performance test writing to a topic with 10 partitions on a cluster with a single broker.
```
> bin/kafka-producer-perf-test.sh --topic foo --num-records 250000000 --throughput -1 --record-size 256 --producer-props bootstrap.servers=localhost:9092
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r521927723
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceRequest.java
##########
@@ -194,7 +106,27 @@ private ProduceRequest build(short version, boolean validate) {
ProduceRequest.validateRecords(version, records);
}
}
- return new ProduceRequest(version, acks, timeout, partitionRecords, transactionalId);
+
+ List<ProduceRequestData.TopicProduceData> tpd = partitionRecords
Review comment:
nice suggestion.
Could I address this in follow-up? I had filed jira (KAFKA-10696 ~ KAFKA-10698) to have ```Sender``` use auto-generated protocol directly.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r521957221
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceRequest.java
##########
@@ -194,7 +106,27 @@ private ProduceRequest build(short version, boolean validate) {
ProduceRequest.validateRecords(version, records);
}
}
- return new ProduceRequest(version, acks, timeout, partitionRecords, transactionalId);
+
+ List<ProduceRequestData.TopicProduceData> tpd = partitionRecords
Review comment:
oh. The jira I created does not cover this issue. open a new ticket (https://issues.apache.org/jira/browse/KAFKA-10709)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 edited a comment on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 edited a comment on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728812062
@hachikuji @ijuma It seems to me the root cause of regression is caused by the conversion between old data struct and auto-generated protocol. As we all care for performance, I address more improvements (they were viewed as follow-up before) in this PR.
There are 5 possible improvements.
1. - [x] git rid of struct allocation (thanks to @hachikuji)
1. - [x] rewrite RequestUtils.hasTransactionalRecords & RequestUtils.hasIdempotentRecords to avoid duplicate loop and record instantiation (thanks to @hachikuji)
1. - [x] Sender#sendProduceRequest should use auto-generated protocol directly (thanks to @dajac)
1. - [ ] Replace ProduceResponse.PartitionResponse by auto-generated PartitionProduceResponse (https://issues.apache.org/jira/browse/KAFKA-10709)
1. - [ ] KafkaApis#handleProduceRequest should use auto-generated protocol (https://issues.apache.org/jira/browse/KAFKA-10730)
The recent commits include only 1, 2, and 3 since they touch fewer code. I also re-run all perf tests ~and all tests cases show better throughput with current PR even though 4. and 5. are not included.~
Most of test cases show good improvements. By the contrast, the other tests (single partition + single producer) get insignificant improvement. However, it seems to me they can get good benefited by remaining improvement (4 and 5)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r521931887
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceRequest.java
##########
@@ -323,27 +222,30 @@ public String toString(boolean verbose) {
@Override
public ProduceResponse getErrorResponse(int throttleTimeMs, Throwable e) {
/* In case the producer doesn't actually want any response */
- if (acks == 0)
- return null;
-
+ if (acks == 0) return null;
Errors error = Errors.forException(e);
- Map<TopicPartition, ProduceResponse.PartitionResponse> responseMap = new HashMap<>();
- ProduceResponse.PartitionResponse partitionResponse = new ProduceResponse.PartitionResponse(error);
-
- for (TopicPartition tp : partitions())
- responseMap.put(tp, partitionResponse);
-
- return new ProduceResponse(responseMap, throttleTimeMs);
+ return new ProduceResponse(new ProduceResponseData()
+ .setResponses(partitionSizes().keySet().stream().collect(Collectors.groupingBy(TopicPartition::topic)).entrySet()
+ .stream()
+ .map(entry -> new ProduceResponseData.TopicProduceResponse()
+ .setPartitionResponses(entry.getValue().stream().map(p -> new ProduceResponseData.PartitionProduceResponse()
+ .setIndex(p.partition())
+ .setRecordErrors(Collections.emptyList())
+ .setBaseOffset(INVALID_OFFSET)
+ .setLogAppendTimeMs(RecordBatch.NO_TIMESTAMP)
+ .setLogStartOffset(INVALID_OFFSET)
+ .setErrorMessage(e.getMessage())
+ .setErrorCode(error.code()))
+ .collect(Collectors.toList()))
+ .setName(entry.getKey()))
+ .collect(Collectors.toList()))
+ .setThrottleTimeMs(throttleTimeMs));
Review comment:
I used ```data``` to generate ProduceResponseData. However, the ```data``` may be null when create ProduceResponseData. That is to say, it require if-else to handle null ```data``` in ```getErrorResponse```. It seems to me that is a bit ugly so not sure whether it is worth doing that.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-723875285
> Can we summarize the regression here for a real world workload?
@ijuma I have attached benchmark result to description. I will loop more benchmark later.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r525586697
##########
File path: clients/src/main/java/org/apache/kafka/clients/producer/internals/Sender.java
##########
@@ -560,13 +562,24 @@ private void handleProduceResponse(ClientResponse response, Map<TopicPartition,
log.trace("Received produce response from node {} with correlation id {}", response.destination(), correlationId);
// if we have a response, parse it
if (response.hasResponse()) {
+ // TODO: Sender should exercise PartitionProduceResponse rather than ProduceResponse.PartitionResponse
+ // https://issues.apache.org/jira/browse/KAFKA-10696
Review comment:
nit: since we have the jira for tracking, can we remove the TODO? A few more of these in the PR.
##########
File path: clients/src/test/java/org/apache/kafka/common/requests/ProduceResponseTest.java
##########
@@ -100,16 +113,92 @@ public void produceResponseRecordErrorsTest() {
ProduceResponse response = new ProduceResponse(responseData);
Struct struct = response.toStruct(ver);
assertEquals("Should use schema version " + ver, ApiKeys.PRODUCE.responseSchema(ver), struct.schema());
- ProduceResponse.PartitionResponse deserialized = new ProduceResponse(struct).responses().get(tp);
+ ProduceResponse.PartitionResponse deserialized = new ProduceResponse(new ProduceResponseData(struct, ver)).responses().get(tp);
if (ver >= 8) {
assertEquals(1, deserialized.recordErrors.size());
assertEquals(3, deserialized.recordErrors.get(0).batchIndex);
assertEquals("Record error", deserialized.recordErrors.get(0).message);
assertEquals("Produce failed", deserialized.errorMessage);
} else {
assertEquals(0, deserialized.recordErrors.size());
- assertEquals(null, deserialized.errorMessage);
+ assertNull(deserialized.errorMessage);
}
}
}
+
+ /**
+ * the schema in this test is from previous code and the automatic protocol should be compatible to previous schema.
+ */
+ @Test
+ public void testCompatibility() {
Review comment:
I think this test might be overkill. We haven't done anything like this for the other converted APIs. It's a little similar to `MessageTest.testRequestSchemas`, which was useful verifying the generated schemas when the message generator was being written. Soon `testRequestSchemas` will be redundant, so I guess we have to decide if we just trust the generator and our compatibility system tests or if we want some other canonical representation. Thoughts?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r526029843
##########
File path: clients/src/main/java/org/apache/kafka/clients/producer/internals/Sender.java
##########
@@ -560,13 +562,24 @@ private void handleProduceResponse(ClientResponse response, Map<TopicPartition,
log.trace("Received produce response from node {} with correlation id {}", response.destination(), correlationId);
// if we have a response, parse it
if (response.hasResponse()) {
+ // Sender should exercise PartitionProduceResponse rather than ProduceResponse.PartitionResponse
+ // https://issues.apache.org/jira/browse/KAFKA-10696
ProduceResponse produceResponse = (ProduceResponse) response.responseBody();
- for (Map.Entry<TopicPartition, ProduceResponse.PartitionResponse> entry : produceResponse.responses().entrySet()) {
- TopicPartition tp = entry.getKey();
- ProduceResponse.PartitionResponse partResp = entry.getValue();
+ produceResponse.data().responses().forEach(r -> r.partitionResponses().forEach(p -> {
+ TopicPartition tp = new TopicPartition(r.name(), p.index());
+ ProduceResponse.PartitionResponse partResp = new ProduceResponse.PartitionResponse(
+ Errors.forCode(p.errorCode()),
+ p.baseOffset(),
+ p.logAppendTimeMs(),
+ p.logStartOffset(),
+ p.recordErrors()
+ .stream()
+ .map(e -> new ProduceResponse.RecordError(e.batchIndex(), e.batchIndexErrorMessage()))
+ .collect(Collectors.toList()),
Review comment:
The reason we got rid of streaming APIs is because it produces extra collection (groupBy). However, in this case we have to create a new collection to carry non-auto-generated data (and https://issues.apache.org/jira/browse/KAFKA-10696 will eliminate such conversion) even if we get rid of stream APIs. Hence, it should be fine to keep stream APIs here.
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceResponse.java
##########
@@ -203,119 +77,88 @@ public ProduceResponse(Map<TopicPartition, PartitionResponse> responses) {
* @param responses Produced data grouped by topic-partition
* @param throttleTimeMs Time in milliseconds the response was throttled
*/
+ @Deprecated
public ProduceResponse(Map<TopicPartition, PartitionResponse> responses, int throttleTimeMs) {
- this.responses = responses;
- this.throttleTimeMs = throttleTimeMs;
+ this(toData(responses, throttleTimeMs));
}
- /**
- * Constructor from a {@link Struct}.
- */
- public ProduceResponse(Struct struct) {
- responses = new HashMap<>();
- for (Object topicResponse : struct.getArray(RESPONSES_KEY_NAME)) {
- Struct topicRespStruct = (Struct) topicResponse;
- String topic = topicRespStruct.get(TOPIC_NAME);
-
- for (Object partResponse : topicRespStruct.getArray(PARTITION_RESPONSES_KEY_NAME)) {
- Struct partRespStruct = (Struct) partResponse;
- int partition = partRespStruct.get(PARTITION_ID);
- Errors error = Errors.forCode(partRespStruct.get(ERROR_CODE));
- long offset = partRespStruct.getLong(BASE_OFFSET_KEY_NAME);
- long logAppendTime = partRespStruct.hasField(LOG_APPEND_TIME_KEY_NAME) ?
- partRespStruct.getLong(LOG_APPEND_TIME_KEY_NAME) : RecordBatch.NO_TIMESTAMP;
- long logStartOffset = partRespStruct.getOrElse(LOG_START_OFFSET_FIELD, INVALID_OFFSET);
-
- List<RecordError> recordErrors = Collections.emptyList();
- if (partRespStruct.hasField(RECORD_ERRORS_KEY_NAME)) {
- Object[] recordErrorsArray = partRespStruct.getArray(RECORD_ERRORS_KEY_NAME);
- if (recordErrorsArray.length > 0) {
- recordErrors = new ArrayList<>(recordErrorsArray.length);
- for (Object indexAndMessage : recordErrorsArray) {
- Struct indexAndMessageStruct = (Struct) indexAndMessage;
- recordErrors.add(new RecordError(
- indexAndMessageStruct.getInt(BATCH_INDEX_KEY_NAME),
- indexAndMessageStruct.get(BATCH_INDEX_ERROR_MESSAGE_FIELD)
- ));
- }
- }
- }
+ @Override
+ protected Send toSend(String destination, ResponseHeader header, short apiVersion) {
+ return SendBuilder.buildResponseSend(destination, header, this.data, apiVersion);
+ }
- String errorMessage = partRespStruct.getOrElse(ERROR_MESSAGE_FIELD, null);
- TopicPartition tp = new TopicPartition(topic, partition);
- responses.put(tp, new PartitionResponse(error, offset, logAppendTime, logStartOffset, recordErrors, errorMessage));
+ private static ProduceResponseData toData(Map<TopicPartition, PartitionResponse> responses, int throttleTimeMs) {
+ ProduceResponseData data = new ProduceResponseData().setThrottleTimeMs(throttleTimeMs);
+ responses.forEach((tp, response) -> {
+ ProduceResponseData.TopicProduceResponse tpr = data.responses().find(tp.topic());
+ if (tpr == null) {
+ tpr = new ProduceResponseData.TopicProduceResponse().setName(tp.topic());
+ data.responses().add(tpr);
}
- }
- this.throttleTimeMs = struct.getOrElse(THROTTLE_TIME_MS, DEFAULT_THROTTLE_TIME);
+ tpr.partitionResponses()
+ .add(new ProduceResponseData.PartitionProduceResponse()
+ .setIndex(tp.partition())
+ .setBaseOffset(response.baseOffset)
+ .setLogStartOffset(response.logStartOffset)
+ .setLogAppendTimeMs(response.logAppendTime)
+ .setErrorMessage(response.errorMessage)
+ .setErrorCode(response.error.code())
+ .setRecordErrors(response.recordErrors
+ .stream()
+ .map(e -> new ProduceResponseData.BatchIndexAndErrorMessage()
+ .setBatchIndex(e.batchIndex)
+ .setBatchIndexErrorMessage(e.message))
+ .collect(Collectors.toList())));
Review comment:
ditto
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r521927723
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceRequest.java
##########
@@ -194,7 +106,27 @@ private ProduceRequest build(short version, boolean validate) {
ProduceRequest.validateRecords(version, records);
}
}
- return new ProduceRequest(version, acks, timeout, partitionRecords, transactionalId);
+
+ List<ProduceRequestData.TopicProduceData> tpd = partitionRecords
Review comment:
nice suggestion.
Could I address this in follow-up? I had filed jira (KAFKA-10696 ~ KAFKA-10698) to have ```Sender`` use auto-generated protocol directly.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r520740954
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceResponse.java
##########
@@ -204,118 +75,78 @@ public ProduceResponse(Map<TopicPartition, PartitionResponse> responses) {
* @param throttleTimeMs Time in milliseconds the response was throttled
*/
public ProduceResponse(Map<TopicPartition, PartitionResponse> responses, int throttleTimeMs) {
- this.responses = responses;
- this.throttleTimeMs = throttleTimeMs;
+ this(new ProduceResponseData()
+ .setResponses(responses.entrySet()
+ .stream()
+ .collect(Collectors.groupingBy(e -> e.getKey().topic()))
+ .entrySet()
+ .stream()
+ .map(topicData -> new ProduceResponseData.TopicProduceResponse()
Review comment:
Oh, I was just emphasizing that it is a matter of taste. It's up to you if you agree or not.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728999480
> Can you check that the @hachikuji's perf test doesn't result in significantly increased latency?
I don't observer significantly increased latency on my local. The env is shown below.
- INTEL 10900K 10C20T 3.70 GHz ~ 5.30 GHz
- DDR4-2933 128 GB
- SSD
- Ubuntu 20.04
- OpenJDK 11.0.9.1
**trunk** (53026b799c609373696382c685b9080630128af2)
> 250000000 records sent, 1143578.577571 records/sec (279.19 MB/sec), 109.01 ms avg latency, 422.00 ms max latency, 107 ms 50th, 132 ms 95th, 146 ms 99th, 263 ms 99.9th.
**patch**
> 250000000 records sent, 1202958.315088 records/sec (293.69 MB/sec), 103.60 ms avg latency, 432.00 ms max latency, 101 ms 50th, 122 ms 95th, 146 ms 99th, 278 ms 99.9th.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-721487169
@lbradstreet Thanks for your response.
> is this the overall broker side regression since you need both the construction and toStruct?
you are right and it seems to me the solution to fix regression is that server should use automatic protocol response rather than wrapped response. However, it may make a big patch so it would be better to address in another PR. (BTW, fetch protocol has similar issue https://github.com/apache/kafka/blob/trunk/clients/src/main/java/org/apache/kafka/common/requests/FetchResponse.java#L281)
> Could you please also provide an analysis of the garbage generation using gc.alloc.rate.norm?
construction regression:
- 3.293 -> 580.099 ns/op
- 24.000 -> 2776.000 B/op
toStruct improvement:
- 825.889 -> 318.530 ns/op
- 2208.000 -> 896.000 B/op
We can reduce the regression (in construction) by replacing steam APIs by for-loop. However, I prefer stream Apis since it is more readable and the true solution is to use auto-generated protocols on server-side.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r518984064
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceResponse.java
##########
@@ -204,118 +75,78 @@ public ProduceResponse(Map<TopicPartition, PartitionResponse> responses) {
* @param throttleTimeMs Time in milliseconds the response was throttled
*/
public ProduceResponse(Map<TopicPartition, PartitionResponse> responses, int throttleTimeMs) {
- this.responses = responses;
- this.throttleTimeMs = throttleTimeMs;
+ this(new ProduceResponseData()
+ .setResponses(responses.entrySet()
+ .stream()
+ .collect(Collectors.groupingBy(e -> e.getKey().topic()))
+ .entrySet()
+ .stream()
+ .map(topicData -> new ProduceResponseData.TopicProduceResponse()
Review comment:
Not required, but this would be easier to follow up if we had some helpers.
##########
File path: clients/src/main/java/org/apache/kafka/clients/producer/internals/Sender.java
##########
@@ -560,13 +561,23 @@ private void handleProduceResponse(ClientResponse response, Map<TopicPartition,
log.trace("Received produce response from node {} with correlation id {}", response.destination(), correlationId);
// if we have a response, parse it
if (response.hasResponse()) {
+ // TODO: Sender should exercise PartitionProduceResponse rather than ProduceResponse.PartitionResponse
Review comment:
Is the plan to save this for a follow-up? It looks like it will be a bit of effort to trace down all the uses, but seems doable.
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceResponse.java
##########
@@ -204,118 +75,78 @@ public ProduceResponse(Map<TopicPartition, PartitionResponse> responses) {
* @param throttleTimeMs Time in milliseconds the response was throttled
*/
public ProduceResponse(Map<TopicPartition, PartitionResponse> responses, int throttleTimeMs) {
- this.responses = responses;
- this.throttleTimeMs = throttleTimeMs;
+ this(new ProduceResponseData()
+ .setResponses(responses.entrySet()
+ .stream()
+ .collect(Collectors.groupingBy(e -> e.getKey().topic()))
+ .entrySet()
+ .stream()
+ .map(topicData -> new ProduceResponseData.TopicProduceResponse()
+ .setTopic(topicData.getKey())
+ .setPartitionResponses(topicData.getValue()
+ .stream()
+ .map(p -> new ProduceResponseData.PartitionProduceResponse()
+ .setPartition(p.getKey().partition())
+ .setBaseOffset(p.getValue().baseOffset)
+ .setLogStartOffset(p.getValue().logStartOffset)
+ .setLogAppendTime(p.getValue().logAppendTime)
+ .setErrorMessage(p.getValue().errorMessage)
+ .setErrorCode(p.getValue().error.code())
+ .setRecordErrors(p.getValue().recordErrors
+ .stream()
+ .map(e -> new ProduceResponseData.BatchIndexAndErrorMessage()
+ .setBatchIndex(e.batchIndex)
+ .setBatchIndexErrorMessage(e.message))
+ .collect(Collectors.toList())))
+ .collect(Collectors.toList())))
+ .collect(Collectors.toList()))
+ .setThrottleTimeMs(throttleTimeMs));
}
/**
- * Constructor from a {@link Struct}.
+ * Visible for testing.
*/
- public ProduceResponse(Struct struct) {
- responses = new HashMap<>();
- for (Object topicResponse : struct.getArray(RESPONSES_KEY_NAME)) {
- Struct topicRespStruct = (Struct) topicResponse;
- String topic = topicRespStruct.get(TOPIC_NAME);
-
- for (Object partResponse : topicRespStruct.getArray(PARTITION_RESPONSES_KEY_NAME)) {
- Struct partRespStruct = (Struct) partResponse;
- int partition = partRespStruct.get(PARTITION_ID);
- Errors error = Errors.forCode(partRespStruct.get(ERROR_CODE));
- long offset = partRespStruct.getLong(BASE_OFFSET_KEY_NAME);
- long logAppendTime = partRespStruct.hasField(LOG_APPEND_TIME_KEY_NAME) ?
- partRespStruct.getLong(LOG_APPEND_TIME_KEY_NAME) : RecordBatch.NO_TIMESTAMP;
- long logStartOffset = partRespStruct.getOrElse(LOG_START_OFFSET_FIELD, INVALID_OFFSET);
-
- List<RecordError> recordErrors = Collections.emptyList();
- if (partRespStruct.hasField(RECORD_ERRORS_KEY_NAME)) {
- Object[] recordErrorsArray = partRespStruct.getArray(RECORD_ERRORS_KEY_NAME);
- if (recordErrorsArray.length > 0) {
- recordErrors = new ArrayList<>(recordErrorsArray.length);
- for (Object indexAndMessage : recordErrorsArray) {
- Struct indexAndMessageStruct = (Struct) indexAndMessage;
- recordErrors.add(new RecordError(
- indexAndMessageStruct.getInt(BATCH_INDEX_KEY_NAME),
- indexAndMessageStruct.get(BATCH_INDEX_ERROR_MESSAGE_FIELD)
- ));
- }
- }
- }
-
- String errorMessage = partRespStruct.getOrElse(ERROR_MESSAGE_FIELD, null);
- TopicPartition tp = new TopicPartition(topic, partition);
- responses.put(tp, new PartitionResponse(error, offset, logAppendTime, logStartOffset, recordErrors, errorMessage));
- }
- }
- this.throttleTimeMs = struct.getOrElse(THROTTLE_TIME_MS, DEFAULT_THROTTLE_TIME);
- }
-
@Override
- protected Struct toStruct(short version) {
- Struct struct = new Struct(ApiKeys.PRODUCE.responseSchema(version));
-
- Map<String, Map<Integer, PartitionResponse>> responseByTopic = CollectionUtils.groupPartitionDataByTopic(responses);
- List<Struct> topicDatas = new ArrayList<>(responseByTopic.size());
- for (Map.Entry<String, Map<Integer, PartitionResponse>> entry : responseByTopic.entrySet()) {
- Struct topicData = struct.instance(RESPONSES_KEY_NAME);
- topicData.set(TOPIC_NAME, entry.getKey());
- List<Struct> partitionArray = new ArrayList<>();
- for (Map.Entry<Integer, PartitionResponse> partitionEntry : entry.getValue().entrySet()) {
- PartitionResponse part = partitionEntry.getValue();
- short errorCode = part.error.code();
- // If producer sends ProduceRequest V3 or earlier, the client library is not guaranteed to recognize the error code
- // for KafkaStorageException. In this case the client library will translate KafkaStorageException to
- // UnknownServerException which is not retriable. We can ensure that producer will update metadata and retry
- // by converting the KafkaStorageException to NotLeaderOrFollowerException in the response if ProduceRequest version <= 3
- if (errorCode == Errors.KAFKA_STORAGE_ERROR.code() && version <= 3)
- errorCode = Errors.NOT_LEADER_OR_FOLLOWER.code();
- Struct partStruct = topicData.instance(PARTITION_RESPONSES_KEY_NAME)
- .set(PARTITION_ID, partitionEntry.getKey())
- .set(ERROR_CODE, errorCode)
- .set(BASE_OFFSET_KEY_NAME, part.baseOffset);
- partStruct.setIfExists(LOG_APPEND_TIME_KEY_NAME, part.logAppendTime);
- partStruct.setIfExists(LOG_START_OFFSET_FIELD, part.logStartOffset);
-
- if (partStruct.hasField(RECORD_ERRORS_KEY_NAME)) {
- List<Struct> recordErrors = Collections.emptyList();
- if (!part.recordErrors.isEmpty()) {
- recordErrors = new ArrayList<>();
- for (RecordError indexAndMessage : part.recordErrors) {
- Struct indexAndMessageStruct = partStruct.instance(RECORD_ERRORS_KEY_NAME)
- .set(BATCH_INDEX_KEY_NAME, indexAndMessage.batchIndex)
- .set(BATCH_INDEX_ERROR_MESSAGE_FIELD, indexAndMessage.message);
- recordErrors.add(indexAndMessageStruct);
- }
- }
- partStruct.set(RECORD_ERRORS_KEY_NAME, recordErrors.toArray());
- }
-
- partStruct.setIfExists(ERROR_MESSAGE_FIELD, part.errorMessage);
- partitionArray.add(partStruct);
- }
- topicData.set(PARTITION_RESPONSES_KEY_NAME, partitionArray.toArray());
- topicDatas.add(topicData);
- }
- struct.set(RESPONSES_KEY_NAME, topicDatas.toArray());
- struct.setIfExists(THROTTLE_TIME_MS, throttleTimeMs);
+ public Struct toStruct(short version) {
+ return data.toStruct(version);
+ }
- return struct;
+ public ProduceResponseData data() {
+ return this.data;
}
+ /**
+ * this method is used by testing only.
+ * TODO: refactor the tests which are using this method and then remove this method from production code.
Review comment:
Sounds good to refactor. Perhaps we can turn this TODO into a jira?
##########
File path: core/src/main/scala/kafka/server/KafkaApis.scala
##########
@@ -517,19 +517,23 @@ class KafkaApis(val requestChannel: RequestChannel,
}
// Note that authorization to a transactionalId implies ProducerId authorization
- } else if (produceRequest.hasIdempotentRecords && !authorize(request.context, IDEMPOTENT_WRITE, CLUSTER, CLUSTER_NAME)) {
+ } else if (RequestUtils.hasIdempotentRecords(produceRequest) && !authorize(request.context, IDEMPOTENT_WRITE, CLUSTER, CLUSTER_NAME)) {
sendErrorResponseMaybeThrottle(request, Errors.CLUSTER_AUTHORIZATION_FAILED.exception)
return
}
- val produceRecords = produceRequest.partitionRecordsOrFail.asScala
val unauthorizedTopicResponses = mutable.Map[TopicPartition, PartitionResponse]()
val nonExistingTopicResponses = mutable.Map[TopicPartition, PartitionResponse]()
val invalidRequestResponses = mutable.Map[TopicPartition, PartitionResponse]()
val authorizedRequestInfo = mutable.Map[TopicPartition, MemoryRecords]()
- val authorizedTopics = filterByAuthorized(request.context, WRITE, TOPIC, produceRecords)(_._1.topic)
-
- for ((topicPartition, memoryRecords) <- produceRecords) {
+ val authorizedTopics = filterByAuthorized(request.context, WRITE, TOPIC, produceRequest.dataOrException().topicData().asScala)(_.topic())
+
+ produceRequest.dataOrException().topicData().forEach(topic => topic.data().forEach { partition =>
+ val topicPartition = new TopicPartition(topic.topic(), partition.partition())
+ // This caller assumes the type is MemoryRecords and that is true on current serialization
+ // We cast the type to avoid causing big change to code base.
+ // TODO: maybe we need to refactor code to avoid this casting
Review comment:
That's a good question. I can't think of any great options. We ended up making `FetchResponse` generic to address a similar issue. I think the cast is reasonable for now. Can we move the TODO to a jira?
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceRequest.java
##########
@@ -194,7 +107,27 @@ private ProduceRequest build(short version, boolean validate) {
ProduceRequest.validateRecords(version, records);
}
}
- return new ProduceRequest(version, acks, timeout, partitionRecords, transactionalId);
+
+ List<ProduceRequestData.TopicProduceData> tpd = partitionRecords
Review comment:
I wonder if we would get any benefit computing `partitionSizes` during this pass.
##########
File path: core/src/main/scala/kafka/server/KafkaApis.scala
##########
@@ -517,19 +517,23 @@ class KafkaApis(val requestChannel: RequestChannel,
}
// Note that authorization to a transactionalId implies ProducerId authorization
- } else if (produceRequest.hasIdempotentRecords && !authorize(request.context, IDEMPOTENT_WRITE, CLUSTER, CLUSTER_NAME)) {
+ } else if (RequestUtils.hasIdempotentRecords(produceRequest) && !authorize(request.context, IDEMPOTENT_WRITE, CLUSTER, CLUSTER_NAME)) {
sendErrorResponseMaybeThrottle(request, Errors.CLUSTER_AUTHORIZATION_FAILED.exception)
return
}
- val produceRecords = produceRequest.partitionRecordsOrFail.asScala
val unauthorizedTopicResponses = mutable.Map[TopicPartition, PartitionResponse]()
val nonExistingTopicResponses = mutable.Map[TopicPartition, PartitionResponse]()
val invalidRequestResponses = mutable.Map[TopicPartition, PartitionResponse]()
val authorizedRequestInfo = mutable.Map[TopicPartition, MemoryRecords]()
- val authorizedTopics = filterByAuthorized(request.context, WRITE, TOPIC, produceRecords)(_._1.topic)
-
- for ((topicPartition, memoryRecords) <- produceRecords) {
+ val authorizedTopics = filterByAuthorized(request.context, WRITE, TOPIC, produceRequest.dataOrException().topicData().asScala)(_.topic())
+
+ produceRequest.dataOrException().topicData().forEach(topic => topic.data().forEach { partition =>
+ val topicPartition = new TopicPartition(topic.topic(), partition.partition())
Review comment:
nit: unnecessary parenthesis (a few of these around here)
##########
File path: core/src/main/scala/kafka/server/KafkaApis.scala
##########
@@ -517,19 +517,23 @@ class KafkaApis(val requestChannel: RequestChannel,
}
// Note that authorization to a transactionalId implies ProducerId authorization
- } else if (produceRequest.hasIdempotentRecords && !authorize(request.context, IDEMPOTENT_WRITE, CLUSTER, CLUSTER_NAME)) {
+ } else if (RequestUtils.hasIdempotentRecords(produceRequest) && !authorize(request.context, IDEMPOTENT_WRITE, CLUSTER, CLUSTER_NAME)) {
sendErrorResponseMaybeThrottle(request, Errors.CLUSTER_AUTHORIZATION_FAILED.exception)
return
}
- val produceRecords = produceRequest.partitionRecordsOrFail.asScala
val unauthorizedTopicResponses = mutable.Map[TopicPartition, PartitionResponse]()
val nonExistingTopicResponses = mutable.Map[TopicPartition, PartitionResponse]()
val invalidRequestResponses = mutable.Map[TopicPartition, PartitionResponse]()
val authorizedRequestInfo = mutable.Map[TopicPartition, MemoryRecords]()
- val authorizedTopics = filterByAuthorized(request.context, WRITE, TOPIC, produceRecords)(_._1.topic)
-
- for ((topicPartition, memoryRecords) <- produceRecords) {
+ val authorizedTopics = filterByAuthorized(request.context, WRITE, TOPIC, produceRequest.dataOrException().topicData().asScala)(_.topic())
Review comment:
This logic surprised me a little bit until I realized that we were trying to avoid redundant authorization calls. Might be worth adding a comment since I was almost ready to suggest moving this logic into the loop.
##########
File path: clients/src/main/resources/common/message/ProduceRequest.json
##########
@@ -33,21 +33,21 @@
"validVersions": "0-8",
"flexibleVersions": "none",
"fields": [
- { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "0+", "entityType": "transactionalId",
+ { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "3+", "ignorable": true, "entityType": "transactionalId",
"about": "The transactional ID, or null if the producer is not transactional." },
{ "name": "Acks", "type": "int16", "versions": "0+",
"about": "The number of acknowledgments the producer requires the leader to have received before considering a request complete. Allowed values: 0 for no acknowledgments, 1 for only the leader and -1 for the full ISR." },
- { "name": "TimeoutMs", "type": "int32", "versions": "0+",
+ { "name": "Timeout", "type": "int32", "versions": "0+",
Review comment:
The names do not get serialized, so I think we can make them whatever we want.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r518989756
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceRequest.java
##########
@@ -194,7 +107,27 @@ private ProduceRequest build(short version, boolean validate) {
ProduceRequest.validateRecords(version, records);
}
}
- return new ProduceRequest(version, acks, timeout, partitionRecords, transactionalId);
+
+ List<ProduceRequestData.TopicProduceData> tpd = partitionRecords
Review comment:
We could probably also compute `partitionSizes` lazily. I think the broker is the only one that uses it.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 edited a comment on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 edited a comment on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728812062
@hachikuji @ijuma It seems to me the root cause of regression is caused by the conversion between old data struct and auto-generated protocol. As we all care for performance, I address more improvements (they were viewed as follow-up before) in this PR.
There are 5 possible improvements.
1. - [x] git rid of struct allocation (thanks to @hachikuji)
1. - [x] rewrite RequestUtils.hasTransactionalRecords & RequestUtils.hasIdempotentRecords to avoid duplicate loop and record instantiation (thanks to @hachikuji)
1. - [x] Sender#sendProduceRequest should use auto-generated protocol directly (thanks to @dajac)
1. - [ ] [client side] Replace ProduceResponse.PartitionResponse by auto-generated PartitionProduceResponse (https://issues.apache.org/jira/browse/KAFKA-10709)
1. - [ ] [server side] KafkaApis#handleProduceRequest should use auto-generated protocol (https://issues.apache.org/jira/browse/KAFKA-10730)
The recent commits include only 1, 2, and 3 since they touch fewer code. I also re-run all perf tests:
1. currently all tests cases show better throughput with current PR even though 4. and 5. are not included.
1. it seems to me they can get better improvement by remaining tasks (4 and 5)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r514326022
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceRequest.java
##########
@@ -210,65 +142,42 @@ public String toString() {
}
}
+ /**
+ * We have to copy acks, timeout, transactionalId and partitionSizes from data since data maybe reset to eliminate
+ * the reference to ByteBuffer but those metadata are still useful.
+ */
private final short acks;
private final int timeout;
private final String transactionalId;
-
- private final Map<TopicPartition, Integer> partitionSizes;
-
+ // visible for testing
+ final Map<TopicPartition, Integer> partitionSizes;
+ private boolean hasTransactionalRecords = false;
+ private boolean hasIdempotentRecords = false;
// This is set to null by `clearPartitionRecords` to prevent unnecessary memory retention when a produce request is
// put in the purgatory (due to client throttling, it can take a while before the response is sent).
// Care should be taken in methods that use this field.
- private volatile Map<TopicPartition, MemoryRecords> partitionRecords;
- private boolean hasTransactionalRecords = false;
- private boolean hasIdempotentRecords = false;
-
- private ProduceRequest(short version, short acks, int timeout, Map<TopicPartition, MemoryRecords> partitionRecords, String transactionalId) {
- super(ApiKeys.PRODUCE, version);
- this.acks = acks;
- this.timeout = timeout;
-
- this.transactionalId = transactionalId;
- this.partitionRecords = partitionRecords;
- this.partitionSizes = createPartitionSizes(partitionRecords);
+ private volatile ProduceRequestData data;
- for (MemoryRecords records : partitionRecords.values()) {
- setFlags(records);
- }
- }
-
- private static Map<TopicPartition, Integer> createPartitionSizes(Map<TopicPartition, MemoryRecords> partitionRecords) {
- Map<TopicPartition, Integer> result = new HashMap<>(partitionRecords.size());
- for (Map.Entry<TopicPartition, MemoryRecords> entry : partitionRecords.entrySet())
- result.put(entry.getKey(), entry.getValue().sizeInBytes());
- return result;
- }
-
- public ProduceRequest(Struct struct, short version) {
+ public ProduceRequest(ProduceRequestData produceRequestData, short version) {
super(ApiKeys.PRODUCE, version);
- partitionRecords = new HashMap<>();
- for (Object topicDataObj : struct.getArray(TOPIC_DATA_KEY_NAME)) {
- Struct topicData = (Struct) topicDataObj;
- String topic = topicData.get(TOPIC_NAME);
- for (Object partitionResponseObj : topicData.getArray(PARTITION_DATA_KEY_NAME)) {
- Struct partitionResponse = (Struct) partitionResponseObj;
- int partition = partitionResponse.get(PARTITION_ID);
- MemoryRecords records = (MemoryRecords) partitionResponse.getRecords(RECORD_SET_KEY_NAME);
- setFlags(records);
- partitionRecords.put(new TopicPartition(topic, partition), records);
- }
- }
- partitionSizes = createPartitionSizes(partitionRecords);
- acks = struct.getShort(ACKS_KEY_NAME);
- timeout = struct.getInt(TIMEOUT_KEY_NAME);
- transactionalId = struct.getOrElse(NULLABLE_TRANSACTIONAL_ID, null);
- }
-
- private void setFlags(MemoryRecords records) {
- Iterator<MutableRecordBatch> iterator = records.batches().iterator();
- MutableRecordBatch entry = iterator.next();
- hasIdempotentRecords = hasIdempotentRecords || entry.hasProducerId();
- hasTransactionalRecords = hasTransactionalRecords || entry.isTransactional();
+ this.data = produceRequestData;
+ this.data.topicData().forEach(topicProduceData -> topicProduceData.partitions()
+ .forEach(partitionProduceData -> {
+ MemoryRecords records = MemoryRecords.readableRecords(partitionProduceData.records());
+ Iterator<MutableRecordBatch> iterator = records.batches().iterator();
+ MutableRecordBatch entry = iterator.next();
+ hasIdempotentRecords = hasIdempotentRecords || entry.hasProducerId();
Review comment:
Would it make sense to move this to the builder where we are already doing a pass over the partitions?
##########
File path: clients/src/main/resources/common/message/ProduceRequest.json
##########
@@ -33,21 +33,21 @@
"validVersions": "0-8",
"flexibleVersions": "none",
"fields": [
- { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "0+", "entityType": "transactionalId",
+ { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "3+", "ignorable": true, "entityType": "transactionalId",
"about": "The transactional ID, or null if the producer is not transactional." },
{ "name": "Acks", "type": "int16", "versions": "0+",
"about": "The number of acknowledgments the producer requires the leader to have received before considering a request complete. Allowed values: 0 for no acknowledgments, 1 for only the leader and -1 for the full ISR." },
- { "name": "TimeoutMs", "type": "int32", "versions": "0+",
+ { "name": "Timeout", "type": "int32", "versions": "0+",
Review comment:
nit: I kind of liked the original name to make the unit clear. We're probably not consistent on this convention though.
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceResponse.java
##########
@@ -17,179 +17,48 @@
package org.apache.kafka.common.requests;
import org.apache.kafka.common.TopicPartition;
-import org.apache.kafka.common.protocol.ApiKeys;
+import org.apache.kafka.common.message.ProduceResponseData;
+import org.apache.kafka.common.protocol.ByteBufferAccessor;
import org.apache.kafka.common.protocol.Errors;
-import org.apache.kafka.common.protocol.types.ArrayOf;
-import org.apache.kafka.common.protocol.types.Field;
-import org.apache.kafka.common.protocol.types.Schema;
import org.apache.kafka.common.protocol.types.Struct;
import org.apache.kafka.common.record.RecordBatch;
-import org.apache.kafka.common.utils.CollectionUtils;
import java.nio.ByteBuffer;
-import java.util.ArrayList;
+import java.util.AbstractMap;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
-
-import static org.apache.kafka.common.protocol.CommonFields.ERROR_CODE;
-import static org.apache.kafka.common.protocol.CommonFields.PARTITION_ID;
-import static org.apache.kafka.common.protocol.CommonFields.THROTTLE_TIME_MS;
-import static org.apache.kafka.common.protocol.CommonFields.TOPIC_NAME;
-import static org.apache.kafka.common.protocol.types.Type.INT64;
+import java.util.stream.Collectors;
/**
- * This wrapper supports both v0 and v1 of ProduceResponse.
+ * This wrapper supports both v0 and v8 of ProduceResponse.
*/
public class ProduceResponse extends AbstractResponse {
-
- private static final String RESPONSES_KEY_NAME = "responses";
-
- // topic level field names
- private static final String PARTITION_RESPONSES_KEY_NAME = "partition_responses";
-
public static final long INVALID_OFFSET = -1L;
+ private final ProduceResponseData data;
+ private final Map<TopicPartition, PartitionResponse> responses;
- /**
Review comment:
Kind of a pity to lose this. Can we move it to the class documentation?
##########
File path: clients/src/test/java/org/apache/kafka/clients/NetworkClientTest.java
##########
@@ -218,6 +218,7 @@ private void checkSimpleRequestResponse(NetworkClient networkClient) {
request.apiKey().responseHeaderVersion(PRODUCE.latestVersion()));
Struct resp = new Struct(PRODUCE.responseSchema(PRODUCE.latestVersion()));
resp.set("responses", new Object[0]);
+ resp.set(CommonFields.THROTTLE_TIME_MS, 100);
Review comment:
Wondering if we may as well rewrite this using `ProduceResponseData`.
##########
File path: clients/src/main/resources/common/message/ProduceRequest.json
##########
@@ -33,21 +33,21 @@
"validVersions": "0-8",
"flexibleVersions": "none",
"fields": [
- { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "0+", "entityType": "transactionalId",
+ { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "3+", "ignorable": true, "entityType": "transactionalId",
Review comment:
Hmm, not sure about making this ignorable. For transactional data, I think the broker would just fail if it cannot authorize the transactionalId.
Also, should we set the default to null?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji edited a comment on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji edited a comment on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728383115
Posting allocation flame graphs from the producer before and after this patch:

So we succeeded in getting rid of the extra allocations in the network layer!
I generated these graphs using the producer performance test writing to a topic with 10 partitions on a cluster with a single broker.
```
> bin/kafka-producer-perf-test.sh --topic foo --num-records 250000000 --throughput -1 --record-size 256 --producer-props bootstrap.servers=localhost:9092
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r514594596
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceRequest.java
##########
@@ -210,65 +142,42 @@ public String toString() {
}
}
+ /**
+ * We have to copy acks, timeout, transactionalId and partitionSizes from data since data maybe reset to eliminate
+ * the reference to ByteBuffer but those metadata are still useful.
+ */
private final short acks;
private final int timeout;
private final String transactionalId;
-
- private final Map<TopicPartition, Integer> partitionSizes;
-
+ // visible for testing
+ final Map<TopicPartition, Integer> partitionSizes;
+ private boolean hasTransactionalRecords = false;
+ private boolean hasIdempotentRecords = false;
// This is set to null by `clearPartitionRecords` to prevent unnecessary memory retention when a produce request is
// put in the purgatory (due to client throttling, it can take a while before the response is sent).
// Care should be taken in methods that use this field.
- private volatile Map<TopicPartition, MemoryRecords> partitionRecords;
- private boolean hasTransactionalRecords = false;
- private boolean hasIdempotentRecords = false;
-
- private ProduceRequest(short version, short acks, int timeout, Map<TopicPartition, MemoryRecords> partitionRecords, String transactionalId) {
- super(ApiKeys.PRODUCE, version);
- this.acks = acks;
- this.timeout = timeout;
-
- this.transactionalId = transactionalId;
- this.partitionRecords = partitionRecords;
- this.partitionSizes = createPartitionSizes(partitionRecords);
+ private volatile ProduceRequestData data;
- for (MemoryRecords records : partitionRecords.values()) {
- setFlags(records);
- }
- }
-
- private static Map<TopicPartition, Integer> createPartitionSizes(Map<TopicPartition, MemoryRecords> partitionRecords) {
- Map<TopicPartition, Integer> result = new HashMap<>(partitionRecords.size());
- for (Map.Entry<TopicPartition, MemoryRecords> entry : partitionRecords.entrySet())
- result.put(entry.getKey(), entry.getValue().sizeInBytes());
- return result;
- }
-
- public ProduceRequest(Struct struct, short version) {
+ public ProduceRequest(ProduceRequestData produceRequestData, short version) {
super(ApiKeys.PRODUCE, version);
- partitionRecords = new HashMap<>();
- for (Object topicDataObj : struct.getArray(TOPIC_DATA_KEY_NAME)) {
- Struct topicData = (Struct) topicDataObj;
- String topic = topicData.get(TOPIC_NAME);
- for (Object partitionResponseObj : topicData.getArray(PARTITION_DATA_KEY_NAME)) {
- Struct partitionResponse = (Struct) partitionResponseObj;
- int partition = partitionResponse.get(PARTITION_ID);
- MemoryRecords records = (MemoryRecords) partitionResponse.getRecords(RECORD_SET_KEY_NAME);
- setFlags(records);
- partitionRecords.put(new TopicPartition(topic, partition), records);
- }
- }
- partitionSizes = createPartitionSizes(partitionRecords);
- acks = struct.getShort(ACKS_KEY_NAME);
- timeout = struct.getInt(TIMEOUT_KEY_NAME);
- transactionalId = struct.getOrElse(NULLABLE_TRANSACTIONAL_ID, null);
- }
-
- private void setFlags(MemoryRecords records) {
- Iterator<MutableRecordBatch> iterator = records.batches().iterator();
- MutableRecordBatch entry = iterator.next();
- hasIdempotentRecords = hasIdempotentRecords || entry.hasProducerId();
- hasTransactionalRecords = hasTransactionalRecords || entry.isTransactional();
+ this.data = produceRequestData;
+ this.data.topicData().forEach(topicProduceData -> topicProduceData.partitions()
+ .forEach(partitionProduceData -> {
+ MemoryRecords records = MemoryRecords.readableRecords(partitionProduceData.records());
+ Iterator<MutableRecordBatch> iterator = records.batches().iterator();
+ MutableRecordBatch entry = iterator.next();
+ hasIdempotentRecords = hasIdempotentRecords || entry.hasProducerId();
Review comment:
On the other hand, we might want to move this logic into a helper in `KafkaApis` so that these objects are dedicated only to serialization logic. Eventually we'll want to get rid of `ProduceRequest` and just use `ProduceRequestData`.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] dajac commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
dajac commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r526074777
##########
File path: clients/src/main/java/org/apache/kafka/clients/producer/internals/Sender.java
##########
@@ -560,13 +562,24 @@ private void handleProduceResponse(ClientResponse response, Map<TopicPartition,
log.trace("Received produce response from node {} with correlation id {}", response.destination(), correlationId);
// if we have a response, parse it
if (response.hasResponse()) {
+ // Sender should exercise PartitionProduceResponse rather than ProduceResponse.PartitionResponse
+ // https://issues.apache.org/jira/browse/KAFKA-10696
ProduceResponse produceResponse = (ProduceResponse) response.responseBody();
- for (Map.Entry<TopicPartition, ProduceResponse.PartitionResponse> entry : produceResponse.responses().entrySet()) {
- TopicPartition tp = entry.getKey();
- ProduceResponse.PartitionResponse partResp = entry.getValue();
+ produceResponse.data().responses().forEach(r -> r.partitionResponses().forEach(p -> {
+ TopicPartition tp = new TopicPartition(r.name(), p.index());
+ ProduceResponse.PartitionResponse partResp = new ProduceResponse.PartitionResponse(
+ Errors.forCode(p.errorCode()),
+ p.baseOffset(),
+ p.logAppendTimeMs(),
+ p.logStartOffset(),
+ p.recordErrors()
+ .stream()
+ .map(e -> new ProduceResponse.RecordError(e.batchIndex(), e.batchIndexErrorMessage()))
+ .collect(Collectors.toList()),
Review comment:
Yeah, I do agree. It won't change much from a performance point of view. I was more thinking about this from a code consistency point of view. I don't feel strong about this at all. It is just that I usually prefer not to mix paradigms. I recognise that this is a personal taste :).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r519067655
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceRequest.java
##########
@@ -194,7 +107,27 @@ private ProduceRequest build(short version, boolean validate) {
ProduceRequest.validateRecords(version, records);
}
}
- return new ProduceRequest(version, acks, timeout, partitionRecords, transactionalId);
+
+ List<ProduceRequestData.TopicProduceData> tpd = partitionRecords
Review comment:
The "data" may be cleared to null (for GC) so it is a risk if we lazily initialize the partition size.
I considered to remove it as it is used by log only (toString).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-725786213
@hachikuji @ijuma @lbradstreet Could you take a look? There are some follow-ups which can get back the performance we lose here and I'd like to work on them as soon as possible :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] ijuma commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
ijuma commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-723675299
Can we summarize the regression here for a real world workload?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r519066134
##########
File path: clients/src/main/resources/common/message/ProduceRequest.json
##########
@@ -33,21 +33,21 @@
"validVersions": "0-8",
"flexibleVersions": "none",
"fields": [
- { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "0+", "entityType": "transactionalId",
+ { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "3+", "ignorable": true, "entityType": "transactionalId",
"about": "The transactional ID, or null if the producer is not transactional." },
{ "name": "Acks", "type": "int16", "versions": "0+",
"about": "The number of acknowledgments the producer requires the leader to have received before considering a request complete. Allowed values: 0 for no acknowledgments, 1 for only the leader and -1 for the full ISR." },
- { "name": "TimeoutMs", "type": "int32", "versions": "0+",
+ { "name": "Timeout", "type": "int32", "versions": "0+",
Review comment:
This is a major question when I am processing those protocol migration PRs.
The Struct deserialization depends on the "name" (https://github.com/apache/kafka/blob/8e211eb72f9a45897cc37fed394a38096aa47feb/clients/src/main/java/org/apache/kafka/common/requests/ProduceRequest.java#L250). Struct.get(xxx) searches the index according to "name". Hence, changing the name breaks compatibility since the Struct serialization can not find the correct field. (That is to say, the previous protocol fails to deserialize the data from new auto-generated protocol)
Please correct me if I misunderstood protocol mechanism.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728669194
@chia7712 It might be worth checking the fancy new `toSend` implementation. I did a quick test and found that gc overhead actually increased with this change even though the new implementation seemed much better for cpu.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji merged pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji merged pull request #9401:
URL: https://github.com/apache/kafka/pull/9401
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 edited a comment on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 edited a comment on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728812062
@hachikuji @ijuma It seems to me the root cause of regression is caused by the conversion between old data struct and auto-generated protocol. As we all care for performance, I address more improvements (they were viewed as follow-up before) in this PR.
There are 5 possible improvements.
1. - [x] git rid of struct allocation (thanks to @hachikuji)
1. - [x] rewrite RequestUtils.hasTransactionalRecords & RequestUtils.hasIdempotentRecords to avoid duplicate loop and record instantiation (thanks to @hachikuji)
1. - [x] Sender#sendProduceRequest should use auto-generated protocol directly (thanks to @dajac)
1. - [ ] [client side] Replace ProduceResponse.PartitionResponse by auto-generated PartitionProduceResponse (https://issues.apache.org/jira/browse/KAFKA-10709)
1. - [ ] [server side] KafkaApis#handleProduceRequest should use auto-generated protocol (https://issues.apache.org/jira/browse/KAFKA-10730)
The recent commits include only 1, 2, and 3 since they touch fewer code. I also re-run all perf tests:
1. currently all tests cases show better throughput with current PR even though 4. and 5. are not included.
1. it seems to me they can get better improvement by remaining tasks (4 and 5)
More perf tests are running and I will update the PR description later.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 edited a comment on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 edited a comment on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728812062
@hachikuji @ijuma It seems to me the root cause of regression is caused by the conversion between old data struct and auto-generated protocol. As we all care for performance, I address more improvements (they were viewed as follow-up before) in this PR.
There are 5 possible improvements.
1. - [x] git rid of struct allocation (thanks to @hachikuji)
1. - [x] rewrite RequestUtils.hasTransactionalRecords & RequestUtils.hasIdempotentRecords to avoid duplicate loop and record instantiation (thanks to @hachikuji)
1. - [x] Sender#sendProduceRequest should use auto-generated protocol directly (thanks to @dajac)
1. - [ ] Replace ProduceResponse.PartitionResponse by auto-generated PartitionProduceResponse (https://issues.apache.org/jira/browse/KAFKA-10709)
1. - [ ] KafkaApis#handleProduceRequest should use auto-generated protocol (https://issues.apache.org/jira/browse/KAFKA-10730)
The recent commits include only 1, 2, and 3 since they touch fewer code. I also re-run all perf tests and all tests cases show better throughput with current PR even if 4. and 5. are not included.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r519251671
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceResponse.java
##########
@@ -204,118 +75,78 @@ public ProduceResponse(Map<TopicPartition, PartitionResponse> responses) {
* @param throttleTimeMs Time in milliseconds the response was throttled
*/
public ProduceResponse(Map<TopicPartition, PartitionResponse> responses, int throttleTimeMs) {
- this.responses = responses;
- this.throttleTimeMs = throttleTimeMs;
+ this(new ProduceResponseData()
+ .setResponses(responses.entrySet()
+ .stream()
+ .collect(Collectors.groupingBy(e -> e.getKey().topic()))
+ .entrySet()
+ .stream()
+ .map(topicData -> new ProduceResponseData.TopicProduceResponse()
Review comment:
Pardon me. why it is not required?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r525690436
##########
File path: clients/src/test/java/org/apache/kafka/common/requests/ProduceResponseTest.java
##########
@@ -100,16 +113,92 @@ public void produceResponseRecordErrorsTest() {
ProduceResponse response = new ProduceResponse(responseData);
Struct struct = response.toStruct(ver);
assertEquals("Should use schema version " + ver, ApiKeys.PRODUCE.responseSchema(ver), struct.schema());
- ProduceResponse.PartitionResponse deserialized = new ProduceResponse(struct).responses().get(tp);
+ ProduceResponse.PartitionResponse deserialized = new ProduceResponse(new ProduceResponseData(struct, ver)).responses().get(tp);
if (ver >= 8) {
assertEquals(1, deserialized.recordErrors.size());
assertEquals(3, deserialized.recordErrors.get(0).batchIndex);
assertEquals("Record error", deserialized.recordErrors.get(0).message);
assertEquals("Produce failed", deserialized.errorMessage);
} else {
assertEquals(0, deserialized.recordErrors.size());
- assertEquals(null, deserialized.errorMessage);
+ assertNull(deserialized.errorMessage);
}
}
}
+
+ /**
+ * the schema in this test is from previous code and the automatic protocol should be compatible to previous schema.
+ */
+ @Test
+ public void testCompatibility() {
Review comment:
That makes sense to me. Will remove redundant test.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-727825315
The last commit borrows some improvement from #9563.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 edited a comment on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 edited a comment on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728812062
@hachikuji @ijuma It seems to me the root cause of regression is caused by the conversion between old data struct and auto-generated protocol. As we all care for performance, I address more improvements (they were viewed as follow-up before) in this PR.
There are 5 possible improvements.
1. - [x] git rid of struct allocation (thanks to @hachikuji)
1. - [x] rewrite RequestUtils.hasTransactionalRecords & RequestUtils.hasIdempotentRecords to avoid duplicate loop and record instantiation (thanks to @hachikuji)
1. - [x] Sender#sendProduceRequest should use auto-generated protocol directly (thanks to @dajac)
1. - [ ] Replace ProduceResponse.PartitionResponse by auto-generated PartitionProduceResponse (https://issues.apache.org/jira/browse/KAFKA-10709)
1. - [ ] KafkaApis#handleProduceRequest should use auto-generated protocol (https://issues.apache.org/jira/browse/KAFKA-10730)
The recent commits include only 1, 2, and 3 since they touch fewer code. I also re-run all perf tests and all tests cases show better throughput with current PR even though 4. and 5. are not included.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728383115
Posting allocation flame graphs from the producer before and after this patch:


So we succeeded in getting rid of the extra allocations in the network layer!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-729258346
Here are a couple additional test runs. This was on Ubuntu 20 (ami-00831fc7c1e3ddc60). The machine type was m5a.xlarge with 200GB gp2 EBS storage. One instance was running the broker and one instance was running the producer perf test.
Commands:
```
bin/kafka-topics.sh --create --topic foo --replication-factor 1 --partitions 10 --bootstrap-server $BROKER
bin/kafka-producer-perf-test.sh --topic foo --num-records 250000000 --throughput -1 --record-size 256 --producer-props bootstrap.servers=$BROKER
```
Here are the results:
```
Patch:
250000000 records sent, 826003.925171 records/sec (201.66 MB/sec), 149.39 ms avg latency, 1623.00 ms max latency, 131 ms 50th, 380 ms 95th, 464 ms 99th, 650 ms 99.9th.
250000000 records sent, 825684.740355 records/sec (201.58 MB/sec), 149.22 ms avg latency, 1276.00 ms max latency, 124 ms 50th, 364 ms 95th, 451 ms 99th, 775 ms 99.9th.
Trunk:
250000000 records sent, 833144.487250 records/sec (203.40 MB/sec), 148.20 ms avg latency, 1361.00 ms max latency, 111 ms 50th, 437 ms 95th, 551 ms 99th, 807 ms 99.9th.
250000000 records sent, 810927.409022 records/sec (197.98 MB/sec), 152.59 ms avg latency, 1430.00 ms max latency, 127 ms 50th, 382 ms 95th, 467 ms 99th, 809 ms 99.9th.
```
Given variance in these tests, I think we're probably inline with trunk. I looked at the flame graph as well and did not observe any substantial difference in performance. Here are a few interesting highlights from one run. This patch is listed first with trunk second.
`Sender.sendProduceRequests`:

`KafkaChannel.write`:


----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-727856785
@hachikuji @ijuma @lbradstreet @dajac I have updated the perf result. The regression is reduced by last commit. Please take a look.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] dajac commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
dajac commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r525965065
##########
File path: clients/src/main/java/org/apache/kafka/clients/producer/internals/Sender.java
##########
@@ -560,13 +562,24 @@ private void handleProduceResponse(ClientResponse response, Map<TopicPartition,
log.trace("Received produce response from node {} with correlation id {}", response.destination(), correlationId);
// if we have a response, parse it
if (response.hasResponse()) {
+ // Sender should exercise PartitionProduceResponse rather than ProduceResponse.PartitionResponse
+ // https://issues.apache.org/jira/browse/KAFKA-10696
ProduceResponse produceResponse = (ProduceResponse) response.responseBody();
- for (Map.Entry<TopicPartition, ProduceResponse.PartitionResponse> entry : produceResponse.responses().entrySet()) {
- TopicPartition tp = entry.getKey();
- ProduceResponse.PartitionResponse partResp = entry.getValue();
+ produceResponse.data().responses().forEach(r -> r.partitionResponses().forEach(p -> {
+ TopicPartition tp = new TopicPartition(r.name(), p.index());
+ ProduceResponse.PartitionResponse partResp = new ProduceResponse.PartitionResponse(
+ Errors.forCode(p.errorCode()),
+ p.baseOffset(),
+ p.logAppendTimeMs(),
+ p.logStartOffset(),
+ p.recordErrors()
+ .stream()
+ .map(e -> new ProduceResponse.RecordError(e.batchIndex(), e.batchIndexErrorMessage()))
+ .collect(Collectors.toList()),
Review comment:
nit: As we got rid of the streaming api in this section, would it make sense to also remove this one?
##########
File path: clients/src/test/java/org/apache/kafka/clients/NetworkClientTest.java
##########
@@ -198,8 +202,9 @@ private void checkSimpleRequestResponse(NetworkClient networkClient) {
ResponseHeader respHeader =
new ResponseHeader(request.correlationId(),
request.apiKey().responseHeaderVersion(PRODUCE.latestVersion()));
- Struct resp = new Struct(PRODUCE.responseSchema(PRODUCE.latestVersion()));
- resp.set("responses", new Object[0]);
+ Struct resp = new ProduceResponseData()
+ .setThrottleTimeMs(100)
+ .toStruct(ProduceResponseData.HIGHEST_SUPPORTED_VERSION);
Review comment:
nit: It may be better to use `PRODUCE.latestVersion()` to stay inline with L204. There are few cases like this in the file.
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/RequestUtils.java
##########
@@ -48,4 +53,41 @@ public static ByteBuffer serialize(Struct headerStruct, Struct bodyStruct) {
buffer.rewind();
return buffer;
}
-}
+
+ // visible for testing
+ public static boolean hasIdempotentRecords(ProduceRequest request) {
+ return flags(request).getKey();
+ }
+
+ // visible for testing
+ public static boolean hasTransactionalRecords(ProduceRequest request) {
+ return flags(request).getValue();
+ }
+
+ /**
+ * Get both hasIdempotentRecords flag and hasTransactionalRecords flag from produce request.
+ * Noted that we find all flags at once to avoid duplicate loop and record batch construction.
+ * @return first flag is "hasIdempotentRecords" and another is "hasTransactionalRecords"
+ */
+ public static AbstractMap.SimpleEntry<Boolean, Boolean> flags(ProduceRequest request) {
+ boolean hasIdempotentRecords = false;
+ boolean hasTransactionalRecords = false;
+ for (ProduceRequestData.TopicProduceData tpd : request.dataOrException().topicData()) {
+ for (ProduceRequestData.PartitionProduceData ppd : tpd.partitionData()) {
+ BaseRecords records = ppd.records();
+ if (records instanceof Records) {
+ Iterator<? extends RecordBatch> iterator = ((Records) records).batches().iterator();
+ if (iterator.hasNext()) {
+ RecordBatch batch = iterator.next();
+ hasIdempotentRecords = hasIdempotentRecords || batch.hasProducerId();
+ hasTransactionalRecords = hasTransactionalRecords || batch.isTransactional();
+ }
+ }
+ // return early
+ if (hasIdempotentRecords && hasTransactionalRecords)
+ return new AbstractMap.SimpleEntry<>(true, true);
+ }
+ }
+ return new AbstractMap.SimpleEntry<>(hasIdempotentRecords, hasTransactionalRecords);
+ }
+}
Review comment:
nit: Add a new line.
##########
File path: clients/src/main/resources/common/message/ProduceRequest.json
##########
@@ -33,21 +33,21 @@
"validVersions": "0-8",
"flexibleVersions": "none",
"fields": [
- { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "0+", "entityType": "transactionalId",
+ { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "3+", "default": "null", "entityType": "transactionalId",
Review comment:
I wonder if this one should be `ignorable`. It seems that we were ignoring it before when it was not present in the target version:
```
struct.setIfExists(NULLABLE_TRANSACTIONAL_ID, transactionalId)
```
##########
File path: clients/src/test/java/org/apache/kafka/clients/NetworkClientTest.java
##########
@@ -154,8 +155,11 @@ public void testClose() {
client.poll(1, time.milliseconds());
assertTrue("The client should be ready", client.isReady(node, time.milliseconds()));
- ProduceRequest.Builder builder = ProduceRequest.Builder.forCurrentMagic((short) 1, 1000,
- Collections.emptyMap());
+ ProduceRequest.Builder builder = ProduceRequest.forCurrentMagic(new ProduceRequestData()
+ .setTopicData(new ProduceRequestData.TopicProduceDataCollection())
+ .setAcks((short) 1)
+ .setTimeoutMs(1000)
+ .setTransactionalId(null));
Review comment:
nit: It seem that `TransactionalId` is `null` by default so we don't have to set it explicitly all the time. There are few cases in the this file and in others. I am not sure if this was intentional so I am also fine if you want to keep them.
##########
File path: clients/src/test/java/org/apache/kafka/common/requests/ProduceRequestTest.java
##########
@@ -192,16 +258,21 @@ public void testMixedTransactionalData() {
final MemoryRecords txnRecords = MemoryRecords.withTransactionalRecords(CompressionType.NONE, producerId,
producerEpoch, sequence, new SimpleRecord("bar".getBytes()));
- final Map<TopicPartition, MemoryRecords> recordsByPartition = new LinkedHashMap<>();
- recordsByPartition.put(new TopicPartition("foo", 0), txnRecords);
- recordsByPartition.put(new TopicPartition("foo", 1), nonTxnRecords);
-
- final ProduceRequest.Builder builder = ProduceRequest.Builder.forMagic(RecordVersion.current().value, (short) -1, 5000,
- recordsByPartition, transactionalId);
+ ProduceRequest.Builder builder = ProduceRequest.forMagic(RecordBatch.CURRENT_MAGIC_VALUE,
+ new ProduceRequestData()
+ .setTopicData(new ProduceRequestData.TopicProduceDataCollection(Arrays.asList(
+ new ProduceRequestData.TopicProduceData().setName("foo").setPartitionData(Collections.singletonList(
+ new ProduceRequestData.PartitionProduceData().setIndex(0).setRecords(txnRecords))),
+ new ProduceRequestData.TopicProduceData().setName("foo").setPartitionData(Collections.singletonList(
+ new ProduceRequestData.PartitionProduceData().setIndex(1).setRecords(nonTxnRecords))))
+ .iterator()))
+ .setAcks((short) 1)
Review comment:
nit: I am not sure if this is important or not but we were using `-1` previously.
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceResponse.java
##########
@@ -203,119 +77,88 @@ public ProduceResponse(Map<TopicPartition, PartitionResponse> responses) {
* @param responses Produced data grouped by topic-partition
* @param throttleTimeMs Time in milliseconds the response was throttled
*/
+ @Deprecated
public ProduceResponse(Map<TopicPartition, PartitionResponse> responses, int throttleTimeMs) {
- this.responses = responses;
- this.throttleTimeMs = throttleTimeMs;
+ this(toData(responses, throttleTimeMs));
}
- /**
- * Constructor from a {@link Struct}.
- */
- public ProduceResponse(Struct struct) {
- responses = new HashMap<>();
- for (Object topicResponse : struct.getArray(RESPONSES_KEY_NAME)) {
- Struct topicRespStruct = (Struct) topicResponse;
- String topic = topicRespStruct.get(TOPIC_NAME);
-
- for (Object partResponse : topicRespStruct.getArray(PARTITION_RESPONSES_KEY_NAME)) {
- Struct partRespStruct = (Struct) partResponse;
- int partition = partRespStruct.get(PARTITION_ID);
- Errors error = Errors.forCode(partRespStruct.get(ERROR_CODE));
- long offset = partRespStruct.getLong(BASE_OFFSET_KEY_NAME);
- long logAppendTime = partRespStruct.hasField(LOG_APPEND_TIME_KEY_NAME) ?
- partRespStruct.getLong(LOG_APPEND_TIME_KEY_NAME) : RecordBatch.NO_TIMESTAMP;
- long logStartOffset = partRespStruct.getOrElse(LOG_START_OFFSET_FIELD, INVALID_OFFSET);
-
- List<RecordError> recordErrors = Collections.emptyList();
- if (partRespStruct.hasField(RECORD_ERRORS_KEY_NAME)) {
- Object[] recordErrorsArray = partRespStruct.getArray(RECORD_ERRORS_KEY_NAME);
- if (recordErrorsArray.length > 0) {
- recordErrors = new ArrayList<>(recordErrorsArray.length);
- for (Object indexAndMessage : recordErrorsArray) {
- Struct indexAndMessageStruct = (Struct) indexAndMessage;
- recordErrors.add(new RecordError(
- indexAndMessageStruct.getInt(BATCH_INDEX_KEY_NAME),
- indexAndMessageStruct.get(BATCH_INDEX_ERROR_MESSAGE_FIELD)
- ));
- }
- }
- }
+ @Override
+ protected Send toSend(String destination, ResponseHeader header, short apiVersion) {
+ return SendBuilder.buildResponseSend(destination, header, this.data, apiVersion);
+ }
- String errorMessage = partRespStruct.getOrElse(ERROR_MESSAGE_FIELD, null);
- TopicPartition tp = new TopicPartition(topic, partition);
- responses.put(tp, new PartitionResponse(error, offset, logAppendTime, logStartOffset, recordErrors, errorMessage));
+ private static ProduceResponseData toData(Map<TopicPartition, PartitionResponse> responses, int throttleTimeMs) {
+ ProduceResponseData data = new ProduceResponseData().setThrottleTimeMs(throttleTimeMs);
+ responses.forEach((tp, response) -> {
+ ProduceResponseData.TopicProduceResponse tpr = data.responses().find(tp.topic());
+ if (tpr == null) {
+ tpr = new ProduceResponseData.TopicProduceResponse().setName(tp.topic());
+ data.responses().add(tpr);
}
- }
- this.throttleTimeMs = struct.getOrElse(THROTTLE_TIME_MS, DEFAULT_THROTTLE_TIME);
+ tpr.partitionResponses()
+ .add(new ProduceResponseData.PartitionProduceResponse()
+ .setIndex(tp.partition())
+ .setBaseOffset(response.baseOffset)
+ .setLogStartOffset(response.logStartOffset)
+ .setLogAppendTimeMs(response.logAppendTime)
+ .setErrorMessage(response.errorMessage)
+ .setErrorCode(response.error.code())
+ .setRecordErrors(response.recordErrors
+ .stream()
+ .map(e -> new ProduceResponseData.BatchIndexAndErrorMessage()
+ .setBatchIndex(e.batchIndex)
+ .setBatchIndexErrorMessage(e.message))
+ .collect(Collectors.toList())));
Review comment:
nit: Should we remove this usage of the stream api here as well?
##########
File path: clients/src/test/java/org/apache/kafka/common/requests/ProduceRequestTest.java
##########
@@ -192,16 +258,21 @@ public void testMixedTransactionalData() {
final MemoryRecords txnRecords = MemoryRecords.withTransactionalRecords(CompressionType.NONE, producerId,
producerEpoch, sequence, new SimpleRecord("bar".getBytes()));
- final Map<TopicPartition, MemoryRecords> recordsByPartition = new LinkedHashMap<>();
- recordsByPartition.put(new TopicPartition("foo", 0), txnRecords);
- recordsByPartition.put(new TopicPartition("foo", 1), nonTxnRecords);
-
- final ProduceRequest.Builder builder = ProduceRequest.Builder.forMagic(RecordVersion.current().value, (short) -1, 5000,
- recordsByPartition, transactionalId);
+ ProduceRequest.Builder builder = ProduceRequest.forMagic(RecordBatch.CURRENT_MAGIC_VALUE,
+ new ProduceRequestData()
+ .setTopicData(new ProduceRequestData.TopicProduceDataCollection(Arrays.asList(
+ new ProduceRequestData.TopicProduceData().setName("foo").setPartitionData(Collections.singletonList(
+ new ProduceRequestData.PartitionProduceData().setIndex(0).setRecords(txnRecords))),
+ new ProduceRequestData.TopicProduceData().setName("foo").setPartitionData(Collections.singletonList(
+ new ProduceRequestData.PartitionProduceData().setIndex(1).setRecords(nonTxnRecords))))
+ .iterator()))
+ .setAcks((short) 1)
+ .setTimeoutMs(5000)
+ .setTransactionalId(null));
Review comment:
We were setting `transactionalId` previously.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r526252595
##########
File path: clients/src/main/resources/common/message/ProduceRequest.json
##########
@@ -33,21 +33,21 @@
"validVersions": "0-8",
"flexibleVersions": "none",
"fields": [
- { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "0+", "entityType": "transactionalId",
+ { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "3+", "default": "null", "entityType": "transactionalId",
Review comment:
Hmm I don't think it should be ignorable. The request would just fail if we drop it.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r526309208
##########
File path: clients/src/main/resources/common/message/ProduceRequest.json
##########
@@ -33,21 +33,21 @@
"validVersions": "0-8",
"flexibleVersions": "none",
"fields": [
- { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "0+", "entityType": "transactionalId",
+ { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "3+", "default": "null", "ignorable": true, "entityType": "transactionalId",
Review comment:
The previous code probably relied on the range checking of the message format to imply support here. My point is that the request is doomed to fail if it holds transactional data and we drop the transactionalId. So we may as well fail fast.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 edited a comment on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 edited a comment on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728812062
@hachikuji @ijuma It seems to me the root cause of regression is caused by the conversion between old data struct and auto-generated protocol. As we all care for performance, I address more improvements (they were viewed as follow-up before) in this PR.
There are 5 possible improvements.
1. - [x] git rid of struct allocation (thanks to @hachikuji)
1. - [x] rewrite RequestUtils.hasTransactionalRecords & RequestUtils.hasIdempotentRecords to avoid duplicate loop and record instantiation (thanks to @hachikuji)
1. - [x] Sender#sendProduceRequest should use auto-generated protocol directly (thanks to @dajac)
1. - [ ] [client side] Replace ProduceResponse.PartitionResponse by auto-generated PartitionProduceResponse (https://issues.apache.org/jira/browse/KAFKA-10709)
1. - [ ] [server side] KafkaApis#handleProduceRequest should use auto-generated protocol (https://issues.apache.org/jira/browse/KAFKA-10730)
The recent commits include only 1, 2, and 3 since they touch fewer code. I also re-run all perf tests ~and all tests cases show better throughput with current PR even though 4. and 5. are not included.~
Most of test cases show good improvements. By the contrast, the other tests (single partition + single producer) get either insignificant improvement or small regression. However, it seems to me they can get good improvement by remaining improvement (4 and 5)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 edited a comment on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 edited a comment on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728812062
@hachikuji @ijuma It seems to me the root cause of regression is caused by the conversion between old data struct and auto-generated protocol. As we all care for performance, I address more improvements (they were viewed as follow-up before) in this PR.
There are 5 possible improvements.
1. - [x] git rid of struct allocation (thanks to @hachikuji)
1. - [x] rewrite RequestUtils.hasTransactionalRecords & RequestUtils.hasIdempotentRecords to avoid duplicate loop and record instantiation (thanks to @hachikuji)
1. - [x] Sender#sendProduceRequest should use auto-generated protocol directly (thanks to @dajac)
1. - [ ] [client side] Replace ProduceResponse.PartitionResponse by auto-generated PartitionProduceResponse (https://issues.apache.org/jira/browse/KAFKA-10709)
1. - [ ] [server side] KafkaApis#handleProduceRequest should use auto-generated protocol (https://issues.apache.org/jira/browse/KAFKA-10730)
The recent commits include only 1, 2, and 3 since they touch fewer code. I also re-run all perf tests ~and all tests cases show better throughput with current PR even though 4. and 5. are not included.~
Most of test cases show good improvements. By the contrast, the other tests (single partition + single producer) get either insignificant improvement or small regression. However, it seems to me they can get good benefited by remaining improvement (4 and 5)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 edited a comment on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 edited a comment on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728812062
@hachikuji @ijuma It seems to me the root cause of regression is caused by the conversion between old data struct and auto-generated protocol. As we all care for performance, I address more improvements (they were viewed as follow-up before) in this PR.
There are 5 possible improvements.
1. - [x] git rid of struct allocation (thanks to @hachikuji)
1. - [x] rewrite RequestUtils.hasTransactionalRecords & RequestUtils.hasIdempotentRecords to avoid duplicate loop and record instantiation (thanks to @hachikuji)
1. - [x] Sender#sendProduceRequest should use auto-generated protocol directly (thanks to @dajac)
1. - [ ] [client side] Replace ProduceResponse.PartitionResponse by auto-generated PartitionProduceResponse (https://issues.apache.org/jira/browse/KAFKA-10709)
1. - [ ] [server side] KafkaApis#handleProduceRequest should use auto-generated protocol (https://issues.apache.org/jira/browse/KAFKA-10730)
The recent commits include only 1, 2, and 3 since they touch fewer code. I also re-run all perf tests ~and all tests cases show better throughput with current PR even though 4. and 5. are not included.~
Most of test cases show good improvements. By the contrast, the other tests (single partition + single producer) get insignificant improvement. However, it seems to me they can get good benefited by remaining improvement (4 and 5)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728486374
Yeah, there is something strange going on, especially in regard to latency. Running the same producer performance test, I saw the following:
```
Patch:
250000000 records sent, 1347222.297068 records/sec (328.91 MB/sec), 91.98 ms avg latency, 1490.00 ms max latency, 71 ms 50th, 242 ms 95th, 320 ms 99th, 728 ms 99.9th.
Trunk:
250000000 records sent, 1426264.954388 records/sec (348.21 MB/sec), 15.11 ms avg latency, 348.00 ms max latency, 3 ms 50th, 94 ms 95th, 179 ms 99th, 265 ms 99.9th.
```
I was able to reproduce similar results several times. Take this with a grain of salt, but from the flame graphs, I see the following differences:
`RequestContext.parseRequest`: 1% -> 0.45%
`RequestUtils.hasTransactionalRecords`: 0% -> 0.59%
`RequestUtils.hasIdempotentRecords`: 0% -> 0.14%
`KafkaApis.sendResponseCallback`: 3.20% -> 2.33%
`KafkaApis.clearPartitionRecords`: 0% -> 0.16%
I think `hasTransactionalRecords` and `hasIdempotentRecords` are the most obvious optimization targets (they also show up in allocations), but I do not think they explain the increase in latency. Just to be sure, I commented out these lines and I got similar results.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r519250823
##########
File path: clients/src/main/java/org/apache/kafka/clients/producer/internals/Sender.java
##########
@@ -560,13 +561,23 @@ private void handleProduceResponse(ClientResponse response, Map<TopicPartition,
log.trace("Received produce response from node {} with correlation id {}", response.destination(), correlationId);
// if we have a response, parse it
if (response.hasResponse()) {
+ // TODO: Sender should exercise PartitionProduceResponse rather than ProduceResponse.PartitionResponse
Review comment:
https://issues.apache.org/jira/browse/KAFKA-10696
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r526190510
##########
File path: clients/src/test/java/org/apache/kafka/common/requests/RequestResponseTest.java
##########
@@ -1730,7 +1768,6 @@ private DeleteTopicsResponse createDeleteTopicsResponse() {
private InitProducerIdRequest createInitPidRequest() {
InitProducerIdRequestData requestData = new InitProducerIdRequestData()
- .setTransactionalId(null)
Review comment:
thanks!!!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r526260184
##########
File path: clients/src/main/resources/common/message/ProduceRequest.json
##########
@@ -33,21 +33,21 @@
"validVersions": "0-8",
"flexibleVersions": "none",
"fields": [
- { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "0+", "entityType": "transactionalId",
+ { "name": "TransactionalId", "type": "string", "versions": "3+", "nullableVersions": "3+", "default": "null", "ignorable": true, "entityType": "transactionalId",
Review comment:
I don't think it should be ignorable. Transactional requests require this in order to authorize.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r519079153
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceRequest.java
##########
@@ -194,7 +107,27 @@ private ProduceRequest build(short version, boolean validate) {
ProduceRequest.validateRecords(version, records);
}
}
- return new ProduceRequest(version, acks, timeout, partitionRecords, transactionalId);
+
+ List<ProduceRequestData.TopicProduceData> tpd = partitionRecords
Review comment:
Right. I thought we might consider computing it just before the data gets cleared.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728664200
@hachikuji @ijuma Thanks for all feedback. I'm going to do more tests :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] ijuma commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
ijuma commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728531187
That is really weird. The difference seems significant enough that we need to understand it better before we can merge IMO.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] ijuma commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
ijuma commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728385188
Nice! So what's the reason for the small regression in the PR description?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r522005653
##########
File path: clients/src/main/java/org/apache/kafka/common/requests/ProduceResponse.java
##########
@@ -204,118 +75,79 @@ public ProduceResponse(Map<TopicPartition, PartitionResponse> responses) {
* @param throttleTimeMs Time in milliseconds the response was throttled
*/
public ProduceResponse(Map<TopicPartition, PartitionResponse> responses, int throttleTimeMs) {
- this.responses = responses;
- this.throttleTimeMs = throttleTimeMs;
+ this(new ProduceResponseData()
+ .setResponses(responses.entrySet()
Review comment:
> It may be worth trying different implementation to compare their performances.
As we all care for performance, I'm ok to say goodbye to stream api :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-728643380
I think the large difference in latency in my test is due to the producer's buffer pool getting exhausted. I was looking at the "bufferpool-wait-ratio" metric exposed in the producer. With this patch, it was hovering around 0.6 while on trunk it remained around 0.01. I'll need to lower the throughput a little bit in order to get a better estimate of the regression.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
hachikuji commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-729081330
@chia7712 Thanks for the updates, looks promising. I'm more inclined to trust your results on linux. I have been testing on macos. Let me see if I can reproduce in a better environment and then we're probably good to go.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-709709526
@hachikuji Could you please take a look?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] lbradstreet commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
lbradstreet commented on pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#issuecomment-721201536
@chia7712 @hachikuji for the ProduceResponse handling, is this the overall broker side regression since you need both the construction and toStruct?
```
construction regression: 3.293 -> 580.099 ns/op
toStruct improvement: 825.889 -> 318.530 ns/op
overall response: 3.293+825.889 (old) = 829.182 vs 898.629 (new)
```
Could you please also provide an analysis of the garbage generation using `gc.alloc.rate.norm`?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r519251328
##########
File path: core/src/main/scala/kafka/server/KafkaApis.scala
##########
@@ -517,19 +517,23 @@ class KafkaApis(val requestChannel: RequestChannel,
}
// Note that authorization to a transactionalId implies ProducerId authorization
- } else if (produceRequest.hasIdempotentRecords && !authorize(request.context, IDEMPOTENT_WRITE, CLUSTER, CLUSTER_NAME)) {
+ } else if (RequestUtils.hasIdempotentRecords(produceRequest) && !authorize(request.context, IDEMPOTENT_WRITE, CLUSTER, CLUSTER_NAME)) {
sendErrorResponseMaybeThrottle(request, Errors.CLUSTER_AUTHORIZATION_FAILED.exception)
return
}
- val produceRecords = produceRequest.partitionRecordsOrFail.asScala
val unauthorizedTopicResponses = mutable.Map[TopicPartition, PartitionResponse]()
val nonExistingTopicResponses = mutable.Map[TopicPartition, PartitionResponse]()
val invalidRequestResponses = mutable.Map[TopicPartition, PartitionResponse]()
val authorizedRequestInfo = mutable.Map[TopicPartition, MemoryRecords]()
- val authorizedTopics = filterByAuthorized(request.context, WRITE, TOPIC, produceRecords)(_._1.topic)
-
- for ((topicPartition, memoryRecords) <- produceRecords) {
+ val authorizedTopics = filterByAuthorized(request.context, WRITE, TOPIC, produceRequest.dataOrException().topicData().asScala)(_.topic())
+
+ produceRequest.dataOrException().topicData().forEach(topic => topic.data().forEach { partition =>
+ val topicPartition = new TopicPartition(topic.topic(), partition.partition())
+ // This caller assumes the type is MemoryRecords and that is true on current serialization
+ // We cast the type to avoid causing big change to code base.
+ // TODO: maybe we need to refactor code to avoid this casting
Review comment:
https://issues.apache.org/jira/browse/KAFKA-10698
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] dajac commented on a change in pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
Posted by GitBox <gi...@apache.org>.
dajac commented on a change in pull request #9401:
URL: https://github.com/apache/kafka/pull/9401#discussion_r526179984
##########
File path: clients/src/main/java/org/apache/kafka/clients/producer/internals/TransactionManager.java
##########
@@ -580,7 +580,6 @@ synchronized void bumpIdempotentEpochAndResetIdIfNeeded() {
if (currentState != State.INITIALIZING && !hasProducerId()) {
transitionTo(State.INITIALIZING);
InitProducerIdRequestData requestData = new InitProducerIdRequestData()
- .setTransactionalId(null)
Review comment:
We should keep this one as well.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org