You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by "gamblewin (via GitHub)" <gi...@apache.org> on 2023/03/21 15:46:12 UTC
[GitHub] [hudi] gamblewin opened a new issue, #8260: [SUPPORT] How to implement incremental join
gamblewin opened a new issue, #8260:
URL: https://github.com/apache/hudi/issues/8260
- Problem
Now I want to do a poc on hudi with flinksql. That is I have table A and table B, and I join table A and table B to get a new table C. Now when I make changes to base table(table A or table B), how to make table C auto update?
- Example
1 create table hudi_patient
```sql
create table hudi_patient(
id bigint,
name String,
PRIMARY KEY (`id`) NOT ENFORCED
)
with(
'connector'='hudi',
'path'='/Users/gamblewin/hudi/hudi_patient',
'hoodie.datasource.write.recordkey.field'='id',
'hoodie.parquet.max.file.size'='268435456',
'hoodie.datasource.write.recordkey.field'='id',
'changelog.enabled'='true',
'table.type'='COPY_ON_WRITE'
);
```
2 insert data into hudi_patient
```sql
insert into hudi_patient(id, name) VALUES(1, 'otis');
```
3 create table hudi_disease
```sql
create table hudi_disease(
id bigint,
disease_name String,
PRIMARY KEY (`id`) NOT ENFORCED
)
with(
'connector'='hudi',
'path'='/Users/gamblewin/hudi/hudi_disease',
'hoodie.datasource.write.recordkey.field'='id',
'hoodie.parquet.max.file.size'='268435456',
'hoodie.datasource.write.recordkey.field'='id',
'table.type'='COPY_ON_WRITE'
);
```
4 insert data into hudi_disease
```sql
insert into hudi_disease(id, disease_name) VALUES (1, 'headache');
```
5 create a join table hudi_pat_disease
```sql
create table hudi_pat_disease(
id BIGINT,
name STRING,
disease_name STRING,
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector'='hudi',
'path'='/Users/gamblewin/hudi/hudi_pat_diesease',
'hoodie.datasource.write.recordkey.field'='id',
'hoodie.parquet.max.file.size'='268435456',
'hoodie.datasource.write.recordkey.field'='id',
'changelog.enabled'='true',
'table.type'='COPY_ON_WRITE'
)
```
6 insert join data into hudi_pat_disease
```sql
insert into hudi_pat_disease
select
hudi_patient.id as id,
hudi_patient.name as name,
hudi_disease.disease_name as disease_name
from
hudi_patient
left join
hudi_disease
on
hudi_patient.id = hudi_disease.id;
```
7 now I can get data `1 otis headache` from `hudi_pat_disease`,
but when I `insert into hudi_patient(id, name) VALUES (2, 'gamblewin`),
I expect a new record `2, gambelwin, NULL` from table `hudi_pat_disease`,
but `hudi_pat_disease` will not automatically update this record based on changes of `hudi_patient`,
so how does hudi implement this auto incremental functionality.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] gamblewin commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "gamblewin (via GitHub)" <gi...@apache.org>.
gamblewin commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1479105251
> please follow my code snippets :D
@soumishah1995 thx for replying, I've read your code and watched the tutorial video, they are really detailed and intriguing. However, the POC I'm doing might be a little bit different.
What I'm trying to test is join two hudi tables to get a wide hudi table, when hudi base tables change, how does hudi join table capture those changes of hudi base tables and auto update?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] gamblewin commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "gamblewin (via GitHub)" <gi...@apache.org>.
gamblewin commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1478377153
I find that all of the insert operation I did is one-time operation in flink, which means after inserting data, the task will end, so the final join table `hudi_pat_disease` will not auto update according to changes of base table.
So how can I make `insert into hudi_pat_disease` as a consistently running streaming job, which means once base table changes, final join table will capture those changes and auto update itself.
I wonder if this is related to payload setting?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1478618985
please follow my code snippets :D
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1488906484
What I demonstrated in the video was for Spark, not Flink, and I'm not sure how Flink CDC :D .
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1483022972
what do you think does this solve your issue ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] gamblewin commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "gamblewin (via GitHub)" <gi...@apache.org>.
gamblewin commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1488904448
ah oh, there is a new mistake. So recently I try to use `Flink-1.13.6` write data into `Hudi-0.13.0`, and when I add these two options to hudi table (cuz according to ur video, this is the way to get delta info from a COW table):
`'hoodie.table.cdc.enabled'='true',
'hoodie.table.cdc.supplemental.logging.mode'='data_befor_after'`,
then I get following mistake:
```java
2023-03-28 17:28:38,187 WARN org.apache.flink.table.client.cli.CliClient [] - Could not execute SQL statement.
org.apache.flink.table.client.gateway.SqlExecutionException: Could not execute SQL statement.
at org.apache.flink.table.client.gateway.local.LocalExecutor.executeModifyOperations(LocalExecutor.java:228) ~[flink-sql-client_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.client.cli.CliClient.callInserts(CliClient.java:518) ~[flink-sql-client_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.client.cli.CliClient.callInsert(CliClient.java:507) ~[flink-sql-client_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.client.cli.CliClient.callOperation(CliClient.java:409) ~[flink-sql-client_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.client.cli.CliClient.lambda$executeStatement$0(CliClient.java:327) [flink-sql-client_2.12-1.13.6.jar:1.13.6]
at java.util.Optional.ifPresent(Optional.java:159) ~[?:1.8.0_331]
at org.apache.flink.table.client.cli.CliClient.executeStatement(CliClient.java:327) [flink-sql-client_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.client.cli.CliClient.executeInteractive(CliClient.java:297) [flink-sql-client_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.client.cli.CliClient.executeInInteractiveMode(CliClient.java:221) [flink-sql-client_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.client.SqlClient.openCli(SqlClient.java:151) [flink-sql-client_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.client.SqlClient.start(SqlClient.java:95) [flink-sql-client_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.client.SqlClient.startClient(SqlClient.java:187) [flink-sql-client_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.client.SqlClient.main(SqlClient.java:161) [flink-sql-client_2.12-1.13.6.jar:1.13.6]
Caused by: org.apache.flink.table.api.TableException: Failed to execute sql
at org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:777) ~[flink-table-blink_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:742) ~[flink-table-blink_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.client.gateway.local.LocalExecutor.lambda$executeModifyOperations$4(LocalExecutor.java:226) ~[flink-sql-client_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.client.gateway.context.ExecutionContext.wrapClassLoader(ExecutionContext.java:90) ~[flink-sql-client_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.client.gateway.local.LocalExecutor.executeModifyOperations(LocalExecutor.java:226) ~[flink-sql-client_2.12-1.13.6.jar:1.13.6]
... 12 more
Caused by: org.apache.flink.util.FlinkException: Failed to execute job 'insert-into_default_catalog.default_database.hudi_patient_cow'.
at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.executeAsync(StreamExecutionEnvironment.java:1969) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.planner.delegation.ExecutorBase.executeAsync(ExecutorBase.java:55) ~[flink-table-blink_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:759) ~[flink-table-blink_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:742) ~[flink-table-blink_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.client.gateway.local.LocalExecutor.lambda$executeModifyOperations$4(LocalExecutor.java:226) ~[flink-sql-client_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.client.gateway.context.ExecutionContext.wrapClassLoader(ExecutionContext.java:90) ~[flink-sql-client_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.table.client.gateway.local.LocalExecutor.executeModifyOperations(LocalExecutor.java:226) ~[flink-sql-client_2.12-1.13.6.jar:1.13.6]
... 12 more
Caused by: java.lang.RuntimeException: Error while waiting for job to be initialized
at org.apache.flink.client.ClientUtils.waitUntilJobInitializationFinished(ClientUtils.java:160) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.client.deployment.executors.AbstractSessionClusterExecutor.lambda$execute$2(AbstractSessionClusterExecutor.java:82) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.util.function.FunctionUtils.lambda$uncheckedFunction$2(FunctionUtils.java:73) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:616) ~[?:1.8.0_331]
at java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:591) ~[?:1.8.0_331]
at java.util.concurrent.CompletableFuture$Completion.exec(CompletableFuture.java:457) ~[?:1.8.0_331]
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289) ~[?:1.8.0_331]
at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1067) ~[?:1.8.0_331]
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1703) ~[?:1.8.0_331]
at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:172) ~[?:1.8.0_331]
Caused by: java.util.concurrent.ExecutionException: org.apache.flink.runtime.concurrent.FutureUtils$RetryException: Could not complete the operation. Number of retries has been exhausted.
at java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357) ~[?:1.8.0_331]
at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1908) ~[?:1.8.0_331]
at org.apache.flink.client.deployment.executors.AbstractSessionClusterExecutor.lambda$null$0(AbstractSessionClusterExecutor.java:83) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.client.ClientUtils.waitUntilJobInitializationFinished(ClientUtils.java:144) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.client.deployment.executors.AbstractSessionClusterExecutor.lambda$execute$2(AbstractSessionClusterExecutor.java:82) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.util.function.FunctionUtils.lambda$uncheckedFunction$2(FunctionUtils.java:73) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:616) ~[?:1.8.0_331]
at java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:591) ~[?:1.8.0_331]
at java.util.concurrent.CompletableFuture$Completion.exec(CompletableFuture.java:457) ~[?:1.8.0_331]
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289) ~[?:1.8.0_331]
at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1067) ~[?:1.8.0_331]
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1703) ~[?:1.8.0_331]
at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:172) ~[?:1.8.0_331]
Caused by: org.apache.flink.runtime.concurrent.FutureUtils$RetryException: Could not complete the operation. Number of retries has been exhausted.
at org.apache.flink.runtime.concurrent.FutureUtils.lambda$retryOperationWithDelay$9(FutureUtils.java:386) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774) ~[?:1.8.0_331]
at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750) ~[?:1.8.0_331]
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488) ~[?:1.8.0_331]
at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1990) ~[?:1.8.0_331]
at org.apache.flink.runtime.rest.RestClient.lambda$submitRequest$1(RestClient.java:430) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.DefaultPromise.notifyListener0(DefaultPromise.java:577) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.DefaultPromise.notifyListeners0(DefaultPromise.java:570) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.DefaultPromise.notifyListenersNow(DefaultPromise.java:549) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.DefaultPromise.notifyListeners(DefaultPromise.java:490) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.DefaultPromise.setValue0(DefaultPromise.java:615) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.DefaultPromise.setFailure0(DefaultPromise.java:608) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.DefaultPromise.tryFailure(DefaultPromise.java:117) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.fulfillConnectPromise(AbstractNioChannel.java:321) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.finishConnect(AbstractNioChannel.java:337) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:702) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:650) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:576) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:493) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:989) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at java.lang.Thread.run(Thread.java:750) ~[?:1.8.0_331]
Caused by: java.util.concurrent.CompletionException: org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannel$AnnotatedConnectException: Connection refused: /192.168.100.253:60728
at java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:292) ~[?:1.8.0_331]
at java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:308) ~[?:1.8.0_331]
at java.util.concurrent.CompletableFuture.uniCompose(CompletableFuture.java:957) ~[?:1.8.0_331]
at java.util.concurrent.CompletableFuture$UniCompose.tryFire(CompletableFuture.java:940) ~[?:1.8.0_331]
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488) ~[?:1.8.0_331]
at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1990) ~[?:1.8.0_331]
at org.apache.flink.runtime.rest.RestClient.lambda$submitRequest$1(RestClient.java:430) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.DefaultPromise.notifyListener0(DefaultPromise.java:577) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.DefaultPromise.notifyListeners0(DefaultPromise.java:570) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.DefaultPromise.notifyListenersNow(DefaultPromise.java:549) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.DefaultPromise.notifyListeners(DefaultPromise.java:490) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.DefaultPromise.setValue0(DefaultPromise.java:615) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.DefaultPromise.setFailure0(DefaultPromise.java:608) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.DefaultPromise.tryFailure(DefaultPromise.java:117) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.fulfillConnectPromise(AbstractNioChannel.java:321) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.finishConnect(AbstractNioChannel.java:337) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:702) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:650) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:576) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:493) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:989) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at java.lang.Thread.run(Thread.java:750) ~[?:1.8.0_331]
Caused by: org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannel$AnnotatedConnectException: Connection refused: /192.168.100.253:60728
Caused by: java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) ~[?:1.8.0_331]
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:715) ~[?:1.8.0_331]
at org.apache.flink.shaded.netty4.io.netty.channel.socket.nio.NioSocketChannel.doFinishConnect(NioSocketChannel.java:330) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.finishConnect(AbstractNioChannel.java:334) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:702) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:650) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:576) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:493) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:989) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at org.apache.flink.shaded.netty4.io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74) ~[flink-dist_2.12-1.13.6.jar:1.13.6]
at java.lang.Thread.run(Thread.java:750) ~[?:1.8.0_331]
```
But if I don't add these two options when creating hudi table, I can successfully insert data.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] gamblewin commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "gamblewin (via GitHub)" <gi...@apache.org>.
gamblewin commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1488919062
> What I demonstrated in the video was for Spark, not Flink, and I'm not sure how Flink CDC :D .
Cuz hudi-0.13.0 still uses hadoop2 dependency, so I have to change pom.xml and compile hudi-0.13.0 by myself.
However, when I change hive dependency version to 3.1.3, compilation failed. Then I have to change some source codes of hudi-0.13.0, so I don't know whether the current mistake has something todo with the change or src code.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] gamblewin commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "gamblewin (via GitHub)" <gi...@apache.org>.
gamblewin commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1483880124
> Q Can I get changelog from COW table or is there any way to catch data change info from COW table?
>
> #### Answer:
> ##### Hudi announced CDC RFC 51
> * Attaching some references which may help you
>
> RFC-51 Change Data Capture in Apache Hudi like Debezium and AWS DMS Hands on Labs https://www.youtube.com/watch?v=n6D_es6RmHM&t=5s
>
> Power your Down Stream ElasticSearch Stack From Apache Hudi Transaction Datalake with CDC|Demo Video https://www.youtube.com/watch?v=rr2V5xhgPeM&t=25s
>
> Despite my limited experience with Flink, I am certain that Spark will work just as well. I've used Flink for streaming joins, but I haven't yet used it for incremental data or CDC events.
thx so much, I will watch these.
Actually I wonder if I have to use Spark or Flink to read delta data and perform INC join operations and upsert operation, what does hudi actually offer in this scenario, just offer Spark and Flink some delta data? If this is true, then mysql binlog can do the same thing, I'm just not sure if I have some misunderstandings about the capabilities of Hudi.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] kazdy commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "kazdy (via GitHub)" <gi...@apache.org>.
kazdy commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1478615373
@soumilshah1995 I think you did some work on incremental joins with hudi and flink?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1479404643
so what you need to do is read data INC from a Source and then perform left outer join with RAW source
i have template for reading INC data in Spark
https://github.com/soumilshah1995/An-easy-to-use-Python-utility-class-for-accessing-incremental-data-from-Hudi-Data-Lakes
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1478616922
Yes i have done streaming ETL with Flink

REPO https://github.com/soumilshah1995/dynamodb-streaming-etl-kinesis-
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1483881585
I'm not sure if I get your query completely, however RFC 51 gives you a means to access changes occurring on your data lake.
INSERT | UPDATE | DELETE example You can power your downstream pipeline by capturing these CDC events. Well, let me say that it's similar to Debezium, giving you access to all Datalake modifications.
However, based on the diagram you provided and what I have read so far, I would conclude that your main goal is to obtain changes that have occurred in your Transactional Data Lake, query them incrementally, and conduct left outer join with RAW source.
Actually, once I have some free time, I plan to try these architectural designs; they are on my list of things to do.
I'm happy to connect with you on Slack and talk more with you on the Hudi Slack channel. :D
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1483881419
I'm not sure if I get your query completely, however RFC 51 gives you a means to access changes occurring on your data lake.
INSERT | UPDATE | DELETE example You can power your downstream pipeline by capturing these CDC events. Well, let me say that it's similar to Debezium, giving you access to all Datalake modifications.
However, based on the diagram you provided and what I have read so far, I would conclude that your main goal is to obtain changes that have occurred in your Transactional Data Lake, query them incrementally, and conduct left outer join with RAW source.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] gamblewin commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "gamblewin (via GitHub)" <gi...@apache.org>.
gamblewin commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1488910706
> What I demonstrated in the video was for Spark, not Flink, and I'm not sure how Flink CDC :D .
Yeah, I see.
One more question, do u use official hudi-0.13.0 jar or u compile hudi-0.13.0 by yourself.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1479382946
Hi
so i have done work in past on INC query a lot. i have done using Spark and not FLink
are you seeking advice for Flink ?
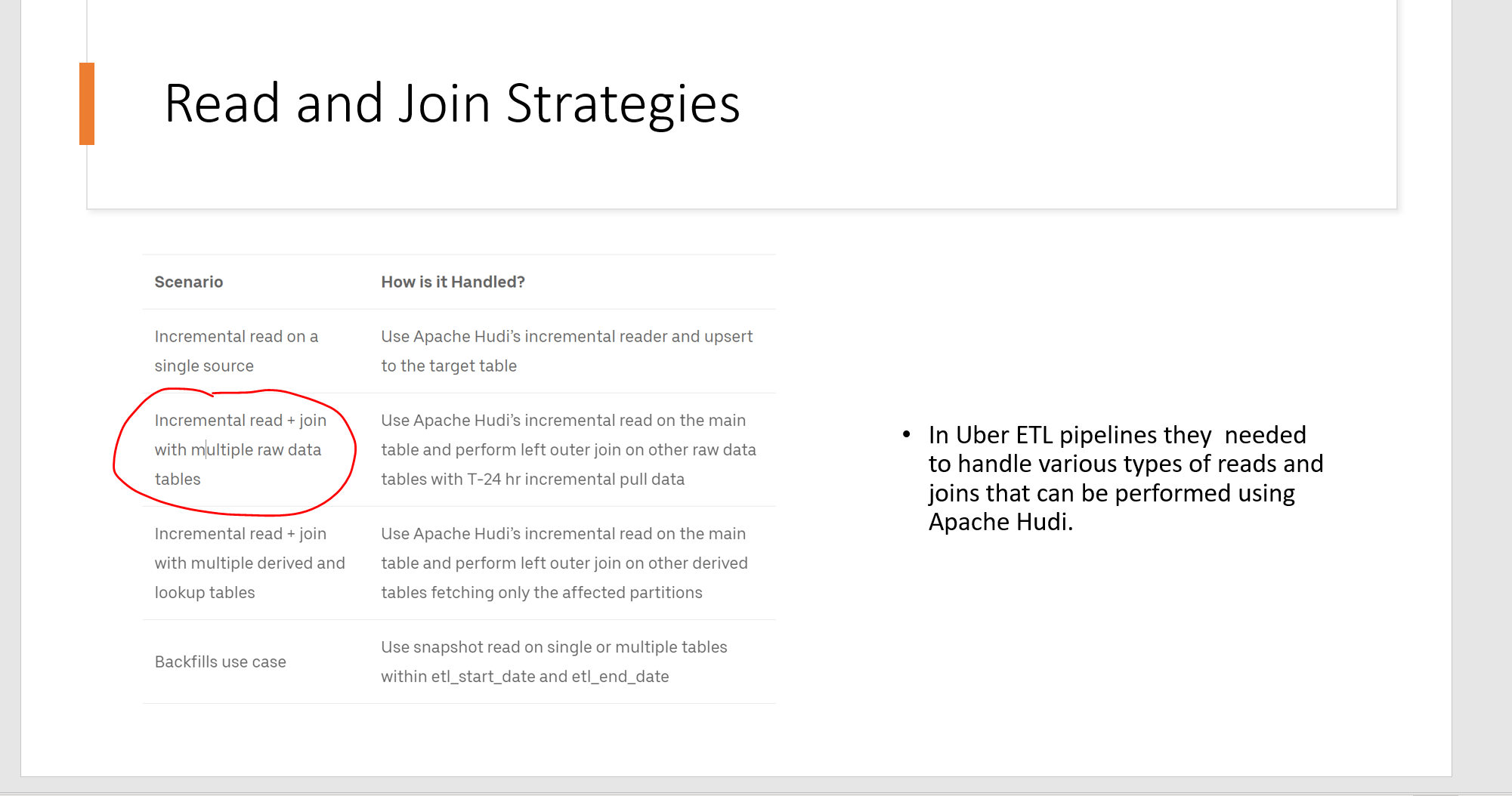
are you following scenarios 2 ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1484085562
i am going to try these out
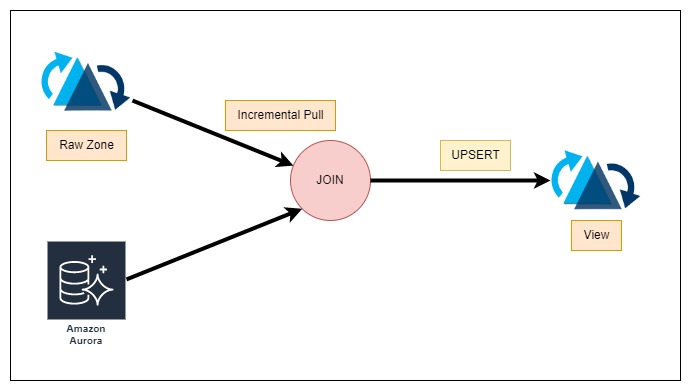
i will incrementally pull data from hudi and then perform join on aurora table and then build a view
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] gamblewin commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "gamblewin (via GitHub)" <gi...@apache.org>.
gamblewin commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1483873637
> what do you think does this solve your issue ?
sry, it's been really busy lately, thx so much for your help again.
yeah, I want to use Flink to catch changed data from hudi raw table and perform INC join on these changed data and upsert INC join result into the wide hudi table.
Actually, The scenario I want to test is same as the one shown in the image below.
<img width="712" alt="image" src="https://user-images.githubusercontent.com/39117591/227730611-2548d069-75a6-47fa-8939-8bf7314c005f.png">
For now, I have a few questions about hudi:
1. Can I get changelog from COW table or is there any way to catch data change info from COW table?
2. If I want to get data change info from a MOR table, is there any differences between using timestamp and using changelog?
3. Now back to the scenario I want to test, so the possible way is:
- Use Flink to get delta data from hudi raw dataset
- Use Flink to perform join operation on these delta data
- Then upsert INC join result into hudi wide table?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1483874807
Q Can I get changelog from COW table or is there any way to catch data change info from COW table?
#### Answer:
##### Hudi announced CDC RFC 51
* Attaching some references which may help you
RFC-51 Change Data Capture in Apache Hudi like Debezium and AWS DMS Hands on Labs
https://www.youtube.com/watch?v=n6D_es6RmHM&t=5s
Power your Down Stream ElasticSearch Stack From Apache Hudi Transaction Datalake with CDC|Demo Video
https://www.youtube.com/watch?v=rr2V5xhgPeM&t=25s
Despite my limited experience with Flink, I am certain that Spark will work just as well. I've used Flink for streaming joins, but I haven't yet used it for incremental data or CDC events.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] gamblewin commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "gamblewin (via GitHub)" <gi...@apache.org>.
gamblewin commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1484166820
> i am going to try these out 
>
> i will incrementally pull data from hudi and then perform join on aurora table and then build a view
oki, I wonder whether this upsert operation has something to do with hudi payload mechanism?
And btw, really appreciate ur help of sending me RFC-51, it helped me a lot. Now I'm trying to use FLINK to capture data change info from COW table.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8260: [SUPPORT] How to implement incremental join
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8260:
URL: https://github.com/apache/hudi/issues/8260#issuecomment-1486890768
Thanks let me know if i can provide any other details or information
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org