You are viewing a plain text version of this content. The canonical link for it is here.
Posted to dev@uniffle.apache.org by GitBox <gi...@apache.org> on 2023/01/19 06:35:41 UTC
[GitHub] [incubator-uniffle] zuston opened a new issue, #503: [Bug] Frequent and long lasting full GCs when there are too many partitions on a shuffle server
zuston opened a new issue, #503:
URL: https://github.com/apache/incubator-uniffle/issues/503
### Code of Conduct
- [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct)
### Search before asking
- [X] I have searched in the [issues](https://github.com/apache/incubator-uniffle/issues?q=is%3Aissue) and found no similar issues.
### Describe the bug
I found the full GC occurs when there are too many partitions on a shuffle server, and the duration could be 20s+.
Env:
1. using java8
2. xmx=30g, buffer-capacity=10g, read-capacity=10g
3. from the metric dashboard, during peek hours, there are 20k partitions in a shuffle-server, but disk used capacity ratio is 0.1-0.2
I guess the object creating or allocation request speed is greater than the gc speed, which causes the STW.
### Affects Version(s)
master
### Uniffle Server Log Output
_No response_
### Uniffle Engine Log Output
_No response_
### Uniffle Server Configurations
```yaml
We use the default g1 GC configuration.
```
### Uniffle Engine Configurations
_No response_
### Additional context
### Possible solutions
1. Garbage collector changes to CMS
2. Expand the uniffle cluster by adding more shuffle-servers
3. If one shuffle-server has partition number exceeding the threshold, we should make it fallback to ess.
### Are you willing to submit PR?
- [ ] Yes I am willing to submit a PR!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@uniffle.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-uniffle] advancedxy commented on issue #503: [Bug] Frequent and long lasting full GCs when there are too many partitions on a shuffle server
Posted by "advancedxy (via GitHub)" <gi...@apache.org>.
advancedxy commented on issue #503:
URL: https://github.com/apache/incubator-uniffle/issues/503#issuecomment-1407593361
> By the way, if the netty is introduced, I think this is not a problem in the future.
Yeah, I just pinged xianming in #133
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For additional commands, e-mail: issues-help@uniffle.apache.org
[GitHub] [incubator-uniffle] zuston commented on issue #503: [Bug] Frequent and long lasting full GCs when there are too many partitions on a shuffle server
Posted by "zuston (via GitHub)" <gi...@apache.org>.
zuston commented on issue #503:
URL: https://github.com/apache/incubator-uniffle/issues/503#issuecomment-1411791067
> I found the full GC occurs when there are too many partitions on a shuffle server, and the duration could be 20s+.
> Env:
> using java8
> xmx=30g, buffer-capacity=10g, read-capacity=10g
10g
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For additional commands, e-mail: issues-help@uniffle.apache.org
[GitHub] [incubator-uniffle] jerqi commented on issue #503: [Bug] Frequent and long lasting full GCs when there are too many partitions on a shuffle server
Posted by "jerqi (via GitHub)" <gi...@apache.org>.
jerqi commented on issue #503:
URL: https://github.com/apache/incubator-uniffle/issues/503#issuecomment-1411886318
> > What's your client's size of read buffer?
>
> 14m
OK, if we use a bigger read buffer size, it will cause more GC.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For additional commands, e-mail: issues-help@uniffle.apache.org
[GitHub] [incubator-uniffle] xianjingfeng commented on issue #503: [Bug] Frequent and long lasting full GCs when there are too many partitions on a shuffle server
Posted by "xianjingfeng (via GitHub)" <gi...@apache.org>.
xianjingfeng commented on issue #503:
URL: https://github.com/apache/incubator-uniffle/issues/503#issuecomment-1413043692
> > > @leixm @xianjingfeng Do you encounter similar problems?
> >
> >
> > I haven't found this situation yet. xmx=80g, buffer-capacity=40g, read-capacity=20g
>
> I don't enable the single buffer flush. And I found this occurrence of full GC is always along with the huge partition appearance although I have switched GC to CMS.
>
> So I guess the big memory shuffleBlock reference of huge partition is released but gc throughout is slower than receiving data speed and then gc happened.
>
> Based on this guess, I will enable the single buffer flush to avoid this problem. Could you help give some advice? @advancedxy @xianjingfeng @jerqi
The size of RPC queue is unlimited, is it possible relate to this?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For additional commands, e-mail: issues-help@uniffle.apache.org
[GitHub] [incubator-uniffle] advancedxy commented on issue #503: [Bug] Frequent and long lasting full GCs when there are too many partitions on a shuffle server
Posted by "advancedxy (via GitHub)" <gi...@apache.org>.
advancedxy commented on issue #503:
URL: https://github.com/apache/incubator-uniffle/issues/503#issuecomment-1413620158
> > The size of RPC queue is unlimited, is it possible relate to this?
>
> Maybe. But from the metric dashboard, the GC is always along with the huge partition appearance. I will share some metrics of one shuffle-server.
>
> **CMS single GC cost 20s** 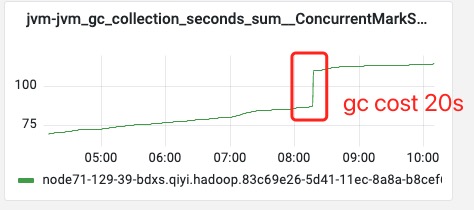
>
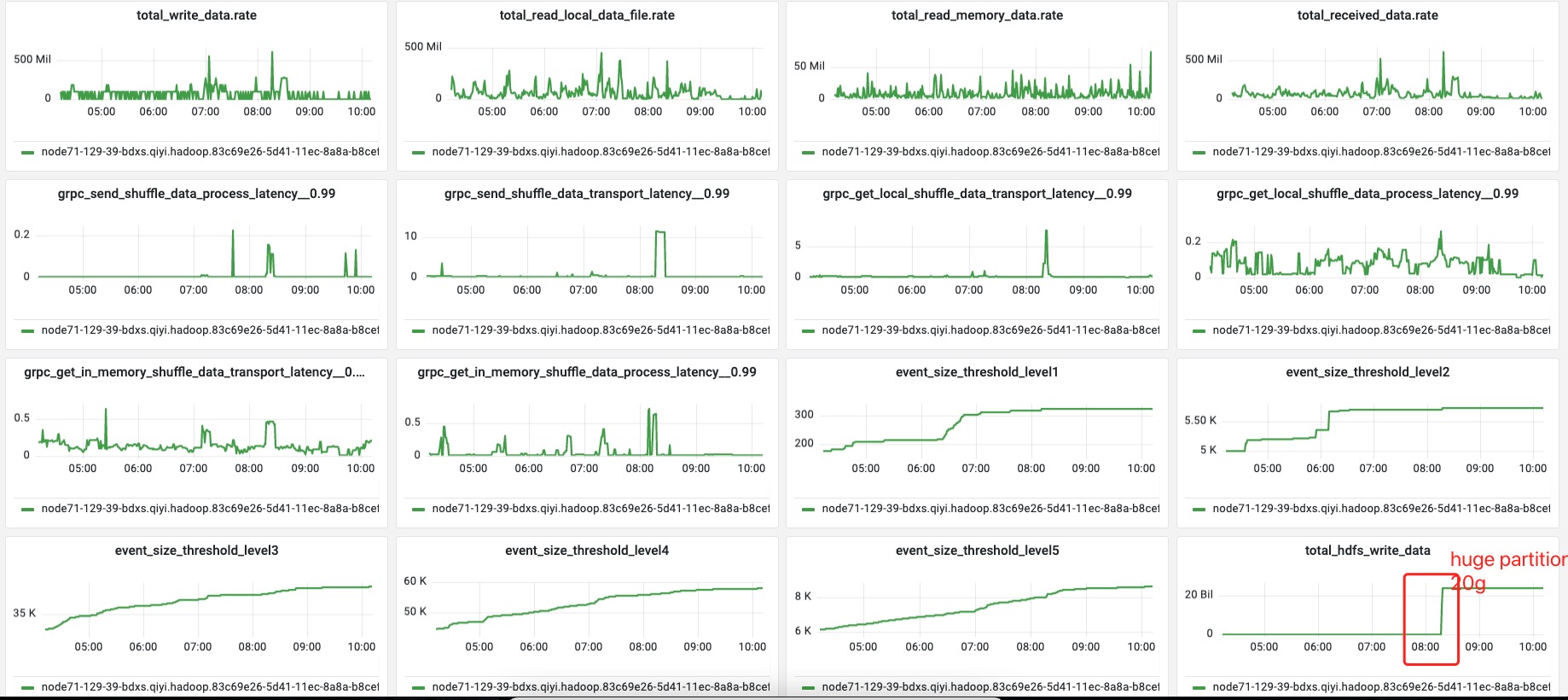
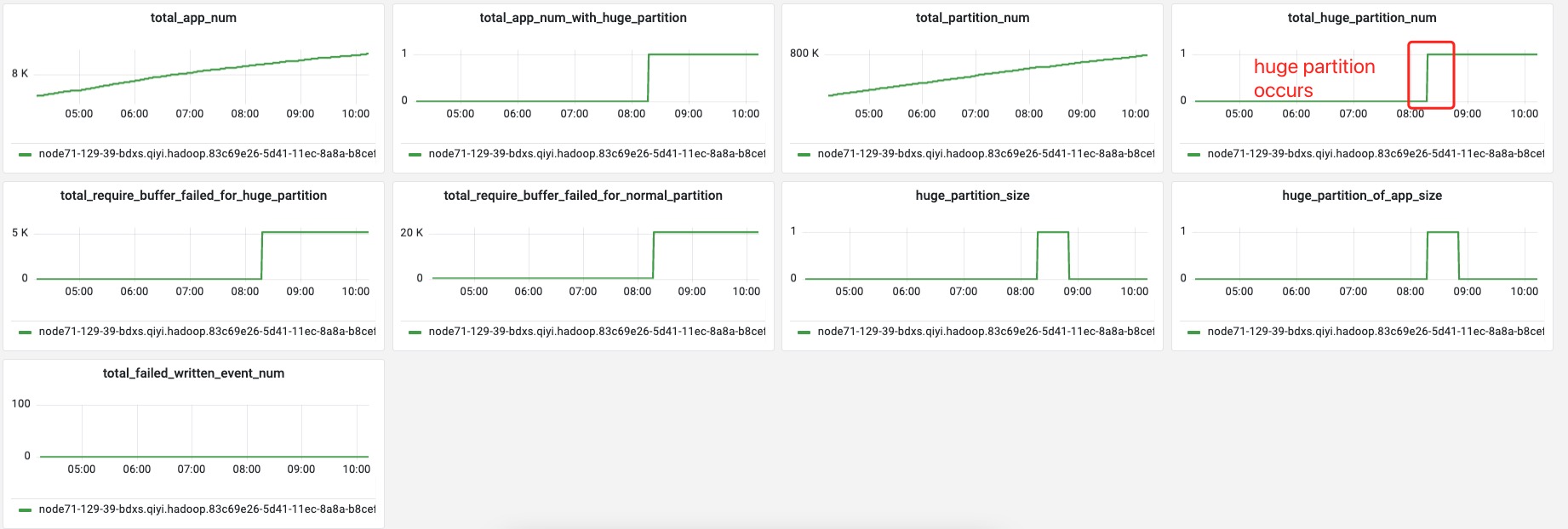
>   
>
> From this metric, I think the single buffer flush may solve this problem.
<img width="917" alt="image" src="https://user-images.githubusercontent.com/807537/216317369-a41ea271-2861-4899-9b15-0c670dcd04a8.png">
Seems like the pre-allocation is also failed when the huge partition is arriving. I think this should match your speculation, shuffle server just cannot gc data quicker than the shuffle server.
> I will enable the single buffer flush to avoid this problem
Single buffer flush should have some effect.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For additional commands, e-mail: issues-help@uniffle.apache.org
[GitHub] [incubator-uniffle] zuston commented on issue #503: [Bug] Frequent and long lasting full GCs when there are too many partitions on a shuffle server
Posted by GitBox <gi...@apache.org>.
zuston commented on issue #503:
URL: https://github.com/apache/incubator-uniffle/issues/503#issuecomment-1396599949
> bump the maxHeapSize to 60G.
It's impossible for us, shuffle-servers are colocated with nodemanager.
> For 1, I doubt its effectiveness. But you experiment report is much appreciated.
I do a comparison experiment which shows CMS is more stable. But this should be observed more long to prove this.
> For 2, this could always be a simple and direct solution.
For 3, you mean coordinator reject the app upon app startup or at app's stage level? Stage level fallback is a big change. Itself may deserve a issue and a design doc.
App's stage level is enough, but stage level will be better. Currently, let's introduce this config to reject app when using delegate rss shuffle manager.
> If possible, could you share more data, such as, average partition size, min/max partition size, disk capacity, how many disks per shuffle server?
average partition size, min/max partition size, these metrics can't be collected in current codebase, but I will add it firstly in our internal version.
single disk capacity: 1TB, 4disk per shuffle server. From the dashboard, disk is not the root cause.
By the way, if the netty is introduced, I think this is not a problem in the future.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@uniffle.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-uniffle] xianjingfeng commented on issue #503: [Bug] Frequent and long lasting full GCs when there are too many partitions on a shuffle server
Posted by "xianjingfeng (via GitHub)" <gi...@apache.org>.
xianjingfeng commented on issue #503:
URL: https://github.com/apache/incubator-uniffle/issues/503#issuecomment-1407270352
> @leixm @xianjingfeng Do you encounter similar problems?
I haven't found this situation yet.
xmx=80g, buffer-capacity=40g, read-capacity=20g
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For additional commands, e-mail: issues-help@uniffle.apache.org
[GitHub] [incubator-uniffle] zuston commented on issue #503: [Bug] Frequent and long lasting full GCs when there are too many partitions on a shuffle server
Posted by "zuston (via GitHub)" <gi...@apache.org>.
zuston commented on issue #503:
URL: https://github.com/apache/incubator-uniffle/issues/503#issuecomment-1411858926
> What's your client's size of read buffer?
14m
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For additional commands, e-mail: issues-help@uniffle.apache.org
[GitHub] [incubator-uniffle] zuston commented on issue #503: [Bug] Frequent and long lasting full GCs when there are too many partitions on a shuffle server
Posted by GitBox <gi...@apache.org>.
zuston commented on issue #503:
URL: https://github.com/apache/incubator-uniffle/issues/503#issuecomment-1396503732
@leixm @xianjingfeng Do you encounter similar problems?
cc @advancedxy @jerqi
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@uniffle.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-uniffle] zuston commented on issue #503: [Bug] Frequent and long lasting full GCs when there are too many partitions on a shuffle server
Posted by "zuston (via GitHub)" <gi...@apache.org>.
zuston commented on issue #503:
URL: https://github.com/apache/incubator-uniffle/issues/503#issuecomment-1411680276
> > @leixm @xianjingfeng Do you encounter similar problems?
>
> I haven't found this situation yet. xmx=80g, buffer-capacity=40g, read-capacity=20g
I don't enable the single buffer flush. And I found this occurrence of full GC is always along with the huge partition appearance although I have switched GC to CMS.
So I guess the big memory shuffleBlock reference of huge partition is released but gc throughout is slower than receiving data speed and then gc happened.
Based on this guess, I will enable the single buffer flush to avoid this problem. Could you help give some advice? @advancedxy @xianjingfeng @jerqi
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For additional commands, e-mail: issues-help@uniffle.apache.org
[GitHub] [incubator-uniffle] zuston commented on issue #503: [Bug] Frequent and long lasting full GCs when there are too many partitions on a shuffle server
Posted by "zuston (via GitHub)" <gi...@apache.org>.
zuston commented on issue #503:
URL: https://github.com/apache/incubator-uniffle/issues/503#issuecomment-1413055534
> The size of RPC queue is unlimited, is it possible relate to this?
Maybe. But from the metric dashboard, the GC is always along with the huge partition appearance. I will share some metrics of one shuffle-server.
__CMS single GC cost 20s__




From this metric, I think the single buffer flush may solve this problem.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For additional commands, e-mail: issues-help@uniffle.apache.org
[GitHub] [incubator-uniffle] advancedxy commented on issue #503: [Bug] Frequent and long lasting full GCs when there are too many partitions on a shuffle server
Posted by GitBox <gi...@apache.org>.
advancedxy commented on issue #503:
URL: https://github.com/apache/incubator-uniffle/issues/503#issuecomment-1396537726
> 1. Garbage collector changes to CMS
> 2. Expand the uniffle cluster by adding more shuffle-servers
> 3. If one shuffle-server has partition number exceeding the threshold, we should make it fallback to ess.
If possible, you could also scale-up the shuffle-server, let's say, bump the maxHeapSize to 60G.
For 1, I doubt its effectiveness. But you experiment report is much appreciated.
For 2, this could always be a simple and direct solution.
For 3, you mean coordinator reject the app upon app startup or at app's stage level? Stage level fallback is a big change. Itself may deserve a issue and a design doc.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@uniffle.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-uniffle] advancedxy commented on issue #503: [Bug] Frequent and long lasting full GCs when there are too many partitions on a shuffle server
Posted by GitBox <gi...@apache.org>.
advancedxy commented on issue #503:
URL: https://github.com/apache/incubator-uniffle/issues/503#issuecomment-1396538481
> from the metric dashboard, during peek hours, there are 20k partitions in a shuffle-server, but disk used capacity ratio is 0.1-0.2
If possible, could you share more data, such as, average partition size, min/max partition size, disk capacity, how many disks per shuffle server?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@uniffle.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-uniffle] jerqi commented on issue #503: [Bug] Frequent and long lasting full GCs when there are too many partitions on a shuffle server
Posted by "jerqi (via GitHub)" <gi...@apache.org>.
jerqi commented on issue #503:
URL: https://github.com/apache/incubator-uniffle/issues/503#issuecomment-1411776427
> > > @leixm @xianjingfeng Do you encounter similar problems?
> >
> >
> > I haven't found this situation yet. xmx=80g, buffer-capacity=40g, read-capacity=20g
>
> I don't enable the single buffer flush. And I found this occurrence of full GC is always along with the huge partition appearance although I have switched GC to CMS.
>
> So I guess the big memory shuffleBlock reference of huge partition is released but gc throughout is slower than receiving data speed and then gc happened.
>
> Based on this guess, I will enable the single buffer flush to avoid this problem. Could you help give some advice? @advancedxy @xianjingfeng @jerqi
What's your size of read buffer?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For additional commands, e-mail: issues-help@uniffle.apache.org
[GitHub] [incubator-uniffle] jerqi commented on issue #503: [Bug] Frequent and long lasting full GCs when there are too many partitions on a shuffle server
Posted by "jerqi (via GitHub)" <gi...@apache.org>.
jerqi commented on issue #503:
URL: https://github.com/apache/incubator-uniffle/issues/503#issuecomment-1411844997
> > I found the full GC occurs when there are too many partitions on a shuffle server, and the duration could be 20s+.
>
> > Env:
>
> > using java8
> > xmx=30g, buffer-capacity=10g, read-capacity=10g
>
> 10g
What's your client's size of read buffer?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@uniffle.apache.org
For additional commands, e-mail: issues-help@uniffle.apache.org