You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2020/08/04 08:13:33 UTC
[GitHub] [hudi] mingujotemp opened a new issue #1910: [SUPPORT] Upsert operation duplicating records in a partition
mingujotemp opened a new issue #1910:
URL: https://github.com/apache/hudi/issues/1910
**Describe the problem you faced**
Upsert operation duplicates records in a partition.
We use EMR 6.0.0 (Hudi 0.5.0)
**To Reproduce**
Steps to reproduce the behavior:
1. Create a pyspark dataframe. Let's say it looks like the following
```
[
Row(id=1, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 1)),
Row(id=2, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 2)),
Row(id=3, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 3)),
Row(id=4, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 4)),
Row(id=5, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 5)),
Row(id=6, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 6)),
Row(id=7, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 7)),
Row(id=8, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 8)),
Row(id=9, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 9)),
Row(id=10, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 10)),
]
```
2. Use following codes to `overwrite` to initiate the table on S3 (Glue)
```
hudi_options = {
'hoodie.table.name': tableName,
'hoodie.datasource.write.recordkey.field': 'id',
'hoodie.index.type': 'BLOOM',
'hoodie.datasource.write.partitionpath.field': 'partition_test',
'hoodie.datasource.write.table.name': tableName,
'hoodie.datasource.write.operation': 'upsert',
'hoodie.datasource.write.precombine.field': 'updated_at',
'hoodie.upsert.shuffle.parallelism': 2,
'hoodie.insert.shuffle.parallelism': 2,
'hoodie.bulkinsert.shuffle.parallelism': 10,
'hoodie.datasource.hive_sync.database': databaseName,
'hoodie.datasource.hive_sync.table': tableName,
'hoodie.datasource.hive_sync.enable': 'true',
'hoodie.datasource.hive_sync.assume_date_partitioning': 'true',
'hoodie.datasource.hive_sync.partition_fields': 'partition_test',
'hoodie.consistency.check.enabled': 'true',
}
df.write.format("org.apache.hudi"). \
options(**hudi_options). \
mode("overwrite"). \
save(basePath) # some s3 path
```
3. Check on Athena/Redshift to see if the table has been written successfully. (We use Glue as our metastore)
4. Upsert the following data on same partition ('2020/08/01'). See that `issue_type` has been changed to `blah`.
See `updated_at` is now 2020/1/2. In my understanding, the previous record with id=1 in partition 2020/08/01 should be deleted and change to this new record as the new one has bigger `updated_at`
```
[
Row(id=1, issue_type='blah', partition_test='2020/08/01', updated_at=datetime(2020, 1, 2)),
]
```
5. Use the exact same hudi options from above, and use below to "append".
```
upsert_df.write.format("org.apache.hudi"). \
options(**hudi_options). \
mode("append"). \
save(basePath) # same s3 path
```
6. Below is what I see after the above operation.
```
[
Row(id=1, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 1)),
Row(id=1, issue_type='blah', partition_test='2020/08/01', updated_at=datetime(2020, 1, 2)),
Row(id=2, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 2)),
Row(id=2, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 2)),
Row(id=3, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 3)),
Row(id=3, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 3)),
Row(id=4, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 4)),
Row(id=4, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 4)),
Row(id=5, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 5)),
Row(id=5, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 5)),
Row(id=6, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 6)),
Row(id=6, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 6)),
Row(id=7, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 7)),
Row(id=7, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 7)),
Row(id=8, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 8)),
Row(id=8, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 8)),
Row(id=9, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 9)),
Row(id=9, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 9)),
Row(id=10, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 10)),
Row(id=10, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 10)),
]
```
I checked the `_hoodie_file_name` and all of the records have same file names
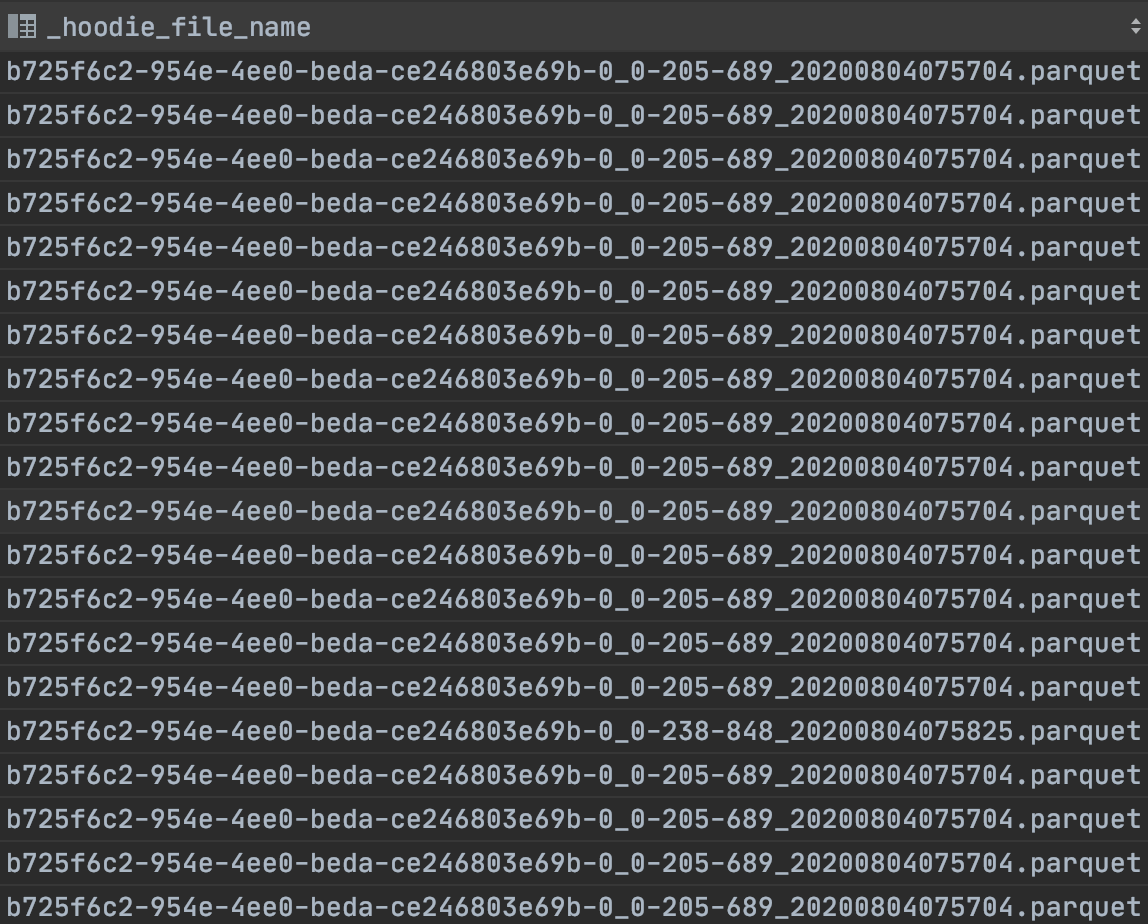
**Expected behavior**
I explained altogether above.
**Environment Description**
* Hudi version : 0.5.0 (EMR 6.0.0)
* Spark version : 2.4.4
* Hive version : 3.1.2 (We use Glue as metastore)
* Hadoop version : 3.2.1-amzn-0
* Storage (HDFS/S3/GCS..) : S3
* Running on Docker? (yes/no) : no (EMR)
**Additional context**
Add any other context about the problem here.
**Stacktrace**
All the operations I ran above didn't error.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #1910: [SUPPORT] Upsert operation duplicating records in a partition
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #1910:
URL: https://github.com/apache/hudi/issues/1910#issuecomment-675441022
@mingujotemp : Any updates ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #1910: [SUPPORT] Upsert operation duplicating records in a partition
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #1910:
URL: https://github.com/apache/hudi/issues/1910#issuecomment-685860529
Closing this due to inactivity.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] mingujotemp commented on issue #1910: [SUPPORT] Upsert operation duplicating records in a partition
Posted by GitBox <gi...@apache.org>.
mingujotemp commented on issue #1910:
URL: https://github.com/apache/hudi/issues/1910#issuecomment-670277613
yup that has been set for sure
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #1910: [SUPPORT] Upsert operation duplicating records in a partition
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #1910:
URL: https://github.com/apache/hudi/issues/1910#issuecomment-669681168
For Spark SQL, "--conf spark.sql.hive.convertMetastoreParquet=false" needs to be passed when starting up Spark. Can you check if this is being set ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #1910: [SUPPORT] Upsert operation duplicating records in a partition
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #1910:
URL: https://github.com/apache/hudi/issues/1910#issuecomment-668651417
This looks like you are not using hudi format to read the table. Did you try spark.read.format("hudi").xxxx ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar closed issue #1910: [SUPPORT] Upsert operation duplicating records in a partition
Posted by GitBox <gi...@apache.org>.
bvaradar closed issue #1910:
URL: https://github.com/apache/hudi/issues/1910
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #1910: [SUPPORT] Upsert operation duplicating records in a partition
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #1910:
URL: https://github.com/apache/hudi/issues/1910#issuecomment-670341009
@mingujotemp : I just noticed you are using hive 3.x. I have not seen similar issues with Hive 2.x. Can you enable debug logging to see if your spark sql query triggers HoodiParquetInputFormat. You can paste the logs in this ticket.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] mingujotemp commented on issue #1910: [SUPPORT] Upsert operation duplicating records in a partition
Posted by GitBox <gi...@apache.org>.
mingujotemp commented on issue #1910:
URL: https://github.com/apache/hudi/issues/1910#issuecomment-668936259
@bvaradar I'm reading the table with `spark.sql` through hive metastore not directly reading parquet using `spark.read.format("hudi")`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org