You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2022/04/04 19:38:58 UTC
[GitHub] [hudi] sharathkola opened a new issue, #5223: [SUPPORT] - HUDI clustering - read issues
sharathkola opened a new issue, #5223:
URL: https://github.com/apache/hudi/issues/5223
**_Tips before filing an issue_**
- Have you gone through our [FAQs](https://hudi.apache.org/learn/faq/)? Yes
- Join the mailing list to engage in conversations and get faster support at dev-subscribe@hudi.apache.org.
- If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly.
**Describe the problem you faced**
Hudi clustered table reads all the files instead of reading only clustered files generated.
I have created a hudi clustered table using deltastreamer.. its command and configuration are below -
aws emr add-steps --cluster-id j-3W0PJEH4IJMOB --steps Type=Spark,Name="Deltastreamer_account_t_c",ActionOnFailure=CONTINUE,Args=[--master,yarn,--deploy-mode,client,--executor-memory,10G,--driver-memory,10G,--executor-cores,5,--driver-cores,5,--jars,s3://XX/hudi/jars/spark-avro_2.12-3.1.2-amzn-0.jar,--class,org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer,s3://XX/hudi/jars/hudi-utilities-bundle_2.12-0.8.0-amzn-0.jar,--props,s3://XX/hudi/props/test/cluster/account_t.properties,--enable-hive-sync,--table-type,COPY_ON_WRITE,--source-class,org.apache.hudi.utilities.sources.ParquetDFSSource,--source-ordering-field,commit_ts,--target-base-path,s3://XX/hudi/test/cluster/account_t,--target-table,account_t,--continuous,--min-sync-interval-seconds,10,--op,UPSERT] --region us-east-1
properties file info -
hoodie.datasource.write.recordkey.field=poid_id0
hoodie.datasource.write.precombine.field=commit_ts
hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.NonpartitionedKeyGenerator
hoodie.datasource.write.partitionpath.field=
hoodie.write.lock.zookeeper.lock_key=account_t
hoodie.datasource.hive_sync.enable=true
hoodie.datasource.hive_sync.database=hudi_c
hoodie.datasource.hive_sync.table=account_t
hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.NonPartitionedExtractor
hoodie.deltastreamer.source.dfs.root=s3://XXXX/account_t/
hoodie.upsert.shuffle.parallelism=200
hoodie.datasource.write.row.writer.enable=true
hoodie.index.type=BLOOM
hoodie.bloom.index.filter.type=DYNAMIC_V0
hoodie.parquet.small.file.limit=0
hoodie.clustering.inline=true
hoodie.clustering.inline.max.commits=1
hoodie.clustering.plan.strategy.target.file.max.bytes=1073741824
hoodie.clustering.plan.strategy.small.file.limit=629145600
hoodie.clustering.plan.strategy.sort.columns=poid_id0,status
commit information below -
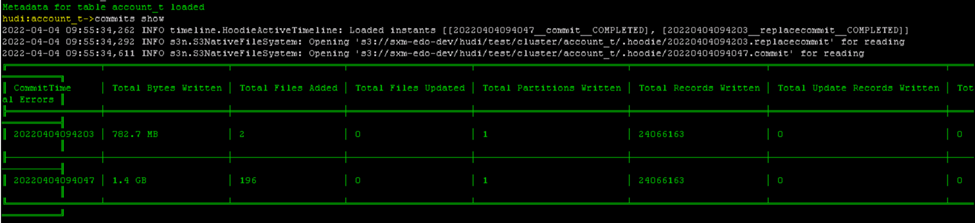
After first commit, clustering is done where 196 small files are converted into 2 larger files.
I am running below query in a spark program against hudi external table–
select * from hudi_c.account_t a where a.poid_id0 =1234567
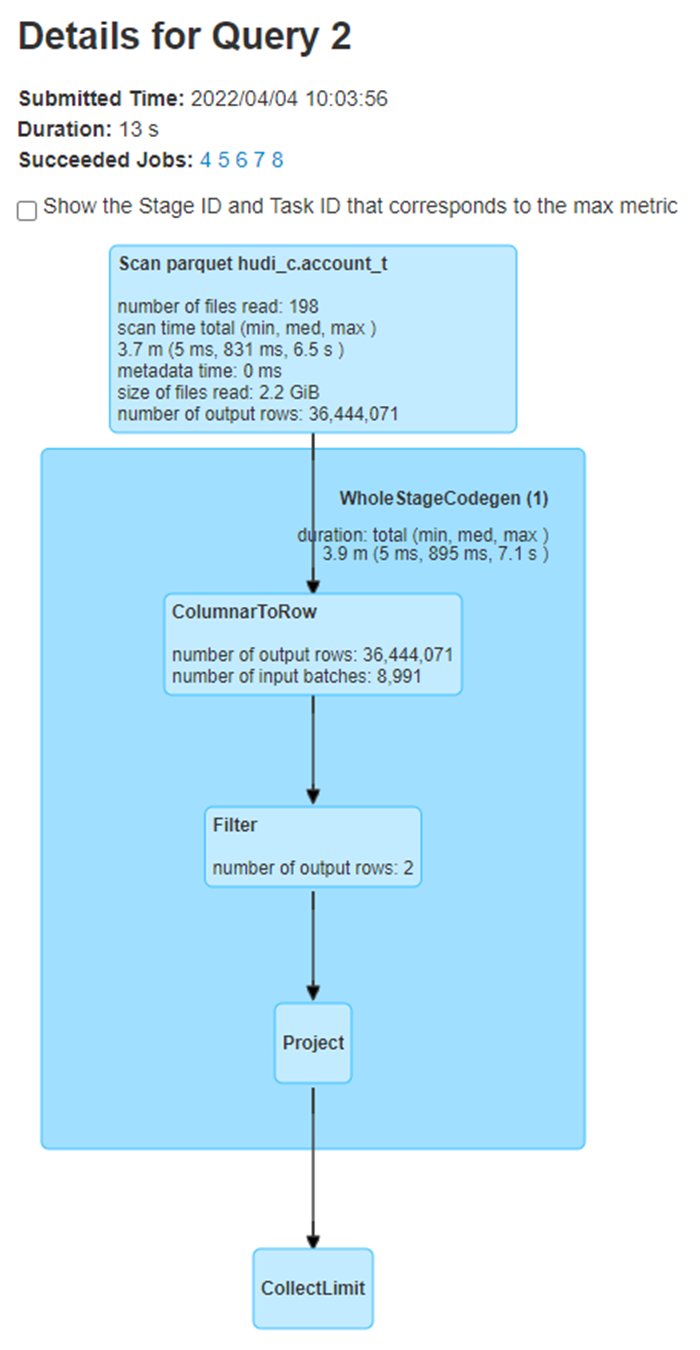
In spark UI I see that all the files (196+2=198 files) are being read instead of only 2 larger files.
**To Reproduce**
Steps to reproduce the behavior:
1. create properties file with configs as mentioned above.
2. run the deltastreamer command as mentioned above.
3. run the spark sql query mentioned above.
4. verify spark UI to see the S3 file scans
**Expected behavior**
Clustered hudi table should read only the new clustered files instead of all the old+new files.
**Environment Description**
* Hudi version : 0.8.0
* Spark version : 3.1.2
* Hive version : 3.1.2
* Hadoop version :
* Storage (HDFS/S3/GCS..) : S3
* Running on Docker? (yes/no) : no
**Additional context**
Adding a screenshot of .hoodie folder
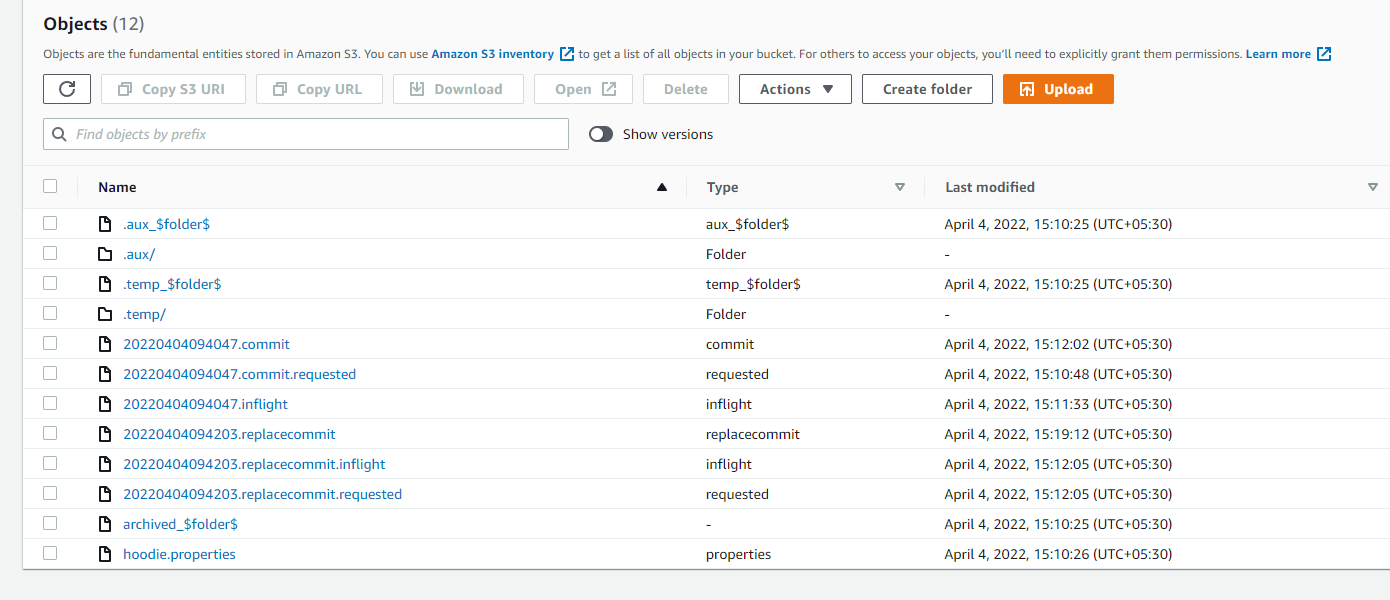
**Stacktrace**
```Add the stacktrace of the error.```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] sharathkola commented on issue #5223: [SUPPORT] - HUDI clustering - read issues
Posted by GitBox <gi...@apache.org>.
sharathkola commented on issue #5223:
URL: https://github.com/apache/hudi/issues/5223#issuecomment-1109352692
@suryaprasanna
Can you please verify the commit_files.zip that I have attached above (it has 20220404094047.commit and 20220404094203.replacecommit files) to confirm if it has the right entries/content ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan closed issue #5223: [SUPPORT] - HUDI clustering - read issues
Posted by GitBox <gi...@apache.org>.
nsivabalan closed issue #5223: [SUPPORT] - HUDI clustering - read issues
URL: https://github.com/apache/hudi/issues/5223
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] suryaprasanna commented on issue #5223: [SUPPORT] - HUDI clustering - read issues
Posted by GitBox <gi...@apache.org>.
suryaprasanna commented on issue #5223:
URL: https://github.com/apache/hudi/issues/5223#issuecomment-1109245586
@nsivabalan
I tried out both 0.8.0 and 0.10.1 versions. My job is not returning duplicates and considering only the latest files. I tried on both partitioned and non-partitioned tables as well. Can the issue be due to any custom code from the AWS side?
<img width="816" alt="Screen Shot 2022-04-25 at 7 40 05 PM" src="https://user-images.githubusercontent.com/20996567/165210088-42df9491-d576-4f31-9edc-7c1e20a2ee3f.png">
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #5223: [SUPPORT] - HUDI clustering - read issues
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #5223:
URL: https://github.com/apache/hudi/issues/5223#issuecomment-1125505391
```
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.spark.sql.functions._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val inputDataset = "PATH_TO_PARQUET_DATASET"
val hudiBasePath = "/tmp/hudi/tbl1"
val hudiTableName = "tbl1"
val df = spark.read.format("parquet").load(inputDataset)
spark.time(df.write.format("hudi").
option(OPERATION_OPT_KEY,"bulk_insert").
option(PRECOMBINE_FIELD_OPT_KEY, "tpep_dropoff_datetime").
option(RECORDKEY_FIELD_OPT_KEY, "date_col").
option(TABLE_NAME, hudiTableName).
option("hoodie.parquet.compression.codec", "SNAPPY").
option("hoodie.write.markers.type","DIRECT").
option("hoodie.embed.timeline.server","false").
option("hoodie.bulkinsert.shuffle.parallelism","12").
option("hoodie.metadata.enable", "false").
option("hoodie.parquet.max.file.size","10485760").
option("hoodie.datasource.write.keygenerator.class","org.apache.hudi.keygen.NonpartitionedKeyGenerator").
mode(Overwrite).
save(hudiBasePath))
// read hudi
val hudiDf = spark.read.format("hudi").load(hudiBasePath)
hudiDf.registerTempTable("tbl1")
spark.sql("select count(*) from tbl1").show()
// trigger clustering
spark.time(df.limit(10000).write.format("hudi").
option(OPERATION_OPT_KEY,"bulk_insert").
option(PRECOMBINE_FIELD_OPT_KEY, "tpep_dropoff_datetime").
option(RECORDKEY_FIELD_OPT_KEY, "date_col").
option(TABLE_NAME, hudiTableName).
option("hoodie.parquet.compression.codec", "SNAPPY").
option("hoodie.write.markers.type","DIRECT").
option("hoodie.embed.timeline.server","false").
option("hoodie.bulkinsert.shuffle.parallelism","12").
option("hoodie.metadata.enable", "false").
option("hoodie.parquet.max.file.size","10485760").
option("hoodie.clustering.inline.max.commits","1").
option("hoodie.clustering.inline","true").
option("hoodie.clustering.plan.strategy.target.file.max.bytes","1073741824").
option("hoodie.datasource.write.keygenerator.class","org.apache.hudi.keygen.NonpartitionedKeyGenerator").
mode(Append).
save(hudiBasePath))
// read hudi
val hudiDf = spark.read.format("hudi").load(hudiBasePath)
hudiDf.registerTempTable("tbl1")
spark.sql("select count(*) from tbl1").show()
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] suryaprasanna commented on issue #5223: [SUPPORT] - HUDI clustering - read issues
Posted by GitBox <gi...@apache.org>.
suryaprasanna commented on issue #5223:
URL: https://github.com/apache/hudi/issues/5223#issuecomment-1101721223
@sharathkola
I do not have much context if at all aws is having any custom implementation on hudi code.
In the spark DAG, the filter block is showing output rows as 2. Does that mean duplicates rows are returned?
If there are duplicates, then one problem I can think of is, completed replacecommit file not having partitionToReplaceFileIds, so, it maybe considering all 198 files as valid files even though only 2 of them are valid.
For further investigation, could you share us the contents of 20220404094047.commit and 20220404094203.replacecommit files?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] xushiyan commented on issue #5223: [SUPPORT] - HUDI clustering - read issues
Posted by GitBox <gi...@apache.org>.
xushiyan commented on issue #5223:
URL: https://github.com/apache/hudi/issues/5223#issuecomment-1130157997
> @nsivabalan I tried out both 0.8.0 and 0.10.1 versions. My job is not returning duplicates and considering only the latest files. I tried on both partitioned and non-partitioned tables as well. Can the issue be due to any custom code from the AWS side? <img alt="Screen Shot 2022-04-25 at 7 40 05 PM" width="816" src="https://user-images.githubusercontent.com/20996567/165210088-42df9491-d576-4f31-9edc-7c1e20a2ee3f.png">
@suryaprasanna have you filed aws support case? this should be followed up with aws support team then
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #5223: [SUPPORT] - HUDI clustering - read issues
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #5223:
URL: https://github.com/apache/hudi/issues/5223#issuecomment-1109018000
@suryaprasanna : thanks for assisting here. Can you take hudi 0.8.0 oss, try out clustering after few commits. And trigger a query and paste what you see in spark sql tab in spark ui. if you also see hudi is reading all data instead of replaced file groups, then we have a problem. I assume you already verified w/ latest master that its not the case. If not, can you try that as well.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #5223: [SUPPORT] - HUDI clustering - read issues
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #5223:
URL: https://github.com/apache/hudi/issues/5223#issuecomment-1095438907
@satishkotha @suryaprasanna : Can you folks chime in here please.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] suryaprasanna commented on issue #5223: [SUPPORT] - HUDI clustering - read issues
Posted by GitBox <gi...@apache.org>.
suryaprasanna commented on issue #5223:
URL: https://github.com/apache/hudi/issues/5223#issuecomment-1111412056
@sharathkola I have already verified the commit files, they look good.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #5223: [SUPPORT] - HUDI clustering - read issues
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #5223:
URL: https://github.com/apache/hudi/issues/5223#issuecomment-1210064232
Closing it out as non-reproducible. Please reach out to us if you are still stuck at the issue. we can take a deeper look, but as of now, we could not reproduce the issue being reported.
thanks for raising the issue.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] sharathkola commented on issue #5223: [SUPPORT] - HUDI clustering - read issues
Posted by GitBox <gi...@apache.org>.
sharathkola commented on issue #5223:
URL: https://github.com/apache/hudi/issues/5223#issuecomment-1102288392
@suryaprasanna
Yes, duplicate rows are returned.
I have attached both the files you requested.
[commit_files.zip](https://github.com/apache/hudi/files/8510790/commit_files.zip)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #5223: [SUPPORT] - HUDI clustering - read issues
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #5223:
URL: https://github.com/apache/hudi/issues/5223#issuecomment-1125503984
I could not reproduce. I tried a bulk insert by setting very small parquet max file size. which created 1300 file groups. And then triggered another small commit during which I triggered clustering. before clustering, I do see from sql tab in spark UI, that 1300+ files are read. after clustering, I see only 5 files are read.
<img width="629" alt="Screen Shot 2022-05-12 at 4 32 29 PM" src="https://user-images.githubusercontent.com/513218/168182811-53499b46-3c59-4873-9315-c598819f3a67.png">
<img width="655" alt="Screen Shot 2022-05-12 at 7 18 17 PM" src="https://user-images.githubusercontent.com/513218/168182816-71e424c4-e2df-4688-a69d-eac14e17a588.png">
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org