You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2020/09/28 05:16:58 UTC
[GitHub] [spark] wangyum commented on a change in pull request #28032: [SPARK-31264][SQL] Repartition by dynamic partition columns before insert partition table
wangyum commented on a change in pull request #28032:
URL: https://github.com/apache/spark/pull/28032#discussion_r495693386
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -2038,6 +2038,15 @@ object SQLConf {
.booleanConf
.createWithDefault(true)
+ val REPARTITION_BEFORE_INSERT =
+ buildConf("spark.sql.execution.repartitionBeforeInsert")
Review comment:
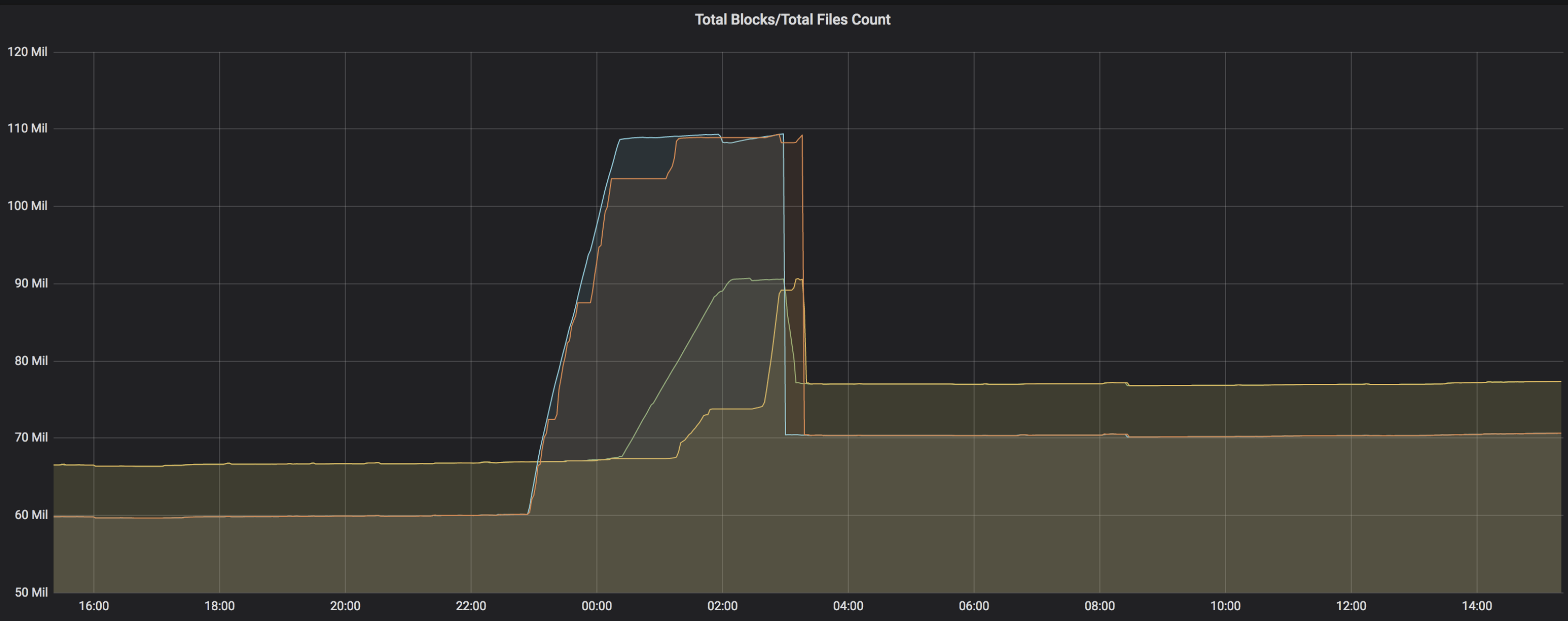
Because we cannot prevent users from using inappropriate columns for partition columns, such as primary keys.
This will generate too many files and affect the stability of NameNode and the entire cluster.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org