You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@flink.apache.org by GJL <gi...@git.apache.org> on 2018/04/27 15:21:13 UTC
[GitHub] flink pull request #5931: [FLINK-9190][flip6,yarn] Request new container if ...
GitHub user GJL opened a pull request:
https://github.com/apache/flink/pull/5931
[FLINK-9190][flip6,yarn] Request new container if container completed unexpectedly
## What is the purpose of the change
*Request new YARN container if container completed unexpectedly.*
cc: @sihuazhou @StephanEwen @tillrohrmann
## Brief change log
- *Request new container if container completed unexpectedly.*
- *Reduce visibility of some fields in `YarnResourceManager`.*
## Verifying this change
This change added tests and can be verified as follows:
- *Manually verified the change by deploying a Flink cluster on YARN and killing `TaskExecutorRunner`s randomly.*
## Does this pull request potentially affect one of the following parts:
- Dependencies (does it add or upgrade a dependency): (yes / **no**)
- The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / **no**)
- The serializers: (yes / **no** / don't know)
- The runtime per-record code paths (performance sensitive): (yes / **no** / don't know)
- Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: (**yes** / no / don't know)
- The S3 file system connector: (yes / **no** / don't know)
## Documentation
- Does this pull request introduce a new feature? (yes / **no**)
- If yes, how is the feature documented? (**not applicable** / docs / JavaDocs / not documented)
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/GJL/flink FLINK-9190
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/flink/pull/5931.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #5931
----
commit 35b02327fcbcb9a7fed3ad162e26f9900c774558
Author: gyao <ga...@...>
Date: 2018-04-27T13:49:31Z
[FLINK-9190][flip6,yarn] Request new container if container completed unexpectedly.
commit 3d02f3c171a4473b25377c2319506901228ff8f3
Author: gyao <ga...@...>
Date: 2018-04-27T13:51:38Z
[hotfix][yarn] Reduce visibility of fields.
----
---
[GitHub] flink pull request #5931: [FLINK-9190][flip6,yarn] Request new container if ...
Posted by sihuazhou <gi...@git.apache.org>.
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5931#discussion_r184832034
--- Diff: flink-yarn/src/main/java/org/apache/flink/yarn/YarnResourceManager.java ---
@@ -293,21 +293,16 @@ public void startNewWorker(ResourceProfile resourceProfile) {
}
@Override
- public boolean stopWorker(YarnWorkerNode workerNode) {
- if (workerNode != null) {
- Container container = workerNode.getContainer();
- log.info("Stopping container {}.", container.getId());
- // release the container on the node manager
- try {
- nodeManagerClient.stopContainer(container.getId(), container.getNodeId());
- } catch (Throwable t) {
- log.warn("Error while calling YARN Node Manager to stop container", t);
- }
- resourceManagerClient.releaseAssignedContainer(container.getId());
- workerNodeMap.remove(workerNode.getResourceID());
- } else {
- log.error("Can not find container for null workerNode.");
+ public boolean stopWorker(final YarnWorkerNode workerNode) {
+ final Container container = workerNode.getContainer();
+ log.info("Stopping container {}.", container.getId());
+ try {
+ nodeManagerClient.stopContainer(container.getId(), container.getNodeId());
+ } catch (final Exception e) {
+ log.warn("Error while calling YARN Node Manager to stop container", e);
}
+ resourceManagerClient.releaseAssignedContainer(container.getId());
+ workerNodeMap.remove(workerNode.getResourceID());
return true;
--- End diff --
These seems to lead us to have a very little chance to require a new unnecessary Container... Since we call `nodeManagerClient.stopContainer(container.getId(), container.getNodeId());` firstly, then call `workerNodeMap.remove(workerNode.getResourceID())`. I'm not sure whether we can reverse the invocation order of them in this function(I'm not sure because I don't know whether this would lead to new problem...), what do you think?
---
[GitHub] flink pull request #5931: [FLINK-9190][flip6,yarn] Request new container if ...
Posted by sihuazhou <gi...@git.apache.org>.
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5931#discussion_r184831311
--- Diff: flink-yarn/src/main/java/org/apache/flink/yarn/YarnResourceManager.java ---
@@ -293,21 +293,16 @@ public void startNewWorker(ResourceProfile resourceProfile) {
}
@Override
- public boolean stopWorker(YarnWorkerNode workerNode) {
- if (workerNode != null) {
- Container container = workerNode.getContainer();
- log.info("Stopping container {}.", container.getId());
- // release the container on the node manager
- try {
- nodeManagerClient.stopContainer(container.getId(), container.getNodeId());
- } catch (Throwable t) {
- log.warn("Error while calling YARN Node Manager to stop container", t);
- }
- resourceManagerClient.releaseAssignedContainer(container.getId());
- workerNodeMap.remove(workerNode.getResourceID());
- } else {
- log.error("Can not find container for null workerNode.");
+ public boolean stopWorker(final YarnWorkerNode workerNode) {
+ final Container container = workerNode.getContainer();
+ log.info("Stopping container {}.", container.getId());
+ try {
+ nodeManagerClient.stopContainer(container.getId(), container.getNodeId());
+ } catch (final Exception e) {
+ log.warn("Error while calling YARN Node Manager to stop container", e);
--- End diff --
Previous version was the `Throwable` here, currently changed to `Exception`, what the reason here? Beside, if we change here from `Throwable` -> `Exception` then maybe we should also change the other places where have a similar operation with `nodeManagerClient` like here, e.g.
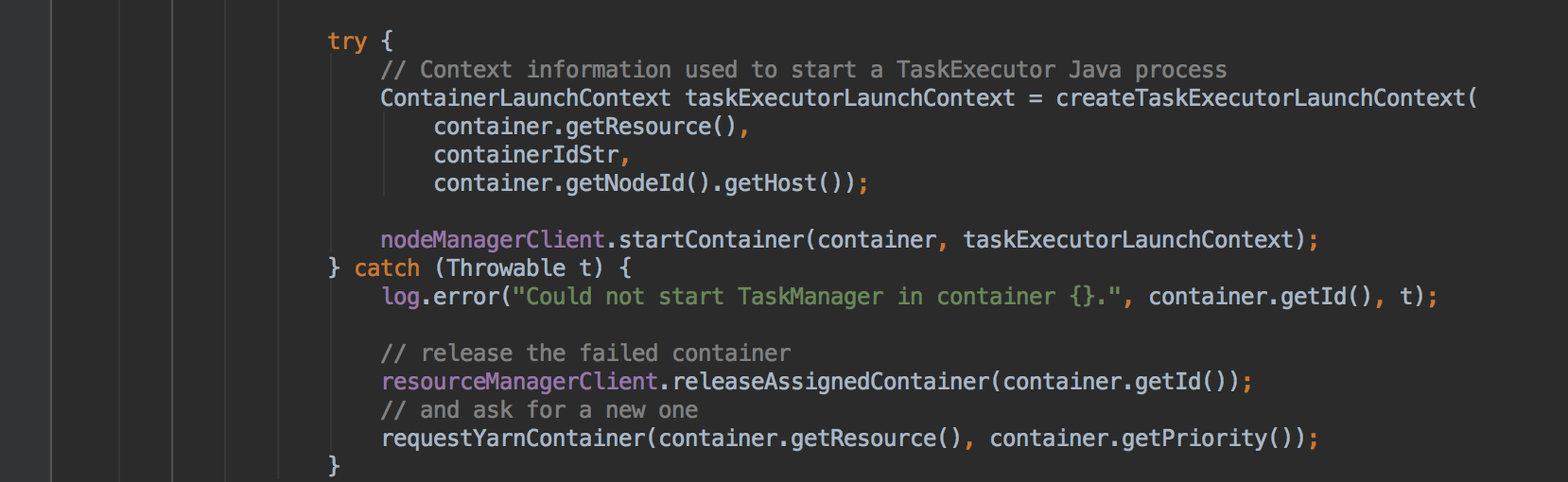
---
[GitHub] flink issue #5931: [FLINK-9190][flip6,yarn] Request new container if contain...
Posted by tillrohrmann <gi...@git.apache.org>.
Github user tillrohrmann commented on the issue:
https://github.com/apache/flink/pull/5931
I looked into the problem @GJL reported and I think it is not caused by killed TMs which don't have the chance to tell the JMs about the slot allocations (even though this can theoretically happen). In such a case, the protocol currently relies on the slot request timeout on the JM side to resend new requests.
I think the actual problem is related to #5980. The problem there is that the `ExecutionGraph` does not wait until all of its slots have been properly returned to the `SlotPool` before it is restarted in case of a recovery. Due to this, it might happen that some of the old tasks occupy some slots which are actually needed for the new tasks. If this happens, the actual task to slot assignment might be suboptimal meaning that the tasks are spread across more slots than needed. For example, assume that we have two slots with a mapper and sink task:
`S1: M1_old, S1_old`
`S2: M2_old, S2_old`
Now a failover happens and the system restarts the `ExecutionGraph`. When this happens `M1_old` and `S2_old` have not been properly released.
`S1: M1_old`
`S2: S2_old`
Now we try to schedule the new tasks which suddenly needs 3 slots.
`S1: M1_old, S1_new`
`S2: M2_new, S2_old`
`S3: M1_new, S2_new`
After the old tasks have been released it would like that:
`S1: S1_new`
`S2: M2_new`
`S3:M1_new, S2_new`
With @GJL tests we had the situation that we could only allocate one additional container due to resource limitations. Thus, if we actually needed 2 additional container, the program could not start.
By properly waiting for the slot release such a situation should no longer happen.
However, #5980 does not solve the problem of early killed TMs which could not communicate with the JM. At the moment we would have to rely on the slot request timeouts to resolve this situation.
---
[GitHub] flink issue #5931: [FLINK-9190][flip6,yarn] Request new container if contain...
Posted by StephanEwen <gi...@git.apache.org>.
Github user StephanEwen commented on the issue:
https://github.com/apache/flink/pull/5931
@GJL Briefly digging through the log, there are a few strange things happening:
- `YarnResourceManager` still has 8 pending requests even when 11 containers are running:
```Received new container: container_1524853016208_0001_01_000184 - Remaining pending container requests: 8```
- Some slots are requested and then the requests are cancelled again
- In the end, one request is not fulfilled: `aeec2a9f010a187e04e31e6efd6f0f88`
Might be an inconsistency in either in the `SlotManager` or `SlotPool`.
---
[GitHub] flink issue #5931: [FLINK-9190][flip6,yarn] Request new container if contain...
Posted by sihuazhou <gi...@git.apache.org>.
Github user sihuazhou commented on the issue:
https://github.com/apache/flink/pull/5931
I also `+1` for the first approach, but I would like to wait for @tillrohrmann 's opinion.
And I also curious about one thing, that is currently when ResourceManager allocate a slot for the `pendingSlotRequest`, it send JM's information to the TM, and let TM offer the slot to the JM. What I wonder is that why the ResourceManager doesn't send the slot's TM information to the JM, and let the JM fetch slot from TM, is there some special reasons? This problem seems should not exists, if RM send slot's TM information to JM and let JM fetch slot from TM.
---
[GitHub] flink pull request #5931: [FLINK-9190][flip6,yarn] Request new container if ...
Posted by sihuazhou <gi...@git.apache.org>.
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5931#discussion_r187227128
--- Diff: flink-yarn/src/main/java/org/apache/flink/yarn/YarnResourceManager.java ---
@@ -293,21 +293,16 @@ public void startNewWorker(ResourceProfile resourceProfile) {
}
@Override
- public boolean stopWorker(YarnWorkerNode workerNode) {
- if (workerNode != null) {
- Container container = workerNode.getContainer();
- log.info("Stopping container {}.", container.getId());
- // release the container on the node manager
- try {
- nodeManagerClient.stopContainer(container.getId(), container.getNodeId());
- } catch (Throwable t) {
- log.warn("Error while calling YARN Node Manager to stop container", t);
- }
- resourceManagerClient.releaseAssignedContainer(container.getId());
- workerNodeMap.remove(workerNode.getResourceID());
- } else {
- log.error("Can not find container for null workerNode.");
+ public boolean stopWorker(final YarnWorkerNode workerNode) {
+ final Container container = workerNode.getContainer();
+ log.info("Stopping container {}.", container.getId());
+ try {
+ nodeManagerClient.stopContainer(container.getId(), container.getNodeId());
+ } catch (final Exception e) {
+ log.warn("Error while calling YARN Node Manager to stop container", e);
}
+ resourceManagerClient.releaseAssignedContainer(container.getId());
+ workerNodeMap.remove(workerNode.getResourceID());
return true;
--- End diff --
Ah, I think I am a bit confused here, even though the `stopWorker` method only called from the main thread, but the `onContainersCompleted` is not.
So, imagine that if we insert a `Thread.MILLISECOND.sleep(1000)`(this represents the latency of code execution in reality) between line 304 and 305, then `onContainersCompleted` would be called during the main thread was sleeping. Then, we require a new unnecessary container in `onContainersCompleted`, because the `workerNodeMap.remove(workerNode.getResourceID())` hasn't been called yet(during to the sleep). Am I misunderstand something? What do you think?
---
[GitHub] flink issue #5931: [FLINK-9190][flip6,yarn] Request new container if contain...
Posted by StephanEwen <gi...@git.apache.org>.
Github user StephanEwen commented on the issue:
https://github.com/apache/flink/pull/5931
@sihuazhou and @shuai-xu thank you for your help in understanding the bug here.
Let me rephrase it to make sure I understand the problem exactly. The steps are the following:
1. JobMaster / SlotPool requests a slot (AllocationID) from the ResourceManager
2. ResourceManager starts a container with a TaskManager
3. TaskManager registers at ResourceManager, which tells the TaskManager to push a slot to the JobManager.
4. TaskManager container is killed
5. The ResourceManager does not queue back the slot requests (AllocationIDs) that it sent to the previous TaskManager, so the requests are lost and need to time out before another attempt is tried.
Some thoughts on how to deal with this:
- It seems the ResourceManager should put the slots from the TaskManager that was failed back to "pending" so they are given to the next TaskManager that starts.
- I assume that is not happening, because there is concern that the failure is also detected on the JobManager/SlotPool and retried there and there are double re-tries
- The solution would be to better define the protocol with respect to who is responsible for what retries.
Two ideas on how to fix that:
1. The ResourceManager notifies the SlotPool that a certain set of AllocationIDs has failed, and the SlotPool directly retries the allocations, resulting in directly starting new containers.
2. The ResourceManager always retries allocations for AllocationIDs it knows. The SlotPool would not retry, it would keep the same allocations always unless they are released as unneeded. We would probably need something to make sure that the SlotPool can distinguish from different offers of the same AllocationID (in case the ResourceManager assumes a timeout but a request goes actually through) - possibly something like an attempt-counter (higher wins).
@tillrohrmann also interested in your thoughts here.
---
[GitHub] flink pull request #5931: [FLINK-9190][flip6,yarn] Request new container if ...
Posted by sihuazhou <gi...@git.apache.org>.
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5931#discussion_r187514050
--- Diff: flink-yarn/src/main/java/org/apache/flink/yarn/YarnResourceManager.java ---
@@ -293,21 +293,16 @@ public void startNewWorker(ResourceProfile resourceProfile) {
}
@Override
- public boolean stopWorker(YarnWorkerNode workerNode) {
- if (workerNode != null) {
- Container container = workerNode.getContainer();
- log.info("Stopping container {}.", container.getId());
- // release the container on the node manager
- try {
- nodeManagerClient.stopContainer(container.getId(), container.getNodeId());
- } catch (Throwable t) {
- log.warn("Error while calling YARN Node Manager to stop container", t);
- }
- resourceManagerClient.releaseAssignedContainer(container.getId());
- workerNodeMap.remove(workerNode.getResourceID());
- } else {
- log.error("Can not find container for null workerNode.");
+ public boolean stopWorker(final YarnWorkerNode workerNode) {
+ final Container container = workerNode.getContainer();
+ log.info("Stopping container {}.", container.getId());
+ try {
+ nodeManagerClient.stopContainer(container.getId(), container.getNodeId());
+ } catch (final Exception e) {
+ log.warn("Error while calling YARN Node Manager to stop container", e);
}
+ resourceManagerClient.releaseAssignedContainer(container.getId());
+ workerNodeMap.remove(workerNode.getResourceID());
return true;
--- End diff --
@GJL Thanks for figure out that for me, I missed that, I feel I'm a bit stupid now...
---
[GitHub] flink issue #5931: [FLINK-9190][flip6,yarn] Request new container if contain...
Posted by shuai-xu <gi...@git.apache.org>.
Github user shuai-xu commented on the issue:
https://github.com/apache/flink/pull/5931
@GJL In blink, we solve this problem like this.
When a container complete, we will first whether the container has registered yet, if it has registered before, RM will not request a new container, as the job master will ask for it when failover. If it has not registered, RM will request a new one.
---
[GitHub] flink pull request #5931: [FLINK-9190][flip6,yarn] Request new container if ...
Posted by tillrohrmann <gi...@git.apache.org>.
Github user tillrohrmann commented on a diff in the pull request:
https://github.com/apache/flink/pull/5931#discussion_r187102871
--- Diff: flink-yarn/src/main/java/org/apache/flink/yarn/YarnResourceManager.java ---
@@ -293,21 +293,16 @@ public void startNewWorker(ResourceProfile resourceProfile) {
}
@Override
- public boolean stopWorker(YarnWorkerNode workerNode) {
- if (workerNode != null) {
- Container container = workerNode.getContainer();
- log.info("Stopping container {}.", container.getId());
- // release the container on the node manager
- try {
- nodeManagerClient.stopContainer(container.getId(), container.getNodeId());
- } catch (Throwable t) {
- log.warn("Error while calling YARN Node Manager to stop container", t);
- }
- resourceManagerClient.releaseAssignedContainer(container.getId());
- workerNodeMap.remove(workerNode.getResourceID());
- } else {
- log.error("Can not find container for null workerNode.");
+ public boolean stopWorker(final YarnWorkerNode workerNode) {
+ final Container container = workerNode.getContainer();
+ log.info("Stopping container {}.", container.getId());
+ try {
+ nodeManagerClient.stopContainer(container.getId(), container.getNodeId());
+ } catch (final Exception e) {
+ log.warn("Error while calling YARN Node Manager to stop container", e);
--- End diff --
I think the reason is that @GJL does not want to swallow `Errors`.
---
[GitHub] flink issue #5931: [FLINK-9190][flip6,yarn] Request new container if contain...
Posted by sihuazhou <gi...@git.apache.org>.
Github user sihuazhou commented on the issue:
https://github.com/apache/flink/pull/5931
Hi @shuai-xu, If I'm not misunderstand, I think your approach is exactly what I have done in the previous [PR](https://github.com/apache/flink/pull/5881) for this ticket, but it faces the same problem as that faced by this PR. That's even the container registered with RM successfully, but after RM offering the slot to JM, the container was killed before it registered with JM successfully. I think one way to overcome this is that the RM should notify the JM which TM it will connect with before the RM assign the slot to it, this way JM could be notified that the TM was killed before connecting with it successfully.
---
[GitHub] flink issue #5931: [FLINK-9190][flip6,yarn] Request new container if contain...
Posted by shuai-xu <gi...@git.apache.org>.
Github user shuai-xu commented on the issue:
https://github.com/apache/flink/pull/5931
@StephanEwen, Good idea, I prefer the first one. As for the second one, the pending request may have been fulfilled when task executor is killed. so job master can not cancel the pending request. And when job master failover the job at the same time with resource manager request a new container, it may ask one more container than needed.
---
[GitHub] flink pull request #5931: [FLINK-9190][flip6,yarn] Request new container if ...
Posted by tillrohrmann <gi...@git.apache.org>.
Github user tillrohrmann commented on a diff in the pull request:
https://github.com/apache/flink/pull/5931#discussion_r187106742
--- Diff: flink-yarn/src/main/java/org/apache/flink/yarn/YarnResourceManager.java ---
@@ -293,21 +293,16 @@ public void startNewWorker(ResourceProfile resourceProfile) {
}
@Override
- public boolean stopWorker(YarnWorkerNode workerNode) {
- if (workerNode != null) {
- Container container = workerNode.getContainer();
- log.info("Stopping container {}.", container.getId());
- // release the container on the node manager
- try {
- nodeManagerClient.stopContainer(container.getId(), container.getNodeId());
- } catch (Throwable t) {
- log.warn("Error while calling YARN Node Manager to stop container", t);
- }
- resourceManagerClient.releaseAssignedContainer(container.getId());
- workerNodeMap.remove(workerNode.getResourceID());
- } else {
- log.error("Can not find container for null workerNode.");
+ public boolean stopWorker(final YarnWorkerNode workerNode) {
+ final Container container = workerNode.getContainer();
+ log.info("Stopping container {}.", container.getId());
+ try {
+ nodeManagerClient.stopContainer(container.getId(), container.getNodeId());
+ } catch (final Exception e) {
+ log.warn("Error while calling YARN Node Manager to stop container", e);
}
+ resourceManagerClient.releaseAssignedContainer(container.getId());
+ workerNodeMap.remove(workerNode.getResourceID());
return true;
--- End diff --
the `stopWorker` method should only be called from the main thread. Therefore, there should be no race condition.
---
[GitHub] flink pull request #5931: [FLINK-9190][flip6,yarn] Request new container if ...
Posted by GJL <gi...@git.apache.org>.
Github user GJL commented on a diff in the pull request:
https://github.com/apache/flink/pull/5931#discussion_r187466146
--- Diff: flink-yarn/src/main/java/org/apache/flink/yarn/YarnResourceManager.java ---
@@ -293,21 +293,16 @@ public void startNewWorker(ResourceProfile resourceProfile) {
}
@Override
- public boolean stopWorker(YarnWorkerNode workerNode) {
- if (workerNode != null) {
- Container container = workerNode.getContainer();
- log.info("Stopping container {}.", container.getId());
- // release the container on the node manager
- try {
- nodeManagerClient.stopContainer(container.getId(), container.getNodeId());
- } catch (Throwable t) {
- log.warn("Error while calling YARN Node Manager to stop container", t);
- }
- resourceManagerClient.releaseAssignedContainer(container.getId());
- workerNodeMap.remove(workerNode.getResourceID());
- } else {
- log.error("Can not find container for null workerNode.");
+ public boolean stopWorker(final YarnWorkerNode workerNode) {
+ final Container container = workerNode.getContainer();
+ log.info("Stopping container {}.", container.getId());
+ try {
+ nodeManagerClient.stopContainer(container.getId(), container.getNodeId());
+ } catch (final Exception e) {
+ log.warn("Error while calling YARN Node Manager to stop container", e);
}
+ resourceManagerClient.releaseAssignedContainer(container.getId());
+ workerNodeMap.remove(workerNode.getResourceID());
return true;
--- End diff --
@sihuazhou The body in `onContainersCompleted` is wrapped in `runAsync`
```
protected void runAsync(Runnable runnable)
Execute the runnable in the main thread of the underlying RPC endpoint.
Parameters:
runnable - Runnable to be executed in the main thread of the underlying RPC endpoint
```
---
[GitHub] flink issue #5931: [FLINK-9190][flip6,yarn] Request new container if contain...
Posted by sihuazhou <gi...@git.apache.org>.
Github user sihuazhou commented on the issue:
https://github.com/apache/flink/pull/5931
Hi @GJL , is it possible that the reason is the same as in the previous PR for this ticket, that is even the container setup successfully and connect with ResourceManager successfully, but the TM was killed before connecting to JobManager successfully. In this case, even though there are enough TMs, JobManager won't fire any new request, and the ResourceManager doesn't know that the container it assigned to JobManager has been killed either, so both JobManager & ResourceManager won't do anything but waiting for timeout... What do you think?
---
[GitHub] flink pull request #5931: [FLINK-9190][flip6,yarn] Request new container if ...
Posted by asfgit <gi...@git.apache.org>.
Github user asfgit closed the pull request at:
https://github.com/apache/flink/pull/5931
---
[GitHub] flink issue #5931: [FLINK-9190][flip6,yarn] Request new container if contain...
Posted by GJL <gi...@git.apache.org>.
Github user GJL commented on the issue:
https://github.com/apache/flink/pull/5931
@sihuazhou Thx for the review. I'll take a look at your comments later. Unfortunately with this patch it can still happen that a job is not running even if enough TMs are available. I have uploaded the JM logs here https://gist.github.com/GJL/3b109db48734ff40103f47d04fc54bd3
---