You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by xuanyuanking <gi...@git.apache.org> on 2018/05/19 12:03:36 UTC
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
GitHub user xuanyuanking opened a pull request:
https://github.com/apache/spark/pull/21370
[SPARK-24215][PySpark] Implement _repr_html_ for dataframes in PySpark
## What changes were proposed in this pull request?
Implement _repr_html_ for PySpark while in notebook and add config named "spark.jupyter.eagerEval.enabled" to control this.
The dev list thread for context: http://apache-spark-developers-list.1001551.n3.nabble.com/eager-execution-and-debuggability-td23928.html
## How was this patch tested?
New ut in DataFrameSuite and manual test in jupyter. Some screenshot below:


You can merge this pull request into a Git repository by running:
$ git pull https://github.com/xuanyuanking/spark SPARK-24215
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/21370.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #21370
----
commit ebc0b11fd006386d32949f56228e2671297373fc
Author: Yuanjian Li <xy...@...>
Date: 2018-05-19T11:56:02Z
SPARK-24215: Implement __repr__ and _repr_html_ for dataframes in PySpark
----
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91205/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189567315
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically
+ and html table will feedback the queries user have defined (see
+ <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
+ </td>
+</tr>
+<tr>
+ <td><code>spark.jupyter.default.showRows</code></td>
--- End diff --
change to spark.jupyter.eagerEval.showRows,thanks
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190153907
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
--- End diff --
Thanks, done. feb5f4a.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189613358
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -292,31 +297,25 @@ class Dataset[T] private[sql](
}
// Create SeparateLine
- val sep: String = colWidths.map("-" * _).addString(sb, "+", "+", "+\n").toString()
+ val sep: String = if (html) {
+ // Initial append table label
+ sb.append("<table border='1'>\n")
+ "\n"
+ } else {
+ colWidths.map("-" * _).addString(sb, "+", "+", "+\n").toString()
+ }
// column names
- rows.head.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
- StringUtils.leftPad(cell, colWidths(i))
- } else {
- StringUtils.rightPad(cell, colWidths(i))
- }
- }.addString(sb, "|", "|", "|\n")
-
+ appendRowString(rows.head, truncate, colWidths, html, true, sb)
sb.append(sep)
// data
- rows.tail.foreach {
- _.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
- StringUtils.leftPad(cell.toString, colWidths(i))
- } else {
- StringUtils.rightPad(cell.toString, colWidths(i))
- }
- }.addString(sb, "|", "|", "|\n")
+ rows.tail.foreach { row =>
+ appendRowString(row.map(_.toString), truncate, colWidths, html, false, sb)
--- End diff --
I see, the `cell.toString` has been called here. https://github.com/apache/spark/pull/21370/files/f2bb8f334631734869ddf5d8ef1eca1fa29d334a#diff-7a46f10c3cedbf013cf255564d9483cdR271
Got it, I'll fix this in next commit.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #91205 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91205/testReport)** for PR 21370 at commit [`94f3414`](https://github.com/apache/spark/commit/94f3414ebb689f4435018eab2e888e7d2974dc98).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192207299
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,70 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+
+ @property
+ def _max_num_rows(self):
+ """Returns the max row number for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", "20"))
+
+ @property
+ def _truncate(self):
+ """Returns the truncate length for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", "20"))
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ if not self._support_repr_html and self._eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ self._max_num_rows, self._truncate, vertical)
+ else:
+ return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+
+ def _repr_html_(self):
+ """Returns a dataframe with html code when you enabled eager evaluation
+ by 'spark.sql.repl.eagerEval.enabled', this only called by REPL you are
+ using support eager evaluation with HTML.
+ """
+ import cgi
+ if not self._support_repr_html:
+ self._support_repr_html = True
+ if self._eager_eval:
+ max_num_rows = self._max_num_rows
--- End diff --
We need to adjust `max_num_rows` as the same as Scala side like `val numRows = _numRows.max(0).min(Int.MaxValue - 1)`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191594348
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,62 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ def _get_repl_config(self):
+ """Return the configs for eager evaluation each time when __repr__ or
+ _repr_html_ called by user or notebook.
+ """
+ eager_eval = self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+ console_row = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", u"20"))
+ console_truncate = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", u"20"))
--- End diff --
ditto.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192348972
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and REPL you are using supports eager evaluation,
+ dataframe will be ran automatically and html table will feedback the queries user have defined
+ (see <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
+ </td>
+</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.maxNumRows</code></td>
+ <td>20</td>
+ <td>
+ Default number of rows in HTML table.
--- End diff --
Got it, more detailed description in 7f43a8b. Please check.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement eager evaluation...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194784664
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -3209,6 +3222,19 @@ class Dataset[T] private[sql](
}
}
+ private[sql] def getRowsToPython(
+ _numRows: Int,
+ truncate: Int,
+ vertical: Boolean): Array[Any] = {
+ EvaluatePython.registerPicklers()
+ val numRows = _numRows.max(0).min(Int.MaxValue - 1)
+ val rows = getRows(numRows, truncate, vertical).map(_.toArray).toArray
+ val toJava: (Any) => Any = EvaluatePython.toJava(_, ArrayType(ArrayType(StringType)))
+ val iter: Iterator[Array[Byte]] = new SerDeUtil.AutoBatchedPickler(
+ rows.iterator.map(toJava))
+ PythonRDD.serveIterator(iter, "serve-GetRows")
--- End diff --
Same answer with @HyukjinKwon about the return type, and actually the exact return type we need here is Array[Array[String]], this defined in `toJava` func.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement eager evaluation...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194794700
--- Diff: docs/configuration.md ---
@@ -456,6 +456,33 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and the REPL you are using supports eager evaluation,
+ Dataset will be ran automatically. The HTML table which generated by <code>_repl_html_</code>
+ called by notebooks like Jupyter will feedback the queries user have defined. For plain Python
+ REPL, the output will be shown like <code>dataframe.show()</code>
+ (see <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
+ </td>
+</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.maxNumRows</code></td>
+ <td>20</td>
+ <td>
+ Default number of rows in eager evaluation output HTML table generated by <code>_repr_html_</code> or plain text,
+ this only take effect when <code>spark.sql.repl.eagerEval.enabled</code> is set to true.
--- End diff --
Got it, thanks.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192772009
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +354,70 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+
+ @property
+ def _max_num_rows(self):
+ """Returns the max row number for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", "20"))
+
+ @property
+ def _truncate(self):
+ """Returns the truncate length for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", "20"))
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ if not self._support_repr_html and self._eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ self._max_num_rows, self._truncate, vertical)
+ else:
+ return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+
+ def _repr_html_(self):
+ """Returns a dataframe with html code when you enabled eager evaluation
+ by 'spark.sql.repl.eagerEval.enabled', this only called by REPL you are
+ using support eager evaluation with HTML.
+ """
+ import cgi
+ if not self._support_repr_html:
+ self._support_repr_html = True
+ if self._eager_eval:
+ max_num_rows = max(self._max_num_rows, 0)
+ with SCCallSiteSync(self._sc) as css:
+ vertical = False
+ sock_info = self._jdf.getRowsToPython(
+ max_num_rows, self._truncate, vertical)
+ rows = list(_load_from_socket(sock_info, BatchedSerializer(PickleSerializer())))
+ head = rows[0]
+ row_data = rows[1:]
+ has_more_data = len(row_data) > max_num_rows
+ row_data = row_data[0:max_num_rows]
+
+ html = "<table border='1'>\n<tr><th>"
+ # generate table head
+ html += "</th><th>".join(map(lambda x: cgi.escape(x), head)) + "</th></tr>\n"
+ # generate table rows
+ for row in row_data:
+ data = "<tr><td>" + "</td><td>".join(map(lambda x: cgi.escape(x), row)) + \
+ "</td></tr>\n"
--- End diff --
Thanks, more clearer.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194276179
--- Diff: python/pyspark/sql/tests.py ---
@@ -3074,6 +3074,36 @@ def test_checking_csv_header(self):
finally:
shutil.rmtree(path)
+ def test_repr_html(self):
--- End diff --
This function only covers the most basic positive case. We need also add more test cases. For example, the results when `spark.sql.repl.eagerEval.enabled` is set to `false`.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190172068
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -358,6 +357,43 @@ class Dataset[T] private[sql](
sb.toString()
}
+ /**
+ * Transform current row string and append to builder
+ *
+ * @param row Current row of string
+ * @param truncate If set to more than 0, truncates strings to `truncate` characters and
+ * all cells will be aligned right.
+ * @param colWidths The width of each column
+ * @param html If set to true, return output as html table.
+ * @param head Set to true while current row is table head.
+ * @param sb StringBuilder for current row.
+ */
+ private[sql] def appendRowString(
+ row: Seq[String],
+ truncate: Int,
+ colWidths: Array[Int],
+ html: Boolean,
+ head: Boolean,
+ sb: StringBuilder): Unit = {
+ val data = row.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ (html, head) match {
+ case (true, true) =>
+ data.map(StringEscapeUtils.escapeHtml).addString(
+ sb, "<tr><th>", "</th>\n<th>", "</th></tr>\n")
+ case (true, false) =>
+ data.map(StringEscapeUtils.escapeHtml).addString(
+ sb, "<tr><td>", "</td>\n<td>", "</td></tr>\n")
--- End diff --
ditto.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #91449 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91449/testReport)** for PR 21370 at commit [`597b8d5`](https://github.com/apache/spark/commit/597b8d515fd3bcd117b22ae29b05cd8a58d37ca2).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189512922
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically
+ and html table will feedback the queries user have defined (see
+ <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
--- End diff --
Yea, I felt the same thing too but there were the same few instances in this page.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191692934
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -291,37 +289,57 @@ class Dataset[T] private[sql](
}
}
+ rows = rows.map {
+ _.zipWithIndex.map { case (cell, i) =>
--- End diff --
nit:
```
rows.map { row =>
row.zipWithIndex...
``
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #90871 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90871/testReport)** for PR 21370 at commit [`ebc0b11`](https://github.com/apache/spark/commit/ebc0b11fd006386d32949f56228e2671297373fc).
* This patch **fails SparkR unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #90834 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90834/testReport)** for PR 21370 at commit [`ebc0b11`](https://github.com/apache/spark/commit/ebc0b11fd006386d32949f56228e2671297373fc).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by rxin <gi...@git.apache.org>.
Github user rxin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190803641
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and repl you're using supports eager evaluation,
+ dataframe will be ran automatically and html table will feedback the queries user have defined
+ (see <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
+ </td>
+</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.showRows</code></td>
--- End diff --
maxNumRows
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191693929
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -291,37 +289,57 @@ class Dataset[T] private[sql](
}
}
+ rows = rows.map {
+ _.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ }
+ }
+ rows
+ }
+
+ /**
+ * Compose the string representing rows for output
+ *
+ * @param _numRows Number of rows to show
+ * @param truncate If set to more than 0, truncates strings to `truncate` characters and
+ * all cells will be aligned right.
+ * @param vertical If set to true, prints output rows vertically (one line per column value).
+ */
+ private[sql] def showString(
+ _numRows: Int,
+ truncate: Int = 20,
+ vertical: Boolean = false): String = {
+ val numRows = _numRows.max(0).min(Int.MaxValue - 1)
+ // Get rows represented by Seq[Seq[String]], we may get one more line if it has more data.
+ val rows = getRows(numRows, truncate, vertical)
+ val fieldNames = rows.head
+ val data = rows.tail
+
+ val hasMoreData = data.length > numRows
+ val dataRows = data.take(numRows)
+
+ val sb = new StringBuilder
+ if (!vertical) {
// Create SeparateLine
- val sep: String = colWidths.map("-" * _).addString(sb, "+", "+", "+\n").toString()
+ val sep: String = fieldNames.map(_.length).toArray
+ .map("-" * _).addString(sb, "+", "+", "+\n").toString()
// column names
- rows.head.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
- StringUtils.leftPad(cell, colWidths(i))
- } else {
- StringUtils.rightPad(cell, colWidths(i))
- }
- }.addString(sb, "|", "|", "|\n")
-
+ fieldNames.addString(sb, "|", "|", "|\n")
sb.append(sep)
// data
- rows.tail.foreach {
- _.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
- StringUtils.leftPad(cell.toString, colWidths(i))
- } else {
- StringUtils.rightPad(cell.toString, colWidths(i))
- }
- }.addString(sb, "|", "|", "|\n")
+ dataRows.foreach {
+ _.addString(sb, "|", "|", "|\n")
--- End diff --
nit: we could just make it inlined
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189661812
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,26 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
- print(self._jdf.showString(n, 20, vertical))
+ print(self._jdf.showString(n, 20, vertical, False))
else:
- print(self._jdf.showString(n, int(truncate), vertical))
+ print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ def _repr_html_(self):
--- End diff --
Add comments above this to explain this goal of this function.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3772/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3623/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement eager evaluation...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194951791
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -3209,6 +3222,19 @@ class Dataset[T] private[sql](
}
}
+ private[sql] def getRowsToPython(
+ _numRows: Int,
+ truncate: Int,
+ vertical: Boolean): Array[Any] = {
+ EvaluatePython.registerPicklers()
+ val numRows = _numRows.max(0).min(Int.MaxValue - 1)
+ val rows = getRows(numRows, truncate, vertical).map(_.toArray).toArray
+ val toJava: (Any) => Any = EvaluatePython.toJava(_, ArrayType(ArrayType(StringType)))
+ val iter: Iterator[Array[Byte]] = new SerDeUtil.AutoBatchedPickler(
+ rows.iterator.map(toJava))
+ PythonRDD.serveIterator(iter, "serve-GetRows")
--- End diff --
re the py4j commit - there's a good reason for it @gatorsmile
not sure if the change to return type is required with the py4j change though
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190154145
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -237,9 +238,13 @@ class Dataset[T] private[sql](
* @param truncate If set to more than 0, truncates strings to `truncate` characters and
* all cells will be aligned right.
* @param vertical If set to true, prints output rows vertically (one line per column value).
+ * @param html If set to true, return output as html table.
--- End diff --
Thanks for guidance, I will do this in next commit.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90872/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192548361
--- Diff: docs/configuration.md ---
@@ -456,6 +456,33 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and REPL you are using supports eager evaluation,
--- End diff --
Thanks, done in 5b36604.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189447446
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -78,6 +78,12 @@ def __init__(self, jdf, sql_ctx):
self.is_cached = False
self._schema = None # initialized lazily
self._lazy_rdd = None
+ self._eager_eval = sql_ctx.getConf(
+ "spark.jupyter.eagerEval.enabled", "false").lower() == "true"
--- End diff --
let's add all these to documentation too
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191853613
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -291,37 +289,57 @@ class Dataset[T] private[sql](
}
}
+ rows = rows.map {
+ _.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ }
--- End diff --
Seems like the truncation is already done when creating `rows` above?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91354/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #91206 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91206/testReport)** for PR 21370 at commit [`425bee1`](https://github.com/apache/spark/commit/425bee1628917859b58dc87faccb7bc6146b7f1f).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189493218
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -292,31 +297,25 @@ class Dataset[T] private[sql](
}
// Create SeparateLine
- val sep: String = colWidths.map("-" * _).addString(sb, "+", "+", "+\n").toString()
+ val sep: String = if (html) {
+ // Initial append table label
+ sb.append("<table border='1'>\n")
+ "\n"
+ } else {
+ colWidths.map("-" * _).addString(sb, "+", "+", "+\n").toString()
+ }
// column names
- rows.head.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
- StringUtils.leftPad(cell, colWidths(i))
- } else {
- StringUtils.rightPad(cell, colWidths(i))
- }
- }.addString(sb, "|", "|", "|\n")
-
+ appendRowString(rows.head, truncate, colWidths, html, true, sb)
sb.append(sep)
// data
- rows.tail.foreach {
- _.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
- StringUtils.leftPad(cell.toString, colWidths(i))
- } else {
- StringUtils.rightPad(cell.toString, colWidths(i))
- }
- }.addString(sb, "|", "|", "|\n")
+ rows.tail.foreach { row =>
+ appendRowString(row.map(_.toString), truncate, colWidths, html, false, sb)
--- End diff --
We don't need `.map(_.toString)`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #91449 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91449/testReport)** for PR 21370 at commit [`597b8d5`](https://github.com/apache/spark/commit/597b8d515fd3bcd117b22ae29b05cd8a58d37ca2).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by rdblue <gi...@git.apache.org>.
Github user rdblue commented on the issue:
https://github.com/apache/spark/pull/21370
@rxin, `__repr__` is the equivalent for ipython and the python REPL. `_repr_html_` is the convention used by jupyter to replicate `__repr__` in notebooks with HTML output.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194629747
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -3209,6 +3222,19 @@ class Dataset[T] private[sql](
}
}
+ private[sql] def getRowsToPython(
+ _numRows: Int,
+ truncate: Int,
+ vertical: Boolean): Array[Any] = {
+ EvaluatePython.registerPicklers()
+ val numRows = _numRows.max(0).min(Int.MaxValue - 1)
+ val rows = getRows(numRows, truncate, vertical).map(_.toArray).toArray
+ val toJava: (Any) => Any = EvaluatePython.toJava(_, ArrayType(ArrayType(StringType)))
+ val iter: Iterator[Array[Byte]] = new SerDeUtil.AutoBatchedPickler(
+ rows.iterator.map(toJava))
+ PythonRDD.serveIterator(iter, "serve-GetRows")
--- End diff --
`PythonRDD.serveIterator(iter, "serve-GetRows")` returns `Int`, but the return type of `getRowsToPython ` is `Array[Any]`. How does it work? cc @xuanyuanking @HyukjinKwon
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189574938
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -237,9 +238,13 @@ class Dataset[T] private[sql](
* @param truncate If set to more than 0, truncates strings to `truncate` characters and
* all cells will be aligned right.
* @param vertical If set to true, prints output rows vertically (one line per column value).
+ * @param html If set to true, return output as html table.
--- End diff --
We can do this in python side, I implement it in scala side mainly consider to reuse the code and logic of `show()`, maybe it's more natural in `show df as html` call showString.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191702826
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -231,16 +234,17 @@ class Dataset[T] private[sql](
}
/**
- * Compose the string representing rows for output
+ * Get rows represented in Sequence by specific truncate and vertical requirement.
*
- * @param _numRows Number of rows to show
+ * @param numRows Number of rows to return
* @param truncate If set to more than 0, truncates strings to `truncate` characters and
* all cells will be aligned right.
- * @param vertical If set to true, prints output rows vertically (one line per column value).
+ * @param vertical If set to true, the rows to return don't need truncate.
--- End diff --
Yep, all abbreviation done in d4bf01a.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3413/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #91354 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91354/testReport)** for PR 21370 at commit [`9c6b3bb`](https://github.com/apache/spark/commit/9c6b3bbc430ffbcb752dc9870df877728f356cb8).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194278100
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +354,68 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
--- End diff --
Probably, we should access to SQLConf object. 1. Agree with not hardcoding it in general but 2. IMHO I want to avoid Py4J JVM accesses in the test because the test can likely be more flaky up to my knowledge, on the other hand (unlike Scala or Java side).
Maybe we should try to take a look about this hardcoding if we see more occurrences next time
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement eager evaluation...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194794008
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -3209,6 +3222,19 @@ class Dataset[T] private[sql](
}
}
+ private[sql] def getRowsToPython(
--- End diff --
Got it, the follow up pr I'm working on will add more test for `getRows` and `getRowsToPython`.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189660891
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -237,9 +238,13 @@ class Dataset[T] private[sql](
* @param truncate If set to more than 0, truncates strings to `truncate` characters and
* all cells will be aligned right.
* @param vertical If set to true, prints output rows vertically (one line per column value).
+ * @param html If set to true, return output as html table.
--- End diff --
This should not be done in Dataset.scala.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191687426
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -231,16 +234,17 @@ class Dataset[T] private[sql](
}
/**
- * Compose the string representing rows for output
+ * Get rows represented in Sequence by specific truncate and vertical requirement.
*
- * @param _numRows Number of rows to show
+ * @param numRows Number of rows to return
* @param truncate If set to more than 0, truncates strings to `truncate` characters and
* all cells will be aligned right.
- * @param vertical If set to true, prints output rows vertically (one line per column value).
+ * @param vertical If set to true, the rows to return don't need truncate.
*/
- private[sql] def showString(
- _numRows: Int, truncate: Int = 20, vertical: Boolean = false): String = {
- val numRows = _numRows.max(0).min(Int.MaxValue - 1)
--- End diff --
Yep, thanks, my mistake here.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189447465
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -237,9 +236,13 @@ class Dataset[T] private[sql](
* @param truncate If set to more than 0, truncates strings to `truncate` characters and
* all cells will be aligned right.
* @param vertical If set to true, prints output rows vertically (one line per column value).
+ * @param html If set to true, return output as html table.
*/
private[sql] def showString(
- _numRows: Int, truncate: Int = 20, vertical: Boolean = false): String = {
+ _numRows: Int,
+ truncate: Int = 20,
--- End diff --
when the output is truncated, does jupyter handle that properly?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194277082
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -3209,6 +3222,19 @@ class Dataset[T] private[sql](
}
}
+ private[sql] def getRowsToPython(
--- End diff --
In DataFrameSuite, we have multiple test cases for `showString` instead of `getRows `, which is introduced in this PR.
We also need the unit test cases for `getRowsToPython`.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192446542
--- Diff: docs/configuration.md ---
@@ -456,6 +456,33 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and REPL you are using supports eager evaluation,
+ dataframe will be ran automatically. HTML table will feedback the queries user have defined if
+ <code>_repl_html_</code> called by notebooks like Jupyter, otherwise for plain Python REPL, output
+ will be shown like <code>dataframe.show()</code>
+ (see <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
+ </td>
+</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.maxNumRows</code></td>
+ <td>20</td>
+ <td>
+ Default number of rows in eager evaluation output HTML table generated by <code>_repr_html_</code> or plain text,
+ this only take effect when <code>spark.sql.repl.eagerEval.enabled</code> set to true.
--- End diff --
`set to` -> `is set to`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on the issue:
https://github.com/apache/spark/pull/21370
```
Test coverage is the most critical when we refactor the existing code and add new features. Hopefully, when you submit new PRs in the future, could you also improve this part?
```
Of cause, I'll do this in a follow up PR and answer all question from Xiao this night. Thanks for all your comments.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189570764
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -358,6 +357,43 @@ class Dataset[T] private[sql](
sb.toString()
}
+ /**
+ * Transform current row string and append to builder
+ *
+ * @param row Current row of string
+ * @param truncate If set to more than 0, truncates strings to `truncate` characters and
+ * all cells will be aligned right.
+ * @param colWidths The width of each column
+ * @param html If set to true, return output as html table.
+ * @param head Set to true while current row is table head.
+ * @param sb StringBuilder for current row.
+ */
+ private[sql] def appendRowString(
+ row: Seq[String],
+ truncate: Int,
+ colWidths: Array[Int],
+ html: Boolean,
+ head: Boolean,
+ sb: StringBuilder): Unit = {
+ val data = row.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ (html, head) match {
+ case (true, true) =>
+ data.map(StringEscapeUtils.escapeHtml).addString(
+ sb, "<tr><th>", "</th><th>", "</th></tr>")
--- End diff --
the "\n" added in seperatedLine:https://github.com/apache/spark/pull/21370/files#diff-7a46f10c3cedbf013cf255564d9483cdR300
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194276795
--- Diff: docs/configuration.md ---
@@ -456,6 +456,33 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
--- End diff --
These confs are not part of `spark.sql("SET -v").show(numRows = 200, truncate = false)`.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194275282
--- Diff: docs/configuration.md ---
@@ -456,6 +456,33 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and the REPL you are using supports eager evaluation,
+ Dataset will be ran automatically. The HTML table which generated by <code>_repl_html_</code>
+ called by notebooks like Jupyter will feedback the queries user have defined. For plain Python
+ REPL, the output will be shown like <code>dataframe.show()</code>
+ (see <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
+ </td>
+</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.maxNumRows</code></td>
+ <td>20</td>
+ <td>
+ Default number of rows in eager evaluation output HTML table generated by <code>_repr_html_</code> or plain text,
+ this only take effect when <code>spark.sql.repl.eagerEval.enabled</code> is set to true.
--- End diff --
take -> takes
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #90834 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90834/testReport)** for PR 21370 at commit [`ebc0b11`](https://github.com/apache/spark/commit/ebc0b11fd006386d32949f56228e2671297373fc).
* This patch **fails to build**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by rxin <gi...@git.apache.org>.
Github user rxin commented on the issue:
https://github.com/apache/spark/pull/21370
Can we also do something a bit more generic that works for non-Jupyter notebooks as well? For example, in IPython or just plain Python REPL.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189606444
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -292,31 +297,25 @@ class Dataset[T] private[sql](
}
// Create SeparateLine
- val sep: String = colWidths.map("-" * _).addString(sb, "+", "+", "+\n").toString()
+ val sep: String = if (html) {
+ // Initial append table label
+ sb.append("<table border='1'>\n")
+ "\n"
+ } else {
+ colWidths.map("-" * _).addString(sb, "+", "+", "+\n").toString()
+ }
// column names
- rows.head.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
- StringUtils.leftPad(cell, colWidths(i))
- } else {
- StringUtils.rightPad(cell, colWidths(i))
- }
- }.addString(sb, "|", "|", "|\n")
-
+ appendRowString(rows.head, truncate, colWidths, html, true, sb)
sb.append(sep)
// data
- rows.tail.foreach {
- _.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
- StringUtils.leftPad(cell.toString, colWidths(i))
- } else {
- StringUtils.rightPad(cell.toString, colWidths(i))
- }
- }.addString(sb, "|", "|", "|\n")
+ rows.tail.foreach { row =>
+ appendRowString(row.map(_.toString), truncate, colWidths, html, false, sb)
--- End diff --
I know this is not your change, but the `rows` is already `Seq[Seq[String]]` and the `row` is `Seq[String]`, so I think we can remove it.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192772218
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +354,70 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+
+ @property
+ def _max_num_rows(self):
+ """Returns the max row number for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", "20"))
+
+ @property
+ def _truncate(self):
+ """Returns the truncate length for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", "20"))
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ if not self._support_repr_html and self._eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ self._max_num_rows, self._truncate, vertical)
+ else:
+ return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+
+ def _repr_html_(self):
+ """Returns a dataframe with html code when you enabled eager evaluation
+ by 'spark.sql.repl.eagerEval.enabled', this only called by REPL you are
+ using support eager evaluation with HTML.
+ """
+ import cgi
+ if not self._support_repr_html:
+ self._support_repr_html = True
+ if self._eager_eval:
+ max_num_rows = max(self._max_num_rows, 0)
+ with SCCallSiteSync(self._sc) as css:
+ vertical = False
+ sock_info = self._jdf.getRowsToPython(
+ max_num_rows, self._truncate, vertical)
+ rows = list(_load_from_socket(sock_info, BatchedSerializer(PickleSerializer())))
+ head = rows[0]
+ row_data = rows[1:]
+ has_more_data = len(row_data) > max_num_rows
+ row_data = row_data[0:max_num_rows]
+
+ html = "<table border='1'>\n<tr><th>"
+ # generate table head
+ html += "</th><th>".join(map(lambda x: cgi.escape(x), head)) + "</th></tr>\n"
+ # generate table rows
+ for row in row_data:
+ data = "<tr><td>" + "</td><td>".join(map(lambda x: cgi.escape(x), row)) + \
+ "</td></tr>\n"
+ html += data
+ html += "</table>\n"
+ if has_more_data:
+ html += "only showing top %d %s\n" % (
--- End diff --
Maybe we need this? Just want to keep same with `df.show()`.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91410/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190154231
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -358,6 +357,43 @@ class Dataset[T] private[sql](
sb.toString()
}
+ /**
+ * Transform current row string and append to builder
+ *
+ * @param row Current row of string
+ * @param truncate If set to more than 0, truncates strings to `truncate` characters and
+ * all cells will be aligned right.
+ * @param colWidths The width of each column
+ * @param html If set to true, return output as html table.
+ * @param head Set to true while current row is table head.
+ * @param sb StringBuilder for current row.
+ */
+ private[sql] def appendRowString(
+ row: Seq[String],
+ truncate: Int,
+ colWidths: Array[Int],
+ html: Boolean,
+ head: Boolean,
+ sb: StringBuilder): Unit = {
+ val data = row.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ (html, head) match {
+ case (true, true) =>
+ data.map(StringEscapeUtils.escapeHtml).addString(
+ sb, "<tr><th>", "</th><th>", "</th></tr>")
--- End diff --
Thanks, done. feb5f4a.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #91206 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91206/testReport)** for PR 21370 at commit [`425bee1`](https://github.com/apache/spark/commit/425bee1628917859b58dc87faccb7bc6146b7f1f).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by viirya <gi...@git.apache.org>.
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190251443
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,30 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
- print(self._jdf.showString(n, 20, vertical))
+ print(self._jdf.showString(n, 20, vertical, False))
else:
- print(self._jdf.showString(n, int(truncate), vertical))
+ print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ def _repr_html_(self):
+ """Returns a dataframe with html code when you enabled eager evaluation
+ by 'spark.sql.repl.eagerEval.enabled', this only called by repr you're
--- End diff --
repr -> repl?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3494/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91022/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194287915
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +354,68 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
--- End diff --
In the ongoing release, a nice-to-have refactoring is to move all the Core Confs into a single file just like what we did in Spark SQL Conf. Default values, boundary checking, types and descriptions. Thus, in PySpark, it would be better to do it starting from now.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by viirya <gi...@git.apache.org>.
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189509097
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically
--- End diff --
nit: Open -> Enable
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192292453
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and REPL you are using supports eager evaluation,
+ dataframe will be ran automatically and html table will feedback the queries user have defined
+ (see <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
+ </td>
+</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.maxNumRows</code></td>
+ <td>20</td>
+ <td>
+ Default number of rows in HTML table.
--- End diff --
Shell we explain a bit more what's the HTML table here a bit more? For example, I think at least we should say it's `_repr_html_`.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192446886
--- Diff: docs/configuration.md ---
@@ -456,6 +456,33 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and REPL you are using supports eager evaluation,
--- End diff --
`REPL` -> `the REPL`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194276298
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -3209,6 +3222,19 @@ class Dataset[T] private[sql](
}
}
+ private[sql] def getRowsToPython(
+ _numRows: Int,
+ truncate: Int,
+ vertical: Boolean): Array[Any] = {
+ EvaluatePython.registerPicklers()
+ val numRows = _numRows.max(0).min(Int.MaxValue - 1)
--- End diff --
This should be also part of the conf description.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192291498
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,70 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+
+ @property
+ def _max_num_rows(self):
+ """Returns the max row number for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", "20"))
+
+ @property
+ def _truncate(self):
+ """Returns the truncate length for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", "20"))
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ if not self._support_repr_html and self._eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ self._max_num_rows, self._truncate, vertical)
+ else:
+ return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+
+ def _repr_html_(self):
+ """Returns a dataframe with html code when you enabled eager evaluation
+ by 'spark.sql.repl.eagerEval.enabled', this only called by REPL you are
+ using support eager evaluation with HTML.
+ """
+ import cgi
+ if not self._support_repr_html:
+ self._support_repr_html = True
+ if self._eager_eval:
+ max_num_rows = self._max_num_rows
--- End diff --
I see. I think it's okay with max(0) only.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191686126
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,62 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ def _get_repl_config(self):
+ """Return the configs for eager evaluation each time when __repr__ or
+ _repr_html_ called by user or notebook.
+ """
+ eager_eval = self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+ console_row = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", u"20"))
+ console_truncate = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", u"20"))
+ return (eager_eval, console_row, console_truncate)
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ (eager_eval, console_row, console_truncate) = self._get_repl_config()
+ if not self._support_repr_html and eager_eval:
--- End diff --
As comment before, this is the flag to check whether \_repr_html\_ is called.

---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190485347
--- Diff: python/pyspark/sql/tests.py ---
@@ -3040,6 +3040,50 @@ def test_csv_sampling_ratio(self):
.csv(rdd, samplingRatio=0.5).schema
self.assertEquals(schema, StructType([StructField("_c0", IntegerType(), True)]))
+ def _get_content(self, content):
+ """
+ Strips leading spaces from content up to the first '|' in each line.
+ """
+ import re
+ pattern = re.compile(r'^ *\|', re.MULTILINE)
--- End diff --
We don't have to compile the pattern each time here since it's not going to be reused. You could just put this into re.sub I believe.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191080082
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -358,6 +357,43 @@ class Dataset[T] private[sql](
sb.toString()
}
+ /**
+ * Transform current row string and append to builder
+ *
+ * @param row Current row of string
+ * @param truncate If set to more than 0, truncates strings to `truncate` characters and
+ * all cells will be aligned right.
+ * @param colWidths The width of each column
+ * @param html If set to true, return output as html table.
+ * @param head Set to true while current row is table head.
+ * @param sb StringBuilder for current row.
+ */
+ private[sql] def appendRowString(
+ row: Seq[String],
+ truncate: Int,
+ colWidths: Array[Int],
+ html: Boolean,
+ head: Boolean,
+ sb: StringBuilder): Unit = {
+ val data = row.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ (html, head) match {
+ case (true, true) =>
+ data.map(StringEscapeUtils.escapeHtml).addString(
+ sb, "<tr><th>", "</th>\n<th>", "</th></tr>\n")
--- End diff --
I change the format in python \_repr\_html\_ in 94f3414.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91297/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #91354 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91354/testReport)** for PR 21370 at commit [`9c6b3bb`](https://github.com/apache/spark/commit/9c6b3bbc430ffbcb752dc9870df877728f356cb8).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192349023
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and REPL you are using supports eager evaluation,
+ dataframe will be ran automatically and html table will feedback the queries user have defined
--- End diff --
Sorry for this...again. 7f43a8b
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194275288
--- Diff: docs/configuration.md ---
@@ -456,6 +456,33 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and the REPL you are using supports eager evaluation,
+ Dataset will be ran automatically. The HTML table which generated by <code>_repl_html_</code>
+ called by notebooks like Jupyter will feedback the queries user have defined. For plain Python
+ REPL, the output will be shown like <code>dataframe.show()</code>
+ (see <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
+ </td>
+</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.maxNumRows</code></td>
+ <td>20</td>
+ <td>
+ Default number of rows in eager evaluation output HTML table generated by <code>_repr_html_</code> or plain text,
+ this only take effect when <code>spark.sql.repl.eagerEval.enabled</code> is set to true.
+ </td>
+</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.truncate</code></td>
+ <td>20</td>
+ <td>
+ Default number of truncate in eager evaluation output HTML table generated by <code>_repr_html_</code> or
+ plain text, this only take effect when <code>spark.sql.repl.eagerEval.enabled</code> set to true.
--- End diff --
take -> takes
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194276735
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +354,68 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
--- End diff --
Is that possible we can avoid hard-coding these conf key values? cc @ueshin @HyukjinKwon
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement eager evaluation...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194783738
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +354,68 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+
+ @property
+ def _max_num_rows(self):
+ """Returns the max row number for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", "20"))
+
+ @property
+ def _truncate(self):
+ """Returns the truncate length for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", "20"))
+
def __repr__(self):
--- End diff --
Done for this and also the PR description as your [comment](https://github.com/apache/spark/pull/21370#issuecomment-396453495), sorry for this and I'll pay more attention to that next time when the implementation changes during PR review. Is there any way to change the committed git log? Sorry for this.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189483903
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically
+ and html table will feedback the queries user have defined (see
--- End diff --
Got it.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #91022 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91022/testReport)** for PR 21370 at commit [`feb5f4a`](https://github.com/apache/spark/commit/feb5f4a9d8228437aa2bfc39714ee3f79505d0ac).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191080049
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,30 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
- print(self._jdf.showString(n, 20, vertical))
+ print(self._jdf.showString(n, 20, vertical, False))
else:
- print(self._jdf.showString(n, int(truncate), vertical))
+ print(self._jdf.showString(n, int(truncate), vertical, False))
--- End diff --
Fix in 94f3414.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192610512
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +354,70 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+
+ @property
+ def _max_num_rows(self):
+ """Returns the max row number for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", "20"))
+
+ @property
+ def _truncate(self):
+ """Returns the truncate length for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", "20"))
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ if not self._support_repr_html and self._eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ self._max_num_rows, self._truncate, vertical)
+ else:
+ return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+
+ def _repr_html_(self):
+ """Returns a dataframe with html code when you enabled eager evaluation
+ by 'spark.sql.repl.eagerEval.enabled', this only called by REPL you are
+ using support eager evaluation with HTML.
+ """
+ import cgi
+ if not self._support_repr_html:
+ self._support_repr_html = True
+ if self._eager_eval:
+ max_num_rows = max(self._max_num_rows, 0)
+ with SCCallSiteSync(self._sc) as css:
+ vertical = False
+ sock_info = self._jdf.getRowsToPython(
+ max_num_rows, self._truncate, vertical)
+ rows = list(_load_from_socket(sock_info, BatchedSerializer(PickleSerializer())))
+ head = rows[0]
+ row_data = rows[1:]
+ has_more_data = len(row_data) > max_num_rows
+ row_data = row_data[0:max_num_rows]
+
+ html = "<table border='1'>\n<tr><th>"
+ # generate table head
+ html += "</th><th>".join(map(lambda x: cgi.escape(x), head)) + "</th></tr>\n"
--- End diff --
maybe:
```
"<tr><th>%s</th></tr>\n" % "</th><th>".join(map(lambda x: cgi.escape(x), head))
```
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194277542
--- Diff: docs/configuration.md ---
@@ -456,6 +456,33 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and the REPL you are using supports eager evaluation,
--- End diff --
Just a question. When the REPL does not support eager evaluation, could we do anything better instead of silently ignoring the user inputs?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192548359
--- Diff: docs/configuration.md ---
@@ -456,6 +456,33 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and REPL you are using supports eager evaluation,
+ dataframe will be ran automatically. HTML table will feedback the queries user have defined if
+ <code>_repl_html_</code> called by notebooks like Jupyter, otherwise for plain Python REPL, output
--- End diff --
Thanks, done in 5b36604.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192292200
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -78,6 +78,7 @@ def __init__(self, jdf, sql_ctx):
self.is_cached = False
self._schema = None # initialized lazily
self._lazy_rdd = None
+ self._support_repr_html = False
--- End diff --
Shall we explain why we need this (as talked in https://github.com/apache/spark/pull/21370#discussion_r191591799)? It took me a while to understand too.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189493817
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically
+ and html table will feedback the queries user have defined (see
+ <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
+ </td>
+</tr>
+<tr>
+ <td><code>spark.jupyter.default.showRows</code></td>
--- End diff --
`spark.jupyter.eagerEval.showRows` or something?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189463098
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -78,6 +78,12 @@ def __init__(self, jdf, sql_ctx):
self.is_cached = False
self._schema = None # initialized lazily
self._lazy_rdd = None
+ self._eager_eval = sql_ctx.getConf(
+ "spark.jupyter.eagerEval.enabled", "false").lower() == "true"
--- End diff --
Got it. Do it in next commit. Thanks for reminding.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189663210
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
--- End diff --
Is this Jupyter specific? Can we make it more general?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189606746
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
--- End diff --
Oh, yes, I'd prefer to add `sql`.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192292278
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and REPL you are using supports eager evaluation,
+ dataframe will be ran automatically and html table will feedback the queries user have defined
--- End diff --
html -> HTML
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192349637
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,62 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ def _get_repl_config(self):
+ """Return the configs for eager evaluation each time when __repr__ or
+ _repr_html_ called by user or notebook.
+ """
+ eager_eval = self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+ console_row = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", u"20"))
+ console_truncate = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", u"20"))
+ return (eager_eval, console_row, console_truncate)
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ (eager_eval, console_row, console_truncate) = self._get_repl_config()
+ if not self._support_repr_html and eager_eval:
--- End diff --
Just want to avoid calling `_jdf` twice here, cause the second time called by `__repr__ ` is useless while `_repr_html_` is supported. The return string of `__repr__` will not finally be shown to notebook.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191696389
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -291,37 +289,57 @@ class Dataset[T] private[sql](
}
}
+ rows = rows.map {
+ _.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ }
--- End diff --
Do this in getRows here is to reuse the truncate logic. I think its the same problem with we discuss in here:
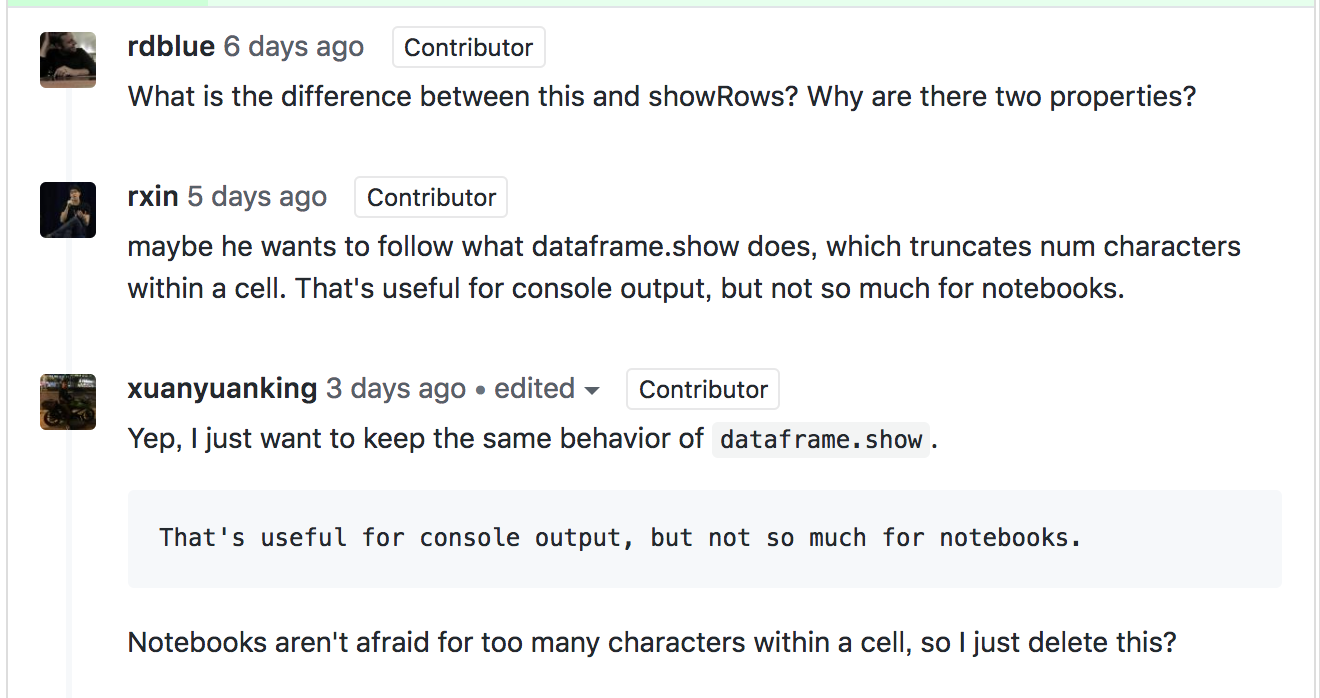
If we don't need truncate, we can move the logic and `minimumColWidth` in `showString`. I would like to hear your suggestions.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192446664
--- Diff: docs/configuration.md ---
@@ -456,6 +456,33 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and REPL you are using supports eager evaluation,
+ dataframe will be ran automatically. HTML table will feedback the queries user have defined if
+ <code>_repl_html_</code> called by notebooks like Jupyter, otherwise for plain Python REPL, output
--- End diff --
`output ` -> `the output`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #91389 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91389/testReport)** for PR 21370 at commit [`7f43a8b`](https://github.com/apache/spark/commit/7f43a8be81d6a668f08a4b5912afe8111432cca3).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192291854
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -291,37 +310,30 @@ class Dataset[T] private[sql](
}
}
+ val paddedRows = rows.map { row =>
+ row.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ }
+
// Create SeparateLine
val sep: String = colWidths.map("-" * _).addString(sb, "+", "+", "+\n").toString()
// column names
- rows.head.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
- StringUtils.leftPad(cell, colWidths(i))
- } else {
- StringUtils.rightPad(cell, colWidths(i))
- }
- }.addString(sb, "|", "|", "|\n")
-
+ paddedRows.head.addString(sb, "|", "|", "|\n")
sb.append(sep)
// data
- rows.tail.foreach {
- _.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
- StringUtils.leftPad(cell.toString, colWidths(i))
- } else {
- StringUtils.rightPad(cell.toString, colWidths(i))
- }
- }.addString(sb, "|", "|", "|\n")
- }
-
+ paddedRows.tail.foreach(_.addString(sb, "|", "|", "|\n"))
sb.append(sep)
} else {
// Extended display mode enabled
val fieldNames = rows.head
val dataRows = rows.tail
-
--- End diff --
Shall we revive this newline back?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189662795
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -237,9 +238,13 @@ class Dataset[T] private[sql](
* @param truncate If set to more than 0, truncates strings to `truncate` characters and
* all cells will be aligned right.
* @param vertical If set to true, prints output rows vertically (one line per column value).
+ * @param html If set to true, return output as html table.
--- End diff --
Can we create refactor showString to make it reusable for both show and _repr_html_?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by viirya <gi...@git.apache.org>.
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189512868
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +353,18 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
- print(self._jdf.showString(n, 20, vertical))
+ print(self._jdf.showString(n, 20, vertical, False))
else:
- print(self._jdf.showString(n, int(truncate), vertical))
+ print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ def _repr_html_(self):
+ if self._eager_eval:
+ return self._jdf.showString(
+ self._default_console_row, self._default_console_truncate, False, True)
--- End diff --
We need to return `None` if `self._eager_eval` is `False`.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189614136
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
--- End diff --
Got it, fix it in next commit.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91389/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement eager evaluation...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r195316251
--- Diff: docs/configuration.md ---
@@ -456,6 +456,33 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and the REPL you are using supports eager evaluation,
--- End diff --
That is true. We are not adding the eager execution in the our Dataset/DataFrame. We just rely on the REPL to trigger it. We need an update on the parameter description to emphasize it.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement eager evaluation...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194794493
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -3209,6 +3222,19 @@ class Dataset[T] private[sql](
}
}
+ private[sql] def getRowsToPython(
+ _numRows: Int,
+ truncate: Int,
+ vertical: Boolean): Array[Any] = {
+ EvaluatePython.registerPicklers()
+ val numRows = _numRows.max(0).min(Int.MaxValue - 1)
--- End diff --
Got it, will be fixed in another pr.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement eager evaluation...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194795581
--- Diff: docs/configuration.md ---
@@ -456,6 +456,33 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and the REPL you are using supports eager evaluation,
+ Dataset will be ran automatically. The HTML table which generated by <code>_repl_html_</code>
+ called by notebooks like Jupyter will feedback the queries user have defined. For plain Python
+ REPL, the output will be shown like <code>dataframe.show()</code>
+ (see <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
+ </td>
+</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.maxNumRows</code></td>
+ <td>20</td>
+ <td>
+ Default number of rows in eager evaluation output HTML table generated by <code>_repr_html_</code> or plain text,
+ this only take effect when <code>spark.sql.repl.eagerEval.enabled</code> is set to true.
+ </td>
+</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.truncate</code></td>
+ <td>20</td>
+ <td>
+ Default number of truncate in eager evaluation output HTML table generated by <code>_repr_html_</code> or
+ plain text, this only take effect when <code>spark.sql.repl.eagerEval.enabled</code> set to true.
--- End diff --
Got it, thanks, address in next follow up PR.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on the issue:
https://github.com/apache/spark/pull/21370
So one thing we might want to take a look at is application/vnd.dataresource+json for tables in the notebooks (see https://github.com/nteract/improved-spark-viz ).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3778/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #91205 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91205/testReport)** for PR 21370 at commit [`94f3414`](https://github.com/apache/spark/commit/94f3414ebb689f4435018eab2e888e7d2974dc98).
* This patch **fails Python style tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190153812
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,26 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
- print(self._jdf.showString(n, 20, vertical))
+ print(self._jdf.showString(n, 20, vertical, False))
else:
- print(self._jdf.showString(n, int(truncate), vertical))
+ print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ def _repr_html_(self):
--- End diff --
Thanks, done. feb5f4a.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement eager evaluation...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194797201
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +354,68 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+
+ @property
+ def _max_num_rows(self):
+ """Returns the max row number for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", "20"))
+
+ @property
+ def _truncate(self):
+ """Returns the truncate length for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", "20"))
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ if not self._support_repr_html and self._eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ self._max_num_rows, self._truncate, vertical)
+ else:
+ return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+
+ def _repr_html_(self):
+ """Returns a dataframe with html code when you enabled eager evaluation
+ by 'spark.sql.repl.eagerEval.enabled', this only called by REPL you are
+ using support eager evaluation with HTML.
+ """
+ import cgi
+ if not self._support_repr_html:
+ self._support_repr_html = True
+ if self._eager_eval:
+ max_num_rows = max(self._max_num_rows, 0)
+ vertical = False
--- End diff --
Yes, the discussion before linked below:
https://github.com/apache/spark/pull/21370#discussion_r190803855
and
https://github.com/apache/spark/pull/21370#discussion_r191593927
We need a named arguments for boolean flags here, but here limited by the named arguments can't work during python call _jdf func, so we do the work around like this.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90834/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91206/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191870129
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,62 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ def _get_repl_config(self):
+ """Return the configs for eager evaluation each time when __repr__ or
+ _repr_html_ called by user or notebook.
+ """
+ eager_eval = self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+ console_row = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", u"20"))
+ console_truncate = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", u"20"))
+ return (eager_eval, console_row, console_truncate)
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ (eager_eval, console_row, console_truncate) = self._get_repl_config()
+ if not self._support_repr_html and eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ console_row, console_truncate, vertical)
--- End diff --
Oh, I see. Good to know. Thanks!
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3736/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by viirya <gi...@git.apache.org>.
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189509246
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically
+ and html table will feedback the queries user have defined (see
+ <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
--- End diff --
Is it usually we include a JIRA ticket in user document like this?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192349210
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,70 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+
+ @property
+ def _max_num_rows(self):
+ """Returns the max row number for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", "20"))
+
+ @property
+ def _truncate(self):
+ """Returns the truncate length for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", "20"))
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ if not self._support_repr_html and self._eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ self._max_num_rows, self._truncate, vertical)
+ else:
+ return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+
+ def _repr_html_(self):
+ """Returns a dataframe with html code when you enabled eager evaluation
+ by 'spark.sql.repl.eagerEval.enabled', this only called by REPL you are
+ using support eager evaluation with HTML.
+ """
+ import cgi
+ if not self._support_repr_html:
+ self._support_repr_html = True
+ if self._eager_eval:
+ max_num_rows = self._max_num_rows
--- End diff --
Thanks, done in 7f43a8b.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191080037
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,30 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
- print(self._jdf.showString(n, 20, vertical))
+ print(self._jdf.showString(n, 20, vertical, False))
else:
- print(self._jdf.showString(n, int(truncate), vertical))
+ print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
--- End diff --
Thanks for your reply, this implement in 94f3414.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191687183
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,62 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ def _get_repl_config(self):
+ """Return the configs for eager evaluation each time when __repr__ or
+ _repr_html_ called by user or notebook.
+ """
+ eager_eval = self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+ console_row = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", u"20"))
+ console_truncate = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", u"20"))
+ return (eager_eval, console_row, console_truncate)
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ (eager_eval, console_row, console_truncate) = self._get_repl_config()
+ if not self._support_repr_html and eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ console_row, console_truncate, vertical)
--- End diff --
Actually I firstly implement like this but we'll got an TypeError Exception
```
TypeError: __call__() got an unexpected keyword argument 'vertical'
```
The named arguments can't work during python call _jdf func.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192349075
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -291,37 +310,30 @@ class Dataset[T] private[sql](
}
}
+ val paddedRows = rows.map { row =>
+ row.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ }
+
// Create SeparateLine
val sep: String = colWidths.map("-" * _).addString(sb, "+", "+", "+\n").toString()
// column names
- rows.head.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
- StringUtils.leftPad(cell, colWidths(i))
- } else {
- StringUtils.rightPad(cell, colWidths(i))
- }
- }.addString(sb, "|", "|", "|\n")
-
+ paddedRows.head.addString(sb, "|", "|", "|\n")
sb.append(sep)
// data
- rows.tail.foreach {
- _.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
- StringUtils.leftPad(cell.toString, colWidths(i))
- } else {
- StringUtils.rightPad(cell.toString, colWidths(i))
- }
- }.addString(sb, "|", "|", "|\n")
- }
-
+ paddedRows.tail.foreach(_.addString(sb, "|", "|", "|\n"))
sb.append(sep)
} else {
// Extended display mode enabled
val fieldNames = rows.head
val dataRows = rows.tail
-
--- End diff --
Thanks, done in 7f43a8b.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3701/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by rdblue <gi...@git.apache.org>.
Github user rdblue commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190683568
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,30 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
- print(self._jdf.showString(n, 20, vertical))
+ print(self._jdf.showString(n, 20, vertical, False))
else:
- print(self._jdf.showString(n, int(truncate), vertical))
+ print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
--- End diff --
I agree that it would be better to respect `spark.sql.repr.eagerEval.enabled` here as well.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3795/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191593927
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,62 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ def _get_repl_config(self):
+ """Return the configs for eager evaluation each time when __repr__ or
+ _repr_html_ called by user or notebook.
+ """
+ eager_eval = self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+ console_row = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", u"20"))
+ console_truncate = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", u"20"))
+ return (eager_eval, console_row, console_truncate)
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ (eager_eval, console_row, console_truncate) = self._get_repl_config()
+ if not self._support_repr_html and eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ console_row, console_truncate, vertical)
--- End diff --
I guess
```python
return self._jdf.showString(
console_row, console_truncate, vertical=False)
```
should work without `vertical` variable.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192771103
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +354,70 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+
+ @property
+ def _max_num_rows(self):
+ """Returns the max row number for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", "20"))
+
+ @property
+ def _truncate(self):
+ """Returns the truncate length for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", "20"))
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ if not self._support_repr_html and self._eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ self._max_num_rows, self._truncate, vertical)
+ else:
+ return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+
+ def _repr_html_(self):
+ """Returns a dataframe with html code when you enabled eager evaluation
+ by 'spark.sql.repl.eagerEval.enabled', this only called by REPL you are
+ using support eager evaluation with HTML.
+ """
+ import cgi
+ if not self._support_repr_html:
+ self._support_repr_html = True
+ if self._eager_eval:
+ max_num_rows = max(self._max_num_rows, 0)
+ with SCCallSiteSync(self._sc) as css:
--- End diff --
Thanks, delete it.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #90871 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90871/testReport)** for PR 21370 at commit [`ebc0b11`](https://github.com/apache/spark/commit/ebc0b11fd006386d32949f56228e2671297373fc).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on the issue:
https://github.com/apache/spark/pull/21370
@xuanyuanking Thanks for your contributions! Test coverage is the most critical when we refactor the existing code and add new features. Hopefully, when you submit new PRs in the future, could you also improve this part?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189483017
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically
--- End diff --
Jjupyter
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189493461
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -358,6 +357,43 @@ class Dataset[T] private[sql](
sb.toString()
}
+ /**
+ * Transform current row string and append to builder
+ *
+ * @param row Current row of string
+ * @param truncate If set to more than 0, truncates strings to `truncate` characters and
+ * all cells will be aligned right.
+ * @param colWidths The width of each column
+ * @param html If set to true, return output as html table.
+ * @param head Set to true while current row is table head.
+ * @param sb StringBuilder for current row.
+ */
+ private[sql] def appendRowString(
+ row: Seq[String],
+ truncate: Int,
+ colWidths: Array[Int],
+ html: Boolean,
+ head: Boolean,
+ sb: StringBuilder): Unit = {
+ val data = row.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ (html, head) match {
+ case (true, true) =>
+ data.map(StringEscapeUtils.escapeHtml).addString(
+ sb, "<tr><th>", "</th><th>", "</th></tr>")
+ case (true, false) =>
+ data.map(StringEscapeUtils.escapeHtml).addString(
+ sb, "<tr><td>", "</td><td>", "</td></tr>")
--- End diff --
ditto.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement eager evaluation...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194793637
--- Diff: docs/configuration.md ---
@@ -456,6 +456,33 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and the REPL you are using supports eager evaluation,
--- End diff --
Maybe it's hard to have a better way because we can hardly perceive it in dataset while REPL does not support eager evaluation.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189463652
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -237,9 +236,13 @@ class Dataset[T] private[sql](
* @param truncate If set to more than 0, truncates strings to `truncate` characters and
* all cells will be aligned right.
* @param vertical If set to true, prints output rows vertically (one line per column value).
+ * @param html If set to true, return output as html table.
*/
private[sql] def showString(
- _numRows: Int, truncate: Int = 20, vertical: Boolean = false): String = {
+ _numRows: Int,
+ truncate: Int = 20,
--- End diff --
Yes, the truncated string will be showed in table row and controlled by `spark.jupyter.default.truncate`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189567259
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically
--- End diff --
Got it, thanks.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement eager evaluation...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194790063
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -3209,6 +3222,19 @@ class Dataset[T] private[sql](
}
}
+ private[sql] def getRowsToPython(
+ _numRows: Int,
+ truncate: Int,
+ vertical: Boolean): Array[Any] = {
+ EvaluatePython.registerPicklers()
+ val numRows = _numRows.max(0).min(Int.MaxValue - 1)
+ val rows = getRows(numRows, truncate, vertical).map(_.toArray).toArray
+ val toJava: (Any) => Any = EvaluatePython.toJava(_, ArrayType(ArrayType(StringType)))
+ val iter: Iterator[Array[Byte]] = new SerDeUtil.AutoBatchedPickler(
+ rows.iterator.map(toJava))
+ PythonRDD.serveIterator(iter, "serve-GetRows")
--- End diff --
Yup ..
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189611792
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -358,6 +357,43 @@ class Dataset[T] private[sql](
sb.toString()
}
+ /**
+ * Transform current row string and append to builder
+ *
+ * @param row Current row of string
+ * @param truncate If set to more than 0, truncates strings to `truncate` characters and
+ * all cells will be aligned right.
+ * @param colWidths The width of each column
+ * @param html If set to true, return output as html table.
+ * @param head Set to true while current row is table head.
+ * @param sb StringBuilder for current row.
+ */
+ private[sql] def appendRowString(
+ row: Seq[String],
+ truncate: Int,
+ colWidths: Array[Int],
+ html: Boolean,
+ head: Boolean,
+ sb: StringBuilder): Unit = {
+ val data = row.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ (html, head) match {
+ case (true, true) =>
+ data.map(StringEscapeUtils.escapeHtml).addString(
+ sb, "<tr><th>", "</th><th>", "</th></tr>")
--- End diff --
Ah, I understand your consideration. I'll add this in next commit.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192610308
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +354,70 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+
+ @property
+ def _max_num_rows(self):
+ """Returns the max row number for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", "20"))
+
+ @property
+ def _truncate(self):
+ """Returns the truncate length for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", "20"))
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ if not self._support_repr_html and self._eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ self._max_num_rows, self._truncate, vertical)
+ else:
+ return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+
+ def _repr_html_(self):
+ """Returns a dataframe with html code when you enabled eager evaluation
+ by 'spark.sql.repl.eagerEval.enabled', this only called by REPL you are
+ using support eager evaluation with HTML.
+ """
+ import cgi
+ if not self._support_repr_html:
+ self._support_repr_html = True
+ if self._eager_eval:
+ max_num_rows = max(self._max_num_rows, 0)
+ with SCCallSiteSync(self._sc) as css:
--- End diff --
`css` seems not used.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191594326
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,62 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ def _get_repl_config(self):
+ """Return the configs for eager evaluation each time when __repr__ or
+ _repr_html_ called by user or notebook.
+ """
+ eager_eval = self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+ console_row = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", u"20"))
--- End diff --
Do we need `u` here?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by asfgit <gi...@git.apache.org>.
Github user asfgit closed the pull request at:
https://github.com/apache/spark/pull/21370
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191702931
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,62 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ def _get_repl_config(self):
+ """Return the configs for eager evaluation each time when __repr__ or
+ _repr_html_ called by user or notebook.
+ """
+ eager_eval = self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+ console_row = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", u"20"))
+ console_truncate = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", u"20"))
+ return (eager_eval, console_row, console_truncate)
--- End diff --
Done in d4bf01a. Please check.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on the issue:
https://github.com/apache/spark/pull/21370
Merged to master
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194641579
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -3209,6 +3222,19 @@ class Dataset[T] private[sql](
}
}
+ private[sql] def getRowsToPython(
+ _numRows: Int,
+ truncate: Int,
+ vertical: Boolean): Array[Any] = {
+ EvaluatePython.registerPicklers()
+ val numRows = _numRows.max(0).min(Int.MaxValue - 1)
+ val rows = getRows(numRows, truncate, vertical).map(_.toArray).toArray
+ val toJava: (Any) => Any = EvaluatePython.toJava(_, ArrayType(ArrayType(StringType)))
+ val iter: Iterator[Array[Byte]] = new SerDeUtil.AutoBatchedPickler(
+ rows.iterator.map(toJava))
+ PythonRDD.serveIterator(iter, "serve-GetRows")
--- End diff --
I think we return `Array[Any]` for `PythonRDD.serveIterator` too.
https://github.com/apache/spark/blob/628c7b517969c4a7ccb26ea67ab3dd61266073ca/core/src/main/scala/org/apache/spark/api/python/PythonRDD.scala#L400
Did I maybe miss something?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #90872 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90872/testReport)** for PR 21370 at commit [`f2bb8f3`](https://github.com/apache/spark/commit/f2bb8f334631734869ddf5d8ef1eca1fa29d334a).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement eager evaluation...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194788437
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -3209,6 +3222,19 @@ class Dataset[T] private[sql](
}
}
+ private[sql] def getRowsToPython(
+ _numRows: Int,
+ truncate: Int,
+ vertical: Boolean): Array[Any] = {
+ EvaluatePython.registerPicklers()
+ val numRows = _numRows.max(0).min(Int.MaxValue - 1)
+ val rows = getRows(numRows, truncate, vertical).map(_.toArray).toArray
+ val toJava: (Any) => Any = EvaluatePython.toJava(_, ArrayType(ArrayType(StringType)))
+ val iter: Iterator[Array[Byte]] = new SerDeUtil.AutoBatchedPickler(
+ rows.iterator.map(toJava))
+ PythonRDD.serveIterator(iter, "serve-GetRows")
--- End diff --
The changes of the return types were made in a commit `[PYSPARK] Update py4j to version 0.10.7.`... No PR was opened...
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on the issue:
https://github.com/apache/spark/pull/21370
Thanks all reviewer's comments, I address all comments in this commit. Please have a look.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191702754
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -291,37 +289,57 @@ class Dataset[T] private[sql](
}
}
+ rows = rows.map {
+ _.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ }
+ }
+ rows
+ }
+
+ /**
+ * Compose the string representing rows for output
+ *
+ * @param _numRows Number of rows to show
+ * @param truncate If set to more than 0, truncates strings to `truncate` characters and
+ * all cells will be aligned right.
+ * @param vertical If set to true, prints output rows vertically (one line per column value).
+ */
+ private[sql] def showString(
+ _numRows: Int,
+ truncate: Int = 20,
+ vertical: Boolean = false): String = {
+ val numRows = _numRows.max(0).min(Int.MaxValue - 1)
+ // Get rows represented by Seq[Seq[String]], we may get one more line if it has more data.
+ val rows = getRows(numRows, truncate, vertical)
+ val fieldNames = rows.head
+ val data = rows.tail
+
+ val hasMoreData = data.length > numRows
+ val dataRows = data.take(numRows)
+
+ val sb = new StringBuilder
+ if (!vertical) {
// Create SeparateLine
- val sep: String = colWidths.map("-" * _).addString(sb, "+", "+", "+\n").toString()
+ val sep: String = fieldNames.map(_.length).toArray
+ .map("-" * _).addString(sb, "+", "+", "+\n").toString()
// column names
- rows.head.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
- StringUtils.leftPad(cell, colWidths(i))
- } else {
- StringUtils.rightPad(cell, colWidths(i))
- }
- }.addString(sb, "|", "|", "|\n")
-
+ fieldNames.addString(sb, "|", "|", "|\n")
sb.append(sep)
// data
- rows.tail.foreach {
- _.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
- StringUtils.leftPad(cell.toString, colWidths(i))
- } else {
- StringUtils.rightPad(cell.toString, colWidths(i))
- }
- }.addString(sb, "|", "|", "|\n")
+ dataRows.foreach {
+ _.addString(sb, "|", "|", "|\n")
--- End diff --
Thanks, done in d4bf01a
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192610620
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +354,70 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+
+ @property
+ def _max_num_rows(self):
+ """Returns the max row number for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", "20"))
+
+ @property
+ def _truncate(self):
+ """Returns the truncate length for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", "20"))
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ if not self._support_repr_html and self._eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ self._max_num_rows, self._truncate, vertical)
+ else:
+ return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+
+ def _repr_html_(self):
+ """Returns a dataframe with html code when you enabled eager evaluation
+ by 'spark.sql.repl.eagerEval.enabled', this only called by REPL you are
+ using support eager evaluation with HTML.
+ """
+ import cgi
+ if not self._support_repr_html:
+ self._support_repr_html = True
+ if self._eager_eval:
+ max_num_rows = max(self._max_num_rows, 0)
+ with SCCallSiteSync(self._sc) as css:
+ vertical = False
+ sock_info = self._jdf.getRowsToPython(
+ max_num_rows, self._truncate, vertical)
+ rows = list(_load_from_socket(sock_info, BatchedSerializer(PickleSerializer())))
+ head = rows[0]
+ row_data = rows[1:]
+ has_more_data = len(row_data) > max_num_rows
+ row_data = row_data[0:max_num_rows]
+
+ html = "<table border='1'>\n<tr><th>"
+ # generate table head
+ html += "</th><th>".join(map(lambda x: cgi.escape(x), head)) + "</th></tr>\n"
+ # generate table rows
+ for row in row_data:
+ data = "<tr><td>" + "</td><td>".join(map(lambda x: cgi.escape(x), row)) + \
+ "</td></tr>\n"
+ html += data
+ html += "</table>\n"
+ if has_more_data:
+ html += "only showing top %d %s\n" % (
--- End diff --
I'd just way `row(s)`. Don't have to be super clever on this.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189447423
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -3056,7 +3059,6 @@ class Dataset[T] private[sql](
* view, e.g. `SELECT * FROM global_temp.view1`.
*
* @throws AnalysisException if the view name is invalid or already exists
- *
--- End diff --
why all these comment changes? could you revert them
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement eager evaluation...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194951918
--- Diff: docs/configuration.md ---
@@ -456,6 +456,33 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and the REPL you are using supports eager evaluation,
--- End diff --
I don't completely follow actually - what makes a "REPL does not support eager evaluation"?
in fact, this "eager evaluation" is just object rendering support build into REPL, notebook etc (like print), it's not really design to be "eager evaluation"
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189606695
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -358,6 +357,43 @@ class Dataset[T] private[sql](
sb.toString()
}
+ /**
+ * Transform current row string and append to builder
+ *
+ * @param row Current row of string
+ * @param truncate If set to more than 0, truncates strings to `truncate` characters and
+ * all cells will be aligned right.
+ * @param colWidths The width of each column
+ * @param html If set to true, return output as html table.
+ * @param head Set to true while current row is table head.
+ * @param sb StringBuilder for current row.
+ */
+ private[sql] def appendRowString(
+ row: Seq[String],
+ truncate: Int,
+ colWidths: Array[Int],
+ html: Boolean,
+ head: Boolean,
+ sb: StringBuilder): Unit = {
+ val data = row.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ (html, head) match {
+ case (true, true) =>
+ data.map(StringEscapeUtils.escapeHtml).addString(
+ sb, "<tr><th>", "</th><th>", "</th></tr>")
--- End diff --
Hmm, the header looks okay, but the data section will be a long line without `\n`? How about adding `\n` here and the data section, and just using `""` for the seperatedLine?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191591921
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,62 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ def _get_repl_config(self):
+ """Return the configs for eager evaluation each time when __repr__ or
+ _repr_html_ called by user or notebook.
+ """
+ eager_eval = self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+ console_row = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", u"20"))
+ console_truncate = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", u"20"))
+ return (eager_eval, console_row, console_truncate)
--- End diff --
How about declaring those as `@property`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by viirya <gi...@git.apache.org>.
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189589333
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,26 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
- print(self._jdf.showString(n, 20, vertical))
+ print(self._jdf.showString(n, 20, vertical, False))
else:
- print(self._jdf.showString(n, int(truncate), vertical))
+ print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ def _repr_html_(self):
--- End diff --
Add a simple test for `_repr_html` too?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189614067
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,26 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
- print(self._jdf.showString(n, 20, vertical))
+ print(self._jdf.showString(n, 20, vertical, False))
else:
- print(self._jdf.showString(n, int(truncate), vertical))
+ print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ def _repr_html_(self):
--- End diff --
No problem, I'll added in `SQLTests` in next commit.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91416/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192610839
--- Diff: python/pyspark/sql/tests.py ---
@@ -3040,6 +3040,36 @@ def test_csv_sampling_ratio(self):
.csv(rdd, samplingRatio=0.5).schema
self.assertEquals(schema, StructType([StructField("_c0", IntegerType(), True)]))
+ def test_repr_html(self):
+ import re
+ pattern = re.compile(r'^ *\|', re.MULTILINE)
+ df = self.spark.createDataFrame([(1, "1"), (22222, "22222")], ("key", "value"))
+ self.assertEquals(None, df._repr_html_())
+ self.spark.conf.set("spark.sql.repl.eagerEval.enabled", "true")
--- End diff --
Can we use `with self.sql_conf(...)`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192150368
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,62 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ def _get_repl_config(self):
+ """Return the configs for eager evaluation each time when __repr__ or
+ _repr_html_ called by user or notebook.
+ """
+ eager_eval = self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+ console_row = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", u"20"))
+ console_truncate = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", u"20"))
+ return (eager_eval, console_row, console_truncate)
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ (eager_eval, console_row, console_truncate) = self._get_repl_config()
+ if not self._support_repr_html and eager_eval:
--- End diff --
Yes that's right.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90871/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by rxin <gi...@git.apache.org>.
Github user rxin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190803855
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,30 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
- print(self._jdf.showString(n, 20, vertical))
+ print(self._jdf.showString(n, 20, vertical, False))
--- End diff --
use named arguments for boolean flags
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #90872 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90872/testReport)** for PR 21370 at commit [`f2bb8f3`](https://github.com/apache/spark/commit/f2bb8f334631734869ddf5d8ef1eca1fa29d334a).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement eager evaluation...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194794284
--- Diff: docs/configuration.md ---
@@ -456,6 +456,33 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
--- End diff --
Got it, I'll add there configurations into SQLConf.scala in the follow up pr.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement eager evaluation...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194952924
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -3209,6 +3222,19 @@ class Dataset[T] private[sql](
}
}
+ private[sql] def getRowsToPython(
+ _numRows: Int,
+ truncate: Int,
+ vertical: Boolean): Array[Any] = {
+ EvaluatePython.registerPicklers()
+ val numRows = _numRows.max(0).min(Int.MaxValue - 1)
+ val rows = getRows(numRows, truncate, vertical).map(_.toArray).toArray
+ val toJava: (Any) => Any = EvaluatePython.toJava(_, ArrayType(ArrayType(StringType)))
+ val iter: Iterator[Array[Byte]] = new SerDeUtil.AutoBatchedPickler(
+ rows.iterator.map(toJava))
+ PythonRDD.serveIterator(iter, "serve-GetRows")
--- End diff --
I think we better don't talk about this here though.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on the issue:
https://github.com/apache/spark/pull/21370
@xuanyuanking Just for your reference, for this PR, the PR description can be improved to something like
> This PR is to add eager execution into the __repr__ and _repr_html_ of the DataFrame APIs in PySpark. When eager evaluation is enabled, _repr_html_ returns a rich HTML version of the top-K rows of the DataFrame output. If `_repr_html_` is not called by REPL, `_repr_` will return the plain text of the top-K rows.
> This PR adds three new external SQL confs for controlling the behavior of eager evaluation:
> - spark.sql.repl.eagerEval.enabled: Enables eager evaluation or not. When true, the top K rows of Dataset will be displayed if and only if the REPL supports the eager evaluation. Currently, the eager evaluation is only supported in PySpark. For the notebooks like Jupyter, the HTML table (generated by _repr_html_) will be returned. For plain Python REPL, the returned outputs are formatted like <code>dataframe.show()</code>.
> - spark.sql.repl.eagerEval.maxNumRows: The max number of rows that are returned by eager evaluation. This only takes effect when <code>spark.sql.repl.eagerEval.enabled</code> is set to true.
> - spark.sql.repl.eagerEval.truncate: The max number of characters of each row that is returned by eager evaluation. This only takes effect when <code>spark.sql.repl.eagerEval.enabled</code> is set to true.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192349063
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -78,6 +78,7 @@ def __init__(self, jdf, sql_ctx):
self.is_cached = False
self._schema = None # initialized lazily
self._lazy_rdd = None
+ self._support_repr_html = False
--- End diff --
Got it, more comments in 7f43a8b.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189567614
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -78,6 +78,12 @@ def __init__(self, jdf, sql_ctx):
self.is_cached = False
self._schema = None # initialized lazily
self._lazy_rdd = None
+ self._eager_eval = sql_ctx.getConf(
+ "spark.jupyter.eagerEval.enabled", "false").lower() == "true"
+ self._default_console_row = int(sql_ctx.getConf(
+ "spark.jupyter.default.showRows", u"20"))
+ self._default_console_truncate = int(sql_ctx.getConf(
+ "spark.jupyter.default.showRows", u"20"))
--- End diff --
My bad, sorry for this.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194292067
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +354,68 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+
+ @property
+ def _max_num_rows(self):
+ """Returns the max row number for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", "20"))
+
+ @property
+ def _truncate(self):
+ """Returns the truncate length for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", "20"))
+
def __repr__(self):
--- End diff --
This PR also changed `__repr__`. Thus, we need to update the PR title and description.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189496454
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically
--- End diff --
`true` instead of `yes`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by rxin <gi...@git.apache.org>.
Github user rxin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189669772
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
--- End diff --
btw the config flag isn't jupyter specific.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by rxin <gi...@git.apache.org>.
Github user rxin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190803873
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,30 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
- print(self._jdf.showString(n, 20, vertical))
+ print(self._jdf.showString(n, 20, vertical, False))
else:
- print(self._jdf.showString(n, int(truncate), vertical))
+ print(self._jdf.showString(n, int(truncate), vertical, False))
--- End diff --
use named arguments for boolean flags
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190244648
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -358,6 +357,43 @@ class Dataset[T] private[sql](
sb.toString()
}
+ /**
+ * Transform current row string and append to builder
+ *
+ * @param row Current row of string
+ * @param truncate If set to more than 0, truncates strings to `truncate` characters and
+ * all cells will be aligned right.
+ * @param colWidths The width of each column
+ * @param html If set to true, return output as html table.
+ * @param head Set to true while current row is table head.
+ * @param sb StringBuilder for current row.
+ */
+ private[sql] def appendRowString(
+ row: Seq[String],
+ truncate: Int,
+ colWidths: Array[Int],
+ html: Boolean,
+ head: Boolean,
+ sb: StringBuilder): Unit = {
+ val data = row.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ (html, head) match {
+ case (true, true) =>
+ data.map(StringEscapeUtils.escapeHtml).addString(
+ sb, "<tr><th>", "</th>\n<th>", "</th></tr>\n")
--- End diff --
Got it, I'll change it.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on the issue:
https://github.com/apache/spark/pull/21370
@xuanyuanking @HyukjinKwon Sorry for the delay. Super busy in the week of Spark summit. Will carefully review this PR today or tomorrow.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189493846
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically
+ and html table will feedback the queries user have defined (see
+ <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
+ </td>
+</tr>
+<tr>
+ <td><code>spark.jupyter.default.showRows</code></td>
+ <td>20</td>
+ <td>
+ Default number of rows in jupyter html table.
+ </td>
+</tr>
+<tr>
+ <td><code>spark.jupyter.default.truncate</code></td>
--- End diff --
`spark.jupyter.eagerEval.truncate` or something?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on the issue:
https://github.com/apache/spark/pull/21370
```
this will need to escape the values to make sure it is legal html too right?
```
Yes you're right, thanks for your guidance, the new patch consider the escape and add new UT.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189570479
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -292,31 +297,25 @@ class Dataset[T] private[sql](
}
// Create SeparateLine
- val sep: String = colWidths.map("-" * _).addString(sb, "+", "+", "+\n").toString()
+ val sep: String = if (html) {
+ // Initial append table label
+ sb.append("<table border='1'>\n")
+ "\n"
+ } else {
+ colWidths.map("-" * _).addString(sb, "+", "+", "+\n").toString()
+ }
// column names
- rows.head.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
- StringUtils.leftPad(cell, colWidths(i))
- } else {
- StringUtils.rightPad(cell, colWidths(i))
- }
- }.addString(sb, "|", "|", "|\n")
-
+ appendRowString(rows.head, truncate, colWidths, html, true, sb)
sb.append(sep)
// data
- rows.tail.foreach {
- _.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
- StringUtils.leftPad(cell.toString, colWidths(i))
- } else {
- StringUtils.rightPad(cell.toString, colWidths(i))
- }
- }.addString(sb, "|", "|", "|\n")
+ rows.tail.foreach { row =>
+ appendRowString(row.map(_.toString), truncate, colWidths, html, false, sb)
--- End diff --
I think we need this toString, because the appendRowString method including both column names and data in original logic, which call `toString` in data part.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189603851
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,26 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
- print(self._jdf.showString(n, 20, vertical))
+ print(self._jdf.showString(n, 20, vertical, False))
else:
- print(self._jdf.showString(n, int(truncate), vertical))
+ print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ def _repr_html_(self):
--- End diff --
No problem, is the SQLTests in pyspark/sql/tests.py the right place?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #90896 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90896/testReport)** for PR 21370 at commit [`a798cf2`](https://github.com/apache/spark/commit/a798cf20d20b9b0f899ce477a56502549672482a).
* This patch **fails SparkR unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by rdblue <gi...@git.apache.org>.
Github user rdblue commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189733089
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -237,9 +238,13 @@ class Dataset[T] private[sql](
* @param truncate If set to more than 0, truncates strings to `truncate` characters and
* all cells will be aligned right.
* @param vertical If set to true, prints output rows vertically (one line per column value).
+ * @param html If set to true, return output as html table.
--- End diff --
+1 for reusing relevant parts of `show`.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191080057
--- Diff: python/pyspark/sql/tests.py ---
@@ -3040,6 +3040,50 @@ def test_csv_sampling_ratio(self):
.csv(rdd, samplingRatio=0.5).schema
self.assertEquals(schema, StructType([StructField("_c0", IntegerType(), True)]))
+ def _get_content(self, content):
+ """
+ Strips leading spaces from content up to the first '|' in each line.
+ """
+ import re
+ pattern = re.compile(r'^ *\|', re.MULTILINE)
--- End diff --
Thanks! Fix it in 94f3414.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90896/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on the issue:
https://github.com/apache/spark/pull/21370
retest this please
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191595442
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -231,16 +234,17 @@ class Dataset[T] private[sql](
}
/**
- * Compose the string representing rows for output
+ * Get rows represented in Sequence by specific truncate and vertical requirement.
*
- * @param _numRows Number of rows to show
+ * @param numRows Number of rows to return
* @param truncate If set to more than 0, truncates strings to `truncate` characters and
* all cells will be aligned right.
- * @param vertical If set to true, prints output rows vertically (one line per column value).
+ * @param vertical If set to true, the rows to return don't need truncate.
*/
- private[sql] def showString(
- _numRows: Int, truncate: Int = 20, vertical: Boolean = false): String = {
- val numRows = _numRows.max(0).min(Int.MaxValue - 1)
--- End diff --
Don't we need to check the `numRows` range when called from `getRowsToPython`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191694501
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and repl you're using supports eager evaluation,
--- End diff --
ditto for abbreviation `you're`.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189495783
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -78,6 +78,12 @@ def __init__(self, jdf, sql_ctx):
self.is_cached = False
self._schema = None # initialized lazily
self._lazy_rdd = None
+ self._eager_eval = sql_ctx.getConf(
+ "spark.jupyter.eagerEval.enabled", "false").lower() == "true"
+ self._default_console_row = int(sql_ctx.getConf(
+ "spark.jupyter.default.showRows", u"20"))
+ self._default_console_truncate = int(sql_ctx.getConf(
+ "spark.jupyter.default.showRows", u"20"))
--- End diff --
`spark.jupyter.default.truncate`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191854585
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,70 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def eagerEval(self):
--- End diff --
Btw, we should use snake case, e.g. `_eager_eval`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192147588
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -291,37 +289,57 @@ class Dataset[T] private[sql](
}
}
+ rows = rows.map {
+ _.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ }
--- End diff --
Oh, I see, the pad rows only useful in console mode, so not need in html code. I'll do this ASAP.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #91297 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91297/testReport)** for PR 21370 at commit [`d4bf01a`](https://github.com/apache/spark/commit/d4bf01a7c24ea12e94afb8366c1f5230484f356f).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191694631
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,62 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ def _get_repl_config(self):
+ """Return the configs for eager evaluation each time when __repr__ or
+ _repr_html_ called by user or notebook.
+ """
+ eager_eval = self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+ console_row = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", u"20"))
+ console_truncate = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", u"20"))
+ return (eager_eval, console_row, console_truncate)
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ (eager_eval, console_row, console_truncate) = self._get_repl_config()
+ if not self._support_repr_html and eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ console_row, console_truncate, vertical)
+ else:
+ return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+
+ def _repr_html_(self):
+ """Returns a dataframe with html code when you enabled eager evaluation
+ by 'spark.sql.repl.eagerEval.enabled', this only called by REPL you're
--- End diff --
ditto for abbreviation
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #91410 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91410/testReport)** for PR 21370 at commit [`5b36604`](https://github.com/apache/spark/commit/5b3660458945eb318b51b327fcaf10dc94dde82e).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192209239
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,62 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ def _get_repl_config(self):
+ """Return the configs for eager evaluation each time when __repr__ or
+ _repr_html_ called by user or notebook.
+ """
+ eager_eval = self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+ console_row = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", u"20"))
+ console_truncate = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", u"20"))
+ return (eager_eval, console_row, console_truncate)
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ (eager_eval, console_row, console_truncate) = self._get_repl_config()
+ if not self._support_repr_html and eager_eval:
--- End diff --
I see, thanks.
I thinks it's okay, but I'm just curious why you want to restrict it?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91449/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194276557
--- Diff: docs/configuration.md ---
@@ -456,6 +456,33 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
--- End diff --
All the SQL configurations should follow what we did in the section of `Spark SQL` https://spark.apache.org/docs/latest/configuration.html#spark-sql.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191869090
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,62 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ def _get_repl_config(self):
+ """Return the configs for eager evaluation each time when __repr__ or
+ _repr_html_ called by user or notebook.
+ """
+ eager_eval = self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+ console_row = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", u"20"))
+ console_truncate = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", u"20"))
+ return (eager_eval, console_row, console_truncate)
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ (eager_eval, console_row, console_truncate) = self._get_repl_config()
+ if not self._support_repr_html and eager_eval:
--- End diff --
So you want to restrict `__repr__` to always return the original string like `"DataFrame[key: bigint, value: string]"` after `_repr_html_` is called?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by viirya <gi...@git.apache.org>.
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189509532
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically
--- End diff --
true is better since the default value is false.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191080044
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,30 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
- print(self._jdf.showString(n, 20, vertical))
+ print(self._jdf.showString(n, 20, vertical, False))
--- End diff --
Thanks, fix in 94f3414.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #91389 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91389/testReport)** for PR 21370 at commit [`7f43a8b`](https://github.com/apache/spark/commit/7f43a8be81d6a668f08a4b5912afe8111432cca3).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192282041
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,70 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+
+ @property
+ def _max_num_rows(self):
+ """Returns the max row number for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", "20"))
+
+ @property
+ def _truncate(self):
+ """Returns the truncate length for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", "20"))
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ if not self._support_repr_html and self._eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ self._max_num_rows, self._truncate, vertical)
+ else:
+ return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+
+ def _repr_html_(self):
+ """Returns a dataframe with html code when you enabled eager evaluation
+ by 'spark.sql.repl.eagerEval.enabled', this only called by REPL you are
+ using support eager evaluation with HTML.
+ """
+ import cgi
+ if not self._support_repr_html:
+ self._support_repr_html = True
+ if self._eager_eval:
+ max_num_rows = self._max_num_rows
--- End diff --
Yes, but I do this in scala side `getRowsToPython`. Link here: https://github.com/apache/spark/pull/21370/files/9c6b3bbc430ffbcb752dc9870df877728f356cb8#diff-7a46f10c3cedbf013cf255564d9483cdR3229
This is because during my test, I found python `sys.intmax` actually cast to long with 2 ^ 63 - 1 while scala `Int.MaxValue` is 2 ^ 31 - 1.

---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189569437
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +353,18 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
- print(self._jdf.showString(n, 20, vertical))
+ print(self._jdf.showString(n, 20, vertical, False))
else:
- print(self._jdf.showString(n, int(truncate), vertical))
+ print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ def _repr_html_(self):
+ if self._eager_eval:
+ return self._jdf.showString(
+ self._default_console_row, self._default_console_truncate, False, True)
--- End diff --
```
What will be shown if spark.jupyter.eagerEval.enabled is False? Fallback the original automatically?
```
Yes, it will fallback to call __repr__.
```
We need to return None if self._eager_eval is False.
```
Got it, more clear in code logic.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189495803
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -78,6 +78,12 @@ def __init__(self, jdf, sql_ctx):
self.is_cached = False
self._schema = None # initialized lazily
self._lazy_rdd = None
+ self._eager_eval = sql_ctx.getConf(
+ "spark.jupyter.eagerEval.enabled", "false").lower() == "true"
+ self._default_console_row = int(sql_ctx.getConf(
+ "spark.jupyter.default.showRows", u"20"))
+ self._default_console_truncate = int(sql_ctx.getConf(
+ "spark.jupyter.default.showRows", u"20"))
--- End diff --
I guess we shouldn't hold these three values but extract as `@property` or refer each time in `_repr_html_`. Otherwise, we'll hit unexpected behavior, e.g.:
```python
df = ...
spark.conf.set("spark.jupyter.eagerEval.enabled", True)
df
```
won't show the html.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on the issue:
https://github.com/apache/spark/pull/21370
@HyukjinKwon @holdenk @ueshin
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189483025
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically
+ and html table will feedback the queries user have defined (see
--- End diff --
HTML
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191080194
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -237,9 +238,13 @@ class Dataset[T] private[sql](
* @param truncate If set to more than 0, truncates strings to `truncate` characters and
* all cells will be aligned right.
* @param vertical If set to true, prints output rows vertically (one line per column value).
+ * @param html If set to true, return output as html table.
--- End diff --
@viirya @gatorsmile @rdblue Sorry for the late commit, the refactor do in 94f3414. I spend some time on testing and implementing the transformation of rows between python and scala.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190172035
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -358,6 +357,43 @@ class Dataset[T] private[sql](
sb.toString()
}
+ /**
+ * Transform current row string and append to builder
+ *
+ * @param row Current row of string
+ * @param truncate If set to more than 0, truncates strings to `truncate` characters and
+ * all cells will be aligned right.
+ * @param colWidths The width of each column
+ * @param html If set to true, return output as html table.
+ * @param head Set to true while current row is table head.
+ * @param sb StringBuilder for current row.
+ */
+ private[sql] def appendRowString(
+ row: Seq[String],
+ truncate: Int,
+ colWidths: Array[Int],
+ html: Boolean,
+ head: Boolean,
+ sb: StringBuilder): Unit = {
+ val data = row.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ (html, head) match {
+ case (true, true) =>
+ data.map(StringEscapeUtils.escapeHtml).addString(
+ sb, "<tr><th>", "</th>\n<th>", "</th></tr>\n")
--- End diff --
I'm sorry, but I don't think we need the middle `\n`, it's okay with only the last one.
`"<tr><th>", "</th><th>", "</th></tr>\n"`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #91022 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91022/testReport)** for PR 21370 at commit [`feb5f4a`](https://github.com/apache/spark/commit/feb5f4a9d8228437aa2bfc39714ee3f79505d0ac).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191080026
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and repl you're using supports eager evaluation,
+ dataframe will be ran automatically and html table will feedback the queries user have defined
+ (see <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
+ </td>
+</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.showRows</code></td>
--- End diff --
Thanks, change it in 94f3414.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191685596
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,62 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ def _get_repl_config(self):
+ """Return the configs for eager evaluation each time when __repr__ or
+ _repr_html_ called by user or notebook.
+ """
+ eager_eval = self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+ console_row = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", u"20"))
+ console_truncate = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", u"20"))
+ return (eager_eval, console_row, console_truncate)
--- End diff --
OK.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3399/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by rdblue <gi...@git.apache.org>.
Github user rdblue commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190683035
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,30 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
- print(self._jdf.showString(n, 20, vertical))
+ print(self._jdf.showString(n, 20, vertical, False))
else:
- print(self._jdf.showString(n, int(truncate), vertical))
+ print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ def _repr_html_(self):
+ """Returns a dataframe with html code when you enabled eager evaluation
+ by 'spark.sql.repl.eagerEval.enabled', this only called by repr you're
--- End diff --
I think it works either way. REPL is better in my opinion because these settings should (ideally) apply when using any REPL.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190153833
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,26 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
- print(self._jdf.showString(n, 20, vertical))
+ print(self._jdf.showString(n, 20, vertical, False))
else:
- print(self._jdf.showString(n, int(truncate), vertical))
+ print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ def _repr_html_(self):
--- End diff --
Thanks, done. feb5f4a.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #91410 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91410/testReport)** for PR 21370 at commit [`5b36604`](https://github.com/apache/spark/commit/5b3660458945eb318b51b327fcaf10dc94dde82e).
* This patch **fails due to an unknown error code, -9**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192167463
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,70 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def eagerEval(self):
--- End diff --
Thanks, done in 9c6b3bb.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on the issue:
https://github.com/apache/spark/pull/21370
we will wait for the tests to be fixed first.
@xuanyuanking could you update the PR description to clarify which is "before" which is "after"?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191702675
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -291,37 +289,57 @@ class Dataset[T] private[sql](
}
}
+ rows = rows.map {
+ _.zipWithIndex.map { case (cell, i) =>
--- End diff --
Thanks, done in d4bf01a.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192771951
--- Diff: python/pyspark/sql/tests.py ---
@@ -3040,6 +3040,36 @@ def test_csv_sampling_ratio(self):
.csv(rdd, samplingRatio=0.5).schema
self.assertEquals(schema, StructType([StructField("_c0", IntegerType(), True)]))
+ def test_repr_html(self):
+ import re
+ pattern = re.compile(r'^ *\|', re.MULTILINE)
+ df = self.spark.createDataFrame([(1, "1"), (22222, "22222")], ("key", "value"))
+ self.assertEquals(None, df._repr_html_())
+ self.spark.conf.set("spark.sql.repl.eagerEval.enabled", "true")
--- End diff --
Thanks, done in next commit.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191694169
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -231,16 +234,17 @@ class Dataset[T] private[sql](
}
/**
- * Compose the string representing rows for output
+ * Get rows represented in Sequence by specific truncate and vertical requirement.
*
- * @param _numRows Number of rows to show
+ * @param numRows Number of rows to return
* @param truncate If set to more than 0, truncates strings to `truncate` characters and
* all cells will be aligned right.
- * @param vertical If set to true, prints output rows vertically (one line per column value).
+ * @param vertical If set to true, the rows to return don't need truncate.
--- End diff --
I would avoid abbreviation in the documentation. `don't` -> `do not`.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3760/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191854612
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,70 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def eagerEval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+
+ @property
+ def maxNumRows(self):
--- End diff --
ditto.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on the issue:
https://github.com/apache/spark/pull/21370
Not sure who is the right reviewer, maybe @rdblue @gatorsmile ?
Could you help me check whether it is the right implementation for the discussion in the dev list?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #91416 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91416/testReport)** for PR 21370 at commit [`5b36604`](https://github.com/apache/spark/commit/5b3660458945eb318b51b327fcaf10dc94dde82e).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3622/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191854703
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,70 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def eagerEval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+
+ @property
+ def maxNumRows(self):
+ """Returns the max row number for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", "20"))
+
+ @property
+ def truncate(self):
--- End diff --
ditto.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189567350
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically
+ and html table will feedback the queries user have defined (see
+ <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
+ </td>
+</tr>
+<tr>
+ <td><code>spark.jupyter.default.showRows</code></td>
+ <td>20</td>
+ <td>
+ Default number of rows in jupyter html table.
+ </td>
+</tr>
+<tr>
+ <td><code>spark.jupyter.default.truncate</code></td>
--- End diff --
Yep, change to spark.jupyter.eagerEval.truncate
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191080316
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and repl you're using supports eager evaluation,
+ dataframe will be ran automatically and html table will feedback the queries user have defined
+ (see <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
+ </td>
+</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.showRows</code></td>
+ <td>20</td>
+ <td>
+ Default number of rows in HTML table.
+ </td>
+</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.truncate</code></td>
--- End diff --
Yep, I just want to keep the same behavior of `dataframe.show`.
```
That's useful for console output, but not so much for notebooks.
```
Notebooks aren't afraid for too many chaacters within a cell, so I just delete this?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3398/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/21370
**[Test build #91416 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91416/testReport)** for PR 21370 at commit [`5b36604`](https://github.com/apache/spark/commit/5b3660458945eb318b51b327fcaf10dc94dde82e).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by rdblue <gi...@git.apache.org>.
Github user rdblue commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190682484
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and repl you're using supports eager evaluation,
+ dataframe will be ran automatically and html table will feedback the queries user have defined
+ (see <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
+ </td>
+</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.showRows</code></td>
--- End diff --
I don't think it is obvious what "showRows" does. I would assume that it is a boolean, but it is a limit instead. What about calling this "limit" or "numRows"?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191593987
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,62 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ def _get_repl_config(self):
+ """Return the configs for eager evaluation each time when __repr__ or
+ _repr_html_ called by user or notebook.
+ """
+ eager_eval = self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+ console_row = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", u"20"))
+ console_truncate = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", u"20"))
+ return (eager_eval, console_row, console_truncate)
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ (eager_eval, console_row, console_truncate) = self._get_repl_config()
+ if not self._support_repr_html and eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ console_row, console_truncate, vertical)
+ else:
+ return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+
+ def _repr_html_(self):
+ """Returns a dataframe with html code when you enabled eager evaluation
+ by 'spark.sql.repl.eagerEval.enabled', this only called by REPL you're
+ using support eager evaluation with HTML.
+ """
+ import cgi
+ if not self._support_repr_html:
+ self._support_repr_html = True
+ (eager_eval, console_row, console_truncate) = self._get_repl_config()
+ if eager_eval:
+ with SCCallSiteSync(self._sc) as css:
+ vertical = False
+ sock_info = self._jdf.getRowsToPython(
+ console_row, console_truncate, vertical)
--- End diff --
ditto.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189447477
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -237,9 +236,13 @@ class Dataset[T] private[sql](
* @param truncate If set to more than 0, truncates strings to `truncate` characters and
* all cells will be aligned right.
* @param vertical If set to true, prints output rows vertically (one line per column value).
+ * @param html If set to true, return output as html table.
*/
private[sql] def showString(
- _numRows: Int, truncate: Int = 20, vertical: Boolean = false): String = {
+ _numRows: Int,
+ truncate: Int = 20,
--- End diff --
or does that depend on the html output on L300?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192771787
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +354,70 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+
+ @property
+ def _max_num_rows(self):
+ """Returns the max row number for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", "20"))
+
+ @property
+ def _truncate(self):
+ """Returns the truncate length for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", "20"))
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ if not self._support_repr_html and self._eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ self._max_num_rows, self._truncate, vertical)
+ else:
+ return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+
+ def _repr_html_(self):
+ """Returns a dataframe with html code when you enabled eager evaluation
+ by 'spark.sql.repl.eagerEval.enabled', this only called by REPL you are
+ using support eager evaluation with HTML.
+ """
+ import cgi
+ if not self._support_repr_html:
+ self._support_repr_html = True
+ if self._eager_eval:
+ max_num_rows = max(self._max_num_rows, 0)
+ with SCCallSiteSync(self._sc) as css:
+ vertical = False
+ sock_info = self._jdf.getRowsToPython(
+ max_num_rows, self._truncate, vertical)
+ rows = list(_load_from_socket(sock_info, BatchedSerializer(PickleSerializer())))
+ head = rows[0]
+ row_data = rows[1:]
+ has_more_data = len(row_data) > max_num_rows
+ row_data = row_data[0:max_num_rows]
--- End diff --
Thanks, done in next commit.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by rxin <gi...@git.apache.org>.
Github user rxin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190803772
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.enabled</code></td>
+ <td>false</td>
+ <td>
+ Enable eager evaluation or not. If true and repl you're using supports eager evaluation,
+ dataframe will be ran automatically and html table will feedback the queries user have defined
+ (see <a href="https://issues.apache.org/jira/browse/SPARK-24215">SPARK-24215</a> for more details).
+ </td>
+</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.showRows</code></td>
+ <td>20</td>
+ <td>
+ Default number of rows in HTML table.
+ </td>
+</tr>
+<tr>
+ <td><code>spark.sql.repl.eagerEval.truncate</code></td>
--- End diff --
maybe he wants to follow what dataframe.show does, which truncates num characters within a cell. That's useful for console output, but not so much for notebooks.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21370
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191591799
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +352,62 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ def _get_repl_config(self):
+ """Return the configs for eager evaluation each time when __repr__ or
+ _repr_html_ called by user or notebook.
+ """
+ eager_eval = self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+ console_row = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", u"20"))
+ console_truncate = int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", u"20"))
+ return (eager_eval, console_row, console_truncate)
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ (eager_eval, console_row, console_truncate) = self._get_repl_config()
+ if not self._support_repr_html and eager_eval:
--- End diff --
What's `_support_repr_html` for?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on the issue:
https://github.com/apache/spark/pull/21370
```
Can we also do something a bit more generic that works for non-Jupyter notebooks as well?
```
Can we accept `spark.sql.repl.eagerEval.enabled` to control both \_\_repr\_\_ and \_repr\_html\_ ?
The behavior like below:
1. If not support _repr_html_ and open eagerEval.enable, just call something like `show` and trigger `take` inside.
2. If support _repr_html_, use the html output. (Here need a small trick, we should add a var in python dataframe to check whether _repr_html_ called or not, otherwise in this mode _repr_html and __repr__ will both call showString).
I test offline an it can work both python shell and Jupyter, if we agree this way, I'll add this support in next commit together will the refactor of showString in scala Dataset.
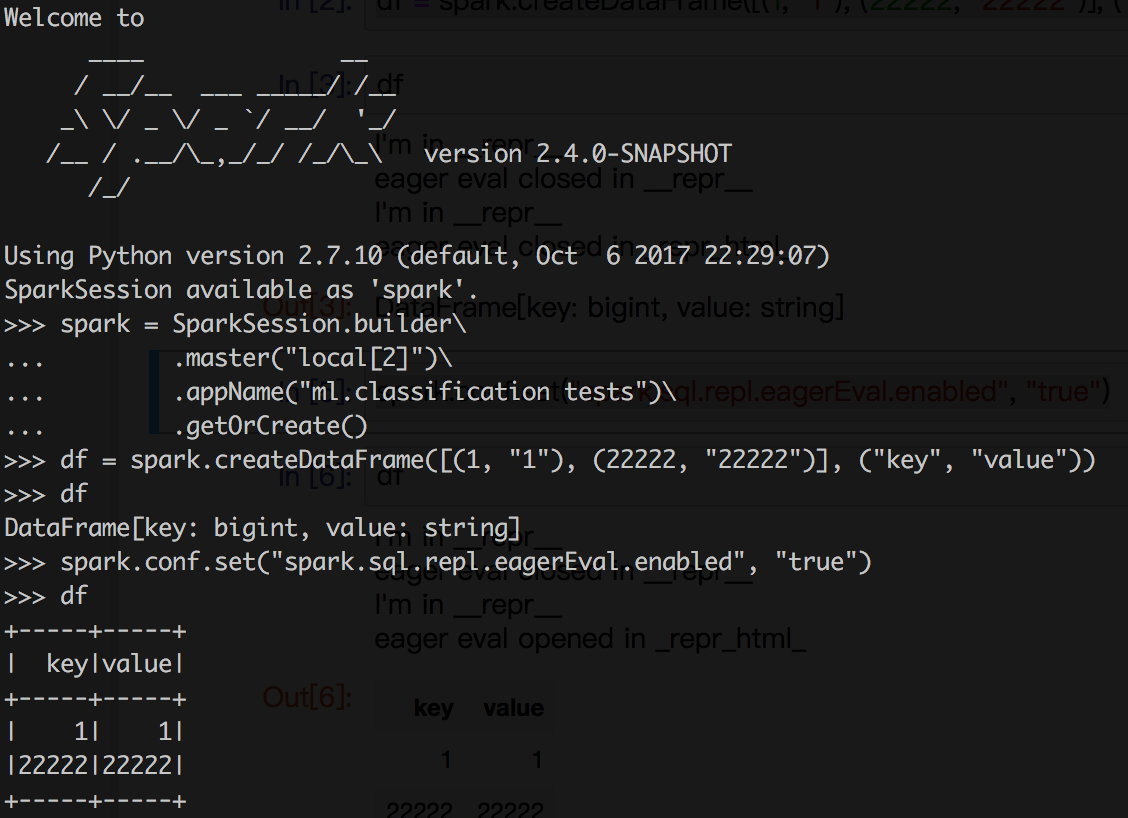
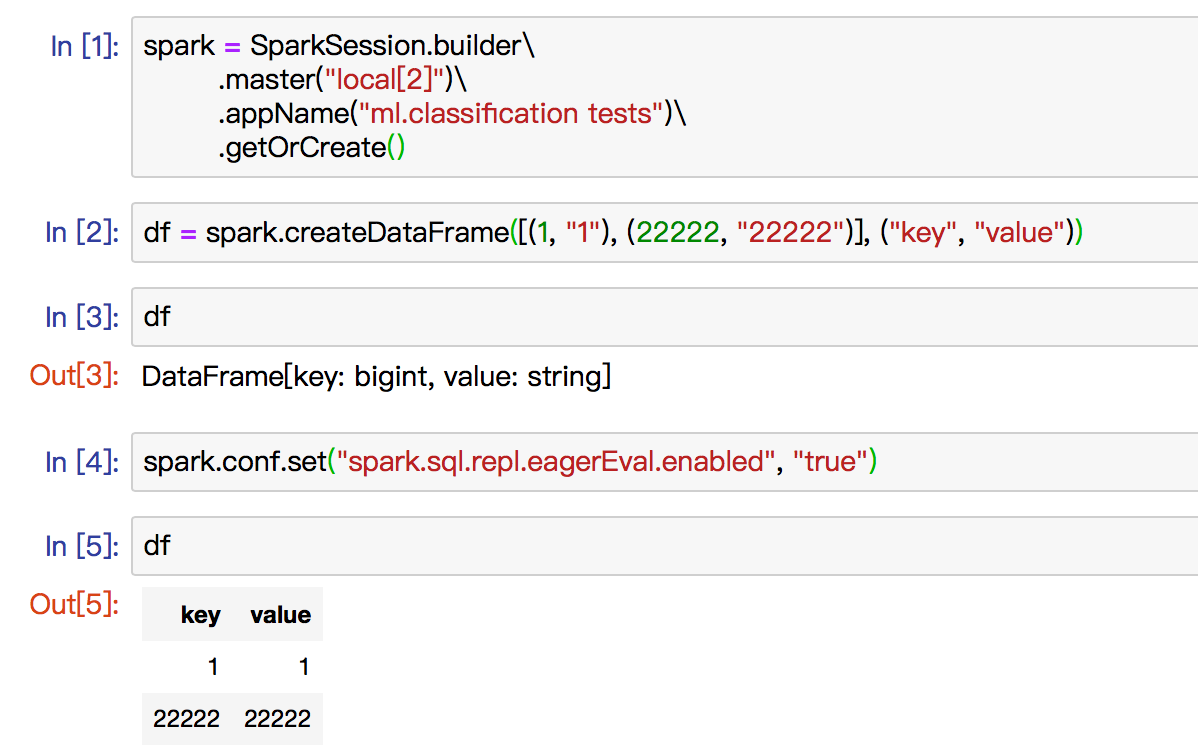
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191591455
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -291,37 +289,57 @@ class Dataset[T] private[sql](
}
}
+ rows = rows.map {
+ _.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ }
--- End diff --
We should do this in `showString`? And we can move `minimumColWidth` into the `showString` in that case?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on the issue:
https://github.com/apache/spark/pull/21370
retest this please
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r192167547
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -291,37 +289,57 @@ class Dataset[T] private[sql](
}
}
+ rows = rows.map {
+ _.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ }
--- End diff --
Thanks, done in 9c6b3bb.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189493455
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -358,6 +357,43 @@ class Dataset[T] private[sql](
sb.toString()
}
+ /**
+ * Transform current row string and append to builder
+ *
+ * @param row Current row of string
+ * @param truncate If set to more than 0, truncates strings to `truncate` characters and
+ * all cells will be aligned right.
+ * @param colWidths The width of each column
+ * @param html If set to true, return output as html table.
+ * @param head Set to true while current row is table head.
+ * @param sb StringBuilder for current row.
+ */
+ private[sql] def appendRowString(
+ row: Seq[String],
+ truncate: Int,
+ colWidths: Array[Int],
+ html: Boolean,
+ head: Boolean,
+ sb: StringBuilder): Unit = {
+ val data = row.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+ StringUtils.leftPad(cell, colWidths(i))
+ } else {
+ StringUtils.rightPad(cell, colWidths(i))
+ }
+ }
+ (html, head) match {
+ case (true, true) =>
+ data.map(StringEscapeUtils.escapeHtml).addString(
+ sb, "<tr><th>", "</th><th>", "</th></tr>")
--- End diff --
nit: add `\n`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189569952
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -78,6 +78,12 @@ def __init__(self, jdf, sql_ctx):
self.is_cached = False
self._schema = None # initialized lazily
self._lazy_rdd = None
+ self._eager_eval = sql_ctx.getConf(
+ "spark.jupyter.eagerEval.enabled", "false").lower() == "true"
+ self._default_console_row = int(sql_ctx.getConf(
+ "spark.jupyter.default.showRows", u"20"))
+ self._default_console_truncate = int(sql_ctx.getConf(
+ "spark.jupyter.default.showRows", u"20"))
--- End diff --
Yep, I'll fix it in next commit.
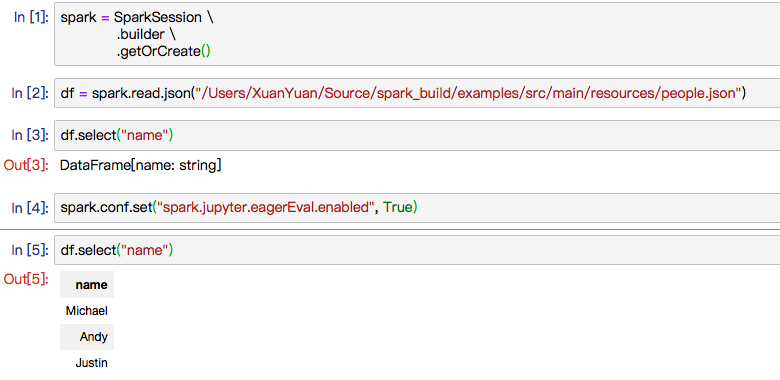
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by viirya <gi...@git.apache.org>.
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189591160
--- Diff: docs/configuration.md ---
@@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful
from JVM to Python worker for every task.
</td>
</tr>
+<tr>
+ <td><code>spark.jupyter.eagerEval.enabled</code></td>
--- End diff --
Should we add `sql`? E.g., `spark.sql.jupyter.eagerEval.enabled`? Because this is just for SQL `Dataset`. @HyukjinKwon @ueshin
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Posted by xuanyuanking <gi...@git.apache.org>.
Github user xuanyuanking commented on the issue:
https://github.com/apache/spark/pull/21370
Thanks @HyukjinKwon and all reviewers.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r194276329
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -351,8 +354,68 @@ def show(self, n=20, truncate=True, vertical=False):
else:
print(self._jdf.showString(n, int(truncate), vertical))
+ @property
+ def _eager_eval(self):
+ """Returns true if the eager evaluation enabled.
+ """
+ return self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.enabled", "false").lower() == "true"
+
+ @property
+ def _max_num_rows(self):
+ """Returns the max row number for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.maxNumRows", "20"))
+
+ @property
+ def _truncate(self):
+ """Returns the truncate length for eager evaluation.
+ """
+ return int(self.sql_ctx.getConf(
+ "spark.sql.repl.eagerEval.truncate", "20"))
+
def __repr__(self):
- return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+ if not self._support_repr_html and self._eager_eval:
+ vertical = False
+ return self._jdf.showString(
+ self._max_num_rows, self._truncate, vertical)
+ else:
+ return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in self.dtypes))
+
+ def _repr_html_(self):
+ """Returns a dataframe with html code when you enabled eager evaluation
+ by 'spark.sql.repl.eagerEval.enabled', this only called by REPL you are
+ using support eager evaluation with HTML.
+ """
+ import cgi
+ if not self._support_repr_html:
+ self._support_repr_html = True
+ if self._eager_eval:
+ max_num_rows = max(self._max_num_rows, 0)
+ vertical = False
--- End diff --
Any discussion about this?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org