You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@kylin.apache.org by GitBox <gi...@apache.org> on 2021/03/04 16:25:05 UTC
[GitHub] [kylin] xiacongling opened a new pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
xiacongling opened a new pull request #1601:
URL: https://github.com/apache/kylin/pull/1601
## Proposed changes
Describe the big picture of your changes here to communicate to the maintainers why we should accept this pull request. If it fixes a bug or resolves a feature request, be sure to link to that issue.
## Types of changes
What types of changes does your code introduce to Kylin?
_Put an `x` in the boxes that apply_
- [ ] Bugfix (non-breaking change which fixes an issue)
- [x] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or feature that would cause existing functionality to not work as expected)
- [ ] Documentation Update (if none of the other choices apply)
## Checklist
_Put an `x` in the boxes that apply. You can also fill these out after creating the PR. If you're unsure about any of them, don't hesitate to ask. We're here to help! This is simply a reminder of what we are going to look for before merging your code._
- [x] I have create an issue on [Kylin's jira](https://issues.apache.org/jira/browse/KYLIN-4925), and have described the bug/feature there in detail
- [x] Commit messages in my PR start with the related jira ID, like "KYLIN-0000 Make Kylin project open-source"
- [x] Compiling and unit tests pass locally with my changes
- [ ] I have added tests that prove my fix is effective or that my feature works
- [ ] If this change need a document change, I will prepare another pr against the `document` branch
- [ ] Any dependent changes have been merged
## Further comments
Tested for Spark 2.4.7 and Spark 3.0.2. We make it compatible to use either Spark 2.4 (default) or Spark 3.0. When build with spark 3.0, active profile with `mvn -Dspark3`.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r635062155
##########
File path: kylin-spark-project/kylin-spark-common/src/main/spark31/org/apache/spark/sql/execution/KylinJoinSelection.scala
##########
@@ -0,0 +1,283 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+*/
+
+package org.apache.spark.sql.execution
+
+import javax.annotation.concurrent.GuardedBy
+import org.apache.kylin.common.KylinConfig
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.catalyst.expressions.{PredicateHelper, RowOrdering}
+import org.apache.spark.sql.catalyst.optimizer.{BuildLeft, BuildRight, BuildSide}
+import org.apache.spark.sql.catalyst.planning.ExtractEquiJoinKeys
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.catalyst.plans.logical.{JoinHint, LogicalPlan}
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.{SparkSession, Strategy}
+
+/**
+ * Select the proper physical plan for join based on joining keys and size of logical plan.
+ *
+ * At first, uses the [[ExtractEquiJoinKeys]] pattern to find joins where at least some of the
+ * predicates can be evaluated by matching join keys. If found, join implementations are chosen
+ * with the following precedence:
+ *
+ * - Broadcast hash join (BHJ):
+ * BHJ is not supported for full outer join. For right outer join, we only can broadcast the
+ * left side. For left outer, left semi, left anti and the internal join type ExistenceJoin,
+ * we only can broadcast the right side. For inner like join, we can broadcast both sides.
+ * Normally, BHJ can perform faster than the other join algorithms when the broadcast side is
+ * small. However, broadcasting tables is a network-intensive operation. It could cause OOM
+ * or perform worse than the other join algorithms, especially when the build/broadcast side
+ * is big.
+ *
+ * For the supported cases, users can specify the broadcast hint (e.g. the user applied the
+ * [[org.apache.spark.sql.functions.broadcast()]] function to a DataFrame) and session-based
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold to adjust whether BHJ is used and
+ * which join side is broadcast.
+ *
+ * 1) Broadcast the join side with the broadcast hint, even if the size is larger than
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]]. If both sides have the hint (only when the type
+ * is inner like join), the side with a smaller estimated physical size will be broadcast.
+ * 2) Respect the [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold and broadcast the side
+ * whose estimated physical size is smaller than the threshold. If both sides are below the
+ * threshold, broadcast the smaller side. If neither is smaller, BHJ is not used.
+ *
+ * - Shuffle hash join: if the average size of a single partition is small enough to build a hash
+ * table.
+ *
+ * - Sort merge: if the matching join keys are sortable.
+ *
+ * If there is no joining keys, Join implementations are chosen with the following precedence:
+ * - BroadcastNestedLoopJoin (BNLJ):
+ * BNLJ supports all the join types but the impl is OPTIMIZED for the following scenarios:
+ * For right outer join, the left side is broadcast. For left outer, left semi, left anti
+ * and the internal join type ExistenceJoin, the right side is broadcast. For inner like
+ * joins, either side is broadcast.
+ *
+ * Like BHJ, users still can specify the broadcast hint and session-based
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold to impact which side is broadcast.
+ *
+ * 1) Broadcast the join side with the broadcast hint, even if the size is larger than
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]]. If both sides have the hint (i.e., just for
+ * inner-like join), the side with a smaller estimated physical size will be broadcast.
+ * 2) Respect the [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold and broadcast the side
+ * whose estimated physical size is smaller than the threshold. If both sides are below the
+ * threshold, broadcast the smaller side. If neither is smaller, BNLJ is not used.
+ *
+ * - CartesianProduct: for inner like join, CartesianProduct is the fallback option.
+ *
+ * - BroadcastNestedLoopJoin (BNLJ):
+ * For the other join types, BNLJ is the fallback option. Here, we just pick the broadcast
+ * side with the broadcast hint. If neither side has a hint, we broadcast the side with
+ * the smaller estimated physical size.
+ */
+case class KylinJoinSelection(session: SparkSession) extends Strategy with PredicateHelper with Logging {
+
+ val conf: SQLConf = session.sessionState.conf
+
+ /**
+ * Matches a plan whose output should be small enough to be used in broadcast join.
+ */
+ private def canBroadcast(plan: LogicalPlan): Boolean = {
+ val sizeInBytes = plan.stats.sizeInBytes
+ sizeInBytes >= 0 && sizeInBytes <= conf.autoBroadcastJoinThreshold && JoinMemoryManager.acquireMemory(sizeInBytes.toLong)
+ }
+
+ /**
+ * Matches a plan whose single partition should be small enough to build a hash table.
+ *
+ * Note: this assume that the number of partition is fixed, requires additional work if it's
+ * dynamic.
+ */
+ private def canBuildLocalHashMap(plan: LogicalPlan): Boolean = {
+ plan.stats.sizeInBytes < conf.autoBroadcastJoinThreshold * conf.numShufflePartitions
+ }
+
+ /**
+ * Returns whether plan a is much smaller (3X) than plan b.
+ *
+ * The cost to build hash map is higher than sorting, we should only build hash map on a table
+ * that is much smaller than other one. Since we does not have the statistic for number of rows,
+ * use the size of bytes here as estimation.
+ */
+ private def muchSmaller(a: LogicalPlan, b: LogicalPlan): Boolean = {
+ a.stats.sizeInBytes * 3 <= b.stats.sizeInBytes
+ }
+
+ private def canBuildRight(joinType: JoinType): Boolean = joinType match {
+ case _: InnerLike | LeftOuter | LeftSemi | LeftAnti | _: ExistenceJoin => true
+ case _ => false
+ }
+
+ private def canBuildLeft(joinType: JoinType): Boolean = joinType match {
+ case _: InnerLike | RightOuter => true
+ case _ => false
+ }
+
+ private def broadcastSide(
+ canBuildLeft: Boolean,
+ canBuildRight: Boolean,
+ left: LogicalPlan,
+ right: LogicalPlan): BuildSide = {
+
+ def smallerSide =
+ if (right.stats.sizeInBytes <= left.stats.sizeInBytes) BuildRight else BuildLeft
+
+ if (canBuildRight && canBuildLeft) {
+ // Broadcast smaller side base on its estimated physical size
+ // if both sides have broadcast hint
+ smallerSide
+ } else if (canBuildRight) {
+ BuildRight
+ } else if (canBuildLeft) {
+ BuildLeft
+ } else {
+ // for the last default broadcast nested loop join
+ smallerSide
+ }
+ }
+
+ private def canBroadcastByHints(joinType: JoinType, left: LogicalPlan, right: LogicalPlan, hint: JoinHint)
+ : Boolean = {
+// val buildLeft = canBuildLeft(joinType) && logical.BROADCAST.equals(hint.leftHint.get.strategy.get)
+// val buildRight = canBuildRight(joinType) && logical.BROADCAST.equals(hint.rightHint.get.strategy.get)
+// buildLeft || buildRight
+ false
Review comment:
Why comments these lines and return false directly ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r635062296
##########
File path: kylin-spark-project/kylin-spark-common/src/main/spark31/org/apache/spark/sql/execution/KylinJoinSelection.scala
##########
@@ -0,0 +1,283 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+*/
+
+package org.apache.spark.sql.execution
+
+import javax.annotation.concurrent.GuardedBy
+import org.apache.kylin.common.KylinConfig
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.catalyst.expressions.{PredicateHelper, RowOrdering}
+import org.apache.spark.sql.catalyst.optimizer.{BuildLeft, BuildRight, BuildSide}
+import org.apache.spark.sql.catalyst.planning.ExtractEquiJoinKeys
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.catalyst.plans.logical.{JoinHint, LogicalPlan}
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.{SparkSession, Strategy}
+
+/**
+ * Select the proper physical plan for join based on joining keys and size of logical plan.
+ *
+ * At first, uses the [[ExtractEquiJoinKeys]] pattern to find joins where at least some of the
+ * predicates can be evaluated by matching join keys. If found, join implementations are chosen
+ * with the following precedence:
+ *
+ * - Broadcast hash join (BHJ):
+ * BHJ is not supported for full outer join. For right outer join, we only can broadcast the
+ * left side. For left outer, left semi, left anti and the internal join type ExistenceJoin,
+ * we only can broadcast the right side. For inner like join, we can broadcast both sides.
+ * Normally, BHJ can perform faster than the other join algorithms when the broadcast side is
+ * small. However, broadcasting tables is a network-intensive operation. It could cause OOM
+ * or perform worse than the other join algorithms, especially when the build/broadcast side
+ * is big.
+ *
+ * For the supported cases, users can specify the broadcast hint (e.g. the user applied the
+ * [[org.apache.spark.sql.functions.broadcast()]] function to a DataFrame) and session-based
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold to adjust whether BHJ is used and
+ * which join side is broadcast.
+ *
+ * 1) Broadcast the join side with the broadcast hint, even if the size is larger than
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]]. If both sides have the hint (only when the type
+ * is inner like join), the side with a smaller estimated physical size will be broadcast.
+ * 2) Respect the [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold and broadcast the side
+ * whose estimated physical size is smaller than the threshold. If both sides are below the
+ * threshold, broadcast the smaller side. If neither is smaller, BHJ is not used.
+ *
+ * - Shuffle hash join: if the average size of a single partition is small enough to build a hash
+ * table.
+ *
+ * - Sort merge: if the matching join keys are sortable.
+ *
+ * If there is no joining keys, Join implementations are chosen with the following precedence:
+ * - BroadcastNestedLoopJoin (BNLJ):
+ * BNLJ supports all the join types but the impl is OPTIMIZED for the following scenarios:
+ * For right outer join, the left side is broadcast. For left outer, left semi, left anti
+ * and the internal join type ExistenceJoin, the right side is broadcast. For inner like
+ * joins, either side is broadcast.
+ *
+ * Like BHJ, users still can specify the broadcast hint and session-based
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold to impact which side is broadcast.
+ *
+ * 1) Broadcast the join side with the broadcast hint, even if the size is larger than
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]]. If both sides have the hint (i.e., just for
+ * inner-like join), the side with a smaller estimated physical size will be broadcast.
+ * 2) Respect the [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold and broadcast the side
+ * whose estimated physical size is smaller than the threshold. If both sides are below the
+ * threshold, broadcast the smaller side. If neither is smaller, BNLJ is not used.
+ *
+ * - CartesianProduct: for inner like join, CartesianProduct is the fallback option.
+ *
+ * - BroadcastNestedLoopJoin (BNLJ):
+ * For the other join types, BNLJ is the fallback option. Here, we just pick the broadcast
+ * side with the broadcast hint. If neither side has a hint, we broadcast the side with
+ * the smaller estimated physical size.
+ */
+case class KylinJoinSelection(session: SparkSession) extends Strategy with PredicateHelper with Logging {
+
+ val conf: SQLConf = session.sessionState.conf
+
+ /**
+ * Matches a plan whose output should be small enough to be used in broadcast join.
+ */
+ private def canBroadcast(plan: LogicalPlan): Boolean = {
+ val sizeInBytes = plan.stats.sizeInBytes
+ sizeInBytes >= 0 && sizeInBytes <= conf.autoBroadcastJoinThreshold && JoinMemoryManager.acquireMemory(sizeInBytes.toLong)
+ }
+
+ /**
+ * Matches a plan whose single partition should be small enough to build a hash table.
+ *
+ * Note: this assume that the number of partition is fixed, requires additional work if it's
+ * dynamic.
+ */
+ private def canBuildLocalHashMap(plan: LogicalPlan): Boolean = {
+ plan.stats.sizeInBytes < conf.autoBroadcastJoinThreshold * conf.numShufflePartitions
+ }
+
+ /**
+ * Returns whether plan a is much smaller (3X) than plan b.
+ *
+ * The cost to build hash map is higher than sorting, we should only build hash map on a table
+ * that is much smaller than other one. Since we does not have the statistic for number of rows,
+ * use the size of bytes here as estimation.
+ */
+ private def muchSmaller(a: LogicalPlan, b: LogicalPlan): Boolean = {
+ a.stats.sizeInBytes * 3 <= b.stats.sizeInBytes
+ }
+
+ private def canBuildRight(joinType: JoinType): Boolean = joinType match {
+ case _: InnerLike | LeftOuter | LeftSemi | LeftAnti | _: ExistenceJoin => true
+ case _ => false
+ }
+
+ private def canBuildLeft(joinType: JoinType): Boolean = joinType match {
+ case _: InnerLike | RightOuter => true
+ case _ => false
+ }
+
+ private def broadcastSide(
+ canBuildLeft: Boolean,
+ canBuildRight: Boolean,
+ left: LogicalPlan,
+ right: LogicalPlan): BuildSide = {
+
+ def smallerSide =
+ if (right.stats.sizeInBytes <= left.stats.sizeInBytes) BuildRight else BuildLeft
+
+ if (canBuildRight && canBuildLeft) {
+ // Broadcast smaller side base on its estimated physical size
+ // if both sides have broadcast hint
+ smallerSide
+ } else if (canBuildRight) {
+ BuildRight
+ } else if (canBuildLeft) {
+ BuildLeft
+ } else {
+ // for the last default broadcast nested loop join
+ smallerSide
+ }
+ }
+
+ private def canBroadcastByHints(joinType: JoinType, left: LogicalPlan, right: LogicalPlan, hint: JoinHint)
+ : Boolean = {
+// val buildLeft = canBuildLeft(joinType) && logical.BROADCAST.equals(hint.leftHint.get.strategy.get)
+// val buildRight = canBuildRight(joinType) && logical.BROADCAST.equals(hint.rightHint.get.strategy.get)
+// buildLeft || buildRight
+ false
+ }
+
+ private def broadcastSideByHints(joinType: JoinType, left: LogicalPlan, right: LogicalPlan, hint: JoinHint)
+ : BuildSide = {
+// val buildLeft = canBuildLeft(joinType) && logical.BROADCAST.equals(hint.leftHint.get.strategy.get)
+// val buildRight = canBuildRight(joinType) && logical.BROADCAST.equals(hint.rightHint.get.strategy.get)
Review comment:
ditto
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r643265569
##########
File path: kylin-spark-project/kylin-spark-engine/src/test/scala/org/apache/kylin/engine/spark/builder/TestCreateFlatTable.scala
##########
@@ -81,7 +81,8 @@ class TestCreateFlatTable extends SparderBaseFunSuite with SharedSparkSession wi
//DefaultScheduler.destroyInstance()
}
- test("Check the flattable spark jobs num correctness") {
+ // todo: [Spark 3.0] BroadcastExchangeExec overwrites job group ID
+ ignore("Check the flattable spark jobs num correctness") {
Review comment:
modify this test case to :
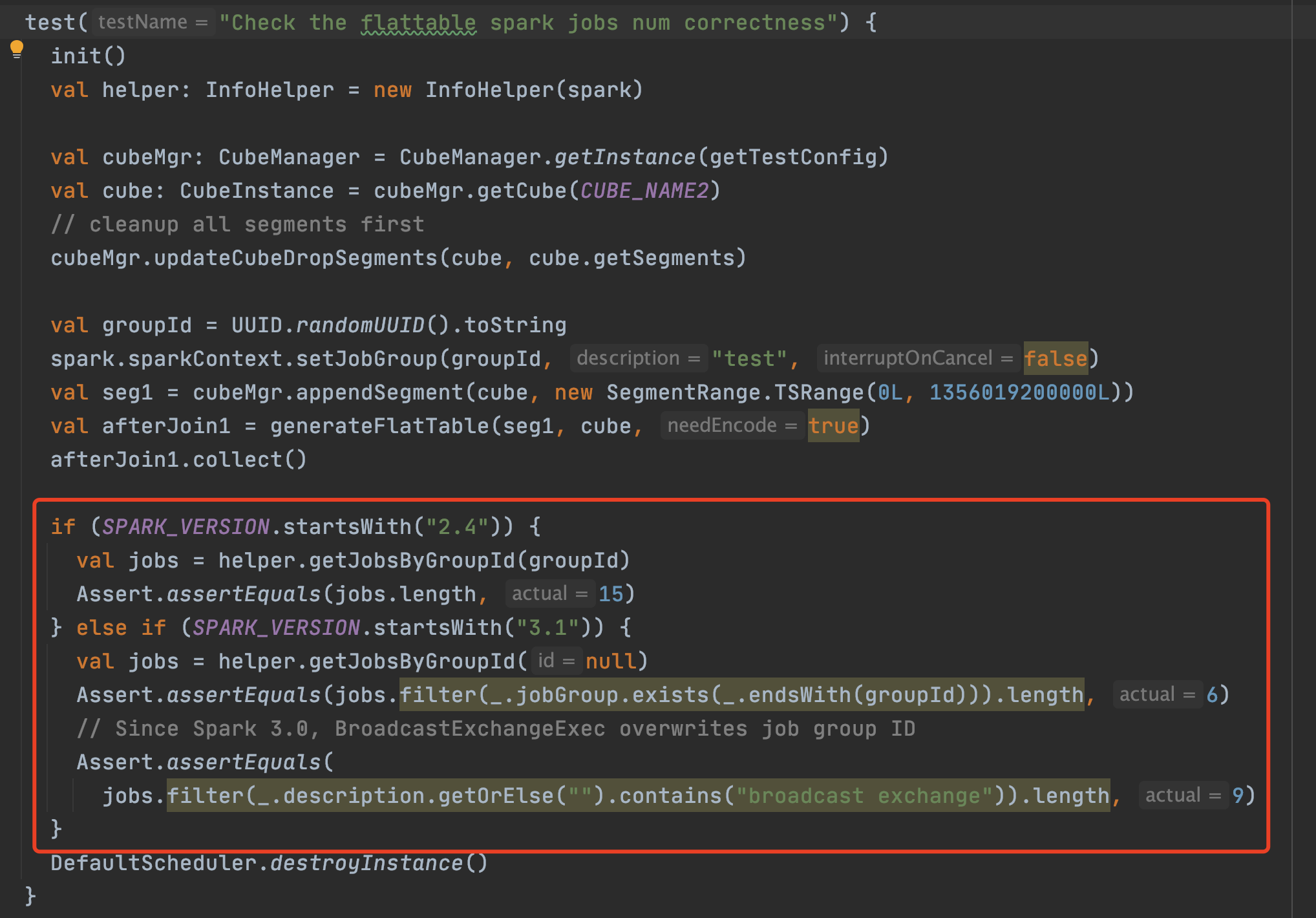
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] codecov-commenter edited a comment on pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
codecov-commenter edited a comment on pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#issuecomment-846865473
# [Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) Report
> :exclamation: No coverage uploaded for pull request base (`kylin-on-parquet-v2@f5ec8f3`). [Click here to learn what that means](https://docs.codecov.io/docs/error-reference?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#section-missing-base-commit).
> The diff coverage is `n/a`.
[](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation)
```diff
@@ Coverage Diff @@
## kylin-on-parquet-v2 #1601 +/- ##
======================================================
Coverage ? 24.31%
Complexity ? 4650
======================================================
Files ? 1151
Lines ? 65123
Branches ? 9352
======================================================
Hits ? 15836
Misses ? 47640
Partials ? 1647
```
------
[Continue to review full report at Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=footer&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation). Last update [f5ec8f3...9850eb1](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=lastupdated&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r647045104
##########
File path: kylin-spark-project/kylin-spark-engine/src/test/scala/org/apache/kylin/engine/spark/builder/TestCreateFlatTable.scala
##########
@@ -96,17 +96,32 @@ class TestCreateFlatTable extends SparderBaseFunSuite with SharedSparkSession wi
val afterJoin1 = generateFlatTable(seg1, cube, true)
afterJoin1.collect()
- val jobs = helper.getJobsByGroupId(groupId)
- Assert.assertEquals(jobs.length, 15)
+ if (SPARK_VERSION.startsWith("2.4")) {
+ val jobs = helper.getJobsByGroupId(groupId)
+ Assert.assertEquals(jobs.length, 15)
+ } else if (SPARK_VERSION.startsWith("3.1")) {
+ val jobs = helper.getJobsByGroupId(null)
+ Assert.assertEquals(jobs.length, 15)
+ Assert.assertEquals(6, jobs.count(_.jobGroup.exists(_.endsWith(groupId))))
+ Assert.assertEquals(9, jobs.count(_.description.exists(_.contains("broadcast exchange"))))
Review comment:
Add a comment: Since Spark 3.X, BroadcastExchangeExec overwrites job group ID
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r634834282
##########
File path: .travis.yml
##########
@@ -46,7 +46,8 @@ before_script:
script:
# mvn clean org.jacoco:jacoco-maven-plugin:prepare-agent test coveralls:report -e
# Skip coveralls temporarily, fix it asap
- - mvn clean test
+ - mvn clean test -q
+ - mvn clean test -q -Psandbox -Pspark3
Review comment:
Why needs to add these two commands? remove the first one?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r635031842
##########
File path: kylin-spark-project/kylin-spark-common/src/main/spark31/org/apache/spark/sql/execution/KylinFileSourceScanExec.scala
##########
@@ -0,0 +1,252 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution
+
+import org.apache.hadoop.fs.{BlockLocation, FileStatus, LocatedFileStatus, Path}
+import org.apache.kylin.common.KylinConfig
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, Expression, ExpressionUtils, SortOrder}
+import org.apache.spark.sql.catalyst.plans.physical.{HashPartitioning, Partitioning, UnknownPartitioning}
+import org.apache.spark.sql.catalyst.{InternalRow, TableIdentifier}
+import org.apache.spark.sql.execution.datasource.{FilePruner, ShardSpec}
+import org.apache.spark.sql.execution.datasources._
+import org.apache.spark.sql.execution.metric.SQLMetrics
Review comment:
remove this unused import
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r635030677
##########
File path: kylin-spark-project/kylin-spark-common/src/main/spark31/org/apache/spark/sql/execution/KylinFileSourceScanExec.scala
##########
@@ -0,0 +1,252 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution
+
+import org.apache.hadoop.fs.{BlockLocation, FileStatus, LocatedFileStatus, Path}
+import org.apache.kylin.common.KylinConfig
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, Expression, ExpressionUtils, SortOrder}
+import org.apache.spark.sql.catalyst.plans.physical.{HashPartitioning, Partitioning, UnknownPartitioning}
+import org.apache.spark.sql.catalyst.{InternalRow, TableIdentifier}
+import org.apache.spark.sql.execution.datasource.{FilePruner, ShardSpec}
+import org.apache.spark.sql.execution.datasources._
+import org.apache.spark.sql.execution.metric.SQLMetrics
+import org.apache.spark.sql.types.StructType
+
+import scala.collection.mutable.ArrayBuffer
+
+class KylinFileSourceScanExec(
+ @transient override val relation: HadoopFsRelation,
+ override val output: Seq[Attribute],
+ override val requiredSchema: StructType,
+ override val partitionFilters: Seq[Expression],
+ val optionalShardSpec: Option[ShardSpec],
+ override val dataFilters: Seq[Expression],
+ override val tableIdentifier: Option[TableIdentifier]) extends FileSourceScanExec(
+ relation, output, requiredSchema, partitionFilters, None, None, dataFilters, tableIdentifier, false) {
+
+ private lazy val _inputRDD: RDD[InternalRow] = {
+ val readFile: (PartitionedFile) => Iterator[InternalRow] =
+ relation.fileFormat.buildReaderWithPartitionValues(
+ sparkSession = relation.sparkSession,
+ dataSchema = relation.dataSchema,
+ partitionSchema = relation.partitionSchema,
+ requiredSchema = requiredSchema,
+ filters = pushedDownFilters,
+ options = relation.options,
+ hadoopConf = relation.sparkSession.sessionState.newHadoopConfWithOptions(relation.options))
+
+ optionalShardSpec match {
+ case Some(spec) if KylinConfig.getInstanceFromEnv.isShardingJoinOptEnabled =>
+ createShardingReadRDD(spec, readFile, selectedPartitions, relation)
+ case _ =>
+ createNonShardingReadRDD(readFile, selectedPartitions, relation)
+ }
Review comment:
need to send metrics here, otherwise it will miss.
```
sendDriverMetrics()
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r634968378
##########
File path: kylin-spark-project/kylin-spark-common/src/main/scala/org/apache/spark/utils/KylinReflectUtils.scala
##########
@@ -27,19 +27,21 @@ object KylinReflectUtils {
private val rm = universe.runtimeMirror(getClass.getClassLoader)
def getSessionState(sparkContext: SparkContext, kylinSession: Object): Any = {
- if (SPARK_VERSION.startsWith("2.4")) {
- var className: String =
- "org.apache.spark.sql.hive.KylinHiveSessionStateBuilder"
- if (!"hive".equals(sparkContext.getConf
- .get(CATALOG_IMPLEMENTATION.key, "in-memory"))) {
- className = "org.apache.spark.sql.hive.KylinSessionStateBuilder"
- }
- val tuple = createObject(className, kylinSession, None)
- val method = tuple._2.getMethod("build")
- method.invoke(tuple._1)
+ var className: String =
+ "org.apache.spark.sql.hive.KylinHiveSessionStateBuilder"
+ if (!"hive".equals(sparkContext.getConf
+ .get(CATALOG_IMPLEMENTATION.key, "in-memory"))) {
+ className = "org.apache.spark.sql.hive.KylinSessionStateBuilder"
+ }
+
+ val (instance, clazz) = if (SPARK_VERSION.startsWith("2.4") || SPARK_VERSION.startsWith("3.0")) {
+ createObject(className, kylinSession, None)
+ } else if (SPARK_VERSION.startsWith("3.1")) {
+ createObject(className, kylinSession, None, Map.empty)
} else {
throw new UnsupportedOperationException("Spark version not supported")
Review comment:
better to point out which version not supported:
```
throw new UnsupportedOperationException(s"Spark version ${SPARK_VERSION} not supported")
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r643277767
##########
File path: kylin-spark-project/kylin-spark-common/src/main/spark31/org/apache/spark/sql/execution/KylinJoinSelection.scala
##########
@@ -0,0 +1,285 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+*/
+
+package org.apache.spark.sql.execution
+
+import javax.annotation.concurrent.GuardedBy
+import org.apache.kylin.common.KylinConfig
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.catalyst.expressions.{PredicateHelper, RowOrdering}
+import org.apache.spark.sql.catalyst.optimizer.{BuildLeft, BuildRight, BuildSide}
+import org.apache.spark.sql.catalyst.planning.ExtractEquiJoinKeys
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.catalyst.plans.logical.{BROADCAST, HintInfo, JoinHint, LogicalPlan}
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.{SparkSession, Strategy}
+
+/**
+ * Select the proper physical plan for join based on joining keys and size of logical plan.
+ *
+ * At first, uses the [[ExtractEquiJoinKeys]] pattern to find joins where at least some of the
+ * predicates can be evaluated by matching join keys. If found, join implementations are chosen
+ * with the following precedence:
+ *
+ * - Broadcast hash join (BHJ):
+ * BHJ is not supported for full outer join. For right outer join, we only can broadcast the
+ * left side. For left outer, left semi, left anti and the internal join type ExistenceJoin,
+ * we only can broadcast the right side. For inner like join, we can broadcast both sides.
+ * Normally, BHJ can perform faster than the other join algorithms when the broadcast side is
+ * small. However, broadcasting tables is a network-intensive operation. It could cause OOM
+ * or perform worse than the other join algorithms, especially when the build/broadcast side
+ * is big.
+ *
+ * For the supported cases, users can specify the broadcast hint (e.g. the user applied the
+ * [[org.apache.spark.sql.functions.broadcast()]] function to a DataFrame) and session-based
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold to adjust whether BHJ is used and
+ * which join side is broadcast.
+ *
+ * 1) Broadcast the join side with the broadcast hint, even if the size is larger than
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]]. If both sides have the hint (only when the type
+ * is inner like join), the side with a smaller estimated physical size will be broadcast.
+ * 2) Respect the [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold and broadcast the side
+ * whose estimated physical size is smaller than the threshold. If both sides are below the
+ * threshold, broadcast the smaller side. If neither is smaller, BHJ is not used.
+ *
+ * - Shuffle hash join: if the average size of a single partition is small enough to build a hash
+ * table.
+ *
+ * - Sort merge: if the matching join keys are sortable.
+ *
+ * If there is no joining keys, Join implementations are chosen with the following precedence:
+ * - BroadcastNestedLoopJoin (BNLJ):
+ * BNLJ supports all the join types but the impl is OPTIMIZED for the following scenarios:
+ * For right outer join, the left side is broadcast. For left outer, left semi, left anti
+ * and the internal join type ExistenceJoin, the right side is broadcast. For inner like
+ * joins, either side is broadcast.
+ *
+ * Like BHJ, users still can specify the broadcast hint and session-based
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold to impact which side is broadcast.
+ *
+ * 1) Broadcast the join side with the broadcast hint, even if the size is larger than
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]]. If both sides have the hint (i.e., just for
+ * inner-like join), the side with a smaller estimated physical size will be broadcast.
+ * 2) Respect the [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold and broadcast the side
+ * whose estimated physical size is smaller than the threshold. If both sides are below the
+ * threshold, broadcast the smaller side. If neither is smaller, BNLJ is not used.
+ *
+ * - CartesianProduct: for inner like join, CartesianProduct is the fallback option.
+ *
+ * - BroadcastNestedLoopJoin (BNLJ):
+ * For the other join types, BNLJ is the fallback option. Here, we just pick the broadcast
+ * side with the broadcast hint. If neither side has a hint, we broadcast the side with
+ * the smaller estimated physical size.
+ */
+case class KylinJoinSelection(session: SparkSession) extends Strategy with PredicateHelper with Logging {
+
+ val conf: SQLConf = session.sessionState.conf
+
+ /**
+ * Matches a plan whose output should be small enough to be used in broadcast join.
+ */
+ private def canBroadcast(plan: LogicalPlan): Boolean = {
+ val sizeInBytes = plan.stats.sizeInBytes
+ sizeInBytes >= 0 && sizeInBytes <= conf.autoBroadcastJoinThreshold && JoinMemoryManager.acquireMemory(sizeInBytes.toLong)
+ }
+
+ /**
+ * Matches a plan whose single partition should be small enough to build a hash table.
+ *
+ * Note: this assume that the number of partition is fixed, requires additional work if it's
+ * dynamic.
+ */
+ private def canBuildLocalHashMap(plan: LogicalPlan): Boolean = {
+ plan.stats.sizeInBytes < conf.autoBroadcastJoinThreshold * conf.numShufflePartitions
+ }
+
+ /**
+ * Returns whether plan a is much smaller (3X) than plan b.
+ *
+ * The cost to build hash map is higher than sorting, we should only build hash map on a table
+ * that is much smaller than other one. Since we does not have the statistic for number of rows,
+ * use the size of bytes here as estimation.
+ */
+ private def muchSmaller(a: LogicalPlan, b: LogicalPlan): Boolean = {
+ a.stats.sizeInBytes * 3 <= b.stats.sizeInBytes
+ }
+
+ private def canBuildRight(joinType: JoinType): Boolean = joinType match {
+ case _: InnerLike | LeftOuter | LeftSemi | LeftAnti | _: ExistenceJoin => true
+ case _ => false
+ }
+
+ private def canBuildLeft(joinType: JoinType): Boolean = joinType match {
+ case _: InnerLike | RightOuter => true
+ case _ => false
+ }
+
+ private def broadcastSide(
+ canBuildLeft: Boolean,
+ canBuildRight: Boolean,
+ left: LogicalPlan,
+ right: LogicalPlan): BuildSide = {
+
+ def smallerSide =
+ if (right.stats.sizeInBytes <= left.stats.sizeInBytes) BuildRight else BuildLeft
+
+ if (canBuildRight && canBuildLeft) {
+ // Broadcast smaller side base on its estimated physical size
+ // if both sides have broadcast hint
+ smallerSide
+ } else if (canBuildRight) {
+ BuildRight
+ } else if (canBuildLeft) {
+ BuildLeft
+ } else {
+ // for the last default broadcast nested loop join
+ smallerSide
+ }
+ }
+
+ private def canBroadcastByHints(joinType: JoinType, left: LogicalPlan, right: LogicalPlan, hint: JoinHint)
+ : Boolean = {
+ val buildLeft = canBuildLeft(joinType) && hintBroadcast(hint.leftHint)
+ val buildRight = canBuildRight(joinType) && hintBroadcast(hint.rightHint)
+ buildLeft || buildRight
+ }
+
+ private def broadcastSideByHints(joinType: JoinType, left: LogicalPlan, right: LogicalPlan, hint: JoinHint)
+ : BuildSide = {
+ val buildLeft = canBuildLeft(joinType) && hintBroadcast(hint.leftHint)
+ val buildRight = canBuildRight(joinType) && hintBroadcast(hint.rightHint)
+ broadcastSide(buildLeft, buildRight, left, right)
+ }
+
+ private def canBroadcastBySizes(joinType: JoinType, left: LogicalPlan, right: LogicalPlan)
+ : Boolean = {
+ val buildLeft = canBuildLeft(joinType) && canBroadcast(left)
+ val buildRight = canBuildRight(joinType) && canBroadcast(right)
+ buildLeft || buildRight
+ }
+
+ private def broadcastSideBySizes(joinType: JoinType, left: LogicalPlan, right: LogicalPlan)
+ : BuildSide = {
+ val buildLeft = canBuildLeft(joinType) && canBroadcast(left)
+ val buildRight = canBuildRight(joinType) && canBroadcast(right)
+ broadcastSide(buildLeft, buildRight, left, right)
+ }
+
+ def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
Review comment:
It's better to implementation this strategy according to the `JoinSelection` in Spark 3.1, the implementation in Spark 3.1 is very different from the one in Spark 2.4.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] codecov-commenter edited a comment on pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
codecov-commenter edited a comment on pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#issuecomment-846865473
# [Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) Report
> :exclamation: No coverage uploaded for pull request base (`kylin-on-parquet-v2@f5ec8f3`). [Click here to learn what that means](https://docs.codecov.io/docs/error-reference?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#section-missing-base-commit).
> The diff coverage is `n/a`.
[](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation)
```diff
@@ Coverage Diff @@
## kylin-on-parquet-v2 #1601 +/- ##
======================================================
Coverage ? 24.51%
Complexity ? 4648
======================================================
Files ? 1141
Lines ? 64546
Branches ? 9311
======================================================
Hits ? 15823
Misses ? 47076
Partials ? 1647
```
------
[Continue to review full report at Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=footer&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation). Last update [f5ec8f3...74e6259](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=lastupdated&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r635132848
##########
File path: kylin-spark-project/kylin-spark-metadata/src/main/spark24/org/apache/kylin/engine/spark/cross/CrossDateTimeUtils.scala
##########
@@ -0,0 +1,34 @@
+package org.apache.kylin.engine.spark.cross
Review comment:
please add license.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r635133025
##########
File path: kylin-spark-project/kylin-spark-metadata/src/main/spark31/org/apache/kylin/engine/spark/cross/CrossDateTimeUtils.scala
##########
@@ -0,0 +1,37 @@
+package org.apache.kylin.engine.spark.cross
Review comment:
ditto
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r635085201
##########
File path: kylin-spark-project/kylin-spark-common/src/main/spark31/org/apache/spark/sql/hive/utils/QueryMetricUtils.scala
##########
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.utils
+
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.execution.adaptive.{AdaptiveSparkPlanExec, ShuffleQueryStageExec}
+import org.apache.spark.sql.execution.{FileSourceScanExec, KylinFileSourceScanExec, SparkPlan}
+import org.apache.spark.sql.hive.execution.HiveTableScanExec
+
+import scala.collection.JavaConverters.seqAsJavaListConverter
+
+object QueryMetricUtils extends Logging {
+ def collectScanMetrics(plan: SparkPlan): (java.util.List[java.lang.Long], java.util.List[java.lang.Long],
+ java.util.List[java.lang.Long], java.util.List[java.lang.Long], java.util.List[java.lang.Long]) = {
+ try {
+ val metrics = plan.collect {
+ case exec: KylinFileSourceScanExec =>
+ //(exec.metrics.apply("numOutputRows").value, exec.metrics.apply("readBytes").value)
+ (exec.metrics.apply("numOutputRows").value, exec.metrics.apply("numFiles").value,
+ exec.metrics.apply("metadataTime").value, exec.metrics.apply("scanTime").value, -1l)
+ case exec: FileSourceScanExec =>
+ //(exec.metrics.apply("numOutputRows").value, exec.metrics.apply("readBytes").value)
+ (exec.metrics.apply("numOutputRows").value, exec.metrics.apply("numFiles").value,
+ exec.metrics.apply("metadataTime").value, exec.metrics.apply("scanTime").value, -1l)
Review comment:
ditto
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r634836857
##########
File path: kylin-spark-project/kylin-spark-common/src/main/java/org/apache/kylin/engine/spark/common/util/KylinDateTimeUtils.scala
##########
@@ -19,6 +19,7 @@
package org.apache.kylin.engine.spark.common.util
import org.apache.calcite.avatica.util.TimeUnitRange
+import org.apache.kylin.engine.spark.cross.CrossDateTimeUtils
import org.apache.spark.sql.catalyst.util.DateTimeUtils
Review comment:
remove this unused import
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r635033446
##########
File path: kylin-spark-project/kylin-spark-common/src/main/spark31/org/apache/spark/sql/execution/KylinFileSourceScanExec.scala
##########
@@ -0,0 +1,252 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution
+
+import org.apache.hadoop.fs.{BlockLocation, FileStatus, LocatedFileStatus, Path}
+import org.apache.kylin.common.KylinConfig
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, Expression, ExpressionUtils, SortOrder}
+import org.apache.spark.sql.catalyst.plans.physical.{HashPartitioning, Partitioning, UnknownPartitioning}
+import org.apache.spark.sql.catalyst.{InternalRow, TableIdentifier}
+import org.apache.spark.sql.execution.datasource.{FilePruner, ShardSpec}
+import org.apache.spark.sql.execution.datasources._
+import org.apache.spark.sql.execution.metric.SQLMetrics
+import org.apache.spark.sql.types.StructType
+
+import scala.collection.mutable.ArrayBuffer
+
+class KylinFileSourceScanExec(
+ @transient override val relation: HadoopFsRelation,
+ override val output: Seq[Attribute],
+ override val requiredSchema: StructType,
+ override val partitionFilters: Seq[Expression],
+ val optionalShardSpec: Option[ShardSpec],
+ override val dataFilters: Seq[Expression],
+ override val tableIdentifier: Option[TableIdentifier]) extends FileSourceScanExec(
+ relation, output, requiredSchema, partitionFilters, None, None, dataFilters, tableIdentifier, false) {
+
+ private lazy val _inputRDD: RDD[InternalRow] = {
+ val readFile: (PartitionedFile) => Iterator[InternalRow] =
+ relation.fileFormat.buildReaderWithPartitionValues(
+ sparkSession = relation.sparkSession,
+ dataSchema = relation.dataSchema,
+ partitionSchema = relation.partitionSchema,
+ requiredSchema = requiredSchema,
+ filters = pushedDownFilters,
+ options = relation.options,
+ hadoopConf = relation.sparkSession.sessionState.newHadoopConfWithOptions(relation.options))
+
+ optionalShardSpec match {
+ case Some(spec) if KylinConfig.getInstanceFromEnv.isShardingJoinOptEnabled =>
+ createShardingReadRDD(spec, readFile, selectedPartitions, relation)
+ case _ =>
+ createNonShardingReadRDD(readFile, selectedPartitions, relation)
+ }
Review comment:
Please reference to the implementation of FileSourceScanExec.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r635033446
##########
File path: kylin-spark-project/kylin-spark-common/src/main/spark31/org/apache/spark/sql/execution/KylinFileSourceScanExec.scala
##########
@@ -0,0 +1,252 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution
+
+import org.apache.hadoop.fs.{BlockLocation, FileStatus, LocatedFileStatus, Path}
+import org.apache.kylin.common.KylinConfig
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, Expression, ExpressionUtils, SortOrder}
+import org.apache.spark.sql.catalyst.plans.physical.{HashPartitioning, Partitioning, UnknownPartitioning}
+import org.apache.spark.sql.catalyst.{InternalRow, TableIdentifier}
+import org.apache.spark.sql.execution.datasource.{FilePruner, ShardSpec}
+import org.apache.spark.sql.execution.datasources._
+import org.apache.spark.sql.execution.metric.SQLMetrics
+import org.apache.spark.sql.types.StructType
+
+import scala.collection.mutable.ArrayBuffer
+
+class KylinFileSourceScanExec(
+ @transient override val relation: HadoopFsRelation,
+ override val output: Seq[Attribute],
+ override val requiredSchema: StructType,
+ override val partitionFilters: Seq[Expression],
+ val optionalShardSpec: Option[ShardSpec],
+ override val dataFilters: Seq[Expression],
+ override val tableIdentifier: Option[TableIdentifier]) extends FileSourceScanExec(
+ relation, output, requiredSchema, partitionFilters, None, None, dataFilters, tableIdentifier, false) {
+
+ private lazy val _inputRDD: RDD[InternalRow] = {
+ val readFile: (PartitionedFile) => Iterator[InternalRow] =
+ relation.fileFormat.buildReaderWithPartitionValues(
+ sparkSession = relation.sparkSession,
+ dataSchema = relation.dataSchema,
+ partitionSchema = relation.partitionSchema,
+ requiredSchema = requiredSchema,
+ filters = pushedDownFilters,
+ options = relation.options,
+ hadoopConf = relation.sparkSession.sessionState.newHadoopConfWithOptions(relation.options))
+
+ optionalShardSpec match {
+ case Some(spec) if KylinConfig.getInstanceFromEnv.isShardingJoinOptEnabled =>
+ createShardingReadRDD(spec, readFile, selectedPartitions, relation)
+ case _ =>
+ createNonShardingReadRDD(readFile, selectedPartitions, relation)
+ }
Review comment:
Please reference to the implementation of FileSourceScanExec.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] xiacongling commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
xiacongling commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r637856886
##########
File path: .travis.yml
##########
@@ -46,7 +46,8 @@ before_script:
script:
# mvn clean org.jacoco:jacoco-maven-plugin:prepare-agent test coveralls:report -e
# Skip coveralls temporarily, fix it asap
- - mvn clean test
+ - mvn clean test -q
+ - mvn clean test -q -Psandbox -Pspark3
Review comment:
The former is for spark24 which is the default profile, the latter is for spark31. We should make sure that test cases are passed in both versions.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r634841122
##########
File path: kylin-spark-project/kylin-spark-common/src/main/scala/org/apache/spark/sql/catalyst/expressions/TimestampDiffImpl.scala
##########
@@ -19,17 +19,17 @@
package org.apache.spark.sql.catalyst.expressions
import java.util.Locale
-
import org.apache.kylin.engine.spark.common.util.KylinDateTimeUtils._
import org.apache.kylin.engine.spark.common.util.KylinDateTimeUtils
+import org.apache.kylin.engine.spark.cross.CrossDateTimeUtils
import org.apache.spark.sql.catalyst.util.DateTimeUtils
Review comment:
remove this unused import
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] xiacongling commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
xiacongling commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r646607363
##########
File path: kylin-spark-project/kylin-spark-engine/src/test/scala/org/apache/kylin/engine/spark/builder/TestCreateFlatTable.scala
##########
@@ -81,7 +81,8 @@ class TestCreateFlatTable extends SparderBaseFunSuite with SharedSparkSession wi
//DefaultScheduler.destroyInstance()
}
- test("Check the flattable spark jobs num correctness") {
+ // todo: [Spark 3.0] BroadcastExchangeExec overwrites job group ID
+ ignore("Check the flattable spark jobs num correctness") {
Review comment:
test case recovered
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#issuecomment-869096384
@pan3793 Thanks for your mentioning, I will check later.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@kylin.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#issuecomment-869019077
LGTM, thank you for your contribution, this feature is great.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@kylin.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] codecov-commenter edited a comment on pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
codecov-commenter edited a comment on pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#issuecomment-846865473
# [Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) Report
> :exclamation: No coverage uploaded for pull request base (`kylin-on-parquet-v2@25080df`). [Click here to learn what that means](https://docs.codecov.io/docs/error-reference?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#section-missing-base-commit).
> The diff coverage is `n/a`.
[](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation)
```diff
@@ Coverage Diff @@
## kylin-on-parquet-v2 #1601 +/- ##
======================================================
Coverage ? 24.29%
Complexity ? 4649
======================================================
Files ? 1152
Lines ? 65208
Branches ? 9363
======================================================
Hits ? 15842
Misses ? 47717
Partials ? 1649
```
------
[Continue to review full report at Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=footer&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation). Last update [25080df...624b100](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=lastupdated&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#issuecomment-839861562
@xiacongling Thank you for your contribution, I will review this PR ASAP.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] xiacongling commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
xiacongling commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r641311369
##########
File path: kylin-spark-project/kylin-spark-common/src/main/spark31/org/apache/spark/sql/execution/KylinJoinSelection.scala
##########
@@ -0,0 +1,283 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+*/
+
+package org.apache.spark.sql.execution
+
+import javax.annotation.concurrent.GuardedBy
+import org.apache.kylin.common.KylinConfig
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.catalyst.expressions.{PredicateHelper, RowOrdering}
+import org.apache.spark.sql.catalyst.optimizer.{BuildLeft, BuildRight, BuildSide}
+import org.apache.spark.sql.catalyst.planning.ExtractEquiJoinKeys
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.catalyst.plans.logical.{JoinHint, LogicalPlan}
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.{SparkSession, Strategy}
+
+/**
+ * Select the proper physical plan for join based on joining keys and size of logical plan.
+ *
+ * At first, uses the [[ExtractEquiJoinKeys]] pattern to find joins where at least some of the
+ * predicates can be evaluated by matching join keys. If found, join implementations are chosen
+ * with the following precedence:
+ *
+ * - Broadcast hash join (BHJ):
+ * BHJ is not supported for full outer join. For right outer join, we only can broadcast the
+ * left side. For left outer, left semi, left anti and the internal join type ExistenceJoin,
+ * we only can broadcast the right side. For inner like join, we can broadcast both sides.
+ * Normally, BHJ can perform faster than the other join algorithms when the broadcast side is
+ * small. However, broadcasting tables is a network-intensive operation. It could cause OOM
+ * or perform worse than the other join algorithms, especially when the build/broadcast side
+ * is big.
+ *
+ * For the supported cases, users can specify the broadcast hint (e.g. the user applied the
+ * [[org.apache.spark.sql.functions.broadcast()]] function to a DataFrame) and session-based
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold to adjust whether BHJ is used and
+ * which join side is broadcast.
+ *
+ * 1) Broadcast the join side with the broadcast hint, even if the size is larger than
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]]. If both sides have the hint (only when the type
+ * is inner like join), the side with a smaller estimated physical size will be broadcast.
+ * 2) Respect the [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold and broadcast the side
+ * whose estimated physical size is smaller than the threshold. If both sides are below the
+ * threshold, broadcast the smaller side. If neither is smaller, BHJ is not used.
+ *
+ * - Shuffle hash join: if the average size of a single partition is small enough to build a hash
+ * table.
+ *
+ * - Sort merge: if the matching join keys are sortable.
+ *
+ * If there is no joining keys, Join implementations are chosen with the following precedence:
+ * - BroadcastNestedLoopJoin (BNLJ):
+ * BNLJ supports all the join types but the impl is OPTIMIZED for the following scenarios:
+ * For right outer join, the left side is broadcast. For left outer, left semi, left anti
+ * and the internal join type ExistenceJoin, the right side is broadcast. For inner like
+ * joins, either side is broadcast.
+ *
+ * Like BHJ, users still can specify the broadcast hint and session-based
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold to impact which side is broadcast.
+ *
+ * 1) Broadcast the join side with the broadcast hint, even if the size is larger than
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]]. If both sides have the hint (i.e., just for
+ * inner-like join), the side with a smaller estimated physical size will be broadcast.
+ * 2) Respect the [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold and broadcast the side
+ * whose estimated physical size is smaller than the threshold. If both sides are below the
+ * threshold, broadcast the smaller side. If neither is smaller, BNLJ is not used.
+ *
+ * - CartesianProduct: for inner like join, CartesianProduct is the fallback option.
+ *
+ * - BroadcastNestedLoopJoin (BNLJ):
+ * For the other join types, BNLJ is the fallback option. Here, we just pick the broadcast
+ * side with the broadcast hint. If neither side has a hint, we broadcast the side with
+ * the smaller estimated physical size.
+ */
+case class KylinJoinSelection(session: SparkSession) extends Strategy with PredicateHelper with Logging {
+
+ val conf: SQLConf = session.sessionState.conf
+
+ /**
+ * Matches a plan whose output should be small enough to be used in broadcast join.
+ */
+ private def canBroadcast(plan: LogicalPlan): Boolean = {
+ val sizeInBytes = plan.stats.sizeInBytes
+ sizeInBytes >= 0 && sizeInBytes <= conf.autoBroadcastJoinThreshold && JoinMemoryManager.acquireMemory(sizeInBytes.toLong)
+ }
+
+ /**
+ * Matches a plan whose single partition should be small enough to build a hash table.
+ *
+ * Note: this assume that the number of partition is fixed, requires additional work if it's
+ * dynamic.
+ */
+ private def canBuildLocalHashMap(plan: LogicalPlan): Boolean = {
+ plan.stats.sizeInBytes < conf.autoBroadcastJoinThreshold * conf.numShufflePartitions
+ }
+
+ /**
+ * Returns whether plan a is much smaller (3X) than plan b.
+ *
+ * The cost to build hash map is higher than sorting, we should only build hash map on a table
+ * that is much smaller than other one. Since we does not have the statistic for number of rows,
+ * use the size of bytes here as estimation.
+ */
+ private def muchSmaller(a: LogicalPlan, b: LogicalPlan): Boolean = {
+ a.stats.sizeInBytes * 3 <= b.stats.sizeInBytes
+ }
+
+ private def canBuildRight(joinType: JoinType): Boolean = joinType match {
+ case _: InnerLike | LeftOuter | LeftSemi | LeftAnti | _: ExistenceJoin => true
+ case _ => false
+ }
+
+ private def canBuildLeft(joinType: JoinType): Boolean = joinType match {
+ case _: InnerLike | RightOuter => true
+ case _ => false
+ }
+
+ private def broadcastSide(
+ canBuildLeft: Boolean,
+ canBuildRight: Boolean,
+ left: LogicalPlan,
+ right: LogicalPlan): BuildSide = {
+
+ def smallerSide =
+ if (right.stats.sizeInBytes <= left.stats.sizeInBytes) BuildRight else BuildLeft
+
+ if (canBuildRight && canBuildLeft) {
+ // Broadcast smaller side base on its estimated physical size
+ // if both sides have broadcast hint
+ smallerSide
+ } else if (canBuildRight) {
+ BuildRight
+ } else if (canBuildLeft) {
+ BuildLeft
+ } else {
+ // for the last default broadcast nested loop join
+ smallerSide
+ }
+ }
+
+ private def canBroadcastByHints(joinType: JoinType, left: LogicalPlan, right: LogicalPlan, hint: JoinHint)
+ : Boolean = {
+// val buildLeft = canBuildLeft(joinType) && logical.BROADCAST.equals(hint.leftHint.get.strategy.get)
+// val buildRight = canBuildRight(joinType) && logical.BROADCAST.equals(hint.rightHint.get.strategy.get)
+// buildLeft || buildRight
+ false
+ }
+
+ private def broadcastSideByHints(joinType: JoinType, left: LogicalPlan, right: LogicalPlan, hint: JoinHint)
+ : BuildSide = {
+// val buildLeft = canBuildLeft(joinType) && logical.BROADCAST.equals(hint.leftHint.get.strategy.get)
+// val buildRight = canBuildRight(joinType) && logical.BROADCAST.equals(hint.rightHint.get.strategy.get)
Review comment:
@zzcclp fixed
##########
File path: kylin-spark-project/kylin-spark-common/src/main/spark31/org/apache/spark/sql/execution/KylinJoinSelection.scala
##########
@@ -0,0 +1,283 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+*/
+
+package org.apache.spark.sql.execution
+
+import javax.annotation.concurrent.GuardedBy
+import org.apache.kylin.common.KylinConfig
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.catalyst.expressions.{PredicateHelper, RowOrdering}
+import org.apache.spark.sql.catalyst.optimizer.{BuildLeft, BuildRight, BuildSide}
+import org.apache.spark.sql.catalyst.planning.ExtractEquiJoinKeys
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.catalyst.plans.logical.{JoinHint, LogicalPlan}
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.{SparkSession, Strategy}
+
+/**
+ * Select the proper physical plan for join based on joining keys and size of logical plan.
+ *
+ * At first, uses the [[ExtractEquiJoinKeys]] pattern to find joins where at least some of the
+ * predicates can be evaluated by matching join keys. If found, join implementations are chosen
+ * with the following precedence:
+ *
+ * - Broadcast hash join (BHJ):
+ * BHJ is not supported for full outer join. For right outer join, we only can broadcast the
+ * left side. For left outer, left semi, left anti and the internal join type ExistenceJoin,
+ * we only can broadcast the right side. For inner like join, we can broadcast both sides.
+ * Normally, BHJ can perform faster than the other join algorithms when the broadcast side is
+ * small. However, broadcasting tables is a network-intensive operation. It could cause OOM
+ * or perform worse than the other join algorithms, especially when the build/broadcast side
+ * is big.
+ *
+ * For the supported cases, users can specify the broadcast hint (e.g. the user applied the
+ * [[org.apache.spark.sql.functions.broadcast()]] function to a DataFrame) and session-based
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold to adjust whether BHJ is used and
+ * which join side is broadcast.
+ *
+ * 1) Broadcast the join side with the broadcast hint, even if the size is larger than
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]]. If both sides have the hint (only when the type
+ * is inner like join), the side with a smaller estimated physical size will be broadcast.
+ * 2) Respect the [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold and broadcast the side
+ * whose estimated physical size is smaller than the threshold. If both sides are below the
+ * threshold, broadcast the smaller side. If neither is smaller, BHJ is not used.
+ *
+ * - Shuffle hash join: if the average size of a single partition is small enough to build a hash
+ * table.
+ *
+ * - Sort merge: if the matching join keys are sortable.
+ *
+ * If there is no joining keys, Join implementations are chosen with the following precedence:
+ * - BroadcastNestedLoopJoin (BNLJ):
+ * BNLJ supports all the join types but the impl is OPTIMIZED for the following scenarios:
+ * For right outer join, the left side is broadcast. For left outer, left semi, left anti
+ * and the internal join type ExistenceJoin, the right side is broadcast. For inner like
+ * joins, either side is broadcast.
+ *
+ * Like BHJ, users still can specify the broadcast hint and session-based
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold to impact which side is broadcast.
+ *
+ * 1) Broadcast the join side with the broadcast hint, even if the size is larger than
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]]. If both sides have the hint (i.e., just for
+ * inner-like join), the side with a smaller estimated physical size will be broadcast.
+ * 2) Respect the [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold and broadcast the side
+ * whose estimated physical size is smaller than the threshold. If both sides are below the
+ * threshold, broadcast the smaller side. If neither is smaller, BNLJ is not used.
+ *
+ * - CartesianProduct: for inner like join, CartesianProduct is the fallback option.
+ *
+ * - BroadcastNestedLoopJoin (BNLJ):
+ * For the other join types, BNLJ is the fallback option. Here, we just pick the broadcast
+ * side with the broadcast hint. If neither side has a hint, we broadcast the side with
+ * the smaller estimated physical size.
+ */
+case class KylinJoinSelection(session: SparkSession) extends Strategy with PredicateHelper with Logging {
+
+ val conf: SQLConf = session.sessionState.conf
+
+ /**
+ * Matches a plan whose output should be small enough to be used in broadcast join.
+ */
+ private def canBroadcast(plan: LogicalPlan): Boolean = {
+ val sizeInBytes = plan.stats.sizeInBytes
+ sizeInBytes >= 0 && sizeInBytes <= conf.autoBroadcastJoinThreshold && JoinMemoryManager.acquireMemory(sizeInBytes.toLong)
+ }
+
+ /**
+ * Matches a plan whose single partition should be small enough to build a hash table.
+ *
+ * Note: this assume that the number of partition is fixed, requires additional work if it's
+ * dynamic.
+ */
+ private def canBuildLocalHashMap(plan: LogicalPlan): Boolean = {
+ plan.stats.sizeInBytes < conf.autoBroadcastJoinThreshold * conf.numShufflePartitions
+ }
+
+ /**
+ * Returns whether plan a is much smaller (3X) than plan b.
+ *
+ * The cost to build hash map is higher than sorting, we should only build hash map on a table
+ * that is much smaller than other one. Since we does not have the statistic for number of rows,
+ * use the size of bytes here as estimation.
+ */
+ private def muchSmaller(a: LogicalPlan, b: LogicalPlan): Boolean = {
+ a.stats.sizeInBytes * 3 <= b.stats.sizeInBytes
+ }
+
+ private def canBuildRight(joinType: JoinType): Boolean = joinType match {
+ case _: InnerLike | LeftOuter | LeftSemi | LeftAnti | _: ExistenceJoin => true
+ case _ => false
+ }
+
+ private def canBuildLeft(joinType: JoinType): Boolean = joinType match {
+ case _: InnerLike | RightOuter => true
+ case _ => false
+ }
+
+ private def broadcastSide(
+ canBuildLeft: Boolean,
+ canBuildRight: Boolean,
+ left: LogicalPlan,
+ right: LogicalPlan): BuildSide = {
+
+ def smallerSide =
+ if (right.stats.sizeInBytes <= left.stats.sizeInBytes) BuildRight else BuildLeft
+
+ if (canBuildRight && canBuildLeft) {
+ // Broadcast smaller side base on its estimated physical size
+ // if both sides have broadcast hint
+ smallerSide
+ } else if (canBuildRight) {
+ BuildRight
+ } else if (canBuildLeft) {
+ BuildLeft
+ } else {
+ // for the last default broadcast nested loop join
+ smallerSide
+ }
+ }
+
+ private def canBroadcastByHints(joinType: JoinType, left: LogicalPlan, right: LogicalPlan, hint: JoinHint)
+ : Boolean = {
+// val buildLeft = canBuildLeft(joinType) && logical.BROADCAST.equals(hint.leftHint.get.strategy.get)
+// val buildRight = canBuildRight(joinType) && logical.BROADCAST.equals(hint.rightHint.get.strategy.get)
+// buildLeft || buildRight
+ false
Review comment:
@zzcclp fixed
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] pan3793 commented on pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
pan3793 commented on pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#issuecomment-869091995
Why put classes of `package org.apache.spark.memory` into folder `org/apache/spark/monitor`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@kylin.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r635030677
##########
File path: kylin-spark-project/kylin-spark-common/src/main/spark31/org/apache/spark/sql/execution/KylinFileSourceScanExec.scala
##########
@@ -0,0 +1,252 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution
+
+import org.apache.hadoop.fs.{BlockLocation, FileStatus, LocatedFileStatus, Path}
+import org.apache.kylin.common.KylinConfig
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, Expression, ExpressionUtils, SortOrder}
+import org.apache.spark.sql.catalyst.plans.physical.{HashPartitioning, Partitioning, UnknownPartitioning}
+import org.apache.spark.sql.catalyst.{InternalRow, TableIdentifier}
+import org.apache.spark.sql.execution.datasource.{FilePruner, ShardSpec}
+import org.apache.spark.sql.execution.datasources._
+import org.apache.spark.sql.execution.metric.SQLMetrics
+import org.apache.spark.sql.types.StructType
+
+import scala.collection.mutable.ArrayBuffer
+
+class KylinFileSourceScanExec(
+ @transient override val relation: HadoopFsRelation,
+ override val output: Seq[Attribute],
+ override val requiredSchema: StructType,
+ override val partitionFilters: Seq[Expression],
+ val optionalShardSpec: Option[ShardSpec],
+ override val dataFilters: Seq[Expression],
+ override val tableIdentifier: Option[TableIdentifier]) extends FileSourceScanExec(
+ relation, output, requiredSchema, partitionFilters, None, None, dataFilters, tableIdentifier, false) {
+
+ private lazy val _inputRDD: RDD[InternalRow] = {
+ val readFile: (PartitionedFile) => Iterator[InternalRow] =
+ relation.fileFormat.buildReaderWithPartitionValues(
+ sparkSession = relation.sparkSession,
+ dataSchema = relation.dataSchema,
+ partitionSchema = relation.partitionSchema,
+ requiredSchema = requiredSchema,
+ filters = pushedDownFilters,
+ options = relation.options,
+ hadoopConf = relation.sparkSession.sessionState.newHadoopConfWithOptions(relation.options))
+
+ optionalShardSpec match {
+ case Some(spec) if KylinConfig.getInstanceFromEnv.isShardingJoinOptEnabled =>
+ createShardingReadRDD(spec, readFile, selectedPartitions, relation)
+ case _ =>
+ createNonShardingReadRDD(readFile, selectedPartitions, relation)
+ }
Review comment:
need to send metrics here, otherwise it will miss.
Please reference to the implementation in FileSourceScanExec:
```
sendDriverMetrics()
```
The method above is private, can't be used in KylinFileSourceScanExec.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] codecov-commenter commented on pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
codecov-commenter commented on pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#issuecomment-846865473
# [Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) Report
> :exclamation: No coverage uploaded for pull request base (`kylin-on-parquet-v2@f5ec8f3`). [Click here to learn what that means](https://docs.codecov.io/docs/error-reference?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#section-missing-base-commit).
> The diff coverage is `n/a`.
[](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation)
```diff
@@ Coverage Diff @@
## kylin-on-parquet-v2 #1601 +/- ##
======================================================
Coverage ? 24.52%
Complexity ? 4648
======================================================
Files ? 1141
Lines ? 64530
Branches ? 9309
======================================================
Hits ? 15823
Misses ? 47060
Partials ? 1647
```
------
[Continue to review full report at Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=footer&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation). Last update [f5ec8f3...1616657](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=lastupdated&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r642811754
##########
File path: kylin-spark-project/kylin-spark-common/src/main/spark24/org/apache/spark/sql/execution/datasource/FilterExt.scala
##########
@@ -0,0 +1,18 @@
+package org.apache.spark.sql.execution.datasource
Review comment:
Please add the license header
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r657063364
##########
File path: kylin-spark-project/kylin-spark-common/src/main/spark31/org/apache/spark/sql/execution/KylinJoinSelection.scala
##########
@@ -0,0 +1,285 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+*/
+
+package org.apache.spark.sql.execution
+
+import javax.annotation.concurrent.GuardedBy
+import org.apache.kylin.common.KylinConfig
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.catalyst.expressions.{PredicateHelper, RowOrdering}
+import org.apache.spark.sql.catalyst.optimizer.{BuildLeft, BuildRight, BuildSide}
+import org.apache.spark.sql.catalyst.planning.ExtractEquiJoinKeys
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.catalyst.plans.logical.{BROADCAST, HintInfo, JoinHint, LogicalPlan}
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.{SparkSession, Strategy}
+
+/**
+ * Select the proper physical plan for join based on joining keys and size of logical plan.
+ *
+ * At first, uses the [[ExtractEquiJoinKeys]] pattern to find joins where at least some of the
+ * predicates can be evaluated by matching join keys. If found, join implementations are chosen
+ * with the following precedence:
+ *
+ * - Broadcast hash join (BHJ):
+ * BHJ is not supported for full outer join. For right outer join, we only can broadcast the
+ * left side. For left outer, left semi, left anti and the internal join type ExistenceJoin,
+ * we only can broadcast the right side. For inner like join, we can broadcast both sides.
+ * Normally, BHJ can perform faster than the other join algorithms when the broadcast side is
+ * small. However, broadcasting tables is a network-intensive operation. It could cause OOM
+ * or perform worse than the other join algorithms, especially when the build/broadcast side
+ * is big.
+ *
+ * For the supported cases, users can specify the broadcast hint (e.g. the user applied the
+ * [[org.apache.spark.sql.functions.broadcast()]] function to a DataFrame) and session-based
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold to adjust whether BHJ is used and
+ * which join side is broadcast.
+ *
+ * 1) Broadcast the join side with the broadcast hint, even if the size is larger than
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]]. If both sides have the hint (only when the type
+ * is inner like join), the side with a smaller estimated physical size will be broadcast.
+ * 2) Respect the [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold and broadcast the side
+ * whose estimated physical size is smaller than the threshold. If both sides are below the
+ * threshold, broadcast the smaller side. If neither is smaller, BHJ is not used.
+ *
+ * - Shuffle hash join: if the average size of a single partition is small enough to build a hash
+ * table.
+ *
+ * - Sort merge: if the matching join keys are sortable.
+ *
+ * If there is no joining keys, Join implementations are chosen with the following precedence:
+ * - BroadcastNestedLoopJoin (BNLJ):
+ * BNLJ supports all the join types but the impl is OPTIMIZED for the following scenarios:
+ * For right outer join, the left side is broadcast. For left outer, left semi, left anti
+ * and the internal join type ExistenceJoin, the right side is broadcast. For inner like
+ * joins, either side is broadcast.
+ *
+ * Like BHJ, users still can specify the broadcast hint and session-based
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold to impact which side is broadcast.
+ *
+ * 1) Broadcast the join side with the broadcast hint, even if the size is larger than
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]]. If both sides have the hint (i.e., just for
+ * inner-like join), the side with a smaller estimated physical size will be broadcast.
+ * 2) Respect the [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold and broadcast the side
+ * whose estimated physical size is smaller than the threshold. If both sides are below the
+ * threshold, broadcast the smaller side. If neither is smaller, BNLJ is not used.
+ *
+ * - CartesianProduct: for inner like join, CartesianProduct is the fallback option.
+ *
+ * - BroadcastNestedLoopJoin (BNLJ):
+ * For the other join types, BNLJ is the fallback option. Here, we just pick the broadcast
+ * side with the broadcast hint. If neither side has a hint, we broadcast the side with
+ * the smaller estimated physical size.
+ */
+case class KylinJoinSelection(session: SparkSession) extends Strategy with PredicateHelper with Logging {
+
+ val conf: SQLConf = session.sessionState.conf
+
+ /**
+ * Matches a plan whose output should be small enough to be used in broadcast join.
+ */
+ private def canBroadcast(plan: LogicalPlan): Boolean = {
+ val sizeInBytes = plan.stats.sizeInBytes
+ sizeInBytes >= 0 && sizeInBytes <= conf.autoBroadcastJoinThreshold && JoinMemoryManager.acquireMemory(sizeInBytes.toLong)
+ }
+
+ /**
+ * Matches a plan whose single partition should be small enough to build a hash table.
+ *
+ * Note: this assume that the number of partition is fixed, requires additional work if it's
+ * dynamic.
+ */
+ private def canBuildLocalHashMap(plan: LogicalPlan): Boolean = {
+ plan.stats.sizeInBytes < conf.autoBroadcastJoinThreshold * conf.numShufflePartitions
+ }
+
+ /**
+ * Returns whether plan a is much smaller (3X) than plan b.
+ *
+ * The cost to build hash map is higher than sorting, we should only build hash map on a table
+ * that is much smaller than other one. Since we does not have the statistic for number of rows,
+ * use the size of bytes here as estimation.
+ */
+ private def muchSmaller(a: LogicalPlan, b: LogicalPlan): Boolean = {
+ a.stats.sizeInBytes * 3 <= b.stats.sizeInBytes
+ }
+
+ private def canBuildRight(joinType: JoinType): Boolean = joinType match {
+ case _: InnerLike | LeftOuter | LeftSemi | LeftAnti | _: ExistenceJoin => true
+ case _ => false
+ }
+
+ private def canBuildLeft(joinType: JoinType): Boolean = joinType match {
+ case _: InnerLike | RightOuter => true
+ case _ => false
+ }
+
+ private def broadcastSide(
+ canBuildLeft: Boolean,
+ canBuildRight: Boolean,
+ left: LogicalPlan,
+ right: LogicalPlan): BuildSide = {
+
+ def smallerSide =
+ if (right.stats.sizeInBytes <= left.stats.sizeInBytes) BuildRight else BuildLeft
+
+ if (canBuildRight && canBuildLeft) {
+ // Broadcast smaller side base on its estimated physical size
+ // if both sides have broadcast hint
+ smallerSide
+ } else if (canBuildRight) {
+ BuildRight
+ } else if (canBuildLeft) {
+ BuildLeft
+ } else {
+ // for the last default broadcast nested loop join
+ smallerSide
+ }
+ }
+
+ private def canBroadcastByHints(joinType: JoinType, left: LogicalPlan, right: LogicalPlan, hint: JoinHint)
+ : Boolean = {
+ val buildLeft = canBuildLeft(joinType) && hintBroadcast(hint.leftHint)
+ val buildRight = canBuildRight(joinType) && hintBroadcast(hint.rightHint)
+ buildLeft || buildRight
+ }
+
+ private def broadcastSideByHints(joinType: JoinType, left: LogicalPlan, right: LogicalPlan, hint: JoinHint)
+ : BuildSide = {
+ val buildLeft = canBuildLeft(joinType) && hintBroadcast(hint.leftHint)
+ val buildRight = canBuildRight(joinType) && hintBroadcast(hint.rightHint)
+ broadcastSide(buildLeft, buildRight, left, right)
+ }
+
+ private def canBroadcastBySizes(joinType: JoinType, left: LogicalPlan, right: LogicalPlan)
+ : Boolean = {
+ val buildLeft = canBuildLeft(joinType) && canBroadcast(left)
+ val buildRight = canBuildRight(joinType) && canBroadcast(right)
+ buildLeft || buildRight
+ }
+
+ private def broadcastSideBySizes(joinType: JoinType, left: LogicalPlan, right: LogicalPlan)
+ : BuildSide = {
+ val buildLeft = canBuildLeft(joinType) && canBroadcast(left)
+ val buildRight = canBuildRight(joinType) && canBroadcast(right)
+ broadcastSide(buildLeft, buildRight, left, right)
+ }
+
+ def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
Review comment:
It seems a mistake. Thanks for your reporting about this issue, I will check this later.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r638420793
##########
File path: .travis.yml
##########
@@ -46,7 +46,8 @@ before_script:
script:
# mvn clean org.jacoco:jacoco-maven-plugin:prepare-agent test coveralls:report -e
# Skip coveralls temporarily, fix it asap
- - mvn clean test
+ - mvn clean test -q
+ - mvn clean test -q -Psandbox -Pspark3
Review comment:
Got it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r634969077
##########
File path: kylin-spark-project/kylin-spark-common/src/main/spark24/org/apache/spark/monitor/MonitorExecutorExtension.scala
##########
@@ -18,6 +18,8 @@
package org.apache.spark.memory
+import java.util
Review comment:
remove this import
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r635122826
##########
File path: kylin-spark-project/kylin-spark-engine/src/main/scala/org/apache/kylin/query/runtime/ExpressionConverter.scala
##########
@@ -18,17 +18,18 @@
package org.apache.kylin.query.runtime
+import java.time.ZoneId
import java.util.Locale
-
import org.apache.calcite.rel.`type`.RelDataType
import org.apache.calcite.sql.SqlKind
import org.apache.calcite.sql.SqlKind._
import org.apache.calcite.sql.`type`.SqlTypeName
+import org.apache.kylin.engine.spark.cross.CrossDateTimeUtils
import org.apache.kylin.query.util.UnsupportedSparkFunctionException
import org.apache.spark.sql.Column
import org.apache.spark.sql.KylinFunctions._
import org.apache.spark.sql.catalyst.expressions.{If, IfNull, StringLocate}
-import org.apache.spark.sql.catalyst.util.DateTimeUtils
+import org.apache.spark.sql.catalyst.util.{DateTimeUtils, TimestampFormatter}
Review comment:
remove this unused import
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r635103927
##########
File path: kylin-spark-project/kylin-spark-engine/src/main/scala/org/apache/kylin/engine/spark/job/CuboidAggregator.scala
##########
@@ -26,12 +26,15 @@ import org.apache.kylin.engine.spark.metadata.cube.model.SpanningTree
import org.apache.kylin.engine.spark.metadata.{ColumnDesc, DTType, FunctionDesc, LiteralColumnDesc}
import org.apache.kylin.measure.bitmap.BitmapMeasureType
import org.apache.kylin.measure.hllc.HLLCMeasureType
+import org.apache.spark.sql.catalyst.InternalRow
import org.apache.spark.sql.catalyst.expressions.aggregate.AggregateFunction
import org.apache.spark.sql.functions.{col, _}
-import org.apache.spark.sql.types.{StringType, _}
+import org.apache.spark.sql.types.{BinaryType, BooleanType, ByteType, CalendarIntervalType, DoubleType, FloatType, ShortType, StringType, _}
import org.apache.spark.sql.udaf._
import org.apache.spark.sql.{Column, DataFrame, SparkSession}
import org.apache.spark.sql.catalyst.expressions.Literal
+import org.apache.spark.sql.catalyst.util.{ArrayData, MapData}
+import org.apache.spark.unsafe.types.{CalendarInterval, UTF8String}
Review comment:
remove some unused import, please check.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] xiacongling commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
xiacongling commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r647049639
##########
File path: kylin-spark-project/kylin-spark-common/src/main/spark31/org/apache/spark/sql/execution/KylinJoinSelection.scala
##########
@@ -0,0 +1,285 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+*/
+
+package org.apache.spark.sql.execution
+
+import javax.annotation.concurrent.GuardedBy
+import org.apache.kylin.common.KylinConfig
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.catalyst.expressions.{PredicateHelper, RowOrdering}
+import org.apache.spark.sql.catalyst.optimizer.{BuildLeft, BuildRight, BuildSide}
+import org.apache.spark.sql.catalyst.planning.ExtractEquiJoinKeys
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.catalyst.plans.logical.{BROADCAST, HintInfo, JoinHint, LogicalPlan}
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.{SparkSession, Strategy}
+
+/**
+ * Select the proper physical plan for join based on joining keys and size of logical plan.
+ *
+ * At first, uses the [[ExtractEquiJoinKeys]] pattern to find joins where at least some of the
+ * predicates can be evaluated by matching join keys. If found, join implementations are chosen
+ * with the following precedence:
+ *
+ * - Broadcast hash join (BHJ):
+ * BHJ is not supported for full outer join. For right outer join, we only can broadcast the
+ * left side. For left outer, left semi, left anti and the internal join type ExistenceJoin,
+ * we only can broadcast the right side. For inner like join, we can broadcast both sides.
+ * Normally, BHJ can perform faster than the other join algorithms when the broadcast side is
+ * small. However, broadcasting tables is a network-intensive operation. It could cause OOM
+ * or perform worse than the other join algorithms, especially when the build/broadcast side
+ * is big.
+ *
+ * For the supported cases, users can specify the broadcast hint (e.g. the user applied the
+ * [[org.apache.spark.sql.functions.broadcast()]] function to a DataFrame) and session-based
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold to adjust whether BHJ is used and
+ * which join side is broadcast.
+ *
+ * 1) Broadcast the join side with the broadcast hint, even if the size is larger than
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]]. If both sides have the hint (only when the type
+ * is inner like join), the side with a smaller estimated physical size will be broadcast.
+ * 2) Respect the [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold and broadcast the side
+ * whose estimated physical size is smaller than the threshold. If both sides are below the
+ * threshold, broadcast the smaller side. If neither is smaller, BHJ is not used.
+ *
+ * - Shuffle hash join: if the average size of a single partition is small enough to build a hash
+ * table.
+ *
+ * - Sort merge: if the matching join keys are sortable.
+ *
+ * If there is no joining keys, Join implementations are chosen with the following precedence:
+ * - BroadcastNestedLoopJoin (BNLJ):
+ * BNLJ supports all the join types but the impl is OPTIMIZED for the following scenarios:
+ * For right outer join, the left side is broadcast. For left outer, left semi, left anti
+ * and the internal join type ExistenceJoin, the right side is broadcast. For inner like
+ * joins, either side is broadcast.
+ *
+ * Like BHJ, users still can specify the broadcast hint and session-based
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold to impact which side is broadcast.
+ *
+ * 1) Broadcast the join side with the broadcast hint, even if the size is larger than
+ * [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]]. If both sides have the hint (i.e., just for
+ * inner-like join), the side with a smaller estimated physical size will be broadcast.
+ * 2) Respect the [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold and broadcast the side
+ * whose estimated physical size is smaller than the threshold. If both sides are below the
+ * threshold, broadcast the smaller side. If neither is smaller, BNLJ is not used.
+ *
+ * - CartesianProduct: for inner like join, CartesianProduct is the fallback option.
+ *
+ * - BroadcastNestedLoopJoin (BNLJ):
+ * For the other join types, BNLJ is the fallback option. Here, we just pick the broadcast
+ * side with the broadcast hint. If neither side has a hint, we broadcast the side with
+ * the smaller estimated physical size.
+ */
+case class KylinJoinSelection(session: SparkSession) extends Strategy with PredicateHelper with Logging {
+
+ val conf: SQLConf = session.sessionState.conf
+
+ /**
+ * Matches a plan whose output should be small enough to be used in broadcast join.
+ */
+ private def canBroadcast(plan: LogicalPlan): Boolean = {
+ val sizeInBytes = plan.stats.sizeInBytes
+ sizeInBytes >= 0 && sizeInBytes <= conf.autoBroadcastJoinThreshold && JoinMemoryManager.acquireMemory(sizeInBytes.toLong)
+ }
+
+ /**
+ * Matches a plan whose single partition should be small enough to build a hash table.
+ *
+ * Note: this assume that the number of partition is fixed, requires additional work if it's
+ * dynamic.
+ */
+ private def canBuildLocalHashMap(plan: LogicalPlan): Boolean = {
+ plan.stats.sizeInBytes < conf.autoBroadcastJoinThreshold * conf.numShufflePartitions
+ }
+
+ /**
+ * Returns whether plan a is much smaller (3X) than plan b.
+ *
+ * The cost to build hash map is higher than sorting, we should only build hash map on a table
+ * that is much smaller than other one. Since we does not have the statistic for number of rows,
+ * use the size of bytes here as estimation.
+ */
+ private def muchSmaller(a: LogicalPlan, b: LogicalPlan): Boolean = {
+ a.stats.sizeInBytes * 3 <= b.stats.sizeInBytes
+ }
+
+ private def canBuildRight(joinType: JoinType): Boolean = joinType match {
+ case _: InnerLike | LeftOuter | LeftSemi | LeftAnti | _: ExistenceJoin => true
+ case _ => false
+ }
+
+ private def canBuildLeft(joinType: JoinType): Boolean = joinType match {
+ case _: InnerLike | RightOuter => true
+ case _ => false
+ }
+
+ private def broadcastSide(
+ canBuildLeft: Boolean,
+ canBuildRight: Boolean,
+ left: LogicalPlan,
+ right: LogicalPlan): BuildSide = {
+
+ def smallerSide =
+ if (right.stats.sizeInBytes <= left.stats.sizeInBytes) BuildRight else BuildLeft
+
+ if (canBuildRight && canBuildLeft) {
+ // Broadcast smaller side base on its estimated physical size
+ // if both sides have broadcast hint
+ smallerSide
+ } else if (canBuildRight) {
+ BuildRight
+ } else if (canBuildLeft) {
+ BuildLeft
+ } else {
+ // for the last default broadcast nested loop join
+ smallerSide
+ }
+ }
+
+ private def canBroadcastByHints(joinType: JoinType, left: LogicalPlan, right: LogicalPlan, hint: JoinHint)
+ : Boolean = {
+ val buildLeft = canBuildLeft(joinType) && hintBroadcast(hint.leftHint)
+ val buildRight = canBuildRight(joinType) && hintBroadcast(hint.rightHint)
+ buildLeft || buildRight
+ }
+
+ private def broadcastSideByHints(joinType: JoinType, left: LogicalPlan, right: LogicalPlan, hint: JoinHint)
+ : BuildSide = {
+ val buildLeft = canBuildLeft(joinType) && hintBroadcast(hint.leftHint)
+ val buildRight = canBuildRight(joinType) && hintBroadcast(hint.rightHint)
+ broadcastSide(buildLeft, buildRight, left, right)
+ }
+
+ private def canBroadcastBySizes(joinType: JoinType, left: LogicalPlan, right: LogicalPlan)
+ : Boolean = {
+ val buildLeft = canBuildLeft(joinType) && canBroadcast(left)
+ val buildRight = canBuildRight(joinType) && canBroadcast(right)
+ buildLeft || buildRight
+ }
+
+ private def broadcastSideBySizes(joinType: JoinType, left: LogicalPlan, right: LogicalPlan)
+ : BuildSide = {
+ val buildLeft = canBuildLeft(joinType) && canBroadcast(left)
+ val buildRight = canBuildRight(joinType) && canBroadcast(right)
+ broadcastSide(buildLeft, buildRight, left, right)
+ }
+
+ def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
Review comment:
@zzcclp Hi, I've done the rewrite, but a little different from the 2.4 implementation. I've found in 2.4 implementation that it acquires memory twice for both left and right side. For example:
```
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if canBroadcastBySizes(joinType, left, right) =>
val buildSide = broadcastSideBySizes(joinType, left, right)
Seq(joins.BroadcastHashJoinExec(
leftKeys, rightKeys, joinType, buildSide, condition, planLater(left), planLater(right)))
```
`canBroadcastBySizes` and `broadcastSideBySizes` both tries to acquire memory for two sides. Is that a mistake? Should we add a method like `tryAcquireMemory` in `JoinMemoryManager` for checks and acquire memory only if we decide to create BHJ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] codecov-commenter edited a comment on pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
codecov-commenter edited a comment on pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#issuecomment-846865473
# [Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) Report
> :exclamation: No coverage uploaded for pull request base (`kylin-on-parquet-v2@c943745`). [Click here to learn what that means](https://docs.codecov.io/docs/error-reference?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#section-missing-base-commit).
> The diff coverage is `n/a`.
[](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation)
```diff
@@ Coverage Diff @@
## kylin-on-parquet-v2 #1601 +/- ##
======================================================
Coverage ? 24.29%
Complexity ? 4649
======================================================
Files ? 1152
Lines ? 65196
Branches ? 9362
======================================================
Hits ? 15837
Misses ? 47711
Partials ? 1648
```
------
[Continue to review full report at Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=footer&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation). Last update [c943745...5e655c8](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=lastupdated&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] codecov-commenter edited a comment on pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
codecov-commenter edited a comment on pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#issuecomment-846865473
# [Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) Report
> :exclamation: No coverage uploaded for pull request base (`kylin-on-parquet-v2@f5ec8f3`). [Click here to learn what that means](https://docs.codecov.io/docs/error-reference?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#section-missing-base-commit).
> The diff coverage is `n/a`.
[](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation)
```diff
@@ Coverage Diff @@
## kylin-on-parquet-v2 #1601 +/- ##
======================================================
Coverage ? 24.51%
Complexity ? 4648
======================================================
Files ? 1141
Lines ? 64546
Branches ? 9311
======================================================
Hits ? 15823
Misses ? 47075
Partials ? 1648
```
------
[Continue to review full report at Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=footer&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation). Last update [f5ec8f3...070dd1c](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=lastupdated&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r634963118
##########
File path: kylin-spark-project/kylin-spark-common/src/main/scala/org/apache/spark/utils/KylinReflectUtils.scala
##########
@@ -27,19 +27,21 @@ object KylinReflectUtils {
private val rm = universe.runtimeMirror(getClass.getClassLoader)
def getSessionState(sparkContext: SparkContext, kylinSession: Object): Any = {
- if (SPARK_VERSION.startsWith("2.4")) {
- var className: String =
- "org.apache.spark.sql.hive.KylinHiveSessionStateBuilder"
- if (!"hive".equals(sparkContext.getConf
- .get(CATALOG_IMPLEMENTATION.key, "in-memory"))) {
- className = "org.apache.spark.sql.hive.KylinSessionStateBuilder"
- }
- val tuple = createObject(className, kylinSession, None)
- val method = tuple._2.getMethod("build")
- method.invoke(tuple._1)
+ var className: String =
+ "org.apache.spark.sql.hive.KylinHiveSessionStateBuilder"
+ if (!"hive".equals(sparkContext.getConf
+ .get(CATALOG_IMPLEMENTATION.key, "in-memory"))) {
+ className = "org.apache.spark.sql.hive.KylinSessionStateBuilder"
+ }
+
+ val (instance, clazz) = if (SPARK_VERSION.startsWith("2.4") || SPARK_VERSION.startsWith("3.0")) {
Review comment:
remove `SPARK_VERSION.startsWith("3.0")`, not support Spark 3.0.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r635085054
##########
File path: kylin-spark-project/kylin-spark-common/src/main/spark31/org/apache/spark/sql/hive/utils/QueryMetricUtils.scala
##########
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.utils
+
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.execution.adaptive.{AdaptiveSparkPlanExec, ShuffleQueryStageExec}
+import org.apache.spark.sql.execution.{FileSourceScanExec, KylinFileSourceScanExec, SparkPlan}
+import org.apache.spark.sql.hive.execution.HiveTableScanExec
+
+import scala.collection.JavaConverters.seqAsJavaListConverter
+
+object QueryMetricUtils extends Logging {
+ def collectScanMetrics(plan: SparkPlan): (java.util.List[java.lang.Long], java.util.List[java.lang.Long],
+ java.util.List[java.lang.Long], java.util.List[java.lang.Long], java.util.List[java.lang.Long]) = {
+ try {
+ val metrics = plan.collect {
+ case exec: KylinFileSourceScanExec =>
+ //(exec.metrics.apply("numOutputRows").value, exec.metrics.apply("readBytes").value)
+ (exec.metrics.apply("numOutputRows").value, exec.metrics.apply("numFiles").value,
+ exec.metrics.apply("metadataTime").value, exec.metrics.apply("scanTime").value, -1l)
Review comment:
Use the new metric 'filesSize' added by Spark 3 to set the value of the last metric, now is -1.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r634970078
##########
File path: kylin-spark-project/kylin-spark-common/src/main/spark24/org/apache/spark/monitor/MonitorExecutorExtension.scala
##########
@@ -18,6 +18,8 @@
package org.apache.spark.memory
+import java.util
+
import org.apache.spark.internal.Logging
import org.apache.spark.rpc.{RpcAddress, RpcEnv}
import org.apache.spark.util.RpcUtils
Review comment:
ditto
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp merged pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp merged pull request #1601:
URL: https://github.com/apache/kylin/pull/1601
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@kylin.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] zzcclp commented on a change in pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
zzcclp commented on a change in pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#discussion_r635122548
##########
File path: kylin-spark-project/kylin-spark-engine/src/main/scala/org/apache/kylin/query/runtime/ExpressionConverter.scala
##########
@@ -18,17 +18,18 @@
package org.apache.kylin.query.runtime
+import java.time.ZoneId
Review comment:
remove
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kylin] codecov-commenter edited a comment on pull request #1601: KYLIN-4925 Use Spark3 for Kylin 4.0
Posted by GitBox <gi...@apache.org>.
codecov-commenter edited a comment on pull request #1601:
URL: https://github.com/apache/kylin/pull/1601#issuecomment-846865473
# [Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) Report
> :exclamation: No coverage uploaded for pull request base (`kylin-on-parquet-v2@f5ec8f3`). [Click here to learn what that means](https://docs.codecov.io/docs/error-reference?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#section-missing-base-commit).
> The diff coverage is `n/a`.
> :exclamation: Current head fe86b1a differs from pull request most recent head 74e6259. Consider uploading reports for the commit 74e6259 to get more accurate results
[](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation)
```diff
@@ Coverage Diff @@
## kylin-on-parquet-v2 #1601 +/- ##
======================================================
Coverage ? 24.51%
Complexity ? 4648
======================================================
Files ? 1141
Lines ? 64546
Branches ? 9311
======================================================
Hits ? 15825
Misses ? 47074
Partials ? 1647
```
------
[Continue to review full report at Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=footer&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation). Last update [f5ec8f3...74e6259](https://codecov.io/gh/apache/kylin/pull/1601?src=pr&el=lastupdated&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org