You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by BryanCutler <gi...@git.apache.org> on 2017/08/22 18:45:16 UTC
[GitHub] spark pull request #19024: [SPARK-21810][ML][EXAMPLES] Adding Examples for F...
GitHub user BryanCutler opened a pull request:
https://github.com/apache/spark/pull/19024
[SPARK-21810][ML][EXAMPLES] Adding Examples for FeatureHasher
## What changes were proposed in this pull request?
This PR adds ML examples for the FeatureHasher transform in Scala, Java, Python.
## How was this patch tested?
Manually ran examples and verified that output is consistent for different APIs
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/BryanCutler/spark ml-examples-FeatureHasher-SPARK-21810
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/19024.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #19024
----
commit 1f1f31f7f13d54131c194a64f103f24335594488
Author: Bryan Cutler <cu...@gmail.com>
Date: 2017-08-22T18:42:41Z
Added all examples
----
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19024
Merged build finished. Test PASSed.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on the issue:
https://github.com/apache/spark/pull/19024
Updated doc screenshot

---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19024
**[Test build #81002 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/81002/testReport)** for PR 19024 at commit [`1f1f31f`](https://github.com/apache/spark/commit/1f1f31f7f13d54131c194a64f103f24335594488).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds the following public classes _(experimental)_:
* `public class JavaFeatureHasherExample `
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19024
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/81136/
Test PASSed.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for F...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19024#discussion_r134887435
--- Diff: docs/ml-features.md ---
@@ -211,6 +211,89 @@ for more details on the API.
</div>
</div>
+## FeatureHasher
+
+Feature hashing projects a set of categorical or numerical features into a feature vector of
+specified dimension (typically substantially smaller than that of the original feature
+space). This is done using the [hashing trick](https://en.wikipedia.org/wiki/Feature_hashing)
+to map features to indices in the feature vector.
+
+The `FeatureHasher` transformer operates on multiple columns. Each column may contain either
+numeric or categorical features. Behavior and handling of column data types is as follows:
+
+- Numeric columns: For numeric features, the hash value of the column name is used to map the
+feature value to its index in the feature vector. Numeric features are never treated as
+categorical, even when they are integers. You must explicitly convert numeric columns containing
+categorical features to strings first.
+- String columns: For categorical features, the hash value of the string "column_name=value"
+is used to map to the vector index, with an indicator value of `1.0`. Thus, categorical features
+are "one-hot" encoded (similarly to using [OneHotEncoder](ml-features.html#onehotencoder) with
+`dropLast=false`).
+- Boolean columns: Boolean values are treated in the same way as string columns. That is,
+boolean features are represented as "column_name=true" or "column_name=false", with an indicator
+value of `1.0`.
+
+Null (missing) values are ignored (implicitly zero in the resulting feature vector).
+
+The hash function used here is also the [MurmurHash 3](https://en.wikipedia.org/wiki/MurmurHash)
+used in [HashingTF](ml-features.html#tf-idf). Since a simple modulo is used to transform the hash
+function to a vector index, it is advisable to use a power of two as the numFeatures parameter;
--- End diff --
I read this as the hash function itself is transformed instead of the output of it. Would it be more correct to say here
"Since a simple modulo is used to determine the vector index for the hashed value,.."?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on the issue:
https://github.com/apache/spark/pull/19024
Doc Preview:
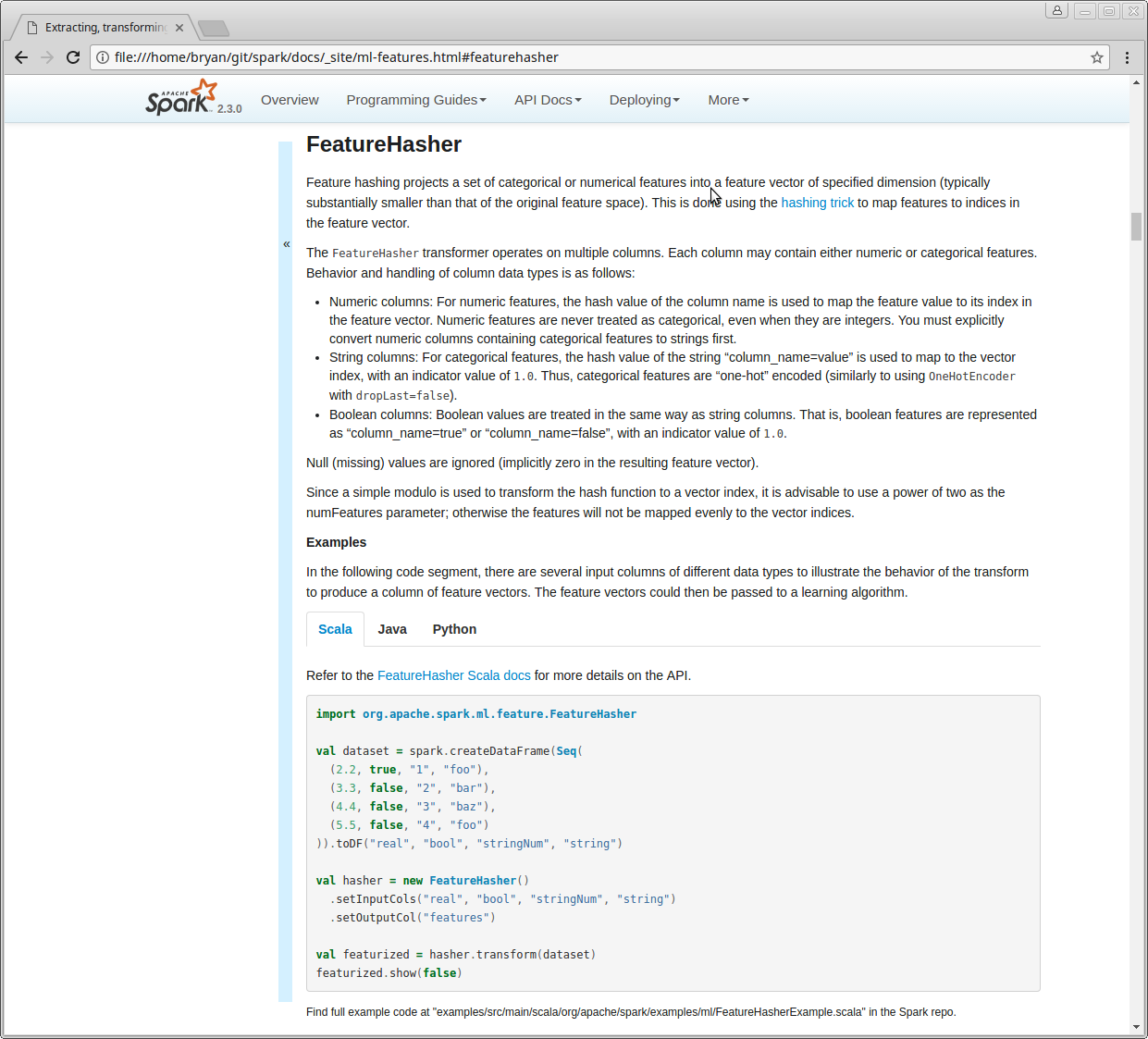
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19024
Merged build finished. Test PASSed.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for F...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19024#discussion_r134604034
--- Diff: docs/ml-features.md ---
@@ -211,6 +211,65 @@ for more details on the API.
</div>
</div>
+## FeatureHasher
--- End diff --
I put the doc under the Feature Extractors section, let me know if it's not the right place
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on the issue:
https://github.com/apache/spark/pull/19024
@MLnick , I pretty much copied your example in the scaladoc, just added a couple more rows of data. Please take a look when you can, thanks!
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19024
Merged build finished. Test PASSed.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19024
**[Test build #81003 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/81003/testReport)** for PR 19024 at commit [`962f658`](https://github.com/apache/spark/commit/962f658476eef78a54887a27553f4aa42badb8ae).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19024
**[Test build #81234 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/81234/testReport)** for PR 19024 at commit [`a7a439c`](https://github.com/apache/spark/commit/a7a439cea226607d4bc955ff5dd13f625836ef90).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for F...
Posted by mgaido91 <gi...@git.apache.org>.
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/19024#discussion_r134596865
--- Diff: examples/src/main/scala/org/apache/spark/examples/ml/FeatureHasherExample.scala ---
@@ -0,0 +1,53 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+// scalastyle:off println
--- End diff --
why do you need this?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for F...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19024#discussion_r134603526
--- Diff: examples/src/main/scala/org/apache/spark/examples/ml/FeatureHasherExample.scala ---
@@ -0,0 +1,53 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+// scalastyle:off println
--- End diff --
Yeah, it's not necessary since this example doesn't use `println` and it looks like all other scala examples are wrapped with this also. Not sure if there was a reason, but doesn't really hurt anything either.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for F...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19024#discussion_r134874786
--- Diff: docs/ml-features.md ---
@@ -211,6 +211,65 @@ for more details on the API.
</div>
</div>
+## FeatureHasher
+
+Feature hashing projects a set of categorical or numerical features into a feature vector of
+specified dimension (typically substantially smaller than that of the original feature
+space). This is done using the [hashing trick](https://en.wikipedia.org/wiki/Feature_hashing)
+to map features to indices in the feature vector.
+
+The `FeatureHasher` transformer operates on multiple columns. Each column may contain either
+numeric or categorical features. Behavior and handling of column data types is as follows:
+
+- Numeric columns: For numeric features, the hash value of the column name is used to map the
+feature value to its index in the feature vector. Numeric features are never treated as
+categorical, even when they are integers. You must explicitly convert numeric columns containing
+categorical features to strings first.
+- String columns: For categorical features, the hash value of the string "column_name=value"
+is used to map to the vector index, with an indicator value of `1.0`. Thus, categorical features
+are "one-hot" encoded (similarly to using `OneHotEncoder` with `dropLast=false`).
+- Boolean columns: Boolean values are treated in the same way as string columns. That is,
+boolean features are represented as "column_name=true" or "column_name=false", with an indicator
+value of `1.0`.
+
+Null (missing) values are ignored (implicitly zero in the resulting feature vector).
+
+Since a simple modulo is used to transform the hash function to a vector index,
--- End diff --
Sure, I can do that. Would it be more correct to say "Since a simple modulo is used to determine the vector index for the hashed value,.."?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21810][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19024
**[Test build #81003 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/81003/testReport)** for PR 19024 at commit [`962f658`](https://github.com/apache/spark/commit/962f658476eef78a54887a27553f4aa42badb8ae).
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for F...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19024#discussion_r134865300
--- Diff: examples/src/main/scala/org/apache/spark/examples/ml/FeatureHasherExample.scala ---
@@ -0,0 +1,53 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+// scalastyle:off println
--- End diff --
I agree with that. I was wondering if I should add something but I think it's best described in the scaladoc and letting the user see some results. I'll remove the `scalastyle:off println` then
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19024
**[Test build #81136 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/81136/testReport)** for PR 19024 at commit [`a7a439c`](https://github.com/apache/spark/commit/a7a439cea226607d4bc955ff5dd13f625836ef90).
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for F...
Posted by asfgit <gi...@git.apache.org>.
Github user asfgit closed the pull request at:
https://github.com/apache/spark/pull/19024
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for F...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19024#discussion_r134889199
--- Diff: docs/ml-features.md ---
@@ -53,9 +53,9 @@ are calculated based on the mapped indices. This approach avoids the need to com
term-to-index map, which can be expensive for a large corpus, but it suffers from potential hash
collisions, where different raw features may become the same term after hashing. To reduce the
chance of collision, we can increase the target feature dimension, i.e. the number of buckets
-of the hash table. Since a simple modulo is used to transform the hash function to a column index,
+of the hash table. Since a simple modulo is used to transform the hash function to a vector index,
it is advisable to use a power of two as the feature dimension, otherwise the features will
-not be mapped evenly to the columns. The default feature dimension is `$2^{18} = 262,144$`.
+not be mapped evenly in the vector. The default feature dimension is `$2^{18} = 262,144$`.
--- End diff --
@MLnick , as I read this section on TF-IDF, it didn't seem right how it referred to columns, so I made some changes. Does it seem ok?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19024
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/81052/
Test PASSed.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19024
Merged build finished. Test PASSed.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19024
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/81003/
Test PASSed.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for F...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19024#discussion_r135307551
--- Diff: docs/ml-features.md ---
@@ -53,9 +53,9 @@ are calculated based on the mapped indices. This approach avoids the need to com
term-to-index map, which can be expensive for a large corpus, but it suffers from potential hash
collisions, where different raw features may become the same term after hashing. To reduce the
chance of collision, we can increase the target feature dimension, i.e. the number of buckets
-of the hash table. Since a simple modulo is used to transform the hash function to a column index,
+of the hash table. Since a simple modulo is used to transform the hash function to a vector index,
it is advisable to use a power of two as the feature dimension, otherwise the features will
-not be mapped evenly to the columns. The default feature dimension is `$2^{18} = 262,144$`.
+not be mapped evenly in the vector. The default feature dimension is `$2^{18} = 262,144$`.
--- End diff --
yeah that's better
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19024
**[Test build #81234 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/81234/testReport)** for PR 19024 at commit [`a7a439c`](https://github.com/apache/spark/commit/a7a439cea226607d4bc955ff5dd13f625836ef90).
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19024
**[Test build #81052 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/81052/testReport)** for PR 19024 at commit [`a61fb07`](https://github.com/apache/spark/commit/a61fb07ecc2bd69a47418d4aeb7ef43621dbb3e7).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19024
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/81002/
Test PASSed.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for F...
Posted by mgaido91 <gi...@git.apache.org>.
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/19024#discussion_r134726421
--- Diff: examples/src/main/scala/org/apache/spark/examples/ml/FeatureHasherExample.scala ---
@@ -0,0 +1,53 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+// scalastyle:off println
--- End diff --
All the other examples use `println`, also to explain what is happening. I think it'd be good to add some `print` to explain what is happening. It is an example, thus people reading it would understand better what is happening if you print some details on it. But if you don't add, I'd remove this since it is useless.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19024
**[Test build #81007 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/81007/testReport)** for PR 19024 at commit [`ee8afcf`](https://github.com/apache/spark/commit/ee8afcfadea7bc94542750b6b4e29cf6ec0cdfc5).
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19024
**[Test build #81007 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/81007/testReport)** for PR 19024 at commit [`ee8afcf`](https://github.com/apache/spark/commit/ee8afcfadea7bc94542750b6b4e29cf6ec0cdfc5).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19024
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/81234/
Test PASSed.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19024
**[Test build #81052 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/81052/testReport)** for PR 19024 at commit [`a61fb07`](https://github.com/apache/spark/commit/a61fb07ecc2bd69a47418d4aeb7ef43621dbb3e7).
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by MLnick <gi...@git.apache.org>.
Github user MLnick commented on the issue:
https://github.com/apache/spark/pull/19024
Ran example and checked doc locally. LGTM, merged to master. Thanks!
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for F...
Posted by MLnick <gi...@git.apache.org>.
Github user MLnick commented on a diff in the pull request:
https://github.com/apache/spark/pull/19024#discussion_r135261324
--- Diff: docs/ml-features.md ---
@@ -211,6 +211,89 @@ for more details on the API.
</div>
</div>
+## FeatureHasher
+
+Feature hashing projects a set of categorical or numerical features into a feature vector of
+specified dimension (typically substantially smaller than that of the original feature
+space). This is done using the [hashing trick](https://en.wikipedia.org/wiki/Feature_hashing)
+to map features to indices in the feature vector.
+
+The `FeatureHasher` transformer operates on multiple columns. Each column may contain either
+numeric or categorical features. Behavior and handling of column data types is as follows:
+
+- Numeric columns: For numeric features, the hash value of the column name is used to map the
+feature value to its index in the feature vector. Numeric features are never treated as
+categorical, even when they are integers. You must explicitly convert numeric columns containing
+categorical features to strings first.
+- String columns: For categorical features, the hash value of the string "column_name=value"
+is used to map to the vector index, with an indicator value of `1.0`. Thus, categorical features
+are "one-hot" encoded (similarly to using [OneHotEncoder](ml-features.html#onehotencoder) with
+`dropLast=false`).
+- Boolean columns: Boolean values are treated in the same way as string columns. That is,
+boolean features are represented as "column_name=true" or "column_name=false", with an indicator
+value of `1.0`.
+
+Null (missing) values are ignored (implicitly zero in the resulting feature vector).
+
+The hash function used here is also the [MurmurHash 3](https://en.wikipedia.org/wiki/MurmurHash)
+used in [HashingTF](ml-features.html#tf-idf). Since a simple modulo is used to transform the hash
+function to a vector index, it is advisable to use a power of two as the numFeatures parameter;
--- End diff --
Yeah that sounds better
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for F...
Posted by MLnick <gi...@git.apache.org>.
Github user MLnick commented on a diff in the pull request:
https://github.com/apache/spark/pull/19024#discussion_r134741953
--- Diff: docs/ml-features.md ---
@@ -211,6 +211,65 @@ for more details on the API.
</div>
</div>
+## FeatureHasher
+
+Feature hashing projects a set of categorical or numerical features into a feature vector of
+specified dimension (typically substantially smaller than that of the original feature
+space). This is done using the [hashing trick](https://en.wikipedia.org/wiki/Feature_hashing)
+to map features to indices in the feature vector.
+
+The `FeatureHasher` transformer operates on multiple columns. Each column may contain either
+numeric or categorical features. Behavior and handling of column data types is as follows:
+
+- Numeric columns: For numeric features, the hash value of the column name is used to map the
+feature value to its index in the feature vector. Numeric features are never treated as
+categorical, even when they are integers. You must explicitly convert numeric columns containing
+categorical features to strings first.
+- String columns: For categorical features, the hash value of the string "column_name=value"
+is used to map to the vector index, with an indicator value of `1.0`. Thus, categorical features
+are "one-hot" encoded (similarly to using `OneHotEncoder` with `dropLast=false`).
+- Boolean columns: Boolean values are treated in the same way as string columns. That is,
+boolean features are represented as "column_name=true" or "column_name=false", with an indicator
+value of `1.0`.
+
+Null (missing) values are ignored (implicitly zero in the resulting feature vector).
+
+Since a simple modulo is used to transform the hash function to a vector index,
--- End diff --
We should probably say something to the effect that the hashing mechanism is the same as used for `HashingTF`
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for F...
Posted by MLnick <gi...@git.apache.org>.
Github user MLnick commented on a diff in the pull request:
https://github.com/apache/spark/pull/19024#discussion_r135261228
--- Diff: docs/ml-features.md ---
@@ -53,9 +53,9 @@ are calculated based on the mapped indices. This approach avoids the need to com
term-to-index map, which can be expensive for a large corpus, but it suffers from potential hash
collisions, where different raw features may become the same term after hashing. To reduce the
chance of collision, we can increase the target feature dimension, i.e. the number of buckets
-of the hash table. Since a simple modulo is used to transform the hash function to a column index,
+of the hash table. Since a simple modulo is used to transform the hash function to a vector index,
it is advisable to use a power of two as the feature dimension, otherwise the features will
-not be mapped evenly to the columns. The default feature dimension is `$2^{18} = 262,144$`.
+not be mapped evenly in the vector. The default feature dimension is `$2^{18} = 262,144$`.
--- End diff --
"to vector indices" perhaps?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for F...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19024#discussion_r134886536
--- Diff: docs/ml-features.md ---
@@ -65,7 +65,7 @@ model binary, rather than integer, counts.
**IDF**: `IDF` is an `Estimator` which is fit on a dataset and produces an `IDFModel`. The
`IDFModel` takes feature vectors (generally created from `HashingTF` or `CountVectorizer`) and
-scales each column. Intuitively, it down-weights columns which appear frequently in a corpus.
+scales each feature. Intuitively, it down-weights features which appear frequently in a corpus.
--- End diff --
@MLnick , as I read this section on TF-IDF, it didn't seem right how it referred to columns, so I made some changes. Does it seem ok?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19024
Merged build finished. Test PASSed.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for F...
Posted by MLnick <gi...@git.apache.org>.
Github user MLnick commented on a diff in the pull request:
https://github.com/apache/spark/pull/19024#discussion_r134742952
--- Diff: examples/src/main/scala/org/apache/spark/examples/ml/FeatureHasherExample.scala ---
@@ -0,0 +1,53 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+// scalastyle:off println
--- End diff --
I think we can remove it.
It's not uncommon for examples to not have any illustrative `println` statements. In fact many example rather use `show` to show the results.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for F...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19024#discussion_r135307673
--- Diff: docs/ml-features.md ---
@@ -211,6 +211,89 @@ for more details on the API.
</div>
</div>
+## FeatureHasher
+
+Feature hashing projects a set of categorical or numerical features into a feature vector of
+specified dimension (typically substantially smaller than that of the original feature
+space). This is done using the [hashing trick](https://en.wikipedia.org/wiki/Feature_hashing)
+to map features to indices in the feature vector.
+
+The `FeatureHasher` transformer operates on multiple columns. Each column may contain either
+numeric or categorical features. Behavior and handling of column data types is as follows:
+
+- Numeric columns: For numeric features, the hash value of the column name is used to map the
+feature value to its index in the feature vector. Numeric features are never treated as
+categorical, even when they are integers. You must explicitly convert numeric columns containing
+categorical features to strings first.
+- String columns: For categorical features, the hash value of the string "column_name=value"
+is used to map to the vector index, with an indicator value of `1.0`. Thus, categorical features
+are "one-hot" encoded (similarly to using [OneHotEncoder](ml-features.html#onehotencoder) with
+`dropLast=false`).
+- Boolean columns: Boolean values are treated in the same way as string columns. That is,
+boolean features are represented as "column_name=true" or "column_name=false", with an indicator
+value of `1.0`.
+
+Null (missing) values are ignored (implicitly zero in the resulting feature vector).
+
+The hash function used here is also the [MurmurHash 3](https://en.wikipedia.org/wiki/MurmurHash)
+used in [HashingTF](ml-features.html#tf-idf). Since a simple modulo is used to transform the hash
+function to a vector index, it is advisable to use a power of two as the numFeatures parameter;
--- End diff --
ok, I'll change the wording in HashingTF also to be consistent
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19024
Merged build finished. Test PASSed.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21810][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19024
**[Test build #81002 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/81002/testReport)** for PR 19024 at commit [`1f1f31f`](https://github.com/apache/spark/commit/1f1f31f7f13d54131c194a64f103f24335594488).
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19024
**[Test build #81136 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/81136/testReport)** for PR 19024 at commit [`a7a439c`](https://github.com/apache/spark/commit/a7a439cea226607d4bc955ff5dd13f625836ef90).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for F...
Posted by MLnick <gi...@git.apache.org>.
Github user MLnick commented on a diff in the pull request:
https://github.com/apache/spark/pull/19024#discussion_r134741609
--- Diff: docs/ml-features.md ---
@@ -211,6 +211,65 @@ for more details on the API.
</div>
</div>
+## FeatureHasher
+
+Feature hashing projects a set of categorical or numerical features into a feature vector of
+specified dimension (typically substantially smaller than that of the original feature
+space). This is done using the [hashing trick](https://en.wikipedia.org/wiki/Feature_hashing)
+to map features to indices in the feature vector.
+
+The `FeatureHasher` transformer operates on multiple columns. Each column may contain either
+numeric or categorical features. Behavior and handling of column data types is as follows:
+
+- Numeric columns: For numeric features, the hash value of the column name is used to map the
+feature value to its index in the feature vector. Numeric features are never treated as
+categorical, even when they are integers. You must explicitly convert numeric columns containing
+categorical features to strings first.
+- String columns: For categorical features, the hash value of the string "column_name=value"
+is used to map to the vector index, with an indicator value of `1.0`. Thus, categorical features
+are "one-hot" encoded (similarly to using `OneHotEncoder` with `dropLast=false`).
--- End diff --
Should link to `OneHotEncoder` section within the guide here.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19024: [SPARK-21469][ML][EXAMPLES] Adding Examples for FeatureH...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19024
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/81007/
Test PASSed.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org