You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@zeppelin.apache.org by zj...@apache.org on 2020/07/14 07:06:04 UTC
[zeppelin] branch master updated: [ZEPPELIN-4943]. Support hdfs
jars for flink.execution.jars & flink.udf.jars
This is an automated email from the ASF dual-hosted git repository.
zjffdu pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/zeppelin.git
The following commit(s) were added to refs/heads/master by this push:
new c044d7a [ZEPPELIN-4943]. Support hdfs jars for flink.execution.jars & flink.udf.jars
c044d7a is described below
commit c044d7a43e64e25883f6108709af6fecb4d6a3ef
Author: Jeff Zhang <zj...@apache.org>
AuthorDate: Sat Jul 11 19:32:45 2020 +0800
[ZEPPELIN-4943]. Support hdfs jars for flink.execution.jars & flink.udf.jars
### What is this PR for?
This PR is to support using hdfs jars for `flink.execution.jars` and `flink.udf.jars`. So that user don't need to copy jars to the zeppelin machine in case that they don't have permission to do that.
### What type of PR is it?
[ Feature ]
### Todos
* [ ] - Task
### What is the Jira issue?
* https://issues.apache.org/jira/browse/ZEPPELIN-4943
### How should this be tested?
* Manually tested
### Screenshots (if appropriate)
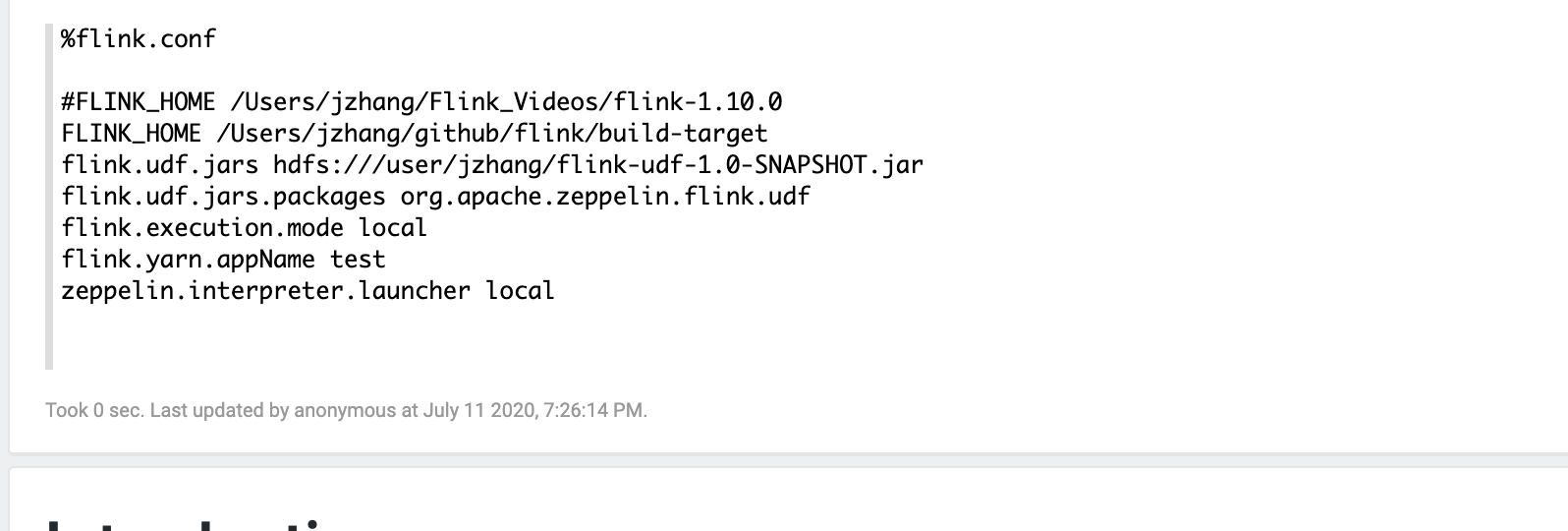

### Questions:
* Does the licenses files need update? No
* Is there breaking changes for older versions? No
* Does this needs documentation? NO
Author: Jeff Zhang <zj...@apache.org>
Closes #3849 from zjffdu/ZEPPELIN-4943 and squashes the following commits:
23d2a4172 [Jeff Zhang] [ZEPPELIN-4943]. Support hdfs jars for flink.execution.jars & flink.udf.jars
---
docs/interpreter/flink.md | 4 +--
.../org/apache/zeppelin/flink/HadoopUtils.java | 11 +++++++
.../src/main/resources/interpreter-setting.json | 4 +--
.../zeppelin/flink/FlinkScalaInterpreter.scala | 38 ++++++++++++----------
4 files changed, 35 insertions(+), 22 deletions(-)
diff --git a/docs/interpreter/flink.md b/docs/interpreter/flink.md
index 5eb7f5c..5ae7798 100644
--- a/docs/interpreter/flink.md
+++ b/docs/interpreter/flink.md
@@ -148,7 +148,7 @@ You can also add and set other flink properties which are not listed in the tabl
<tr>
<td>flink.udf.jars</td>
<td></td>
- <td>Flink udf jars (comma separated), zeppelin will register udf in this jar automatically for user. The udf name is the class name.</td>
+ <td>Flink udf jars (comma separated), zeppelin will register udf in this jar automatically for user. These udf jars could be either local files or hdfs files if you have hadoop installed. The udf name is the class name.</td>
</tr>
<tr>
<td>flink.udf.jars.packages</td>
@@ -158,7 +158,7 @@ You can also add and set other flink properties which are not listed in the tabl
<tr>
<td>flink.execution.jars</td>
<td></td>
- <td>Additional user jars (comma separated)</td>
+ <td>Additional user jars (comma separated), these jars could be either local files or hdfs files if you have hadoop installed.</td>
</tr>
<tr>
<td>flink.execution.packages</td>
diff --git a/flink/interpreter/src/main/java/org/apache/zeppelin/flink/HadoopUtils.java b/flink/interpreter/src/main/java/org/apache/zeppelin/flink/HadoopUtils.java
index 6e7a489..e8cefba 100644
--- a/flink/interpreter/src/main/java/org/apache/zeppelin/flink/HadoopUtils.java
+++ b/flink/interpreter/src/main/java/org/apache/zeppelin/flink/HadoopUtils.java
@@ -18,6 +18,7 @@
package org.apache.zeppelin.flink;
+import com.google.common.io.Files;
import org.apache.flink.client.program.ClusterClient;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
@@ -29,6 +30,7 @@ import org.apache.hadoop.yarn.exceptions.YarnException;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
+import java.io.File;
import java.io.IOException;
/**
@@ -65,4 +67,13 @@ public class HadoopUtils {
LOGGER.warn("Failed to cleanup staging dir", e);
}
}
+
+ public static String downloadJar(String jarOnHdfs) throws IOException {
+ File tmpDir = Files.createTempDir();
+ FileSystem fs = FileSystem.get(new Configuration());
+ Path sourcePath = fs.makeQualified(new Path(jarOnHdfs));
+ Path destPath = new Path(tmpDir.getAbsolutePath() + "/" + sourcePath.getName());
+ fs.copyToLocalFile(sourcePath, destPath);
+ return new File(destPath.toString()).getAbsolutePath();
+ }
}
diff --git a/flink/interpreter/src/main/resources/interpreter-setting.json b/flink/interpreter/src/main/resources/interpreter-setting.json
index 203bdd1..44560a6 100644
--- a/flink/interpreter/src/main/resources/interpreter-setting.json
+++ b/flink/interpreter/src/main/resources/interpreter-setting.json
@@ -107,7 +107,7 @@
"envName": null,
"propertyName": null,
"defaultValue": "",
- "description": "Flink udf jars (comma separated), Zeppelin will register udfs in this jar for user automatically",
+ "description": "Flink udf jars (comma separated), Zeppelin will register udfs in this jar for user automatically, these udf jars could be either local files or hdfs files if you have hadoop installed, the udf name is the class name",
"type": "string"
},
"flink.udf.jars.packages": {
@@ -121,7 +121,7 @@
"envName": null,
"propertyName": null,
"defaultValue": "",
- "description": "Additional user jars (comma separated)",
+ "description": "Additional user jars (comma separated), these jars could be either local files or hdfs files if you have hadoop installed",
"type": "string"
},
"flink.execution.packages": {
diff --git a/flink/interpreter/src/main/scala/org/apache/zeppelin/flink/FlinkScalaInterpreter.scala b/flink/interpreter/src/main/scala/org/apache/zeppelin/flink/FlinkScalaInterpreter.scala
index 329722e..d18a559 100644
--- a/flink/interpreter/src/main/scala/org/apache/zeppelin/flink/FlinkScalaInterpreter.scala
+++ b/flink/interpreter/src/main/scala/org/apache/zeppelin/flink/FlinkScalaInterpreter.scala
@@ -105,6 +105,7 @@ class FlinkScalaInterpreter(val properties: Properties) {
private var defaultParallelism = 1
private var defaultSqlParallelism = 1
private var userJars: Seq[String] = _
+ private var userUdfJars: Seq[String] = _
def open(): Unit = {
val config = initFlinkConfig()
@@ -135,12 +136,7 @@ class FlinkScalaInterpreter(val properties: Properties) {
}
// load udf jar
- val udfJars = properties.getProperty("flink.udf.jars", "")
- if (!StringUtils.isBlank(udfJars)) {
- udfJars.split(",").foreach(jar => {
- loadUDFJar(jar)
- })
- }
+ this.userUdfJars.foreach(jar => loadUDFJar(jar))
}
private def initFlinkConfig(): Config = {
@@ -190,7 +186,8 @@ class FlinkScalaInterpreter(val properties: Properties) {
Some(ensureYarnConfig(config)
.copy(queue = Some(queue))))
- this.userJars = getUserJars
+ this.userUdfJars = getUserUdfJars()
+ this.userJars = getUserJarsExceptUdfJars ++ this.userUdfJars
LOGGER.info("UserJars: " + userJars.mkString(","))
config = config.copy(externalJars = Some(userJars.toArray))
LOGGER.info("Config: " + config)
@@ -473,7 +470,7 @@ class FlinkScalaInterpreter(val properties: Properties) {
val udfPackages = properties.getProperty("flink.udf.jars.packages", "").split(",").toSet
val urls = Array(new URL("jar:file:" + jar + "!/"))
- val cl = new URLClassLoader(urls)
+ val cl = new URLClassLoader(urls, getFlinkScalaShellLoader)
while (entries.hasMoreElements) {
val je = entries.nextElement
@@ -761,17 +758,10 @@ class FlinkScalaInterpreter(val properties: Properties) {
def getDefaultSqlParallelism = this.defaultSqlParallelism
- def getUserJars: Seq[String] = {
+ private def getUserJarsExceptUdfJars: Seq[String] = {
val flinkJars =
if (!StringUtils.isBlank(properties.getProperty("flink.execution.jars", ""))) {
- properties.getProperty("flink.execution.jars").split(",").toSeq
- } else {
- Seq.empty[String]
- }
-
- val flinkUDFJars =
- if (!StringUtils.isBlank(properties.getProperty("flink.udf.jars", ""))) {
- properties.getProperty("flink.udf.jars").split(",").toSeq
+ getOrDownloadJars(properties.getProperty("flink.execution.jars").split(",").toSeq)
} else {
Seq.empty[String]
}
@@ -784,7 +774,19 @@ class FlinkScalaInterpreter(val properties: Properties) {
Seq.empty[String]
}
- flinkJars ++ flinkPackageJars ++ flinkUDFJars
+ flinkJars ++ flinkPackageJars
+ }
+
+ private def getUserUdfJars(): Seq[String] = {
+ if (!StringUtils.isBlank(properties.getProperty("flink.udf.jars", ""))) {
+ getOrDownloadJars(properties.getProperty("flink.udf.jars").split(",").toSeq)
+ } else {
+ Seq.empty[String]
+ }
+ }
+
+ private def getOrDownloadJars(jars: Seq[String]): Seq[String] = {
+ jars.map(jar => if (jar.contains("://")) HadoopUtils.downloadJar(jar) else jar)
}
def getJobManager = this.jobManager