You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2021/09/20 15:02:02 UTC
[GitHub] [iceberg] nastra opened a new issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark not working
nastra opened a new issue #3157:
URL: https://github.com/apache/iceberg/issues/3157
`./gradlew :iceberg-spark3:jmh -PjmhIncludeRegex=VectorizedReadDictionaryEncodedFlatParquetDataBenchmark -PjmhOutputPath=benchmark/vectorized-read-dict-encoded-flat-parquet-data-result.txt` fails after about **10 mins** with the following exception:
```
# Benchmark mode: Single shot invocation time
# Benchmark: org.apache.iceberg.spark.source.parquet.vectorized.VectorizedReadDictionaryEncodedFlatParquetDataBenchmark.readDatesIcebergVectorized5k
# Run progress: 0.00% complete, ETA 00:00:00
# Fork: 1 of 1
# Warmup Iteration 1: WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.hadoop.security.authentication.util.KerberosUtil (file:/home/nastra/Development/workspace/iceberg/spark3/build/libs/iceberg-spark3-154fe7e-jmh.jar) to method sun.security.krb5.Config.getInstance()
WARNING: Please consider reporting this to the maintainers of org.apache.hadoop.security.authentication.util.KerberosUtil
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
(*interrupt*) <failure>
java.lang.InterruptedException
at java.base/java.util.concurrent.locks.AbstractQueuedSynchronizer.doAcquireSharedInterruptibly(AbstractQueuedSynchronizer.java:1040)
at java.base/java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireSharedInterruptibly(AbstractQueuedSynchronizer.java:1345)
at scala.concurrent.impl.Promise$DefaultPromise.tryAwait(Promise.scala:242)
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:258)
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:187)
at org.apache.spark.util.ThreadUtils$.awaitReady(ThreadUtils.scala:335)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:766)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2114)
at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.writeWithV2(WriteToDataSourceV2Exec.scala:382)
at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.writeWithV2$(WriteToDataSourceV2Exec.scala:361)
at org.apache.spark.sql.execution.datasources.v2.AppendDataExec.writeWithV2(WriteToDataSourceV2Exec.scala:253)
at org.apache.spark.sql.execution.datasources.v2.AppendDataExec.run(WriteToDataSourceV2Exec.scala:259)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result$lzycompute(V2CommandExec.scala:39)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result(V2CommandExec.scala:39)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.doExecute(V2CommandExec.scala:54)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:180)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:176)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:127)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:126)
at org.apache.spark.sql.DataFrameWriter.$anonfun$runCommand$1(DataFrameWriter.scala:962)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:100)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:160)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:87)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:767)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:962)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:353)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:287)
at org.apache.iceberg.spark.source.IcebergSourceBenchmark.appendAsFile(IcebergSourceBenchmark.java:129)
at org.apache.iceberg.spark.source.parquet.vectorized.VectorizedReadDictionaryEncodedFlatParquetDataBenchmark.appendData(VectorizedReadDictionaryEncodedFlatParquetDataBenchmark.java:83)
at org.apache.iceberg.spark.source.parquet.vectorized.VectorizedReadDictionaryEncodedFlatParquetDataBenchmark.setupBenchmark(VectorizedReadDictionaryEncodedFlatParquetDataBenchmark.java:57)
at org.apache.iceberg.spark.source.parquet.vectorized.jmh_generated.VectorizedReadDictionaryEncodedFlatParquetDataBenchmark_readDatesIcebergVectorized5k_jmhTest._jmh_tryInit_f_vectorizedreaddictionaryencodedflatparquetdatabenchmark0_G(VectorizedReadDictionaryEncodedFlatParquetDataBenchmark_readDatesIcebergVectorized5k_jmhTest.java:438)
at org.apache.iceberg.spark.source.parquet.vectorized.jmh_generated.VectorizedReadDictionaryEncodedFlatParquetDataBenchmark_readDatesIcebergVectorized5k_jmhTest.readDatesIcebergVectorized5k_SingleShotTime(VectorizedReadDictionaryEncodedFlatParquetDataBenchmark_readDatesIcebergVectorized5k_jmhTest.java:363)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at org.openjdk.jmh.runner.BenchmarkHandler$BenchmarkTask.call(BenchmarkHandler.java:453)
at org.openjdk.jmh.runner.BenchmarkHandler$BenchmarkTask.call(BenchmarkHandler.java:437)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:829)
```
A thread dump indicates this:
```
java.lang.Thread.State: TIMED_WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000006c0190528> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078)
at java.util.concurrent.LinkedBlockingQueue.poll(LinkedBlockingQueue.java:467)
at java.util.concurrent.ExecutorCompletionService.poll(ExecutorCompletionService.java:202)
at org.openjdk.jmh.runner.BenchmarkHandler.runIteration(BenchmarkHandler.java:376)
at org.openjdk.jmh.runner.BaseRunner.runBenchmark(BaseRunner.java:261)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] nastra closed issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark taking 20+ mins for setup
Posted by GitBox <gi...@apache.org>.
nastra closed issue #3157:
URL: https://github.com/apache/iceberg/issues/3157
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] nastra commented on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark not working
Posted by GitBox <gi...@apache.org>.
nastra commented on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-927707463
@samarthjain since you wrote the original version of the Benchmark, any idea why it requires such a long setup time?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] RussellSpitzer edited a comment on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark not working
Posted by GitBox <gi...@apache.org>.
RussellSpitzer edited a comment on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-923046069
Ok checking the interior workings, we are timing out on an iteration. The setup phase time is included with the iteration time so if the time limit is set to 10 minutes, and setup takes 27 minutes you will never start.
I turned on the UI and saw we start this test by writing 10 files during the setup phase. On my excellent MBP (2020) it takes almost 3 minutes to write each file. The test itself completes nearly immediately following the final file being written taking almost no time at all for any of the read iterations.
Here are the results when I modified the test to allow 30 minutes per iteration. Again this is almost completely devoted to the "setup" and "appendFile" phase.
```
# Warmup: 3 iterations, single-shot each
# Measurement: 5 iterations, single-shot each
# Timeout: 30 min per iteration
# Threads: 1 thread
# Benchmark mode: Single shot invocation time
# Benchmark: org.apache.iceberg.spark.source.parquet.vectorized.VectorizedReadDictionaryEncodedFlatParquetDataBenchmark.readDatesIcebergVectorized5k
# Run progress: 0.00% complete, ETA 00:00:00
# Fork: 1 of 1
# Warmup Iteration 1: 3.800 s/op
# Warmup Iteration 2: 3.178 s/op
# Warmup Iteration 3: 3.038 s/op
Iteration 1: 3.122 s/op
Iteration 2: ok 3.014 s/op
Iteration 3: 3.057 s/op
Iteration 4: 3.182 s/op
Iteration 5: 2.979 s/op
Result "org.apache.iceberg.spark.source.parquet.vectorized.VectorizedReadDictionaryEncodedFlatParquetDataBenchmark.readDatesIcebergVectorized5k":
N = 5
mean = 3.071 ±(99.9%) 0.314 s/op
Histogram, s/op:
[2.900, 2.925) = 0
[2.925, 2.950) = 0
[2.950, 2.975) = 0
[2.975, 3.000) = 1
[3.000, 3.025) = 1
[3.025, 3.050) = 0
[3.050, 3.075) = 1
[3.075, 3.100) = 0
[3.100, 3.125) = 1
[3.125, 3.150) = 0
[3.150, 3.175) = 0
Percentiles, s/op:
p(0.0000) = 2.979 s/op
p(50.0000) = 3.057 s/op
p(90.0000) = 3.182 s/op
p(95.0000) = 3.182 s/op
p(99.0000) = 3.182 s/op
p(99.9000) = 3.182 s/op
p(99.9900) = 3.182 s/op
p(99.9990) = 3.182 s/op
p(99.9999) = 3.182 s/op
p(100.0000) = 3.182 s/op
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] nastra commented on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark not working
Posted by GitBox <gi...@apache.org>.
nastra commented on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-927993915
I did some bisecting with `./gradlew :iceberg-spark2:jmh -PjmhIncludeRegex=VectorizedReadDictionaryEncodedFlatParquetDataBenchmark -PjmhOutputPath=benchmark/vectorized-read-dict-encoded-flat-parquet-data-996ed979f396f2c7cc12ca824a3fe758f2c486ce.txt` and the commit where `VectorizedReadDictionaryEncodedFlatParquetDataBenchmark` starts to take **>20 mins** for setup is 996ed979.
/cc @rdblue @samarthjain
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] nastra edited a comment on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark taking 20+ mins for setup
Posted by GitBox <gi...@apache.org>.
nastra edited a comment on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-927993915
I did some bisecting with `./gradlew :iceberg-spark2:jmh -PjmhIncludeRegex=VectorizedReadDictionaryEncodedFlatParquetDataBenchmark -PjmhOutputPath=benchmark/vectorized-read-dict-encoded-flat-parquet-data-996ed979f396f2c7cc12ca824a3fe758f2c486ce.txt` and the commit where `VectorizedReadDictionaryEncodedFlatParquetDataBenchmark` starts to take **>20 mins** for setup is 996ed979.
https://github.com/apache/spark/compare/v2.4.5...v2.4.6 <-- anything that stands out to you guys?
/cc @rdblue @samarthjain @RussellSpitzer
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] nastra edited a comment on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark taking 20+ mins for setup
Posted by GitBox <gi...@apache.org>.
nastra edited a comment on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-928928939
> @nastra, can we avoid using Spark 2.4 for this and run the benchmarks in 3.1? I have no idea what might have changed in 2.4.6 that caused this.
@rdblue the goal is definitely to run those benchmarks for Spark3 but I was rather trying to figure out when `VectorizedReadDictionaryEncodedFlatParquetDataBenchmark` started to take so long for setup (which was 2020-08-06 with 996ed97 when it wasn't possible to run that benchmark with Spark3).
The same benchmark for Spark3 was only recently (2021-06-21) introduced with ed0c70284e1f6506331a60d8c9e9706df2e32ec9, meaning that `VectorizedReadDictionaryEncodedFlatParquetDataBenchmark` actually never worked with Spark3 in the first place and setup always took so long.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] nastra commented on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark taking 20+ mins for setup
Posted by GitBox <gi...@apache.org>.
nastra commented on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-928928939
> @nastra, can we avoid using Spark 2.4 for this and run the benchmarks in 3.1? I have no idea what might have changed in 2.4.6 that caused this.
@rdblue the goal is definitely to run those benchmarks for Spark3 but I was rather trying to figure out when `VectorizedReadDictionaryEncodedFlatParquetDataBenchmark` started to take so long for setup (which was 2020-08-06 with 996ed97 when it wasn't possible to run that benchmark with Spark3). The same benchmark for Spark3 was only recently (2021-06-21) introduced with ed0c70284e1f6506331a60d8c9e9706df2e32ec9.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] nastra commented on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark taking 20+ mins for setup
Posted by GitBox <gi...@apache.org>.
nastra commented on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-945800570
For completeness, here's the thread dump:
```
"org.apache.iceberg.spark.source.parquet.vectorized.VectorizedReadDictionaryEncodedFlatParquetDataBenchmark.readDatesIcebergVectorized5k-jmh-worker-1" #24 daemon prio=5 os_prio=0 cpu=5302.39ms elapsed=71.73s allocated=664M defined_classes=11244 tid=0x00007fce504e5800 nid=0x12fe waiting on condition [0x00007fce0e45a000]
java.lang.Thread.State: WAITING (parking)
at jdk.internal.misc.Unsafe.park(java.base@11.0.12/Native Method)
- parking to wait for <0x000000060cad0600> (a scala.concurrent.impl.Promise$CompletionLatch)
at java.util.concurrent.locks.LockSupport.park(java.base@11.0.12/LockSupport.java:194)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(java.base@11.0.12/AbstractQueuedSynchronizer.java:885)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.doAcquireSharedInterruptibly(java.base@11.0.12/AbstractQueuedSynchronizer.java:1039)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireSharedInterruptibly(java.base@11.0.12/AbstractQueuedSynchronizer.java:1345)
at scala.concurrent.impl.Promise$DefaultPromise.tryAwait(Promise.scala:242)
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:258)
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:187)
at org.apache.spark.util.ThreadUtils$.awaitReady(ThreadUtils.scala:335)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:766)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2114)
at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.writeWithV2(WriteToDataSourceV2Exec.scala:382)
at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.writeWithV2$(WriteToDataSourceV2Exec.scala:361)
at org.apache.spark.sql.execution.datasources.v2.AppendDataExec.writeWithV2(WriteToDataSourceV2Exec.scala:253)
at org.apache.spark.sql.execution.datasources.v2.AppendDataExec.run(WriteToDataSourceV2Exec.scala:259)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result$lzycompute(V2CommandExec.scala:39)
- locked <0x000000060cad07e8> (a org.apache.spark.sql.execution.datasources.v2.AppendDataExec)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result(V2CommandExec.scala:39)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.doExecute(V2CommandExec.scala:54)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:180)
at org.apache.spark.sql.execution.SparkPlan$$Lambda$1416/0x0000000800c9f840.apply(Unknown Source)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)
at org.apache.spark.sql.execution.SparkPlan$$Lambda$1441/0x0000000800cbc440.apply(Unknown Source)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:176)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:127)
- locked <0x000000060cad09f0> (a org.apache.spark.sql.execution.QueryExecution)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:126)
at org.apache.spark.sql.DataFrameWriter.$anonfun$runCommand$1(DataFrameWriter.scala:962)
at org.apache.spark.sql.DataFrameWriter$$Lambda$1674/0x0000000800e42040.apply(Unknown Source)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:100)
at org.apache.spark.sql.execution.SQLExecution$$$Lambda$1679/0x0000000800e44840.apply(Unknown Source)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:160)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:87)
at org.apache.spark.sql.execution.SQLExecution$$$Lambda$1675/0x0000000800e42440.apply(Unknown Source)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:767)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:962)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:353)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:287)
at org.apache.iceberg.spark.source.IcebergSourceBenchmark.appendAsFile(IcebergSourceBenchmark.java:127)
at org.apache.iceberg.spark.source.parquet.vectorized.VectorizedReadDictionaryEncodedFlatParquetDataBenchmark.appendData(VectorizedReadDictionaryEncodedFlatParquetDataBenchmark.java:83)
at org.apache.iceberg.spark.source.parquet.vectorized.VectorizedReadDictionaryEncodedFlatParquetDataBenchmark.setupBenchmark(VectorizedReadDictionaryEncodedFlatParquetDataBenchmark.java:57)
at org.apache.iceberg.spark.source.parquet.vectorized.jmh_generated.VectorizedReadDictionaryEncodedFlatParquetDataBenchmark_readDatesIcebergVectorized5k_jmhTest._jmh_tryInit_f_vectorizedreaddictionaryencodedflatparquetdatabenchmark0_G(VectorizedReadDictionaryEncodedFlatParquetDataBenchmark_readDatesIcebergVectorized5k_jmhTest.java:438)
- locked <0x000000060aaa13b0> (a java.lang.Class for org.apache.iceberg.spark.source.parquet.vectorized.jmh_generated.VectorizedReadDictionaryEncodedFlatParquetDataBenchmark_readDatesIcebergVectorized5k_jmhTest)
at org.apache.iceberg.spark.source.parquet.vectorized.jmh_generated.VectorizedReadDictionaryEncodedFlatParquetDataBenchmark_readDatesIcebergVectorized5k_jmhTest.readDatesIcebergVectorized5k_SingleShotTime(VectorizedReadDictionaryEncodedFlatParquetDataBenchmark_readDatesIcebergVectorized5k_jmhTest.java:363)
at jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(java.base@11.0.12/Native Method)
at jdk.internal.reflect.NativeMethodAccessorImpl.invoke(java.base@11.0.12/NativeMethodAccessorImpl.java:62)
at jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(java.base@11.0.12/DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(java.base@11.0.12/Method.java:566)
at org.openjdk.jmh.runner.BenchmarkHandler$BenchmarkTask.call(BenchmarkHandler.java:470)
at org.openjdk.jmh.runner.BenchmarkHandler$BenchmarkTask.call(BenchmarkHandler.java:453)
at java.util.concurrent.FutureTask.run(java.base@11.0.12/FutureTask.java:264)
at java.util.concurrent.Executors$RunnableAdapter.call(java.base@11.0.12/Executors.java:515)
at java.util.concurrent.FutureTask.run(java.base@11.0.12/FutureTask.java:264)
at java.util.concurrent.ThreadPoolExecutor.runWorker(java.base@11.0.12/ThreadPoolExecutor.java:1128)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(java.base@11.0.12/ThreadPoolExecutor.java:628)
at java.lang.Thread.run(java.base@11.0.12/Thread.java:829)
Locked ownable synchronizers:
- <0x000000060b7b9a80> (a java.util.concurrent.ThreadPoolExecutor$Worker)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] nastra commented on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark taking 20+ mins for setup
Posted by GitBox <gi...@apache.org>.
nastra commented on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-948385754
I can confirm that this is now fixed by #3329. I did a benchmark run [here](https://github.com/nastra/iceberg/actions/runs/1366744441) and it passes now :yay:
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark taking 20+ mins for setup
Posted by GitBox <gi...@apache.org>.
rdblue commented on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-947182438
That thread dump is for the thread that submitted a Spark job. It's just waiting on tasks to do the write, so I don't think that's where the problem is.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] nastra edited a comment on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark taking 20+ mins for setup
Posted by GitBox <gi...@apache.org>.
nastra edited a comment on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-928928939
> @nastra, can we avoid using Spark 2.4 for this and run the benchmarks in 3.1? I have no idea what might have changed in 2.4.6 that caused this.
@rdblue the goal is definitely to run those benchmarks for Spark3 but I was rather trying to figure out when `VectorizedReadDictionaryEncodedFlatParquetDataBenchmark` started to take so long for setup (which was 2020-08-06 with 996ed97 when it wasn't possible to run that benchmark with Spark3).
The same benchmark for Spark3 was only recently (2021-06-21) introduced with ed0c70284e1f6506331a60d8c9e9706df2e32ec9, meaning that `VectorizedReadDictionaryEncodedFlatParquetDataBenchmark` actually never worked with Spark3 in the first place and setup always took so long.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark taking 20+ mins for setup
Posted by GitBox <gi...@apache.org>.
rdblue commented on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-928101048
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] RussellSpitzer commented on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark not working
Posted by GitBox <gi...@apache.org>.
RussellSpitzer commented on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-923055190
Writing the 10M row files
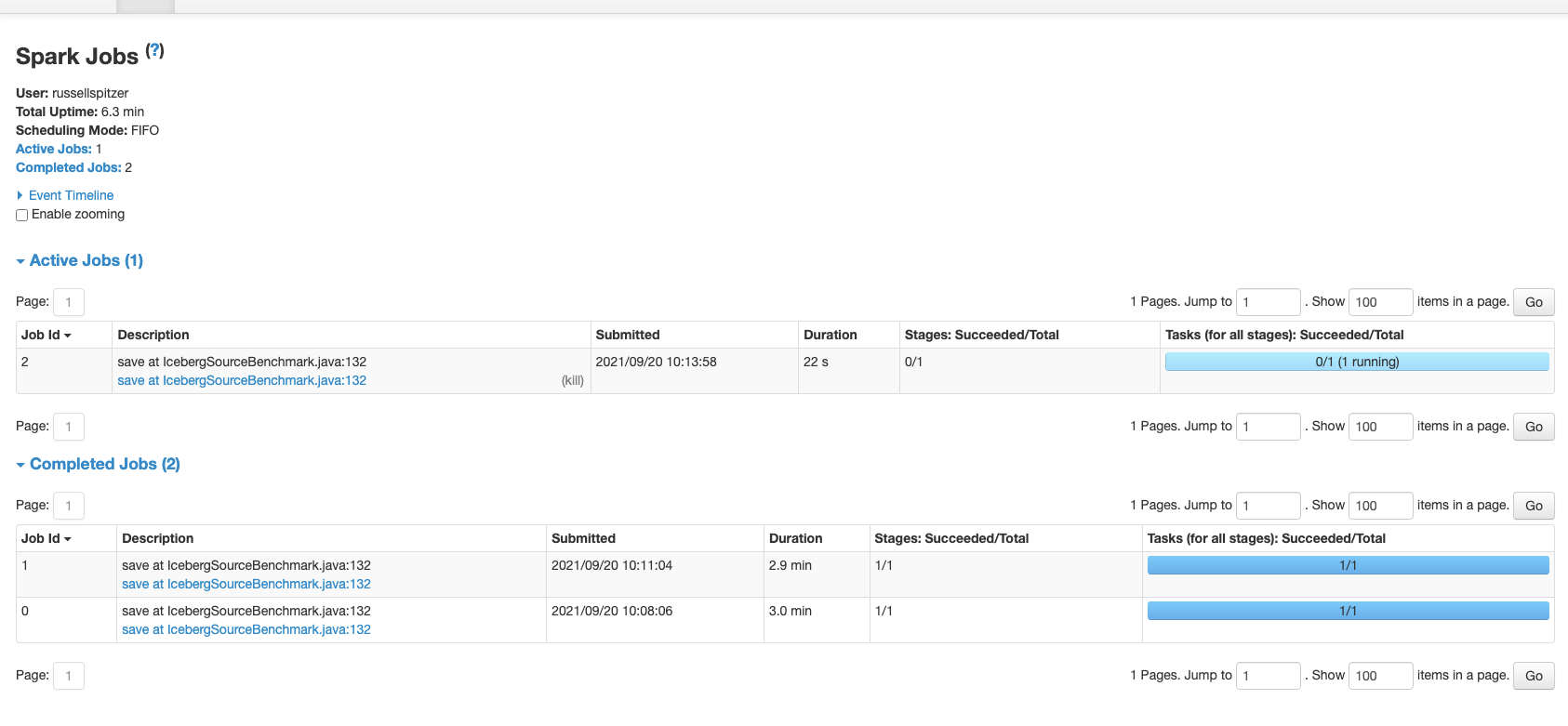
For some reason on my machine this writes 10 files even though NUM_FILES is set to 5
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark taking 20+ mins for setup
Posted by GitBox <gi...@apache.org>.
rdblue commented on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-928101048
@nastra, can we avoid using Spark 2.4 for this and run the benchmarks in 3.1? I have no idea what might have changed in 2.4.6 that caused this.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] RussellSpitzer commented on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark not working
Posted by GitBox <gi...@apache.org>.
RussellSpitzer commented on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-923046069
Ok checking the interior workings, we are timing out on an iteration. The setup phase time is included with the iteration time so if the time limit is set to 10 minutes, and setup takes 27 minutes you will never start.
I turned on the UI and saw we start this test by writing 10 files during the setup phase. On my excellent MBP (2020) it takes almost 3 minutes to write each file. The test itself completes nearly immediately following the final file being written taking almost no time at all for any of the read iterations.
```
# Warmup: 3 iterations, single-shot each
# Measurement: 5 iterations, single-shot each
# Timeout: 30 min per iteration
# Threads: 1 thread
# Benchmark mode: Single shot invocation time
# Benchmark: org.apache.iceberg.spark.source.parquet.vectorized.VectorizedReadDictionaryEncodedFlatParquetDataBenchmark.readDatesIcebergVectorized5k
# Run progress: 0.00% complete, ETA 00:00:00
# Fork: 1 of 1
# Warmup Iteration 1: 3.800 s/op
# Warmup Iteration 2: 3.178 s/op
# Warmup Iteration 3: 3.038 s/op
Iteration 1: 3.122 s/op
Iteration 2: ok 3.014 s/op
Iteration 3: 3.057 s/op
Iteration 4: 3.182 s/op
Iteration 5: 2.979 s/op
Result "org.apache.iceberg.spark.source.parquet.vectorized.VectorizedReadDictionaryEncodedFlatParquetDataBenchmark.readDatesIcebergVectorized5k":
N = 5
mean = 3.071 ±(99.9%) 0.314 s/op
Histogram, s/op:
[2.900, 2.925) = 0
[2.925, 2.950) = 0
[2.950, 2.975) = 0
[2.975, 3.000) = 1
[3.000, 3.025) = 1
[3.025, 3.050) = 0
[3.050, 3.075) = 1
[3.075, 3.100) = 0
[3.100, 3.125) = 1
[3.125, 3.150) = 0
[3.150, 3.175) = 0
Percentiles, s/op:
p(0.0000) = 2.979 s/op
p(50.0000) = 3.057 s/op
p(90.0000) = 3.182 s/op
p(95.0000) = 3.182 s/op
p(99.0000) = 3.182 s/op
p(99.9000) = 3.182 s/op
p(99.9900) = 3.182 s/op
p(99.9990) = 3.182 s/op
p(99.9999) = 3.182 s/op
p(100.0000) = 3.182 s/op
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark taking 20+ mins for setup
Posted by GitBox <gi...@apache.org>.
rdblue commented on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-928101241
(Alternatively, we can downgrade to run benchmarks for now?)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] RussellSpitzer edited a comment on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark taking 20+ mins for setup
Posted by GitBox <gi...@apache.org>.
RussellSpitzer edited a comment on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-947845241
Solved with #3329 - I took a guess after @nastra debugged and tried a bunch of things out. By removing the "when" clauses and just working on base column functions I get the setup time down to ~ 1 minute. As for the actual regression in spark? no idea. Someone should check out the codegen between 2.4.5 and 2.4.6 if they really care :)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] nastra commented on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark taking 20+ mins for setup
Posted by GitBox <gi...@apache.org>.
nastra commented on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-928928939
> @nastra, can we avoid using Spark 2.4 for this and run the benchmarks in 3.1? I have no idea what might have changed in 2.4.6 that caused this.
@rdblue the goal is definitely to run those benchmarks for Spark3 but I was rather trying to figure out when `VectorizedReadDictionaryEncodedFlatParquetDataBenchmark` started to take so long for setup (which was 2020-08-06 with 996ed97 when it wasn't possible to run that benchmark with Spark3). The same benchmark for Spark3 was only recently (2021-06-21) introduced with ed0c70284e1f6506331a60d8c9e9706df2e32ec9.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] nastra commented on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark taking 20+ mins for setup
Posted by GitBox <gi...@apache.org>.
nastra commented on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-947441885
Attaching the full dump: [sparkprocessdump.txt](https://github.com/apache/iceberg/files/7379451/sparkprocessdump.txt)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] nastra commented on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark taking 20+ mins for setup
Posted by GitBox <gi...@apache.org>.
nastra commented on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-946776641
As @RussellSpitzer already pointed out in his comment, we're spending quite a lot of time writing a single parquet file. In my case it seems to take 3-5 mins to write a single Parquet file (<1MB in size) with 10M rows
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] RussellSpitzer commented on issue #3157: VectorizedReadDictionaryEncodedFlatParquetDataBenchmark taking 20+ mins for setup
Posted by GitBox <gi...@apache.org>.
RussellSpitzer commented on issue #3157:
URL: https://github.com/apache/iceberg/issues/3157#issuecomment-947845241
https://github.com/apache/iceberg/pull/3329/files - I took a guess after @nastra debugged and tried a bunch of things out. By removing the "when" clauses and just working on base column functions I get the setup time down to ~ 1 minute.
https://github.com/apache/iceberg/pull/3329/files
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org