You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by "awk6873 (via GitHub)" <gi...@apache.org> on 2023/03/29 12:45:52 UTC
[GitHub] [hudi] awk6873 opened a new issue, #8316: [SUPPORT]
awk6873 opened a new issue, #8316:
URL: https://github.com/apache/hudi/issues/8316
**_Tips before filing an issue_**
- Have you gone through our [FAQs](https://hudi.apache.org/learn/faq/)?
- Join the mailing list to engage in conversations and get faster support at dev-subscribe@hudi.apache.org.
- If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly.
**Describe the problem you faced**
INSERT operation works with almost the same performance as UPSERT operation.
There's no acceleration with using INSERT operation.
**To Reproduce**
We use non partitioned table with BUCKET CONSISTENT_HASHING index.
Here is config:
val hudiWriteConfigs = Map(
"hoodie.datasource.write.table.type" -> "MERGE_ON_READ",
"hoodie.write.markers.type" -> "direct",
"hoodie.metadata.enable" -> "true",
"hoodie.index.type" -> "BUCKET",
"hoodie.index.bucket.engine" -> "CONSISTENT_HASHING",
"hoodie.bucket.index.num.buckets" -> "10000",
"hoodie.storage.layout.partitioner.class" -> "org.apache.hudi.table.action.commit.SparkBucketIndexPartitioner",
"hoodie.compact.inline" -> "true",
"hoodie.compact.inline.max.delta.commits" -> "10",
"hoodie.compact.inline.max.delta.seconds" -> "3600",
"hoodie.compact.inline.trigger.strategy" -> "NUM_OR_TIME",
"hoodie.clean.async" -> "false",
"hoodie.clean.max.commits" -> "10",
"hoodie.cleaner.commits.retained" -> "10",
"hoodie.keep.min.commits" -> "20",
"hoodie.keep.max.commits" -> "30",
"hoodie.datasource.write.keygenerator.class" -> "org.apache.hudi.keygen.NonpartitionedKeyGenerator"
)
Steps to reproduce the behavior:
1. Run UPSERT of batch of 3000 rows
df_u.write.format("hudi").options(hudiWriteConfigs).option("hoodie.datasource.write.recordkey.field", "_Fld19066_TYPE,_Fld19066_RTRef,_Fld19066_RRRef,_Fld19067RRef,_Fld19068RRef,_Fld19069,_Fld24101RRef").option("hoodie.datasource.write.precombine.field", "_ts_ms").option("hoodie.merge.allow.duplicate.on.inserts", "true").option("hoodie.datasource.write.operation", "**upsert**").mode("append").option("hoodie.table.name", "_InfoRg19065").save("/warehouse/debezium_hudi_test/data/_InfoRg19065")
2. Run INSERT of batch of 3000 rows
df_u.write.format("hudi").options(hudiWriteConfigs).option("hoodie.datasource.write.recordkey.field", "_Fld19066_TYPE,_Fld19066_RTRef,_Fld19066_RRRef,_Fld19067RRef,_Fld19068RRef,_Fld19069,_Fld24101RRef").option("hoodie.datasource.write.precombine.field", "_ts_ms").option("hoodie.merge.allow.duplicate.on.inserts", "true").option("hoodie.datasource.write.operation", "**insert**").mode("append").option("hoodie.table.name", "_InfoRg19065").save("/warehouse/debezium_hudi_test/data/_InfoRg19065")
3. View and compare jobs executed in Spark UI
UPSERT execution
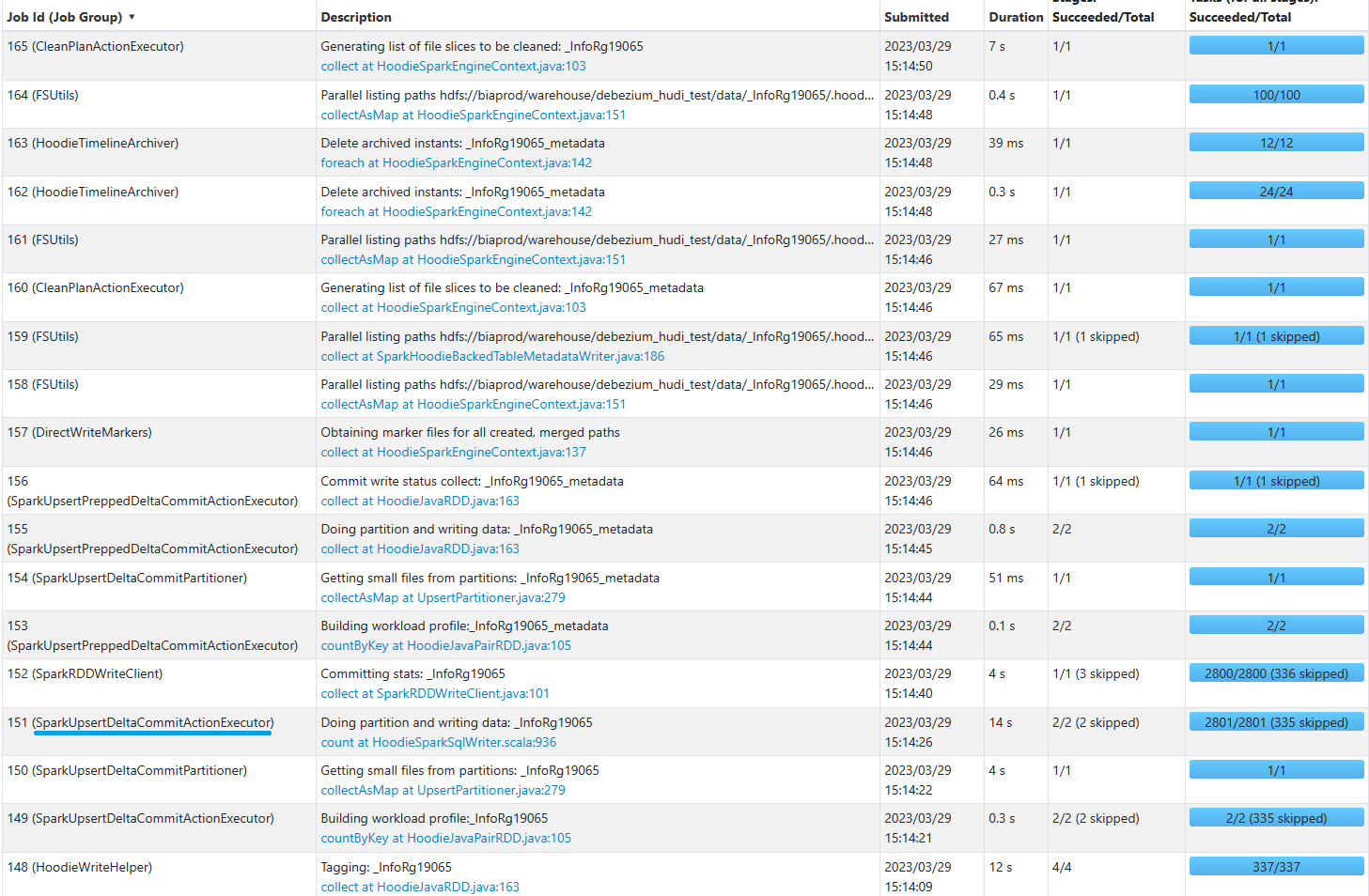
INSERT execution
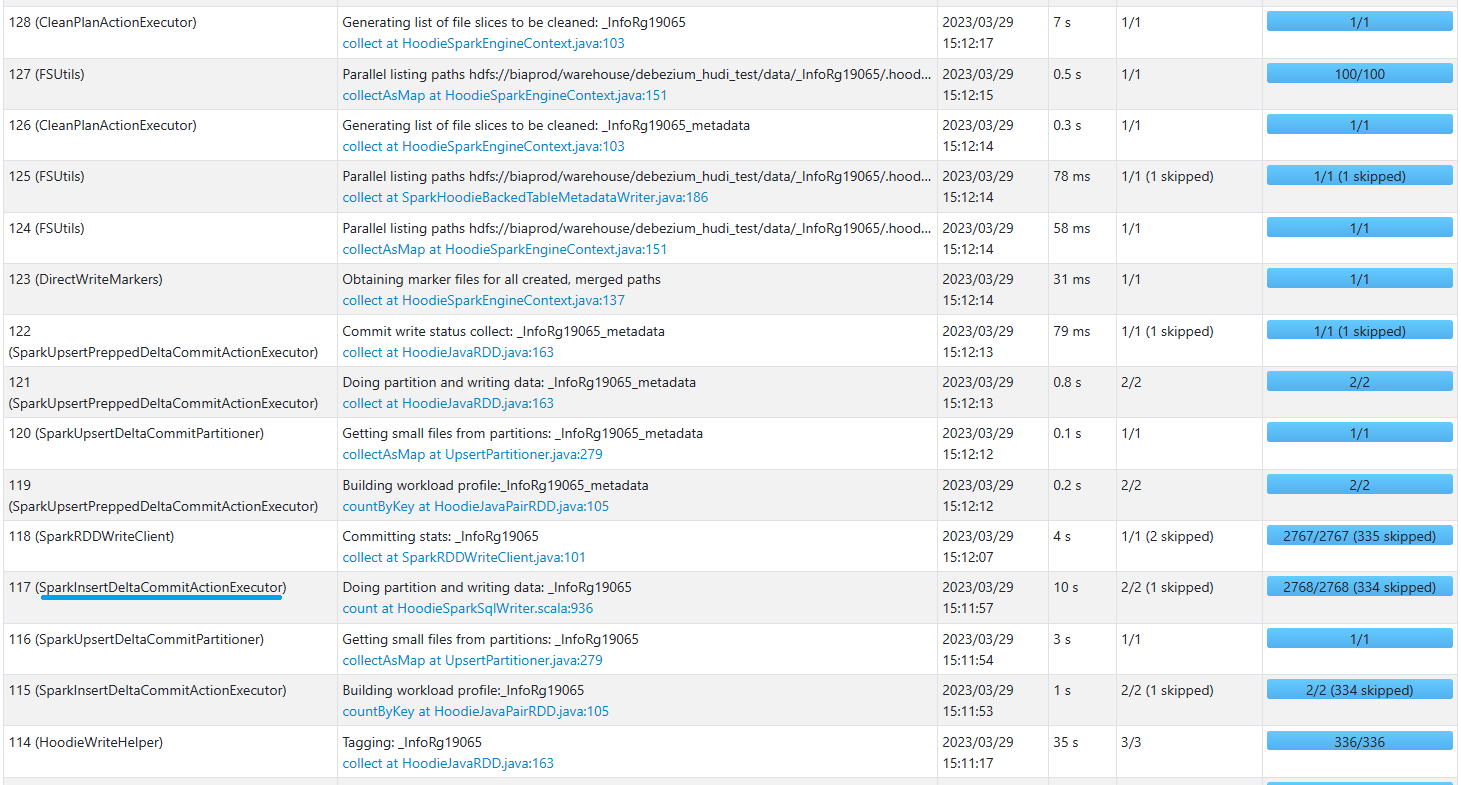
**Expected behavior**
Expected that performance of INSERT operation would be better than of UPSERT operation
**Environment Description**
* Hudi version : 0.13.0
* Spark version : 3.2.2
* Hive version :
* Hadoop version : 3.3.2
* Storage (HDFS/S3/GCS..) : HDFS
* Running on Docker? (yes/no) : no
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] awk6873 commented on issue #8316: [SUPPORT] INSERT operation performance vs UPSERT operation
Posted by "awk6873 (via GitHub)" <gi...@apache.org>.
awk6873 commented on issue #8316:
URL: https://github.com/apache/hudi/issues/8316#issuecomment-1520246322
> @awk6873 Do you need any other info on this ticket?
No, thanks
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] ad1happy2go commented on issue #8316: [SUPPORT] INSERT operation performance vs UPSERT operation
Posted by "ad1happy2go (via GitHub)" <gi...@apache.org>.
ad1happy2go commented on issue #8316:
URL: https://github.com/apache/hudi/issues/8316#issuecomment-1511298675
@awk6873 Why are you not using Bulk insert?
Insert operation also takes the similar write path as upsert so the performance can be similar although it doesn't do index lookup. Bulk insert should be very fast, and you can do separate clustering job to handle small files problem.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] ad1happy2go commented on issue #8316: [SUPPORT] INSERT operation performance vs UPSERT operation
Posted by "ad1happy2go (via GitHub)" <gi...@apache.org>.
ad1happy2go commented on issue #8316:
URL: https://github.com/apache/hudi/issues/8316#issuecomment-1520159519
@awk6873 Do you need any other info on this ticket?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] xushiyan closed issue #8316: [SUPPORT] INSERT operation performance vs UPSERT operation
Posted by "xushiyan (via GitHub)" <gi...@apache.org>.
xushiyan closed issue #8316: [SUPPORT] INSERT operation performance vs UPSERT operation
URL: https://github.com/apache/hudi/issues/8316
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] KnightChess commented on issue #8316: [SUPPORT] INSERT operation performance vs UPSERT operation
Posted by "KnightChess (via GitHub)" <gi...@apache.org>.
KnightChess commented on issue #8316:
URL: https://github.com/apache/hudi/issues/8316#issuecomment-1488815133
in this case, all of them will append to logFile in the same way in writting data stage because this is mor table which use bucket.
And in addition, the task look like exec very fast, the update/insert count is small. Other factors may have a certain impact, like task schedule time, the current maximum parallelism, scheduling situation
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] ad1happy2go commented on issue #8316: [SUPPORT] INSERT operation performance vs UPSERT operation
Posted by "ad1happy2go (via GitHub)" <gi...@apache.org>.
ad1happy2go commented on issue #8316:
URL: https://github.com/apache/hudi/issues/8316#issuecomment-1493389519
@awk6873 I tried to run with a bigger dataset also and it gave similar performance as @KnightChess explained.
Do you still see it a issue or need more clarifications?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org