You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2020/04/11 19:57:28 UTC
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1469:
[HUDI-686] Implement BloomIndexV2 that does not depend on memory caching
lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2 that does not depend on memory caching
URL: https://github.com/apache/incubator-hudi/pull/1469#issuecomment-612500968
Also, index performance has been greatly improved, your idea and design is amazing 👍 👍 👍 @vinothchandar
I tested `upsert` 500,0000 records, `bulk_insert` first, then do `upsert` operation with the same dataset
1. Download CSV data with 5M records
```
https://drive.google.com/open?id=1uwJ68_RrKMUTbEtsGl56_P5b_mNX3k2S
```
2. Run demo command
```
export SPARK_HOME=/work/BigData/install/spark/spark-2.4.4-bin-hadoop2.7
${SPARK_HOME}/bin/spark-shell \
--driver-memory 6G \
--packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.1-incubating,org.apache.spark:spark-avro_2.11:2.4.4 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
export SPARK_HOME=/work/BigData/install/spark/spark-2.4.4-bin-hadoop2.7
${SPARK_HOME}/bin/spark-shell \
--driver-memory 6G \
--jars `ls packaging/hudi-spark-bundle/target/hudi-spark-bundle_*.*-*.*.*-SNAPSHOT.jar` \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
import org.apache.spark.sql.functions._
val tableName = "hudi_mor_table"
val basePath = "file:///tmp/hudi_mor_table"
var inputDF = spark.read.format("csv").option("header", "true").load("file:///work/hudi-debug/2.csv")
val hudiOptions = Map[String,String](
"hoodie.insert.shuffle.parallelism" -> "10",
"hoodie.upsert.shuffle.parallelism" -> "10",
"hoodie.delete.shuffle.parallelism" -> "10",
"hoodie.bulkinsert.shuffle.parallelism" -> "10",
"hoodie.datasource.write.recordkey.field" -> "tds_cid",
"hoodie.datasource.write.partitionpath.field" -> "hit_date",
"hoodie.table.name" -> tableName,
"hoodie.datasource.write.precombine.field" -> "hit_timestamp",
"hoodie.datasource.write.operation" -> "upsert",
"hoodie.memory.merge.max.size" -> "2004857600000",
"hoodie.index.type" -> "BLOOM_V2",
"hoodie.bloom.index.v2.buffer.max.size" -> "102000000000"
)
inputDF.write.format("org.apache.hudi").
options(hudiOptions).
mode("Append").
save(basePath)
spark.read.format("org.apache.hudi").load(basePath + "/2020-03-19/*").count();
```
<br>
### Performance comparison
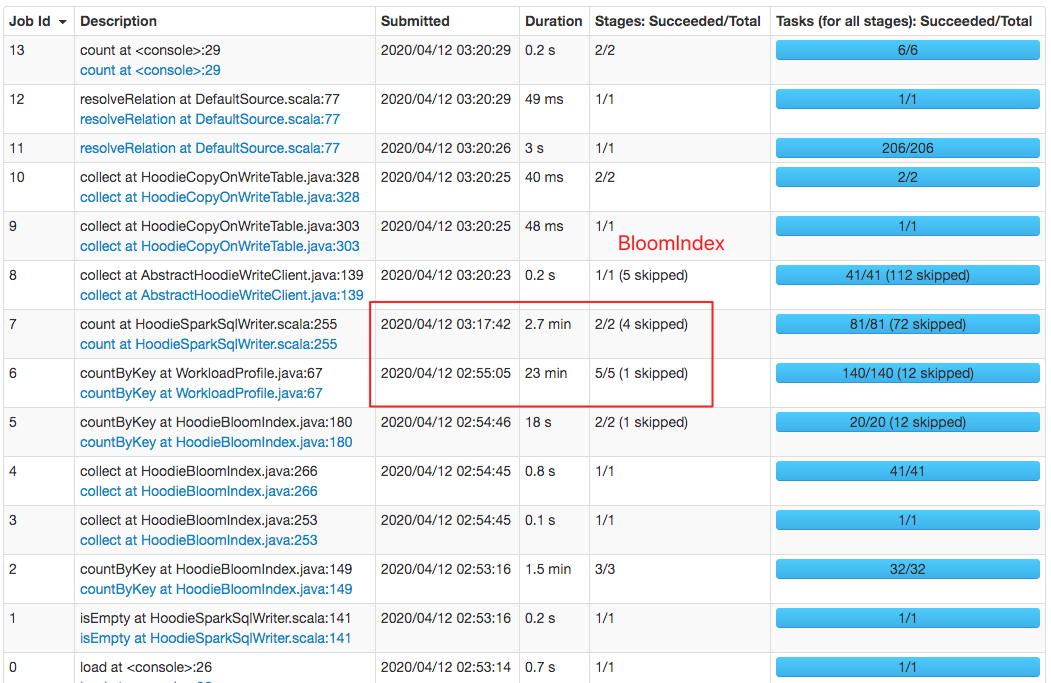
#### `HoodieBloomIndex`: cost about 20min
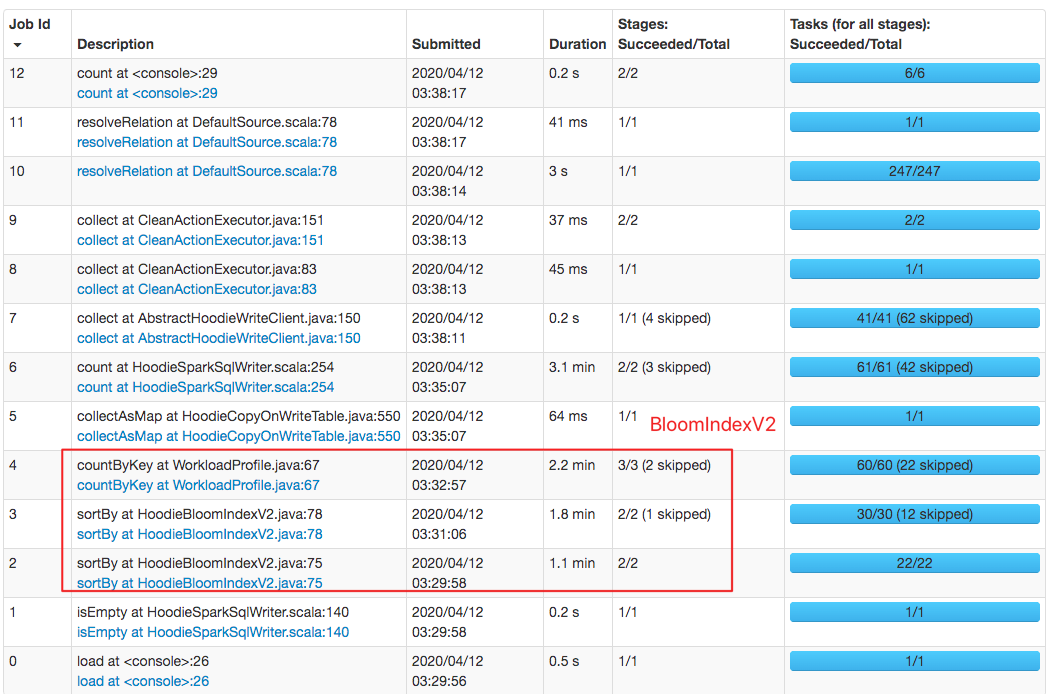
#### `HoodieBloomIndexV2`: cost about 3min
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services