You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@devlake.apache.org by zk...@apache.org on 2022/10/19 08:57:52 UTC
[incubator-devlake-website] branch main updated (33e4315d3 -> 2e5b063ac)
This is an automated email from the ASF dual-hosted git repository.
zky pushed a change to branch main
in repository https://gitbox.apache.org/repos/asf/incubator-devlake-website.git
from 33e4315d3 fix: updated demo links
new c527de0c0 feat: updated blogs and live demo
new 2e5b063ac fix: updated dead links
The 2 revisions listed above as "new" are entirely new to this
repository and will be described in separate emails. The revisions
listed as "add" were already present in the repository and have only
been added to this reference.
Summary of changes:
.../ants_source_code_1.png | Bin 26314 -> 0 bytes
.../ants_source_code_flowchart.png | Bin 97974 -> 0 bytes
.../index.md | 197 -----------
...ds.093a76ac-457b-4498-a472-7dbea580bca9.001.png | Bin 39514 -> 0 bytes
...ds.093a76ac-457b-4498-a472-7dbea580bca9.002.png | Bin 27018 -> 0 bytes
...ds.093a76ac-457b-4498-a472-7dbea580bca9.003.png | Bin 41209 -> 0 bytes
...ds.093a76ac-457b-4498-a472-7dbea580bca9.004.png | Bin 26120 -> 0 bytes
...ds.093a76ac-457b-4498-a472-7dbea580bca9.005.png | Bin 28689 -> 0 bytes
...ds.093a76ac-457b-4498-a472-7dbea580bca9.006.png | Bin 34773 -> 0 bytes
...ds.093a76ac-457b-4498-a472-7dbea580bca9.007.png | Bin 28548 -> 0 bytes
blog/2022-05-18-how-apache-devlake-runs/index.md | 152 --------
.../index.md" | 38 --
.../Architecture_Diagram.png" | Bin 62224 -> 0 bytes
.../index.md" | 239 -------------
.../wechat_community_barcode.png" | Bin 4668 -> 0 bytes
.../7b2a6f29-ea2a-4a84-97c8-7eba5a5131a8.png" | Bin 67022 -> 0 bytes
.../8afb097c-a0b3-4bdc-80f3-7241c3fa566f.png" | Bin 114716 -> 0 bytes
.../df2f9837-121e-4a64-976c-c5039d452bfd.png" | Bin 99412 -> 0 bytes
.../efea0188-80e4-4519-a010-977a7fd5432e.png" | Bin 349376 -> 0 bytes
.../index.md" | 180 ----------
.../index.md | 2 +-
.../dfs.gif" | Bin 8701776 -> 0 bytes
.../dfs.webm" | Bin 2844648 -> 0 bytes
.../index.md" | 389 ---------------------
...50\241\345\236\213\346\236\204\345\233\276.png" | Bin 84765 -> 0 bytes
.../\346\267\273\345\212\240Compare.png" | Bin 2797 -> 0 bytes
...33\256\346\240\207\345\210\206\346\224\257.png" | Bin 73006 -> 0 bytes
...11\210\346\234\254\345\257\271\346\257\224.png" | Bin 125303 -> 0 bytes
...35\242\346\235\277\345\233\276\347\211\207.png" | Bin 260049 -> 0 bytes
.../index.md | 2 +-
blog/2022-07-15-welcome-open-source/en.md.bak | 23 --
blog/2022-07-15-welcome-open-source/index.md | 165 ---------
docs/UserManuals/ConfigUI/GitHub.md | 2 +-
docusaurus.config.js | 8 +-
i18n/zh/code.json | 225 ------------
.../ants_source_code_1.png" | Bin 26314 -> 0 bytes
.../ants_source_code_flowchart.png" | Bin 97974 -> 0 bytes
.../index.md" | 122 -------
...s.093a76ac-457b-4498-a472-7dbea580bca9.001.png" | Bin 39514 -> 0 bytes
...s.093a76ac-457b-4498-a472-7dbea580bca9.002.png" | 0
...s.093a76ac-457b-4498-a472-7dbea580bca9.003.png" | 0
...s.093a76ac-457b-4498-a472-7dbea580bca9.004.png" | 0
...s.093a76ac-457b-4498-a472-7dbea580bca9.005.png" | 0
...s.093a76ac-457b-4498-a472-7dbea580bca9.006.png" | 0
...s.093a76ac-457b-4498-a472-7dbea580bca9.007.png" | 0
.../index.md" | 144 --------
.../0.11-architecture-diagram.jpg | Bin 237316 -> 0 bytes
.../Dashboard-1.jpg | Bin 194544 -> 0 bytes
.../Dashboard-2.jpg | Bin 206712 -> 0 bytes
.../incubation-screenshot.jpg | Bin 122770 -> 0 bytes
.../2022-05-18-apache-welcomes-devLake/index.md | 126 -------
.../index.md" | 31 --
.../index.md | 65 ----
.../Architecture_Diagram.png" | Bin 62224 -> 0 bytes
.../index.md" | 239 -------------
.../wechat_community_barcode.png" | Bin 4668 -> 0 bytes
.../7b2a6f29-ea2a-4a84-97c8-7eba5a5131a8.png" | Bin 67022 -> 0 bytes
.../8afb097c-a0b3-4bdc-80f3-7241c3fa566f.png" | Bin 114716 -> 0 bytes
.../df2f9837-121e-4a64-976c-c5039d452bfd.png" | Bin 99412 -> 0 bytes
.../efea0188-80e4-4519-a010-977a7fd5432e.png" | Bin 349376 -> 0 bytes
.../index.md" | 180 ----------
.../dfs.gif" | Bin 8701776 -> 0 bytes
.../dfs.webm" | Bin 2844648 -> 0 bytes
.../index.md" | 389 ---------------------
...50\241\345\236\213\346\236\204\345\233\276.png" | Bin 84765 -> 0 bytes
.../\346\267\273\345\212\240Compare.png" | Bin 2797 -> 0 bytes
...33\256\346\240\207\345\210\206\346\224\257.png" | Bin 73006 -> 0 bytes
...11\210\346\234\254\345\257\271\346\257\224.png" | Bin 125303 -> 0 bytes
...35\242\346\235\277\345\233\276\347\211\207.png" | Bin 260049 -> 0 bytes
i18n/zh/docusaurus-plugin-content-blog/authors.yml | 59 ----
.../zh/docusaurus-plugin-content-blog/options.json | 14 -
.../current.json | 10 -
.../zh/docusaurus-plugin-content-docs/current.json | 22 --
.../current/01-Overview/02-WhatIsDevLake.md | 30 --
.../current/01-Overview/03-Architecture.md | 29 --
.../current/01-Overview/04-Roadmap.md | 36 --
.../current/01-Overview/_category_.json | 4 -
.../current/02-Quick Start/01-LocalSetup.md | 81 -----
.../current/02-Quick Start/02-KubernetesSetup.md | 9 -
.../current/02-Quick Start/03-DeveloperSetup.md | 123 -------
.../current/02-Quick Start/_category_.json | 4 -
.../current/03-Features.md | 20 --
.../current/04-EngineeringMetrics.md | 197 -----------
.../current/DeveloperManuals/E2E-Test-Guide.md | 202 -----------
.../DeveloperManuals/PluginImplementation.md | 337 ------------------
.../current/GettingStarted/RainbondSetup.md | 34 --
.../version-v0.13/01-Overview/02-WhatIsDevLake.md | 30 --
.../version-v0.13/01-Overview/03-Architecture.md | 29 --
.../version-v0.13/01-Overview/04-Roadmap.md | 36 --
.../version-v0.13/01-Overview/_category_.json | 4 -
.../version-v0.13/02-Quick Start/01-LocalSetup.md | 81 -----
.../02-Quick Start/02-KubernetesSetup.md | 9 -
.../02-Quick Start/03-DeveloperSetup.md | 123 -------
.../version-v0.13/02-Quick Start/_category_.json | 4 -
.../version-v0.13/03-Features.md | 20 --
.../version-v0.13/04-EngineeringMetrics.md | 197 -----------
.../DeveloperManuals/E2E-Test-Guide.md | 202 -----------
.../DeveloperManuals/PluginImplementation.md | 337 ------------------
i18n/zh/docusaurus-theme-classic/footer.json | 34 --
i18n/zh/docusaurus-theme-classic/navbar.json | 26 --
livedemo/AverageRequirementLeadTime.md | 2 +-
livedemo/CommitCountByAuthor.md | 2 +-
livedemo/CommunityExperience.md | 2 +-
livedemo/DORA.md | 2 +-
livedemo/DetailedBugInfo.md | 2 +-
livedemo/EngineeringOverview.md | 8 +
livedemo/EngineeringThroughputAndCycleTime.md | 8 +
livedemo/GitHub.md | 8 +
livedemo/GitHubBasic.md | 8 -
.../GitHubReleaseQualityAndContributionAnalysis.md | 2 +-
livedemo/GitLab.md | 8 +
livedemo/GitextractorMetricsDashboard.md | 8 +
livedemo/Jenkins.md | 2 +-
livedemo/WeeklyBugRetro.md | 2 +-
livedemo/WeeklyCommunityRetro.md | 2 +-
src/components/Sections/UserFlow.tsx | 2 +-
.../version-v0.12/UserManuals/ConfigUI/GitHub.md | 2 +-
.../version-v0.13/UserManuals/ConfigUI/GitHub.md | 2 +-
118 files changed, 59 insertions(+), 5274 deletions(-)
delete mode 100644 blog/2022-04-30-deadlock-caused-by-using-ants/ants_source_code_1.png
delete mode 100644 blog/2022-04-30-deadlock-caused-by-using-ants/ants_source_code_flowchart.png
delete mode 100644 blog/2022-04-30-deadlock-caused-by-using-ants/index.md
delete mode 100644 blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.001.png
delete mode 100644 blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.002.png
delete mode 100644 blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.003.png
delete mode 100644 blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.004.png
delete mode 100644 blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.005.png
delete mode 100644 blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.006.png
delete mode 100644 blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.007.png
delete mode 100644 blog/2022-05-18-how-apache-devlake-runs/index.md
delete mode 100644 "blog/2022-05-20-\345\246\202\344\275\225\350\264\241\347\214\256issues/index.md"
delete mode 100644 "blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/Architecture_Diagram.png"
delete mode 100644 "blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/index.md"
delete mode 100644 "blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/wechat_community_barcode.png"
delete mode 100644 "blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/7b2a6f29-ea2a-4a84-97c8-7eba5a5131a8.png"
delete mode 100644 "blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/8afb097c-a0b3-4bdc-80f3-7241c3fa566f.png"
delete mode 100644 "blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/df2f9837-121e-4a64-976c-c5039d452bfd.png"
delete mode 100644 "blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/efea0188-80e4-4519-a010-977a7fd5432e.png"
delete mode 100644 "blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/index.md"
delete mode 100644 "blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/dfs.gif"
delete mode 100644 "blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/dfs.webm"
delete mode 100644 "blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/index.md"
delete mode 100644 "blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\225\260\345\255\246\346\250\241\345\236\213\346\236\204\345\233\276.png"
delete mode 100644 "blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\267\273\345\212\240Compare.png"
delete mode 100644 "blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\272\220\345\210\206\346\224\257-\347\233\256\346\240\207\345\210\206\346\224\257.png"
delete mode 100644 "blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\347\211\210\346\234\254\345\257\271\346\257\224.png"
delete mode 100644 "blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\351\235\242\346\235\277\345\233\276\347\211\207.png"
delete mode 100644 blog/2022-07-15-welcome-open-source/en.md.bak
delete mode 100644 blog/2022-07-15-welcome-open-source/index.md
delete mode 100644 i18n/zh/code.json
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-04-30-\344\275\277\347\224\250ants\345\274\225\345\217\221\347\232\204\346\255\273\351\224\201/ants_source_code_1.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-04-30-\344\275\277\347\224\250ants\345\274\225\345\217\221\347\232\204\346\255\273\351\224\201/ants_source_code_flowchart.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-04-30-\344\275\277\347\224\250ants\345\274\225\345\217\221\347\232\204\346\255\273\351\224\201/index.md"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.001.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.002.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.003.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.004.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.005.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.006.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.007.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/index.md"
delete mode 100644 i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/0.11-architecture-diagram.jpg
delete mode 100644 i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/Dashboard-1.jpg
delete mode 100644 i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/Dashboard-2.jpg
delete mode 100644 i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/incubation-screenshot.jpg
delete mode 100644 i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/index.md
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-05-20-\345\246\202\344\275\225\350\264\241\347\214\256issues/index.md"
delete mode 100644 i18n/zh/docusaurus-plugin-content-blog/2022-05-25-what-did-we-do-during-march-april/index.md
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/Architecture_Diagram.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/index.md"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/wechat_community_barcode.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/7b2a6f29-ea2a-4a84-97c8-7eba5a5131a8.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/8afb097c-a0b3-4bdc-80f3-7241c3fa566f.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/df2f9837-121e-4a64-976c-c5039d452bfd.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/efea0188-80e4-4519-a010-977a7fd5432e.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/index.md"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/dfs.gif"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/dfs.webm"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/index.md"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\225\260\345\255\246\346\250\241\345\236\213\346\236\204\345\233\276.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\267\273\345\212\240Compare.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\272\220\345\210\206\346\224\257-\347\233\256\346\240\207\345\210\206\346\224\257.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\347\211\210\346\234\254\345\257\271\346\257\224.png"
delete mode 100644 "i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\351\235\242\346\235\277\345\233\276\347\211\207.png"
delete mode 100644 i18n/zh/docusaurus-plugin-content-blog/authors.yml
delete mode 100644 i18n/zh/docusaurus-plugin-content-blog/options.json
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs-community/current.json
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/current.json
delete mode 100755 i18n/zh/docusaurus-plugin-content-docs/current/01-Overview/02-WhatIsDevLake.md
delete mode 100755 i18n/zh/docusaurus-plugin-content-docs/current/01-Overview/03-Architecture.md
delete mode 100755 i18n/zh/docusaurus-plugin-content-docs/current/01-Overview/04-Roadmap.md
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/current/01-Overview/_category_.json
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/current/02-Quick Start/01-LocalSetup.md
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/current/02-Quick Start/02-KubernetesSetup.md
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/current/02-Quick Start/03-DeveloperSetup.md
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/current/02-Quick Start/_category_.json
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/current/03-Features.md
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/current/04-EngineeringMetrics.md
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/current/DeveloperManuals/E2E-Test-Guide.md
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/current/DeveloperManuals/PluginImplementation.md
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/current/GettingStarted/RainbondSetup.md
delete mode 100755 i18n/zh/docusaurus-plugin-content-docs/version-v0.13/01-Overview/02-WhatIsDevLake.md
delete mode 100755 i18n/zh/docusaurus-plugin-content-docs/version-v0.13/01-Overview/03-Architecture.md
delete mode 100755 i18n/zh/docusaurus-plugin-content-docs/version-v0.13/01-Overview/04-Roadmap.md
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/version-v0.13/01-Overview/_category_.json
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/version-v0.13/02-Quick Start/01-LocalSetup.md
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/version-v0.13/02-Quick Start/02-KubernetesSetup.md
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/version-v0.13/02-Quick Start/03-DeveloperSetup.md
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/version-v0.13/02-Quick Start/_category_.json
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/version-v0.13/03-Features.md
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/version-v0.13/04-EngineeringMetrics.md
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/version-v0.13/DeveloperManuals/E2E-Test-Guide.md
delete mode 100644 i18n/zh/docusaurus-plugin-content-docs/version-v0.13/DeveloperManuals/PluginImplementation.md
delete mode 100644 i18n/zh/docusaurus-theme-classic/footer.json
delete mode 100644 i18n/zh/docusaurus-theme-classic/navbar.json
create mode 100644 livedemo/EngineeringOverview.md
create mode 100644 livedemo/EngineeringThroughputAndCycleTime.md
create mode 100644 livedemo/GitHub.md
delete mode 100644 livedemo/GitHubBasic.md
create mode 100644 livedemo/GitLab.md
create mode 100644 livedemo/GitextractorMetricsDashboard.md
[incubator-devlake-website] 01/02: feat: updated blogs and live demo
Posted by zk...@apache.org.
This is an automated email from the ASF dual-hosted git repository.
zky pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/incubator-devlake-website.git
commit c527de0c01b9a42b71318585b492febbf83859d0
Author: yumengwang03 <yu...@merico.dev>
AuthorDate: Wed Oct 19 16:32:36 2022 +0800
feat: updated blogs and live demo
---
.../ants_source_code_1.png | Bin 26314 -> 0 bytes
.../ants_source_code_flowchart.png | Bin 97974 -> 0 bytes
.../index.md | 197 -----------
...ds.093a76ac-457b-4498-a472-7dbea580bca9.001.png | Bin 39514 -> 0 bytes
...ds.093a76ac-457b-4498-a472-7dbea580bca9.002.png | Bin 27018 -> 0 bytes
...ds.093a76ac-457b-4498-a472-7dbea580bca9.003.png | Bin 41209 -> 0 bytes
...ds.093a76ac-457b-4498-a472-7dbea580bca9.004.png | Bin 26120 -> 0 bytes
...ds.093a76ac-457b-4498-a472-7dbea580bca9.005.png | Bin 28689 -> 0 bytes
...ds.093a76ac-457b-4498-a472-7dbea580bca9.006.png | Bin 34773 -> 0 bytes
...ds.093a76ac-457b-4498-a472-7dbea580bca9.007.png | Bin 28548 -> 0 bytes
blog/2022-05-18-how-apache-devlake-runs/index.md | 152 --------
.../index.md" | 38 --
.../Architecture_Diagram.png" | Bin 62224 -> 0 bytes
.../index.md" | 239 -------------
.../wechat_community_barcode.png" | Bin 4668 -> 0 bytes
.../7b2a6f29-ea2a-4a84-97c8-7eba5a5131a8.png" | Bin 67022 -> 0 bytes
.../8afb097c-a0b3-4bdc-80f3-7241c3fa566f.png" | Bin 114716 -> 0 bytes
.../df2f9837-121e-4a64-976c-c5039d452bfd.png" | Bin 99412 -> 0 bytes
.../efea0188-80e4-4519-a010-977a7fd5432e.png" | Bin 349376 -> 0 bytes
.../index.md" | 180 ----------
.../index.md | 2 +-
.../dfs.gif" | Bin 8701776 -> 0 bytes
.../dfs.webm" | Bin 2844648 -> 0 bytes
.../index.md" | 389 ---------------------
...50\241\345\236\213\346\236\204\345\233\276.png" | Bin 84765 -> 0 bytes
.../\346\267\273\345\212\240Compare.png" | Bin 2797 -> 0 bytes
...33\256\346\240\207\345\210\206\346\224\257.png" | Bin 73006 -> 0 bytes
...11\210\346\234\254\345\257\271\346\257\224.png" | Bin 125303 -> 0 bytes
...35\242\346\235\277\345\233\276\347\211\207.png" | Bin 260049 -> 0 bytes
.../index.md | 2 +-
blog/2022-07-15-welcome-open-source/en.md.bak | 23 --
blog/2022-07-15-welcome-open-source/index.md | 165 ---------
docusaurus.config.js | 8 +-
i18n/zh/code.json | 225 ------------
.../ants_source_code_1.png" | Bin 26314 -> 0 bytes
.../ants_source_code_flowchart.png" | Bin 97974 -> 0 bytes
.../index.md" | 122 -------
...s.093a76ac-457b-4498-a472-7dbea580bca9.001.png" | Bin 39514 -> 0 bytes
...s.093a76ac-457b-4498-a472-7dbea580bca9.002.png" | 0
...s.093a76ac-457b-4498-a472-7dbea580bca9.003.png" | 0
...s.093a76ac-457b-4498-a472-7dbea580bca9.004.png" | 0
...s.093a76ac-457b-4498-a472-7dbea580bca9.005.png" | 0
...s.093a76ac-457b-4498-a472-7dbea580bca9.006.png" | 0
...s.093a76ac-457b-4498-a472-7dbea580bca9.007.png" | 0
.../index.md" | 144 --------
.../0.11-architecture-diagram.jpg | Bin 237316 -> 0 bytes
.../Dashboard-1.jpg | Bin 194544 -> 0 bytes
.../Dashboard-2.jpg | Bin 206712 -> 0 bytes
.../incubation-screenshot.jpg | Bin 122770 -> 0 bytes
.../2022-05-18-apache-welcomes-devLake/index.md | 126 -------
.../index.md" | 31 --
.../index.md | 65 ----
.../Architecture_Diagram.png" | Bin 62224 -> 0 bytes
.../index.md" | 239 -------------
.../wechat_community_barcode.png" | Bin 4668 -> 0 bytes
.../7b2a6f29-ea2a-4a84-97c8-7eba5a5131a8.png" | Bin 67022 -> 0 bytes
.../8afb097c-a0b3-4bdc-80f3-7241c3fa566f.png" | Bin 114716 -> 0 bytes
.../df2f9837-121e-4a64-976c-c5039d452bfd.png" | Bin 99412 -> 0 bytes
.../efea0188-80e4-4519-a010-977a7fd5432e.png" | Bin 349376 -> 0 bytes
.../index.md" | 180 ----------
.../dfs.gif" | Bin 8701776 -> 0 bytes
.../dfs.webm" | Bin 2844648 -> 0 bytes
.../index.md" | 389 ---------------------
...50\241\345\236\213\346\236\204\345\233\276.png" | Bin 84765 -> 0 bytes
.../\346\267\273\345\212\240Compare.png" | Bin 2797 -> 0 bytes
...33\256\346\240\207\345\210\206\346\224\257.png" | Bin 73006 -> 0 bytes
...11\210\346\234\254\345\257\271\346\257\224.png" | Bin 125303 -> 0 bytes
...35\242\346\235\277\345\233\276\347\211\207.png" | Bin 260049 -> 0 bytes
i18n/zh/docusaurus-plugin-content-blog/authors.yml | 59 ----
.../zh/docusaurus-plugin-content-blog/options.json | 14 -
.../current.json | 10 -
.../zh/docusaurus-plugin-content-docs/current.json | 22 --
.../current/01-Overview/02-WhatIsDevLake.md | 30 --
.../current/01-Overview/03-Architecture.md | 29 --
.../current/01-Overview/04-Roadmap.md | 36 --
.../current/01-Overview/_category_.json | 4 -
.../current/02-Quick Start/01-LocalSetup.md | 81 -----
.../current/02-Quick Start/02-KubernetesSetup.md | 9 -
.../current/02-Quick Start/03-DeveloperSetup.md | 123 -------
.../current/02-Quick Start/_category_.json | 4 -
.../current/03-Features.md | 20 --
.../current/04-EngineeringMetrics.md | 197 -----------
.../current/DeveloperManuals/E2E-Test-Guide.md | 202 -----------
.../DeveloperManuals/PluginImplementation.md | 337 ------------------
.../current/GettingStarted/RainbondSetup.md | 34 --
.../version-v0.13/01-Overview/02-WhatIsDevLake.md | 30 --
.../version-v0.13/01-Overview/03-Architecture.md | 29 --
.../version-v0.13/01-Overview/04-Roadmap.md | 36 --
.../version-v0.13/01-Overview/_category_.json | 4 -
.../version-v0.13/02-Quick Start/01-LocalSetup.md | 81 -----
.../02-Quick Start/02-KubernetesSetup.md | 9 -
.../02-Quick Start/03-DeveloperSetup.md | 123 -------
.../version-v0.13/02-Quick Start/_category_.json | 4 -
.../version-v0.13/03-Features.md | 20 --
.../version-v0.13/04-EngineeringMetrics.md | 197 -----------
.../DeveloperManuals/E2E-Test-Guide.md | 202 -----------
.../DeveloperManuals/PluginImplementation.md | 337 ------------------
i18n/zh/docusaurus-theme-classic/footer.json | 34 --
i18n/zh/docusaurus-theme-classic/navbar.json | 26 --
livedemo/AverageRequirementLeadTime.md | 2 +-
livedemo/CommitCountByAuthor.md | 2 +-
livedemo/CommunityExperience.md | 2 +-
livedemo/DORA.md | 2 +-
livedemo/DetailedBugInfo.md | 2 +-
livedemo/EngineeringOverview.md | 8 +
livedemo/EngineeringThroughputAndCycleTime.md | 8 +
livedemo/GitHub.md | 8 +
livedemo/GitHubBasic.md | 8 -
.../GitHubReleaseQualityAndContributionAnalysis.md | 2 +-
livedemo/GitLab.md | 8 +
livedemo/GitextractorMetricsDashboard.md | 8 +
livedemo/Jenkins.md | 2 +-
livedemo/WeeklyBugRetro.md | 2 +-
livedemo/WeeklyCommunityRetro.md | 2 +-
src/components/Sections/UserFlow.tsx | 2 +-
115 files changed, 56 insertions(+), 5271 deletions(-)
diff --git a/blog/2022-04-30-deadlock-caused-by-using-ants/ants_source_code_1.png b/blog/2022-04-30-deadlock-caused-by-using-ants/ants_source_code_1.png
deleted file mode 100644
index 935aa93be..000000000
Binary files a/blog/2022-04-30-deadlock-caused-by-using-ants/ants_source_code_1.png and /dev/null differ
diff --git a/blog/2022-04-30-deadlock-caused-by-using-ants/ants_source_code_flowchart.png b/blog/2022-04-30-deadlock-caused-by-using-ants/ants_source_code_flowchart.png
deleted file mode 100644
index 42effec7f..000000000
Binary files a/blog/2022-04-30-deadlock-caused-by-using-ants/ants_source_code_flowchart.png and /dev/null differ
diff --git a/blog/2022-04-30-deadlock-caused-by-using-ants/index.md b/blog/2022-04-30-deadlock-caused-by-using-ants/index.md
deleted file mode 100644
index 1d163ca6f..000000000
--- a/blog/2022-04-30-deadlock-caused-by-using-ants/index.md
+++ /dev/null
@@ -1,197 +0,0 @@
----
-slug: deadlock-caused-by-using-ants
-title: 使用ants引发的死锁
-authors: warren
-tags: [devlake, ants]
----
-
-### 1. 背景
-
-我们的项目有大量的api请求由goroutine完成,所以我们需要引入一个pool来节省频繁创建goroutine所造成的的开销,同时也可以更简易的调度goroutine,在对github上多个协程池的对比后,我们最终选定了[ants](https://github.com/panjf2000/ants)作为我们的调度管理pool。
-
-1. 最近在测试中偶然发现系统出现了“死锁”的情况,进而采取断网的方式发现“死锁”在极端情况下是稳定出现,经过满篇的log,break,最终把问题定位到了ants的submit方法。这个问题来自于在使用ants pool的过程中,为了实现重试,我们在方法中又递归调用了方法本身,也就是submit task内部又submit一个task,下面是简化后的代码:
-
-<!--truncate-->
-
-
-```Go
-func (apiClient *ApiAsyncClient) DoAsync(
-
- retry int,
-
-) error {
-
- return apiClient.scheduler.Submit(func() error {
-
- _, err := apiClient.Do()
-
- if err != nil {
-
- if retry < apiClient.maxRetry {
-
- return apiClient.DoAsync(retry+1)
-
- }
-
- }
-
- return err
-
- })
-
-}
-```
-
-在上面的代码块中,可以看到return apiClient.DoAsync(retry+1)这一步递归调用了自己,即在submit中又调用了submit
-
-
-### 2. 深入ants分析
-
-
-
-- 在上面submit源码中可以看到,首先是通过retrieveWorker回去一个worker,然后把task放入到worker的task channel当中,很简单,也看不出来为什么会“dead lock”,没办法,去到retrieveWorker
-
-```Go
-// retrieveWorker returns a available worker to run the tasks.
-
-func (p *Pool) retrieveWorker() (w *goWorker) {
-
- spawnWorker := func() {
-
- w = p.workerCache.Get().(*goWorker)
-
- w.run()
-
- }
-
-
-
- p.lock.Lock()
-
-
-
- w = p.workers.detach()
-
- if w != nil { // first try to fetch the worker from the queue
-
- p.lock.Unlock()
-
- } else if capacity := p.Cap(); capacity == -1 || capacity > p.Running() {
-
- // if the worker queue is empty and we don't run out of the pool capacity,
-
- // then just spawn a new worker goroutine.
-
- p.lock.Unlock()
-
- spawnWorker()
-
- } else { // otherwise, we'll have to keep them blocked and wait for at least one worker to be put back into pool.
-
- if p.options.Nonblocking {
-
- p.lock.Unlock()
-
- return
-
- }
-
- retry:
-
- if p.options.MaxBlockingTasks != 0 && p.blockingNum >= p.options.MaxBlockingTasks {
-
- p.lock.Unlock()
-
- return
-
- }
-
- p.blockingNum++
-
- p.cond.Wait() // block and wait for an available worker
-
- p.blockingNum--
-
- var nw int
-
- if nw = p.Running(); nw == 0 { // awakened by the scavenger
-
- p.lock.Unlock()
-
- if !p.IsClosed() {
-
- spawnWorker()
-
- }
-
- return
-
- }
-
- if w = p.workers.detach(); w == nil {
-
- if nw < capacity {
-
- p.lock.Unlock()
-
- spawnWorker()
-
- return
-
- }
-
- goto retry
-
- }
-
-
-
- p.lock.Unlock()
-
- }
-
- return
-
-}
-```
-
-
-
-- 这个方法的大概流程就是先对pool上锁,然后从pool的worker队列中去取一个worker,detach其实就是返回了worker,并且把这个worker从队列中删除掉了,接下来有三种情况
- - 如果成功取到worker,解锁p,返回取到的worker
- - 如果worker队列是空的并且pool的容量没有耗尽,就解锁pool并生成一个新的worker返回给submit
- - 最后一种情况就是pool容量耗尽了,worker队列也没有空闲的worker,那就要根据我们创建pool时传入的参数来决定下一步情况了
- - 首先说一下这里涉及的两个重要参数,一个是capacity,这个值如果在new pool的时候不设置,会是MaxInt32,相当于无限制的goroutine,但是情况不同的是,我们会首先复用空闲的worker,还可以定时清空多余的空闲worker,blockingNum为正在等待的goroutine,初始为0
- - 如果设置了Nonblocking为true,直接解锁,返回nil,submit就会直接返回一个错误ErrPoolOverload,代表pool超负荷了,不做任何其他处理,submit失败,结束~~
- - 另一种情况就是没有设置Nonblocking,默认为false,就进入到了一个retry标签,这里面就涉及到了另一个创建pool时候的参数MaxBlockingTasks,这个MaxBlockingTasks就是一个threshold
- - 首先判断如果设置了MaxBlockingTasks并且当前blockingNum大于或者等于MaxBlockingTasks,那么直接解锁pool并且返回nil,submit失败,结束~~
- - 上面的条件不满足,则首先blockingNum++,然后开始wait一直到有worker摸完鱼回来工作,则blockingNum--。问题就在这里了!!!如果所有的worker都在工作(也许是看起来在工作,实际上在摸鱼),这里就会一直wait(),也就是我们自己代码中return后面的DoAsync会一直wait(),从我们自己的项目来讲,就是所有worker这个时候都在submit一个新的task到同一个pool中,而这个时候pool已经满了,导致所有worker都阻塞在了这里,“死锁”也就出现了
-
-### 3. 最后聊几句自己对于golang内存模型的理解
-
-1. go的调度流程本质上是一个生产-消费的过程,我们利用go func是生产了一个task放到队列中,由系统线程从队列中获取协程然后执行
-2. 讲到go的调度流程,咱们就不能不说一下go的MPG(分别解释一下,就不做深入了,如果有人看,后期再努力整理一份详细聊聊)
- 1. M 代表着一个内核线程,也可以称为一个工作线程,所有的goroutine都是跑在M之上的
- 2. P可以理解为一个逻辑处理器,主要由P来执行goroutine
- 3. G就是go func封装的这个方法
-3. 真正的并发数是由GOMAXPROCS来决定的,并不是提交多少goroutine,并发数就是多少,GOMAXPROCS是由机器的cpu核数来决定的
-4. 所以回到第2部分,pool.cond.wait等待的是绑定上一个goroutine,和其他语言的等待线程具有相似却完全不同的意义,每一个worker是一个G,pool也就是一个队列,而M会从队列中获取可以执行的G,当所有的G都在等待创建新的G时,M全部都处于空闲状态
-
-### 4. 解决方案
-
-1. 当然,最靠谱的应该是尽量避免类似这样的递归调用操作
-2. 如果实在不行,可以考虑添加一个sub pool,作为次级队列,让递归生成的G可以在sub pool里等待空闲的M来处理
-
-### 5. 对比不同size的pool和两个pool的内存(alloc_space)和CPU开销
-
-| Pool size | CPU(ants)% | CPU(runtime.gcBgMarkWorker)% | CPU(runtime.mcall)% | 内存(runtime.allocm)kB | 内存(runtime.gcBgMarkWorker)kB | 内存(root) |
-| ------------------- | ---------- | ---------------------------- | ------------------- | ---------------------- | ------------------------------ | ---------- |
-| Two pools(158, 632) | 27.98 | 7.73 | 25.44 | 2050.25 | 512.02 | 8798 |
-| Pool 158 | 28.11 | 6.61 | 25.08 | 2050 | | 6661 |
-| Pool 1580 | 27.41 | 12.96 | 23.17 | 3075.38 | | 10264 |
-| Pool 7900 | 25.89 | 9.82 | 22.52 | 3587.94 | | 5725 |
-| Pool 790000 | 25.12 | 12.79 | 23.44 | 3075.38 | | 9748 |
-
-runtime.gcBgMarkWorker: 用于标记垃圾对象
-
-从上面的表格可以看到,可能存在多核的影响,所以对于我们公司现在需要的并发数量级来讲,pool的size对系统影响并不大。
\ No newline at end of file
diff --git a/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.001.png b/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.001.png
deleted file mode 100644
index 33885b93a..000000000
Binary files a/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.001.png and /dev/null differ
diff --git a/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.002.png b/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.002.png
deleted file mode 100644
index 9f3e4be62..000000000
Binary files a/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.002.png and /dev/null differ
diff --git a/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.003.png b/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.003.png
deleted file mode 100644
index b8bb2e266..000000000
Binary files a/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.003.png and /dev/null differ
diff --git a/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.004.png b/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.004.png
deleted file mode 100644
index 158741f17..000000000
Binary files a/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.004.png and /dev/null differ
diff --git a/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.005.png b/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.005.png
deleted file mode 100644
index 62e420895..000000000
Binary files a/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.005.png and /dev/null differ
diff --git a/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.006.png b/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.006.png
deleted file mode 100644
index 962ae0024..000000000
Binary files a/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.006.png and /dev/null differ
diff --git a/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.007.png b/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.007.png
deleted file mode 100644
index 753baf0f4..000000000
Binary files a/blog/2022-05-18-how-apache-devlake-runs/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.007.png and /dev/null differ
diff --git a/blog/2022-05-18-how-apache-devlake-runs/index.md b/blog/2022-05-18-how-apache-devlake-runs/index.md
deleted file mode 100644
index 55d371586..000000000
--- a/blog/2022-05-18-how-apache-devlake-runs/index.md
+++ /dev/null
@@ -1,152 +0,0 @@
----
-slug: how-apache-devlake-runs
-title: Apache DevLake是怎么跑起来的
-authors: warren
-tags: [devlake, apache]
----
-
-
-[Apache DevLake](https://github.com/apache/incubator-devlake) 是一个DevOps数据收集和整合工具,通过 Grafana 为开发团队呈现出不同阶段的数据,让团队能够以数据为驱动改进开发流程。
-
-### Apache DevLake 架构概述
-- 左边是[可集成的DevOps数据插件](https://devlake.apache.org/docs/DataModels/DataSupport),目前已有的插件包括 Github,Gitlab,JIRA,Jenkins,Tapd,Feishu 以及思码逸主打的代码分析引擎
-- 中间是主体框架,通过主体框架运行插件中的子任务,完成数据的收集,扩展,并转换到领域层,用户可以通过 config-ui 或者 api 调用的形式来触发任务
-- RMDBS 目前支持 Mysql 和 PostgreSQL,后期还会继续支持更多的数据库
-- Grafana 可以通过sql语句生成团队需要的各种数据
-
-
-
-> 接下来我们就详细聊一聊系统是怎么跑起来的。
-
-<!--truncate-->
-
-### 系统启动
-
-在我们的 golang 程序启动之前,首先会自动调用各个 package 的 init() 方法,我们主要看看services 包的载入,下面的代码有详细注释:
-
-```go
-func init() {
-var err error
-// 获取配置信息
-cfg = config.GetConfig()
-// 获取到数据库
-db, err = runner.NewGormDb(cfg, logger.Global.Nested("db"))
-// 配置时区
-location := cron.WithLocation(time.UTC)
-// 创建定时任务管理器
-cronManager = cron.New(location)
-if err != nil {
-panic(err)
-}
-// 初始化数据迁移
-migration.Init(db)
-// 注册框架的数据迁移脚本
-migrationscripts.RegisterAll()
-// 载入插件,从cfg.GetString("PLUGIN_DIR")获取到的文件夹中载入所有.so文件,在LoadPlugins方法中,具体来讲,通过调用runner.LoadPlugins将pluginName:PluginMeta键值对存入到core.plugins中
-err = runner.LoadPlugins(
-cfg.GetString("PLUGIN_DIR"),
-cfg,
-logger.Global.Nested("plugin"),
-db,
-)
-if err != nil {
-panic(err)
-}
-// 执行数据迁移脚本,完成数据库框架层各个表的初始化
-err = migration.Execute(context.Background())
-if err != nil {
-panic(err)
-}
-
-// call service init
-pipelineServiceInit()
-}
-
-```
-### DevLake的任务执行原理
-
-**Pipeline的运行流程**
-
-在讲解Pipeline流程之前,我们需要先解释一下[Blueprint](https://devlake.apache.org/docs/Glossary#blueprints)。
-
-Blueprint是一个定时任务,包含了需要执行的子任务以及执行计划。Blueprint 的每一次执行记录是一条Historical Run(也称为 Pipeline),代表 DevLake 一次触发,通过一个或多个插件,完成了一个或多个数据收集转换的任务。
-
-
-
-以下是 Pipeline 运行流程图:
-
-
-
-一个pipeline包含一个二维数组tasks,主要是为了保证一系列任务按预设顺序执行。如果下图中的 Stage3 的插件需要依赖其他插件准备数据(例如 refdiff 的运行需要依赖 gitextractor 和 github,数据源与插件的更多信息请看[文档](https://devlake.apache.org/docs/DataModels/DataSupport)),那么 Stage 3 开始执行时,需要保证其依赖项已在 Stage1 和 Stage2 执行完成:
-
-
-
-**Task的运行流程**
-
-在stage1,stage2,stage3中的各插件任务都是并行执行:
-
-
-
-**接下来就是顺序执行插件中的子任务**
-
-
-
-1. RunTask 之前的工作都是在准备 RunTask 方法需要的参数,比如 logger,db,context 等等。
-2. RunTask 方法中主要是对数据库中的tasks进行状态更新,同时,准备运行插件任务的 options(把从 config-ui 传过来的 json 转成 map 传到 RunPluginTask 中)
-3. RunPluginTask 首先通过 core.GetPlugin(pluginName) 获取到对应 [PluginMeta](#pm),然后通过 PluginMeta 获取到 [PluginTask](#pt),再执行 RunPluginSubTasks
-
-**每一个插件子任务的运行流程(涉及到的 interface 及 func 会在[下一节](#DevLake中的重要接口)详细阐述)**
-
-
-
-1. 通过调用SubTaskMetas()获取到所有插件所有的可用子任务[subtaskMeta](#stm)
-2. 通过`options["tasks"]`以及subtaskMeta组建需要执行的子任务集合subtaskMetas
-3. 计算总共多少个子任务
-4. 通过`helper.NewDefaultTaskContext`构建[taskCtx](#tc)
-5. 调用`pluginTask.PrepareTaskData`构建[taskData](#td),
-6. 接下来迭代subtaskMetas里面的所有子任务
- 1. 通过`taskCtx.SubTaskContext(subtaskMeta.Name)`获取到子任务的[subtaskCtx](#sc)
- 2. 执行[`subtaskMeta.EntryPoint(subtaskCtx)`](#step)
-### DevLake中的重要接口
-1. <a id="pm">PluginMeta</a>: 包含了插件最基本的两个方法,所有插件都需要实现,系统启动的时候存在core.plugins中,在执行插件任务的时候通过core.GetPlugin获取
-
-```go
-type PluginMeta interface {
- Description() string
- //PkgPath information will be lost when compiled as plugin(.so), this func will return that info
- RootPkgPath() string
-}
-
-```
-2. <a id="pt">PluginTask</a>: 通过PluginMeta获取,插件实现这个方法之后,Framework就能直接运行子任务,而不是扔给插件自己去执行,最大的好处就是插件的子任务实现更加简单,在插件运行当中,我们也可以更容易的去干涉(比如增加日志等等)
-
-```go
-type PluginTask interface {
- // return all available subtasks, framework will run them for you in order
- SubTaskMetas() []SubTaskMeta
- // based on task context and user input options, return data that shared among all subtasks
- PrepareTaskData(taskCtx TaskContext, options map[string]interface{}) (interface{}, error)
-}
-```
-3. 每个插件还有一个<a id="td">taskData</a>,里面包含了配置选项,apiClient以及一些插件其它属性(比如github有Repo信息)
-4. <a id="stm">SubTaskMeta</a>: 一个子任务的元数据,每个子任务都会定义一个SubTaskMeta
-
-
-```go
-var CollectMeetingTopUserItemMeta = core.SubTaskMeta{
- Name: "collectMeetingTopUserItem",
- EntryPoint: CollectMeetingTopUserItem,
- EnabledByDefault: true,
- Description: "Collect top user meeting data from Feishu api",
-}
-```
-5. <a id="ec">ExecContext</a>: 定义了执行(子)任务需要的所有资源
-6. <a id="stc">SubTaskContext</a>: 定义了执行子任务所需要的资源(包含了ExecContext)
-7. <a id="tc">TaskContext</a>: 定义了执行插件任务所需要的资源(包含了ExecContext)。与SubTaskContext的区别在于SubTaskContext中的TaskContext()方法可以返回TaskContext,而TaskContext中的方法SubTaskContext(subtask string)方法可以返回SubTaskContext,子任务隶属于插件任务,所以把这两个Context进行了区分
-8. <a id="step">SubTaskEntryPoint</a>: 所有的插件子任务都需要实现这个函数,这样才能由框架层统一协调安排
-
-### 后续
-
-这篇文章介绍了 DevLake 的架构以及运行流程,还有三个核心 api\_collector、api\_extractor 和 data\_convertor 将会在下一篇文章进行剖析。
-
-
diff --git "a/blog/2022-05-20-\345\246\202\344\275\225\350\264\241\347\214\256issues/index.md" "b/blog/2022-05-20-\345\246\202\344\275\225\350\264\241\347\214\256issues/index.md"
deleted file mode 100644
index 0e77e642c..000000000
--- "a/blog/2022-05-20-\345\246\202\344\275\225\350\264\241\347\214\256issues/index.md"
+++ /dev/null
@@ -1,38 +0,0 @@
----
-slug: how-to-contribute-to-issues
-title: 如何贡献issues
-authors: klesh
-tags: [devlake, apache]
----
-
-# 如何贡献issues
-
-上周(2022-05-12),我们以先到先得的方式为大家列出了两个"good first issue"。
-这很有趣,它们几乎立刻就被拿走了......
-但对于那些有兴趣但没有得到的人来说可能就不那么有趣了。
-
-### 所以...
-
-我们决定,不再有竞争,你可以从我们的github issue pages中挑选你喜欢的issue。如果没有了,甚至可以创建你自己的。
-我们毕竟是社区!
-
-### 怎么做呢?这很简单!
-
-进入我们的[问题页面](https://github.com/apache/incubator-devlake/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22),然后点击这里。我们所有的Good First Issue都列在这里!
-
-
-- 首先,寻找现有的issues,找到一个你喜欢的。
- 你可以通过评论"I'll take it!"来预订它。
- 接下来你可以写一份“攻略”,以展示你对问题的理解和你将采取什么样的步骤来解决这个issue,然后开始Coding。
-
-- 如果没有GFI了怎么办?创造你自己的issue! 现在,通过查看我们的代码库。
- 你肯定能发现很多问题,比如文档、单元测试,甚至是错字。
- 把你觉得不对的地方提出来,我们会验证它是否必要,
- 然后你就可以开始Coding了。
-
-- 最后,你可能会问,我为什么要费尽心思为你写代码?
- 不不不,你不是为我们写代码,你是为社区里的每个人写代码,你是为自己写代码。
- 为了提高你的技能,为了学习如何与他人合作。而对于那些做出重大贡献的人,
- 我们为您提供一个Apache Committer的席位,甚至是PPMC!
-
-### 就这些了,有任何问题请随时提出。编码快乐!
diff --git "a/blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/Architecture_Diagram.png" "b/blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/Architecture_Diagram.png"
deleted file mode 100644
index ab45e7fc5..000000000
Binary files "a/blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/Architecture_Diagram.png" and /dev/null differ
diff --git "a/blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/index.md" "b/blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/index.md"
deleted file mode 100644
index 4d1d7322d..000000000
--- "a/blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/index.md"
+++ /dev/null
@@ -1,239 +0,0 @@
----
-slug: apache-devlake-codebase-walkthrough
-title: Apache DevLake代码库导览
-authors: abeizn
-tags: [devlake, codebase]
----
-
-# Apache DevLake 代码库导览
-### Apache DevLake是什么?
-研发数据散落在软件研发生命周期的不同阶段、不同工作流、不同DevOps工具中,且标准化程度低,导致效能数据难以留存、汇集并转化为有效洞见。为了解决这一痛点,[Apache DevLake](https://github.com/apache/incubator-devlake) 应运而生。Apache DevLake是一款开源的研发数据平台,它通过提供自动化、一站式的数据收集、分析以及可视化能力,帮助研发团队更好地理解开发过程,挖掘关键瓶颈与提效机会。
-
-
-### Apache DevLake架构概述
-
-<center>Apache DevLake 架构图</center>
-<br />
-
-- Config UI: 人如其名,配置的可视化,其主要承载Apache DevLake的配置工作。通过Config UI,用户可以建立数据源连接,并实现数据的收集范围,部分数据的转换规则,以及收集频率等任务。
-- Api Sever:Apache DevLake的Api接口,是前端调用后端数据的通道。
-- Runner:Apache DevLake运行的底层支撑机制。
-- Plugins:具体执行的插件业务,主要承载Apache DevLake的后端数据收集、扩展和转换的工作。除dbt插件外的插件产出Apache DevLake的预置数据,预置数据主要包括三层;
- - raw layer:负责储存最原始的api response json。
- - tool layer:根据raw layer提取出此插件所需的数据。
- - domain layer:根据tool layer层抽象出共性的数据,这些数据会被使用在Grafana图表中,用于多种研发指标的展示。
-- RDBS: 关系型数据库。目前Apache DavLake支持MySQL和PostgreSQL,后期还会继续支持更多的数据库。
-- Grafana Dashboards: 其主要承载Apache DevLake的前端展示工作。根据Apache DevLake收集的数据,通过sql语句来生成团队需要的交付效率、质量、成本、能力等各种研发效能指标。
-
-### 目录结构Tree
-```
-├── api
-│ ├── blueprints
-│ ├── docs
-│ ├── domainlayer
-│ ├── ping
-│ ├── pipelines
-│ ├── push
-│ ├── shared
-│ ├── task
-│ └── version
-├── config
-├── config-ui
-├── devops
-│ └── lake-builder
-├── e2e
-├── errors
-├── grafana
-│ ├── _archive
-│ ├── dashboards
-│ ├── img
-│ └── provisioning
-│ ├── dashboards
-│ └── datasources
-├── img
-├── logger
-├── logs
-├── migration
-├── models
-│ ├── common
-│ ├── domainlayer
-│ │ ├── code
-│ │ ├── crossdomain
-│ │ ├── devops
-│ │ ├── didgen
-│ │ ├── ticket
-│ │ └── user
-│ └── migrationscripts
-│ └── archived
-├── plugins
-│ ├── ae
-│ │ ├── api
-│ │ ├── models
-│ │ │ └── migrationscripts
-│ │ │ └── archived
-│ │ └── tasks
-│ ├── core
-│ ├── dbt
-│ │ └── tasks
-│ ├── feishu
-│ │ ├── apimodels
-│ │ ├── models
-│ │ │ └── migrationscripts
-│ │ │ └── archived
-│ │ └── tasks
-│ ├── gitextractor
-│ │ ├── models
-│ │ ├── parser
-│ │ ├── store
-│ │ └── tasks
-│ ├── github
-│ │ ├── api
-│ │ ├── models
-│ │ │ └── migrationscripts
-│ │ │ └── archived
-│ │ ├── tasks
-│ │ └── utils
-│ ├── gitlab
-│ │ ├── api
-│ │ ├── e2e
-│ │ │ └── tables
-│ │ ├── impl
-│ │ ├── models
-│ │ │ └── migrationscripts
-│ │ │ └── archived
-│ │ └── tasks
-│ ├── helper
-│ ├── jenkins
-│ │ ├── api
-│ │ ├── models
-│ │ │ └── migrationscripts
-│ │ │ └── archived
-│ │ └── tasks
-│ ├── jira
-│ │ ├── api
-│ │ ├── models
-│ │ │ └── migrationscripts
-│ │ │ └── archived
-│ │ └── tasks
-│ │ └── apiv2models
-│ ├── refdiff
-│ │ ├── tasks
-│ │ └── utils
-│ └── tapd
-│ ├── api
-│ ├── models
-│ │ └── migrationscripts
-│ │ └── archived
-│ └── tasks
-├── releases
-│ ├── lake-v0.10.0
-│ ├── lake-v0.10.0-beta1
-│ ├── lake-v0.10.1
-│ ├── lake-v0.7.0
-│ ├── lake-v0.8.0
-│ └── lake-v0.9.0
-├── runner
-├── scripts
-├── services
-├── test
-│ ├── api
-│ │ └── task
-│ └── example
-├── testhelper
-├── utils
-├── version
-├── worker
-├── Dockerfile
-├── docker-compose.yml
-├── docker-compose-temporal.yml
-├── k8s-deploy.yaml
-├── Makefile
-└── .env.exemple
-
-
-```
-
-### 目录导览
-- 后端部分:
- - config:对.env配置文件的读、写以及修改的操作。
- - logger:log日志的level、format等设置。
- - errors:Error的定义。
- - utils:工具包,它包含一些基础通用的函数。
- - runner:提供基础执行服务,包括数据库,cmd,pipelines,tasks以及加载编译后的插件等基础服务。
- - models:定义框架级别的实体。
- - common:基础struct定义。
- - [domainlayer](https://devlake.apache.org/docs/DataModels/DevLakeDomainLayerSchema):领域层是来自不同工具数据的通用抽象。
- - ticket:Issue Tracking,即问题跟踪领域。
- - code:包括Source Code源代码关联领域。以及Code Review代码审查领域。
- - devops:CI/CD,即持续集成、持续交付和持续部署领域。
- - crossdomain:跨域实体,这些实体用于关联不同领域之间的实体,这是建立全方面分析的基础。
- - user:对用户的抽象领域,user也属于crossdomain范畴。
- - migrationscripts:初始化并更新数据库。
- - plugins:
- - core:插件通用接口的定义以及管理。
- - helper:插件通用工具的集合,提供插件所需要的辅助类,如api收集,数据ETL,时间处理等。
- - 网络请求Api Client工具。
- - 收集数据Collector辅助类,我们基于api相同的处理模式,统一了并发,限速以及重试等功能,最终实现了一套通用的框架,极大地减少了开发和维护成本。
- - 提取数据Extractor辅助类,同时也内建了批量处理机制。
- - 转换数据Convertor辅助类。
- - 数据库处理工具。
- - 时间处理工具。
- - 函数工具。
- - ae:分析引擎,用于导入merico ae分析引擎的数据。
- - feishu:收集飞书数据,目前主要是获取一段时间内组织内会议使用的top用户列表的数据。
- - github:收集Github数据并计算相关指标。(其他的大部分插件的目录结构和实现功能和github大同小异,这里以github为例来介绍)。
- - github.go:github启动入口。
- - tasks:具体执行的4类任务。
- - *_collector.go:收集数据到raw layer层。
- - *_extractor.go:提取所需的数据到tool layer层。
- - *_convertor.go:转换所需的数据到domain layer层。
- - *_enricher.go:domain layer层更进一步的数据计算转换。
- - models:定义github对应实体entity。
- - api:api接口。
- - utils:github提取的一些基本通用函数。
- - gitextractor:git数据提取工具,该插件可以从远端或本地git仓库提取commit和reference信息,并保存到数据库或csv文件。用来代替github插件收集commit信息以减少api请求的数量,提高收集速度。
- - refdiff:在分析开发工作产生代码量时,经常需要知道两个版本之间的diff。本插件基于数据库中存储的commits父子关系信息,提供了计算ref(branch/tag)之间相差commits列表的能力。
- - gitlab:收集Gitlab数据并计算相关指标。
- - jenkins:收集jenkins的build和job相关指标。
- - jira:收集jira数据并计算相关指标。
- - tapd:收集tapd数据并计算相关指标。
- - dbt:(data build tool)是一款流行的开源数据转换工具,能够通过SQL实现数据转化,将命令转化为表或者视图,提升数据分析师的工作效率。Apache DevLake增加了dbt插件,用于数据定制的需要。
- - services:创建、管理Apache DevLake各种服务,包含notifications、blueprints、pipelines、tasks、plugins等。
- - api:使用Gin框架搭建的一个通用Apache DevLake API服务。
-- 前端部分:
- - congfig-ui:主要是Apache DevLake的插件配置信息的可视化。[一些术语的解释](https://devlake.apache.org/docs/Glossary)
- - 常规模式
- - blueprints的配置。
- - data connections的配置。
- - transformation rules的配置。
- - 高级模式:主要是通过json的方式来请求api,可选择对应的插件,对应的subtasks,以及插件所需要的其他信息。
- - Grafana:其主要承载Apache DevLake的前端展示工作。根据收集的数据,通过sql语句来生成团队需要的各种数据。目前sql主要用domain layer层的表来实现通用数据展示需求。
-- migration:数据库迁移工具。
- - migration:数据库迁移工具migration的具体实现。
- - models/migrationscripts:domian layer层的数据库迁移脚本。
- - plugins/xxx/models/migrationscripts:插件的数据库迁移脚本。主要是_raw_和_tool_开头的数据库的迁移。
-- 测试部分:
- - testhelper和plugins下的*_test.go文件:即单元测试,属于白盒测试范畴。针对目标对象自身的逻辑,执行路径的正确性进行测试,如果目标对象有依赖其它资源或对够用,采用注入或者 mock 等方式进行模拟,可以比较方便地制造一些难以复现的极端情况。
- - test:集成测试,灰盒测试范畴。在单元测试的基础上,将所有模块按照设计要求(如根据结构图)组装成为子系统或系统,进行集成测试。
- - e2e: 端到端测试,属于黑盒测试范畴。相对于单元测试更注重于目标自身,e2e更重视目标与系统其它部分互动的整体正确性,相对于单元测试着重逻辑测试,e2e侧重于输出结果的正确性。
-- 编译,发布部分:
- - devops/lake-builder: mericodev/lake-builder的docker构建。
- - Dockerfile:主要用于构建devlake镜像。
- - docker-compose.yml:是用于定义和运行多容器Docker应用程序的工具,用户可以使用YML文件来配置Apache DevLake所需要的服务组件。
- - docker-compose-temporal.yml:Temporal是一个微服务编排平台,以分布式的模式来部署Apache DevLake,目前处于试验阶段,仅供参考。
- - worker:Temporal分布式部署形式中的worker实现,目前处于试验阶段,仅供参考。
- - k8s-deploy.yaml:Kubernetes是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。目前Apache DevLake已支持在k8s集群上部署。
- - Makefile:是一个工程文件的编译规则,描述了整个工程的编译和链接等规则。
- - releases:Apache DevLake历史release版本的配置文件,包括docker-compose.yml和env.example。
- - scripts:shell脚本,包括编译plugins脚本。
-- 其他:
- - img:logo、社区微信二维码等图像信息。
- - version:实现版本显示的支持,在正式的镜像中会显示对应release的版本。
- - .env.exemple:配置文件实例,包括DB URL, LOG以及各插件的配置示例信息。
-
-### 如何联系我们
-- Github地址:https://github.com/apache/incubator-devlake
-- 官网地址:https://devlake.apache.org/
-- <a href="https://join.slack.com/t/devlake-io/shared_invite/zt-18uayb6ut-cHOjiYcBwERQ8VVPZ9cQQw" target="_blank">Slack</a>: 通过Slack联系
-- 微信联系:<br />
- 
\ No newline at end of file
diff --git "a/blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/wechat_community_barcode.png" "b/blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/wechat_community_barcode.png"
deleted file mode 100644
index a7870d727..000000000
Binary files "a/blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/wechat_community_barcode.png" and /dev/null differ
diff --git "a/blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/7b2a6f29-ea2a-4a84-97c8-7eba5a5131a8.png" "b/blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/7b2a6f29-ea2a-4a84-97c8-7eba5a5131a8.png"
deleted file mode 100644
index 099c1e854..000000000
Binary files "a/blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/7b2a6f29-ea2a-4a84-97c8-7eba5a5131a8.png" and /dev/null differ
diff --git "a/blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/8afb097c-a0b3-4bdc-80f3-7241c3fa566f.png" "b/blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/8afb097c-a0b3-4bdc-80f3-7241c3fa566f.png"
deleted file mode 100644
index 41af9289b..000000000
Binary files "a/blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/8afb097c-a0b3-4bdc-80f3-7241c3fa566f.png" and /dev/null differ
diff --git "a/blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/df2f9837-121e-4a64-976c-c5039d452bfd.png" "b/blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/df2f9837-121e-4a64-976c-c5039d452bfd.png"
deleted file mode 100644
index c7319595c..000000000
Binary files "a/blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/df2f9837-121e-4a64-976c-c5039d452bfd.png" and /dev/null differ
diff --git "a/blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/efea0188-80e4-4519-a010-977a7fd5432e.png" "b/blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/efea0188-80e4-4519-a010-977a7fd5432e.png"
deleted file mode 100644
index a9b35cd21..000000000
Binary files "a/blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/efea0188-80e4-4519-a010-977a7fd5432e.png" and /dev/null differ
diff --git "a/blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/index.md" "b/blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/index.md"
deleted file mode 100644
index 9e7c2a88e..000000000
--- "a/blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/index.md"
+++ /dev/null
@@ -1,180 +0,0 @@
----
-slug: some-practices-of-supporting-postgresql
-title: Apache DevLake 兼容 PostgreSQL 踩坑小结
-authors: ZhangLiang
-tags: [devlake, database, postgresql]
----
-
-# Apache DevLake 兼容 PostgreSQL 踩坑小结
-
-
-本文作者:ZhangLiang
-个人主页:https://github.com/mindlesscloud
-
-Apache DevLake 是一个研发数据平台,可以收集和整合各类研发工具的数据,比如 Jira、Github、Gitlab、Jenkins。
-
-**本文并不打算对数据库兼容这个问题做全面的总结,只是对我们实际遇到的问题做一个记录,希望能对有相似需求的人提供一个参考。**
-
-**1、数据类型差异**
-
-### PostgreSQL 不支持 uint 类型的数据类型
-```go
-type JenkinsBuild struct {
- common.NoPKModel
- JobName string `gorm:"primaryKey;type:varchar(255)"`
- Duration float64 // build time
- DisplayName string // "#7"
- EstimatedDuration float64
- Number int64 `gorm:"primaryKey;type:INT(10) UNSIGNED NOT NULL"`
- Result string
- Timestamp int64 // start time
- StartTime time.Time // convered by timestamp
- CommitSha string
-}
-
-```
-其中的`JenkinsBuild.Number`字段的`gorm` struct tag 使用了`UNSIGNED`会导致建表失败,需要去掉。
-
-
-
-
-### MySQL 没有 bool 型
-对于 model 里定义为 bool 型的字段,gorm 会把它映射成 MySQL 的 TINYINT 类型,在 SQL 里可以直接用 0 或者 1 查询,但是 PostgreSQL 里是有 bool 类型的,所以 gorm 会把它映射成 BOOL 类型,如果 SQL 里还是用的 0 或者 1 去查询就会报错。
-
-以下是一个具体的例子(为了清晰起见我们删掉了无关的字段),下面的查询语句在 MySQL 里是没有问题的,但是在 PostgreSQL 上就会报错。
-```go
-type GitlabMergeRequestNote struct {
- MergeRequestId int `gorm:"index"`
- System bool
-}
-
-db.Where("merge_request_id = ? AND `system` = 0", gitlabMr.GitlabId).
-```
-语句改成这样后仍然会有错误,具体请见下面关于反引号的问题。
-```go
-db.Where("merge_request_id = ? AND `system` = ?", gitlabMr.GitlabId, false)
-```
-
-**2、行为差异**
-
-### 批量插入
-如果使用了`ON CONFLIT UPDATE ALL`从句批量插入的时候,本批次如果有多条主键相同的记录会导致 PostgreSQL 报错,MySQL 则不会。
-
-
-
-
-
-
-### 字段类型 model 定义与 schema 不一致
-例如在 model 定义中`GithubPullRequest.AuthorId`是 int 类型,但是数据库里这个字段是 VARCHAR 类型,插入数据的时候 MySQL 是允许的,PostgreSQL 则会报错。
-```go
-type GithubPullRequest struct {
- GithubId int `gorm:"primaryKey"`
- RepoId int `gorm:"index"`
- Number int `gorm:"index"`
- State string `gorm:"type:varchar(255)"`
- Title string `gorm:"type:varchar(255)"`
- GithubCreatedAt time.Time
- GithubUpdatedAt time.Time `gorm:"index"`
- ClosedAt *time.Time
- // In order to get the following fields, we need to collect PRs individually from GitHub
- Additions int
- Deletions int
- Comments int
- Commits int
- ReviewComments int
- Merged bool
- MergedAt *time.Time
- Body string
- Type string `gorm:"type:varchar(255)"`
- Component string `gorm:"type:varchar(255)"`
- MergeCommitSha string `gorm:"type:varchar(40)"`
- HeadRef string `gorm:"type:varchar(255)"`
- BaseRef string `gorm:"type:varchar(255)"`
- BaseCommitSha string `gorm:"type:varchar(255)"`
- HeadCommitSha string `gorm:"type:varchar(255)"`
- Url string `gorm:"type:varchar(255)"`
- AuthorName string `gorm:"type:varchar(100)"`
- AuthorId int
- common.NoPKModel
-}
-
-```
-
-
-
-
-**3、MySQL 特有的函数**
-
-在一个复杂查询中我们曾经使用了 `GROUP_CONCAT` 函数,虽然 PostgreSQL 中有功能类似的函数但是函数名不同,使用方式也有细微差别。
-
-```go
-cursor2, err := db.Table("pull_requests pr1").
- Joins("left join pull_requests pr2 on pr1.parent_pr_id = pr2.id").Group("pr1.parent_pr_id, pr2.created_date").Where("pr1.parent_pr_id != ''").
- Joins("left join repos on pr2.base_repo_id = repos.id").
- Order("pr2.created_date ASC").
- Select(`pr2.key as parent_pr_key, pr1.parent_pr_id as parent_pr_id, GROUP_CONCAT(pr1.base_ref order by pr1.base_ref ASC) as cherrypick_base_branches,
- GROUP_CONCAT(pr1.key order by pr1.base_ref ASC) as cherrypick_pr_keys, repos.name as repo_name,
- concat(repos.url, '/pull/', pr2.key) as parent_pr_url`).Rows()
-```
-解决方案:
-我们最终决定把` GROUP_CONCAT `函数的功能拆分成两步,先用最简单的 SQL 查询得到排序好的多条数据,然后用代码做聚合。
-
-
-修改后:
-```go
-cursor2, err := db.Raw(
- `
- SELECT pr2.pull_request_key AS parent_pr_key,
- pr1.parent_pr_id AS parent_pr_id,
- pr1.base_ref AS cherrypick_base_branch,
- pr1.pull_request_key AS cherrypick_pr_key,
- repos.NAME AS repo_name,
- Concat(repos.url, '/pull/', pr2.pull_request_key) AS parent_pr_url,
- pr2.created_date
- FROM pull_requests pr1
- LEFT JOIN pull_requests pr2
- ON pr1.parent_pr_id = pr2.id
- LEFT JOIN repos
- ON pr2.base_repo_id = repos.id
- WHERE pr1.parent_pr_id != ''
- ORDER BY pr1.parent_pr_id,
- pr2.created_date,
- pr1.base_ref ASC
- `).Rows()
-```
-
-**4、语法差异**
-
-### 反引号
-某些 SQL 语句中我们使用了反引号,用来保护字段名,以免跟 MySQL 保留字有冲突,这种做法在 PostgreSQL 会导致语法错误。为了解决这个问题我们重新审视了我们的代码,把所有跟保留字冲突的字段名做了修改,同时去掉了 SQL 语句中的反引号。例如刚才提到的这个例子:
-```go
-db.Where("merge_request_id = ? AND `system` = ?", gitlabMr.GitlabId, false)
-```
-解决方案:我们把`system`改个名字`is_system`,这样就可以把反引号去掉。
-```go
-db.Where("merge_request_id = ? AND is_system = ?", gitlabMr.GitlabId, false)
-```
-### 不规范的删除语句
-我们的代码中曾经出现过这种删除语句,这在 MySQL 中是合法的,但是在 PostgreSQL 中会报语法错误。
-```go
-err := db.Exec(`
- DELETE ic
- FROM jira_issue_commits ic
- LEFT JOIN jira_board_issues bi ON (bi.source_id = ic.source_id AND bi.issue_id = ic.issue_id)
- WHERE ic.source_id = ? AND bi.board_id = ?
- `, sourceId, boardId).Error
-```
-解决方案:我们把` DELETE `后面的表别名去掉就可以了。
-
-**了解更多最新动态**
-
-官网:[https://devlake.incubator.apache.org/](https://devlake.incubator.apache.org/)
-
-GitHub:[https://github.com/apache/incubator-devlake/](https://github.com/apache/incubator-devlake/)
-
-Slack:通过 [Slack](https://devlake-io.slack.com/join/shared_invite/zt-18uayb6ut-cHOjiYcBwERQ8VVPZ9cQQw#/shared-invite/email) 联系我们
-
-
-
-
\ No newline at end of file
diff --git a/blog/2022-06-17-How DevLake is up and running/index.md b/blog/2022-06-17-How DevLake is up and running/index.md
index 616ca8543..682ce6a40 100644
--- a/blog/2022-06-17-How DevLake is up and running/index.md
+++ b/blog/2022-06-17-How DevLake is up and running/index.md
@@ -1,7 +1,7 @@
---
slug: how-DevLake-is-up-and-running
title: How DevLake is Up and Running
-authors: Danna
+authors: warren
tags: [devlake, apache]
---
diff --git "a/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/dfs.gif" "b/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/dfs.gif"
deleted file mode 100644
index 73bfc8739..000000000
Binary files "a/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/dfs.gif" and /dev/null differ
diff --git "a/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/dfs.webm" "b/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/dfs.webm"
deleted file mode 100644
index 79ca4e3a1..000000000
Binary files "a/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/dfs.webm" and /dev/null differ
diff --git "a/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/index.md" "b/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/index.md"
deleted file mode 100644
index 6162cec5f..000000000
--- "a/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/index.md"
+++ /dev/null
@@ -1,389 +0,0 @@
----
-slug: refdiff-calculate-commits-diff
-title: refdiff插件的计算提交版本差异算法
-authors: Nddtfjiang
-tags: [devlake, refdiff, algorithm, graph]
----
-
-本文作者:Nddtfjiang
-个人主页:https://nddtf.com/github
-
-## 什么是 `计算提交版本差异`(CalculateCommitsDiff)?
-我们常常需要计算两个`提交版本`之间的差异。具体的说,就是需要知道两个不同的`分支/标签`之间相差了哪些`提交版本`。
-
-对于一般用户来说,通过`计算提交版本差异`,用户能迅速的判断两个不同的`分支/标签`之间在功能、BUG 修复等等方面的区别。以帮助用户选择不同的`分支/标签`来使用。
-
-而如果只是使用 `diff` 命令来查看这两个不同的`分支/标签`的话,大量庞杂冗余的代码修改信息就会毫无组织的混杂在其中,要从中提取出具体的功能变更之类的信息,等同于大海捞针。
-
-对于一款致力于提升研发效能的产品来说,通过`计算提交版本差异`,就能查看一组组不同的`分支/标签`的变迁状况,这一数据的获取,有助于我们做进一步的效能分析。
-
-例如,当一个项目的管理者,想要看看为什么最近的几个版本发版越来越慢了的时候。就可以对最近的几组`分支/标签`来计算`计算提交版本差异`。此时有些`分支/标签`组之间有着大量的`提交版本`,而有些`分支/标签`组之间有着较少的提交版本。项目管理者可以更进一步的计算这些提交版本各自的代码当量,把这些数据以图表的形式展示出来,最终得到一组很直观的`分支/标签`的图像。此时他或许就能发现,原来是因为最近的几次发版涉及到的变更越来越复杂了。通过这样的直观的信息,开发者和管理者们都能做出相应的调整,以便提升研发效能。
-
-
-
-## 已有的解决方案
-
-当我们在 `GitLab` 上打开一个代码仓库的时候,我们可以通过在 url 末尾追加 compare 的方式来进入到仓库的比对页面。
-
-
-
-
-
-在该页面,我们可以通过设置`源分支/标签` 和`目标分支/标签`让 `GitLab` 向我们展示 目标分支落后于源分支哪些版本,以及落后了多少个版本。
-
-设置完毕后,`GitLab` 会展示如下:
-
-
-
-在这里,我们能看到我们选择的`目标分支/标签`比`源分支/标签`少了如图所示的`提交版本`(Commits)
-
-然而遗憾的是,像 `GitLab` 这类解决方案,都没有做批量化,自动化的处理。也更没有对后续的计算出来的结果进行相应的数据汇总处理。用户面对海量的分支提交的时候,既不可能手动的一个一个去比较,也不可能手动的去把数据结果自己复制粘贴后再分析。
-
-因此 `DevLake` 就必须要解决这个问题。
-
-## 所谓的`计算提交版本差异`具体是在计算什么?
-
-以 `GitLab` 的计算过程为例来说的话,所谓的`计算提交版本差异`也就是当一个`提交版本`在`源分支/标签`中`存在`,但是在`目标分支/标签`中**不存在**的时候,这个提交版本就会被 `GitLab` 给逮出来。
-
-
-那么,或许有人会问,假如一个`提交版本`在`源分支/标签`中**不存在**,相反的,在`目标分支/标签`中`存在`,那是不是也会被抓起来呢?
-
-答案是,**不会**。
-
-也就是说,当我们计算`提交版本`的差异的时候,我们只关心`目标分支/标签`缺少了什么,而并不关心`目标分支/标签`多出来了什么东西。
-
-这就好像以前有一位算法竞赛的学生,在 NOI 比赛结束后被相关学校面试的时候,一个劲的自我介绍自己担任过什么广播站青协学生会,什么会长副会长之类的经历。结果很快就惹得面试官老师们忍无可忍的告诫道:
-
-> 我们只想知道你信息学方面的自我介绍,其余的我都不感兴趣!!!
-
-在计算`提交版本`差异时,`GitLab` 是这样。 `GitHub` 也是这样。事实上,在使用 git 命令 `git log branch1...branch2` 的时候,git 也是这样的。
-
-它们都只关心`目标分支/标签`相对于`源分支/标签`缺少的部分。
-
-计算`提交版本`差异实际上就是:
-
-- 计算待计算的`目标分支/标签`相对于`源分支/标签`缺少了哪些`提交版本`。
-
-## 对`提交版本`进行数学建模
-
-想要做计算,那么首先,我们需要把一个抽象的现实问题,转换成一个数学问题。
-
-这里我们就需要进行数学建模了。
-
-我们需要把像`目标分支/标签`、`源分支/标签`、`提交版本` 这样一系列的概念变成数学模型中的对象。
-
-如此我们才能为其设计算法。
-
-想当然的,我们就想到了使用图的方式来进行数学建模。
-
-我们将每一个`提交版本`都看作是图上的一个节点,把`提交版本`合并之前的一组`提交版本`与当前`提交版本`之间的父子关系,看作成是一条`有向边`。
-
-由于`目标分支`和`源分支`事实上也各自与一个特定的`提交版本`相绑定,因此也能将它们看作是图上的特别节点。
-
-- 将`目标分支/标签`所对应的节点,命名为`旧节点`
-- 将`源分支/标签`所对应的节点,命名为`新节点`
-
-当然,这里我们还有一个需要特别关注的节点,就是初始的`提交版本`所代表的节点
-
-- 将初始`提交版本`所对应的节点,命名为`根节点`
-
-
-上述的描述或许显得有点儿抽象。
-
-我们现在来实际举一个例子。来看看如何对一个仓库进行上述数学建模。
-
-假设现在有基于如下描述而产生的一个仓库:
-
-1. 创建空仓库
-1. 在 `main` 分支上创建`提交版本` `1` 作为初始提交
-1. 在 `main` 分支上创建`提交版本` `2`
-1. 在 `main` 分支上创建新分支 `nd`
-1. 在 `nd` 分支上创建`提交版本` `3`
-1. 在 `main` 分支上创建`提交版本` `4`
-1. 在 `main` 分支上创建新分支 `dtf`
-1. 在 `main` 分支上创建`提交版本` `5`
-1. 在 `dtf` 分支上创建`提交版本` `6`
-1. 在 `main` 分支上创建新分支 `nddtf`
-1. 在 `nddtf` 分支上创建`提交版本` `7`
-1. 把 `nd` 分支合并到 `nddtf`分支
-1. 把 `dtf` 分支合并到 `nddtf`分支
-1. 在 `main` 分支上创建`提交版本` `8`
-1. 在 `nddtf` 分支上创建`提交版本` `9`
-
-我们对上述的仓库进行构图之后,最终会得到如下图所示的一个有向图:
-
-
-
-
-- 此时彩色节点 `1` 为`根节点`
-- `main` 分支为 `1` `2` `4` `5` `8`
-- `nd` 分支为 `1` `2` `3` 随后合并入 `nddtf` 分支
-- `dtf` 分支为 `1` `2` `4` `6` 随后合并入 `nddtf` 分支
-- `nddtf` 分支为 `1` `2` `3` `4` `5` `6` `7` `9`
-
-
-可以看到,每一个`提交版本`在图中都相对应的有一个节点
-
-此时我们把`提交版本` `1` 所代表的节点,作为`根节点`
-
-当然这里可能会有同学提问了:
-
-- 假如我这个仓库有**一万个**`根节点`怎么破?
-
-相信一些经常做图的建模的同学应该都知道破法。
-
-- 创建一个名叫为`一万个根节点`的虚拟节点,把它设为这些个虚假的`根节点`的父节点,来当作真正的`根节点`即可。
-
-在这个有向图中,我们并没有实际的去指定具体的`目标分支/标签`或者`源分支/标签`
-
-在实际使用中,我们可以把任意的两个`提交版本`作为一对`目标分支/标签`和`源分支/标签`
-当然,有的同学在这里可能又会产生一个问题:
-
-- `目标分支/标签`和`源分支/标签` 虽然都能映射到其最后的`提交版本`上,但是实际上来说`提交版本`与`分支/标签`本质上就是两种不同的概念。
-
-`分支/标签`的实质,是包含一系列的`提交版本`的集合。而特定的`提交版本`仅仅是这个集合中的最后一个元素罢了。
-
-当我们把一个仓库通过上述数学建模抽象成一个有向图之后,这个集合的信息,会因此而丢失掉吗?
-
-对于一个合法的仓库来说,答案显然是,`不会`
-
-实际上,这也就是为什么我们一定要在该有向图中强调`根节点`的原因。
-
-我们这里这里,先给出结论:
-
-**`分支/标签`所对应的节点,到`根节点`的全部路径中途径的`所有节点`的集合,即为该`分支/标签`所包含的`提交版本`集合。**
-
-## 简单证明 上述结论
-- 设`根节点`为节点 `A`
-- 设要求的`分支/标签`所代表的节点为节点 `B`
-
-----------
-
-- 当 节点 `C` 是属于要求的`分支/标签`
-- 因为 节点 `C` 是属于要求的`分支/标签`
-- 所以 必然存在一组提交或者合并 使得 节点 `C` 可以一直提交到节点 `B`
-- 又因为 每一个新增的提交 或者 合并操作,均会切实的建立一条从新增的提交/合并到当前提交的边
-- 所以,反过来说,每一个提交或者合并后的节点,均可以抵达节点 `C`
-- 所以 节点 `B` 存在至少一条路径 可以 抵达节点 `C`
-- 同理可证,节点 `C` 存在至少一条路径抵达`根节点` 也就是节点 `A`
-- 综上,存在一条从节点 `B` 到节点 `A` 的路径,经过节点 `C`
-
-----------
-
-- 当 节点 `C` 不属于要求的`分支/标签`
-- 假设 存在一条从节点 `B` 到节点 `A` 的路径,经过节点 `C`
-- 因为 每一条边都是由新增的提交或者合并操作建立的
-- 所以 必然存在一系列的新增提交或者合并操作,使得节点 `C` 成为节点 `B`
-- 又因为 每一个提交在抽象逻辑上都是独一无二的
-- 因此,如果缺失了节点 `C` 则必然导致在构建节点 `B` 所代表的`分支/标签`的过程中,至少存在一个提交或者合并操作无法执行。
-- 这将导致分支非法
-- 因此 假设不成立
-- 因此 其逆否命题 对任意一条从节点 `B` 到节点 `A` 的路径,都不会经过节点 `C` 成立
-
-----------
-
-- 根据
-- 当 节点 `C` 是属于要求的`分支/标签`,存在一条从节点 `B` 到节点 `A` 的路径,经过节点 `C` (必要性)
-- 当 节点 `C` 不属于要求的`分支/标签`,对任意一条从节点 `B` 到节点 `A` 的路径,都不会经过节点 `C` (充分性)
-- 可得 `分支/标签`所对应的节点,到`根节点`的全部路径中途径的`所有节点`的集合,即为该`分支/标签`所包含的`提交版本`集合。
-
-
-
-
-
-
-## 算法选择
-
-我们现在已经完成了数学建模,并且已经为数学建模做了基本的证明。现在,我们终于可以开始在这个数学模型的基础上来设计并实现我们的算法了。
-
-如果没有做上述基本论证的同学,这里可能会犯一个小错误:那就是它们会误以为,只要计算两个节点之间的最短路径即可。若真是如此的话,`SPFA`,`迪杰斯特拉`(Dijkstra),甚至头铁一点儿,来个`弗洛伊德`(Floyd)都是很容易想到的。当然由于该有向图的所有边长都是 1,所以更简单的方法是直接使用`广/宽度优先搜索算法(BFS)`来计算最短路。
-
-上述的一系列耳熟能详的算法,或多或少都有成熟的库可以直接使用。但是遗憾的是,如果真的是去算最短路的话,那最终结果恐怕会不尽如人意。
-
-在 `DevLake` 的早期不成熟的版本中,曾经使用过最短路的算法来计算。尽管对于比较简单线性的仓库来说,可以歪打正着的算出结果。但是当仓库的分支和合并变得复杂的时候,最短路所计算的结果往往都会遗漏大量的`提交版本`。
-
-因为在刚才我们已经论证过了,这个`分支/标签`所包含的`提交版本`集合,是必须要全部路径才行的。只有全部路径,才能满足充分且必要条件。
-
-也就是说,中间只要漏了一条路径,那就会漏掉一系列的`提交版本`。
-
-要计算这个有向图上的`旧节点`所代表的`分支/标签`比`新节点`所代表的`分支/标签`缺少了哪些`提交版本`。
-
-实质上就是在计算`旧节点`到`根节点`的全部路径所经节点,对比`新节点`到`根节点`的全部路径所经节点,缺少了哪些节点。
-
-如果我们数学建模的时候,把这个有向图建立成一棵树的话。
-
-那么熟悉算法的同学,就可以很自然的使用最近公共祖先(LCA)算法,求出其并集,然后再来计算其对应的缺失的部分。
-
-但是作为一个有向图来说,树结构的算法是没法直接使用的。所幸的是,我们的这个图,在由合法仓库生成的情况下,必然是一个有向无环图。
-
-一个有向无环图,也是有自己的最近公共祖先(LCA)算法的。
-
-只是,这里有两个问题:
-- 我们真的对 最近公共祖先 这个特定的节点感兴趣吗?
-- 在有多个不同路径的公共祖先的情况下,只求一个最近公共祖先有什么意义呢?
-
-首先,我们需要明确我们的需求。
-
-我们只是为了计算 。
-- `旧节点`到`根节点`的全部路径所经节点,对比`新节点`到`根节点`的全部路径所经节点,缺少了哪些节点。
-
-除此之外的,我们不感兴趣。
-
-换句话说,我们想知道其公共祖先,但是,不关心它是不是最近的。
-
-它是近的也好,它是远的也罢,只要是公共祖先,都得抓起来。去求最近公共祖先,在树结构下,可以近似等价于求其全部祖先。因此可以使用该算法。
-
-但是在有向无环图下,最近公共祖先就是个废物。求出来了又能如何?
-
-根本上,还是应该去求全部的公共祖先。
-
-所以我们别无选择,只能用最直接的算法。
-
-- 计算出`旧节点`到`根节点`的全部路径所经节点
-- 计算出`新节点`到`根节点`的全部路径所经节点
-- 检查`新节点`的全部路径所经节点缺少了哪些节点
-
-如何计算任意节点到`根节点`的全部路径所经节点?
-
-在 OI 上熟练于骗分导论的同学们,应该很自然的就意识到了
-
-`深度优先搜索(DFS)`
-
-当然,这里补充一下,由于`根节点`的性质,事实上,无论是从哪个方向出发,无论走那条边,只要是能走的边,最终都会抵达`根节点`
-
-因此,在上述条件成立的基础上,没有记录路径状态的`广/宽度优先搜索(BFS)`也是可以使用的。因为在必然能抵达`根节点`的前提下,可以忽略路径状态,不做路径的可行性判断。
-
-当然,这一前提,也有利于我们`深度优先搜索(DFS)`进行优化。
-
-在我们执行`深度优先搜索(DFS)`的时候,我们可以将所有访问到的节点,均添加到集合中,而无需等待确认该节点能确实抵达`根节点`后再进行添加。
-
-实际上这里在一个问题上我们又会出现了两种分歧。
-问题是,如何将一个节点添加到集合中。方案有如下两种。
-
-染色法:添加到集合中的节点进行染色,未添加到集合中的节点不进行染色。
-集合法:使用平衡树算法建立一个集合,将节点添加到该集合中。
-
-这两种算法各有优劣。
-
-- 染色法的优势在于,染色法添加一个元素的时间复杂度是 O(1) 的,快准狠。相比较而言,集合法添加一个元素的时间复杂度是 O(log(n))。
-- 集合法的优势在于,集合法遍历所有元素的时间复杂度是 O(n) 的,而染色法下,要遍历所有元素时间复杂度会是 O(m),同时集合法可以通过设计一个优秀的 hash 算法代替平衡树,来将时间复杂度优化到接近 O(1).(这里 n 表示集合大小,m 表示整个图的大小)
-
-我们这里选择使用集合法。实际上这两种算法都差不多。
-
-
-## 算法实现
-
-- 根据提交建图
-- 我们对`旧节点`使用`深度优先搜索(DFS)`计算出其到`根节点`的全部路径所经节点,添加到`集合 A` 中
-- 接着,我们对`新节点`使用`深度优先搜索(DFS)`计算出其到`根节点`的全部路径所经节点,添加到`集合 B`
-- 注意,这里有一个优化,这个优化是建立在我们的需求上
-- 重复一遍我们的需求
-- 我们只关心`目标分支/标签`缺少了什么,而并不关心`目标分支/标签`多出来了什么东西。
-- 因此当对`新节点`使用`深度优先搜索(DFS)`搜索到已经在`集合 A` 中的节点时,可以认为该节点已搜索过,无需再次搜索。
-- 此时的`集合 B`,可以恰好的避开`集合 A` 中已有的所有节点,因此,恰好就是我们所需的结果。
-
-核心的计算代码如下所示:
-```golang
-oldGroup := make(map[string]*CommitNode)
-var dfs func(*CommitNode)
-// put all commit sha which can be depth-first-searched by old commit
-dfs = func(now *CommitNode) {
- if _, ok = oldGroup[now.Sha]; ok {
- return
- }
- oldGroup[now.Sha] = now
- for _, node := range now.Parent {
- dfs(node)
- }
-}
-dfs(oldCommitNode)
-
-var newGroup = make(map[string]*CommitNode)
-// put all commit sha which can be depth-first-searched by new commit, will stop when find any in either group
-dfs = func(now *CommitNode) {
- if _, ok = oldGroup[now.Sha]; ok {
- return
- }
- if _, ok = newGroup[now.Sha]; ok {
- return
- }
- newGroup[now.Sha] = now
- lostSha = append(lostSha, now.Sha)
- for _, node := range now.Parent {
- dfs(node)
- }
-}
-dfs(newCommitNode)
-```
-
-这里的 lostSha 即为我们最终求得的缺失的部分
-
-## 算法执行的演示动画
-
-我们用一个简陋的动画来简单的演示一下,上述算法在逻辑上执行的情况。
-
-- `旧节点`为节点 `8`
-- `新节点`为节点 `9`
-
-
-
-如上述[动画](https://devlake.apache.org/assets/images/dfs-3464f1398b150e893646c4f21e95ea10.gif)所演示的一般
-从节点 `8` 开始执行`深度优先搜索(DFS)`到`根节点`中止
-从节点 `9` 开始执行`深度优先搜索(DFS)`到已经在节点 `8` 的集合中的节点为止
-此时,在节点 `9` 执行`深度优先搜索(DFS)`过程中被访问到的所有非节点 `8` 的节点
-
-- 节点 `3`
-- 节点 `6`
-- 节点 `7`
-- 节点 `9`
-
-它们所对应的`提交版本`就是我们要求的差集
-
-> 此时最短路为 `9` -> `7` -> `5` -> `8`
-> 此时最近公共父节点为 `5`,到该节点的路径为 `9` -> `7` -> `5`
-> 从上图中也可以直观的看到如果使用最短路算法,或者最近公共父节点算法的情况下,我们是无法得到正确答案的。
-
-## 时空复杂度
-
-设`提交版本`的总大小为 m,每一组`源分支/标签`和`目标分支/标签`的平均大小为 n,一共有 k 组数据
-
-DFS 每访问一个节点,需要执行一次加入集合操作。我们按照我们实际实现中使用的 平衡树算法来计算 时间复杂度为 O(log(n))
-
-此时我们可以计算得出
-
-- 建图的时间复杂度:O(m)
-- 计算一组`源分支/标签`和`目标分支/标签`时间复杂度:O(n\*log(n))
-- 计算所有`源分支/标签`和`目标分支/标签`时间复杂度:O(k\*n\*log(n))
-- 读取、统计结果时间复杂度:O(k\*n)
-- 总体时间复杂度:O(m + k\*n\*log(n))
-
-----------
-
-- 图的空间复杂度:O(m)
-- 每组`源分支/标签`和`目标分支/标签`集合的空间复杂度:O(n) (非并发情况下,k组数据可共用)
-- 总体空间复杂度:O(m+n)
-
-
-## 关键词
-- `DevLake`
-- `CalculateCommitsDiff`
-- `算法`
-- `数学建模`
-- `证明逻辑`
-- `充分条件`
-- `必要条件`
-- `图论`
-- `深度优先搜索(DFS)`
-- `广/宽度优先搜索(BFS)`
-- `时间复杂度`
-- `空间复杂度`
-- `时空复杂度`
-
-----------
-## 了解更多最新动态
-
-官网:[https://devlake.incubator.apache.org/](https://devlake.incubator.apache.org/)
-
-GitHub:[https://github.com/apache/incubator-devlake/](https://github.com/apache/incubator-devlake/)
-
-Slack:通过 [Slack](https://devlake-io.slack.com/join/shared_invite/zt-18uayb6ut-cHOjiYcBwERQ8VVPZ9cQQw#/shared-invite/email) 联系我们
\ No newline at end of file
diff --git "a/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\225\260\345\255\246\346\250\241\345\236\213\346\236\204\345\233\276.png" "b/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\225\260\345\255\246\346\250\241\3 [...]
deleted file mode 100644
index 46e5b41cf..000000000
Binary files "a/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\225\260\345\255\246\346\250\241\345\236\213\346\236\204\345\233\276.png" and /dev/null differ
diff --git "a/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\267\273\345\212\240Compare.png" "b/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\267\273\345\212\240Compare.png"
deleted file mode 100644
index e3573e030..000000000
Binary files "a/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\267\273\345\212\240Compare.png" and /dev/null differ
diff --git "a/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\272\220\345\210\206\346\224\257-\347\233\256\346\240\207\345\210\206\346\224\257.png" "b/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\272\220\345\210\206\ [...]
deleted file mode 100644
index 474372eba..000000000
Binary files "a/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\272\220\345\210\206\346\224\257-\347\233\256\346\240\207\345\210\206\346\224\257.png" and /dev/null differ
diff --git "a/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\347\211\210\346\234\254\345\257\271\346\257\224.png" "b/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\347\211\210\346\234\254\345\257\271\346\257\224.png"
deleted file mode 100644
index 58e020d4c..000000000
Binary files "a/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\347\211\210\346\234\254\345\257\271\346\257\224.png" and /dev/null differ
diff --git "a/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\351\235\242\346\235\277\345\233\276\347\211\207.png" "b/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\351\235\242\346\235\277\345\233\276\347\211\207.png"
deleted file mode 100644
index 6438442ee..000000000
Binary files "a/blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\351\235\242\346\235\277\345\233\276\347\211\207.png" and /dev/null differ
diff --git a/blog/2022-06-23-compatibility-of-apache-devLake-with-postgreSQL/index.md b/blog/2022-06-23-compatibility-of-apache-devLake-with-postgreSQL/index.md
index 6de4eebc5..92475271e 100644
--- a/blog/2022-06-23-compatibility-of-apache-devLake-with-postgreSQL/index.md
+++ b/blog/2022-06-23-compatibility-of-apache-devLake-with-postgreSQL/index.md
@@ -1,7 +1,7 @@
---
slug: compatibility-of-apache-devLake-with-postgreSQL
title: Compatibility of Apache DevLake with PostgreSQL
-authors: Geyu
+authors: ZhangLiang
tags: [devlake, database, postgresql]
---
diff --git a/blog/2022-07-15-welcome-open-source/en.md.bak b/blog/2022-07-15-welcome-open-source/en.md.bak
deleted file mode 100644
index 6e67ee2b3..000000000
--- a/blog/2022-07-15-welcome-open-source/en.md.bak
+++ /dev/null
@@ -1,23 +0,0 @@
----
-title: "Welcome to OpenSource"
-weight: 50000
-description: >
- Welcome to OpenSource
-
----
-
-# Welcome to Open Source
-
-
-
-
-
-From https://web.archive.org/web/20110503183702/http://pbagwl.com/post/5078147450/description-of-popular-software-licenses#5078147450-zoom
-
-
-
-
-
-Git 知识
-
-https://github.com/RichardLitt/knowledge/blob/master/github/amending-a-commit-guide.md
\ No newline at end of file
diff --git a/blog/2022-07-15-welcome-open-source/index.md b/blog/2022-07-15-welcome-open-source/index.md
deleted file mode 100644
index 4b2e397a3..000000000
--- a/blog/2022-07-15-welcome-open-source/index.md
+++ /dev/null
@@ -1,165 +0,0 @@
----
-title: "拥抱开源指南"
-authors: likyh
-description: >
- 拥抱开源指南
-
----
-
-# 拥抱开源指南
-
-近年来,开源正在变得越来越火,在很多开发者眼中,「开源」也是非常极客的体现。同时参与开源项目也能给职业发展带来巨大的好处。可一些小伙伴却因为不知道参与的方法和途径没能参与,这里就向大家介绍一下作为开发者,可以怎么拥抱开源软件,以及怎么成为大家认可的开源贡献者。
-
-当然,本文会更多的从大的背景知识上进行叙述,关于代码提交的详细步骤,可以看看这一篇文章:[如何参与开源项目 - 细说 GitHub 上的 PR 全过程](https://mp.weixin.qq.com/s/b1mKPgOm1mnwsBbEBDRvKw)。
-
-## 什么是开源软件
-
-开源是源代码可以任意获取的计算机软件,任何人都能查看、修改和分发他们认为合适的代码,但这并不意味着可以使用源代码而没有任何著作权或发行权的约束,我们接触到的开源软件一般都有对应的开源许可证(Open Source License)对软件的使用、复制、修改和再发布等进行限制。许可证即授权条款,开源许可证就是说明这些限制的文件,常见的开源许可证主要有 Apache、MIT、BSD、GPL、LGPL、MPL、SSPL 等。
-
-下面,我们通过一张表来简单了解一下常见**宽松**开源许可证之间的区别:
-
-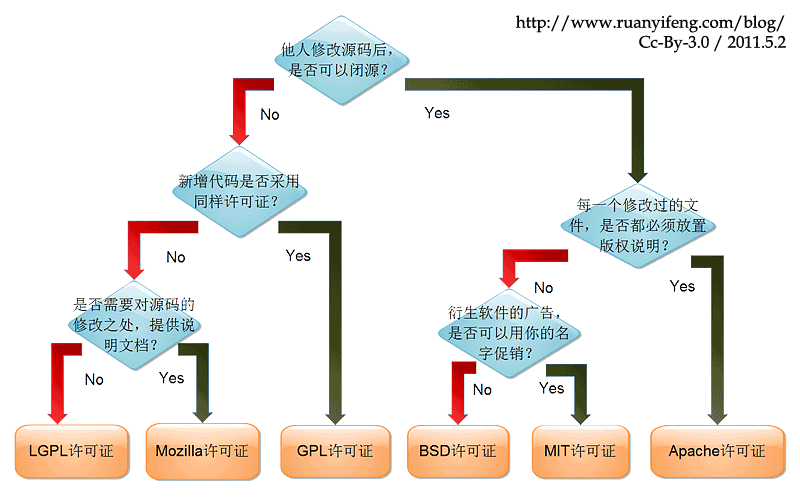
-
-(图片来自: https://www.ruanyifeng.com/blog/2011/05/how_to_choose_free_software_licenses.html)
-
-其中,Apache 许可证(Apache License)是目前全球最大的开源软件基金会之一ASF (Apache Software Foundation) 发布的License。这是一个最初为 Apache http 服务器而撰写。此许可证最新版本于 2004 年 1 月发布,并要求所有ASF的项目均采用此项License。
-
-## 寻找运行良好的开源项目
-
-目前,开源项目主要是两类,一类由团队自行维护,一类由特定的基金会运行。现在大部分项目均托管在 GitHub 上,因此在GitHub上直接搜索点赞较高较活跃的项目,往往就是一个不错的选择。比如想参与数据分析相关的项目,可以在GitHub搜索 data analyzes,注意观察项目最近的提交时间和issue数量,更新快说明项目成员活跃,有issue说明是一个正在快速发展的项目,更适合参与。
-
-
-
-第二种寻找方式,由开源基金会维护的运行良好的项目,还可以在对应的开源基金会官网找到。
-
-比如Linux基金会的项目地址:https://www.linuxfoundation.org/projects/
-
-
-
-比如CNCF的项目页:https://landscape.cncf.io/
-
-
-
-比如ASF的项目页:https://projects.apache.org/projects.html
-
-
-
-最后,还有一些第三方的评估面板,从一些独特的视角了解现存的开源项目。
-比如ossinsight:https://ossinsight.io/collections/open-source-database ,可以了解本月点赞最多的项目有些什么,
-
-再比如从 DevLake 的 [OSS 项目面板](https://grafana-oss.demo.devlake.io/d/KXWvOFQnz/github_basic_metrics?orgId=1&var-repo_id=github:GithubRepo:482676524&from=1642498327554&to=1658136727554) 更加深入的了解项目,这都是了解开源项目运行状况的有效途径。
-
-
-
-## Apache开源软件基金会
-
-因为笔者更了解 ASF ,所以这里就对它做一些更详细的介绍。
-
-Apache 开源基金会目前维护着380余个开源项目,但一年的开销仅一百多万美元左右。这是一个非常低的数(而其他基金会比如Linux基金会,每年开销在上亿美元),平均每个项目仅2000余美元,这就决定了Apache的开源项目更依赖社区和开源贡献者,在Apache社区中,「Community over Code」即社区先于编码体现得淋漓尽致。Apache 基金会每年的支出其中80%用在**基础设施**,其余会用在**营销、宣传和品牌管理服务,研讨会和发展社区,法律咨询等方面**,而其他诸如日常维护、编码等工作均由各个项目的成员维护。
-
-Apache开源项目中,一般有如下几个基本的角色:
-
-* Contributor
- 普通贡献者,这种就是很容易获得,只需要提交一个PR并被官方合并到主分支即可获得,例如提交一个文档,修改几行代码就行。
-
-* Committer
- 核心开发,对贡献特别大的 Contributor,官方社区会考虑将其吸收,提升到commiter,成为核心开发,此时就有项目的写入权限,**并可以申请@apache.com结尾的邮箱**。
-
-* PMC
- 开源项目决策成员。
-
-
-
-## 参与项目讨论
-
-一旦选择好一个开源项目后,我们又该如何找到组织呢?
-
-首先是阅读官方文档,全面了解该项目的架构设计文档和解决的问题,之后可以尝试参与项目日常的讨论。尽管在微信群中提问很方便,但 Apache 项目的大部分讨论需要公开地在邮件列表中进行,方便所有人查看及查询,因此我们也需要了解如何参与 Apache 的邮件讨论。
-
-Apache下面的每一个项目都有自己的邮件列表,同时分不同的邮件组,以Apache DevLake为例,有如下订阅列表:
-
-| 邮箱 | 用途 |
-| :----------------------------------------------------------- | :----------------------------------------- |
-| [user-subscribe@devlake.apache.org](mailto:user-subscribe@devlake.apache.org) | 订阅该邮件可以参与讨论普通用户遇到的问题 |
-| [dev-subscribe@devlake.apache.org](mailto:dev-subscribe@devlake.apache.org) | 订阅该邮件可以参与讨论**开发者**遇到的问题 |
-| commits-subscribe@devlake.apache.org | 所有的代码的提交变动信息都会发到该邮件 |
-
-具体操作是首先给dev-subscribe@devlake.apache.org发一封邮件,等收到确认邮件后再次确认即可。
-
-添加后就可以收到所有开发讨论的信息了,另外也可以关注官网的 maillist(https://lists.apache.org/list.html?dev@devlake.apache.org) 查看全部历史邮件。
-
-另外,大部分项目会有一些线上的聚会,往往可以在Readme页面找到,参与线上聚会可以更直接的获取所需的信息,也能有机会和项目PMC直接交流。
-
-## 向开源项目反馈问题
-
-如果在项目的使用中,遇到了 bug,或者希望撸起袖子修改某个功能点,但这个功能点需要进一步讨论。可以在前面的邮件中发起讨论,当然也可以在 GitHub 的 issue 中做一个较正式的记录。
-
-一般的项目都会针对不同的目的,提供一些 issue 创建的模板。
-
-
-
-常见的类型有:
-
-* Bug 提出一个功能实现的错误
-* Document Issue 提出一项文档改进的建议
-* Feature Request 请求增加或表示你将增加一个产品特性
-* Refactor 发起一项不影响功能的重构
-* Security Vulnerability 报告一个安全问题,在问题修复以前,该问题不会公布。
-
-提出一个清晰明了的 issue 往往会让社区的其他成员更愿意响应你的号召,相信我,这会是一个非常享受的过程~
-
-## 成为项目的贡献者
-
-在参与讨论的基础上,只要能在 GitHub 社区中帮助验证一些发布的新功能或者提一些建议或者缺陷,或者修改源码,就能成为该项目的贡献者(Contributor)。
-
-刚参与项目时,可以考虑编写文档,或完善一些模块的单元测试,或者进行一些简单编码工作。比如可以在 GitHub Issues 列表中寻找带有`good first issue`标记且暂未被认领的事情,这往往是社区维护者为了引导贡献者专门创建的issue,很适合作为第一个提交。完成第一个提交后,可以再去看看其他open的issue并解决。
-
-目前开源项目一般采用 Git 来管理源代码,如果你从未使用过代码管理工具的话,可以现在网上寻找教程了解,比如:https://www.liaoxuefeng.com/wiki/896043488029600 。一般的提交流程是:先 fork 对应的项目,在 fork 项目提交代码后,向开源项目发起代码合并请求等待合并。
-
-需要注意的是,任何代码提交后,都不会立刻合并,需要寻找社区维护者 Review 后才会进入主干。
-
-### 编写好代码的注意事项
-
-
-
-(图片来自网络)
-
-代码不是写完就好,还需要其他人阅读的。因此,写出赏心悦目的代码很值得点赞,当然,水平的提升总是有一个过程,因此任何开源项目都是鼓励尝试与提升的过程。这里就只说几点更容易得到社区成员帮助的注意事项:
-
-1. 写完代码提交 PR 后,注意在 PR 描述中补充完善的编码思路和背景知识,这会让其他成员更容易了解修改目标;
-2. 注意控制 PR 的大小,一个小的 PR 更容易让其他人了解全部修改项,如果有一个大的功能,可以按照模块拆成几个能分别运行的 PR;
-3. 注意补充适当的单元测试,因为 Reviewer 并不负责确定代码能跑,只负责看代码设计思路是否正确。因此增加合适的测试,能让 Reviewer 确定这段代码是可以运行的。有时 Reviewer 也会针对容易出错的地方提出补充测试的建议。
-
-
-
-(图片来自网络,超大的提交会让 Reviewer 欲仙欲死的 😹)
-
-### Code Review 常见术语
-
-在提交代码与Code Review的过程中,有时会遇到下面这些缩写,了解后参与开源社区更轻松。
-
-| 缩写 | 全称 | 使用场景 |
-| --------- | ------------------------- | ------------------------------------------------------------ |
-| - | I'll take it. | 表示会尝试做这个任务 |
-| PR/MR/CR | Pull/Merge/Change Request | 如果要提交代码给开源项目,就会发起一个合并请求,在不同平台有不同的名字,但都是同一个东西 |
-| WIP | Work In Progress | 表示PR尚未完成,暂时还不需要review |
-| PTAL | Please Take A Look | 请求项目维护人员进行 code review |
-| TBD | To Be Done | 提示有一个事情需要完成 |
-| TL;DR | Too Long; Didn't Read | 太长了,懒得看。也有时在文档中用作概览信息的标题 |
-| LGTM/SGTM | Looks/Sounds Good To Me | 表示review完并觉得可以合并了,即Approve的意思 |
-| CC to | Carbon Copy to | 抄送给 |
-
-顺便再说几个 GitHub 中实用的小技巧:
-
-1. 如果你的 PR 解决了某个 issue,可以在描述中加上 close #1234,1234需要改成对应的issue号,在 PR 合并时该issue也会同时关闭([更多信息](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword#linking-a-pull-request-to-an-issue-using-a-keyword))
- 
-2. GitHub 的 Markdown 编辑器可以将默认字体设置为等宽字体,便于代码的书写,具体设置为: **Settings** - **Appearance** - **Use a fixed-width (monospace) font when editing Markdown**. ([更多信息](https://docs.github.com/en/get-started/writing-on-github/getting-started-with-writing-and-formatting-on-github/about-writing-and-formatting-on-github))
- 
-3. 当发现一个 issue 和其他 issue 重复时,可以设置在评论区留下 Duplicate of #1234 来标记与某个issue重复([更多信息](https://docs.github.com/en/issues/tracking-your-work-with-issues/marking-issues-or-pull-requests-as-a-duplicate))
- 
-
-## 结语
-
-好啦,大体的情况应该介绍的差不多了,其实参与开源项目并没有想象中的难,成为一个开源项目的Commiter,给职场和技术实力带来的助力将不可估量。另外,如果你还是较为初级的开发者,迫切的想要知道具体的参与步骤,可以看看开头提到的这篇文章,[如何参与开源项目 - 细说 GitHub 上的 PR 全过程](https://mp.weixin.qq.com/s/b1mKPgOm1mnwsBbEBDRvKw)。
-
-我们的 DevLake (https://github.com/apache/incubator-devlake) 和 DevStream (https://github.com/devstream-io/devstream) 也是优秀的开源项目,欢迎你的参与哦~
diff --git a/docusaurus.config.js b/docusaurus.config.js
index 5a8e3a2cf..f4c9f92b6 100644
--- a/docusaurus.config.js
+++ b/docusaurus.config.js
@@ -204,10 +204,10 @@ const versions = require('./versions.json');
}
],
},
- {
- type: 'localeDropdown',
- position: 'right',
- },
+ // {
+ // type: 'localeDropdown',
+ // position: 'right',
+ // },
],
},
footer: {
diff --git a/i18n/zh/code.json b/i18n/zh/code.json
deleted file mode 100644
index 3f5638eb2..000000000
--- a/i18n/zh/code.json
+++ /dev/null
@@ -1,225 +0,0 @@
-{
- "theme.ErrorPageContent.title": {
- "message": "页面已崩溃。",
- "description": "The title of the fallback page when the page crashed"
- },
- "theme.ErrorPageContent.tryAgain": {
- "message": "重试",
- "description": "The label of the button to try again when the page crashed"
- },
- "theme.NotFound.title": {
- "message": "找不到页面",
- "description": "The title of the 404 page"
- },
- "theme.NotFound.p1": {
- "message": "我们找不到您要找的页面。",
- "description": "The first paragraph of the 404 page"
- },
- "theme.NotFound.p2": {
- "message": "请联系原始链接来源网站的所有者,并告知他们链接已损坏。",
- "description": "The 2nd paragraph of the 404 page"
- },
- "theme.blog.archive.title": {
- "message": "历史博文",
- "description": "The page & hero title of the blog archive page"
- },
- "theme.blog.archive.description": {
- "message": "历史博文",
- "description": "The page & hero description of the blog archive page"
- },
- "theme.BackToTopButton.buttonAriaLabel": {
- "message": "回到顶部",
- "description": "The ARIA label for the back to top button"
- },
- "theme.AnnouncementBar.closeButtonAriaLabel": {
- "message": "关闭",
- "description": "The ARIA label for close button of announcement bar"
- },
- "theme.blog.paginator.navAriaLabel": {
- "message": "博文列表分页导航",
- "description": "The ARIA label for the blog pagination"
- },
- "theme.blog.paginator.newerEntries": {
- "message": "较新的博文",
- "description": "The label used to navigate to the newer blog posts page (previous page)"
- },
- "theme.blog.paginator.olderEntries": {
- "message": "较旧的博文",
- "description": "The label used to navigate to the older blog posts page (next page)"
- },
- "theme.blog.post.readingTime.plurals": {
- "message": "{readingTime} 分钟阅读",
- "description": "Pluralized label for \"{readingTime} min read\". Use as much plural forms (separated by \"|\") as your language support (see https://www.unicode.org/cldr/cldr-aux/charts/34/supplemental/language_plural_rules.html)"
- },
- "theme.blog.post.readMoreLabel": {
- "message": "阅读 {title} 的全文",
- "description": "The ARIA label for the link to full blog posts from excerpts"
- },
- "theme.blog.post.readMore": {
- "message": "阅读更多",
- "description": "The label used in blog post item excerpts to link to full blog posts"
- },
- "theme.blog.post.paginator.navAriaLabel": {
- "message": "博文分页导航",
- "description": "The ARIA label for the blog posts pagination"
- },
- "theme.blog.post.paginator.newerPost": {
- "message": "较新一篇",
- "description": "The blog post button label to navigate to the newer/previous post"
- },
- "theme.blog.post.paginator.olderPost": {
- "message": "较旧一篇",
- "description": "The blog post button label to navigate to the older/next post"
- },
- "theme.blog.sidebar.navAriaLabel": {
- "message": "最近博文导航",
- "description": "The ARIA label for recent posts in the blog sidebar"
- },
- "theme.blog.post.plurals": {
- "message": "{count} 篇博文",
- "description": "Pluralized label for \"{count} posts\". Use as much plural forms (separated by \"|\") as your language support (see https://www.unicode.org/cldr/cldr-aux/charts/34/supplemental/language_plural_rules.html)"
- },
- "theme.blog.tagTitle": {
- "message": "{nPosts} 含有标签「{tagName}」",
- "description": "The title of the page for a blog tag"
- },
- "theme.tags.tagsPageLink": {
- "message": "查看所有标签",
- "description": "The label of the link targeting the tag list page"
- },
- "theme.colorToggle.ariaLabel": {
- "message": "切换浅色/暗黑模式(当前为{mode})",
- "description": "The ARIA label for the navbar color mode toggle"
- },
- "theme.colorToggle.ariaLabel.mode.dark": {
- "message": "暗黑模式",
- "description": "The name for the dark color mode"
- },
- "theme.colorToggle.ariaLabel.mode.light": {
- "message": "浅色模式",
- "description": "The name for the light color mode"
- },
- "theme.docs.DocCard.categoryDescription": {
- "message": "{count} 个项目",
- "description": "The default description for a category card in the generated index about how many items this category includes"
- },
- "theme.docs.sidebar.expandButtonTitle": {
- "message": "展开侧边栏",
- "description": "The ARIA label and title attribute for expand button of doc sidebar"
- },
- "theme.docs.sidebar.expandButtonAriaLabel": {
- "message": "展开侧边栏",
- "description": "The ARIA label and title attribute for expand button of doc sidebar"
- },
- "theme.docs.paginator.navAriaLabel": {
- "message": "文档分页导航",
- "description": "The ARIA label for the docs pagination"
- },
- "theme.docs.paginator.previous": {
- "message": "上一页",
- "description": "The label used to navigate to the previous doc"
- },
- "theme.docs.paginator.next": {
- "message": "下一页",
- "description": "The label used to navigate to the next doc"
- },
- "theme.DocSidebarItem.toggleCollapsedCategoryAriaLabel": {
- "message": "打开/收起侧边栏菜单「{label}」",
- "description": "The ARIA label to toggle the collapsible sidebar category"
- },
- "theme.docs.tagDocListPageTitle.nDocsTagged": {
- "message": "{count} 篇文档带有标签",
- "description": "Pluralized label for \"{count} docs tagged\". Use as much plural forms (separated by \"|\") as your language support (see https://www.unicode.org/cldr/cldr-aux/charts/34/supplemental/language_plural_rules.html)"
- },
- "theme.docs.tagDocListPageTitle": {
- "message": "{nDocsTagged}「{tagName}」",
- "description": "The title of the page for a docs tag"
- },
- "theme.docs.versionBadge.label": {
- "message": "版本:{versionLabel}"
- },
- "theme.docs.versions.unreleasedVersionLabel": {
- "message": "此为 {siteTitle} {versionLabel} 版尚未发行的文档。",
- "description": "The label used to tell the user that he's browsing an unreleased doc version"
- },
- "theme.docs.versions.unmaintainedVersionLabel": {
- "message": "此为 {siteTitle} {versionLabel} 版的文档,现已不再积极维护。",
- "description": "The label used to tell the user that he's browsing an unmaintained doc version"
- },
- "theme.docs.versions.latestVersionSuggestionLabel": {
- "message": "最新的文档请参阅 {latestVersionLink} ({versionLabel})。",
- "description": "The label used to tell the user to check the latest version"
- },
- "theme.docs.versions.latestVersionLinkLabel": {
- "message": "最新版本",
- "description": "The label used for the latest version suggestion link label"
- },
- "theme.common.editThisPage": {
- "message": "编辑此页",
- "description": "The link label to edit the current page"
- },
- "theme.common.headingLinkTitle": {
- "message": "标题的直接链接",
- "description": "Title for link to heading"
- },
- "theme.lastUpdated.atDate": {
- "message": "于 {date} ",
- "description": "The words used to describe on which date a page has been last updated"
- },
- "theme.lastUpdated.byUser": {
- "message": "由 {user} ",
- "description": "The words used to describe by who the page has been last updated"
- },
- "theme.lastUpdated.lastUpdatedAtBy": {
- "message": "最后{byUser}{atDate}更新",
- "description": "The sentence used to display when a page has been last updated, and by who"
- },
- "theme.navbar.mobileVersionsDropdown.label": {
- "message": "选择版本",
- "description": "The label for the navbar versions dropdown on mobile view"
- },
- "theme.common.skipToMainContent": {
- "message": "跳到主要内容",
- "description": "The skip to content label used for accessibility, allowing to rapidly navigate to main content with keyboard tab/enter navigation"
- },
- "theme.TOCCollapsible.toggleButtonLabel": {
- "message": "本页总览",
- "description": "The label used by the button on the collapsible TOC component"
- },
- "theme.tags.tagsListLabel": {
- "message": "标签:",
- "description": "The label alongside a tag list"
- },
- "theme.CodeBlock.copied": {
- "message": "复制成功",
- "description": "The copied button label on code blocks"
- },
- "theme.CodeBlock.copyButtonAriaLabel": {
- "message": "复制代码到剪贴板",
- "description": "The ARIA label for copy code blocks button"
- },
- "theme.CodeBlock.copy": {
- "message": "复制",
- "description": "The copy button label on code blocks"
- },
- "theme.navbar.mobileLanguageDropdown.label": {
- "message": "选择语言",
- "description": "The label for the mobile language switcher dropdown"
- },
- "theme.docs.sidebar.collapseButtonTitle": {
- "message": "收起侧边栏",
- "description": "The title attribute for collapse button of doc sidebar"
- },
- "theme.docs.sidebar.collapseButtonAriaLabel": {
- "message": "收起侧边栏",
- "description": "The title attribute for collapse button of doc sidebar"
- },
- "theme.navbar.mobileSidebarSecondaryMenu.backButtonLabel": {
- "message": "← 回到主菜单",
- "description": "The label of the back button to return to main menu, inside the mobile navbar sidebar secondary menu (notably used to display the docs sidebar)"
- },
- "theme.tags.tagsPageTitle": {
- "message": "标签",
- "description": "The title of the tag list page"
- }
-}
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-04-30-\344\275\277\347\224\250ants\345\274\225\345\217\221\347\232\204\346\255\273\351\224\201/ants_source_code_1.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-04-30-\344\275\277\347\224\250ants\345\274\225\345\217\221\347\232\204\346\255\273\351\224\201/ants_source_code_1.png"
deleted file mode 100644
index 935aa93be..000000000
Binary files "a/i18n/zh/docusaurus-plugin-content-blog/2022-04-30-\344\275\277\347\224\250ants\345\274\225\345\217\221\347\232\204\346\255\273\351\224\201/ants_source_code_1.png" and /dev/null differ
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-04-30-\344\275\277\347\224\250ants\345\274\225\345\217\221\347\232\204\346\255\273\351\224\201/ants_source_code_flowchart.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-04-30-\344\275\277\347\224\250ants\345\274\225\345\217\221\347\232\204\346\255\273\351\224\201/ants_source_code_flowchart.png"
deleted file mode 100644
index 42effec7f..000000000
Binary files "a/i18n/zh/docusaurus-plugin-content-blog/2022-04-30-\344\275\277\347\224\250ants\345\274\225\345\217\221\347\232\204\346\255\273\351\224\201/ants_source_code_flowchart.png" and /dev/null differ
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-04-30-\344\275\277\347\224\250ants\345\274\225\345\217\221\347\232\204\346\255\273\351\224\201/index.md" "b/i18n/zh/docusaurus-plugin-content-blog/2022-04-30-\344\275\277\347\224\250ants\345\274\225\345\217\221\347\232\204\346\255\273\351\224\201/index.md"
deleted file mode 100644
index 6c0a1e229..000000000
--- "a/i18n/zh/docusaurus-plugin-content-blog/2022-04-30-\344\275\277\347\224\250ants\345\274\225\345\217\221\347\232\204\346\255\273\351\224\201/index.md"
+++ /dev/null
@@ -1,122 +0,0 @@
-### 1. 背景
-
-我们的项目有大量的api请求由goroutine完成,所以我们需要引入一个pool来节省频繁创建goroutine所造成的的开销,同时也可以更简易的调度goroutine,在对github上多个协程池的对比后,我们最终选定了[ants](https://github.com/panjf2000/ants)作为我们的调度管理pool。
-
-1. 最近在测试中偶然发现系统出现了“死锁”的情况,进而采取断网的方式发现“死锁”在极端情况下是稳定出现,经过满篇的log,break,最终把问题定位到了ants的submit方法。这个问题来自于在使用ants pool的过程中,为了实现重试,我们在方法中又递归调用了方法本身,也就是submit task内部又submit一个task,下面是简化后的代码
-
-```Go
-func (apiClient *ApiAsyncClient) DoAsync(
- retry int,
-) error {
- return apiClient.scheduler.Submit(func() error {
- _, err := apiClient.Do()
- if err != nil {
- if retry < apiClient.maxRetry {
- return apiClient.DoAsync(retry+1)
- }
- }
- return err
- })
-}
-```
-
-在上面的代码块中,可以看到return apiClient.DoAsync(retry+1)这一步递归调用了自己,即在submit中又调用了submit
-
-### 2. 深入ants分析
-
-
-
-- 在上面submit源码中可以看到,首先是通过retrieveWorker回去一个worker,然后把task放入到worker的task channel当中,很简单,也看不出来为什么会“dead lock”,没办法,去到retrieveWorker
-
-```Go
-// retrieveWorker returns a available worker to run the tasks.
-func (p *Pool) retrieveWorker() (w *goWorker) {
- spawnWorker := func() {
- w = p.workerCache.Get().(*goWorker)
- w.run()
- }
- p.lock.Lock()
- w = p.workers.detach()
- if w != nil { // first try to fetch the worker from the queue
- p.lock.Unlock()
- } else if capacity := p.Cap(); capacity == -1 || capacity > p.Running() {
- // if the worker queue is empty and we don't run out of the pool capacity,
- // then just spawn a new worker goroutine.
- p.lock.Unlock()
- spawnWorker()
- } else { // otherwise, we'll have to keep them blocked and wait for at least one worker to be put back into pool.
- if p.options.Nonblocking {
- p.lock.Unlock()
- return
- }
- retry:
- if p.options.MaxBlockingTasks != 0 && p.blockingNum >= p.options.MaxBlockingTasks {
- p.lock.Unlock()
- return
- }
- p.blockingNum++
- p.cond.Wait() // block and wait for an available worker
- p.blockingNum--
- var nw int
- if nw = p.Running(); nw == 0 { // awakened by the scavenger
- p.lock.Unlock()
- if !p.IsClosed() {
- spawnWorker()
- }
- return
- }
- if w = p.workers.detach(); w == nil {
- if nw < capacity {
- p.lock.Unlock()
- spawnWorker()
- return
- }
- goto retry
- }
- p.lock.Unlock()
- }
- return
-}
-
-```
-
-
-
-- 这个方法的大概流程就是先对pool上锁,然后从pool的worker队列中去取一个worker,detach其实就是返回了worker,并且把这个worker从队列中删除掉了,接下来有三种情况
- - 如果成功取到worker,解锁p,返回取到的worker
- - 如果worker队列是空的并且pool的容量没有耗尽,就解锁pool并生成一个新的worker返回给submit
- - 最后一种情况就是pool容量耗尽了,worker队列也没有空闲的worker,那就要根据我们创建pool时传入的参数来决定下一步情况了
- - 首先说一下这里涉及的两个重要参数,一个是capacity,这个值如果在new pool的时候不设置,会是MaxInt32,相当于无限制的goroutine,但是情况不同的是,我们会首先复用空闲的worker,还可以定时清空多余的空闲worker,blockingNum为正在等待的goroutine,初始为0
- - 如果设置了Nonblocking为true,直接解锁,返回nil,submit就会直接返回一个错误ErrPoolOverload,代表pool超负荷了,不做任何其他处理,submit失败,结束~~
- - 另一种情况就是没有设置Nonblocking,默认为false,就进入到了一个retry标签,这里面就涉及到了另一个创建pool时候的参数MaxBlockingTasks,这个MaxBlockingTasks就是一个threshold
- - 首先判断如果设置了MaxBlockingTasks并且当前blockingNum大于或者等于MaxBlockingTasks,那么直接解锁pool并且返回nil,submit失败,结束~~
- - 上面的条件不满足,则首先blockingNum++,然后开始wait一直到有worker摸完鱼回来工作,则blockingNum--。问题就在这里了!!!如果所有的worker都在工作(也许是看起来在工作,实际上在摸鱼),这里就会一直wait(),也就是我们自己代码中return后面的DoAsync会一直wait(),从我们自己的项目来讲,就是所有worker这个时候都在submit一个新的task到同一个pool中,而这个时候pool已经满了,导致所有worker都阻塞在了这里,“死锁”也就出现了
-
-### 3. 最后聊几句自己对于golang内存模型的理解
-
-1. go的调度流程本质上是一个生产-消费的过程,我们利用go func是生产了一个task放到队列中,由系统线程从队列中获取协程然后执行
-2. 讲到go的调度流程,咱们就不能不说一下go的MPG(分别解释一下,就不做深入了,如果有人看,后期再努力整理一份详细聊聊)
- 1. M 代表着一个内核线程,也可以称为一个工作线程,所有的goroutine都是跑在M之上的
- 2. P可以理解为一个逻辑处理器,主要由P来执行goroutine
- 3. G就是go func封装的这个方法
-3. 真正的并发数是由GOMAXPROCS来决定的,并不是提交多少goroutine,并发数就是多少,GOMAXPROCS是由机器的cpu核数来决定的
-4. 所以回到第2部分,pool.cond.wait等待的是绑定上一个goroutine,和其他语言的等待线程具有相似却完全不同的意义,每一个worker是一个G,pool也就是一个队列,而M会从队列中获取可以执行的G,当所有的G都在等待创建新的G时,M全部都处于空闲状态
-
-### 4. 解决方案
-
-1. 当然,最靠谱的应该是尽量避免类似这样的递归调用操作
-2. 如果实在不行,可以考虑添加一个sub pool,作为次级队列,让递归生成的G可以在sub pool里等待空闲的M来处理
-
-### 5. 对比不同size的pool和两个pool的内存(alloc_space)和CPU开销
-
-| Pool size | CPU(ants)% | CPU(runtime.gcBgMarkWorker)% | CPU(runtime.mcall)% | 内存(runtime.allocm)kB | 内存(runtime.gcBgMarkWorker)kB | 内存(root) |
-| ------------------- | ---------- | ---------------------------- | ------------------- | ---------------------- | ------------------------------ | ---------- |
-| Two pools(158, 632) | 27.98 | 7.73 | 25.44 | 2050.25 | 512.02 | 8798 |
-| Pool 158 | 28.11 | 6.61 | 25.08 | 2050 | | 6661 |
-| Pool 1580 | 27.41 | 12.96 | 23.17 | 3075.38 | | 10264 |
-| Pool 7900 | 25.89 | 9.82 | 22.52 | 3587.94 | | 5725 |
-| Pool 790000 | 25.12 | 12.79 | 23.44 | 3075.38 | | 9748 |
-
-runtime.gcBgMarkWorker: 用于标记垃圾对象
-
-从上面的表格可以看到,可能存在多核的影响,所以对于我们公司现在需要的并发数量级来讲,pool的size对系统影响并不大。
\ No newline at end of file
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.001.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.001.png"
deleted file mode 100644
index 33885b93a..000000000
Binary files "a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.001.png" and /dev/null differ
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.002.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.002.png"
deleted file mode 100644
index e69de29bb..000000000
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.003.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.003.png"
deleted file mode 100644
index e69de29bb..000000000
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.004.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.004.png"
deleted file mode 100644
index e69de29bb..000000000
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.005.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.005.png"
deleted file mode 100644
index e69de29bb..000000000
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.006.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.006.png"
deleted file mode 100644
index e69de29bb..000000000
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.007.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/Aspose.Words.093a76ac-457b-4498-a472-7dbea580bca9.007.png"
deleted file mode 100644
index e69de29bb..000000000
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/index.md" "b/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/index.md"
deleted file mode 100644
index 8f817409e..000000000
--- "a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-DevLake\346\230\257\346\200\216\344\271\210\350\267\221\350\265\267\346\235\245\347\232\204/index.md"
+++ /dev/null
@@ -1,144 +0,0 @@
-# DevLake是怎么跑起来的
-
-[DevLake](https://github.com/merico-dev/lake) 是一个DevOps数据收集和整合工具,通过 Grafana 为开发团队呈现出不同阶段的数据,让团队能够以数据为驱动改进开发流程。
-
-### DevLake 架构概述
-- 左边是[可集成的DevOps数据插件](https://www.devlake.io/docs/DataModels/DataSupport),目前已有的插件包括 Github,Gitlab,JIRA,Jenkins,Tapd,Feishu 以及思码逸主打的代码分析引擎
-- 中间是主体框架,通过主体框架运行插件中的子任务,完成数据的收集,扩展,并转换到领域层,用户可以通过 config-ui 或者 api 调用的形式来触发任务
-- RMDBS 目前支持 Mysql 和 PostgreSQL,后期还会继续支持更多的数据库
-- Grafana 可以通过sql语句生成团队需要的各种数据
-
-
-
-> 接下来我们就详细聊一聊系统是怎么跑起来的。
-
-### 系统启动
-
-在我们的 golang 程序启动之前,首先会自动调用各个 package 的 init() 方法,我们主要看看services 包的载入,下面的代码有详细注释:
-
-```go
-func init() {
-var err error
-// 获取配置信息
-cfg = config.GetConfig()
-// 获取到数据库
-db, err = runner.NewGormDb(cfg, logger.Global.Nested("db"))
-// 配置时区
-location := cron.WithLocation(time.UTC)
-// 创建定时任务管理器
-cronManager = cron.New(location)
-if err != nil {
-panic(err)
-}
-// 初始化数据迁移
-migration.Init(db)
-// 注册框架的数据迁移脚本
-migrationscripts.RegisterAll()
-// 载入插件,从cfg.GetString("PLUGIN_DIR")获取到的文件夹中载入所有.so文件,在LoadPlugins方法中,具体来讲,通过调用runner.LoadPlugins将pluginName:PluginMeta键值对存入到core.plugins中
-err = runner.LoadPlugins(
-cfg.GetString("PLUGIN_DIR"),
-cfg,
-logger.Global.Nested("plugin"),
-db,
-)
-if err != nil {
-panic(err)
-}
-// 执行数据迁移脚本,完成数据库框架层各个表的初始化
-err = migration.Execute(context.Background())
-if err != nil {
-panic(err)
-}
-
-// call service init
-pipelineServiceInit()
-}
-
-```
-### DevLake的任务执行原理
-
-**Pipeline的运行流程**
-
-在讲解Pipeline流程之前,我们需要先解释一下[Blueprint](https://www.devlake.io/docs/glossary/#blueprints)。
-
-Blueprint是一个定时任务,包含了需要执行的子任务以及执行计划。Blueprint 的每一次执行记录是一条Historical Run(也称为 Pipeline),代表 DevLake 一次触发,通过一个或多个插件,完成了一个或多个数据收集转换的任务。
-
-
-
-以下是 Pipeline 运行流程图:
-
-
-
-一个pipeline包含一个二维数组tasks,主要是为了保证一系列任务按预设顺序执行。如果下图中的 Stage3 的插件需要依赖其他插件准备数据(例如 refdiff 的运行需要依赖 gitextractor 和 github,数据源与插件的更多信息请看[文档](https://www.devlake.io/docs/DataModels/DataSupport)),那么 Stage 3 开始执行时,需要保证其依赖项已在 Stage1 和 Stage2 执行完成:
-
-
-
-**Task的运行流程**
-
-在stage1,stage2,stage3中的各插件任务都是并行执行:
-
-
-
-**接下来就是顺序执行插件中的子任务**
-
-
-
-1. RunTask 之前的工作都是在准备 RunTask 方法需要的参数,比如 logger,db,context 等等。
-2. RunTask 方法中主要是对数据库中的tasks进行状态更新,同时,准备运行插件任务的 options(把从 config-ui 传过来的 json 转成 map 传到 RunPluginTask 中)
-3. RunPluginTask 首先通过 core.GetPlugin(pluginName) 获取到对应 [PluginMeta](#pm),然后通过 PluginMeta 获取到 [PluginTask](#pt),再执行 RunPluginSubTasks
-
-**每一个插件子任务的运行流程(涉及到的 interface 及 func 会在[下一节](#DevLake中的重要接口)详细阐述)**
-
-
-
-1. 通过调用SubTaskMetas()获取到所有插件所有的可用子任务[subtaskMeta](#stm)
-2. 通过`options["tasks"]`以及subtaskMeta组建需要执行的子任务集合subtaskMetas
-3. 计算总共多少个子任务
-4. 通过`helper.NewDefaultTaskContext`构建[taskCtx](#tc)
-5. 调用`pluginTask.PrepareTaskData`构建[taskData](#td),
-6. 接下来迭代subtaskMetas里面的所有子任务
- 1. 通过`taskCtx.SubTaskContext(subtaskMeta.Name)`获取到子任务的[subtaskCtx](#sc)
- 2. 执行[`subtaskMeta.EntryPoint(subtaskCtx)`](#step)
-### DevLake中的重要接口
-1. <a id="pm">PluginMeta</a>: 包含了插件最基本的两个方法,所有插件都需要实现,系统启动的时候存在core.plugins中,在执行插件任务的时候通过core.GetPlugin获取
-
-```go
-type PluginMeta interface {
- Description() string
- //PkgPath information will be lost when compiled as plugin(.so), this func will return that info
- RootPkgPath() string
-}
-
-```
-2. <a id="pt">PluginTask</a>: 通过PluginMeta获取,插件实现这个方法之后,Framework就能直接运行子任务,而不是扔给插件自己去执行,最大的好处就是插件的子任务实现更加简单,在插件运行当中,我们也可以更容易的去干涉(比如增加日志等等)
-
-```go
-type PluginTask interface {
- // return all available subtasks, framework will run them for you in order
- SubTaskMetas() []SubTaskMeta
- // based on task context and user input options, return data that shared among all subtasks
- PrepareTaskData(taskCtx TaskContext, options map[string]interface{}) (interface{}, error)
-}
-```
-3. 每个插件还有一个<a id="td">taskData</a>,里面包含了配置选项,apiClient以及一些插件其它属性(比如github有Repo信息)
-4. <a id="stm">SubTaskMeta</a>: 一个子任务的元数据,每个子任务都会定义一个SubTaskMeta
-
-
-```go
-var CollectMeetingTopUserItemMeta = core.SubTaskMeta{
- Name: "collectMeetingTopUserItem",
- EntryPoint: CollectMeetingTopUserItem,
- EnabledByDefault: true,
- Description: "Collect top user meeting data from Feishu api",
-}
-```
-5. <a id="ec">ExecContext</a>: 定义了执行(子)任务需要的所有资源
-6. <a id="stc">SubTaskContext</a>: 定义了执行子任务所需要的资源(包含了ExecContext)
-7. <a id="tc">TaskContext</a>: 定义了执行插件任务所需要的资源(包含了ExecContext)。与SubTaskContext的区别在于SubTaskContext中的TaskContext()方法可以返回TaskContext,而TaskContext中的方法SubTaskContext(subtask string)方法可以返回SubTaskContext,子任务隶属于插件任务,所以把这两个Context进行了区分
-8. <a id="step">SubTaskEntryPoint</a>: 所有的插件子任务都需要实现这个函数,这样才能由框架层统一协调安排
-
-### 后续
-
-这篇文章介绍了 DevLake 的架构以及运行流程,还有三个核心 api\_collector、api\_extractor 和 data\_convertor 将会在下一篇文章进行剖析。
-
-
diff --git a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/0.11-architecture-diagram.jpg b/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/0.11-architecture-diagram.jpg
deleted file mode 100644
index 21b6df159..000000000
Binary files a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/0.11-architecture-diagram.jpg and /dev/null differ
diff --git a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/Dashboard-1.jpg b/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/Dashboard-1.jpg
deleted file mode 100644
index ea0ba8cd3..000000000
Binary files a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/Dashboard-1.jpg and /dev/null differ
diff --git a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/Dashboard-2.jpg b/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/Dashboard-2.jpg
deleted file mode 100644
index b33d6a8d1..000000000
Binary files a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/Dashboard-2.jpg and /dev/null differ
diff --git a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/incubation-screenshot.jpg b/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/incubation-screenshot.jpg
deleted file mode 100644
index c841b2695..000000000
Binary files a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/incubation-screenshot.jpg and /dev/null differ
diff --git a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/index.md b/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/index.md
deleted file mode 100644
index f5c72c709..000000000
--- a/i18n/zh/docusaurus-plugin-content-blog/2022-05-18-apache-welcomes-devLake/index.md
+++ /dev/null
@@ -1,126 +0,0 @@
----
-slug: apache-welcomes-devlake
-title: DevLake 加入 Apache 孵化器,来和我们一起玩开源!
-authors: weisi
-tags: [devlake, apache]
----
-
-4 月 29 日,开源研发数据平台 DevLake 通过投票决议,正式成为 Apache 软件基金会 (ASF) 的孵化项目。
-
-
-
-进入孵化器后,DevLake 将遵循 [The Apache Way](https://www.apache.org/theapacheway/index.html),在导师们的引导下,坚持以人为本、社区高于代码的理念,持续建设包容、多元、崇尚知识的社区。
-
-<!--truncate-->
-
-
-### DevLake 主要特性
-
-
-作为开源的研发数据平台,DevLake 向软件研发团队提供自动化、一站式的数据收集、分析以及可视化能力,帮助研发团队借助数据更好地理解开发过程,挖掘关键瓶颈与提效机会。
-
-
-#### 归集 DevOps 全流程效能数据,连接数据孤岛
-
-针对 DevOps 工具链复杂、数据收集难的痛点,DevLake 将需求-设计-开发-测试-交付-运营全流程、不同工具的效能数据汇集于一个平台,避免用户重复造轮子。
-
-这些数据可以互相关联分析,进而更加准确、全面地刻画研发过程。举个例子,在了解项目 bug 修复的近况时,不仅可以了解已修复 bug 的个数,还可以了解这些 bug 的分布、bug 修复相关的代码工作量、所占总工作量比例等信息。
-
-当前 DevLake 已支持主流项目管理工具 [JIRA cloud](https://github.com/apache/incubator-devlake/tree/main/plugins/jira)、[JIRA server](https://github.com/apache/incubator-devlake/tree/main/plugins/jira)、[TAPD](https://github.com/apache/incubator-devlake/tree/main/plugins/tapd),代码托管工具 [Git](https://github.com/apache/incubator-devlake/tree/main/plugins/gitextractor)、[GitHub](https://github.com/apache/incubator-devlake/tree/main/plugins/github)、[GitLab](https://github.com/apache/incubator-devlake/tree/main/ [...]
-
-数据源列表正在快速拓展中,您可以查看 Apache DevLake 已支持数据的[详细文档](https://devlake.apache.org/docs/DataModels/DataSupport),同时非常欢迎[参与贡献新的数据源插件](https://github.com/apache/incubator-devlake/blob/main/plugins/README.md)!
-
-
-#### 标准化研发数据模型和开箱即用的效能指标
-
-研发过程数据的标准化程度低,用户难以直接使用这些数据进一步分析;而效能指标定义与计算方法模糊,又给研发数据的应用带来了额外的成本。
-
-Apache DevLake 提供了便捷的数据转化能力,将收集来的数据清洗转换为[标准数据模型](https://devlake.apache.org/docs/DataModels/DevLakeDomainLayerSchema),并基于标准模型生成一系列[研发效能指标](https://devlake.apache.org/docs/category/metrics),对用户来说简单易懂、开箱即用。一方面节省了治理数据和定义指标的成本,另一方面使效能指标更加透明,便于研发数据的应用落地。
-
-目前 Apache DevLake 已支持 20+常见研发效能指标,可应用于交付效率、质量、成本、能力等不同认知域。
-
-结合用户使用研发数据的具体场景,Apache DevLake 基于 Grafana 搭建数据看板,支持趋势分析、按照成员/阶段下钻等分析能力,帮助用户快速定位研发效能提升的关键环节。您可以查看[预设数据看板](https://devlake.apache.org/livedemo),后续我们将在 blog 中介绍每一个数据看板及其背后的真实用户场景。
-
-
-
-
-
-
-
-#### 灵活的数据源插件系统及数据处理框架,支持自定义
-
-Apache DevLake 将数据加工、关联与转换的底层能力开放出来,提供可拓展的数据底座。
-用户可以根据实际需求,实现以下自定义:
-
-- 数据源自定义:Apache DevLake 基于 Golang plugin 系统设计了灵活的插件系统,支持用户独立开发接入任意 DevOps 工具
-- 数据实体自定义:基于 dbt 插件,支持用户自定义数据转换模型
-- 效能指标自定义:支持用户基于数据模型自定义指标,或调整指标计算方式
-- 数据看板自定义:SQL 查询,在 Grafana 中拖拽搭建数据看板
-
-以下是 [Apache DevLake 架构图](https://github.com/apache/incubator-devlake/blob/main/ARCHITECTURE.md):
-
-
-
-
-
-
-### 未来规划
-
-#### 技术与产品方面
-
-- 集成更多数据源,覆盖整个软件开发生命周期 (SDLC)
-- 提供更丰富的研发数据分析场景,与用户共建 Dashboard,实现更进一步的开箱即用
-- 提升灵活性,用户能够根据自身业务需求,轻松地自定义数据模型和指标
-- 优化用户体验,降低安装、配置、收集的成本,使用户专注数据分析
-- 增强系统可伸缩性, 提升大规模数据场景下的系统性能
-
-#### 社区建设方面
-
-- 组织多种多样的社区活动,积极进行线上和线下技术布道,吸引更多用户、开发者和开源爱好者参与到 DevLake 的社区中来
-- 打造开放、友好的交流环境,完善和丰富 DevLake 相关内容体系,完善用户文档和贡献指南,降低用户使用和参与门槛,向社区提供更及时的响应,积极与用户互动,解决用户问题并进一步促进项目迭代
-- 积极与其他开源项目和社区展开合作,让更多生态合作伙伴了解和参与到 DevLake 社区,共建繁荣生态
-
-
-
-### 为什么加入 ASF 孵化器
-
-首先,DevLake 相信 The Apache way 是社区成功之道,以人为本开放、社区高于代码等理念将帮助 DevLake 健康、持续地成长。
-
-其次,DevLake 和数据基建相关,与 Apache 基金会的关注点高度契合。DevLake 期待与 Apache 生态的其他大数据开源项目共同发展,共建生态。
-
-
-### 导师介绍
-
-- [姜宁](https://github.com/WillemJiang):DevLake Champion,ASF Member,同时也今年当选的 Apache 董事
-- [张亮](https://github.com/terrymanu):SphereEx 公司创始人 & CEO,ASF Member,Apache ShardingSphere 创始人 & PMC Chair
-- [代立冬](https://github.com/dailidong):白鲸开源联合创始人,ASF Member,Apache DolphinScheduler PMC Chair
-- [郭斯杰](https://github.com/sijie):ASF Member, PMC Member on Apache Pulsar,StreamNative 创始人 & CEO
-- [Felix Cheung](https://github.com/felixcheung): ASF Member,Apache Zeppelin、Spark、SuperSet、YuniKorn、Pinot 等项目 PMC,SafeGraph 技术高级副总裁
-- [Jean-Baptiste Onofré](https://github.com/jbonofre):ASF Member,Karaf PMC Chair,ActiveMQ、Archiva、Aries、Beam、Brooklyn、Camel、Carbondata、Felix 等项目 PMC
-
-
-
-### 导师寄语
-
-- 姜宁:非常高兴能够成为 DevLake 的开源孵化领路人,帮助 DevLake 加入的 ASF 孵化器。 DevLake 着力于解决软件研发领域数据收集,以及研发瓶颈分析的痛点问题。欢迎对提升软件研发效率感兴趣的小伙伴参与到 DevLake 的使用和开发中来,一同构建繁荣发展的社区生态。
-
-- 张亮:欢迎 Apache 孵化器的新成员 DevLake。它将使工程效能领域的发展更加开放和繁荣,进而推动整个领域的标准化进程。欢迎更多的贡献者参与 ASF 社区,望 DevLake 早日毕业!
-
-- 代立冬:很高兴看到 DevLake 加入到 Apache 孵化器,DevLake 是一个专为开发团队分析和提高工程生产力的平台,欢迎广大的开发伙伴们一起参与让 DevLake 社区更加繁荣、早日成为顶级项目!
-
-- 郭斯杰:祝贺 DevLake 进入 Apache 软件基金会孵化器,这是 DevLake 走向世界的一大步,期待有更多技术爱好者和用户加入,共建繁荣。祝社区快速成长成为顶级项目,成为研发数据平台的中流砥柱。
-
-
-
-### 如何参与 DevLake 社区?
-
-DevLake 的发展离不开社区用户的支持,欢迎所有人参与社区建设,让 DevLake 越来越有生命力🥳
-
-- 加入社群
- - 加入 [Slack]( https://join.slack.com/t/devlake-io/shared_invite/zt-18uayb6ut-cHOjiYcBwERQ8VVPZ9cQQw)
- - 点击下方代码仓库地址 > Readme > 扫描微信群二维码
-- DevLake 代码仓库:https://github.com/apache/incubator-devlake/
-- DevLake 官网:https://devlake.apache.org/
-- DevLake Podling Website:https://incubator.apache.org/projects/devlake.html
-- 如何参与贡献:https://github.com/apache/incubator-devlake#how-to-contribute
-- 订阅邮件列表了解动态:dev@devlake.incubator.apache.org
\ No newline at end of file
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-05-20-\345\246\202\344\275\225\350\264\241\347\214\256issues/index.md" "b/i18n/zh/docusaurus-plugin-content-blog/2022-05-20-\345\246\202\344\275\225\350\264\241\347\214\256issues/index.md"
deleted file mode 100644
index 8c2355d80..000000000
--- "a/i18n/zh/docusaurus-plugin-content-blog/2022-05-20-\345\246\202\344\275\225\350\264\241\347\214\256issues/index.md"
+++ /dev/null
@@ -1,31 +0,0 @@
-# 如何贡献issue
-
-上周(2022-05-12),我们以先到先得的方式为大家列出了两个"good first issue"。
-这很有趣,它们几乎立刻就被拿走了......
-但对于那些有兴趣但没有得到的人来说可能就不那么有趣了。
-
-### 所以...
-
-我们决定,不再有竞争,你可以从我们的github issue pages中挑选你喜欢的issue。如果没有了,甚至可以创建你自己的。
-我们毕竟是社区!
-
-### 怎么做呢?这很简单!
-
-进入我们的[问题页面](https://github.com/apache/incubator-devlake/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22),然后点击这里。我们所有的Good First Issue都列在这里!
-
-
-- 首先,寻找现有的issues,找到一个你喜欢的。
- 你可以通过评论"I'll take it!"来预订它。
- 接下来你可以写一份“攻略”,以展示你对问题的理解和你将采取什么样的步骤来解决这个issue,然后开始Coding。
-
-- 如果没有GFI了怎么办?创造你自己的issue! 现在,通过查看我们的代码库。
- 你肯定能发现很多问题,比如文档、单元测试,甚至是错字。
- 把你觉得不对的地方提出来,我们会验证它是否必要,
- 然后你就可以开始Coding了。
-
-- 最后,你可能会问,我为什么要费尽心思为你写代码?
- 不不不,你不是为我们写代码,你是为社区里的每个人写代码,你是为自己写代码。
- 为了提高你的技能,为了学习如何与他人合作。而对于那些做出重大贡献的人,
- 我们为您提供一个Apache Committer的席位,甚至是PPMC!
-
-### 就这些了,有任何问题请随时提出。编码快乐!
diff --git a/i18n/zh/docusaurus-plugin-content-blog/2022-05-25-what-did-we-do-during-march-april/index.md b/i18n/zh/docusaurus-plugin-content-blog/2022-05-25-what-did-we-do-during-march-april/index.md
deleted file mode 100644
index 09940dab7..000000000
--- a/i18n/zh/docusaurus-plugin-content-blog/2022-05-25-what-did-we-do-during-march-april/index.md
+++ /dev/null
@@ -1,65 +0,0 @@
----
-slug: what-did-we-do-during-march-april
-title: 3-4月份我们干了些什么?
-authors: klesh
-tags: [devlake, refactor]
----
-
-## 引述
-
-自去年7月份 DevLake kicked off 以来,项目一直处于被各种 demo / event 追赶的状态,为此,我们放弃了很多,比如代码风格,单元测试,代码注释,文档的维护,issue的维护,用户的友好性等。当然,也不是说完全一点没有,只是在大面上,项目总体呈一种野蛮生长的状态。大家对项目的期望也一直是能“跑起来就行”,“主流程正常就OK”,至于一些稳定性,对异常情况的忍耐度,嗯,大抵只用重启大法解决。这说明了,项目整体代码质量存在着基础不稳的情况,需要夯实,架构上也需要演进,帮助插件最大程度地解决一些共性的问题。
-
-没有一种架构,或者具体到设计,是万能的,可以解决一切的问题。不基于实际情况,凭空去猜想,再做出设计,其结果容易过度优化,甚至更糟,比如,由于现实与理想差距过大,导致整个设计要推倒重来。从这个角度来看,野蛮生长也并不完全是一件坏事,早期我们有很多要怎么怎么做,处理哪些哪些场景的讨论,怎么满足用户画象1的前提下,同时兼顾画像2的情景等等。要考虑的情况太多了,要不要队列?要不要多级队列?任务编排怎么做?要不要做DAG?结果是谁也说服不了谁,因为A提出的方案,随即就会有B提出一种或多种情况是该方案无法解决的,而大家又不能确定A方案要解决的问题到底有多严重,或者B提出的情况会不会出现?幸运的是,我们最后放弃了各种高大上的架构,选择在框架级只做了一个简单的任务执行逻辑,把具体的处�
��逻辑都交由插件自行解决,自由发挥。
-
-经过半年多的发展,我们慢慢地发现了一些共通的模式,最终在 3-4 月份实现大爆发:
-
-## 我们发现了什么?
-
-### 数据流的模式
-
-所有的数据源插件,都需要从 api 读取数据 (collection),然后提取(extraction),再转换(conversion)到统一的实体层(Domain Layer Data,比如 jira 的 issue 和 github 的 issue 得统一到 issue 这张表里面),在此之前可能还会有一些维护转换的任务要做,比如基于 jira issue changelog 的信息,归结出 issue 在 sprints 之间的停留时间之类的,我们称之为 enrichment。基本上,这几个类型的任务就能涵盖大多数数据源集成的需要。
-
-在这一条数据流动的路径中,我们发现,最大的瓶颈和难点在于 collection 这一步,包括但不限于:
-
-1. api 会有 rate limit,比如每秒10个,每小时2000个之类
-2. 在 rate limit 的限制下,希望尽量快地拉取数据,并发是必须的
-3. 在并发的情况下,必须支持随时可以取消正在运行的任务
-4. 在遇到可恢复的错误,需要自动化地重试,超限后变成不可恢复的错误
-5. 对于不可恢复的错误,需要记录出错的信息,以便 debug
-
-这上面的每一个问题,单独处理相对简单,但要全部顾及,复杂度直接原地爆炸。如果每个插件都要自己实现一次的话,工作量极大还不好维护,出问题了要一个个地修,非常麻烦。虽然具体的 api 是不同的,但上面这些模式却是相通的,我们就考虑,是不是可以由框架提供某种辅助类来统一地处理。同理,extraction/conversion一样有不少共性的操作,可以由框架来提供相应的辅助类,使得插件开发的工作量极大缩小。这便是我们的重头戏之一 **提供一系列 subtask helpers 来减轻插件的开发和维护的负担**。
-
-从 api 获取数据(collection),还存在着另一个问题,就是拉取数据所花费的时间与数据源的规模成正比,这个过程往往是整个数据流程中的耗时最长的,因为不同于其它的任务只依赖于自身数据库,它依赖的是外部数据源,除了规模,还要要受网络延时的影响,还有 api 的速率限制等因素的影响。按原有的设计,数据的拉取和提取(collection/extraction)是在一个任务里面同时进行的,一步到位存储到数据库。这样的实现虽然简单,但有一个很大的弊端,就是 api 返回的数据,有很大一部分被直接丢弃了,当后续的任务需要重跑时,就需要重新去 api 拉取。举个例子,JIRA 插件中的 Issue 实体中,我们需要提取它是属于哪个 Epic 的,而在 JIRA API 中,Epic 这个属于是通过 自定义字段的功能实现的,它在 Issue 结构体中的属性名大概是 `customfield_1234` 这样,其中 `123
4` 在每个 JIRA 的实例都不一样,这就需要用户进行配置,我们才能知道取哪个属性作为 Epic 信息,而一旦用户配错了,就得重跑整个流程,奇慢无比。为此, [...]
-
-### 用户对于数据定制的需要
-
-其实,支持用户对 DevLake 进行定制化,一直是我们的方针。早期我们更关注的是对于图表的定制化,数据层面的定制性基本没有。具体地讲,用户可能需要基于我们现有的表,汇总出一些新的表,或者我们预置的表结构不够方便,他想要自己转化出一些宽表。又或者,他想导入自己的一些表,然后与我们的表进行整合?虽然,原则上,这些事都可以通过写插件的方式来实现,但考虑到我们的用户群体可能有不少是是数据分析师,让他们去写 golang 插件还是有一定门槛。因此,我们开发了 **dbt插件** ,用户可以基于 sql 编写自己的转换逻辑,可编入 DevLake 的 pipeline 接受统一调度,简单地说就是用户可以在原有的任务执行流程中插入他需要的 dbt 任务 。
-
-### 大用户的吞吐
-
-直到 v0.9,DevLake 都只是单机模式,也就是说,所有的任务都只能在一台机器上面执行。这对大部分的用户来讲,也就够用了。但体量大的用户也是存在的,当用户需要同步的数据太多,分布太广的时候,单机的吞吐量是个极大的限制。为了解决这个问题,我们支持了 **基于 temporal 的分布式执行** 模式。整个系统拆成 server 和 worker 两部分,server 接受任务请求,具体的任务由 worker 执行。这听起来是个简单的事情,然而却对我们架构提出了重大挑战,原因是在单机模式下,我们所有的子任务,都直接依赖了一些全局资源,比如说,数据库,日志这些。也许你会认为,这没啥大不了的吧,全局就全局呗,只要在 worker 启动之前把这些全局变量初始化好不就行了吗?是的,但那远远称不上是一个合理的设计,更加不是一个优雅的模式。假设,要是这个�
�据库连接变了呢?难道得把所有的 server / workers 的配置都手动改一下,然后重启吗?还有太多其它的问题,就不一一提了,都是些分布式系统要考虑基本问题。所以,最合理的做法,是把这些子任务全部进行解耦,所有依赖的资源, [...]
-
-### 升级竟然要 drop database?
-
-是的,在 v0.9 及之前的版本,所有的的升级,需要把原来的数据库给干掉,才能确保系统能正常运行。虽说 DevLake 本身没有什么业务数据,只要重新同步一下,总能得到相同的结果。但操作起来一是别扭,二是耗费时间。DevLake 支持数据库迁移的难点在于,不同于一般的商业系统,在升级的时候由专门的人员针对特定数据库跑一下 sql 脚本就行。我们希望我们的数据迁移是全自动化的,智能的,还同时能兼容各种关系型数据库。在经过长期的调研和各种 battle ,我们基于 gorm 的 Migrator 设计了一套适 DevLake 的 **db migration 系统**。不需要用户干预,直接换镜像版本,启动后自动升级。
-
-### 插件接口的拆分
-
-以前,我们的插件只需要实现唯一的一个接口 `Plugin`,这个接口定义了所有插件可能会提供的功能,比如说插件一般会需要跑任务,对外暴露 api ,在初始化的时候做一些事情,或者声明自己的 db migration scripts 等等。慢慢地,我们发现,这样很不科学:如果一个插件它没有 api ,也一样要实现这个方法,否则它就不会被系统认可。那么,接口拆分就是顺理成章的事情。于是乎,秉承着一不做二不休的理念,我们把它按功能拆分到最小粒度,分别是`PluginMeta/PluginInit/PluginTask/PluginApi/PluginDbMigration`等接口,而唯一必须要实现的接口是 `PluginMeta`,其它的,则是根据插件自身能提供的,或者需要的功能进行选择性实现。
-
-### 其它
-
-除此以后,还有进度明细的优化,日志的优化,canceling 优化等等, 点太多了,也有很多细节由于时间关系来不及一一覆盖。
-
-## 总结与展望
-
-经过这次重构,我总结了几点经验:
-
-- 对于不确定性太高的系统,不要着急进行设计,过多的讨论也没有意义,不如有一个简陋的框架先跑起来再说
-- 站在用户角度去考虑,从具体的场景出发,解决实际的问题比什么都重要
-- 优先考虑绝大多数用户的需要,但也不能放弃少数派的用户,因为他们的价值很高
-- 有时候现成的轮子,不一定有自己造的好用,要根据自己的场景仔细去分析,结合工作量进行考量
-
-这两个月以来,我们完成的事情,在我看来,是平时半年都未必做得完的。能达到这个程度,我们放弃了很多,比如说流程上,简化了,测试全靠手工,文档凑合着写,等等。最重要的是,全体小伙伴毫无怨言地全力付出!很感谢全体 DevLake 成员的奉献,你们是我遇到过所有战友中最棒的。
-
-现在 DevLake 还是有很多不足,从技术上看,缺少测试/完善的文档是个硬伤。从用户体验上来看,也不够流畅。而现在,我们也正式进入了 apache incubator ,希望在不远的将来,我们能很好地解决这些问题,更进一步,接受更大的挑战!
\ No newline at end of file
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/Architecture_Diagram.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/Architecture_Diagram.png"
deleted file mode 100644
index ab45e7fc5..000000000
Binary files "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/Architecture_Diagram.png" and /dev/null differ
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/index.md" "b/i18n/zh/docusaurus-plugin-content-blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/index.md"
deleted file mode 100644
index 9a83f3694..000000000
--- "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/index.md"
+++ /dev/null
@@ -1,239 +0,0 @@
----
-slug: apache-devlake-codebase-walkthrough
-title: Apache DevLake代码库导览
-authors: abeizn
-tags: [devlake, codebase]
----
-
-# Apache DevLake 代码库导览
-### Apache DevLake是什么?
-研发数据散落在软件研发生命周期的不同阶段、不同工作流、不同DevOps工具中,且标准化程度低,导致效能数据难以留存、汇集并转化为有效洞见。为了解决这一痛点,[Apache DevLake](https://github.com/apache/incubator-devlake) 应运而生。Apache DevLake是一款开源的研发数据平台,它通过提供自动化、一站式的数据收集、分析以及可视化能力,帮助研发团队更好地理解开发过程,挖掘关键瓶颈与提效机会。
-
-
-### Apache DevLake架构概述
-
-<center>Apache DevLake 架构图</center>
-<br />
-
-- Config UI: 人如其名,配置的可视化,其主要承载Apache DevLake的配置工作。通过Config UI,用户可以建立数据源连接,并实现数据的收集范围,部分数据的转换规则,以及收集频率等任务。
-- Api Sever:Apache DevLake的Api接口,是前端调用后端数据的通道。
-- Runner:Apache DevLake运行的底层支撑机制。
-- Plugins:具体执行的插件业务,主要承载Apache DevLake的后端数据收集、扩展和转换的工作。除dbt插件外的插件产出Apache DevLake的预置数据,预置数据主要包括三层;
- - raw layer:负责储存最原始的api response json。
- - tool layer:根据raw layer提取出此插件所需的数据。
- - domain layer:根据tool layer层抽象出共性的数据,这些数据会被使用在Grafana图表中,用于多种研发指标的展示。
-- RDBS: 关系型数据库。目前Apache DavLake支持MySQL和PostgreSQL,后期还会继续支持更多的数据库。
-- Grafana Dashboards: 其主要承载Apache DevLake的前端展示工作。根据Apache DevLake收集的数据,通过sql语句来生成团队需要的交付效率、质量、成本、能力等各种研发效能指标。
-
-### 目录结构Tree
-```
-├── api
-│ ├── blueprints
-│ ├── docs
-│ ├── domainlayer
-│ ├── ping
-│ ├── pipelines
-│ ├── push
-│ ├── shared
-│ ├── task
-│ └── version
-├── config
-├── config-ui
-├── devops
-│ └── lake-builder
-├── e2e
-├── errors
-├── grafana
-│ ├── _archive
-│ ├── dashboards
-│ ├── img
-│ └── provisioning
-│ ├── dashboards
-│ └── datasources
-├── img
-├── logger
-├── logs
-├── migration
-├── models
-│ ├── common
-│ ├── domainlayer
-│ │ ├── code
-│ │ ├── crossdomain
-│ │ ├── devops
-│ │ ├── didgen
-│ │ ├── ticket
-│ │ └── user
-│ └── migrationscripts
-│ └── archived
-├── plugins
-│ ├── ae
-│ │ ├── api
-│ │ ├── models
-│ │ │ └── migrationscripts
-│ │ │ └── archived
-│ │ └── tasks
-│ ├── core
-│ ├── dbt
-│ │ └── tasks
-│ ├── feishu
-│ │ ├── apimodels
-│ │ ├── models
-│ │ │ └── migrationscripts
-│ │ │ └── archived
-│ │ └── tasks
-│ ├── gitextractor
-│ │ ├── models
-│ │ ├── parser
-│ │ ├── store
-│ │ └── tasks
-│ ├── github
-│ │ ├── api
-│ │ ├── models
-│ │ │ └── migrationscripts
-│ │ │ └── archived
-│ │ ├── tasks
-│ │ └── utils
-│ ├── gitlab
-│ │ ├── api
-│ │ ├── e2e
-│ │ │ └── tables
-│ │ ├── impl
-│ │ ├── models
-│ │ │ └── migrationscripts
-│ │ │ └── archived
-│ │ └── tasks
-│ ├── helper
-│ ├── jenkins
-│ │ ├── api
-│ │ ├── models
-│ │ │ └── migrationscripts
-│ │ │ └── archived
-│ │ └── tasks
-│ ├── jira
-│ │ ├── api
-│ │ ├── models
-│ │ │ └── migrationscripts
-│ │ │ └── archived
-│ │ └── tasks
-│ │ └── apiv2models
-│ ├── refdiff
-│ │ ├── tasks
-│ │ └── utils
-│ └── tapd
-│ ├── api
-│ ├── models
-│ │ └── migrationscripts
-│ │ └── archived
-│ └── tasks
-├── releases
-│ ├── lake-v0.10.0
-│ ├── lake-v0.10.0-beta1
-│ ├── lake-v0.10.1
-│ ├── lake-v0.7.0
-│ ├── lake-v0.8.0
-│ └── lake-v0.9.0
-├── runner
-├── scripts
-├── services
-├── test
-│ ├── api
-│ │ └── task
-│ └── example
-├── testhelper
-├── utils
-├── version
-├── worker
-├── Dockerfile
-├── docker-compose.yml
-├── docker-compose-temporal.yml
-├── k8s-deploy.yaml
-├── Makefile
-└── .env.exemple
-
-
-```
-
-### 目录导览
-- 后端部分:
- - config:对.env配置文件的读、写以及修改的操作。
- - logger:log日志的level、format等设置。
- - errors:Error的定义。
- - utils:工具包,它包含一些基础通用的函数。
- - runner:提供基础执行服务,包括数据库,cmd,pipelines,tasks以及加载编译后的插件等基础服务。
- - models:定义框架级别的实体。
- - common:基础struct定义。
- - [domainlayer](https://devlake.apache.org/docs/DataModels/DevLakeDomainLayerSchema):领域层是来自不同工具数据的通用抽象。
- - ticket:Issue Tracking,即问题跟踪领域。
- - code:包括Source Code源代码关联领域。以及Code Review代码审查领域。
- - devops:CI/CD,即持续集成、持续交付和持续部署领域。
- - crossdomain:跨域实体,这些实体用于关联不同领域之间的实体,这是建立全方面分析的基础。
- - user:对用户的抽象领域,user也属于crossdomain范畴。
- - migrationscripts:初始化并更新数据库。
- - plugins:
- - core:插件通用接口的定义以及管理。
- - helper:插件通用工具的集合,提供插件所需要的辅助类,如api收集,数据ETL,时间处理等。
- - 网络请求Api Client工具。
- - 收集数据Collector辅助类,我们基于api相同的处理模式,统一了并发,限速以及重试等功能,最终实现了一套通用的框架,极大地减少了开发和维护成本。
- - 提取数据Extractor辅助类,同时也内建了批量处理机制。
- - 转换数据Convertor辅助类。
- - 数据库处理工具。
- - 时间处理工具。
- - 函数工具。
- - ae:分析引擎,用于导入merico ae分析引擎的数据。
- - feishu:收集飞书数据,目前主要是获取一段时间内组织内会议使用的top用户列表的数据。
- - github:收集Github数据并计算相关指标。(其他的大部分插件的目录结构和实现功能和github大同小异,这里以github为例来介绍)。
- - github.go:github启动入口。
- - tasks:具体执行的4类任务。
- - *_collector.go:收集数据到raw layer层。
- - *_extractor.go:提取所需的数据到tool layer层。
- - *_convertor.go:转换所需的数据到domain layer层。
- - *_enricher.go:domain layer层更进一步的数据计算转换。
- - models:定义github对应实体entity。
- - api:api接口。
- - utils:github提取的一些基本通用函数。
- - gitextractor:git数据提取工具,该插件可以从远端或本地git仓库提取commit和reference信息,并保存到数据库或csv文件。用来代替github插件收集commit信息以减少api请求的数量,提高收集速度。
- - refdiff:在分析开发工作产生代码量时,经常需要知道两个版本之间的diff。本插件基于数据库中存储的commits父子关系信息,提供了计算ref(branch/tag)之间相差commits列表的能力。
- - gitlab:收集Gitlab数据并计算相关指标。
- - jenkins:收集jenkins的build和job相关指标。
- - jira:收集jira数据并计算相关指标。
- - tapd:收集tapd数据并计算相关指标。
- - dbt:(data build tool)是一款流行的开源数据转换工具,能够通过SQL实现数据转化,将命令转化为表或者视图,提升数据分析师的工作效率。Apache DevLake增加了dbt插件,用于数据定制的需要。
- - services:创建、管理Apache DevLake各种服务,包含notifications、blueprints、pipelines、tasks、plugins等。
- - api:使用Gin框架搭建的一个通用Apache DevLake API服务。
-- 前端部分:
- - congfig-ui:主要是Apache DevLake的插件配置信息的可视化。[一些术语的解释](https://devlake.apache.org/docs/Glossary)
- - 常规模式
- - blueprints的配置。
- - data connections的配置。
- - transformation rules的配置。
- - 高级模式:主要是通过json的方式来请求api,可选择对应的插件,对应的subtasks,以及插件所需要的其他信息。
- - Grafana:其主要承载Apache DevLake的前端展示工作。根据收集的数据,通过sql语句来生成团队需要的各种数据。目前sql主要用domain layer层的表来实现通用数据展示需求。
-- migration:数据库迁移工具。
- - migration:数据库迁移工具migration的具体实现。
- - models/migrationscripts:domian layer层的数据库迁移脚本。
- - plugins/xxx/models/migrationscripts:插件的数据库迁移脚本。主要是_raw_和_tool_开头的数据库的迁移。
-- 测试部分:
- - testhelper和plugins下的*_test.go文件:即单元测试,属于白盒测试范畴。针对目标对象自身的逻辑,执行路径的正确性进行测试,如果目标对象有依赖其它资源或对够用,采用注入或者 mock 等方式进行模拟,可以比较方便地制造一些难以复现的极端情况。
- - test:集成测试,灰盒测试范畴。在单元测试的基础上,将所有模块按照设计要求(如根据结构图)组装成为子系统或系统,进行集成测试。
- - e2e: 端到端测试,属于黑盒测试范畴。相对于单元测试更注重于目标自身,e2e更重视目标与系统其它部分互动的整体正确性,相对于单元测试着重逻辑测试,e2e侧重于输出结果的正确性。
-- 编译,发布部分:
- - devops/lake-builder: mericodev/lake-builder的docker构建。
- - Dockerfile:主要用于构建devlake镜像。
- - docker-compose.yml:是用于定义和运行多容器Docker应用程序的工具,用户可以使用YML文件来配置Apache DevLake所需要的服务组件。
- - docker-compose-temporal.yml:Temporal是一个微服务编排平台,以分布式的模式来部署Apache DevLake,目前处于试验阶段,仅供参考。
- - worker:Temporal分布式部署形式中的worker实现,目前处于试验阶段,仅供参考。
- - k8s-deploy.yaml:Kubernetes是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。目前Apache DevLake已支持在k8s集群上部署。
- - Makefile:是一个工程文件的编译规则,描述了整个工程的编译和链接等规则。
- - releases:Apache DevLake历史release版本的配置文件,包括docker-compose.yml和env.example。
- - scripts:shell脚本,包括编译plugins脚本。
-- 其他:
- - img:logo、社区微信二维码等图像信息。
- - version:实现版本显示的支持,在正式的镜像中会显示对应release的版本。
- - .env.exemple:配置文件实例,包括DB URL, LOG以及各插件的配置示例信息。
-
-### 如何联系我们
-- Github地址:https://github.com/apache/incubator-devlake
-- 官网地址:https://devlake.apache.org/
-- <a href="https://join.slack.com/t/devlake-io/shared_invite/zt-18uayb6ut-cHOjiYcBwERQ8VVPZ9cQQw" target="_blank">Slack</a>: 通过Slack联系
-- 微信联系:<br />
- 
\ No newline at end of file
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/wechat_community_barcode.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/wechat_community_barcode.png"
deleted file mode 100644
index a7870d727..000000000
Binary files "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-06-Apache-Devlake\344\273\243\347\240\201\345\272\223\345\257\274\350\247\210/wechat_community_barcode.png" and /dev/null differ
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/7b2a6f29-ea2a-4a84-97c8-7eba5a5131a8.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/7b2a6f29-ea2a-4a84-97c8-7eba5a5131a8.png"
deleted file mode 100644
index 099c1e854..000000000
Binary files "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/7b2a6f29-ea2a-4a84-97c8-7eba5a5131a8.png" and /dev/null differ
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/8afb097c-a0b3-4bdc-80f3-7241c3fa566f.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/8afb097c-a0b3-4bdc-80f3-7241c3fa566f.png"
deleted file mode 100644
index 41af9289b..000000000
Binary files "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/8afb097c-a0b3-4bdc-80f3-7241c3fa566f.png" and /dev/null differ
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/df2f9837-121e-4a64-976c-c5039d452bfd.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/df2f9837-121e-4a64-976c-c5039d452bfd.png"
deleted file mode 100644
index c7319595c..000000000
Binary files "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/df2f9837-121e-4a64-976c-c5039d452bfd.png" and /dev/null differ
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/efea0188-80e4-4519-a010-977a7fd5432e.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/efea0188-80e4-4519-a010-977a7fd5432e.png"
deleted file mode 100644
index a9b35cd21..000000000
Binary files "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/efea0188-80e4-4519-a010-977a7fd5432e.png" and /dev/null differ
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/index.md" "b/i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/index.md"
deleted file mode 100644
index 9e7c2a88e..000000000
--- "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-17-Apache-DevLake\345\205\274\345\256\271PostgreSQL\350\270\251\345\235\221\345\260\217\347\273\223/index.md"
+++ /dev/null
@@ -1,180 +0,0 @@
----
-slug: some-practices-of-supporting-postgresql
-title: Apache DevLake 兼容 PostgreSQL 踩坑小结
-authors: ZhangLiang
-tags: [devlake, database, postgresql]
----
-
-# Apache DevLake 兼容 PostgreSQL 踩坑小结
-
-
-本文作者:ZhangLiang
-个人主页:https://github.com/mindlesscloud
-
-Apache DevLake 是一个研发数据平台,可以收集和整合各类研发工具的数据,比如 Jira、Github、Gitlab、Jenkins。
-
-**本文并不打算对数据库兼容这个问题做全面的总结,只是对我们实际遇到的问题做一个记录,希望能对有相似需求的人提供一个参考。**
-
-**1、数据类型差异**
-
-### PostgreSQL 不支持 uint 类型的数据类型
-```go
-type JenkinsBuild struct {
- common.NoPKModel
- JobName string `gorm:"primaryKey;type:varchar(255)"`
- Duration float64 // build time
- DisplayName string // "#7"
- EstimatedDuration float64
- Number int64 `gorm:"primaryKey;type:INT(10) UNSIGNED NOT NULL"`
- Result string
- Timestamp int64 // start time
- StartTime time.Time // convered by timestamp
- CommitSha string
-}
-
-```
-其中的`JenkinsBuild.Number`字段的`gorm` struct tag 使用了`UNSIGNED`会导致建表失败,需要去掉。
-
-
-
-
-### MySQL 没有 bool 型
-对于 model 里定义为 bool 型的字段,gorm 会把它映射成 MySQL 的 TINYINT 类型,在 SQL 里可以直接用 0 或者 1 查询,但是 PostgreSQL 里是有 bool 类型的,所以 gorm 会把它映射成 BOOL 类型,如果 SQL 里还是用的 0 或者 1 去查询就会报错。
-
-以下是一个具体的例子(为了清晰起见我们删掉了无关的字段),下面的查询语句在 MySQL 里是没有问题的,但是在 PostgreSQL 上就会报错。
-```go
-type GitlabMergeRequestNote struct {
- MergeRequestId int `gorm:"index"`
- System bool
-}
-
-db.Where("merge_request_id = ? AND `system` = 0", gitlabMr.GitlabId).
-```
-语句改成这样后仍然会有错误,具体请见下面关于反引号的问题。
-```go
-db.Where("merge_request_id = ? AND `system` = ?", gitlabMr.GitlabId, false)
-```
-
-**2、行为差异**
-
-### 批量插入
-如果使用了`ON CONFLIT UPDATE ALL`从句批量插入的时候,本批次如果有多条主键相同的记录会导致 PostgreSQL 报错,MySQL 则不会。
-
-
-
-
-
-
-### 字段类型 model 定义与 schema 不一致
-例如在 model 定义中`GithubPullRequest.AuthorId`是 int 类型,但是数据库里这个字段是 VARCHAR 类型,插入数据的时候 MySQL 是允许的,PostgreSQL 则会报错。
-```go
-type GithubPullRequest struct {
- GithubId int `gorm:"primaryKey"`
- RepoId int `gorm:"index"`
- Number int `gorm:"index"`
- State string `gorm:"type:varchar(255)"`
- Title string `gorm:"type:varchar(255)"`
- GithubCreatedAt time.Time
- GithubUpdatedAt time.Time `gorm:"index"`
- ClosedAt *time.Time
- // In order to get the following fields, we need to collect PRs individually from GitHub
- Additions int
- Deletions int
- Comments int
- Commits int
- ReviewComments int
- Merged bool
- MergedAt *time.Time
- Body string
- Type string `gorm:"type:varchar(255)"`
- Component string `gorm:"type:varchar(255)"`
- MergeCommitSha string `gorm:"type:varchar(40)"`
- HeadRef string `gorm:"type:varchar(255)"`
- BaseRef string `gorm:"type:varchar(255)"`
- BaseCommitSha string `gorm:"type:varchar(255)"`
- HeadCommitSha string `gorm:"type:varchar(255)"`
- Url string `gorm:"type:varchar(255)"`
- AuthorName string `gorm:"type:varchar(100)"`
- AuthorId int
- common.NoPKModel
-}
-
-```
-
-
-
-
-**3、MySQL 特有的函数**
-
-在一个复杂查询中我们曾经使用了 `GROUP_CONCAT` 函数,虽然 PostgreSQL 中有功能类似的函数但是函数名不同,使用方式也有细微差别。
-
-```go
-cursor2, err := db.Table("pull_requests pr1").
- Joins("left join pull_requests pr2 on pr1.parent_pr_id = pr2.id").Group("pr1.parent_pr_id, pr2.created_date").Where("pr1.parent_pr_id != ''").
- Joins("left join repos on pr2.base_repo_id = repos.id").
- Order("pr2.created_date ASC").
- Select(`pr2.key as parent_pr_key, pr1.parent_pr_id as parent_pr_id, GROUP_CONCAT(pr1.base_ref order by pr1.base_ref ASC) as cherrypick_base_branches,
- GROUP_CONCAT(pr1.key order by pr1.base_ref ASC) as cherrypick_pr_keys, repos.name as repo_name,
- concat(repos.url, '/pull/', pr2.key) as parent_pr_url`).Rows()
-```
-解决方案:
-我们最终决定把` GROUP_CONCAT `函数的功能拆分成两步,先用最简单的 SQL 查询得到排序好的多条数据,然后用代码做聚合。
-
-
-修改后:
-```go
-cursor2, err := db.Raw(
- `
- SELECT pr2.pull_request_key AS parent_pr_key,
- pr1.parent_pr_id AS parent_pr_id,
- pr1.base_ref AS cherrypick_base_branch,
- pr1.pull_request_key AS cherrypick_pr_key,
- repos.NAME AS repo_name,
- Concat(repos.url, '/pull/', pr2.pull_request_key) AS parent_pr_url,
- pr2.created_date
- FROM pull_requests pr1
- LEFT JOIN pull_requests pr2
- ON pr1.parent_pr_id = pr2.id
- LEFT JOIN repos
- ON pr2.base_repo_id = repos.id
- WHERE pr1.parent_pr_id != ''
- ORDER BY pr1.parent_pr_id,
- pr2.created_date,
- pr1.base_ref ASC
- `).Rows()
-```
-
-**4、语法差异**
-
-### 反引号
-某些 SQL 语句中我们使用了反引号,用来保护字段名,以免跟 MySQL 保留字有冲突,这种做法在 PostgreSQL 会导致语法错误。为了解决这个问题我们重新审视了我们的代码,把所有跟保留字冲突的字段名做了修改,同时去掉了 SQL 语句中的反引号。例如刚才提到的这个例子:
-```go
-db.Where("merge_request_id = ? AND `system` = ?", gitlabMr.GitlabId, false)
-```
-解决方案:我们把`system`改个名字`is_system`,这样就可以把反引号去掉。
-```go
-db.Where("merge_request_id = ? AND is_system = ?", gitlabMr.GitlabId, false)
-```
-### 不规范的删除语句
-我们的代码中曾经出现过这种删除语句,这在 MySQL 中是合法的,但是在 PostgreSQL 中会报语法错误。
-```go
-err := db.Exec(`
- DELETE ic
- FROM jira_issue_commits ic
- LEFT JOIN jira_board_issues bi ON (bi.source_id = ic.source_id AND bi.issue_id = ic.issue_id)
- WHERE ic.source_id = ? AND bi.board_id = ?
- `, sourceId, boardId).Error
-```
-解决方案:我们把` DELETE `后面的表别名去掉就可以了。
-
-**了解更多最新动态**
-
-官网:[https://devlake.incubator.apache.org/](https://devlake.incubator.apache.org/)
-
-GitHub:[https://github.com/apache/incubator-devlake/](https://github.com/apache/incubator-devlake/)
-
-Slack:通过 [Slack](https://devlake-io.slack.com/join/shared_invite/zt-18uayb6ut-cHOjiYcBwERQ8VVPZ9cQQw#/shared-invite/email) 联系我们
-
-
-
-
\ No newline at end of file
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/dfs.gif" "b/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/dfs.gif"
deleted file mode 100644
index 73bfc8739..000000000
Binary files "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/dfs.gif" and /dev/null differ
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/dfs.webm" "b/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/dfs.webm"
deleted file mode 100644
index 79ca4e3a1..000000000
Binary files "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/dfs.webm" and /dev/null differ
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/index.md" "b/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/index.md"
deleted file mode 100644
index 6162cec5f..000000000
--- "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/index.md"
+++ /dev/null
@@ -1,389 +0,0 @@
----
-slug: refdiff-calculate-commits-diff
-title: refdiff插件的计算提交版本差异算法
-authors: Nddtfjiang
-tags: [devlake, refdiff, algorithm, graph]
----
-
-本文作者:Nddtfjiang
-个人主页:https://nddtf.com/github
-
-## 什么是 `计算提交版本差异`(CalculateCommitsDiff)?
-我们常常需要计算两个`提交版本`之间的差异。具体的说,就是需要知道两个不同的`分支/标签`之间相差了哪些`提交版本`。
-
-对于一般用户来说,通过`计算提交版本差异`,用户能迅速的判断两个不同的`分支/标签`之间在功能、BUG 修复等等方面的区别。以帮助用户选择不同的`分支/标签`来使用。
-
-而如果只是使用 `diff` 命令来查看这两个不同的`分支/标签`的话,大量庞杂冗余的代码修改信息就会毫无组织的混杂在其中,要从中提取出具体的功能变更之类的信息,等同于大海捞针。
-
-对于一款致力于提升研发效能的产品来说,通过`计算提交版本差异`,就能查看一组组不同的`分支/标签`的变迁状况,这一数据的获取,有助于我们做进一步的效能分析。
-
-例如,当一个项目的管理者,想要看看为什么最近的几个版本发版越来越慢了的时候。就可以对最近的几组`分支/标签`来计算`计算提交版本差异`。此时有些`分支/标签`组之间有着大量的`提交版本`,而有些`分支/标签`组之间有着较少的提交版本。项目管理者可以更进一步的计算这些提交版本各自的代码当量,把这些数据以图表的形式展示出来,最终得到一组很直观的`分支/标签`的图像。此时他或许就能发现,原来是因为最近的几次发版涉及到的变更越来越复杂了。通过这样的直观的信息,开发者和管理者们都能做出相应的调整,以便提升研发效能。
-
-
-
-## 已有的解决方案
-
-当我们在 `GitLab` 上打开一个代码仓库的时候,我们可以通过在 url 末尾追加 compare 的方式来进入到仓库的比对页面。
-
-
-
-
-
-在该页面,我们可以通过设置`源分支/标签` 和`目标分支/标签`让 `GitLab` 向我们展示 目标分支落后于源分支哪些版本,以及落后了多少个版本。
-
-设置完毕后,`GitLab` 会展示如下:
-
-
-
-在这里,我们能看到我们选择的`目标分支/标签`比`源分支/标签`少了如图所示的`提交版本`(Commits)
-
-然而遗憾的是,像 `GitLab` 这类解决方案,都没有做批量化,自动化的处理。也更没有对后续的计算出来的结果进行相应的数据汇总处理。用户面对海量的分支提交的时候,既不可能手动的一个一个去比较,也不可能手动的去把数据结果自己复制粘贴后再分析。
-
-因此 `DevLake` 就必须要解决这个问题。
-
-## 所谓的`计算提交版本差异`具体是在计算什么?
-
-以 `GitLab` 的计算过程为例来说的话,所谓的`计算提交版本差异`也就是当一个`提交版本`在`源分支/标签`中`存在`,但是在`目标分支/标签`中**不存在**的时候,这个提交版本就会被 `GitLab` 给逮出来。
-
-
-那么,或许有人会问,假如一个`提交版本`在`源分支/标签`中**不存在**,相反的,在`目标分支/标签`中`存在`,那是不是也会被抓起来呢?
-
-答案是,**不会**。
-
-也就是说,当我们计算`提交版本`的差异的时候,我们只关心`目标分支/标签`缺少了什么,而并不关心`目标分支/标签`多出来了什么东西。
-
-这就好像以前有一位算法竞赛的学生,在 NOI 比赛结束后被相关学校面试的时候,一个劲的自我介绍自己担任过什么广播站青协学生会,什么会长副会长之类的经历。结果很快就惹得面试官老师们忍无可忍的告诫道:
-
-> 我们只想知道你信息学方面的自我介绍,其余的我都不感兴趣!!!
-
-在计算`提交版本`差异时,`GitLab` 是这样。 `GitHub` 也是这样。事实上,在使用 git 命令 `git log branch1...branch2` 的时候,git 也是这样的。
-
-它们都只关心`目标分支/标签`相对于`源分支/标签`缺少的部分。
-
-计算`提交版本`差异实际上就是:
-
-- 计算待计算的`目标分支/标签`相对于`源分支/标签`缺少了哪些`提交版本`。
-
-## 对`提交版本`进行数学建模
-
-想要做计算,那么首先,我们需要把一个抽象的现实问题,转换成一个数学问题。
-
-这里我们就需要进行数学建模了。
-
-我们需要把像`目标分支/标签`、`源分支/标签`、`提交版本` 这样一系列的概念变成数学模型中的对象。
-
-如此我们才能为其设计算法。
-
-想当然的,我们就想到了使用图的方式来进行数学建模。
-
-我们将每一个`提交版本`都看作是图上的一个节点,把`提交版本`合并之前的一组`提交版本`与当前`提交版本`之间的父子关系,看作成是一条`有向边`。
-
-由于`目标分支`和`源分支`事实上也各自与一个特定的`提交版本`相绑定,因此也能将它们看作是图上的特别节点。
-
-- 将`目标分支/标签`所对应的节点,命名为`旧节点`
-- 将`源分支/标签`所对应的节点,命名为`新节点`
-
-当然,这里我们还有一个需要特别关注的节点,就是初始的`提交版本`所代表的节点
-
-- 将初始`提交版本`所对应的节点,命名为`根节点`
-
-
-上述的描述或许显得有点儿抽象。
-
-我们现在来实际举一个例子。来看看如何对一个仓库进行上述数学建模。
-
-假设现在有基于如下描述而产生的一个仓库:
-
-1. 创建空仓库
-1. 在 `main` 分支上创建`提交版本` `1` 作为初始提交
-1. 在 `main` 分支上创建`提交版本` `2`
-1. 在 `main` 分支上创建新分支 `nd`
-1. 在 `nd` 分支上创建`提交版本` `3`
-1. 在 `main` 分支上创建`提交版本` `4`
-1. 在 `main` 分支上创建新分支 `dtf`
-1. 在 `main` 分支上创建`提交版本` `5`
-1. 在 `dtf` 分支上创建`提交版本` `6`
-1. 在 `main` 分支上创建新分支 `nddtf`
-1. 在 `nddtf` 分支上创建`提交版本` `7`
-1. 把 `nd` 分支合并到 `nddtf`分支
-1. 把 `dtf` 分支合并到 `nddtf`分支
-1. 在 `main` 分支上创建`提交版本` `8`
-1. 在 `nddtf` 分支上创建`提交版本` `9`
-
-我们对上述的仓库进行构图之后,最终会得到如下图所示的一个有向图:
-
-
-
-
-- 此时彩色节点 `1` 为`根节点`
-- `main` 分支为 `1` `2` `4` `5` `8`
-- `nd` 分支为 `1` `2` `3` 随后合并入 `nddtf` 分支
-- `dtf` 分支为 `1` `2` `4` `6` 随后合并入 `nddtf` 分支
-- `nddtf` 分支为 `1` `2` `3` `4` `5` `6` `7` `9`
-
-
-可以看到,每一个`提交版本`在图中都相对应的有一个节点
-
-此时我们把`提交版本` `1` 所代表的节点,作为`根节点`
-
-当然这里可能会有同学提问了:
-
-- 假如我这个仓库有**一万个**`根节点`怎么破?
-
-相信一些经常做图的建模的同学应该都知道破法。
-
-- 创建一个名叫为`一万个根节点`的虚拟节点,把它设为这些个虚假的`根节点`的父节点,来当作真正的`根节点`即可。
-
-在这个有向图中,我们并没有实际的去指定具体的`目标分支/标签`或者`源分支/标签`
-
-在实际使用中,我们可以把任意的两个`提交版本`作为一对`目标分支/标签`和`源分支/标签`
-当然,有的同学在这里可能又会产生一个问题:
-
-- `目标分支/标签`和`源分支/标签` 虽然都能映射到其最后的`提交版本`上,但是实际上来说`提交版本`与`分支/标签`本质上就是两种不同的概念。
-
-`分支/标签`的实质,是包含一系列的`提交版本`的集合。而特定的`提交版本`仅仅是这个集合中的最后一个元素罢了。
-
-当我们把一个仓库通过上述数学建模抽象成一个有向图之后,这个集合的信息,会因此而丢失掉吗?
-
-对于一个合法的仓库来说,答案显然是,`不会`
-
-实际上,这也就是为什么我们一定要在该有向图中强调`根节点`的原因。
-
-我们这里这里,先给出结论:
-
-**`分支/标签`所对应的节点,到`根节点`的全部路径中途径的`所有节点`的集合,即为该`分支/标签`所包含的`提交版本`集合。**
-
-## 简单证明 上述结论
-- 设`根节点`为节点 `A`
-- 设要求的`分支/标签`所代表的节点为节点 `B`
-
-----------
-
-- 当 节点 `C` 是属于要求的`分支/标签`
-- 因为 节点 `C` 是属于要求的`分支/标签`
-- 所以 必然存在一组提交或者合并 使得 节点 `C` 可以一直提交到节点 `B`
-- 又因为 每一个新增的提交 或者 合并操作,均会切实的建立一条从新增的提交/合并到当前提交的边
-- 所以,反过来说,每一个提交或者合并后的节点,均可以抵达节点 `C`
-- 所以 节点 `B` 存在至少一条路径 可以 抵达节点 `C`
-- 同理可证,节点 `C` 存在至少一条路径抵达`根节点` 也就是节点 `A`
-- 综上,存在一条从节点 `B` 到节点 `A` 的路径,经过节点 `C`
-
-----------
-
-- 当 节点 `C` 不属于要求的`分支/标签`
-- 假设 存在一条从节点 `B` 到节点 `A` 的路径,经过节点 `C`
-- 因为 每一条边都是由新增的提交或者合并操作建立的
-- 所以 必然存在一系列的新增提交或者合并操作,使得节点 `C` 成为节点 `B`
-- 又因为 每一个提交在抽象逻辑上都是独一无二的
-- 因此,如果缺失了节点 `C` 则必然导致在构建节点 `B` 所代表的`分支/标签`的过程中,至少存在一个提交或者合并操作无法执行。
-- 这将导致分支非法
-- 因此 假设不成立
-- 因此 其逆否命题 对任意一条从节点 `B` 到节点 `A` 的路径,都不会经过节点 `C` 成立
-
-----------
-
-- 根据
-- 当 节点 `C` 是属于要求的`分支/标签`,存在一条从节点 `B` 到节点 `A` 的路径,经过节点 `C` (必要性)
-- 当 节点 `C` 不属于要求的`分支/标签`,对任意一条从节点 `B` 到节点 `A` 的路径,都不会经过节点 `C` (充分性)
-- 可得 `分支/标签`所对应的节点,到`根节点`的全部路径中途径的`所有节点`的集合,即为该`分支/标签`所包含的`提交版本`集合。
-
-
-
-
-
-
-## 算法选择
-
-我们现在已经完成了数学建模,并且已经为数学建模做了基本的证明。现在,我们终于可以开始在这个数学模型的基础上来设计并实现我们的算法了。
-
-如果没有做上述基本论证的同学,这里可能会犯一个小错误:那就是它们会误以为,只要计算两个节点之间的最短路径即可。若真是如此的话,`SPFA`,`迪杰斯特拉`(Dijkstra),甚至头铁一点儿,来个`弗洛伊德`(Floyd)都是很容易想到的。当然由于该有向图的所有边长都是 1,所以更简单的方法是直接使用`广/宽度优先搜索算法(BFS)`来计算最短路。
-
-上述的一系列耳熟能详的算法,或多或少都有成熟的库可以直接使用。但是遗憾的是,如果真的是去算最短路的话,那最终结果恐怕会不尽如人意。
-
-在 `DevLake` 的早期不成熟的版本中,曾经使用过最短路的算法来计算。尽管对于比较简单线性的仓库来说,可以歪打正着的算出结果。但是当仓库的分支和合并变得复杂的时候,最短路所计算的结果往往都会遗漏大量的`提交版本`。
-
-因为在刚才我们已经论证过了,这个`分支/标签`所包含的`提交版本`集合,是必须要全部路径才行的。只有全部路径,才能满足充分且必要条件。
-
-也就是说,中间只要漏了一条路径,那就会漏掉一系列的`提交版本`。
-
-要计算这个有向图上的`旧节点`所代表的`分支/标签`比`新节点`所代表的`分支/标签`缺少了哪些`提交版本`。
-
-实质上就是在计算`旧节点`到`根节点`的全部路径所经节点,对比`新节点`到`根节点`的全部路径所经节点,缺少了哪些节点。
-
-如果我们数学建模的时候,把这个有向图建立成一棵树的话。
-
-那么熟悉算法的同学,就可以很自然的使用最近公共祖先(LCA)算法,求出其并集,然后再来计算其对应的缺失的部分。
-
-但是作为一个有向图来说,树结构的算法是没法直接使用的。所幸的是,我们的这个图,在由合法仓库生成的情况下,必然是一个有向无环图。
-
-一个有向无环图,也是有自己的最近公共祖先(LCA)算法的。
-
-只是,这里有两个问题:
-- 我们真的对 最近公共祖先 这个特定的节点感兴趣吗?
-- 在有多个不同路径的公共祖先的情况下,只求一个最近公共祖先有什么意义呢?
-
-首先,我们需要明确我们的需求。
-
-我们只是为了计算 。
-- `旧节点`到`根节点`的全部路径所经节点,对比`新节点`到`根节点`的全部路径所经节点,缺少了哪些节点。
-
-除此之外的,我们不感兴趣。
-
-换句话说,我们想知道其公共祖先,但是,不关心它是不是最近的。
-
-它是近的也好,它是远的也罢,只要是公共祖先,都得抓起来。去求最近公共祖先,在树结构下,可以近似等价于求其全部祖先。因此可以使用该算法。
-
-但是在有向无环图下,最近公共祖先就是个废物。求出来了又能如何?
-
-根本上,还是应该去求全部的公共祖先。
-
-所以我们别无选择,只能用最直接的算法。
-
-- 计算出`旧节点`到`根节点`的全部路径所经节点
-- 计算出`新节点`到`根节点`的全部路径所经节点
-- 检查`新节点`的全部路径所经节点缺少了哪些节点
-
-如何计算任意节点到`根节点`的全部路径所经节点?
-
-在 OI 上熟练于骗分导论的同学们,应该很自然的就意识到了
-
-`深度优先搜索(DFS)`
-
-当然,这里补充一下,由于`根节点`的性质,事实上,无论是从哪个方向出发,无论走那条边,只要是能走的边,最终都会抵达`根节点`
-
-因此,在上述条件成立的基础上,没有记录路径状态的`广/宽度优先搜索(BFS)`也是可以使用的。因为在必然能抵达`根节点`的前提下,可以忽略路径状态,不做路径的可行性判断。
-
-当然,这一前提,也有利于我们`深度优先搜索(DFS)`进行优化。
-
-在我们执行`深度优先搜索(DFS)`的时候,我们可以将所有访问到的节点,均添加到集合中,而无需等待确认该节点能确实抵达`根节点`后再进行添加。
-
-实际上这里在一个问题上我们又会出现了两种分歧。
-问题是,如何将一个节点添加到集合中。方案有如下两种。
-
-染色法:添加到集合中的节点进行染色,未添加到集合中的节点不进行染色。
-集合法:使用平衡树算法建立一个集合,将节点添加到该集合中。
-
-这两种算法各有优劣。
-
-- 染色法的优势在于,染色法添加一个元素的时间复杂度是 O(1) 的,快准狠。相比较而言,集合法添加一个元素的时间复杂度是 O(log(n))。
-- 集合法的优势在于,集合法遍历所有元素的时间复杂度是 O(n) 的,而染色法下,要遍历所有元素时间复杂度会是 O(m),同时集合法可以通过设计一个优秀的 hash 算法代替平衡树,来将时间复杂度优化到接近 O(1).(这里 n 表示集合大小,m 表示整个图的大小)
-
-我们这里选择使用集合法。实际上这两种算法都差不多。
-
-
-## 算法实现
-
-- 根据提交建图
-- 我们对`旧节点`使用`深度优先搜索(DFS)`计算出其到`根节点`的全部路径所经节点,添加到`集合 A` 中
-- 接着,我们对`新节点`使用`深度优先搜索(DFS)`计算出其到`根节点`的全部路径所经节点,添加到`集合 B`
-- 注意,这里有一个优化,这个优化是建立在我们的需求上
-- 重复一遍我们的需求
-- 我们只关心`目标分支/标签`缺少了什么,而并不关心`目标分支/标签`多出来了什么东西。
-- 因此当对`新节点`使用`深度优先搜索(DFS)`搜索到已经在`集合 A` 中的节点时,可以认为该节点已搜索过,无需再次搜索。
-- 此时的`集合 B`,可以恰好的避开`集合 A` 中已有的所有节点,因此,恰好就是我们所需的结果。
-
-核心的计算代码如下所示:
-```golang
-oldGroup := make(map[string]*CommitNode)
-var dfs func(*CommitNode)
-// put all commit sha which can be depth-first-searched by old commit
-dfs = func(now *CommitNode) {
- if _, ok = oldGroup[now.Sha]; ok {
- return
- }
- oldGroup[now.Sha] = now
- for _, node := range now.Parent {
- dfs(node)
- }
-}
-dfs(oldCommitNode)
-
-var newGroup = make(map[string]*CommitNode)
-// put all commit sha which can be depth-first-searched by new commit, will stop when find any in either group
-dfs = func(now *CommitNode) {
- if _, ok = oldGroup[now.Sha]; ok {
- return
- }
- if _, ok = newGroup[now.Sha]; ok {
- return
- }
- newGroup[now.Sha] = now
- lostSha = append(lostSha, now.Sha)
- for _, node := range now.Parent {
- dfs(node)
- }
-}
-dfs(newCommitNode)
-```
-
-这里的 lostSha 即为我们最终求得的缺失的部分
-
-## 算法执行的演示动画
-
-我们用一个简陋的动画来简单的演示一下,上述算法在逻辑上执行的情况。
-
-- `旧节点`为节点 `8`
-- `新节点`为节点 `9`
-
-
-
-如上述[动画](https://devlake.apache.org/assets/images/dfs-3464f1398b150e893646c4f21e95ea10.gif)所演示的一般
-从节点 `8` 开始执行`深度优先搜索(DFS)`到`根节点`中止
-从节点 `9` 开始执行`深度优先搜索(DFS)`到已经在节点 `8` 的集合中的节点为止
-此时,在节点 `9` 执行`深度优先搜索(DFS)`过程中被访问到的所有非节点 `8` 的节点
-
-- 节点 `3`
-- 节点 `6`
-- 节点 `7`
-- 节点 `9`
-
-它们所对应的`提交版本`就是我们要求的差集
-
-> 此时最短路为 `9` -> `7` -> `5` -> `8`
-> 此时最近公共父节点为 `5`,到该节点的路径为 `9` -> `7` -> `5`
-> 从上图中也可以直观的看到如果使用最短路算法,或者最近公共父节点算法的情况下,我们是无法得到正确答案的。
-
-## 时空复杂度
-
-设`提交版本`的总大小为 m,每一组`源分支/标签`和`目标分支/标签`的平均大小为 n,一共有 k 组数据
-
-DFS 每访问一个节点,需要执行一次加入集合操作。我们按照我们实际实现中使用的 平衡树算法来计算 时间复杂度为 O(log(n))
-
-此时我们可以计算得出
-
-- 建图的时间复杂度:O(m)
-- 计算一组`源分支/标签`和`目标分支/标签`时间复杂度:O(n\*log(n))
-- 计算所有`源分支/标签`和`目标分支/标签`时间复杂度:O(k\*n\*log(n))
-- 读取、统计结果时间复杂度:O(k\*n)
-- 总体时间复杂度:O(m + k\*n\*log(n))
-
-----------
-
-- 图的空间复杂度:O(m)
-- 每组`源分支/标签`和`目标分支/标签`集合的空间复杂度:O(n) (非并发情况下,k组数据可共用)
-- 总体空间复杂度:O(m+n)
-
-
-## 关键词
-- `DevLake`
-- `CalculateCommitsDiff`
-- `算法`
-- `数学建模`
-- `证明逻辑`
-- `充分条件`
-- `必要条件`
-- `图论`
-- `深度优先搜索(DFS)`
-- `广/宽度优先搜索(BFS)`
-- `时间复杂度`
-- `空间复杂度`
-- `时空复杂度`
-
-----------
-## 了解更多最新动态
-
-官网:[https://devlake.incubator.apache.org/](https://devlake.incubator.apache.org/)
-
-GitHub:[https://github.com/apache/incubator-devlake/](https://github.com/apache/incubator-devlake/)
-
-Slack:通过 [Slack](https://devlake-io.slack.com/join/shared_invite/zt-18uayb6ut-cHOjiYcBwERQ8VVPZ9cQQw#/shared-invite/email) 联系我们
\ No newline at end of file
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\225\260\345\255\246\346\250\241\345\236\213\346\236\204\345\233\276.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\27 [...]
deleted file mode 100644
index 46e5b41cf..000000000
Binary files "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\225\260\345\255\246\346\250\241\345\236\213\346\236\204\345\233\276.png" and /dev/null differ
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\267\273\345\212\240Compare.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\267\27 [...]
deleted file mode 100644
index e3573e030..000000000
Binary files "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\267\273\345\212\240Compare.png" and /dev/null differ
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\272\220\345\210\206\346\224\257-\347\233\256\346\240\207\345\210\206\346\224\257.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\2 [...]
deleted file mode 100644
index 474372eba..000000000
Binary files "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\346\272\220\345\210\206\346\224\257-\347\233\256\346\240\207\345\210\206\346\224\257.png" and /dev/null differ
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\347\211\210\346\234\254\345\257\271\346\257\224.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\26 [...]
deleted file mode 100644
index 58e020d4c..000000000
Binary files "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\347\211\210\346\234\254\345\257\271\346\257\224.png" and /dev/null differ
diff --git "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\351\235\242\346\235\277\345\233\276\347\211\207.png" "b/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\26 [...]
deleted file mode 100644
index 6438442ee..000000000
Binary files "a/i18n/zh/docusaurus-plugin-content-blog/2022-06-22-refdiff\346\217\222\344\273\266\347\232\204\350\256\241\347\256\227\346\217\220\344\272\244\347\211\210\346\234\254\345\267\256\345\274\202\347\256\227\346\263\225/\351\235\242\346\235\277\345\233\276\347\211\207.png" and /dev/null differ
diff --git a/i18n/zh/docusaurus-plugin-content-blog/authors.yml b/i18n/zh/docusaurus-plugin-content-blog/authors.yml
deleted file mode 100644
index 4761bd59b..000000000
--- a/i18n/zh/docusaurus-plugin-content-blog/authors.yml
+++ /dev/null
@@ -1,59 +0,0 @@
-abeizn:
- name: 安自宽
- title: Apache DevLake Committer
- url: https://github.com/abeizn
- image_url: https://github.com/abeizn.png
-
-Danna:
- name: Danna Wang
- title: DevLake Contributor
- url: https://github.com/banshengbushu
- image_url: https://github.com/banshengbushu.png
-
-Geyu:
- name: 陈舸禹
- title: Apache DevLake Contributor
- url: https://github.com/fredtheflat
- image_url: https://github.com/fredtheflat.png
-
-likyh:
- name: Likyh
- title: Apache DevLake Contributor
- url: https://github.com/likyh
- image_url: https://avatars.githubusercontent.com/u/3294100?v=4
-
-klesh:
- name: Klesh Wong
- title: Apache DevLake PPMC
- url: https://kleshwong.com
- image_url: https://github.com/klesh.png
-
-maxim:
- name: Maxim Wheatley
- title: Apache DevLake PPMC
- url: https://github.com/MaximDub
- image_url: https://github.com/MaximDub.png
-
-Nddtfjiang:
- name: Nddtfjiang
- title: Apache DevLake Committer
- url: http://nddtf.com/github
- image_url: http://nddtf.com/github/png.html
-
-warren:
- name: 陈映初
- title: Apache DevLake PPMC
- url: https://github.com/warren830
- image_url: https://github.com/warren830.png
-
-weisi:
- name: Weisi Deng
- title: DevLake 社区成员
- url: https://github.com/Ushuaiaff
- image_url: https://github.com/Ushuaiaff.png
-
-ZhangLiang:
- name: ZhangLiang
- title: Apache DevLake PPMC
- url: https://github.com/mindlesscloud
- image_url: https://avatars.githubusercontent.com/u/8455907?s=400&v=4
diff --git a/i18n/zh/docusaurus-plugin-content-blog/options.json b/i18n/zh/docusaurus-plugin-content-blog/options.json
deleted file mode 100644
index 9239ff706..000000000
--- a/i18n/zh/docusaurus-plugin-content-blog/options.json
+++ /dev/null
@@ -1,14 +0,0 @@
-{
- "title": {
- "message": "Blog",
- "description": "The title for the blog used in SEO"
- },
- "description": {
- "message": "Blog",
- "description": "The description for the blog used in SEO"
- },
- "sidebar.title": {
- "message": "Recent posts",
- "description": "The label for the left sidebar"
- }
-}
diff --git a/i18n/zh/docusaurus-plugin-content-docs-community/current.json b/i18n/zh/docusaurus-plugin-content-docs-community/current.json
deleted file mode 100644
index 247598f2a..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs-community/current.json
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "version.label": {
- "message": "Next",
- "description": "The label for version current"
- },
- "sidebar.communitySidebar.category.Contributor": {
- "message": "贡献",
- "description": "The label for category Contributor in sidebar communitySidebar"
- }
-}
diff --git a/i18n/zh/docusaurus-plugin-content-docs/current.json b/i18n/zh/docusaurus-plugin-content-docs/current.json
deleted file mode 100644
index 3aac664ad..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/current.json
+++ /dev/null
@@ -1,22 +0,0 @@
-{
- "version.label": {
- "message": "Next",
- "description": "The label for version current"
- },
- "sidebar.docsSidebar.category.Plugins": {
- "message": "Plugins",
- "description": "The label for category Plugins in sidebar docsSidebar"
- },
- "sidebar.docsSidebar.category.Best Practices": {
- "message": "Best Practices",
- "description": "The label for category Best Practices in sidebar docsSidebar"
- },
- "sidebar.docsSidebar.category.Overview": {
- "message": "Overview",
- "description": "The label for category Overview in sidebar docsSidebar"
- },
- "sidebar.docsSidebar.category.Quick Stack": {
- "message": "Quick Stack",
- "description": "The label for category Quick Stack in sidebar docsSidebar"
- }
-}
diff --git a/i18n/zh/docusaurus-plugin-content-docs/current/01-Overview/02-WhatIsDevLake.md b/i18n/zh/docusaurus-plugin-content-docs/current/01-Overview/02-WhatIsDevLake.md
deleted file mode 100755
index 9cf249c72..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/current/01-Overview/02-WhatIsDevLake.md
+++ /dev/null
@@ -1,30 +0,0 @@
----
-title: "What is DevLake?"
-linkTitle: "What is DevLake?"
-tags: []
-categories: []
-weight: 1
-description: >
- General introduction of DevLake
----
-
-
-DevLake brings your DevOps data into one practical, customized, extensible view. Ingest, analyze, and visualize data from an ever-growing list of developer tools, with our open source product.
-
-DevLake is designed for developer teams looking to make better sense of their development process and to bring a more data-driven approach to their own practices. You can ask DevLake many questions regarding your development process. Just connect and query.
-
-<a href="https://app-259373083972538368-3002.ars.teamcode.com/d/0Rjxknc7z/demo-homepage?orgId=1">See demo</a>. Username/password:test/test. The demo is based on the data from this repo, merico-dev/lake.
-
-
-
-<div align="left">
-<img src="https://user-images.githubusercontent.com/14050754/145056261-ceaf7044-f5c5-420f-80ca-54e56eb8e2a7.png" width="100%" alt="User Flow" style={{borderRadius: '15px' }}/>
-<p align="center">User Flow</p>
-</div>
-<br/>
-
-### What can be accomplished with DevLake?
-1. Collect DevOps data across the entire SDLC process and connect data silos.
-2. A standard <a href="https://github.com/merico-dev/lake/wiki/DataModel.Domain-layer-schema">data model</a> and out-of-the-box <a href="https://github.com/merico-dev/lake/wiki/Metric-Cheatsheet">metrics</a> for software engineering.
-3. Flexible <a href="https://github.com/merico-dev/lake/blob/main/ARCHITECTURE.md">framework</a> for data collection and ETL, support customized analysis.
-<br/><br/><br/>
diff --git a/i18n/zh/docusaurus-plugin-content-docs/current/01-Overview/03-Architecture.md b/i18n/zh/docusaurus-plugin-content-docs/current/01-Overview/03-Architecture.md
deleted file mode 100755
index db3cdedcf..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/current/01-Overview/03-Architecture.md
+++ /dev/null
@@ -1,29 +0,0 @@
----
-title: "Architecture"
-linkTitle: "Architecture"
-tags: []
-categories: []
-weight: 2
-description: >
- Understand the architecture of DevLake.
----
-
-
-
-<p align="center">Architecture Diagram</p>
-
-## Stack (from low to high)
-
-1. config
-2. logger
-3. models
-4. plugins
-5. services
-6. api / cli
-
-## Rules
-
-1. Higher layer calls lower layer, not the other way around
-2. Whenever lower layer neeeds something from higher layer, a interface should be introduced for decoupling
-3. Components should be initialized in a low to high order during bootstraping
-<br/><br/><br/>
diff --git a/i18n/zh/docusaurus-plugin-content-docs/current/01-Overview/04-Roadmap.md b/i18n/zh/docusaurus-plugin-content-docs/current/01-Overview/04-Roadmap.md
deleted file mode 100755
index 39e229d99..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/current/01-Overview/04-Roadmap.md
+++ /dev/null
@@ -1,36 +0,0 @@
----
-title: "Roadmap"
-linkTitle: "Roadmap"
-tags: []
-categories: []
-weight: 3
-description: >
- The goals and roadmap for DevLake in 2022.
----
-
-
-## Goals
-1. Moving to Apache Incubator and making DevLake a graduation-ready project.
-2. Explore and implement 3 typical use scenarios to help certain engineering teams and developers:
- - Observation of open-source project contribution and quality
- - DORA metrics for the DevOps team
- - SDLC workflow monitoring and improvement
-3. Better UX for end-users and contributors.
-
-
-## DevLake 2022 Roadmap
-DevLake is currently under rapid development. This page describes the project’s public roadmap, the result of an ongoing collaboration between the core maintainers and the broader DevLake community.<br/><br/>
-This roadmap is broken down by the goals in the last section.
-
-
-| Category | Features|
-| --- | --- |
-| More data sources across different [DevOps domains](https://github.com/merico-dev/lake/wiki/DevOps-Domain-Definition)| 1. **Issue/Task Management - Jira server** <br/> 2. **Issue/Task Management - Jira data center** <br/> 3. Issue/Task Management - GitLab Issues <br/> 4. Issue/Task Management - Trello <br/> 5. **Issue/Task Management - TPAD** <br/> 6. Issue/Task Management - Teambition <br/> 7. Issue/Task Management - Trello <br/> 8. **Source Code Management - GitLab on-premise** <br/> [...]
-| More comprehensive and flexible [engineering data model](https://github.com/merico-dev/lake/issues/700) | 1. complete and polish standard data models for different [DevOps domains](https://github.com/merico-dev/lake/wiki/DevOps-Domain-Definition) <br/> 2. allow users to modify standard tables <br/> 3. allow users to create new tables <br/> 4. allow users to easily define ETL rules <br/> |
-| Better UX | 1. improve config-UI design for better onboard experience <br/> 2. improve data collection speed for Github and other plugins with strict API rate limit <br/> 3. build a website to present well-organized documentation to DevLake users and contributors <br/> |
-
-
-## How to Influence Roadmap
-A roadmap is only useful when it captures real user needs. We are glad to hear from you if you have specific use cases, feedback, or ideas. You can submit an issue to let us know!
-Also, if you plan to work (or are already working) on a new or existing feature, tell us, so that we can update the roadmap accordingly. We are happy to share knowledge and context to help your feature land successfully.
-<br/><br/><br/>
diff --git a/i18n/zh/docusaurus-plugin-content-docs/current/01-Overview/_category_.json b/i18n/zh/docusaurus-plugin-content-docs/current/01-Overview/_category_.json
deleted file mode 100644
index e224ed81c..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/current/01-Overview/_category_.json
+++ /dev/null
@@ -1,4 +0,0 @@
-{
- "label": "Overview",
- "position": 1
-}
diff --git a/i18n/zh/docusaurus-plugin-content-docs/current/02-Quick Start/01-LocalSetup.md b/i18n/zh/docusaurus-plugin-content-docs/current/02-Quick Start/01-LocalSetup.md
deleted file mode 100644
index 98ed3bb25..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/current/02-Quick Start/01-LocalSetup.md
+++ /dev/null
@@ -1,81 +0,0 @@
----
-title: "Local Setup"
-linkTitle: "Local Setup"
-tags: []
-categories: []
-weight: 1
-description: >
- The steps to install DevLake locally.
----
-
-
-- If you only plan to run the product locally, this is the **ONLY** section you should need.
-- Commands written `like this` are to be run in your terminal.
-
-#### Required Packages to Install<a id="user-setup-requirements"></a>
-
-- [Docker](https://docs.docker.com/get-docker)
-- [docker-compose](https://docs.docker.com/compose/install/)
-
-NOTE: After installing docker, you may need to run the docker application and restart your terminal
-
-#### Commands to run in your terminal<a id="user-setup-commands"></a>
-
-**IMPORTANT: DevLake doesn't support Database Schema Migration yet, upgrading an existing instance is likely to break, we recommend that you deploy a new instance instead.**
-
-1. Download `docker-compose.yml` and `env.example` from [latest release page](https://github.com/merico-dev/lake/releases/latest) into a folder.
-2. Rename `env.example` to `.env`. For Mac/Linux users, please run `mv env.example .env` in the terminal.
-3. Start Docker on your machine, then run `docker-compose up -d` to start the services.
-4. Visit `localhost:4000` to set up configuration files.
- >- Navigate to desired plugins on the Integrations page
- >- Please reference the following for more details on how to configure each one:<br/>
- - **jira**
- - **gitlab**
- - **jenkins**
- - **github**
- >- Submit the form to update the values by clicking on the **Save Connection** button on each form page
- >- `devlake` takes a while to fully boot up. if `config-ui` complaining about api being unreachable, please wait a few seconds and try refreshing the page.
-
-
-5. Visit `localhost:4000/pipelines/create` to RUN a Pipeline and trigger data collection.
-
-
- Pipelines Runs can be initiated by the new "Create Run" Interface. Simply enable the **Data Source Providers** you wish to run collection for, and specify the data you want to collect, for instance, **Project ID** for Gitlab and **Repository Name** for GitHub.
-
- Once a valid pipeline configuration has been created, press **Create Run** to start/run the pipeline.
- After the pipeline starts, you will be automatically redirected to the **Pipeline Activity** screen to monitor collection activity.
-
- **Pipelines** is accessible from the main menu of the config-ui for easy access.
-
- - Manage All Pipelines: `http://localhost:4000/pipelines`
- - Create Pipeline RUN: `http://localhost:4000/pipelines/create`
- - Track Pipeline Activity: `http://localhost:4000/pipelines/activity/[RUN_ID]`
-
- For advanced use cases and complex pipelines, please use the Raw JSON API to manually initiate a run using **cURL** or graphical API tool such as **Postman**. `POST` the following request to the DevLake API Endpoint.
-
- ```json
- [
- [
- {
- "plugin": "github",
- "options": {
- "repo": "lake",
- "owner": "merico-dev"
- }
- }
- ]
- ]
- ```
-
- Please refer to this wiki [How to trigger data collection](https://github.com/merico-dev/lake/wiki/How-to-use-the-triggers-page).
-
-6. Click *View Dashboards* button in the top left when done, or visit `localhost:3002` (username: `admin`, password: `admin`).
-
- We use <a href="https://grafana.com/" target="_blank">Grafana</a> as a visualization tool to build charts for the <a href="https://github.com/merico-dev/lake/wiki/DataModel.Domain-layer-schema">data stored in our database</a>. Using SQL queries, we can add panels to build, save, and edit customized dashboards.
-
- All the details on provisioning and customizing a dashboard can be found in the **Grafana Doc**
-
-#### Setup cron job
-
-To synchronize data periodically, we provide **lake-cli** for easily sending data collection requests along with **a cron job** to periodically trigger the cli tool.
-<br/><br/><br/>
diff --git a/i18n/zh/docusaurus-plugin-content-docs/current/02-Quick Start/02-KubernetesSetup.md b/i18n/zh/docusaurus-plugin-content-docs/current/02-Quick Start/02-KubernetesSetup.md
deleted file mode 100644
index 4327e319c..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/current/02-Quick Start/02-KubernetesSetup.md
+++ /dev/null
@@ -1,9 +0,0 @@
----
-title: "Kubernetes Setup"
-linkTitle: "Kubernetes Setup"
-tags: []
-categories: []
-weight: 2
-description: >
- The steps to install DevLake in Kubernetes.
----
diff --git a/i18n/zh/docusaurus-plugin-content-docs/current/02-Quick Start/03-DeveloperSetup.md b/i18n/zh/docusaurus-plugin-content-docs/current/02-Quick Start/03-DeveloperSetup.md
deleted file mode 100644
index b1696d098..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/current/02-Quick Start/03-DeveloperSetup.md
+++ /dev/null
@@ -1,123 +0,0 @@
----
-title: "Developer Setup"
-linkTitle: "Developer Setup"
-tags: []
-categories: []
-weight: 3
-description: >
- The steps to install DevLake in develper mode.
----
-
-
-
-#### Requirements
-
-- <a href="https://docs.docker.com/get-docker" target="_blank">Docker</a>
-- <a href="https://golang.org/doc/install" target="_blank">Golang v1.17+</a>
-- Make
- - Mac (Already installed)
- - Windows: [Download](http://gnuwin32.sourceforge.net/packages/make.htm)
- - Ubuntu: `sudo apt-get install build-essential`
-
-#### How to setup dev environment
-1. Navigate to where you would like to install this project and clone the repository:
-
- ```sh
- git clone https://github.com/merico-dev/lake.git
- cd lake
- ```
-
-2. Install dependencies for plugins:
-
- - **RefDiff**
-
-3. Install Go packages
-
- ```sh
- go get
- ```
-
-4. Copy the sample config file to new local file:
-
- ```sh
- cp .env.example .env
- ```
-
-5. Update the following variables in the file `.env`:
-
- * `DB_URL`: Replace `mysql:3306` with `127.0.0.1:3306`
-
-5. Start the MySQL and Grafana containers:
-
- > Make sure the Docker daemon is running before this step.
-
- ```sh
- docker-compose up -d mysql grafana
- ```
-
-6. Run lake and config UI in dev mode in two seperate terminals:
-
- ```sh
- # run lake
- make dev
- # run config UI
- make configure-dev
- ```
-
-7. Visit config UI at `localhost:4000` to configure data sources.
- >- Navigate to desired plugins pages on the Integrations page
- >- You will need to enter the required information for the plugins you intend to use.
- >- Please reference the following for more details on how to configure each one:
- **jira**
- **gitlab**
- **jenkins**
- **github**
-
- >- Submit the form to update the values by clicking on the **Save Connection** button on each form page
-
-8. Visit `localhost:4000/pipelines/create` to RUN a Pipeline and trigger data collection.
-
-
- Pipelines Runs can be initiated by the new "Create Run" Interface. Simply enable the **Data Source Providers** you wish to run collection for, and specify the data you want to collect, for instance, **Project ID** for Gitlab and **Repository Name** for GitHub.
-
- Once a valid pipeline configuration has been created, press **Create Run** to start/run the pipeline.
- After the pipeline starts, you will be automatically redirected to the **Pipeline Activity** screen to monitor collection activity.
-
- **Pipelines** is accessible from the main menu of the config-ui for easy access.
-
- - Manage All Pipelines: `http://localhost:4000/pipelines`
- - Create Pipeline RUN: `http://localhost:4000/pipelines/create`
- - Track Pipeline Activity: `http://localhost:4000/pipelines/activity/[RUN_ID]`
-
- For advanced use cases and complex pipelines, please use the Raw JSON API to manually initiate a run using **cURL** or graphical API tool such as **Postman**. `POST` the following request to the DevLake API Endpoint.
-
- ```json
- [
- [
- {
- "plugin": "github",
- "options": {
- "repo": "lake",
- "owner": "merico-dev"
- }
- }
- ]
- ]
- ```
-
- Please refer to this wiki [How to trigger data collection](https://github.com/merico-dev/lake/wiki/How-to-use-the-triggers-page).
-
-
-9. Click *View Dashboards* button in the top left when done, or visit `localhost:3002` (username: `admin`, password: `admin`).
-
- We use <a href="https://grafana.com/" target="_blank">Grafana</a> as a visualization tool to build charts for the <a href="https://github.com/merico-dev/lake/wiki/DataModel.Domain-layer-schema">data stored in our database</a>. Using SQL queries, we can add panels to build, save, and edit customized dashboards.
-
- All the details on provisioning and customizing a dashboard can be found in the **Grafana Doc**
-
-
-10. (Optional) To run the tests:
-
-
- make test
-
-<br/><br/><br/><br/>
diff --git a/i18n/zh/docusaurus-plugin-content-docs/current/02-Quick Start/_category_.json b/i18n/zh/docusaurus-plugin-content-docs/current/02-Quick Start/_category_.json
deleted file mode 100644
index 9620a0534..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/current/02-Quick Start/_category_.json
+++ /dev/null
@@ -1,4 +0,0 @@
-{
- "label": "Quick Start",
- "position": 2
-}
diff --git a/i18n/zh/docusaurus-plugin-content-docs/current/03-Features.md b/i18n/zh/docusaurus-plugin-content-docs/current/03-Features.md
deleted file mode 100644
index 2b2bb24b5..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/current/03-Features.md
+++ /dev/null
@@ -1,20 +0,0 @@
----
-sidebar_position: 03
-title: "Features"
-linkTitle: "Features"
-tags: []
-categories: []
-weight: 30000
-description: >
- Features of the latest version of DevLake.
----
-
-
-1. Collect data from [mainstream DevOps tools](https://github.com/merico-dev/lake#project-roadmap), including Jira (Cloud), Jira Server v8+, Git, GitLab, GitHub, Jenkins etc., supported by [plugins](https://github.com/merico-dev/lake/blob/main/ARCHITECTURE.md).
-2. Receive data through Push API.
-3. Standardize DevOps data based on [domain layer schema](https://github.com/merico-dev/lake/wiki/DataModel.Domain-layer-schema). Support 20+ [built-in engineering metrics](https://github.com/merico-dev/lake/wiki/Metric-Cheatsheet) to observe productivity, quality and delivery capability.
-4. Connect "commit" entity with "issue" entity, and generate composite metrics such as `Bugs Count per 1k Lines of Code`.
-5. Identify new commits based on [RefDiff](https://github.com/merico-dev/lake/tree/main/plugins/refdiff#refdiff) plugin, and analyze productivity and quality of each version.
-6. Flexible dashboards to support data visualization and queries, based on Grafana.
-
-<br/><br/><br/>
diff --git a/i18n/zh/docusaurus-plugin-content-docs/current/04-EngineeringMetrics.md b/i18n/zh/docusaurus-plugin-content-docs/current/04-EngineeringMetrics.md
deleted file mode 100644
index 3b8a08b20..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/current/04-EngineeringMetrics.md
+++ /dev/null
@@ -1,197 +0,0 @@
----
-sidebar_position: 04
-title: "Engineering Metrics"
-linkTitle: "Engineering Metrics"
-tags: []
-categories: []
-weight: 40000
-description: >
- The definition, values and data required for the 20+ engineering metrics supported by DevLake.
----
-
-<table>
- <tr>
- <th><b>Category</b></th>
- <th><b>Metric Name</b></th>
- <th><b>Definition</b></th>
- <th><b>Data Required</b></th>
- <th style={{width:'70%'}}><b>Use Scenarios and Recommended Practices</b></th>
- <th><b>Value </b></th>
- </tr>
- <tr>
- <td rowspan="10">Delivery Velocity</td>
- <td>Requirement Count</td>
- <td>Number of issues in type "Requirement"</td>
- <td>Issue/Task Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jira/README.md">Jira issues</a>, <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub issues</a>, etc</td>
- <td rowspan="2">
-1. Analyze the number of requirements and delivery rate of different time cycles to find the stability and trend of the development process.
-<br/>2. Analyze and compare the number of requirements delivered and delivery rate of each project/team, and compare the scale of requirements of different projects.
-<br/>3. Based on historical data, establish a baseline of the delivery capacity of a single iteration (optimistic, probable and pessimistic values) to provide a reference for iteration estimation.
-<br/>4. Drill down to analyze the number and percentage of requirements in different phases of SDLC. Analyze rationality and identify the requirements stuck in the backlog.</td>
- <td rowspan="2">1. Based on historical data, establish a baseline of the delivery capacity of a single iteration to improve the organization and planning of R&D resources.
-<br/>2. Evaluate whether the delivery capacity matches the business phase and demand scale. Identify key bottlenecks and reasonably allocate resources.</td>
- </tr>
- <tr>
- <td>Requirement Delivery Rate</td>
- <td>Ratio of delivered requirements to all requirements</td>
- <td>Issue/Task Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jira/README.md">Jira issues</a>, <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub issues</a>, etc</td>
- </tr>
- <tr>
- <td>Requirement Lead Time</td>
- <td>Lead time of issues with type "Requirement"</td>
- <td>Issue/Task Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jira/README.md">Jira issues</a>, <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub issues</a>, etc</td>
- <td>
-1. Analyze the trend of requirement lead time to observe if it has improved over time.
-<br/>2. Analyze and compare the requirement lead time of each project/team to identify key projects with abnormal lead time.
-<br/>3. Drill down to analyze a requirement's staying time in different phases of SDLC. Analyze the bottleneck of delivery velocity and improve the workflow.</td>
- <td>1. Analyze key projects and critical points, identify good/to-be-improved practices that affect requirement lead time, and reduce the risk of delays
-<br/>2. Focus on the end-to-end velocity of value delivery process; coordinate different parts of R&D to avoid efficiency shafts; make targeted improvements to bottlenecks.</td>
- </tr>
- <tr>
- <td>Requirement Granularity</td>
- <td>Number of story points associated with an issue</td>
- <td>Issue/Task Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jira/README.md">Jira issues</a>, <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub issues</a>, etc</td>
- <td>
-1. Analyze the story points/requirement lead time of requirements to evaluate whether the ticket size, ie. requirement complexity is optimal.
-<br/>2. Compare the estimated requirement granularity with the actual situation and evaluate whether the difference is reasonable by combining more microscopic workload metrics (e.g. lines of code/code equivalents)</td>
- <td>1. Promote product teams to split requirements carefully, improve requirements quality, help developers understand requirements clearly, deliver efficiently and with high quality, and improve the project management capability of the team.
-<br/>2. Establish a data-supported workload estimation model to help R&D teams calibrate their estimation methods and more accurately assess the granularity of requirements, which is useful to achieve better issue planning in project management.</td>
- </tr>
- <tr>
- <td>Commit Count</td>
- <td>Number of Commits</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitextractor/README.md">Git</a>/<a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a>/<a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> commits</td>
- <td>
-1. Identify the main reasons for the unusual number of commits and the possible impact on the number of commits through comparison
-<br/>2. Evaluate whether the number of commits is reasonable in conjunction with more microscopic workload metrics (e.g. lines of code/code equivalents)</td>
- <td>1. Identify potential bottlenecks that may affect output
-<br/>2. Encourage R&D practices of small step submissions and develop excellent coding habits</td>
- </tr>
- <tr>
- <td>Added Lines of Code</td>
- <td>Accumulated number of added lines of code</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitextractor/README.md">Git</a>/<a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a>/<a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> commits</td>
- <td rowspan="2">
-1. From the project/team dimension, observe the accumulated change in Added lines to assess the team activity and code growth rate
-<br/>2. From version cycle dimension, observe the active time distribution of code changes, and evaluate the effectiveness of project development model.
-<br/>3. From the member dimension, observe the trend and stability of code output of each member, and identify the key points that affect code output by comparison.</td>
- <td rowspan="2">1. identify potential bottlenecks that may affect the output
-<br/>2. Encourage the team to implement a development model that matches the business requirements; develop excellent coding habits</td>
- </tr>
- <tr>
- <td>Deleted Lines of Code</td>
- <td>Accumulated number of deleted lines of code</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitextractor/README.md">Git</a>/<a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a>/<a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> commits</td>
- </tr>
- <tr>
- <td>Pull Request Review Time</td>
- <td>Time from Pull/Merge created time until merged</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> MRs, etc</td>
- <td>
-1. Observe the mean and distribution of code review time from the project/team/individual dimension to assess the rationality of the review time</td>
- <td>1. Take inventory of project/team code review resources to avoid lack of resources and backlog of review sessions, resulting in long waiting time
-<br/>2. Encourage teams to implement an efficient and responsive code review mechanism</td>
- </tr>
- <tr>
- <td>Bug Age</td>
- <td>Lead time of issues in type "Bug"</td>
- <td>Issue/Task Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jira/README.md">Jira issues</a>, <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub issues</a>, etc</td>
- <td rowspan="2">
-1. Observe the trend of bug age and locate the key reasons.<br/>
-2. According to the severity level, type (business, functional classification), affected module, source of bugs, count and observe the length of bug and incident age.</td>
- <td rowspan="2">1. Help the team to establish an effective hierarchical response mechanism for bugs and incidents. Focus on the resolution of important problems in the backlog.<br/>
-2. Improve team's and individual's bug/incident fixing efficiency. Identify good/to-be-improved practices that affect bug age or incident age</td>
- </tr>
- <tr>
- <td>Incident Age</td>
- <td>Lead time of issues in type "Incident"</td>
- <td>Issue/Task Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jira/README.md">Jira issues</a>, <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub issues</a>, etc</td>
- </tr>
- <tr>
- <td rowspan="8">Delivery Quality</td>
- <td>Pull Request Count</td>
- <td>Number of Pull/Merge Requests</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> MRs, etc</td>
- <td rowspan="3">
-1. From the developer dimension, we evaluate the code quality of developers by combining the task complexity with the metrics related to the number of review passes and review rounds.<br/>
-2. From the reviewer dimension, we observe the reviewer's review style by taking into account the task complexity, the number of passes and the number of review rounds.<br/>
-3. From the project/team dimension, we combine the project phase and team task complexity to aggregate the metrics related to the number of review passes and review rounds, and identify the modules with abnormal code review process and possible quality risks.</td>
- <td rowspan="3">1. Code review metrics are process indicators to provide quick feedback on developers' code quality<br/>
-2. Promote the team to establish a unified coding specification and standardize the code review criteria<br/>
-3. Identify modules with low-quality risks in advance, optimize practices, and precipitate into reusable knowledge and tools to avoid technical debt accumulation</td>
- </tr>
- <tr>
- <td>Pull Request Pass Rate</td>
- <td>Ratio of Pull/Merge Review requests to merged</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> MRs, etc</td>
- </tr>
- <tr>
- <td>Pull Request Review Rounds</td>
- <td>Number of cycles of commits followed by comments/final merge</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> MRs, etc</td>
- </tr>
- <tr>
- <td>Pull Request Review Count</td>
- <td>Number of Pull/Merge Reviewers</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> MRs, etc</td>
- <td>1. As a secondary indicator, assess the cost of labor invested in the code review process</td>
- <td>1. Take inventory of project/team code review resources to avoid long waits for review sessions due to insufficient resource input</td>
- </tr>
- <tr>
- <td>Bug Count</td>
- <td>Number of bugs found during testing</td>
- <td>Issue/Task Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jira/README.md">Jira issues</a>, <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub issues</a>, etc</td>
- <td rowspan="4">
-1. From the project or team dimension, observe the statistics on the total number of defects, the distribution of the number of defects in each severity level/type/owner, the cumulative trend of defects, and the change trend of the defect rate in thousands of lines, etc.<br/>
-2. From version cycle dimension, observe the statistics on the cumulative trend of the number of defects/defect rate, which can be used to determine whether the growth rate of defects is slowing down, showing a flat convergence trend, and is an important reference for judging the stability of software version quality<br/>
-3. From the time dimension, analyze the trend of the number of test defects, defect rate to locate the key items/key points<br/>
-4. Evaluate whether the software quality and test plan are reasonable by referring to CMMI standard values</td>
- <td rowspan="4">1. Defect drill-down analysis to inform the development of design and code review strategies and to improve the internal QA process<br/>
-2. Assist teams to locate projects/modules with higher defect severity and density, and clean up technical debts<br/>
-3. Analyze critical points, identify good/to-be-improved practices that affect defect count or defect rate, to reduce the amount of future defects</td>
- </tr>
- <tr>
- <td>Incident Count</td>
- <td>Number of Incidents found after shipping</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> MRs, etc</td>
- </tr>
- <tr>
- <td>Bugs Count per 1k Lines of Code</td>
- <td>Amount of bugs per 1,000 lines of code</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> MRs, etc</td>
- </tr>
- <tr>
- <td>Incidents Count per 1k Lines of Code</td>
- <td>Amount of incidents per 1,000 lines of code</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> MRs, etc</td>
- </tr>
- <tr>
- <td>Delivery Cost</td>
- <td>Commit Author Count</td>
- <td>Number of Contributors who have committed code</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitextractor/README.md">Git</a>/<a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a>/<a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> commits</td>
- <td>1. As a secondary indicator, this helps assess the labor cost of participating in coding</td>
- <td>1. Take inventory of project/team R&D resource inputs, assess input-output ratio, and rationalize resource deployment</td>
- </tr>
- <tr>
- <td rowspan="3">Delivery Capability</td>
- <td>Build Count</td>
- <td>The number of builds started</td>
- <td>CI/CD entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jenkins/README.md">Jenkins</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLabCI</a> MRs, etc</td>
- <td rowspan="3">1. From the project dimension, compare the number of builds and success rate by combining the project phase and the complexity of tasks<br/>
-2. From the time dimension, analyze the trend of the number of builds and success rate to see if it has improved over time</td>
- <td rowspan="3">1. As a process indicator, it reflects the value flow efficiency of upstream production and research links<br/>
-2. Identify excellent/to-be-improved practices that impact the build, and drive the team to precipitate reusable tools and mechanisms to build infrastructure for fast and high-frequency delivery</td>
- </tr>
- <tr>
- <td>Build Duration</td>
- <td>The duration of successful builds</td>
- <td>CI/CD entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jenkins/README.md">Jenkins</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLabCI</a> MRs, etc</td>
- </tr>
- <tr>
- <td>Build Success Rate</td>
- <td>The percentage of successful builds</td>
- <td>CI/CD entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jenkins/README.md">Jenkins</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLabCI</a> MRs, etc</td>
- </tr>
-</table>
-<br/><br/><br/>
diff --git a/i18n/zh/docusaurus-plugin-content-docs/current/DeveloperManuals/E2E-Test-Guide.md b/i18n/zh/docusaurus-plugin-content-docs/current/DeveloperManuals/E2E-Test-Guide.md
deleted file mode 100644
index fc9efd0b1..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/current/DeveloperManuals/E2E-Test-Guide.md
+++ /dev/null
@@ -1,202 +0,0 @@
----
-title: "E2E Test Guide"
-description: >
- The steps to write E2E tests for plugins.
----
-
-# 如何为插件编写E2E测试
-
-## 为什么要写 E2E 测试
-
-E2E 测试,作为自动化测试的一环,一般是指文件与模块级别的黑盒测试,或者允许使用一些数据库等外部服务的单元测试。书写E2E测试的目的是屏蔽一些内部实现逻辑,仅从数据正确性的角度来看同样的外部输入,是否可以得到同样的输出。另外,相较于黑盒的集成测试来说,可以避免一些网络等因素带来的偶然问题。更多关于插件的介绍,可以在这里获取更多信息: 为什么要编写 E2E 测试(未完成)
-在 DevLake 中,E2E 测试包含接口测试和插件 Extract/Convert 子任务的输入输出结果验证,本篇仅介绍后者的编写流程。
-
-## 准备数据
-
-我们这里以一个简单的插件——飞书会议时长收集举例,他的目录结构目前是这样的。
-
-接下来我们将进行次插件的 E2E 测试的编写。
-
-编写测试的第一步,就是运行一下对应插件的 Collect 任务,完成数据的收集,也就是让数据库的`_raw_feishu_`开头的表中,保存有对应的数据。
-以下是采用 DirectRun (cmd) 运行方式的运行日志和数据库结果。
-
-```
-$ go run plugins/feishu/main.go --numOfDaysToCollect 2 --connectionId 1 (注意:随着版本的升级,命令可能产生变化)
-[2022-06-22 23:03:29] INFO failed to create dir logs: mkdir logs: file exists
-press `c` to send cancel signal
-[2022-06-22 23:03:29] INFO [feishu] start plugin
-[2022-06-22 23:03:33] INFO [feishu] scheduler for api https://open.feishu.cn/open-apis/vc/v1 worker: 13, request: 10000, duration: 1h0m0s
-[2022-06-22 23:03:33] INFO [feishu] total step: 2
-[2022-06-22 23:03:33] INFO [feishu] executing subtask collectMeetingTopUserItem
-[2022-06-22 23:03:33] INFO [feishu] [collectMeetingTopUserItem] start api collection
-[2022-06-22 23:03:34] INFO [feishu] [collectMeetingTopUserItem] finished records: 1
-[2022-06-22 23:03:34] INFO [feishu] [collectMeetingTopUserItem] end api collection error: %!w(<nil>)
-[2022-06-22 23:03:34] INFO [feishu] finished step: 1 / 2
-[2022-06-22 23:03:34] INFO [feishu] executing subtask extractMeetingTopUserItem
-[2022-06-22 23:03:34] INFO [feishu] [extractMeetingTopUserItem] get data from _raw_feishu_meeting_top_user_item where params={"connectionId":1} and got 148
-[2022-06-22 23:03:34] INFO [feishu] [extractMeetingTopUserItem] finished records: 1
-[2022-06-22 23:03:34] INFO [feishu] finished step: 2 / 2
-```
-
-<img width="993" alt="image" src="https://user-images.githubusercontent.com/3294100/175064505-bc2f98d6-3f2e-4ccf-be68-a1cab1e46401.png"/>
-好的,目前数据已经被保存到了`_raw_feishu_*`表中,`data`列就是插件运行的返回信息。这里我们只收集了最近2天的数据,数据信息并不多,但也覆盖了各种情况,即同一个人不同天都有数据。
-
-另外值得一提的是,插件跑了两个任务,`collectMeetingTopUserItem`和`extractMeetingTopUserItem`,前者是收集数据的任务,是本次需要跑的,后者是解析数据的任务,是本次需要测试的。在准备数据环节是否运行无关紧要。
-
-接下来我们需要将数据导出为.csv格式,这一步很多种方案,大家可以八仙过海各显神通,我这里仅仅介绍几种常见的方案。
-
-### DevLake Code Generator 导出
-
-直接运行`go run generator/main.go create-e2e-raw`,根据指引来完成导出。此方案最简单,但也有一定的局限性,比如导出的字段是固定的,如果需要更多的自定义选项,可以参考接下来的方案。
-
-
-
-### GoLand Database 导出
-
-
-
-这种方案很简单,无论使用Postgres或者MySQL,都不会出现什么问题。
-
-csv导出的成功标准就是go程序可以无误的读取,因此有以下几点值得注意:
-
-1. csv文件中的值,可以用双引号包裹,避免值中的逗号等特殊符号破坏了csv格式
-2. csv文件中双引号转义,一般是`""`代表一个双引号
-3. 注意观察data是否是真实值,而不是base64后的值
-
-导出后,将.csv文件放到`plugins/feishu/e2e/raw_tables/_raw_feishu_meeting_top_user_item.csv`。
-
-### MySQL Select Into Outfile
-
-这是 MySQL 将查询结果导出为文件的方案。目前docker-compose.yml中启动的MySQL,是带有--security参数的,因此不允许`select ... into outfile`,首先需要关闭安全参数,关闭方法大致如下图:
-
-关闭后,使用`select ... into outfile`导出csv文件,导出结果大致如下图:
-
-可以注意到,data字段多了hexsha字段,需要人工将其转化为字面量。
-
-### Vscode Database
-
-这是 Vscode 将查询结果导出为文件的方案,但使用起来并不容易。以下是不修改任何配置的导出结果
-
-但可以明显发现,转义符号并不符合csv规范,并且data并没有成功导出,调整配置且手工替换`\"`为`""`后,得到如下结果。
-
-此文件data字段被base64编码,因此需要人工将其解码为字面量。解码成功后即可使用
-
-### MySQL workerbench
-
-此工具必须要自己书写SQL完成数据的导出,可以模仿以下SQL改写:
-```sql
-SELECT id, params, CAST(`data` as char) as data, url, input,created_at FROM _raw_feishu_meeting_top_user_item;
-```
-
-保存格式选择csv,导出后即可直接使用。
-
-### Postgres Copy with csv header;
-
-`Copy(SQL语句) to '/var/lib/postgresql/data/raw.csv' with csv header;`是PG常用的导出csv方法,这里也可以使用。
-```sql
-COPY (
-SELECT id, params, convert_from(data, 'utf-8') as data, url, input,created_at FROM _raw_feishu_meeting_top_user_item
-) to '/var/lib/postgresql/data/raw.csv' with csv header;
-```
-使用以上语句,完成文件的导出。如果你的pg运行在docker中,那么还需要使用 `docker cp`命令将文件导出到宿主机上以便使用。
-
-## 编写E2E测试
-
-首先需要创建测试环境,比如这里创建了`meeting_test.go`
-
-接着在其中输入测试准备代码,如下。其大意为创建了一个`feishu`插件的实例,然后调用`ImportCsvIntoRawTable`将csv文件的数据导入`_raw_feishu_meeting_top_user_item`表中。
-```go
-func TestMeetingDataFlow(t *testing.T) {
- var plugin impl.Feishu
- dataflowTester := e2ehelper.NewDataFlowTester(t, "feishu", plugin)
-
- // import raw data table
- dataflowTester.ImportCsvIntoRawTable("./raw_tables/_raw_feishu_meeting_top_user_item.csv", "_raw_feishu_meeting_top_user_item")
-}
-```
-导入函数的签名如下:
-```func (t *DataFlowTester) ImportCsvIntoRawTable(csvRelPath string, rawTableName string)```
-他有一个孪生兄弟,仅仅是参数略有区别。
-```func (t *DataFlowTester) ImportCsvIntoTabler(csvRelPath string, dst schema.Tabler)```
-前者用于导入raw layer层的表,后者用于导入任意表。
-**注意:** 另外这两个函数会在导入数据前,先删除数据表并使用`gorm.AutoMigrate`重新表以达到清除表数据的目的。
-
-导入数据完成后,可以尝试运行,目前没有任何测试逻辑,因此一定是PASS的。接着在`TestMeetingDataFlow`继续编写调用调用`extract`任务的逻辑。
-
-```go
-func TestMeetingDataFlow(t *testing.T) {
- var plugin impl.Feishu
- dataflowTester := e2ehelper.NewDataFlowTester(t, "feishu", plugin)
-
- taskData := &tasks.FeishuTaskData{
- Options: &tasks.FeishuOptions{
- ConnectionId: 1,
- },
- }
-
- // import raw data table
- dataflowTester.ImportCsvIntoRawTable("./raw_tables/_raw_feishu_meeting_top_user_item.csv", "_raw_feishu_meeting_top_user_item")
-
- // verify extraction
- dataflowTester.FlushTabler(&models.FeishuMeetingTopUserItem{})
- dataflowTester.Subtask(tasks.ExtractMeetingTopUserItemMeta, taskData)
-
-}
-```
-新增的代码包括调用`dataflowTester.FlushTabler`清空`FeishuMeetingTopUserItem`对应的表,调用`dataflowTester.Subtask`模拟子任务`ExtractMeetingTopUserItemMeta`的运行。
-
-现在在运行试试吧,看看子任务`ExtractMeetingTopUserItemMeta`是否能没有错误的完成运行。`extract`运行的数据结果一般来自raw表,因此,插件子任务编写如果没有差错的话,会正确运行,并且可以在 toolLayer 层的数据表中观察到数据成功解析,在本案例中,即`_tool_feishu_meeting_top_user_items`表中有正确的数据。
-
-如果运行不正确,那么需要先排查插件本身编写的问题,然后才能进入下一步。
-
-## 验证运行结果是否正确
-
-我们继续编写测试,在测试函数的最后,继续加上如下代码
-```go
-
-func TestMeetingDataFlow(t *testing.T) {
- ……
-
- dataflowTester.VerifyTable(
- models.FeishuMeetingTopUserItem{},
- "./snapshot_tables/_tool_feishu_meeting_top_user_items.csv",
- []string{"connection_id", "start_time", "name"},
- []string{
- "meeting_count",
- "meeting_duration",
- "user_type",
- "_raw_data_params",
- "_raw_data_table",
- "_raw_data_id",
- "_raw_data_remark",
- },
- )
-}
-```
-它的功能是调用`dataflowTester.VerifyTable`完成数据结果的验证。第三个参数是表的主键,第四个参数是表所有需要验证的字段。用于验证的数据存在`./snapshot_tables/_tool_feishu_meeting_top_user_items.csv`中,当然,目前此文件还不存在。
-
-为了方便生成前述文件,DevLake采取了一种称为`Snapshot`的测试技术,在调用`VerifyTable`文件且csv不存在时,将会根据运行结果自动生成文件。
-
-但注意!自动生成后并不是高枕无忧,还需要做两件事:1. 检查文件生成是否正确 2. 再次运行,以便于确定生成结果和再次运行的结果没有差错。
-这两项操作非常重要,直接关系到测试编写的质量,我们应该像对待代码文件一样对待`.csv`格式的 snapshot 文件。
-
-如果这一步出现了问题,一般会有2种可能,
-1. 验证的字段中含有类似create_at运行时间或者自增id的字段,这些无法重复验证的字段应该排除。
-2. 运行的结果中存在`\n`或`\r\n`等转义不匹配的字段,一般是解析`httpResponse`时出现的错误,可以参考如下方案解决:
- 1. 修改api模型中,内容的字段类型为`json.RawMessage`
- 2. 在解析时再将其转化为string
- 3. 经过以上操作,即可原封不动的保存`\n`符号,避免数据库或操作系统对换行符的解析
-
-
-比如在`github`插件中,是这么处理的:
-
-
-
-好了,到这一步,E2E的编写就完成了。我们本次修改一共新增了3个文件,就完成了对会议时长收集任务的测试,是不是还挺简单的~
-
-
-## 像 CI 一样运行所有插件的 E2E 测试
-
-非常简单,只需要运行`make e2e-plugins`,因为DevLake已经将其固化为一个脚本了~
-
-
diff --git a/i18n/zh/docusaurus-plugin-content-docs/current/DeveloperManuals/PluginImplementation.md b/i18n/zh/docusaurus-plugin-content-docs/current/DeveloperManuals/PluginImplementation.md
deleted file mode 100644
index 41c441949..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/current/DeveloperManuals/PluginImplementation.md
+++ /dev/null
@@ -1,337 +0,0 @@
----
-title: "如何制作一个DevLake插件?"
-sidebar_position: 2
-description: >
- 如何制作一个DevLake插件?
----
-
-
-如果你喜欢的DevOps工具还没有被DevLake支持,不要担心。实现一个DevLake插件并不困难。在这篇文章中,我们将了解DevLake插件的基础知识,并一起从头开始建立一个插件的例子。
-
-## 什么是插件?
-
-DevLake插件是用Go的`plugin`包构建的共享库,在运行时与DevLake核心挂钩。
-
-一个插件可以通过三种方式扩展DevLake的能力。
-
-1. 与新的数据源集成
-2. 转化/丰富现有数据
-3. 将DevLake数据导出到其他数据系统
-
-
-## 插件是如何工作的?
-
-一个插件主要包括可以由DevLake核心执行的子任务的集合。对于数据源插件,一个子任务可能是从数据源中收集一个实体(例如,来自Jira的问题)。除了子任务,还有一些钩子,插件可以实现自定义其初始化、迁移等。最重要的接口列表见下文。
-
-1. [PluginMeta](https://github.com/apache/incubator-devlake/blob/main/plugins/core/plugin_meta.go) 包含一个插件最少应该实现的接口,只有两个函数;
- - Description() 返回插件的描述
- - RootPkgPath() 返回插件的包路径。
-2. [PluginInit](https://github.com/apache/incubator-devlake/blob/main/plugins/core/plugin_init.go) 实现自定义的初始化方法;
-3. [PluginTask](https://github.com/apache/incubator-devlake/blob/main/plugins/core/plugin_task.go) 实现自定义准备数据,其在子任务之前执行;
-4. [PluginApi](https://github.com/apache/incubator-devlake/blob/main/plugins/core/plugin_api.go) 实现插件自定义的API;
-5. [Migratable](https://github.com/apache/incubator-devlake/blob/main/plugins/core/plugin_db_migration.go) 返回插件自定义的数据库迁移的脚本。
-6. [PluginModel](https://github.com/apache/incubator-devlake/blob/main/plugins/core/plugin_model.go) 实现允许其他插件通过 GetTablesInfo() 的方法来获取当前插件的全部数据库表的 model 信息。(若需domain layer的 model 信息,可访问[DomainLayerSchema](https://devlake.apache.org/zh/docs/DataModels/DevLakeDomainLayerSchema/))
-
-下图是一个插件执行的流程:
-
-```mermaid
-flowchart TD
- subgraph S4[Step4 Extractor 运行流程]
- direction LR
- D4[DevLake]
- D4 -- "Step4.1 创建\n ApiExtractor 并执行" --> E["ExtractXXXMeta.\nEntryPoint"];
- E <-- "Step4.2 读取raw table" --> E2["RawDataSubTaskArgs\n.Table"];
- E -- "Step4.3 解析 RawData" --> ApiExtractor.Extract
- ApiExtractor.Extract -- "返回 gorm 模型" --> E
- end
- subgraph S3[Step3 Collector 运行流程]
- direction LR
- D3[DevLake]
- D3 -- "Step3.1 创建\n ApiCollector 并执行" --> C["CollectXXXMeta.\nEntryPoint"];
- C <-- "Step3.2 创建raw table" --> C2["RawDataSubTaskArgs\n.RAW_BBB_TABLE"];
- C <-- "Step3.3 构造请求query" --> ApiCollectorArgs.\nQuery/UrlTemplate;
- C <-. "Step3.4 通过 ApiClient \n请求并返回HTTP" --> A1["HTTP APIs"];
- C <-- "Step3.5 解析\n并返回请求结果" --> ResponseParser;
- end
- subgraph S2[Step2 DevLake 的自定义插件]
- direction LR
- D2[DevLake]
- D2 <-- "Step2.1 在\`Init\` \n初始化插件" --> plugin.Init;
- D2 <-- "Step2.2 (Optional) 调用\n与返回 migration 脚本" --> plugin.MigrationScripts;
- D2 <-- "Step2.3 (Optional) \n初始化并返回taskCtx" --> plugin.PrepareTaskData;
- D2 <-- "Step2.4 返回\n 需要执行的子函数" --> plugin.SubTaskContext;
- end
- subgraph S1[Step1 DevLake 的运行]
- direction LR
- main -- "通过 \`runner.DirectRun\`\n 移交控制权" --> D1[DevLake];
- end
- S1-->S2-->S3-->S4
-```
-图中信息非常多,当然并不期望马上就能消化完,仅仅作为阅读后文的参考即可。
-
-## 一起来实现一个最简单的插件
-
-在本节中,我们将介绍如何从头创建一个数据收集插件。要收集的数据是 Apache 项目的所有 Committers 和 Contributors 信息,目的是检查其是否签署了 CLA。我们将通过:
-
-* 请求 `https://people.apache.org/public/icla-info.json` 获取 Committers 信息
-* 请求`邮件列表` 获取 Contributors 信息
- 我们将演示如何通过 Apache API 请求并缓存所有 Committers 的信息,并提取出结构化的数据。Contributors 的收集仅做一些思路的介绍。
-
-
-### 一、 创建新的插件
-
-**注意:**在开始之前,请确保DevLake已经能正确启动了。
-
-> 关于插件的其他信息:
-> 一般来说, 我们需要这几个目录: `api`, `models` 和 `tasks`
-> `api` 实现 `config-ui` 等其他服务所需的api
->
-> - connection [example](https://github.com/apache/incubator-devlake/blob/main/plugins/gitlab/api/connection.go)
-> connection model [example](https://github.com/apache/incubator-devlake/blob/main/plugins/gitlab/models/connection.go)
-> `models` 保存数据库模型和Migration脚本.
-> - entity
-> data migrations [template](https://github.com/apache/incubator-devlake/tree/main/generator/template/migrationscripts)
-> `tasks` 包含所有子任务
-> - task data [template](https://github.com/apache/incubator-devlake/blob/main/generator/template/plugin/tasks/task_data.go-template)
-> - api client [template](https://github.com/apache/incubator-devlake/blob/main/generator/template/plugin/tasks/task_data_with_api_client.go-template)
->
-> 注:如果这些概念让你感到迷惑,不要担心,我们稍后会逐一解释。
-
-DevLake 提供了专门的工具 Generator 来创建插件,可以通过运行`go run generator/main.go creat-plugin icla`来构建新插件,创建的时候会需要输入「是否需要默认的apiClient `with_api_client`」和「要收集的网站`endpoint`」。
-
-* `with_api_client`用于选择是否需要通过api_client发送HTTP APIs。
-* `endpoint`用于确认插件将请求哪个网站,在本案例中是`https://people.apache.org/`。
-
-
-
-现在我们的插件里有三个文件,其中`api_client.go`和`task_data.go`在子文件夹`tasks/`中。
-
-
-接下来让我们试着运行`plugin_main.go`中的`main`函数来启动插件,运行结果应该如下:
-```
-$go run plugins/icla/plugin_main.go
-[2022-06-02 18:07:30] INFO failed to create dir logs: mkdir logs: file exists
-press `c` to send cancel signal
-[2022-06-02 18:07:30] INFO [icla] start plugin
-invalid ICLA_TOKEN, but ignore this error now
-[2022-06-02 18:07:30] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
-[2022-06-02 18:07:30] INFO [icla] total step: 0
-```
-😋 没有报错,那就是成功啦~ `plugin_main.go`这里定义了插件,有一些配置是保存在`task_data.go`中。这两个文件就构成了最简单的插件,而文件`api_client.go`后面会用来发送HTTP APIs。
-
-### 二、 创建数据收集子任务
-在开始创建之前,我们需要先了解一下子任务的执行过程。
-
-1. Apache DevLake会调用`plugin_main.PrepareTaskData()`,准备一些子任务所需要的环境数据,本项任务中需要创建一个apiClient。
-2. Apache DevLake接着会调用定义在`plugin_main.SubTaskMetas()`的子任务,子任务都是互相独立的函数,可以用于完成注入发送API请求,处理数据等任务。
-
-> 每个子任务必须在`SubTaskMeta`中定义,并实现其中的SubTaskEntryPoint函数,其结构为
-> ```去
-> type SubTaskEntryPoint func(c SubTaskContext) error
-> ```
-> 更多信息见:https://devlake.apache.org/blog/how-apache-devlake-runs/
->
-> 注:如果这些概念让你感到迷惑,跳过跟着一步步做就好。
-
-#### 2.1 创建 Collector 来请求数据
-
-同样的,运行`go run generator/main.go create-collector icla committer`来创建子任务。Generator运行完成后,会自动创建新的文件,并在`plugin_main.go/SubTaskMetas`中激活。
-
-
-
-> - Collector将从HTTP或其他数据源收集数据,并将数据保存到rawLayer中。
-> - `httpCollector`的`SubTaskEntryPoint`中,默认会使用`helper.NewApiCollector`来创建新的[ApiCollector](https://github.com/apache/incubator-devlake/blob/main/generator/template/plugin/tasks/api_collector.go-template)对象,并调用其`execute()`来并行收集。
->
-> 注:如果这些概念让你感到迷惑,跳过就好。
-
-现在你可以注意到在`plugin_main.go/PrepareTaskData.ApiClient`中有引用`data.ApiClient`,它是Apache DevLake推荐用于从HTTP APIs请求数据的工具。这个工具支持一些很有用的功能,比如请求限制、代理和重试。当然,如果你喜欢,也可以使用`http`库来代替,只示会显得更加繁琐而已。
-
-回到正题,现在的目标是从`https://people.apache.org/public/icla-info.json`收集数据,因此需要完成以下步骤:
-
-1.
-我们已经在之前中把`https://people.apache.org/`填入`tasks/api_client.go/ENDPOINT`了,现在在看一眼确认下。
-
-
-
-2. 将`public/icla-info.json`填入`UrlTemplate`,删除不必要的迭代器,并在`ResponseParser`中添加`println("receive data:", res)`以查看收集是否成功。
-
-
-
-好了,现在Collector已经创建好了,再次运行`main`来启动插件,如果一切顺利的话,输出应该是这样的:
-```bash
-[2022-06-06 12:24:52] INFO [icla] start plugin
-invalid ICLA_TOKEN, but ignore this error now
-[2022-06-06 12:24:52] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
-[2022-06-06 12:24:52] INFO [icla] total step: 1
-[2022-06-06 12:24:52] INFO [icla] executing subtask CollectCommitter
-[2022-06-06 12:24:52] INFO [icla] [CollectCommitter] start api collection
-receive data: 0x140005763f0
-[2022-06-06 12:24:55] INFO [icla] [CollectCommitter] finished records: 1
-[2022-06-06 12:24:55] INFO [icla] [CollectCommitter] end api collection
-[2022-06-06 12:24:55] INFO [icla] finished step: 1 / 1
-```
-
-从以上日志中,可以看到已经能打印出收到数据的日志了,最后一步是在`ResponseParser`中对响应体进行解码,并将其返回给DevLake,以便将其存储在数据库中。
-```go
-ResponseParser: func(res *http.Response) ([]json.RawMessage, error) {
- body := &struct {
- LastUpdated string `json:"last_updated"`
- Committers json.RawMessage `json:"committers"`
- }{}
- err := helper.UnmarshalResponse(res, body)
- if err != nil {
- return nil, err
- }
- println("receive data:", len(body.Committers))
- return []json.RawMessage{body.Committers}, nil
-},
-```
-再次运行函数`main`,结果如下,此时可以在数据库表`_raw_icla_committer`中看到一条新的数据。
-```bash
-……
-receive data: 272956 /* <- 这个数字表示收到了272956个Committer */
-[2022-06-06 13:46:57] INFO [icla] [CollectCommitter] finished records: 1
-[2022-06-06 13:46:57] INFO [icla] [CollectCommitter] end api collection
-[2022-06-06 13:46:57] INFO [icla] finished step: 1 / 1
-```
-
-
-
-#### 2.2 创建 Extractor,从 rawLayer 中提取数据
-
-> - Extractor将从rawLayer中提取数据并保存到工具db表中。
-> - 除了一些具体的处理内容,主流程与采集器类似。
-
-从HTTP API收集的数据目前仅仅保存在表`_raw_XXXX`中,但其使用起来却很不容易。因此我们将继续从其中提取Committer的名字。目前Apache DevLake建议用[gorm](https://gorm.io/docs/index.html)来保存数据,所以我们将用gorm创建一个模型,并将其添加到`plugin_main.go/AutoMigrate()`中。
-
-plugins/icla/models/committer.go
-```go
-package models
-
-import (
- "github.com/apache/incubator-devlake/models/common"
-)
-
-type IclaCommitter struct {
- UserName string `gorm:"primaryKey;type:varchar(255)"`
- Name string `gorm:"primaryKey;type:varchar(255)"`
- common.NoPKModel
-}
-
-func (IclaCommitter) TableName() string {
- return "_tool_icla_committer"
-}
-```
-
-plugins/icla/plugin_main.go
-
-
-在做完以上步骤以后,就可以再次运行插件,刚定义的数据表`_tool_icla_committer`会自动创建,就像下面的截图。
-
-
-接下来,让我们运行`go run generator/main.go create-extractor icla committer`并输入命令行提示的内容,来创建新的子任务。
-
-
-
-运行完成后,来看看刚才创建的`committer_extractor.go`中的函数`extract`,很明显参数中的`resData.data`是原始数据,我们需要用json解码,并创建`IclaCommitter`模型来保存它们。
-```go
-Extract: func(resData *helper.RawData) ([]interface{}, error) {
- names := &map[string]string{}
- err := json.Unmarshal(resData.Data, names)
- if err != nil {
- return nil, err
- }
- extractedModels := make([]interface{}, 0)
- for userName, name := range *names {
- extractedModels = append(extractedModels, &models.IclaCommitter{
- UserName: userName,
- Name: name,
- })fco
- }
- return extractedModels, nil
-},
-```
-
-再次运行插件,结果如下:
-```
-[2022-06-06 15:39:40] INFO [icla] start plugin
-invalid ICLA_TOKEN, but ignore this error now
-[2022-06-06 15:39:40] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
-[2022-06-06 15:39:40] INFO [icla] total step: 2
-[2022-06-06 15:39:40] INFO [icla] executing subtask CollectCommitter
-[2022-06-06 15:39:40] INFO [icla] [CollectCommitter] start api collection
-receive data: 272956
-[2022-06-06 15:39:44] INFO [icla] [CollectCommitter] finished records: 1
-[2022-06-06 15:39:44] INFO [icla] [CollectCommitter] end api collection
-[2022-06-06 15:39:44] INFO [icla] finished step: 1 / 2
-[2022-06-06 15:39:44] INFO [icla] executing subtask ExtractCommitter
-[2022-06-06 15:39:46] INFO [icla] [ExtractCommitter] finished records: 1
-[2022-06-06 15:39:46] INFO [icla] finished step: 2 / 2
-```
-可以看到有两个任务运行完成,同时观察数据库发现,提交者的数据已经保存在_tool_icla_committer中了~
-
-
-#### 2.3 子任务 - Converter
-
-注意。这里有两种方式(开源或自己使用)。因此 Converter 不是必须的,但我们鼓励使用它,因为 Converter 和 DomainLayer 非常有助于建立通用的仪表盘。关于 DomainLayer 的更多信息请见:https://devlake.apache.org/docs/DataModels/DevLakeDomainLayerSchema/
-
-> - Converter 将处理 DomainLayer 的数据,并将其保存到 DomainLayer 层中。
-> - 使用`helper.NewDataConverter`来创建一个 DataConvertor 的对象,然后调用`execute()`来运行。
-
-#### 2.4 动手试试更多类型的请求吧~
-有时 OpenApi 会受到 token 或其他保护,只有获得 token 才来能访问。例如在本案例中,我们只有在登录`private@apahce.com`后,才能收集到关于普通 Contributor 签署ICLA的数据。但这里受限于篇幅,仅仅简单介绍一下如何收集需要授权的数据。
-
-让我们注意`api_client.go`文件,其中`NewIclaApiClient`通过`.env`加载配置了`ICLA_TOKEN`,它让我们可以在`.env`中添加`ICLA_TOKEN=XXXX`,并在`apiClient.SetHeaders()`中使用它来模拟登录状态。代码如下。
-
-
-当然,我们可以使用`username/password`来获取模拟登录后的token,试着根据实际情况进行调整即可。
-
-更多相关细节请看https://github.com/apache/incubator-devlake
-
-#### Step 2.5 实现 PluginModel 接口的 GetTablesInfo() 方法
-
-如下gitlab插件示例所示
-将所有需要被外部插件访问到的 model 均添加到返回值中。
-
-```golang
-var _ core.PluginModel = (*Gitlab)(nil)
-
-func (plugin Gitlab) GetTablesInfo() []core.Tabler {
- return []core.Tabler{
- &models.GitlabConnection{},
- &models.GitlabAccount{},
- &models.GitlabCommit{},
- &models.GitlabIssue{},
- &models.GitlabIssueLabel{},
- &models.GitlabJob{},
- &models.GitlabMergeRequest{},
- &models.GitlabMrComment{},
- &models.GitlabMrCommit{},
- &models.GitlabMrLabel{},
- &models.GitlabMrNote{},
- &models.GitlabPipeline{},
- &models.GitlabProject{},
- &models.GitlabProjectCommit{},
- &models.GitlabReviewer{},
- &models.GitlabTag{},
- }
-}
-```
-
-可以使用如下方式来使用该接口
-
-```
-if pm, ok := plugin.(core.PluginModel); ok {
- tables := pm.GetTablesInfo()
- for _, table := range tables {
- // do something
- }
-}
-
-```
-
-#### 2.6 将插件提交给开源社区
-恭喜你! 第一个插件已经创建完毕! 🎖 我们鼓励开源贡献~ 接下来还需要学习 migrationScripts 和 domainLayers 来编写规范的、平台无关的代码。更多信息请访问https://devlake.apache.org/docs/DataModels/DevLakeDomainLayerSchema,或联系我们以获得热情洋溢的帮助。
-
-
-
diff --git a/i18n/zh/docusaurus-plugin-content-docs/current/GettingStarted/RainbondSetup.md b/i18n/zh/docusaurus-plugin-content-docs/current/GettingStarted/RainbondSetup.md
deleted file mode 100644
index b0d6606b0..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/current/GettingStarted/RainbondSetup.md
+++ /dev/null
@@ -1,34 +0,0 @@
----
-title: "通过 Rainbond 安装"
-sidebar_position: 7
-description: >
- 在Rainbond中安装DevLake的步骤。
----
-
-本篇文档适用于不了解 Kubernetes 的用户。[Rainbond](https://www.rainbond.com/) 是建立在 Kubernetes 之上的开源云原生应用管理平台,简单易用,无需了解 Kubernetes 相关知识,轻松在 Kubernetes 上部署应用。
-
-在 Rainbond 中可以很便捷、快速的安装 DevLake。
-
-## 前提要求
-
-* Rainbond 5.8.x 或以上
-
-## 部署 DevLake
-
-1.登录 Rainbond 控制台,点击左侧菜单的 `市场` 按钮,切换到开源应用商店, 在搜索框中搜索 `DevLake`,并点击安装按钮。
-
-
-
-2.填写安装信息, 并点击确认按钮开始安装 DevLake。
- * 团队: 选择或者创建新的团队
- * 集群: 选择或者创建新的集群
- * 应用: 选择或者创建新的应用
- * 版本: 选择 DevLake 版本
-
-3.片刻之后,DevLake 安装完成,通过应用内的访问按钮访问 DevLake,默认访问策略由 Rainbond 自动生成。
-
-
-
-## Next Step
-
-创建 Blueprint, 参阅 [教程](/docs/UserManuals/ConfigUI/Tutorial#creating-a-blueprint)
\ No newline at end of file
diff --git a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/01-Overview/02-WhatIsDevLake.md b/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/01-Overview/02-WhatIsDevLake.md
deleted file mode 100755
index 9cf249c72..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/01-Overview/02-WhatIsDevLake.md
+++ /dev/null
@@ -1,30 +0,0 @@
----
-title: "What is DevLake?"
-linkTitle: "What is DevLake?"
-tags: []
-categories: []
-weight: 1
-description: >
- General introduction of DevLake
----
-
-
-DevLake brings your DevOps data into one practical, customized, extensible view. Ingest, analyze, and visualize data from an ever-growing list of developer tools, with our open source product.
-
-DevLake is designed for developer teams looking to make better sense of their development process and to bring a more data-driven approach to their own practices. You can ask DevLake many questions regarding your development process. Just connect and query.
-
-<a href="https://app-259373083972538368-3002.ars.teamcode.com/d/0Rjxknc7z/demo-homepage?orgId=1">See demo</a>. Username/password:test/test. The demo is based on the data from this repo, merico-dev/lake.
-
-
-
-<div align="left">
-<img src="https://user-images.githubusercontent.com/14050754/145056261-ceaf7044-f5c5-420f-80ca-54e56eb8e2a7.png" width="100%" alt="User Flow" style={{borderRadius: '15px' }}/>
-<p align="center">User Flow</p>
-</div>
-<br/>
-
-### What can be accomplished with DevLake?
-1. Collect DevOps data across the entire SDLC process and connect data silos.
-2. A standard <a href="https://github.com/merico-dev/lake/wiki/DataModel.Domain-layer-schema">data model</a> and out-of-the-box <a href="https://github.com/merico-dev/lake/wiki/Metric-Cheatsheet">metrics</a> for software engineering.
-3. Flexible <a href="https://github.com/merico-dev/lake/blob/main/ARCHITECTURE.md">framework</a> for data collection and ETL, support customized analysis.
-<br/><br/><br/>
diff --git a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/01-Overview/03-Architecture.md b/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/01-Overview/03-Architecture.md
deleted file mode 100755
index db3cdedcf..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/01-Overview/03-Architecture.md
+++ /dev/null
@@ -1,29 +0,0 @@
----
-title: "Architecture"
-linkTitle: "Architecture"
-tags: []
-categories: []
-weight: 2
-description: >
- Understand the architecture of DevLake.
----
-
-
-
-<p align="center">Architecture Diagram</p>
-
-## Stack (from low to high)
-
-1. config
-2. logger
-3. models
-4. plugins
-5. services
-6. api / cli
-
-## Rules
-
-1. Higher layer calls lower layer, not the other way around
-2. Whenever lower layer neeeds something from higher layer, a interface should be introduced for decoupling
-3. Components should be initialized in a low to high order during bootstraping
-<br/><br/><br/>
diff --git a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/01-Overview/04-Roadmap.md b/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/01-Overview/04-Roadmap.md
deleted file mode 100755
index 39e229d99..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/01-Overview/04-Roadmap.md
+++ /dev/null
@@ -1,36 +0,0 @@
----
-title: "Roadmap"
-linkTitle: "Roadmap"
-tags: []
-categories: []
-weight: 3
-description: >
- The goals and roadmap for DevLake in 2022.
----
-
-
-## Goals
-1. Moving to Apache Incubator and making DevLake a graduation-ready project.
-2. Explore and implement 3 typical use scenarios to help certain engineering teams and developers:
- - Observation of open-source project contribution and quality
- - DORA metrics for the DevOps team
- - SDLC workflow monitoring and improvement
-3. Better UX for end-users and contributors.
-
-
-## DevLake 2022 Roadmap
-DevLake is currently under rapid development. This page describes the project’s public roadmap, the result of an ongoing collaboration between the core maintainers and the broader DevLake community.<br/><br/>
-This roadmap is broken down by the goals in the last section.
-
-
-| Category | Features|
-| --- | --- |
-| More data sources across different [DevOps domains](https://github.com/merico-dev/lake/wiki/DevOps-Domain-Definition)| 1. **Issue/Task Management - Jira server** <br/> 2. **Issue/Task Management - Jira data center** <br/> 3. Issue/Task Management - GitLab Issues <br/> 4. Issue/Task Management - Trello <br/> 5. **Issue/Task Management - TPAD** <br/> 6. Issue/Task Management - Teambition <br/> 7. Issue/Task Management - Trello <br/> 8. **Source Code Management - GitLab on-premise** <br/> [...]
-| More comprehensive and flexible [engineering data model](https://github.com/merico-dev/lake/issues/700) | 1. complete and polish standard data models for different [DevOps domains](https://github.com/merico-dev/lake/wiki/DevOps-Domain-Definition) <br/> 2. allow users to modify standard tables <br/> 3. allow users to create new tables <br/> 4. allow users to easily define ETL rules <br/> |
-| Better UX | 1. improve config-UI design for better onboard experience <br/> 2. improve data collection speed for Github and other plugins with strict API rate limit <br/> 3. build a website to present well-organized documentation to DevLake users and contributors <br/> |
-
-
-## How to Influence Roadmap
-A roadmap is only useful when it captures real user needs. We are glad to hear from you if you have specific use cases, feedback, or ideas. You can submit an issue to let us know!
-Also, if you plan to work (or are already working) on a new or existing feature, tell us, so that we can update the roadmap accordingly. We are happy to share knowledge and context to help your feature land successfully.
-<br/><br/><br/>
diff --git a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/01-Overview/_category_.json b/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/01-Overview/_category_.json
deleted file mode 100644
index e224ed81c..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/01-Overview/_category_.json
+++ /dev/null
@@ -1,4 +0,0 @@
-{
- "label": "Overview",
- "position": 1
-}
diff --git a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/02-Quick Start/01-LocalSetup.md b/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/02-Quick Start/01-LocalSetup.md
deleted file mode 100644
index 98ed3bb25..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/02-Quick Start/01-LocalSetup.md
+++ /dev/null
@@ -1,81 +0,0 @@
----
-title: "Local Setup"
-linkTitle: "Local Setup"
-tags: []
-categories: []
-weight: 1
-description: >
- The steps to install DevLake locally.
----
-
-
-- If you only plan to run the product locally, this is the **ONLY** section you should need.
-- Commands written `like this` are to be run in your terminal.
-
-#### Required Packages to Install<a id="user-setup-requirements"></a>
-
-- [Docker](https://docs.docker.com/get-docker)
-- [docker-compose](https://docs.docker.com/compose/install/)
-
-NOTE: After installing docker, you may need to run the docker application and restart your terminal
-
-#### Commands to run in your terminal<a id="user-setup-commands"></a>
-
-**IMPORTANT: DevLake doesn't support Database Schema Migration yet, upgrading an existing instance is likely to break, we recommend that you deploy a new instance instead.**
-
-1. Download `docker-compose.yml` and `env.example` from [latest release page](https://github.com/merico-dev/lake/releases/latest) into a folder.
-2. Rename `env.example` to `.env`. For Mac/Linux users, please run `mv env.example .env` in the terminal.
-3. Start Docker on your machine, then run `docker-compose up -d` to start the services.
-4. Visit `localhost:4000` to set up configuration files.
- >- Navigate to desired plugins on the Integrations page
- >- Please reference the following for more details on how to configure each one:<br/>
- - **jira**
- - **gitlab**
- - **jenkins**
- - **github**
- >- Submit the form to update the values by clicking on the **Save Connection** button on each form page
- >- `devlake` takes a while to fully boot up. if `config-ui` complaining about api being unreachable, please wait a few seconds and try refreshing the page.
-
-
-5. Visit `localhost:4000/pipelines/create` to RUN a Pipeline and trigger data collection.
-
-
- Pipelines Runs can be initiated by the new "Create Run" Interface. Simply enable the **Data Source Providers** you wish to run collection for, and specify the data you want to collect, for instance, **Project ID** for Gitlab and **Repository Name** for GitHub.
-
- Once a valid pipeline configuration has been created, press **Create Run** to start/run the pipeline.
- After the pipeline starts, you will be automatically redirected to the **Pipeline Activity** screen to monitor collection activity.
-
- **Pipelines** is accessible from the main menu of the config-ui for easy access.
-
- - Manage All Pipelines: `http://localhost:4000/pipelines`
- - Create Pipeline RUN: `http://localhost:4000/pipelines/create`
- - Track Pipeline Activity: `http://localhost:4000/pipelines/activity/[RUN_ID]`
-
- For advanced use cases and complex pipelines, please use the Raw JSON API to manually initiate a run using **cURL** or graphical API tool such as **Postman**. `POST` the following request to the DevLake API Endpoint.
-
- ```json
- [
- [
- {
- "plugin": "github",
- "options": {
- "repo": "lake",
- "owner": "merico-dev"
- }
- }
- ]
- ]
- ```
-
- Please refer to this wiki [How to trigger data collection](https://github.com/merico-dev/lake/wiki/How-to-use-the-triggers-page).
-
-6. Click *View Dashboards* button in the top left when done, or visit `localhost:3002` (username: `admin`, password: `admin`).
-
- We use <a href="https://grafana.com/" target="_blank">Grafana</a> as a visualization tool to build charts for the <a href="https://github.com/merico-dev/lake/wiki/DataModel.Domain-layer-schema">data stored in our database</a>. Using SQL queries, we can add panels to build, save, and edit customized dashboards.
-
- All the details on provisioning and customizing a dashboard can be found in the **Grafana Doc**
-
-#### Setup cron job
-
-To synchronize data periodically, we provide **lake-cli** for easily sending data collection requests along with **a cron job** to periodically trigger the cli tool.
-<br/><br/><br/>
diff --git a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/02-Quick Start/02-KubernetesSetup.md b/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/02-Quick Start/02-KubernetesSetup.md
deleted file mode 100644
index 4327e319c..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/02-Quick Start/02-KubernetesSetup.md
+++ /dev/null
@@ -1,9 +0,0 @@
----
-title: "Kubernetes Setup"
-linkTitle: "Kubernetes Setup"
-tags: []
-categories: []
-weight: 2
-description: >
- The steps to install DevLake in Kubernetes.
----
diff --git a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/02-Quick Start/03-DeveloperSetup.md b/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/02-Quick Start/03-DeveloperSetup.md
deleted file mode 100644
index b1696d098..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/02-Quick Start/03-DeveloperSetup.md
+++ /dev/null
@@ -1,123 +0,0 @@
----
-title: "Developer Setup"
-linkTitle: "Developer Setup"
-tags: []
-categories: []
-weight: 3
-description: >
- The steps to install DevLake in develper mode.
----
-
-
-
-#### Requirements
-
-- <a href="https://docs.docker.com/get-docker" target="_blank">Docker</a>
-- <a href="https://golang.org/doc/install" target="_blank">Golang v1.17+</a>
-- Make
- - Mac (Already installed)
- - Windows: [Download](http://gnuwin32.sourceforge.net/packages/make.htm)
- - Ubuntu: `sudo apt-get install build-essential`
-
-#### How to setup dev environment
-1. Navigate to where you would like to install this project and clone the repository:
-
- ```sh
- git clone https://github.com/merico-dev/lake.git
- cd lake
- ```
-
-2. Install dependencies for plugins:
-
- - **RefDiff**
-
-3. Install Go packages
-
- ```sh
- go get
- ```
-
-4. Copy the sample config file to new local file:
-
- ```sh
- cp .env.example .env
- ```
-
-5. Update the following variables in the file `.env`:
-
- * `DB_URL`: Replace `mysql:3306` with `127.0.0.1:3306`
-
-5. Start the MySQL and Grafana containers:
-
- > Make sure the Docker daemon is running before this step.
-
- ```sh
- docker-compose up -d mysql grafana
- ```
-
-6. Run lake and config UI in dev mode in two seperate terminals:
-
- ```sh
- # run lake
- make dev
- # run config UI
- make configure-dev
- ```
-
-7. Visit config UI at `localhost:4000` to configure data sources.
- >- Navigate to desired plugins pages on the Integrations page
- >- You will need to enter the required information for the plugins you intend to use.
- >- Please reference the following for more details on how to configure each one:
- **jira**
- **gitlab**
- **jenkins**
- **github**
-
- >- Submit the form to update the values by clicking on the **Save Connection** button on each form page
-
-8. Visit `localhost:4000/pipelines/create` to RUN a Pipeline and trigger data collection.
-
-
- Pipelines Runs can be initiated by the new "Create Run" Interface. Simply enable the **Data Source Providers** you wish to run collection for, and specify the data you want to collect, for instance, **Project ID** for Gitlab and **Repository Name** for GitHub.
-
- Once a valid pipeline configuration has been created, press **Create Run** to start/run the pipeline.
- After the pipeline starts, you will be automatically redirected to the **Pipeline Activity** screen to monitor collection activity.
-
- **Pipelines** is accessible from the main menu of the config-ui for easy access.
-
- - Manage All Pipelines: `http://localhost:4000/pipelines`
- - Create Pipeline RUN: `http://localhost:4000/pipelines/create`
- - Track Pipeline Activity: `http://localhost:4000/pipelines/activity/[RUN_ID]`
-
- For advanced use cases and complex pipelines, please use the Raw JSON API to manually initiate a run using **cURL** or graphical API tool such as **Postman**. `POST` the following request to the DevLake API Endpoint.
-
- ```json
- [
- [
- {
- "plugin": "github",
- "options": {
- "repo": "lake",
- "owner": "merico-dev"
- }
- }
- ]
- ]
- ```
-
- Please refer to this wiki [How to trigger data collection](https://github.com/merico-dev/lake/wiki/How-to-use-the-triggers-page).
-
-
-9. Click *View Dashboards* button in the top left when done, or visit `localhost:3002` (username: `admin`, password: `admin`).
-
- We use <a href="https://grafana.com/" target="_blank">Grafana</a> as a visualization tool to build charts for the <a href="https://github.com/merico-dev/lake/wiki/DataModel.Domain-layer-schema">data stored in our database</a>. Using SQL queries, we can add panels to build, save, and edit customized dashboards.
-
- All the details on provisioning and customizing a dashboard can be found in the **Grafana Doc**
-
-
-10. (Optional) To run the tests:
-
-
- make test
-
-<br/><br/><br/><br/>
diff --git a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/02-Quick Start/_category_.json b/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/02-Quick Start/_category_.json
deleted file mode 100644
index 9620a0534..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/02-Quick Start/_category_.json
+++ /dev/null
@@ -1,4 +0,0 @@
-{
- "label": "Quick Start",
- "position": 2
-}
diff --git a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/03-Features.md b/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/03-Features.md
deleted file mode 100644
index 2b2bb24b5..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/03-Features.md
+++ /dev/null
@@ -1,20 +0,0 @@
----
-sidebar_position: 03
-title: "Features"
-linkTitle: "Features"
-tags: []
-categories: []
-weight: 30000
-description: >
- Features of the latest version of DevLake.
----
-
-
-1. Collect data from [mainstream DevOps tools](https://github.com/merico-dev/lake#project-roadmap), including Jira (Cloud), Jira Server v8+, Git, GitLab, GitHub, Jenkins etc., supported by [plugins](https://github.com/merico-dev/lake/blob/main/ARCHITECTURE.md).
-2. Receive data through Push API.
-3. Standardize DevOps data based on [domain layer schema](https://github.com/merico-dev/lake/wiki/DataModel.Domain-layer-schema). Support 20+ [built-in engineering metrics](https://github.com/merico-dev/lake/wiki/Metric-Cheatsheet) to observe productivity, quality and delivery capability.
-4. Connect "commit" entity with "issue" entity, and generate composite metrics such as `Bugs Count per 1k Lines of Code`.
-5. Identify new commits based on [RefDiff](https://github.com/merico-dev/lake/tree/main/plugins/refdiff#refdiff) plugin, and analyze productivity and quality of each version.
-6. Flexible dashboards to support data visualization and queries, based on Grafana.
-
-<br/><br/><br/>
diff --git a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/04-EngineeringMetrics.md b/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/04-EngineeringMetrics.md
deleted file mode 100644
index 3b8a08b20..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/04-EngineeringMetrics.md
+++ /dev/null
@@ -1,197 +0,0 @@
----
-sidebar_position: 04
-title: "Engineering Metrics"
-linkTitle: "Engineering Metrics"
-tags: []
-categories: []
-weight: 40000
-description: >
- The definition, values and data required for the 20+ engineering metrics supported by DevLake.
----
-
-<table>
- <tr>
- <th><b>Category</b></th>
- <th><b>Metric Name</b></th>
- <th><b>Definition</b></th>
- <th><b>Data Required</b></th>
- <th style={{width:'70%'}}><b>Use Scenarios and Recommended Practices</b></th>
- <th><b>Value </b></th>
- </tr>
- <tr>
- <td rowspan="10">Delivery Velocity</td>
- <td>Requirement Count</td>
- <td>Number of issues in type "Requirement"</td>
- <td>Issue/Task Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jira/README.md">Jira issues</a>, <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub issues</a>, etc</td>
- <td rowspan="2">
-1. Analyze the number of requirements and delivery rate of different time cycles to find the stability and trend of the development process.
-<br/>2. Analyze and compare the number of requirements delivered and delivery rate of each project/team, and compare the scale of requirements of different projects.
-<br/>3. Based on historical data, establish a baseline of the delivery capacity of a single iteration (optimistic, probable and pessimistic values) to provide a reference for iteration estimation.
-<br/>4. Drill down to analyze the number and percentage of requirements in different phases of SDLC. Analyze rationality and identify the requirements stuck in the backlog.</td>
- <td rowspan="2">1. Based on historical data, establish a baseline of the delivery capacity of a single iteration to improve the organization and planning of R&D resources.
-<br/>2. Evaluate whether the delivery capacity matches the business phase and demand scale. Identify key bottlenecks and reasonably allocate resources.</td>
- </tr>
- <tr>
- <td>Requirement Delivery Rate</td>
- <td>Ratio of delivered requirements to all requirements</td>
- <td>Issue/Task Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jira/README.md">Jira issues</a>, <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub issues</a>, etc</td>
- </tr>
- <tr>
- <td>Requirement Lead Time</td>
- <td>Lead time of issues with type "Requirement"</td>
- <td>Issue/Task Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jira/README.md">Jira issues</a>, <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub issues</a>, etc</td>
- <td>
-1. Analyze the trend of requirement lead time to observe if it has improved over time.
-<br/>2. Analyze and compare the requirement lead time of each project/team to identify key projects with abnormal lead time.
-<br/>3. Drill down to analyze a requirement's staying time in different phases of SDLC. Analyze the bottleneck of delivery velocity and improve the workflow.</td>
- <td>1. Analyze key projects and critical points, identify good/to-be-improved practices that affect requirement lead time, and reduce the risk of delays
-<br/>2. Focus on the end-to-end velocity of value delivery process; coordinate different parts of R&D to avoid efficiency shafts; make targeted improvements to bottlenecks.</td>
- </tr>
- <tr>
- <td>Requirement Granularity</td>
- <td>Number of story points associated with an issue</td>
- <td>Issue/Task Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jira/README.md">Jira issues</a>, <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub issues</a>, etc</td>
- <td>
-1. Analyze the story points/requirement lead time of requirements to evaluate whether the ticket size, ie. requirement complexity is optimal.
-<br/>2. Compare the estimated requirement granularity with the actual situation and evaluate whether the difference is reasonable by combining more microscopic workload metrics (e.g. lines of code/code equivalents)</td>
- <td>1. Promote product teams to split requirements carefully, improve requirements quality, help developers understand requirements clearly, deliver efficiently and with high quality, and improve the project management capability of the team.
-<br/>2. Establish a data-supported workload estimation model to help R&D teams calibrate their estimation methods and more accurately assess the granularity of requirements, which is useful to achieve better issue planning in project management.</td>
- </tr>
- <tr>
- <td>Commit Count</td>
- <td>Number of Commits</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitextractor/README.md">Git</a>/<a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a>/<a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> commits</td>
- <td>
-1. Identify the main reasons for the unusual number of commits and the possible impact on the number of commits through comparison
-<br/>2. Evaluate whether the number of commits is reasonable in conjunction with more microscopic workload metrics (e.g. lines of code/code equivalents)</td>
- <td>1. Identify potential bottlenecks that may affect output
-<br/>2. Encourage R&D practices of small step submissions and develop excellent coding habits</td>
- </tr>
- <tr>
- <td>Added Lines of Code</td>
- <td>Accumulated number of added lines of code</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitextractor/README.md">Git</a>/<a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a>/<a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> commits</td>
- <td rowspan="2">
-1. From the project/team dimension, observe the accumulated change in Added lines to assess the team activity and code growth rate
-<br/>2. From version cycle dimension, observe the active time distribution of code changes, and evaluate the effectiveness of project development model.
-<br/>3. From the member dimension, observe the trend and stability of code output of each member, and identify the key points that affect code output by comparison.</td>
- <td rowspan="2">1. identify potential bottlenecks that may affect the output
-<br/>2. Encourage the team to implement a development model that matches the business requirements; develop excellent coding habits</td>
- </tr>
- <tr>
- <td>Deleted Lines of Code</td>
- <td>Accumulated number of deleted lines of code</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitextractor/README.md">Git</a>/<a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a>/<a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> commits</td>
- </tr>
- <tr>
- <td>Pull Request Review Time</td>
- <td>Time from Pull/Merge created time until merged</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> MRs, etc</td>
- <td>
-1. Observe the mean and distribution of code review time from the project/team/individual dimension to assess the rationality of the review time</td>
- <td>1. Take inventory of project/team code review resources to avoid lack of resources and backlog of review sessions, resulting in long waiting time
-<br/>2. Encourage teams to implement an efficient and responsive code review mechanism</td>
- </tr>
- <tr>
- <td>Bug Age</td>
- <td>Lead time of issues in type "Bug"</td>
- <td>Issue/Task Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jira/README.md">Jira issues</a>, <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub issues</a>, etc</td>
- <td rowspan="2">
-1. Observe the trend of bug age and locate the key reasons.<br/>
-2. According to the severity level, type (business, functional classification), affected module, source of bugs, count and observe the length of bug and incident age.</td>
- <td rowspan="2">1. Help the team to establish an effective hierarchical response mechanism for bugs and incidents. Focus on the resolution of important problems in the backlog.<br/>
-2. Improve team's and individual's bug/incident fixing efficiency. Identify good/to-be-improved practices that affect bug age or incident age</td>
- </tr>
- <tr>
- <td>Incident Age</td>
- <td>Lead time of issues in type "Incident"</td>
- <td>Issue/Task Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jira/README.md">Jira issues</a>, <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub issues</a>, etc</td>
- </tr>
- <tr>
- <td rowspan="8">Delivery Quality</td>
- <td>Pull Request Count</td>
- <td>Number of Pull/Merge Requests</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> MRs, etc</td>
- <td rowspan="3">
-1. From the developer dimension, we evaluate the code quality of developers by combining the task complexity with the metrics related to the number of review passes and review rounds.<br/>
-2. From the reviewer dimension, we observe the reviewer's review style by taking into account the task complexity, the number of passes and the number of review rounds.<br/>
-3. From the project/team dimension, we combine the project phase and team task complexity to aggregate the metrics related to the number of review passes and review rounds, and identify the modules with abnormal code review process and possible quality risks.</td>
- <td rowspan="3">1. Code review metrics are process indicators to provide quick feedback on developers' code quality<br/>
-2. Promote the team to establish a unified coding specification and standardize the code review criteria<br/>
-3. Identify modules with low-quality risks in advance, optimize practices, and precipitate into reusable knowledge and tools to avoid technical debt accumulation</td>
- </tr>
- <tr>
- <td>Pull Request Pass Rate</td>
- <td>Ratio of Pull/Merge Review requests to merged</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> MRs, etc</td>
- </tr>
- <tr>
- <td>Pull Request Review Rounds</td>
- <td>Number of cycles of commits followed by comments/final merge</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> MRs, etc</td>
- </tr>
- <tr>
- <td>Pull Request Review Count</td>
- <td>Number of Pull/Merge Reviewers</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> MRs, etc</td>
- <td>1. As a secondary indicator, assess the cost of labor invested in the code review process</td>
- <td>1. Take inventory of project/team code review resources to avoid long waits for review sessions due to insufficient resource input</td>
- </tr>
- <tr>
- <td>Bug Count</td>
- <td>Number of bugs found during testing</td>
- <td>Issue/Task Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jira/README.md">Jira issues</a>, <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub issues</a>, etc</td>
- <td rowspan="4">
-1. From the project or team dimension, observe the statistics on the total number of defects, the distribution of the number of defects in each severity level/type/owner, the cumulative trend of defects, and the change trend of the defect rate in thousands of lines, etc.<br/>
-2. From version cycle dimension, observe the statistics on the cumulative trend of the number of defects/defect rate, which can be used to determine whether the growth rate of defects is slowing down, showing a flat convergence trend, and is an important reference for judging the stability of software version quality<br/>
-3. From the time dimension, analyze the trend of the number of test defects, defect rate to locate the key items/key points<br/>
-4. Evaluate whether the software quality and test plan are reasonable by referring to CMMI standard values</td>
- <td rowspan="4">1. Defect drill-down analysis to inform the development of design and code review strategies and to improve the internal QA process<br/>
-2. Assist teams to locate projects/modules with higher defect severity and density, and clean up technical debts<br/>
-3. Analyze critical points, identify good/to-be-improved practices that affect defect count or defect rate, to reduce the amount of future defects</td>
- </tr>
- <tr>
- <td>Incident Count</td>
- <td>Number of Incidents found after shipping</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> MRs, etc</td>
- </tr>
- <tr>
- <td>Bugs Count per 1k Lines of Code</td>
- <td>Amount of bugs per 1,000 lines of code</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> MRs, etc</td>
- </tr>
- <tr>
- <td>Incidents Count per 1k Lines of Code</td>
- <td>Amount of incidents per 1,000 lines of code</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> MRs, etc</td>
- </tr>
- <tr>
- <td>Delivery Cost</td>
- <td>Commit Author Count</td>
- <td>Number of Contributors who have committed code</td>
- <td>Source Code Management entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitextractor/README.md">Git</a>/<a href="https://github.com/merico-dev/lake/blob/main/plugins/github/README.md">GitHub</a>/<a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLab</a> commits</td>
- <td>1. As a secondary indicator, this helps assess the labor cost of participating in coding</td>
- <td>1. Take inventory of project/team R&D resource inputs, assess input-output ratio, and rationalize resource deployment</td>
- </tr>
- <tr>
- <td rowspan="3">Delivery Capability</td>
- <td>Build Count</td>
- <td>The number of builds started</td>
- <td>CI/CD entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jenkins/README.md">Jenkins</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLabCI</a> MRs, etc</td>
- <td rowspan="3">1. From the project dimension, compare the number of builds and success rate by combining the project phase and the complexity of tasks<br/>
-2. From the time dimension, analyze the trend of the number of builds and success rate to see if it has improved over time</td>
- <td rowspan="3">1. As a process indicator, it reflects the value flow efficiency of upstream production and research links<br/>
-2. Identify excellent/to-be-improved practices that impact the build, and drive the team to precipitate reusable tools and mechanisms to build infrastructure for fast and high-frequency delivery</td>
- </tr>
- <tr>
- <td>Build Duration</td>
- <td>The duration of successful builds</td>
- <td>CI/CD entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jenkins/README.md">Jenkins</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLabCI</a> MRs, etc</td>
- </tr>
- <tr>
- <td>Build Success Rate</td>
- <td>The percentage of successful builds</td>
- <td>CI/CD entities: <a href="https://github.com/merico-dev/lake/blob/main/plugins/jenkins/README.md">Jenkins</a> PRs, <a href="https://github.com/merico-dev/lake/blob/main/plugins/gitlab/README.md">GitLabCI</a> MRs, etc</td>
- </tr>
-</table>
-<br/><br/><br/>
diff --git a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/DeveloperManuals/E2E-Test-Guide.md b/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/DeveloperManuals/E2E-Test-Guide.md
deleted file mode 100644
index fc9efd0b1..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/DeveloperManuals/E2E-Test-Guide.md
+++ /dev/null
@@ -1,202 +0,0 @@
----
-title: "E2E Test Guide"
-description: >
- The steps to write E2E tests for plugins.
----
-
-# 如何为插件编写E2E测试
-
-## 为什么要写 E2E 测试
-
-E2E 测试,作为自动化测试的一环,一般是指文件与模块级别的黑盒测试,或者允许使用一些数据库等外部服务的单元测试。书写E2E测试的目的是屏蔽一些内部实现逻辑,仅从数据正确性的角度来看同样的外部输入,是否可以得到同样的输出。另外,相较于黑盒的集成测试来说,可以避免一些网络等因素带来的偶然问题。更多关于插件的介绍,可以在这里获取更多信息: 为什么要编写 E2E 测试(未完成)
-在 DevLake 中,E2E 测试包含接口测试和插件 Extract/Convert 子任务的输入输出结果验证,本篇仅介绍后者的编写流程。
-
-## 准备数据
-
-我们这里以一个简单的插件——飞书会议时长收集举例,他的目录结构目前是这样的。
-
-接下来我们将进行次插件的 E2E 测试的编写。
-
-编写测试的第一步,就是运行一下对应插件的 Collect 任务,完成数据的收集,也就是让数据库的`_raw_feishu_`开头的表中,保存有对应的数据。
-以下是采用 DirectRun (cmd) 运行方式的运行日志和数据库结果。
-
-```
-$ go run plugins/feishu/main.go --numOfDaysToCollect 2 --connectionId 1 (注意:随着版本的升级,命令可能产生变化)
-[2022-06-22 23:03:29] INFO failed to create dir logs: mkdir logs: file exists
-press `c` to send cancel signal
-[2022-06-22 23:03:29] INFO [feishu] start plugin
-[2022-06-22 23:03:33] INFO [feishu] scheduler for api https://open.feishu.cn/open-apis/vc/v1 worker: 13, request: 10000, duration: 1h0m0s
-[2022-06-22 23:03:33] INFO [feishu] total step: 2
-[2022-06-22 23:03:33] INFO [feishu] executing subtask collectMeetingTopUserItem
-[2022-06-22 23:03:33] INFO [feishu] [collectMeetingTopUserItem] start api collection
-[2022-06-22 23:03:34] INFO [feishu] [collectMeetingTopUserItem] finished records: 1
-[2022-06-22 23:03:34] INFO [feishu] [collectMeetingTopUserItem] end api collection error: %!w(<nil>)
-[2022-06-22 23:03:34] INFO [feishu] finished step: 1 / 2
-[2022-06-22 23:03:34] INFO [feishu] executing subtask extractMeetingTopUserItem
-[2022-06-22 23:03:34] INFO [feishu] [extractMeetingTopUserItem] get data from _raw_feishu_meeting_top_user_item where params={"connectionId":1} and got 148
-[2022-06-22 23:03:34] INFO [feishu] [extractMeetingTopUserItem] finished records: 1
-[2022-06-22 23:03:34] INFO [feishu] finished step: 2 / 2
-```
-
-<img width="993" alt="image" src="https://user-images.githubusercontent.com/3294100/175064505-bc2f98d6-3f2e-4ccf-be68-a1cab1e46401.png"/>
-好的,目前数据已经被保存到了`_raw_feishu_*`表中,`data`列就是插件运行的返回信息。这里我们只收集了最近2天的数据,数据信息并不多,但也覆盖了各种情况,即同一个人不同天都有数据。
-
-另外值得一提的是,插件跑了两个任务,`collectMeetingTopUserItem`和`extractMeetingTopUserItem`,前者是收集数据的任务,是本次需要跑的,后者是解析数据的任务,是本次需要测试的。在准备数据环节是否运行无关紧要。
-
-接下来我们需要将数据导出为.csv格式,这一步很多种方案,大家可以八仙过海各显神通,我这里仅仅介绍几种常见的方案。
-
-### DevLake Code Generator 导出
-
-直接运行`go run generator/main.go create-e2e-raw`,根据指引来完成导出。此方案最简单,但也有一定的局限性,比如导出的字段是固定的,如果需要更多的自定义选项,可以参考接下来的方案。
-
-
-
-### GoLand Database 导出
-
-
-
-这种方案很简单,无论使用Postgres或者MySQL,都不会出现什么问题。
-
-csv导出的成功标准就是go程序可以无误的读取,因此有以下几点值得注意:
-
-1. csv文件中的值,可以用双引号包裹,避免值中的逗号等特殊符号破坏了csv格式
-2. csv文件中双引号转义,一般是`""`代表一个双引号
-3. 注意观察data是否是真实值,而不是base64后的值
-
-导出后,将.csv文件放到`plugins/feishu/e2e/raw_tables/_raw_feishu_meeting_top_user_item.csv`。
-
-### MySQL Select Into Outfile
-
-这是 MySQL 将查询结果导出为文件的方案。目前docker-compose.yml中启动的MySQL,是带有--security参数的,因此不允许`select ... into outfile`,首先需要关闭安全参数,关闭方法大致如下图:
-
-关闭后,使用`select ... into outfile`导出csv文件,导出结果大致如下图:
-
-可以注意到,data字段多了hexsha字段,需要人工将其转化为字面量。
-
-### Vscode Database
-
-这是 Vscode 将查询结果导出为文件的方案,但使用起来并不容易。以下是不修改任何配置的导出结果
-
-但可以明显发现,转义符号并不符合csv规范,并且data并没有成功导出,调整配置且手工替换`\"`为`""`后,得到如下结果。
-
-此文件data字段被base64编码,因此需要人工将其解码为字面量。解码成功后即可使用
-
-### MySQL workerbench
-
-此工具必须要自己书写SQL完成数据的导出,可以模仿以下SQL改写:
-```sql
-SELECT id, params, CAST(`data` as char) as data, url, input,created_at FROM _raw_feishu_meeting_top_user_item;
-```
-
-保存格式选择csv,导出后即可直接使用。
-
-### Postgres Copy with csv header;
-
-`Copy(SQL语句) to '/var/lib/postgresql/data/raw.csv' with csv header;`是PG常用的导出csv方法,这里也可以使用。
-```sql
-COPY (
-SELECT id, params, convert_from(data, 'utf-8') as data, url, input,created_at FROM _raw_feishu_meeting_top_user_item
-) to '/var/lib/postgresql/data/raw.csv' with csv header;
-```
-使用以上语句,完成文件的导出。如果你的pg运行在docker中,那么还需要使用 `docker cp`命令将文件导出到宿主机上以便使用。
-
-## 编写E2E测试
-
-首先需要创建测试环境,比如这里创建了`meeting_test.go`
-
-接着在其中输入测试准备代码,如下。其大意为创建了一个`feishu`插件的实例,然后调用`ImportCsvIntoRawTable`将csv文件的数据导入`_raw_feishu_meeting_top_user_item`表中。
-```go
-func TestMeetingDataFlow(t *testing.T) {
- var plugin impl.Feishu
- dataflowTester := e2ehelper.NewDataFlowTester(t, "feishu", plugin)
-
- // import raw data table
- dataflowTester.ImportCsvIntoRawTable("./raw_tables/_raw_feishu_meeting_top_user_item.csv", "_raw_feishu_meeting_top_user_item")
-}
-```
-导入函数的签名如下:
-```func (t *DataFlowTester) ImportCsvIntoRawTable(csvRelPath string, rawTableName string)```
-他有一个孪生兄弟,仅仅是参数略有区别。
-```func (t *DataFlowTester) ImportCsvIntoTabler(csvRelPath string, dst schema.Tabler)```
-前者用于导入raw layer层的表,后者用于导入任意表。
-**注意:** 另外这两个函数会在导入数据前,先删除数据表并使用`gorm.AutoMigrate`重新表以达到清除表数据的目的。
-
-导入数据完成后,可以尝试运行,目前没有任何测试逻辑,因此一定是PASS的。接着在`TestMeetingDataFlow`继续编写调用调用`extract`任务的逻辑。
-
-```go
-func TestMeetingDataFlow(t *testing.T) {
- var plugin impl.Feishu
- dataflowTester := e2ehelper.NewDataFlowTester(t, "feishu", plugin)
-
- taskData := &tasks.FeishuTaskData{
- Options: &tasks.FeishuOptions{
- ConnectionId: 1,
- },
- }
-
- // import raw data table
- dataflowTester.ImportCsvIntoRawTable("./raw_tables/_raw_feishu_meeting_top_user_item.csv", "_raw_feishu_meeting_top_user_item")
-
- // verify extraction
- dataflowTester.FlushTabler(&models.FeishuMeetingTopUserItem{})
- dataflowTester.Subtask(tasks.ExtractMeetingTopUserItemMeta, taskData)
-
-}
-```
-新增的代码包括调用`dataflowTester.FlushTabler`清空`FeishuMeetingTopUserItem`对应的表,调用`dataflowTester.Subtask`模拟子任务`ExtractMeetingTopUserItemMeta`的运行。
-
-现在在运行试试吧,看看子任务`ExtractMeetingTopUserItemMeta`是否能没有错误的完成运行。`extract`运行的数据结果一般来自raw表,因此,插件子任务编写如果没有差错的话,会正确运行,并且可以在 toolLayer 层的数据表中观察到数据成功解析,在本案例中,即`_tool_feishu_meeting_top_user_items`表中有正确的数据。
-
-如果运行不正确,那么需要先排查插件本身编写的问题,然后才能进入下一步。
-
-## 验证运行结果是否正确
-
-我们继续编写测试,在测试函数的最后,继续加上如下代码
-```go
-
-func TestMeetingDataFlow(t *testing.T) {
- ……
-
- dataflowTester.VerifyTable(
- models.FeishuMeetingTopUserItem{},
- "./snapshot_tables/_tool_feishu_meeting_top_user_items.csv",
- []string{"connection_id", "start_time", "name"},
- []string{
- "meeting_count",
- "meeting_duration",
- "user_type",
- "_raw_data_params",
- "_raw_data_table",
- "_raw_data_id",
- "_raw_data_remark",
- },
- )
-}
-```
-它的功能是调用`dataflowTester.VerifyTable`完成数据结果的验证。第三个参数是表的主键,第四个参数是表所有需要验证的字段。用于验证的数据存在`./snapshot_tables/_tool_feishu_meeting_top_user_items.csv`中,当然,目前此文件还不存在。
-
-为了方便生成前述文件,DevLake采取了一种称为`Snapshot`的测试技术,在调用`VerifyTable`文件且csv不存在时,将会根据运行结果自动生成文件。
-
-但注意!自动生成后并不是高枕无忧,还需要做两件事:1. 检查文件生成是否正确 2. 再次运行,以便于确定生成结果和再次运行的结果没有差错。
-这两项操作非常重要,直接关系到测试编写的质量,我们应该像对待代码文件一样对待`.csv`格式的 snapshot 文件。
-
-如果这一步出现了问题,一般会有2种可能,
-1. 验证的字段中含有类似create_at运行时间或者自增id的字段,这些无法重复验证的字段应该排除。
-2. 运行的结果中存在`\n`或`\r\n`等转义不匹配的字段,一般是解析`httpResponse`时出现的错误,可以参考如下方案解决:
- 1. 修改api模型中,内容的字段类型为`json.RawMessage`
- 2. 在解析时再将其转化为string
- 3. 经过以上操作,即可原封不动的保存`\n`符号,避免数据库或操作系统对换行符的解析
-
-
-比如在`github`插件中,是这么处理的:
-
-
-
-好了,到这一步,E2E的编写就完成了。我们本次修改一共新增了3个文件,就完成了对会议时长收集任务的测试,是不是还挺简单的~
-
-
-## 像 CI 一样运行所有插件的 E2E 测试
-
-非常简单,只需要运行`make e2e-plugins`,因为DevLake已经将其固化为一个脚本了~
-
-
diff --git a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/DeveloperManuals/PluginImplementation.md b/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/DeveloperManuals/PluginImplementation.md
deleted file mode 100644
index 41c441949..000000000
--- a/i18n/zh/docusaurus-plugin-content-docs/version-v0.13/DeveloperManuals/PluginImplementation.md
+++ /dev/null
@@ -1,337 +0,0 @@
----
-title: "如何制作一个DevLake插件?"
-sidebar_position: 2
-description: >
- 如何制作一个DevLake插件?
----
-
-
-如果你喜欢的DevOps工具还没有被DevLake支持,不要担心。实现一个DevLake插件并不困难。在这篇文章中,我们将了解DevLake插件的基础知识,并一起从头开始建立一个插件的例子。
-
-## 什么是插件?
-
-DevLake插件是用Go的`plugin`包构建的共享库,在运行时与DevLake核心挂钩。
-
-一个插件可以通过三种方式扩展DevLake的能力。
-
-1. 与新的数据源集成
-2. 转化/丰富现有数据
-3. 将DevLake数据导出到其他数据系统
-
-
-## 插件是如何工作的?
-
-一个插件主要包括可以由DevLake核心执行的子任务的集合。对于数据源插件,一个子任务可能是从数据源中收集一个实体(例如,来自Jira的问题)。除了子任务,还有一些钩子,插件可以实现自定义其初始化、迁移等。最重要的接口列表见下文。
-
-1. [PluginMeta](https://github.com/apache/incubator-devlake/blob/main/plugins/core/plugin_meta.go) 包含一个插件最少应该实现的接口,只有两个函数;
- - Description() 返回插件的描述
- - RootPkgPath() 返回插件的包路径。
-2. [PluginInit](https://github.com/apache/incubator-devlake/blob/main/plugins/core/plugin_init.go) 实现自定义的初始化方法;
-3. [PluginTask](https://github.com/apache/incubator-devlake/blob/main/plugins/core/plugin_task.go) 实现自定义准备数据,其在子任务之前执行;
-4. [PluginApi](https://github.com/apache/incubator-devlake/blob/main/plugins/core/plugin_api.go) 实现插件自定义的API;
-5. [Migratable](https://github.com/apache/incubator-devlake/blob/main/plugins/core/plugin_db_migration.go) 返回插件自定义的数据库迁移的脚本。
-6. [PluginModel](https://github.com/apache/incubator-devlake/blob/main/plugins/core/plugin_model.go) 实现允许其他插件通过 GetTablesInfo() 的方法来获取当前插件的全部数据库表的 model 信息。(若需domain layer的 model 信息,可访问[DomainLayerSchema](https://devlake.apache.org/zh/docs/DataModels/DevLakeDomainLayerSchema/))
-
-下图是一个插件执行的流程:
-
-```mermaid
-flowchart TD
- subgraph S4[Step4 Extractor 运行流程]
- direction LR
- D4[DevLake]
- D4 -- "Step4.1 创建\n ApiExtractor 并执行" --> E["ExtractXXXMeta.\nEntryPoint"];
- E <-- "Step4.2 读取raw table" --> E2["RawDataSubTaskArgs\n.Table"];
- E -- "Step4.3 解析 RawData" --> ApiExtractor.Extract
- ApiExtractor.Extract -- "返回 gorm 模型" --> E
- end
- subgraph S3[Step3 Collector 运行流程]
- direction LR
- D3[DevLake]
- D3 -- "Step3.1 创建\n ApiCollector 并执行" --> C["CollectXXXMeta.\nEntryPoint"];
- C <-- "Step3.2 创建raw table" --> C2["RawDataSubTaskArgs\n.RAW_BBB_TABLE"];
- C <-- "Step3.3 构造请求query" --> ApiCollectorArgs.\nQuery/UrlTemplate;
- C <-. "Step3.4 通过 ApiClient \n请求并返回HTTP" --> A1["HTTP APIs"];
- C <-- "Step3.5 解析\n并返回请求结果" --> ResponseParser;
- end
- subgraph S2[Step2 DevLake 的自定义插件]
- direction LR
- D2[DevLake]
- D2 <-- "Step2.1 在\`Init\` \n初始化插件" --> plugin.Init;
- D2 <-- "Step2.2 (Optional) 调用\n与返回 migration 脚本" --> plugin.MigrationScripts;
- D2 <-- "Step2.3 (Optional) \n初始化并返回taskCtx" --> plugin.PrepareTaskData;
- D2 <-- "Step2.4 返回\n 需要执行的子函数" --> plugin.SubTaskContext;
- end
- subgraph S1[Step1 DevLake 的运行]
- direction LR
- main -- "通过 \`runner.DirectRun\`\n 移交控制权" --> D1[DevLake];
- end
- S1-->S2-->S3-->S4
-```
-图中信息非常多,当然并不期望马上就能消化完,仅仅作为阅读后文的参考即可。
-
-## 一起来实现一个最简单的插件
-
-在本节中,我们将介绍如何从头创建一个数据收集插件。要收集的数据是 Apache 项目的所有 Committers 和 Contributors 信息,目的是检查其是否签署了 CLA。我们将通过:
-
-* 请求 `https://people.apache.org/public/icla-info.json` 获取 Committers 信息
-* 请求`邮件列表` 获取 Contributors 信息
- 我们将演示如何通过 Apache API 请求并缓存所有 Committers 的信息,并提取出结构化的数据。Contributors 的收集仅做一些思路的介绍。
-
-
-### 一、 创建新的插件
-
-**注意:**在开始之前,请确保DevLake已经能正确启动了。
-
-> 关于插件的其他信息:
-> 一般来说, 我们需要这几个目录: `api`, `models` 和 `tasks`
-> `api` 实现 `config-ui` 等其他服务所需的api
->
-> - connection [example](https://github.com/apache/incubator-devlake/blob/main/plugins/gitlab/api/connection.go)
-> connection model [example](https://github.com/apache/incubator-devlake/blob/main/plugins/gitlab/models/connection.go)
-> `models` 保存数据库模型和Migration脚本.
-> - entity
-> data migrations [template](https://github.com/apache/incubator-devlake/tree/main/generator/template/migrationscripts)
-> `tasks` 包含所有子任务
-> - task data [template](https://github.com/apache/incubator-devlake/blob/main/generator/template/plugin/tasks/task_data.go-template)
-> - api client [template](https://github.com/apache/incubator-devlake/blob/main/generator/template/plugin/tasks/task_data_with_api_client.go-template)
->
-> 注:如果这些概念让你感到迷惑,不要担心,我们稍后会逐一解释。
-
-DevLake 提供了专门的工具 Generator 来创建插件,可以通过运行`go run generator/main.go creat-plugin icla`来构建新插件,创建的时候会需要输入「是否需要默认的apiClient `with_api_client`」和「要收集的网站`endpoint`」。
-
-* `with_api_client`用于选择是否需要通过api_client发送HTTP APIs。
-* `endpoint`用于确认插件将请求哪个网站,在本案例中是`https://people.apache.org/`。
-
-
-
-现在我们的插件里有三个文件,其中`api_client.go`和`task_data.go`在子文件夹`tasks/`中。
-
-
-接下来让我们试着运行`plugin_main.go`中的`main`函数来启动插件,运行结果应该如下:
-```
-$go run plugins/icla/plugin_main.go
-[2022-06-02 18:07:30] INFO failed to create dir logs: mkdir logs: file exists
-press `c` to send cancel signal
-[2022-06-02 18:07:30] INFO [icla] start plugin
-invalid ICLA_TOKEN, but ignore this error now
-[2022-06-02 18:07:30] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
-[2022-06-02 18:07:30] INFO [icla] total step: 0
-```
-😋 没有报错,那就是成功啦~ `plugin_main.go`这里定义了插件,有一些配置是保存在`task_data.go`中。这两个文件就构成了最简单的插件,而文件`api_client.go`后面会用来发送HTTP APIs。
-
-### 二、 创建数据收集子任务
-在开始创建之前,我们需要先了解一下子任务的执行过程。
-
-1. Apache DevLake会调用`plugin_main.PrepareTaskData()`,准备一些子任务所需要的环境数据,本项任务中需要创建一个apiClient。
-2. Apache DevLake接着会调用定义在`plugin_main.SubTaskMetas()`的子任务,子任务都是互相独立的函数,可以用于完成注入发送API请求,处理数据等任务。
-
-> 每个子任务必须在`SubTaskMeta`中定义,并实现其中的SubTaskEntryPoint函数,其结构为
-> ```去
-> type SubTaskEntryPoint func(c SubTaskContext) error
-> ```
-> 更多信息见:https://devlake.apache.org/blog/how-apache-devlake-runs/
->
-> 注:如果这些概念让你感到迷惑,跳过跟着一步步做就好。
-
-#### 2.1 创建 Collector 来请求数据
-
-同样的,运行`go run generator/main.go create-collector icla committer`来创建子任务。Generator运行完成后,会自动创建新的文件,并在`plugin_main.go/SubTaskMetas`中激活。
-
-
-
-> - Collector将从HTTP或其他数据源收集数据,并将数据保存到rawLayer中。
-> - `httpCollector`的`SubTaskEntryPoint`中,默认会使用`helper.NewApiCollector`来创建新的[ApiCollector](https://github.com/apache/incubator-devlake/blob/main/generator/template/plugin/tasks/api_collector.go-template)对象,并调用其`execute()`来并行收集。
->
-> 注:如果这些概念让你感到迷惑,跳过就好。
-
-现在你可以注意到在`plugin_main.go/PrepareTaskData.ApiClient`中有引用`data.ApiClient`,它是Apache DevLake推荐用于从HTTP APIs请求数据的工具。这个工具支持一些很有用的功能,比如请求限制、代理和重试。当然,如果你喜欢,也可以使用`http`库来代替,只示会显得更加繁琐而已。
-
-回到正题,现在的目标是从`https://people.apache.org/public/icla-info.json`收集数据,因此需要完成以下步骤:
-
-1.
-我们已经在之前中把`https://people.apache.org/`填入`tasks/api_client.go/ENDPOINT`了,现在在看一眼确认下。
-
-
-
-2. 将`public/icla-info.json`填入`UrlTemplate`,删除不必要的迭代器,并在`ResponseParser`中添加`println("receive data:", res)`以查看收集是否成功。
-
-
-
-好了,现在Collector已经创建好了,再次运行`main`来启动插件,如果一切顺利的话,输出应该是这样的:
-```bash
-[2022-06-06 12:24:52] INFO [icla] start plugin
-invalid ICLA_TOKEN, but ignore this error now
-[2022-06-06 12:24:52] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
-[2022-06-06 12:24:52] INFO [icla] total step: 1
-[2022-06-06 12:24:52] INFO [icla] executing subtask CollectCommitter
-[2022-06-06 12:24:52] INFO [icla] [CollectCommitter] start api collection
-receive data: 0x140005763f0
-[2022-06-06 12:24:55] INFO [icla] [CollectCommitter] finished records: 1
-[2022-06-06 12:24:55] INFO [icla] [CollectCommitter] end api collection
-[2022-06-06 12:24:55] INFO [icla] finished step: 1 / 1
-```
-
-从以上日志中,可以看到已经能打印出收到数据的日志了,最后一步是在`ResponseParser`中对响应体进行解码,并将其返回给DevLake,以便将其存储在数据库中。
-```go
-ResponseParser: func(res *http.Response) ([]json.RawMessage, error) {
- body := &struct {
- LastUpdated string `json:"last_updated"`
- Committers json.RawMessage `json:"committers"`
- }{}
- err := helper.UnmarshalResponse(res, body)
- if err != nil {
- return nil, err
- }
- println("receive data:", len(body.Committers))
- return []json.RawMessage{body.Committers}, nil
-},
-```
-再次运行函数`main`,结果如下,此时可以在数据库表`_raw_icla_committer`中看到一条新的数据。
-```bash
-……
-receive data: 272956 /* <- 这个数字表示收到了272956个Committer */
-[2022-06-06 13:46:57] INFO [icla] [CollectCommitter] finished records: 1
-[2022-06-06 13:46:57] INFO [icla] [CollectCommitter] end api collection
-[2022-06-06 13:46:57] INFO [icla] finished step: 1 / 1
-```
-
-
-
-#### 2.2 创建 Extractor,从 rawLayer 中提取数据
-
-> - Extractor将从rawLayer中提取数据并保存到工具db表中。
-> - 除了一些具体的处理内容,主流程与采集器类似。
-
-从HTTP API收集的数据目前仅仅保存在表`_raw_XXXX`中,但其使用起来却很不容易。因此我们将继续从其中提取Committer的名字。目前Apache DevLake建议用[gorm](https://gorm.io/docs/index.html)来保存数据,所以我们将用gorm创建一个模型,并将其添加到`plugin_main.go/AutoMigrate()`中。
-
-plugins/icla/models/committer.go
-```go
-package models
-
-import (
- "github.com/apache/incubator-devlake/models/common"
-)
-
-type IclaCommitter struct {
- UserName string `gorm:"primaryKey;type:varchar(255)"`
- Name string `gorm:"primaryKey;type:varchar(255)"`
- common.NoPKModel
-}
-
-func (IclaCommitter) TableName() string {
- return "_tool_icla_committer"
-}
-```
-
-plugins/icla/plugin_main.go
-
-
-在做完以上步骤以后,就可以再次运行插件,刚定义的数据表`_tool_icla_committer`会自动创建,就像下面的截图。
-
-
-接下来,让我们运行`go run generator/main.go create-extractor icla committer`并输入命令行提示的内容,来创建新的子任务。
-
-
-
-运行完成后,来看看刚才创建的`committer_extractor.go`中的函数`extract`,很明显参数中的`resData.data`是原始数据,我们需要用json解码,并创建`IclaCommitter`模型来保存它们。
-```go
-Extract: func(resData *helper.RawData) ([]interface{}, error) {
- names := &map[string]string{}
- err := json.Unmarshal(resData.Data, names)
- if err != nil {
- return nil, err
- }
- extractedModels := make([]interface{}, 0)
- for userName, name := range *names {
- extractedModels = append(extractedModels, &models.IclaCommitter{
- UserName: userName,
- Name: name,
- })fco
- }
- return extractedModels, nil
-},
-```
-
-再次运行插件,结果如下:
-```
-[2022-06-06 15:39:40] INFO [icla] start plugin
-invalid ICLA_TOKEN, but ignore this error now
-[2022-06-06 15:39:40] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
-[2022-06-06 15:39:40] INFO [icla] total step: 2
-[2022-06-06 15:39:40] INFO [icla] executing subtask CollectCommitter
-[2022-06-06 15:39:40] INFO [icla] [CollectCommitter] start api collection
-receive data: 272956
-[2022-06-06 15:39:44] INFO [icla] [CollectCommitter] finished records: 1
-[2022-06-06 15:39:44] INFO [icla] [CollectCommitter] end api collection
-[2022-06-06 15:39:44] INFO [icla] finished step: 1 / 2
-[2022-06-06 15:39:44] INFO [icla] executing subtask ExtractCommitter
-[2022-06-06 15:39:46] INFO [icla] [ExtractCommitter] finished records: 1
-[2022-06-06 15:39:46] INFO [icla] finished step: 2 / 2
-```
-可以看到有两个任务运行完成,同时观察数据库发现,提交者的数据已经保存在_tool_icla_committer中了~
-
-
-#### 2.3 子任务 - Converter
-
-注意。这里有两种方式(开源或自己使用)。因此 Converter 不是必须的,但我们鼓励使用它,因为 Converter 和 DomainLayer 非常有助于建立通用的仪表盘。关于 DomainLayer 的更多信息请见:https://devlake.apache.org/docs/DataModels/DevLakeDomainLayerSchema/
-
-> - Converter 将处理 DomainLayer 的数据,并将其保存到 DomainLayer 层中。
-> - 使用`helper.NewDataConverter`来创建一个 DataConvertor 的对象,然后调用`execute()`来运行。
-
-#### 2.4 动手试试更多类型的请求吧~
-有时 OpenApi 会受到 token 或其他保护,只有获得 token 才来能访问。例如在本案例中,我们只有在登录`private@apahce.com`后,才能收集到关于普通 Contributor 签署ICLA的数据。但这里受限于篇幅,仅仅简单介绍一下如何收集需要授权的数据。
-
-让我们注意`api_client.go`文件,其中`NewIclaApiClient`通过`.env`加载配置了`ICLA_TOKEN`,它让我们可以在`.env`中添加`ICLA_TOKEN=XXXX`,并在`apiClient.SetHeaders()`中使用它来模拟登录状态。代码如下。
-
-
-当然,我们可以使用`username/password`来获取模拟登录后的token,试着根据实际情况进行调整即可。
-
-更多相关细节请看https://github.com/apache/incubator-devlake
-
-#### Step 2.5 实现 PluginModel 接口的 GetTablesInfo() 方法
-
-如下gitlab插件示例所示
-将所有需要被外部插件访问到的 model 均添加到返回值中。
-
-```golang
-var _ core.PluginModel = (*Gitlab)(nil)
-
-func (plugin Gitlab) GetTablesInfo() []core.Tabler {
- return []core.Tabler{
- &models.GitlabConnection{},
- &models.GitlabAccount{},
- &models.GitlabCommit{},
- &models.GitlabIssue{},
- &models.GitlabIssueLabel{},
- &models.GitlabJob{},
- &models.GitlabMergeRequest{},
- &models.GitlabMrComment{},
- &models.GitlabMrCommit{},
- &models.GitlabMrLabel{},
- &models.GitlabMrNote{},
- &models.GitlabPipeline{},
- &models.GitlabProject{},
- &models.GitlabProjectCommit{},
- &models.GitlabReviewer{},
- &models.GitlabTag{},
- }
-}
-```
-
-可以使用如下方式来使用该接口
-
-```
-if pm, ok := plugin.(core.PluginModel); ok {
- tables := pm.GetTablesInfo()
- for _, table := range tables {
- // do something
- }
-}
-
-```
-
-#### 2.6 将插件提交给开源社区
-恭喜你! 第一个插件已经创建完毕! 🎖 我们鼓励开源贡献~ 接下来还需要学习 migrationScripts 和 domainLayers 来编写规范的、平台无关的代码。更多信息请访问https://devlake.apache.org/docs/DataModels/DevLakeDomainLayerSchema,或联系我们以获得热情洋溢的帮助。
-
-
-
diff --git a/i18n/zh/docusaurus-theme-classic/footer.json b/i18n/zh/docusaurus-theme-classic/footer.json
deleted file mode 100644
index 26b50f78c..000000000
--- a/i18n/zh/docusaurus-theme-classic/footer.json
+++ /dev/null
@@ -1,34 +0,0 @@
-{
- "link.title.Docs": {
- "message": "Docs",
- "description": "The title of the footer links column with title=Docs in the footer"
- },
- "link.title.Community": {
- "message": "Community",
- "description": "The title of the footer links column with title=Community in the footer"
- },
- "link.title.More": {
- "message": "More",
- "description": "The title of the footer links column with title=More in the footer"
- },
- "link.item.label.Docs": {
- "message": "Docs",
- "description": "The label of footer link with label=Docs linking to /docs/Overview/WhatIsDevLake"
- },
- "link.item.label.Slack": {
- "message": "Slack",
- "description": "The label of footer link with label=Slack linking to https://join.slack.com/t/devlake-io/shared_invite/zt-17b6vuvps-x98pqseoUagM7EAmKC82xQ"
- },
- "link.item.label.Blog": {
- "message": "Blog",
- "description": "The label of footer link with label=Blog linking to /blog"
- },
- "link.item.label.GitHub": {
- "message": "GitHub",
- "description": "The label of footer link with label=GitHub linking to https://github.com/merico-dev/lake"
- },
- "copyright": {
- "message": "Copyright © 2022 DevLake@Merico Inc.",
- "description": "The footer copyright"
- }
-}
diff --git a/i18n/zh/docusaurus-theme-classic/navbar.json b/i18n/zh/docusaurus-theme-classic/navbar.json
deleted file mode 100644
index e5cf5626a..000000000
--- a/i18n/zh/docusaurus-theme-classic/navbar.json
+++ /dev/null
@@ -1,26 +0,0 @@
-{
- "title": {
- "message": "DevLake",
- "description": "The title in the navbar"
- },
- "item.label.Docs": {
- "message": "文档",
- "description": "Navbar item with label Docs"
- },
- "item.label.Community": {
- "message": "社区",
- "description": "Navbar item with label Community"
- },
- "item.label.Blog": {
- "message": "博客",
- "description": "Navbar item with label Blog"
- },
- "item.label.GitHub": {
- "message": "GitHub",
- "description": "Navbar item with label GitHub"
- },
- "item.label.Team": {
- "message": "Team",
- "description": "Navbar item with label Team"
- }
-}
diff --git a/livedemo/AverageRequirementLeadTime.md b/livedemo/AverageRequirementLeadTime.md
index afbb7c0fb..4e708ce07 100644
--- a/livedemo/AverageRequirementLeadTime.md
+++ b/livedemo/AverageRequirementLeadTime.md
@@ -5,4 +5,4 @@ description: >
---
# Average Requirement Lead Time by Assignee
-<iframe src="https://grafana-lake.demo.devlake.io/d/q27fk7cnk/demo-average-requirement-lead-time-by-assignee?orgId=1&from=now-6M&to=now" width="100%" height="940px"></iframe>
\ No newline at end of file
+<iframe src="https://grafana-lake.demo.devlake.io/d/q27fk7cnk/demo-average-requirement-lead-time-by-assignee?orgId=1&from=now-6M&to=now" width="135%" height="960px"></iframe>
\ No newline at end of file
diff --git a/livedemo/CommitCountByAuthor.md b/livedemo/CommitCountByAuthor.md
index ee6a69b26..710e7bc86 100644
--- a/livedemo/CommitCountByAuthor.md
+++ b/livedemo/CommitCountByAuthor.md
@@ -5,4 +5,4 @@ description: >
---
# Commit Count by Author
-<iframe src="https://grafana-lake.demo.devlake.io/d/F0iYknc7z/demo-commit-count-by-author?orgId=1&from=now-6M&to=now" width="100%" height="820px"></iframe>
+<iframe src="https://grafana-lake.demo.devlake.io/d/F0iYknc7z/demo-commit-count-by-author?orgId=1&from=now-6M&to=now" width="135%" height="880px"></iframe>
diff --git a/livedemo/CommunityExperience.md b/livedemo/CommunityExperience.md
index 3d285dfa1..ffc6bacf8 100644
--- a/livedemo/CommunityExperience.md
+++ b/livedemo/CommunityExperience.md
@@ -5,4 +5,4 @@ description: >
---
# Community Experience
-<iframe src="https://grafana-lake.demo.devlake.io/grafana/d/bwsP5Nz4z/community-experience?orgId=1&from=now-6M&to=now" width="100%" height="1000px"></iframe>
+<iframe src="https://grafana-lake.demo.devlake.io/grafana/d/bwsP5Nz4z/community-experience?orgId=1&from=now-6M&to=now" width="135%" height="1000px"></iframe>
diff --git a/livedemo/DORA.md b/livedemo/DORA.md
index e5905d133..01fc0d6b9 100644
--- a/livedemo/DORA.md
+++ b/livedemo/DORA.md
@@ -5,4 +5,4 @@ description: >
---
# DORA
-<iframe src="https://grafana-lake.demo.devlake.io/grafana/d/qNo8_0M4z/dora?orgId=1&from=now-6M&to=now" width="100%" height="2300px"></iframe>
+<iframe src="https://grafana-lake.demo.devlake.io/grafana/d/qNo8_0M4z/dora?orgId=1&from=now-6M&to=now" width="135%" height="1140px"></iframe>
diff --git a/livedemo/DetailedBugInfo.md b/livedemo/DetailedBugInfo.md
index e517c6c0b..2b53b91ad 100644
--- a/livedemo/DetailedBugInfo.md
+++ b/livedemo/DetailedBugInfo.md
@@ -5,4 +5,4 @@ description: >
---
# Detailed Bug Info
-<iframe src="https://grafana-lake.demo.devlake.io/d/s48Lzn5nz/demo-detailed-bug-info?orgId=1&from=now-6M&to=now" width="100%" height="800px"></iframe>
\ No newline at end of file
+<iframe src="https://grafana-lake.demo.devlake.io/d/s48Lzn5nz/demo-detailed-bug-info?orgId=1&from=now-6M&to=now" width="135%" height="800px"></iframe>
\ No newline at end of file
diff --git a/livedemo/EngineeringOverview.md b/livedemo/EngineeringOverview.md
new file mode 100644
index 000000000..e9df67906
--- /dev/null
+++ b/livedemo/EngineeringOverview.md
@@ -0,0 +1,8 @@
+---
+title: "Engineering Overview"
+description: >
+ DevLake Live Demo
+---
+
+# Engineering Overview
+<iframe src="https://grafana-lake.demo.devlake.io/grafana/goto/w0AqclS4z?orgId=1" width="135%" height="3080px"></iframe>
\ No newline at end of file
diff --git a/livedemo/EngineeringThroughputAndCycleTime.md b/livedemo/EngineeringThroughputAndCycleTime.md
new file mode 100644
index 000000000..67bb6efa1
--- /dev/null
+++ b/livedemo/EngineeringThroughputAndCycleTime.md
@@ -0,0 +1,8 @@
+---
+title: "Engineering Throughput and Cycyle Time"
+description: >
+ DevLake Live Demo
+---
+
+# Engineering Throughput and Cycyle Time
+<iframe src="https://grafana-lake.demo.devlake.io/grafana/goto/tJEGp_S4z?orgId=1" width="135%" height="1740px"></iframe>
\ No newline at end of file
diff --git a/livedemo/GitHub.md b/livedemo/GitHub.md
new file mode 100644
index 000000000..fad92ea7c
--- /dev/null
+++ b/livedemo/GitHub.md
@@ -0,0 +1,8 @@
+---
+title: "GitHub"
+description: >
+ DevLake Live Demo
+---
+
+# GitHub
+<iframe src="https://grafana-lake.demo.devlake.io/d/KXWvOFQnz/github_basic_metrics?orgId=1&from=now-6M&to=now" width="135%" height="3000px"></iframe>
\ No newline at end of file
diff --git a/livedemo/GitHubBasic.md b/livedemo/GitHubBasic.md
deleted file mode 100644
index c5d821224..000000000
--- a/livedemo/GitHubBasic.md
+++ /dev/null
@@ -1,8 +0,0 @@
----
-title: "GitHub Basic Metrics"
-description: >
- DevLake Live Demo
----
-
-# GitHub Basic Metrics
-<iframe src="https://grafana-lake.demo.devlake.io/d/KXWvOFQnz/github_basic_metrics?orgId=1&from=now-6M&to=now" width="100%" height="3080px"></iframe>
\ No newline at end of file
diff --git a/livedemo/GitHubReleaseQualityAndContributionAnalysis.md b/livedemo/GitHubReleaseQualityAndContributionAnalysis.md
index 4b77a0953..7fe429cfa 100644
--- a/livedemo/GitHubReleaseQualityAndContributionAnalysis.md
+++ b/livedemo/GitHubReleaseQualityAndContributionAnalysis.md
@@ -5,4 +5,4 @@ description: >
---
# GitHub Release Quality and Contribution Analysis
-<iframe src="https://grafana-lake.demo.devlake.io/grafana/d/2xuOaQUnk4/github_release_quality_and_contribution_analysis?orgId=1&from=now-6M&to=now" width="100%" height="2800px"></iframe>
\ No newline at end of file
+<iframe src="https://grafana-lake.demo.devlake.io/grafana/d/2xuOaQUnk4/github_release_quality_and_contribution_analysis?orgId=1&from=now-6M&to=now" width="135%" height="3240px"></iframe>
\ No newline at end of file
diff --git a/livedemo/GitLab.md b/livedemo/GitLab.md
new file mode 100644
index 000000000..142ba92e7
--- /dev/null
+++ b/livedemo/GitLab.md
@@ -0,0 +1,8 @@
+---
+title: "GitLab"
+description: >
+ DevLake Live Demo
+---
+
+# GitLab
+<iframe src="https://grafana-lake.demo.devlake.io/grafana/goto/KcWhO_IVk?orgId=1" width="135%" height="1800px"></iframe>
\ No newline at end of file
diff --git a/livedemo/GitextractorMetricsDashboard.md b/livedemo/GitextractorMetricsDashboard.md
new file mode 100644
index 000000000..a2ef5f532
--- /dev/null
+++ b/livedemo/GitextractorMetricsDashboard.md
@@ -0,0 +1,8 @@
+---
+title: "Gitextractor Metrics Dashboard"
+description: >
+ DevLake Live Demo
+---
+
+# Gitextractor Metrics Dashboard
+<iframe src="https://grafana-lake.demo.devlake.io/grafana/goto/x1lKtlSVz?orgId=1" width="135%" height="1500px"></iframe>
\ No newline at end of file
diff --git a/livedemo/Jenkins.md b/livedemo/Jenkins.md
index c07e6c155..f8fb0bf9a 100644
--- a/livedemo/Jenkins.md
+++ b/livedemo/Jenkins.md
@@ -5,4 +5,4 @@ description: >
---
# Jenkins
-<iframe src="https://grafana-lake.demo.devlake.io/d/W8AiDFQnk/jenkins?orgId=1&from=now-6M&to=now" width="100%" height="1060px"></iframe>
\ No newline at end of file
+<iframe src="https://grafana-lake.demo.devlake.io/d/W8AiDFQnk/jenkins?orgId=1&from=now-6M&to=now" width="135%" height="1240px"></iframe>
\ No newline at end of file
diff --git a/livedemo/WeeklyBugRetro.md b/livedemo/WeeklyBugRetro.md
index 4ff1a0de5..74e0d60f5 100644
--- a/livedemo/WeeklyBugRetro.md
+++ b/livedemo/WeeklyBugRetro.md
@@ -5,4 +5,4 @@ description: >
---
# Weekly Bug Retro
-<iframe src="https://grafana-lake.demo.devlake.io/d/-5EKA5w7k/weekly-bug-retro?orgId=1&from=now-6M&to=now" width="100%" height="2240px"></iframe>
+<iframe src="https://grafana-lake.demo.devlake.io/d/-5EKA5w7k/weekly-bug-retro?orgId=1&from=now-6M&to=now" width="135%" height="3040px"></iframe>
diff --git a/livedemo/WeeklyCommunityRetro.md b/livedemo/WeeklyCommunityRetro.md
index d6d5afb0b..aad5323b3 100644
--- a/livedemo/WeeklyCommunityRetro.md
+++ b/livedemo/WeeklyCommunityRetro.md
@@ -5,4 +5,4 @@ description: >
---
# Weekly Community Retro
-<iframe src="https://grafana-lake.demo.devlake.io/grafana/d/VTr6Y_q7z/weekly-community-retro?orgId=1&from=now-6M&to=now" width="100%" height="2300px"></iframe>
+<iframe src="https://grafana-lake.demo.devlake.io/grafana/d/VTr6Y_q7z/weekly-community-retro?orgId=1&from=now-6M&to=now" width="135%" height="2300px"></iframe>
diff --git a/src/components/Sections/UserFlow.tsx b/src/components/Sections/UserFlow.tsx
index 681709d6f..d2d176e83 100644
--- a/src/components/Sections/UserFlow.tsx
+++ b/src/components/Sections/UserFlow.tsx
@@ -50,7 +50,7 @@ export function UserFlow() {
icon={<UF3 width={40} height={40} />}
text="View Dashboards"
>
- <InlineLink link="https://devlake.apache.org/livedemo">View pre-built dashboards</InlineLink> of a variety of use cases and learn engineering insights from the <InlineLink link="https://devlake.apache.org/docs/Metrics">metrics</InlineLink>.
+ <InlineLink link="https://devlake.apache.org/livedemo/AverageRequirementLeadTime">View pre-built dashboards</InlineLink> of a variety of use cases and learn engineering insights from the <InlineLink link="https://devlake.apache.org/docs/Metrics">metrics</InlineLink>.
</Card>
<Arrow />
<Card
[incubator-devlake-website] 02/02: fix: updated dead links
Posted by zk...@apache.org.
This is an automated email from the ASF dual-hosted git repository.
zky pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/incubator-devlake-website.git
commit 2e5b063acd73d12e0d9e8594e47b6c2ba2a626dc
Author: yumengwang03 <yu...@merico.dev>
AuthorDate: Wed Oct 19 16:44:55 2022 +0800
fix: updated dead links
---
docs/UserManuals/ConfigUI/GitHub.md | 2 +-
versioned_docs/version-v0.12/UserManuals/ConfigUI/GitHub.md | 2 +-
versioned_docs/version-v0.13/UserManuals/ConfigUI/GitHub.md | 2 +-
3 files changed, 3 insertions(+), 3 deletions(-)
diff --git a/docs/UserManuals/ConfigUI/GitHub.md b/docs/UserManuals/ConfigUI/GitHub.md
index fc85cca42..4bca1f7ea 100644
--- a/docs/UserManuals/ConfigUI/GitHub.md
+++ b/docs/UserManuals/ConfigUI/GitHub.md
@@ -47,7 +47,7 @@ Usually, you don't have to modify this part. However, if you don't want to colle


-Without adding transformation rules, you can still view the "[GitHub Basic Metrics](/livedemo/GitHubBasic)" dashboard. However, if you want to view "[Weekly Bug Retro](/livedemo/WeeklyBugRetro)", "[Weekly Community Retro](/livedemo/WeeklyCommunityRetro)" or other pre-built dashboards, the following transformation rules, especially "Type/Bug", should be added.<br/>
+Without adding transformation rules, you can still view the "[GitHub Metrics](/livedemo/GitHub)" dashboard. However, if you want to view "[Weekly Bug Retro](/livedemo/WeeklyBugRetro)", "[Weekly Community Retro](/livedemo/WeeklyCommunityRetro)" or other pre-built dashboards, the following transformation rules, especially "Type/Bug", should be added.<br/>
Each GitHub repo has at most ONE set of transformation rules.
diff --git a/versioned_docs/version-v0.12/UserManuals/ConfigUI/GitHub.md b/versioned_docs/version-v0.12/UserManuals/ConfigUI/GitHub.md
index 432303827..5e8fee944 100644
--- a/versioned_docs/version-v0.12/UserManuals/ConfigUI/GitHub.md
+++ b/versioned_docs/version-v0.12/UserManuals/ConfigUI/GitHub.md
@@ -43,7 +43,7 @@ Usually, you don't have to modify this part. However, if you don't want to colle


-Without adding transformation rules, you can still view the "[GitHub Basic Metrics](/livedemo/GitHubBasic)" dashboard. However, if you want to view "[Weekly Bug Retro](/livedemo/WeeklyBugRetro)", "[Weekly Community Retro](/livedemo/WeeklyCommunityRetro)" or other pre-built dashboards, the following transformation rules, especially "Type/Bug", should be added.<br/>
+Without adding transformation rules, you can still view the "[GitHub Metrics](/livedemo/GitHub)" dashboard. However, if you want to view "[Weekly Bug Retro](/livedemo/WeeklyBugRetro)", "[Weekly Community Retro](/livedemo/WeeklyCommunityRetro)" or other pre-built dashboards, the following transformation rules, especially "Type/Bug", should be added.<br/>
Each GitHub repo has at most ONE set of transformation rules.
diff --git a/versioned_docs/version-v0.13/UserManuals/ConfigUI/GitHub.md b/versioned_docs/version-v0.13/UserManuals/ConfigUI/GitHub.md
index 643b179a8..228f9536e 100644
--- a/versioned_docs/version-v0.13/UserManuals/ConfigUI/GitHub.md
+++ b/versioned_docs/version-v0.13/UserManuals/ConfigUI/GitHub.md
@@ -43,7 +43,7 @@ Usually, you don't have to modify this part. However, if you don't want to colle


-Without adding transformation rules, you can still view the "[GitHub Basic Metrics](/livedemo/GitHubBasic)" dashboard. However, if you want to view "[Weekly Bug Retro](/livedemo/WeeklyBugRetro)", "[Weekly Community Retro](/livedemo/WeeklyCommunityRetro)" or other pre-built dashboards, the following transformation rules, especially "Type/Bug", should be added.<br/>
+Without adding transformation rules, you can still view the "[GitHub Metrics](/livedemo/GitHub)" dashboard. However, if you want to view "[Weekly Bug Retro](/livedemo/WeeklyBugRetro)", "[Weekly Community Retro](/livedemo/WeeklyCommunityRetro)" or other pre-built dashboards, the following transformation rules, especially "Type/Bug", should be added.<br/>
Each GitHub repo has at most ONE set of transformation rules.