You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@tvm.apache.org by GitBox <gi...@apache.org> on 2019/12/19 11:05:59 UTC
[GitHub] [incubator-tvm] Orion34C opened a new pull request #4546: support
cuda tensorcore subbyte int data type in auto tensorcore
Orion34C opened a new pull request #4546: support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546
In our former RFC [Auto TensorCore CodeGen](https://github.com/apache/incubator-tvm/issues/4105),we have present the performance of fp16/int8 gemm based on auto tensor-core implementation. However, cuda's wmma instructions support more data types in the [experimental namespace](https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#wmma-subbyte) since cuda10, which can be useful when combining with low bit quantizations.
Several hacks still remain in the code which needs to discussion with you guys, because we have not found an elegant solution to deal with newly added data type int4/int1 in the arg bind pass.
In our implementation, we store 8 int4/uint4 data or 32 int1 data into one int32,because int4/int1 is not a basic data type in cuda c or even numpy.
We implement support for int4/int1 tensor-core codegen based on auto tensor-core pass and provide an example on how to use it to generate gemm kernels. The command to run the sample int4/int1 gemm schedule is:
python tutorials/autotvm/tensor_core_matmul_subbyte_int.py $M $N $K $dtype
Supported data types are int4, int1. Only TN layout is supported for int4/int since it is the only layout supported by wmma's sub-byte fragments.
# Perf on T4, CUDA10.1, Driver 418.39
The baseline data is cuBLASLt for int8 tensor-core gemm since no impls for int4/int1 were provided by cublas so far.
|M, N, K| cuBLASLt int8 | TVM TensorCore int4 | TVM TensorCore int1 |
|-------|---------------|----------------------|---------------------|
|512, 128, 512|10.844us|7.200us|3.633us|
|512, 64, 512|8.6300us|4.2560us|2.2720us|
|512, 32, 512|8.3660us|2.7990us|2.0760us|
|512, 16, 512|8.3750us|2.0330us|1.5590us|
|256, 256, 256|8.0650us|4.2030us|2.5690us|
|1024, 32, 512|8.3460us|4.255us|2.3370us|
|2048, 32, 512|8.4680us|5.956us|3.6890us|
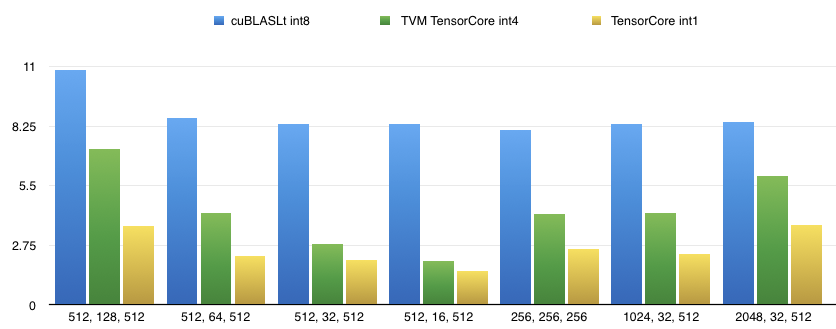
The performance tuning is still on-going.
Thanks!
-- Lanbo Li, Minmin Sun, Chenfan Jia and Jun Yang of Alibaba PAI team
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] Orion34C commented on a change in pull request
#4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto
tensorcore
Posted by GitBox <gi...@apache.org>.
Orion34C commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r380001507
##########
File path: src/target/source/codegen_cuda.cc
##########
@@ -410,8 +450,11 @@ void CodeGenCUDA::VisitStmt_(const AllocateNode* op) {
if (scope == "wmma.matrix_a" || scope == "wmma.matrix_b") {
CHECK(op->dtype == DataType::Float(16) ||
op->dtype == DataType::Int(8) ||
- op->dtype == DataType::UInt(8))
- << "Matrix_a and matrix_b only support half or char or unsigned char type for now";
+ op->dtype == DataType::UInt(8) ||
Review comment:
uint4 added
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] Orion34C commented on a change in pull request
#4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto
tensorcore
Posted by GitBox <gi...@apache.org>.
Orion34C commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r380001452
##########
File path: include/tvm/tir/expr.h
##########
@@ -1260,6 +1260,18 @@ constexpr const char* tvm_load_matrix_sync = "tvm_load_matrix_sync";
* }
*/
constexpr const char* tvm_mma_sync = "tvm_mma_sync";
+/*!
+ * \brief tvm intrinsic for tensor core mma_sync operators.
+ *
+ * void tvm_bmma_sync(Var fragment_d, Expr index_d,
+ * Var fragment_a, Expr index_a,
+ * Var fragment_b, Expr index_b,
+ * Var fragment_c, Expr index_c) {
Review comment:
done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] vinx13 commented on a change in pull request #4546:
[CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
Posted by GitBox <gi...@apache.org>.
vinx13 commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r380751172
##########
File path: include/tvm/runtime/data_type.h
##########
@@ -231,7 +231,15 @@ inline int GetVectorBytes(DataType dtype) {
int data_bits = dtype.bits() * dtype.lanes();
// allow bool to exist
if (dtype == DataType::Bool()) return 1;
- return data_bits;
+ // allow int4/uint4/int1 to exist
+ if (dtype == DataType::Int(4) ||
+ dtype == DataType::UInt(4) ||
+ dtype == DataType::Int(1)) {
+ return data_bits;
Review comment:
why date_bits here, instead of bytes? is there any trick here?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] vinx13 commented on a change in pull request #4546:
[CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
Posted by GitBox <gi...@apache.org>.
vinx13 commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r379973104
##########
File path: src/target/source/codegen_cuda.cc
##########
@@ -410,8 +450,11 @@ void CodeGenCUDA::VisitStmt_(const AllocateNode* op) {
if (scope == "wmma.matrix_a" || scope == "wmma.matrix_b") {
CHECK(op->dtype == DataType::Float(16) ||
op->dtype == DataType::Int(8) ||
- op->dtype == DataType::UInt(8))
- << "Matrix_a and matrix_b only support half or char or unsigned char type for now";
+ op->dtype == DataType::UInt(8) ||
Review comment:
uint4 missing here?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] Orion34C commented on a change in pull request
#4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto
tensorcore
Posted by GitBox <gi...@apache.org>.
Orion34C commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r362204403
##########
File path: src/codegen/codegen_cuda.cc
##########
@@ -401,8 +441,10 @@ void CodeGenCUDA::VisitStmt_(const Allocate* op) {
std::string scope = alloc_storage_scope_.at(buffer);
if (scope.find("wmma.") == 0) {
if (scope == "wmma.matrix_a" || scope == "wmma.matrix_b") {
- CHECK(op->type == Float(16) || op->type == Int(8) || op->type == UInt(8))
- << "Matrix_a and matrix_b only support half or char or unsigned char type for now";
+ CHECK(op->type == Float(16) || op->type == Int(8) || op->type == UInt(8)
+ || op->type == Int(4) || op->type == Int(1))
Review comment:
done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] Orion34C commented on issue #4546: [CODEGEN]
Support cuda tensorcore subbyte int data type in auto tensorcore
Posted by GitBox <gi...@apache.org>.
Orion34C commented on issue #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#issuecomment-587318245
@vinx13 would you please see the cr again? I have address the requested changes and all checks have passed. Thanks!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] vinx13 commented on a change in pull request #4546:
[CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
Posted by GitBox <gi...@apache.org>.
vinx13 commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r379972352
##########
File path: include/tvm/tir/expr.h
##########
@@ -1260,6 +1260,18 @@ constexpr const char* tvm_load_matrix_sync = "tvm_load_matrix_sync";
* }
*/
constexpr const char* tvm_mma_sync = "tvm_mma_sync";
+/*!
+ * \brief tvm intrinsic for tensor core mma_sync operators.
+ *
+ * void tvm_bmma_sync(Var fragment_d, Expr index_d,
+ * Var fragment_a, Expr index_a,
+ * Var fragment_b, Expr index_b,
+ * Var fragment_c, Expr index_c) {
Review comment:
add a space for alignment
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] vinx13 commented on issue #4546: [CODEGEN] Support
cuda tensorcore subbyte int data type in auto tensorcore
Posted by GitBox <gi...@apache.org>.
vinx13 commented on issue #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#issuecomment-589471873
Thanks @Orion34C @masahi @Hzfengsy @Laurawly
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] Orion34C commented on a change in pull request
#4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto
tensorcore
Posted by GitBox <gi...@apache.org>.
Orion34C commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r362204881
##########
File path: tutorials/autotvm/tensor_core_matmul_subbyte_int.py
##########
@@ -0,0 +1,231 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import logging
+import sys
+
+import numpy as np
+import tvm
+
+from tvm import autotvm
+
+
+def matmul_nn(A, B, L, dtype='int4', layout='TN'):
+ k = tvm.reduce_axis((0, L), name='k')
+ out_type = 'int'
+ return tvm.compute((N, M), lambda i, j: tvm.sum((A[i, k] * B[j, k]).astype(out_type), axis=k))
+
+@autotvm.template
+def test_gemm_nn(N, L, M, dtype, layout):
+ shape_a = (N, L)
+ shape_b = (M, L)
+ A = tvm.placeholder(shape_a, name='A', dtype=dtype)
+ B = tvm.placeholder(shape_b, name='B', dtype=dtype)
+ C = matmul_nn(A, B, L, dtype, layout)
+
+ s = tvm.create_schedule(C.op)
+ y, x = s[C].op.axis
+ k = s[C].op.reduce_axis[0]
+
+ # storage_align params
+ factor = 64
+ offset = 32
+ if dtype == 'int1':
+ factor = 256
+ offset = 128
+
+ AA = s.cache_read(A, "shared", [C])
+ s[AA].storage_align(AA.op.axis[0], factor, offset)
+ AL = s.cache_read(AA, "local", [C])
+ BB = s.cache_read(B, "shared", [C])
+ BL = s.cache_read(BB, "local", [C])
+ CL = s.cache_write(C, "local")
+
+ cfg = autotvm.get_config()
+ cfg.define_knob("bx", [4, 8])
+ cfg.define_knob("by", [8, 16, 32, 64])
+ cfg.define_knob("step_k", [1, 2, 4, 8, 16, 32])
+ cfg.define_knob("v", [8, 16, 32])
+ by = cfg['by'].val
+ bx = cfg['bx'].val
+ step_k = cfg['step_k'].val
+ v = cfg['v'].val
+ '''
+ bx = 4
+ by = 16
+ step_k = 32
+ '''
+
+ TX = 2
+ TY = 1
+ tile_x = bx * TX
+ tile_y = by * TY
+ WX = min(8, tile_x)
+ tile_k = 32
+ if dtype == 'int1':
+ tile_k = 128
+ vthread = 1
+
+ yo, ty = s[C].split(y, tile_y*vthread)
+ vy, ty = s[C].split(ty, tile_y)
+ ty, yi = s[C].split(ty, TY)
+
+ xo, xi = s[C].split(x, tile_x)
+ tz, xi = s[C].split(xi, WX)
+ tx, xi = s[C].split(xi, TX)
+ ko, ki = s[CL].split(k, step_k * tile_k)
+ kl, ki = s[CL].split(ki, tile_k)
+
+ s[C].reorder(yo, xo, tz, ty, tx, yi, xi)
+ s[C].bind(yo, tvm.thread_axis("blockIdx.y"))
+ s[C].bind(xo, tvm.thread_axis("blockIdx.x"))
+ s[C].bind(ty, tvm.thread_axis("threadIdx.y"))
+ s[C].bind(tz, tvm.thread_axis("threadIdx.z"))
+ s[C].bind(tx, tvm.thread_axis("threadIdx.x"))
+ s[C].bind(vy, tvm.thread_axis((0, vthread), "vthread", name="vy"))
+ s[CL].compute_at(s[C], tx)
+ yo, xo = CL.op.axis
+ s[CL].reorder(ko, kl, ki, yo, xo)
+
+ s[AA].compute_at(s[CL], ko)
+ xo, xi = s[AA].split(s[AA].op.axis[1], factor=bx*v)
+ tz, tx = s[AA].split(xi, factor=(WX//TX)*v)
+ tx, vec = s[AA].split(tx, factor=v)
+ fused = s[AA].fuse(s[AA].op.axis[0], xo)
+ _, ty = s[AA].split(fused, factor=by)
+ s[AA].bind(ty, tvm.thread_axis("threadIdx.y"))
+ s[AA].bind(tz, tvm.thread_axis("threadIdx.z"))
+ s[AA].bind(tx, tvm.thread_axis("threadIdx.x"))
+ s[AA].vectorize(vec)
+
+ s[BB].compute_at(s[CL], ko)
+ xo, xi = s[BB].split(s[BB].op.axis[1], factor=bx*v)
+ tz, tx = s[BB].split(xi, factor=(WX//TX)*v)
+ tx, vec = s[BB].split(tx, factor=v)
+ fused = s[BB].fuse(s[BB].op.axis[0], xo)
+ _, ty = s[BB].split(fused, factor=by)
+ s[BB].bind(ty, tvm.thread_axis("threadIdx.y"))
+ s[BB].bind(tz, tvm.thread_axis("threadIdx.z"))
+ s[BB].bind(tx, tvm.thread_axis("threadIdx.x"))
+ s[BB].vectorize(vec)
+
+ s[AL].compute_at(s[CL], kl)
+ s[BL].compute_at(s[CL], kl)
+ s[CL].pragma(ko, 'tensor_core')
+
+ return s, [A, B, C]
+
+M, N, L = 512, 16, 512
+dtype = 'int4'
+layout = 'TN'
+if len(sys.argv) >= 4:
+ M, N, L = int(sys.argv[1]), int(sys.argv[2]), int(sys.argv[3])
+if len(sys.argv) >= 5:
+ dtype = sys.argv[4]
+if len(sys.argv) >= 6:
+ layout = sys.argv[5]
+if (dtype == 'int4' or dtype == 'int1'):
+ assert(layout == 'TN')
+print ("M=%d, N=%d, K=%d, dtype=%s, layout=%s" % (M, N, L, dtype, layout))
+
+task = autotvm.task.create(test_gemm_nn, args=(N, L, M, dtype, layout), target='cuda')
+print(task.config_space)
+
+logging.getLogger('autotvm').setLevel(logging.DEBUG)
+logging.getLogger('autotvm').addHandler(logging.StreamHandler(sys.stdout))
+
+measure_option = autotvm.measure_option(
+ builder='local',
+ runner=autotvm.LocalRunner(number=5))
+
+tuner = autotvm.tuner.XGBTuner(task)
+with tvm.build_config():
Review comment:
A check for sm75 is added.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] Orion34C commented on a change in pull request
#4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto
tensorcore
Posted by GitBox <gi...@apache.org>.
Orion34C commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r362204788
##########
File path: src/pass/arg_binder.cc
##########
@@ -184,7 +184,9 @@ void ArgBinder::BindDLTensor(const Buffer& buffer,
UIntImm::make(UInt(8), dtype.bits()) &&
TVMArrayGet(UInt(16), handle, intrinsic::kArrTypeLanes) ==
UIntImm::make(UInt(16), dtype.lanes()));
- asserts_.emplace_back(AssertStmt::make(cond, type_err_msg.str(), nop));
+ if (!(dtype == Int(4) || dtype == UInt(4) || dtype == Int(1))) {
Review comment:
This hack is added because int4/int1 is not supported in basic data types as in numpy or c, we can only feed int4/int1 data in int8 or int32,which is not aligned with tvm ir's data type Int(4) or Int(1) etc. I wonder if you guys have a better solution than this hacky one.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] Orion34C commented on a change in pull request
#4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto
tensorcore
Posted by GitBox <gi...@apache.org>.
Orion34C commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r362204942
##########
File path: include/tvm/ir.h
##########
@@ -1589,6 +1589,18 @@ constexpr const char* tvm_load_matrix_sync = "tvm_load_matrix_sync";
* }
*/
constexpr const char* tvm_mma_sync = "tvm_mma_sync";
+/*!
+ * \brief tvm intrinsic for tensor core mma_sync operators.
+ *
+ * void tvm_bmma_sync(Var fragment_d, Expr index_d,
+ * Var fragment_a, Expr index_a,
Review comment:
fixed
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] Orion34C commented on a change in pull request
#4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto
tensorcore
Posted by GitBox <gi...@apache.org>.
Orion34C commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r362204823
##########
File path: tutorials/autotvm/tensor_core_matmul_subbyte_int.py
##########
@@ -0,0 +1,231 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import logging
+import sys
+
+import numpy as np
+import tvm
+
+from tvm import autotvm
+
+
+def matmul_nn(A, B, L, dtype='int4', layout='TN'):
Review comment:
removed not used params
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] Orion34C commented on a change in pull request
#4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto
tensorcore
Posted by GitBox <gi...@apache.org>.
Orion34C commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r381993872
##########
File path: include/tvm/runtime/data_type.h
##########
@@ -231,7 +231,15 @@ inline int GetVectorBytes(DataType dtype) {
int data_bits = dtype.bits() * dtype.lanes();
// allow bool to exist
if (dtype == DataType::Bool()) return 1;
- return data_bits;
+ // allow int4/uint4/int1 to exist
+ if (dtype == DataType::Int(4) ||
+ dtype == DataType::UInt(4) ||
+ dtype == DataType::Int(1)) {
+ return data_bits;
Review comment:
Sorry, this is a mistake when merge code to latest code base, for int1/int4/uint4 1 is a more appropriate return value. I already fix it in my latest commit.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] vinx13 commented on a change in pull request #4546:
[CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
Posted by GitBox <gi...@apache.org>.
vinx13 commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r379972079
##########
File path: include/tvm/tir/expr.h
##########
@@ -1260,6 +1260,18 @@ constexpr const char* tvm_load_matrix_sync = "tvm_load_matrix_sync";
* }
*/
constexpr const char* tvm_mma_sync = "tvm_mma_sync";
+/*!
+ * \brief tvm intrinsic for tensor core mma_sync operators.
Review comment:
```suggestion
* \brief tvm intrinsic for tensor core bmma_sync operators.
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] Orion34C commented on a change in pull request
#4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto
tensorcore
Posted by GitBox <gi...@apache.org>.
Orion34C commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r362204912
##########
File path: tutorials/autotvm/tensor_core_matmul_subbyte_int.py
##########
@@ -0,0 +1,231 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import logging
+import sys
+
+import numpy as np
+import tvm
+
+from tvm import autotvm
+
+
+def matmul_nn(A, B, L, dtype='int4', layout='TN'):
+ k = tvm.reduce_axis((0, L), name='k')
+ out_type = 'int'
+ return tvm.compute((N, M), lambda i, j: tvm.sum((A[i, k] * B[j, k]).astype(out_type), axis=k))
+
+@autotvm.template
+def test_gemm_nn(N, L, M, dtype, layout):
+ shape_a = (N, L)
+ shape_b = (M, L)
+ A = tvm.placeholder(shape_a, name='A', dtype=dtype)
+ B = tvm.placeholder(shape_b, name='B', dtype=dtype)
+ C = matmul_nn(A, B, L, dtype, layout)
+
+ s = tvm.create_schedule(C.op)
+ y, x = s[C].op.axis
+ k = s[C].op.reduce_axis[0]
+
+ # storage_align params
+ factor = 64
+ offset = 32
+ if dtype == 'int1':
+ factor = 256
+ offset = 128
+
+ AA = s.cache_read(A, "shared", [C])
+ s[AA].storage_align(AA.op.axis[0], factor, offset)
+ AL = s.cache_read(AA, "local", [C])
+ BB = s.cache_read(B, "shared", [C])
+ BL = s.cache_read(BB, "local", [C])
+ CL = s.cache_write(C, "local")
+
+ cfg = autotvm.get_config()
+ cfg.define_knob("bx", [4, 8])
+ cfg.define_knob("by", [8, 16, 32, 64])
+ cfg.define_knob("step_k", [1, 2, 4, 8, 16, 32])
+ cfg.define_knob("v", [8, 16, 32])
+ by = cfg['by'].val
+ bx = cfg['bx'].val
+ step_k = cfg['step_k'].val
+ v = cfg['v'].val
+ '''
+ bx = 4
+ by = 16
+ step_k = 32
+ '''
+
+ TX = 2
+ TY = 1
+ tile_x = bx * TX
+ tile_y = by * TY
+ WX = min(8, tile_x)
+ tile_k = 32
+ if dtype == 'int1':
+ tile_k = 128
+ vthread = 1
+
+ yo, ty = s[C].split(y, tile_y*vthread)
+ vy, ty = s[C].split(ty, tile_y)
+ ty, yi = s[C].split(ty, TY)
+
+ xo, xi = s[C].split(x, tile_x)
+ tz, xi = s[C].split(xi, WX)
+ tx, xi = s[C].split(xi, TX)
+ ko, ki = s[CL].split(k, step_k * tile_k)
+ kl, ki = s[CL].split(ki, tile_k)
+
+ s[C].reorder(yo, xo, tz, ty, tx, yi, xi)
+ s[C].bind(yo, tvm.thread_axis("blockIdx.y"))
+ s[C].bind(xo, tvm.thread_axis("blockIdx.x"))
+ s[C].bind(ty, tvm.thread_axis("threadIdx.y"))
+ s[C].bind(tz, tvm.thread_axis("threadIdx.z"))
+ s[C].bind(tx, tvm.thread_axis("threadIdx.x"))
+ s[C].bind(vy, tvm.thread_axis((0, vthread), "vthread", name="vy"))
+ s[CL].compute_at(s[C], tx)
+ yo, xo = CL.op.axis
+ s[CL].reorder(ko, kl, ki, yo, xo)
+
+ s[AA].compute_at(s[CL], ko)
+ xo, xi = s[AA].split(s[AA].op.axis[1], factor=bx*v)
+ tz, tx = s[AA].split(xi, factor=(WX//TX)*v)
+ tx, vec = s[AA].split(tx, factor=v)
+ fused = s[AA].fuse(s[AA].op.axis[0], xo)
+ _, ty = s[AA].split(fused, factor=by)
+ s[AA].bind(ty, tvm.thread_axis("threadIdx.y"))
+ s[AA].bind(tz, tvm.thread_axis("threadIdx.z"))
+ s[AA].bind(tx, tvm.thread_axis("threadIdx.x"))
+ s[AA].vectorize(vec)
+
+ s[BB].compute_at(s[CL], ko)
+ xo, xi = s[BB].split(s[BB].op.axis[1], factor=bx*v)
+ tz, tx = s[BB].split(xi, factor=(WX//TX)*v)
+ tx, vec = s[BB].split(tx, factor=v)
+ fused = s[BB].fuse(s[BB].op.axis[0], xo)
+ _, ty = s[BB].split(fused, factor=by)
+ s[BB].bind(ty, tvm.thread_axis("threadIdx.y"))
+ s[BB].bind(tz, tvm.thread_axis("threadIdx.z"))
+ s[BB].bind(tx, tvm.thread_axis("threadIdx.x"))
+ s[BB].vectorize(vec)
+
+ s[AL].compute_at(s[CL], kl)
+ s[BL].compute_at(s[CL], kl)
+ s[CL].pragma(ko, 'tensor_core')
+
+ return s, [A, B, C]
+
+M, N, L = 512, 16, 512
+dtype = 'int4'
+layout = 'TN'
+if len(sys.argv) >= 4:
+ M, N, L = int(sys.argv[1]), int(sys.argv[2]), int(sys.argv[3])
+if len(sys.argv) >= 5:
+ dtype = sys.argv[4]
+if len(sys.argv) >= 6:
+ layout = sys.argv[5]
+if (dtype == 'int4' or dtype == 'int1'):
+ assert(layout == 'TN')
+print ("M=%d, N=%d, K=%d, dtype=%s, layout=%s" % (M, N, L, dtype, layout))
+
+task = autotvm.task.create(test_gemm_nn, args=(N, L, M, dtype, layout), target='cuda')
+print(task.config_space)
+
+logging.getLogger('autotvm').setLevel(logging.DEBUG)
+logging.getLogger('autotvm').addHandler(logging.StreamHandler(sys.stdout))
+
+measure_option = autotvm.measure_option(
+ builder='local',
+ runner=autotvm.LocalRunner(number=5))
+
+tuner = autotvm.tuner.XGBTuner(task)
+with tvm.build_config():
+ tuner.tune(n_trial=1000,
+ measure_option=measure_option,
+ callbacks=[autotvm.callback.log_to_file('matmul.log')])
+
+dispatch_context = autotvm.apply_history_best("matmul.log")
+best_config = dispatch_context.query(task.target, task.workload)
+print("\nBest config:")
+print(best_config)
+with autotvm.apply_history_best('matmul.log'):
+ with tvm.target.create("cuda"):
+ with tvm.build_config():
+ s, arg_bufs = test_gemm_nn(N, L, M, dtype, layout)
+ print(tvm.lower(s, arg_bufs, simple_mode=True))
+ func = tvm.build(s, arg_bufs)
+dev_module = func.imported_modules[0]
+print(dev_module.get_source())
+
+# check correctness
+shape_a = (N, L)
+shape_b = (M, L)
+
+a_np = None
+b_np = None
+a_np_int = None
+b_np_int = None
+c_np = None
+c_np_type = None
+
+if dtype == 'int4':
+ c_np_type = np.int32
Review comment:
Already fixed
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] Laurawly commented on a change in pull request
#4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto
tensorcore
Posted by GitBox <gi...@apache.org>.
Laurawly commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r360222767
##########
File path: include/tvm/ir.h
##########
@@ -1589,6 +1589,18 @@ constexpr const char* tvm_load_matrix_sync = "tvm_load_matrix_sync";
* }
*/
constexpr const char* tvm_mma_sync = "tvm_mma_sync";
+/*!
+ * \brief tvm intrinsic for tensor core mma_sync operators.
+ *
+ * void tvm_bmma_sync(Var fragment_d, Expr index_d,
+ * Var fragment_a, Expr index_a,
Review comment:
indent
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] vinx13 merged pull request #4546: [CODEGEN] Support
cuda tensorcore subbyte int data type in auto tensorcore
Posted by GitBox <gi...@apache.org>.
vinx13 merged pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] Laurawly commented on a change in pull request
#4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto
tensorcore
Posted by GitBox <gi...@apache.org>.
Laurawly commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r361253764
##########
File path: tutorials/autotvm/tensor_core_matmul_subbyte_int.py
##########
@@ -0,0 +1,231 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import logging
+import sys
+
+import numpy as np
+import tvm
+
+from tvm import autotvm
+
+
+def matmul_nn(A, B, L, dtype='int4', layout='TN'):
+ k = tvm.reduce_axis((0, L), name='k')
+ out_type = 'int'
+ return tvm.compute((N, M), lambda i, j: tvm.sum((A[i, k] * B[j, k]).astype(out_type), axis=k))
+
+@autotvm.template
+def test_gemm_nn(N, L, M, dtype, layout):
+ shape_a = (N, L)
+ shape_b = (M, L)
+ A = tvm.placeholder(shape_a, name='A', dtype=dtype)
+ B = tvm.placeholder(shape_b, name='B', dtype=dtype)
+ C = matmul_nn(A, B, L, dtype, layout)
+
+ s = tvm.create_schedule(C.op)
+ y, x = s[C].op.axis
+ k = s[C].op.reduce_axis[0]
+
+ # storage_align params
+ factor = 64
+ offset = 32
+ if dtype == 'int1':
+ factor = 256
+ offset = 128
+
+ AA = s.cache_read(A, "shared", [C])
+ s[AA].storage_align(AA.op.axis[0], factor, offset)
+ AL = s.cache_read(AA, "local", [C])
+ BB = s.cache_read(B, "shared", [C])
+ BL = s.cache_read(BB, "local", [C])
+ CL = s.cache_write(C, "local")
+
+ cfg = autotvm.get_config()
+ cfg.define_knob("bx", [4, 8])
+ cfg.define_knob("by", [8, 16, 32, 64])
+ cfg.define_knob("step_k", [1, 2, 4, 8, 16, 32])
+ cfg.define_knob("v", [8, 16, 32])
+ by = cfg['by'].val
+ bx = cfg['bx'].val
+ step_k = cfg['step_k'].val
+ v = cfg['v'].val
+ '''
+ bx = 4
+ by = 16
+ step_k = 32
+ '''
+
+ TX = 2
+ TY = 1
+ tile_x = bx * TX
+ tile_y = by * TY
+ WX = min(8, tile_x)
+ tile_k = 32
+ if dtype == 'int1':
+ tile_k = 128
+ vthread = 1
Review comment:
Is vthread tunable in this PR?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] Orion34C commented on a change in pull request
#4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto
tensorcore
Posted by GitBox <gi...@apache.org>.
Orion34C commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r362204375
##########
File path: include/tvm/ir.h
##########
@@ -1589,6 +1589,18 @@ constexpr const char* tvm_load_matrix_sync = "tvm_load_matrix_sync";
* }
*/
constexpr const char* tvm_mma_sync = "tvm_mma_sync";
+/*!
+ * \brief tvm intrinsic for tensor core mma_sync operators.
Review comment:
done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] Orion34C commented on a change in pull request
#4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto
tensorcore
Posted by GitBox <gi...@apache.org>.
Orion34C commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r379838810
##########
File path: tutorials/autotvm/tensor_core_matmul_subbyte_int.py
##########
@@ -0,0 +1,231 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import logging
+import sys
+
+import numpy as np
+import tvm
+
+from tvm import autotvm
+
+
+def matmul_nn(A, B, L, dtype='int4', layout='TN'):
+ k = tvm.reduce_axis((0, L), name='k')
+ out_type = 'int'
+ return tvm.compute((N, M), lambda i, j: tvm.sum((A[i, k] * B[j, k]).astype(out_type), axis=k))
+
+@autotvm.template
+def test_gemm_nn(N, L, M, dtype, layout):
+ shape_a = (N, L)
+ shape_b = (M, L)
+ A = tvm.placeholder(shape_a, name='A', dtype=dtype)
+ B = tvm.placeholder(shape_b, name='B', dtype=dtype)
+ C = matmul_nn(A, B, L, dtype, layout)
+
+ s = tvm.create_schedule(C.op)
+ y, x = s[C].op.axis
+ k = s[C].op.reduce_axis[0]
+
+ # storage_align params
+ factor = 64
+ offset = 32
+ if dtype == 'int1':
+ factor = 256
+ offset = 128
+
+ AA = s.cache_read(A, "shared", [C])
+ s[AA].storage_align(AA.op.axis[0], factor, offset)
+ AL = s.cache_read(AA, "local", [C])
+ BB = s.cache_read(B, "shared", [C])
+ BL = s.cache_read(BB, "local", [C])
+ CL = s.cache_write(C, "local")
+
+ cfg = autotvm.get_config()
+ cfg.define_knob("bx", [4, 8])
+ cfg.define_knob("by", [8, 16, 32, 64])
+ cfg.define_knob("step_k", [1, 2, 4, 8, 16, 32])
+ cfg.define_knob("v", [8, 16, 32])
+ by = cfg['by'].val
+ bx = cfg['bx'].val
+ step_k = cfg['step_k'].val
+ v = cfg['v'].val
+ '''
+ bx = 4
+ by = 16
+ step_k = 32
+ '''
+
+ TX = 2
+ TY = 1
+ tile_x = bx * TX
+ tile_y = by * TY
+ WX = min(8, tile_x)
+ tile_k = 32
+ if dtype == 'int1':
+ tile_k = 128
+ vthread = 1
Review comment:
It's not used, removed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] vinx13 commented on issue #4546: [CODEGEN] Support
cuda tensorcore subbyte int data type in auto tensorcore
Posted by GitBox <gi...@apache.org>.
vinx13 commented on issue #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#issuecomment-572343213
@Orion34C Could you please rebase against master?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] tqchen commented on issue #4546: [CODEGEN] Support
cuda tensorcore subbyte int data type in auto tensorcore
Posted by GitBox <gi...@apache.org>.
tqchen commented on issue #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#issuecomment-587091708
see if you can reprod the error locally. I wonder if it has things to do with the join running of the testcase, or a memory corruption case where the change caused some changes in a memory locaiton. would be great if you can investigate further.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] Orion34C commented on a change in pull request
#4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto
tensorcore
Posted by GitBox <gi...@apache.org>.
Orion34C commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r379838785
##########
File path: tutorials/autotvm/tensor_core_matmul_subbyte_int.py
##########
@@ -0,0 +1,231 @@
+# Licensed to the Apache Software Foundation (ASF) under one
Review comment:
the latest commit modify the existing one to support int4/int1 codegen
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] tqchen commented on issue #4546: [CODEGEN] Support
cuda tensorcore subbyte int data type in auto tensorcore
Posted by GitBox <gi...@apache.org>.
tqchen commented on issue #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#issuecomment-586790675
@Orion34C please rebase against the master and try tomake the CI green. Note that if the test depends on availability of GPU feature, we might need to skip the test by checking the gpu type.
@jwfromm @Hzfengsy would be great if you can also help to take a look
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] yangjunpro commented on issue #4546: [CODEGEN]
Support cuda tensorcore subbyte int data type in auto tensorcore
Posted by GitBox <gi...@apache.org>.
yangjunpro commented on issue #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#issuecomment-586786630
@tqchen @vinx13 @Hzfengsy could you please help review this PR? Since this has been pending for a while we wish to push it into the mainstream ASAP. Any comments are welcome.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] Orion34C commented on a change in pull request
#4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto
tensorcore
Posted by GitBox <gi...@apache.org>.
Orion34C commented on a change in pull request #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#discussion_r380072928
##########
File path: tutorials/autotvm/tensor_core_matmul_subbyte_int.py
##########
@@ -0,0 +1,231 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import logging
+import sys
+
+import numpy as np
+import tvm
+
+from tvm import autotvm
+
+
+def matmul_nn(A, B, L, dtype='int4', layout='TN'):
+ k = tvm.reduce_axis((0, L), name='k')
+ out_type = 'int'
+ return tvm.compute((N, M), lambda i, j: tvm.sum((A[i, k] * B[j, k]).astype(out_type), axis=k))
+
+@autotvm.template
+def test_gemm_nn(N, L, M, dtype, layout):
+ shape_a = (N, L)
+ shape_b = (M, L)
+ A = tvm.placeholder(shape_a, name='A', dtype=dtype)
+ B = tvm.placeholder(shape_b, name='B', dtype=dtype)
+ C = matmul_nn(A, B, L, dtype, layout)
+
+ s = tvm.create_schedule(C.op)
+ y, x = s[C].op.axis
+ k = s[C].op.reduce_axis[0]
+
+ # storage_align params
+ factor = 64
+ offset = 32
+ if dtype == 'int1':
+ factor = 256
+ offset = 128
+
+ AA = s.cache_read(A, "shared", [C])
+ s[AA].storage_align(AA.op.axis[0], factor, offset)
+ AL = s.cache_read(AA, "local", [C])
+ BB = s.cache_read(B, "shared", [C])
+ BL = s.cache_read(BB, "local", [C])
+ CL = s.cache_write(C, "local")
+
+ cfg = autotvm.get_config()
+ cfg.define_knob("bx", [4, 8])
+ cfg.define_knob("by", [8, 16, 32, 64])
+ cfg.define_knob("step_k", [1, 2, 4, 8, 16, 32])
+ cfg.define_knob("v", [8, 16, 32])
+ by = cfg['by'].val
+ bx = cfg['bx'].val
+ step_k = cfg['step_k'].val
+ v = cfg['v'].val
+ '''
+ bx = 4
+ by = 16
+ step_k = 32
+ '''
Review comment:
done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-tvm] Orion34C commented on issue #4546: [CODEGEN]
Support cuda tensorcore subbyte int data type in auto tensorcore
Posted by GitBox <gi...@apache.org>.
Orion34C commented on issue #4546: [CODEGEN] Support cuda tensorcore subbyte int data type in auto tensorcore
URL: https://github.com/apache/incubator-tvm/pull/4546#issuecomment-586994714
@vinx13 Hi, I re-run the tests several times, the same error happened in the test_workspace_add with simply a TVM error in the cpu env. Is there any docs or tutorials that can help me figure out where went wrong in my commit? Thanks!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services