You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2023/01/02 10:49:26 UTC
[GitHub] [hudi] maheshguptags opened a new issue, #7589: Keep only clustered file(all) after cleaning
maheshguptags opened a new issue, #7589:
URL: https://github.com/apache/hudi/issues/7589
**Want to clean only the Avro and Parquet file not the clustered file( previous version of clustered file)**
Hi Team,
I want to perform clustering with cleaning which is working fine but my use case is bit different where I want to clean all AVRO + parquet( being generated by compaction) but keep all the clustered file to maintain the historical data of users.
Steps to reproduce the behavior:
** hudi Configuration**
hudi_options_write = {
'hoodie.datasource.write.table.type': 'MERGE_ON_READ',
'hoodie.datasource.write.recordkey.field': 'xxxx,yyyy',
'hoodie.table.name': tableName,
'hoodie.datasource.write.hive_style_partitioning': 'true',
'hoodie.archivelog.folder': 'archived',
'hoodie.datasource.write.partitionpath.field': 'xxxxx',
'hoodie.datasource.write.keygenerator.class': 'org.apache.hudi.keygen.ComplexKeyGenerator',
'hoodie.datasource.write.partitionpath.urlencode': 'false',
'hoodie.upsert.shuffle.parallelism': 2,
'hoodie.datasource.write.precombine.field': 'updated_date',
'hoodie.compact.inline.max.delta.commits': 4,
'hoodie.clean.automatic': 'false',
'hoodie.compact.inline': 'true',
'hoodie.parquet.small.file.limit': '0',
'hoodie.clustering.inline': 'true',
'hoodie.clustering.inline.max.commits': '4',
'hoodie.clustering.plan.strategy.target.file.max.bytes': '1073741824',
'hoodie.clustering.plan.strategy.small.file.limit': '629145600',
##Files smaller than the size in bytes specified here are candidates for clustering
'hoodie.clustering.plan.strategy.sort.columns': 'xxxxx'
}
**Expected behavior**
After every cleaning procedure it would clean only AVRO and PARQUET(compacted ) not Clustered.
**Environment Description**
* Hudi version : 11.01
* Spark version : Spark 3.3.0
* Hive version : Hive 3.1.3
* Hadoop version : Hadoop 3.2.1
* Storage (HDFS/S3/GCS..) : S3
* Running on Docker? (yes/no) : No
**Stacktrace**
I want to explore the feature to store the historical data by keeping the clustered parquet file. If this is supported by existing hudi system, Can someone from hudi team help me to achieve this, if not then is there any workaround for it?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] maheshguptags commented on issue #7589: [Support] Keep only clustered file(all) after cleaning
Posted by "maheshguptags (via GitHub)" <gi...@apache.org>.
maheshguptags commented on issue #7589:
URL: https://github.com/apache/hudi/issues/7589#issuecomment-1480617541
Hi @yihua ,
thank you for looking into this request.
I tried the same configuration above and am still getting the same error.
please have a look at the stack trace and code.
**CODE**
```
hsc.sql("use default")
table_path = "s3a://test-spark-hudi/clustering_mor/"
df = spark.read.format('org.apache.hudi').load(table_path)
df.createOrReplaceTempView("clustering_mor")
print('2',spark.sql("show tables from default").show())
print('=========================')
print('=========================',spark.catalog.listTables(),'=========================')
print('========================')
df1 = spark.sql("select * from clustering_mor")
print("dddd",df1.printSchema())
print(df1.show())
# print(spark.sql("""call show_savepoints(table =>'clustering_mor')""").show())
spark.sql("""call create_savepoint(path => table_path, commit_time => '20221228054602665'""")
print(f"done................")
```
**Stacktrace**
```
import of spark session is done !!!!
============================================
23/03/23 10:44:13 WARN MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-s3a-file-system.properties,hadoop-metrics2.properties
23/03/23 10:44:18 WARN DFSPropertiesConfiguration: Cannot find HUDI_CONF_DIR, please set it as the dir of hudi-defaults.conf
23/03/23 10:44:18 WARN DFSPropertiesConfiguration: Properties file file:/etc/hudi/conf/hudi-defaults.conf not found. Ignoring to load props file
+---------+--------------+-----------+
|namespace| tableName|isTemporary|
+---------+--------------+-----------+
| |clustering_mor| false|
+---------+--------------+-----------+
2 None
=========================
========================= [Table(name='clustering_mor', database=None, description=None, tableType='TEMPORARY', isTemporary=True)] =========================
========================
root
|-- _hoodie_commit_time: string (nullable = true)
|-- _hoodie_commit_seqno: string (nullable = true)
|-- _hoodie_record_key: string (nullable = true)
|-- _hoodie_partition_path: string (nullable = true)
|-- _hoodie_file_name: string (nullable = true)
|-- campaign_id: string (nullable = true)
|-- client_id: string (nullable = true)
|-- created_by: string (nullable = true)
|-- created_date: string (nullable = true)
|-- event_count: string (nullable = true)
|-- event_id: string (nullable = true)
|-- updated_by: string (nullable = true)
|-- updated_date: string (nullable = true)
dddd None
# WARNING: Unable to get Instrumentation. Dynamic Attach failed. You may add this JAR as -javaagent manually, or supply -Djdk.attach.allowAttachSelf
# WARNING: Unable to attach Serviceability Agent. Unable to attach even with module exceptions: [org.apache.hudi.org.openjdk.jol.vm.sa.SASupportException: Sense failed., org.apache.hudi.org.openjdk.jol.vm.sa.SASupportException: Sense failed., org.apache.hudi.org.openjdk.jol.vm.sa.SASupportException: Sense failed.]
+-------------------+--------------------+--------------------+----------------------+--------------------+-----------+----------+--------------------+--------------------+-----------+--------+--------------------+-------------------+
|_hoodie_commit_time|_hoodie_commit_seqno| _hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|campaign_id| client_id| created_by| created_date|event_count|event_id| updated_by| updated_date|
+-------------------+--------------------+--------------------+----------------------+--------------------+-----------+----------+--------------------+--------------------+-----------+--------+--------------------+-------------------+
| 20230109092536279|20230109092536279...|campaign_id:350,e...| campaign_id=350|fe1ae9e1-f3b1-463...| 350|cl-WJxiIuA|Campaign_Event_Su...|2022-09-12T13:54:...| 79| 2|Campaign_Event_Su...|2023-01-09T09:25:24|
+-------------------+--------------------+--------------------+----------------------+--------------------+-----------+----------+--------------------+--------------------+-----------+--------+--------------------+-------------------+
None
Traceback (most recent call last):
File "/Users/maheshgupta/PycharmProjects/aws_hudi_connection/code/aws_hudi_spark_cluster_savepoint.py", line 52, in <module>
spark.sql("""call create_savepoint(path => table_path, commit_time => '20221228054602665'""")
File "/Library/Python/3.9/site-packages/pyspark/sql/session.py", line 1034, in sql
return DataFrame(self._jsparkSession.sql(sqlQuery), self)
File "/Library/Python/3.9/site-packages/py4j/java_gateway.py", line 1321, in __call__
return_value = get_return_value(
File "/Library/Python/3.9/site-packages/pyspark/sql/utils.py", line 196, in deco
raise converted from None
pyspark.sql.utils.ParseException:
Syntax error at or near 'call'(line 1, pos 0)
== SQL ==
call create_savepoint(path => table_path, commit_time => '20221228054602665'
^^^
Process finished with exit code 1
```
Please let me know if I am not using it properly
Thanks
Mahesh
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] maheshguptags commented on issue #7589: [Support] Keep only clustered file(all) after cleaning
Posted by "maheshguptags (via GitHub)" <gi...@apache.org>.
maheshguptags commented on issue #7589:
URL: https://github.com/apache/hudi/issues/7589#issuecomment-1455961547
Hi @codope and @xushiyan can you please update me on this ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] maheshguptags commented on issue #7589: [Support] Keep only clustered file(all) after cleaning
Posted by "maheshguptags (via GitHub)" <gi...@apache.org>.
maheshguptags commented on issue #7589:
URL: https://github.com/apache/hudi/issues/7589#issuecomment-1484875006
@codope and @yihua it is not working and you have closed the issue.
can you please take a look at my latest comment?
Thanks,
Mahesh
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] codope commented on issue #7589: [Support] Keep only clustered file(all) after cleaning
Posted by "codope (via GitHub)" <gi...@apache.org>.
codope commented on issue #7589:
URL: https://github.com/apache/hudi/issues/7589#issuecomment-1411993722
@XuQianJin-Stars Can you please take a look why savepoint procedure is failing?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] maheshguptags commented on issue #7589: Keep only clustered file(all) after cleaning
Posted by GitBox <gi...@apache.org>.
maheshguptags commented on issue #7589:
URL: https://github.com/apache/hudi/issues/7589#issuecomment-1370489489
Hi @yihua ,Thanks for looking into this. you are partially right but I want to preserve all the clustered file from 1 clustered file to till very end of the pipeline.
let me give you the example.
step 1 image : it contains the 3 commit of the file

step 2 image contain after the clustering file :
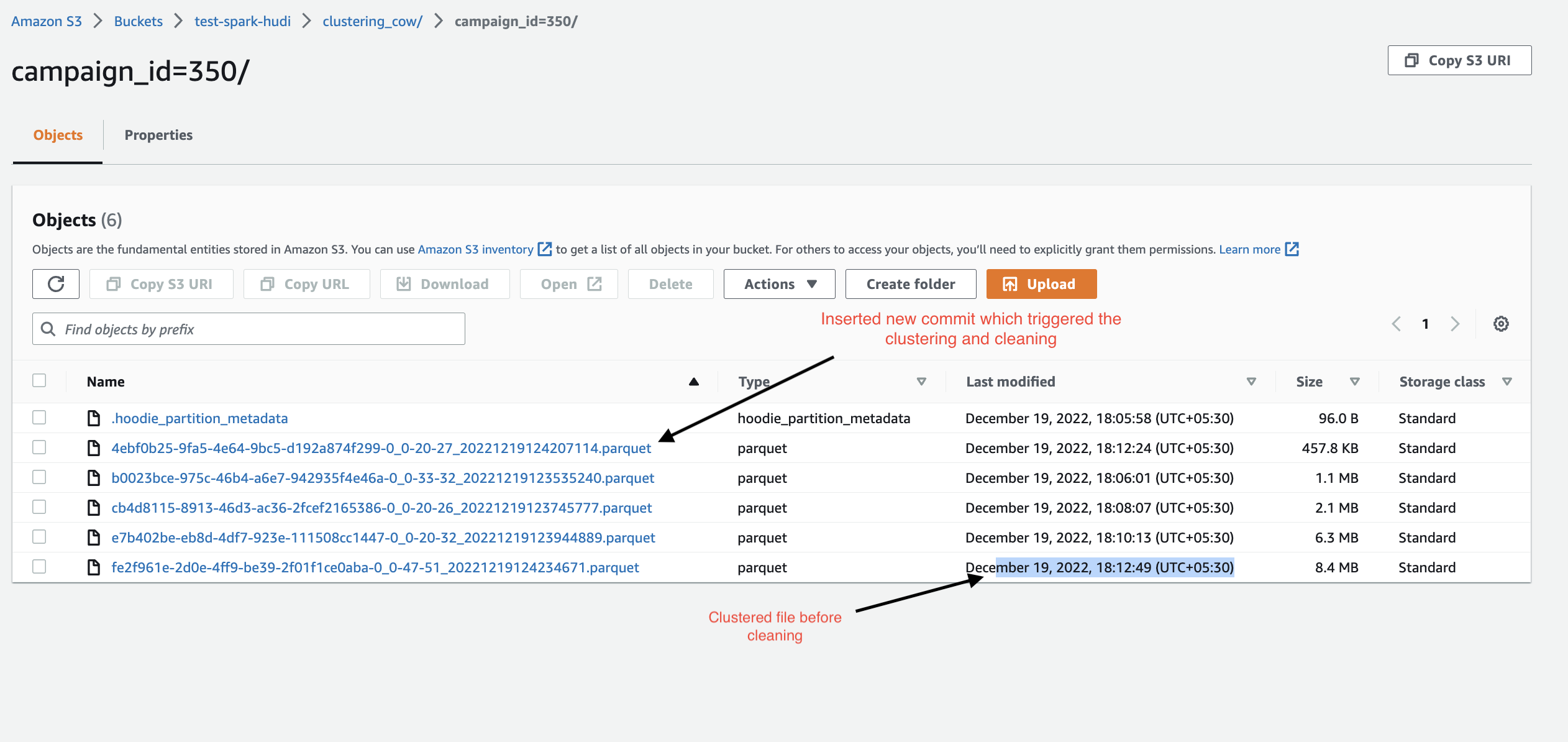
step 3 it contains only the clustered file and the latest commit files

step 4 image inserted few more commit then perform the clustering

Step 5 Image : Now this time clustering and cleaning will be triggered (4 commits completed) so it will clean the last cluster file (size exactly 8.4MB) and create new cluster file having all updated data. Whereas my wish is to preserve the old clustered file (8.4MB) file and create new clustered file. This way I will be able to maintain historical data of my process.

I hope I am able to explain the use case, If not we can quick catch up on call.
Let me know your thought on this
Thanks!!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] maheshguptags commented on issue #7589: Keep only clustered file(all) after cleaning
Posted by GitBox <gi...@apache.org>.
maheshguptags commented on issue #7589:
URL: https://github.com/apache/hudi/issues/7589#issuecomment-1375128230
@xushiyan Thanks for the reply, allow me to test this suggestion and get back to you.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yihua commented on issue #7589: [Support] Keep only clustered file(all) after cleaning
Posted by "yihua (via GitHub)" <gi...@apache.org>.
yihua commented on issue #7589:
URL: https://github.com/apache/hudi/issues/7589#issuecomment-1557557503
@maheshguptags Cool, thanks. Just to clarify, for a Hudi table on storage, you can always create a savepoint using the base path, regardless of whether the table is registered in the temp view or not in Spark.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] maheshguptags commented on issue #7589: [Support] Keep only clustered file(all) after cleaning
Posted by "maheshguptags (via GitHub)" <gi...@apache.org>.
maheshguptags commented on issue #7589:
URL: https://github.com/apache/hudi/issues/7589#issuecomment-1556545267
HI @yihua it is an issue with table creation not in syntax(it is not working with temp view of spark)
Now I have resolved this.
thanks for you help
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] maheshguptags commented on issue #7589: [Support] Keep only clustered file(all) after cleaning
Posted by "maheshguptags (via GitHub)" <gi...@apache.org>.
maheshguptags commented on issue #7589:
URL: https://github.com/apache/hudi/issues/7589#issuecomment-1425186536
@XuQianJin-Stars any update on this ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yihua commented on issue #7589: Keep only clustered file(all) after cleaning
Posted by GitBox <gi...@apache.org>.
yihua commented on issue #7589:
URL: https://github.com/apache/hudi/issues/7589#issuecomment-1376825649
Hi @maheshguptags you can also create savepoints using [Spark SQL procedures](https://hudi.apache.org/docs/0.11.1/procedures#create_savepoints): `call create_savepoints(table => 'hudi_trips_cow', commit_Time => '20230110224424600')` . We'll update the docs ([HUDI-5522](https://issues.apache.org/jira/browse/HUDI-5522)).
If you're comfortable using Hudi APIs, you may also call [SparkRDDWriteClient#savepoint](https://github.com/apache/hudi/blob/master/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/BaseHoodieWriteClient.java#L716) to programmatically create savepoints.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] maheshguptags commented on issue #7589: Keep only clustered file(all) after cleaning
Posted by GitBox <gi...@apache.org>.
maheshguptags commented on issue #7589:
URL: https://github.com/apache/hudi/issues/7589#issuecomment-1375606828
@xushiyan thank you for this suggestion and it is working fine.
I am able to preserve clustered file using Savepoint.
But there is one constraint with Savepoint, that
1. Savepoint and restore can only be triggered from `hudi-cli` as per the documentation of HUDI. https://hudi.apache.org/docs/disaster_recovery#runbook
This is not feasible to execute the command in cli on PROD Env
2. I also tried to find a way to execute the HUDI command using language like `Pyspark` and `Flink` but I haven't got any link/doc for same.
I would really appreciate if you can help me/send me the links of docs.
Thanks
-Mahesh
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] maheshguptags commented on issue #7589: Keep only clustered file(all) after cleaning
Posted by GitBox <gi...@apache.org>.
maheshguptags commented on issue #7589:
URL: https://github.com/apache/hudi/issues/7589#issuecomment-1368833025
CC :
@bhasudha
@codope
@nsivabalan
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yihua commented on issue #7589: Keep only clustered file(all) after cleaning
Posted by GitBox <gi...@apache.org>.
yihua commented on issue #7589:
URL: https://github.com/apache/hudi/issues/7589#issuecomment-1370361242
Hi @maheshguptags Thanks for the question. To clarify, are you asking to keep the new parquet files after clustering, which replace the compacted file groups that have parquet files? This should already be the case. If not, could you provide reproducible steps to show the failure?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yihua commented on issue #7589: [Support] Keep only clustered file(all) after cleaning
Posted by "yihua (via GitHub)" <gi...@apache.org>.
yihua commented on issue #7589:
URL: https://github.com/apache/hudi/issues/7589#issuecomment-1555373180
Hi @maheshguptags I think your CALL statement misses a right bracket. This should be the right command:
```
spark.sql("""call create_savepoint(path => table_path, commit_time => '20221228054602665')""")
```
I tested the following locally and it works for me:
```
pyspark --jars ~/Work/repo/hudi/packaging/hudi-spark-bundle/target/hudi-spark3.2-bundle_2.12-0.14.0-SNAPSHOT.jar \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
spark.sql("CALL create_savepoint(path => '/tmp/hudi_trips_cow', commit_time => '20230519161354886');")
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] codope closed issue #7589: [Support] Keep only clustered file(all) after cleaning
Posted by "codope (via GitHub)" <gi...@apache.org>.
codope closed issue #7589: [Support] Keep only clustered file(all) after cleaning
URL: https://github.com/apache/hudi/issues/7589
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] xushiyan commented on issue #7589: Keep only clustered file(all) after cleaning
Posted by GitBox <gi...@apache.org>.
xushiyan commented on issue #7589:
URL: https://github.com/apache/hudi/issues/7589#issuecomment-1374517461
@maheshguptags what you need is to do savepointing. see https://hudi.apache.org/docs/disaster_recovery
For each clustering (replace commit), you just need to trigger a savepoint and then cleaner won't delete the savepointed commit and its files, hence retain it forever (until you delete the savepoint).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] maheshguptags commented on issue #7589: Keep only clustered file(all) after cleaning
Posted by GitBox <gi...@apache.org>.
maheshguptags commented on issue #7589:
URL: https://github.com/apache/hudi/issues/7589#issuecomment-1379849852
@yihua thank you for above suggestion. I tried the run `CALL Procedure` by pyspark(spark.sql) but it is throwing errors.
the problem i am facing, I am able to list the table from `spark catalog` even from `default database` but when i call `call procedure` to `show savepoint` it is not able to get that table.
you can check the code and error logs.
Attaching code snippet & error for same.
Error Screen shot

Code
```
from pyspark.sql import *
from datetime import datetime
import random
print("import module........")
spark = SparkSession.builder.appName("clustering on COR") \
.config("spark.jar", "hudi-spark3.3-bundle_2.12-0.11.1-amzn-0.jar") \
.config("spark.jars.packages", "org.apache.spark:spark-hadoop-cloud_2.12:3.3.0,"
"org.apache.hadoop:hadoop-aws:3.3.0,net.java.dev.jets3t:jets3t:0.9.4,"
"com.amazonaws:aws-java-sdk:1.12.303"
) \
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.hudi.catalog.HoodieCatalog") \
.config("spark.sql.extensions", "org.apache.spark.sql.hudi.HoodieSparkSessionExtension") \
.config('spark.sql.parquet.enableVectorizedReader', 'false') \
.enableHiveSupport() \
.getOrCreate()
# org.apache.hudi:hudi-spark3-bundle_2.12:0.11.1,"org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.0"
sc = spark.sparkContext
print(f'access key and secret key is done')
sc._jsc.hadoopConfiguration().set('fs.s3a.access.key', "xxxxxxxxxxxxxxx")
sc._jsc.hadoopConfiguration().set('fs.s3a.secret.key', "xxxxxxxxxxxxxxxx")
from pyspark.sql import SQLContext
hsc = SQLContext(sc)
print(f'spark is {spark} and spark-context is {sc}')
print("============================================")
print("import of spark session is done !!!!")
print("============================================")
hsc.sql("use default")
df = spark.read.format('org.apache.hudi').load("s3://test-spark-hudi/clustering_mor/")
df.createOrReplaceTempView("clustering_mor")
print('2',spark.sql("show tables from default").show())
print('===========================================================================')
print('=========================',spark.catalog.listTables())
print('===========================================================================')
df1 = spark.sql("select * from clustering_mor")
print(df1.show())
print(spark.sql("""call show_savepoints(table =>'clustering_mor')""").show())
```
Error:
```
:: loading settings :: url = jar:file:/usr/lib/spark/jars/ivy-2.5.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
Ivy Default Cache set to: /home/hadoop/.ivy2/cache
The jars for the packages stored in: /home/hadoop/.ivy2/jars
org.apache.spark#spark-streaming-kafka-0-10_2.12 added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-5063ef7d-38d8-442b-bc98-ea87161dc6ae;1.0
confs: [default]
found org.apache.spark#spark-streaming-kafka-0-10_2.12;3.3.0 in central
found org.apache.spark#spark-token-provider-kafka-0-10_2.12;3.3.0 in central
found org.apache.kafka#kafka-clients;2.8.1 in central
found org.lz4#lz4-java;1.8.0 in central
found org.xerial.snappy#snappy-java;1.1.8.4 in central
found org.slf4j#slf4j-api;1.7.32 in central
found org.apache.hadoop#hadoop-client-runtime;3.3.2 in central
found org.spark-project.spark#unused;1.0.0 in central
found org.apache.hadoop#hadoop-client-api;3.3.2 in central
found commons-logging#commons-logging;1.1.3 in central
found com.google.code.findbugs#jsr305;3.0.0 in central
:: resolution report :: resolve 466ms :: artifacts dl 15ms
:: modules in use:
com.google.code.findbugs#jsr305;3.0.0 from central in [default]
commons-logging#commons-logging;1.1.3 from central in [default]
org.apache.hadoop#hadoop-client-api;3.3.2 from central in [default]
org.apache.hadoop#hadoop-client-runtime;3.3.2 from central in [default]
org.apache.kafka#kafka-clients;2.8.1 from central in [default]
org.apache.spark#spark-streaming-kafka-0-10_2.12;3.3.0 from central in [default]
org.apache.spark#spark-token-provider-kafka-0-10_2.12;3.3.0 from central in [default]
org.lz4#lz4-java;1.8.0 from central in [default]
org.slf4j#slf4j-api;1.7.32 from central in [default]
org.spark-project.spark#unused;1.0.0 from central in [default]
org.xerial.snappy#snappy-java;1.1.8.4 from central in [default]
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 11 | 0 | 0 | 0 || 11 | 0 |
---------------------------------------------------------------------
:: retrieving :: org.apache.spark#spark-submit-parent-5063ef7d-38d8-442b-bc98-ea87161dc6ae
confs: [default]
0 artifacts copied, 11 already retrieved (0kB/9ms)
import module........
23/01/12 05:31:15 INFO SparkContext: Running Spark version 3.3.0-amzn-0
23/01/12 05:31:15 INFO ResourceUtils: ==============================================================
23/01/12 05:31:15 INFO ResourceUtils: No custom resources configured for spark.driver.
23/01/12 05:31:15 INFO ResourceUtils: ==============================================================
23/01/12 05:31:15 INFO SparkContext: Submitted application: clustering on COR
23/01/12 05:31:15 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores,
23/01/12 05:31:15 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); groups with view permissions: Set(); users with modify permissions: Set(hadoop); groups with modify permissions: Set()
23/01/12 05:31:16 INFO Utils: Successfully started service 'sparkDriver' on port 46779.
23/01/12 05:31:16 INFO SparkEnv: Registering MapOutputTracker
23/01/12 05:31:16 INFO SparkEnv: Registering BlockManagerMaster
23/01/12 05:31:16 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
23/01/12 05:31:16 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
23/01/12 05:31:16 INFO SparkEnv: Registering BlockManagerMasterHeartbeat
23/01/12 05:31:16 INFO DiskBlockManager: Created local directory at /mnt/tmp/blockmgr-f4403214-599d-49b0-bba0-fd2136128568
23/01/12 05:31.compute.internal/10.224.51.200:8032
23/01/12 05:31:17 INFO Configuration: resource-types.xml not found
23/01/12 05:31:17 INFO ResourceUtils: Unable to find 'resource-types.xml'.
23/01/12 05:31:17 INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster (12288 MB per container)
23/01/12 05:31:17 INFO Client: Will allocate AM container, with 896 MB memory including 384 MB overhead
23/01/12 05:31:17 INFO Client: Setting up container launch context for our AM
23/01/12 05:31:17 INFO Client: Setting up the launch environment for our AM container
23/01/12 05:31:17 INFO Client: Preparing resources for our AM container
23/01/12 05:31:17 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
23/01/12 05:31:20 INFO Client: Uploading resource file:/mnt/tmp/spark-76ce116e-57b6-4ab0-9b19-40220d2d67c3/__spark_libs__4646235866736797652.zip -> hdfs://ip-10-224-51-200.ap-south-1.compute.internal:8020/user/hadoop/.sparkStaging/application_1671433588099_0213/__spark_libs__4646235866736797652.zip
23/01/12 05:31:21 INFO Client: Uploading resource file:/usr/lib/hudi/hudi-spark3.3-bundle_2.12-0.11.1-amzn-0.jar -> hdfs://ip-10-224-51-200.ap-south-1.compute.internal:8020/user/hadoop/.sparkStaging/application_1671433588099_0213/hudi-spark3.3-bundle_2.12-0.11.1-amzn-0.jar
23/01/12 05:31:21 INFO Client: Uploading resource file:/home/hadoop/.ivy2/jars/org.apache.spark_spark-streaming-kafka-0-10_2.12-3.3.0.jar -> hdfs://ip-10-224-51-200.ap-south-1.compute.internal:8020/user/hadoop/.sparkStaging/application_1671433588099_0213/org.apache.spark_spark-streaming-kafka-0-10_2.12-3.3.0.jar
23/01/12 05:31:21 INFO Client: Uploading resource file:/home/hadoop/.ivy2/jars/org.apache.hadoop_hadoop-client-runtime-3.3.2.jar -> hdfs://ip-10-224-51-200.ap-south-1.compute.internal:8020/user/hadoop/.sparkStaging/application_1671433588099_0213/org.apache.hadoop_hadoop-client-runtime-3.3.2.jar
23/01/12 05:31:21 INFO Client: Uploading resource file:/home/hadoop/.ivy2/jars/org.lz4_lz4-java-1.8.0.jar -> hdfs://ip-10-224-51-200.ap-south-1.compute.internal:8020/user/hadoop/.sparkStaging/application_1671433588099_0213/org.lz4_lz4-java-1.8.0.jar
23/01/12 05:31:21 INFO Client: Uploading resource file:/home/hadoop/.ivy2/jars/org.xerial.snappy_snappy-java-1.1.8.4.jar -> hdfs://ip-10-224-51-200.ap-south-
23/01/12 05:31:21 INFO Client: Uploading resource file:/mnt/tmp/spark-76ce116e-57b6-4ab0-9b19-40220d2d67c3/__spark_conf__2936504612168698213.zip -> hdfs://ip-10-224-51-200.ap-south-1.compute.internal:8020/user/hadoop/.sparkStaging/application_1671433588099_0213/__spark_conf__.zip
23/01/12 05:31:21 INFO SecurityManager: Changing view acls to: hadoop
23/01/12 05:31:21 INFO SecurityManager: Changing modify acls to: hadoop
23/01/12 05:31:21 INFO SecurityManager: Changing view acls groups to:
23/01/12 05:31:21 INFO SecurityManager: Changing modify acls groups to:
23/01/12 05:31:21 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); groups with view permissions: Set(); users with modify permissions: Set(hadoop); groups with modify permissions: Set()
23/01/12 05:31:21 INFO Client: Submitting application application_1671433588099_0213 to ResourceManager
23/01/12 05:31:21 INFO YarnClientImpl: Submitted application application_1671433588099_0213
23/01/12 05:31:22 INFO Client: Application report for application_1671433588099_0213 (state: ACCEPTED)
23/01/12 05:31:22 INFO Client:
client token: N/A
diagnostics: AM container is launched, waiting for AM container to Register with RM
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1673501481664
final status: UNDEFINED
tracking URL: http://ip-10-224-51-200.ap-south-1.compute.internal:20888/proxy/application_1671433588099_0213/
user: hadoop
23/01/12 05:31:23 INFO Client: Application report for application_1671433588099_0213 (state: ACCEPTED)
23/01/12 05:31:26 INFO SingleEventLogFileWriter: Logging events to hdfs:/var/log/spark/apps/application_1671433588099_0213.inprogress
23/01/12 05:31:27 INFO Utils: Using 50 preallocated executors (minExecutors: 0). Set spark.dynamicAllocation.preallocateExecutors to `false` disable executor preallocation.
23/01/12 05:31:27 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Attempted to request executors before the AM has registered!
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /jobs: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /jobs/json: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /jobs/job: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /jobs/job/json: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /stages: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /stages/json: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /stages/stage: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /stages/stage/json: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /stages/pool: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /stages/pool/json: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /storage: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /storage/json: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /storage/rdd: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /storage/rdd/json: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /environment: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /environment/json: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /executors: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /executors/json: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /executors/threadDump: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /executors/thr
23/01/12 05:31:27 INFO ServerInfo: Adding filter to /metrics/json: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
23/01/12 05:31:27 INFO YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0
23/01/12 05:31:27 INFO YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(spark-client://YarnAM)
access key and secret key is done
/usr/lib/spark/python/lib/pyspark.zip/pyspark/sql/context.py:114: FutureWarning: Deprecated in 3.0.0. Use SparkSession.builder.getOrCreate() instead.
spark is <pyspark.sql.session.SparkSession object at 0x7f3c169f0750> and spark-context is <SparkContext master=yarn appName=clustering on COR>
============================================
import of spark session is done !!!!
============================================
23/01/12 05:31:27 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir.
23/01/12 05:31:27 INFO SharedState: Warehouse path is 'hdfs://ip- Found configuration file file:/etc/spark/conf.dist/hive-site.xml
23/01/12 05:31:31 WARN HiveConf: HiveConf of name hive.server2.thrift.url does not exist
23/01/12 05:31:31 INFO HiveClientImpl: Warehouse location for Hive client (version 2.3.9) is hdfs://ip-10-224-51-200.ap-south-1.compute.internal:8020/user/spark/warehouse
23/01/12 05:31:31 INFO metastore: Trying to connect to metastore with URI thrift://ip-10-224-51-200.ap-south-1.compute.internal:9083
23/01/12 05:31:31 INFO metastore: Opened a connection to metastore, current connections: 1
23/01/12 05:31:31 INFO metastore: Connected to metastore.
23/01/12 05:31:32 INFO ClientConfigurationFactory: Set initial getObject socket timeout to 2000 ms.
23/01/12 05:31:33 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (10.224.51.220:51532) with ID 1, ResourceProfileId 0
23/01/12 05:31:33 INFO ExecutorMonitor: New executor 1 has registered (new total is 2)
23/01/12 05:31:33 INFO BlockManagerMasterEndpoint: Registering block manager ip-10-224-51-220.ap-south-1.compute.internal:38397 with 4.8 GiB RAM, BlockManagerId(1, ip-10-224-51-220.ap-south-1.compute.internal, 38397, None)
23/01/12 05:31:33 INFO S3NativeFileSystem: Opening 's3://test-spark-hudi/clustering_mor/.hoodie/hoodie.properties' for reading
23/01/12 05:31:34 INFO S3NativeFileSystem: Opening 's3://test-spark-hudi/clustering_mor/.hoodie/20230109092536279.deltacommit' for reading
23/01/12 05:31:34 INFO S3NativeFileSystem: Opening 's3://test-spark-hudi/clustering_mor/.hoodie/20230109092536279.deltacommit' for reading
23/01/12 05:31:34 INFO S3NativeFileSystem: Opening 's3://test-spark-hudi/clustering_mor/campaign_id=350/.fe1ae9e1-f3b1-463d-920d-c58d12231cec-0_20230109092436558.log.1_0-24-28' for reading
23/01/12 05:31:35 INFO CodeGenerator: Code generated in 226.844628 ms
23/01/12 05:31:35 INFO CodeGenerator: Code generated in 8.402992 ms
23/01/12 05:31:35 INFO CodeGenerator: Code generated in 16.767879 ms
23/01/12 05:31:35 INFO SparkContext: Starting job: showString at NativeMethodAc
23/01/12 05:31:35 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 7.8 KiB, free 912.3 MiB)
23/01/12 05:31:35 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 3.9 KiB, free 912.3 MiB)
23/01/12 05:31:35 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on ip-10-224-51-200.ap-south-1.compute.internal:44241 (size: 3.9 KiB, free: 912.3 MiB)
23/01/12 05:31:35 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1570
23/01/12 05:31:35 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 0 (MapPartitionsRDD[2] at showString at NativeMethodAccessorImpl.java:0) (first 15 tasks are
23/01/12 05:31:37 INFO DAGScheduler: ResultStage 0 (showString at NativeMethodAccessorImpl.java:0) finished in 2.106 s
23/01/12 05:31:37 INFO DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job
23/01/12 05:31:37 INFO YarnScheduler: Killing all running tasks in stage 0: Stage finished
23/01/12 05:31:37 INFO DAGScheduler: Job 0 finished: showString at NativeMethodAccessorImpl.java:0, took 2.171787 s
23/01/12 05:31:37 INFO CodeGenerator: Code generated in 11.952856 ms
########################
# Default Database details #
########################
+---------+--------------+-----------+
|namespace| tableName|isTemporary|
+---------+--------------+-----------+
| |clustering_mor| false|
+---------+--------------+-----------+
2 None
=========================
23/01/12 05:31:38 INFO CodeGenerator: Code generated in 29.306587 ms
23/01/12 05:31:38 INFO CodeGenerator: Code generated in 11.81622 ms
23/01/12 05:31:38 INFO SparkContext: Starting job: hasNext at NativeMethodAccessorImpl.java:0
23/01/12 05:31:38 INFO DAGScheduler: Got job 1 (hasNext at NativeMethodAccessorImpl.java:0) with 1 output partitions
23/01/12 05:31:38 INFO DAGScheduler: Final stage: ResultStage 1 (hasNext at NativeMethodAccessorImpl.java:0)
23/01/12 05:31:38 INFO DAGScheduler: Parents of final stage: List()
23/01/12 05:31:38 INFO DAGScheduler: Missing parents: List()
23/01/12 05:31:38 INFO DAGScheduler: Submitting ResultStage 1 (MapPartitionsRDD[6] at toLocalIterator at NativeMethodAccessorImpl.java:0), which has no missing parents
23/01/12 05:31:38 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 5.5 KiB, free 912.3 MiB)
23/01/12 05:31:38 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.9 KiB, free 912.3 MiB)
23/01/12 05:31:38 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on ip-10-224-51-200.ap-south-1.compute.internal:44241 (size: 2.9 KiB, free: 912.3 MiB)
23/01/12 05:31:38 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1570
23/01/12 05:31:38 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[6] at toLocalIterator at NativeMethodAccessorImpl.java:0) (first 15 tasks are for partitions Vector(0))
23/01/12 05:31:38 INFO YarnScheduler: Adding task set 1.0 with 1 tasks resource profile 0
23/01/12 05:31:38 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1) (ip-10-224-50-165.ap-south-1.compute.internal, executor 2, partition 0, PROCESS_LOCAL, 4519 bytes) taskResourceAssignments Map()
23/01/12 05:31:38 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on ip-10-224-50-165.ap-south-1.compute.internal:38209 (size: 2.9 KiB, free: 4.8 GiB)
23/01/12 05:31:38 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 39 ms on ip-10-224-50-165.ap-south-1.compute.internal (executor 2) (1/1)
23/01/12 05:31:38 INFO YarnScheduler: Removed TaskSet 1.0, whose tasks have all completed, from pool
23/01/12 05:31:38 INFO DAGScheduler: ResultStage 1 (hasNext at NativeMethodAccessorImpl.java:0) finished in 0.052 s
23/01/12 05:31:38 INFO DAGScheduler: Job 1 is finished. Cancelling potential speculative or zombie tasks for this job
23/01/12 05:31:38 INFO YarnScheduler: Killing all running tasks in stage 1: Stage finished
23/01/12 05:31:38 INFO DAGScheduler: Job 1 finished: hasNext at NativeMethodAccessorImpl.java:0, took 0.060118 s
23/01/12 05:31:38 INFO CodeGenerator: Code generated in 16.381346 ms
==================================================================================================
[Table(name='clustering_mor', database=None, description=None, tableType='TEMPORARY', isTemporary=True)]
==================================================================================================
23/01/12 05:31:38 INFO SparkContext: Starting job: collect at HoodieSparkEngineContext.java:103
23/01/12 05:31:38 INFO DAGScheduler: Got job 2 (collect at HoodieSparkEngineContext.java:103) with 1 output partitions
23/01/12 05:31:38 INFO DAGScheduler: Final stage: ResultStage 2 (collect at HoodieSparkEngineContext.java:103)
23/01/12 05:31:38 INFO DAGScheduler: Parents of final stage: List()
23/01/12 05:31:38 INFO DAGScheduler: Missing parents: List()
23/01/12 05:31:38 INFO DAGScheduler: Submitting ResultStage 2 (MapPartitionsRDD[8] at map at HoodieSparkEngineContext.java:103), which has no missing parents
23/01/12 05:31:38 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 96.9 KiB, free 912.2 MiB)
23/01/12 05:31:38 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 35.8 KiB, free 912.2 MiB)
23/01/12 05:31:38 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on ip-10-224-51-200.ap-south-1.compute.internal:44241 (size: 35.8 KiB, free: 912.3 MiB)
23/01/12 05:31:38 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1570
23/01/12 05:31:38 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 2 (MapPartitionsRDD[8] at map at HoodieSparkEngineContext.java:103) (first 15 tasks are for partitions Vector(0))
23/01/12 05:31:38 INFO YarnScheduler: Adding task set 2.0 with 1 tasks resource profile 0
23/01/12 05:31:38 INFO TaskSetManager: Starting task 0.0 in stage 2.0 (TID 2) (ip-10-224-51-220.ap-south-1.compute.internal, executor 1, partition 0, PROCESS_LOCAL, 4405 bytes) taskResourceAssignments Map()
23/01/12 05:31:39 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on ip-10-224-51-220.ap-south-1.compute.internal:38397 (size: 35.8 KiB, free: 4.8 GiB)
23/01/12 05:31:40 INFO TaskSetManager: Finished task 0.0 in stage 2.0 (TID 2) in 1904 ms on ip-10-224-51-220.ap-south-1.compute.internal (executor 1) (1/1)
23/01/12 05:31:40 INFO YarnScheduler: Removed TaskSet 2.0, whose tasks have all completed, from pool
23/01/12 05:31:40 INFO DAGScheduler: ResultStage 2 (collect at HoodieSparkEngineContext.java:103) finished in 1.922 s
23/01/12 05:31:40 INFO DAGScheduler: Job 2 is finished. Cancelling potential speculative or zombie tasks for this job
23/01/12 05:31:40 INFO YarnScheduler: Killing all running tasks in stage 2: Stage finished
23/01/12 05:31:40 INFO DAGScheduler: Job 2 finished: collect at HoodieSparkEngineContext.java:103, took 1.927174 s
23/01/12 05:31:40 INFO SparkContext: Starting job: collect at HoodieSparkEngineContext.java:103
23/01/12 05:31:40 INFO DAGScheduler: Got job 3 (collect at HoodieSparkEngineContext.java:103) with 1 output partitions
23/01/12 05:31:40 INFO DAGScheduler: Final stage: ResultStage 3 (collect at HoodieSparkEngineContext.java:103)
23/01/12 05:31:40 INFO DAGScheduler: Parents of final stage: List()
23/01/12 05:31:40 INFO DAGScheduler: Missing parents: List()
23/01/12 05:31:40 INFO DAGScheduler: Submitting ResultStage 3 (MapPartitionsRDD[10] at map at HoodieSparkEngineContext.java:103), which has no missing parents
23/01/12 05:31:40 INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 96.9 KiB, free 912.1 MiB)
23/01/12 05:31:40 INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 35.8 KiB, free 912.0 MiB)
23/01/12 05:31:40 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on ip-10-224-51-200.ap-south-1.compute.internal:44241 (size: 35.8 KiB, free: 912.2 MiB)
23/01/12 05:31:40 INFO SparkContext: Created broadcast 3 from broadcast at DAGScheduler.scala:1570
23/01/12 05:31:40 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 3 (MapPartitionsRDD[10] at map at HoodieSparkEngineContext.java:103) (first 15 tasks are for partitions Vector(0))
23/01/12 05:31:40 INFO YarnScheduler: Adding task set 3.0 with 1 tasks resource profile 0
23/01/12 05:31:40 INFO TaskSetManager: Starting task 0.0 in stage 3.0 (TID 3) (ip-10-224-50-165.ap-south-1.compute.internal, executor 2, partition 0, PROCESS_LOCAL, 4421 bytes) taskResourceAssignments Map()
23/01/12 05:31:40 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on ip-10-224-50-165.ap-south-1.compute.internal:38209 (size: 35.8 KiB, free: 4.8 GiB)
23/01/12 05:31:41 INFO TaskSetManager: Finished task 0.0 in stage 3.0 (TID 3) in 952 ms on ip-10-224-50-165.ap-south-1.compute.internal (executor 2) (1/1)
23/01/12 05:31:41 INFO DAGScheduler: ResultStage 3 (collect at HoodieSparkEngineContext.java:103) finished in 0.970 s
23/01/12 05:31:41 INFO DAGScheduler: Job 3 is finished. Cancelling potential speculative or zombie tasks for this job
23/01/12 05:31:41 INFO YarnScheduler: Removed TaskSet 3.0, whose tasks have all completed, from pool
23/01/12 05:31:41 INFO YarnScheduler: Killing all running tasks in stage 3: Stage finished
23/01/12 05:31:41 INFO DAGScheduler: Job 3 finished: collect at HoodieSparkEngineContext.java:103, took 0.977347 s
23/01/12 05:31:41 INFO SparkContext: Starting job: collect at HoodieSparkEngineContext.java:103
23/01/12 05:31:41 INFO DAGScheduler: Got job 4 (collect at HoodieSparkEngineContext.java:103) with 1 output partitions
23/01/12 05:31:41 INFO DAGScheduler: Final stage: ResultStage 4 (collect at HoodieSparkEngineContext.java:103)
23/01/12 05:31:41 INFO DAGScheduler: Parents of final stage: List()
23/01/12 05:31:41 INFO DAGScheduler: Missing parents: List()
23/01/12 05:31:41 INFO DAGScheduler: Submitting ResultStage 4 (MapPartitionsRDD[12] at map at HoodieSparkEngineContext.java:103), which has no missing parents
23/01/12 05:31:41 INFO MemoryStore: Block broadcast_4 stored as values in memory (estimated size 96.9 KiB, free 911.9 MiB)
23/01/12 05:31:41 INFO MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 35.8 KiB, free 911.9 MiB)
23/01/12 05:31:41 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on ip-10-224-51-200.ap-south-1.compute.internal:44241 (size: 35.8 KiB, free: 912.2 MiB)
23/01/12 05:31:41 INFO SparkContext: Created broadcast 4 from broadcast at DAGScheduler.scala:1570
23/01/12 05:31:41 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 4 (MapPartitionsRDD[12] at map at HoodieSparkEngineContext.java:103) (first 15 tasks are for partitions Vector(0))
23/01/12 05:31:41 INFO YarnScheduler: Adding task set 4.0 with 1 tasks resource profile 0
23/01/12 05:31:41 INFO TaskSetManager: Starting task 0.0 in stage 4.0 (TID 4) (ip-10-224-50-165.ap-south-1.compute.internal, executor 2, partition 0, PROCESS_LOCAL, 4394 bytes) taskResourceAssignments Map()
23/01/12 05:31:41 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on ip-10-224-50-165.ap-south-1.compute.internal:38209 (size: 35.8 KiB, free: 4.8 GiB)
23/01/12 05:31:41 INFO TaskSetManager: Finished task 0.0 in stage 4.0 (TID 4) in 101 ms on ip-10-224-50-165.ap-south-1.compute.internal (executor 2) (1/1)
23/01/12 05:31:41 INFO YarnScheduler: Removed TaskSet 4.0, whose tasks have all completed, from pool
23/01/12 05:31:41 INFO DAGScheduler: ResultStage 4 (collect at HoodieSparkEngineContext.java:103) finished in 0.118 s
23/01/12 05:31:41 INFO DAGScheduler: Job 4 is finished. Cancelling potential speculative or zombie tasks for this job
23/01/12 05:31:41 INFO YarnScheduler: Killing all running tasks in stage 4: Stage finished
23/01/12 05:31:41 INFO DAGScheduler: Job 4 finished: collect at HoodieSparkEngineContext.java:103, took 0.124767 s
23/01/12 05:31:41 INFO S3NativeFileSystem: Opening 's3://test-spark-hudi/clustering_mor/.hoodie/20230109084319407.replacecommit' for reading
23/01/12 05:31:41 INFO S3NativeFileSystem: Opening 's3://test-spark-hudi/clustering_mor/.hoodie/20230109090044937.replacecommit' for reading
23/01/12 05:31:41 INFO S3NativeFileSystem: Opening 's3://test-spark-hudi/clustering_mor/.hoodie/20230109092436558.replacecommit' for reading
23/01/12 05:31:42 INFO MemoryStore: Block broadcast_5 stored as values in memory (estimated size 347.4 KiB, free 911.6 MiB)
23/01/12 05:31:42 INFO MemoryStore: Block broadcast_5_piece0 stored as bytes in memory (estimated size 33.0 KiB, free 911.5 MiB)
23/01/12 05:31:42 INFO BlockManagerInfo: Added broadcast_5_piece0 in memory on ip-10-224-51-200.ap-south-1.compute.internal:44241 (size: 33.0 KiB, free: 912.2 MiB)
23/01/12 05:31:42 INFO SparkContext: Created broadcast 5 from broadcast at HoodieBaseRelation.scala:539
23/01/12 05:31:42 INFO MemoryStore: Block broadcast_6 stored as values in memory (estimated size 355.1 KiB, free 911.2 MiB)
23/01/12 05:31:42 INFO MemoryStore: Block broadcast_6_piece0 stored as bytes in memory (estimated size 33.9 KiB, free 911.1 MiB)
23/01/12 05:31:42 INFO BlockManagerInfo: Added broadcast_6_piece0 in memory on ip-10-224-51-200.ap-south-1.compute.internal:44241 (size: 33.9 KiB, free: 912.1 MiB)
23/01/12 05:31:42 INFO SparkContext: Created broadcast 6 from buildReaderWithPartitionValues at HoodieDataSourceHelper.scala:61
23/01/12 05:31:42 INFO MemoryStore: Block broadcast_7 stored as values in memory (estimated size 347.4 KiB, free 910.8 MiB)
23/01/12 05:31:42 INFO MemoryStore: Block broadcast_7_piece0 stored as bytes in memory (estimated size 33.0 KiB, free 910.8 MiB)
23/01/12 05:31:42 INFO BlockManagerInfo: Added broadcast_7_piece0 in memory on ip-10-224-51-200.ap-south-1.compute.internal:44241 (size: 33.0 KiB, free: 912.1 MiB)
23/01/12 05:31:42 INFO SparkContext: Created broadcast 7 from broadcast at HoodieBaseRelation.scala:539
23/01/12 05:31:42 INFO MemoryStore: Block broadcast_8 stored as values in memory (estimated size 355.1 KiB, free 910.4 MiB)
23/01/12 05:31:42 INFO MemoryStore: Block broadcast_8_piece0 stored as bytes in memory (estimated size 33.9 KiB, free 910.4 MiB)
23/01/12 05:31:42 INFO BlockManagerInfo: Added broadcast_8_piece0 in memory on ip-10-224-51-200.ap-south-1.compute.internal:44241 (size: 33.9 KiB, free: 912.1 MiB)
23/01/12 05:31:42 INFO SparkContext: Created broadcast 8 from buildReaderWithPartitionValues at HoodieDataSourceHelper.scala:61
23/01/12 05:31:42 INFO MemoryStore: Block broadcast_9 stored as values in memory (estimated size 347.5 KiB, free 910.0 MiB)
23/01/12 05:31:42 INFO MemoryStore: Block broadcast_9_piece0 stored as bytes in memory (estimated size 33.0 KiB, free 910.0 MiB)
23/01/12 05:31:42 INFO BlockManagerInfo: Added broadcast_9_piece0 in memory on ip-10-224-51-200.ap-south-1.compute.internal:44241 (size: 33.0 KiB, free: 912.0 MiB)
23/01/12 05:31:42 INFO SparkContext: Created broadcast 9 from broadcast at HoodieMergeOnReadRDD.scala:71
23/01/12 05:31:42 INFO CodeGenerator: Code generated in 17.905044 ms
23/01/12 05:31:42 INFO SparkContext: Starting job: showString at NativeMethodAccessorImpl.java:0
23/01/12 05:31:42 INFO DAGScheduler: Got job 5 (showString at NativeMethodAccessorImpl.java:0) with 1 output partitions
23/01/12 05:31:42 INFO DAGScheduler: Final stage: ResultStage 5 (showString at NativeMethodAccessorImpl.java:0)
23/01/12 05:31:42 INFO DAGScheduler: Parents of final stage: List()
23/01/12 05:31:42 INFO DAGScheduler: Missing parents: List()
23/01/12 05:31:42 INFO DAGScheduler: Submitting ResultStage 5 (MapPartitionsRDD[15] at showString at NativeMethodAccessorImpl.java:0), which has no missing parents
23/01/12 05:31:42 INFO MemoryStore: Block broadcast_10 stored as values in memory (estimated size 20.7 KiB, free 910.0 MiB)
23/01/12 05:31:42 INFO MemoryStore: Block broadcast_10_piece0 stored as bytes in memory (estimated size 8.4 KiB, free 910.0 MiB)
23/01/12 05:31:42 INFO BlockManagerInfo: Added broadcast_10_piece0 in memory on ip-10-224-51-200.ap-south-1.compute.internal:44241 (size: 8.4 KiB, free: 912.0 MiB)
23/01/12 05:31:42 INFO SparkContext: Created broadcast 10 from broadcast at DAGScheduler.scala:1570
23/01/12 05:31:42 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 5 (MapPartitionsRDD[15] at showString at NativeMethodAccessorImpl.java:0) (first 15 tasks are for partitions Vector(0))
23/01/12 05:31:42 INFO YarnScheduler: Adding task set 5.0 with 1 tasks resource profile 0
23/01/12 05:31:42 INFO TaskSetManager: Starting task 0.0 in stage 5.0 (TID 5) (ip-10-224-51-220.ap-south-1.compute.internal, executor 1, partition 0, PROCESS_LOCAL, 5479 bytes) taskResourceAssignments Map()
23/01/12 05:31:42 INFO BlockManagerInfo: Added broadcast_10_piece0 in memory on ip-10-224-51-220.ap-south-1.compute.internal:38397 (size: 8.4 KiB, free: 4.8 GiB)
23/01/12 05:31:42 INFO BlockManagerInfo: Added broadcast_8_piece0 in memory on ip-10-224-51-220.ap-south-1.compute.internal:38397 (size: 33.9 KiB, free: 4.8 GiB)
23/01/12 05:31:43 INFO BlockManagerInfo: Added broadcast_9_piece0 in memory on ip-10-224-51-220.ap-south-1.compute.internal:38397 (size: 33.0 KiB, free: 4.8 GiB)
23/01/12 05:31:44 INFO TaskSetManager: Finished task 0.0 in stage 5.0 (TID 5) in 2598 ms on ip-10-224-51-220.ap-south-1.compute.internal (executor 1) (1/1)
23/01/12 05:31:44 INFO YarnScheduler: Removed TaskSet 5.0, whose tasks have all completed, from pool
23/01/12 05:31:44 INFO DAGScheduler: ResultStage 5 (showString at NativeMethodAccessorImpl.java:0) finished in 2.659 s
23/01/12 05:31:44 INFO DAGScheduler: Job 5 is finished. Cancelling potential speculative or zombie tasks for this job
23/01/12 05:31:44 INFO YarnScheduler: Killing all running tasks in stage 5: Stage finished
23/01/12 05:31:44 INFO DAGScheduler: Job 5 finished: showString at NativeMethodAccessorImpl.java:0, took 2.666745 s
23/01/12 05:31:44 INFO CodeGenerator: Code generated in 22.199602 ms
+-------------------+--------------------+--------------------+----------------------+--------------------+-----------+----------+--------------------+--------------------+-----------+--------+--------------------+-------------------+
|_hoodie_commit_time|_hoodie_commit_seqno| _hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|campaign_id| client_id| created_by| created_date|event_count|event_id| updated_by| updated_date|
+-------------------+--------------------+--------------------+----------------------+--------------------+-----------+----------+--------------------+--------------------+-----------+--------+--------------------+-------------------+
| 20230109092536279|20230109092536279...|campaign_id:350,e...| campaign_id=350|fe1ae9e1-f3b1-463...| 350|cl-WJxiIuA|Campaign_Event_Su...|2022-09-12T13:54:...| 79| 2|Campaign_Event_Su...|2023-01-09T09:25:24|
+-------------------+--------------------+--------------------+----------------------+--------------------+-----------+----------+--------------------+--------------------+-----------+--------+--------------------+-------------------+
None
Traceback (most recent call last):
==================================================================================================
File "/home/hadoop/mg/spark_savepoint.py", line 49, in <module>
print(spark.sql("""call show_savepoints(table =>'clustering_mor')""").show())
File "/usr/lib/spark/python/lib/pyspark.zip/pyspark/sql/session.py", line 1034, in sql
File "/usr/lib/spark/python/lib/py4j-0.10.9.5-src.zip/py4j/java_gateway.py", line 1322, in __call__
File "/usr/lib/spark/python/lib/pyspark.zip/pyspark/sql/utils.py", line 196, in deco
pyspark.sql.utils.AnalysisException: Table or view 'clustering_mor' not found in database 'default'
==================================================================================================
23/01/12 05:31:45 INFO SparkContext: Invoking stop() from shutdown hook
23/01/12 05:31:45 INFO SparkUI: Stopped Spark web UI at http://ip-10-224-51-200.ap-south-1.compute.internal:4040
23/01/12 05:31:45 INFO YarnClientSchedulerBackend: Interrupting monitor thread
23/01/12 05:31:45 INFO YarnClientSchedulerBackend: Shutting down all executors
23/01/12 05:31:45 INFO YarnSchedulerBackend$YarnDriverEndpoint: Asking each executor to shut down
23/01/12 05:31:45 INFO YarnClientSchedulerBackend: YARN client scheduler backend Stopped
23/01/12 05:31:45 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
23/01/12 05:31:45 INFO MemoryStore: MemoryStore cleared
23/01/12 05:31:45 INFO BlockManager: BlockManager stopped
23/01/12 05:31:45 INFO BlockManagerMaster: BlockManagerMaster stopped
23/01/12 05:31:45 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
23/01/12 05:31:45 INFO SparkContext: Successfully stopped SparkContext
23/01/12 05:31:45 INFO ShutdownHookManager: Shutdown hook called
23/01/12 05:31:45 INFO ShutdownHookManager: Deleting directory /mnt/tmp/spark-76ce116e-57b6-4ab0-9b19-40220d2d67c3/pyspark-eb511084-1773-46e9-ac13-379513b577b7
23/01/12 05:31:45 INFO ShutdownHookManager: Deleting directory /mnt/tmp/spark-017294b5-55c6-47d6-a065-c8d3066d7ddb
23/01/12 05:31:45 INFO ShutdownHookManager: Deleting directory /mnt/tmp/spark-76ce116e-57b6-4ab0-9b19-40220d2d67c3
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yihua commented on issue #7589: [Support] Keep only clustered file(all) after cleaning
Posted by "yihua (via GitHub)" <gi...@apache.org>.
yihua commented on issue #7589:
URL: https://github.com/apache/hudi/issues/7589#issuecomment-1480379081
Hi @maheshguptags, sorry for the late reply. I put up a PR to support the savepoint call procedure with the base path of the Hudi table: #8271. I tested them locally and they work. Could you try it on your end to see if it solves your problem?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org