You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@systemml.apache.org by ac...@apache.org on 2017/05/12 08:12:27 UTC
incubator-systemml git commit: [SYSTEMML-1606] Update notebook
samples with latest code
Repository: incubator-systemml
Updated Branches:
refs/heads/master a27663946 -> 7fe372b9a
[SYSTEMML-1606] Update notebook samples with latest code
Project: http://git-wip-us.apache.org/repos/asf/incubator-systemml/repo
Commit: http://git-wip-us.apache.org/repos/asf/incubator-systemml/commit/7fe372b9
Tree: http://git-wip-us.apache.org/repos/asf/incubator-systemml/tree/7fe372b9
Diff: http://git-wip-us.apache.org/repos/asf/incubator-systemml/diff/7fe372b9
Branch: refs/heads/master
Commit: 7fe372b9adcb91d6ac5fb22646f33e488d29cf2a
Parents: a276639
Author: Arvind Surve <ac...@yahoo.com>
Authored: Fri May 12 01:11:51 2017 -0700
Committer: Arvind Surve <ac...@yahoo.com>
Committed: Fri May 12 01:11:51 2017 -0700
----------------------------------------------------------------------
.../Deep Learning Image Classification.ipynb | 489 -------------------
.../Deep_Learning_Image_Classification.ipynb | 406 +++++++++++++++
2 files changed, 406 insertions(+), 489 deletions(-)
----------------------------------------------------------------------
http://git-wip-us.apache.org/repos/asf/incubator-systemml/blob/7fe372b9/samples/jupyter-notebooks/Deep Learning Image Classification.ipynb
----------------------------------------------------------------------
diff --git a/samples/jupyter-notebooks/Deep Learning Image Classification.ipynb b/samples/jupyter-notebooks/Deep Learning Image Classification.ipynb
deleted file mode 100644
index eac20fd..0000000
--- a/samples/jupyter-notebooks/Deep Learning Image Classification.ipynb
+++ /dev/null
@@ -1,489 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "# Deep Learning Image Classification\n",
- "\n",
- "This notebook shows SystemML Deep Learning functionality to map images of single digit numbers to their corresponding numeric representations. See [Getting Started with Deep Learning and Python](http://www.pyimagesearch.com/2014/09/22/getting-started-deep-learning-python/) for an explanation of the used deep learning concepts and assumptions.\n",
- "\n",
- "The downloaded MNIST dataset contains labeled images of handwritten digits, where each example is a 28x28 pixel image of grayscale values in the range [0,255] stretched out as 784 pixels, and each label is one of 10 possible digits in [0,9]. We download 60,000 training examples, and 10,000 test examples, where the format is \"label, pixel_1, pixel_2, ..., pixel_n\". We train a SystemML LeNet model. The results of the learning algorithms have an accuracy of 98 percent.\n",
- "\n",
- "1. [Install and load SystemML and other libraries](#load_systemml)\n",
- "1. [Download and Access MNIST data](#access_data)\n",
- "1. [Train a CNN classifier for MNIST handwritten digits](#train)\n",
- "1. [Detect handwritten Digits](#predict)\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "collapsed": true
- },
- "source": [
- "<div style=\"text-align:center\" markdown=\"1\">\n",
- "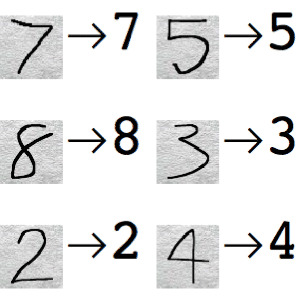\n",
- "Mapping images of numbers to numbers\n",
- "</div>"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "<a id=\"load_systemml\"></a>\n",
- "## Install and load SystemML and other libraries"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false,
- "scrolled": false
- },
- "outputs": [],
- "source": [
- "#!pip install --user systemml>0.13.0\n",
- "!pip install ~/git/incubator-systemml/target/systemml-0.15.0-incubating-SNAPSHOT-python.tgz"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false,
- "scrolled": false
- },
- "outputs": [],
- "source": [
- "!pip show systemml"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false,
- "scrolled": false
- },
- "outputs": [],
- "source": [
- "# Create symbolic link in ~/data/libs to use installed site-packages SystemML jar as opposed to DSX platform SystemML jar\n",
- "# !ln -s -f ~/.local/lib/python2.7/site-packages/systemml/systemml-java/*.jar ~/data/libs/"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false
- },
- "outputs": [],
- "source": [
- "from systemml import MLContext, dml\n",
- "\n",
- "ml = MLContext(sc)\n",
- "\n",
- "print \"Spark Version:\", sc.version\n",
- "print \"SystemML Version:\", ml.version()\n",
- "print \"SystemML Built-Time:\", ml.buildTime()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false
- },
- "outputs": [],
- "source": [
- "import warnings\n",
- "warnings.filterwarnings(\"ignore\")\n",
- "from sklearn import datasets\n",
- "from sklearn.cross_validation import train_test_split\n",
- "from sklearn.metrics import classification_report\n",
- "import pandas as pd\n",
- "import numpy as np\n",
- "import matplotlib.pyplot as plt\n",
- "#import matplotlib.image as mpimg\n",
- "%matplotlib inline"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "<a id=\"access_data\"></a>\n",
- "## Download and Access MNIST data\n",
- "\n",
- "Download the [MNIST data from the MLData repository](http://mldata.org/repository/data/viewslug/mnist-original/), and then split and save."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false,
- "scrolled": true
- },
- "outputs": [],
- "source": [
- "mnist = datasets.fetch_mldata(\"MNIST Original\")\n",
- "\n",
- "print \"Mnist data features:\", mnist.data.shape\n",
- "print \"Mnist data label:\", mnist.target.shape\n",
- "\n",
- "trainX, testX, trainY, testY = train_test_split(mnist.data, mnist.target.astype(\"int0\"), test_size = 0.142857)\n",
- "\n",
- "trainD = np.concatenate((trainY.reshape(trainY.size, 1), trainX),axis=1)\n",
- "testD = np.concatenate((testY.reshape (testY.size, 1), testX),axis=1)\n",
- "\n",
- "print \"Images for training:\", trainD.shape\n",
- "print \"Images used for testing:\", testD.shape\n",
- "pix = int(np.sqrt(trainD.shape[1]))\n",
- "print \"Each image is:\", pix, \"by\", pix, \"pixels\"\n",
- "\n",
- "np.savetxt('data/mnist/mnist_train.csv', trainD, fmt='%u', delimiter=\",\")\n",
- "np.savetxt('data/mnist/mnist_test.csv', testD, fmt='%u', delimiter=\",\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Alternatively get the data from here."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false,
- "scrolled": true
- },
- "outputs": [],
- "source": [
- "%%sh\n",
- "mkdir -p data/mnist/\n",
- "cd data/mnist/\n",
- "curl -O https://pjreddie.com/media/files/mnist_train.csv\n",
- "curl -O https://pjreddie.com/media/files/mnist_test.csv\n",
- "wc -l mnist*"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### Read the data."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false
- },
- "outputs": [],
- "source": [
- "trainData = np.genfromtxt('data/mnist/mnist_train.csv', delimiter=\",\")\n",
- "testData = np.genfromtxt('data/mnist/mnist_test.csv', delimiter=\",\")\n",
- "\n",
- "print \"Training data: \", trainData.shape\n",
- "print \"Test data: \", testData.shape"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false
- },
- "outputs": [],
- "source": [
- "pd.set_option('display.max_columns', 200)\n",
- "pd.DataFrame(testData[1:10,],dtype='uint')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "<a id=\"train\"></a>\n",
- "## Develop LeNet CNN classifier on Training Data"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "<div style=\"text-align:center\" markdown=\"1\">\n",
- "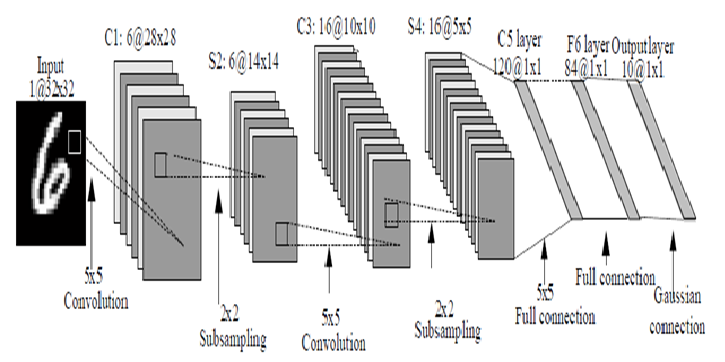\n",
- "MNIST digit recognition – LeNet architecture\n",
- "</div>"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### Download the SystemML LeNet Implementation"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false,
- "scrolled": false
- },
- "outputs": [],
- "source": [
- "!wget -N -q 'https://raw.githubusercontent.com/apache/incubator-systemml/master/scripts/staging/SystemML-NN/examples/mnist_lenet.dml'\n",
- "#!cat mnist_lenet.dml"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false,
- "scrolled": true
- },
- "outputs": [],
- "source": [
- "#import requests\n",
- "#get = requests.get('https://raw.githubusercontent.com/apache/incubator-systemml/master/scripts/staging/SystemML-NN/examples/mnist_lenet.dml')\n",
- "#mnist_lenet = get.text.replace(\"epochs = 10\", \"epochs = 1\")\n",
- "#with open('mnist_lenet.dml','wb') as out:\n",
- "# out.write(mnist_lenet)\n",
- "#print mnist_lenet "
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### Download SystemML neural network library"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": true
- },
- "outputs": [],
- "source": [
- "!svn --force export https://github.com/apache/incubator-systemml/trunk/scripts/staging/SystemML-NN/nn"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### Train Model using SystemML LeNet CNN."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "(on a Mac Book, this takes approx. 5-6 mins for 1 epoch)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false,
- "scrolled": true
- },
- "outputs": [],
- "source": [
- "script = \"\"\"\n",
- " source(\"mnist_lenet.dml\") as mnist_lenet\n",
- "\n",
- " # Bind training data\n",
- " n = nrow(data)\n",
- "\n",
- " # Extract images and labels\n",
- " images = data[,2:ncol(data)]\n",
- " labels = data[,1]\n",
- "\n",
- " # Scale images to [-1,1], and one-hot encode the labels\n",
- " images = (images / 255.0) * 2 - 1\n",
- " labels = table(seq(1, n), labels+1, n, 10)\n",
- "\n",
- " # Split into training (55,000 examples) and validation (5,000 examples)\n",
- " X = images[5001:nrow(images),]\n",
- " X_val = images[1:5000,]\n",
- " y = labels[5001:nrow(images),]\n",
- " y_val = labels[1:5000,]\n",
- "\n",
- " # Train the model using channel, height, and width to produce weights/biases.\n",
- " [W1, b1, W2, b2, W3, b3, W4, b4] = mnist_lenet::train(X, y, X_val, y_val, C, Hin, Win, epochs)\n",
- "\"\"\"\n",
- "rets = ('W1', 'b1','W2','b2','W3','b3','W4','b4')\n",
- "\n",
- "script = (dml(script).input(data=trainData, epochs=1, C=1, Hin=28, Win=28)\n",
- " .output(*rets)) \n",
- "\n",
- "W1, b1, W2, b2, W3, b3, W4, b4 = (ml.execute(script).get(*rets))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "collapsed": true
- },
- "source": [
- "Use trained model and predict on test data, and evaluate the quality of the predictions for each digit."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false
- },
- "outputs": [],
- "source": [
- "scriptPredict = \"\"\"\n",
- " source(\"mnist_lenet.dml\") as mnist_lenet\n",
- "\n",
- " # Separate images from lables and scale images to [-1,1]\n",
- " X_test = data[,2:ncol(data)]\n",
- " X_test = (X_test / 255.0) * 2 - 1\n",
- "\n",
- " # Predict\n",
- " probs = mnist_lenet::predict(X_test, C, Hin, Win, W1, b1, W2, b2, W3, b3, W4, b4)\n",
- " predictions = rowIndexMax(probs) - 1\n",
- "\"\"\"\n",
- "script = (dml(scriptPredict).input(data=testData, C=1, Hin=28, Win=28, W1=W1, b1=b1, W2=W2, b2=b2, W3=W3, b3=b3, W4=W4, b4=b4)\n",
- " .output(\"predictions\"))\n",
- "\n",
- "predictions = ml.execute(script).get(\"predictions\").toNumPy()\n",
- "\n",
- "print classification_report(testData[:,0], predictions)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "<a id=\"predict\"></a>\n",
- "## Detect handwritten Digits"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Define a function that randomly selects a test image, display the image, and scores it."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false
- },
- "outputs": [],
- "source": [
- "img_size = np.sqrt(testData.shape[1] - 1)\n",
- "\n",
- "def displayImage(i):\n",
- " image = (testData[i,1:]).reshape((img_size, img_size)).astype(\"uint8\")\n",
- " imgplot = plt.imshow(image, cmap='gray') "
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false
- },
- "outputs": [],
- "source": [
- "def predictImage(i):\n",
- " image = testData[i,:].reshape(1,testData.shape[1])\n",
- " prog = dml(scriptPredict).input(data=image, C=1, Hin=28, Win=28, W1=W1, b1=b1, W2=W2, b2=b2, W3=W3, b3=b3, W4=W4, b4=b4) \\\n",
- " .output(\"predictions\")\n",
- " result = ml.execute(prog)\n",
- " return (result.get(\"predictions\").toNumPy())[0]"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false,
- "scrolled": true
- },
- "outputs": [],
- "source": [
- "i = np.random.choice(np.arange(0, len(testData)), size = (1,))\n",
- "\n",
- "p = predictImage(i)\n",
- "\n",
- "print \"Image\", i, \"\\nPredicted digit:\", p, \"\\nActual digit: \", testData[i,0], \"\\nResult: \", (p == testData[i,0])\n",
- "\n",
- "displayImage(i)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": true
- },
- "outputs": [],
- "source": []
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false
- },
- "outputs": [],
- "source": [
- "pd.set_option('display.max_columns', 28)\n",
- "pd.DataFrame((testData[i,1:]).reshape(img_size, img_size),dtype='uint')"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": true
- },
- "outputs": [],
- "source": []
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 2",
- "language": "python",
- "name": "python2"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 2
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython2",
- "version": "2.7.11"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
http://git-wip-us.apache.org/repos/asf/incubator-systemml/blob/7fe372b9/samples/jupyter-notebooks/Deep_Learning_Image_Classification.ipynb
----------------------------------------------------------------------
diff --git a/samples/jupyter-notebooks/Deep_Learning_Image_Classification.ipynb b/samples/jupyter-notebooks/Deep_Learning_Image_Classification.ipynb
new file mode 100644
index 0000000..d7f00c9
--- /dev/null
+++ b/samples/jupyter-notebooks/Deep_Learning_Image_Classification.ipynb
@@ -0,0 +1,406 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Deep Learning Image Classification\n",
+ "\n",
+ "This notebook shows SystemML Deep Learning functionality to map images of single digit numbers to their corresponding numeric representations. See [Getting Started with Deep Learning and Python](http://www.pyimagesearch.com/2014/09/22/getting-started-deep-learning-python/) for an explanation of the used deep learning concepts and assumptions.\n",
+ "\n",
+ "The downloaded MNIST dataset contains labeled images of handwritten digits, where each example is a 28x28 pixel image of grayscale values in the range [0,255] stretched out as 784 pixels, and each label is one of 10 possible digits in [0,9]. We download 60,000 training examples, and 10,000 test examples, where the format is \"label, pixel_1, pixel_2, ..., pixel_n\". We train a SystemML LeNet model. The results of the learning algorithms have an accuracy of 98 percent.\n",
+ "\n",
+ "1. [Install and load SystemML and other libraries](#load_systemml)\n",
+ "1. [Download and Access MNIST data](#access_data)\n",
+ "1. [Train a CNN classifier for MNIST handwritten digits](#train)\n",
+ "1. [Detect handwritten Digits](#predict)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": true
+ },
+ "source": [
+ "<div style=\"text-align:center\" markdown=\"1\">\n",
+ "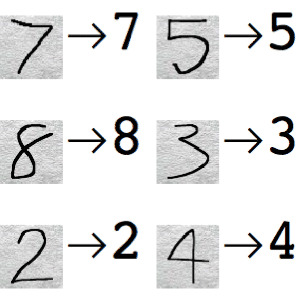\n",
+ "Mapping images of numbers to numbers\n",
+ "</div>"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "<a id=\"load_systemml\"></a>\n",
+ "## Install and load SystemML and other libraries"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": false
+ },
+ "outputs": [],
+ "source": [
+ "#!pip install --user systemml>=0.14.0\n",
+ "!pip install ~/git/systemml_scala/incubator-systemml/target/systemml-1.0.0-incubating-SNAPSHOT-python.tgz"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": false
+ },
+ "outputs": [],
+ "source": [
+ "!pip show systemml"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from systemml import MLContext, dml\n",
+ "\n",
+ "ml = MLContext(sc)\n",
+ "\n",
+ "print \"Spark Version:\", sc.version\n",
+ "print \"SystemML Version:\", ml.version()\n",
+ "print \"SystemML Built-Time:\", ml.buildTime()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "import warnings\n",
+ "warnings.filterwarnings(\"ignore\")\n",
+ "from sklearn import datasets\n",
+ "from sklearn.cross_validation import train_test_split\n",
+ "from sklearn.metrics import classification_report\n",
+ "import pandas as pd\n",
+ "import numpy as np\n",
+ "import matplotlib.pyplot as plt\n",
+ "#import matplotlib.image as mpimg\n",
+ "%matplotlib inline"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Create data directory."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "collapsed": true
+ },
+ "outputs": [],
+ "source": [
+ "%%sh\n",
+ "mkdir -p data/mnist/\n",
+ "cd data/mnist/"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "<a id=\"access_data\"></a>\n",
+ "## Download and Access MNIST data\n",
+ "\n",
+ "Download the [MNIST data from the MLData repository](http://mldata.org/repository/data/viewslug/mnist-original/), and then split and save."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "mnist = datasets.fetch_mldata(\"MNIST Original\")\n",
+ "\n",
+ "print \"Mnist data features:\", mnist.data.shape\n",
+ "print \"Mnist data label:\", mnist.target.shape\n",
+ "\n",
+ "trainX, testX, trainY, testY = train_test_split(mnist.data, mnist.target.astype(\"int0\"), test_size = 0.142857)\n",
+ "\n",
+ "trainD = np.concatenate((trainY.reshape(trainY.size, 1), trainX),axis=1)\n",
+ "testD = np.concatenate((testY.reshape (testY.size, 1), testX),axis=1)\n",
+ "\n",
+ "print \"Images for training:\", trainD.shape\n",
+ "print \"Images used for testing:\", testD.shape\n",
+ "pix = int(np.sqrt(trainD.shape[1]))\n",
+ "print \"Each image is:\", pix, \"by\", pix, \"pixels\"\n",
+ "\n",
+ "np.savetxt('data/mnist/mnist_train.csv', trainD, fmt='%u', delimiter=\",\")\n",
+ "np.savetxt('data/mnist/mnist_test.csv', testD, fmt='%u', delimiter=\",\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Alternatively get the data from here."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "%%sh\n",
+ "curl -O https://pjreddie.com/media/files/mnist_train.csv\n",
+ "curl -O https://pjreddie.com/media/files/mnist_test.csv\n",
+ "wc -l mnist*"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Read the data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "trainData = np.genfromtxt('data/mnist/mnist_train.csv', delimiter=\",\")\n",
+ "testData = np.genfromtxt('data/mnist/mnist_test.csv', delimiter=\",\")\n",
+ "\n",
+ "print \"Training data: \", trainData.shape\n",
+ "print \"Test data: \", testData.shape"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "pd.set_option('display.max_columns', 200)\n",
+ "pd.DataFrame(testData[1:10,],dtype='uint')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "<a id=\"train\"></a>\n",
+ "## Develop LeNet CNN classifier on Training Data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "<div style=\"text-align:center\" markdown=\"1\">\n",
+ "\n",
+ "MNIST digit recognition – LeNet architecture\n",
+ "</div>"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Train Model using SystemML LeNet CNN."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "(on a Mac Book, this takes approx. 5-6 mins for 1 epoch)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "collapsed": true,
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "script = \"\"\"\n",
+ " source(\"nn/examples/mnist_lenet.dml\") as mnist_lenet\n",
+ "\n",
+ " # Bind training data\n",
+ " n = nrow(data)\n",
+ "\n",
+ " # Extract images and labels\n",
+ " images = data[,2:ncol(data)]\n",
+ " labels = data[,1]\n",
+ "\n",
+ " # Scale images to [-1,1], and one-hot encode the labels\n",
+ " images = (images / 255.0) * 2 - 1\n",
+ " labels = table(seq(1, n), labels+1, n, 10)\n",
+ "\n",
+ " # Split into training (55,000 examples) and validation (5,000 examples)\n",
+ " X = images[5001:nrow(images),]\n",
+ " X_val = images[1:5000,]\n",
+ " y = labels[5001:nrow(images),]\n",
+ " y_val = labels[1:5000,]\n",
+ "\n",
+ " # Train the model using channel, height, and width to produce weights/biases.\n",
+ " [W1, b1, W2, b2, W3, b3, W4, b4] = mnist_lenet::train(X, y, X_val, y_val, C, Hin, Win, epochs)\n",
+ "\"\"\"\n",
+ "rets = ('W1', 'b1','W2','b2','W3','b3','W4','b4')\n",
+ "\n",
+ "script = (dml(script).input(data=trainData, epochs=1, C=1, Hin=28, Win=28)\n",
+ " .output(*rets)) \n",
+ "\n",
+ "W1, b1, W2, b2, W3, b3, W4, b4 = (ml.execute(script).get(*rets))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": true
+ },
+ "source": [
+ "Use trained model and predict on test data, and evaluate the quality of the predictions for each digit."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "scriptPredict = \"\"\"\n",
+ " source(\"nn/examples/mnist_lenet.dml\") as mnist_lenet\n",
+ "\n",
+ " # Separate images from lables and scale images to [-1,1]\n",
+ " X_test = data[,2:ncol(data)]\n",
+ " X_test = (X_test / 255.0) * 2 - 1\n",
+ "\n",
+ " # Predict\n",
+ " probs = mnist_lenet::predict(X_test, C, Hin, Win, W1, b1, W2, b2, W3, b3, W4, b4)\n",
+ " predictions = rowIndexMax(probs) - 1\n",
+ "\"\"\"\n",
+ "script = (dml(scriptPredict).input(data=testData, C=1, Hin=28, Win=28, W1=W1, b1=b1, W2=W2, b2=b2, W3=W3, b3=b3, W4=W4, b4=b4)\n",
+ " .output(\"predictions\"))\n",
+ "\n",
+ "predictions = ml.execute(script).get(\"predictions\").toNumPy()\n",
+ "\n",
+ "print classification_report(testData[:,0], predictions)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "<a id=\"predict\"></a>\n",
+ "## Detect handwritten Digits"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Define a function that randomly selects a test image, display the image, and scores it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "collapsed": true
+ },
+ "outputs": [],
+ "source": [
+ "img_size = np.sqrt(testData.shape[1] - 1)\n",
+ "\n",
+ "def displayImage(i):\n",
+ " image = (testData[i,1:]).reshape((img_size, img_size)).astype(\"uint8\")\n",
+ " imgplot = plt.imshow(image, cmap='gray') "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "collapsed": true
+ },
+ "outputs": [],
+ "source": [
+ "def predictImage(i):\n",
+ " image = testData[i,:].reshape(1,testData.shape[1])\n",
+ " prog = dml(scriptPredict).input(data=image, C=1, Hin=28, Win=28, W1=W1, b1=b1, W2=W2, b2=b2, W3=W3, b3=b3, W4=W4, b4=b4) \\\n",
+ " .output(\"predictions\")\n",
+ " result = ml.execute(prog)\n",
+ " return (result.get(\"predictions\").toNumPy())[0]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "i = np.random.choice(np.arange(0, len(testData)), size = (1,))\n",
+ "\n",
+ "p = predictImage(i)\n",
+ "\n",
+ "print \"Image\", i, \"\\nPredicted digit:\", p, \"\\nActual digit: \", testData[i,0], \"\\nResult: \", (p == testData[i,0])\n",
+ "\n",
+ "displayImage(i)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "pd.set_option('display.max_columns', 28)\n",
+ "pd.DataFrame((testData[i,1:]).reshape(img_size, img_size),dtype='uint')"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 2",
+ "language": "python",
+ "name": "python2"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 2
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython2",
+ "version": "2.7.11"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 1
+}