You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by "soumilshah1995 (via GitHub)" <gi...@apache.org> on 2023/04/09 13:43:50 UTC
[GitHub] [hudi] soumilshah1995 opened a new issue, #8412: [SUPPORT] Hudi Bootstrapping Fails when Using it with Hive Sync with Glue EMR 6.10
soumilshah1995 opened a new issue, #8412:
URL: https://github.com/apache/hudi/issues/8412
Hello i was playing with Hudi Bootstrapping feature and when trying to use with Hive Sync the Jobs fails
# Dataset
```
https://drive.google.com/drive/folders/1BwNEK649hErbsWcYLZhqCWnaXFX3mIsg?usp=share_link
```
# EMR Job
```
"""
Download the dataset
https://drive.google.com/drive/folders/1BwNEK649hErbsWcYLZhqCWnaXFX3mIsg?usp=share_link
"""
try:
import json
import uuid
import os
import boto3
from dotenv import load_dotenv
load_dotenv("../.env")
except Exception as e:
pass
global AWS_ACCESS_KEY
global AWS_SECRET_KEY
global AWS_REGION_NAME
AWS_ACCESS_KEY = os.getenv("DEV_ACCESS_KEY")
AWS_SECRET_KEY = os.getenv("DEV_SECRET_KEY")
AWS_REGION_NAME = os.getenv("DEV_REGION")
client = boto3.client("emr-serverless",
aws_access_key_id=AWS_ACCESS_KEY,
aws_secret_access_key=AWS_SECRET_KEY,
region_name=AWS_REGION_NAME)
def lambda_handler_test_emr(event, context):
# ------------------Hudi settings ---------------------------------------------
glue_db = "hudidb"
table_name = "tbl_tbl_invoices"
op = "UPSERT"
table_type = "COPY_ON_WRITE"
record_key = 'invoiceid'
precombine = "replicadmstimestamp"
target_path = "s3://delta-streamer-demo-hudi/hudi/"
raw_path = "s3://delta-streamer-demo-hudi/parquet_files/"
partition_feild = "destinationstate"
MODE = 'FULL_RECORD' # FULL_RECORD | METADATA_ONLY
# ---------------------------------------------------------------------------------
# EMR
# --------------------------------------------------------------------------------
ApplicationId = "XXXXX"
ExecutionTime = 600
ExecutionArn = "arn:aws:iam::XXXX1645"
JobName = 'delta_streamer_bootstrap_{}'.format(table_name)
# --------------------------------------------------------------------------------
spark_submit_parameters = ' --conf spark.jars=/usr/lib/hudi/hudi-utilities-bundle.jar'
spark_submit_parameters += ' --conf spark.serializer=org.apache.spark.serializer.KryoSerializer'
spark_submit_parameters += ' --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer'
arguments = [
'--run-bootstrap',
"--target-base-path", target_path,
"--target-table", table_name,
"--table-type", table_type,
"--hoodie-conf", "hoodie.bootstrap.base.path={}".format(raw_path),
"--hoodie-conf", "hoodie.datasource.write.recordkey.field={}".format(record_key),
"--hoodie-conf", "hoodie.datasource.write.precombine.field={}".format(precombine),
"--hoodie-conf", "hoodie.datasource.write.partitionpath.field={}".format(partition_feild),
"--hoodie-conf", "hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.SimpleKeyGenerator",
"--hoodie-conf",
"hoodie.bootstrap.full.input.provider=org.apache.hudi.bootstrap.SparkParquetBootstrapDataProvider",
"--hoodie-conf",
"hoodie.bootstrap.mode.selector=org.apache.hudi.client.bootstrap.selector.BootstrapRegexModeSelector",
"--hoodie-conf", "hoodie.bootstrap.mode.selector.regex.mode={}".format(MODE),
"--enable-sync",
"--hoodie-conf", "hoodie.database.name={}".format(glue_db),
"--hoodie-conf", "hoodie.datasource.hive_sync.enable=true",
"--hoodie-conf", "hoodie.datasource.hive_sync.table={}".format(table_name),
"--hoodie-conf", "hoodie.datasource.hive_sync.partition_fields={}".format(partition_feild),
]
response = client.start_job_run(
applicationId=ApplicationId,
clientToken=uuid.uuid4().__str__(),
executionRoleArn=ExecutionArn,
jobDriver={
'sparkSubmit': {
'entryPoint': "command-runner.jar",
'entryPointArguments': arguments,
'sparkSubmitParameters': spark_submit_parameters
},
},
executionTimeoutMinutes=ExecutionTime,
name=JobName,
)
print("response", end="\n")
print(response)
lambda_handler_test_emr(context=None, event=None)
```
# Error Message
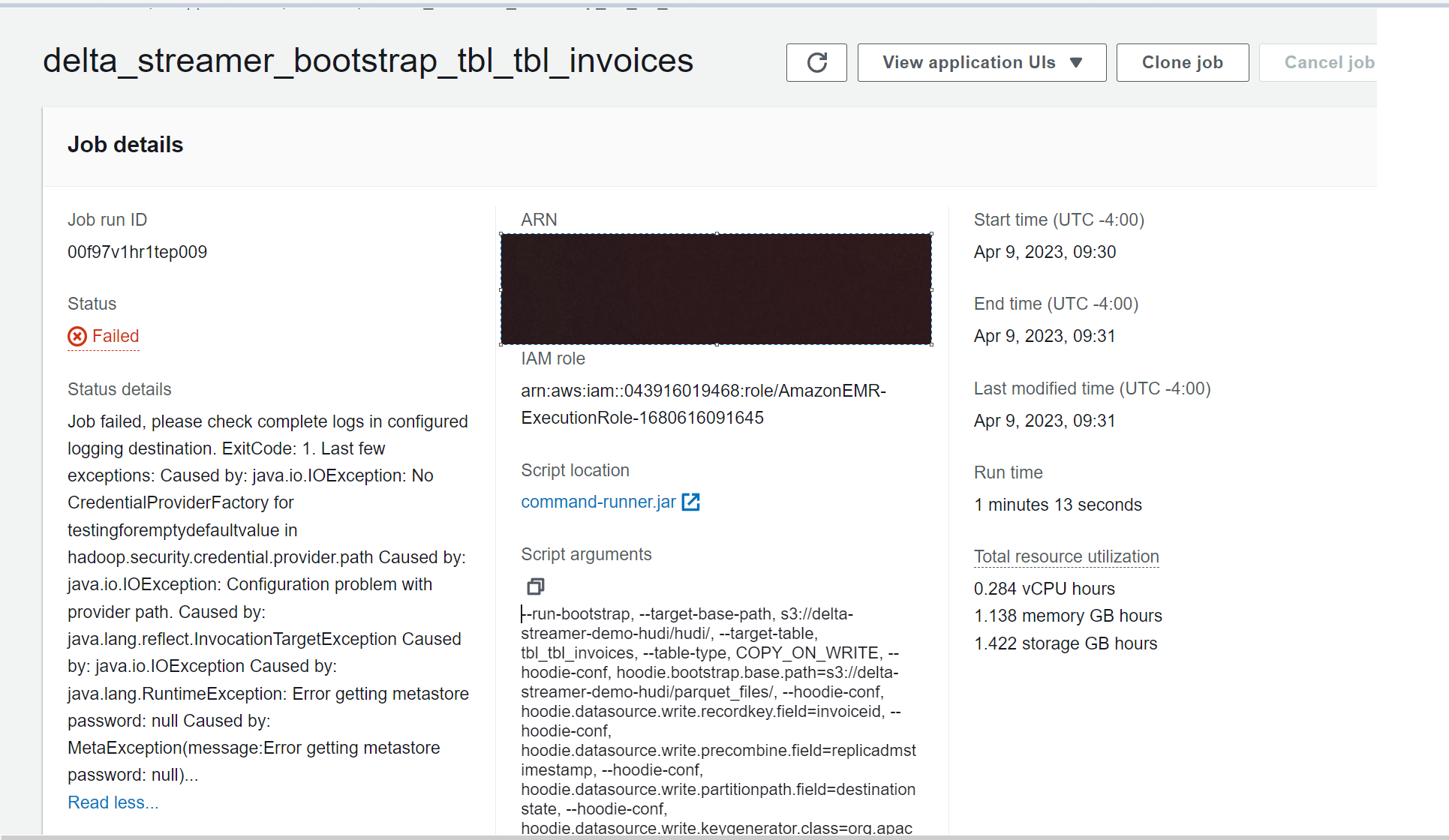
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8412: [SUPPORT] Hudi Bootstrapping Fails when Using it with Hive Sync with Glue EMR 6.10
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8412:
URL: https://github.com/apache/hudi/issues/8412#issuecomment-1505828525
Please note bootstrapping works fine if i remove hive-sync
only when you add hive-sync it throws error on EMR serverless
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] ad1happy2go commented on issue #8412: [SUPPORT] Hudi Bootstrapping Fails when Using it with Hive Sync with Glue EMR 6.10
Posted by "ad1happy2go (via GitHub)" <gi...@apache.org>.
ad1happy2go commented on issue #8412:
URL: https://github.com/apache/hudi/issues/8412#issuecomment-1514432659
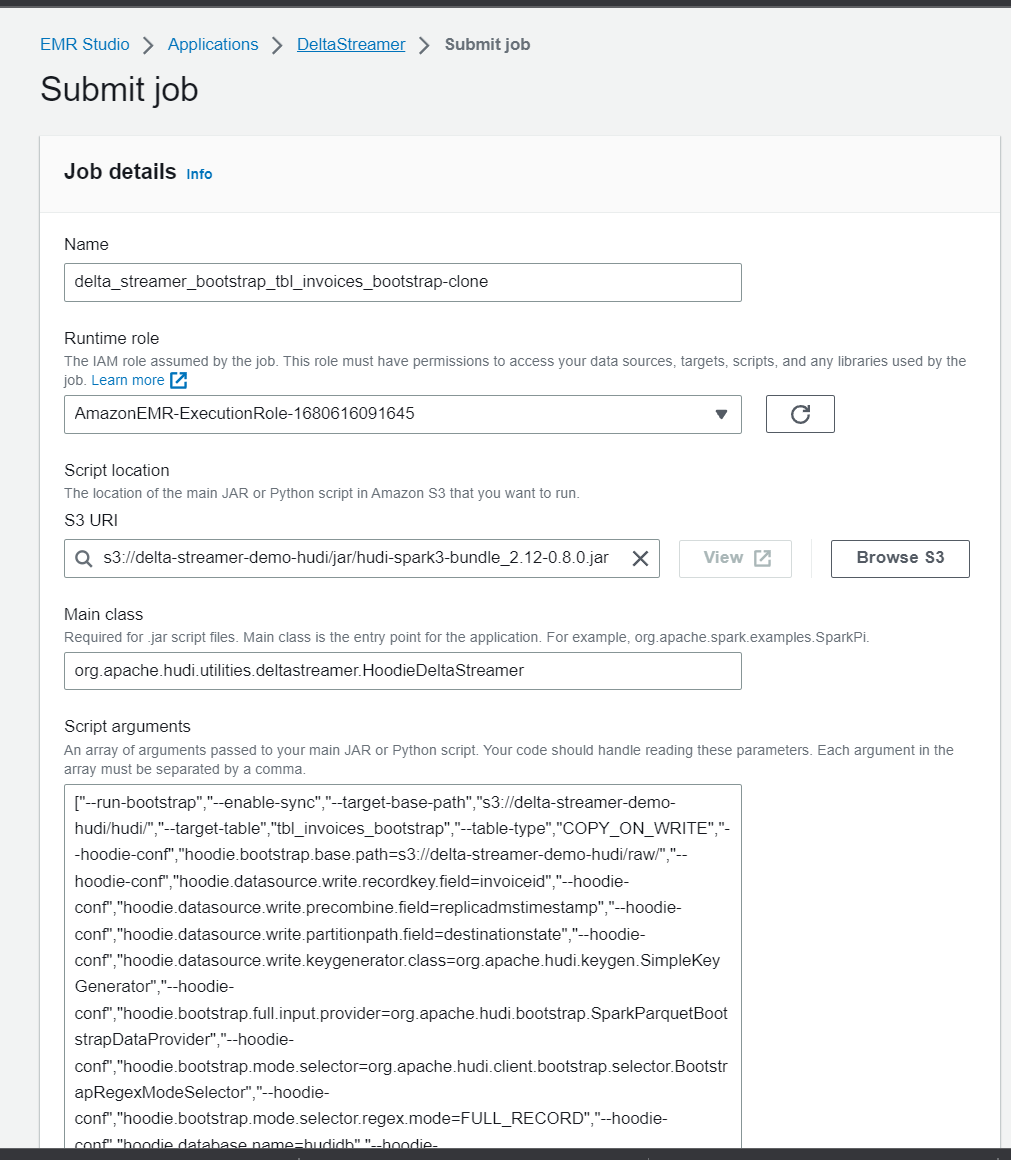
@soumilshah1995 I was able to make it succeed with following params -
<img width="420" alt="image" src="https://user-images.githubusercontent.com/63430370/233034482-902f7eae-ef6a-4339-913e-81b2653760ef.png">
<img width="1033" alt="image" src="https://user-images.githubusercontent.com/63430370/233033024-c92318bd-50a5-4903-9d6f-557cc2bab389.png">
Can you directly try to directly create EMR serverless function instead of going through lambda.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8412: [SUPPORT] Hudi Bootstrapping Fails when Using it with Hive Sync with Glue EMR 6.10
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8412:
URL: https://github.com/apache/hudi/issues/8412#issuecomment-1515030586
Thanks a lot Aditya has been great help issue was with JAR AWS provided JAR does not work aditya gave me jar tried with that and it works
hudi-utilities-bundle_2.12-0.13.0
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8412: [SUPPORT] Hudi Bootstrapping Fails when Using it with Hive Sync with Glue EMR 6.10
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8412:
URL: https://github.com/apache/hudi/issues/8412#issuecomment-1514656803
tried what you said still having issue with Hive Sync
# Old Py Code
```
"""
Download the dataset
https://drive.google.com/drive/folders/1BwNEK649hErbsWcYLZhqCWnaXFX3mIsg?usp=share_link
"""
try:
import json
import uuid
import os
import boto3
from dotenv import load_dotenv
load_dotenv("../.env")
except Exception as e:
pass
global AWS_ACCESS_KEY
global AWS_SECRET_KEY
global AWS_REGION_NAME
AWS_ACCESS_KEY = os.getenv("DEV_ACCESS_KEY")
AWS_SECRET_KEY = os.getenv("DEV_SECRET_KEY")
AWS_REGION_NAME = os.getenv("DEV_REGION")
client = boto3.client("emr-serverless",
aws_access_key_id=AWS_ACCESS_KEY,
aws_secret_access_key=AWS_SECRET_KEY,
region_name=AWS_REGION_NAME)
def lambda_handler_test_emr(event, context):
# ------------------Hudi settings ---------------------------------------------
glue_db = "hudidb"
table_name = "tbl_tbl_invoices"
op = "UPSERT"
table_type = "COPY_ON_WRITE"
record_key = 'invoiceid'
precombine = "replicadmstimestamp"
target_path = "s3://delta-streamer-demo-hudi/hudi/"
raw_path = "s3://delta-streamer-demo-hudi/raw/"
partition_feild = "destinationstate"
MODE = 'FULL_RECORD' # FULL_RECORD | METADATA_ONLY
# ---------------------------------------------------------------------------------
# EMR
# --------------------------------------------------------------------------------
ApplicationId = os.getenv("ApplicationId")
ExecutionTime = 600
ExecutionArn = os.getenv("ExecutionArn")
JobName = 'delta_streamer_bootstrap_{}'.format(table_name)
# --------------------------------------------------------------------------------
spark_submit_parameters = ' --conf spark.jars=/usr/lib/hudi/hudi-utilities-bundle.jar'
spark_submit_parameters += ' --conf spark.serializer=org.apache.spark.serializer.KryoSerializer'
spark_submit_parameters += ' --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer'
arguments = [
'--run-bootstrap',
# "--enable-sync",
"--target-base-path", target_path,
"--target-table", table_name,
"--table-type", table_type,
"--hoodie-conf", "hoodie.bootstrap.base.path={}".format(raw_path),
"--hoodie-conf", "hoodie.datasource.write.recordkey.field={}".format(record_key),
"--hoodie-conf", "hoodie.datasource.write.precombine.field={}".format(precombine),
"--hoodie-conf", "hoodie.datasource.write.partitionpath.field={}".format(partition_feild),
"--hoodie-conf", "hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.SimpleKeyGenerator",
"--hoodie-conf",
"hoodie.bootstrap.full.input.provider=org.apache.hudi.bootstrap.SparkParquetBootstrapDataProvider",
"--hoodie-conf",
"hoodie.bootstrap.mode.selector=org.apache.hudi.client.bootstrap.selector.BootstrapRegexModeSelector",
"--hoodie-conf", "hoodie.bootstrap.mode.selector.regex.mode={}".format(MODE),
# "--hoodie-conf", "hoodie.database.name={}".format(glue_db),
# "--hoodie-conf", "hoodie.datasource.hive_sync.enable=true",
# "--hoodie-conf", "hoodie.datasource.hive_sync.table={}".format(table_name),
# "--hoodie-conf", "hoodie.datasource.hive_sync.partition_fields={}".format(partition_feild),
]
response = client.start_job_run(
applicationId=ApplicationId,
clientToken=uuid.uuid4().__str__(),
executionRoleArn=ExecutionArn,
jobDriver={
'sparkSubmit': {
'entryPoint': "command-runner.jar",
'entryPointArguments': arguments,
'sparkSubmitParameters': spark_submit_parameters
},
},
executionTimeoutMinutes=ExecutionTime,
name=JobName,
)
print("response", end="\n")
print(response)
lambda_handler_test_emr(context=None, event=None)
```
# New Py Code
```
"""
Download the dataset
https://drive.google.com/drive/folders/1BwNEK649hErbsWcYLZhqCWnaXFX3mIsg?usp=share_link
"""
try:
import json
import uuid
import os
import boto3
from dotenv import load_dotenv
load_dotenv("../.env")
except Exception as e:
pass
global AWS_ACCESS_KEY
global AWS_SECRET_KEY
global AWS_REGION_NAME
AWS_ACCESS_KEY = os.getenv("DEV_ACCESS_KEY")
AWS_SECRET_KEY = os.getenv("DEV_SECRET_KEY")
AWS_REGION_NAME = os.getenv("DEV_REGION")
client = boto3.client("emr-serverless",
aws_access_key_id=AWS_ACCESS_KEY,
aws_secret_access_key=AWS_SECRET_KEY,
region_name=AWS_REGION_NAME)
def lambda_handler_test_emr(event, context):
# ------------------Hudi settings ---------------------------------------------
glue_db = "hudidb"
table_name = "tbl_invoices_bootstrap"
op = "UPSERT"
table_type = "COPY_ON_WRITE"
record_key = 'invoiceid'
precombine = "replicadmstimestamp"
target_path = "s3://delta-streamer-demo-hudi/hudi/"
raw_path = "s3://delta-streamer-demo-hudi/raw/"
partition_feild = "destinationstate"
MODE = 'FULL_RECORD' # FULL_RECORD | METADATA_ONLY
# ---------------------------------------------------------------------------------
# EMR
# --------------------------------------------------------------------------------
ApplicationId = os.getenv("ApplicationId")
ExecutionTime = 600
ExecutionArn = os.getenv("ExecutionArn")
JobName = 'delta_streamer_bootstrap_{}'.format(table_name)
jar_path = "s3://delta-streamer-demo-hudi/jar/hudi-spark3-bundle_2.12-0.8.0.jar"
# --------------------------------------------------------------------------------
spark_submit_parameters = ' --conf spark.jars=/usr/lib/hudi/hudi-utilities-bundle.jar'
spark_submit_parameters += ' --conf spark.serializer=org.apache.spark.serializer.KryoSerializer'
spark_submit_parameters += ' --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer'
arguments = [
'--run-bootstrap',
"--enable-sync",
"--target-base-path", target_path,
"--target-table", table_name,
"--table-type", table_type,
"--hoodie-conf", "hoodie.bootstrap.base.path={}".format(raw_path),
"--hoodie-conf", "hoodie.datasource.write.recordkey.field={}".format(record_key),
"--hoodie-conf", "hoodie.datasource.write.precombine.field={}".format(precombine),
"--hoodie-conf", "hoodie.datasource.write.partitionpath.field={}".format(partition_feild),
"--hoodie-conf", "hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.SimpleKeyGenerator",
"--hoodie-conf","hoodie.bootstrap.full.input.provider=org.apache.hudi.bootstrap.SparkParquetBootstrapDataProvider",
"--hoodie-conf","hoodie.bootstrap.mode.selector=org.apache.hudi.client.bootstrap.selector.BootstrapRegexModeSelector",
"--hoodie-conf", "hoodie.bootstrap.mode.selector.regex.mode={}".format(MODE),
"--hoodie-conf", "hoodie.database.name={}".format(glue_db),
"--hoodie-conf", "hoodie.datasource.hive_sync.enable=true",
"--hoodie-conf", "hoodie.datasource.hive_sync.table={}".format(table_name),
"--hoodie-conf", "hoodie.datasource.hive_sync.partition_fields={}".format(partition_feild),
]
response = client.start_job_run(
applicationId=ApplicationId,
clientToken=uuid.uuid4().__str__(),
executionRoleArn=ExecutionArn,
jobDriver={
'sparkSubmit': {
'entryPoint': jar_path,
'entryPointArguments': arguments,
'sparkSubmitParameters': spark_submit_parameters
},
},
executionTimeoutMinutes=ExecutionTime,
name=JobName,
)
print("response", end="\n")
print(response)
lambda_handler_test_emr(context=None, event=None)
```
lets connect on slack and see if we can resolve the issue maybe i am missing something here
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 closed issue #8412: [SUPPORT] Hudi Bootstrapping Fails when Using it with Hive Sync with Glue EMR 6.10
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 closed issue #8412: [SUPPORT] Hudi Bootstrapping Fails when Using it with Hive Sync with Glue EMR 6.10
URL: https://github.com/apache/hudi/issues/8412
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org