You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@nifi.apache.org by alopresto <gi...@git.apache.org> on 2018/01/04 16:29:00 UTC
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
GitHub user alopresto opened a pull request:
https://github.com/apache/nifi/pull/2371
NIFI-4727 Add CountText processor
This new processor performs basic text metrics on incoming flowfile content (line count, non-empty line count, word count, and character count). Each metric is independent, and word count can be configured to accept or split on symbol boundaries.
The performance is fairly decent (a document with ~370k lines / words ~= 80 - 90 ms on a commodity laptop) and handles the text in a streaming manner so as not to damage the heap.
A sample flow.xml.gz is [posted here](https://gist.github.com/alopresto/86eb04437c079cf2a48e2aeadf2df7c0) to allow for local testing (relying on a locally downloaded file or an HTTP GET to a GitHub hosted file).
Thank you for submitting a contribution to Apache NiFi.
In order to streamline the review of the contribution we ask you
to ensure the following steps have been taken:
### For all changes:
- [x] Is there a JIRA ticket associated with this PR? Is it referenced
in the commit message?
- [x] Does your PR title start with NIFI-XXXX where XXXX is the JIRA number you are trying to resolve? Pay particular attention to the hyphen "-" character.
- [x] Has your PR been rebased against the latest commit within the target branch (typically master)?
- [ ] Is your initial contribution a single, squashed commit?
### For code changes:
- [x] Have you ensured that the full suite of tests is executed via mvn -Pcontrib-check clean install at the root nifi folder?
- [x] Have you written or updated unit tests to verify your changes?
- [ ] If adding new dependencies to the code, are these dependencies licensed in a way that is compatible for inclusion under [ASF 2.0](http://www.apache.org/legal/resolved.html#category-a)?
- [ ] If applicable, have you updated the LICENSE file, including the main LICENSE file under nifi-assembly?
- [ ] If applicable, have you updated the NOTICE file, including the main NOTICE file found under nifi-assembly?
- [x] If adding new Properties, have you added .displayName in addition to .name (programmatic access) for each of the new properties?
### For documentation related changes:
- [x] Have you ensured that format looks appropriate for the output in which it is rendered?
### Note:
Please ensure that once the PR is submitted, you check travis-ci for build issues and submit an update to your PR as soon as possible.
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/alopresto/nifi NIFI-4727
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/nifi/pull/2371.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #2371
----
commit 3bcc023d7141c5027ddef7738c86f9dde364850b
Author: Andy LoPresto <al...@...>
Date: 2018-01-02T19:47:33Z
NIFI-4727 Added CountText processor and unit test (character count not yet tested).
commit 00847974996fc0e825fd9ee788a61fce7485b95c
Author: Andy LoPresto <al...@...>
Date: 2018-01-03T20:11:21Z
NIFI-4727 Fixed character count.
Improved metrics log message.
Added unit tests.
commit e9d48c9905d043ff0f3993f6a33f993c0a6465e6
Author: Andy LoPresto <al...@...>
Date: 2018-01-04T13:37:30Z
NIFI-4727 Fixed symbol regex.
Added unit tests.
commit 66bd335c7423712191f200a5b7dbc236e9587fec
Author: Andy LoPresto <al...@...>
Date: 2018-01-04T15:41:51Z
NIFI-4727 Fixed checkstyle issues.
Fixed RAT issue with test resource.
Reset metrics to 0 on new run (was maintaining running count before).
Added unit tests.
----
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by alopresto <gi...@git.apache.org>.
Github user alopresto commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r159743739
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/main/java/org/apache/nifi/processors/standard/CountText.java ---
@@ -0,0 +1,318 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard;
+
+import java.io.BufferedReader;
+import java.io.InputStreamReader;
+import java.nio.charset.Charset;
+import java.nio.charset.StandardCharsets;
+import java.text.DecimalFormat;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Collectors;
+import org.apache.nifi.annotation.behavior.EventDriven;
+import org.apache.nifi.annotation.behavior.InputRequirement;
+import org.apache.nifi.annotation.behavior.InputRequirement.Requirement;
+import org.apache.nifi.annotation.behavior.SideEffectFree;
+import org.apache.nifi.annotation.behavior.SupportsBatching;
+import org.apache.nifi.annotation.behavior.WritesAttribute;
+import org.apache.nifi.annotation.behavior.WritesAttributes;
+import org.apache.nifi.annotation.documentation.CapabilityDescription;
+import org.apache.nifi.annotation.documentation.SeeAlso;
+import org.apache.nifi.annotation.documentation.Tags;
+import org.apache.nifi.annotation.lifecycle.OnScheduled;
+import org.apache.nifi.components.PropertyDescriptor;
+import org.apache.nifi.flowfile.FlowFile;
+import org.apache.nifi.processor.AbstractProcessor;
+import org.apache.nifi.processor.ProcessContext;
+import org.apache.nifi.processor.ProcessSession;
+import org.apache.nifi.processor.Relationship;
+import org.apache.nifi.processor.exception.ProcessException;
+import org.apache.nifi.processor.util.StandardValidators;
+import org.apache.nifi.util.StringUtils;
+
+@EventDriven
+@SideEffectFree
+@SupportsBatching
+@Tags({"count", "text", "line", "word", "character"})
+@InputRequirement(Requirement.INPUT_REQUIRED)
+@CapabilityDescription("Counts various metrics on incoming text. The requested results will be recorded as attributes. "
+ + "The resulting flowfile will not have its content modified.")
+@WritesAttributes({
+ @WritesAttribute(attribute = "text.line.count", description = "The number of lines of text present in the FlowFile content"),
+ @WritesAttribute(attribute = "text.line.nonempty.count", description = "The number of lines of text (with at least one non-whitespace character) present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.word.count", description = "The number of words present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.character.count", description = "The number of characters (given the specified character encoding) present in the original FlowFile"),
+})
+@SeeAlso(SplitText.class)
+public class CountText extends AbstractProcessor {
+ private static final List<Charset> STANDARD_CHARSETS = Arrays.asList(
+ StandardCharsets.UTF_8,
+ StandardCharsets.US_ASCII,
+ StandardCharsets.ISO_8859_1,
+ StandardCharsets.UTF_16,
+ StandardCharsets.UTF_16LE,
+ StandardCharsets.UTF_16BE);
+
+ private static final String SYMBOL_REGEX = "[\\s-\\._]";
+ private static final String WHITESPACE_ONLY_REGEX = "\\s";
+
+ // Attribute keys
+ public static final String TEXT_LINE_COUNT = "text.line.count";
+ public static final String TEXT_LINE_NONEMPTY_COUNT = "text.line.nonempty.count";
+ public static final String TEXT_WORD_COUNT = "text.word.count";
+ public static final String TEXT_CHARACTER_COUNT = "text.character.count";
+
+
+ public static final PropertyDescriptor TEXT_LINE_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-count")
+ .displayName("Text Line Count")
--- End diff --
I can change these to be clearer as you suggested.
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by kevdoran <gi...@git.apache.org>.
Github user kevdoran commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r160244250
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/test/groovy/org/apache/nifi/processors/standard/CountTextTest.groovy ---
@@ -0,0 +1,324 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License") you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard
+
+import org.apache.nifi.components.PropertyDescriptor
+import org.apache.nifi.flowfile.FlowFile
+import org.apache.nifi.util.MockProcessSession
+import org.apache.nifi.util.TestRunner
+import org.apache.nifi.util.TestRunners
+import org.bouncycastle.jce.provider.BouncyCastleProvider
+import org.junit.After
+import org.junit.Before
+import org.junit.BeforeClass
+import org.junit.Test
+import org.junit.runner.RunWith
+import org.junit.runners.JUnit4
+import org.mockito.Mockito
+import org.slf4j.Logger
+import org.slf4j.LoggerFactory
+
+import java.nio.charset.StandardCharsets
+import java.security.Security
+
+import static org.mockito.Matchers.anyBoolean
+import static org.mockito.Matchers.anyString
+import static org.mockito.Mockito.when
+
+@RunWith(JUnit4.class)
+class CountTextTest extends GroovyTestCase {
+ private static final Logger logger = LoggerFactory.getLogger(CountTextTest.class)
+
+ @BeforeClass
+ static void setUpOnce() throws Exception {
+ Security.addProvider(new BouncyCastleProvider())
+
+ logger.metaClass.methodMissing = { String name, args ->
+ logger.info("[${name?.toUpperCase()}] ${(args as List).join(" ")}")
+ }
+ }
+
+ @Before
+ void setUp() throws Exception {
+ }
+
+ @After
+ void tearDown() throws Exception {
+ }
+
+ @Test
+ void testShouldCountAllMetrics() throws Exception {
+ // Arrange
+ final TestRunner runner = TestRunners.newTestRunner(CountText.class)
+
+ runner.setProperty(CountText.TEXT_LINE_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_LINE_NONEMPTY_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_WORD_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_CHARACTER_COUNT_PD, "true")
+
+ String INPUT_TEXT = """’Twas brillig, and the slithy toves
+Did gyre and gimble in the wade;
+All mimsy were the borogoves,
+And the mome raths outgrabe.
+
+"Beware the Jabberwock, my son!
+The jaws that bite, the claws that catch!
+Beware the Jubjub bird, and shun
+The frumious Bandersnatch!"
+
+He took his vorpal sword in hand:
+Long time the manxome foe he sought—
+So rested he by the Tumtum tree,
+And stood awhile in thought.
+
+And as in uffish thought he stood,
+The Jabberwock, with eyes of flame,
+Came whiffling through the tulgey wood.
+And burbled as it came!
+
+One, two! One, two! And through and through
+The vorpal blade went snicker-snack!
+He left it dead, and with its head
+He went galumphing back.
+
+"And hast thou slain the Jabberwock?
+Come to my arms, my beamish boy!
+O frabjous day! Callooh! Callay!"
+He chortled in his joy.
+
+’Twas brillig, and the slithy toves
+Did gyre and gimble in the wabe;
+All mimsy were the borogoves,
+And the mome raths outgrabe."""
+
+ runner.enqueue(INPUT_TEXT.bytes)
+
+ // Act
+ runner.run()
+
+ // Assert
+ runner.assertAllFlowFilesTransferred(CountText.REL_SUCCESS, 1)
+ FlowFile flowFile = runner.getFlowFilesForRelationship(CountText.REL_SUCCESS).first()
+ assert flowFile.attributes."text.line.count" == 34 as String
+ assert flowFile.attributes."text.line.nonempty.count" == 28 as String
+ assert flowFile.attributes."text.word.count" == 166 as String
+ assert flowFile.attributes."text.character.count" == 900 as String
+ }
+
+ @Test
+ void testShouldCountEachMetric() throws Exception {
+ // Arrange
+ final TestRunner runner = TestRunners.newTestRunner(CountText.class)
+ String INPUT_TEXT = new File("src/test/resources/TestCountText/jabberwocky.txt").text
+
+ final def EXPECTED_VALUES = [
+ "text.line.count" : 34,
+ "text.line.nonempty.count": 28,
+ "text.word.count" : 166,
+ "text.character.count" : 900,
+ ]
--- End diff --
Rather than redefining these constants in each test case, they could be made static class members.
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by alopresto <gi...@git.apache.org>.
Github user alopresto commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r159744615
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/test/resources/TestCountText/jabberwocky.txt ---
@@ -0,0 +1,34 @@
+’Twas brillig, and the slithy toves
--- End diff --
I selected it because it is no longer under copyright. I used [these laws](https://fairuse.stanford.edu/overview/public-domain/welcome/) as guidelines, but perhaps the ASF has additional rules?
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by alopresto <gi...@git.apache.org>.
Github user alopresto commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r159744070
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/main/java/org/apache/nifi/processors/standard/CountText.java ---
@@ -0,0 +1,318 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard;
+
+import java.io.BufferedReader;
+import java.io.InputStreamReader;
+import java.nio.charset.Charset;
+import java.nio.charset.StandardCharsets;
+import java.text.DecimalFormat;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Collectors;
+import org.apache.nifi.annotation.behavior.EventDriven;
+import org.apache.nifi.annotation.behavior.InputRequirement;
+import org.apache.nifi.annotation.behavior.InputRequirement.Requirement;
+import org.apache.nifi.annotation.behavior.SideEffectFree;
+import org.apache.nifi.annotation.behavior.SupportsBatching;
+import org.apache.nifi.annotation.behavior.WritesAttribute;
+import org.apache.nifi.annotation.behavior.WritesAttributes;
+import org.apache.nifi.annotation.documentation.CapabilityDescription;
+import org.apache.nifi.annotation.documentation.SeeAlso;
+import org.apache.nifi.annotation.documentation.Tags;
+import org.apache.nifi.annotation.lifecycle.OnScheduled;
+import org.apache.nifi.components.PropertyDescriptor;
+import org.apache.nifi.flowfile.FlowFile;
+import org.apache.nifi.processor.AbstractProcessor;
+import org.apache.nifi.processor.ProcessContext;
+import org.apache.nifi.processor.ProcessSession;
+import org.apache.nifi.processor.Relationship;
+import org.apache.nifi.processor.exception.ProcessException;
+import org.apache.nifi.processor.util.StandardValidators;
+import org.apache.nifi.util.StringUtils;
+
+@EventDriven
+@SideEffectFree
+@SupportsBatching
+@Tags({"count", "text", "line", "word", "character"})
+@InputRequirement(Requirement.INPUT_REQUIRED)
+@CapabilityDescription("Counts various metrics on incoming text. The requested results will be recorded as attributes. "
+ + "The resulting flowfile will not have its content modified.")
+@WritesAttributes({
+ @WritesAttribute(attribute = "text.line.count", description = "The number of lines of text present in the FlowFile content"),
+ @WritesAttribute(attribute = "text.line.nonempty.count", description = "The number of lines of text (with at least one non-whitespace character) present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.word.count", description = "The number of words present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.character.count", description = "The number of characters (given the specified character encoding) present in the original FlowFile"),
+})
+@SeeAlso(SplitText.class)
+public class CountText extends AbstractProcessor {
+ private static final List<Charset> STANDARD_CHARSETS = Arrays.asList(
+ StandardCharsets.UTF_8,
+ StandardCharsets.US_ASCII,
+ StandardCharsets.ISO_8859_1,
+ StandardCharsets.UTF_16,
+ StandardCharsets.UTF_16LE,
+ StandardCharsets.UTF_16BE);
+
+ private static final String SYMBOL_REGEX = "[\\s-\\._]";
+ private static final String WHITESPACE_ONLY_REGEX = "\\s";
+
+ // Attribute keys
+ public static final String TEXT_LINE_COUNT = "text.line.count";
+ public static final String TEXT_LINE_NONEMPTY_COUNT = "text.line.nonempty.count";
+ public static final String TEXT_WORD_COUNT = "text.word.count";
+ public static final String TEXT_CHARACTER_COUNT = "text.character.count";
+
+
+ public static final PropertyDescriptor TEXT_LINE_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-count")
+ .displayName("Text Line Count")
+ .description("If enabled, will count the number of lines present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("true")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_LINE_NONEMPTY_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-nonempty-count")
+ .displayName("Text Line (non-empty) Count")
+ .description("If enabled, will count the number of lines that contain a non-whitespace character present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_WORD_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-word-count")
+ .displayName("Text Word Count")
+ .description("If enabled, will count the number of words (alphanumeric character groups bounded by whitespace)" +
+ " present in the incoming text. Common logical delimiters [_-.] do not bound a word unless 'Split Words on Symbols' is true.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_CHARACTER_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-character-count")
+ .displayName("Text Character Count")
+ .description("If enabled, will count the number of characters (including whitespace and symbols) present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor SPLIT_WORDS_ON_SYMBOLS_PD = new PropertyDescriptor.Builder()
+ .name("split-words-on-symbols")
+ .displayName("Split Words on Symbols")
+ .description("If enabled, the word count will identify strings separated by common logical delimiters [_-.] as independent words (ex. split-words-on-symbols = 4 words).")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ // TODO: Stream map allowable values to name/key pair?
+ public static final PropertyDescriptor CHARACTER_ENCODING_PD = new PropertyDescriptor.Builder()
+ .name("character-encoding")
+ .displayName("Character Encoding")
+ .description("Specifies a character encoding to use.")
+ .required(true)
+ .allowableValues(getStandardCharsetNames())
+ .defaultValue(StandardCharsets.UTF_8.displayName())
+ .build();
+
+ private static Set<String> getStandardCharsetNames() {
+ return STANDARD_CHARSETS.stream().map(c -> c.displayName()).collect(Collectors.toSet());
+ }
+
+ public static final Relationship REL_SUCCESS = new Relationship.Builder()
+ .name("success")
+ .description("The flowfile contains the original content with one or more attributes added containing the respective counts")
+ .build();
+ public static final Relationship REL_FAILURE = new Relationship.Builder()
+ .name("failure")
+ .description("If the flowfile text cannot be counted for some reason, the original file will be routed to this destination and nothing will be routed elsewhere")
+ .build();
+
+ private static final List<PropertyDescriptor> properties;
+ private static final Set<Relationship> relationships;
+
+ static {
+ properties = Collections.unmodifiableList(Arrays.asList(TEXT_LINE_COUNT_PD,
+ TEXT_LINE_NONEMPTY_COUNT_PD,
+ TEXT_WORD_COUNT_PD,
+ TEXT_CHARACTER_COUNT_PD,
+ SPLIT_WORDS_ON_SYMBOLS_PD,
+ CHARACTER_ENCODING_PD));
+
+ relationships = Collections.unmodifiableSet(new HashSet<>(Arrays.asList(REL_SUCCESS,
+ REL_FAILURE)));
+ }
+
+ private volatile boolean countLines;
+ private volatile boolean countLinesNonEmpty;
+ private volatile boolean countWords;
+ private volatile boolean countCharacters;
+ private volatile boolean splitWordsOnSymbols;
+ private volatile String characterEncoding;
+
+ private volatile int lineCount;
+ private volatile int lineNonEmptyCount;
+ private volatile int wordCount;
+ private volatile int characterCount;
+
+ @Override
+ public Set<Relationship> getRelationships() {
+ return relationships;
+ }
+
+ @OnScheduled
+ public void onSchedule(ProcessContext context) {
+ this.countLines = context.getProperty(TEXT_LINE_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_COUNT_PD).asBoolean() : false;
+ this.countLinesNonEmpty = context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).asBoolean() : false;
+ this.countWords = context.getProperty(TEXT_WORD_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_WORD_COUNT_PD).asBoolean() : false;
+ this.countCharacters = context.getProperty(TEXT_CHARACTER_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_CHARACTER_COUNT_PD).asBoolean() : false;
+ this.splitWordsOnSymbols = context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).isSet()
+ ? context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).asBoolean() : false;
+ this.characterEncoding = context.getProperty(CHARACTER_ENCODING_PD).getValue();
+ }
+
+ /**
+ * Will count text attributes of the incoming stream.
+ */
+ @Override
+ public void onTrigger(ProcessContext context, ProcessSession processSession) throws ProcessException {
+ FlowFile sourceFlowFile = processSession.get();
+ if (sourceFlowFile == null) {
+ return;
+ }
+ AtomicBoolean error = new AtomicBoolean();
+
+ lineCount = 0;
+ lineNonEmptyCount = 0;
+ wordCount = 0;
+ characterCount = 0;
+
+ processSession.read(sourceFlowFile, in -> {
+ long start = System.nanoTime();
+
+ // Iterate over the lines in the text input
+ try {
+ BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(in, characterEncoding));
+ String line;
+ while ((line = bufferedReader.readLine()) != null) {
+ if (countLines) {
+ lineCount++;
+ }
+
+ if (countLinesNonEmpty) {
+ if (line.trim().length() > 0) {
+ lineNonEmptyCount++;
+ }
+ }
+
+ if (countWords) {
+ wordCount += countWordsInLine(line, splitWordsOnSymbols);
+ }
+
+ if (countCharacters) {
+ characterCount += line.length();
+ }
+ }
+ long stop = System.nanoTime();
+ if (getLogger().isDebugEnabled()) {
+ final long durationNanos = stop - start;
+ DecimalFormat df = new DecimalFormat("#.###");
+ getLogger().debug("Computed metrics in " + durationNanos + " nanoseconds (" + df.format(durationNanos / 1_000_000_000.0) + " seconds).");
+ }
+ String message = generateMetricsMessage();
+ getLogger().info(message);
+ } catch (IllegalStateException e) {
--- End diff --
I copied the `onTrigger()` method from `SplitText` and this is probably an unnecessary artifact. I'll make a unit test that throws an unexpected error and handle it better.
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by markap14 <gi...@git.apache.org>.
Github user markap14 commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r159699620
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/main/java/org/apache/nifi/processors/standard/CountText.java ---
@@ -0,0 +1,318 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard;
+
+import java.io.BufferedReader;
+import java.io.InputStreamReader;
+import java.nio.charset.Charset;
+import java.nio.charset.StandardCharsets;
+import java.text.DecimalFormat;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Collectors;
+import org.apache.nifi.annotation.behavior.EventDriven;
+import org.apache.nifi.annotation.behavior.InputRequirement;
+import org.apache.nifi.annotation.behavior.InputRequirement.Requirement;
+import org.apache.nifi.annotation.behavior.SideEffectFree;
+import org.apache.nifi.annotation.behavior.SupportsBatching;
+import org.apache.nifi.annotation.behavior.WritesAttribute;
+import org.apache.nifi.annotation.behavior.WritesAttributes;
+import org.apache.nifi.annotation.documentation.CapabilityDescription;
+import org.apache.nifi.annotation.documentation.SeeAlso;
+import org.apache.nifi.annotation.documentation.Tags;
+import org.apache.nifi.annotation.lifecycle.OnScheduled;
+import org.apache.nifi.components.PropertyDescriptor;
+import org.apache.nifi.flowfile.FlowFile;
+import org.apache.nifi.processor.AbstractProcessor;
+import org.apache.nifi.processor.ProcessContext;
+import org.apache.nifi.processor.ProcessSession;
+import org.apache.nifi.processor.Relationship;
+import org.apache.nifi.processor.exception.ProcessException;
+import org.apache.nifi.processor.util.StandardValidators;
+import org.apache.nifi.util.StringUtils;
+
+@EventDriven
+@SideEffectFree
+@SupportsBatching
+@Tags({"count", "text", "line", "word", "character"})
+@InputRequirement(Requirement.INPUT_REQUIRED)
+@CapabilityDescription("Counts various metrics on incoming text. The requested results will be recorded as attributes. "
+ + "The resulting flowfile will not have its content modified.")
+@WritesAttributes({
+ @WritesAttribute(attribute = "text.line.count", description = "The number of lines of text present in the FlowFile content"),
+ @WritesAttribute(attribute = "text.line.nonempty.count", description = "The number of lines of text (with at least one non-whitespace character) present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.word.count", description = "The number of words present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.character.count", description = "The number of characters (given the specified character encoding) present in the original FlowFile"),
+})
+@SeeAlso(SplitText.class)
+public class CountText extends AbstractProcessor {
+ private static final List<Charset> STANDARD_CHARSETS = Arrays.asList(
+ StandardCharsets.UTF_8,
+ StandardCharsets.US_ASCII,
+ StandardCharsets.ISO_8859_1,
+ StandardCharsets.UTF_16,
+ StandardCharsets.UTF_16LE,
+ StandardCharsets.UTF_16BE);
+
+ private static final String SYMBOL_REGEX = "[\\s-\\._]";
+ private static final String WHITESPACE_ONLY_REGEX = "\\s";
+
+ // Attribute keys
+ public static final String TEXT_LINE_COUNT = "text.line.count";
+ public static final String TEXT_LINE_NONEMPTY_COUNT = "text.line.nonempty.count";
+ public static final String TEXT_WORD_COUNT = "text.word.count";
+ public static final String TEXT_CHARACTER_COUNT = "text.character.count";
+
+
+ public static final PropertyDescriptor TEXT_LINE_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-count")
+ .displayName("Text Line Count")
+ .description("If enabled, will count the number of lines present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("true")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_LINE_NONEMPTY_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-nonempty-count")
+ .displayName("Text Line (non-empty) Count")
+ .description("If enabled, will count the number of lines that contain a non-whitespace character present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_WORD_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-word-count")
+ .displayName("Text Word Count")
+ .description("If enabled, will count the number of words (alphanumeric character groups bounded by whitespace)" +
+ " present in the incoming text. Common logical delimiters [_-.] do not bound a word unless 'Split Words on Symbols' is true.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_CHARACTER_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-character-count")
+ .displayName("Text Character Count")
+ .description("If enabled, will count the number of characters (including whitespace and symbols) present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor SPLIT_WORDS_ON_SYMBOLS_PD = new PropertyDescriptor.Builder()
+ .name("split-words-on-symbols")
+ .displayName("Split Words on Symbols")
+ .description("If enabled, the word count will identify strings separated by common logical delimiters [_-.] as independent words (ex. split-words-on-symbols = 4 words).")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ // TODO: Stream map allowable values to name/key pair?
+ public static final PropertyDescriptor CHARACTER_ENCODING_PD = new PropertyDescriptor.Builder()
+ .name("character-encoding")
+ .displayName("Character Encoding")
+ .description("Specifies a character encoding to use.")
+ .required(true)
+ .allowableValues(getStandardCharsetNames())
+ .defaultValue(StandardCharsets.UTF_8.displayName())
+ .build();
+
+ private static Set<String> getStandardCharsetNames() {
+ return STANDARD_CHARSETS.stream().map(c -> c.displayName()).collect(Collectors.toSet());
+ }
+
+ public static final Relationship REL_SUCCESS = new Relationship.Builder()
+ .name("success")
+ .description("The flowfile contains the original content with one or more attributes added containing the respective counts")
+ .build();
+ public static final Relationship REL_FAILURE = new Relationship.Builder()
+ .name("failure")
+ .description("If the flowfile text cannot be counted for some reason, the original file will be routed to this destination and nothing will be routed elsewhere")
+ .build();
+
+ private static final List<PropertyDescriptor> properties;
+ private static final Set<Relationship> relationships;
+
+ static {
+ properties = Collections.unmodifiableList(Arrays.asList(TEXT_LINE_COUNT_PD,
+ TEXT_LINE_NONEMPTY_COUNT_PD,
+ TEXT_WORD_COUNT_PD,
+ TEXT_CHARACTER_COUNT_PD,
+ SPLIT_WORDS_ON_SYMBOLS_PD,
+ CHARACTER_ENCODING_PD));
+
+ relationships = Collections.unmodifiableSet(new HashSet<>(Arrays.asList(REL_SUCCESS,
+ REL_FAILURE)));
+ }
+
+ private volatile boolean countLines;
+ private volatile boolean countLinesNonEmpty;
+ private volatile boolean countWords;
+ private volatile boolean countCharacters;
+ private volatile boolean splitWordsOnSymbols;
+ private volatile String characterEncoding;
+
+ private volatile int lineCount;
+ private volatile int lineNonEmptyCount;
+ private volatile int wordCount;
+ private volatile int characterCount;
+
+ @Override
+ public Set<Relationship> getRelationships() {
+ return relationships;
+ }
+
+ @OnScheduled
+ public void onSchedule(ProcessContext context) {
+ this.countLines = context.getProperty(TEXT_LINE_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_COUNT_PD).asBoolean() : false;
+ this.countLinesNonEmpty = context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).asBoolean() : false;
+ this.countWords = context.getProperty(TEXT_WORD_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_WORD_COUNT_PD).asBoolean() : false;
+ this.countCharacters = context.getProperty(TEXT_CHARACTER_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_CHARACTER_COUNT_PD).asBoolean() : false;
+ this.splitWordsOnSymbols = context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).isSet()
+ ? context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).asBoolean() : false;
+ this.characterEncoding = context.getProperty(CHARACTER_ENCODING_PD).getValue();
+ }
+
+ /**
+ * Will count text attributes of the incoming stream.
+ */
+ @Override
+ public void onTrigger(ProcessContext context, ProcessSession processSession) throws ProcessException {
+ FlowFile sourceFlowFile = processSession.get();
+ if (sourceFlowFile == null) {
+ return;
+ }
+ AtomicBoolean error = new AtomicBoolean();
+
+ lineCount = 0;
+ lineNonEmptyCount = 0;
+ wordCount = 0;
+ characterCount = 0;
+
+ processSession.read(sourceFlowFile, in -> {
+ long start = System.nanoTime();
+
+ // Iterate over the lines in the text input
+ try {
+ BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(in, characterEncoding));
+ String line;
+ while ((line = bufferedReader.readLine()) != null) {
+ if (countLines) {
+ lineCount++;
+ }
+
+ if (countLinesNonEmpty) {
+ if (line.trim().length() > 0) {
+ lineNonEmptyCount++;
+ }
+ }
+
+ if (countWords) {
+ wordCount += countWordsInLine(line, splitWordsOnSymbols);
+ }
+
+ if (countCharacters) {
+ characterCount += line.length();
+ }
+ }
+ long stop = System.nanoTime();
+ if (getLogger().isDebugEnabled()) {
+ final long durationNanos = stop - start;
+ DecimalFormat df = new DecimalFormat("#.###");
+ getLogger().debug("Computed metrics in " + durationNanos + " nanoseconds (" + df.format(durationNanos / 1_000_000_000.0) + " seconds).");
+ }
+ String message = generateMetricsMessage();
--- End diff --
Given that the default log level for processors is WARN, perhaps we should avoid all of this concatenation if log level of info is not enabled?
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by alopresto <gi...@git.apache.org>.
Github user alopresto commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r159744222
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/main/java/org/apache/nifi/processors/standard/CountText.java ---
@@ -0,0 +1,318 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard;
+
+import java.io.BufferedReader;
+import java.io.InputStreamReader;
+import java.nio.charset.Charset;
+import java.nio.charset.StandardCharsets;
+import java.text.DecimalFormat;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Collectors;
+import org.apache.nifi.annotation.behavior.EventDriven;
+import org.apache.nifi.annotation.behavior.InputRequirement;
+import org.apache.nifi.annotation.behavior.InputRequirement.Requirement;
+import org.apache.nifi.annotation.behavior.SideEffectFree;
+import org.apache.nifi.annotation.behavior.SupportsBatching;
+import org.apache.nifi.annotation.behavior.WritesAttribute;
+import org.apache.nifi.annotation.behavior.WritesAttributes;
+import org.apache.nifi.annotation.documentation.CapabilityDescription;
+import org.apache.nifi.annotation.documentation.SeeAlso;
+import org.apache.nifi.annotation.documentation.Tags;
+import org.apache.nifi.annotation.lifecycle.OnScheduled;
+import org.apache.nifi.components.PropertyDescriptor;
+import org.apache.nifi.flowfile.FlowFile;
+import org.apache.nifi.processor.AbstractProcessor;
+import org.apache.nifi.processor.ProcessContext;
+import org.apache.nifi.processor.ProcessSession;
+import org.apache.nifi.processor.Relationship;
+import org.apache.nifi.processor.exception.ProcessException;
+import org.apache.nifi.processor.util.StandardValidators;
+import org.apache.nifi.util.StringUtils;
+
+@EventDriven
+@SideEffectFree
+@SupportsBatching
+@Tags({"count", "text", "line", "word", "character"})
+@InputRequirement(Requirement.INPUT_REQUIRED)
+@CapabilityDescription("Counts various metrics on incoming text. The requested results will be recorded as attributes. "
+ + "The resulting flowfile will not have its content modified.")
+@WritesAttributes({
+ @WritesAttribute(attribute = "text.line.count", description = "The number of lines of text present in the FlowFile content"),
+ @WritesAttribute(attribute = "text.line.nonempty.count", description = "The number of lines of text (with at least one non-whitespace character) present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.word.count", description = "The number of words present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.character.count", description = "The number of characters (given the specified character encoding) present in the original FlowFile"),
+})
+@SeeAlso(SplitText.class)
+public class CountText extends AbstractProcessor {
+ private static final List<Charset> STANDARD_CHARSETS = Arrays.asList(
+ StandardCharsets.UTF_8,
+ StandardCharsets.US_ASCII,
+ StandardCharsets.ISO_8859_1,
+ StandardCharsets.UTF_16,
+ StandardCharsets.UTF_16LE,
+ StandardCharsets.UTF_16BE);
+
+ private static final String SYMBOL_REGEX = "[\\s-\\._]";
+ private static final String WHITESPACE_ONLY_REGEX = "\\s";
+
+ // Attribute keys
+ public static final String TEXT_LINE_COUNT = "text.line.count";
+ public static final String TEXT_LINE_NONEMPTY_COUNT = "text.line.nonempty.count";
+ public static final String TEXT_WORD_COUNT = "text.word.count";
+ public static final String TEXT_CHARACTER_COUNT = "text.character.count";
+
+
+ public static final PropertyDescriptor TEXT_LINE_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-count")
+ .displayName("Text Line Count")
+ .description("If enabled, will count the number of lines present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("true")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_LINE_NONEMPTY_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-nonempty-count")
+ .displayName("Text Line (non-empty) Count")
+ .description("If enabled, will count the number of lines that contain a non-whitespace character present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_WORD_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-word-count")
+ .displayName("Text Word Count")
+ .description("If enabled, will count the number of words (alphanumeric character groups bounded by whitespace)" +
+ " present in the incoming text. Common logical delimiters [_-.] do not bound a word unless 'Split Words on Symbols' is true.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_CHARACTER_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-character-count")
+ .displayName("Text Character Count")
+ .description("If enabled, will count the number of characters (including whitespace and symbols) present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor SPLIT_WORDS_ON_SYMBOLS_PD = new PropertyDescriptor.Builder()
+ .name("split-words-on-symbols")
+ .displayName("Split Words on Symbols")
+ .description("If enabled, the word count will identify strings separated by common logical delimiters [_-.] as independent words (ex. split-words-on-symbols = 4 words).")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ // TODO: Stream map allowable values to name/key pair?
+ public static final PropertyDescriptor CHARACTER_ENCODING_PD = new PropertyDescriptor.Builder()
+ .name("character-encoding")
+ .displayName("Character Encoding")
+ .description("Specifies a character encoding to use.")
+ .required(true)
+ .allowableValues(getStandardCharsetNames())
+ .defaultValue(StandardCharsets.UTF_8.displayName())
+ .build();
+
+ private static Set<String> getStandardCharsetNames() {
+ return STANDARD_CHARSETS.stream().map(c -> c.displayName()).collect(Collectors.toSet());
+ }
+
+ public static final Relationship REL_SUCCESS = new Relationship.Builder()
+ .name("success")
+ .description("The flowfile contains the original content with one or more attributes added containing the respective counts")
+ .build();
+ public static final Relationship REL_FAILURE = new Relationship.Builder()
+ .name("failure")
+ .description("If the flowfile text cannot be counted for some reason, the original file will be routed to this destination and nothing will be routed elsewhere")
+ .build();
+
+ private static final List<PropertyDescriptor> properties;
+ private static final Set<Relationship> relationships;
+
+ static {
+ properties = Collections.unmodifiableList(Arrays.asList(TEXT_LINE_COUNT_PD,
+ TEXT_LINE_NONEMPTY_COUNT_PD,
+ TEXT_WORD_COUNT_PD,
+ TEXT_CHARACTER_COUNT_PD,
+ SPLIT_WORDS_ON_SYMBOLS_PD,
+ CHARACTER_ENCODING_PD));
+
+ relationships = Collections.unmodifiableSet(new HashSet<>(Arrays.asList(REL_SUCCESS,
+ REL_FAILURE)));
+ }
+
+ private volatile boolean countLines;
+ private volatile boolean countLinesNonEmpty;
+ private volatile boolean countWords;
+ private volatile boolean countCharacters;
+ private volatile boolean splitWordsOnSymbols;
+ private volatile String characterEncoding;
+
+ private volatile int lineCount;
+ private volatile int lineNonEmptyCount;
+ private volatile int wordCount;
+ private volatile int characterCount;
+
+ @Override
+ public Set<Relationship> getRelationships() {
+ return relationships;
+ }
+
+ @OnScheduled
+ public void onSchedule(ProcessContext context) {
+ this.countLines = context.getProperty(TEXT_LINE_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_COUNT_PD).asBoolean() : false;
+ this.countLinesNonEmpty = context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).asBoolean() : false;
+ this.countWords = context.getProperty(TEXT_WORD_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_WORD_COUNT_PD).asBoolean() : false;
+ this.countCharacters = context.getProperty(TEXT_CHARACTER_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_CHARACTER_COUNT_PD).asBoolean() : false;
+ this.splitWordsOnSymbols = context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).isSet()
+ ? context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).asBoolean() : false;
+ this.characterEncoding = context.getProperty(CHARACTER_ENCODING_PD).getValue();
+ }
+
+ /**
+ * Will count text attributes of the incoming stream.
+ */
+ @Override
+ public void onTrigger(ProcessContext context, ProcessSession processSession) throws ProcessException {
+ FlowFile sourceFlowFile = processSession.get();
+ if (sourceFlowFile == null) {
+ return;
+ }
+ AtomicBoolean error = new AtomicBoolean();
+
+ lineCount = 0;
+ lineNonEmptyCount = 0;
+ wordCount = 0;
+ characterCount = 0;
+
+ processSession.read(sourceFlowFile, in -> {
+ long start = System.nanoTime();
+
+ // Iterate over the lines in the text input
+ try {
+ BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(in, characterEncoding));
+ String line;
+ while ((line = bufferedReader.readLine()) != null) {
+ if (countLines) {
+ lineCount++;
+ }
+
+ if (countLinesNonEmpty) {
+ if (line.trim().length() > 0) {
+ lineNonEmptyCount++;
+ }
+ }
+
+ if (countWords) {
+ wordCount += countWordsInLine(line, splitWordsOnSymbols);
+ }
+
+ if (countCharacters) {
+ characterCount += line.length();
+ }
+ }
+ long stop = System.nanoTime();
+ if (getLogger().isDebugEnabled()) {
+ final long durationNanos = stop - start;
+ DecimalFormat df = new DecimalFormat("#.###");
+ getLogger().debug("Computed metrics in " + durationNanos + " nanoseconds (" + df.format(durationNanos / 1_000_000_000.0) + " seconds).");
+ }
+ String message = generateMetricsMessage();
+ getLogger().info(message);
+ } catch (IllegalStateException e) {
+ error.set(true);
+ getLogger().error(e.getMessage() + " Routing to failure.", e);
+ }
+ });
+
+ if (error.get()) {
+ processSession.transfer(sourceFlowFile, REL_FAILURE);
+ } else {
+ Map<String, String> metricAttributes = new HashMap<>();
+ if (countLines) {
+ metricAttributes.put(TEXT_LINE_COUNT, String.valueOf(lineCount));
+ }
+ if (countLinesNonEmpty) {
+ metricAttributes.put(TEXT_LINE_NONEMPTY_COUNT, String.valueOf(lineNonEmptyCount));
+ }
+ if (countWords) {
+ metricAttributes.put(TEXT_WORD_COUNT, String.valueOf(wordCount));
+ }
+ if (countCharacters) {
+ metricAttributes.put(TEXT_CHARACTER_COUNT, String.valueOf(characterCount));
+ }
+ FlowFile updatedFlowFile = processSession.putAllAttributes(sourceFlowFile, metricAttributes);
+ processSession.transfer(updatedFlowFile, REL_SUCCESS);
+ }
+ }
+
+ private String generateMetricsMessage() {
+ StringBuilder sb = new StringBuilder("Counted ");
+ List<String> metrics = new ArrayList<>();
+ if (countLines) {
+ metrics.add(lineCount + " lines");
+ }
+ if (countLinesNonEmpty) {
+ metrics.add(lineNonEmptyCount + " non-empty lines");
+ }
+ if (countWords) {
+ metrics.add(wordCount + " words");
+ }
+ if (countCharacters) {
+ metrics.add(characterCount + " characters");
+ }
+ sb.append(StringUtils.join(metrics, ", "));
+ return sb.toString();
+ }
+
+ private int countWordsInLine(String line, boolean splitWordsOnSymbols) {
+ if (line == null || line.trim().length() == 0) {
+ return 0;
+ } else {
+ String regex = splitWordsOnSymbols ? SYMBOL_REGEX : WHITESPACE_ONLY_REGEX;
--- End diff --
Good idea.
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by markap14 <gi...@git.apache.org>.
Github user markap14 commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r159697649
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/main/java/org/apache/nifi/processors/standard/CountText.java ---
@@ -0,0 +1,318 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard;
+
+import java.io.BufferedReader;
+import java.io.InputStreamReader;
+import java.nio.charset.Charset;
+import java.nio.charset.StandardCharsets;
+import java.text.DecimalFormat;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Collectors;
+import org.apache.nifi.annotation.behavior.EventDriven;
+import org.apache.nifi.annotation.behavior.InputRequirement;
+import org.apache.nifi.annotation.behavior.InputRequirement.Requirement;
+import org.apache.nifi.annotation.behavior.SideEffectFree;
+import org.apache.nifi.annotation.behavior.SupportsBatching;
+import org.apache.nifi.annotation.behavior.WritesAttribute;
+import org.apache.nifi.annotation.behavior.WritesAttributes;
+import org.apache.nifi.annotation.documentation.CapabilityDescription;
+import org.apache.nifi.annotation.documentation.SeeAlso;
+import org.apache.nifi.annotation.documentation.Tags;
+import org.apache.nifi.annotation.lifecycle.OnScheduled;
+import org.apache.nifi.components.PropertyDescriptor;
+import org.apache.nifi.flowfile.FlowFile;
+import org.apache.nifi.processor.AbstractProcessor;
+import org.apache.nifi.processor.ProcessContext;
+import org.apache.nifi.processor.ProcessSession;
+import org.apache.nifi.processor.Relationship;
+import org.apache.nifi.processor.exception.ProcessException;
+import org.apache.nifi.processor.util.StandardValidators;
+import org.apache.nifi.util.StringUtils;
+
+@EventDriven
+@SideEffectFree
+@SupportsBatching
+@Tags({"count", "text", "line", "word", "character"})
+@InputRequirement(Requirement.INPUT_REQUIRED)
+@CapabilityDescription("Counts various metrics on incoming text. The requested results will be recorded as attributes. "
+ + "The resulting flowfile will not have its content modified.")
+@WritesAttributes({
+ @WritesAttribute(attribute = "text.line.count", description = "The number of lines of text present in the FlowFile content"),
+ @WritesAttribute(attribute = "text.line.nonempty.count", description = "The number of lines of text (with at least one non-whitespace character) present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.word.count", description = "The number of words present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.character.count", description = "The number of characters (given the specified character encoding) present in the original FlowFile"),
+})
+@SeeAlso(SplitText.class)
+public class CountText extends AbstractProcessor {
+ private static final List<Charset> STANDARD_CHARSETS = Arrays.asList(
+ StandardCharsets.UTF_8,
+ StandardCharsets.US_ASCII,
+ StandardCharsets.ISO_8859_1,
+ StandardCharsets.UTF_16,
+ StandardCharsets.UTF_16LE,
+ StandardCharsets.UTF_16BE);
+
+ private static final String SYMBOL_REGEX = "[\\s-\\._]";
+ private static final String WHITESPACE_ONLY_REGEX = "\\s";
+
+ // Attribute keys
+ public static final String TEXT_LINE_COUNT = "text.line.count";
+ public static final String TEXT_LINE_NONEMPTY_COUNT = "text.line.nonempty.count";
+ public static final String TEXT_WORD_COUNT = "text.word.count";
+ public static final String TEXT_CHARACTER_COUNT = "text.character.count";
+
+
+ public static final PropertyDescriptor TEXT_LINE_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-count")
+ .displayName("Text Line Count")
--- End diff --
Given that these are boolean properties, I wonder if it makes more sense to word as "Count Lines", "Count Non-Empty Lines", "Count Words"?
Is a minor point, and if you don't agree it's okay to keep as-is but I found the wording less intuitive personally. Up to you.
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by kevdoran <gi...@git.apache.org>.
Github user kevdoran commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r160245113
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/test/groovy/org/apache/nifi/processors/standard/CountTextTest.groovy ---
@@ -0,0 +1,277 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License") you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard
+
+import org.apache.nifi.components.PropertyDescriptor
+import org.apache.nifi.components.ValidationResult
+import org.apache.nifi.flowfile.FlowFile
+import org.apache.nifi.security.util.EncryptionMethod
+import org.apache.nifi.security.util.KeyDerivationFunction
+import org.apache.nifi.security.util.crypto.PasswordBasedEncryptor
+import org.apache.nifi.util.MockProcessContext
+import org.apache.nifi.util.TestRunner
+import org.apache.nifi.util.TestRunners
+import org.bouncycastle.jce.provider.BouncyCastleProvider
+import org.junit.After
+import org.junit.Assert
+import org.junit.Before
+import org.junit.BeforeClass
+import org.junit.Ignore
+import org.junit.Test
+import org.junit.runner.RunWith
+import org.junit.runners.JUnit4
+import org.slf4j.Logger
+import org.slf4j.LoggerFactory
+
+import java.security.Security
+
+@RunWith(JUnit4.class)
+class CountTextTest extends GroovyTestCase {
+ private static final Logger logger = LoggerFactory.getLogger(CountTextTest.class)
+
+ @BeforeClass
+ static void setUpOnce() throws Exception {
+ Security.addProvider(new BouncyCastleProvider())
+
+ logger.metaClass.methodMissing = { String name, args ->
+ logger.info("[${name?.toUpperCase()}] ${(args as List).join(" ")}")
+ }
+ }
+
+ @Before
+ void setUp() throws Exception {
+ }
+
+ @After
+ void tearDown() throws Exception {
+ }
+
+ @Test
+ void testShouldCountAllMetrics() throws Exception {
+ // Arrange
+ final TestRunner runner = TestRunners.newTestRunner(CountText.class)
+
+ runner.setProperty(CountText.TEXT_LINE_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_LINE_NONEMPTY_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_WORD_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_CHARACTER_COUNT_PD, "true")
+
+ String INPUT_TEXT = """’Twas brillig, and the slithy toves
--- End diff --
In that case, it might be worth just adding a code comment that the inline text is intentional to test expected values are independent. Or change the context to make it more obvious, as it's not clear the test case is performing that additional function.
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by alopresto <gi...@git.apache.org>.
Github user alopresto commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r159743870
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/main/java/org/apache/nifi/processors/standard/CountText.java ---
@@ -0,0 +1,318 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard;
+
+import java.io.BufferedReader;
+import java.io.InputStreamReader;
+import java.nio.charset.Charset;
+import java.nio.charset.StandardCharsets;
+import java.text.DecimalFormat;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Collectors;
+import org.apache.nifi.annotation.behavior.EventDriven;
+import org.apache.nifi.annotation.behavior.InputRequirement;
+import org.apache.nifi.annotation.behavior.InputRequirement.Requirement;
+import org.apache.nifi.annotation.behavior.SideEffectFree;
+import org.apache.nifi.annotation.behavior.SupportsBatching;
+import org.apache.nifi.annotation.behavior.WritesAttribute;
+import org.apache.nifi.annotation.behavior.WritesAttributes;
+import org.apache.nifi.annotation.documentation.CapabilityDescription;
+import org.apache.nifi.annotation.documentation.SeeAlso;
+import org.apache.nifi.annotation.documentation.Tags;
+import org.apache.nifi.annotation.lifecycle.OnScheduled;
+import org.apache.nifi.components.PropertyDescriptor;
+import org.apache.nifi.flowfile.FlowFile;
+import org.apache.nifi.processor.AbstractProcessor;
+import org.apache.nifi.processor.ProcessContext;
+import org.apache.nifi.processor.ProcessSession;
+import org.apache.nifi.processor.Relationship;
+import org.apache.nifi.processor.exception.ProcessException;
+import org.apache.nifi.processor.util.StandardValidators;
+import org.apache.nifi.util.StringUtils;
+
+@EventDriven
+@SideEffectFree
+@SupportsBatching
+@Tags({"count", "text", "line", "word", "character"})
+@InputRequirement(Requirement.INPUT_REQUIRED)
+@CapabilityDescription("Counts various metrics on incoming text. The requested results will be recorded as attributes. "
+ + "The resulting flowfile will not have its content modified.")
+@WritesAttributes({
+ @WritesAttribute(attribute = "text.line.count", description = "The number of lines of text present in the FlowFile content"),
+ @WritesAttribute(attribute = "text.line.nonempty.count", description = "The number of lines of text (with at least one non-whitespace character) present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.word.count", description = "The number of words present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.character.count", description = "The number of characters (given the specified character encoding) present in the original FlowFile"),
+})
+@SeeAlso(SplitText.class)
+public class CountText extends AbstractProcessor {
+ private static final List<Charset> STANDARD_CHARSETS = Arrays.asList(
+ StandardCharsets.UTF_8,
+ StandardCharsets.US_ASCII,
+ StandardCharsets.ISO_8859_1,
+ StandardCharsets.UTF_16,
+ StandardCharsets.UTF_16LE,
+ StandardCharsets.UTF_16BE);
+
+ private static final String SYMBOL_REGEX = "[\\s-\\._]";
+ private static final String WHITESPACE_ONLY_REGEX = "\\s";
+
+ // Attribute keys
+ public static final String TEXT_LINE_COUNT = "text.line.count";
+ public static final String TEXT_LINE_NONEMPTY_COUNT = "text.line.nonempty.count";
+ public static final String TEXT_WORD_COUNT = "text.word.count";
+ public static final String TEXT_CHARACTER_COUNT = "text.character.count";
+
+
+ public static final PropertyDescriptor TEXT_LINE_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-count")
+ .displayName("Text Line Count")
+ .description("If enabled, will count the number of lines present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("true")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_LINE_NONEMPTY_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-nonempty-count")
+ .displayName("Text Line (non-empty) Count")
+ .description("If enabled, will count the number of lines that contain a non-whitespace character present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_WORD_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-word-count")
+ .displayName("Text Word Count")
+ .description("If enabled, will count the number of words (alphanumeric character groups bounded by whitespace)" +
+ " present in the incoming text. Common logical delimiters [_-.] do not bound a word unless 'Split Words on Symbols' is true.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_CHARACTER_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-character-count")
+ .displayName("Text Character Count")
+ .description("If enabled, will count the number of characters (including whitespace and symbols) present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor SPLIT_WORDS_ON_SYMBOLS_PD = new PropertyDescriptor.Builder()
+ .name("split-words-on-symbols")
+ .displayName("Split Words on Symbols")
+ .description("If enabled, the word count will identify strings separated by common logical delimiters [_-.] as independent words (ex. split-words-on-symbols = 4 words).")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ // TODO: Stream map allowable values to name/key pair?
+ public static final PropertyDescriptor CHARACTER_ENCODING_PD = new PropertyDescriptor.Builder()
+ .name("character-encoding")
+ .displayName("Character Encoding")
+ .description("Specifies a character encoding to use.")
+ .required(true)
+ .allowableValues(getStandardCharsetNames())
+ .defaultValue(StandardCharsets.UTF_8.displayName())
+ .build();
+
+ private static Set<String> getStandardCharsetNames() {
+ return STANDARD_CHARSETS.stream().map(c -> c.displayName()).collect(Collectors.toSet());
+ }
+
+ public static final Relationship REL_SUCCESS = new Relationship.Builder()
+ .name("success")
+ .description("The flowfile contains the original content with one or more attributes added containing the respective counts")
+ .build();
+ public static final Relationship REL_FAILURE = new Relationship.Builder()
+ .name("failure")
+ .description("If the flowfile text cannot be counted for some reason, the original file will be routed to this destination and nothing will be routed elsewhere")
+ .build();
+
+ private static final List<PropertyDescriptor> properties;
+ private static final Set<Relationship> relationships;
+
+ static {
+ properties = Collections.unmodifiableList(Arrays.asList(TEXT_LINE_COUNT_PD,
+ TEXT_LINE_NONEMPTY_COUNT_PD,
+ TEXT_WORD_COUNT_PD,
+ TEXT_CHARACTER_COUNT_PD,
+ SPLIT_WORDS_ON_SYMBOLS_PD,
+ CHARACTER_ENCODING_PD));
+
+ relationships = Collections.unmodifiableSet(new HashSet<>(Arrays.asList(REL_SUCCESS,
+ REL_FAILURE)));
+ }
+
+ private volatile boolean countLines;
+ private volatile boolean countLinesNonEmpty;
+ private volatile boolean countWords;
+ private volatile boolean countCharacters;
+ private volatile boolean splitWordsOnSymbols;
+ private volatile String characterEncoding;
+
+ private volatile int lineCount;
+ private volatile int lineNonEmptyCount;
+ private volatile int wordCount;
+ private volatile int characterCount;
+
+ @Override
+ public Set<Relationship> getRelationships() {
+ return relationships;
+ }
+
+ @OnScheduled
+ public void onSchedule(ProcessContext context) {
+ this.countLines = context.getProperty(TEXT_LINE_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_COUNT_PD).asBoolean() : false;
+ this.countLinesNonEmpty = context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).asBoolean() : false;
+ this.countWords = context.getProperty(TEXT_WORD_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_WORD_COUNT_PD).asBoolean() : false;
+ this.countCharacters = context.getProperty(TEXT_CHARACTER_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_CHARACTER_COUNT_PD).asBoolean() : false;
+ this.splitWordsOnSymbols = context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).isSet()
+ ? context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).asBoolean() : false;
+ this.characterEncoding = context.getProperty(CHARACTER_ENCODING_PD).getValue();
+ }
+
+ /**
+ * Will count text attributes of the incoming stream.
+ */
+ @Override
+ public void onTrigger(ProcessContext context, ProcessSession processSession) throws ProcessException {
+ FlowFile sourceFlowFile = processSession.get();
+ if (sourceFlowFile == null) {
+ return;
+ }
+ AtomicBoolean error = new AtomicBoolean();
+
+ lineCount = 0;
+ lineNonEmptyCount = 0;
+ wordCount = 0;
+ characterCount = 0;
+
+ processSession.read(sourceFlowFile, in -> {
+ long start = System.nanoTime();
+
+ // Iterate over the lines in the text input
+ try {
+ BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(in, characterEncoding));
+ String line;
+ while ((line = bufferedReader.readLine()) != null) {
+ if (countLines) {
+ lineCount++;
+ }
+
+ if (countLinesNonEmpty) {
+ if (line.trim().length() > 0) {
+ lineNonEmptyCount++;
+ }
+ }
+
+ if (countWords) {
+ wordCount += countWordsInLine(line, splitWordsOnSymbols);
+ }
+
+ if (countCharacters) {
--- End diff --
I mirrored the behavior of standard word processors which count whitespace but do not count newline and carriage returns. I'll make this clearer in the documentation.
---
[GitHub] nifi issue #2371: NIFI-4727 Add CountText processor
Posted by alopresto <gi...@git.apache.org>.
Github user alopresto commented on the issue:
https://github.com/apache/nifi/pull/2371
@markap14 I made the changes you requested. Please give it a once-over and let me know if there's anything outstanding. Thanks.
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by alopresto <gi...@git.apache.org>.
Github user alopresto commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r159744183
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/main/java/org/apache/nifi/processors/standard/CountText.java ---
@@ -0,0 +1,318 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard;
+
+import java.io.BufferedReader;
+import java.io.InputStreamReader;
+import java.nio.charset.Charset;
+import java.nio.charset.StandardCharsets;
+import java.text.DecimalFormat;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Collectors;
+import org.apache.nifi.annotation.behavior.EventDriven;
+import org.apache.nifi.annotation.behavior.InputRequirement;
+import org.apache.nifi.annotation.behavior.InputRequirement.Requirement;
+import org.apache.nifi.annotation.behavior.SideEffectFree;
+import org.apache.nifi.annotation.behavior.SupportsBatching;
+import org.apache.nifi.annotation.behavior.WritesAttribute;
+import org.apache.nifi.annotation.behavior.WritesAttributes;
+import org.apache.nifi.annotation.documentation.CapabilityDescription;
+import org.apache.nifi.annotation.documentation.SeeAlso;
+import org.apache.nifi.annotation.documentation.Tags;
+import org.apache.nifi.annotation.lifecycle.OnScheduled;
+import org.apache.nifi.components.PropertyDescriptor;
+import org.apache.nifi.flowfile.FlowFile;
+import org.apache.nifi.processor.AbstractProcessor;
+import org.apache.nifi.processor.ProcessContext;
+import org.apache.nifi.processor.ProcessSession;
+import org.apache.nifi.processor.Relationship;
+import org.apache.nifi.processor.exception.ProcessException;
+import org.apache.nifi.processor.util.StandardValidators;
+import org.apache.nifi.util.StringUtils;
+
+@EventDriven
+@SideEffectFree
+@SupportsBatching
+@Tags({"count", "text", "line", "word", "character"})
+@InputRequirement(Requirement.INPUT_REQUIRED)
+@CapabilityDescription("Counts various metrics on incoming text. The requested results will be recorded as attributes. "
+ + "The resulting flowfile will not have its content modified.")
+@WritesAttributes({
+ @WritesAttribute(attribute = "text.line.count", description = "The number of lines of text present in the FlowFile content"),
+ @WritesAttribute(attribute = "text.line.nonempty.count", description = "The number of lines of text (with at least one non-whitespace character) present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.word.count", description = "The number of words present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.character.count", description = "The number of characters (given the specified character encoding) present in the original FlowFile"),
+})
+@SeeAlso(SplitText.class)
+public class CountText extends AbstractProcessor {
+ private static final List<Charset> STANDARD_CHARSETS = Arrays.asList(
+ StandardCharsets.UTF_8,
+ StandardCharsets.US_ASCII,
+ StandardCharsets.ISO_8859_1,
+ StandardCharsets.UTF_16,
+ StandardCharsets.UTF_16LE,
+ StandardCharsets.UTF_16BE);
+
+ private static final String SYMBOL_REGEX = "[\\s-\\._]";
+ private static final String WHITESPACE_ONLY_REGEX = "\\s";
+
+ // Attribute keys
+ public static final String TEXT_LINE_COUNT = "text.line.count";
+ public static final String TEXT_LINE_NONEMPTY_COUNT = "text.line.nonempty.count";
+ public static final String TEXT_WORD_COUNT = "text.word.count";
+ public static final String TEXT_CHARACTER_COUNT = "text.character.count";
+
+
+ public static final PropertyDescriptor TEXT_LINE_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-count")
+ .displayName("Text Line Count")
+ .description("If enabled, will count the number of lines present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("true")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_LINE_NONEMPTY_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-nonempty-count")
+ .displayName("Text Line (non-empty) Count")
+ .description("If enabled, will count the number of lines that contain a non-whitespace character present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_WORD_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-word-count")
+ .displayName("Text Word Count")
+ .description("If enabled, will count the number of words (alphanumeric character groups bounded by whitespace)" +
+ " present in the incoming text. Common logical delimiters [_-.] do not bound a word unless 'Split Words on Symbols' is true.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_CHARACTER_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-character-count")
+ .displayName("Text Character Count")
+ .description("If enabled, will count the number of characters (including whitespace and symbols) present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor SPLIT_WORDS_ON_SYMBOLS_PD = new PropertyDescriptor.Builder()
+ .name("split-words-on-symbols")
+ .displayName("Split Words on Symbols")
+ .description("If enabled, the word count will identify strings separated by common logical delimiters [_-.] as independent words (ex. split-words-on-symbols = 4 words).")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ // TODO: Stream map allowable values to name/key pair?
+ public static final PropertyDescriptor CHARACTER_ENCODING_PD = new PropertyDescriptor.Builder()
+ .name("character-encoding")
+ .displayName("Character Encoding")
+ .description("Specifies a character encoding to use.")
+ .required(true)
+ .allowableValues(getStandardCharsetNames())
+ .defaultValue(StandardCharsets.UTF_8.displayName())
+ .build();
+
+ private static Set<String> getStandardCharsetNames() {
+ return STANDARD_CHARSETS.stream().map(c -> c.displayName()).collect(Collectors.toSet());
+ }
+
+ public static final Relationship REL_SUCCESS = new Relationship.Builder()
+ .name("success")
+ .description("The flowfile contains the original content with one or more attributes added containing the respective counts")
+ .build();
+ public static final Relationship REL_FAILURE = new Relationship.Builder()
+ .name("failure")
+ .description("If the flowfile text cannot be counted for some reason, the original file will be routed to this destination and nothing will be routed elsewhere")
+ .build();
+
+ private static final List<PropertyDescriptor> properties;
+ private static final Set<Relationship> relationships;
+
+ static {
+ properties = Collections.unmodifiableList(Arrays.asList(TEXT_LINE_COUNT_PD,
+ TEXT_LINE_NONEMPTY_COUNT_PD,
+ TEXT_WORD_COUNT_PD,
+ TEXT_CHARACTER_COUNT_PD,
+ SPLIT_WORDS_ON_SYMBOLS_PD,
+ CHARACTER_ENCODING_PD));
+
+ relationships = Collections.unmodifiableSet(new HashSet<>(Arrays.asList(REL_SUCCESS,
+ REL_FAILURE)));
+ }
+
+ private volatile boolean countLines;
+ private volatile boolean countLinesNonEmpty;
+ private volatile boolean countWords;
+ private volatile boolean countCharacters;
+ private volatile boolean splitWordsOnSymbols;
+ private volatile String characterEncoding;
+
+ private volatile int lineCount;
+ private volatile int lineNonEmptyCount;
+ private volatile int wordCount;
+ private volatile int characterCount;
+
+ @Override
+ public Set<Relationship> getRelationships() {
+ return relationships;
+ }
+
+ @OnScheduled
+ public void onSchedule(ProcessContext context) {
+ this.countLines = context.getProperty(TEXT_LINE_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_COUNT_PD).asBoolean() : false;
+ this.countLinesNonEmpty = context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).asBoolean() : false;
+ this.countWords = context.getProperty(TEXT_WORD_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_WORD_COUNT_PD).asBoolean() : false;
+ this.countCharacters = context.getProperty(TEXT_CHARACTER_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_CHARACTER_COUNT_PD).asBoolean() : false;
+ this.splitWordsOnSymbols = context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).isSet()
+ ? context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).asBoolean() : false;
+ this.characterEncoding = context.getProperty(CHARACTER_ENCODING_PD).getValue();
+ }
+
+ /**
+ * Will count text attributes of the incoming stream.
+ */
+ @Override
+ public void onTrigger(ProcessContext context, ProcessSession processSession) throws ProcessException {
+ FlowFile sourceFlowFile = processSession.get();
+ if (sourceFlowFile == null) {
+ return;
+ }
+ AtomicBoolean error = new AtomicBoolean();
+
+ lineCount = 0;
+ lineNonEmptyCount = 0;
+ wordCount = 0;
+ characterCount = 0;
+
+ processSession.read(sourceFlowFile, in -> {
+ long start = System.nanoTime();
+
+ // Iterate over the lines in the text input
+ try {
+ BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(in, characterEncoding));
+ String line;
+ while ((line = bufferedReader.readLine()) != null) {
+ if (countLines) {
+ lineCount++;
+ }
+
+ if (countLinesNonEmpty) {
+ if (line.trim().length() > 0) {
+ lineNonEmptyCount++;
+ }
+ }
+
+ if (countWords) {
+ wordCount += countWordsInLine(line, splitWordsOnSymbols);
+ }
+
+ if (countCharacters) {
+ characterCount += line.length();
+ }
+ }
+ long stop = System.nanoTime();
+ if (getLogger().isDebugEnabled()) {
+ final long durationNanos = stop - start;
+ DecimalFormat df = new DecimalFormat("#.###");
+ getLogger().debug("Computed metrics in " + durationNanos + " nanoseconds (" + df.format(durationNanos / 1_000_000_000.0) + " seconds).");
+ }
+ String message = generateMetricsMessage();
+ getLogger().info(message);
+ } catch (IllegalStateException e) {
+ error.set(true);
+ getLogger().error(e.getMessage() + " Routing to failure.", e);
+ }
+ });
+
+ if (error.get()) {
+ processSession.transfer(sourceFlowFile, REL_FAILURE);
+ } else {
+ Map<String, String> metricAttributes = new HashMap<>();
+ if (countLines) {
--- End diff --
I'll look into this. Do you have an example of another processor that does what you expect with this value?
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by markap14 <gi...@git.apache.org>.
Github user markap14 commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r159698768
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/main/java/org/apache/nifi/processors/standard/CountText.java ---
@@ -0,0 +1,318 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard;
+
+import java.io.BufferedReader;
+import java.io.InputStreamReader;
+import java.nio.charset.Charset;
+import java.nio.charset.StandardCharsets;
+import java.text.DecimalFormat;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Collectors;
+import org.apache.nifi.annotation.behavior.EventDriven;
+import org.apache.nifi.annotation.behavior.InputRequirement;
+import org.apache.nifi.annotation.behavior.InputRequirement.Requirement;
+import org.apache.nifi.annotation.behavior.SideEffectFree;
+import org.apache.nifi.annotation.behavior.SupportsBatching;
+import org.apache.nifi.annotation.behavior.WritesAttribute;
+import org.apache.nifi.annotation.behavior.WritesAttributes;
+import org.apache.nifi.annotation.documentation.CapabilityDescription;
+import org.apache.nifi.annotation.documentation.SeeAlso;
+import org.apache.nifi.annotation.documentation.Tags;
+import org.apache.nifi.annotation.lifecycle.OnScheduled;
+import org.apache.nifi.components.PropertyDescriptor;
+import org.apache.nifi.flowfile.FlowFile;
+import org.apache.nifi.processor.AbstractProcessor;
+import org.apache.nifi.processor.ProcessContext;
+import org.apache.nifi.processor.ProcessSession;
+import org.apache.nifi.processor.Relationship;
+import org.apache.nifi.processor.exception.ProcessException;
+import org.apache.nifi.processor.util.StandardValidators;
+import org.apache.nifi.util.StringUtils;
+
+@EventDriven
+@SideEffectFree
+@SupportsBatching
+@Tags({"count", "text", "line", "word", "character"})
+@InputRequirement(Requirement.INPUT_REQUIRED)
+@CapabilityDescription("Counts various metrics on incoming text. The requested results will be recorded as attributes. "
+ + "The resulting flowfile will not have its content modified.")
+@WritesAttributes({
+ @WritesAttribute(attribute = "text.line.count", description = "The number of lines of text present in the FlowFile content"),
+ @WritesAttribute(attribute = "text.line.nonempty.count", description = "The number of lines of text (with at least one non-whitespace character) present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.word.count", description = "The number of words present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.character.count", description = "The number of characters (given the specified character encoding) present in the original FlowFile"),
+})
+@SeeAlso(SplitText.class)
+public class CountText extends AbstractProcessor {
+ private static final List<Charset> STANDARD_CHARSETS = Arrays.asList(
+ StandardCharsets.UTF_8,
+ StandardCharsets.US_ASCII,
+ StandardCharsets.ISO_8859_1,
+ StandardCharsets.UTF_16,
+ StandardCharsets.UTF_16LE,
+ StandardCharsets.UTF_16BE);
+
+ private static final String SYMBOL_REGEX = "[\\s-\\._]";
+ private static final String WHITESPACE_ONLY_REGEX = "\\s";
+
+ // Attribute keys
+ public static final String TEXT_LINE_COUNT = "text.line.count";
+ public static final String TEXT_LINE_NONEMPTY_COUNT = "text.line.nonempty.count";
+ public static final String TEXT_WORD_COUNT = "text.word.count";
+ public static final String TEXT_CHARACTER_COUNT = "text.character.count";
+
+
+ public static final PropertyDescriptor TEXT_LINE_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-count")
+ .displayName("Text Line Count")
+ .description("If enabled, will count the number of lines present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("true")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_LINE_NONEMPTY_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-nonempty-count")
+ .displayName("Text Line (non-empty) Count")
+ .description("If enabled, will count the number of lines that contain a non-whitespace character present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_WORD_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-word-count")
+ .displayName("Text Word Count")
+ .description("If enabled, will count the number of words (alphanumeric character groups bounded by whitespace)" +
+ " present in the incoming text. Common logical delimiters [_-.] do not bound a word unless 'Split Words on Symbols' is true.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_CHARACTER_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-character-count")
+ .displayName("Text Character Count")
+ .description("If enabled, will count the number of characters (including whitespace and symbols) present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor SPLIT_WORDS_ON_SYMBOLS_PD = new PropertyDescriptor.Builder()
+ .name("split-words-on-symbols")
+ .displayName("Split Words on Symbols")
+ .description("If enabled, the word count will identify strings separated by common logical delimiters [_-.] as independent words (ex. split-words-on-symbols = 4 words).")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ // TODO: Stream map allowable values to name/key pair?
+ public static final PropertyDescriptor CHARACTER_ENCODING_PD = new PropertyDescriptor.Builder()
+ .name("character-encoding")
+ .displayName("Character Encoding")
+ .description("Specifies a character encoding to use.")
+ .required(true)
+ .allowableValues(getStandardCharsetNames())
+ .defaultValue(StandardCharsets.UTF_8.displayName())
+ .build();
+
+ private static Set<String> getStandardCharsetNames() {
+ return STANDARD_CHARSETS.stream().map(c -> c.displayName()).collect(Collectors.toSet());
+ }
+
+ public static final Relationship REL_SUCCESS = new Relationship.Builder()
+ .name("success")
+ .description("The flowfile contains the original content with one or more attributes added containing the respective counts")
+ .build();
+ public static final Relationship REL_FAILURE = new Relationship.Builder()
+ .name("failure")
+ .description("If the flowfile text cannot be counted for some reason, the original file will be routed to this destination and nothing will be routed elsewhere")
+ .build();
+
+ private static final List<PropertyDescriptor> properties;
+ private static final Set<Relationship> relationships;
+
+ static {
+ properties = Collections.unmodifiableList(Arrays.asList(TEXT_LINE_COUNT_PD,
+ TEXT_LINE_NONEMPTY_COUNT_PD,
+ TEXT_WORD_COUNT_PD,
+ TEXT_CHARACTER_COUNT_PD,
+ SPLIT_WORDS_ON_SYMBOLS_PD,
+ CHARACTER_ENCODING_PD));
+
+ relationships = Collections.unmodifiableSet(new HashSet<>(Arrays.asList(REL_SUCCESS,
+ REL_FAILURE)));
+ }
+
+ private volatile boolean countLines;
+ private volatile boolean countLinesNonEmpty;
+ private volatile boolean countWords;
+ private volatile boolean countCharacters;
+ private volatile boolean splitWordsOnSymbols;
+ private volatile String characterEncoding;
+
+ private volatile int lineCount;
+ private volatile int lineNonEmptyCount;
+ private volatile int wordCount;
+ private volatile int characterCount;
+
+ @Override
+ public Set<Relationship> getRelationships() {
+ return relationships;
+ }
+
+ @OnScheduled
+ public void onSchedule(ProcessContext context) {
+ this.countLines = context.getProperty(TEXT_LINE_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_COUNT_PD).asBoolean() : false;
+ this.countLinesNonEmpty = context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).asBoolean() : false;
+ this.countWords = context.getProperty(TEXT_WORD_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_WORD_COUNT_PD).asBoolean() : false;
+ this.countCharacters = context.getProperty(TEXT_CHARACTER_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_CHARACTER_COUNT_PD).asBoolean() : false;
+ this.splitWordsOnSymbols = context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).isSet()
+ ? context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).asBoolean() : false;
+ this.characterEncoding = context.getProperty(CHARACTER_ENCODING_PD).getValue();
+ }
+
+ /**
+ * Will count text attributes of the incoming stream.
+ */
+ @Override
+ public void onTrigger(ProcessContext context, ProcessSession processSession) throws ProcessException {
+ FlowFile sourceFlowFile = processSession.get();
+ if (sourceFlowFile == null) {
+ return;
+ }
+ AtomicBoolean error = new AtomicBoolean();
+
+ lineCount = 0;
+ lineNonEmptyCount = 0;
+ wordCount = 0;
+ characterCount = 0;
+
+ processSession.read(sourceFlowFile, in -> {
+ long start = System.nanoTime();
+
+ // Iterate over the lines in the text input
+ try {
+ BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(in, characterEncoding));
+ String line;
+ while ((line = bufferedReader.readLine()) != null) {
+ if (countLines) {
+ lineCount++;
+ }
+
+ if (countLinesNonEmpty) {
+ if (line.trim().length() > 0) {
+ lineNonEmptyCount++;
+ }
+ }
+
+ if (countWords) {
+ wordCount += countWordsInLine(line, splitWordsOnSymbols);
+ }
+
+ if (countCharacters) {
+ characterCount += line.length();
+ }
+ }
+ long stop = System.nanoTime();
+ if (getLogger().isDebugEnabled()) {
+ final long durationNanos = stop - start;
+ DecimalFormat df = new DecimalFormat("#.###");
+ getLogger().debug("Computed metrics in " + durationNanos + " nanoseconds (" + df.format(durationNanos / 1_000_000_000.0) + " seconds).");
+ }
+ String message = generateMetricsMessage();
+ getLogger().info(message);
+ } catch (IllegalStateException e) {
--- End diff --
Why would we have an IllegalStateException here? That seems an odd thing to catch...
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by asfgit <gi...@git.apache.org>.
Github user asfgit closed the pull request at:
https://github.com/apache/nifi/pull/2371
---
[GitHub] nifi issue #2371: NIFI-4727 Add CountText processor
Posted by markap14 <gi...@git.apache.org>.
Github user markap14 commented on the issue:
https://github.com/apache/nifi/pull/2371
Will review
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by alopresto <gi...@git.apache.org>.
Github user alopresto commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r159697969
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/test/groovy/org/apache/nifi/processors/standard/CountTextTest.groovy ---
@@ -0,0 +1,277 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License") you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard
+
+import org.apache.nifi.components.PropertyDescriptor
+import org.apache.nifi.components.ValidationResult
+import org.apache.nifi.flowfile.FlowFile
+import org.apache.nifi.security.util.EncryptionMethod
+import org.apache.nifi.security.util.KeyDerivationFunction
+import org.apache.nifi.security.util.crypto.PasswordBasedEncryptor
+import org.apache.nifi.util.MockProcessContext
+import org.apache.nifi.util.TestRunner
+import org.apache.nifi.util.TestRunners
+import org.bouncycastle.jce.provider.BouncyCastleProvider
+import org.junit.After
+import org.junit.Assert
+import org.junit.Before
+import org.junit.BeforeClass
+import org.junit.Ignore
+import org.junit.Test
+import org.junit.runner.RunWith
+import org.junit.runners.JUnit4
+import org.slf4j.Logger
+import org.slf4j.LoggerFactory
+
+import java.security.Security
+
+@RunWith(JUnit4.class)
+class CountTextTest extends GroovyTestCase {
+ private static final Logger logger = LoggerFactory.getLogger(CountTextTest.class)
+
+ @BeforeClass
+ static void setUpOnce() throws Exception {
+ Security.addProvider(new BouncyCastleProvider())
+
+ logger.metaClass.methodMissing = { String name, args ->
+ logger.info("[${name?.toUpperCase()}] ${(args as List).join(" ")}")
+ }
+ }
+
+ @Before
+ void setUp() throws Exception {
+ }
+
+ @After
+ void tearDown() throws Exception {
+ }
+
+ @Test
+ void testShouldCountAllMetrics() throws Exception {
+ // Arrange
+ final TestRunner runner = TestRunners.newTestRunner(CountText.class)
+
+ runner.setProperty(CountText.TEXT_LINE_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_LINE_NONEMPTY_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_WORD_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_CHARACTER_COUNT_PD, "true")
+
+ String INPUT_TEXT = """’Twas brillig, and the slithy toves
+Did gyre and gimble in the wade;
+All mimsy were the borogoves,
+And the mome raths outgrabe.
+
+"Beware the Jabberwock, my son!
+The jaws that bite, the claws that catch!
+Beware the Jubjub bird, and shun
+The frumious Bandersnatch!"
+
+He took his vorpal sword in hand:
+Long time the manxome foe he sought—
+So rested he by the Tumtum tree,
+And stood awhile in thought.
+
+And as in uffish thought he stood,
+The Jabberwock, with eyes of flame,
+Came whiffling through the tulgey wood.
+And burbled as it came!
+
+One, two! One, two! And through and through
+The vorpal blade went snicker-snack!
+He left it dead, and with its head
+He went galumphing back.
+
+"And hast thou slain the Jabberwock?
+Come to my arms, my beamish boy!
+O frabjous day! Callooh! Callay!"
+He chortled in his joy.
+
+’Twas brillig, and the slithy toves
+Did gyre and gimble in the wabe;
+All mimsy were the borogoves,
+And the mome raths outgrabe."""
+
+ runner.enqueue(INPUT_TEXT.bytes)
+
+ // Act
+ runner.run()
+
+ // Assert
+ runner.assertAllFlowFilesTransferred(CountText.REL_SUCCESS, 1)
+ FlowFile flowFile = runner.getFlowFilesForRelationship(CountText.REL_SUCCESS).first()
+ assert flowFile.attributes."text.line.count" == 34 as String
+ assert flowFile.attributes."text.line.nonempty.count" == 28 as String
+ assert flowFile.attributes."text.word.count" == 166 as String
+ assert flowFile.attributes."text.character.count" == 900 as String
+ }
+
+ @Test
+ void testShouldCountEachMetric() throws Exception {
+ // Arrange
+ final TestRunner runner = TestRunners.newTestRunner(CountText.class)
+ String INPUT_TEXT = new File("src/test/resources/TestCountText/jabberwocky.txt").text
+
+ final def EXPECTED_VALUES = [
+ "text.line.count" : 34,
+ "text.line.nonempty.count": 28,
+ "text.word.count" : 166,
+ "text.character.count" : 900,
+ ]
+
+ def linesOnly = [(CountText.TEXT_LINE_COUNT_PD): "true"]
+ def linesNonEmptyOnly = [(CountText.TEXT_LINE_NONEMPTY_COUNT_PD): "true"]
+ def wordsOnly = [(CountText.TEXT_WORD_COUNT_PD): "true"]
+ def charactersOnly = [(CountText.TEXT_CHARACTER_COUNT_PD): "true"]
+
+ final List<Map<PropertyDescriptor, String>> SCENARIOS = [linesOnly, linesNonEmptyOnly, wordsOnly, charactersOnly]
+
+ SCENARIOS.each { map ->
+ // Reset the processor properties
+ runner.setProperty(CountText.TEXT_LINE_COUNT_PD, "false")
+ runner.setProperty(CountText.TEXT_LINE_NONEMPTY_COUNT_PD, "false")
+ runner.setProperty(CountText.TEXT_WORD_COUNT_PD, "false")
+ runner.setProperty(CountText.TEXT_CHARACTER_COUNT_PD, "false")
+
+ // Apply the scenario-specific properties
+ map.each { key, value ->
+ runner.setProperty(key, value)
+ }
+
+ runner.clearProvenanceEvents()
+ runner.clearTransferState()
+ runner.enqueue(INPUT_TEXT.bytes)
+
+ // Act
+ runner.run()
+
+ // Assert
+ runner.assertAllFlowFilesTransferred(CountText.REL_SUCCESS, 1)
+ FlowFile flowFile = runner.getFlowFilesForRelationship(CountText.REL_SUCCESS).first()
+ logger.info("Generated flowfile: ${flowFile} | ${flowFile.attributes}")
+ EXPECTED_VALUES.each { key, value ->
+ if (flowFile.attributes.containsKey(key)) {
+ assert flowFile.attributes.get(key) == value as String
+ }
+ }
+ }
+ }
+
+ @Test
+ void testShouldCountWordsSplitOnSymbol() throws Exception {
+ // Arrange
+ final TestRunner runner = TestRunners.newTestRunner(CountText.class)
+ String INPUT_TEXT = new File("src/test/resources/TestCountText/jabberwocky.txt").text
+
+ final int EXPECTED_WORD_COUNT = 167
+
+ // Reset the processor properties
+ runner.setProperty(CountText.TEXT_LINE_COUNT_PD, "false")
+ runner.setProperty(CountText.TEXT_LINE_NONEMPTY_COUNT_PD, "false")
+ runner.setProperty(CountText.TEXT_WORD_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_CHARACTER_COUNT_PD, "false")
+ runner.setProperty(CountText.SPLIT_WORDS_ON_SYMBOLS_PD, "true")
+
+ runner.clearProvenanceEvents()
+ runner.clearTransferState()
+ runner.enqueue(INPUT_TEXT.bytes)
+
+ // Act
+ runner.run()
+
+ // Assert
+ runner.assertAllFlowFilesTransferred(CountText.REL_SUCCESS, 1)
+ FlowFile flowFile = runner.getFlowFilesForRelationship(CountText.REL_SUCCESS).first()
+ logger.info("Generated flowfile: ${flowFile} | ${flowFile.attributes}")
+ assert flowFile.attributes.get(CountText.TEXT_WORD_COUNT) == EXPECTED_WORD_COUNT as String
+ }
+
+ @Test
+ void testShouldCountIndependentlyPerFlowFile() throws Exception {
+ // Arrange
+ final TestRunner runner = TestRunners.newTestRunner(CountText.class)
+ String INPUT_TEXT = new File("src/test/resources/TestCountText/jabberwocky.txt").text
+
+ final def EXPECTED_VALUES = [
+ "text.line.count" : 34,
+ "text.line.nonempty.count": 28,
+ "text.word.count" : 166,
+ "text.character.count" : 900,
+ ]
+
+ // Reset the processor properties
+ runner.setProperty(CountText.TEXT_LINE_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_LINE_NONEMPTY_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_WORD_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_CHARACTER_COUNT_PD, "true")
+
+ 2.times { int i ->
+ runner.clearProvenanceEvents()
+ runner.clearTransferState()
+ runner.enqueue(INPUT_TEXT.bytes)
+
+ // Act
+ runner.run()
+
+ // Assert
+ runner.assertAllFlowFilesTransferred(CountText.REL_SUCCESS, 1)
+ FlowFile flowFile = runner.getFlowFilesForRelationship(CountText.REL_SUCCESS).first()
+ logger.info("Generated flowfile: ${flowFile} | ${flowFile.attributes}")
+ EXPECTED_VALUES.each { key, value ->
+ if (flowFile.attributes.containsKey(key)) {
+ assert flowFile.attributes.get(key) == value as String
+ }
+ }
+ }
+ }
+
+ @Ignore("Not yet implemented")
--- End diff --
This should get dropped.
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by alopresto <gi...@git.apache.org>.
Github user alopresto commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r159743902
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/main/java/org/apache/nifi/processors/standard/CountText.java ---
@@ -0,0 +1,318 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard;
+
+import java.io.BufferedReader;
+import java.io.InputStreamReader;
+import java.nio.charset.Charset;
+import java.nio.charset.StandardCharsets;
+import java.text.DecimalFormat;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Collectors;
+import org.apache.nifi.annotation.behavior.EventDriven;
+import org.apache.nifi.annotation.behavior.InputRequirement;
+import org.apache.nifi.annotation.behavior.InputRequirement.Requirement;
+import org.apache.nifi.annotation.behavior.SideEffectFree;
+import org.apache.nifi.annotation.behavior.SupportsBatching;
+import org.apache.nifi.annotation.behavior.WritesAttribute;
+import org.apache.nifi.annotation.behavior.WritesAttributes;
+import org.apache.nifi.annotation.documentation.CapabilityDescription;
+import org.apache.nifi.annotation.documentation.SeeAlso;
+import org.apache.nifi.annotation.documentation.Tags;
+import org.apache.nifi.annotation.lifecycle.OnScheduled;
+import org.apache.nifi.components.PropertyDescriptor;
+import org.apache.nifi.flowfile.FlowFile;
+import org.apache.nifi.processor.AbstractProcessor;
+import org.apache.nifi.processor.ProcessContext;
+import org.apache.nifi.processor.ProcessSession;
+import org.apache.nifi.processor.Relationship;
+import org.apache.nifi.processor.exception.ProcessException;
+import org.apache.nifi.processor.util.StandardValidators;
+import org.apache.nifi.util.StringUtils;
+
+@EventDriven
+@SideEffectFree
+@SupportsBatching
+@Tags({"count", "text", "line", "word", "character"})
+@InputRequirement(Requirement.INPUT_REQUIRED)
+@CapabilityDescription("Counts various metrics on incoming text. The requested results will be recorded as attributes. "
+ + "The resulting flowfile will not have its content modified.")
+@WritesAttributes({
+ @WritesAttribute(attribute = "text.line.count", description = "The number of lines of text present in the FlowFile content"),
+ @WritesAttribute(attribute = "text.line.nonempty.count", description = "The number of lines of text (with at least one non-whitespace character) present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.word.count", description = "The number of words present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.character.count", description = "The number of characters (given the specified character encoding) present in the original FlowFile"),
+})
+@SeeAlso(SplitText.class)
+public class CountText extends AbstractProcessor {
+ private static final List<Charset> STANDARD_CHARSETS = Arrays.asList(
+ StandardCharsets.UTF_8,
+ StandardCharsets.US_ASCII,
+ StandardCharsets.ISO_8859_1,
+ StandardCharsets.UTF_16,
+ StandardCharsets.UTF_16LE,
+ StandardCharsets.UTF_16BE);
+
+ private static final String SYMBOL_REGEX = "[\\s-\\._]";
+ private static final String WHITESPACE_ONLY_REGEX = "\\s";
+
+ // Attribute keys
+ public static final String TEXT_LINE_COUNT = "text.line.count";
+ public static final String TEXT_LINE_NONEMPTY_COUNT = "text.line.nonempty.count";
+ public static final String TEXT_WORD_COUNT = "text.word.count";
+ public static final String TEXT_CHARACTER_COUNT = "text.character.count";
+
+
+ public static final PropertyDescriptor TEXT_LINE_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-count")
+ .displayName("Text Line Count")
+ .description("If enabled, will count the number of lines present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("true")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_LINE_NONEMPTY_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-nonempty-count")
+ .displayName("Text Line (non-empty) Count")
+ .description("If enabled, will count the number of lines that contain a non-whitespace character present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_WORD_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-word-count")
+ .displayName("Text Word Count")
+ .description("If enabled, will count the number of words (alphanumeric character groups bounded by whitespace)" +
+ " present in the incoming text. Common logical delimiters [_-.] do not bound a word unless 'Split Words on Symbols' is true.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_CHARACTER_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-character-count")
+ .displayName("Text Character Count")
+ .description("If enabled, will count the number of characters (including whitespace and symbols) present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor SPLIT_WORDS_ON_SYMBOLS_PD = new PropertyDescriptor.Builder()
+ .name("split-words-on-symbols")
+ .displayName("Split Words on Symbols")
+ .description("If enabled, the word count will identify strings separated by common logical delimiters [_-.] as independent words (ex. split-words-on-symbols = 4 words).")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ // TODO: Stream map allowable values to name/key pair?
+ public static final PropertyDescriptor CHARACTER_ENCODING_PD = new PropertyDescriptor.Builder()
+ .name("character-encoding")
+ .displayName("Character Encoding")
+ .description("Specifies a character encoding to use.")
+ .required(true)
+ .allowableValues(getStandardCharsetNames())
+ .defaultValue(StandardCharsets.UTF_8.displayName())
+ .build();
+
+ private static Set<String> getStandardCharsetNames() {
+ return STANDARD_CHARSETS.stream().map(c -> c.displayName()).collect(Collectors.toSet());
+ }
+
+ public static final Relationship REL_SUCCESS = new Relationship.Builder()
+ .name("success")
+ .description("The flowfile contains the original content with one or more attributes added containing the respective counts")
+ .build();
+ public static final Relationship REL_FAILURE = new Relationship.Builder()
+ .name("failure")
+ .description("If the flowfile text cannot be counted for some reason, the original file will be routed to this destination and nothing will be routed elsewhere")
+ .build();
+
+ private static final List<PropertyDescriptor> properties;
+ private static final Set<Relationship> relationships;
+
+ static {
+ properties = Collections.unmodifiableList(Arrays.asList(TEXT_LINE_COUNT_PD,
+ TEXT_LINE_NONEMPTY_COUNT_PD,
+ TEXT_WORD_COUNT_PD,
+ TEXT_CHARACTER_COUNT_PD,
+ SPLIT_WORDS_ON_SYMBOLS_PD,
+ CHARACTER_ENCODING_PD));
+
+ relationships = Collections.unmodifiableSet(new HashSet<>(Arrays.asList(REL_SUCCESS,
+ REL_FAILURE)));
+ }
+
+ private volatile boolean countLines;
+ private volatile boolean countLinesNonEmpty;
+ private volatile boolean countWords;
+ private volatile boolean countCharacters;
+ private volatile boolean splitWordsOnSymbols;
+ private volatile String characterEncoding;
+
+ private volatile int lineCount;
+ private volatile int lineNonEmptyCount;
+ private volatile int wordCount;
+ private volatile int characterCount;
+
+ @Override
+ public Set<Relationship> getRelationships() {
+ return relationships;
+ }
+
+ @OnScheduled
+ public void onSchedule(ProcessContext context) {
+ this.countLines = context.getProperty(TEXT_LINE_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_COUNT_PD).asBoolean() : false;
+ this.countLinesNonEmpty = context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).asBoolean() : false;
+ this.countWords = context.getProperty(TEXT_WORD_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_WORD_COUNT_PD).asBoolean() : false;
+ this.countCharacters = context.getProperty(TEXT_CHARACTER_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_CHARACTER_COUNT_PD).asBoolean() : false;
+ this.splitWordsOnSymbols = context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).isSet()
+ ? context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).asBoolean() : false;
+ this.characterEncoding = context.getProperty(CHARACTER_ENCODING_PD).getValue();
+ }
+
+ /**
+ * Will count text attributes of the incoming stream.
+ */
+ @Override
+ public void onTrigger(ProcessContext context, ProcessSession processSession) throws ProcessException {
+ FlowFile sourceFlowFile = processSession.get();
+ if (sourceFlowFile == null) {
+ return;
+ }
+ AtomicBoolean error = new AtomicBoolean();
+
+ lineCount = 0;
+ lineNonEmptyCount = 0;
+ wordCount = 0;
+ characterCount = 0;
+
+ processSession.read(sourceFlowFile, in -> {
+ long start = System.nanoTime();
+
+ // Iterate over the lines in the text input
+ try {
+ BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(in, characterEncoding));
+ String line;
+ while ((line = bufferedReader.readLine()) != null) {
+ if (countLines) {
+ lineCount++;
+ }
+
+ if (countLinesNonEmpty) {
+ if (line.trim().length() > 0) {
+ lineNonEmptyCount++;
+ }
+ }
+
+ if (countWords) {
+ wordCount += countWordsInLine(line, splitWordsOnSymbols);
+ }
+
+ if (countCharacters) {
+ characterCount += line.length();
+ }
+ }
+ long stop = System.nanoTime();
+ if (getLogger().isDebugEnabled()) {
+ final long durationNanos = stop - start;
+ DecimalFormat df = new DecimalFormat("#.###");
+ getLogger().debug("Computed metrics in " + durationNanos + " nanoseconds (" + df.format(durationNanos / 1_000_000_000.0) + " seconds).");
+ }
+ String message = generateMetricsMessage();
--- End diff --
Will do.
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by kevdoran <gi...@git.apache.org>.
Github user kevdoran commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r160242565
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/main/java/org/apache/nifi/processors/standard/CountText.java ---
@@ -0,0 +1,327 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard;
+
+import java.io.BufferedReader;
+import java.io.IOException;
+import java.io.InputStreamReader;
+import java.nio.charset.Charset;
+import java.nio.charset.StandardCharsets;
+import java.text.DecimalFormat;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.regex.Pattern;
+import java.util.stream.Collectors;
+import org.apache.nifi.annotation.behavior.EventDriven;
+import org.apache.nifi.annotation.behavior.InputRequirement;
+import org.apache.nifi.annotation.behavior.InputRequirement.Requirement;
+import org.apache.nifi.annotation.behavior.SideEffectFree;
+import org.apache.nifi.annotation.behavior.SupportsBatching;
+import org.apache.nifi.annotation.behavior.WritesAttribute;
+import org.apache.nifi.annotation.behavior.WritesAttributes;
+import org.apache.nifi.annotation.documentation.CapabilityDescription;
+import org.apache.nifi.annotation.documentation.SeeAlso;
+import org.apache.nifi.annotation.documentation.Tags;
+import org.apache.nifi.annotation.lifecycle.OnScheduled;
+import org.apache.nifi.components.PropertyDescriptor;
+import org.apache.nifi.flowfile.FlowFile;
+import org.apache.nifi.processor.AbstractProcessor;
+import org.apache.nifi.processor.ProcessContext;
+import org.apache.nifi.processor.ProcessSession;
+import org.apache.nifi.processor.Relationship;
+import org.apache.nifi.processor.exception.ProcessException;
+import org.apache.nifi.processor.util.StandardValidators;
+import org.apache.nifi.util.StringUtils;
+
+@EventDriven
+@SideEffectFree
+@SupportsBatching
+@Tags({"count", "text", "line", "word", "character"})
+@InputRequirement(Requirement.INPUT_REQUIRED)
+@CapabilityDescription("Counts various metrics on incoming text. The requested results will be recorded as attributes. "
+ + "The resulting flowfile will not have its content modified.")
+@WritesAttributes({
+ @WritesAttribute(attribute = "text.line.count", description = "The number of lines of text present in the FlowFile content"),
+ @WritesAttribute(attribute = "text.line.nonempty.count", description = "The number of lines of text (with at least one non-whitespace character) present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.word.count", description = "The number of words present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.character.count", description = "The number of characters (given the specified character encoding) present in the original FlowFile"),
+})
+@SeeAlso(SplitText.class)
+public class CountText extends AbstractProcessor {
+ private static final List<Charset> STANDARD_CHARSETS = Arrays.asList(
+ StandardCharsets.UTF_8,
+ StandardCharsets.US_ASCII,
+ StandardCharsets.ISO_8859_1,
+ StandardCharsets.UTF_16,
+ StandardCharsets.UTF_16LE,
+ StandardCharsets.UTF_16BE);
+
+ private static final Pattern SYMBOL_PATTERN = Pattern.compile("[\\s-\\._]");
+ private static final Pattern WHITESPACE_ONLY_PATTERN = Pattern.compile("\\s");
+
+ // Attribute keys
+ public static final String TEXT_LINE_COUNT = "text.line.count";
+ public static final String TEXT_LINE_NONEMPTY_COUNT = "text.line.nonempty.count";
+ public static final String TEXT_WORD_COUNT = "text.word.count";
+ public static final String TEXT_CHARACTER_COUNT = "text.character.count";
+
+
+ public static final PropertyDescriptor TEXT_LINE_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-count")
+ .displayName("Count Lines")
+ .description("If enabled, will count the number of lines present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("true")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_LINE_NONEMPTY_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-nonempty-count")
+ .displayName("Count Non-Empty Lines")
+ .description("If enabled, will count the number of lines that contain a non-whitespace character present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_WORD_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-word-count")
+ .displayName("Count Words")
+ .description("If enabled, will count the number of words (alphanumeric character groups bounded by whitespace)" +
+ " present in the incoming text. Common logical delimiters [_-.] do not bound a word unless 'Split Words on Symbols' is true.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_CHARACTER_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-character-count")
+ .displayName("Count Characters")
+ .description("If enabled, will count the number of characters (including whitespace and symbols, but not including newlines and carriage returns) present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor SPLIT_WORDS_ON_SYMBOLS_PD = new PropertyDescriptor.Builder()
+ .name("split-words-on-symbols")
+ .displayName("Split Words on Symbols")
+ .description("If enabled, the word count will identify strings separated by common logical delimiters [_-.] as independent words (ex. split-words-on-symbols = 4 words).")
--- End diff --
This is minor issue, but I noticed when rendered using variable-width font in the tooltip the character group `[_-.]` is difficult to read (see screenshot). It might be better to write this a different way for legibility.
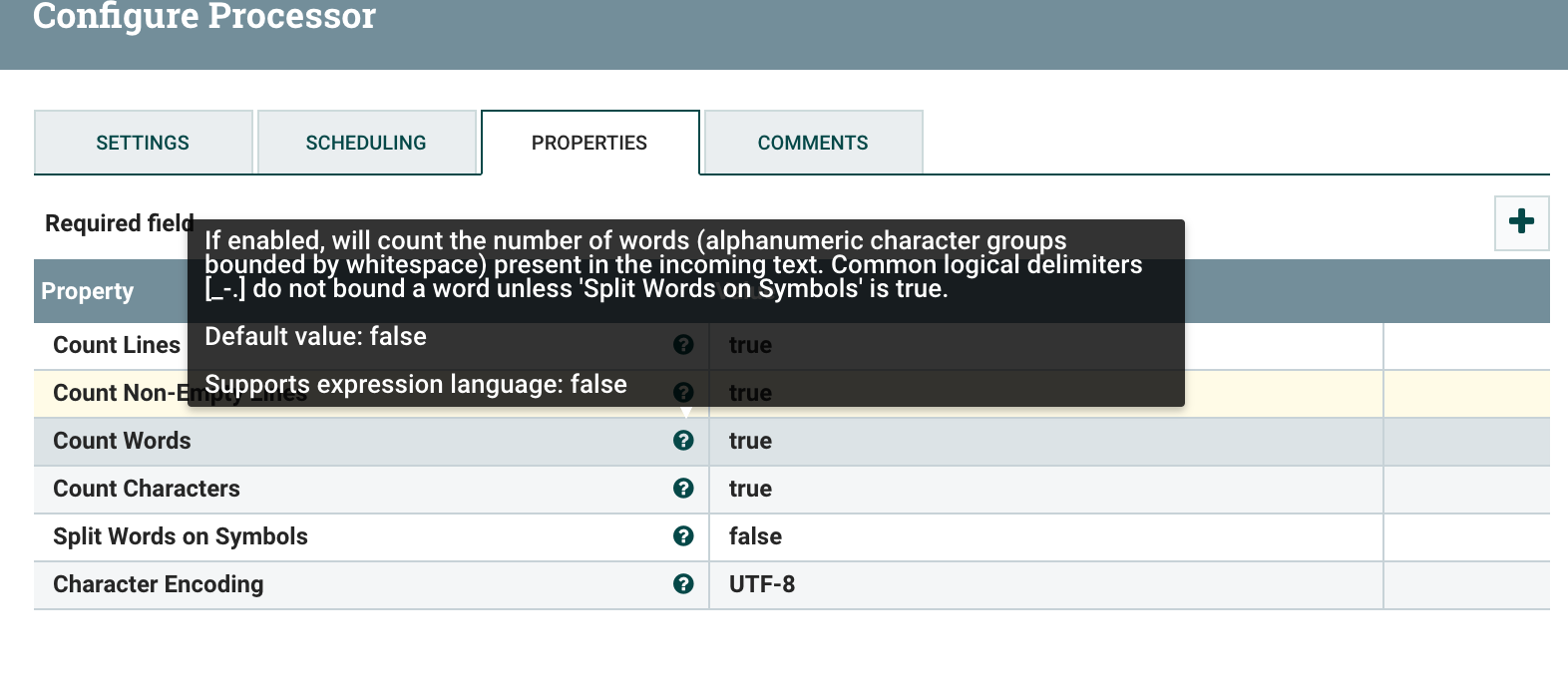
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by markap14 <gi...@git.apache.org>.
Github user markap14 commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r159700877
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/test/resources/TestCountText/jabberwocky.txt ---
@@ -0,0 +1,34 @@
+’Twas brillig, and the slithy toves
--- End diff --
Do we have a specific license for this text? Is it included in the nar's LICENSE/NOTICE file? I'm just totally guessing that this wasn't test data that you made up just to test this? :)
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by markap14 <gi...@git.apache.org>.
Github user markap14 commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r159697890
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/main/java/org/apache/nifi/processors/standard/CountText.java ---
@@ -0,0 +1,318 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard;
+
+import java.io.BufferedReader;
+import java.io.InputStreamReader;
+import java.nio.charset.Charset;
+import java.nio.charset.StandardCharsets;
+import java.text.DecimalFormat;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Collectors;
+import org.apache.nifi.annotation.behavior.EventDriven;
+import org.apache.nifi.annotation.behavior.InputRequirement;
+import org.apache.nifi.annotation.behavior.InputRequirement.Requirement;
+import org.apache.nifi.annotation.behavior.SideEffectFree;
+import org.apache.nifi.annotation.behavior.SupportsBatching;
+import org.apache.nifi.annotation.behavior.WritesAttribute;
+import org.apache.nifi.annotation.behavior.WritesAttributes;
+import org.apache.nifi.annotation.documentation.CapabilityDescription;
+import org.apache.nifi.annotation.documentation.SeeAlso;
+import org.apache.nifi.annotation.documentation.Tags;
+import org.apache.nifi.annotation.lifecycle.OnScheduled;
+import org.apache.nifi.components.PropertyDescriptor;
+import org.apache.nifi.flowfile.FlowFile;
+import org.apache.nifi.processor.AbstractProcessor;
+import org.apache.nifi.processor.ProcessContext;
+import org.apache.nifi.processor.ProcessSession;
+import org.apache.nifi.processor.Relationship;
+import org.apache.nifi.processor.exception.ProcessException;
+import org.apache.nifi.processor.util.StandardValidators;
+import org.apache.nifi.util.StringUtils;
+
+@EventDriven
+@SideEffectFree
+@SupportsBatching
+@Tags({"count", "text", "line", "word", "character"})
+@InputRequirement(Requirement.INPUT_REQUIRED)
+@CapabilityDescription("Counts various metrics on incoming text. The requested results will be recorded as attributes. "
+ + "The resulting flowfile will not have its content modified.")
+@WritesAttributes({
+ @WritesAttribute(attribute = "text.line.count", description = "The number of lines of text present in the FlowFile content"),
+ @WritesAttribute(attribute = "text.line.nonempty.count", description = "The number of lines of text (with at least one non-whitespace character) present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.word.count", description = "The number of words present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.character.count", description = "The number of characters (given the specified character encoding) present in the original FlowFile"),
+})
+@SeeAlso(SplitText.class)
+public class CountText extends AbstractProcessor {
+ private static final List<Charset> STANDARD_CHARSETS = Arrays.asList(
+ StandardCharsets.UTF_8,
+ StandardCharsets.US_ASCII,
+ StandardCharsets.ISO_8859_1,
+ StandardCharsets.UTF_16,
+ StandardCharsets.UTF_16LE,
+ StandardCharsets.UTF_16BE);
+
+ private static final String SYMBOL_REGEX = "[\\s-\\._]";
+ private static final String WHITESPACE_ONLY_REGEX = "\\s";
+
+ // Attribute keys
+ public static final String TEXT_LINE_COUNT = "text.line.count";
+ public static final String TEXT_LINE_NONEMPTY_COUNT = "text.line.nonempty.count";
+ public static final String TEXT_WORD_COUNT = "text.word.count";
+ public static final String TEXT_CHARACTER_COUNT = "text.character.count";
+
+
+ public static final PropertyDescriptor TEXT_LINE_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-count")
+ .displayName("Text Line Count")
+ .description("If enabled, will count the number of lines present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("true")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_LINE_NONEMPTY_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-nonempty-count")
+ .displayName("Text Line (non-empty) Count")
+ .description("If enabled, will count the number of lines that contain a non-whitespace character present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_WORD_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-word-count")
+ .displayName("Text Word Count")
+ .description("If enabled, will count the number of words (alphanumeric character groups bounded by whitespace)" +
+ " present in the incoming text. Common logical delimiters [_-.] do not bound a word unless 'Split Words on Symbols' is true.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_CHARACTER_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-character-count")
+ .displayName("Text Character Count")
+ .description("If enabled, will count the number of characters (including whitespace and symbols) present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor SPLIT_WORDS_ON_SYMBOLS_PD = new PropertyDescriptor.Builder()
+ .name("split-words-on-symbols")
+ .displayName("Split Words on Symbols")
+ .description("If enabled, the word count will identify strings separated by common logical delimiters [_-.] as independent words (ex. split-words-on-symbols = 4 words).")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ // TODO: Stream map allowable values to name/key pair?
+ public static final PropertyDescriptor CHARACTER_ENCODING_PD = new PropertyDescriptor.Builder()
+ .name("character-encoding")
+ .displayName("Character Encoding")
+ .description("Specifies a character encoding to use.")
+ .required(true)
+ .allowableValues(getStandardCharsetNames())
+ .defaultValue(StandardCharsets.UTF_8.displayName())
+ .build();
+
+ private static Set<String> getStandardCharsetNames() {
+ return STANDARD_CHARSETS.stream().map(c -> c.displayName()).collect(Collectors.toSet());
+ }
+
+ public static final Relationship REL_SUCCESS = new Relationship.Builder()
+ .name("success")
+ .description("The flowfile contains the original content with one or more attributes added containing the respective counts")
+ .build();
+ public static final Relationship REL_FAILURE = new Relationship.Builder()
+ .name("failure")
+ .description("If the flowfile text cannot be counted for some reason, the original file will be routed to this destination and nothing will be routed elsewhere")
+ .build();
+
+ private static final List<PropertyDescriptor> properties;
+ private static final Set<Relationship> relationships;
+
+ static {
+ properties = Collections.unmodifiableList(Arrays.asList(TEXT_LINE_COUNT_PD,
+ TEXT_LINE_NONEMPTY_COUNT_PD,
+ TEXT_WORD_COUNT_PD,
+ TEXT_CHARACTER_COUNT_PD,
+ SPLIT_WORDS_ON_SYMBOLS_PD,
+ CHARACTER_ENCODING_PD));
+
+ relationships = Collections.unmodifiableSet(new HashSet<>(Arrays.asList(REL_SUCCESS,
+ REL_FAILURE)));
+ }
+
+ private volatile boolean countLines;
+ private volatile boolean countLinesNonEmpty;
+ private volatile boolean countWords;
+ private volatile boolean countCharacters;
+ private volatile boolean splitWordsOnSymbols;
+ private volatile String characterEncoding;
+
+ private volatile int lineCount;
+ private volatile int lineNonEmptyCount;
+ private volatile int wordCount;
+ private volatile int characterCount;
+
+ @Override
+ public Set<Relationship> getRelationships() {
+ return relationships;
+ }
+
+ @OnScheduled
+ public void onSchedule(ProcessContext context) {
+ this.countLines = context.getProperty(TEXT_LINE_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_COUNT_PD).asBoolean() : false;
+ this.countLinesNonEmpty = context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).asBoolean() : false;
+ this.countWords = context.getProperty(TEXT_WORD_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_WORD_COUNT_PD).asBoolean() : false;
+ this.countCharacters = context.getProperty(TEXT_CHARACTER_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_CHARACTER_COUNT_PD).asBoolean() : false;
+ this.splitWordsOnSymbols = context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).isSet()
+ ? context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).asBoolean() : false;
+ this.characterEncoding = context.getProperty(CHARACTER_ENCODING_PD).getValue();
+ }
+
+ /**
+ * Will count text attributes of the incoming stream.
+ */
+ @Override
+ public void onTrigger(ProcessContext context, ProcessSession processSession) throws ProcessException {
+ FlowFile sourceFlowFile = processSession.get();
+ if (sourceFlowFile == null) {
+ return;
+ }
+ AtomicBoolean error = new AtomicBoolean();
+
+ lineCount = 0;
+ lineNonEmptyCount = 0;
+ wordCount = 0;
+ characterCount = 0;
+
+ processSession.read(sourceFlowFile, in -> {
+ long start = System.nanoTime();
+
+ // Iterate over the lines in the text input
+ try {
+ BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(in, characterEncoding));
+ String line;
+ while ((line = bufferedReader.readLine()) != null) {
+ if (countLines) {
+ lineCount++;
+ }
+
+ if (countLinesNonEmpty) {
+ if (line.trim().length() > 0) {
+ lineNonEmptyCount++;
+ }
+ }
+
+ if (countWords) {
+ wordCount += countWordsInLine(line, splitWordsOnSymbols);
+ }
+
+ if (countCharacters) {
--- End diff --
I'm not sure that this logic is exactly right... the documentation indicates that the character count includes white space. However, in this case, it is including white space that is not a newline (excludes \r and \n that are consumed by the Buffered Reader).
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by markap14 <gi...@git.apache.org>.
Github user markap14 commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r159700474
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/test/groovy/org/apache/nifi/processors/standard/CountTextTest.groovy ---
@@ -0,0 +1,277 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License") you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard
+
+import org.apache.nifi.components.PropertyDescriptor
+import org.apache.nifi.components.ValidationResult
+import org.apache.nifi.flowfile.FlowFile
+import org.apache.nifi.security.util.EncryptionMethod
+import org.apache.nifi.security.util.KeyDerivationFunction
+import org.apache.nifi.security.util.crypto.PasswordBasedEncryptor
+import org.apache.nifi.util.MockProcessContext
+import org.apache.nifi.util.TestRunner
+import org.apache.nifi.util.TestRunners
+import org.bouncycastle.jce.provider.BouncyCastleProvider
+import org.junit.After
+import org.junit.Assert
+import org.junit.Before
+import org.junit.BeforeClass
+import org.junit.Ignore
+import org.junit.Test
+import org.junit.runner.RunWith
+import org.junit.runners.JUnit4
+import org.slf4j.Logger
+import org.slf4j.LoggerFactory
+
+import java.security.Security
+
+@RunWith(JUnit4.class)
+class CountTextTest extends GroovyTestCase {
+ private static final Logger logger = LoggerFactory.getLogger(CountTextTest.class)
+
+ @BeforeClass
+ static void setUpOnce() throws Exception {
+ Security.addProvider(new BouncyCastleProvider())
+
+ logger.metaClass.methodMissing = { String name, args ->
+ logger.info("[${name?.toUpperCase()}] ${(args as List).join(" ")}")
+ }
+ }
+
+ @Before
+ void setUp() throws Exception {
+ }
+
+ @After
+ void tearDown() throws Exception {
+ }
+
+ @Test
+ void testShouldCountAllMetrics() throws Exception {
+ // Arrange
+ final TestRunner runner = TestRunners.newTestRunner(CountText.class)
+
+ runner.setProperty(CountText.TEXT_LINE_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_LINE_NONEMPTY_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_WORD_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_CHARACTER_COUNT_PD, "true")
+
+ String INPUT_TEXT = """’Twas brillig, and the slithy toves
--- End diff --
Is generally a good idea to externalize test data that is lengthy, rather than having it inline. It looks to me like it already is externalized in jabberwocky.txt though - perhaps that should be used.
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by markap14 <gi...@git.apache.org>.
Github user markap14 commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r159700110
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/main/java/org/apache/nifi/processors/standard/CountText.java ---
@@ -0,0 +1,318 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard;
+
+import java.io.BufferedReader;
+import java.io.InputStreamReader;
+import java.nio.charset.Charset;
+import java.nio.charset.StandardCharsets;
+import java.text.DecimalFormat;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Collectors;
+import org.apache.nifi.annotation.behavior.EventDriven;
+import org.apache.nifi.annotation.behavior.InputRequirement;
+import org.apache.nifi.annotation.behavior.InputRequirement.Requirement;
+import org.apache.nifi.annotation.behavior.SideEffectFree;
+import org.apache.nifi.annotation.behavior.SupportsBatching;
+import org.apache.nifi.annotation.behavior.WritesAttribute;
+import org.apache.nifi.annotation.behavior.WritesAttributes;
+import org.apache.nifi.annotation.documentation.CapabilityDescription;
+import org.apache.nifi.annotation.documentation.SeeAlso;
+import org.apache.nifi.annotation.documentation.Tags;
+import org.apache.nifi.annotation.lifecycle.OnScheduled;
+import org.apache.nifi.components.PropertyDescriptor;
+import org.apache.nifi.flowfile.FlowFile;
+import org.apache.nifi.processor.AbstractProcessor;
+import org.apache.nifi.processor.ProcessContext;
+import org.apache.nifi.processor.ProcessSession;
+import org.apache.nifi.processor.Relationship;
+import org.apache.nifi.processor.exception.ProcessException;
+import org.apache.nifi.processor.util.StandardValidators;
+import org.apache.nifi.util.StringUtils;
+
+@EventDriven
+@SideEffectFree
+@SupportsBatching
+@Tags({"count", "text", "line", "word", "character"})
+@InputRequirement(Requirement.INPUT_REQUIRED)
+@CapabilityDescription("Counts various metrics on incoming text. The requested results will be recorded as attributes. "
+ + "The resulting flowfile will not have its content modified.")
+@WritesAttributes({
+ @WritesAttribute(attribute = "text.line.count", description = "The number of lines of text present in the FlowFile content"),
+ @WritesAttribute(attribute = "text.line.nonempty.count", description = "The number of lines of text (with at least one non-whitespace character) present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.word.count", description = "The number of words present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.character.count", description = "The number of characters (given the specified character encoding) present in the original FlowFile"),
+})
+@SeeAlso(SplitText.class)
+public class CountText extends AbstractProcessor {
+ private static final List<Charset> STANDARD_CHARSETS = Arrays.asList(
+ StandardCharsets.UTF_8,
+ StandardCharsets.US_ASCII,
+ StandardCharsets.ISO_8859_1,
+ StandardCharsets.UTF_16,
+ StandardCharsets.UTF_16LE,
+ StandardCharsets.UTF_16BE);
+
+ private static final String SYMBOL_REGEX = "[\\s-\\._]";
+ private static final String WHITESPACE_ONLY_REGEX = "\\s";
+
+ // Attribute keys
+ public static final String TEXT_LINE_COUNT = "text.line.count";
+ public static final String TEXT_LINE_NONEMPTY_COUNT = "text.line.nonempty.count";
+ public static final String TEXT_WORD_COUNT = "text.word.count";
+ public static final String TEXT_CHARACTER_COUNT = "text.character.count";
+
+
+ public static final PropertyDescriptor TEXT_LINE_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-count")
+ .displayName("Text Line Count")
+ .description("If enabled, will count the number of lines present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("true")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_LINE_NONEMPTY_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-nonempty-count")
+ .displayName("Text Line (non-empty) Count")
+ .description("If enabled, will count the number of lines that contain a non-whitespace character present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_WORD_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-word-count")
+ .displayName("Text Word Count")
+ .description("If enabled, will count the number of words (alphanumeric character groups bounded by whitespace)" +
+ " present in the incoming text. Common logical delimiters [_-.] do not bound a word unless 'Split Words on Symbols' is true.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_CHARACTER_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-character-count")
+ .displayName("Text Character Count")
+ .description("If enabled, will count the number of characters (including whitespace and symbols) present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor SPLIT_WORDS_ON_SYMBOLS_PD = new PropertyDescriptor.Builder()
+ .name("split-words-on-symbols")
+ .displayName("Split Words on Symbols")
+ .description("If enabled, the word count will identify strings separated by common logical delimiters [_-.] as independent words (ex. split-words-on-symbols = 4 words).")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ // TODO: Stream map allowable values to name/key pair?
+ public static final PropertyDescriptor CHARACTER_ENCODING_PD = new PropertyDescriptor.Builder()
+ .name("character-encoding")
+ .displayName("Character Encoding")
+ .description("Specifies a character encoding to use.")
+ .required(true)
+ .allowableValues(getStandardCharsetNames())
+ .defaultValue(StandardCharsets.UTF_8.displayName())
+ .build();
+
+ private static Set<String> getStandardCharsetNames() {
+ return STANDARD_CHARSETS.stream().map(c -> c.displayName()).collect(Collectors.toSet());
+ }
+
+ public static final Relationship REL_SUCCESS = new Relationship.Builder()
+ .name("success")
+ .description("The flowfile contains the original content with one or more attributes added containing the respective counts")
+ .build();
+ public static final Relationship REL_FAILURE = new Relationship.Builder()
+ .name("failure")
+ .description("If the flowfile text cannot be counted for some reason, the original file will be routed to this destination and nothing will be routed elsewhere")
+ .build();
+
+ private static final List<PropertyDescriptor> properties;
+ private static final Set<Relationship> relationships;
+
+ static {
+ properties = Collections.unmodifiableList(Arrays.asList(TEXT_LINE_COUNT_PD,
+ TEXT_LINE_NONEMPTY_COUNT_PD,
+ TEXT_WORD_COUNT_PD,
+ TEXT_CHARACTER_COUNT_PD,
+ SPLIT_WORDS_ON_SYMBOLS_PD,
+ CHARACTER_ENCODING_PD));
+
+ relationships = Collections.unmodifiableSet(new HashSet<>(Arrays.asList(REL_SUCCESS,
+ REL_FAILURE)));
+ }
+
+ private volatile boolean countLines;
+ private volatile boolean countLinesNonEmpty;
+ private volatile boolean countWords;
+ private volatile boolean countCharacters;
+ private volatile boolean splitWordsOnSymbols;
+ private volatile String characterEncoding;
+
+ private volatile int lineCount;
+ private volatile int lineNonEmptyCount;
+ private volatile int wordCount;
+ private volatile int characterCount;
+
+ @Override
+ public Set<Relationship> getRelationships() {
+ return relationships;
+ }
+
+ @OnScheduled
+ public void onSchedule(ProcessContext context) {
+ this.countLines = context.getProperty(TEXT_LINE_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_COUNT_PD).asBoolean() : false;
+ this.countLinesNonEmpty = context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).asBoolean() : false;
+ this.countWords = context.getProperty(TEXT_WORD_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_WORD_COUNT_PD).asBoolean() : false;
+ this.countCharacters = context.getProperty(TEXT_CHARACTER_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_CHARACTER_COUNT_PD).asBoolean() : false;
+ this.splitWordsOnSymbols = context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).isSet()
+ ? context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).asBoolean() : false;
+ this.characterEncoding = context.getProperty(CHARACTER_ENCODING_PD).getValue();
+ }
+
+ /**
+ * Will count text attributes of the incoming stream.
+ */
+ @Override
+ public void onTrigger(ProcessContext context, ProcessSession processSession) throws ProcessException {
+ FlowFile sourceFlowFile = processSession.get();
+ if (sourceFlowFile == null) {
+ return;
+ }
+ AtomicBoolean error = new AtomicBoolean();
+
+ lineCount = 0;
+ lineNonEmptyCount = 0;
+ wordCount = 0;
+ characterCount = 0;
+
+ processSession.read(sourceFlowFile, in -> {
+ long start = System.nanoTime();
+
+ // Iterate over the lines in the text input
+ try {
+ BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(in, characterEncoding));
+ String line;
+ while ((line = bufferedReader.readLine()) != null) {
+ if (countLines) {
+ lineCount++;
+ }
+
+ if (countLinesNonEmpty) {
+ if (line.trim().length() > 0) {
+ lineNonEmptyCount++;
+ }
+ }
+
+ if (countWords) {
+ wordCount += countWordsInLine(line, splitWordsOnSymbols);
+ }
+
+ if (countCharacters) {
+ characterCount += line.length();
+ }
+ }
+ long stop = System.nanoTime();
+ if (getLogger().isDebugEnabled()) {
+ final long durationNanos = stop - start;
+ DecimalFormat df = new DecimalFormat("#.###");
+ getLogger().debug("Computed metrics in " + durationNanos + " nanoseconds (" + df.format(durationNanos / 1_000_000_000.0) + " seconds).");
+ }
+ String message = generateMetricsMessage();
+ getLogger().info(message);
+ } catch (IllegalStateException e) {
+ error.set(true);
+ getLogger().error(e.getMessage() + " Routing to failure.", e);
+ }
+ });
+
+ if (error.get()) {
+ processSession.transfer(sourceFlowFile, REL_FAILURE);
+ } else {
+ Map<String, String> metricAttributes = new HashMap<>();
+ if (countLines) {
+ metricAttributes.put(TEXT_LINE_COUNT, String.valueOf(lineCount));
+ }
+ if (countLinesNonEmpty) {
+ metricAttributes.put(TEXT_LINE_NONEMPTY_COUNT, String.valueOf(lineNonEmptyCount));
+ }
+ if (countWords) {
+ metricAttributes.put(TEXT_WORD_COUNT, String.valueOf(wordCount));
+ }
+ if (countCharacters) {
+ metricAttributes.put(TEXT_CHARACTER_COUNT, String.valueOf(characterCount));
+ }
+ FlowFile updatedFlowFile = processSession.putAllAttributes(sourceFlowFile, metricAttributes);
+ processSession.transfer(updatedFlowFile, REL_SUCCESS);
+ }
+ }
+
+ private String generateMetricsMessage() {
+ StringBuilder sb = new StringBuilder("Counted ");
+ List<String> metrics = new ArrayList<>();
+ if (countLines) {
+ metrics.add(lineCount + " lines");
+ }
+ if (countLinesNonEmpty) {
+ metrics.add(lineNonEmptyCount + " non-empty lines");
+ }
+ if (countWords) {
+ metrics.add(wordCount + " words");
+ }
+ if (countCharacters) {
+ metrics.add(characterCount + " characters");
+ }
+ sb.append(StringUtils.join(metrics, ", "));
+ return sb.toString();
+ }
+
+ private int countWordsInLine(String line, boolean splitWordsOnSymbols) {
+ if (line == null || line.trim().length() == 0) {
+ return 0;
+ } else {
+ String regex = splitWordsOnSymbols ? SYMBOL_REGEX : WHITESPACE_ONLY_REGEX;
--- End diff --
We should pre-compile these regexes, and a Pattern object as the member variable, then call regex.split(line) -- this way we don't re-compile the regex for every line and instead only compile it once for the processor lifecycle.
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by markap14 <gi...@git.apache.org>.
Github user markap14 commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r159699147
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/main/java/org/apache/nifi/processors/standard/CountText.java ---
@@ -0,0 +1,318 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard;
+
+import java.io.BufferedReader;
+import java.io.InputStreamReader;
+import java.nio.charset.Charset;
+import java.nio.charset.StandardCharsets;
+import java.text.DecimalFormat;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Collectors;
+import org.apache.nifi.annotation.behavior.EventDriven;
+import org.apache.nifi.annotation.behavior.InputRequirement;
+import org.apache.nifi.annotation.behavior.InputRequirement.Requirement;
+import org.apache.nifi.annotation.behavior.SideEffectFree;
+import org.apache.nifi.annotation.behavior.SupportsBatching;
+import org.apache.nifi.annotation.behavior.WritesAttribute;
+import org.apache.nifi.annotation.behavior.WritesAttributes;
+import org.apache.nifi.annotation.documentation.CapabilityDescription;
+import org.apache.nifi.annotation.documentation.SeeAlso;
+import org.apache.nifi.annotation.documentation.Tags;
+import org.apache.nifi.annotation.lifecycle.OnScheduled;
+import org.apache.nifi.components.PropertyDescriptor;
+import org.apache.nifi.flowfile.FlowFile;
+import org.apache.nifi.processor.AbstractProcessor;
+import org.apache.nifi.processor.ProcessContext;
+import org.apache.nifi.processor.ProcessSession;
+import org.apache.nifi.processor.Relationship;
+import org.apache.nifi.processor.exception.ProcessException;
+import org.apache.nifi.processor.util.StandardValidators;
+import org.apache.nifi.util.StringUtils;
+
+@EventDriven
+@SideEffectFree
+@SupportsBatching
+@Tags({"count", "text", "line", "word", "character"})
+@InputRequirement(Requirement.INPUT_REQUIRED)
+@CapabilityDescription("Counts various metrics on incoming text. The requested results will be recorded as attributes. "
+ + "The resulting flowfile will not have its content modified.")
+@WritesAttributes({
+ @WritesAttribute(attribute = "text.line.count", description = "The number of lines of text present in the FlowFile content"),
+ @WritesAttribute(attribute = "text.line.nonempty.count", description = "The number of lines of text (with at least one non-whitespace character) present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.word.count", description = "The number of words present in the original FlowFile"),
+ @WritesAttribute(attribute = "text.character.count", description = "The number of characters (given the specified character encoding) present in the original FlowFile"),
+})
+@SeeAlso(SplitText.class)
+public class CountText extends AbstractProcessor {
+ private static final List<Charset> STANDARD_CHARSETS = Arrays.asList(
+ StandardCharsets.UTF_8,
+ StandardCharsets.US_ASCII,
+ StandardCharsets.ISO_8859_1,
+ StandardCharsets.UTF_16,
+ StandardCharsets.UTF_16LE,
+ StandardCharsets.UTF_16BE);
+
+ private static final String SYMBOL_REGEX = "[\\s-\\._]";
+ private static final String WHITESPACE_ONLY_REGEX = "\\s";
+
+ // Attribute keys
+ public static final String TEXT_LINE_COUNT = "text.line.count";
+ public static final String TEXT_LINE_NONEMPTY_COUNT = "text.line.nonempty.count";
+ public static final String TEXT_WORD_COUNT = "text.word.count";
+ public static final String TEXT_CHARACTER_COUNT = "text.character.count";
+
+
+ public static final PropertyDescriptor TEXT_LINE_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-count")
+ .displayName("Text Line Count")
+ .description("If enabled, will count the number of lines present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("true")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_LINE_NONEMPTY_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-line-nonempty-count")
+ .displayName("Text Line (non-empty) Count")
+ .description("If enabled, will count the number of lines that contain a non-whitespace character present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_WORD_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-word-count")
+ .displayName("Text Word Count")
+ .description("If enabled, will count the number of words (alphanumeric character groups bounded by whitespace)" +
+ " present in the incoming text. Common logical delimiters [_-.] do not bound a word unless 'Split Words on Symbols' is true.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor TEXT_CHARACTER_COUNT_PD = new PropertyDescriptor.Builder()
+ .name("text-character-count")
+ .displayName("Text Character Count")
+ .description("If enabled, will count the number of characters (including whitespace and symbols) present in the incoming text.")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ public static final PropertyDescriptor SPLIT_WORDS_ON_SYMBOLS_PD = new PropertyDescriptor.Builder()
+ .name("split-words-on-symbols")
+ .displayName("Split Words on Symbols")
+ .description("If enabled, the word count will identify strings separated by common logical delimiters [_-.] as independent words (ex. split-words-on-symbols = 4 words).")
+ .required(true)
+ .allowableValues("true", "false")
+ .defaultValue("false")
+ .addValidator(StandardValidators.BOOLEAN_VALIDATOR)
+ .build();
+ // TODO: Stream map allowable values to name/key pair?
+ public static final PropertyDescriptor CHARACTER_ENCODING_PD = new PropertyDescriptor.Builder()
+ .name("character-encoding")
+ .displayName("Character Encoding")
+ .description("Specifies a character encoding to use.")
+ .required(true)
+ .allowableValues(getStandardCharsetNames())
+ .defaultValue(StandardCharsets.UTF_8.displayName())
+ .build();
+
+ private static Set<String> getStandardCharsetNames() {
+ return STANDARD_CHARSETS.stream().map(c -> c.displayName()).collect(Collectors.toSet());
+ }
+
+ public static final Relationship REL_SUCCESS = new Relationship.Builder()
+ .name("success")
+ .description("The flowfile contains the original content with one or more attributes added containing the respective counts")
+ .build();
+ public static final Relationship REL_FAILURE = new Relationship.Builder()
+ .name("failure")
+ .description("If the flowfile text cannot be counted for some reason, the original file will be routed to this destination and nothing will be routed elsewhere")
+ .build();
+
+ private static final List<PropertyDescriptor> properties;
+ private static final Set<Relationship> relationships;
+
+ static {
+ properties = Collections.unmodifiableList(Arrays.asList(TEXT_LINE_COUNT_PD,
+ TEXT_LINE_NONEMPTY_COUNT_PD,
+ TEXT_WORD_COUNT_PD,
+ TEXT_CHARACTER_COUNT_PD,
+ SPLIT_WORDS_ON_SYMBOLS_PD,
+ CHARACTER_ENCODING_PD));
+
+ relationships = Collections.unmodifiableSet(new HashSet<>(Arrays.asList(REL_SUCCESS,
+ REL_FAILURE)));
+ }
+
+ private volatile boolean countLines;
+ private volatile boolean countLinesNonEmpty;
+ private volatile boolean countWords;
+ private volatile boolean countCharacters;
+ private volatile boolean splitWordsOnSymbols;
+ private volatile String characterEncoding;
+
+ private volatile int lineCount;
+ private volatile int lineNonEmptyCount;
+ private volatile int wordCount;
+ private volatile int characterCount;
+
+ @Override
+ public Set<Relationship> getRelationships() {
+ return relationships;
+ }
+
+ @OnScheduled
+ public void onSchedule(ProcessContext context) {
+ this.countLines = context.getProperty(TEXT_LINE_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_COUNT_PD).asBoolean() : false;
+ this.countLinesNonEmpty = context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_LINE_NONEMPTY_COUNT_PD).asBoolean() : false;
+ this.countWords = context.getProperty(TEXT_WORD_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_WORD_COUNT_PD).asBoolean() : false;
+ this.countCharacters = context.getProperty(TEXT_CHARACTER_COUNT_PD).isSet()
+ ? context.getProperty(TEXT_CHARACTER_COUNT_PD).asBoolean() : false;
+ this.splitWordsOnSymbols = context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).isSet()
+ ? context.getProperty(SPLIT_WORDS_ON_SYMBOLS_PD).asBoolean() : false;
+ this.characterEncoding = context.getProperty(CHARACTER_ENCODING_PD).getValue();
+ }
+
+ /**
+ * Will count text attributes of the incoming stream.
+ */
+ @Override
+ public void onTrigger(ProcessContext context, ProcessSession processSession) throws ProcessException {
+ FlowFile sourceFlowFile = processSession.get();
+ if (sourceFlowFile == null) {
+ return;
+ }
+ AtomicBoolean error = new AtomicBoolean();
+
+ lineCount = 0;
+ lineNonEmptyCount = 0;
+ wordCount = 0;
+ characterCount = 0;
+
+ processSession.read(sourceFlowFile, in -> {
+ long start = System.nanoTime();
+
+ // Iterate over the lines in the text input
+ try {
+ BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(in, characterEncoding));
+ String line;
+ while ((line = bufferedReader.readLine()) != null) {
+ if (countLines) {
+ lineCount++;
+ }
+
+ if (countLinesNonEmpty) {
+ if (line.trim().length() > 0) {
+ lineNonEmptyCount++;
+ }
+ }
+
+ if (countWords) {
+ wordCount += countWordsInLine(line, splitWordsOnSymbols);
+ }
+
+ if (countCharacters) {
+ characterCount += line.length();
+ }
+ }
+ long stop = System.nanoTime();
+ if (getLogger().isDebugEnabled()) {
+ final long durationNanos = stop - start;
+ DecimalFormat df = new DecimalFormat("#.###");
+ getLogger().debug("Computed metrics in " + durationNanos + " nanoseconds (" + df.format(durationNanos / 1_000_000_000.0) + " seconds).");
+ }
+ String message = generateMetricsMessage();
+ getLogger().info(message);
+ } catch (IllegalStateException e) {
+ error.set(true);
+ getLogger().error(e.getMessage() + " Routing to failure.", e);
+ }
+ });
+
+ if (error.get()) {
+ processSession.transfer(sourceFlowFile, REL_FAILURE);
+ } else {
+ Map<String, String> metricAttributes = new HashMap<>();
+ if (countLines) {
--- End diff --
For each case, I would recommend also calling session.adjustCounter. This would give us metrics that we can see in the "Stats History" for the processor, which would be a nice-to-have.
---
[GitHub] nifi pull request #2371: NIFI-4727 Add CountText processor
Posted by alopresto <gi...@git.apache.org>.
Github user alopresto commented on a diff in the pull request:
https://github.com/apache/nifi/pull/2371#discussion_r159744322
--- Diff: nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/src/test/groovy/org/apache/nifi/processors/standard/CountTextTest.groovy ---
@@ -0,0 +1,277 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License") you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.nifi.processors.standard
+
+import org.apache.nifi.components.PropertyDescriptor
+import org.apache.nifi.components.ValidationResult
+import org.apache.nifi.flowfile.FlowFile
+import org.apache.nifi.security.util.EncryptionMethod
+import org.apache.nifi.security.util.KeyDerivationFunction
+import org.apache.nifi.security.util.crypto.PasswordBasedEncryptor
+import org.apache.nifi.util.MockProcessContext
+import org.apache.nifi.util.TestRunner
+import org.apache.nifi.util.TestRunners
+import org.bouncycastle.jce.provider.BouncyCastleProvider
+import org.junit.After
+import org.junit.Assert
+import org.junit.Before
+import org.junit.BeforeClass
+import org.junit.Ignore
+import org.junit.Test
+import org.junit.runner.RunWith
+import org.junit.runners.JUnit4
+import org.slf4j.Logger
+import org.slf4j.LoggerFactory
+
+import java.security.Security
+
+@RunWith(JUnit4.class)
+class CountTextTest extends GroovyTestCase {
+ private static final Logger logger = LoggerFactory.getLogger(CountTextTest.class)
+
+ @BeforeClass
+ static void setUpOnce() throws Exception {
+ Security.addProvider(new BouncyCastleProvider())
+
+ logger.metaClass.methodMissing = { String name, args ->
+ logger.info("[${name?.toUpperCase()}] ${(args as List).join(" ")}")
+ }
+ }
+
+ @Before
+ void setUp() throws Exception {
+ }
+
+ @After
+ void tearDown() throws Exception {
+ }
+
+ @Test
+ void testShouldCountAllMetrics() throws Exception {
+ // Arrange
+ final TestRunner runner = TestRunners.newTestRunner(CountText.class)
+
+ runner.setProperty(CountText.TEXT_LINE_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_LINE_NONEMPTY_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_WORD_COUNT_PD, "true")
+ runner.setProperty(CountText.TEXT_CHARACTER_COUNT_PD, "true")
+
+ String INPUT_TEXT = """’Twas brillig, and the slithy toves
--- End diff --
While *reading from a file* isn't under test here, I wanted to ensure that the newlines from static text and file loading weren't causing an issue.
---