You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by "soumilshah1995 (via GitHub)" <gi...@apache.org> on 2023/02/22 13:32:42 UTC
[GitHub] [hudi] soumilshah1995 opened a new issue, #8019: [SUPPORT] How to Restore from Checkpoints from disaster recovery in hudi using Pyspark and not Hudi CLI
soumilshah1995 opened a new issue, #8019:
URL: https://github.com/apache/hudi/issues/8019
Hello
hope you are doing well. this is aa Question from one of hudi members in slack and i am creating support ticket on his behalf
Question is :
How can we run Disaster recovery in Pyspark and not HUDI ClI
following links shows using HUDI CLI is there any code or example using PYSPARK and also how you can call procedure using pyspark

https://hudi.apache.org/docs/next/disaster_recovery/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8019: [SUPPORT] How to Restore from Checkpoints from disaster recovery in hudi using Pyspark and not Hudi CLI and use proc in PySpark
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8019:
URL: https://github.com/apache/hudi/issues/8019#issuecomment-1440244262
Hi @papablus
if i add this configuration shall i be able to call proc ? in glue 4.0 ?
and also would you please help with snippets for taking backup or how to rollback to older commits in pyspark
i see there is doc on hudi-cli there is no examples on pyspark
would really help community if you can help ;D
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8019: [SUPPORT] How to Restore from Checkpoints from disaster recovery in hudi using Pyspark and not Hudi CLI and use proc in PySpark
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8019:
URL: https://github.com/apache/hudi/issues/8019#issuecomment-1440353963
Hi @papablus
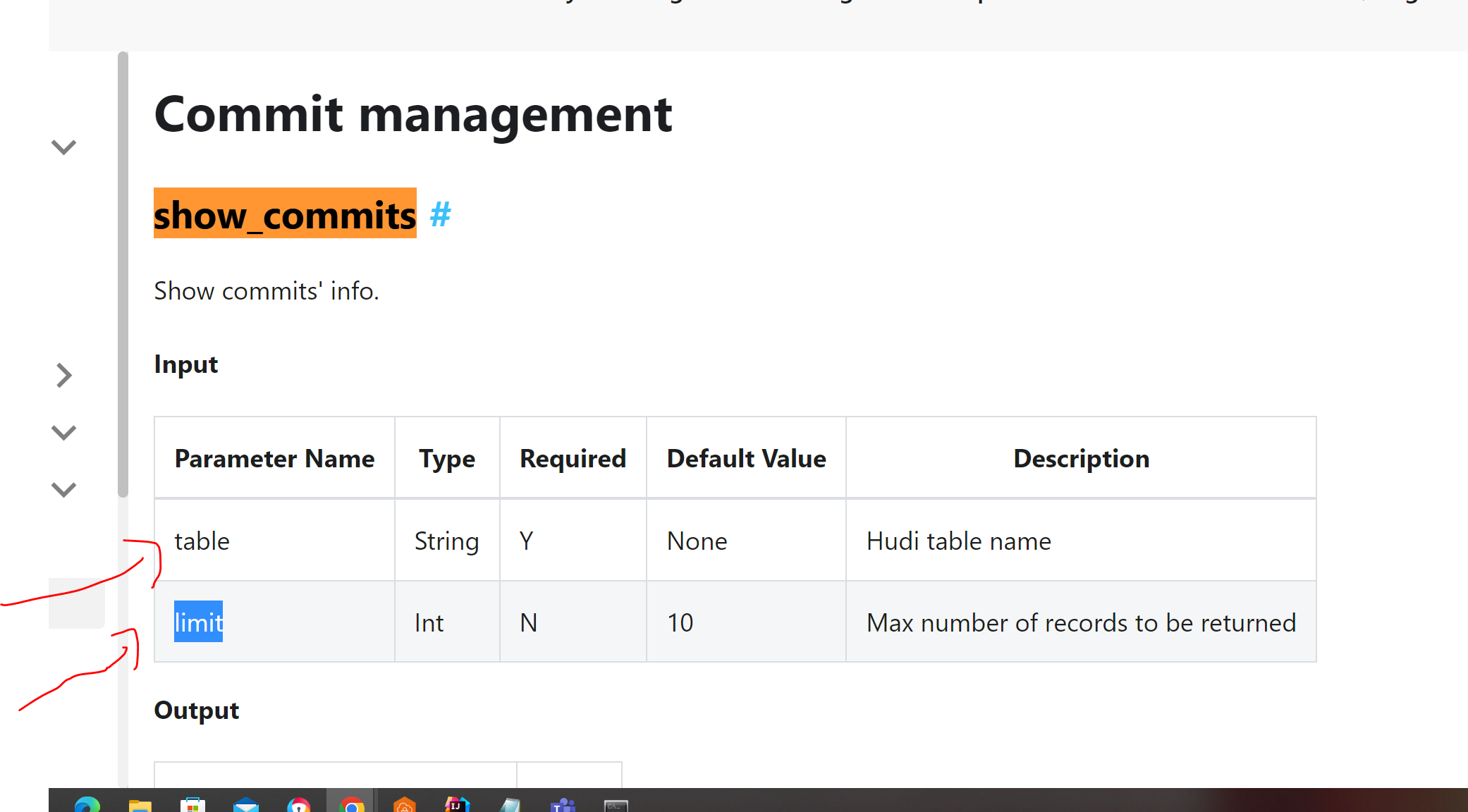
is this right way to call show commits procedure ?
```
try:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.session import SparkSession
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import col, to_timestamp, monotonically_increasing_id, to_date, when
from pyspark.sql.functions import *
from awsglue.utils import getResolvedOptions
from awsglueml.transforms import EntityDetector
from pyspark.sql.types import StringType
from pyspark.sql.types import *
from datetime import datetime
import boto3
from functools import reduce
except Exception as e:
print("Error ")
spark = (SparkSession.builder
.config('spark.serializer', 'org.apache.spark.serializer.KryoSerializer')
.config('spark.sql.hive.convertMetastoreParquet', 'false')
.config('spark.sql.catalog.spark_catalog', 'org.apache.spark.sql.hudi.catalog.HoodieCatalog')
.config('spark.sql.extensions', 'org.apache.spark.sql.hudi.HoodieSparkSessionExtension')
.config('spark.sql.legacy.pathOptionBehavior.enabled', 'true').getOrCreate())
sc = spark.sparkContext
glueContext = GlueContext(sc)
job = Job(glueContext)
logger = glueContext.get_logger()
db_name = "hudidb"
table_name = "hudi_table"
recordkey = 'emp_id'
path = "s3://hudi-demos-emr-serverless-project-soumil/tmp/"
method = 'upsert'
table_type = "COPY_ON_WRITE"
precombine = "ts"
partiton_field = "date"
connection_options = {
"path": path,
"connectionName": "hudi-connection",
"hoodie.datasource.write.storage.type": table_type,
'hoodie.datasource.write.precombine.field': precombine,
'className': 'org.apache.hudi',
'hoodie.table.name': table_name,
'hoodie.datasource.write.recordkey.field': recordkey,
'hoodie.datasource.write.table.name': table_name,
'hoodie.datasource.write.operation': method,
'hoodie.datasource.hive_sync.enable': 'true',
"hoodie.datasource.hive_sync.mode": "hms",
'hoodie.datasource.hive_sync.sync_as_datasource': 'false',
'hoodie.datasource.hive_sync.database': db_name,
'hoodie.datasource.hive_sync.table': table_name,
'hoodie.datasource.hive_sync.use_jdbc': 'false',
'hoodie.datasource.hive_sync.partition_extractor_class': 'org.apache.hudi.hive.MultiPartKeysValueExtractor',
'hoodie.datasource.write.hive_style_partitioning': 'true',
}
df = spark. \
read. \
format("hudi"). \
load(path)
print("\n")
print(df.show(2))
print("\n")
try:
query = """
call show_commits(hudidb.hudi_table);
"""
print(spark.sql(query).show())
except Exception as e:
print("Error 1", e)
try:
query = """
call show_commits();
"""
print(spark.sql(query).show())
except Exception as e:
print("Error 2", e)
try:
query = """
call show_commits(hudidb.hudi_table);
"""
print(spark.sql(query).show())
except Exception as e:
print("Error 1", e)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8019: [SUPPORT] How to Restore from Checkpoints from disaster recovery in hudi using Pyspark and not Hudi CLI and use proc in PySpark
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8019:
URL: https://github.com/apache/hudi/issues/8019#issuecomment-1440260111
Hi @papablus
im trying that and update you shortly :D
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8019: [SUPPORT] How to Restore from Checkpoints from disaster recovery in hudi using Pyspark and not Hudi CLI and use proc in PySpark
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8019:
URL: https://github.com/apache/hudi/issues/8019#issuecomment-1440395879
Hi @papablus
i tried show_commit and im getting following error can you please tell me if there is something i am not doing right
```
try:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.session import SparkSession
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import col, to_timestamp, monotonically_increasing_id, to_date, when
from pyspark.sql.functions import *
from awsglue.utils import getResolvedOptions
from awsglueml.transforms import EntityDetector
from pyspark.sql.types import StringType
from pyspark.sql.types import *
from datetime import datetime
import boto3
from functools import reduce
except Exception as e:
print("Error ")
spark = (SparkSession.builder
.config('spark.serializer', 'org.apache.spark.serializer.KryoSerializer')
.config('spark.sql.hive.convertMetastoreParquet', 'false')
.config('spark.sql.catalog.spark_catalog', 'org.apache.spark.sql.hudi.catalog.HoodieCatalog')
.config('spark.sql.extensions', 'org.apache.spark.sql.hudi.HoodieSparkSessionExtension')
.config('spark.sql.legacy.pathOptionBehavior.enabled', 'true').getOrCreate())
sc = spark.sparkContext
glueContext = GlueContext(sc)
job = Job(glueContext)
logger = glueContext.get_logger()
db_name = "hudidb"
table_name = "hudi_table"
recordkey = 'emp_id'
path = "s3://hudi-demos-emr-serverless-project-soumil/tmp/"
method = 'upsert'
table_type = "COPY_ON_WRITE"
precombine = "ts"
partiton_field = "date"
connection_options = {
"path": path,
"connectionName": "hudi-connection",
"hoodie.datasource.write.storage.type": table_type,
'hoodie.datasource.write.precombine.field': precombine,
'className': 'org.apache.hudi',
'hoodie.table.name': table_name,
'hoodie.datasource.write.recordkey.field': recordkey,
'hoodie.datasource.write.table.name': table_name,
'hoodie.datasource.write.operation': method,
'hoodie.datasource.hive_sync.enable': 'true',
"hoodie.datasource.hive_sync.mode": "hms",
'hoodie.datasource.hive_sync.sync_as_datasource': 'false',
'hoodie.datasource.hive_sync.database': db_name,
'hoodie.datasource.hive_sync.table': table_name,
'hoodie.datasource.hive_sync.use_jdbc': 'false',
'hoodie.datasource.hive_sync.partition_extractor_class': 'org.apache.hudi.hive.MultiPartKeysValueExtractor',
'hoodie.datasource.write.hive_style_partitioning': 'true',
}
df = spark. \
read. \
format("hudi"). \
load(path)
print("\n")
print(df.show(2))
print("\n")
try:
varSP = spark.sql("call show_commits('hudidb.hudi_table', 10)")
print(varSP.show())
except Exception as e:
print("Error 1", e)
try:
varSP = spark.sql("call show_commits('hudidb.hudi_table', '10')")
print(varSP.show())
except Exception as e:
print("Error 2", e)
```
### Error Message
```
<html>
<body>
<!--StartFragment-->
An error occurred while calling o90.sql.: java.lang.AssertionError: assertion failed: It's not a Hudi table at scala.Predef$.assert(Predef.scala:219) at org.apache.spark.sql.catalyst.catalog.HoodieCatalogTable.<init>(HoodieCatalogTable.scala:51) at org.apache.spark.sql.catalyst.catalog.HoodieCatalogTable$.apply(HoodieCatalogTable.scala:367) at org.apache.spark.sql.catalyst.catalog.HoodieCatalogTable$.apply(HoodieCatalogTable.scala:363) at org.apache.hudi.HoodieCLIUtils$.getHoodieCatalogTable(HoodieCLIUtils.scala:70) at org.apache.spark.sql.hudi.command.procedures.ShowCommitsProcedure.call(ShowCommitsProcedure.scala:82) at org.apache.spark.sql.hudi.command.CallProcedureHoodieCommand.run(CallProcedureHoodieCommand.scala:33) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:75) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:73) at org.apache.spark.sql.execution.command.ExecutedComman
dExec.executeColle
--
ct(commands.scala:84) at org.apache.spark.sql.execution.QueryExecution$anonfun$eagerlyExecuteCommands$1.$anonfun$applyOrElse$1(QueryExecution.scala:103) at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:107) at org.apache.spark.sql.execution.SQLExecution$.withTracker(SQLExecution.scala:224) at org.apache.spark.sql.execution.SQLExecution$.executeQuery$1(SQLExecution.scala:114) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$7(SQLExecution.scala:139) at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:107) at org.apache.spark.sql.execution.SQLExecution$.withTracker(SQLExecution.scala:224) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:139) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:245) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.
scala:138) at org
.apache.spark.sql.SparkSession.withActive(SparkSession.scala:779) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:68) at org.apache.spark.sql.execution.QueryExecution$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:100) at org.apache.spark.sql.execution.QueryExecution$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:96) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:615) at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:177) at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:615) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$super$transformDownWithPruning(LogicalPlan.scala:30) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:267) at org.apache.spark.sql.catalyst.p
lans.logical.Anal
ysisHelper.transformDownWithPruning$(AnalysisHelper.scala:263) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30) at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:591) at org.apache.spark.sql.execution.QueryExecution.eagerlyExecuteCommands(QueryExecution.scala:96) at org.apache.spark.sql.execution.QueryExecution.commandExecuted$lzycompute(QueryExecution.scala:83) at org.apache.spark.sql.execution.QueryExecution.commandExecuted(QueryExecution.scala:81) at org.apache.spark.sql.Dataset.<init>(Dataset.scala:222) at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:102) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:779) at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:99) at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:622) at org.apache.sp
ark.sql.SparkSess
ion.withActive(SparkSession.scala:779) at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:617) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357) at py4j.Gateway.invoke(Gateway.java:282) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182) at py4j.ClientServerConnection.run(ClientServerConnection.java:106) at java.lang.Thread.run(Thread.java:750)
<!--EndFragment-->
</body>
</html>
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 closed issue #8019: [SUPPORT] How to Restore from Checkpoints from disaster recovery in hudi using Pyspark and not Hudi CLI and use proc in PySpark
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 closed issue #8019: [SUPPORT] How to Restore from Checkpoints from disaster recovery in hudi using Pyspark and not Hudi CLI and use proc in PySpark
URL: https://github.com/apache/hudi/issues/8019
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8019: [SUPPORT] How to Restore from Checkpoints from disaster recovery in hudi using Pyspark and not Hudi CLI
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8019:
URL: https://github.com/apache/hudi/issues/8019#issuecomment-1440080735
Hello @kazdy thank you very much for such a prompt reply
there are lot of python users which would love to see some python examples is there any python example that shows how to recover or rollback to older checkpoints ?
if not we can post sample code i am okay creating tutorials for community that way we can make information accessible to everyone easily :D
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8019: [SUPPORT] How to Restore from Checkpoints from disaster recovery in hudi using Pyspark and not Hudi CLI and use proc in PySpark
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8019:
URL: https://github.com/apache/hudi/issues/8019#issuecomment-1440886019
# My Issue have been resolved and would be making content for community
<img width="784" alt="1231" src="https://user-images.githubusercontent.com/39345855/220772505-259d7685-c52d-4884-8d25-427004532ba5.PNG">
<img width="790" alt="Capture" src="https://user-images.githubusercontent.com/39345855/220772510-858060a7-f3b4-4214-8799-5b4f145dd9b7.PNG">
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nfarah86 commented on issue #8019: [SUPPORT] How to Restore from Checkpoints from disaster recovery in hudi using Pyspark and not Hudi CLI and use proc in PySpark
Posted by "nfarah86 (via GitHub)" <gi...@apache.org>.
nfarah86 commented on issue #8019:
URL: https://github.com/apache/hudi/issues/8019#issuecomment-1441199915
thanks @soumilshah1995
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8019: [SUPPORT] How to Restore from Checkpoints from disaster recovery in hudi using Pyspark and not Hudi CLI
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8019:
URL: https://github.com/apache/hudi/issues/8019#issuecomment-1440153705
Here is sample code and not sure how really to call this in pyspark
```
"""
%connections hudi-connection
%glue_version 3.0
%region us-east-1
%worker_type G.1X
%number_of_workers 3
%spark_conf spark.serializer=org.apache.spark.serializer.KryoSerializer
%additional_python_modules Faker
"""
try:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.session import SparkSession
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import col, to_timestamp, monotonically_increasing_id, to_date, when
from pyspark.sql.functions import *
from awsglue.utils import getResolvedOptions
from awsglueml.transforms import EntityDetector
from pyspark.sql.types import StringType
from pyspark.sql.types import *
from datetime import datetime
import boto3
from functools import reduce
except Exception as e:
print("Error ")
spark = SparkSession.builder.config('spark.serializer','org.apache.spark.serializer.KryoSerializer') \
.config('spark.sql.hive.convertMetastoreParquet','false') \
.config('spark.sql.legacy.pathOptionBehavior.enabled', 'true') .getOrCreate()
sc = spark.sparkContext
glueContext = GlueContext(sc)
job = Job(glueContext)
logger = glueContext.get_logger()
import uuid
from faker import Faker
global faker
faker = Faker()
class DataGenerator(object):
@staticmethod
def get_data():
return [
(
uuid.uuid4().__str__(),
faker.name(),
faker.random_element(elements=('IT', 'HR', 'Sales', 'Marketing')),
faker.random_element(elements=('CA', 'NY', 'TX', 'FL', 'IL', 'RJ')),
str(faker.random_int(min=10000, max=150000)),
str(faker.random_int(min=18, max=60)),
str(faker.random_int(min=0, max=100000)),
str(faker.unix_time()),
faker.email(),
faker.credit_card_number(card_type='amex'),
faker.date()
) for x in range(100)
]
data = DataGenerator.get_data()
columns = ["emp_id", "employee_name", "department", "state", "salary", "age", "bonus", "ts", "email", "credit_card", "date"]
spark_df = spark.createDataFrame(data=data, schema=columns)
db_name = "hudidb"
table_name="hudi_table"
recordkey = 'emp_id'
path = "s3://hudi-demos-emr-serverless-project-soumil/tmp/"
method = 'upsert'
table_type = "COPY_ON_WRITE"
precombine = "ts"
partiton_field = "date"
connection_options={
"path": path,
"connectionName": "hudi-connection",
"hoodie.datasource.write.storage.type": table_type,
'hoodie.datasource.write.precombine.field': precombine,
'className': 'org.apache.hudi',
'hoodie.table.name': table_name,
'hoodie.datasource.write.recordkey.field': recordkey,
'hoodie.datasource.write.table.name': table_name,
'hoodie.datasource.write.operation': method,
'hoodie.datasource.hive_sync.enable': 'true',
"hoodie.datasource.hive_sync.mode":"hms",
'hoodie.datasource.hive_sync.sync_as_datasource': 'false',
'hoodie.datasource.hive_sync.database': db_name,
'hoodie.datasource.hive_sync.table': table_name,
'hoodie.datasource.hive_sync.use_jdbc': 'false',
'hoodie.datasource.hive_sync.partition_extractor_class': 'org.apache.hudi.hive.MultiPartKeysValueExtractor',
'hoodie.datasource.write.hive_style_partitioning': 'true',
}
WriteDF = (
glueContext.write_dynamic_frame.from_options(
frame=DynamicFrame.fromDF(spark_df, glueContext,"glue_df"),
connection_type="marketplace.spark",
connection_options=connection_options,
transformation_ctx="glue_df",
)
)
df = spark. \
read. \
format("hudi"). \
load(path)
#### tried
query = """
call show_commits(table = 'hudi_table' limit 10 );
"""
spark.sql(query).show()
#### tried
query = """
call show_commits(table => 'hudi_table', limit => 10);
"""
spark.sql(query).show()
```
#### Error Message
```
ParseException:
mismatched input 'call' expecting {'(', 'ADD', 'ALTER', 'ANALYZE', 'CACHE', 'CLEAR', 'COMMENT', 'COMMIT', 'CREATE', 'DELETE', 'DESC', 'DESCRIBE', 'DFS', 'DROP', 'EXPLAIN', 'EXPORT', 'FROM', 'GRANT', 'IMPORT', 'INSERT', 'LIST', 'LOAD', 'LOCK', 'MAP', 'MERGE', 'MSCK', 'REDUCE', 'REFRESH', 'REPLACE', 'RESET', 'REVOKE', 'ROLLBACK', 'SELECT', 'SET', 'SHOW', 'START', 'TABLE', 'TRUNCATE', 'UNCACHE', 'UNLOCK', 'UPDATE', 'USE', 'VALUES', 'WITH'}(line 2, pos 0)
== SQL ==
call show_commits(table = 'hudi_table' limit 10 );
^^^
``
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] papablus commented on issue #8019: [SUPPORT] How to Restore from Checkpoints from disaster recovery in hudi using Pyspark and not Hudi CLI and use proc in PySpark
Posted by "papablus (via GitHub)" <gi...@apache.org>.
papablus commented on issue #8019:
URL: https://github.com/apache/hudi/issues/8019#issuecomment-1440237517
Hi, i am restoring savepoint using glue4 and hudi 0.12.1 using this spark configuration
```
spark = (SparkSession.builder.config('spark.serializer','org.apache.spark.serializer.KryoSerializer') \
.config('spark.sql.hive.convertMetastoreParquet','false') \
.config('spark.sql.catalog.spark_catalog','org.apache.spark.sql.hudi.catalog.HoodieCatalog') \
.config('spark.sql.extensions','org.apache.spark.sql.hudi.HoodieSparkSessionExtension') \
.config('spark.sql.legacy.pathOptionBehavior.enabled', 'true').getOrCreate())
```
I see that the spark.sql.extensions is mandatory when you are going to call a procedure.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] papablus commented on issue #8019: [SUPPORT] How to Restore from Checkpoints from disaster recovery in hudi using Pyspark and not Hudi CLI and use proc in PySpark
Posted by "papablus (via GitHub)" <gi...@apache.org>.
papablus commented on issue #8019:
URL: https://github.com/apache/hudi/issues/8019#issuecomment-1440254996
Hi @soumilshah1995,
This is my glue job (Glue 4 - Spark 3.3 - Python 3)
`import sys
from pyspark.context import SparkContext
from pyspark.sql.session import SparkSession
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import col, to_timestamp, monotonically_increasing_id, to_date, when
from pyspark.sql.functions import *
from awsglue.utils import getResolvedOptions
from pyspark.sql.types import *
from datetime import datetime, date
import boto3
from functools import reduce
from pyspark.sql import Row
args = getResolvedOptions(sys.argv, ['JOB_NAME',
'OUTPUT_BUCKET',
'HUDI_INIT_SORT_OPTION',
'HUDI_TABLE_NAME',
'HUDI_DB_NAME',
'CATEGORY_ID'
])
print(args)
# print("The name of the bucket is :- ", args['curated_bucket'])
job_start_ts = datetime.now()
ts_format = '%Y-%m-%d %H:%M:%S'
spark = (SparkSession.builder.config('spark.serializer','org.apache.spark.serializer.KryoSerializer') \
.config('spark.sql.hive.convertMetastoreParquet','false') \
.config('spark.sql.catalog.spark_catalog','org.apache.spark.sql.hudi.catalog.HoodieCatalog') \
.config('spark.sql.extensions','org.apache.spark.sql.hudi.HoodieSparkSessionExtension') \
.config('spark.sql.legacy.pathOptionBehavior.enabled', 'true').getOrCreate())
sc = spark.sparkContext
glueContext = GlueContext(sc)
job = Job(glueContext)
logger = glueContext.get_logger()
job.init(args['JOB_NAME'], args)
def perform_hudi_bulk_insert(
hudi_init_sort_option,
hudi_output_bucket,
hudi_table_name,
hudi_db_name,
category_id
):
hudi_table_type = 'COPY_ON_WRITE'
hudi_table_name = hudi_table_name.lower() + '_' + hudi_init_sort_option.lower()
# create the schema for the ny trips raw data file in CSV format.
#RECORD_KEY: C
#PRECOMBINE FIELD: F
#PARTITION FIELD: D
# PySpark DataFrame with Ecplicit Schema.
df = spark.createDataFrame([
(10000001, '110000001', 'part1', 'date(1100000001, 81, 1)', 19, 201),
(10000001, '110000001', 'part1', 'date(1100000001, 81, 1)', 19, 202),
(20000001, '220000001', 'part1', 'date(2200000001, 82, 1)', 29, 202),
(20000001, '220000001', 'part1', 'date(2200000001, 82, 1)', 29, 201),
(30000001, '330000001', 'part1', 'date(3300000001, 83, 1)', 30, 203),
(30000001, '330000001', 'part1', 'date(3300000001, 83, 1)', 32, 203),
(30000001, '330000001', 'part1', 'date(3300000001, 83, 1)', 34, 203),
(30000001, '330000001', 'part1', 'date(3300000001, 83, 1)', 36, 203),
(40000001, '440000001', 'part1', 'date(4400000001, 84, 1)', 47, 888),
(40000001, '440000001', 'part1', 'date(4400000001, 84, 1)', 43, 888),
(40000001, '440000001', 'part1', 'date(4400000001, 84, 1)', 45, 888),
(40000001, '440000001', 'part1', 'date(4400000001, 84, 1)', 41, 888)
],
schema='a int, c string, d string, e string, f int, g int')
#df = spark.createDataFrame([
#],
#schema='a int, c string, d string, e string, f int, g int')
# show table
df.show()
# show schema
df.printSchema()
RECORD_KEY = "c"
PARTITION_FIELD = "d"
PRECOMBINE_FIELD = "f"
table_schema = StructType(
[ StructField("a",IntegerType(),True),
StructField("b",DoubleType(),True),
StructField("c",StringType(),True),
StructField("d", DateType(), True),
StructField("e", DateType(), True),
StructField("f", IntegerType(), True)
])
#table_schema2 = '{"type" : "record","name" : "userInfo","namespace" : "my.example","fields" : [{"name" : "a", "type" : "int"},{"name" : "b", "type" : "int"},{"name" : "c", "type" : "string"},{"name" : "d", "type" : "string"},{"name" : "e", "type" : "string"},{"name" : "f", "type" : "int"}]}'
curr_session = boto3.session.Session()
curr_region = curr_session.region_name
# set the hudi configuration
hudi_part_write_config = {
'className': 'org.apache.hudi',
'hoodie.datasource.hive_sync.enable':'true',
'hoodie.datasource.hive_sync.use_jdbc':'false',
'hoodie.datasource.hive_sync.support_timestamp': 'false',
'hoodie.datasource.write.operation': 'bulk_insert',
'hoodie.datasource.write.table.type': hudi_table_type,
'hoodie.table.name': hudi_table_name,
'hoodie.datasource.hive_sync.table': hudi_table_name,
'hoodie.datasource.write.recordkey.field': RECORD_KEY,
'hoodie.datasource.write.precombine.field': PRECOMBINE_FIELD,
'hoodie.datasource.write.partitionpath.field': 'd:SIMPLE',
'hoodie.datasource.write.hive_style_partitioning': 'true',
'hoodie.datasource.hive_sync.partition_extractor_class': 'org.apache.hudi.hive.MultiPartKeysValueExtractor',
'hoodie.datasource.write.hive_style_partitioning': 'true',
'hoodie.datasource.hive_sync.partition_fields': PARTITION_FIELD,
'hoodie.datasource.hive_sync.database': hudi_db_name,
'hoodie.datasource.write.keygenerator.class': 'org.apache.hudi.keygen.CustomKeyGenerator',
'hoodie.datasource.write.keygenerator.consistent.logical.timestamp.enabled' : 'true',
'hoodie.write.concurrency.mode' : 'single_writer',
'hoodie.cleaner.policy.failed.writes' : 'EAGER',
'hoodie.combine.before.insert' : 'true'
,'hoodie.cleaner.policy' : 'KEEP_LATEST_COMMITS'
,'hoodie.clean.automatic':'true'
#,'hoodie.clean.async':'true'
,'hoodie.cleaner.commits.retained' : 4
,'hoodie.datasource.hive_sync.mode' : 'hms'
}
table_path = 's3://{}/{}'.format(hudi_output_bucket, hudi_table_name)
print('The path for Hudi table where data is stored', table_path)
# only set this hudi parameter is a bulk insert sort option other than default is choosen
if hudi_init_sort_option.upper() in ['PARTITION_SORT', 'NONE']:
hudi_part_write_config['hoodie.bulkinsert.sort.mode'] = hudi_init_sort_option
start_tm = datetime.now()
print('The start time for the Bulk Insert :-' , start_tm)
df.write.format("hudi").options(**hudi_part_write_config).mode("append").save(table_path)
end_tm = datetime.now()
print('The End time for the Bulk Insert :-' , end_tm)
time_diff = end_tm - start_tm
print('The time it took for Bulk Insert operation :-' , time_diff)
#Creacion del Save Point
#varSP = spark.sql("call create_savepoint('hudi2.live_demo_restore_global_sort', '20230124192052120')")
#print(varSP.show())
#Eliminación del SavePoint
#varSP0 = spark.sql("call delete_savepoint('hudi2.live_demo_restore_global_sort', '20230124192052120')")
#print(varSP0.show())
#Visualizacion del SavePoint
#varSP2 = spark.sql("call show_savepoints('hudi2.live_demo_restore_global_sort')")
#print(varSP2.show())
#Eliminación del SavePoint
#varSP0 = spark.sql("call delete_savepoint('hudi2.live_demo_restore_global_sort', '20230118154353907')")
#print(varSP0.show())
#Restauración del SavePoint
#varSP = spark.sql("call rollback_to_savepoint('hudi2.live_demo_restore_global_sort', '20230124192052120')")
#print(varSP.show())
if __name__ == "__main__":
try:
perform_hudi_bulk_insert(args['HUDI_INIT_SORT_OPTION'],
args['OUTPUT_BUCKET'],
args['HUDI_TABLE_NAME'],
args['HUDI_DB_NAME'],
args['CATEGORY_ID']
)
except Exception as e:
print(e)
raise
job.commit()`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] kazdy commented on issue #8019: [SUPPORT] How to Restore from Checkpoints from disaster recovery in hudi using Pyspark and not Hudi CLI
Posted by "kazdy (via GitHub)" <gi...@apache.org>.
kazdy commented on issue #8019:
URL: https://github.com/apache/hudi/issues/8019#issuecomment-1440075626
Hi
Yes you can call spark procedures using pyspark, simply wrap your call command in
`spark.sql("call <procedure>(<args>>)")`.
Just make sure spark session is properly configured for Hudi (catalog, sql extensions, as described in quickstart for spark)
Here are spark procedures available to users, most are not documented yet:
https://github.com/apache/hudi/tree/master/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures
For disaster recovery you are probably looking for:
CreateSavepointProcedure.scala
DeleteSavepointProcedure.scala
RollbackToSavepointProcedure.scala
ShowSavepointsProcedure.scala
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org