You are viewing a plain text version of this content. The canonical link for it is here.
Posted to notifications@shardingsphere.apache.org by pa...@apache.org on 2020/10/13 03:00:22 UTC
[shardingsphere] branch master updated: Update result.en.md (#7756)
This is an automated email from the ASF dual-hosted git repository.
panjuan pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/shardingsphere.git
The following commit(s) were added to refs/heads/master by this push:
new be42925 Update result.en.md (#7756)
be42925 is described below
commit be42925d34b0fbbe799df379871bc16ba08db29b
Author: yang-7777 <67...@users.noreply.github.com>
AuthorDate: Tue Oct 13 10:59:53 2020 +0800
Update result.en.md (#7756)
add a pic in the summary section
---
docs/blog/content/material/result.en.md | 8 +++++---
1 file changed, 5 insertions(+), 3 deletions(-)
diff --git a/docs/blog/content/material/result.en.md b/docs/blog/content/material/result.en.md
index 71e100d..89fc0d7 100644
--- a/docs/blog/content/material/result.en.md
+++ b/docs/blog/content/material/result.en.md
@@ -23,12 +23,12 @@ Since the result set returned from the database is returned one by one, it is no
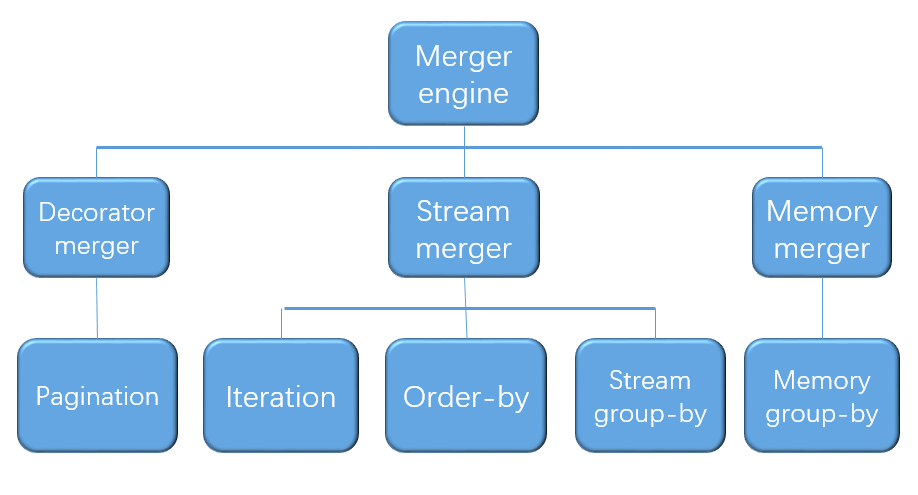
Streaming merge means that each time the data is fetched from the result set, the correct individual data can be returned by fetching it one by one, which is most compatible with the way the database returns the result set natively. Traversal, sorting, and Stream Group-by Merger are all types of stream imputation.
In-memory merging, on the other hand, requires that all data in the result set be traversed and stored in memory, and then after unified grouping, sorting, and aggregation calculations, it is encapsulated to return the result set of data accessed one item at a time.
+
The decorator merge is a unified functional enhancement of all the result set merge, currently the decorator merge only paging this type of merge.
### Categorization
-
#### Iteration Merger
It is the simplest form of aggregation. Simply merge multiple result sets into a one-way chain table. After iterating through the current result set in the chain table, move the chain table element back one place and continue to iterate through the next result set.
@@ -112,11 +112,13 @@ Sharding-Sphere's Pagination capabilities are rather misleading to users, who of
However, it is also important to note that a large amount of data still needs to be transferred to Sharding-Sphere's memory space due to the sorting needs. Therefore, it is not a best practice to use LIMIT for Pagination in this manner. Since LIMIT does not query data by index, Pagination by ID is a better solution if continuity of ID can be guaranteed, e.g..
-

Or by recording the ID of the last record of the last query result for the next page, for example.
-

+### Summary
+
+The whole structure of merger engine is showing below:
+