You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@mxnet.apache.org by GitBox <gi...@apache.org> on 2022/08/23 13:14:14 UTC
[GitHub] [incubator-mxnet] anko-intel opened a new pull request, #21127: [DOC] Add tutotrial about improving accuracy of quantization with oneDNN
anko-intel opened a new pull request, #21127:
URL: https://github.com/apache/incubator-mxnet/pull/21127
## Description ##
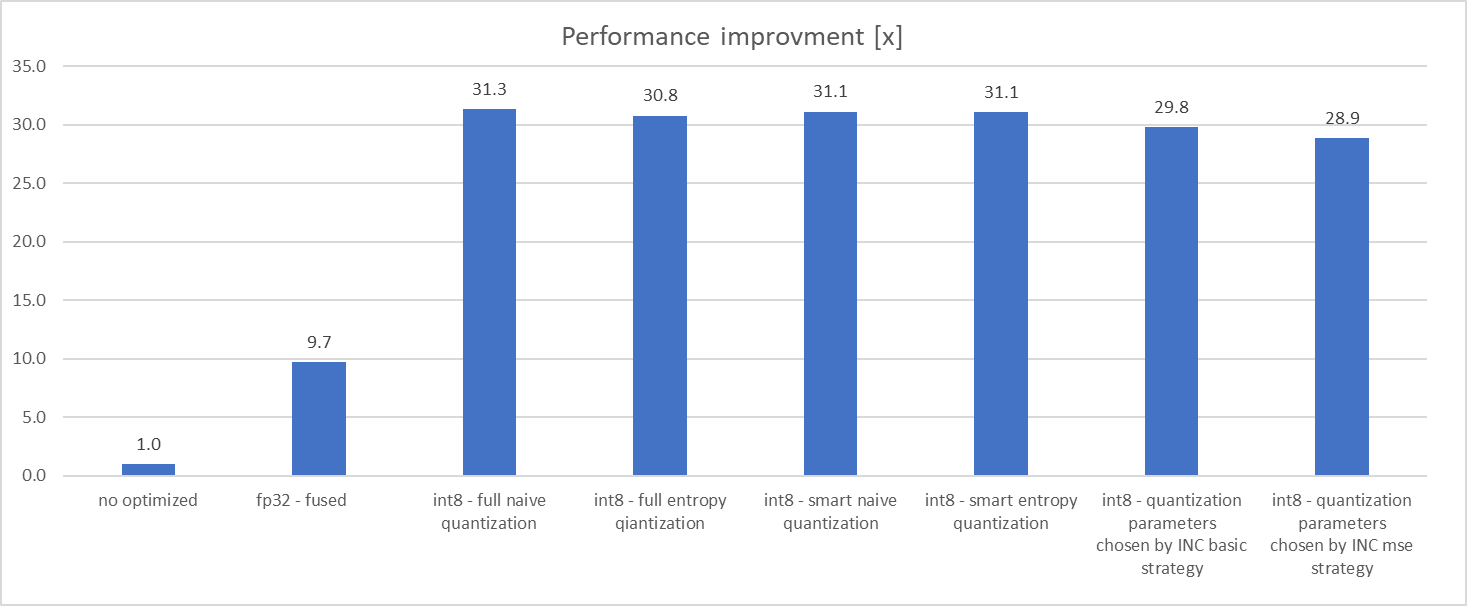
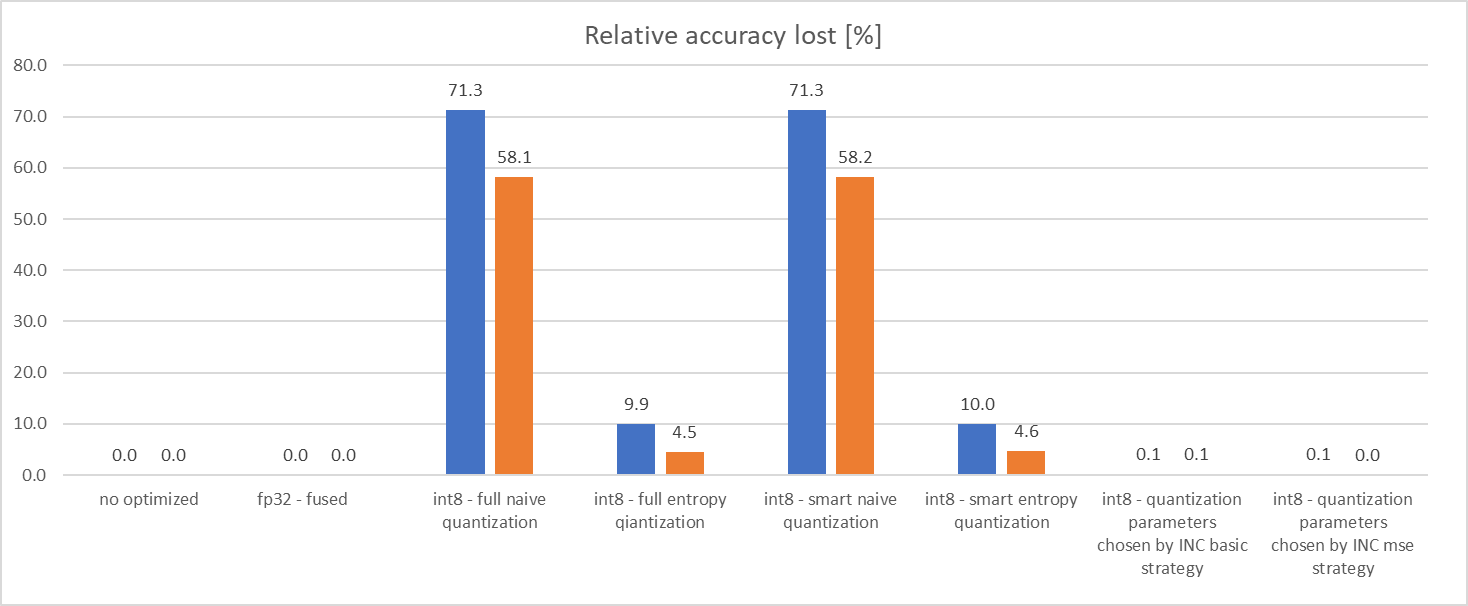
Added tutorial showing advantage of using INC with MXNet for quantization. It shows that INC can find operators mostly introduced loss of accuracy and eliminate it from quantization. This way partially quantized model achieves accuracy results almost the same as original floating point model, but with about 3 times performance improvement in comparison to optimized floating point model (or 30 times in comparison to not optimized floating point model)
## Checklist ##
### Essentials ###
- [ ] PR's title starts with a category (e.g. [BUGFIX], [MODEL], [TUTORIAL], [FEATURE], [DOC], etc)
- [ ] Changes are complete (i.e. I finished coding on this PR)
- [ ] All changes have test coverage
- [ ] Code is well-documented
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@mxnet.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] mxnet-bot commented on pull request #21127: [DOC] Add tutotrial about improving accuracy of quantization with oneDNN
Posted by GitBox <gi...@apache.org>.
mxnet-bot commented on PR #21127:
URL: https://github.com/apache/incubator-mxnet/pull/21127#issuecomment-1224059750
Hey @anko-intel , Thanks for submitting the PR
All tests are already queued to run once. If tests fail, you can trigger one or more tests again with the following commands:
- To trigger all jobs: @mxnet-bot run ci [all]
- To trigger specific jobs: @mxnet-bot run ci [job1, job2]
***
**CI supported jobs**: [windows-cpu, website, centos-gpu, unix-gpu, windows-gpu, edge, sanity, miscellaneous, unix-cpu, clang, centos-cpu]
***
_Note_:
Only following 3 categories can trigger CI :PR Author, MXNet Committer, Jenkins Admin.
All CI tests must pass before the PR can be merged.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@mxnet.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] bartekkuncer commented on a diff in pull request #21127: [DOC] Add tutotrial about improving accuracy of quantization with oneDNN
Posted by GitBox <gi...@apache.org>.
bartekkuncer commented on code in PR #21127:
URL: https://github.com/apache/incubator-mxnet/pull/21127#discussion_r954852841
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
Review Comment:
```suggestion
- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`.)
```
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
Review Comment:
```suggestion
If you get into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`.
```
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
+
+## Configuration file
+
+Quantization tuning process can be customized in the yaml configuration file. Below is a simple example:
+
+```yaml
+# cnn.yaml
+
+version: 1.0
+
+model:
+ name: cnn
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 160 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: basic
+ accuracy_criterion:
+ relative: 0.01
+ exit_policy:
+ timeout: 0
+ random_seed: 9527
+```
+
+We are using the `basic` strategy, but you could also try out different ones. [Here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md) you can find a list of strategies available in INC and details of how they work. You can also add your own strategy if the existing ones do not suit your needs.
+
+Since the value of `timeout` is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
Review Comment:
```suggestion
Since the value of `timeout` in the example above is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
```
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
+
+## Configuration file
+
+Quantization tuning process can be customized in the yaml configuration file. Below is a simple example:
+
+```yaml
+# cnn.yaml
+
+version: 1.0
+
+model:
+ name: cnn
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 160 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: basic
+ accuracy_criterion:
+ relative: 0.01
+ exit_policy:
+ timeout: 0
+ random_seed: 9527
+```
+
+We are using the `basic` strategy, but you could also try out different ones. [Here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md) you can find a list of strategies available in INC and details of how they work. You can also add your own strategy if the existing ones do not suit your needs.
+
+Since the value of `timeout` is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
+
+For more information about the configuration file, see the [template](https://github.com/intel/neural-compressor/blob/master/neural_compressor/template/ptq.yaml) from the official INC repo. Keep in mind that only the `post training quantization` is currently supported for MXNet.
+
+## Model quantization and tuning
+
+In general, Intel® Neural Compressor requires 4 elements in order to run:
+1. Config file - like the example above
Review Comment:
```suggestion
1. Configuration file - like the example above
```
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
+
+## Configuration file
+
+Quantization tuning process can be customized in the yaml configuration file. Below is a simple example:
+
+```yaml
+# cnn.yaml
+
+version: 1.0
+
+model:
+ name: cnn
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 160 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: basic
+ accuracy_criterion:
+ relative: 0.01
+ exit_policy:
+ timeout: 0
+ random_seed: 9527
+```
+
+We are using the `basic` strategy, but you could also try out different ones. [Here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md) you can find a list of strategies available in INC and details of how they work. You can also add your own strategy if the existing ones do not suit your needs.
+
+Since the value of `timeout` is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
+
+For more information about the configuration file, see the [template](https://github.com/intel/neural-compressor/blob/master/neural_compressor/template/ptq.yaml) from the official INC repo. Keep in mind that only the `post training quantization` is currently supported for MXNet.
+
+## Model quantization and tuning
+
+In general, Intel® Neural Compressor requires 4 elements in order to run:
+1. Config file - like the example above
+2. Model to be quantized
+3. Calibration dataloader
+4. Evaluation function - a function that takes a model as an argument and returns the accuracy it achieves on a certain evaluation dataset.
+
+### Quantizing ResNet
+
+The [quantization](https://mxnet.apache.org/versions/master/api/python/docs/tutorials/performance/backend/dnnl/dnnl_quantization.html#Quantization) sections described how to quantize ResNet using the native MXNet quantization. This example shows how we can achieve the similar results (with the auto-tuning) using INC.
+
+1. Get the model
+
+```python
+import logging
+import mxnet as mx
+from mxnet.gluon.model_zoo import vision
+
+logging.basicConfig()
+logger = logging.getLogger('logger')
+logger.setLevel(logging.INFO)
+
+batch_shape = (1, 3, 224, 224)
+resnet18 = vision.resnet18_v1(pretrained=True)
+```
+
+2. Prepare the dataset:
+
+```python
+mx.test_utils.download('http://data.mxnet.io/data/val_256_q90.rec', 'data/val_256_q90.rec')
+
+batch_size = 16
+mean_std = {'mean_r': 123.68, 'mean_g': 116.779, 'mean_b': 103.939,
+ 'std_r': 58.393, 'std_g': 57.12, 'std_b': 57.375}
+
+data = mx.io.ImageRecordIter(path_imgrec='data/val_256_q90.rec',
+ batch_size=batch_size,
+ data_shape=batch_shape[1:],
+ rand_crop=False,
+ rand_mirror=False,
+ shuffle=False,
+ **mean_std)
+data.batch_size = batch_size
+```
+
+3. Prepare the evaluation function:
+
+```python
+eval_samples = batch_size*10
+
+def eval_func(model):
+ data.reset()
+ metric = mx.metric.Accuracy()
+ for i, batch in enumerate(data):
+ if i * batch_size >= eval_samples:
+ break
+ x = batch.data[0].as_in_context(mx.cpu())
+ label = batch.label[0].as_in_context(mx.cpu())
+ outputs = model.forward(x)
+ metric.update(label, outputs)
+ return metric.get()[1]
+```
+
+4. Run Intel® Neural Compressor:
+
+```python
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("./cnn.yaml")
+quantizer.model = resnet18
+quantizer.calib_dataloader = data
+quantizer.eval_func = eval_func
+qnet = quantizer.fit().model
+```
+
+Since this model already achieves good accuracy using native quantization (less than 1% accuracy drop), for the given configuration file, INC will end on the first configuration, quantizing all layers using `naive` calibration mode for each. To see the true potential of INC, we need a model which suffers from a larger accuracy drop after quantization.
+
+### Quantizing ResNet50v2
+
+This example shows how to use INC to quantize ResNet50 v2. In this case, the native MXNet quantization introduce a huge accuracy drop (70% using `naive` calibration mode) and INC allows automatically find better solution.
+
+This is the (TODO link to INC configuration file) for this example:
Review Comment:
TODO?
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
+
+## Configuration file
+
+Quantization tuning process can be customized in the yaml configuration file. Below is a simple example:
+
+```yaml
+# cnn.yaml
+
+version: 1.0
+
+model:
+ name: cnn
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 160 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: basic
+ accuracy_criterion:
+ relative: 0.01
+ exit_policy:
+ timeout: 0
+ random_seed: 9527
+```
+
+We are using the `basic` strategy, but you could also try out different ones. [Here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md) you can find a list of strategies available in INC and details of how they work. You can also add your own strategy if the existing ones do not suit your needs.
+
+Since the value of `timeout` is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
+
+For more information about the configuration file, see the [template](https://github.com/intel/neural-compressor/blob/master/neural_compressor/template/ptq.yaml) from the official INC repo. Keep in mind that only the `post training quantization` is currently supported for MXNet.
+
+## Model quantization and tuning
+
+In general, Intel® Neural Compressor requires 4 elements in order to run:
+1. Config file - like the example above
+2. Model to be quantized
+3. Calibration dataloader
+4. Evaluation function - a function that takes a model as an argument and returns the accuracy it achieves on a certain evaluation dataset.
+
+### Quantizing ResNet
+
+The [quantization](https://mxnet.apache.org/versions/master/api/python/docs/tutorials/performance/backend/dnnl/dnnl_quantization.html#Quantization) sections described how to quantize ResNet using the native MXNet quantization. This example shows how we can achieve the similar results (with the auto-tuning) using INC.
+
+1. Get the model
+
+```python
+import logging
+import mxnet as mx
+from mxnet.gluon.model_zoo import vision
+
+logging.basicConfig()
+logger = logging.getLogger('logger')
+logger.setLevel(logging.INFO)
+
+batch_shape = (1, 3, 224, 224)
+resnet18 = vision.resnet18_v1(pretrained=True)
+```
+
+2. Prepare the dataset:
+
+```python
+mx.test_utils.download('http://data.mxnet.io/data/val_256_q90.rec', 'data/val_256_q90.rec')
+
+batch_size = 16
+mean_std = {'mean_r': 123.68, 'mean_g': 116.779, 'mean_b': 103.939,
+ 'std_r': 58.393, 'std_g': 57.12, 'std_b': 57.375}
+
+data = mx.io.ImageRecordIter(path_imgrec='data/val_256_q90.rec',
+ batch_size=batch_size,
+ data_shape=batch_shape[1:],
+ rand_crop=False,
+ rand_mirror=False,
+ shuffle=False,
+ **mean_std)
+data.batch_size = batch_size
+```
+
+3. Prepare the evaluation function:
+
+```python
+eval_samples = batch_size*10
+
+def eval_func(model):
+ data.reset()
+ metric = mx.metric.Accuracy()
+ for i, batch in enumerate(data):
+ if i * batch_size >= eval_samples:
+ break
+ x = batch.data[0].as_in_context(mx.cpu())
+ label = batch.label[0].as_in_context(mx.cpu())
+ outputs = model.forward(x)
+ metric.update(label, outputs)
+ return metric.get()[1]
+```
+
+4. Run Intel® Neural Compressor:
+
+```python
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("./cnn.yaml")
+quantizer.model = resnet18
+quantizer.calib_dataloader = data
+quantizer.eval_func = eval_func
+qnet = quantizer.fit().model
+```
+
+Since this model already achieves good accuracy using native quantization (less than 1% accuracy drop), for the given configuration file, INC will end on the first configuration, quantizing all layers using `naive` calibration mode for each. To see the true potential of INC, we need a model which suffers from a larger accuracy drop after quantization.
+
+### Quantizing ResNet50v2
+
+This example shows how to use INC to quantize ResNet50 v2. In this case, the native MXNet quantization introduce a huge accuracy drop (70% using `naive` calibration mode) and INC allows automatically find better solution.
+
+This is the (TODO link to INC configuration file) for this example:
+```yaml
+version: 1.0
+
+model:
+ name: resnet50_v2
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 192 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: mse
+ accuracy_criterion:
+ relative: 0.015
+ exit_policy:
+ timeout: 0
+ max_trials: 500
+ random_seed: 9527
+```
+
+It could be used with script below
+(TODO link to resnet_mse.py)
+to find operator which mostly influence accuracy drops and disable it from quantization.
+You can find description of MSE strategy
+[here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md#user-content-mse).
+
+```python
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# set below proper path to ImageNet data set
Review Comment:
```suggestion
# set proper path to ImageNet data set below
```
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
+
+## Configuration file
+
+Quantization tuning process can be customized in the yaml configuration file. Below is a simple example:
+
+```yaml
+# cnn.yaml
+
+version: 1.0
+
+model:
+ name: cnn
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 160 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: basic
+ accuracy_criterion:
+ relative: 0.01
+ exit_policy:
+ timeout: 0
+ random_seed: 9527
+```
+
+We are using the `basic` strategy, but you could also try out different ones. [Here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md) you can find a list of strategies available in INC and details of how they work. You can also add your own strategy if the existing ones do not suit your needs.
+
+Since the value of `timeout` is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
+
+For more information about the configuration file, see the [template](https://github.com/intel/neural-compressor/blob/master/neural_compressor/template/ptq.yaml) from the official INC repo. Keep in mind that only the `post training quantization` is currently supported for MXNet.
+
+## Model quantization and tuning
+
+In general, Intel® Neural Compressor requires 4 elements in order to run:
+1. Config file - like the example above
+2. Model to be quantized
+3. Calibration dataloader
+4. Evaluation function - a function that takes a model as an argument and returns the accuracy it achieves on a certain evaluation dataset.
+
+### Quantizing ResNet
+
+The [quantization](https://mxnet.apache.org/versions/master/api/python/docs/tutorials/performance/backend/dnnl/dnnl_quantization.html#Quantization) sections described how to quantize ResNet using the native MXNet quantization. This example shows how we can achieve the similar results (with the auto-tuning) using INC.
+
+1. Get the model
+
+```python
+import logging
+import mxnet as mx
+from mxnet.gluon.model_zoo import vision
+
+logging.basicConfig()
+logger = logging.getLogger('logger')
+logger.setLevel(logging.INFO)
+
+batch_shape = (1, 3, 224, 224)
+resnet18 = vision.resnet18_v1(pretrained=True)
+```
+
+2. Prepare the dataset:
+
+```python
+mx.test_utils.download('http://data.mxnet.io/data/val_256_q90.rec', 'data/val_256_q90.rec')
+
+batch_size = 16
+mean_std = {'mean_r': 123.68, 'mean_g': 116.779, 'mean_b': 103.939,
+ 'std_r': 58.393, 'std_g': 57.12, 'std_b': 57.375}
+
+data = mx.io.ImageRecordIter(path_imgrec='data/val_256_q90.rec',
+ batch_size=batch_size,
+ data_shape=batch_shape[1:],
+ rand_crop=False,
+ rand_mirror=False,
+ shuffle=False,
+ **mean_std)
+data.batch_size = batch_size
+```
+
+3. Prepare the evaluation function:
+
+```python
+eval_samples = batch_size*10
+
+def eval_func(model):
+ data.reset()
+ metric = mx.metric.Accuracy()
+ for i, batch in enumerate(data):
+ if i * batch_size >= eval_samples:
+ break
+ x = batch.data[0].as_in_context(mx.cpu())
+ label = batch.label[0].as_in_context(mx.cpu())
+ outputs = model.forward(x)
+ metric.update(label, outputs)
+ return metric.get()[1]
+```
+
+4. Run Intel® Neural Compressor:
+
+```python
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("./cnn.yaml")
+quantizer.model = resnet18
+quantizer.calib_dataloader = data
+quantizer.eval_func = eval_func
+qnet = quantizer.fit().model
+```
+
+Since this model already achieves good accuracy using native quantization (less than 1% accuracy drop), for the given configuration file, INC will end on the first configuration, quantizing all layers using `naive` calibration mode for each. To see the true potential of INC, we need a model which suffers from a larger accuracy drop after quantization.
+
+### Quantizing ResNet50v2
+
+This example shows how to use INC to quantize ResNet50 v2. In this case, the native MXNet quantization introduce a huge accuracy drop (70% using `naive` calibration mode) and INC allows automatically find better solution.
+
+This is the (TODO link to INC configuration file) for this example:
+```yaml
+version: 1.0
+
+model:
+ name: resnet50_v2
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 192 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: mse
+ accuracy_criterion:
+ relative: 0.015
+ exit_policy:
+ timeout: 0
+ max_trials: 500
+ random_seed: 9527
+```
+
+It could be used with script below
+(TODO link to resnet_mse.py)
+to find operator which mostly influence accuracy drops and disable it from quantization.
Review Comment:
```suggestion
to find operator, which caused the most significant accuracy drop and disable it from quantization.
```
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
+
+## Configuration file
+
+Quantization tuning process can be customized in the yaml configuration file. Below is a simple example:
+
+```yaml
+# cnn.yaml
+
+version: 1.0
+
+model:
+ name: cnn
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 160 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: basic
+ accuracy_criterion:
+ relative: 0.01
+ exit_policy:
+ timeout: 0
+ random_seed: 9527
+```
+
+We are using the `basic` strategy, but you could also try out different ones. [Here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md) you can find a list of strategies available in INC and details of how they work. You can also add your own strategy if the existing ones do not suit your needs.
+
+Since the value of `timeout` is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
+
+For more information about the configuration file, see the [template](https://github.com/intel/neural-compressor/blob/master/neural_compressor/template/ptq.yaml) from the official INC repo. Keep in mind that only the `post training quantization` is currently supported for MXNet.
+
+## Model quantization and tuning
+
+In general, Intel® Neural Compressor requires 4 elements in order to run:
+1. Config file - like the example above
+2. Model to be quantized
+3. Calibration dataloader
+4. Evaluation function - a function that takes a model as an argument and returns the accuracy it achieves on a certain evaluation dataset.
+
+### Quantizing ResNet
+
+The [quantization](https://mxnet.apache.org/versions/master/api/python/docs/tutorials/performance/backend/dnnl/dnnl_quantization.html#Quantization) sections described how to quantize ResNet using the native MXNet quantization. This example shows how we can achieve the similar results (with the auto-tuning) using INC.
+
+1. Get the model
+
+```python
+import logging
+import mxnet as mx
+from mxnet.gluon.model_zoo import vision
+
+logging.basicConfig()
+logger = logging.getLogger('logger')
+logger.setLevel(logging.INFO)
+
+batch_shape = (1, 3, 224, 224)
+resnet18 = vision.resnet18_v1(pretrained=True)
+```
+
+2. Prepare the dataset:
+
+```python
+mx.test_utils.download('http://data.mxnet.io/data/val_256_q90.rec', 'data/val_256_q90.rec')
+
+batch_size = 16
+mean_std = {'mean_r': 123.68, 'mean_g': 116.779, 'mean_b': 103.939,
+ 'std_r': 58.393, 'std_g': 57.12, 'std_b': 57.375}
+
+data = mx.io.ImageRecordIter(path_imgrec='data/val_256_q90.rec',
+ batch_size=batch_size,
+ data_shape=batch_shape[1:],
+ rand_crop=False,
+ rand_mirror=False,
+ shuffle=False,
+ **mean_std)
+data.batch_size = batch_size
+```
+
+3. Prepare the evaluation function:
+
+```python
+eval_samples = batch_size*10
+
+def eval_func(model):
+ data.reset()
+ metric = mx.metric.Accuracy()
+ for i, batch in enumerate(data):
+ if i * batch_size >= eval_samples:
+ break
+ x = batch.data[0].as_in_context(mx.cpu())
+ label = batch.label[0].as_in_context(mx.cpu())
+ outputs = model.forward(x)
+ metric.update(label, outputs)
+ return metric.get()[1]
+```
+
+4. Run Intel® Neural Compressor:
+
+```python
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("./cnn.yaml")
+quantizer.model = resnet18
+quantizer.calib_dataloader = data
+quantizer.eval_func = eval_func
+qnet = quantizer.fit().model
+```
+
+Since this model already achieves good accuracy using native quantization (less than 1% accuracy drop), for the given configuration file, INC will end on the first configuration, quantizing all layers using `naive` calibration mode for each. To see the true potential of INC, we need a model which suffers from a larger accuracy drop after quantization.
+
+### Quantizing ResNet50v2
+
+This example shows how to use INC to quantize ResNet50 v2. In this case, the native MXNet quantization introduce a huge accuracy drop (70% using `naive` calibration mode) and INC allows automatically find better solution.
Review Comment:
```suggestion
This example shows how to use INC to quantize ResNet50 v2. In this case, the native MXNet quantization introduce a huge accuracy drop (70% using `naive` calibration mode) and INC allows to automatically find better solution.
```
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
+
+## Configuration file
+
+Quantization tuning process can be customized in the yaml configuration file. Below is a simple example:
+
+```yaml
+# cnn.yaml
+
+version: 1.0
+
+model:
+ name: cnn
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 160 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: basic
+ accuracy_criterion:
+ relative: 0.01
+ exit_policy:
+ timeout: 0
+ random_seed: 9527
+```
+
+We are using the `basic` strategy, but you could also try out different ones. [Here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md) you can find a list of strategies available in INC and details of how they work. You can also add your own strategy if the existing ones do not suit your needs.
+
+Since the value of `timeout` is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
+
+For more information about the configuration file, see the [template](https://github.com/intel/neural-compressor/blob/master/neural_compressor/template/ptq.yaml) from the official INC repo. Keep in mind that only the `post training quantization` is currently supported for MXNet.
+
+## Model quantization and tuning
+
+In general, Intel® Neural Compressor requires 4 elements in order to run:
+1. Config file - like the example above
+2. Model to be quantized
+3. Calibration dataloader
+4. Evaluation function - a function that takes a model as an argument and returns the accuracy it achieves on a certain evaluation dataset.
+
+### Quantizing ResNet
+
+The [quantization](https://mxnet.apache.org/versions/master/api/python/docs/tutorials/performance/backend/dnnl/dnnl_quantization.html#Quantization) sections described how to quantize ResNet using the native MXNet quantization. This example shows how we can achieve the similar results (with the auto-tuning) using INC.
+
+1. Get the model
+
+```python
+import logging
+import mxnet as mx
+from mxnet.gluon.model_zoo import vision
+
+logging.basicConfig()
+logger = logging.getLogger('logger')
+logger.setLevel(logging.INFO)
+
+batch_shape = (1, 3, 224, 224)
+resnet18 = vision.resnet18_v1(pretrained=True)
+```
+
+2. Prepare the dataset:
+
+```python
+mx.test_utils.download('http://data.mxnet.io/data/val_256_q90.rec', 'data/val_256_q90.rec')
+
+batch_size = 16
+mean_std = {'mean_r': 123.68, 'mean_g': 116.779, 'mean_b': 103.939,
+ 'std_r': 58.393, 'std_g': 57.12, 'std_b': 57.375}
+
+data = mx.io.ImageRecordIter(path_imgrec='data/val_256_q90.rec',
+ batch_size=batch_size,
+ data_shape=batch_shape[1:],
+ rand_crop=False,
+ rand_mirror=False,
+ shuffle=False,
+ **mean_std)
+data.batch_size = batch_size
+```
+
+3. Prepare the evaluation function:
+
+```python
+eval_samples = batch_size*10
+
+def eval_func(model):
+ data.reset()
+ metric = mx.metric.Accuracy()
+ for i, batch in enumerate(data):
+ if i * batch_size >= eval_samples:
+ break
+ x = batch.data[0].as_in_context(mx.cpu())
+ label = batch.label[0].as_in_context(mx.cpu())
+ outputs = model.forward(x)
+ metric.update(label, outputs)
+ return metric.get()[1]
+```
+
+4. Run Intel® Neural Compressor:
+
+```python
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("./cnn.yaml")
+quantizer.model = resnet18
+quantizer.calib_dataloader = data
+quantizer.eval_func = eval_func
+qnet = quantizer.fit().model
+```
+
+Since this model already achieves good accuracy using native quantization (less than 1% accuracy drop), for the given configuration file, INC will end on the first configuration, quantizing all layers using `naive` calibration mode for each. To see the true potential of INC, we need a model which suffers from a larger accuracy drop after quantization.
+
+### Quantizing ResNet50v2
+
+This example shows how to use INC to quantize ResNet50 v2. In this case, the native MXNet quantization introduce a huge accuracy drop (70% using `naive` calibration mode) and INC allows automatically find better solution.
+
+This is the (TODO link to INC configuration file) for this example:
+```yaml
+version: 1.0
+
+model:
+ name: resnet50_v2
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 192 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: mse
+ accuracy_criterion:
+ relative: 0.015
+ exit_policy:
+ timeout: 0
+ max_trials: 500
+ random_seed: 9527
+```
+
+It could be used with script below
+(TODO link to resnet_mse.py)
Review Comment:
TODO?
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
+
+## Configuration file
+
+Quantization tuning process can be customized in the yaml configuration file. Below is a simple example:
+
+```yaml
+# cnn.yaml
+
+version: 1.0
+
+model:
+ name: cnn
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 160 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: basic
+ accuracy_criterion:
+ relative: 0.01
+ exit_policy:
+ timeout: 0
+ random_seed: 9527
+```
+
+We are using the `basic` strategy, but you could also try out different ones. [Here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md) you can find a list of strategies available in INC and details of how they work. You can also add your own strategy if the existing ones do not suit your needs.
+
+Since the value of `timeout` is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
+
+For more information about the configuration file, see the [template](https://github.com/intel/neural-compressor/blob/master/neural_compressor/template/ptq.yaml) from the official INC repo. Keep in mind that only the `post training quantization` is currently supported for MXNet.
+
+## Model quantization and tuning
+
+In general, Intel® Neural Compressor requires 4 elements in order to run:
+1. Config file - like the example above
+2. Model to be quantized
+3. Calibration dataloader
+4. Evaluation function - a function that takes a model as an argument and returns the accuracy it achieves on a certain evaluation dataset.
+
+### Quantizing ResNet
+
+The [quantization](https://mxnet.apache.org/versions/master/api/python/docs/tutorials/performance/backend/dnnl/dnnl_quantization.html#Quantization) sections described how to quantize ResNet using the native MXNet quantization. This example shows how we can achieve the similar results (with the auto-tuning) using INC.
+
+1. Get the model
+
+```python
+import logging
+import mxnet as mx
+from mxnet.gluon.model_zoo import vision
+
+logging.basicConfig()
+logger = logging.getLogger('logger')
+logger.setLevel(logging.INFO)
+
+batch_shape = (1, 3, 224, 224)
+resnet18 = vision.resnet18_v1(pretrained=True)
+```
+
+2. Prepare the dataset:
+
+```python
+mx.test_utils.download('http://data.mxnet.io/data/val_256_q90.rec', 'data/val_256_q90.rec')
+
+batch_size = 16
+mean_std = {'mean_r': 123.68, 'mean_g': 116.779, 'mean_b': 103.939,
+ 'std_r': 58.393, 'std_g': 57.12, 'std_b': 57.375}
+
+data = mx.io.ImageRecordIter(path_imgrec='data/val_256_q90.rec',
+ batch_size=batch_size,
+ data_shape=batch_shape[1:],
+ rand_crop=False,
+ rand_mirror=False,
+ shuffle=False,
+ **mean_std)
+data.batch_size = batch_size
+```
+
+3. Prepare the evaluation function:
+
+```python
+eval_samples = batch_size*10
+
+def eval_func(model):
+ data.reset()
+ metric = mx.metric.Accuracy()
+ for i, batch in enumerate(data):
+ if i * batch_size >= eval_samples:
+ break
+ x = batch.data[0].as_in_context(mx.cpu())
+ label = batch.label[0].as_in_context(mx.cpu())
+ outputs = model.forward(x)
+ metric.update(label, outputs)
+ return metric.get()[1]
+```
+
+4. Run Intel® Neural Compressor:
+
+```python
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("./cnn.yaml")
+quantizer.model = resnet18
+quantizer.calib_dataloader = data
+quantizer.eval_func = eval_func
+qnet = quantizer.fit().model
+```
+
+Since this model already achieves good accuracy using native quantization (less than 1% accuracy drop), for the given configuration file, INC will end on the first configuration, quantizing all layers using `naive` calibration mode for each. To see the true potential of INC, we need a model which suffers from a larger accuracy drop after quantization.
+
+### Quantizing ResNet50v2
+
+This example shows how to use INC to quantize ResNet50 v2. In this case, the native MXNet quantization introduce a huge accuracy drop (70% using `naive` calibration mode) and INC allows automatically find better solution.
+
+This is the (TODO link to INC configuration file) for this example:
+```yaml
+version: 1.0
+
+model:
+ name: resnet50_v2
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 192 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: mse
+ accuracy_criterion:
+ relative: 0.015
+ exit_policy:
+ timeout: 0
+ max_trials: 500
+ random_seed: 9527
+```
+
+It could be used with script below
+(TODO link to resnet_mse.py)
+to find operator which mostly influence accuracy drops and disable it from quantization.
+You can find description of MSE strategy
+[here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md#user-content-mse).
+
+```python
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+# Tuning in INC on whole data set takes too long time so we take only part of the whole data set
Review Comment:
```suggestion
# Tuning with INC on whole data set takes loads of time. Therefore, we take only a part of the data set
```
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
+
+## Configuration file
+
+Quantization tuning process can be customized in the yaml configuration file. Below is a simple example:
+
+```yaml
+# cnn.yaml
+
+version: 1.0
+
+model:
+ name: cnn
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 160 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: basic
+ accuracy_criterion:
+ relative: 0.01
+ exit_policy:
+ timeout: 0
+ random_seed: 9527
+```
+
+We are using the `basic` strategy, but you could also try out different ones. [Here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md) you can find a list of strategies available in INC and details of how they work. You can also add your own strategy if the existing ones do not suit your needs.
+
+Since the value of `timeout` is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
+
+For more information about the configuration file, see the [template](https://github.com/intel/neural-compressor/blob/master/neural_compressor/template/ptq.yaml) from the official INC repo. Keep in mind that only the `post training quantization` is currently supported for MXNet.
+
+## Model quantization and tuning
+
+In general, Intel® Neural Compressor requires 4 elements in order to run:
+1. Config file - like the example above
+2. Model to be quantized
+3. Calibration dataloader
+4. Evaluation function - a function that takes a model as an argument and returns the accuracy it achieves on a certain evaluation dataset.
+
+### Quantizing ResNet
+
+The [quantization](https://mxnet.apache.org/versions/master/api/python/docs/tutorials/performance/backend/dnnl/dnnl_quantization.html#Quantization) sections described how to quantize ResNet using the native MXNet quantization. This example shows how we can achieve the similar results (with the auto-tuning) using INC.
+
+1. Get the model
+
+```python
+import logging
+import mxnet as mx
+from mxnet.gluon.model_zoo import vision
+
+logging.basicConfig()
+logger = logging.getLogger('logger')
+logger.setLevel(logging.INFO)
+
+batch_shape = (1, 3, 224, 224)
+resnet18 = vision.resnet18_v1(pretrained=True)
+```
+
+2. Prepare the dataset:
+
+```python
+mx.test_utils.download('http://data.mxnet.io/data/val_256_q90.rec', 'data/val_256_q90.rec')
+
+batch_size = 16
+mean_std = {'mean_r': 123.68, 'mean_g': 116.779, 'mean_b': 103.939,
+ 'std_r': 58.393, 'std_g': 57.12, 'std_b': 57.375}
+
+data = mx.io.ImageRecordIter(path_imgrec='data/val_256_q90.rec',
+ batch_size=batch_size,
+ data_shape=batch_shape[1:],
+ rand_crop=False,
+ rand_mirror=False,
+ shuffle=False,
+ **mean_std)
+data.batch_size = batch_size
+```
+
+3. Prepare the evaluation function:
+
+```python
+eval_samples = batch_size*10
+
+def eval_func(model):
+ data.reset()
+ metric = mx.metric.Accuracy()
+ for i, batch in enumerate(data):
+ if i * batch_size >= eval_samples:
+ break
+ x = batch.data[0].as_in_context(mx.cpu())
+ label = batch.label[0].as_in_context(mx.cpu())
+ outputs = model.forward(x)
+ metric.update(label, outputs)
+ return metric.get()[1]
+```
+
+4. Run Intel® Neural Compressor:
+
+```python
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("./cnn.yaml")
+quantizer.model = resnet18
+quantizer.calib_dataloader = data
+quantizer.eval_func = eval_func
+qnet = quantizer.fit().model
+```
+
+Since this model already achieves good accuracy using native quantization (less than 1% accuracy drop), for the given configuration file, INC will end on the first configuration, quantizing all layers using `naive` calibration mode for each. To see the true potential of INC, we need a model which suffers from a larger accuracy drop after quantization.
+
+### Quantizing ResNet50v2
+
+This example shows how to use INC to quantize ResNet50 v2. In this case, the native MXNet quantization introduce a huge accuracy drop (70% using `naive` calibration mode) and INC allows automatically find better solution.
+
+This is the (TODO link to INC configuration file) for this example:
+```yaml
+version: 1.0
+
+model:
+ name: resnet50_v2
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 192 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: mse
+ accuracy_criterion:
+ relative: 0.015
+ exit_policy:
+ timeout: 0
+ max_trials: 500
+ random_seed: 9527
+```
+
+It could be used with script below
+(TODO link to resnet_mse.py)
+to find operator which mostly influence accuracy drops and disable it from quantization.
+You can find description of MSE strategy
+[here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md#user-content-mse).
+
+```python
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+# Tuning in INC on whole data set takes too long time so we take only part of the whole data set
+# as representative part of it:
+dataset = dataset.take(num_calib_batches * batch_size)
+transformer = transforms.Compose([transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=rgb_mean, std=rgb_std)])
+# Note: as input data are used many times during tuning it is better to prepared data earlier,
+# so lazy parameter for transform_first is set to False
+val_data = mx.gluon.data.DataLoader(
+ dataset.transform_first(transformer, lazy=False), batch_size, shuffle=False)
+val_data.batch_size = batch_size
+
+net = resnet50_v2(pretrained=True)
+
+def eval_func(model):
+ metric = mx.gluon.metric.Accuracy()
+ for x, label in val_data:
+ output = model(x)
+ metric.update(label, output)
+ accuracy = metric.get()[1]
+ return accuracy
+
+
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("resnet50v2_mse.yaml")
+quantizer.model = net
+quantizer.calib_dataloader = val_data
+quantizer.eval_func = eval_func
+qnet_inc = quantizer.fit().model
+print("INC finished")
+# You can save optimized model for the later use:
+qnet_inc.export("__quantized_with_inc")
+# You can see what configurations was applied aby INC and which nodes was excluded from quantization
+# to achieve given accuracy lost against floating point calculation
+print(quantizer.strategy.best_qmodel.q_config['quant_cfg'])
+```
+
+#### Results:
+Resnet50 v2 model could be prepared to achieve better performance with various calibration and tuning methods.
+It is done by
+(TODO link to resnet_tuning.py)
Review Comment:
TODO?
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
+
+## Configuration file
+
+Quantization tuning process can be customized in the yaml configuration file. Below is a simple example:
+
+```yaml
+# cnn.yaml
+
+version: 1.0
+
+model:
+ name: cnn
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 160 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: basic
+ accuracy_criterion:
+ relative: 0.01
+ exit_policy:
+ timeout: 0
+ random_seed: 9527
+```
+
+We are using the `basic` strategy, but you could also try out different ones. [Here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md) you can find a list of strategies available in INC and details of how they work. You can also add your own strategy if the existing ones do not suit your needs.
+
+Since the value of `timeout` is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
+
+For more information about the configuration file, see the [template](https://github.com/intel/neural-compressor/blob/master/neural_compressor/template/ptq.yaml) from the official INC repo. Keep in mind that only the `post training quantization` is currently supported for MXNet.
+
+## Model quantization and tuning
+
+In general, Intel® Neural Compressor requires 4 elements in order to run:
+1. Config file - like the example above
+2. Model to be quantized
+3. Calibration dataloader
+4. Evaluation function - a function that takes a model as an argument and returns the accuracy it achieves on a certain evaluation dataset.
+
+### Quantizing ResNet
+
+The [quantization](https://mxnet.apache.org/versions/master/api/python/docs/tutorials/performance/backend/dnnl/dnnl_quantization.html#Quantization) sections described how to quantize ResNet using the native MXNet quantization. This example shows how we can achieve the similar results (with the auto-tuning) using INC.
+
+1. Get the model
+
+```python
+import logging
+import mxnet as mx
+from mxnet.gluon.model_zoo import vision
+
+logging.basicConfig()
+logger = logging.getLogger('logger')
+logger.setLevel(logging.INFO)
+
+batch_shape = (1, 3, 224, 224)
+resnet18 = vision.resnet18_v1(pretrained=True)
+```
+
+2. Prepare the dataset:
+
+```python
+mx.test_utils.download('http://data.mxnet.io/data/val_256_q90.rec', 'data/val_256_q90.rec')
+
+batch_size = 16
+mean_std = {'mean_r': 123.68, 'mean_g': 116.779, 'mean_b': 103.939,
+ 'std_r': 58.393, 'std_g': 57.12, 'std_b': 57.375}
+
+data = mx.io.ImageRecordIter(path_imgrec='data/val_256_q90.rec',
+ batch_size=batch_size,
+ data_shape=batch_shape[1:],
+ rand_crop=False,
+ rand_mirror=False,
+ shuffle=False,
+ **mean_std)
+data.batch_size = batch_size
+```
+
+3. Prepare the evaluation function:
+
+```python
+eval_samples = batch_size*10
+
+def eval_func(model):
+ data.reset()
+ metric = mx.metric.Accuracy()
+ for i, batch in enumerate(data):
+ if i * batch_size >= eval_samples:
+ break
+ x = batch.data[0].as_in_context(mx.cpu())
+ label = batch.label[0].as_in_context(mx.cpu())
+ outputs = model.forward(x)
+ metric.update(label, outputs)
+ return metric.get()[1]
+```
+
+4. Run Intel® Neural Compressor:
+
+```python
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("./cnn.yaml")
+quantizer.model = resnet18
+quantizer.calib_dataloader = data
+quantizer.eval_func = eval_func
+qnet = quantizer.fit().model
+```
+
+Since this model already achieves good accuracy using native quantization (less than 1% accuracy drop), for the given configuration file, INC will end on the first configuration, quantizing all layers using `naive` calibration mode for each. To see the true potential of INC, we need a model which suffers from a larger accuracy drop after quantization.
+
+### Quantizing ResNet50v2
+
+This example shows how to use INC to quantize ResNet50 v2. In this case, the native MXNet quantization introduce a huge accuracy drop (70% using `naive` calibration mode) and INC allows automatically find better solution.
+
+This is the (TODO link to INC configuration file) for this example:
+```yaml
+version: 1.0
+
+model:
+ name: resnet50_v2
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 192 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: mse
+ accuracy_criterion:
+ relative: 0.015
+ exit_policy:
+ timeout: 0
+ max_trials: 500
+ random_seed: 9527
+```
+
+It could be used with script below
+(TODO link to resnet_mse.py)
+to find operator which mostly influence accuracy drops and disable it from quantization.
+You can find description of MSE strategy
+[here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md#user-content-mse).
+
+```python
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+# Tuning in INC on whole data set takes too long time so we take only part of the whole data set
+# as representative part of it:
+dataset = dataset.take(num_calib_batches * batch_size)
+transformer = transforms.Compose([transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=rgb_mean, std=rgb_std)])
+# Note: as input data are used many times during tuning it is better to prepared data earlier,
+# so lazy parameter for transform_first is set to False
+val_data = mx.gluon.data.DataLoader(
+ dataset.transform_first(transformer, lazy=False), batch_size, shuffle=False)
+val_data.batch_size = batch_size
+
+net = resnet50_v2(pretrained=True)
+
+def eval_func(model):
+ metric = mx.gluon.metric.Accuracy()
+ for x, label in val_data:
+ output = model(x)
+ metric.update(label, output)
+ accuracy = metric.get()[1]
+ return accuracy
+
+
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("resnet50v2_mse.yaml")
+quantizer.model = net
+quantizer.calib_dataloader = val_data
+quantizer.eval_func = eval_func
+qnet_inc = quantizer.fit().model
+print("INC finished")
+# You can save optimized model for the later use:
+qnet_inc.export("__quantized_with_inc")
+# You can see what configurations was applied aby INC and which nodes was excluded from quantization
+# to achieve given accuracy lost against floating point calculation
+print(quantizer.strategy.best_qmodel.q_config['quant_cfg'])
+```
+
+#### Results:
+Resnet50 v2 model could be prepared to achieve better performance with various calibration and tuning methods.
+It is done by
+(TODO link to resnet_tuning.py)
+script on a small part of data set to reduce time required for tuning (9 batches).
+Later saved model are validated on a whole data set by
Review Comment:
```suggestion
Later saved model is validated on a whole data set by
```
OR
```suggestion
Later saved models are validated on a whole data set by
```
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
+
+## Configuration file
+
+Quantization tuning process can be customized in the yaml configuration file. Below is a simple example:
+
+```yaml
+# cnn.yaml
+
+version: 1.0
+
+model:
+ name: cnn
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 160 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: basic
+ accuracy_criterion:
+ relative: 0.01
+ exit_policy:
+ timeout: 0
+ random_seed: 9527
+```
+
+We are using the `basic` strategy, but you could also try out different ones. [Here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md) you can find a list of strategies available in INC and details of how they work. You can also add your own strategy if the existing ones do not suit your needs.
+
+Since the value of `timeout` is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
+
+For more information about the configuration file, see the [template](https://github.com/intel/neural-compressor/blob/master/neural_compressor/template/ptq.yaml) from the official INC repo. Keep in mind that only the `post training quantization` is currently supported for MXNet.
+
+## Model quantization and tuning
+
+In general, Intel® Neural Compressor requires 4 elements in order to run:
+1. Config file - like the example above
+2. Model to be quantized
+3. Calibration dataloader
+4. Evaluation function - a function that takes a model as an argument and returns the accuracy it achieves on a certain evaluation dataset.
+
+### Quantizing ResNet
+
+The [quantization](https://mxnet.apache.org/versions/master/api/python/docs/tutorials/performance/backend/dnnl/dnnl_quantization.html#Quantization) sections described how to quantize ResNet using the native MXNet quantization. This example shows how we can achieve the similar results (with the auto-tuning) using INC.
+
+1. Get the model
+
+```python
+import logging
+import mxnet as mx
+from mxnet.gluon.model_zoo import vision
+
+logging.basicConfig()
+logger = logging.getLogger('logger')
+logger.setLevel(logging.INFO)
+
+batch_shape = (1, 3, 224, 224)
+resnet18 = vision.resnet18_v1(pretrained=True)
+```
+
+2. Prepare the dataset:
+
+```python
+mx.test_utils.download('http://data.mxnet.io/data/val_256_q90.rec', 'data/val_256_q90.rec')
+
+batch_size = 16
+mean_std = {'mean_r': 123.68, 'mean_g': 116.779, 'mean_b': 103.939,
+ 'std_r': 58.393, 'std_g': 57.12, 'std_b': 57.375}
+
+data = mx.io.ImageRecordIter(path_imgrec='data/val_256_q90.rec',
+ batch_size=batch_size,
+ data_shape=batch_shape[1:],
+ rand_crop=False,
+ rand_mirror=False,
+ shuffle=False,
+ **mean_std)
+data.batch_size = batch_size
+```
+
+3. Prepare the evaluation function:
+
+```python
+eval_samples = batch_size*10
+
+def eval_func(model):
+ data.reset()
+ metric = mx.metric.Accuracy()
+ for i, batch in enumerate(data):
+ if i * batch_size >= eval_samples:
+ break
+ x = batch.data[0].as_in_context(mx.cpu())
+ label = batch.label[0].as_in_context(mx.cpu())
+ outputs = model.forward(x)
+ metric.update(label, outputs)
+ return metric.get()[1]
+```
+
+4. Run Intel® Neural Compressor:
+
+```python
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("./cnn.yaml")
+quantizer.model = resnet18
+quantizer.calib_dataloader = data
+quantizer.eval_func = eval_func
+qnet = quantizer.fit().model
+```
+
+Since this model already achieves good accuracy using native quantization (less than 1% accuracy drop), for the given configuration file, INC will end on the first configuration, quantizing all layers using `naive` calibration mode for each. To see the true potential of INC, we need a model which suffers from a larger accuracy drop after quantization.
+
+### Quantizing ResNet50v2
+
+This example shows how to use INC to quantize ResNet50 v2. In this case, the native MXNet quantization introduce a huge accuracy drop (70% using `naive` calibration mode) and INC allows automatically find better solution.
+
+This is the (TODO link to INC configuration file) for this example:
+```yaml
+version: 1.0
+
+model:
+ name: resnet50_v2
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 192 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: mse
+ accuracy_criterion:
+ relative: 0.015
+ exit_policy:
+ timeout: 0
+ max_trials: 500
+ random_seed: 9527
+```
+
+It could be used with script below
+(TODO link to resnet_mse.py)
+to find operator which mostly influence accuracy drops and disable it from quantization.
+You can find description of MSE strategy
+[here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md#user-content-mse).
+
+```python
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+# Tuning in INC on whole data set takes too long time so we take only part of the whole data set
+# as representative part of it:
+dataset = dataset.take(num_calib_batches * batch_size)
+transformer = transforms.Compose([transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=rgb_mean, std=rgb_std)])
+# Note: as input data are used many times during tuning it is better to prepared data earlier,
+# so lazy parameter for transform_first is set to False
+val_data = mx.gluon.data.DataLoader(
+ dataset.transform_first(transformer, lazy=False), batch_size, shuffle=False)
+val_data.batch_size = batch_size
+
+net = resnet50_v2(pretrained=True)
+
+def eval_func(model):
+ metric = mx.gluon.metric.Accuracy()
+ for x, label in val_data:
+ output = model(x)
+ metric.update(label, output)
+ accuracy = metric.get()[1]
+ return accuracy
+
+
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("resnet50v2_mse.yaml")
+quantizer.model = net
+quantizer.calib_dataloader = val_data
+quantizer.eval_func = eval_func
+qnet_inc = quantizer.fit().model
+print("INC finished")
+# You can save optimized model for the later use:
+qnet_inc.export("__quantized_with_inc")
+# You can see what configurations was applied aby INC and which nodes was excluded from quantization
+# to achieve given accuracy lost against floating point calculation
Review Comment:
```suggestion
# You can see which configuration was applied by INC and which nodes were excluded from quantization,
# to achieve given accuracy loss against floating point calculation.
```
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
+
+## Configuration file
+
+Quantization tuning process can be customized in the yaml configuration file. Below is a simple example:
+
+```yaml
+# cnn.yaml
+
+version: 1.0
+
+model:
+ name: cnn
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 160 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: basic
+ accuracy_criterion:
+ relative: 0.01
+ exit_policy:
+ timeout: 0
+ random_seed: 9527
+```
+
+We are using the `basic` strategy, but you could also try out different ones. [Here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md) you can find a list of strategies available in INC and details of how they work. You can also add your own strategy if the existing ones do not suit your needs.
+
+Since the value of `timeout` is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
+
+For more information about the configuration file, see the [template](https://github.com/intel/neural-compressor/blob/master/neural_compressor/template/ptq.yaml) from the official INC repo. Keep in mind that only the `post training quantization` is currently supported for MXNet.
+
+## Model quantization and tuning
+
+In general, Intel® Neural Compressor requires 4 elements in order to run:
+1. Config file - like the example above
+2. Model to be quantized
+3. Calibration dataloader
+4. Evaluation function - a function that takes a model as an argument and returns the accuracy it achieves on a certain evaluation dataset.
+
+### Quantizing ResNet
+
+The [quantization](https://mxnet.apache.org/versions/master/api/python/docs/tutorials/performance/backend/dnnl/dnnl_quantization.html#Quantization) sections described how to quantize ResNet using the native MXNet quantization. This example shows how we can achieve the similar results (with the auto-tuning) using INC.
+
+1. Get the model
+
+```python
+import logging
+import mxnet as mx
+from mxnet.gluon.model_zoo import vision
+
+logging.basicConfig()
+logger = logging.getLogger('logger')
+logger.setLevel(logging.INFO)
+
+batch_shape = (1, 3, 224, 224)
+resnet18 = vision.resnet18_v1(pretrained=True)
+```
+
+2. Prepare the dataset:
+
+```python
+mx.test_utils.download('http://data.mxnet.io/data/val_256_q90.rec', 'data/val_256_q90.rec')
+
+batch_size = 16
+mean_std = {'mean_r': 123.68, 'mean_g': 116.779, 'mean_b': 103.939,
+ 'std_r': 58.393, 'std_g': 57.12, 'std_b': 57.375}
+
+data = mx.io.ImageRecordIter(path_imgrec='data/val_256_q90.rec',
+ batch_size=batch_size,
+ data_shape=batch_shape[1:],
+ rand_crop=False,
+ rand_mirror=False,
+ shuffle=False,
+ **mean_std)
+data.batch_size = batch_size
+```
+
+3. Prepare the evaluation function:
+
+```python
+eval_samples = batch_size*10
+
+def eval_func(model):
+ data.reset()
+ metric = mx.metric.Accuracy()
+ for i, batch in enumerate(data):
+ if i * batch_size >= eval_samples:
+ break
+ x = batch.data[0].as_in_context(mx.cpu())
+ label = batch.label[0].as_in_context(mx.cpu())
+ outputs = model.forward(x)
+ metric.update(label, outputs)
+ return metric.get()[1]
+```
+
+4. Run Intel® Neural Compressor:
+
+```python
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("./cnn.yaml")
+quantizer.model = resnet18
+quantizer.calib_dataloader = data
+quantizer.eval_func = eval_func
+qnet = quantizer.fit().model
+```
+
+Since this model already achieves good accuracy using native quantization (less than 1% accuracy drop), for the given configuration file, INC will end on the first configuration, quantizing all layers using `naive` calibration mode for each. To see the true potential of INC, we need a model which suffers from a larger accuracy drop after quantization.
+
+### Quantizing ResNet50v2
+
+This example shows how to use INC to quantize ResNet50 v2. In this case, the native MXNet quantization introduce a huge accuracy drop (70% using `naive` calibration mode) and INC allows automatically find better solution.
+
+This is the (TODO link to INC configuration file) for this example:
+```yaml
+version: 1.0
+
+model:
+ name: resnet50_v2
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 192 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: mse
+ accuracy_criterion:
+ relative: 0.015
+ exit_policy:
+ timeout: 0
+ max_trials: 500
+ random_seed: 9527
+```
+
+It could be used with script below
+(TODO link to resnet_mse.py)
+to find operator which mostly influence accuracy drops and disable it from quantization.
+You can find description of MSE strategy
+[here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md#user-content-mse).
+
+```python
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+# Tuning in INC on whole data set takes too long time so we take only part of the whole data set
+# as representative part of it:
+dataset = dataset.take(num_calib_batches * batch_size)
+transformer = transforms.Compose([transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=rgb_mean, std=rgb_std)])
+# Note: as input data are used many times during tuning it is better to prepared data earlier,
+# so lazy parameter for transform_first is set to False
+val_data = mx.gluon.data.DataLoader(
+ dataset.transform_first(transformer, lazy=False), batch_size, shuffle=False)
+val_data.batch_size = batch_size
+
+net = resnet50_v2(pretrained=True)
+
+def eval_func(model):
+ metric = mx.gluon.metric.Accuracy()
+ for x, label in val_data:
+ output = model(x)
+ metric.update(label, output)
+ accuracy = metric.get()[1]
+ return accuracy
+
+
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("resnet50v2_mse.yaml")
+quantizer.model = net
+quantizer.calib_dataloader = val_data
+quantizer.eval_func = eval_func
+qnet_inc = quantizer.fit().model
+print("INC finished")
+# You can save optimized model for the later use:
+qnet_inc.export("__quantized_with_inc")
+# You can see what configurations was applied aby INC and which nodes was excluded from quantization
+# to achieve given accuracy lost against floating point calculation
+print(quantizer.strategy.best_qmodel.q_config['quant_cfg'])
+```
+
+#### Results:
+Resnet50 v2 model could be prepared to achieve better performance with various calibration and tuning methods.
+It is done by
+(TODO link to resnet_tuning.py)
+script on a small part of data set to reduce time required for tuning (9 batches).
+Later saved model are validated on a whole data set by
+(TODO link to resnet_measurment.py)
+script.
+Accuracy results on the whole validation dataset (782 batches) are shown below.
+
+| Optimization method | Top 1 accuracy | Top 5 accuracy | Top 1 relative accuracy loss [%] | Top 5 relative accuracy loss [%] | Cost = one-time optimization on 9 batches [s] | Validation time [s] | Speedup |
+|----------------------|-------:|-------:|-----:|-----:|-------:|--------:|-----:|
+| fp32 no optimization | 0.7699 | 0.9340 | 0.0 | 0.0 | 0.00 | 1448.69 | 1.0 |
+| fp32 fused | 0.7699 | 0.9340 | 99.9 | 99.5 | 0.03 | 149.45 | 9.7 |
+| int8 full naive | 0.2207 | 0.3912 | 71.3 | 58.1 | 12.74 | 46.28 | 31.3 |
+| int8 full entropy | 0.6933 | 0.8917 | 9.9 | 4.5 | 81.50 | 47.07 | 30.8 |
+| int8 smart naive | 0.2210 | 0.3905 | 71.3 | 58.2 | 12.55 | 46.56 | 31.1 |
+| int8 smart entropy | 0.6928 | 0.8910 | 10.0 | 4.6 | 80.89 | 46.58 | 31.1 |
+| int8 INC basic | 0.7692 | 0.9331 | 0.1 | 0.1 | 526.47 | 48.68 | 29.8 |
+| int8 INC mse | 0.7692 | 0.9337 | **0.1** | **0.0** | 227.89 | 50.19 | **28.9** |
+
+Environment:
+- Intel(R) Xeon(R) Platinum 8375C CPU @ 2.90GHz (c6i.16xlarge Amazon EC2 instance)
+- Ubuntu 20.04.4 LTS (GNU/Linux Ubuntu 20.04.4 LTS 5.15.0-1017-aws ami-0558cee5b20db1f9c)
+- MXNet 2.0.0b20220823 (commit daac02c7854ffa71bc11fd950c2d6c9ea356b394 )
+- INC 1.13.1
+- scripts above were run as parameter for [run.sh](https://github.com/apache/incubator-mxnet/blob/master/benchmark/python/dnnl/run.sh)
+script to properly setup parallel computation parameters
Review Comment:
```suggestion
script to properly setup parallel computation parameters.
```
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
+
+## Configuration file
+
+Quantization tuning process can be customized in the yaml configuration file. Below is a simple example:
+
+```yaml
+# cnn.yaml
+
+version: 1.0
+
+model:
+ name: cnn
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 160 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: basic
+ accuracy_criterion:
+ relative: 0.01
+ exit_policy:
+ timeout: 0
+ random_seed: 9527
+```
+
+We are using the `basic` strategy, but you could also try out different ones. [Here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md) you can find a list of strategies available in INC and details of how they work. You can also add your own strategy if the existing ones do not suit your needs.
+
+Since the value of `timeout` is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
+
+For more information about the configuration file, see the [template](https://github.com/intel/neural-compressor/blob/master/neural_compressor/template/ptq.yaml) from the official INC repo. Keep in mind that only the `post training quantization` is currently supported for MXNet.
+
+## Model quantization and tuning
+
+In general, Intel® Neural Compressor requires 4 elements in order to run:
+1. Config file - like the example above
+2. Model to be quantized
+3. Calibration dataloader
+4. Evaluation function - a function that takes a model as an argument and returns the accuracy it achieves on a certain evaluation dataset.
+
+### Quantizing ResNet
+
+The [quantization](https://mxnet.apache.org/versions/master/api/python/docs/tutorials/performance/backend/dnnl/dnnl_quantization.html#Quantization) sections described how to quantize ResNet using the native MXNet quantization. This example shows how we can achieve the similar results (with the auto-tuning) using INC.
+
+1. Get the model
+
+```python
+import logging
+import mxnet as mx
+from mxnet.gluon.model_zoo import vision
+
+logging.basicConfig()
+logger = logging.getLogger('logger')
+logger.setLevel(logging.INFO)
+
+batch_shape = (1, 3, 224, 224)
+resnet18 = vision.resnet18_v1(pretrained=True)
+```
+
+2. Prepare the dataset:
+
+```python
+mx.test_utils.download('http://data.mxnet.io/data/val_256_q90.rec', 'data/val_256_q90.rec')
+
+batch_size = 16
+mean_std = {'mean_r': 123.68, 'mean_g': 116.779, 'mean_b': 103.939,
+ 'std_r': 58.393, 'std_g': 57.12, 'std_b': 57.375}
+
+data = mx.io.ImageRecordIter(path_imgrec='data/val_256_q90.rec',
+ batch_size=batch_size,
+ data_shape=batch_shape[1:],
+ rand_crop=False,
+ rand_mirror=False,
+ shuffle=False,
+ **mean_std)
+data.batch_size = batch_size
+```
+
+3. Prepare the evaluation function:
+
+```python
+eval_samples = batch_size*10
+
+def eval_func(model):
+ data.reset()
+ metric = mx.metric.Accuracy()
+ for i, batch in enumerate(data):
+ if i * batch_size >= eval_samples:
+ break
+ x = batch.data[0].as_in_context(mx.cpu())
+ label = batch.label[0].as_in_context(mx.cpu())
+ outputs = model.forward(x)
+ metric.update(label, outputs)
+ return metric.get()[1]
+```
+
+4. Run Intel® Neural Compressor:
+
+```python
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("./cnn.yaml")
+quantizer.model = resnet18
+quantizer.calib_dataloader = data
+quantizer.eval_func = eval_func
+qnet = quantizer.fit().model
+```
+
+Since this model already achieves good accuracy using native quantization (less than 1% accuracy drop), for the given configuration file, INC will end on the first configuration, quantizing all layers using `naive` calibration mode for each. To see the true potential of INC, we need a model which suffers from a larger accuracy drop after quantization.
+
+### Quantizing ResNet50v2
+
+This example shows how to use INC to quantize ResNet50 v2. In this case, the native MXNet quantization introduce a huge accuracy drop (70% using `naive` calibration mode) and INC allows automatically find better solution.
+
+This is the (TODO link to INC configuration file) for this example:
+```yaml
+version: 1.0
+
+model:
+ name: resnet50_v2
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 192 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: mse
+ accuracy_criterion:
+ relative: 0.015
+ exit_policy:
+ timeout: 0
+ max_trials: 500
+ random_seed: 9527
+```
+
+It could be used with script below
+(TODO link to resnet_mse.py)
+to find operator which mostly influence accuracy drops and disable it from quantization.
+You can find description of MSE strategy
+[here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md#user-content-mse).
+
+```python
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+# Tuning in INC on whole data set takes too long time so we take only part of the whole data set
+# as representative part of it:
+dataset = dataset.take(num_calib_batches * batch_size)
+transformer = transforms.Compose([transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=rgb_mean, std=rgb_std)])
+# Note: as input data are used many times during tuning it is better to prepared data earlier,
+# so lazy parameter for transform_first is set to False
+val_data = mx.gluon.data.DataLoader(
+ dataset.transform_first(transformer, lazy=False), batch_size, shuffle=False)
+val_data.batch_size = batch_size
+
+net = resnet50_v2(pretrained=True)
+
+def eval_func(model):
+ metric = mx.gluon.metric.Accuracy()
+ for x, label in val_data:
+ output = model(x)
+ metric.update(label, output)
+ accuracy = metric.get()[1]
+ return accuracy
+
+
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("resnet50v2_mse.yaml")
+quantizer.model = net
+quantizer.calib_dataloader = val_data
+quantizer.eval_func = eval_func
+qnet_inc = quantizer.fit().model
+print("INC finished")
+# You can save optimized model for the later use:
+qnet_inc.export("__quantized_with_inc")
+# You can see what configurations was applied aby INC and which nodes was excluded from quantization
+# to achieve given accuracy lost against floating point calculation
+print(quantizer.strategy.best_qmodel.q_config['quant_cfg'])
+```
+
+#### Results:
+Resnet50 v2 model could be prepared to achieve better performance with various calibration and tuning methods.
+It is done by
+(TODO link to resnet_tuning.py)
+script on a small part of data set to reduce time required for tuning (9 batches).
+Later saved model are validated on a whole data set by
+(TODO link to resnet_measurment.py)
Review Comment:
TODO?
##########
example/quantization_inc/resnet_measurment.py:
##########
@@ -0,0 +1,68 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import mxnet as mx
+from mxnet.gluon.data.vision import transforms
+import time
+import glob
+
+
+def test_accuracy(net, data_loader, description):
+ count = 0
+ acc_top1 = mx.gluon.metric.Accuracy()
+ acc_top5 = mx.gluon.metric.TopKAccuracy(5)
+ start = time.time()
+ for x, label in data_loader:
+ output = net(x)
+ acc_top1.update(label, output)
+ acc_top5.update(label, output)
+ count += 1
+ time_spend = time.time() - start
+ _, top1 = acc_top1.get()
+ _, top5 = acc_top5.get()
+ print('{:21} Top1 Accuracy: {:.4f} Top5 Accuracy: {:.4f} from {:4} batches in {:8.2f}s'
+ .format(description, top1, top5, count, time_spend))
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+
+start = time.time()
+# Set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+transformer = transforms.Compose([transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=rgb_mean, std=rgb_std)])
+# Note: As the input data are used many times it is better to prepared data once,
+# so lazy parameter for transform_first is set to False
+val_data = mx.gluon.data.DataLoader(
+ dataset.transform_first(transformer, lazy=False), batch_size, shuffle=False)
+val_data.batch_size = batch_size
+time_consumed = time.time() - start
+print("Input data prepared in {:8.2f}s".format(time_consumed))
+
+print("Measure accuracy on whole data set could take a long time. Please wait...")
Review Comment:
```suggestion
print("Measure accuracy on the whole data set could take a long time. Please wait...")
```
##########
example/quantization_inc/resnet_mse.py:
##########
@@ -0,0 +1,65 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# Set below proper path to ImageNet data set
Review Comment:
```suggestion
# Set proper path to ImageNet data set below
```
##########
example/quantization_inc/resnet_measurment.py:
##########
@@ -0,0 +1,68 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import mxnet as mx
+from mxnet.gluon.data.vision import transforms
+import time
+import glob
+
+
+def test_accuracy(net, data_loader, description):
+ count = 0
+ acc_top1 = mx.gluon.metric.Accuracy()
+ acc_top5 = mx.gluon.metric.TopKAccuracy(5)
+ start = time.time()
+ for x, label in data_loader:
+ output = net(x)
+ acc_top1.update(label, output)
+ acc_top5.update(label, output)
+ count += 1
+ time_spend = time.time() - start
+ _, top1 = acc_top1.get()
+ _, top5 = acc_top5.get()
+ print('{:21} Top1 Accuracy: {:.4f} Top5 Accuracy: {:.4f} from {:4} batches in {:8.2f}s'
+ .format(description, top1, top5, count, time_spend))
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+
+start = time.time()
+# Set below proper path to ImageNet data set
Review Comment:
```suggestion
# Set proper path to ImageNet data set below
```
##########
example/quantization_inc/resnet_measurment.py:
##########
@@ -0,0 +1,68 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import mxnet as mx
+from mxnet.gluon.data.vision import transforms
+import time
+import glob
+
+
+def test_accuracy(net, data_loader, description):
+ count = 0
+ acc_top1 = mx.gluon.metric.Accuracy()
+ acc_top5 = mx.gluon.metric.TopKAccuracy(5)
+ start = time.time()
+ for x, label in data_loader:
+ output = net(x)
+ acc_top1.update(label, output)
+ acc_top5.update(label, output)
+ count += 1
+ time_spend = time.time() - start
+ _, top1 = acc_top1.get()
+ _, top5 = acc_top5.get()
+ print('{:21} Top1 Accuracy: {:.4f} Top5 Accuracy: {:.4f} from {:4} batches in {:8.2f}s'
+ .format(description, top1, top5, count, time_spend))
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+
+start = time.time()
+# Set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+transformer = transforms.Compose([transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=rgb_mean, std=rgb_std)])
+# Note: As the input data are used many times it is better to prepared data once,
+# so lazy parameter for transform_first is set to False
Review Comment:
```suggestion
# Note: as the input data is used many times it is better to prepare it once.
# Therefore, lazy parameter for transform_first is set to False.
```
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
+
+## Configuration file
+
+Quantization tuning process can be customized in the yaml configuration file. Below is a simple example:
+
+```yaml
+# cnn.yaml
+
+version: 1.0
+
+model:
+ name: cnn
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 160 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: basic
+ accuracy_criterion:
+ relative: 0.01
+ exit_policy:
+ timeout: 0
+ random_seed: 9527
+```
+
+We are using the `basic` strategy, but you could also try out different ones. [Here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md) you can find a list of strategies available in INC and details of how they work. You can also add your own strategy if the existing ones do not suit your needs.
+
+Since the value of `timeout` is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
+
+For more information about the configuration file, see the [template](https://github.com/intel/neural-compressor/blob/master/neural_compressor/template/ptq.yaml) from the official INC repo. Keep in mind that only the `post training quantization` is currently supported for MXNet.
+
+## Model quantization and tuning
+
+In general, Intel® Neural Compressor requires 4 elements in order to run:
+1. Config file - like the example above
+2. Model to be quantized
+3. Calibration dataloader
+4. Evaluation function - a function that takes a model as an argument and returns the accuracy it achieves on a certain evaluation dataset.
+
+### Quantizing ResNet
+
+The [quantization](https://mxnet.apache.org/versions/master/api/python/docs/tutorials/performance/backend/dnnl/dnnl_quantization.html#Quantization) sections described how to quantize ResNet using the native MXNet quantization. This example shows how we can achieve the similar results (with the auto-tuning) using INC.
+
+1. Get the model
+
+```python
+import logging
+import mxnet as mx
+from mxnet.gluon.model_zoo import vision
+
+logging.basicConfig()
+logger = logging.getLogger('logger')
+logger.setLevel(logging.INFO)
+
+batch_shape = (1, 3, 224, 224)
+resnet18 = vision.resnet18_v1(pretrained=True)
+```
+
+2. Prepare the dataset:
+
+```python
+mx.test_utils.download('http://data.mxnet.io/data/val_256_q90.rec', 'data/val_256_q90.rec')
+
+batch_size = 16
+mean_std = {'mean_r': 123.68, 'mean_g': 116.779, 'mean_b': 103.939,
+ 'std_r': 58.393, 'std_g': 57.12, 'std_b': 57.375}
+
+data = mx.io.ImageRecordIter(path_imgrec='data/val_256_q90.rec',
+ batch_size=batch_size,
+ data_shape=batch_shape[1:],
+ rand_crop=False,
+ rand_mirror=False,
+ shuffle=False,
+ **mean_std)
+data.batch_size = batch_size
+```
+
+3. Prepare the evaluation function:
+
+```python
+eval_samples = batch_size*10
+
+def eval_func(model):
+ data.reset()
+ metric = mx.metric.Accuracy()
+ for i, batch in enumerate(data):
+ if i * batch_size >= eval_samples:
+ break
+ x = batch.data[0].as_in_context(mx.cpu())
+ label = batch.label[0].as_in_context(mx.cpu())
+ outputs = model.forward(x)
+ metric.update(label, outputs)
+ return metric.get()[1]
+```
+
+4. Run Intel® Neural Compressor:
+
+```python
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("./cnn.yaml")
+quantizer.model = resnet18
+quantizer.calib_dataloader = data
+quantizer.eval_func = eval_func
+qnet = quantizer.fit().model
+```
+
+Since this model already achieves good accuracy using native quantization (less than 1% accuracy drop), for the given configuration file, INC will end on the first configuration, quantizing all layers using `naive` calibration mode for each. To see the true potential of INC, we need a model which suffers from a larger accuracy drop after quantization.
+
+### Quantizing ResNet50v2
+
+This example shows how to use INC to quantize ResNet50 v2. In this case, the native MXNet quantization introduce a huge accuracy drop (70% using `naive` calibration mode) and INC allows automatically find better solution.
+
+This is the (TODO link to INC configuration file) for this example:
+```yaml
+version: 1.0
+
+model:
+ name: resnet50_v2
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 192 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: mse
+ accuracy_criterion:
+ relative: 0.015
+ exit_policy:
+ timeout: 0
+ max_trials: 500
+ random_seed: 9527
+```
+
+It could be used with script below
+(TODO link to resnet_mse.py)
+to find operator which mostly influence accuracy drops and disable it from quantization.
+You can find description of MSE strategy
+[here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md#user-content-mse).
+
+```python
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+# Tuning in INC on whole data set takes too long time so we take only part of the whole data set
+# as representative part of it:
+dataset = dataset.take(num_calib_batches * batch_size)
+transformer = transforms.Compose([transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=rgb_mean, std=rgb_std)])
+# Note: as input data are used many times during tuning it is better to prepared data earlier,
+# so lazy parameter for transform_first is set to False
+val_data = mx.gluon.data.DataLoader(
+ dataset.transform_first(transformer, lazy=False), batch_size, shuffle=False)
+val_data.batch_size = batch_size
+
+net = resnet50_v2(pretrained=True)
+
+def eval_func(model):
+ metric = mx.gluon.metric.Accuracy()
+ for x, label in val_data:
+ output = model(x)
+ metric.update(label, output)
+ accuracy = metric.get()[1]
+ return accuracy
+
+
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("resnet50v2_mse.yaml")
+quantizer.model = net
+quantizer.calib_dataloader = val_data
+quantizer.eval_func = eval_func
+qnet_inc = quantizer.fit().model
+print("INC finished")
+# You can save optimized model for the later use:
+qnet_inc.export("__quantized_with_inc")
+# You can see what configurations was applied aby INC and which nodes was excluded from quantization
+# to achieve given accuracy lost against floating point calculation
+print(quantizer.strategy.best_qmodel.q_config['quant_cfg'])
+```
+
+#### Results:
+Resnet50 v2 model could be prepared to achieve better performance with various calibration and tuning methods.
+It is done by
+(TODO link to resnet_tuning.py)
+script on a small part of data set to reduce time required for tuning (9 batches).
+Later saved model are validated on a whole data set by
+(TODO link to resnet_measurment.py)
+script.
+Accuracy results on the whole validation dataset (782 batches) are shown below.
+
+| Optimization method | Top 1 accuracy | Top 5 accuracy | Top 1 relative accuracy loss [%] | Top 5 relative accuracy loss [%] | Cost = one-time optimization on 9 batches [s] | Validation time [s] | Speedup |
+|----------------------|-------:|-------:|-----:|-----:|-------:|--------:|-----:|
+| fp32 no optimization | 0.7699 | 0.9340 | 0.0 | 0.0 | 0.00 | 1448.69 | 1.0 |
+| fp32 fused | 0.7699 | 0.9340 | 99.9 | 99.5 | 0.03 | 149.45 | 9.7 |
+| int8 full naive | 0.2207 | 0.3912 | 71.3 | 58.1 | 12.74 | 46.28 | 31.3 |
+| int8 full entropy | 0.6933 | 0.8917 | 9.9 | 4.5 | 81.50 | 47.07 | 30.8 |
+| int8 smart naive | 0.2210 | 0.3905 | 71.3 | 58.2 | 12.55 | 46.56 | 31.1 |
+| int8 smart entropy | 0.6928 | 0.8910 | 10.0 | 4.6 | 80.89 | 46.58 | 31.1 |
+| int8 INC basic | 0.7692 | 0.9331 | 0.1 | 0.1 | 526.47 | 48.68 | 29.8 |
+| int8 INC mse | 0.7692 | 0.9337 | **0.1** | **0.0** | 227.89 | 50.19 | **28.9** |
+
+Environment:
+- Intel(R) Xeon(R) Platinum 8375C CPU @ 2.90GHz (c6i.16xlarge Amazon EC2 instance)
+- Ubuntu 20.04.4 LTS (GNU/Linux Ubuntu 20.04.4 LTS 5.15.0-1017-aws ami-0558cee5b20db1f9c)
+- MXNet 2.0.0b20220823 (commit daac02c7854ffa71bc11fd950c2d6c9ea356b394 )
+- INC 1.13.1
+- scripts above were run as parameter for [run.sh](https://github.com/apache/incubator-mxnet/blob/master/benchmark/python/dnnl/run.sh)
+script to properly setup parallel computation parameters
+
+For this model INC basic and mse strategies found configurations meeting the 1.5% relative accuracy
+loss criterion. Only the `bayesian` strategy didn't find solution within 500 attempts limit.
+Although these results may suggest that the `mse` strategy is the best compromise between time spent
+to find the optimized model and final model performance efficiency, different strategies may give
+better results for specific models and tasks. You can notice that most imported thing done by INC
+is to find operator which mostly influence loss of accuracy and disable it from quantization if needed.
+You can see below which operator was excluded by `mse` strategy in last print given by
+(TODO link to resnet_mse.py)
Review Comment:
TODO?
```suggestion
better results for specific models and tasks. You can notice, that the most important thing done by INC
was to find the operator, which had the most significant impact on the loss of accuracy and disable it from quantization if needed.
You can see below which operator was excluded by `mse` strategy in last print given by
(TODO link to resnet_mse.py)
```
##########
example/quantization_inc/resnet_mse.py:
##########
@@ -0,0 +1,65 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# Set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+# Tuning in INC on whole data set takes too long time so we take only part of the whole data set
+# as representative part of it:
+dataset = dataset.take(num_calib_batches * batch_size)
+transformer = transforms.Compose([transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=rgb_mean, std=rgb_std)])
+# Note: as input data are used many times during tuning it is better to prepared data earlier,
+# so lazy parameter for transform_first is set to False
+val_data = mx.gluon.data.DataLoader(
+ dataset.transform_first(transformer, lazy=False), batch_size, shuffle=False)
+val_data.batch_size = batch_size
+
+net = resnet50_v2(pretrained=True)
+
+def eval_func(model):
+ metric = mx.gluon.metric.Accuracy()
+ for x, label in val_data:
+ output = model(x)
+ metric.update(label, output)
+ accuracy = metric.get()[1]
+ return accuracy
+
+
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("resnet50v2_mse.yaml")
+quantizer.model = net
+quantizer.calib_dataloader = val_data
+quantizer.eval_func = eval_func
+qnet_inc = quantizer.fit().model
+print("INC finished")
+# You can save optimized model for the later use:
+qnet_inc.export("__quantized_with_inc")
+# You can see what configurations was applied aby INC and which nodes was excluded from quantization
+# to achieve given accuracy lost against floating point calculation
Review Comment:
```suggestion
# You can see which configuration was applied by INC and which nodes were excluded from quantization
# to achieve given accuracy loss against floating point calculation.
```
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
+
+## Configuration file
+
+Quantization tuning process can be customized in the yaml configuration file. Below is a simple example:
+
+```yaml
+# cnn.yaml
+
+version: 1.0
+
+model:
+ name: cnn
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 160 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: basic
+ accuracy_criterion:
+ relative: 0.01
+ exit_policy:
+ timeout: 0
+ random_seed: 9527
+```
+
+We are using the `basic` strategy, but you could also try out different ones. [Here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md) you can find a list of strategies available in INC and details of how they work. You can also add your own strategy if the existing ones do not suit your needs.
+
+Since the value of `timeout` is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
+
+For more information about the configuration file, see the [template](https://github.com/intel/neural-compressor/blob/master/neural_compressor/template/ptq.yaml) from the official INC repo. Keep in mind that only the `post training quantization` is currently supported for MXNet.
+
+## Model quantization and tuning
+
+In general, Intel® Neural Compressor requires 4 elements in order to run:
+1. Config file - like the example above
+2. Model to be quantized
+3. Calibration dataloader
+4. Evaluation function - a function that takes a model as an argument and returns the accuracy it achieves on a certain evaluation dataset.
+
+### Quantizing ResNet
+
+The [quantization](https://mxnet.apache.org/versions/master/api/python/docs/tutorials/performance/backend/dnnl/dnnl_quantization.html#Quantization) sections described how to quantize ResNet using the native MXNet quantization. This example shows how we can achieve the similar results (with the auto-tuning) using INC.
+
+1. Get the model
+
+```python
+import logging
+import mxnet as mx
+from mxnet.gluon.model_zoo import vision
+
+logging.basicConfig()
+logger = logging.getLogger('logger')
+logger.setLevel(logging.INFO)
+
+batch_shape = (1, 3, 224, 224)
+resnet18 = vision.resnet18_v1(pretrained=True)
+```
+
+2. Prepare the dataset:
+
+```python
+mx.test_utils.download('http://data.mxnet.io/data/val_256_q90.rec', 'data/val_256_q90.rec')
+
+batch_size = 16
+mean_std = {'mean_r': 123.68, 'mean_g': 116.779, 'mean_b': 103.939,
+ 'std_r': 58.393, 'std_g': 57.12, 'std_b': 57.375}
+
+data = mx.io.ImageRecordIter(path_imgrec='data/val_256_q90.rec',
+ batch_size=batch_size,
+ data_shape=batch_shape[1:],
+ rand_crop=False,
+ rand_mirror=False,
+ shuffle=False,
+ **mean_std)
+data.batch_size = batch_size
+```
+
+3. Prepare the evaluation function:
+
+```python
+eval_samples = batch_size*10
+
+def eval_func(model):
+ data.reset()
+ metric = mx.metric.Accuracy()
+ for i, batch in enumerate(data):
+ if i * batch_size >= eval_samples:
+ break
+ x = batch.data[0].as_in_context(mx.cpu())
+ label = batch.label[0].as_in_context(mx.cpu())
+ outputs = model.forward(x)
+ metric.update(label, outputs)
+ return metric.get()[1]
+```
+
+4. Run Intel® Neural Compressor:
+
+```python
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("./cnn.yaml")
+quantizer.model = resnet18
+quantizer.calib_dataloader = data
+quantizer.eval_func = eval_func
+qnet = quantizer.fit().model
+```
+
+Since this model already achieves good accuracy using native quantization (less than 1% accuracy drop), for the given configuration file, INC will end on the first configuration, quantizing all layers using `naive` calibration mode for each. To see the true potential of INC, we need a model which suffers from a larger accuracy drop after quantization.
+
+### Quantizing ResNet50v2
+
+This example shows how to use INC to quantize ResNet50 v2. In this case, the native MXNet quantization introduce a huge accuracy drop (70% using `naive` calibration mode) and INC allows automatically find better solution.
+
+This is the (TODO link to INC configuration file) for this example:
+```yaml
+version: 1.0
+
+model:
+ name: resnet50_v2
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 192 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: mse
+ accuracy_criterion:
+ relative: 0.015
+ exit_policy:
+ timeout: 0
+ max_trials: 500
+ random_seed: 9527
+```
+
+It could be used with script below
+(TODO link to resnet_mse.py)
+to find operator which mostly influence accuracy drops and disable it from quantization.
+You can find description of MSE strategy
+[here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md#user-content-mse).
+
+```python
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+# Tuning in INC on whole data set takes too long time so we take only part of the whole data set
+# as representative part of it:
+dataset = dataset.take(num_calib_batches * batch_size)
+transformer = transforms.Compose([transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=rgb_mean, std=rgb_std)])
+# Note: as input data are used many times during tuning it is better to prepared data earlier,
+# so lazy parameter for transform_first is set to False
Review Comment:
```suggestion
# Note: as input data is used many times during tuning, it is better to have it prepared earlier.
# Therefore, lazy parameter for transform_first is set to False.
```
##########
example/quantization_inc/resnet_mse.py:
##########
@@ -0,0 +1,65 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# Set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+# Tuning in INC on whole data set takes too long time so we take only part of the whole data set
+# as representative part of it:
+dataset = dataset.take(num_calib_batches * batch_size)
+transformer = transforms.Compose([transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=rgb_mean, std=rgb_std)])
+# Note: as input data are used many times during tuning it is better to prepared data earlier,
+# so lazy parameter for transform_first is set to False
+val_data = mx.gluon.data.DataLoader(
+ dataset.transform_first(transformer, lazy=False), batch_size, shuffle=False)
+val_data.batch_size = batch_size
+
+net = resnet50_v2(pretrained=True)
+
+def eval_func(model):
+ metric = mx.gluon.metric.Accuracy()
+ for x, label in val_data:
+ output = model(x)
+ metric.update(label, output)
+ accuracy = metric.get()[1]
+ return accuracy
+
+
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("resnet50v2_mse.yaml")
+quantizer.model = net
+quantizer.calib_dataloader = val_data
+quantizer.eval_func = eval_func
+qnet_inc = quantizer.fit().model
+print("INC finished")
+# You can save optimized model for the later use:
Review Comment:
```suggestion
# You can save the optimized model for the later use:
```
##########
example/quantization_inc/resnet_mse.py:
##########
@@ -0,0 +1,65 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# Set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+# Tuning in INC on whole data set takes too long time so we take only part of the whole data set
+# as representative part of it:
+dataset = dataset.take(num_calib_batches * batch_size)
+transformer = transforms.Compose([transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=rgb_mean, std=rgb_std)])
+# Note: as input data are used many times during tuning it is better to prepared data earlier,
+# so lazy parameter for transform_first is set to False
+val_data = mx.gluon.data.DataLoader(
+ dataset.transform_first(transformer, lazy=False), batch_size, shuffle=False)
+val_data.batch_size = batch_size
+
+net = resnet50_v2(pretrained=True)
+
+def eval_func(model):
+ metric = mx.gluon.metric.Accuracy()
+ for x, label in val_data:
+ output = model(x)
+ metric.update(label, output)
+ accuracy = metric.get()[1]
+ return accuracy
+
+
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("resnet50v2_mse.yaml")
+quantizer.model = net
+quantizer.calib_dataloader = val_data
+quantizer.eval_func = eval_func
+qnet_inc = quantizer.fit().model
+print("INC finished")
+# You can save optimized model for the later use:
+qnet_inc.export("__quantized_with_inc")
+# You can see what configurations was applied aby INC and which nodes was excluded from quantization
+# to achieve given accuracy lost against floating point calculation
Review Comment:
Maybe `wanted` instead of `given`?
##########
example/quantization_inc/resnet_tuning.py:
##########
@@ -0,0 +1,115 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+# Disable noisy logging from INC:
+import logging
+logging.disable(logging.INFO)
+
+import time
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+
+def save_model(net, data_loader, description, time_spend):
+ save_model.count += 1
+ print( "{:21s} tuned in {:8.2f}s".format(description, time_spend))
+ net.export("__resnet50_v2_{:02}_".format(save_model.count) + description.replace(' ', '_'))
+
+save_model.count = 0
+
+# Preparing input data
+start = time.time()
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# Set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+# Tuning in INC on whole data set takes too long time so we take only part of the whole data set
+# as representative part of it:
Review Comment:
```suggestion
# Tuning with INC on the whole data set takes too much time. Therefore, we take only a part of the whole data set
# as representative part of it:
```
##########
example/quantization_inc/resnet_tuning.py:
##########
@@ -0,0 +1,115 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+# Disable noisy logging from INC:
+import logging
+logging.disable(logging.INFO)
+
+import time
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+
+def save_model(net, data_loader, description, time_spend):
+ save_model.count += 1
+ print( "{:21s} tuned in {:8.2f}s".format(description, time_spend))
+ net.export("__resnet50_v2_{:02}_".format(save_model.count) + description.replace(' ', '_'))
+
+save_model.count = 0
+
+# Preparing input data
+start = time.time()
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# Set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+# Tuning in INC on whole data set takes too long time so we take only part of the whole data set
+# as representative part of it:
+dataset = dataset.take(num_calib_batches * batch_size)
+transformer = transforms.Compose([transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=rgb_mean, std=rgb_std)])
+# Note: As the input data are used many times during tuning it is better to prepared data erlier,
+# so lazy parameter in transform_first is set to False
Review Comment:
```suggestion
# Note: as the input data is used many times during tuning it is better to have it prepared earlier.
# Therefore, lazy parameter in transform_first is set to False.
```
##########
example/quantization_inc/resnet_mse.py:
##########
@@ -0,0 +1,65 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# Set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+# Tuning in INC on whole data set takes too long time so we take only part of the whole data set
+# as representative part of it:
Review Comment:
```suggestion
# Tuning with INC on the whole data set takes loads of time. Therefore, we take only a part of the whole data set
# as representative part of it:
```
Maybe `its representation` instead of `representative part of it`?
##########
example/quantization_inc/resnet_mse.py:
##########
@@ -0,0 +1,65 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# Set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+# Tuning in INC on whole data set takes too long time so we take only part of the whole data set
+# as representative part of it:
+dataset = dataset.take(num_calib_batches * batch_size)
+transformer = transforms.Compose([transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=rgb_mean, std=rgb_std)])
+# Note: as input data are used many times during tuning it is better to prepared data earlier,
+# so lazy parameter for transform_first is set to False
Review Comment:
```suggestion
# Note: as input data is used many times during tuning it is better to have it prepared earlier.
# Therefore, lazy parameter for transform_first is set to False.
```
##########
example/quantization_inc/resnet_tuning.py:
##########
@@ -0,0 +1,115 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+# Disable noisy logging from INC:
+import logging
+logging.disable(logging.INFO)
+
+import time
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+
+def save_model(net, data_loader, description, time_spend):
+ save_model.count += 1
+ print( "{:21s} tuned in {:8.2f}s".format(description, time_spend))
+ net.export("__resnet50_v2_{:02}_".format(save_model.count) + description.replace(' ', '_'))
+
+save_model.count = 0
+
+# Preparing input data
+start = time.time()
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# Set below proper path to ImageNet data set
Review Comment:
```suggestion
# Set proper path to ImageNet data set below
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@mxnet.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] mxnet-bot commented on pull request #21127: [DOC] Add tutotrial about improving accuracy of quantization with oneDNN
Posted by GitBox <gi...@apache.org>.
mxnet-bot commented on PR #21127:
URL: https://github.com/apache/incubator-mxnet/pull/21127#issuecomment-1227616418
Jenkins CI successfully triggered : [unix-gpu]
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@mxnet.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] anko-intel commented on a diff in pull request #21127: [DOC] Add tutotrial about improving accuracy of quantization with oneDNN
Posted by GitBox <gi...@apache.org>.
anko-intel commented on code in PR #21127:
URL: https://github.com/apache/incubator-mxnet/pull/21127#discussion_r954902884
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
+
+## Configuration file
+
+Quantization tuning process can be customized in the yaml configuration file. Below is a simple example:
+
+```yaml
+# cnn.yaml
+
+version: 1.0
+
+model:
+ name: cnn
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 160 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: basic
+ accuracy_criterion:
+ relative: 0.01
+ exit_policy:
+ timeout: 0
+ random_seed: 9527
+```
+
+We are using the `basic` strategy, but you could also try out different ones. [Here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md) you can find a list of strategies available in INC and details of how they work. You can also add your own strategy if the existing ones do not suit your needs.
+
+Since the value of `timeout` is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
+
+For more information about the configuration file, see the [template](https://github.com/intel/neural-compressor/blob/master/neural_compressor/template/ptq.yaml) from the official INC repo. Keep in mind that only the `post training quantization` is currently supported for MXNet.
+
+## Model quantization and tuning
+
+In general, Intel® Neural Compressor requires 4 elements in order to run:
+1. Config file - like the example above
+2. Model to be quantized
+3. Calibration dataloader
+4. Evaluation function - a function that takes a model as an argument and returns the accuracy it achieves on a certain evaluation dataset.
+
+### Quantizing ResNet
+
+The [quantization](https://mxnet.apache.org/versions/master/api/python/docs/tutorials/performance/backend/dnnl/dnnl_quantization.html#Quantization) sections described how to quantize ResNet using the native MXNet quantization. This example shows how we can achieve the similar results (with the auto-tuning) using INC.
+
+1. Get the model
+
+```python
+import logging
+import mxnet as mx
+from mxnet.gluon.model_zoo import vision
+
+logging.basicConfig()
+logger = logging.getLogger('logger')
+logger.setLevel(logging.INFO)
+
+batch_shape = (1, 3, 224, 224)
+resnet18 = vision.resnet18_v1(pretrained=True)
+```
+
+2. Prepare the dataset:
+
+```python
+mx.test_utils.download('http://data.mxnet.io/data/val_256_q90.rec', 'data/val_256_q90.rec')
+
+batch_size = 16
+mean_std = {'mean_r': 123.68, 'mean_g': 116.779, 'mean_b': 103.939,
+ 'std_r': 58.393, 'std_g': 57.12, 'std_b': 57.375}
+
+data = mx.io.ImageRecordIter(path_imgrec='data/val_256_q90.rec',
+ batch_size=batch_size,
+ data_shape=batch_shape[1:],
+ rand_crop=False,
+ rand_mirror=False,
+ shuffle=False,
+ **mean_std)
+data.batch_size = batch_size
+```
+
+3. Prepare the evaluation function:
+
+```python
+eval_samples = batch_size*10
+
+def eval_func(model):
+ data.reset()
+ metric = mx.metric.Accuracy()
+ for i, batch in enumerate(data):
+ if i * batch_size >= eval_samples:
+ break
+ x = batch.data[0].as_in_context(mx.cpu())
+ label = batch.label[0].as_in_context(mx.cpu())
+ outputs = model.forward(x)
+ metric.update(label, outputs)
+ return metric.get()[1]
+```
+
+4. Run Intel® Neural Compressor:
+
+```python
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("./cnn.yaml")
+quantizer.model = resnet18
+quantizer.calib_dataloader = data
+quantizer.eval_func = eval_func
+qnet = quantizer.fit().model
+```
+
+Since this model already achieves good accuracy using native quantization (less than 1% accuracy drop), for the given configuration file, INC will end on the first configuration, quantizing all layers using `naive` calibration mode for each. To see the true potential of INC, we need a model which suffers from a larger accuracy drop after quantization.
+
+### Quantizing ResNet50v2
+
+This example shows how to use INC to quantize ResNet50 v2. In this case, the native MXNet quantization introduce a huge accuracy drop (70% using `naive` calibration mode) and INC allows automatically find better solution.
+
+This is the (TODO link to INC configuration file) for this example:
Review Comment:
I have to remove links as linkcheck doesn't allow put links to just added files
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@mxnet.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] bgawrych merged pull request #21127: [DOC] Add tutotrial about improving accuracy of quantization with oneDNN
Posted by GitBox <gi...@apache.org>.
bgawrych merged PR #21127:
URL: https://github.com/apache/incubator-mxnet/pull/21127
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@mxnet.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] bartekkuncer commented on a diff in pull request #21127: [DOC] Add tutotrial about improving accuracy of quantization with oneDNN
Posted by GitBox <gi...@apache.org>.
bartekkuncer commented on code in PR #21127:
URL: https://github.com/apache/incubator-mxnet/pull/21127#discussion_r954888145
##########
example/quantization_inc/resnet_mse.py:
##########
@@ -0,0 +1,65 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# Set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+# Tuning in INC on whole data set takes too long time so we take only part of the whole data set
+# as representative part of it:
Review Comment:
```suggestion
# Tuning with INC on the whole data set takes a lot of time. Therefore, we take only a part of the whole data set
# as representative part of it:
```
Maybe `its representation` instead of `representative part of it`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@mxnet.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] anko-intel commented on pull request #21127: [DOC] Add tutotrial about improving accuracy of quantization with oneDNN
Posted by GitBox <gi...@apache.org>.
anko-intel commented on PR #21127:
URL: https://github.com/apache/incubator-mxnet/pull/21127#issuecomment-1227616277
@mxnet-bot run ci [unix-gpu]
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@mxnet.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] bartekkuncer commented on a diff in pull request #21127: [DOC] Add tutotrial about improving accuracy of quantization with oneDNN
Posted by GitBox <gi...@apache.org>.
bartekkuncer commented on code in PR #21127:
URL: https://github.com/apache/incubator-mxnet/pull/21127#discussion_r954869135
##########
docs/python_docs/python/tutorials/performance/backend/dnnl/dnnl_quantization_inc.md:
##########
@@ -0,0 +1,290 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+
+# Improving accuracy with Intel® Neural Compressor
+
+The accuracy of a model can decrease as a result of quantization. When the accuracy drop is significant, we can try to manually find a better quantization configuration (exclude some layers, try different calibration methods, etc.), but for bigger models this might prove to be a difficult and time consuming task. [Intel® Neural Compressor](https://github.com/intel/neural-compressor) (INC) tries to automate this process using several tuning heuristics, which aim to find the quantization configuration that satisfies the specified accuracy requirement.
+
+**NOTE:**
+
+Most tuning strategies will try different configurations on an evaluation dataset in order to find out how each layer affects the accuracy of the model. This means that for larger models, it may take a long time to find a solution (as the tuning space is usually larger and the evaluation itself takes longer).
+
+## Installation and Prerequisites
+
+- Install MXNet with oneDNN enabled as described in the [Get started](https://mxnet.apache.org/versions/master/get_started?platform=linux&language=python&processor=cpu&environ=pip&). (Until the 2.0 release you can use the nightly build version: `pip install --pre mxnet -f https://dist.mxnet.io/python`)
+
+- Install Intel® Neural Compressor:
+
+ Use one of the commands below to install INC (supported python versions are: 3.6, 3.7, 3.8, 3.9):
+
+ ```bash
+ # install stable version from pip
+ pip install neural-compressor
+
+ # install nightly version from pip
+ pip install -i https://test.pypi.org/simple/ neural-compressor
+
+ # install stable version from conda
+ conda install neural-compressor -c conda-forge -c intel
+ ```
+ If you come into trouble with dependencies on `cv2` library you can run: `apt-get update && apt-get install -y python3-opencv`
+
+## Configuration file
+
+Quantization tuning process can be customized in the yaml configuration file. Below is a simple example:
+
+```yaml
+# cnn.yaml
+
+version: 1.0
+
+model:
+ name: cnn
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 160 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: basic
+ accuracy_criterion:
+ relative: 0.01
+ exit_policy:
+ timeout: 0
+ random_seed: 9527
+```
+
+We are using the `basic` strategy, but you could also try out different ones. [Here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md) you can find a list of strategies available in INC and details of how they work. You can also add your own strategy if the existing ones do not suit your needs.
+
+Since the value of `timeout` is 0, INC will run until it finds a configuration that satisfies the accuracy criterion and then exit. Depending on the strategy this may not be ideal, as sometimes it would be better to further explore the tuning space to find a superior configuration both in terms of accuracy and speed. To achieve this, we can set a specific `timeout` value, which will tell INC how long (in seconds) it should run.
+
+For more information about the configuration file, see the [template](https://github.com/intel/neural-compressor/blob/master/neural_compressor/template/ptq.yaml) from the official INC repo. Keep in mind that only the `post training quantization` is currently supported for MXNet.
+
+## Model quantization and tuning
+
+In general, Intel® Neural Compressor requires 4 elements in order to run:
+1. Config file - like the example above
+2. Model to be quantized
+3. Calibration dataloader
+4. Evaluation function - a function that takes a model as an argument and returns the accuracy it achieves on a certain evaluation dataset.
+
+### Quantizing ResNet
+
+The [quantization](https://mxnet.apache.org/versions/master/api/python/docs/tutorials/performance/backend/dnnl/dnnl_quantization.html#Quantization) sections described how to quantize ResNet using the native MXNet quantization. This example shows how we can achieve the similar results (with the auto-tuning) using INC.
+
+1. Get the model
+
+```python
+import logging
+import mxnet as mx
+from mxnet.gluon.model_zoo import vision
+
+logging.basicConfig()
+logger = logging.getLogger('logger')
+logger.setLevel(logging.INFO)
+
+batch_shape = (1, 3, 224, 224)
+resnet18 = vision.resnet18_v1(pretrained=True)
+```
+
+2. Prepare the dataset:
+
+```python
+mx.test_utils.download('http://data.mxnet.io/data/val_256_q90.rec', 'data/val_256_q90.rec')
+
+batch_size = 16
+mean_std = {'mean_r': 123.68, 'mean_g': 116.779, 'mean_b': 103.939,
+ 'std_r': 58.393, 'std_g': 57.12, 'std_b': 57.375}
+
+data = mx.io.ImageRecordIter(path_imgrec='data/val_256_q90.rec',
+ batch_size=batch_size,
+ data_shape=batch_shape[1:],
+ rand_crop=False,
+ rand_mirror=False,
+ shuffle=False,
+ **mean_std)
+data.batch_size = batch_size
+```
+
+3. Prepare the evaluation function:
+
+```python
+eval_samples = batch_size*10
+
+def eval_func(model):
+ data.reset()
+ metric = mx.metric.Accuracy()
+ for i, batch in enumerate(data):
+ if i * batch_size >= eval_samples:
+ break
+ x = batch.data[0].as_in_context(mx.cpu())
+ label = batch.label[0].as_in_context(mx.cpu())
+ outputs = model.forward(x)
+ metric.update(label, outputs)
+ return metric.get()[1]
+```
+
+4. Run Intel® Neural Compressor:
+
+```python
+from neural_compressor.experimental import Quantization
+quantizer = Quantization("./cnn.yaml")
+quantizer.model = resnet18
+quantizer.calib_dataloader = data
+quantizer.eval_func = eval_func
+qnet = quantizer.fit().model
+```
+
+Since this model already achieves good accuracy using native quantization (less than 1% accuracy drop), for the given configuration file, INC will end on the first configuration, quantizing all layers using `naive` calibration mode for each. To see the true potential of INC, we need a model which suffers from a larger accuracy drop after quantization.
+
+### Quantizing ResNet50v2
+
+This example shows how to use INC to quantize ResNet50 v2. In this case, the native MXNet quantization introduce a huge accuracy drop (70% using `naive` calibration mode) and INC allows automatically find better solution.
+
+This is the (TODO link to INC configuration file) for this example:
+```yaml
+version: 1.0
+
+model:
+ name: resnet50_v2
+ framework: mxnet
+
+quantization:
+ calibration:
+ sampling_size: 192 # number of samples for calibration
+
+tuning:
+ strategy:
+ name: mse
+ accuracy_criterion:
+ relative: 0.015
+ exit_policy:
+ timeout: 0
+ max_trials: 500
+ random_seed: 9527
+```
+
+It could be used with script below
+(TODO link to resnet_mse.py)
+to find operator which mostly influence accuracy drops and disable it from quantization.
+You can find description of MSE strategy
+[here](https://github.com/intel/neural-compressor/blob/master/docs/tuning_strategies.md#user-content-mse).
+
+```python
+import mxnet as mx
+from mxnet.gluon.model_zoo.vision import resnet50_v2
+from mxnet.gluon.data.vision import transforms
+from mxnet.contrib.quantization import quantize_net
+
+# Preparing input data
+rgb_mean = (0.485, 0.456, 0.406)
+rgb_std = (0.229, 0.224, 0.225)
+batch_size = 64
+num_calib_batches = 9
+# set below proper path to ImageNet data set
+dataset = mx.gluon.data.vision.ImageRecordDataset('../imagenet/rec/val.rec')
+# Tuning in INC on whole data set takes too long time so we take only part of the whole data set
Review Comment:
```suggestion
# Tuning with INC on whole data set takes a lot of time. Therefore, we take only a part of the data set
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@mxnet.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] bartekkuncer commented on pull request #21127: [DOC] Add tutotrial about improving accuracy of quantization with oneDNN
Posted by GitBox <gi...@apache.org>.
bartekkuncer commented on PR #21127:
URL: https://github.com/apache/incubator-mxnet/pull/21127#issuecomment-1227181142
> ## Description
> Added tutorial showing advantage of using INC with MXNet for quantization. It shows that INC can find operators mostly introduced loss of accuracy and eliminate it from quantization. This way partially quantized model achieves accuracy results almost the same as original floating point model, but with about 3 times performance improvement in comparison to optimized floating point model (or 30 times in comparison to not optimized floating point model)
>
>  
>
> ## Checklist
> ### Essentials
> * [x] PR's title starts with a category (e.g. [BUGFIX], [MODEL], [TUTORIAL], [FEATURE], [DOC], etc)
> * [x] Changes are complete (i.e. I finished coding on this PR)
> * [ ] All changes have test coverage
> * [ ] Code is well-documented
I assume this graphics depicts the results for resnet50 v2? I believe it would be nice to add information about the workload in the description.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@mxnet.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] mxnet-bot commented on pull request #21127: [DOC] Add tutotrial about improving accuracy of quantization with oneDNN
Posted by GitBox <gi...@apache.org>.
mxnet-bot commented on PR #21127:
URL: https://github.com/apache/incubator-mxnet/pull/21127#issuecomment-1225742741
Jenkins CI successfully triggered : [unix-cpu]
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@mxnet.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] anko-intel commented on pull request #21127: [DOC] Add tutotrial about improving accuracy of quantization with oneDNN
Posted by GitBox <gi...@apache.org>.
anko-intel commented on PR #21127:
URL: https://github.com/apache/incubator-mxnet/pull/21127#issuecomment-1225742599
@mxnet-bot run ci [unix-cpu]
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@mxnet.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org