You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2020/07/24 17:47:48 UTC
[GitHub] [hudi] luffyd opened a new issue #1872: [SUPPORT]Getting 503s from S3 during upserts
luffyd opened a new issue #1872:
URL: https://github.com/apache/hudi/issues/1872
**_Tips before filing an issue_**
- Have you gone through our [FAQs](https://cwiki.apache.org/confluence/display/HUDI/FAQ)?
- Join the mailing list to engage in conversations and get faster support at dev-subscribe@hudi.apache.org.
- If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly.
**Describe the problem you faced**
My setup has 1000 partitions and 24Billion records which was created via bulk insert, I am running a test with 3M(million) new records and 9M updates. So in total 12M upserts
I keep getting 503s, when there were 100 partitions. So I increased number of partitions to get around s3 503 throttles. But seems it is not the issue.
Can you help how to debug this further? I am trying to reduce the amount to writes. But want to understand what exactly is the bottle neck in-terms of S3 activity(most often I see a problem with GetObjectMetadataCall throttling)
**To Reproduce**
Steps to reproduce the behavior:
1. Create 24B records with 1000 patirtions
2. I have 25 retries configured on S3 throttles, I was hoping it would process late but not throw FATAL
```
config.set("spark.hadoop.fs.s3.maxRetries", "25")
config.set("spark.hadoop.fs.s3.sleepTimeSeconds", "60")
```
3. Have 12M upserts(1:3 insert to upsert ratio) continuously
**Expected behavior**
I was expecting upsert to happen smoothly
**Environment Description**
* Hudi version : 0.5.3
* Spark version : 2.4.4
* Storage (HDFS/S3/GCS..) : S3
* Running on Docker? (yes/no) :no
**Additional context**
Looking at the stack trace, my thoughts are there is so much S3 activity happening to create and maintain markers and guessed increasing partitions should have helped but it made things worse from my observation, 1000 partitions one is performing bad than 100 partitions data set.
**Stacktrace**
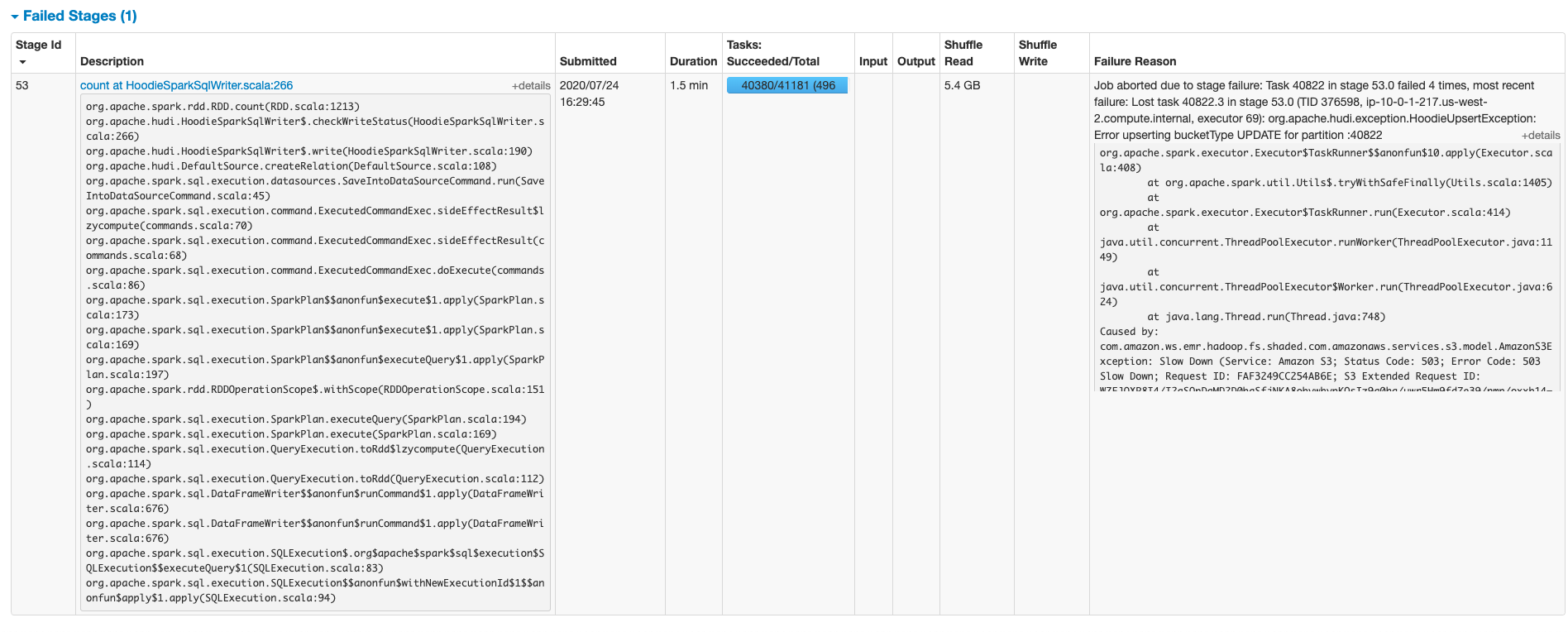
```Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 40822 in stage 53.0 failed 4 times, most recent failure: Lost task 40822.3 in stage 53.0 (TID 376598, ip-10-0-1-217.us-west-2.compute.internal, executor 69): org.apache.hudi
.exception.HoodieUpsertException: Error upserting bucketType UPDATE for partition :40822
at org.apache.hudi.table.action.commit.BaseCommitActionExecutor.handleUpsertPartition(BaseCommitActionExecutor.java:253)
at org.apache.hudi.table.action.commit.BaseCommitActionExecutor.lambda$execute$caffe4c4$1(BaseCommitActionExecutor.java:102)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$mapPartitionsWithIndex$1.apply(JavaRDDLike.scala:102)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$mapPartitionsWithIndex$1.apply(JavaRDDLike.scala:102)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsWithIndex$1$$anonfun$apply$25.apply(RDD.scala:875)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsWithIndex$1$$anonfun$apply$25.apply(RDD.scala:875)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD$$anonfun$7.apply(RDD.scala:359)
at org.apache.spark.rdd.RDD$$anonfun$7.apply(RDD.scala:357)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.model.AmazonS3Exception: Slow Down (Service: Amazon S3; Status Code: 503; Error Code: 503 Slow Down; Request ID: FAF3249CC254AB6E; S3 Extended Request ID: WZFJQXP8I4/I2aSQpDaMD2D0bgSfjNKA8obvwhypKOsIz9g0hg/uwr5Hm9fd7e39/nmp/oxxb14=), S3 Extended Request ID: WZFJQXP8I4/I2aSQpDaMD2D0bgSfjNKA8obvwhypKOsIz9g0hg/uwr5Hm9fd7e39/nmp/oxxb14=
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleErrorResponse(AmazonHttpClient.java:1742)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleServiceErrorResponse(AmazonHttpClient.java:1371)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeOneRequest(AmazonHttpClient.java:1347)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeHelper(AmazonHttpClient.java:1127)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.doExecute(AmazonHttpClient.java:784)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeWithTimer(AmazonHttpClient.java:752)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.execute(AmazonHttpClient.java:726)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.access$500(AmazonHttpClient.java:686)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutionBuilderImpl.execute(AmazonHttpClient.java:668)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:532)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:512)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:5052)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:4998)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.AmazonS3Client.getObjectMetadata(AmazonS3Client.java:1335)
at com.amazon.ws.emr.hadoop.fs.s3.lite.call.GetObjectMetadataCall.perform(GetObjectMetadataCall.java:22)
at com.amazon.ws.emr.hadoop.fs.s3.lite.call.GetObjectMetadataCall.perform(GetObjectMetadataCall.java:8)
at com.amazon.ws.emr.hadoop.fs.s3.lite.executor.GlobalS3Executor.execute(GlobalS3Executor.java:114)
at com.amazon.ws.emr.hadoop.fs.s3.lite.AmazonS3LiteClient.invoke(AmazonS3LiteClient.java:189)
at com.amazon.ws.emr.hadoop.fs.s3.lite.AmazonS3LiteClient.invoke(AmazonS3LiteClient.java:184)
at com.amazon.ws.emr.hadoop.fs.s3.lite.AmazonS3LiteClient.getObjectMetadata(AmazonS3LiteClient.java:96)
at com.amazon.ws.emr.hadoop.fs.s3.lite.AbstractAmazonS3Lite.getObjectMetadata(AbstractAmazonS3Lite.java:43)
at com.amazon.ws.emr.hadoop.fs.s3n.Jets3tNativeFileSystemStore.getFileMetadataFromCacheOrS3(Jets3tNativeFileSystemStore.java:497)
at com.amazon.ws.emr.hadoop.fs.s3n.Jets3tNativeFileSystemStore.retrieveMetadata(Jets3tNativeFileSystemStore.java:223)
at com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem.getFileStatus(S3NativeFileSystem.java:590)
at com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem.mkdir(S3NativeFileSystem.java:1064)
at com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem.mkdirs(S3NativeFileSystem.java:1057)
at org.apache.hadoop.fs.FileSystem.mkdirs(FileSystem.java:1961)
at com.amazon.ws.emr.hadoop.fs.EmrFileSystem.mkdirs(EmrFileSystem.java:443)
at org.apache.hudi.common.fs.HoodieWrapperFileSystem.mkdirs(HoodieWrapperFileSystem.java:527)
at org.apache.hudi.io.HoodieWriteHandle.makeNewMarkerPath(HoodieWriteHandle.java:117)
at org.apache.hudi.io.HoodieWriteHandle.createMarkerFile(HoodieWriteHandle.java:101)
at org.apache.hudi.io.HoodieMergeHandle.init(HoodieMergeHandle.java:130)
at org.apache.hudi.io.HoodieMergeHandle.<init>(HoodieMergeHandle.java:76)
at org.apache.hudi.table.action.commit.CommitActionExecutor.getUpdateHandle(CommitActionExecutor.java:117)
at org.apache.hudi.table.action.commit.CommitActionExecutor.handleUpdate(CommitActionExecutor.java:73)
at org.apache.hudi.table.action.deltacommit.DeltaCommitActionExecutor.handleUpdate(DeltaCommitActionExecutor.java:73)
at org.apache.hudi.table.action.commit.BaseCommitActionExecutor.handleUpsertPartition(BaseCommitActionExecutor.java:246)
... 30 more
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:2043)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2031)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2030)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2030)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2264)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2213)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2202)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:778)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2061)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2082)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2101)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2126)
at org.apache.spark.rdd.RDD.count(RDD.scala:1213)
at org.apache.hudi.HoodieSparkSqlWriter$.checkWriteStatus(HoodieSparkSqlWriter.scala:266)
at org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:190)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:108)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:173)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:169)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:197)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:194)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:169)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:114)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:112)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$executeQuery$1(SQLExecution.scala:83)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1$$anonfun$apply$1.apply(SQLExecution.scala:94)
at org.apache.spark.sql.execution.QueryExecutionMetrics$.withMetrics(QueryExecutionMetrics.scala:141)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$withMetrics(SQLExecution.scala:178)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:93)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:200)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:92)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:285)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:271)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:229)
at com.amazon.chelantestemr.emr.scala.streaming.TestFacesUpsertForLoop$$anonfun$main$1.apply$mcVI$sp(TestFacesUpsertForLoop.scala:137)
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:160)
at com.amazon.chelantestemr.emr.scala.streaming.TestFacesUpsertForLoop$.main(TestFacesUpsertForLoop.scala:56)
at com.amazon.chelantestemr.emr.scala.streaming.TestFacesUpsertForLoop.main(TestFacesUpsertForLoop.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:853)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:928)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:937)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: org.apache.hudi.exception.HoodieUpsertException: Error upserting bucketType UPDATE for partition :40822
at org.apache.hudi.table.action.commit.BaseCommitActionExecutor.handleUpsertPartition(BaseCommitActionExecutor.java:253)
at org.apache.hudi.table.action.commit.BaseCommitActionExecutor.lambda$execute$caffe4c4$1(BaseCommitActionExecutor.java:102)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$mapPartitionsWithIndex$1.apply(JavaRDDLike.scala:102)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$mapPartitionsWithIndex$1.apply(JavaRDDLike.scala:102)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsWithIndex$1$$anonfun$apply$25.apply(RDD.scala:875)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsWithIndex$1$$anonfun$apply$25.apply(RDD.scala:875)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD$$anonfun$7.apply(RDD.scala:359)
at org.apache.spark.rdd.RDD$$anonfun$7.apply(RDD.scala:357)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.model.AmazonS3Exception: Slow Down (Service: Amazon S3; Status Code: 503; Error Code: 503 Slow Down; Request ID: FAF3249CC254AB6E; S3 Extended Request ID: WZFJQXP8I4/I2aSQpDaMD2D0bgSfjNKA8obvwhypKOsIz9g0hg/uwr5Hm9fd7e39/nmp/oxxb14=), S3 Extended Request ID: WZFJQXP8I4/I2aSQpDaMD2D0bgSfjNKA8obvwhypKOsIz9g0hg/uwr5Hm9fd7e39/nmp/oxxb14=
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleErrorResponse(AmazonHttpClient.java:1742)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleServiceErrorResponse(AmazonHttpClient.java:1371)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeOneRequest(AmazonHttpClient.java:1347)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeHelper(AmazonHttpClient.java:1127)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.doExecute(AmazonHttpClient.java:784)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeWithTimer(AmazonHttpClient.java:752)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.execute(AmazonHttpClient.java:726)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.access$500(AmazonHttpClient.java:686)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutionBuilderImpl.execute(AmazonHttpClient.java:668)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:532)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:512)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:5052)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:4998)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.AmazonS3Client.getObjectMetadata(AmazonS3Client.java:1335)
at com.amazon.ws.emr.hadoop.fs.s3.lite.call.GetObjectMetadataCall.perform(GetObjectMetadataCall.java:22)
at com.amazon.ws.emr.hadoop.fs.s3.lite.call.GetObjectMetadataCall.perform(GetObjectMetadataCall.java:8)
at com.amazon.ws.emr.hadoop.fs.s3.lite.executor.GlobalS3Executor.execute(GlobalS3Executor.java:114)
at com.amazon.ws.emr.hadoop.fs.s3.lite.AmazonS3LiteClient.invoke(AmazonS3LiteClient.java:189)
at com.amazon.ws.emr.hadoop.fs.s3.lite.AmazonS3LiteClient.invoke(AmazonS3LiteClient.java:184)
at com.amazon.ws.emr.hadoop.fs.s3.lite.AmazonS3LiteClient.getObjectMetadata(AmazonS3LiteClient.java:96)
at com.amazon.ws.emr.hadoop.fs.s3.lite.AbstractAmazonS3Lite.getObjectMetadata(AbstractAmazonS3Lite.java:43)
at com.amazon.ws.emr.hadoop.fs.s3n.Jets3tNativeFileSystemStore.getFileMetadataFromCacheOrS3(Jets3tNativeFileSystemStore.java:497)
at com.amazon.ws.emr.hadoop.fs.s3n.Jets3tNativeFileSystemStore.retrieveMetadata(Jets3tNativeFileSystemStore.java:223)
at com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem.getFileStatus(S3NativeFileSystem.java:590)
at com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem.mkdir(S3NativeFileSystem.java:1064)
at com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem.mkdirs(S3NativeFileSystem.java:1057)
at org.apache.hadoop.fs.FileSystem.mkdirs(FileSystem.java:1961)
at com.amazon.ws.emr.hadoop.fs.EmrFileSystem.mkdirs(EmrFileSystem.java:443)
at org.apache.hudi.common.fs.HoodieWrapperFileSystem.mkdirs(HoodieWrapperFileSystem.java:527)
at org.apache.hudi.io.HoodieWriteHandle.makeNewMarkerPath(HoodieWriteHandle.java:117)
at org.apache.hudi.io.HoodieWriteHandle.createMarkerFile(HoodieWriteHandle.java:101)
at org.apache.hudi.io.HoodieMergeHandle.init(HoodieMergeHandle.java:130)
at org.apache.hudi.io.HoodieMergeHandle.<init>(HoodieMergeHandle.java:76)
at org.apache.hudi.table.action.commit.CommitActionExecutor.getUpdateHandle(CommitActionExecutor.java:117)
at org.apache.hudi.table.action.commit.CommitActionExecutor.handleUpdate(CommitActionExecutor.java:73)
at org.apache.hudi.table.action.deltacommit.DeltaCommitActionExecutor.handleUpdate(DeltaCommitActionExecutor.java:73)
at org.apache.hudi.table.action.commit.BaseCommitActionExecutor.handleUpsertPartition(BaseCommitActionExecutor.java:246)
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] satishkotha commented on issue #1872: [SUPPORT]Getting 503s from S3 during upserts
Posted by GitBox <gi...@apache.org>.
satishkotha commented on issue #1872:
URL: https://github.com/apache/hudi/issues/1872#issuecomment-663688088
This is likely more of AWS support question. A quick search shows https://aws.amazon.com/premiumsupport/knowledge-center/emr-s3-503-slow-down/
Can you see if any of the solutions there work for you? You may have to slow down ingestion.
(I dont have a lot of experience with AWS EMR. Others in the community, please comment if you have worked around similar problem before)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yuhadooper commented on issue #1872: [SUPPORT]Getting 503s from S3 during upserts
Posted by GitBox <gi...@apache.org>.
yuhadooper commented on issue #1872:
URL: https://github.com/apache/hudi/issues/1872#issuecomment-677882423
@luffyd do you mind sharing what configurations you changed to the EMR cluster for this to work?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] luffyd commented on issue #1872: [SUPPORT]Getting 503s from S3 during upserts
Posted by GitBox <gi...@apache.org>.
luffyd commented on issue #1872:
URL: https://github.com/apache/hudi/issues/1872#issuecomment-668666129
Not seeing right now, after me adding these configuration in the emr cluster configurations.
But not sure, it is because of transient nature or the issue is really solved! Will reopen again in case issues.
you are right adding jitter and retries will really help, emrs3 does seem to have clear documentation for that.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yuhadooper commented on issue #1872: [SUPPORT]Getting 503s from S3 during upserts
Posted by GitBox <gi...@apache.org>.
yuhadooper commented on issue #1872:
URL: https://github.com/apache/hudi/issues/1872#issuecomment-677906212
Thank you! I will give this a try.
Here are the exceptions I'm seeing, doing an upsert on a few billion records with around 15000 partitions. Though the file parquet exists under the path and not running anything else on the EMR or AWS account I see below errors after partitioning the table. Before partitioning the upserts seem were working fine.
> 20/08/20 18:40:45 WARN TaskSetManager: Lost task 8195.0 in stage 4.0 (TID 8236, ip-10-182-67-53.ec2.internal, executor 170): org.apache.hudi.exception.HoodieException: Error checking path :s3://bucket-name/prefix1/prefix2/tablename/partition_col=123/shg34ko2-f1w2-s51d-6743-56340tcbegpl-129_527-7-5041_20200818150341.parquet, under folder: s3://bucket-name/prefix1/prefix2/tablename/partition_col=123/
at org.apache.hudi.hadoop.HoodieROTablePathFilter.accept(HoodieROTablePathFilter.java:178)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$$anonfun$15.apply(InMemoryFileIndex.scala:302)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$$anonfun$15.apply(InMemoryFileIndex.scala:302)
at scala.collection.TraversableLike$$anonfun$filterImpl$1.apply(TraversableLike.scala:248)
at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
at scala.collection.TraversableLike$class.filterImpl(TraversableLike.scala:247)
at scala.collection.TraversableLike$class.filter(TraversableLike.scala:259)
at scala.collection.mutable.ArrayOps$ofRef.filter(ArrayOps.scala:186)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$.org$apache$spark$sql$execution$datasources$InMemoryFileIndex$$listLeafFiles(InMemoryFileIndex.scala:302)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$$anonfun$3$$anonfun$apply$2.apply(InMemoryFileIndex.scala:215)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$$anonfun$3$$anonfun$apply$2.apply(InMemoryFileIndex.scala:214)
at scala.collection.immutable.Stream.map(Stream.scala:418)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$$anonfun$3.apply(InMemoryFileIndex.scala:214)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$$anonfun$3.apply(InMemoryFileIndex.scala:212)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitions$1$$anonfun$apply$23.apply(RDD.scala:823)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitions$1$$anonfun$apply$23.apply(RDD.scala:823)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
> Caused by: com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.model.AmazonS3Exception: Slow Down (Service: Amazon S3; Status Code: 503; Error Code: 503 Slow Down; Request ID: 8W5H2QDTFGAJBW9M; S3 Extended Request ID: 8qJKHGFJHG56KGF58/xxxxxxxxxxxxxx/yyyyyyyyyyyyyyyy/s=), S3 Extended Request ID: 8qJKHGFJHG56KGF58/xxxxxxxxxxxxxx/yyyyyyyyyyyyyyyy/s=
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleErrorResponse(AmazonHttpClient.java:1742)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleServiceErrorResponse(AmazonHttpClient.java:1371)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeOneRequest(AmazonHttpClient.java:1347)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeHelper(AmazonHttpClient.java:1127)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.doExecute(AmazonHttpClient.java:784)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeWithTimer(AmazonHttpClient.java:752)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.execute(AmazonHttpClient.java:726)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.access$500(AmazonHttpClient.java:686)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutionBuilderImpl.execute(AmazonHttpClient.java:668)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:532)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:512)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:5052)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:4998)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.AmazonS3Client.getObjectMetadata(AmazonS3Client.java:1335)
at com.amazon.ws.emr.hadoop.fs.s3.lite.call.GetObjectMetadataCall.perform(GetObjectMetadataCall.java:22)
at com.amazon.ws.emr.hadoop.fs.s3.lite.call.GetObjectMetadataCall.perform(GetObjectMetadataCall.java:8)
at com.amazon.ws.emr.hadoop.fs.s3.lite.executor.GlobalS3Executor.execute(GlobalS3Executor.java:114)
at com.amazon.ws.emr.hadoop.fs.s3.lite.AmazonS3LiteClient.invoke(AmazonS3LiteClient.java:189)
at com.amazon.ws.emr.hadoop.fs.s3.lite.AmazonS3LiteClient.invoke(AmazonS3LiteClient.java:184)
at com.amazon.ws.emr.hadoop.fs.s3.lite.AmazonS3LiteClient.getObjectMetadata(AmazonS3LiteClient.java:96)
at com.amazon.ws.emr.hadoop.fs.s3.lite.AbstractAmazonS3Lite.getObjectMetadata(AbstractAmazonS3Lite.java:43)
at com.amazon.ws.emr.hadoop.fs.s3n.Jets3tNativeFileSystemStore.getFileMetadataFromCacheOrS3(Jets3tNativeFileSystemStore.java:497)
at com.amazon.ws.emr.hadoop.fs.s3n.Jets3tNativeFileSystemStore.retrieveMetadata(Jets3tNativeFileSystemStore.java:223)
at com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem.getFileStatus(S3NativeFileSystem.java:590)
at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1440)
at com.amazon.ws.emr.hadoop.fs.EmrFileSystem.exists(EmrFileSystem.java:357)
at org.apache.hudi.common.model.HoodiePartitionMetadata.hasPartitionMetadata(HoodiePartitionMetadata.java:141)
at org.apache.hudi.hadoop.HoodieROTablePathFilter.accept(HoodieROTablePathFilter.java:129)
... 30 more
> 20/08/20 21:02:01 WARN TaskSetManager: Lost task 1439.0 in stage 32.0 (TID 18549, ip-10-182-67-6.ec2.internal, executor 279): org.apache.hudi.exception.HoodieUpsertException: Error upserting bucketType UPDATE for partition :1439
at org.apache.hudi.table.HoodieCopyOnWriteTable.handleUpsertPartition(HoodieCopyOnWriteTable.java:270)
at org.apache.hudi.client.HoodieWriteClient.lambda$upsertRecordsInternal$9c951a5d$1(HoodieWriteClient.java:472)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$mapPartitionsWithIndex$1.apply(JavaRDDLike.scala:102)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$mapPartitionsWithIndex$1.apply(JavaRDDLike.scala:102)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsWithIndex$1$$anonfun$apply$25.apply(RDD.scala:875)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsWithIndex$1$$anonfun$apply$25.apply(RDD.scala:875)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD$$anonfun$7.apply(RDD.scala:359)
at org.apache.spark.rdd.RDD$$anonfun$7.apply(RDD.scala:357)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.hudi.exception.HoodieUpsertException: Failed to close UpdateHandle
at org.apache.hudi.io.HoodieMergeHandle.close(HoodieMergeHandle.java:353)
at org.apache.hudi.table.HoodieCopyOnWriteTable.handleUpdateInternal(HoodieCopyOnWriteTable.java:210)
at org.apache.hudi.table.HoodieCopyOnWriteTable.handleUpdate(HoodieCopyOnWriteTable.java:184)
at org.apache.hudi.table.HoodieCopyOnWriteTable.handleUpsertPartition(HoodieCopyOnWriteTable.java:263)
... 30 more
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] luffyd commented on issue #1872: [SUPPORT]Getting 503s from S3 during upserts
Posted by GitBox <gi...@apache.org>.
luffyd commented on issue #1872:
URL: https://github.com/apache/hudi/issues/1872#issuecomment-663690493
I have noticed slowing down ingestion worked.
It seems like number of calls to "HoodieWriteHandle.createMarkerFile" is resulting an S3 call.
But can you give any hints on
1. how number calls to "HoodieWriteHandle.createMarkerFile" is related to number of partitions
2. how number calls to "HoodieWriteHandle.createMarkerFile" is related to number of files in a partition
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yuhadooper commented on issue #1872: [SUPPORT]Getting 503s from S3 during upserts
Posted by GitBox <gi...@apache.org>.
yuhadooper commented on issue #1872:
URL: https://github.com/apache/hudi/issues/1872#issuecomment-677916258
to be clear: upserts worked before when we didn't have any partitions (we had about 3000 parquet files) under the table. After partitioning the tables into 15000 partitions we now have 17000 parquet files.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar closed issue #1872: [SUPPORT]Getting 503s from S3 during upserts
Posted by GitBox <gi...@apache.org>.
bvaradar closed issue #1872:
URL: https://github.com/apache/hudi/issues/1872
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] satishkotha commented on issue #1872: [SUPPORT]Getting 503s from S3 during upserts
Posted by GitBox <gi...@apache.org>.
satishkotha commented on issue #1872:
URL: https://github.com/apache/hudi/issues/1872#issuecomment-663788217
Hi,
Number of 'createMarkerFile' calls = (number of partitions) + (number of file groups) *touched* by upsert operation.
What is the partition for your workload? What is the 'hoodie.parquet.small.file.limit'? If you have a lot of small files, then we likely need to create a lot of markers (if upsert workload is distributed across multiple file groups).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] satishkotha edited a comment on issue #1872: [SUPPORT]Getting 503s from S3 during upserts
Posted by GitBox <gi...@apache.org>.
satishkotha edited a comment on issue #1872:
URL: https://github.com/apache/hudi/issues/1872#issuecomment-665278060
@luffyd were you able to figure out a workaround? If not, consider opening a jira. We think adding jitter and retries when hudi calls S3 may help. (feel free to open Pull request too)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yuhadooper edited a comment on issue #1872: [SUPPORT]Getting 503s from S3 during upserts
Posted by GitBox <gi...@apache.org>.
yuhadooper edited a comment on issue #1872:
URL: https://github.com/apache/hudi/issues/1872#issuecomment-677906212
Thank you! I will give this a try.
Here are the exceptions I'm seeing, doing an upsert on a few billion records with around 15000 partitions. Though the parquet file exists under the path and not running anything else on the EMR or AWS account I see below errors after partitioning the table. Before partitioning the upserts seem were working fine.
> 20/08/20 18:40:45 WARN TaskSetManager: Lost task 8195.0 in stage 4.0 (TID 8236, ip-10-182-67-53.ec2.internal, executor 170): org.apache.hudi.exception.HoodieException: Error checking path :s3://bucket-name/prefix1/prefix2/tablename/partition_col=123/shg34ko2-f1w2-s51d-6743-56340tcbegpl-129_527-7-5041_20200818150341.parquet, under folder: s3://bucket-name/prefix1/prefix2/tablename/partition_col=123/
at org.apache.hudi.hadoop.HoodieROTablePathFilter.accept(HoodieROTablePathFilter.java:178)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$$anonfun$15.apply(InMemoryFileIndex.scala:302)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$$anonfun$15.apply(InMemoryFileIndex.scala:302)
at scala.collection.TraversableLike$$anonfun$filterImpl$1.apply(TraversableLike.scala:248)
at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
at scala.collection.TraversableLike$class.filterImpl(TraversableLike.scala:247)
at scala.collection.TraversableLike$class.filter(TraversableLike.scala:259)
at scala.collection.mutable.ArrayOps$ofRef.filter(ArrayOps.scala:186)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$.org$apache$spark$sql$execution$datasources$InMemoryFileIndex$$listLeafFiles(InMemoryFileIndex.scala:302)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$$anonfun$3$$anonfun$apply$2.apply(InMemoryFileIndex.scala:215)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$$anonfun$3$$anonfun$apply$2.apply(InMemoryFileIndex.scala:214)
at scala.collection.immutable.Stream.map(Stream.scala:418)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$$anonfun$3.apply(InMemoryFileIndex.scala:214)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$$anonfun$3.apply(InMemoryFileIndex.scala:212)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitions$1$$anonfun$apply$23.apply(RDD.scala:823)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitions$1$$anonfun$apply$23.apply(RDD.scala:823)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
> Caused by: com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.model.AmazonS3Exception: Slow Down (Service: Amazon S3; Status Code: 503; Error Code: 503 Slow Down; Request ID: 8W5H2QDTFGAJBW9M; S3 Extended Request ID: 8qJKHGFJHG56KGF58/xxxxxxxxxxxxxx/yyyyyyyyyyyyyyyy/s=), S3 Extended Request ID: 8qJKHGFJHG56KGF58/xxxxxxxxxxxxxx/yyyyyyyyyyyyyyyy/s=
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleErrorResponse(AmazonHttpClient.java:1742)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleServiceErrorResponse(AmazonHttpClient.java:1371)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeOneRequest(AmazonHttpClient.java:1347)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeHelper(AmazonHttpClient.java:1127)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.doExecute(AmazonHttpClient.java:784)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeWithTimer(AmazonHttpClient.java:752)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.execute(AmazonHttpClient.java:726)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutor.access$500(AmazonHttpClient.java:686)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient$RequestExecutionBuilderImpl.execute(AmazonHttpClient.java:668)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:532)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:512)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:5052)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:4998)
at com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.AmazonS3Client.getObjectMetadata(AmazonS3Client.java:1335)
at com.amazon.ws.emr.hadoop.fs.s3.lite.call.GetObjectMetadataCall.perform(GetObjectMetadataCall.java:22)
at com.amazon.ws.emr.hadoop.fs.s3.lite.call.GetObjectMetadataCall.perform(GetObjectMetadataCall.java:8)
at com.amazon.ws.emr.hadoop.fs.s3.lite.executor.GlobalS3Executor.execute(GlobalS3Executor.java:114)
at com.amazon.ws.emr.hadoop.fs.s3.lite.AmazonS3LiteClient.invoke(AmazonS3LiteClient.java:189)
at com.amazon.ws.emr.hadoop.fs.s3.lite.AmazonS3LiteClient.invoke(AmazonS3LiteClient.java:184)
at com.amazon.ws.emr.hadoop.fs.s3.lite.AmazonS3LiteClient.getObjectMetadata(AmazonS3LiteClient.java:96)
at com.amazon.ws.emr.hadoop.fs.s3.lite.AbstractAmazonS3Lite.getObjectMetadata(AbstractAmazonS3Lite.java:43)
at com.amazon.ws.emr.hadoop.fs.s3n.Jets3tNativeFileSystemStore.getFileMetadataFromCacheOrS3(Jets3tNativeFileSystemStore.java:497)
at com.amazon.ws.emr.hadoop.fs.s3n.Jets3tNativeFileSystemStore.retrieveMetadata(Jets3tNativeFileSystemStore.java:223)
at com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem.getFileStatus(S3NativeFileSystem.java:590)
at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1440)
at com.amazon.ws.emr.hadoop.fs.EmrFileSystem.exists(EmrFileSystem.java:357)
at org.apache.hudi.common.model.HoodiePartitionMetadata.hasPartitionMetadata(HoodiePartitionMetadata.java:141)
at org.apache.hudi.hadoop.HoodieROTablePathFilter.accept(HoodieROTablePathFilter.java:129)
... 30 more
> 20/08/20 21:02:01 WARN TaskSetManager: Lost task 1439.0 in stage 32.0 (TID 18549, ip-10-182-67-6.ec2.internal, executor 279): org.apache.hudi.exception.HoodieUpsertException: Error upserting bucketType UPDATE for partition :1439
at org.apache.hudi.table.HoodieCopyOnWriteTable.handleUpsertPartition(HoodieCopyOnWriteTable.java:270)
at org.apache.hudi.client.HoodieWriteClient.lambda$upsertRecordsInternal$9c951a5d$1(HoodieWriteClient.java:472)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$mapPartitionsWithIndex$1.apply(JavaRDDLike.scala:102)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$mapPartitionsWithIndex$1.apply(JavaRDDLike.scala:102)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsWithIndex$1$$anonfun$apply$25.apply(RDD.scala:875)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsWithIndex$1$$anonfun$apply$25.apply(RDD.scala:875)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD$$anonfun$7.apply(RDD.scala:359)
at org.apache.spark.rdd.RDD$$anonfun$7.apply(RDD.scala:357)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.hudi.exception.HoodieUpsertException: Failed to close UpdateHandle
at org.apache.hudi.io.HoodieMergeHandle.close(HoodieMergeHandle.java:353)
at org.apache.hudi.table.HoodieCopyOnWriteTable.handleUpdateInternal(HoodieCopyOnWriteTable.java:210)
at org.apache.hudi.table.HoodieCopyOnWriteTable.handleUpdate(HoodieCopyOnWriteTable.java:184)
at org.apache.hudi.table.HoodieCopyOnWriteTable.handleUpsertPartition(HoodieCopyOnWriteTable.java:263)
... 30 more
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] luffyd commented on issue #1872: [SUPPORT]Getting 503s from S3 during upserts
Posted by GitBox <gi...@apache.org>.
luffyd commented on issue #1872:
URL: https://github.com/apache/hudi/issues/1872#issuecomment-677914305
It is weird that increasing in partitions is causing s3 throttles. S3 throttles should be function of number of files per partition and fileSizes a bit.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] satishkotha commented on issue #1872: [SUPPORT]Getting 503s from S3 during upserts
Posted by GitBox <gi...@apache.org>.
satishkotha commented on issue #1872:
URL: https://github.com/apache/hudi/issues/1872#issuecomment-665278060
@luffyd were you able to figure out a workaround? If not, consider opening a jira. We think adding jitter and retries when hudi calls S3 may help. (feel free to open Pull request)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] luffyd commented on issue #1872: [SUPPORT]Getting 503s from S3 during upserts
Posted by GitBox <gi...@apache.org>.
luffyd commented on issue #1872:
URL: https://github.com/apache/hudi/issues/1872#issuecomment-677887900
@yuhadooper
I added logs when hudi calls createMarkerFile, it was not that high. But probably other part of hudi was consuming s3 limits.
Another thing is adding these s3 retry configurations at the time spark context seems to be not working.
I added them at the time of creating the cluster, and did not see the FAULTS again. But it could add latency to the processing
```
{
"Classification": "emrfs-site",
"Properties": {
"fs.s3.maxRetries": "50",
"fs.s3.sleepTimeSeconds": "600"
}
}
```
What error are you noticing? can you share
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org