You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@doris.apache.org by "lxwcodemonkey (via GitHub)" <gi...@apache.org> on 2023/04/05 09:41:15 UTC
[GitHub] [doris-spark-connector] lxwcodemonkey opened a new pull request, #91: improve the sink format handle logic by factory pattern
lxwcodemonkey opened a new pull request, #91:
URL: https://github.com/apache/doris-spark-connector/pull/91
# Proposed changes
1. [improve] improve the sink format(json/csv) handle logic by factory pattern
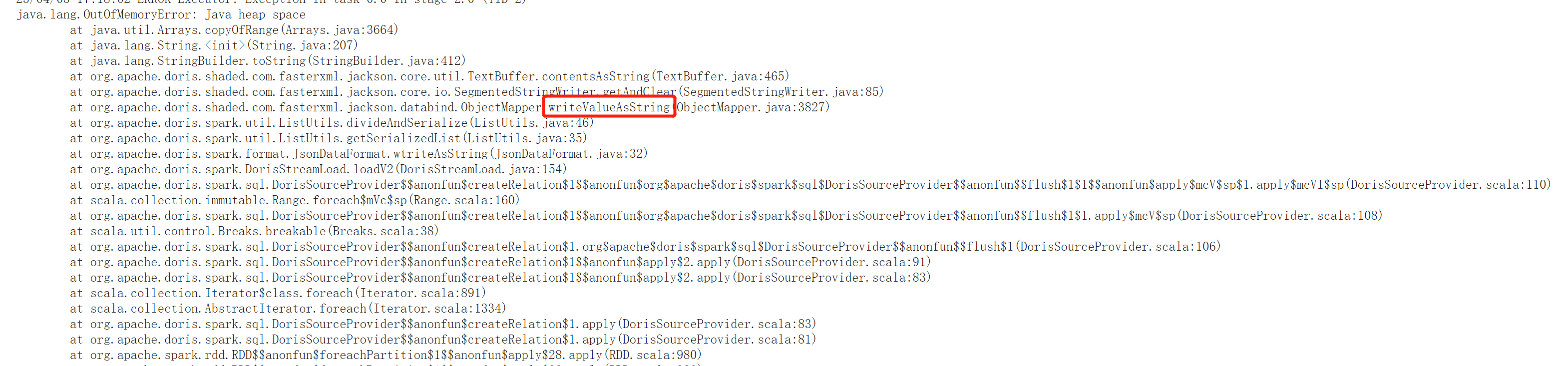
2. [improve] solve OutOfMemoryError when call ObjectMapper.writeValueAsString
3. [improve] add read_json_by_line:ture to HttpPut header to avoid [the size of this batch exceed the max size [104857600] of json type data] when sink format is json
## Problem Summary:
Describe the overview of changes.
## Checklist(Required)
1. Does it affect the original behavior: (Yes/No/I Don't know)
3. Has unit tests been added: (Yes/No/No Need)
4. Has document been added or modified: (Yes/No/No Need)
5. Does it need to update dependencies: (Yes/No)
6. Are there any changes that cannot be rolled back: (Yes/No)
## Further comments
If this is a relatively large or complex change, kick off the discussion at [dev@doris.apache.org](mailto:dev@doris.apache.org) by explaining why you chose the solution you did and what alternatives you considered, etc...
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org
[GitHub] [doris-spark-connector] JNSimba commented on a diff in pull request #91: improve the sink format handle logic by factory pattern
Posted by "JNSimba (via GitHub)" <gi...@apache.org>.
JNSimba commented on code in PR #91:
URL: https://github.com/apache/doris-spark-connector/pull/91#discussion_r1161387749
##########
spark-doris-connector/src/main/java/org/apache/doris/spark/DorisStreamLoad.java:
##########
@@ -162,8 +120,10 @@ private HttpPut getHttpPut(String label, String loadUrlStr) {
.filter(entry -> !"read_json_by_line".equals(entry.getKey()))
.forEach(entry -> httpPut.setHeader(entry.getKey(), entry.getValue()));
}
- if (fileType.equals("json")) {
+ if (dataFormat.getType().equalsIgnoreCase(FormatEnum.json.name())) {
httpPut.setHeader("strip_outer_array", "true");
+ //to solve the error : The size of this batch exceed the max size [104857600] of json type data. Split the file, or use 'read_json_by_line'
+ httpPut.setHeader("read_json_by_line","true");
Review Comment:
The default maximum input of jsonarray is 100MB (be.conf: streaming_load_json_max_mb ), maybe you can add a maximum byte limit
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org
[GitHub] [doris-spark-connector] lxwcodemonkey commented on a diff in pull request #91: improve the sink format handle logic by factory pattern
Posted by "lxwcodemonkey (via GitHub)" <gi...@apache.org>.
lxwcodemonkey commented on code in PR #91:
URL: https://github.com/apache/doris-spark-connector/pull/91#discussion_r1159547449
##########
spark-doris-connector/src/main/java/org/apache/doris/spark/DorisStreamLoad.java:
##########
@@ -162,8 +120,10 @@ private HttpPut getHttpPut(String label, String loadUrlStr) {
.filter(entry -> !"read_json_by_line".equals(entry.getKey()))
.forEach(entry -> httpPut.setHeader(entry.getKey(), entry.getValue()));
}
- if (fileType.equals("json")) {
+ if (dataFormat.getType().equalsIgnoreCase(FormatEnum.json.name())) {
httpPut.setHeader("strip_outer_array", "true");
+ //to solve the error : The size of this batch exceed the max size [104857600] of json type data. Split the file, or use 'read_json_by_line'
+ httpPut.setHeader("read_json_by_line","true");
Review Comment:
I have removed the "read_json_by_line","true" configuration. But I'm confused,I have been using this configura to solve the [The size of this batch exceed the max size] problem for a long time and find nothing wrong。Maybe I need to study the code of be. Thank you!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org
[GitHub] [doris-spark-connector] JNSimba commented on a diff in pull request #91: improve the sink format handle logic by factory pattern
Posted by "JNSimba (via GitHub)" <gi...@apache.org>.
JNSimba commented on code in PR #91:
URL: https://github.com/apache/doris-spark-connector/pull/91#discussion_r1159221392
##########
spark-doris-connector/src/main/java/org/apache/doris/spark/util/ListUtils.java:
##########
@@ -43,10 +43,11 @@ public static List<String> getSerializedList(List<Map<Object, Object>> batch) th
* @throws JsonProcessingException
*/
public static void divideAndSerialize(List<Map<Object, Object>> batch, List<String> result) throws JsonProcessingException {
- String serializedResult = (new ObjectMapper()).writeValueAsString(batch);
+
// if an error occurred in the batch call to getBytes ,average divide the batch
try {
//the "Requested array size exceeds VM limit" exception occurs when the collection is large
+ String serializedResult = (new ObjectMapper()).writeValueAsString(batch);
Review Comment:
Would it be better to create `new ObjectMapper()` only once?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org
[GitHub] [doris-spark-connector] lxwcodemonkey commented on a diff in pull request #91: improve the sink format handle logic by factory pattern
Posted by "lxwcodemonkey (via GitHub)" <gi...@apache.org>.
lxwcodemonkey commented on code in PR #91:
URL: https://github.com/apache/doris-spark-connector/pull/91#discussion_r1161411901
##########
spark-doris-connector/src/main/java/org/apache/doris/spark/DorisStreamLoad.java:
##########
@@ -162,8 +120,10 @@ private HttpPut getHttpPut(String label, String loadUrlStr) {
.filter(entry -> !"read_json_by_line".equals(entry.getKey()))
.forEach(entry -> httpPut.setHeader(entry.getKey(), entry.getValue()));
}
- if (fileType.equals("json")) {
+ if (dataFormat.getType().equalsIgnoreCase(FormatEnum.json.name())) {
httpPut.setHeader("strip_outer_array", "true");
+ //to solve the error : The size of this batch exceed the max size [104857600] of json type data. Split the file, or use 'read_json_by_line'
+ httpPut.setHeader("read_json_by_line","true");
Review Comment:
Maybe I check the size of the data, if it is larger than 100MB, split it and write the split data in blocks? @JNSimba
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org
[GitHub] [doris-spark-connector] lxwcodemonkey commented on a diff in pull request #91: improve the sink format handle logic by factory pattern
Posted by "lxwcodemonkey (via GitHub)" <gi...@apache.org>.
lxwcodemonkey commented on code in PR #91:
URL: https://github.com/apache/doris-spark-connector/pull/91#discussion_r1159547449
##########
spark-doris-connector/src/main/java/org/apache/doris/spark/DorisStreamLoad.java:
##########
@@ -162,8 +120,10 @@ private HttpPut getHttpPut(String label, String loadUrlStr) {
.filter(entry -> !"read_json_by_line".equals(entry.getKey()))
.forEach(entry -> httpPut.setHeader(entry.getKey(), entry.getValue()));
}
- if (fileType.equals("json")) {
+ if (dataFormat.getType().equalsIgnoreCase(FormatEnum.json.name())) {
httpPut.setHeader("strip_outer_array", "true");
+ //to solve the error : The size of this batch exceed the max size [104857600] of json type data. Split the file, or use 'read_json_by_line'
+ httpPut.setHeader("read_json_by_line","true");
Review Comment:
I have removed the "read_json_by_line","true" configuration. But I'm confused,I have been using this configuration to solve the [The size of this batch exceed the max size] problem for a long time and find nothing wrong。Maybe I need to study the code of be. Thank you!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org
[GitHub] [doris-spark-connector] lxwcodemonkey commented on a diff in pull request #91: improve the sink format handle logic by factory pattern
Posted by "lxwcodemonkey (via GitHub)" <gi...@apache.org>.
lxwcodemonkey commented on code in PR #91:
URL: https://github.com/apache/doris-spark-connector/pull/91#discussion_r1159235170
##########
spark-doris-connector/src/main/java/org/apache/doris/spark/util/ListUtils.java:
##########
@@ -43,10 +43,11 @@ public static List<String> getSerializedList(List<Map<Object, Object>> batch) th
* @throws JsonProcessingException
*/
public static void divideAndSerialize(List<Map<Object, Object>> batch, List<String> result) throws JsonProcessingException {
- String serializedResult = (new ObjectMapper()).writeValueAsString(batch);
+
// if an error occurred in the batch call to getBytes ,average divide the batch
try {
//the "Requested array size exceeds VM limit" exception occurs when the collection is large
+ String serializedResult = (new ObjectMapper()).writeValueAsString(batch);
Review Comment:
Yes,thank you for your advice,I will impove it
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org
[GitHub] [doris-spark-connector] lxwcodemonkey commented on a diff in pull request #91: improve the sink format handle logic by factory pattern
Posted by "lxwcodemonkey (via GitHub)" <gi...@apache.org>.
lxwcodemonkey commented on code in PR #91:
URL: https://github.com/apache/doris-spark-connector/pull/91#discussion_r1159235170
##########
spark-doris-connector/src/main/java/org/apache/doris/spark/util/ListUtils.java:
##########
@@ -43,10 +43,11 @@ public static List<String> getSerializedList(List<Map<Object, Object>> batch) th
* @throws JsonProcessingException
*/
public static void divideAndSerialize(List<Map<Object, Object>> batch, List<String> result) throws JsonProcessingException {
- String serializedResult = (new ObjectMapper()).writeValueAsString(batch);
+
// if an error occurred in the batch call to getBytes ,average divide the batch
try {
//the "Requested array size exceeds VM limit" exception occurs when the collection is large
+ String serializedResult = (new ObjectMapper()).writeValueAsString(batch);
Review Comment:
yes,thank you for your advice,I will impove it
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org
[GitHub] [doris-spark-connector] JNSimba commented on a diff in pull request #91: improve the sink format handle logic by factory pattern
Posted by "JNSimba (via GitHub)" <gi...@apache.org>.
JNSimba commented on code in PR #91:
URL: https://github.com/apache/doris-spark-connector/pull/91#discussion_r1161626182
##########
spark-doris-connector/src/main/java/org/apache/doris/spark/DorisStreamLoad.java:
##########
@@ -162,8 +120,10 @@ private HttpPut getHttpPut(String label, String loadUrlStr) {
.filter(entry -> !"read_json_by_line".equals(entry.getKey()))
.forEach(entry -> httpPut.setHeader(entry.getKey(), entry.getValue()));
}
- if (fileType.equals("json")) {
+ if (dataFormat.getType().equalsIgnoreCase(FormatEnum.json.name())) {
httpPut.setHeader("strip_outer_array", "true");
+ //to solve the error : The size of this batch exceed the max size [104857600] of json type data. Split the file, or use 'read_json_by_line'
+ httpPut.setHeader("read_json_by_line","true");
Review Comment:
Yes, but it is better to add a parameter to control the value of this size
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org
[GitHub] [doris-spark-connector] lxwcodemonkey commented on pull request #91: improve the sink format handle logic by factory pattern
Posted by "lxwcodemonkey (via GitHub)" <gi...@apache.org>.
lxwcodemonkey commented on PR #91:
URL: https://github.com/apache/doris-spark-connector/pull/91#issuecomment-1497231855
Excuse me, would it be possible for you to take a look and provide some guidance? I would greatly appreciate it. Thank you. cc @JNSimba
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org
[GitHub] [doris-spark-connector] JNSimba commented on a diff in pull request #91: improve the sink format handle logic by factory pattern
Posted by "JNSimba (via GitHub)" <gi...@apache.org>.
JNSimba commented on code in PR #91:
URL: https://github.com/apache/doris-spark-connector/pull/91#discussion_r1159221981
##########
spark-doris-connector/src/main/java/org/apache/doris/spark/DorisStreamLoad.java:
##########
@@ -162,8 +120,10 @@ private HttpPut getHttpPut(String label, String loadUrlStr) {
.filter(entry -> !"read_json_by_line".equals(entry.getKey()))
.forEach(entry -> httpPut.setHeader(entry.getKey(), entry.getValue()));
}
- if (fileType.equals("json")) {
+ if (dataFormat.getType().equalsIgnoreCase(FormatEnum.json.name())) {
httpPut.setHeader("strip_outer_array", "true");
+ //to solve the error : The size of this batch exceed the max size [104857600] of json type data. Split the file, or use 'read_json_by_line'
+ httpPut.setHeader("read_json_by_line","true");
Review Comment:
The data format required by read_json_by_line is {},{},{}, but the serialization in spark is [{},{},{}]
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org
[GitHub] [doris-spark-connector] lxwcodemonkey commented on a diff in pull request #91: improve the sink format handle logic by factory pattern
Posted by "lxwcodemonkey (via GitHub)" <gi...@apache.org>.
lxwcodemonkey commented on code in PR #91:
URL: https://github.com/apache/doris-spark-connector/pull/91#discussion_r1159521321
##########
spark-doris-connector/src/main/java/org/apache/doris/spark/util/ListUtils.java:
##########
@@ -43,10 +43,11 @@ public static List<String> getSerializedList(List<Map<Object, Object>> batch) th
* @throws JsonProcessingException
*/
public static void divideAndSerialize(List<Map<Object, Object>> batch, List<String> result) throws JsonProcessingException {
- String serializedResult = (new ObjectMapper()).writeValueAsString(batch);
+
// if an error occurred in the batch call to getBytes ,average divide the batch
try {
//the "Requested array size exceeds VM limit" exception occurs when the collection is large
+ String serializedResult = (new ObjectMapper()).writeValueAsString(batch);
Review Comment:
I have improved it by singleton pattern,would you like to take a look again? Thank you! @JNSimba
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org
[GitHub] [doris-spark-connector] lxwcodemonkey commented on a diff in pull request #91: improve the sink format handle logic by factory pattern
Posted by "lxwcodemonkey (via GitHub)" <gi...@apache.org>.
lxwcodemonkey commented on code in PR #91:
URL: https://github.com/apache/doris-spark-connector/pull/91#discussion_r1159241263
##########
spark-doris-connector/src/main/java/org/apache/doris/spark/DorisStreamLoad.java:
##########
@@ -162,8 +120,10 @@ private HttpPut getHttpPut(String label, String loadUrlStr) {
.filter(entry -> !"read_json_by_line".equals(entry.getKey()))
.forEach(entry -> httpPut.setHeader(entry.getKey(), entry.getValue()));
}
- if (fileType.equals("json")) {
+ if (dataFormat.getType().equalsIgnoreCase(FormatEnum.json.name())) {
httpPut.setHeader("strip_outer_array", "true");
+ //to solve the error : The size of this batch exceed the max size [104857600] of json type data. Split the file, or use 'read_json_by_line'
+ httpPut.setHeader("read_json_by_line","true");
Review Comment:
I read https://doris.apache.org/zh-CN/docs/data-operate/import/import-way/load-json-format/ this document, I already know the difference between the two, It may indeed cause some problems, although I haven't found any problems in my current tests, I will remove this read_json_by_line configuration in json format first, and consider optimizing it in the next PR,thank you!!!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org
[GitHub] [doris-spark-connector] lxwcodemonkey commented on a diff in pull request #91: improve the sink format handle logic by factory pattern
Posted by "lxwcodemonkey (via GitHub)" <gi...@apache.org>.
lxwcodemonkey commented on code in PR #91:
URL: https://github.com/apache/doris-spark-connector/pull/91#discussion_r1161644460
##########
spark-doris-connector/src/main/java/org/apache/doris/spark/DorisStreamLoad.java:
##########
@@ -162,8 +120,10 @@ private HttpPut getHttpPut(String label, String loadUrlStr) {
.filter(entry -> !"read_json_by_line".equals(entry.getKey()))
.forEach(entry -> httpPut.setHeader(entry.getKey(), entry.getValue()));
}
- if (fileType.equals("json")) {
+ if (dataFormat.getType().equalsIgnoreCase(FormatEnum.json.name())) {
httpPut.setHeader("strip_outer_array", "true");
+ //to solve the error : The size of this batch exceed the max size [104857600] of json type data. Split the file, or use 'read_json_by_line'
+ httpPut.setHeader("read_json_by_line","true");
Review Comment:
OK,thanks for your advice,I will improve it!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org
[GitHub] [doris-spark-connector] lxwcodemonkey closed pull request #91: improve the sink format handle logic by factory pattern
Posted by "lxwcodemonkey (via GitHub)" <gi...@apache.org>.
lxwcodemonkey closed pull request #91: improve the sink format handle logic by factory pattern
URL: https://github.com/apache/doris-spark-connector/pull/91
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org