You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2020/04/01 03:03:51 UTC
[GitHub] [incubator-iceberg] aokolnychyi edited a comment on issue #796:
Support Spark Structured Streaming Read for Iceberg
aokolnychyi edited a comment on issue #796: Support Spark Structured Streaming Read for Iceberg
URL: https://github.com/apache/incubator-iceberg/pull/796#issuecomment-606999754
@jerryshao @rdblue I've spent some time prototyping the idea I described earlier to avoid loading all snapshot metadata at once. It seems to be pretty straightforward. Naming/logic is preliminary and might contain bugs.
I defined the following bean to represent a micro-batch:
```
public class MicroBatch {
private long snapshotId;
private int startFileIndex;
private int endFileIndex;
private long sizeInBytes;
private List<DataFile> files;
// ...
}
```
In addition, I've built a utility class like this:
```
public class MicroBatchGenerator {
private FileIO io;
private Map<Integer, PartitionSpec> specs;
private long snapshotId;
private List<ManifestFile> manifests;
private Map<Integer, Integer> manifestStartFileIndexMap;
private LoadingCache<Integer, List<DataFile>> manifestCache;
public MicroBatchGenerator(Table table, long snapshotId, int manifestCacheSize) {
this.io = table.io();
this.specs = table.specs();
this.snapshotId = snapshotId;
// TODO: we might want to reverse the list as recent manifests are at the beginning
this.manifests = table.snapshot(snapshotId).manifests();
this.manifestStartFileIndexMap = initManifestStartFileIndexMap();
this.manifestCache = Caffeine.newBuilder()
.weakValues()
.expireAfterAccess(10, TimeUnit.MINUTES)
.maximumSize(manifestCacheSize)
.build(manifestIndex -> {
ManifestFile manifest = manifests.get(manifestIndex);
List<DataFile> files = Lists.newArrayList();
try (ManifestReader reader = ManifestReader.read(manifest, io, specs)) {
reader.forEach(file -> files.add(file.copyWithoutStats()));
}
return files;
});
}
public MicroBatch newMicroBatch(int startFileIndex, int targetBatchSizeBytes) {
List<DataFile> batchFiles = Lists.newArrayList();
int startManifestIndex = manifestIndex(startFileIndex);
int currentFileIndex = manifestStartFileIndexMap.get(startManifestIndex);
long currentBatchSizeBytes = 0L;
for (int manifestIndex = startManifestIndex; manifestIndex < manifests.size(); manifestIndex++) {
List<DataFile> files = manifestCache.get(manifestIndex);
for (DataFile file : files) {
if (currentFileIndex < startFileIndex) {
currentFileIndex++;
continue;
}
if (batchFiles.isEmpty() || currentBatchSizeBytes + file.fileSizeInBytes() <= targetBatchSizeBytes) {
batchFiles.add(file);
currentBatchSizeBytes += file.fileSizeInBytes();
} else {
return new MicroBatch(snapshotId, startFileIndex, currentFileIndex, currentBatchSizeBytes, batchFiles);
}
currentFileIndex++;
}
}
return new MicroBatch(snapshotId, startFileIndex, currentFileIndex, currentBatchSizeBytes, batchFiles);
}
// builds a map from manifest index to starting file index
private Map<Integer, Integer> initManifestStartFileIndexMap() {
ImmutableMap.Builder<Integer, Integer> builder = ImmutableMap.builder();
int currentFileIndex = 0;
for (int manifestIndex = 0; manifestIndex < manifests.size(); manifestIndex++) {
ManifestFile manifest = manifests.get(manifestIndex);
int liveFilesCount = manifest.addedFilesCount() + manifest.existingFilesCount();
builder.put(manifestIndex, currentFileIndex);
currentFileIndex += liveFilesCount;
}
return builder.build();
}
// determines the index of the manifest that will contain the given file index
private int manifestIndex(int fileIndex) {
if (fileIndex == 0) {
return 0;
}
int currentFileIndex = 0;
for (int manifestIndex = 0; manifestIndex < manifests.size(); manifestIndex++) {
ManifestFile manifest = manifests.get(manifestIndex);
int manifestLiveFilesCount = manifest.addedFilesCount() + manifest.existingFilesCount();
if (currentFileIndex + manifestLiveFilesCount > fileIndex) {
return manifestIndex;
} else {
currentFileIndex += manifestLiveFilesCount;
}
}
throw new ValidationException("Snapshot %d does not have a file with index %d", snapshotId, fileIndex);
}
}
```
Then I did some stress testing trying to load batches with around 10000 files on a table with a couple of million files and around 455 manifests. The logic above worked fine and was really quick while I could not load all metadata at the same time due to OOM (I had only 500 MB memory allocated to the program). See the chart below where the bump in memory and GC is when the job planning for the complete table started.
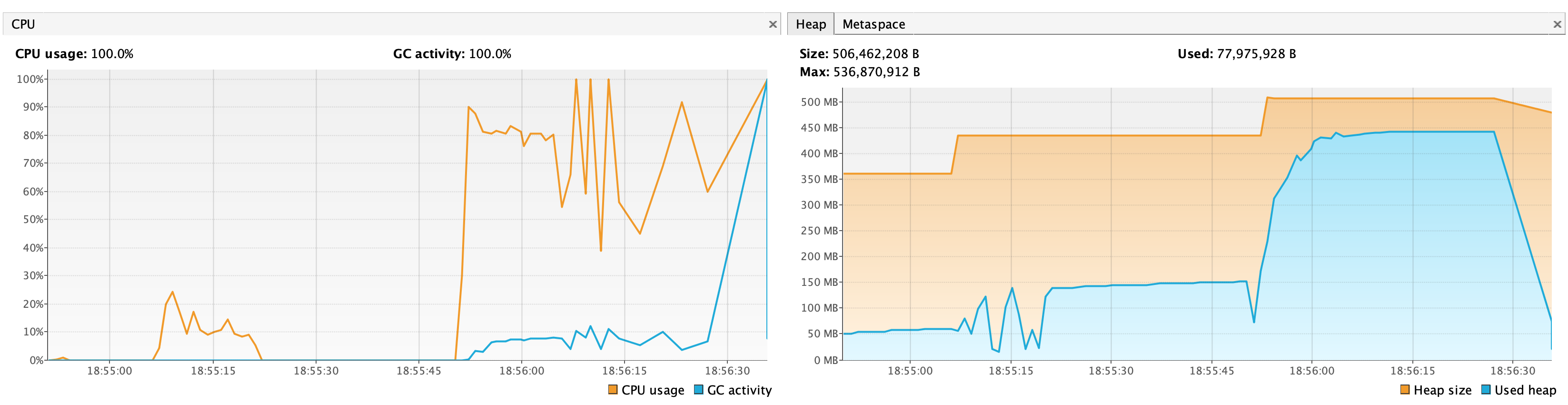
If we think this might help, I can clean up the utility class and contribute it. Note that `newMicroBatch` is determined in terms of data size. The created `MicroBatch` also contains `endFileIndex` that can be used to construct an end offset.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org