You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2021/06/08 16:26:04 UTC
[GitHub] [iceberg] aimenglin opened a new issue #2685: How to realize Write Iceberg Tables via Hive? (Ideas share)
aimenglin opened a new issue #2685:
URL: https://github.com/apache/iceberg/issues/2685
Right now, we can read the Iceberg table via Hive, but the overlay table is an external table, so we cannot write the table via Hive.
I'm thinking about whether we can directly write a managed table via Hive. Any ideas?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] aimenglin commented on issue #2685: How to realize Write Iceberg Tables via Hive? (Ideas share)
Posted by GitBox <gi...@apache.org>.
aimenglin commented on issue #2685:
URL: https://github.com/apache/iceberg/issues/2685#issuecomment-857183739
What if we write the table as iceberg format via Hive?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] aimenglin commented on issue #2685: How to realize Write Iceberg Tables via Hive? (Ideas share)
Posted by GitBox <gi...@apache.org>.
aimenglin commented on issue #2685:
URL: https://github.com/apache/iceberg/issues/2685#issuecomment-859036146
@marton-bod I didn't find anything under this directory. There's a hidden file on test1, but still nothing inside.
```
shenme@wakeup:~$ gsutil ls -la gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1/temp
CommandException: One or more URLs matched no objects.
shenme@wakeup:~$ gsutil ls -la gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
0 2021-06-09T23:25:48Z gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1/#1623281148381224 metageneration=1
gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1/data/
gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1/metadata/
TOTAL: 1 objects, 0 bytes (0 B)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] aimenglin commented on issue #2685: How to realize Write Iceberg Tables via Hive? (Ideas share)
Posted by GitBox <gi...@apache.org>.
aimenglin commented on issue #2685:
URL: https://github.com/apache/iceberg/issues/2685#issuecomment-858180173
1. Created a Iceberg Table using Hadoop Table on Spark:
// Create a Iceberg Table
```
spark-shell --conf spark.sql.warehouse.dir=gs://shenme_dataproc_1/spark-warehouse --jars /usr/lib/iceberg/jars/iceberg-spark-runtime.jar
import org.apache.hadoop.conf.Configuration
import org.apache.iceberg.hadoop.HadoopTables
import org.apache.iceberg.Table
import org.apache.iceberg.Schema
import org.apache.iceberg.types.Types._
import org.apache.iceberg.PartitionSpec
import org.apache.iceberg.spark.SparkSchemaUtil
import org.apache.spark.sql._
```
// Insert a 4 rows
```
scala> val conf = new Configuration();
conf: org.apache.hadoop.conf.Configuration = Configuration: core-default.xml, core-site.xml, mapred-default.xml, mapred-site.xml, yarn-default.xml, yarn-site.xm
l, hdfs-default.xml, hdfs-site.xml, resource-types.xml
scala> val tables = new HadoopTables(conf);
tables: org.apache.iceberg.hadoop.HadoopTables = org.apache.iceberg.hadoop.HadoopTables@6fac8b24
scala> val df1 = Seq((1,"Vincent","Computer Science"),(2,"Dan", "Economics"),(3,"Bob", "Politics"),(4,"Cindy", "UX Design")).toDF("id","name","major");
df1: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> val df1_schema = SparkSchemaUtil.convert(df1.schema);
df1_schema: org.apache.iceberg.Schema =
table {
0: id: required int
1: name: optional string
2: major: optional string
}
scala> val partition_spec = PartitionSpec.builderFor(df1_schema).identity("major").build;
partition_spec: org.apache.iceberg.PartitionSpec =
[
1000: major: identity(2)
]
scala> val table_location = "gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1";
table_location: String = gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
scala> val hadooptable = tables.create(df1_schema, partition_spec, table_location);
hadooptable: org.apache.iceberg.Table = gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
scala> df1.write.format("iceberg").mode("overwrite").save(table_location);
```
// Query 4 rows on Spark
```
scala> val read_df1=spark.read.format("iceberg").load(table_location);
read_df1: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> read_df1.show;
+---+-------+----------------+
| id| name| major|
+---+-------+----------------+
| 1|Vincent|Computer Science|
| 2| Dan| Economics|
| 3| Bob| Politics|
| 4| Cindy| UX Design|
+---+-------+----------------+
```
// Add another column
```
scala> val table = tables.load(table_location);
table: org.apache.iceberg.Table = gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
scala> table.updateSchema.addColumn("grade", StringType.get()).commit();
scala> table.schema.toString;
res8: String =
table {
1: id: required int
2: name: optional string
3: major: optional string
4: grade: optional string
}
```
// Add another 2 rows
```
scala> val df2=Seq((5,"Amy","UX Design","Sophomore")).toDF("id","name","major","grade");
df2: org.apache.spark.sql.DataFrame = [id: int, name: string ... 2 more fields]
scala> df2.write.format("iceberg").mode("append").save(table_location);
scala> val df3=Seq((6,"Rachael","Economics","Freshman")).toDF("id","name","major","grade");
df3: org.apache.spark.sql.DataFrame = [id: int, name: string ... 2 more fields]
scala> df3.write.format("iceberg").mode("append").save(table_location);
scala> val read_df2=spark.read.format("iceberg").load(table_location);
read_df2: org.apache.spark.sql.DataFrame = [id: int, name: string ... 2 more fields]
scala> spark.read.format("iceberg").load(table_location).show(truncate = false)
+---+-------+----------------+---------+
|id |name |major |grade |
+---+-------+----------------+---------+
|6 |Rachael|Economics |Freshman |
|1 |Vincent|Computer Science|null |
|2 |Dan |Economics |null |
|3 |Bob |Politics |null |
|4 |Cindy |UX Design |null |
|5 |Amy |UX Design |Sophomore|
+---+-------+----------------+---------+
```
// We have the data and the right set of metadata generated including snapshots, manifests in the bucket.
2.Created an external table on Hive
```
hive
Hive Session ID = 521d08fa-9fda-4ca3-8bab-3d0b60ddc6de
Logging initialized using configuration in file:/etc/hive/conf.dist/hive-log4j2.properties Async: true
Hive Session ID = 4f8d6c05-19a2-4e1e-8672-52b79d1fd566
hive> add jar /home/shenme_google_com/iceberg-hive-runtime.jar;
Added [/home/shenme_google_com/iceberg-hive-runtime.jar] to class path
Added resources: [/home/shenme_google_com/iceberg-hive-runtime.jar]
hive> set iceberg.engine.hive.enabled=true;
hive> set hive.vectorized.execution.enabled=false;
hive> CREATE EXTERNAL TABLE hadoop_table_1
> STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
> LOCATION 'gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1/'
> TBLPROPERTIES ('iceberg.catalog'='gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1');
OK
Time taken: 3.698 seconds
```
3. Read is fine, and then I insert a new row:
```
// Read via Hive
hive> describe formatted hadoop_table_1;
OK
# col_name data_type comment
id int from deserializer
name string from deserializer
major string from deserializer
grade string from deserializer
# Detailed Table Information
Database: default
OwnerType: USER
Owner: shenme_google_com
CreateTime: Wed Jun 09 23:21:26 UTC 2021
LastAccessTime: UNKNOWN
Retention: 0
Location: gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
Table Type: EXTERNAL_TABLE
Table Parameters:
EXTERNAL TRUE
bucketing_version 2
iceberg.catalog gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
numFiles 18
storage_handler org.apache.iceberg.mr.hive.HiveIcebergStorageHandler
table_type ICEBERG
totalSize 48550
transient_lastDdlTime 1623280886
# Storage Information
SerDe Library: org.apache.iceberg.mr.hive.HiveIcebergSerDe
InputFormat: org.apache.iceberg.mr.hive.HiveIcebergInputFormat
OutputFormat: org.apache.iceberg.mr.hive.HiveIcebergOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
serialization.format 1
Time taken: 0.609 seconds, Fetched: 35 row(s)
hive> select * from hadoop_table_1;
Query ID = shenme_google_com_20210609232347_cc7ce64b-6b80-4169-b1d5-caf42a300e96
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1622522135523_0073)
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... container SUCCEEDED 1 1 0 0 0 0
----------------------------------------------------------------------------------------------
VERTICES: 01/01 [==========================>>] 100% ELAPSED TIME: 8.67 s
----------------------------------------------------------------------------------------------
OK
6 Rachael Economics Freshman
1 Vincent Computer Science NULL
2 Dan Economics NULL
3 Bob Politics NULL
4 Cindy UX Design NULL
5 Amy UX Design Sophomore
Time taken: 13.469 seconds, Fetched: 6 row(s)
```
// Insert a row
```
hive> INSERT INTO TABLE hadoop_table_1
> VALUES (7, "John", "Basketball", "Senior");
Query ID = shenme_google_com_20210609232537_9d2ce449-4ebc-403b-8f74-8b08ba9f62d1
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1622522135523_0073)
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... container SUCCEEDED 1 1 0 0 0 0
----------------------------------------------------------------------------------------------
VERTICES: 01/01 [==========================>>] 100% ELAPSED TIME: 6.71 s
----------------------------------------------------------------------------------------------
OK
Time taken: 10.374 seconds
```
// Read and check whether the data was written into the table
```
hive> select * from hadoop_table_1;
Query ID = shenme_google_com_20210609232620_021c6e8a-cf7a-43d8-9ee9-44913a900e67
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1622522135523_0073)
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... container SUCCEEDED 1 1 0 0 0 0
----------------------------------------------------------------------------------------------
VERTICES: 01/01 [==========================>>] 100% ELAPSED TIME: 7.24 s
----------------------------------------------------------------------------------------------
OK
6 Rachael Economics Freshman
1 Vincent Computer Science NULL
2 Dan Economics NULL
3 Bob Politics NULL
4 Cindy UX Design NULL
5 Amy UX Design Sophomore
Time taken: 9.196 seconds, Fetched: 6 row(s)
```
4. GS bucket screenshot, we got data generated, but no metadata. So after select, the newly inserted row was not in the result.

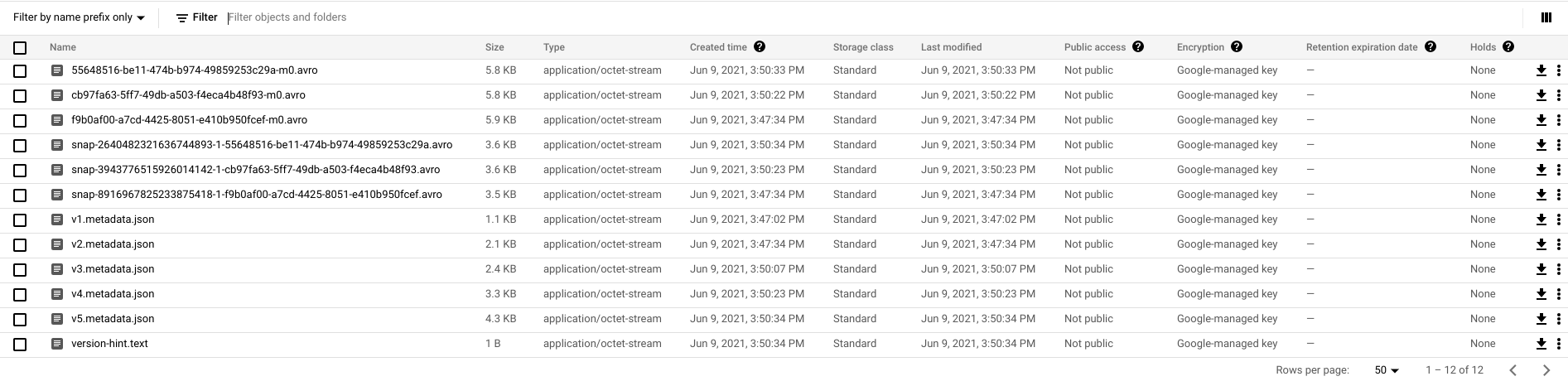
Question:
I'm curious whether it's possible to read the newly inserted data via Hive. Thanks in advance!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] marton-bod commented on issue #2685: How to realize Write Iceberg Tables via Hive? (Ideas share)
Posted by GitBox <gi...@apache.org>.
marton-bod commented on issue #2685:
URL: https://github.com/apache/iceberg/issues/2685#issuecomment-858552340
Thanks for the detailed steps! As you mentioned too, it seems that Hive generated the data files but something went wrong during the job commit (hence the lack of metadata generated). Can you share any logs from the execution side that we could take a look at?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] aimenglin commented on issue #2685: How to realize Write Iceberg Tables via Hive? (Ideas share)
Posted by GitBox <gi...@apache.org>.
aimenglin commented on issue #2685:
URL: https://github.com/apache/iceberg/issues/2685#issuecomment-858084189
@marton-bod
The result I got is that I found the data was stored in the bucket, but no metadata generated. Also, if I read the table via Spark and Hive, the data was not updated and shown. Maybe I missed something when I created the external table, so I'll look at the resource you given. Thanks so much!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] marton-bod commented on issue #2685: How to realize Write Iceberg Tables via Hive? (Ideas share)
Posted by GitBox <gi...@apache.org>.
marton-bod commented on issue #2685:
URL: https://github.com/apache/iceberg/issues/2685#issuecomment-858008951
Hi @aimenglin , you should be able to write to overlay tables as well from Hive. Please refer to our documentation: https://github.com/apache/iceberg/blob/master/site/docs/hive.md. Hope this helps resolve your issue. In case not, please send the exact steps you tried and the error message you encountered, so we may be able to help further.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] marton-bod commented on issue #2685: How to realize Write Iceberg Tables via Hive? (Ideas share)
Posted by GitBox <gi...@apache.org>.
marton-bod commented on issue #2685:
URL: https://github.com/apache/iceberg/issues/2685#issuecomment-859021968
Thanks for details! Sorry, I wasn't clear on which temp folder I'd like to see the contents of. Can you check this one:
`gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1/temp`?
As for the logs, they are from the HS2 side, but is there a chance to get the logs from the Hadoop cluster where the MR job was executing? Unfortunately the job commit happens on the MR job-side and not on the HS2-side.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] aimenglin commented on issue #2685: How to realize Write Iceberg Tables via Hive? (Ideas share)
Posted by GitBox <gi...@apache.org>.
aimenglin commented on issue #2685:
URL: https://github.com/apache/iceberg/issues/2685#issuecomment-858925332
@marton-bod Thanks for your patience and time for helping me debug.
1. Log
```
2021-06-09T23:25:37,850 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Driver: Compiling command(queryId=shenme_google_com_20210609232537_9d2ce449-4ebc-403b-8f74-8b08ba9f62d1): INSERT INTO TABLE hadoop_table_1
VALUES (7, "John", "Basketball", "Senior")
2021-06-09T23:25:37,876 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Driver: Concurrency mode is disabled, not creating a lock manager
2021-06-09T23:25:37,876 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] parse.CalcitePlanner: Starting Semantic Analysis
2021-06-09T23:25:37,903 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] parse.CalcitePlanner: Completed phase 1 of Semantic Analysis
2021-06-09T23:25:37,903 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] parse.CalcitePlanner: Get metadata for source tables
2021-06-09T23:25:37,903 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] parse.CalcitePlanner: Get metadata for subqueries
2021-06-09T23:25:37,903 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] parse.CalcitePlanner: Get metadata for destination tables
2021-06-09T23:25:37,928 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] parse.CalcitePlanner: Completed getting MetaData in Semantic Analysis
2021-06-09T23:25:38,101 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Context: New scratch dir is hdfs://shenme-cluster-3-m/tmp/hive/shenme_google_com/521d08fa-9fda-4ca3-8bab-3d0b60ddc6de/hive_2021-06-09_23-25-37_866_2611149539519878546-1
2021-06-09T23:25:38,619 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] parse.CalcitePlanner: Get metadata for source tables
2021-06-09T23:25:38,620 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] parse.CalcitePlanner: Get metadata for subqueries
2021-06-09T23:25:38,620 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] parse.CalcitePlanner: Get metadata for source tables
2021-06-09T23:25:38,631 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] parse.CalcitePlanner: Get metadata for subqueries
2021-06-09T23:25:38,631 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] parse.CalcitePlanner: Get metadata for destination tables
2021-06-09T23:25:40,604 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Driver: Launching Job 1 out of 1
2021-06-09T23:25:40,604 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Driver: Starting task [Stage-2:MAPRED] in serial mode
2021-06-09T23:25:40,686 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Context: New scratch dir is hdfs://shenme-cluster-3-m/tmp/hive/shenme_google_com/521d08fa-9fda-4ca3-8bab-3d0b60ddc6de/hive_2021-06-09_23-25-37_866_2611149539519878546-1
2021-06-09T23:25:40,691 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] tez.TezSessionPoolManager: The current user: shenme_google_com, session user: shenme_google_com
2021-06-09T23:25:40,691 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] tez.TezSessionPoolManager: Current queue name is null incoming queue name is null
2021-06-09T23:25:40,691 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] exec.Task: Subscribed to counters: [] for queryId: shenme_google_com_20210609232537_9d2ce449-4ebc-403b-8f74-8b08ba9f62d1
2021-06-09T23:25:38,631 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] parse.CalcitePlanner: Get metadata for destination tables
2021-06-09T23:25:38,696 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Context: New scratch dir is hdfs://shenme-cluster-3-m/tmp/hive/shenme_google_com/521d08fa-9fda-4ca3-8bab-3d0b60ddc6de/hive_2021-06-09_23-25-37_866_2611149539519878546-1
2021-06-09T23:25:38,702 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] mr.Catalogs: Catalog is not configured
2021-06-09T23:25:38,944 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] hadoop.HadoopTables: Table location loaded: gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
2021-06-09T23:25:38,944 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] hive.HiveIcebergSerDe: Using schema from existing table {"type":"struct","fields":[{"id":1,"name":"id","required":true,"type":"int"},{"id":2,"name":"name","required":false,"type":"string"},{"id":3,"name":"major","required":false,"type":"string"},{"id":4,"name":"grade","required":false,"type":"string"}]}
2021-06-09T23:25:39,006 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] mr.Catalogs: Catalog is not configured
2021-06-09T23:25:39,238 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] hadoop.HadoopTables: Table location loaded: gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
2021-06-09T23:25:39,238 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] hive.HiveIcebergSerDe: Using schema from existing table {"type":"struct","fields":[{"id":1,"name":"id","required":true,"type":"int"},{"id":2,"name":"name","required":false,"type":"string"},{"id":3,"name":"major","required":false,"type":"string"},{"id":4,"name":"grade","required":false,"type":"string"}]}
2021-06-09T23:25:39,238 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] mr.Catalogs: Catalog is not configured
2021-06-09T23:25:39,436 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] hadoop.HadoopTables: Table location loaded: gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
2021-06-09T23:25:39,436 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] hive.HiveIcebergSerDe: Using schema from existing table {"type":"struct","fields":[{"id":1,"name":"id","required":true,"type":"int"},{"id":2,"name":"name","required":false,"type":"string"},{"id":3,"name":"major","required":false,"type":"string"},{"id":4,"name":"grade","required":false,"type":"string"}]}
2021-06-09T23:25:39,437 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] common.FileUtils: Creating directory if it doesn't exist: gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1/.hive-staging_hive_2021-06-09_23-25-37_866_2611149539519878546-1
2021-06-09T23:25:39,518 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] mr.Catalogs: Catalog is not configured
2021-06-09T23:25:39,707 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] hadoop.HadoopTables: Table location loaded: gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
2021-06-09T23:25:39,800 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] parse.CalcitePlanner: CBO Succeeded; optimized logical plan.
2021-06-09T23:25:39,800 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ppd.OpProcFactory: Processing for FS(4)
2021-06-09T23:25:39,800 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ppd.OpProcFactory: Processing for SEL(3)
2021-06-09T23:25:39,800 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ppd.OpProcFactory: Processing for UDTF(2)
2021-06-09T23:25:39,800 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ppd.OpProcFactory: Processing for SEL(1)
2021-06-09T23:25:39,800 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ppd.OpProcFactory: Processing for TS(0)
2021-06-09T23:25:39,823 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] parse.TezCompiler: Cycle free: true
2021-06-09T23:25:39,828 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] parse.CalcitePlanner: Completed plan generation
2021-06-09T23:25:39,829 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Driver: Semantic Analysis Completed (retrial = false)
2021-06-09T23:25:39,829 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Driver: Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:col1, type:int, comment:null), FieldSchema(name:col2, type:string, comment:null), FieldSchema(name:col3, type:string, comment:null), FieldSchema(name:col4, type:string, comment:null)], properties:null)
2021-06-09T23:25:39,829 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Driver: Completed compiling command(queryId=shenme_google_com_20210609232537_9d2ce449-4ebc-403b-8f74-8b08ba9f62d1); Time taken: 1.979 seconds
2021-06-09T23:25:39,829 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] reexec.ReExecDriver: Execution #1 of query
2021-06-09T23:25:39,829 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Driver: Concurrency mode is disabled, not creating a lock manager
2021-06-09T23:25:39,829 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Driver: Executing command(queryId=shenme_google_com_20210609232537_9d2ce449-4ebc-403b-8f74-8b08ba9f62d1): INSERT INTO TABLE hadoop_table_1
VALUES (7, "John", "Basketball", "Senior")
2021-06-09T23:25:39,829 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Driver: Query ID = shenme_google_com_20210609232537_9d2ce449-4ebc-403b-8f74-8b08ba9f62d1
2021-06-09T23:25:39,829 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Driver: Total jobs = 1
2021-06-09T23:25:39,830 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Driver: Starting task [Stage-0:DDL] in serial mode
2021-06-09T23:25:39,852 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] mr.Catalogs: Catalog is not configured
2021-06-09T23:25:40,093 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] hadoop.HadoopTables: Table location loaded: gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
2021-06-09T23:25:40,093 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] hive.HiveIcebergSerDe: Using schema from existing table {"type":"struct","fields":[{"id":1,"name":"id","required":true,"type":"int"},{"id":2,"name":"name","required":false,"type":"string"},{"id":3,"name":"major","required":false,"type":"string"},{"id":4,"name":"grade","required":false,"type":"string"}]}
2021-06-09T23:25:40,094 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] mr.Catalogs: Catalog is not configured
2021-06-09T23:25:40,327 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] hadoop.HadoopTables: Table location loaded: gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
2021-06-09T23:25:40,327 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] hive.HiveIcebergSerDe: Using schema from existing table {"type":"struct","fields":[{"id":1,"name":"id","required":true,"type":"int"},{"id":2,"name":"name","required":false,"type":"string"},{"id":3,"name":"major","required":false,"type":"string"},{"id":4,"name":"grade","required":false,"type":"string"}]}
2021-06-09T23:25:40,328 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] mr.Catalogs: Catalog is not configured
2021-06-09T23:25:40,528 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] hadoop.HadoopTables: Table location loaded: gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
2021-06-09T23:25:40,528 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] hive.HiveIcebergSerDe: Using schema from existing table {"type":"struct","fields":[{"id":1,"name":"id","required":true,"type":"int"},{"id":2,"name":"name","required":false,"type":"string"},{"id":3,"name":"major","required":false,"type":"string"},{"id":4,"name":"grade","required":false,"type":"string"}]}
2021-06-09T23:25:40,597 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Driver: Starting task [Stage-1:DDL] in serial mode
2021-06-09T23:25:40,604 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Driver: Launching Job 1 out of 1
2021-06-09T23:25:40,604 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Driver: Starting task [Stage-2:MAPRED] in serial mode
2021-06-09T23:25:40,686 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Context: New scratch dir is hdfs://shenme-cluster-3-m/tmp/hive/shenme_google_com/521d08fa-9fda-4ca3-8bab-3d0b60ddc6de/hive_2021-06-09_23-25-37_866_2611149539519878546-1
2021-06-09T23:25:40,691 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] tez.TezSessionPoolManager: The current user: shenme_google_com, session user: shenme_google_com
2021-06-09T23:25:40,691 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] tez.TezSessionPoolManager: Current queue name is null incoming queue name is null
2021-06-09T23:25:40,691 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] exec.Task: Subscribed to counters: [] for queryId: shenme_google_com_20210609232537_9d2ce449-4ebc-403b-8f74-8b08ba9f62d1
2021-06-09T23:25:40,691 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] exec.Task: Session is already open
2021-06-09T23:25:40,694 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] tez.DagUtils: Resource modification time: 1623281030625 for hdfs://shenme-cluster-3-m/tmp/hive/shenme_google_com/_tez_session_dir/521d08fa-9fda-4ca3-8bab-3d0b60ddc6de-resources/iceberg-hive-runtime.jar
2021-06-09T23:25:40,694 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] exec.Task: Dag name: INSERT INTO TABLE hadoop_table_1..."Senior") (Stage-2)
2021-06-09T23:25:40,698 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Context: New scratch dir is hdfs://shenme-cluster-3-m/tmp/hive/shenme_google_com/521d08fa-9fda-4ca3-8bab-3d0b60ddc6de/hive_2021-06-09_23-25-37_866_2611149539519878546-1
2021-06-09T23:25:40,758 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] tez.DagUtils: Vertex has custom input? false
2021-06-09T23:25:40,759 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] exec.SerializationUtilities: Serializing MapWork using kryo
2021-06-09T23:25:40,789 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] exec.Utilities: Serialized plan (via RPC) - name: Map 1 size: 301.80KB
2021-06-09T23:25:40,891 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] client.TezClient: Submitting dag to TezSession, sessionName=HIVE-521d08fa-9fda-4ca3-8bab-3d0b60ddc6de, applicationId=application_1622522135523_0073, dagName=INSERT INTO TABLE hadoop_table_1..."Senior") (Stage-2), callerContext={ context=HIVE, callerType=HIVE_QUERY_ID, callerId=shenme_google_com_20210609232537_9d2ce449-4ebc-403b-8f74-8b08ba9f62d1 }
2021-06-09T23:25:40,991 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] client.TezClient: Submitted dag to TezSession, sessionName=HIVE-521d08fa-9fda-4ca3-8bab-3d0b60ddc6de, applicationId=application_1622522135523_0073, dagId=dag_1622522135523_0073_2, dagName=INSERT INTO TABLE hadoop_table_1..."Senior") (Stage-2)
2021-06-09T23:25:41,513 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] SessionState: Status: Running (Executing on YARN cluster with App id application_1622522135523_0073)
2021-06-09T23:25:41,515 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] SessionState: Map 1: 0/1
2021-06-09T23:25:44,542 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] SessionState: Map 1: 0(+1)/1
2021-06-09T23:25:47,576 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] SessionState: Map 1: 0(+1)/1
2021-06-09T23:25:48,220 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] SessionState: Map 1: 1/1
2021-06-09T23:25:48,223 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Driver: Starting task [Stage-4:DDL] in serial mode
2021-06-09T23:25:48,224 INFO [521d08fa-9fda-4ca3-8bab-3d0b60ddc6de main] ql.Driver: Completed executing command(queryId=shenme_google_com_20210609232537_9d2ce449-4ebc-403b-8f74-8b08ba9f62d1); Time taken: 8.395 seconds
```
2. Version

3. Explain Plan
```
hive> EXPLAIN INSERT INTO TABLE hadoop_table_1 VALUES (8, "Eve", "Zoology", "Senior");
OK
Plan optimized by CBO.
Stage-0
Alter Table Operator:
old name:default.hadoop_table_1,type:drop props
Stage-1
Pre Insert operator:{"Pre-Insert task":{}}
Stage-4
Insert operator:{"Commit-Insert-Hook":{}}
Stage-2
Map 1
File Output Operator [FS_4]
table:{"name:":"default.hadoop_table_1"}
Select Operator [SEL_3] (rows=1 width=8)
Output:["_col0","_col1","_col2","_col3"]
UDTF Operator [UDTF_2] (rows=1 width=48)
function name:inline
Select Operator [SEL_1] (rows=1 width=48)
Output:["_col0"]
TableScan [TS_0] (rows=1 width=10)
_dummy_database@_dummy_table,_dummy_table,Tbl:COMPLETE,Col:COMPLETE
Time taken: 1.592 seconds, Fetched: 22 row(s)
```
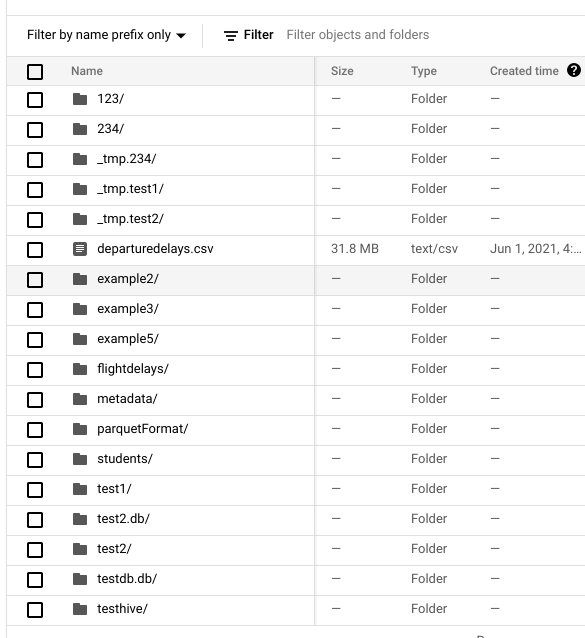
4. Everytime when I insert the data, there'll be a _tmp file, but it's empty.
```
gsutil ls -la gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/_tmp.test1/
gsutil cat gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/_tmp.test1/#1623347746784286
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] marton-bod commented on issue #2685: How to realize Write Iceberg Tables via Hive? (Ideas share)
Posted by GitBox <gi...@apache.org>.
marton-bod commented on issue #2685:
URL: https://github.com/apache/iceberg/issues/2685#issuecomment-858559409
Also, can you please share:
- version of Iceberg and Hive that you use
- the explain plan of the insert query
- the contents of the tableLocation/temp/ directory (this is where Hive stores the write commit related temporary files)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org