You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2022/05/03 08:17:22 UTC
[GitHub] [spark] zhengruifeng opened a new pull request, #36438: [SPARK-39092][SQL][WIP] Propagate Empty Partitions
zhengruifeng opened a new pull request, #36438:
URL: https://github.com/apache/spark/pull/36438
### What changes were proposed in this pull request?
add a new AQE rule to propagate empty partitions
let A inner join B, when the i-th partition in A is empty, then we do not need to read i-th partition in B
### Why are the changes needed?
it can prune shuffle when possible
### Does this PR introduce _any_ user-facing change?
yes, a new sql conf added
### How was this patch tested?
added testsuits
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #36438: [SPARK-39092][SQL][WIP] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on PR #36438:
URL: https://github.com/apache/spark/pull/36438#issuecomment-1116050423
retest this please
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on code in PR #36438:
URL: https://github.com/apache/spark/pull/36438#discussion_r872300669
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/ShufflePartitionsUtil.scala:
##########
@@ -117,6 +118,112 @@ object ShufflePartitionsUtil extends Logging {
return Seq.empty
}
+ val emptyIndexSet = collection.mutable.Set.empty[Int]
+ inputPartitionSpecs.foreach(_.get.iterator.zipWithIndex.foreach {
+ case (EmptyPartitionSpec, i) => emptyIndexSet.add(i)
+ case _ =>
+ })
+
+ if (emptyIndexSet.isEmpty) {
+ return coalescePartitionsWithSkew(mapOutputStatistics, inputPartitionSpecs,
+ targetSize, minPartitionSize, true)
+ }
+
+ // when all partitions are empty, return single EmptyPartitionSpec here to satisfy
+ // SPARK-32083 (AQE coalesce should at least return one partition).
+ if (inputPartitionSpecs.flatten.flatten.forall(_ == EmptyPartitionSpec)) {
+ return inputPartitionSpecs.map(_ => Seq(EmptyPartitionSpec))
+ }
+
+ // ShufflePartitionSpecs at these emptyIndices can NOT be coalesced
+ // split inputPartitionSpecs into sub-sequences by the empty indices, and
+ // call coalescePartitionsWithSkew to optimize each sub-sequence.
+ // let inputPartitionSpecs are:
+ // [A0(empty), A1, A2, A3(empty), A4(empty), A5, A6, A7, A8, A9, A10]
+ // [B0, B1, B2, B3, B4(empty), B5, B6, B7, B8(empty), B9, B10]
+ // then:
+ // 1, specs at index (0, 3, 8) are kept: (A0(empty)-B0), (A3(empty)-B3), (A8-B8(empty))
+ // 2, specs at index 4 are discarded, since they are all empty: (A4(empty)-B4(empty))
+ // 3, sub-sequences [A1-B1, A2-B2], [A5-B5, A6-B6, A7-B7], [A9-B9, A10-B10] are optimized
Review Comment:
Yes, this maybe a regression.
This rule may skiped the second and third partitions (if the jointype is `Inner`), but it will split one task into more tasks.
if partitions can be coalesed by `CoalesceShufflePartitions`, we may need to measure whether it is worthwhile to apply this rule (maybe we only mark a partition empty when its size is larger than a threshold)
if `CoalesceShufflePartitions` is not triggered, it should be always beneficial to mark some non-empty partitions empty.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on code in PR #36438:
URL: https://github.com/apache/spark/pull/36438#discussion_r872295375
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/PropagateEmptyPartitions.scala:
##########
@@ -0,0 +1,199 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.adaptive
+
+import scala.collection.mutable
+
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.exchange._
+import org.apache.spark.sql.execution.joins._
+
+/**
+ * A rule to propagate empty partitions, so that some unnecessary shuffle read can be skipped.
Review Comment:
IIUC, SMJ can skip reading the uncessary (but already fetched) side, but it can not skip fetching the uncessary partitions.
Sorry for the late reply, just back from vacation.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] github-actions[bot] commented on pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
github-actions[bot] commented on PR #36438:
URL: https://github.com/apache/spark/pull/36438#issuecomment-1255683790
We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable.
If you'd like to revive this PR, please reopen it and ask a committer to remove the Stale tag!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on code in PR #36438:
URL: https://github.com/apache/spark/pull/36438#discussion_r889643683
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/PropagateEmptyPartitions.scala:
##########
@@ -0,0 +1,185 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.adaptive
+
+import scala.collection.mutable
+
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.exchange._
+import org.apache.spark.sql.execution.joins._
+
+/**
+ * A rule to propagate empty partitions, so that some unnecessary shuffle read can be skipped.
+ *
+ * The general idea is to utilize the shuffled join to skip some partitions.
+ *
+ * For example, assume the shuffled join has 4 partitions, and L2 and R3 are empty:
+ * left: [L1, L2, L3, L4]
+ * right: [R1, R2, R3, R4]
+ *
+ * Suppose the join type is Inner. Then this rule will skip reading partitions: L2, R2, L3, R3.
+ *
+ * Suppose the join type is LeftOuter. Then this rule will skip reading partitions: L2, R2, R3.
+ *
+ * Suppose the join type is RightOuter. Then this rule will skip reading partitions: L2, L3, R3.
+ *
+ * Suppose the join type is FullOuter. Then this rule will skip reading partitions: L2, R3.
+ */
+object PropagateEmptyPartitions extends AQEShuffleReadRule {
+
+ override val supportedShuffleOrigins: Seq[ShuffleOrigin] =
+ Seq(ENSURE_REQUIREMENTS, REPARTITION_BY_NUM, REPARTITION_BY_COL,
+ REBALANCE_PARTITIONS_BY_NONE, REBALANCE_PARTITIONS_BY_COL)
+
+ override def apply(plan: SparkPlan): SparkPlan = {
+ if (!conf.propagateEmptyPartitionsEnabled) {
+ return plan
+ }
+
+ // If there is no ShuffledJoin, no need to continue.
+ if (plan.collectFirst { case j: ShuffledJoin => j }.isEmpty) {
+ return plan
+ }
+
+ val stages = plan.collect { case s: ShuffleQueryStageExec => s }
+ // currently, empty information is only extracted from and propagated to shuffle data.
+ // TODO: support DataScan in the future.
+ if (stages.size < 2 || !stages.forall(_.isMaterialized)) {
+ return plan
+ }
+
+ val (_, emptyGroupInfos) = collectEmptyGroups(plan)
Review Comment:
When one side is empty, the SMJ ends quickly.
But it seems that the operations ahead of SMJ (shuffle fetch and the sorting in `SortExec`) still need to to be executed.
SMJ need to firstly advance the `streamedIter`, so if the `streamedIter` is not emty and the `bufferedIter` is empty, it still need to fetch and sort all the data in the streamed side.
take this case for example:
```
spark.conf.set("spark.sql.adaptive.enabled", true)
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "-1")
spark.conf.set("spark.sql.shuffle.partitions", 4)
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", false)
spark.range(0, 100000000, 1, 11).selectExpr("id as key1", "id as value1").write.mode("overwrite").parquet("/tmp/df1.parquet")
spark.range(0, 10000000, 1, 6).selectExpr("id as key2", "id as value2").where(pmod(hash(col("key2")), lit(4)) =!= 0).write.mode("overwrite").parquet("/tmp/df2.parquet")
val df1 = spark.read.parquet("/tmp/df1.parquet")
val df2 = spark.read.parquet("/tmp/df2.parquet")
val joined = df1.join(df2, col("key1") === col("key2"), "inner")
spark.conf.set("spark.sql.adaptive.propagateEmptyPartitions.enabled", false)
joined.write.mode("overwrite").parquet("/tmp/tmp1.parquet")
```
there are 4 partitions, and the partition-0 on the buffered side is empty.
SMJ still need to fetch and sort the partion-0 on the streamed side:

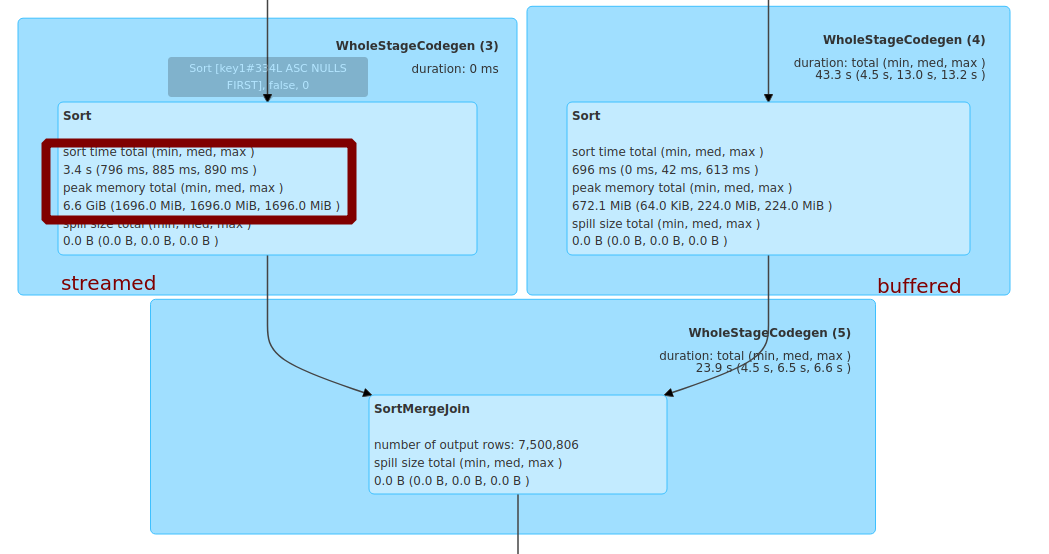
I think the main benefit is to avoid unnecessary shuffle fetch when the cluster is busy,
but it still should be somewhat benefitial to end-to-end performance. let's take another example, the task-parallelism is 12:
```
spark.conf.set("spark.sql.adaptive.enabled", true)
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "-1")
spark.conf.set("spark.sql.shuffle.partitions", 32)
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", false)
spark.range(0, 100000000, 1, 11).selectExpr("id as key1", "id as value1").write.mode("overwrite").parquet("/tmp/df1.parquet")
spark.range(0, 100000000, 1, 6).selectExpr("id as key2", "id as value2").where(pmod(hash(col("key2")), lit(32)) % 2 === 0).write.mode("overwrite").parquet("/tmp/df2.parquet")
val df1 = spark.read.parquet("/tmp/df1.parquet")
val df2 = spark.read.parquet("/tmp/df2.parquet")
val joined = df1.join(df2, col("key1") === col("key2"), "inner")
spark.conf.set("spark.sql.adaptive.propagateEmptyPartitions.enabled", false)
joined.write.mode("overwrite").parquet("/tmp/tmp1.parquet")
val df1 = spark.read.parquet("/tmp/df1.parquet")
val df2 = spark.read.parquet("/tmp/df2.parquet")
val joined = df1.join(df2, col("key1") === col("key2"), "inner")
spark.conf.set("spark.sql.adaptive.propagateEmptyPartitions.enabled", true)
joined.write.mode("overwrite").parquet("/tmp/tmp2.parquet")
```
the total duration was reduced from 16s to 14s, and the `Total Time Across All Tasks`
was reduced from 1.9min to 1.6min.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on code in PR #36438:
URL: https://github.com/apache/spark/pull/36438#discussion_r867336244
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/AdaptiveSparkPlanExec.scala:
##########
@@ -134,7 +134,8 @@ case class AdaptiveSparkPlanExec(
CoalesceShufflePartitions(context.session),
// `OptimizeShuffleWithLocalRead` needs to make use of 'AQEShuffleReadExec.partitionSpecs'
// added by `CoalesceShufflePartitions`, and must be executed after it.
- OptimizeShuffleWithLocalRead
+ OptimizeShuffleWithLocalRead,
+ PropagateEmptyPartitions
Review Comment:
I had try to put this `PropagateEmptyPartitions` before other rules, but it will cause 20 TESTS FAILED in `AdaptiveQueryExecSuite`, since other rules do not support the new `EmptyPartitionSpec` for now. So I conservatively put it at the end.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on code in PR #36438:
URL: https://github.com/apache/spark/pull/36438#discussion_r889643683
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/PropagateEmptyPartitions.scala:
##########
@@ -0,0 +1,185 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.adaptive
+
+import scala.collection.mutable
+
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.exchange._
+import org.apache.spark.sql.execution.joins._
+
+/**
+ * A rule to propagate empty partitions, so that some unnecessary shuffle read can be skipped.
+ *
+ * The general idea is to utilize the shuffled join to skip some partitions.
+ *
+ * For example, assume the shuffled join has 4 partitions, and L2 and R3 are empty:
+ * left: [L1, L2, L3, L4]
+ * right: [R1, R2, R3, R4]
+ *
+ * Suppose the join type is Inner. Then this rule will skip reading partitions: L2, R2, L3, R3.
+ *
+ * Suppose the join type is LeftOuter. Then this rule will skip reading partitions: L2, R2, R3.
+ *
+ * Suppose the join type is RightOuter. Then this rule will skip reading partitions: L2, L3, R3.
+ *
+ * Suppose the join type is FullOuter. Then this rule will skip reading partitions: L2, R3.
+ */
+object PropagateEmptyPartitions extends AQEShuffleReadRule {
+
+ override val supportedShuffleOrigins: Seq[ShuffleOrigin] =
+ Seq(ENSURE_REQUIREMENTS, REPARTITION_BY_NUM, REPARTITION_BY_COL,
+ REBALANCE_PARTITIONS_BY_NONE, REBALANCE_PARTITIONS_BY_COL)
+
+ override def apply(plan: SparkPlan): SparkPlan = {
+ if (!conf.propagateEmptyPartitionsEnabled) {
+ return plan
+ }
+
+ // If there is no ShuffledJoin, no need to continue.
+ if (plan.collectFirst { case j: ShuffledJoin => j }.isEmpty) {
+ return plan
+ }
+
+ val stages = plan.collect { case s: ShuffleQueryStageExec => s }
+ // currently, empty information is only extracted from and propagated to shuffle data.
+ // TODO: support DataScan in the future.
+ if (stages.size < 2 || !stages.forall(_.isMaterialized)) {
+ return plan
+ }
+
+ val (_, emptyGroupInfos) = collectEmptyGroups(plan)
Review Comment:
When one side is empty, the SMJ itself ends quickly.
But it seems that the operations ahead of SMJ (shuffle fetch and the sorting in `SortExec`) still need to to be executed.
SMJ need to firstly advance the `streamedIter`, so if the `streamedIter` is not emty and the `bufferedIter` is empty, it still need to fetch and sort all the data in the streamed side.
take this case for example:
```
spark.conf.set("spark.sql.adaptive.enabled", true)
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "-1")
spark.conf.set("spark.sql.shuffle.partitions", 4)
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", false)
spark.range(0, 100000000, 1, 11).selectExpr("id as key1", "id as value1").write.mode("overwrite").parquet("/tmp/df1.parquet")
spark.range(0, 10000000, 1, 6).selectExpr("id as key2", "id as value2").where(pmod(hash(col("key2")), lit(4)) =!= 0).write.mode("overwrite").parquet("/tmp/df2.parquet")
val df1 = spark.read.parquet("/tmp/df1.parquet")
val df2 = spark.read.parquet("/tmp/df2.parquet")
val joined = df1.join(df2, col("key1") === col("key2"), "inner")
spark.conf.set("spark.sql.adaptive.propagateEmptyPartitions.enabled", false)
joined.write.mode("overwrite").parquet("/tmp/tmp1.parquet")
```
there are 4 partitions, and the partition-0 on the buffered side is empty.
SMJ still need to fetch and sort the partion-0 on the streamed side:


I think the main benefit is to avoid unnecessary shuffle fetch when the cluster is busy,
but it still should be somewhat benefitial to end-to-end performance. let's take another example, the task-parallelism is 12:
```
spark.conf.set("spark.sql.adaptive.enabled", true)
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "-1")
spark.conf.set("spark.sql.shuffle.partitions", 32)
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", false)
spark.range(0, 100000000, 1, 11).selectExpr("id as key1", "id as value1").write.mode("overwrite").parquet("/tmp/df1.parquet")
spark.range(0, 100000000, 1, 6).selectExpr("id as key2", "id as value2").where(pmod(hash(col("key2")), lit(32)) % 2 === 0).write.mode("overwrite").parquet("/tmp/df2.parquet")
val df1 = spark.read.parquet("/tmp/df1.parquet")
val df2 = spark.read.parquet("/tmp/df2.parquet")
val joined = df1.join(df2, col("key1") === col("key2"), "inner")
spark.conf.set("spark.sql.adaptive.propagateEmptyPartitions.enabled", false)
joined.write.mode("overwrite").parquet("/tmp/tmp1.parquet")
val df1 = spark.read.parquet("/tmp/df1.parquet")
val df2 = spark.read.parquet("/tmp/df2.parquet")
val joined = df1.join(df2, col("key1") === col("key2"), "inner")
spark.conf.set("spark.sql.adaptive.propagateEmptyPartitions.enabled", true)
joined.write.mode("overwrite").parquet("/tmp/tmp2.parquet")
```
the total duration was reduced from 16s to 14s, and the `Total Time Across All Tasks`
was reduced from 1.9min to 1.6min.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] github-actions[bot] closed pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
github-actions[bot] closed pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
URL: https://github.com/apache/spark/pull/36438
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #36438: [SPARK-39092][SQL][WIP] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on PR #36438:
URL: https://github.com/apache/spark/pull/36438#issuecomment-1115847768
a simplest case:
```
spark.conf.set("spark.sql.adaptive.enabled", true)
spark.conf.set("spark.sql.adaptive.skewJoin.enabled", true)
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "-1")
spark.conf.set("spark.sql.shuffle.partitions", 100)
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", false)
val df1 = spark.range(0, 100000, 1, 7).selectExpr("id as key1", "id % 10 as value1")
val df2 = spark.range(0, 100000, 1, 8).selectExpr("id % 30 as key2", "id as value2")
val joined = df1.join(df2, col("key1") === col("key2"), "inner")
spark.conf.set("spark.sql.adaptive.propagateEmptyPartitions.enabled", false)
joined.write.mode("overwrite").parquet("/tmp/tmp1.parquet")
spark.conf.set("spark.sql.adaptive.propagateEmptyPartitions.enabled", true)
joined.write.mode("overwrite").parquet("/tmp/tmp2.parquet")
```

existing impl:
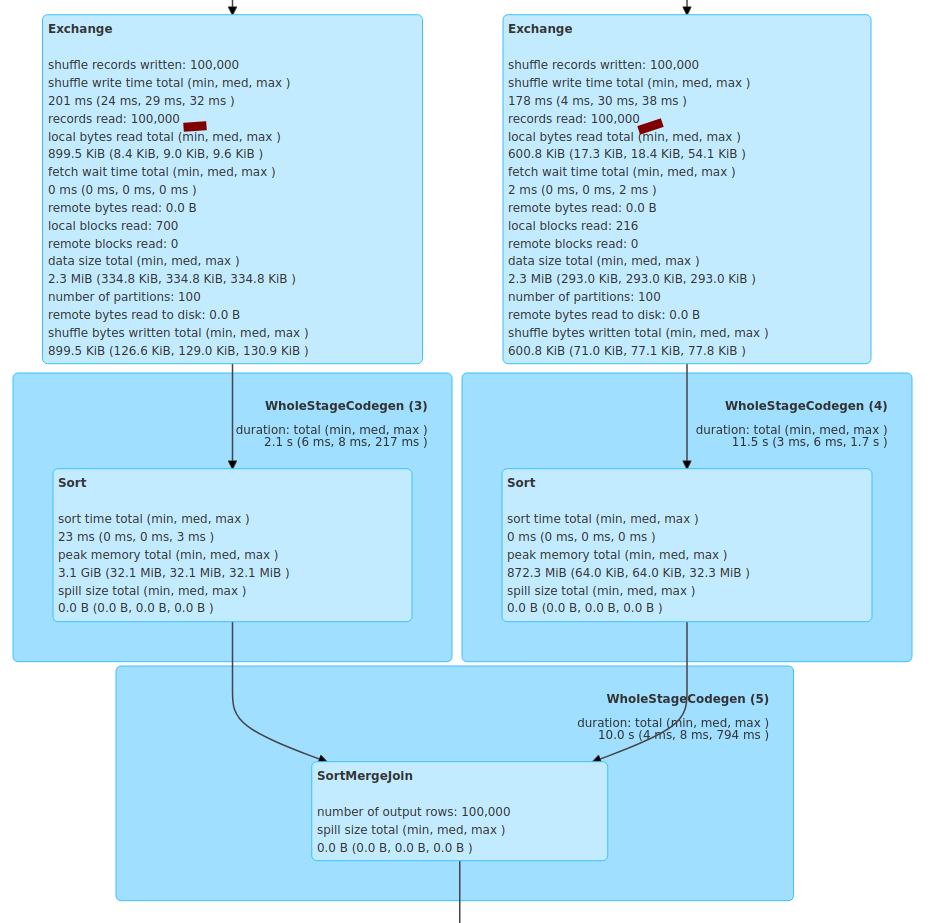
after this PR:

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] ulysses-you commented on a diff in pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
ulysses-you commented on code in PR #36438:
URL: https://github.com/apache/spark/pull/36438#discussion_r869099789
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/ShufflePartitionsUtil.scala:
##########
@@ -117,6 +118,112 @@ object ShufflePartitionsUtil extends Logging {
return Seq.empty
}
+ val emptyIndexSet = collection.mutable.Set.empty[Int]
+ inputPartitionSpecs.foreach(_.get.iterator.zipWithIndex.foreach {
+ case (EmptyPartitionSpec, i) => emptyIndexSet.add(i)
+ case _ =>
+ })
+
+ if (emptyIndexSet.isEmpty) {
+ return coalescePartitionsWithSkew(mapOutputStatistics, inputPartitionSpecs,
+ targetSize, minPartitionSize, true)
+ }
+
+ // when all partitions are empty, return single EmptyPartitionSpec here to satisfy
+ // SPARK-32083 (AQE coalesce should at least return one partition).
+ if (inputPartitionSpecs.flatten.flatten.forall(_ == EmptyPartitionSpec)) {
+ return inputPartitionSpecs.map(_ => Seq(EmptyPartitionSpec))
+ }
+
+ // ShufflePartitionSpecs at these emptyIndices can NOT be coalesced
+ // split inputPartitionSpecs into sub-sequences by the empty indices, and
+ // call coalescePartitionsWithSkew to optimize each sub-sequence.
+ // let inputPartitionSpecs are:
+ // [A0(empty), A1, A2, A3(empty), A4(empty), A5, A6, A7, A8, A9, A10]
+ // [B0, B1, B2, B3, B4(empty), B5, B6, B7, B8(empty), B9, B10]
+ // then:
+ // 1, specs at index (0, 3, 8) are kept: (A0(empty)-B0), (A3(empty)-B3), (A8-B8(empty))
+ // 2, specs at index 4 are discarded, since they are all empty: (A4(empty)-B4(empty))
+ // 3, sub-sequences [A1-B1, A2-B2], [A5-B5, A6-B6, A7-B7], [A9-B9, A10-B10] are optimized
Review Comment:
Would this be a regression ?
If the advisoryPartitionSizeInBytes size is 60 and the two sides of 4 partition size are:
[10, 10, 0, 10]
[10, 0, 10, 10]
The `CoalesceShufflePartitions` will return one reduce task. But if we mark it as empty, we will get three reduce tasks.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on PR #36438:
URL: https://github.com/apache/spark/pull/36438#issuecomment-1134338493
Something is wrong with my google doc, so I just attach a design doc in the ticket https://issues.apache.org/jira/browse/SPARK-39092
@ulysses-you @cloud-fan
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #36438:
URL: https://github.com/apache/spark/pull/36438#discussion_r879181770
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/PropagateEmptyPartitions.scala:
##########
@@ -0,0 +1,185 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.adaptive
+
+import scala.collection.mutable
+
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.exchange._
+import org.apache.spark.sql.execution.joins._
+
+/**
+ * A rule to propagate empty partitions, so that some unnecessary shuffle read can be skipped.
+ *
+ * The general idea is to utilize the shuffled join to skip some partitions.
+ *
+ * For example, assume the shuffled join has 4 partitions, and L2 and R3 are empty:
+ * left: [L1, L2, L3, L4]
+ * right: [R1, R2, R3, R4]
+ *
+ * Suppose the join type is Inner. Then this rule will skip reading partitions: L2, R2, L3, R3.
+ *
+ * Suppose the join type is LeftOuter. Then this rule will skip reading partitions: L2, R2, R3.
+ *
+ * Suppose the join type is RightOuter. Then this rule will skip reading partitions: L2, L3, R3.
+ *
+ * Suppose the join type is FullOuter. Then this rule will skip reading partitions: L2, R3.
+ */
+object PropagateEmptyPartitions extends AQEShuffleReadRule {
+
+ override val supportedShuffleOrigins: Seq[ShuffleOrigin] =
+ Seq(ENSURE_REQUIREMENTS, REPARTITION_BY_NUM, REPARTITION_BY_COL,
+ REBALANCE_PARTITIONS_BY_NONE, REBALANCE_PARTITIONS_BY_COL)
+
+ override def apply(plan: SparkPlan): SparkPlan = {
+ if (!conf.propagateEmptyPartitionsEnabled) {
+ return plan
+ }
+
+ // If there is no ShuffledJoin, no need to continue.
+ if (plan.collectFirst { case j: ShuffledJoin => j }.isEmpty) {
+ return plan
+ }
+
+ val stages = plan.collect { case s: ShuffleQueryStageExec => s }
+ // currently, empty information is only extracted from and propagated to shuffle data.
+ // TODO: support DataScan in the future.
+ if (stages.size < 2 || !stages.forall(_.isMaterialized)) {
+ return plan
+ }
+
+ val (_, emptyGroupInfos) = collectEmptyGroups(plan)
Review Comment:
The shuffle fetch is async. The task ends immediately if one join side is empty. Can we verify the end-to-end performance with this optimization? I think this PR is beneficial but not very much.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #36438:
URL: https://github.com/apache/spark/pull/36438#discussion_r866839375
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/PropagateEmptyPartitions.scala:
##########
@@ -0,0 +1,185 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.adaptive
+
+import scala.collection.mutable
+
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.exchange._
+import org.apache.spark.sql.execution.joins._
+
+/**
+ * A rule to propagate empty partitions, so that some unnecessary shuffle read can be skipped.
+ *
+ * The general idea is to utilize the shuffled join to skip some partitions.
+ *
+ * For example, assume the shuffled join has 4 partitions, and L2 and R3 are empty:
+ * left: [L1, L2, L3, L4]
+ * right: [R1, R2, R3, R4]
+ *
+ * Suppose the join type is Inner. Then this rule will skip reading partitions: L2, R2, L3, R3.
+ *
+ * Suppose the join type is LeftOuter. Then this rule will skip reading partitions: L2, R2, R3.
+ *
+ * Suppose the join type is RightOuter. Then this rule will skip reading partitions: L2, L3, R3.
+ *
+ * Suppose the join type is FullOuter. Then this rule will skip reading partitions: L2, R3.
+ */
+object PropagateEmptyPartitions extends AQEShuffleReadRule {
+
+ override val supportedShuffleOrigins: Seq[ShuffleOrigin] =
+ Seq(ENSURE_REQUIREMENTS, REPARTITION_BY_NUM, REPARTITION_BY_COL,
+ REBALANCE_PARTITIONS_BY_NONE, REBALANCE_PARTITIONS_BY_COL)
+
+ override def apply(plan: SparkPlan): SparkPlan = {
+ if (!conf.propagateEmptyPartitionsEnabled) {
+ return plan
+ }
+
+ // If there is no ShuffledJoin, no need to continue.
+ if (plan.collectFirst { case j: ShuffledJoin => j }.isEmpty) {
+ return plan
+ }
+
+ val stages = plan.collect { case s: ShuffleQueryStageExec => s }
+ // currently, empty information is only extracted from and propagated to shuffle data.
+ // TODO: support DataScan in the future.
+ if (stages.size < 2 || !stages.forall(_.isMaterialized)) {
+ return plan
+ }
+
+ val (_, emptyGroupInfos) = collectEmptyGroups(plan)
Review Comment:
The code looks a bit confusing to me. I'm expecting something similar to `OptimizeSkewedJoin`: we match shuffle join with 2 shuffle stages, and optimize the join node.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on PR #36438:
URL: https://github.com/apache/spark/pull/36438#issuecomment-1120186551
I am going to prepare some slides for this new rule, and will add it to this PR.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #36438:
URL: https://github.com/apache/spark/pull/36438#discussion_r866837234
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/AdaptiveSparkPlanExec.scala:
##########
@@ -134,7 +134,8 @@ case class AdaptiveSparkPlanExec(
CoalesceShufflePartitions(context.session),
// `OptimizeShuffleWithLocalRead` needs to make use of 'AQEShuffleReadExec.partitionSpecs'
// added by `CoalesceShufflePartitions`, and must be executed after it.
- OptimizeShuffleWithLocalRead
+ OptimizeShuffleWithLocalRead,
+ PropagateEmptyPartitions
Review Comment:
shall we run it before `CoalesceShufflePartitions`? otherwise, some empty partitions are coalesced and we are not able to detect them.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on code in PR #36438:
URL: https://github.com/apache/spark/pull/36438#discussion_r879143306
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/ShufflePartitionsUtil.scala:
##########
@@ -117,6 +118,112 @@ object ShufflePartitionsUtil extends Logging {
return Seq.empty
}
+ val emptyIndexSet = collection.mutable.Set.empty[Int]
+ inputPartitionSpecs.foreach(_.get.iterator.zipWithIndex.foreach {
+ case (EmptyPartitionSpec, i) => emptyIndexSet.add(i)
+ case _ =>
+ })
+
+ if (emptyIndexSet.isEmpty) {
+ return coalescePartitionsWithSkew(mapOutputStatistics, inputPartitionSpecs,
+ targetSize, minPartitionSize, true)
+ }
+
+ // when all partitions are empty, return single EmptyPartitionSpec here to satisfy
+ // SPARK-32083 (AQE coalesce should at least return one partition).
+ if (inputPartitionSpecs.flatten.flatten.forall(_ == EmptyPartitionSpec)) {
+ return inputPartitionSpecs.map(_ => Seq(EmptyPartitionSpec))
+ }
+
+ // ShufflePartitionSpecs at these emptyIndices can NOT be coalesced
+ // split inputPartitionSpecs into sub-sequences by the empty indices, and
+ // call coalescePartitionsWithSkew to optimize each sub-sequence.
+ // let inputPartitionSpecs are:
+ // [A0(empty), A1, A2, A3(empty), A4(empty), A5, A6, A7, A8, A9, A10]
+ // [B0, B1, B2, B3, B4(empty), B5, B6, B7, B8(empty), B9, B10]
+ // then:
+ // 1, specs at index (0, 3, 8) are kept: (A0(empty)-B0), (A3(empty)-B3), (A8-B8(empty))
+ // 2, specs at index 4 are discarded, since they are all empty: (A4(empty)-B4(empty))
+ // 3, sub-sequences [A1-B1, A2-B2], [A5-B5, A6-B6, A7-B7], [A9-B9, A10-B10] are optimized
Review Comment:
I think it is nice to put this rule after `CoalesceShufflePartitions`.
To make sure no regression.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on code in PR #36438:
URL: https://github.com/apache/spark/pull/36438#discussion_r872295375
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/PropagateEmptyPartitions.scala:
##########
@@ -0,0 +1,199 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.adaptive
+
+import scala.collection.mutable
+
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.exchange._
+import org.apache.spark.sql.execution.joins._
+
+/**
+ * A rule to propagate empty partitions, so that some unnecessary shuffle read can be skipped.
Review Comment:
IIUC, SMJ can skip reading the unnecessary (but already fetched) side, but it can not skip fetching the unnecessary partitions.
Sorry for the late reply, just back from vacation.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] ulysses-you commented on a diff in pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
ulysses-you commented on code in PR #36438:
URL: https://github.com/apache/spark/pull/36438#discussion_r878992276
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/ShufflePartitionsUtil.scala:
##########
@@ -117,6 +118,112 @@ object ShufflePartitionsUtil extends Logging {
return Seq.empty
}
+ val emptyIndexSet = collection.mutable.Set.empty[Int]
+ inputPartitionSpecs.foreach(_.get.iterator.zipWithIndex.foreach {
+ case (EmptyPartitionSpec, i) => emptyIndexSet.add(i)
+ case _ =>
+ })
+
+ if (emptyIndexSet.isEmpty) {
+ return coalescePartitionsWithSkew(mapOutputStatistics, inputPartitionSpecs,
+ targetSize, minPartitionSize, true)
+ }
+
+ // when all partitions are empty, return single EmptyPartitionSpec here to satisfy
+ // SPARK-32083 (AQE coalesce should at least return one partition).
+ if (inputPartitionSpecs.flatten.flatten.forall(_ == EmptyPartitionSpec)) {
+ return inputPartitionSpecs.map(_ => Seq(EmptyPartitionSpec))
+ }
+
+ // ShufflePartitionSpecs at these emptyIndices can NOT be coalesced
+ // split inputPartitionSpecs into sub-sequences by the empty indices, and
+ // call coalescePartitionsWithSkew to optimize each sub-sequence.
+ // let inputPartitionSpecs are:
+ // [A0(empty), A1, A2, A3(empty), A4(empty), A5, A6, A7, A8, A9, A10]
+ // [B0, B1, B2, B3, B4(empty), B5, B6, B7, B8(empty), B9, B10]
+ // then:
+ // 1, specs at index (0, 3, 8) are kept: (A0(empty)-B0), (A3(empty)-B3), (A8-B8(empty))
+ // 2, specs at index 4 are discarded, since they are all empty: (A4(empty)-B4(empty))
+ // 3, sub-sequences [A1-B1, A2-B2], [A5-B5, A6-B6, A7-B7], [A9-B9, A10-B10] are optimized
Review Comment:
A simple way may be: we can put this rule after the `CoalesceShufflePartitions`, so if we match a empty partition that means we can always skip it for no harm. But compared with applying the rule before `CoalesceShufflePartitions`, we may miss to optimize some empty partition since they may be coalesced.
But I think it seems can be accepted. If the empty partition can be coalesced with other partition, that said the corresponding partition of the other side of join is also small. So if we prefer to coalesce, we actually have small
overhead since the shuffle data is small enough (less than advisory size). Or even faster than skip empty partition since we have less reduce partition number.
So what we really want to skip is one side partition is empty and other side is big (may be a little skew or can not be optimized through skew). What do you thank ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on code in PR #36438:
URL: https://github.com/apache/spark/pull/36438#discussion_r879141455
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/PropagateEmptyPartitions.scala:
##########
@@ -0,0 +1,185 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.adaptive
+
+import scala.collection.mutable
+
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.exchange._
+import org.apache.spark.sql.execution.joins._
+
+/**
+ * A rule to propagate empty partitions, so that some unnecessary shuffle read can be skipped.
+ *
+ * The general idea is to utilize the shuffled join to skip some partitions.
+ *
+ * For example, assume the shuffled join has 4 partitions, and L2 and R3 are empty:
+ * left: [L1, L2, L3, L4]
+ * right: [R1, R2, R3, R4]
+ *
+ * Suppose the join type is Inner. Then this rule will skip reading partitions: L2, R2, L3, R3.
+ *
+ * Suppose the join type is LeftOuter. Then this rule will skip reading partitions: L2, R2, R3.
+ *
+ * Suppose the join type is RightOuter. Then this rule will skip reading partitions: L2, L3, R3.
+ *
+ * Suppose the join type is FullOuter. Then this rule will skip reading partitions: L2, R3.
+ */
+object PropagateEmptyPartitions extends AQEShuffleReadRule {
+
+ override val supportedShuffleOrigins: Seq[ShuffleOrigin] =
+ Seq(ENSURE_REQUIREMENTS, REPARTITION_BY_NUM, REPARTITION_BY_COL,
+ REBALANCE_PARTITIONS_BY_NONE, REBALANCE_PARTITIONS_BY_COL)
+
+ override def apply(plan: SparkPlan): SparkPlan = {
+ if (!conf.propagateEmptyPartitionsEnabled) {
+ return plan
+ }
+
+ // If there is no ShuffledJoin, no need to continue.
+ if (plan.collectFirst { case j: ShuffledJoin => j }.isEmpty) {
+ return plan
+ }
+
+ val stages = plan.collect { case s: ShuffleQueryStageExec => s }
+ // currently, empty information is only extracted from and propagated to shuffle data.
+ // TODO: support DataScan in the future.
+ if (stages.size < 2 || !stages.forall(_.isMaterialized)) {
+ return plan
+ }
+
+ val (_, emptyGroupInfos) = collectEmptyGroups(plan)
Review Comment:
I take a look at `SortMergeJoinScanner#findNextInnerJoinRows` and it seem that if the `Streamed` side (left) is empty, it will skip reading the `Buffered` side (right).
Then I use this test to check:
```
spark.conf.set("spark.sql.adaptive.enabled", true)
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "-1")
spark.conf.set("spark.sql.shuffle.partitions", 100)
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", false)
spark.conf.set("spark.sql.adaptive.propagateEmptyPartitions.enabled", false)
val df1 = spark.range(0, 100000, 1, 7).selectExpr("id as key1", "id % 10 as value1")
val df2 = spark.range(0, 100000, 1, 8).selectExpr("id % 30 as key2", "id as value2")
df1.join(df2, col("key1") === col("key2"), "inner").write.mode("overwrite").parquet("/tmp/tmp1.parquet")
df2.join(df1, col("key2") === col("key1"), "inner").write.mode("overwrite").parquet("/tmp/tmp2.parquet")
```
`df2` the contains some empty partitions.
- `df1.join(df2, col("key1") === col("key2"), "inner").write.mode("overwrite").parquet("/tmp/tmp1.parquet")`


all shuffle data are read;
- `df2.join(df1, col("key2") === col("key1"), "inner").write.mode("overwrite").parquet("/tmp/tmp2.parquet")`

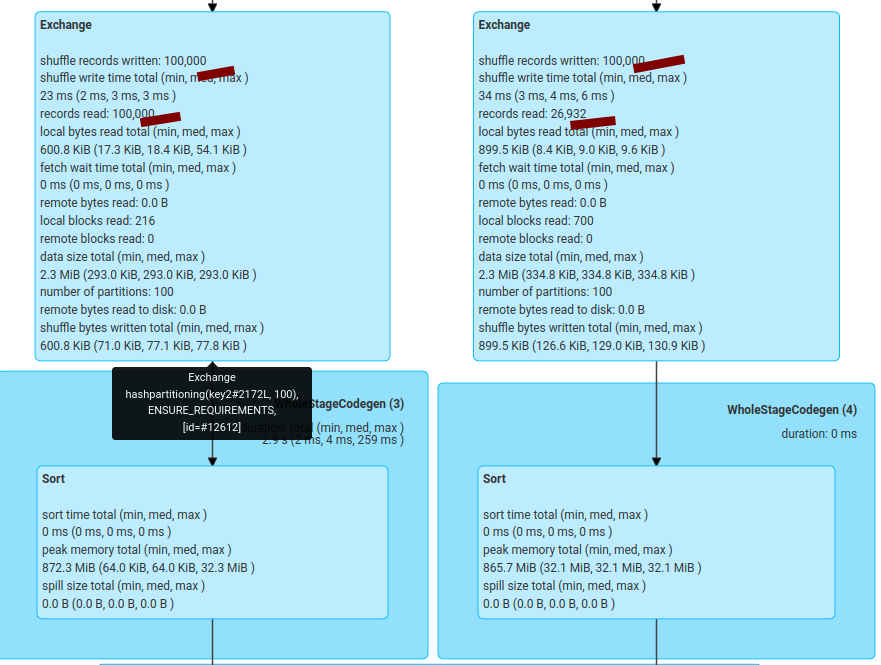
now some partitions in the `Buffered` are not read.
However, according to the `Shuffle Read` metric on the `Stages` tab, all data are fetched.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on code in PR #36438:
URL: https://github.com/apache/spark/pull/36438#discussion_r867338059
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/PropagateEmptyPartitions.scala:
##########
@@ -0,0 +1,185 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.adaptive
+
+import scala.collection.mutable
+
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.exchange._
+import org.apache.spark.sql.execution.joins._
+
+/**
+ * A rule to propagate empty partitions, so that some unnecessary shuffle read can be skipped.
+ *
+ * The general idea is to utilize the shuffled join to skip some partitions.
+ *
+ * For example, assume the shuffled join has 4 partitions, and L2 and R3 are empty:
+ * left: [L1, L2, L3, L4]
+ * right: [R1, R2, R3, R4]
+ *
+ * Suppose the join type is Inner. Then this rule will skip reading partitions: L2, R2, L3, R3.
+ *
+ * Suppose the join type is LeftOuter. Then this rule will skip reading partitions: L2, R2, R3.
+ *
+ * Suppose the join type is RightOuter. Then this rule will skip reading partitions: L2, L3, R3.
+ *
+ * Suppose the join type is FullOuter. Then this rule will skip reading partitions: L2, R3.
+ */
+object PropagateEmptyPartitions extends AQEShuffleReadRule {
+
+ override val supportedShuffleOrigins: Seq[ShuffleOrigin] =
+ Seq(ENSURE_REQUIREMENTS, REPARTITION_BY_NUM, REPARTITION_BY_COL,
+ REBALANCE_PARTITIONS_BY_NONE, REBALANCE_PARTITIONS_BY_COL)
+
+ override def apply(plan: SparkPlan): SparkPlan = {
+ if (!conf.propagateEmptyPartitionsEnabled) {
+ return plan
+ }
+
+ // If there is no ShuffledJoin, no need to continue.
+ if (plan.collectFirst { case j: ShuffledJoin => j }.isEmpty) {
+ return plan
+ }
+
+ val stages = plan.collect { case s: ShuffleQueryStageExec => s }
+ // currently, empty information is only extracted from and propagated to shuffle data.
+ // TODO: support DataScan in the future.
+ if (stages.size < 2 || !stages.forall(_.isMaterialized)) {
+ return plan
+ }
+
+ val (_, emptyGroupInfos) = collectEmptyGroups(plan)
Review Comment:
my bad, the example and comments only show the 2-table case.
this rule aims to handle common cases like multi-table join:
```
spark.conf.set("spark.sql.adaptive.enabled", true)
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "-1")
spark.conf.set("spark.sql.shuffle.partitions", 200)
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", false)
val df0 = spark.range(0, 1000, 1, 5).selectExpr("id % 111 as key0", "id as value0").groupBy("key0").agg(max("value0").as("max_value0"))
val df1 = spark.range(0, 1000, 1, 7).selectExpr("id % 77 as key1", "id as value1")
val df2 = spark.range(0, 1000, 1, 8).selectExpr("id % 55 as key2", "id as value2")
val df3 = spark.range(0, 1000, 1, 9).selectExpr("id % 33 as key3", "id as value3")
val df4 = spark.range(0, 1000, 1, 6).selectExpr("id % 88 as key4", "id as value4")
val joined1 = df1.join(df2, col("key1") === col("key2"), "inner").join(df0, col("key0") === col("key2"), "right")
val joined2 = df3.join(df4, col("key3") === col("key4"), "inner")
val joined3 = joined1.join(joined2, col("key0") === col("key3"), "full")
spark.conf.set("spark.sql.adaptive.propagateEmptyPartitions.enabled", false)
joined3.write.mode("overwrite").parquet("/tmp/tmp1.parquet")
spark.conf.set("spark.sql.adaptive.propagateEmptyPartitions.enabled", true)
joined3.write.mode("overwrite").parquet("/tmp/tmp2.parquet")
```
before
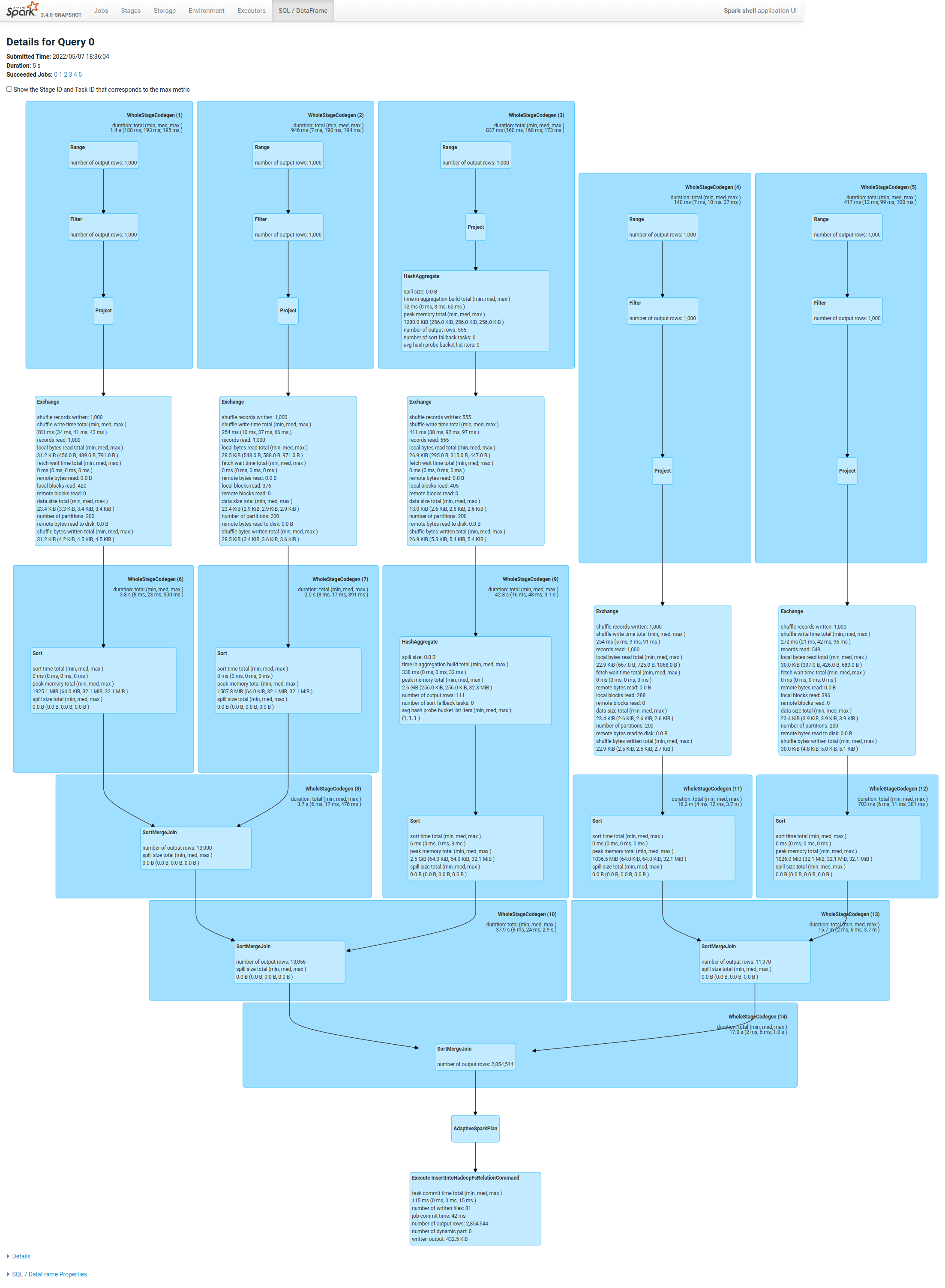
after
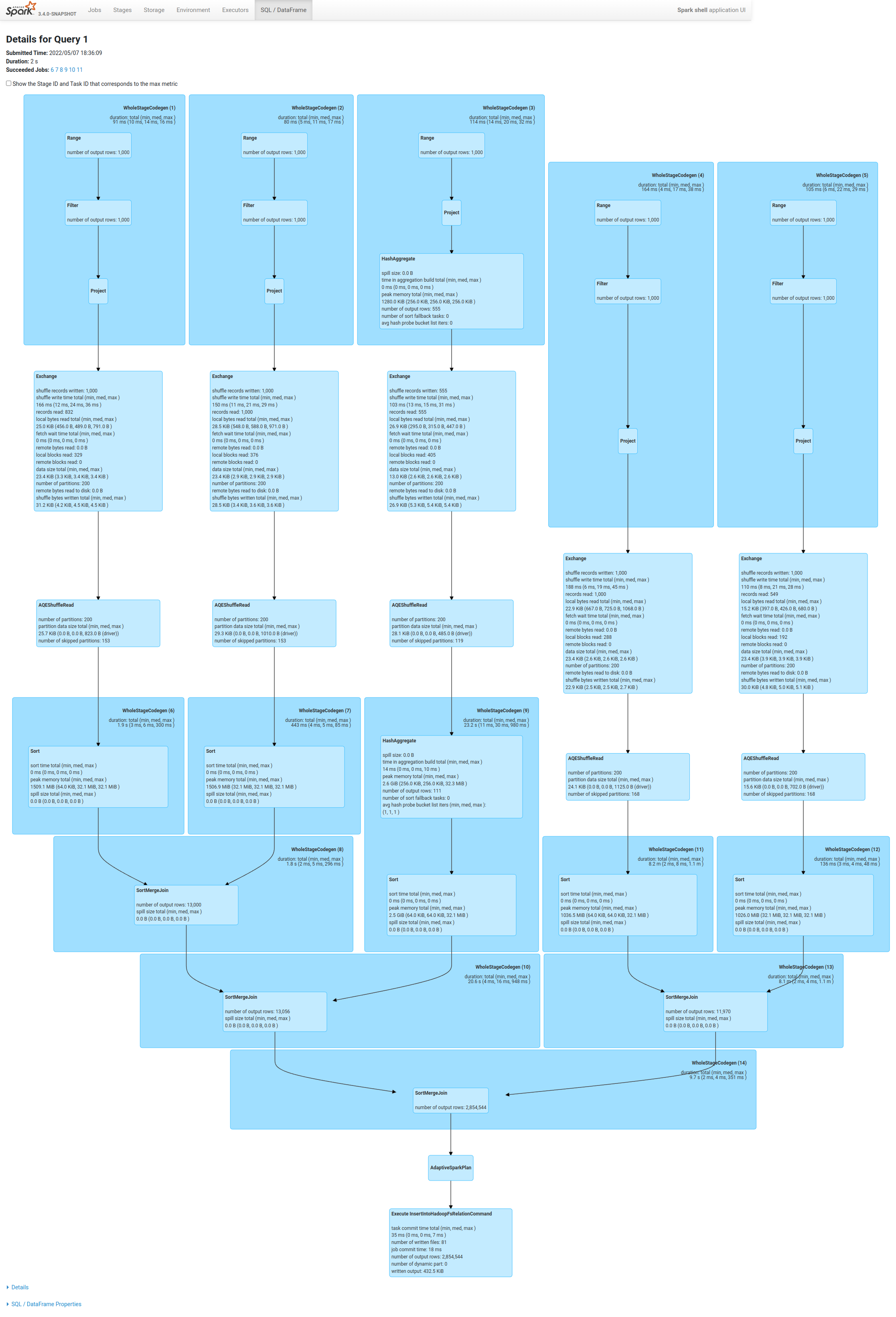
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #36438:
URL: https://github.com/apache/spark/pull/36438#discussion_r868241905
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/PropagateEmptyPartitions.scala:
##########
@@ -0,0 +1,199 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.adaptive
+
+import scala.collection.mutable
+
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.exchange._
+import org.apache.spark.sql.execution.joins._
+
+/**
+ * A rule to propagate empty partitions, so that some unnecessary shuffle read can be skipped.
Review Comment:
Is this specific to shuffle hash join? AFAIK sort merge join already skips reading one side if the other side is empty.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on PR #36438:
URL: https://github.com/apache/spark/pull/36438#issuecomment-1116885854
cc @wangyum @cloud-fan mind take a look when you find some time, thanks!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org