You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@beam.apache.org by da...@apache.org on 2022/11/03 14:51:46 UTC
[beam] branch master updated: Concept guide on orchestrating Beam preprocessing (#23094)
This is an automated email from the ASF dual-hosted git repository.
damccorm pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/beam.git
The following commit(s) were added to refs/heads/master by this push:
new 85b6b643bff Concept guide on orchestrating Beam preprocessing (#23094)
85b6b643bff is described below
commit 85b6b643bff1157fa68787ab9bd6b0afcd6c8bc6
Author: agvdndor <42...@users.noreply.github.com>
AuthorDate: Thu Nov 3 15:51:38 2022 +0100
Concept guide on orchestrating Beam preprocessing (#23094)
* Add dummy ingestion component.
* Remove build script
* Add preprocessing component
* Add dummy model training component.
* Add pipeline compile step.
* Add tfx preprocessing orchestration
* Update argparse help string
* Change image size after resize step
* Rename compile_pipeline to pipeline
* Fix docstring
* Restructure preprocessing function
* Change indent to two spaces
* Fix pylint
* Rename directory containing the mlorchestration examples
* Add documentation to beam site
* Add link to full code examples
* Add trailing newline
* Remove unnecessary file
* Remove whitespaces for paragraph terminatin from markdown
* Fix python formatting with yapf
* Fix pylint violations
* Remove hanging TODOs and add brief README to point to the documentation on the website
* Update sdks/python/apache_beam/examples/ml-orchestration/kfp/components/ingestion/src/ingest.py
Co-authored-by: Andy Ye <an...@gmail.com>
* Update website/www/site/content/en/documentation/ml/orchestration.md
Co-authored-by: Danny McCormick <da...@google.com>
* Update website/www/site/content/en/documentation/ml/orchestration.md
Co-authored-by: Andy Ye <an...@gmail.com>
* Update website/www/site/content/en/documentation/ml/orchestration.md
Co-authored-by: Andy Ye <an...@gmail.com>
* Make argparse arguments for kfp components required
* Commit documentation suggestions and clarify pipeline execution snippet
* Fix yapf formatting and trailing whitespaces
* Add apache license and fix relative link to full code sample on website
* Clarify the requirements file for pipeline compilation and execution
* Explicitly link to the requirements for kfp pipeline execution
* Remove or replace 'Dummy' to more inclusive language
* Change global variables to variables provided by argparse
* Remove global config variables an add additional argparse arguments
* Fix python formatting
* Update website documentation to new code with argparse instead of global config variables
* Fix linting and formatting
* Fix linting and formatting
* Add missing link to yaml specification file in the docs
* Change DoFn to simple function with beam.Map
* Fix python formatting
* Fix python formatting
Co-authored-by: arnevandendorpe <ar...@ml6.eu>
Co-authored-by: Andy Ye <an...@gmail.com>
Co-authored-by: Danny McCormick <da...@google.com>
---
.../examples/ml-orchestration/README.md | 22 ++
.../kfp/components/ingestion/Dockerfile | 28 +++
.../kfp/components/ingestion/component.yaml | 36 +++
.../kfp/components/ingestion/requirements.txt | 14 ++
.../kfp/components/ingestion/src/ingest.py | 74 ++++++
.../kfp/components/preprocessing/Dockerfile | 28 +++
.../kfp/components/preprocessing/component.yaml | 64 ++++++
.../kfp/components/preprocessing/requirements.txt | 21 ++
.../kfp/components/preprocessing/src/preprocess.py | 208 +++++++++++++++++
.../kfp/components/train/Dockerfile | 26 +++
.../kfp/components/train/component.yaml | 41 ++++
.../kfp/components/train/requirements.txt | 18 ++
.../kfp/components/train/src/train.py | 83 +++++++
.../examples/ml-orchestration/kfp/pipeline.json | 247 +++++++++++++++++++++
.../examples/ml-orchestration/kfp/pipeline.py | 132 +++++++++++
.../examples/ml-orchestration/kfp/requirements.txt | 18 ++
.../ml-orchestration/tfx/coco_captions_local.py | 141 ++++++++++++
.../ml-orchestration/tfx/coco_captions_utils.py | 87 ++++++++
.../examples/ml-orchestration/tfx/requirements.txt | 17 ++
.../content/en/documentation/ml/orchestration.md | 223 +++++++++++++++++++
.../site/content/en/documentation/ml/overview.md | 3 +-
.../partials/section-menu/en/documentation.html | 1 +
.../static/images/orchestrated-beam-pipeline.svg | 35 +++
.../static/images/standalone-beam-pipeline.svg | 35 +++
24 files changed, 1601 insertions(+), 1 deletion(-)
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/README.md b/sdks/python/apache_beam/examples/ml-orchestration/README.md
new file mode 100644
index 00000000000..2f886f09e58
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/README.md
@@ -0,0 +1,22 @@
+<!--
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+-->
+
+# Example ML workflow orchestration with Kubeflow Pipelines and Tensorflow Extended
+
+This module contains two examples of simple, orchestrated machine learning workflows that rely on Apache Beam for data preprocessing. A detailed explanation can be found on the Beam website [here](https://beam.apache.org/documentation/ml/orchestration/)
\ No newline at end of file
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/ingestion/Dockerfile b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/ingestion/Dockerfile
new file mode 100644
index 00000000000..98f9262c7f3
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/ingestion/Dockerfile
@@ -0,0 +1,28 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+FROM python:3.9-slim
+
+# optional: install extra dependencies
+
+# install python packages
+# (the requirements file is currently empty
+# because this is a stub ingestion example)
+COPY requirements.txt /
+RUN python3 -m pip install --no-cache-dir -r requirements.txt
+
+# copy src files and set working directory
+COPY src /src
+WORKDIR /src
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/ingestion/component.yaml b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/ingestion/component.yaml
new file mode 100644
index 00000000000..e25d240c5f7
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/ingestion/component.yaml
@@ -0,0 +1,36 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+name: Ingestion
+description: Component that mimicks scraping data from the web and outputs it to a jsonlines format file
+inputs:
+ - name: base_artifact_path
+ description: base path to store data
+ type: String
+outputs:
+ - name: ingested_dataset_path
+ description: target uri for the ingested dataset
+ type: String
+implementation:
+ container:
+ image: <your-docker-registry/ingestion-image-name:latest>
+ command: [
+ python3,
+ ingest.py,
+ --base-artifact-path,
+ {inputValue: base_artifact_path},
+ --ingested-dataset-path,
+ {outputPath: ingested_dataset_path}
+ ]
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/ingestion/requirements.txt b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/ingestion/requirements.txt
new file mode 100644
index 00000000000..91eacc92e8b
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/ingestion/requirements.txt
@@ -0,0 +1,14 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
\ No newline at end of file
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/ingestion/src/ingest.py b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/ingestion/src/ingest.py
new file mode 100644
index 00000000000..5369e95bf92
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/ingestion/src/ingest.py
@@ -0,0 +1,74 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Ingestion function that fetches data from one file and simply copies it to another."""
+
+import argparse
+import time
+from pathlib import Path
+
+
+def parse_args():
+ """Parse ingestion arguments."""
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--ingested-dataset-path",
+ type=str,
+ help="Path to save the ingested dataset to.",
+ required=True)
+ parser.add_argument(
+ "--base-artifact-path",
+ type=str,
+ help="Base path to store pipeline artifacts.",
+ required=True)
+ return parser.parse_args()
+
+
+def ingest_data(ingested_dataset_path: str, base_artifact_path: str):
+ """Data ingestion step that returns an uri
+ to the data it has 'ingested' as jsonlines.
+
+ Args:
+ data_ingestion_target (str): uri to the data that was scraped and
+ ingested by the component"""
+ # timestamp as unique id for the component execution
+ timestamp = int(time.time())
+
+ # create directory to store the actual data
+ target_path = f"{base_artifact_path}/ingestion/ingested_dataset_{timestamp}.jsonl"
+ # if the target path is a google cloud storage path convert the path to the gcsfuse path
+ target_path_gcsfuse = target_path.replace("gs://", "/gcs/")
+ Path(target_path_gcsfuse).parent.mkdir(parents=True, exist_ok=True)
+
+ with open(target_path_gcsfuse, 'w') as f:
+ f.writelines([
+ """{"image_id": 318556, "id": 255, "caption": "An angled view of a beautifully decorated bathroom.", "image_url": "http://farm4.staticflickr.com/3133/3378902101_3c9fa16b84_z.jpg", "image_name": "COCO_train2014_000000318556.jpg", "image_license": "Attribution-NonCommercial-ShareAlike License"}\n""",
+ """{"image_id": 476220, "id": 314, "caption": "An empty kitchen with white and black appliances.", "image_url": "http://farm7.staticflickr.com/6173/6207941582_b69380c020_z.jpg", "image_name": "COCO_train2014_000000476220.jpg", "image_license": "Attribution-NonCommercial License"}\n""",
+ """{"image_id": 134754, "id": 425, "caption": "Two people carrying surf boards on a beach.", "image_url": "http://farm9.staticflickr.com/8500/8398513396_b6a1f11a4b_z.jpg", "image_name": "COCO_train2014_000000134754.jpg", "image_license": "Attribution-NonCommercial-NoDerivs License"}"""
+ ])
+
+ # the directory where the output file is created may or may not exists
+ # so we have to create it.
+ # KFP v1 components can only write output to files. The output of this
+ # component is written to ingested_dataset_path and contains the path
+ # of the actual ingested data
+ Path(ingested_dataset_path).parent.mkdir(parents=True, exist_ok=True)
+ with open(ingested_dataset_path, 'w') as f:
+ f.write(target_path)
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ ingest_data(**vars(args))
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/Dockerfile b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/Dockerfile
new file mode 100644
index 00000000000..f46feded1da
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/Dockerfile
@@ -0,0 +1,28 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# [START component_dockerfile]
+FROM python:3.9-slim
+
+# (Optional) install extra dependencies
+
+# install pypi dependencies
+COPY requirements.txt /
+RUN python3 -m pip install --no-cache-dir -r requirements.txt
+
+# copy src files and set working directory
+COPY src /src
+WORKDIR /src
+# [END component_dockerfile]
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/component.yaml b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/component.yaml
new file mode 100644
index 00000000000..f64c3c11fb6
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/component.yaml
@@ -0,0 +1,64 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# [START preprocessing_component_definition]
+name: preprocessing
+description: Component that mimicks scraping data from the web and outputs it to a jsonlines format file
+inputs:
+ - name: ingested_dataset_path
+ description: source uri of the data to scrape
+ type: String
+ - name: base_artifact_path
+ description: base path to store data
+ type: String
+ - name: gcp_project_id
+ description: ID for the google cloud project to deploy the pipeline to.
+ type: String
+ - name: region
+ description: Region in which to deploy the Dataflow pipeline.
+ type: String
+ - name: dataflow_staging_root
+ description: Path to staging directory for the dataflow runner.
+ type: String
+ - name: beam_runner
+ description: Beam runner, DataflowRunner or DirectRunner.
+ type: String
+outputs:
+ - name: preprocessed_dataset_path
+ description: target uri for the ingested dataset
+ type: String
+implementation:
+ container:
+ image: <your-docker-registry/preprocessing-image-name:latest>
+ command: [
+ python3,
+ preprocess.py,
+ --ingested-dataset-path,
+ {inputValue: ingested_dataset_path},
+ --base-artifact-path,
+ {inputValue: base_artifact_path},
+ --preprocessed-dataset-path,
+ {outputPath: preprocessed_dataset_path},
+ --gcp-project-id,
+ {inputValue: gcp_project_id},
+ --region,
+ {inputValue: region},
+ --dataflow-staging-root,
+ {inputValue: dataflow_staging_root},
+ --beam-runner,
+ {inputValue: beam_runner},
+ ]
+# [END preprocessing_component_definition]
+
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/requirements.txt b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/requirements.txt
new file mode 100644
index 00000000000..2ebbd8cf214
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/requirements.txt
@@ -0,0 +1,21 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+apache_beam[gcp]==2.40.0
+requests==2.28.1
+torch==1.12.0
+torchvision==0.13.0
+numpy==1.22.4
+Pillow==9.2.0
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/src/preprocess.py b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/src/preprocess.py
new file mode 100644
index 00000000000..7cf6d6ead4a
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/src/preprocess.py
@@ -0,0 +1,208 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Functionality for the data preprocessing step."""
+
+import re
+import json
+import io
+import argparse
+import time
+from pathlib import Path
+import logging
+from collections.abc import Iterable
+
+import requests
+from PIL import Image, UnidentifiedImageError
+import numpy as np
+import torch
+import torchvision.transforms as T
+import torchvision.transforms.functional as TF
+import apache_beam as beam
+from apache_beam.options.pipeline_options import PipelineOptions
+
+IMAGE_SIZE = (224, 244)
+
+
+# [START preprocess_component_argparse]
+def parse_args():
+ """Parse preprocessing arguments."""
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--ingested-dataset-path",
+ type=str,
+ help="Path to the ingested dataset",
+ required=True)
+ parser.add_argument(
+ "--preprocessed-dataset-path",
+ type=str,
+ help="The target directory for the ingested dataset.",
+ required=True)
+ parser.add_argument(
+ "--base-artifact-path",
+ type=str,
+ help="Base path to store pipeline artifacts.",
+ required=True)
+ parser.add_argument(
+ "--gcp-project-id",
+ type=str,
+ help="ID for the google cloud project to deploy the pipeline to.",
+ required=True)
+ parser.add_argument(
+ "--region",
+ type=str,
+ help="Region in which to deploy the pipeline.",
+ required=True)
+ parser.add_argument(
+ "--dataflow-staging-root",
+ type=str,
+ help="Path to staging directory for dataflow.",
+ required=True)
+ parser.add_argument(
+ "--beam-runner",
+ type=str,
+ help="Beam runner: DataflowRunner or DirectRunner.",
+ default="DirectRunner")
+
+ return parser.parse_args()
+
+
+# [END preprocess_component_argparse]
+
+
+def preprocess_dataset(
+ ingested_dataset_path: str,
+ preprocessed_dataset_path: str,
+ base_artifact_path: str,
+ gcp_project_id: str,
+ region: str,
+ dataflow_staging_root: str,
+ beam_runner: str):
+ """Preprocess the ingested raw dataset and write the result to avro format.
+
+ Args:
+ ingested_dataset_path (str): Path to the ingested dataset
+ preprocessed_dataset_path (str): Path to where the preprocessed dataset will be saved
+ base_artifact_path (str): path to the base directory of where artifacts can be stored for
+ this component.
+ gcp_project_id (str): ID for the google cloud project to deploy the pipeline to.
+ region (str): Region in which to deploy the pipeline.
+ dataflow_staging_root (str): Path to staging directory for the dataflow runner.
+ beam_runner (str): Beam runner: DataflowRunner or DirectRunner.
+ """
+ # [START kfp_component_input_output]
+ timestamp = time.time()
+ target_path = f"{base_artifact_path}/preprocessing/preprocessed_dataset_{timestamp}"
+
+ # the directory where the output file is created may or may not exists
+ # so we have to create it.
+ Path(preprocessed_dataset_path).parent.mkdir(parents=True, exist_ok=True)
+ with open(preprocessed_dataset_path, 'w') as f:
+ f.write(target_path)
+ # [END kfp_component_input_output]
+
+ # [START deploy_preprocessing_beam_pipeline]
+ # We use the save_main_session option because one or more DoFn's in this
+ # workflow rely on global context (e.g., a module imported at module level).
+ pipeline_options = PipelineOptions(
+ runner=beam_runner,
+ project=gcp_project_id,
+ job_name=f'preprocessing-{int(time.time())}',
+ temp_location=dataflow_staging_root,
+ region=region,
+ requirements_file="/requirements.txt",
+ save_main_session=True,
+ )
+
+ with beam.Pipeline(options=pipeline_options) as pipeline:
+ (
+ pipeline
+ | "Read input jsonlines file" >>
+ beam.io.ReadFromText(ingested_dataset_path)
+ | "Load json" >> beam.Map(json.loads)
+ | "Filter licenses" >> beam.Filter(valid_license)
+ | "Download image from URL" >> beam.FlatMap(download_image_from_url)
+ | "Resize image" >> beam.Map(resize_image, size=IMAGE_SIZE)
+ | "Clean Text" >> beam.Map(clean_text)
+ | "Serialize Example" >> beam.Map(serialize_example)
+ | "Write to Avro files" >> beam.io.WriteToAvro(
+ file_path_prefix=target_path,
+ schema={
+ "namespace": "preprocessing.example",
+ "type": "record",
+ "name": "Sample",
+ "fields": [{
+ "name": "id", "type": "int"
+ }, {
+ "name": "caption", "type": "string"
+ }, {
+ "name": "image", "type": "bytes"
+ }]
+ },
+ file_name_suffix=".avro"))
+ # [END deploy_preprocessing_beam_pipeline]
+
+
+def download_image_from_url(element: dict) -> Iterable[dict]:
+ """download the images from their uri."""
+ response = requests.get(element['image_url'])
+ try:
+ image = Image.open(io.BytesIO(response.content))
+ image = T.ToTensor()(image)
+ yield {**element, 'image': image}
+ except UnidentifiedImageError as e:
+ logging.exception(e)
+
+
+def resize_image(element: dict, size=(256, 256)):
+ "Resize the element's PIL image to the target resolution."
+ image = TF.resize(element['image'], size)
+ return {**element, 'image': image}
+
+
+def clean_text(element: dict):
+ """Perform a series of string cleaning operations."""
+ text = element['caption']
+ text = text.lower() # lower case
+ text = re.sub(r"http\S+", "", text) # remove urls
+ text = re.sub("\s+", " ", text) # remove extra spaces (including \n and \t)
+ text = re.sub(
+ "[()[\].,|:;?!=+~\-\/{}]", ",",
+ text) # all puncutation are replace w commas
+ text = f" {text}" # always start with a space
+ text = text.strip(',') # remove commas at the start or end of the caption
+ text = text[:-1] if text and text[-1] == "," else text
+ text = text[1:] if text and text[0] == "," else text
+ return {**element, "preprocessed_caption": text}
+
+
+def valid_license(element):
+ """Checks whether an element's image has the correct license for our use case."""
+ license = element['image_license']
+ return license in ["Attribution License", "No known copyright restrictions"]
+
+
+def serialize_example(element):
+ """Serialize an elements image."""
+ buffer = io.BytesIO()
+ torch.save(element['image'], buffer)
+ buffer.seek(0)
+ image = buffer.read()
+ return {**element, 'image': image}
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ preprocess_dataset(**vars(args))
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/train/Dockerfile b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/train/Dockerfile
new file mode 100644
index 00000000000..8e2bf86d811
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/train/Dockerfile
@@ -0,0 +1,26 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+FROM python:3.9-slim
+
+# optional install extra dependencies
+
+# install pypi dependencies
+COPY requirements.txt /
+RUN python3 -m pip install --no-cache-dir -r requirements.txt
+
+# copy src files and set working directory
+COPY src /src
+WORKDIR /src
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/train/component.yaml b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/train/component.yaml
new file mode 100644
index 00000000000..240ed13acf9
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/train/component.yaml
@@ -0,0 +1,41 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+name: model training
+description: Train a pytorch model
+inputs:
+ - name: base_artifact_path
+ description: base path to store data
+ type: String
+ - name: preprocessed_dataset_path
+ description: path to the preprocessed dataset
+ type: String
+outputs:
+ - name: trained_model_path
+ description: trained model file
+ type: String
+implementation:
+ container:
+ image: <your-docker-registry/train-image-name:latest>
+ command: [
+ python3,
+ train.py,
+ --preprocessed-dataset-path,
+ {inputValue: preprocessed_dataset_path},
+ --base-artifact-path,
+ {inputValue: base_artifact_path},
+ --trained-model-path,
+ {outputPath: trained_model_path}
+ ]
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/train/requirements.txt b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/train/requirements.txt
new file mode 100644
index 00000000000..72eb2295969
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/train/requirements.txt
@@ -0,0 +1,18 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+torch==1.12.0
+numpy==1.22.4
+Pillow==9.2.0
\ No newline at end of file
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/train/src/train.py b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/train/src/train.py
new file mode 100644
index 00000000000..b15473f2248
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/kfp/components/train/src/train.py
@@ -0,0 +1,83 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Simple training function that loads a pretrained model from the torch hub and saves it."""
+
+import argparse
+import time
+from pathlib import Path
+
+import torch
+
+
+def parse_args():
+ """Parse ingestion arguments."""
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--preprocessed-dataset-path",
+ type=str,
+ help="Path to the preprocessed dataset.",
+ required=True)
+ parser.add_argument(
+ "--trained-model-path",
+ type=str,
+ help="Output path to the trained model.",
+ required=True)
+ parser.add_argument(
+ "--base-artifact-path",
+ type=str,
+ help="Base path to store pipeline artifacts.",
+ required=True)
+ return parser.parse_args()
+
+
+def train_model(
+ preprocessed_dataset_path: str,
+ trained_model_path: str,
+ base_artifact_path: str):
+ """Placeholder method to load a model from the torch hub and save it.
+
+ Args:
+ preprocessed_dataset_path (str): Path to the preprocessed dataset
+ trained_model_path (str): Output path for the trained model
+ base_artifact_path (str): path to the base directory of where artifacts can be stored for
+ this component
+ """
+ # timestamp for the component execution
+ timestamp = time.time()
+
+ # create model or load a pretrained one
+ model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg16', pretrained=True)
+
+ # to implement: train on preprocessed dataset
+ # <insert training loop>
+
+ # create directory to export the model to
+ target_path = f"{base_artifact_path}/training/trained_model_{timestamp}.pt"
+ target_path_gcsfuse = target_path.replace("gs://", "/gcs/")
+ Path(target_path_gcsfuse).parent.mkdir(parents=True, exist_ok=True)
+
+ # save and export the model
+ torch.save(model.state_dict(), target_path_gcsfuse)
+
+ # Write the model path to the component output file
+ Path(trained_model_path).parent.mkdir(parents=True, exist_ok=True)
+ with open(trained_model_path, 'w') as f:
+ f.write(target_path)
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ train_model(**vars(args))
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/kfp/pipeline.json b/sdks/python/apache_beam/examples/ml-orchestration/kfp/pipeline.json
new file mode 100644
index 00000000000..a39bb8d253a
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/kfp/pipeline.json
@@ -0,0 +1,247 @@
+{
+ "pipelineSpec": {
+ "components": {
+ "comp-ingestion": {
+ "executorLabel": "exec-ingestion",
+ "inputDefinitions": {
+ "parameters": {
+ "base_artifact_path": {
+ "type": "STRING"
+ }
+ }
+ },
+ "outputDefinitions": {
+ "parameters": {
+ "ingested_dataset_path": {
+ "type": "STRING"
+ }
+ }
+ }
+ },
+ "comp-model-training": {
+ "executorLabel": "exec-model-training",
+ "inputDefinitions": {
+ "parameters": {
+ "base_artifact_path": {
+ "type": "STRING"
+ },
+ "preprocessed_dataset_path": {
+ "type": "STRING"
+ }
+ }
+ },
+ "outputDefinitions": {
+ "parameters": {
+ "trained_model_path": {
+ "type": "STRING"
+ }
+ }
+ }
+ },
+ "comp-preprocessing": {
+ "executorLabel": "exec-preprocessing",
+ "inputDefinitions": {
+ "parameters": {
+ "base_artifact_path": {
+ "type": "STRING"
+ },
+ "beam_runner": {
+ "type": "STRING"
+ },
+ "dataflow_staging_root": {
+ "type": "STRING"
+ },
+ "gcp_project_id": {
+ "type": "STRING"
+ },
+ "ingested_dataset_path": {
+ "type": "STRING"
+ },
+ "region": {
+ "type": "STRING"
+ }
+ }
+ },
+ "outputDefinitions": {
+ "parameters": {
+ "preprocessed_dataset_path": {
+ "type": "STRING"
+ }
+ }
+ }
+ }
+ },
+ "deploymentSpec": {
+ "executors": {
+ "exec-ingestion": {
+ "container": {
+ "command": [
+ "python3",
+ "ingest.py",
+ "--base-artifact-path",
+ "{{$.inputs.parameters['base_artifact_path']}}",
+ "--ingested-dataset-path",
+ "{{$.outputs.parameters['ingested_dataset_path'].output_file}}"
+ ],
+ "image": "<your-docker-registry/ingestion-image-name:latest>"
+ }
+ },
+ "exec-model-training": {
+ "container": {
+ "command": [
+ "python3",
+ "train.py",
+ "--preprocessed-dataset-path",
+ "{{$.inputs.parameters['preprocessed_dataset_path']}}",
+ "--base-artifact-path",
+ "{{$.inputs.parameters['base_artifact_path']}}",
+ "--trained-model-path",
+ "{{$.outputs.parameters['trained_model_path'].output_file}}"
+ ],
+ "image": "<your-docker-registry/train-image-name:latest>"
+ }
+ },
+ "exec-preprocessing": {
+ "container": {
+ "command": [
+ "python3",
+ "preprocess.py",
+ "--ingested-dataset-path",
+ "{{$.inputs.parameters['ingested_dataset_path']}}",
+ "--base-artifact-path",
+ "{{$.inputs.parameters['base_artifact_path']}}",
+ "--preprocessed-dataset-path",
+ "{{$.outputs.parameters['preprocessed_dataset_path'].output_file}}",
+ "--gcp-project-id",
+ "{{$.inputs.parameters['gcp_project_id']}}",
+ "--region",
+ "{{$.inputs.parameters['region']}}",
+ "--dataflow-staging-root",
+ "{{$.inputs.parameters['dataflow_staging_root']}}",
+ "--beam-runner",
+ "{{$.inputs.parameters['beam_runner']}}"
+ ],
+ "image": "<your-docker-registry/preprocessing-image-name:latest>"
+ }
+ }
+ }
+ },
+ "pipelineInfo": {
+ "name": "beam-preprocessing-kfp-example"
+ },
+ "root": {
+ "dag": {
+ "tasks": {
+ "ingestion": {
+ "cachingOptions": {
+ "enableCache": true
+ },
+ "componentRef": {
+ "name": "comp-ingestion"
+ },
+ "inputs": {
+ "parameters": {
+ "base_artifact_path": {
+ "componentInputParameter": "component_artifact_root"
+ }
+ }
+ },
+ "taskInfo": {
+ "name": "ingestion"
+ }
+ },
+ "model-training": {
+ "cachingOptions": {
+ "enableCache": true
+ },
+ "componentRef": {
+ "name": "comp-model-training"
+ },
+ "dependentTasks": [
+ "preprocessing"
+ ],
+ "inputs": {
+ "parameters": {
+ "base_artifact_path": {
+ "componentInputParameter": "component_artifact_root"
+ },
+ "preprocessed_dataset_path": {
+ "taskOutputParameter": {
+ "outputParameterKey": "preprocessed_dataset_path",
+ "producerTask": "preprocessing"
+ }
+ }
+ }
+ },
+ "taskInfo": {
+ "name": "model-training"
+ }
+ },
+ "preprocessing": {
+ "cachingOptions": {
+ "enableCache": true
+ },
+ "componentRef": {
+ "name": "comp-preprocessing"
+ },
+ "dependentTasks": [
+ "ingestion"
+ ],
+ "inputs": {
+ "parameters": {
+ "base_artifact_path": {
+ "componentInputParameter": "component_artifact_root"
+ },
+ "beam_runner": {
+ "componentInputParameter": "beam_runner"
+ },
+ "dataflow_staging_root": {
+ "componentInputParameter": "dataflow_staging_root"
+ },
+ "gcp_project_id": {
+ "componentInputParameter": "gcp_project_id"
+ },
+ "ingested_dataset_path": {
+ "taskOutputParameter": {
+ "outputParameterKey": "ingested_dataset_path",
+ "producerTask": "ingestion"
+ }
+ },
+ "region": {
+ "componentInputParameter": "region"
+ }
+ }
+ },
+ "taskInfo": {
+ "name": "preprocessing"
+ }
+ }
+ }
+ },
+ "inputDefinitions": {
+ "parameters": {
+ "beam_runner": {
+ "type": "STRING"
+ },
+ "component_artifact_root": {
+ "type": "STRING"
+ },
+ "dataflow_staging_root": {
+ "type": "STRING"
+ },
+ "gcp_project_id": {
+ "type": "STRING"
+ },
+ "region": {
+ "type": "STRING"
+ }
+ }
+ }
+ },
+ "schemaVersion": "2.0.0",
+ "sdkVersion": "kfp-1.8.14"
+ },
+ "runtimeConfig": {
+ "gcsOutputDirectory": "gs://test/test"
+ }
+}
\ No newline at end of file
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/kfp/pipeline.py b/sdks/python/apache_beam/examples/ml-orchestration/kfp/pipeline.py
new file mode 100644
index 00000000000..f687f3dd647
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/kfp/pipeline.py
@@ -0,0 +1,132 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+
+import kfp
+from kfp import components as comp
+from kfp.v2 import dsl
+from kfp.v2.compiler import Compiler
+
+
+def parse_args():
+ """Parse arguments."""
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--gcp-project-id",
+ type=str,
+ help="ID for the google cloud project to deploy the pipeline to.",
+ required=True)
+ parser.add_argument(
+ "--region",
+ type=str,
+ help="Region in which to deploy the pipeline.",
+ required=True)
+ parser.add_argument(
+ "--pipeline-root",
+ type=str,
+ help=
+ "Path to artifact repository where Kubeflow Pipelines stores a pipeline’s artifacts.",
+ required=True)
+ parser.add_argument(
+ "--component-artifact-root",
+ type=str,
+ help=
+ "Path to artifact repository where Kubeflow Pipelines components can store artifacts.",
+ required=True)
+ parser.add_argument(
+ "--dataflow-staging-root",
+ type=str,
+ help="Path to staging directory for dataflow.",
+ required=True)
+ parser.add_argument(
+ "--beam-runner",
+ type=str,
+ help="Beam runner: DataflowRunner or DirectRunner.",
+ default="DirectRunner")
+ return parser.parse_args()
+
+
+# arguments are parsed as a global variable so
+# they can be used in the pipeline decorator below
+ARGS = parse_args()
+PIPELINE_ROOT = vars(ARGS)['pipeline_root']
+
+# [START load_kfp_components]
+# load the kfp components from their yaml files
+DataIngestOp = comp.load_component('components/ingestion/component.yaml')
+DataPreprocessingOp = comp.load_component(
+ 'components/preprocessing/component.yaml')
+TrainModelOp = comp.load_component('components/train/component.yaml')
+# [END load_kfp_components]
+
+
+# [START define_kfp_pipeline]
+@dsl.pipeline(
+ pipeline_root=PIPELINE_ROOT,
+ name="beam-preprocessing-kfp-example",
+ description="Pipeline to show an apache beam preprocessing example in KFP")
+def pipeline(
+ gcp_project_id: str,
+ region: str,
+ component_artifact_root: str,
+ dataflow_staging_root: str,
+ beam_runner: str):
+ """KFP pipeline definition.
+
+ Args:
+ gcp_project_id (str): ID for the google cloud project to deploy the pipeline to.
+ region (str): Region in which to deploy the pipeline.
+ component_artifact_root (str): Path to artifact repository where Kubeflow Pipelines
+ components can store artifacts.
+ dataflow_staging_root (str): Path to staging directory for the dataflow runner.
+ beam_runner (str): Beam runner: DataflowRunner or DirectRunner.
+ """
+
+ ingest_data_task = DataIngestOp(base_artifact_path=component_artifact_root)
+
+ data_preprocessing_task = DataPreprocessingOp(
+ ingested_dataset_path=ingest_data_task.outputs["ingested_dataset_path"],
+ base_artifact_path=component_artifact_root,
+ gcp_project_id=gcp_project_id,
+ region=region,
+ dataflow_staging_root=dataflow_staging_root,
+ beam_runner=beam_runner)
+
+ train_model_task = TrainModelOp(
+ preprocessed_dataset_path=data_preprocessing_task.
+ outputs["preprocessed_dataset_path"],
+ base_artifact_path=component_artifact_root)
+
+
+# [END define_kfp_pipeline]
+
+if __name__ == "__main__":
+ # [START compile_kfp_pipeline]
+ Compiler().compile(pipeline_func=pipeline, package_path="pipeline.json")
+ # [END compile_kfp_pipeline]
+
+ run_arguments = vars(ARGS)
+ del run_arguments['pipeline_root']
+
+ # [START execute_kfp_pipeline]
+ client = kfp.Client()
+ experiment = client.create_experiment("KFP orchestration example")
+ run_result = client.run_pipeline(
+ experiment_id=experiment.id,
+ job_name="KFP orchestration job",
+ pipeline_package_path="pipeline.json",
+ params=run_arguments)
+ # [END execute_kfp_pipeline]
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/kfp/requirements.txt b/sdks/python/apache_beam/examples/ml-orchestration/kfp/requirements.txt
new file mode 100644
index 00000000000..7b2ec602a0a
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/kfp/requirements.txt
@@ -0,0 +1,18 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# requirements to compile the pipeline and execute it on Dataflow
+kfp==1.8.13
+google-cloud-aiplatform==1.15
\ No newline at end of file
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/tfx/coco_captions_local.py b/sdks/python/apache_beam/examples/ml-orchestration/tfx/coco_captions_local.py
new file mode 100644
index 00000000000..2204285a14b
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/tfx/coco_captions_local.py
@@ -0,0 +1,141 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Preprocessing example with TFX with the LocalDagRunner and
+either the beam DirectRunner or DataflowRunner"""
+import argparse
+import os
+
+from tfx import v1 as tfx
+
+
+def parse_args():
+ """Parse arguments."""
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--gcp-project-id",
+ type=str,
+ help="ID for the google cloud project to deploy the pipeline to.",
+ required=True)
+ parser.add_argument(
+ "--region",
+ type=str,
+ help="Region in which to deploy the pipeline.",
+ required=True)
+ parser.add_argument(
+ "--pipeline-name",
+ type=str,
+ help="Name for the Beam pipeline.",
+ required=True)
+ parser.add_argument(
+ "--pipeline-root",
+ type=str,
+ help=
+ "Path to artifact repository where TFX stores a pipeline’s artifacts.",
+ required=True)
+ parser.add_argument(
+ "--csv-file", type=str, help="Path to the csv input file.", required=True)
+ parser.add_argument(
+ "--csv-file", type=str, help="Path to the csv input file.", required=True)
+ parser.add_argument(
+ "--module-file",
+ type=str,
+ help="Path to module file containing the preprocessing_fn and run_fn.",
+ default="coco_captions_utils.py")
+ parser.add_argument(
+ "--beam-runner",
+ type=str,
+ help="Beam runner: DataflowRunner or DirectRunner.",
+ default="DirectRunner")
+ parser.add_argument(
+ "--metadata-file",
+ type=str,
+ help="Path to store a metadata file as a mock metadata database",
+ default="metadata.db")
+ return parser.parse_args()
+
+
+# [START tfx_pipeline]
+def create_pipeline(
+ gcp_project_id,
+ region,
+ pipeline_name,
+ pipeline_root,
+ csv_file,
+ module_file,
+ beam_runner,
+ metadata_file):
+ """Create the TFX pipeline.
+
+ Args:
+ gcp_project_id (str): ID for the google cloud project to deploy the pipeline to.
+ region (str): Region in which to deploy the pipeline.
+ pipeline_name (str): Name for the Beam pipeline
+ pipeline_root (str): Path to artifact repository where TFX
+ stores a pipeline’s artifacts.
+ csv_file (str): Path to the csv input file.
+ module_file (str): Path to module file containing the preprocessing_fn and run_fn.
+ beam_runner (str): Beam runner: DataflowRunner or DirectRunner.
+ metadata_file (str): Path to store a metadata file as a mock metadata database.
+ """
+ example_gen = tfx.components.CsvExampleGen(input_base=csv_file)
+
+ # Computes statistics over data for visualization and example validation.
+ statistics_gen = tfx.components.StatisticsGen(
+ examples=example_gen.outputs['examples'])
+
+ schema_gen = tfx.components.SchemaGen(
+ statistics=statistics_gen.outputs['statistics'], infer_feature_shape=True)
+
+ transform = tfx.components.Transform(
+ examples=example_gen.outputs['examples'],
+ schema=schema_gen.outputs['schema'],
+ module_file=module_file)
+
+ trainer = tfx.components.Trainer(
+ module_file=module_file,
+ examples=transform.outputs['transformed_examples'],
+ transform_graph=transform.outputs['transform_graph'])
+
+ components = [example_gen, statistics_gen, schema_gen, transform, trainer]
+
+ beam_pipeline_args_by_runner = {
+ 'DirectRunner': [],
+ 'DataflowRunner': [
+ '--runner=DataflowRunner',
+ '--project=' + gcp_project_id,
+ '--temp_location=' + os.path.join(pipeline_root, 'tmp'),
+ '--region=' + region,
+ ]
+ }
+
+ return tfx.dsl.Pipeline(
+ pipeline_name=pipeline_name,
+ pipeline_root=pipeline_root,
+ components=components,
+ enable_cache=True,
+ metadata_connection_config=tfx.orchestration.metadata.
+ sqlite_metadata_connection_config(metadata_file),
+ beam_pipeline_args=beam_pipeline_args_by_runner[beam_runner])
+
+
+# [END tfx_pipeline]
+
+if __name__ == "__main__":
+
+ # [START tfx_execute_pipeline]
+ args = parse_args()
+ tfx.orchestration.LocalDagRunner().run(create_pipeline(**vars(args)))
+ # [END tfx_execute_pipeline]
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/tfx/coco_captions_utils.py b/sdks/python/apache_beam/examples/ml-orchestration/tfx/coco_captions_utils.py
new file mode 100644
index 00000000000..c28f54cae19
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/tfx/coco_captions_utils.py
@@ -0,0 +1,87 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Implementation of the tfx component functions for the coco captions example."""
+
+import tempfile
+
+import tensorflow as tf
+import tensorflow_transform as tft
+import tensorflow_transform.beam as tft_beam
+from tfx import v1 as tfx
+
+
+# [START tfx_run_fn]
+def run_fn(fn_args: tfx.components.FnArgs) -> None:
+ """Build the TF model, train it and export it."""
+ # create a model
+ model = tf.keras.Sequential()
+ model.add(tf.keras.layers.Dense(1, input_dim=10))
+ model.compile()
+
+ # train the model on the preprocessed data
+ # model.fit(...)
+
+ # Save model to fn_args.serving_model_dir.
+ model.save(fn_args.serving_model_dir)
+
+
+# [END tfx_run_fn]
+
+
+# [START tfx_preprocessing_fn]
+def preprocessing_fn(inputs):
+ """Transform raw data."""
+ # convert the captions to lowercase
+ # split the captions into separate words
+ lower = tf.strings.lower(inputs['caption'])
+
+ # compute the vocabulary of the captions during a full pass
+ # over the dataset and use this to tokenize.
+ mean_length = tft.mean(tf.strings.length(lower))
+ # <do some preprocessing with the mean length>
+
+ return {
+ 'caption_lower': lower,
+ }
+
+
+# [END tfx_preprocessing_fn]
+
+# [START tfx_analyze_and_transform]
+if __name__ == "__main__":
+ # Test processing_fn directly without the tfx pipeline
+ raw_data = [
+ {
+ "caption": "A bicycle replica with a clock as the front wheel."
+ }, {
+ "caption": "A black Honda motorcycle parked in front of a garage."
+ }, {
+ "caption": "A room with blue walls and a white sink and door."
+ }
+ ]
+
+ # define the feature_spec (in a tfx pipeline this would be generated by a SchemaGen component)
+ feature_spec = dict(caption=tf.io.FixedLenFeature([], tf.string))
+ raw_data_metadata = tft.DatasetMetadata.from_feature_spec(feature_spec)
+
+ # test out the beam implementation of the
+ # processing_fn with AnalyzeAndTransformDataset
+ with tft_beam.Context(temp_dir=tempfile.mkdtemp()):
+ transformed_dataset, transform_fn = (
+ (raw_data, raw_data_metadata)
+ | tft_beam.AnalyzeAndTransformDataset(preprocessing_fn))
+ transformed_data, transformed_metadata = transformed_dataset
+# [END tfx_analyze_and_transform]
diff --git a/sdks/python/apache_beam/examples/ml-orchestration/tfx/requirements.txt b/sdks/python/apache_beam/examples/ml-orchestration/tfx/requirements.txt
new file mode 100644
index 00000000000..3e43eb6dc3c
--- /dev/null
+++ b/sdks/python/apache_beam/examples/ml-orchestration/tfx/requirements.txt
@@ -0,0 +1,17 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+tfx==1.9.0
+tensorflow==2.9.1
\ No newline at end of file
diff --git a/website/www/site/content/en/documentation/ml/orchestration.md b/website/www/site/content/en/documentation/ml/orchestration.md
new file mode 100644
index 00000000000..e3f7b7169e4
--- /dev/null
+++ b/website/www/site/content/en/documentation/ml/orchestration.md
@@ -0,0 +1,223 @@
+---
+title: "Orchestration"
+---
+<!--
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+-->
+
+# Workflow orchestration
+
+## Understanding the Beam DAG
+
+
+Apache Beam is an open source, unified model for defining both batch and streaming data-parallel processing pipelines. One of the central concepts to the Beam programming model is the DAG (= Directed Acyclic Graph). Each Beam pipeline is a DAG that can be constructed through the Beam SDK in your programming language of choice (from the set of supported beam SDKs). Each node of this DAG represents a processing step (PTransform) that accepts a collection of data as input (PCollection) and [...]
+
+
+
+Note that simply defining a pipeline and the corresponding DAG does not mean that data will start flowing through the pipeline. To actually execute the pipeline, it has to be deployed to one of the [supported Beam runners](https://beam.apache.org/documentation/runners/capability-matrix/). These distributed processing back-ends include Apache Flink, Apache Spark and Google Cloud Dataflow. A [Direct Runner](https://beam.apache.org/documentation/runners/direct/) is also provided to execute [...]
+
+## Orchestrating frameworks
+
+Successfully delivering machine learning projects is about a lot more than training a model and calling it a day. A full ML workflow will often contain a range of other steps including data ingestion, data validation, data preprocessing, model evaluation, model deployment, data drift detection, etc. Furthermore, it’s essential to keep track of metadata and artifacts from your experiments to answer important questions like:
+- What data was this model trained on and with which training parameters?
+- When was this model deployed and what accuracy did it get on a test dataset?
+Without this knowledge at your disposal, it will become increasingly difficult to troubleshoot, monitor and improve your ML solutions as they grow in size.
+
+The solution: MLOps. MLOps is an umbrella term used to describe best practices and guiding principles that aim to make the development and maintenance of machine learning systems seamless and efficient. Simply put, MLOps is most often about automating machine learning workflows throughout the model and data lifecycle. Popular frameworks to create these workflow DAGs are [Kubeflow Pipelines](https://www.kubeflow.org/docs/components/pipelines/introduction/), [Apache Airflow](https://airflo [...]
+
+So what does all of this have to do with Beam? Well, since we established that Beam is a great tool for a range of ML tasks, a beam pipeline can either be used as a standalone data processing job or can be part of a larger sequence of steps in such a workflow. In the latter case, the beam DAG is just one node in the overarching DAG composed by the workflow orchestrator. This results in a DAG in a DAG, as illustrated by the example below.
+
+
+
+It is important to understand the key difference between the Beam DAG and the orchestrating DAG. The Beam DAG processes data and passes that data between the nodes of its DAG. The focus of Beam is on parallelization and enabling both batch and streaming jobs. In contrast, the orchestration DAG schedules and monitors steps in the workflow and passed between the nodes of the DAG are execution parameters, metadata and artifacts. An example of such an artifact could be a trained model or a d [...]
+
+Note: TFX creates a workflow DAG, which needs an orchestrator of its own to be executed. [Natively supported orchestrators for TFX](https://www.tensorflow.org/tfx/guide/custom_orchestrator) are Airflow, Kubeflow Pipelines and, here’s the kicker, Beam itself! As mentioned by the [TFX docs](https://www.tensorflow.org/tfx/guide/beam_orchestrator):
+
+> "Several TFX components rely on Beam for distributed data processing. In addition, TFX can use Apache Beam to orchestrate and execute the pipeline DAG. Beam orchestrator uses a different BeamRunner than the one which is used for component data processing."
+
+Caveat: The Beam orchestrator is not meant to be a TFX orchestrator to be used in production environments. It simply enables debugging TFX pipelines locally on Beam’s DirectRunner without the need for the extra setup that is needed for Airflow or Kubeflow.
+
+## Preprocessing example
+
+Let’s get practical and take a look at two such orchestrated ML workflows, one with Kubeflow Pipelines (KFP) and one with Tensorflow Extended (TFX). These two frameworks achieve the same goal of creating workflows, but have their own distinct advantages and disadvantages: KFP requires you to create your workflow components from scratch and requires a user to explicitly indicate which artifacts should be passed between components and in what way. In contrast, TFX offers a number of prebui [...]
+
+For simplicity, we will showcase workflows with only three components: data ingestion, data preprocessing and model training. Depending on the scenario, a range of extra components could be added such as model evaluation, model deployment, etc. We will focus our attention on the preprocessing component, since it showcases how to use Apache beam in an ML workflow for efficient and parallel processing of your ML data.
+
+The dataset we will use consists of image-caption pairs, i.e. images paired with a textual caption describing the content of the image. These pairs are taken from captions subset of the [MSCOCO 2014 dataset](https://cocodataset.org/#home). This multi-modal data (image + text) gives us the opportunity to experiment with preprocessing operations for both modalities.
+
+### Kubeflow pipelines (KFP)
+
+In order to execute our ML workflow with KFP we must perform three steps:
+
+1. Create the KFP components by specifying the interface to the components and by writing and containerizing the implementation of the component logic
+2. Create the KFP pipeline by connecting the created components and specifying how inputs and outputs should be passed from between components and compiling the pipeline definition to a full pipeline definition.
+3. Execute the KFP pipeline by submitting it to a KFP client endpoint.
+
+The full example code can be found [here](https://github.com/apache/beam/tree/master/sdks/python/apache_beam/examples/ml-orchestration/kfp)
+
+#### Create the KFP components
+
+This is our target file structure:
+
+ kfp
+ ├── pipeline.py
+ ├── components
+ │ ├── ingestion
+ │ │ ├── Dockerfile
+ │ │ ├── component.yaml
+ │ │ ├── requirements.txt
+ │ │ └── src
+ │ │ └── ingest.py
+ │ ├── preprocessing
+ │ │ ├── Dockerfile
+ │ │ ├── component.yaml
+ │ │ ├── requirements.txt
+ │ │ └── src
+ │ │ └── preprocess.py
+ │ └── train
+ │ ├── Dockerfile
+ │ ├── component.yaml
+ │ ├── requirements.txt
+ │ └── src
+ │ └── train.py
+ └── requirements.txt
+
+Let’s start with the component specifications. The full preprocessing component specification is illustrated below. The inputs are the path where the ingested dataset was saved by the ingest component and a path to a directory where the component can store artifacts. Additionally, there are some inputs that specify how and where the Beam pipeline should run. The specifications for the ingestion and train component are similar and can be found [here](https://github.com/apache/beam/tree/ma [...]
+
+>Note: we are using the KFP v1 SDK, because v2 is still in [beta](https://www.kubeflow.org/docs/started/support/#application-status). The v2 SDK introduces some new options for specifying the component interface with more native support for input and output artifacts. To see how to migrate components from v1 to v2, consult the [KFP docs](https://www.kubeflow.org/docs/components/pipelines/sdk-v2/v2-component-io/).
+
+{{< highlight file="sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/component.yaml" >}}
+{{< code_sample "sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/component.yaml" preprocessing_component_definition >}}
+{{< /highlight >}}
+
+In this case, each component shares an identical Dockerfile but extra component-specific dependencies could be added where necessary.
+
+{{< highlight language="Dockerfile" file="sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/Dockerfile" >}}
+{{< code_sample "sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/Dockerfile" component_dockerfile >}}
+{{< /highlight >}}
+
+With the component specification and containerization out of the way we can look at the actual implementation of the preprocessing component.
+
+Since KFP provides the input and output arguments as command-line arguments, an `argumentparser` is needed.
+
+{{< highlight file="sdks/python/apache_beam/examples/ml-orchestration/kf/components/preprocessing/src/preprocess.py" >}}
+{{< code_sample "sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/src/preprocess.py" preprocess_component_argparse >}}
+{{< /highlight >}}
+
+The implementation of the `preprocess_dataset` function contains the Beam pipeline code and the Beam pipeline options to select the desired runner. The executed preprocessing involves downloading the image bytes from their url, converting them to a Torch Tensor and resizing to the desired size. The caption undergoes a series of string manipulations to ensure that our model receives clean uniform image descriptions (Tokenization is not yet done here, but could be included here as well if [...]
+
+
+{{< highlight file="sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/src/preprocess.py" >}}
+{{< code_sample "sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/src/preprocess.py" deploy_preprocessing_beam_pipeline >}}
+{{< /highlight >}}
+
+It also contains the necessary code to perform the component IO. First, a target path is constructed to store the preprocessed dataset based on the component input parameter `base_artifact_path` and a timestamp. Output values from components can only be returned as files so we write the value of the constructed target path to an output file that was provided by KFP to our component.
+
+{{< highlight file="sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/src/preprocess.py" >}}
+{{< code_sample "sdks/python/apache_beam/examples/ml-orchestration/kfp/components/preprocessing/src/preprocess.py" kfp_component_input_output >}}
+{{< /highlight >}}
+
+Since we are mainly interested in the preprocessing component to show how a Beam pipeline can be integrated into a larger ML workflow, we will not cover the implementation of the ingestion and train component in depth. Implementations of dummy components that mock their behavior are provided in the full example code.
+
+#### Create the pipeline definition
+
+`pipeline.py` first loads the created components from their specification `.yaml` file.
+
+{{< highlight file="sdks/python/apache_beam/examples/ml-orchestration/kfp/pipeline.py" >}}
+{{< code_sample "sdks/python/apache_beam/examples/ml-orchestration/kfp/pipeline.py" load_kfp_components >}}
+{{< /highlight >}}
+
+After that, the pipeline is created and the required components inputs and outputs are specified manually.
+
+{{< highlight file="sdks/python/apache_beam/examples/ml-orchestration/kfp/pipeline.py" >}}
+{{< code_sample "sdks/python/apache_beam/examples/ml-orchestration/kfp/pipeline.py" define_kfp_pipeline >}}
+{{< /highlight >}}
+
+Finally, the defined pipeline is compiled and a `pipeline.json` specification file is generated.
+
+{{< highlight file="sdks/python/apache_beam/examples/ml-orchestration/kfp/pipeline.py" >}}
+{{< code_sample "sdks/python/apache_beam/examples/ml-orchestration/kfp/pipeline.py" compile_kfp_pipeline >}}
+{{< /highlight >}}
+
+
+#### Execute the KFP pipeline
+
+Using the specification file and the snippet below with the necessary [requirements](https://github.com/apache/beam/tree/master/sdks/python/apache_beam/examples/ml-orchestration/kfp/requirements.txt) installed, the pipeline can now be executed. Consult the [docs](https://kubeflow-pipelines.readthedocs.io/en/latest/source/kfp.client.html#kfp.Client.run_pipeline) for more information. Note that, before executing the pipeline, a container for each component must be built and pushed to a con [...]
+
+{{< highlight file="sdks/python/apache_beam/examples/ml-orchestration/kfp/pipeline.py" >}}
+{{< code_sample "sdks/python/apache_beam/examples/ml-orchestration/kfp/pipeline.py" execute_kfp_pipeline >}}
+{{< /highlight >}}
+
+
+### Tensorflow Extended (TFX)
+
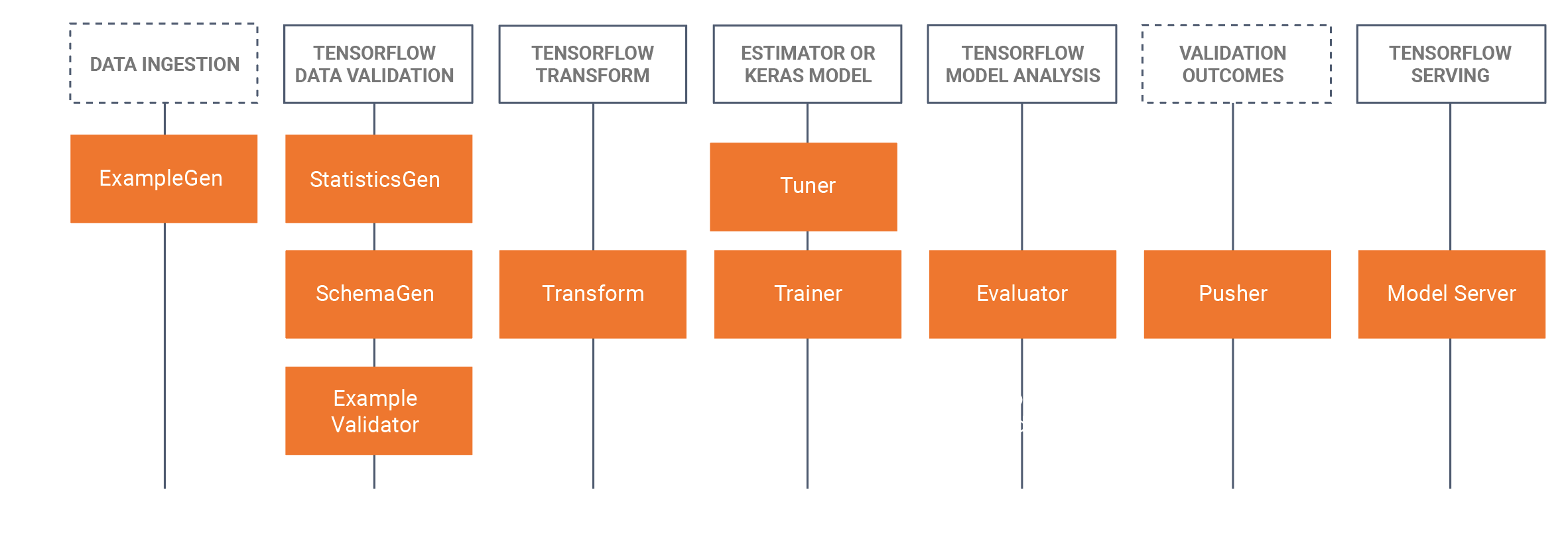
+The way of working for TFX is similar to the approach for KFP as illustrated above: Define the individual workflow components, connect them in a pipeline object and run the pipeline in the target environment. However, what makes TFX different is that it has already built a set of Python packages that are libraries to create workflow components. So unlike the KFP example, we do not need to start from scratch by writing and containerizing our code. What is left for the users to do is pick [...]
+
+
+
+
+We will work out a small example in a similar fashion as for KFP. There we used ingestion, preprocessing and trainer components. Translating this to TFX, we will need the ExampleGen, Transform and Trainer libraries.
+
+This time we will start by looking at the pipeline definition. Note that this looks very similar to our previous example.
+
+{{< highlight file="sdks/python/apache_beam/examples/ml-orchestration/tfx/coco_captions_local.py" >}}
+{{< code_sample "sdks/python/apache_beam/examples/ml-orchestration/tfx/coco_captions_local.py" tfx_pipeline >}}
+{{< /highlight >}}
+
+We will use the same data input as last time, i.e. a couple of image-captions pairs extracted from the [MSCOCO 2014 dataset](https://cocodataset.org/#home). This time, however, in CSV format because the ExampleGen component does not by default have support for jsonlines. (The formats that are supported out of the box are listed [here](https://www.tensorflow.org/tfx/guide/examplegen#data_sources_and_formats). Alternatively, it’s possible to write a [custom ExampleGen](https://www.tensorfl [...]
+
+Copy the snippet below to an input data csv file:
+
+{{< highlight >}}
+image_id,id,caption,image_url,image_name,image_license
+318556,255,"An angled view of a beautifully decorated bathroom.","http://farm4.staticflickr.com/3133/3378902101_3c9fa16b84_z.jpg","COCO_train2014_000000318556.jpg","Attribution-NonCommercial-ShareAlike License"
+476220,14,"An empty kitchen with white and black appliances.","http://farm7.staticflickr.com/6173/6207941582_b69380c020_z.jpg","COCO_train2014_000000476220.jpg","Attribution-NonCommercial License"
+{{< /highlight >}}
+
+So far, we have only imported standard TFX components and chained them together into a pipeline. Both the Transform and Trainer components have a `module_file` argument defined. That’s where we define the behavior we want from these standard components.
+
+#### Preprocess
+
+The Transform component searches the `module_file` for a definition of the function `preprocessing_fn`. This function is the central concept of the `tf.transform` library. As per the [TFX docs](https://www.tensorflow.org/tfx/transform/get_started#define_a_preprocessing_function):
+
+> The preprocessing function is the most important concept of tf.Transform. The preprocessing function is a logical description of a transformation of the dataset. The preprocessing function accepts and returns a dictionary of tensors, where a tensor means Tensor or SparseTensor. There are two kinds of functions used to define the preprocessing function:
+>1. Any function that accepts and returns tensors. These add TensorFlow operations to the graph that transform raw data into transformed data.
+>2. Any of the analyzers provided by tf.Transform. Analyzers also accept and return tensors, but unlike TensorFlow functions, they do not add operations to the graph. Instead, analyzers cause tf.Transform to compute a full-pass operation outside of TensorFlow. They use the input tensor values over the entire dataset to generate a constant tensor that is returned as the output. For example, tft.min computes the minimum of a tensor over the dataset. tf.Transform provides a fixed set of ana [...]
+
+So our `preprocesing_fn` can contain all tf operations that accept and return tensors and also specific `tf.transform` operations. In our simple example below we use the former to convert all incoming captions to lowercase letters only, while the latter does a full pass on all the data in our dataset to compute the average length of the captions to be used for a follow-up preprocessing step.
+
+{{< highlight file="sdks/python/apache_beam/examples/ml-orchestration/tfx/coco_captions_utils.py" >}}
+{{< code_sample "sdks/python/apache_beam/examples/ml-orchestration/tfx/coco_captions_utils.py" tfx_preprocessing_fn >}}
+{{< /highlight >}}
+
+However this function only defines the logical steps that have to be performed during preprocessing and needs a concrete implementation before it can be executed. One such implementation is provided by `tf.Transform` using Apache Beam and provides a PTransform `tft_beam.AnalyzeAndTransformDataset` to process the data. We can test this preproccesing_fn outside of the TFX Transform component using this PTransform explicitly. Calling the `processing_fn` in such a way is not necessary when u [...]
+
+{{< highlight file="sdks/python/apache_beam/examples/ml-orchestration/tfx/coco_captions_utils.py" >}}
+{{< code_sample "sdks/python/apache_beam/examples/ml-orchestration/tfx/coco_captions_utils.py" tfx_analyze_and_transform >}}
+{{< /highlight >}}
+
+#### Train
+
+Finally the Trainer component behaves in a similar way as the Transform component, but instead of looking for a `preprocessing_fn` it requires a `run_fn` function to be present in the specified `module_file`. Our simple implementation, creates a stub model using `tf.Keras` and saves the resulting model to a directory.
+
+{{< highlight file="sdks/python/apache_beam/examples/ml-orchestration/tfx/coco_captions_utils.py" >}}
+{{< code_sample "sdks/python/apache_beam/examples/ml-orchestration/tfx/coco_captions_utils.py" tfx_run_fn >}}
+{{< /highlight >}}
+
+#### Executing the pipeline
+
+To launch the pipeline two configurations must be provided: The orchestrator for the TFX pipeline and the pipeline options to run Beam pipelines. In this case we use the `LocalDagRunner` for orchestration to run the pipeline locally without extra setup dependencies. Where the created pipeline can specify Beam’s pipeline options as usual through the `beam_pipeline_args` argument.
+
+{{< highlight file="sdks/python/apache_beam/examples/ml-orchestration/tfx/coco_captions_local.py" >}}
+{{< code_sample "sdks/python/apache_beam/examples/ml-orchestration/tfx/coco_captions_local.py" tfx_execute_pipeline >}}
+{{< /highlight >}}
diff --git a/website/www/site/content/en/documentation/ml/overview.md b/website/www/site/content/en/documentation/ml/overview.md
old mode 100755
new mode 100644
index a47829c3b38..628dd009b75
--- a/website/www/site/content/en/documentation/ml/overview.md
+++ b/website/www/site/content/en/documentation/ml/overview.md
@@ -75,6 +75,7 @@ In order to automate and track the AI/ML workflows throughout your project, you
## Examples
You can find examples of end-to-end AI/ML pipelines for several use cases:
+* [ML Workflow Orchestration](/documentation/ml/orchestration): illustrates how ML workflows consisting of multiple steps can be orchestrated by using Kubeflow Pipelines and Tensorflow Extended.
* [Multi model pipelines in Beam](/documentation/ml/multi-model-pipelines): explains how multi-model pipelines work and gives an overview of what you need to know to build one using the RunInference API.
* [Online Clustering in Beam](/documentation/ml/online-clustering): demonstrates how to setup a realtime clustering pipeline that can read text from PubSub, convert the text into an embedding using a transformer based language model with the RunInference API, and cluster them using BIRCH with Stateful Processing.
-* [Anomaly Detection in Beam](/documentation/ml/anomaly-detection): demonstrates how to setup an anomaly detection pipeline that reads text from PubSub in real-time, and then detects anomaly using a trained HDBSCAN clustering model with the RunInference API.
+* [Anomaly Detection in Beam](/documentation/ml/anomaly-detection): demonstrates how to setup an anomaly detection pipeline that reads text from PubSub in real-time, and then detects anomaly using a trained HDBSCAN clustering model with the RunInference API.
\ No newline at end of file
diff --git a/website/www/site/layouts/partials/section-menu/en/documentation.html b/website/www/site/layouts/partials/section-menu/en/documentation.html
index 345ab8bc819..b5d8f691360 100644
--- a/website/www/site/layouts/partials/section-menu/en/documentation.html
+++ b/website/www/site/layouts/partials/section-menu/en/documentation.html
@@ -214,6 +214,7 @@
<ul class="section-nav-list">
<li><a href="/documentation/ml/overview/">Overview</a></li>
+ <li><a href="/documentation/ml/orchestration/">Workflow Orchestration</a></li>
<li><a href="/documentation/ml/data-processing/">Data processing</a></li>
<li><a href="/documentation/ml/multi-model-pipelines/">Multi-model pipelines</a></li>
<li><a href="/documentation/ml/online-clustering/">Online Clustering</a></li>
diff --git a/website/www/site/static/images/orchestrated-beam-pipeline.svg b/website/www/site/static/images/orchestrated-beam-pipeline.svg
new file mode 100644
index 00000000000..7270c6df081
--- /dev/null
+++ b/website/www/site/static/images/orchestrated-beam-pipeline.svg
@@ -0,0 +1,35 @@
+<!--
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+-->
+
+<svg version="1.1" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 3720 1006.6666666666665" width="3720" height="1006.6666666666665">
+ <!-- svg-source:excalidraw -->
+
+ <defs>
+ <style>
+ @font-face {
+ font-family: "Virgil";
+ src: url("https://excalidraw.com/Virgil.woff2");
+ }
+ @font-face {
+ font-family: "Cascadia";
+ src: url("https://excalidraw.com/Cascadia.woff2");
+ }
+ </style>
+ </defs>
+ <g stroke-linecap="round" transform="translate(10 10) rotate(0 1850 493.33333333333326)"><path d="M0 0 L3700 0 L3700 986.67 L0 986.67" stroke="none" stroke-width="0" fill="#f6f6f6"></path><path d="M0 0 C1072.37 0, 2144.74 0, 3700 0 M0 0 C1202.77 0, 2405.53 0, 3700 0 M3700 0 C3700 211.2, 3700 422.4, 3700 986.67 M3700 0 C3700 314.16, 3700 628.32, 3700 986.67 M3700 986.67 C2372.88 986.67, 1045.77 986.67, 0 986.67 M3700 986.67 C2644.99 986.67, 1589.98 986.67, 0 986.67 M0 986.67 C0 719.3, 0 [...]
\ No newline at end of file
diff --git a/website/www/site/static/images/standalone-beam-pipeline.svg b/website/www/site/static/images/standalone-beam-pipeline.svg
new file mode 100644
index 00000000000..325b5be3d3e
--- /dev/null
+++ b/website/www/site/static/images/standalone-beam-pipeline.svg
@@ -0,0 +1,35 @@
+<!--
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+-->
+
+<svg version="1.1" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 1760 760" width="1760" height="760">
+ <!-- svg-source:excalidraw -->
+
+ <defs>
+ <style>
+ @font-face {
+ font-family: "Virgil";
+ src: url("https://excalidraw.com/Virgil.woff2");
+ }
+ @font-face {
+ font-family: "Cascadia";
+ src: url("https://excalidraw.com/Cascadia.woff2");
+ }
+ </style>
+ </defs>
+ <g stroke-linecap="round" transform="translate(250 10) rotate(0 630 370)"><path d="M0 0 L1260 0 L1260 740 L0 740" stroke="none" stroke-width="0" fill="#c4e1ff"></path><path d="M0 0 C397.89 0, 795.78 0, 1260 0 M0 0 C477.48 0, 954.96 0, 1260 0 M1260 0 C1260 260.17, 1260 520.35, 1260 740 M1260 0 C1260 187.03, 1260 374.07, 1260 740 M1260 740 C851.51 740, 443.02 740, 0 740 M1260 740 C779.96 740, 299.91 740, 0 740 M0 740 C0 507.56, 0 275.12, 0 0 M0 740 C0 476.82, 0 213.65, 0 0" stroke="#ffff [...]
\ No newline at end of file