You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by holdenk <gi...@git.apache.org> on 2018/08/06 18:08:16 UTC
[GitHub] spark pull request #22010: [SPARK-21436] Take advantage of known partioner f...
GitHub user holdenk opened a pull request:
https://github.com/apache/spark/pull/22010
[SPARK-21436] Take advantage of known partioner for distinct on RDDs to avoid a shuffle
## What changes were proposed in this pull request?
Special case the situation where we know the partioner and the number of requested partions output is the same as the current partioner to avoid a shuffle and instead compute distinct inside of each partion.
## How was this patch tested?
New unit test that verifies partioner does not change if the partioner is known and distinct is called with the same target # of partions.
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/holdenk/spark SPARK-21436-take-advantage-of-known-partioner-for-distinct-on-rdds
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/22010.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #22010
----
commit a7fbc74335c2df27002e8158f8e83a919195eed7
Author: Holden Karau <ho...@...>
Date: 2018-08-06T18:04:31Z
[SPARK-21436] Take advantage of known partioner for distinct on RDDs to avoid a shuffle.
Special case the situation where we know the partioner and the number of requested partions output is the same as the current partioner
to avoid a shuffle and instead compute distinct inside of each partion.
----
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r220672579
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +397,20 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ def removeDuplicatesInPartition(partition: Iterator[T]): Iterator[T] = {
+ // Create an instance of external append only map which ignores values.
+ val map = new ExternalAppendOnlyMap[T, Null, Null](
+ createCombiner = value => null,
+ mergeValue = (a, b) => a,
+ mergeCombiners = (a, b) => a)
--- End diff --
nit: clean them ?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on the issue:
https://github.com/apache/spark/pull/22010
I think this is pretty clearly a win, but since it's been awhile since I did anything in core I'll leave this until Friday morning (pacific) in-case any of the committers who've been working there have something to say (e.g. @jkbradley / @rxin ).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r220399123
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -42,7 +42,8 @@ import org.apache.spark.partial.GroupedCountEvaluator
import org.apache.spark.partial.PartialResult
import org.apache.spark.storage.{RDDBlockId, StorageLevel}
import org.apache.spark.util.{BoundedPriorityQueue, Utils}
-import org.apache.spark.util.collection.{OpenHashMap, Utils => collectionUtils}
+import org.apache.spark.util.collection.{ExternalAppendOnlyMap, OpenHashMap,
+ Utils => collectionUtils}
--- End diff --
nit: AFAIK we don't have length limit for import
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r209340321
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,16 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ // If the data is already approriately partioned with a known partioner we can work locally.
--- End diff --
Thanks!
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95768/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on the issue:
https://github.com/apache/spark/pull/22010
Logically looks right but would you mind if I ask a simple benchmark @holdenk just to make everything clear?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #96652 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96652/testReport)** for PR 22010 at commit [`95357cf`](https://github.com/apache/spark/commit/95357cff3da95c962c575f1b8efe155841ed78a5).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #94634 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/94634/testReport)** for PR 22010 at commit [`5fd3659`](https://github.com/apache/spark/commit/5fd36592a26b07fdb58e79e4efbb6b70daea54df).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #94577 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/94577/testReport)** for PR 22010 at commit [`5fd3659`](https://github.com/apache/spark/commit/5fd36592a26b07fdb58e79e4efbb6b70daea54df).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r217900563
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,26 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ partitioner match {
+ case Some(p) if numPartitions == partitions.length =>
+ def key(x: T): (T, Null) = (x, null)
+ val cleanKey = sc.clean(key _)
+ val keyed = new MapPartitionsRDD[(T, Null), T](
+ this,
+ (context, pid, iter) => iter.map(cleanKey),
+ knownPartitioner = Some(new WrappedPartitioner(p)))
+ val duplicatesRemoved = keyed.reduceByKey((x, y) => x)
--- End diff --
No reduceByKey on a known partioner is fine.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2911/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3496/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on the issue:
https://github.com/apache/spark/pull/22010
@HyukjinKwon sure, I'll do a micro benchmark sometime this week.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/94634/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3505/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by mgaido91 <gi...@git.apache.org>.
Github user mgaido91 commented on the issue:
https://github.com/apache/spark/pull/22010
thanks for checking @rxin @cloud-fan
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/96669/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r214046905
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,16 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ // If the data is already approriately partitioned with a known partitioner we can work locally.
+ def removeDuplicatesInPartition(itr: Iterator[T]): Iterator[T] = {
+ val set = new mutable.HashSet[T]()
+ itr.filter(set.add(_))
--- End diff --
But we need to compute the hash of the key anyways to check if it exists.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95767/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/96680/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on the issue:
https://github.com/apache/spark/pull/22010
I am sorry guys. I rushed to take a look.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #95768 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95768/testReport)** for PR 22010 at commit [`4c89653`](https://github.com/apache/spark/commit/4c8965345fca51ee3accc7707b98c846eea4e01b).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by asfgit <gi...@git.apache.org>.
Github user asfgit closed the pull request at:
https://github.com/apache/spark/pull/22010
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #96583 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96583/testReport)** for PR 22010 at commit [`849f67b`](https://github.com/apache/spark/commit/849f67bf6c9a54007fec63a0b97cecfc7137e0be).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #96680 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96680/testReport)** for PR 22010 at commit [`95357cf`](https://github.com/apache/spark/commit/95357cff3da95c962c575f1b8efe155841ed78a5).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r217876184
--- Diff: core/src/main/scala/org/apache/spark/rdd/MapPartitionsRDD.scala ---
@@ -35,16 +35,24 @@ import org.apache.spark.{Partition, TaskContext}
* @param isOrderSensitive whether or not the function is order-sensitive. If it's order
* sensitive, it may return totally different result when the input order
* is changed. Mostly stateful functions are order-sensitive.
+ * @param knownPartitioner If the result has a known partitioner.
*/
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
var prev: RDD[T],
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator)
preservesPartitioning: Boolean = false,
isFromBarrier: Boolean = false,
- isOrderSensitive: Boolean = false)
+ isOrderSensitive: Boolean = false,
+ knownPartitioner: Option[Partitioner] = None)
extends RDD[U](prev) {
- override val partitioner = if (preservesPartitioning) firstParent[T].partitioner else None
+ override val partitioner = {
+ if (preservesPartitioning) {
+ firstParent[T].partitioner
+ } else {
+ knownPartitioner
+ }
+ }
--- End diff --
We dont need to modify public api to add support for this.
Create a subclass of MapPartitionsRDD which has partitioner method overridden to specify what you need.
Did I miss something here ?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/94607/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on the issue:
https://github.com/apache/spark/pull/22010
@cloud-fan yeah that's totally an option. Since @rxin asked for it to use `reduceByKey` I went with that approach, but I'd be happy to use the `ExternalAppendOnlyMap` if that's ok with folks.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r217901185
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,26 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ partitioner match {
+ case Some(p) if numPartitions == partitions.length =>
+ def key(x: T): (T, Null) = (x, null)
+ val cleanKey = sc.clean(key _)
+ val keyed = new MapPartitionsRDD[(T, Null), T](
+ this,
+ (context, pid, iter) => iter.map(cleanKey),
+ knownPartitioner = Some(new WrappedPartitioner(p)))
+ val duplicatesRemoved = keyed.reduceByKey((x, y) => x)
--- End diff --
Ah yes, no partitioner specified => use parent's partitioner.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on the issue:
https://github.com/apache/spark/pull/22010
I did a quick micro-benchmark on this and got:
> scala> :paste
> // Entering paste mode (ctrl-D to finish)
>
> import scala.collection.{mutable, Map}
> def removeDuplicatesInPartition(itr: Iterator[Int]): Iterator[Int] = {
> val set = new mutable.HashSet[Int]()
> itr.filter(set.add(_))
> }
>
> def time[R](block: => R): (Long, R) = {
> val t0 = System.nanoTime()
> val result = block // call-by-name
> val t1 = System.nanoTime()
> println("Elapsed time: " + (t1 - t0) + "ns")
> (t1, result)
> }
>
> val count = 1000000
> val inputData = sc.parallelize(1.to(count)).cache()
> inputData.count()
>
> val o1 = time(inputData.distinct().count())
> val n1 = time(inputData.mapPartitions(removeDuplicatesInPartition).count())
> val n2 = time(inputData.mapPartitions(removeDuplicatesInPartition).count())
> val o2 = time(inputData.distinct().count())
> val n3 = time(inputData.mapPartitions(removeDuplicatesInPartition).count())
>
>
> // Exiting paste mode, now interpreting.
>
> Elapsed time: 2464151504ns
> Elapsed time: 219130154ns
> Elapsed time: 133545428ns
> Elapsed time: 927133584ns
> Elapsed time: 242432642ns
> import scala.collection.{mutable, Map}
> removeDuplicatesInPartition: (itr: Iterator[Int])Iterator[Int]
> time: [R](block: => R)(Long, R)
> count: Int = 1000000
> inputData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[19] at parallelize at <console>:47
> o1: (Long, Long) = (437102431151279,1000000)
> n1: (Long, Long) = (437102654798968,1000000)
> n2: (Long, Long) = (437102792389328,1000000)
> o2: (Long, Long) = (437103724196085,1000000)
> n3: (Long, Long) = (437103971061275,1000000)
>
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #94303 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/94303/testReport)** for PR 22010 at commit [`a7fbc74`](https://github.com/apache/spark/commit/a7fbc74335c2df27002e8158f8e83a919195eed7).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22010
retest this please
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #96641 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96641/testReport)** for PR 22010 at commit [`95357cf`](https://github.com/apache/spark/commit/95357cff3da95c962c575f1b8efe155841ed78a5).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r220674552
--- Diff: core/src/test/scala/org/apache/spark/rdd/RDDSuite.scala ---
@@ -95,6 +95,18 @@ class RDDSuite extends SparkFunSuite with SharedSparkContext {
assert(!deserial.toString().isEmpty())
}
+ test("distinct with known partitioner preserves partitioning") {
+ val rdd = sc.parallelize(1.to(100), 10).map(x => (x % 10, x % 10)).sortByKey()
+ val initialPartitioner = rdd.partitioner
+ val distinctRdd = rdd.distinct()
+ val resultingPartitioner = distinctRdd.partitioner
+ assert(initialPartitioner === resultingPartitioner)
+ val distinctRddDifferent = rdd.distinct(5)
+ val distinctRddDifferentPartitioner = distinctRddDifferent.partitioner
+ assert(initialPartitioner != distinctRddDifferentPartitioner)
+ assert(distinctRdd.collect().sorted === distinctRddDifferent.collect().sorted)
--- End diff --
We could, but we don't need to.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by rxin <gi...@git.apache.org>.
Github user rxin commented on the issue:
https://github.com/apache/spark/pull/22010
Thanks for pinging. Please don't merge this until you've addressed the OOM issue. The aggregators were created to handle incoming data larger than size of memory. We should never use a Scala or Java hash set to put all the data in.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r218917483
--- Diff: core/src/main/scala/org/apache/spark/rdd/MapPartitionsRDD.scala ---
@@ -35,16 +35,24 @@ import org.apache.spark.{Partition, TaskContext}
* @param isOrderSensitive whether or not the function is order-sensitive. If it's order
* sensitive, it may return totally different result when the input order
* is changed. Mostly stateful functions are order-sensitive.
+ * @param knownPartitioner If the result has a known partitioner.
*/
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
var prev: RDD[T],
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator)
preservesPartitioning: Boolean = false,
isFromBarrier: Boolean = false,
- isOrderSensitive: Boolean = false)
+ isOrderSensitive: Boolean = false,
+ knownPartitioner: Option[Partitioner] = None)
extends RDD[U](prev) {
- override val partitioner = if (preservesPartitioning) firstParent[T].partitioner else None
+ override val partitioner = {
+ if (preservesPartitioning) {
+ firstParent[T].partitioner
+ } else {
+ knownPartitioner
+ }
+ }
--- End diff --
I mean yes we can sub-class just as easily -- is that what you mean?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on the issue:
https://github.com/apache/spark/pull/22010
Did another quick micro benchmark on a small cluster:
```scala
import org.apache.spark.util.collection.ExternalAppendOnlyMap
def removeDuplicatesInPartition(partition: Iterator[(Int, Int)]): Iterator[(Int, Int)] = {
// Create an instance of external append only map which ignores values.
val map = new ExternalAppendOnlyMap[(Int, Int), Null, Null](
createCombiner = value => null,
mergeValue = (a, b) => a,
mergeCombiners = (a, b) => a)
map.insertAll(partition.map(_ -> null))
map.iterator.map(_._1)
}
def time[R](block: => R): (Long, R) = {
val t0 = System.nanoTime()
val result = block // call-by-name
val t1 = System.nanoTime()
println("Elapsed time: " + (t1 - t0) + "ns")
(t1, result)
}
val count = 10000000
val inputData = sc.parallelize(1.to(count))
val keyed = inputData.map(x => (x % 100, x))
val shuffled = keyed.repartition(50).cache()
shuffled.count()
val o1 = time(shuffled.distinct().count())
val n1 = time(shuffled.mapPartitions(removeDuplicatesInPartition).count())
val n2 = time(shuffled.mapPartitions(removeDuplicatesInPartition).count())
val o2 = time(shuffled.distinct().count())
val n3 = time(shuffled.mapPartitions(removeDuplicatesInPartition).count())
```
And the result is:
> Elapsed time: 1790932239ns
> Elapsed time: 381450402ns
> Elapsed time: 340449179ns
> Elapsed time: 1524955492ns
> Elapsed time: 291948041ns
> import org.apache.spark.util.collection.ExternalAppendOnlyMap
> removeDuplicatesInPartition: (partition: Iterator[(Int, Int)])Iterator[(Int, Int)]
> time: [R](block: => R)(Long, R)
> count: Int = 10000000
> inputData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at parallelize at <console>:52
> keyed: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[11] at map at <console>:53
> shuffled: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[15] at repartition at <console>:54
> o1: (Long, Long) = (2943493642271881,10000000)
> n1: (Long, Long) = (2943494027399482,10000000)
> n2: (Long, Long) = (2943494371228656,10000000)
> o2: (Long, Long) = (2943495899580372,10000000)
> n3: (Long, Long) = (2943496195569891,10000000)
>
Increasing count by a factor of 10 we get:
> Elapsed time: 21679193176ns
> Elapsed time: 3114223737ns
> Elapsed time: 3348141004ns
> Elapsed time: 51267597984ns
> Elapsed time: 3931899963ns
> import org.apache.spark.util.collection.ExternalAppendOnlyMap
> removeDuplicatesInPartition: (partition: Iterator[(Int, Int)])Iterator[(Int, Int)]
> time: [R](block: => R)(Long, R)
> count: Int = 100000000
> inputData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[25] at parallelize at <console>:56
> keyed: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[26] at map at <console>:57
> shuffled: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[30] at repartition at <console>:58
> o1: (Long, Long) = (2943648438919959,100000000)
> n1: (Long, Long) = (2943651557292201,100000000)
> n2: (Long, Long) = (2943654909392808,100000000)
> o2: (Long, Long) = (2943706180722021,100000000)
> n3: (Long, Long) = (2943710116461734,100000000)
>
>
So that looks like close to an order of magnitude improvement.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #94634 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/94634/testReport)** for PR 22010 at commit [`5fd3659`](https://github.com/apache/spark/commit/5fd36592a26b07fdb58e79e4efbb6b70daea54df).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r216170355
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,26 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ partitioner match {
--- End diff --
No we can't. Since the original partitioner function takes in the key of the RDD and they key is now changing we can't gaurantee that the previous partitioner preserves partioning when we do (`x => (x, null)`). In fact with the HashBased partitioner this is not the case (if you want I explored this in my live stream - https://youtu.be/NDGM501uUrE?t=19m17s and you can see the Challenger with that approach.)
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r218946895
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,26 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ partitioner match {
+ case Some(p) if numPartitions == partitions.length =>
+ def key(x: T): (T, Null) = (x, null)
+ val cleanKey = sc.clean(key _)
+ val keyed = new MapPartitionsRDD[(T, Null), T](
+ this,
+ (context, pid, iter) => iter.map(cleanKey),
+ knownPartitioner = Some(new WrappedPartitioner(p)))
+ val duplicatesRemoved = keyed.reduceByKey((x, y) => x)
--- End diff --
Yes, would use right partitioner in this case
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r218946996
--- Diff: core/src/main/scala/org/apache/spark/rdd/MapPartitionsRDD.scala ---
@@ -35,16 +35,24 @@ import org.apache.spark.{Partition, TaskContext}
* @param isOrderSensitive whether or not the function is order-sensitive. If it's order
* sensitive, it may return totally different result when the input order
* is changed. Mostly stateful functions are order-sensitive.
+ * @param knownPartitioner If the result has a known partitioner.
*/
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
var prev: RDD[T],
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator)
preservesPartitioning: Boolean = false,
isFromBarrier: Boolean = false,
- isOrderSensitive: Boolean = false)
+ isOrderSensitive: Boolean = false,
+ knownPartitioner: Option[Partitioner] = None)
extends RDD[U](prev) {
- override val partitioner = if (preservesPartitioning) firstParent[T].partitioner else None
+ override val partitioner = {
+ if (preservesPartitioning) {
+ firstParent[T].partitioner
+ } else {
+ knownPartitioner
+ }
+ }
--- End diff --
yes
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2910/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on the issue:
https://github.com/apache/spark/pull/22010
I'll leave this until Friday morning (pacific) in case anyone has last minute comments. cc @rxin / @HyukjinKwon / @mgaido91
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r220672896
--- Diff: core/src/test/scala/org/apache/spark/rdd/RDDSuite.scala ---
@@ -95,6 +95,18 @@ class RDDSuite extends SparkFunSuite with SharedSparkContext {
assert(!deserial.toString().isEmpty())
}
+ test("distinct with known partitioner preserves partitioning") {
+ val rdd = sc.parallelize(1.to(100), 10).map(x => (x % 10, x % 10)).sortByKey()
+ val initialPartitioner = rdd.partitioner
+ val distinctRdd = rdd.distinct()
+ val resultingPartitioner = distinctRdd.partitioner
+ assert(initialPartitioner === resultingPartitioner)
+ val distinctRddDifferent = rdd.distinct(5)
+ val distinctRddDifferentPartitioner = distinctRddDifferent.partitioner
+ assert(initialPartitioner != distinctRddDifferentPartitioner)
+ assert(distinctRdd.collect().sorted === distinctRddDifferent.collect().sorted)
--- End diff --
We could also check if the number of stages is what we expect.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by mgaido91 <gi...@git.apache.org>.
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r209351478
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,16 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ // If the data is already approriately partitioned with a known partitioner we can work locally.
+ def removeDuplicatesInPartition(itr: Iterator[T]): Iterator[T] = {
+ val set = new mutable.HashSet[T]()
+ itr.filter(set.add(_))
--- End diff --
not a big deal, but despite this is really compact and elegant, it adds to the set also the elements which are already there and it is not needed. We can probably check if the key is there and add it only in that case, probably it is a bit faster.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by mgaido91 <gi...@git.apache.org>.
Github user mgaido91 commented on the issue:
https://github.com/apache/spark/pull/22010
retest this please
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #94303 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/94303/testReport)** for PR 22010 at commit [`a7fbc74`](https://github.com/apache/spark/commit/a7fbc74335c2df27002e8158f8e83a919195eed7).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by mgaido91 <gi...@git.apache.org>.
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r208180371
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,16 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ // If the data is already approriately partioned with a known partioner we can work locally.
+ def removeDuplicatesInPartition(itr: Iterator[T]): Iterator[T] = {
+ val set = new mutable.HashSet[T]() ++= itr
--- End diff --
I think here we could return a new iterator which wraps `itr` and uses this set as a state in order to filter out the records we have already met. In this way we could have only one pass over the data, instead of the 2 of the current solution. What do you think?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #96583 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96583/testReport)** for PR 22010 at commit [`849f67b`](https://github.com/apache/spark/commit/849f67bf6c9a54007fec63a0b97cecfc7137e0be).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r209440037
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,16 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ // If the data is already approriately partitioned with a known partitioner we can work locally.
+ def removeDuplicatesInPartition(itr: Iterator[T]): Iterator[T] = {
+ val set = new mutable.HashSet[T]()
+ itr.filter(set.add(_))
--- End diff --
So according to HashSet can only contain one instance for each element so we don't need to worry about adding multiple copies of the elements.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22010
I think this works, can we post some Spark web UI screenshots to confirm the shuffle is indeed eliminated?
BTW one idea to simplify the implementation:
```
def distinct(numPartitions) = {
...
mapPartitions(iter => {
val map = new ExternalAppendOnlyMap[T, Null, Null](
createCombiner = identity,
mergeValue = (a, b) => a,
mergeCombiners = (a, b) => a)
map.insertAll(iter.map(_ -> null))
map.iterator.map(_._1)
}, preservesPartitioning = true)
}
```
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by mgaido91 <gi...@git.apache.org>.
Github user mgaido91 commented on the issue:
https://github.com/apache/spark/pull/22010
LGTM
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #95767 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95767/testReport)** for PR 22010 at commit [`7ed7589`](https://github.com/apache/spark/commit/7ed7589bcba9273aa14ba207bfaf5bb67b57e6c8).
* This patch **fails Spark unit tests**.
* This patch **does not merge cleanly**.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by mgaido91 <gi...@git.apache.org>.
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r209450199
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,16 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ // If the data is already approriately partitioned with a known partitioner we can work locally.
+ def removeDuplicatesInPartition(itr: Iterator[T]): Iterator[T] = {
+ val set = new mutable.HashSet[T]()
+ itr.filter(set.add(_))
--- End diff --
yes, it is not a big deal, but if you check the implementation in the scala lib you can see that the hash and the index for the key is computed despite it not needed (since `addElem` is called anyway). Probably it doesn't change much, but we could save this computation...
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r217901179
--- Diff: core/src/main/scala/org/apache/spark/rdd/MapPartitionsRDD.scala ---
@@ -35,16 +35,24 @@ import org.apache.spark.{Partition, TaskContext}
* @param isOrderSensitive whether or not the function is order-sensitive. If it's order
* sensitive, it may return totally different result when the input order
* is changed. Mostly stateful functions are order-sensitive.
+ * @param knownPartitioner If the result has a known partitioner.
*/
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
var prev: RDD[T],
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator)
preservesPartitioning: Boolean = false,
isFromBarrier: Boolean = false,
- isOrderSensitive: Boolean = false)
+ isOrderSensitive: Boolean = false,
+ knownPartitioner: Option[Partitioner] = None)
extends RDD[U](prev) {
- override val partitioner = if (preservesPartitioning) firstParent[T].partitioner else None
+ override val partitioner = {
+ if (preservesPartitioning) {
+ firstParent[T].partitioner
+ } else {
+ knownPartitioner
+ }
+ }
--- End diff --
Since we are already creating a `MapPartitionsRDD` in distinct, overriding `partitioner` should be trivial.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22010
retest this please
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #94607 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/94607/testReport)** for PR 22010 at commit [`5fd3659`](https://github.com/apache/spark/commit/5fd36592a26b07fdb58e79e4efbb6b70daea54df).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r220399074
--- Diff: core/src/main/scala/org/apache/spark/rdd/MapPartitionsRDD.scala ---
@@ -19,7 +19,7 @@ package org.apache.spark.rdd
import scala.reflect.ClassTag
-import org.apache.spark.{Partition, TaskContext}
+import org.apache.spark.{Partition, Partitioner, TaskContext}
--- End diff --
nit: unnecessary change
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3454/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3519/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3529/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #96652 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96652/testReport)** for PR 22010 at commit [`95357cf`](https://github.com/apache/spark/commit/95357cff3da95c962c575f1b8efe155841ed78a5).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22010
retest this please
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by HeartSaVioR <gi...@git.apache.org>.
Github user HeartSaVioR commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r209230417
--- Diff: core/src/test/scala/org/apache/spark/rdd/RDDSuite.scala ---
@@ -95,6 +95,18 @@ class RDDSuite extends SparkFunSuite with SharedSparkContext {
assert(!deserial.toString().isEmpty())
}
+ test("distinct with known partioner does not cause shuffle") {
--- End diff --
nite: partioner -> partitioner
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #96669 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96669/testReport)** for PR 22010 at commit [`95357cf`](https://github.com/apache/spark/commit/95357cff3da95c962c575f1b8efe155841ed78a5).
* This patch **fails due to an unknown error code, -9**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #94577 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/94577/testReport)** for PR 22010 at commit [`5fd3659`](https://github.com/apache/spark/commit/5fd36592a26b07fdb58e79e4efbb6b70daea54df).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #96641 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96641/testReport)** for PR 22010 at commit [`95357cf`](https://github.com/apache/spark/commit/95357cff3da95c962c575f1b8efe155841ed78a5).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by HeartSaVioR <gi...@git.apache.org>.
Github user HeartSaVioR commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r209230438
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,16 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ // If the data is already approriately partioned with a known partioner we can work locally.
--- End diff --
nit: partioned -> partitioned, partioner -> partitioner
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #95767 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95767/testReport)** for PR 22010 at commit [`7ed7589`](https://github.com/apache/spark/commit/7ed7589bcba9273aa14ba207bfaf5bb67b57e6c8).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/1861/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r220674846
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -42,7 +42,8 @@ import org.apache.spark.partial.GroupedCountEvaluator
import org.apache.spark.partial.PartialResult
import org.apache.spark.storage.{RDDBlockId, StorageLevel}
import org.apache.spark.util.{BoundedPriorityQueue, Utils}
-import org.apache.spark.util.collection.{OpenHashMap, Utils => collectionUtils}
+import org.apache.spark.util.collection.{ExternalAppendOnlyMap, OpenHashMap,
+ Utils => collectionUtils}
--- End diff --
yeah but we generally break anyways based on the rest of the code base.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/96641/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r209338809
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,16 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ // If the data is already approriately partioned with a known partioner we can work locally.
+ def removeDuplicatesInPartition(itr: Iterator[T]): Iterator[T] = {
+ val set = new mutable.HashSet[T]() ++= itr
--- End diff --
I like this suggestion, thanks!
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r214575455
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,16 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ // If the data is already approriately partitioned with a known partitioner we can work locally.
+ def removeDuplicatesInPartition(itr: Iterator[T]): Iterator[T] = {
+ val set = new mutable.HashSet[T]()
+ itr.filter(set.add(_))
--- End diff --
So to reuse `reduceByKey` I'd write a custom partitioner which uses the existing partioner as it's base but takes in the combined key type as input and drop it down to the original key.
Sound right?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22010
thanks, merging to master!
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on the issue:
https://github.com/apache/spark/pull/22010
So by running `sc.parallelize(1.to(1000)).map(x => (x % 10, x)).sortByKey().distinct().count()` in 2.3.0 and my PR we can see the difference:
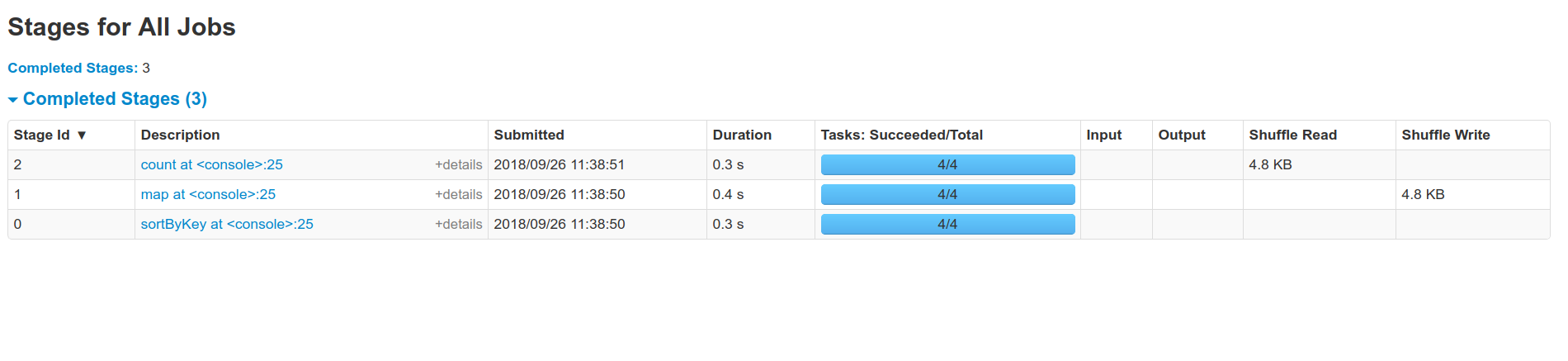
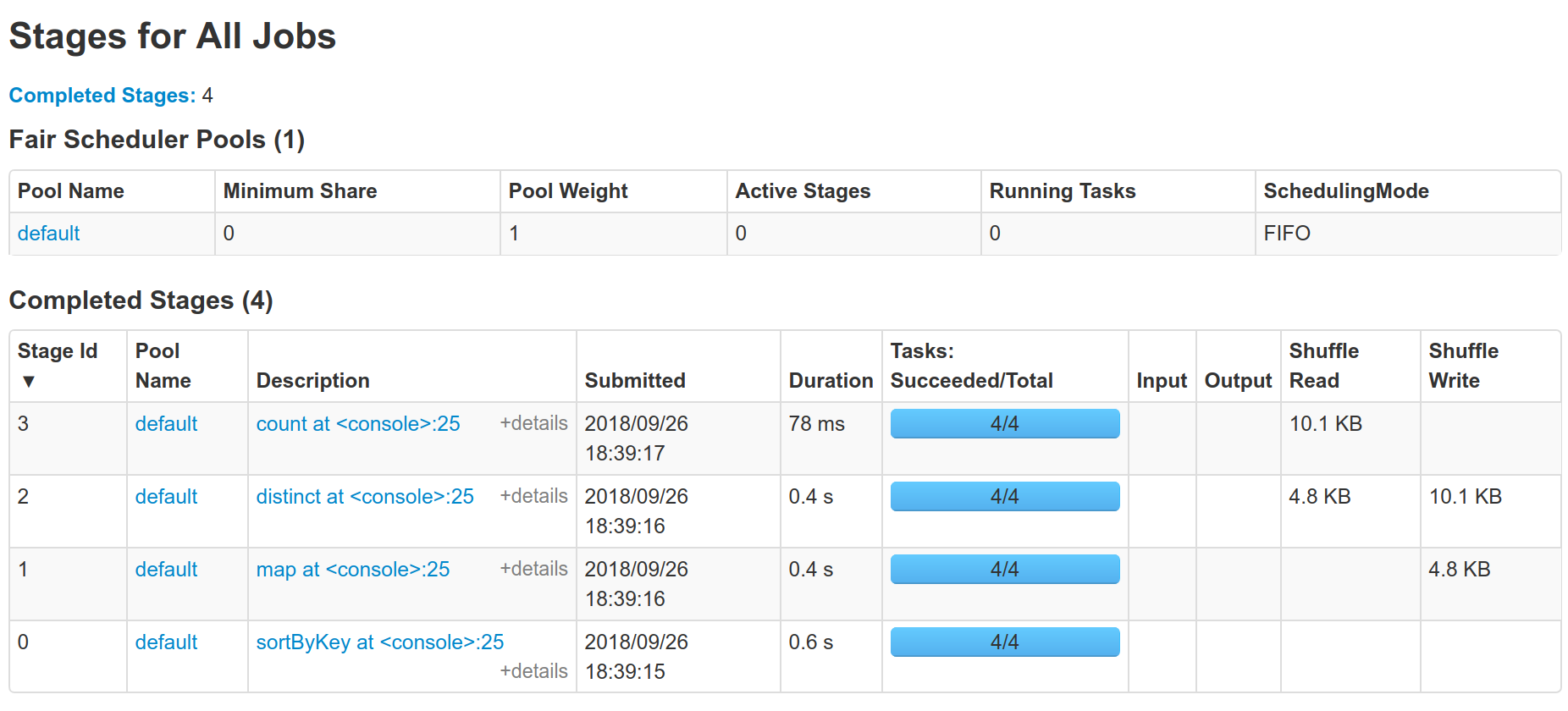
And see one less shuffle.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on the issue:
https://github.com/apache/spark/pull/22010
Test failure is streaming timeout, likely unrelated. Jenkins retest this please.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2076/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on the issue:
https://github.com/apache/spark/pull/22010
Open question: is this suitable for branch-2.4 since it predates the branch cut or not? (I know we've gone back and forth on how we do that).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by rxin <gi...@git.apache.org>.
Github user rxin commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r214103223
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,16 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ // If the data is already approriately partitioned with a known partitioner we can work locally.
+ def removeDuplicatesInPartition(itr: Iterator[T]): Iterator[T] = {
+ val set = new mutable.HashSet[T]()
+ itr.filter(set.add(_))
--- End diff --
This is a bad implementation and could OOM. You should reuse reduceByKey.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by rxin <gi...@git.apache.org>.
Github user rxin commented on the issue:
https://github.com/apache/spark/pull/22010
Actually @holdenk is this change even correct? RDD.distinct is not key based. It is based on the value of the elements in RDD. Even if `numPartitions == partitions.length`, it doesn't mean the RDD is hash partitioned this way.
Consider this RDD:
Partition 1: 1, 2, 3
Partition 2: 1, 2, 3
rdd.distinct() should return 1, 2, 3
with your change it'd still return 1, 2, 3, 1, 2, 3.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #96669 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96669/testReport)** for PR 22010 at commit [`95357cf`](https://github.com/apache/spark/commit/95357cff3da95c962c575f1b8efe155841ed78a5).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by rxin <gi...@git.apache.org>.
Github user rxin commented on the issue:
https://github.com/apache/spark/pull/22010
If this is not yet in 2.4 it shouldn’t be merged now.
On Wed, Oct 10, 2018 at 10:57 AM Holden Karau <no...@github.com>
wrote:
> Open question: is this suitable for branch-2.4 since it predates the
> branch cut or not? (I know we've gone back and forth on how we do that).
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub
> <https://github.com/apache/spark/pull/22010#issuecomment-428492653>, or mute
> the thread
> <https://github.com/notifications/unsubscribe-auth/AATvPO6Nlv4HOCVe9pPZfCd1GHXoVCDxks5ujbZlgaJpZM4Vw2BM>
> .
>
--
-x
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by rxin <gi...@git.apache.org>.
Github user rxin commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r216145892
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,26 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ partitioner match {
--- End diff --
you can just create a new MapPartitionsRDD with preservesPartitioning set to true, can't you?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/96652/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/96583/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by mgaido91 <gi...@git.apache.org>.
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r214057591
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,16 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ // If the data is already approriately partitioned with a known partitioner we can work locally.
+ def removeDuplicatesInPartition(itr: Iterator[T]): Iterator[T] = {
+ val set = new mutable.HashSet[T]()
+ itr.filter(set.add(_))
--- End diff --
yes, the hash should be computed anyway, this is just a nit, I am not sure if the perf gain would be even noticeable, that is why I already gave my LGTM, despite this comment.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2053/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #96680 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96680/testReport)** for PR 22010 at commit [`95357cf`](https://github.com/apache/spark/commit/95357cff3da95c962c575f1b8efe155841ed78a5).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r209340344
--- Diff: core/src/test/scala/org/apache/spark/rdd/RDDSuite.scala ---
@@ -95,6 +95,18 @@ class RDDSuite extends SparkFunSuite with SharedSparkContext {
assert(!deserial.toString().isEmpty())
}
+ test("distinct with known partioner does not cause shuffle") {
--- End diff --
Thanks!
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r218918701
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,26 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ partitioner match {
+ case Some(p) if numPartitions == partitions.length =>
+ def key(x: T): (T, Null) = (x, null)
+ val cleanKey = sc.clean(key _)
+ val keyed = new MapPartitionsRDD[(T, Null), T](
+ this,
+ (context, pid, iter) => iter.map(cleanKey),
+ knownPartitioner = Some(new WrappedPartitioner(p)))
+ val duplicatesRemoved = keyed.reduceByKey((x, y) => x)
--- End diff --
So I _think_ it is partitioner of input RDD if known partitioner otherwise hash partitioner of the default parallelism. Yes?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r220674969
--- Diff: core/src/main/scala/org/apache/spark/rdd/MapPartitionsRDD.scala ---
@@ -19,7 +19,7 @@ package org.apache.spark.rdd
import scala.reflect.ClassTag
-import org.apache.spark.{Partition, TaskContext}
+import org.apache.spark.{Partition, Partitioner, TaskContext}
--- End diff --
Thanks! I'll fix that.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r217900574
--- Diff: core/src/main/scala/org/apache/spark/rdd/MapPartitionsRDD.scala ---
@@ -35,16 +35,24 @@ import org.apache.spark.{Partition, TaskContext}
* @param isOrderSensitive whether or not the function is order-sensitive. If it's order
* sensitive, it may return totally different result when the input order
* is changed. Mostly stateful functions are order-sensitive.
+ * @param knownPartitioner If the result has a known partitioner.
*/
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
var prev: RDD[T],
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator)
preservesPartitioning: Boolean = false,
isFromBarrier: Boolean = false,
- isOrderSensitive: Boolean = false)
+ isOrderSensitive: Boolean = false,
+ knownPartitioner: Option[Partitioner] = None)
extends RDD[U](prev) {
- override val partitioner = if (preservesPartitioning) firstParent[T].partitioner else None
+ override val partitioner = {
+ if (preservesPartitioning) {
+ firstParent[T].partitioner
+ } else {
+ knownPartitioner
+ }
+ }
--- End diff --
`MapPartitionsRDD` is already private. But yes the other option is sub-classing.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r217876215
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,26 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ partitioner match {
+ case Some(p) if numPartitions == partitions.length =>
+ def key(x: T): (T, Null) = (x, null)
+ val cleanKey = sc.clean(key _)
+ val keyed = new MapPartitionsRDD[(T, Null), T](
+ this,
+ (context, pid, iter) => iter.map(cleanKey),
+ knownPartitioner = Some(new WrappedPartitioner(p)))
+ val duplicatesRemoved = keyed.reduceByKey((x, y) => x)
--- End diff --
Dont you need to specify the partitioner here ?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2091/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r220674444
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +397,20 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ def removeDuplicatesInPartition(partition: Iterator[T]): Iterator[T] = {
+ // Create an instance of external append only map which ignores values.
+ val map = new ExternalAppendOnlyMap[T, Null, Null](
+ createCombiner = value => null,
+ mergeValue = (a, b) => a,
+ mergeCombiners = (a, b) => a)
--- End diff --
scratch that - does not matter
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Posted by rxin <gi...@git.apache.org>.
Github user rxin commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r214103667
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,16 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
- map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+ // If the data is already approriately partitioned with a known partitioner we can work locally.
+ def removeDuplicatesInPartition(itr: Iterator[T]): Iterator[T] = {
+ val set = new mutable.HashSet[T]()
+ itr.filter(set.add(_))
--- End diff --
This is a bad implementation and could OOM. You should reuse reduceByKey.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on the issue:
https://github.com/apache/spark/pull/22010
@rxin So that RDD could not exist with a known partitioner (regardless of range-based or hash based the partitioner must be deterministic so two elements with the same key must go to the same partition & if two elements do not have same key they can not be duplicates of each other). Distinct looks at both the input k/v as one elem not just v (e.g an RDD of `[(1, 2), (2, 2), (2, 2)].distinct()` should produce `[(1,2), (2, 2)]`).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/94303/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22010
While this saves a shuffle, but the algorithm becomes different. Previously we use the shuffe aggregator, which stores data in a `ExternalAppendOnlyMap`. Now we use a scala set, which may OOM.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on the issue:
https://github.com/apache/spark/pull/22010
Hey @rxin & @cloud-fan I'd really appreciate your input on the tricks I did to keep the partioniner information present -- is this the right approach?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/94577/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by holdenk <gi...@git.apache.org>.
Github user holdenk commented on the issue:
https://github.com/apache/spark/pull/22010
Updated to use reduceByKey. I'd really appreciate feedback on if adding the param to `MapPartitionsRDD` was the way to go or if I should sub-class it instead.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #95768 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95768/testReport)** for PR 22010 at commit [`4c89653`](https://github.com/apache/spark/commit/4c8965345fca51ee3accc7707b98c846eea4e01b).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22010
**[Test build #94607 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/94607/testReport)** for PR 22010 at commit [`5fd3659`](https://github.com/apache/spark/commit/5fd36592a26b07fdb58e79e4efbb6b70daea54df).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22010
Build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org