You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2022/03/04 03:51:20 UTC
[GitHub] [spark] sleep1661 commented on pull request #32923: [SPARK-35783][SQL] Set the list of read columns in the task configuration to reduce reading of ORC data.
sleep1661 commented on pull request #32923:
URL: https://github.com/apache/spark/pull/32923#issuecomment-1058800304
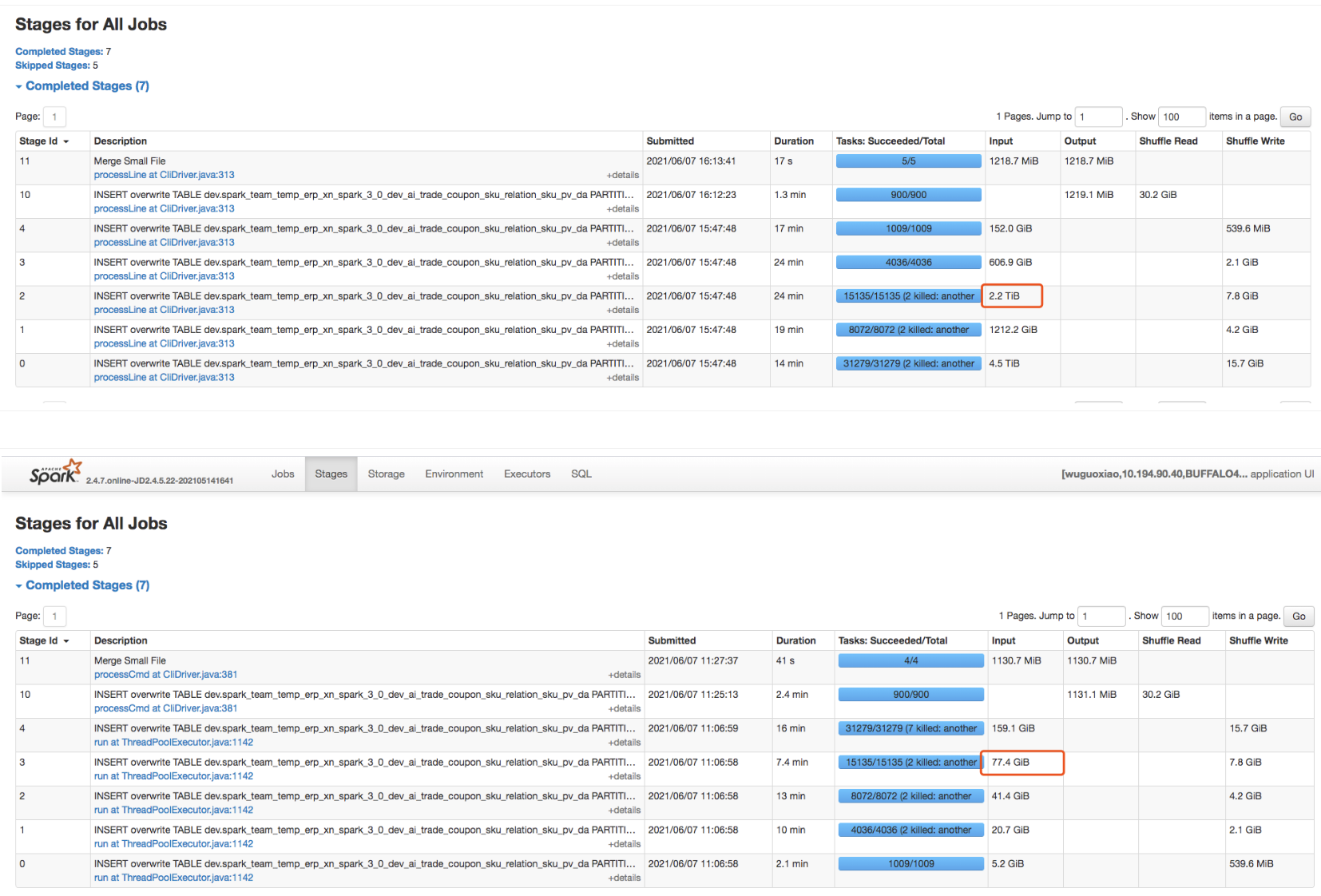
> @cloud-fan We are migrating from 2.4.7 to 3.0.2, and observed a significant regression in some cases due to this issue.
>
> 
> @cloud-fan We are migrating from 2.4.7 to 3.0.2, and observed a significant regression in some cases due to this issue.
>
> 
@zhengruifeng I had run some sql test on 3.1.2 (without this PR), but I didn't reproduce the issue. The result the ORC reader does not read all columns. My sql was like this: select count(id) from dev.test1
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org