You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@zeppelin.apache.org by zj...@apache.org on 2019/10/10 03:46:09 UTC
[zeppelin] branch master updated: [ZEPPELIN-4369] Redundant line
separator for multiple text output
This is an automated email from the ASF dual-hosted git repository.
zjffdu pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/zeppelin.git
The following commit(s) were added to refs/heads/master by this push:
new d91e312 [ZEPPELIN-4369] Redundant line separator for multiple text output
d91e312 is described below
commit d91e312798dbb804f64f6f58d689544d54e4c95d
Author: Jeff Zhang <zj...@apache.org>
AuthorDate: Tue Oct 8 23:04:13 2019 +0800
[ZEPPELIN-4369] Redundant line separator for multiple text output
### What is this PR for?
There's redundant line separator when there's multiple text output. The root cause is that each `%text ` will append new line separator in frontend. This PR fix this issue by removing `%text ` is the previous output type is also `%text `.
### What type of PR is it?
[Bug Fix ]
### Todos
* [ ] - Task
### What is the Jira issue?
* https://issues.apache.org/jira/browse/ZEPPELIN-4369
### How should this be tested?
* CI pass
### Screenshots (if appropriate)
Before
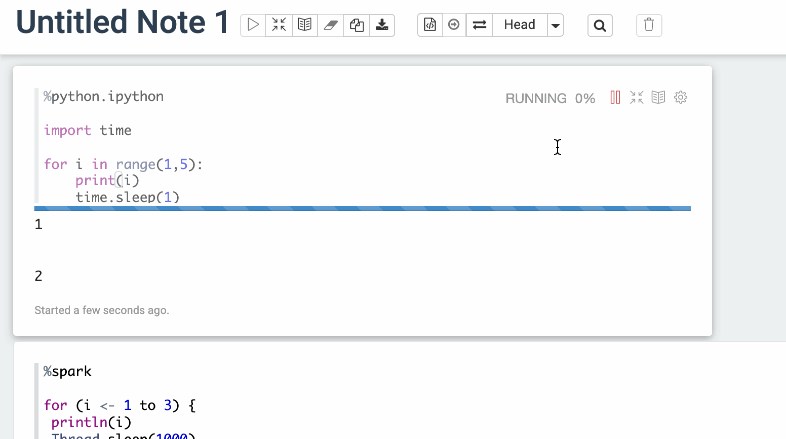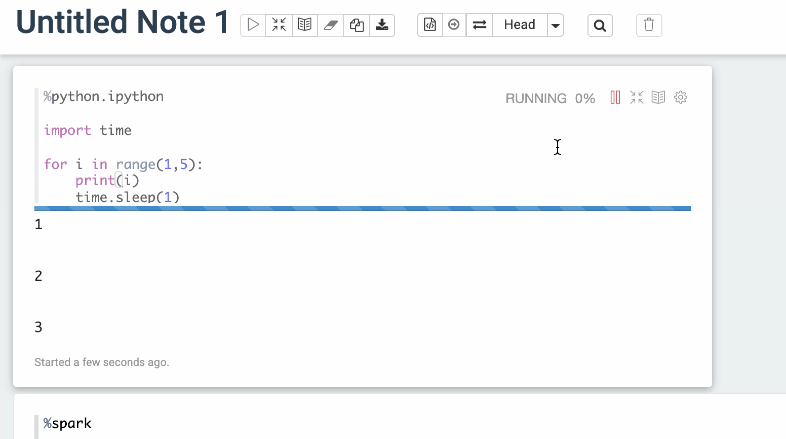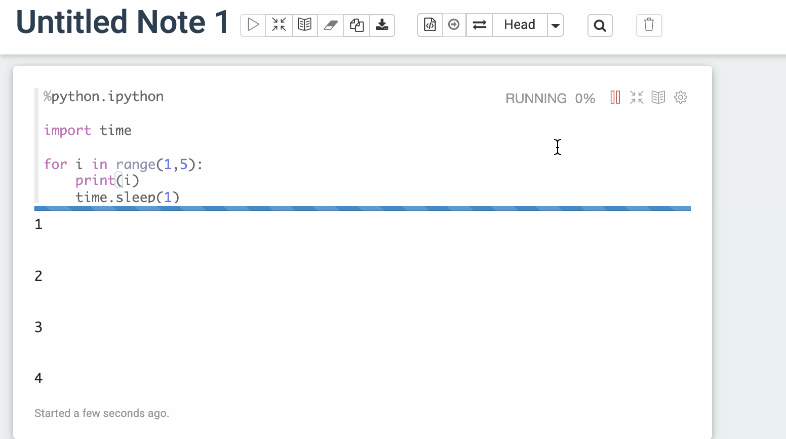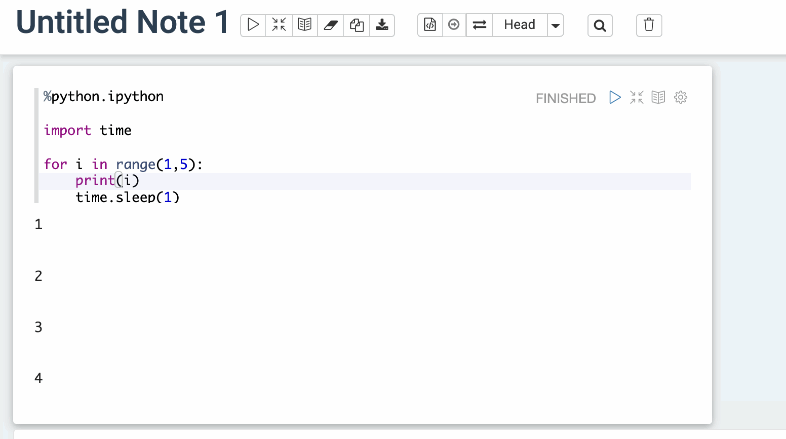
After

### Questions:
* Does the licenses files need update? No
* Is there breaking changes for older versions? No
* Does this needs documentation? No
Author: Jeff Zhang <zj...@apache.org>
Closes #3478 from zjffdu/ZEPPELIN-4369 and squashes the following commits:
8c3d380db [Jeff Zhang] [ZEPPELIN-4369] Redundant line separator for multiple text output
---
.../org/apache/zeppelin/python/IPythonClient.java | 83 +++++++++++-----------
.../zeppelin/python/BasePythonInterpreterTest.java | 9 +++
2 files changed, 52 insertions(+), 40 deletions(-)
diff --git a/python/src/main/java/org/apache/zeppelin/python/IPythonClient.java b/python/src/main/java/org/apache/zeppelin/python/IPythonClient.java
index ec0c052..9ad0031 100644
--- a/python/src/main/java/org/apache/zeppelin/python/IPythonClient.java
+++ b/python/src/main/java/org/apache/zeppelin/python/IPythonClient.java
@@ -87,58 +87,61 @@ public class IPythonClient {
maybeIPythonFailed = false;
LOGGER.debug("stream_execute code:\n" + request.getCode());
asyncStub.execute(request, new StreamObserver<ExecuteResponse>() {
- int index = 0;
+ OutputType lastOutputType = null;
@Override
public void onNext(ExecuteResponse executeResponse) {
LOGGER.debug("Interpreter Streaming Output: " + executeResponse.getType() +
"\t" + executeResponse.getOutput());
- if (index != 0) {
- try {
- // We need to add line separator first, because zeppelin only recoginize the % at
- // the line beginning.
- interpreterOutput.write("\n".getBytes());
- } catch (IOException e) {
- LOGGER.error("Unexpected IOException", e);
- }
- }
-
- if (executeResponse.getType() == OutputType.TEXT) {
- try {
- if (executeResponse.getOutput().startsWith("%")) {
- // the output from ipython kernel maybe specify format already.
- interpreterOutput.write((executeResponse.getOutput()).getBytes());
- } else {
- interpreterOutput.write(("%text " + executeResponse.getOutput()).getBytes());
+ switch (executeResponse.getType()) {
+ case TEXT:
+ try {
+ if (executeResponse.getOutput().startsWith("%")) {
+ // the output from ipython kernel maybe specify format already.
+ interpreterOutput.write((executeResponse.getOutput()).getBytes());
+ } else {
+ // only add %text when the previous output type is not TEXT.
+ // Reason :
+ // 1. if no `%text`, it will be treated as previous output type.
+ // 2. Always prepend `%text `, there will be an extra line separator,
+ // because `%text ` appends line separator first.
+ if (lastOutputType != OutputType.TEXT) {
+ interpreterOutput.write("%text ".getBytes());
+ }
+ interpreterOutput.write(executeResponse.getOutput().getBytes());
+ }
+ interpreterOutput.getInterpreterOutput().flush();
+ } catch (IOException e) {
+ LOGGER.error("Unexpected IOException", e);
}
- interpreterOutput.getInterpreterOutput().flush();
- } catch (IOException e) {
- LOGGER.error("Unexpected IOException", e);
- }
- }
- if (executeResponse.getType() == OutputType.PNG ||
- executeResponse.getType() == OutputType.JPEG) {
- try {
- interpreterOutput.write(("%img " + executeResponse.getOutput()).getBytes());
- interpreterOutput.getInterpreterOutput().flush();
- } catch (IOException e) {
- LOGGER.error("Unexpected IOException", e);
- }
- }
- if (executeResponse.getType() == OutputType.HTML) {
- try {
- interpreterOutput.write(("%html\n" + executeResponse.getOutput()).getBytes());
- interpreterOutput.getInterpreterOutput().flush();
- } catch (IOException e) {
- LOGGER.error("Unexpected IOException", e);
- }
+ break;
+ case PNG:
+ case JPEG:
+ try {
+ interpreterOutput.write(("\n%img " + executeResponse.getOutput()).getBytes());
+ interpreterOutput.getInterpreterOutput().flush();
+ } catch (IOException e) {
+ LOGGER.error("Unexpected IOException", e);
+ }
+ break;
+ case HTML:
+ try {
+ interpreterOutput.write(("\n%html " + executeResponse.getOutput()).getBytes());
+ interpreterOutput.getInterpreterOutput().flush();
+ } catch (IOException e) {
+ LOGGER.error("Unexpected IOException", e);
+ }
+ break;
+ default:
+ LOGGER.error("Unrecognized type:" + executeResponse.getType());
}
+
+ lastOutputType = executeResponse.getType();
if (executeResponse.getStatus() == ExecuteStatus.ERROR) {
// set the finalResponse to ERROR if any ERROR happens, otherwise the finalResponse would
// be SUCCESS.
finalResponseBuilder.setStatus(ExecuteStatus.ERROR);
}
- index++;
}
@Override
diff --git a/python/src/test/java/org/apache/zeppelin/python/BasePythonInterpreterTest.java b/python/src/test/java/org/apache/zeppelin/python/BasePythonInterpreterTest.java
index e37b031..7eece35 100644
--- a/python/src/test/java/org/apache/zeppelin/python/BasePythonInterpreterTest.java
+++ b/python/src/test/java/org/apache/zeppelin/python/BasePythonInterpreterTest.java
@@ -202,6 +202,15 @@ public abstract class BasePythonInterpreterTest extends ConcurrentTestCase {
assertEquals(InterpreterResult.Code.SUCCESS, result.code());
interpreterResultMessages = context.out.toInterpreterResultMessage();
assertEquals(0, interpreterResultMessages.size());
+
+ // multiple text output
+ context = getInterpreterContext();
+ result = interpreter.interpret(
+ "for i in range(1,4):\n" + "\tprint(i)", context);
+ assertEquals(InterpreterResult.Code.SUCCESS, result.code());
+ interpreterResultMessages = context.out.toInterpreterResultMessage();
+ assertEquals(1, interpreterResultMessages.size());
+ assertEquals("1\n2\n3\n", interpreterResultMessages.get(0).getData());
}
@Test