You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2022/02/11 04:01:13 UTC
[GitHub] [hudi] gaoasi opened a new issue #4790: [SUPPORT] hudi-kafka-connect data missing!
gaoasi opened a new issue #4790:
URL: https://github.com/apache/hudi/issues/4790
i used hudi-kafka-connect to load logs from kafka to hudi
config is :
bootstrap.servers=localhost:9092
group.id=hudi-connect-cluster-test
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.topic=connect-offsets
offset.storage.replication.factor=1
config.storage.topic=connect-configs
config.storage.replication.factor=1
status.storage.topic=connect-status
status.storage.replication.factor=1
offset.flush.interval.ms=60000
listeners=HTTP://localhost:8083
plugin.path=/opt/hudi-kaka-connect/kafka/plugins
the result is:
in the hudi table path,there is only the logs file,no data files
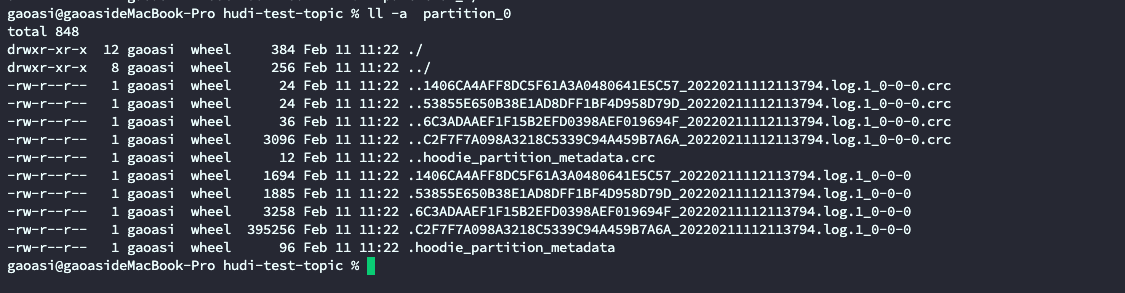
why?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] gaoasi commented on issue #4790: [SUPPORT] hudi-kafka-connect data missing!
Posted by GitBox <gi...@apache.org>.
gaoasi commented on issue #4790:
URL: https://github.com/apache/hudi/issues/4790#issuecomment-1038681195
thanks for answer!
i have a doubt,may i should configure a separate async compaction to execute compactions every time when the new data arrives,or i can configure a separate async compaction to execute compactions only once when the task first start
@nsivabalan
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] gaoasi closed issue #4790: [SUPPORT] hudi-kafka-connect data missing!
Posted by GitBox <gi...@apache.org>.
gaoasi closed issue #4790:
URL: https://github.com/apache/hudi/issues/4790
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] gaoasi commented on issue #4790: [SUPPORT] hudi-kafka-connect data missing!
Posted by GitBox <gi...@apache.org>.
gaoasi commented on issue #4790:
URL: https://github.com/apache/hudi/issues/4790#issuecomment-1039994066
@nsivabalan Thank you very much for your patient answer
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] gaoasi commented on issue #4790: [SUPPORT] hudi-kafka-connect data missing!
Posted by GitBox <gi...@apache.org>.
gaoasi commented on issue #4790:
URL: https://github.com/apache/hudi/issues/4790#issuecomment-1039994066
@nsivabalan Thank you very much for your patient answer
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #4790: [SUPPORT] hudi-kafka-connect data missing!
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #4790:
URL: https://github.com/apache/hudi/issues/4790#issuecomment-1039511479
I will let experts weigh in here. But to my knowledge, scheduling will be done by kafka writers (connect). but for execution, you might have to configure a separate job and ensure compaction gets executed by it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #4790: [SUPPORT] hudi-kafka-connect data missing!
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #4790:
URL: https://github.com/apache/hudi/issues/4790#issuecomment-1039148288
@yihua @rmahindra123 : Can you folks assist here.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #4790: [SUPPORT] hudi-kafka-connect data missing!
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #4790:
URL: https://github.com/apache/hudi/issues/4790#issuecomment-1037429147
yes, in kafka connect hudi directly writes to log files. Expectation is that, user should configure a separate async compaction to execute compactions. And then you can start to see base parquet files. But actual writing from kafka nodes directly go into log files.
so this is expected.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan edited a comment on issue #4790: [SUPPORT] hudi-kafka-connect data missing!
Posted by GitBox <gi...@apache.org>.
nsivabalan edited a comment on issue #4790:
URL: https://github.com/apache/hudi/issues/4790#issuecomment-1039511479
I will let experts weigh in here. But to my knowledge, scheduling will be done by kafka writers (connect). but for execution, you might have to configure a separate job and ensure compaction gets executed by it.
https://hudi.apache.org/docs/compaction/#hudi-compactor-utility
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #4790: [SUPPORT] hudi-kafka-connect data missing!
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #4790:
URL: https://github.com/apache/hudi/issues/4790#issuecomment-1039511479
I will let experts weigh in here. But to my knowledge, scheduling will be done by kafka writers (connect). but for execution, you might have to configure a separate job and ensure compaction gets executed by it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #4790: [SUPPORT] hudi-kafka-connect data missing!
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #4790:
URL: https://github.com/apache/hudi/issues/4790#issuecomment-1037429147
yes, in kafka connect hudi directly writes to log files. Expectation is that, user should configure a separate async compaction to execute compactions. And then you can start to see base parquet files. But actual writing from kafka nodes directly go into log files.
so this is expected.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan edited a comment on issue #4790: [SUPPORT] hudi-kafka-connect data missing!
Posted by GitBox <gi...@apache.org>.
nsivabalan edited a comment on issue #4790:
URL: https://github.com/apache/hudi/issues/4790#issuecomment-1039511479
I will let experts weigh in here. But to my knowledge, scheduling will be done by kafka writers (connect). but for execution, you might have to configure a separate job and ensure compaction gets executed by it.
https://hudi.apache.org/docs/compaction/#hudi-compactor-utility
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org