You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2022/02/03 23:06:06 UTC
[GitHub] [hudi] harishraju-govindaraju opened a new issue #4745: [SUPPORT] Bulk Insert into COW table slow
harishraju-govindaraju opened a new issue #4745:
URL: https://github.com/apache/hudi/issues/4745
**_Tips before filing an issue_**
- Have you gone through our [FAQs](https://hudi.apache.org/learn/faq/)?
- Join the mailing list to engage in conversations and get faster support at dev-subscribe@hudi.apache.org.
- If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly.
**Describe the problem you faced**
Bulk Insert is very slow. Our source folder is stored as CSV Gzip and we are reading this to load into Hudi Managed table. Not sure where the time is taken. Can some one please educate me if this is taking time to read or to write to hudi ?

A clear and concise description of the problem.
**To Reproduce**
Steps to reproduce the behavior:
1.
2.
3.
4.
**Expected behavior**
A clear and concise description of what you expected to happen.
**Environment Description**
We are using GLue 3.0 Pyspark to run this code via Hudi Spark Datrasource.
commonConfig = {
'className' : 'org.apache.hudi',
'hoodie.datasource.hive_sync.use_jdbc':'false',
'hoodie.datasource.write.precombine.field': 'key',
'hoodie.datasource.write.recordkey.field': 'key',
'hoodie.table.name': 'bw_mdtb',
'hoodie.consistency.check.enabled': 'true',
'hoodie.datasource.hive_sync.database': 'hudidb',
'hoodie.datasource.hive_sync.table': 'bw_mdtb',
'hoodie.datasource.hive_sync.mode': 'hms',
'hoodie.datasource.hive_sync.enable': 'true',
'path': args['target_folder'] + '/bw_mdtb',
'hoodie.parquet.small.file.limit':'134217728',
'hoodie.parquet.max.file.size':'268435456',
'hoodie.bulkinsert.shuffle.parallelism':'20000'
}
**Additional context**
Add any other context about the problem here.
**Stacktrace**
```Add the stacktrace of the error.```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] harishraju-govindaraju edited a comment on issue #4745: [SUPPORT] Bulk Insert into COW table slow
Posted by GitBox <gi...@apache.org>.
harishraju-govindaraju edited a comment on issue #4745:
URL: https://github.com/apache/hudi/issues/4745#issuecomment-1032156623
@harsh1231 @nsivabalan
Here are some updates. I have upload initial load to an unpartitioned table with 1.5 billion records in 45 mins. Which seem ok to me given the number of records.
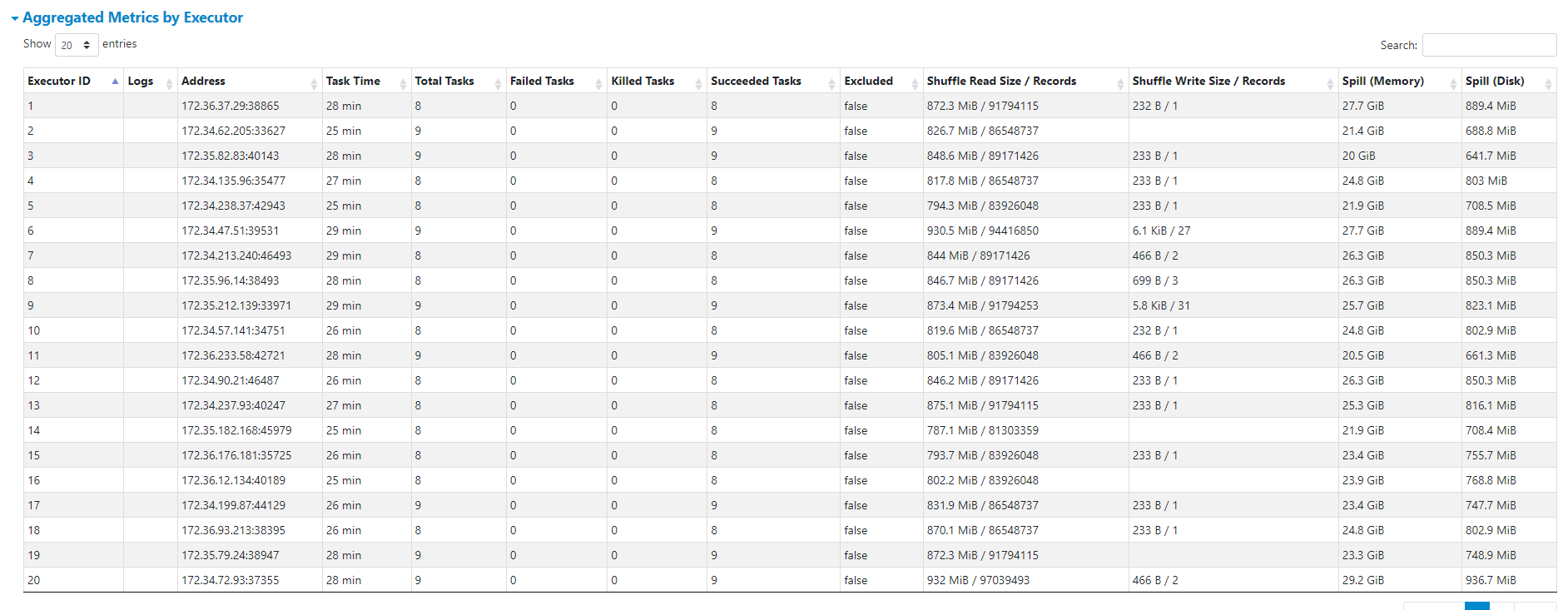
However, when i try to do an Upsert of one 50 MB parquet file as delta, it takes some where between 17 mins to 22 mins to load the deltas. This is what is concerning us as to why the delta updates are so slow. We are not sure if this is due to unpartitioned datasets or are we missing or using wrong type of index. In production, we would offcourse use partition, but for this use case we wanted to load to unpartitioned data sets. Please guide me where this performance could be improved. I also see a lot of spill on memory and disk.
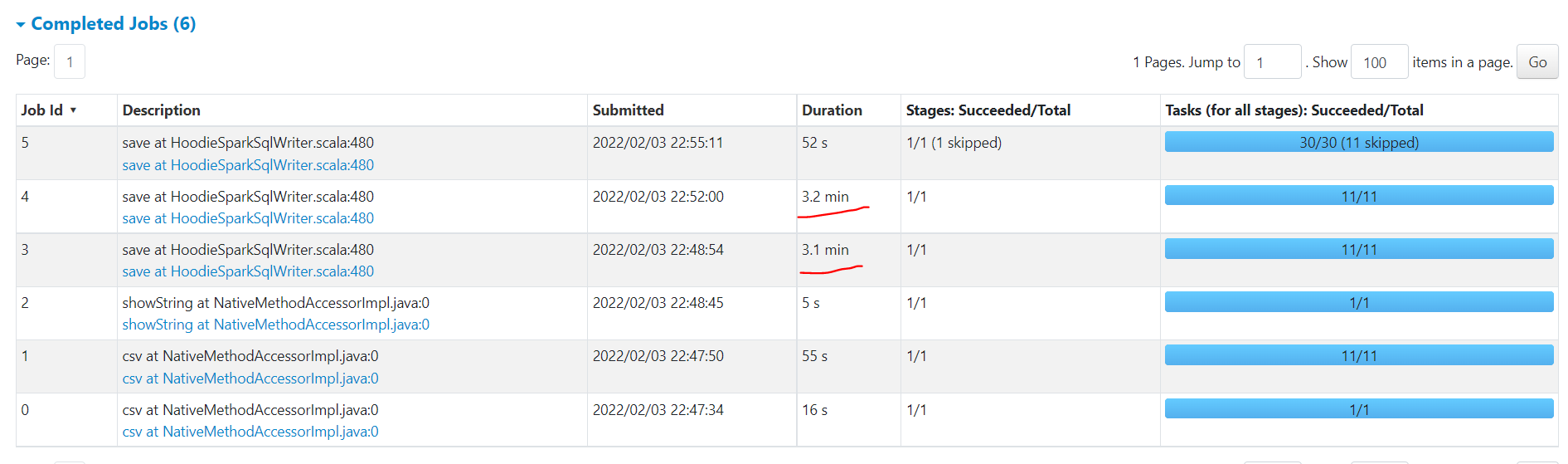
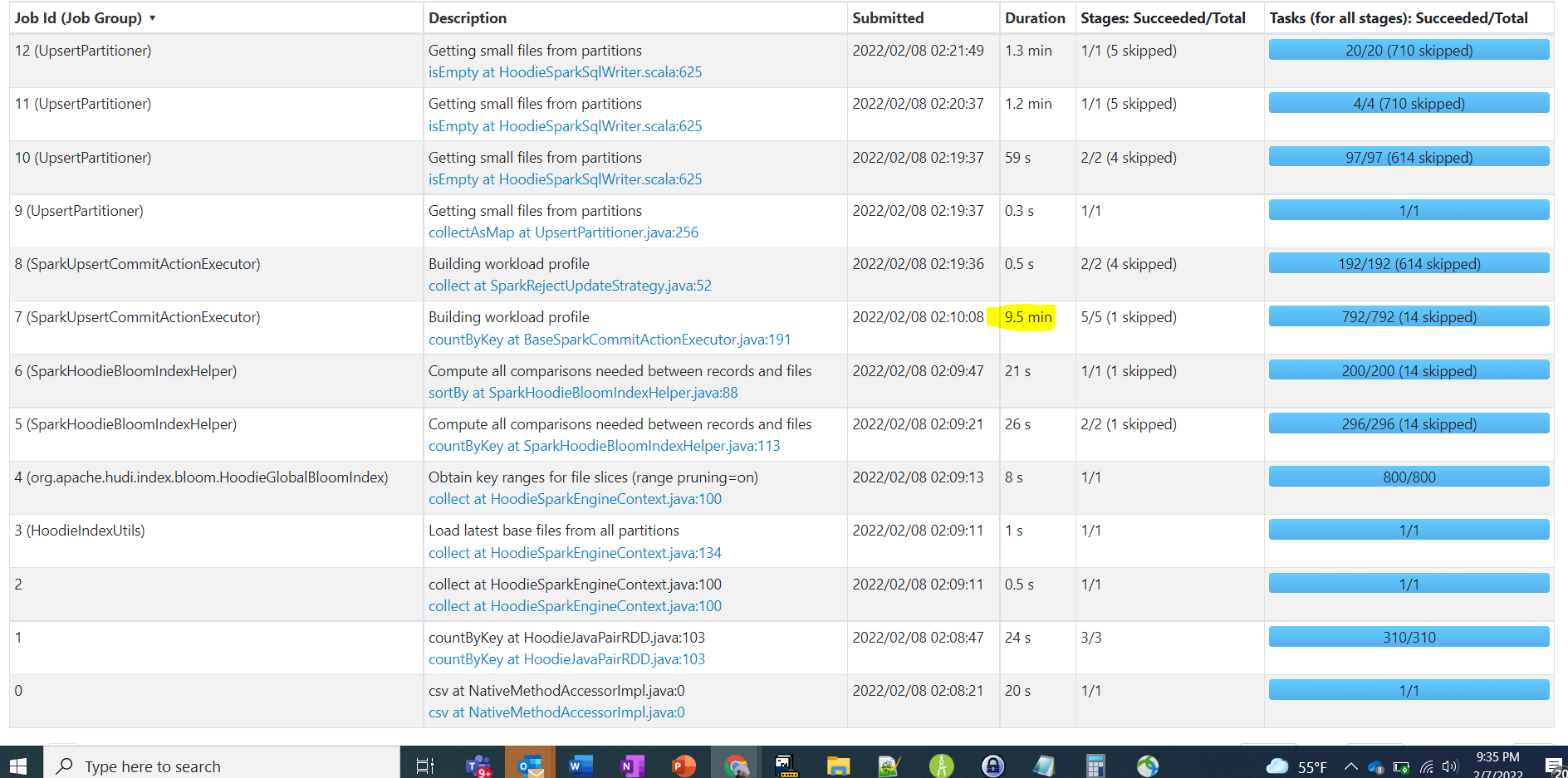
here are the stages. In that a particular stage took 9.5 mins
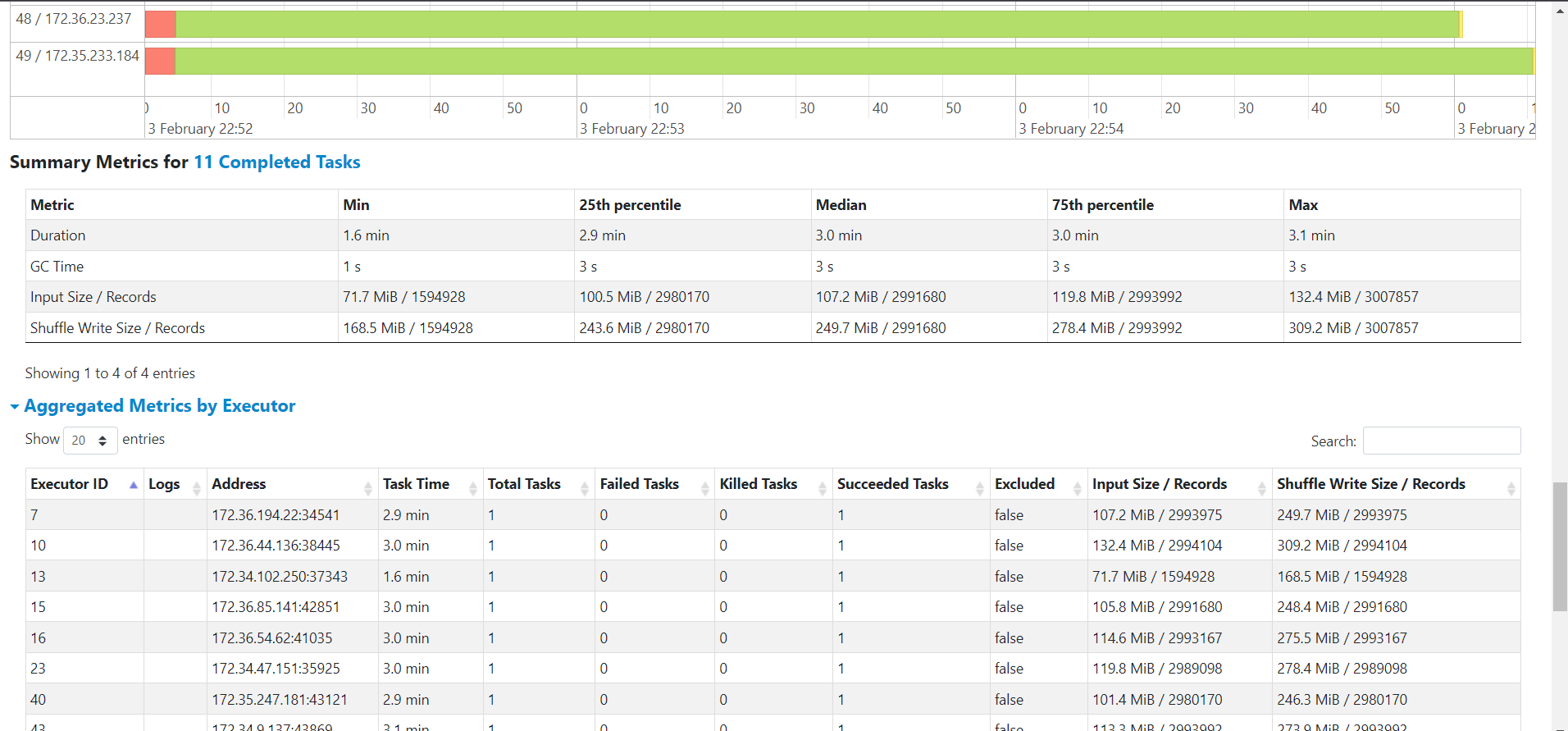
Below picture shows the spill
Here are the config i used.
commonConfig = {
'className' : 'org.apache.hudi',
'hoodie.index.type': 'GLOBAL_BLOOM',
'hoodie.datasource.hive_sync.use_jdbc':'false',
'hoodie.datasource.write.precombine.field': 'EXTRACTED_ON',
'hoodie.datasource.write.recordkey.field': 'key',
'hoodie.table.name': 'unparition',
'hoodie.consistency.check.enabled': 'true',
'hoodie.datasource.hive_sync.database': 'hudidb',
'hoodie.datasource.hive_sync.table': 'unparition',
'hoodie.datasource.hive_sync.mode': 'hms',
'hoodie.datasource.hive_sync.enable': 'true',
'path': args['target_folder'] + '/unparition',
'hoodie.bulkinsert.sort.mode':'NONE',
'hoodie.bloom.index.bucketized.checking':'false'
}
unpartitionDataConfig = {
'hoodie.datasource.hive_sync.partition_extractor_class': 'org.apache.hudi.hive.NonPartitionedExtractor',
'hoodie.datasource.write.keygenerator.class': 'org.apache.hudi.keygen.NonpartitionedKeyGenerator'}
incrementalConfig = {'hoodie.datasource.write.operation': 'upsert'}
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] harishraju-govindaraju commented on issue #4745: [SUPPORT] Bulk Insert into COW table slow
Posted by GitBox <gi...@apache.org>.
harishraju-govindaraju commented on issue #4745:
URL: https://github.com/apache/hudi/issues/4745#issuecomment-1032156623
@harsh1231 @nsivabalan
Here are some updates. I have upload initial load to an unpartitioned table with 1.5 billion records in 45 mins. Which seem ok to me given the number of records.
However, when i try to do an Upsert of one 50 MB parquet file as delta, it takes some where between 17 mins to 22 mins to load the deltas. This is what is concerning us as to why the delta updates are so slow. We are not sure if this is due to unpartitioned datasets or are we missing or using wrong type of index. In production, we would offcourse use partition, but for this use case we wanted to load to unpartitioned data sets. Please guide me where this performance could be improved. I also see a lot of spill on memory and disk.
here are the stages. In that a particular stage took 9.5 mins

Below picture shows the spill

Here are the config i used.
commonConfig = {
'className' : 'org.apache.hudi',
'hoodie.index.type': 'GLOBAL_BLOOM',
'hoodie.datasource.hive_sync.use_jdbc':'false',
'hoodie.datasource.write.precombine.field': 'FRMW_EXTRACTED_ON',
'hoodie.datasource.write.recordkey.field': 'key',
'hoodie.table.name': 'mseg_unparition',
'hoodie.consistency.check.enabled': 'true',
'hoodie.datasource.hive_sync.database': 'hudidb',
'hoodie.datasource.hive_sync.table': 'mseg_unparition',
'hoodie.datasource.hive_sync.mode': 'hms',
'hoodie.datasource.hive_sync.enable': 'true',
'path': args['target_folder'] + '/mseg_unparition',
'hoodie.bulkinsert.sort.mode':'NONE',
'hoodie.bloom.index.bucketized.checking':'false'
}
unpartitionDataConfig = {
'hoodie.datasource.hive_sync.partition_extractor_class': 'org.apache.hudi.hive.NonPartitionedExtractor',
'hoodie.datasource.write.keygenerator.class': 'org.apache.hudi.keygen.NonpartitionedKeyGenerator'}
incrementalConfig = {'hoodie.datasource.write.operation': 'upsert'}
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] harsh1231 edited a comment on issue #4745: [SUPPORT] Bulk Insert into COW table slow
Posted by GitBox <gi...@apache.org>.
harsh1231 edited a comment on issue #4745:
URL: https://github.com/apache/hudi/issues/4745#issuecomment-1033341751
@harishraju-govindaraju Can you check https://hudi.apache.org/docs/0.5.0/admin_guide/
`stats filesizes - File Sizes. Display summary stats on sizes of files
stats wa - Write Amplification. Ratio of how many records were upserted to how many records were actually written`
Also can you share stage level spark ui screen shots
Performance of upsert operation depends on how much underlying dataset overlaps with incoming dataset
Looking at job overall stats -> 792 tasks , check if there are small files created during initial load of data .
`hoodie.copyonwrite.record.size.estimate=100` set this during first load of data if you have large number of small files
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] harishraju-govindaraju commented on issue #4745: [SUPPORT] Bulk Insert into COW table slow
Posted by GitBox <gi...@apache.org>.
harishraju-govindaraju commented on issue #4745:
URL: https://github.com/apache/hudi/issues/4745#issuecomment-1032019632
@nsivabalan - I was not setting the any partition for my folder. I am doing some benchmarking today. I will share the SPARK UI Stages here soon. thanks for getting back.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #4745: [SUPPORT] Bulk Insert into COW table slow
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #4745:
URL: https://github.com/apache/hudi/issues/4745#issuecomment-1031997685
@harsh1231 : can you follow up on this as well.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #4745: [SUPPORT] Bulk Insert into COW table slow
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #4745:
URL: https://github.com/apache/hudi/issues/4745#issuecomment-1030875518
may I know why you are not setting any partition path (hoodie.datasource.write.partitionpath.field)?
and can you post the screen shots for Stages in Spark UI please.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] harsh1231 edited a comment on issue #4745: [SUPPORT] Bulk Insert into COW table slow
Posted by GitBox <gi...@apache.org>.
harsh1231 edited a comment on issue #4745:
URL: https://github.com/apache/hudi/issues/4745#issuecomment-1033341751
@harishraju-govindaraju Can you check https://hudi.apache.org/docs/0.5.0/admin_guide/
`*stats filesizes - File Sizes. Display summary stats on sizes of files
*stats wa - Write Amplification. Ratio of how many records were upserted to how many records were actually written`
Also can you share stage level spark ui screen shots
Performance of upsert operation depends on how much underlying dataset overlaps with incoming dataset
Looking at job overall stats -> 792 tasks , check if there are small files created during initial load of data .
`hoodie.copyonwrite.record.size.estimate=100` set this during first load of data if you have large number of small files
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] harishraju-govindaraju edited a comment on issue #4745: [SUPPORT] Bulk Insert into COW table slow
Posted by GitBox <gi...@apache.org>.
harishraju-govindaraju edited a comment on issue #4745:
URL: https://github.com/apache/hudi/issues/4745#issuecomment-1032156623
@harsh1231 @nsivabalan
Here are some updates. I have upload initial load to an unpartitioned table with 1.5 billion records in 45 mins. Which seem ok to me given the number of records.
However, when i try to do an Upsert of one 50 MB parquet file as delta, it takes some where between 17 mins to 22 mins to load the deltas. This is what is concerning us as to why the delta updates are so slow. We are not sure if this is due to unpartitioned datasets or are we missing or using wrong type of index. In production, we would offcourse use partition, but for this use case we wanted to load to unpartitioned data sets. Please guide me where this performance could be improved. I also see a lot of spill on memory and disk.
here are the stages. In that a particular stage took 9.5 mins

Below picture shows the spill

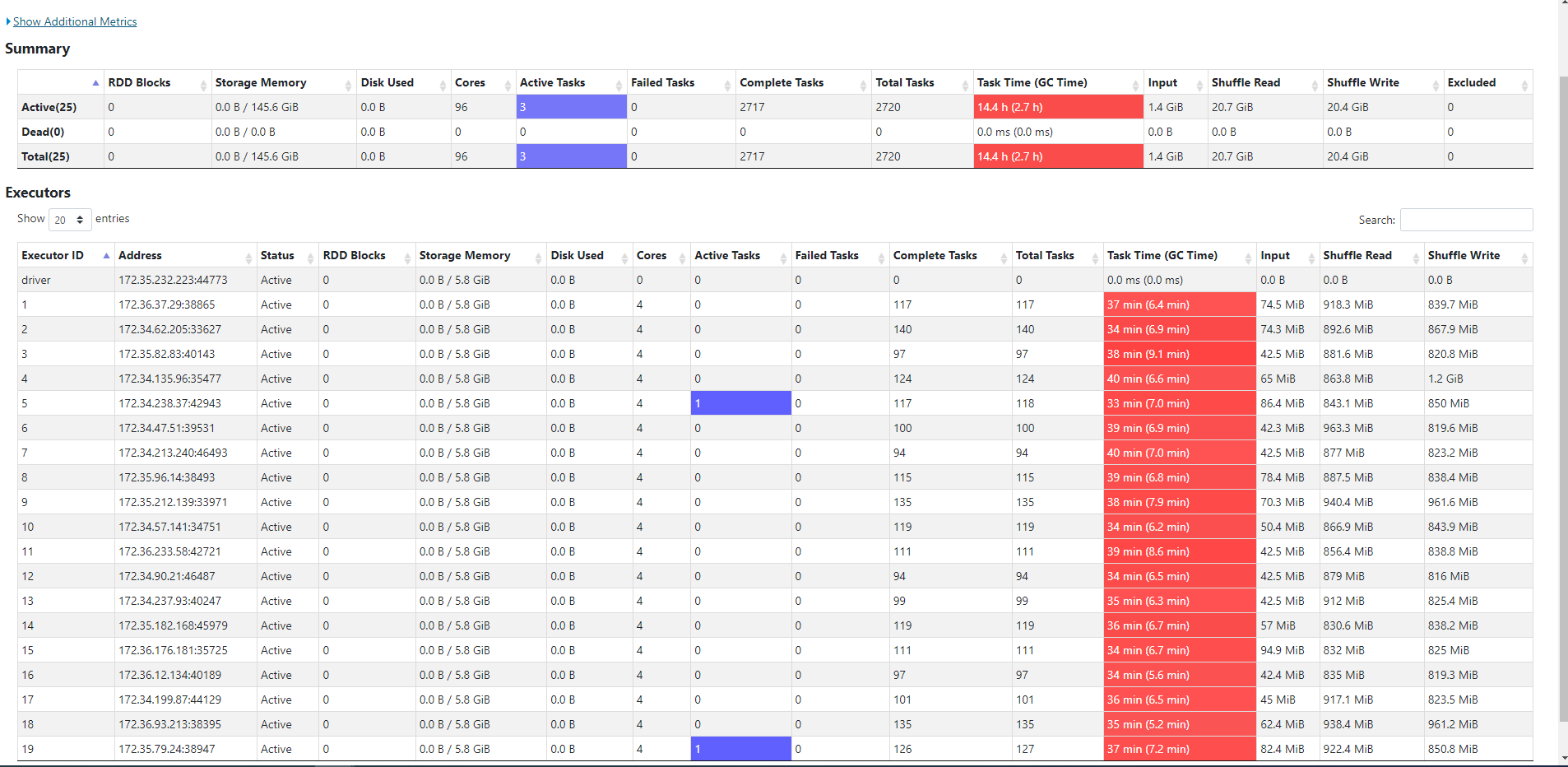
Here are the config i used.
commonConfig = {
'className' : 'org.apache.hudi',
'hoodie.index.type': 'GLOBAL_BLOOM',
'hoodie.datasource.hive_sync.use_jdbc':'false',
'hoodie.datasource.write.precombine.field': 'EXTRACTED_ON',
'hoodie.datasource.write.recordkey.field': 'key',
'hoodie.table.name': 'unparition',
'hoodie.consistency.check.enabled': 'true',
'hoodie.datasource.hive_sync.database': 'hudidb',
'hoodie.datasource.hive_sync.table': 'unparition',
'hoodie.datasource.hive_sync.mode': 'hms',
'hoodie.datasource.hive_sync.enable': 'true',
'path': args['target_folder'] + '/unparition',
'hoodie.bulkinsert.sort.mode':'NONE',
'hoodie.bloom.index.bucketized.checking':'false'
}
unpartitionDataConfig = {
'hoodie.datasource.hive_sync.partition_extractor_class': 'org.apache.hudi.hive.NonPartitionedExtractor',
'hoodie.datasource.write.keygenerator.class': 'org.apache.hudi.keygen.NonpartitionedKeyGenerator'}
incrementalConfig = {'hoodie.datasource.write.operation': 'upsert'}
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] harsh1231 edited a comment on issue #4745: [SUPPORT] Bulk Insert into COW table slow
Posted by GitBox <gi...@apache.org>.
harsh1231 edited a comment on issue #4745:
URL: https://github.com/apache/hudi/issues/4745#issuecomment-1033341751
@harishraju-govindaraju Can you check https://hudi.apache.org/docs/0.5.0/admin_guide/
`* stats filesizes - File Sizes. Display summary stats on sizes of files
* stats wa - Write Amplification. Ratio of how many records were upserted to how many records were actually written
`
Also can you share stage level spark ui screen shots
Performance of upsert operation depends on how much underlying dataset overlaps with incoming dataset
Looking at job overall stats -> 792 tasks , check if there are small files created during initial load of data .
`hoodie.copyonwrite.record.size.estimate=100` set this during first load of data if you have large number of small files
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] harsh1231 commented on issue #4745: [SUPPORT] Bulk Insert into COW table slow
Posted by GitBox <gi...@apache.org>.
harsh1231 commented on issue #4745:
URL: https://github.com/apache/hudi/issues/4745#issuecomment-1033341751
@harishraju-govindaraju Can you check
`* stats filesizes - File Sizes. Display summary stats on sizes of files
* stats wa - Write Amplification. Ratio of how many records were upserted to how many records were actually written`
of upsert operation through https://hudi.apache.org/docs/0.5.0/admin_guide/
Also can you share stage level spark ui screen shots
Performance of upsert operation depends on how much underlying dataset overlaps with incoming dataset
Looking at job overall stats -> 792 tasks , check if there are small files created during initial load of data .
`hoodie.copyonwrite.record.size.estimate=100` set this during first load of data if you have large number of small files
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] harishraju-govindaraju edited a comment on issue #4745: [SUPPORT] Bulk Insert into COW table slow
Posted by GitBox <gi...@apache.org>.
harishraju-govindaraju edited a comment on issue #4745:
URL: https://github.com/apache/hudi/issues/4745#issuecomment-1032019632
@nsivabalan - I was not setting any partition for my folder. I am doing some benchmarking today. I will share the SPARK UI Stages here soon. thanks for getting back.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org