You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by mozammal <gi...@git.apache.org> on 2018/05/28 15:38:13 UTC
[GitHub] spark pull request #21444: Branch 2.3
GitHub user mozammal opened a pull request:
https://github.com/apache/spark/pull/21444
Branch 2.3
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/apache/spark branch-2.3
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/21444.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #21444
----
commit f5f21e8c4261c0dfe8e3e788a30b38b188a18f67
Author: Glen Takahashi <gt...@...>
Date: 2018-01-31T17:14:01Z
[SPARK-23249][SQL] Improved block merging logic for partitions
## What changes were proposed in this pull request?
Change DataSourceScanExec so that when grouping blocks together into partitions, also checks the end of the sorted list of splits to more efficiently fill out partitions.
## How was this patch tested?
Updated old test to reflect the new logic, which causes the # of partitions to drop from 4 -> 3
Also, a current test exists to test large non-splittable files at https://github.com/glentakahashi/spark/blob/c575977a5952bf50b605be8079c9be1e30f3bd36/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/FileSourceStrategySuite.scala#L346
## Rationale
The current bin-packing method of next-fit descending for blocks into partitions is sub-optimal in a lot of cases and will result in extra partitions, un-even distribution of block-counts across partitions, and un-even distribution of partition sizes.
As an example, 128 files ranging from 1MB, 2MB,...127MB,128MB. will result in 82 partitions with the current algorithm, but only 64 using this algorithm. Also in this example, the max # of blocks per partition in NFD is 13, while in this algorithm is is 2.
More generally, running a simulation of 1000 runs using 128MB blocksize, between 1-1000 normally distributed file sizes between 1-500Mb, you can see an improvement of approx 5% reduction of partition counts, and a large reduction in standard deviation of blocks per partition.
This algorithm also runs in O(n) time as NFD does, and in every case is strictly better results than NFD.
Overall, the more even distribution of blocks across partitions and therefore reduced partition counts should result in a small but significant performance increase across the board
Author: Glen Takahashi <gt...@palantir.com>
Closes #20372 from glentakahashi/feature/improved-block-merging.
(cherry picked from commit 8c21170decfb9ca4d3233e1ea13bd1b6e3199ed9)
Signed-off-by: Wenchen Fan <we...@databricks.com>
commit 8ee3a71c9c1b8ed51c5916635d008fdd49cf891a
Author: Dilip Biswal <db...@...>
Date: 2018-01-31T21:52:47Z
[SPARK-23281][SQL] Query produces results in incorrect order when a composite order by clause refers to both original columns and aliases
## What changes were proposed in this pull request?
Here is the test snippet.
``` SQL
scala> Seq[(Integer, Integer)](
| (1, 1),
| (1, 3),
| (2, 3),
| (3, 3),
| (4, null),
| (5, null)
| ).toDF("key", "value").createOrReplaceTempView("src")
scala> sql(
| """
| |SELECT MAX(value) as value, key as col2
| |FROM src
| |GROUP BY key
| |ORDER BY value desc, key
| """.stripMargin).show
+-----+----+
|value|col2|
+-----+----+
| 3| 3|
| 3| 2|
| 3| 1|
| null| 5|
| null| 4|
+-----+----+
```SQL
Here is the explain output :
```SQL
== Parsed Logical Plan ==
'Sort ['value DESC NULLS LAST, 'key ASC NULLS FIRST], true
+- 'Aggregate ['key], ['MAX('value) AS value#9, 'key AS col2#10]
+- 'UnresolvedRelation `src`
== Analyzed Logical Plan ==
value: int, col2: int
Project [value#9, col2#10]
+- Sort [value#9 DESC NULLS LAST, col2#10 DESC NULLS LAST], true
+- Aggregate [key#5], [max(value#6) AS value#9, key#5 AS col2#10]
+- SubqueryAlias src
+- Project [_1#2 AS key#5, _2#3 AS value#6]
+- LocalRelation [_1#2, _2#3]
``` SQL
The sort direction is being wrongly changed from ASC to DSC while resolving ```Sort``` in
resolveAggregateFunctions.
The above testcase models TPCDS-Q71 and thus we have the same issue in Q71 as well.
## How was this patch tested?
A few tests are added in SQLQuerySuite.
Author: Dilip Biswal <db...@us.ibm.com>
Closes #20453 from dilipbiswal/local_spark.
commit 7ccfc753086c3859abe358c87f2e7b7a30422d5e
Author: Henry Robinson <he...@...>
Date: 2018-02-01T02:15:17Z
[SPARK-23157][SQL][FOLLOW-UP] DataFrame -> SparkDataFrame in R comment
Author: Henry Robinson <he...@cloudera.com>
Closes #20443 from henryr/SPARK-23157.
(cherry picked from commit f470df2fcf14e6234c577dc1bdfac27d49b441f5)
Signed-off-by: hyukjinkwon <gu...@gmail.com>
commit 0d0f5793686b98305f98a3d9e494bbfcee9cff13
Author: Wenchen Fan <we...@...>
Date: 2018-02-01T03:56:06Z
[SPARK-23280][SQL] add map type support to ColumnVector
## What changes were proposed in this pull request?
Fill the last missing piece of `ColumnVector`: the map type support.
The idea is similar to the array type support. A map is basically 2 arrays: keys and values. We ask the implementations to provide a key array, a value array, and an offset and length to specify the range of this map in the key/value array.
In `WritableColumnVector`, we put the key array in first child vector, and value array in second child vector, and offsets and lengths in the current vector, which is very similar to how array type is implemented here.
## How was this patch tested?
a new test
Author: Wenchen Fan <we...@databricks.com>
Closes #20450 from cloud-fan/map.
(cherry picked from commit 52e00f70663a87b5837235bdf72a3e6f84e11411)
Signed-off-by: Wenchen Fan <we...@databricks.com>
commit 59e89a2990e4f66839c91f48f41157dac6e670ad
Author: Wang Gengliang <lt...@...>
Date: 2018-02-01T04:33:51Z
[SPARK-23268][SQL] Reorganize packages in data source V2
## What changes were proposed in this pull request?
1. create a new package for partitioning/distribution related classes.
As Spark will add new concrete implementations of `Distribution` in new releases, it is good to
have a new package for partitioning/distribution related classes.
2. move streaming related class to package `org.apache.spark.sql.sources.v2.reader/writer.streaming`, instead of `org.apache.spark.sql.sources.v2.streaming.reader/writer`.
So that the there won't be package reader/writer inside package streaming, which is quite confusing.
Before change:
```
v2
├── reader
├── streaming
│ ├── reader
│ └── writer
└── writer
```
After change:
```
v2
├── reader
│ └── streaming
└── writer
└── streaming
```
## How was this patch tested?
Unit test.
Author: Wang Gengliang <lt...@gmail.com>
Closes #20435 from gengliangwang/new_pkg.
(cherry picked from commit 56ae32657e9e5d1e30b62afe77d9e14eb07cf4fb)
Signed-off-by: gatorsmile <ga...@gmail.com>
commit 871fd48dc381d48e67f7efcc45cc534d36e4ee6e
Author: Atallah Hezbor <at...@...>
Date: 2018-02-01T04:45:55Z
[SPARK-21396][SQL] Fixes MatchError when UDTs are passed through Hive Thriftserver
Signed-off-by: Atallah Hezbor <atallahhezborgmail.com>
## What changes were proposed in this pull request?
This PR proposes modifying the match statement that gets the columns of a row in HiveThriftServer. There was previously no case for `UserDefinedType`, so querying a table that contained them would throw a match error. The changes catch that case and return the string representation.
## How was this patch tested?
While I would have liked to add a unit test, I couldn't easily incorporate UDTs into the ``HiveThriftServer2Suites`` pipeline. With some guidance I would be happy to push a commit with tests.
Instead I did a manual test by loading a `DataFrame` with Point UDT in a spark shell with a HiveThriftServer. Then in beeline, connecting to the server and querying that table.
Here is the result before the change
```
0: jdbc:hive2://localhost:10000> select * from chicago;
Error: scala.MatchError: org.apache.spark.sql.PointUDT2d980dc3 (of class org.apache.spark.sql.PointUDT) (state=,code=0)
```
And after the change:
```
0: jdbc:hive2://localhost:10000> select * from chicago;
+---------------------------------------+--------------+------------------------+---------------------+--+
| __fid__ | case_number | dtg | geom |
+---------------------------------------+--------------+------------------------+---------------------+--+
| 109602f9-54f8-414b-8c6f-42b1a337643e | 2 | 2016-01-01 19:00:00.0 | POINT (-77 38) |
| 709602f9-fcff-4429-8027-55649b6fd7ed | 1 | 2015-12-31 19:00:00.0 | POINT (-76.5 38.5) |
| 009602f9-fcb5-45b1-a867-eb8ba10cab40 | 3 | 2016-01-02 19:00:00.0 | POINT (-78 39) |
+---------------------------------------+--------------+------------------------+---------------------+--+
```
Author: Atallah Hezbor <at...@gmail.com>
Closes #20385 from atallahhezbor/udts_over_hive.
(cherry picked from commit b2e7677f4d3d8f47f5f148680af39d38f2b558f0)
Signed-off-by: gatorsmile <ga...@gmail.com>
commit 205bce974b86bef9d9d507e1b89549cb01c7b535
Author: Yanbo Liang <yb...@...>
Date: 2018-02-01T09:25:01Z
[SPARK-23107][ML] ML 2.3 QA: New Scala APIs, docs.
## What changes were proposed in this pull request?
Audit new APIs and docs in 2.3.0.
## How was this patch tested?
No test.
Author: Yanbo Liang <yb...@gmail.com>
Closes #20459 from yanboliang/SPARK-23107.
(cherry picked from commit e15da5b14c8d845028365a609c0c66731d024ee7)
Signed-off-by: Nick Pentreath <ni...@za.ibm.com>
commit 6b6bc9c4ebeb4c1ebfea3f6ddff0d2f502011e0c
Author: Takuya UESHIN <ue...@...>
Date: 2018-02-01T12:25:02Z
[SPARK-23280][SQL][FOLLOWUP] Fix Java style check issues.
## What changes were proposed in this pull request?
This is a follow-up of #20450 which broke lint-java checks.
This pr fixes the lint-java issues.
```
[ERROR] src/main/java/org/apache/spark/sql/vectorized/ColumnVector.java:[20,8] (imports) UnusedImports: Unused import - org.apache.spark.sql.catalyst.util.MapData.
[ERROR] src/main/java/org/apache/spark/sql/vectorized/ColumnarArray.java:[21,8] (imports) UnusedImports: Unused import - org.apache.spark.sql.catalyst.util.MapData.
[ERROR] src/main/java/org/apache/spark/sql/vectorized/ColumnarRow.java:[22,8] (imports) UnusedImports: Unused import - org.apache.spark.sql.catalyst.util.MapData.
```
## How was this patch tested?
Checked manually in my local environment.
Author: Takuya UESHIN <ue...@databricks.com>
Closes #20468 from ueshin/issues/SPARK-23280/fup1.
(cherry picked from commit 8bb70b068ea782e799e45238fcb093a6acb0fc9f)
Signed-off-by: Takuya UESHIN <ue...@databricks.com>
commit 3aa780ef34492ab1746bbcde8a75bfa8c3d929e1
Author: Takuya UESHIN <ue...@...>
Date: 2018-02-01T12:28:53Z
[SPARK-23280][SQL][FOLLOWUP] Enable `MutableColumnarRow.getMap()`.
## What changes were proposed in this pull request?
This is a followup pr of #20450.
We should've enabled `MutableColumnarRow.getMap()` as well.
## How was this patch tested?
Existing tests.
Author: Takuya UESHIN <ue...@databricks.com>
Closes #20471 from ueshin/issues/SPARK-23280/fup2.
(cherry picked from commit 89e8d556b93d1bf1b28fe153fd284f154045b0ee)
Signed-off-by: Takuya UESHIN <ue...@databricks.com>
commit 2549beae20fe8761242f6fb9cda35ff06a652897
Author: Shixiong Zhu <zs...@...>
Date: 2018-02-01T13:00:47Z
[SPARK-23289][CORE] OneForOneBlockFetcher.DownloadCallback.onData should write the buffer fully
## What changes were proposed in this pull request?
`channel.write(buf)` may not write the whole buffer since the underlying channel is a FileChannel, we should retry until the whole buffer is written.
## How was this patch tested?
Jenkins
Author: Shixiong Zhu <zs...@gmail.com>
Closes #20461 from zsxwing/SPARK-23289.
(cherry picked from commit ec63e2d0743a4f75e1cce21d0fe2b54407a86a4a)
Signed-off-by: Wenchen Fan <we...@databricks.com>
commit 2db7e49dbb58c5b44e22a6a3aae4fa04cd89e5e8
Author: Yuming Wang <wg...@...>
Date: 2018-02-01T18:36:31Z
[SPARK-13983][SQL] Fix HiveThriftServer2 can not get "--hiveconf" and ''--hivevar" variables since 2.0
## What changes were proposed in this pull request?
`--hiveconf` and `--hivevar` variables no longer work since Spark 2.0. The `spark-sql` client has fixed by [SPARK-15730](https://issues.apache.org/jira/browse/SPARK-15730) and [SPARK-18086](https://issues.apache.org/jira/browse/SPARK-18086). but `beeline`/[`Spark SQL HiveThriftServer2`](https://github.com/apache/spark/blob/v2.1.1/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/HiveThriftServer2.scala) is still broken. This pull request fix it.
This pull request works for both `JDBC client` and `beeline`.
## How was this patch tested?
unit tests for `JDBC client`
manual tests for `beeline`:
```
git checkout origin/pr/17886
dev/make-distribution.sh --mvn mvn --tgz -Phive -Phive-thriftserver -Phadoop-2.6 -DskipTests
tar -zxf spark-2.3.0-SNAPSHOT-bin-2.6.5.tgz && cd spark-2.3.0-SNAPSHOT-bin-2.6.5
sbin/start-thriftserver.sh
```
```
cat <<EOF > test.sql
select '\${a}', '\${b}';
EOF
beeline -u jdbc:hive2://localhost:10000 --hiveconf a=avalue --hivevar b=bvalue -f test.sql
```
Author: Yuming Wang <wg...@gmail.com>
Closes #17886 from wangyum/SPARK-13983-dev.
(cherry picked from commit f051f834036e63d5e480d86440ce39924f979e82)
Signed-off-by: gatorsmile <ga...@gmail.com>
commit 07a8f4ddfc2edccde9b1d28b4436a596d2f7db63
Author: Wenchen Fan <we...@...>
Date: 2018-02-01T18:48:34Z
[SPARK-23293][SQL] fix data source v2 self join
`DataSourceV2Relation` should extend `MultiInstanceRelation`, to take care of self-join.
a new test
Author: Wenchen Fan <we...@databricks.com>
Closes #20466 from cloud-fan/dsv2-selfjoin.
(cherry picked from commit 73da3b6968630d9e2cafc742ccb6d4eb54957df4)
Signed-off-by: gatorsmile <ga...@gmail.com>
commit ab23785c70229acd6c22218f722337cf0a9cc55b
Author: Gera Shegalov <ge...@...>
Date: 2018-02-01T23:26:59Z
[SPARK-23296][YARN] Include stacktrace in YARN-app diagnostic
## What changes were proposed in this pull request?
Include stacktrace in the diagnostics message upon abnormal unregister from RM
## How was this patch tested?
Tested with a failing job, and confirmed a stacktrace in the client output and YARN webUI.
Author: Gera Shegalov <ge...@apache.org>
Closes #20470 from gerashegalov/gera/stacktrace-diagnostics.
(cherry picked from commit 032c11b83f0d276bf8085992229b8c598f02798a)
Signed-off-by: Marcelo Vanzin <va...@cloudera.com>
commit 7baae3aef34d16cb0a2d024d96027d8378a03927
Author: Liang-Chi Hsieh <vi...@...>
Date: 2018-02-02T02:18:32Z
[SPARK-23284][SQL] Document the behavior of several ColumnVector's get APIs when accessing null slot
## What changes were proposed in this pull request?
For some ColumnVector get APIs such as getDecimal, getBinary, getStruct, getArray, getInterval, getUTF8String, we should clearly document their behaviors when accessing null slot. They should return null in this case. Then we can remove null checks from the places using above APIs.
For the APIs of primitive values like getInt, getInts, etc., this also documents their behaviors when accessing null slots. Their returning values are undefined and can be anything.
## How was this patch tested?
Added tests into `ColumnarBatchSuite`.
Author: Liang-Chi Hsieh <vi...@gmail.com>
Closes #20455 from viirya/SPARK-23272-followup.
(cherry picked from commit 90848d507457d30abb36e3ba07618dfc87c34cd6)
Signed-off-by: Wenchen Fan <we...@databricks.com>
commit 2b07452cacb4c226c815a216c4cfea2a04227700
Author: Wenchen Fan <we...@...>
Date: 2018-02-02T04:44:46Z
[SPARK-23301][SQL] data source column pruning should work for arbitrary expressions
This PR fixes a mistake in the `PushDownOperatorsToDataSource` rule, the column pruning logic is incorrect about `Project`.
a new test case for column pruning with arbitrary expressions, and improve the existing tests to make sure the `PushDownOperatorsToDataSource` really works.
Author: Wenchen Fan <we...@databricks.com>
Closes #20476 from cloud-fan/push-down.
(cherry picked from commit 19c7c7ebdef6c1c7a02ebac9af6a24f521b52c37)
Signed-off-by: gatorsmile <ga...@gmail.com>
commit e5e9f9a430c827669ecfe9d5c13cc555fc89c980
Author: Wenchen Fan <we...@...>
Date: 2018-02-02T14:43:28Z
[SPARK-23312][SQL] add a config to turn off vectorized cache reader
## What changes were proposed in this pull request?
https://issues.apache.org/jira/browse/SPARK-23309 reported a performance regression about cached table in Spark 2.3. While the investigating is still going on, this PR adds a conf to turn off the vectorized cache reader, to unblock the 2.3 release.
## How was this patch tested?
a new test
Author: Wenchen Fan <we...@databricks.com>
Closes #20483 from cloud-fan/cache.
(cherry picked from commit b9503fcbb3f4a3ce263164d1f11a8e99b9ca5710)
Signed-off-by: Wenchen Fan <we...@databricks.com>
commit 56eb9a310217a5372bdba1e24e4af0d4de1829ca
Author: Tathagata Das <ta...@...>
Date: 2018-02-03T01:37:51Z
[SPARK-23064][SS][DOCS] Stream-stream joins Documentation - follow up
## What changes were proposed in this pull request?
Further clarification of caveats in using stream-stream outer joins.
## How was this patch tested?
N/A
Author: Tathagata Das <ta...@gmail.com>
Closes #20494 from tdas/SPARK-23064-2.
(cherry picked from commit eaf35de2471fac4337dd2920026836d52b1ec847)
Signed-off-by: Tathagata Das <ta...@gmail.com>
commit dcd0af4be752ab61b8caf36f70d98e97c6925473
Author: Reynold Xin <rx...@...>
Date: 2018-02-03T04:36:27Z
[SQL] Minor doc update: Add an example in DataFrameReader.schema
## What changes were proposed in this pull request?
This patch adds a small example to the schema string definition of schema function. It isn't obvious how to use it, so an example would be useful.
## How was this patch tested?
N/A - doc only.
Author: Reynold Xin <rx...@databricks.com>
Closes #20491 from rxin/schema-doc.
(cherry picked from commit 3ff83ad43a704cc3354ef9783e711c065e2a1a22)
Signed-off-by: gatorsmile <ga...@gmail.com>
commit b614c083a4875c874180a93b08ea5031fa90cfec
Author: Wenchen Fan <we...@...>
Date: 2018-02-03T04:49:08Z
[SPARK-23317][SQL] rename ContinuousReader.setOffset to setStartOffset
## What changes were proposed in this pull request?
In the document of `ContinuousReader.setOffset`, we say this method is used to specify the start offset. We also have a `ContinuousReader.getStartOffset` to get the value back. I think it makes more sense to rename `ContinuousReader.setOffset` to `setStartOffset`.
## How was this patch tested?
N/A
Author: Wenchen Fan <we...@databricks.com>
Closes #20486 from cloud-fan/rename.
(cherry picked from commit fe73cb4b439169f16cc24cd851a11fd398ce7edf)
Signed-off-by: gatorsmile <ga...@gmail.com>
commit 1bcb3728db11be6e34060eff670fc8245ad571c6
Author: caoxuewen <ca...@...>
Date: 2018-02-03T08:02:03Z
[SPARK-23311][SQL][TEST] add FilterFunction test case for test CombineTypedFilters
## What changes were proposed in this pull request?
In the current test case for CombineTypedFilters, we lack the test of FilterFunction, so let's add it.
In addition, in TypedFilterOptimizationSuite's existing test cases, Let's extract a common LocalRelation.
## How was this patch tested?
add new test cases.
Author: caoxuewen <ca...@zte.com.cn>
Closes #20482 from heary-cao/TypedFilterOptimizationSuite.
(cherry picked from commit 63b49fa2e599080c2ba7d5189f9dde20a2e01fb4)
Signed-off-by: gatorsmile <ga...@gmail.com>
commit 4de206182c8a1f76e1e5e6b597c4b3890e2ca255
Author: Dongjoon Hyun <do...@...>
Date: 2018-02-03T08:04:00Z
[SPARK-23305][SQL][TEST] Test `spark.sql.files.ignoreMissingFiles` for all file-based data sources
## What changes were proposed in this pull request?
Like Parquet, all file-based data source handles `spark.sql.files.ignoreMissingFiles` correctly. We had better have a test coverage for feature parity and in order to prevent future accidental regression for all data sources.
## How was this patch tested?
Pass Jenkins with a newly added test case.
Author: Dongjoon Hyun <do...@apache.org>
Closes #20479 from dongjoon-hyun/SPARK-23305.
(cherry picked from commit 522e0b1866a0298669c83de5a47ba380dc0b7c84)
Signed-off-by: gatorsmile <ga...@gmail.com>
commit be3de87914f29a56137e391d0cf494c0d1a7ba12
Author: Shashwat Anand <me...@...>
Date: 2018-02-03T18:31:04Z
[MINOR][DOC] Use raw triple double quotes around docstrings where there are occurrences of backslashes.
From [PEP 257](https://www.python.org/dev/peps/pep-0257/):
> For consistency, always use """triple double quotes""" around docstrings. Use r"""raw triple double quotes""" if you use any backslashes in your docstrings. For Unicode docstrings, use u"""Unicode triple-quoted strings""".
For example, this is what help (kafka_wordcount) shows:
```
DESCRIPTION
Counts words in UTF8 encoded, '
' delimited text received from the network every second.
Usage: kafka_wordcount.py <zk> <topic>
To run this on your local machine, you need to setup Kafka and create a producer first, see
http://kafka.apache.org/documentation.html#quickstart
and then run the example
`$ bin/spark-submit --jars external/kafka-assembly/target/scala-*/spark-streaming-kafka-assembly-*.jar examples/src/main/python/streaming/kafka_wordcount.py localhost:2181 test`
```
This is what it shows, after the fix:
```
DESCRIPTION
Counts words in UTF8 encoded, '\n' delimited text received from the network every second.
Usage: kafka_wordcount.py <zk> <topic>
To run this on your local machine, you need to setup Kafka and create a producer first, see
http://kafka.apache.org/documentation.html#quickstart
and then run the example
`$ bin/spark-submit --jars \
external/kafka-assembly/target/scala-*/spark-streaming-kafka-assembly-*.jar \
examples/src/main/python/streaming/kafka_wordcount.py \
localhost:2181 test`
```
The thing worth noticing is no linebreak here in the help.
## What changes were proposed in this pull request?
Change triple double quotes to raw triple double quotes when there are occurrences of backslashes in docstrings.
## How was this patch tested?
Manually as this is a doc fix.
Author: Shashwat Anand <me...@shashwat.me>
Closes #20497 from ashashwat/docstring-fixes.
(cherry picked from commit 4aaa7d40bf495317e740b6d6f9c2a55dfd03521b)
Signed-off-by: gatorsmile <ga...@gmail.com>
commit 45f0f4ff76accab3387b08b3773a0b127333ea3a
Author: hyukjinkwon <gu...@...>
Date: 2018-02-03T18:40:21Z
[SPARK-21658][SQL][PYSPARK] Revert "[] Add default None for value in na.replace in PySpark"
This reverts commit 0fcde87aadc9a92e138f11583119465ca4b5c518.
See the discussion in [SPARK-21658](https://issues.apache.org/jira/browse/SPARK-21658), [SPARK-19454](https://issues.apache.org/jira/browse/SPARK-19454) and https://github.com/apache/spark/pull/16793
Author: hyukjinkwon <gu...@gmail.com>
Closes #20496 from HyukjinKwon/revert-SPARK-21658.
(cherry picked from commit 551dff2bccb65e9b3f77b986f167aec90d9a6016)
Signed-off-by: gatorsmile <ga...@gmail.com>
commit 430025cba1ca8cc652fd11f894cef96203921dab
Author: Yuming Wang <wg...@...>
Date: 2018-02-04T17:15:48Z
[SPARK-22036][SQL][FOLLOWUP] Fix decimalArithmeticOperations.sql
## What changes were proposed in this pull request?
Fix decimalArithmeticOperations.sql test
## How was this patch tested?
N/A
Author: Yuming Wang <wg...@gmail.com>
Author: wangyum <wg...@gmail.com>
Author: Yuming Wang <yu...@ebay.com>
Closes #20498 from wangyum/SPARK-22036.
(cherry picked from commit 6fb3fd15365d43733aefdb396db205d7ccf57f75)
Signed-off-by: gatorsmile <ga...@gmail.com>
commit e688ffee20cf9d7124e03b28521e31e10d0bb7f3
Author: Shixiong Zhu <zs...@...>
Date: 2018-02-05T10:41:49Z
[SPARK-23307][WEBUI] Sort jobs/stages/tasks/queries with the completed timestamp before cleaning up them
## What changes were proposed in this pull request?
Sort jobs/stages/tasks/queries with the completed timestamp before cleaning up them to make the behavior consistent with 2.2.
## How was this patch tested?
- Jenkins.
- Manually ran the following codes and checked the UI for jobs/stages/tasks/queries.
```
spark.ui.retainedJobs 10
spark.ui.retainedStages 10
spark.sql.ui.retainedExecutions 10
spark.ui.retainedTasks 10
```
```
new Thread() {
override def run() {
spark.range(1, 2).foreach { i =>
Thread.sleep(10000)
}
}
}.start()
Thread.sleep(5000)
for (_ <- 1 to 20) {
new Thread() {
override def run() {
spark.range(1, 2).foreach { i =>
}
}
}.start()
}
Thread.sleep(15000)
spark.range(1, 2).foreach { i =>
}
sc.makeRDD(1 to 100, 100).foreach { i =>
}
```
Author: Shixiong Zhu <zs...@gmail.com>
Closes #20481 from zsxwing/SPARK-23307.
(cherry picked from commit a6bf3db20773ba65cbc4f2775db7bd215e78829a)
Signed-off-by: Wenchen Fan <we...@databricks.com>
commit 173449c2bd454a87487f8eebf7d74ee6ed505290
Author: Sital Kedia <sk...@...>
Date: 2018-02-05T18:19:18Z
[SPARK-23310][CORE] Turn off read ahead input stream for unshafe shuffle reader
To fix regression for TPC-DS queries
Author: Sital Kedia <sk...@fb.com>
Closes #20492 from sitalkedia/turn_off_async_inputstream.
(cherry picked from commit 03b7e120dd7ff7848c936c7a23644da5bd7219ab)
Signed-off-by: Sameer Agarwal <sa...@apache.org>
commit 4aa9aafcd542d5f28b7e6bb756c2e965010a757c
Author: Xingbo Jiang <xi...@...>
Date: 2018-02-05T22:17:11Z
[SPARK-23330][WEBUI] Spark UI SQL executions page throws NPE
## What changes were proposed in this pull request?
Spark SQL executions page throws the following error and the page crashes:
```
HTTP ERROR 500
Problem accessing /SQL/. Reason:
Server Error
Caused by:
java.lang.NullPointerException
at scala.collection.immutable.StringOps$.length$extension(StringOps.scala:47)
at scala.collection.immutable.StringOps.length(StringOps.scala:47)
at scala.collection.IndexedSeqOptimized$class.isEmpty(IndexedSeqOptimized.scala:27)
at scala.collection.immutable.StringOps.isEmpty(StringOps.scala:29)
at scala.collection.TraversableOnce$class.nonEmpty(TraversableOnce.scala:111)
at scala.collection.immutable.StringOps.nonEmpty(StringOps.scala:29)
at org.apache.spark.sql.execution.ui.ExecutionTable.descriptionCell(AllExecutionsPage.scala:182)
at org.apache.spark.sql.execution.ui.ExecutionTable.row(AllExecutionsPage.scala:155)
at org.apache.spark.sql.execution.ui.ExecutionTable$$anonfun$8.apply(AllExecutionsPage.scala:204)
at org.apache.spark.sql.execution.ui.ExecutionTable$$anonfun$8.apply(AllExecutionsPage.scala:204)
at org.apache.spark.ui.UIUtils$$anonfun$listingTable$2.apply(UIUtils.scala:339)
at org.apache.spark.ui.UIUtils$$anonfun$listingTable$2.apply(UIUtils.scala:339)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.AbstractTraversable.map(Traversable.scala:104)
at org.apache.spark.ui.UIUtils$.listingTable(UIUtils.scala:339)
at org.apache.spark.sql.execution.ui.ExecutionTable.toNodeSeq(AllExecutionsPage.scala:203)
at org.apache.spark.sql.execution.ui.AllExecutionsPage.render(AllExecutionsPage.scala:67)
at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82)
at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82)
at org.apache.spark.ui.JettyUtils$$anon$3.doGet(JettyUtils.scala:90)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:687)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:790)
at org.eclipse.jetty.servlet.ServletHolder.handle(ServletHolder.java:848)
at org.eclipse.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:584)
at org.eclipse.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1180)
at org.eclipse.jetty.servlet.ServletHandler.doScope(ServletHandler.java:512)
at org.eclipse.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1112)
at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:141)
at org.eclipse.jetty.server.handler.ContextHandlerCollection.handle(ContextHandlerCollection.java:213)
at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:134)
at org.eclipse.jetty.server.Server.handle(Server.java:534)
at org.eclipse.jetty.server.HttpChannel.handle(HttpChannel.java:320)
at org.eclipse.jetty.server.HttpConnection.onFillable(HttpConnection.java:251)
at org.eclipse.jetty.io.AbstractConnection$ReadCallback.succeeded(AbstractConnection.java:283)
at org.eclipse.jetty.io.FillInterest.fillable(FillInterest.java:108)
at org.eclipse.jetty.io.SelectChannelEndPoint$2.run(SelectChannelEndPoint.java:93)
at org.eclipse.jetty.util.thread.strategy.ExecuteProduceConsume.executeProduceConsume(ExecuteProduceConsume.java:303)
at org.eclipse.jetty.util.thread.strategy.ExecuteProduceConsume.produceConsume(ExecuteProduceConsume.java:148)
at org.eclipse.jetty.util.thread.strategy.ExecuteProduceConsume.run(ExecuteProduceConsume.java:136)
at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:671)
at org.eclipse.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:589)
at java.lang.Thread.run(Thread.java:748)
```
One of the possible reason that this page fails may be the `SparkListenerSQLExecutionStart` event get dropped before processed, so the execution description and details don't get updated.
This was not a issue in 2.2 because it would ignore any job start event that arrives before the corresponding execution start event, which doesn't sound like a good decision.
We shall try to handle the null values in the front page side, that is, try to give a default value when `execution.details` or `execution.description` is null.
Another possible approach is not to spill the `LiveExecutionData` in `SQLAppStatusListener.update(exec: LiveExecutionData)` if `exec.details` is null. This is not ideal because this way you will not see the execution if `SparkListenerSQLExecutionStart` event is lost, because `AllExecutionsPage` only read executions from KVStore.
## How was this patch tested?
After the change, the page shows the following:
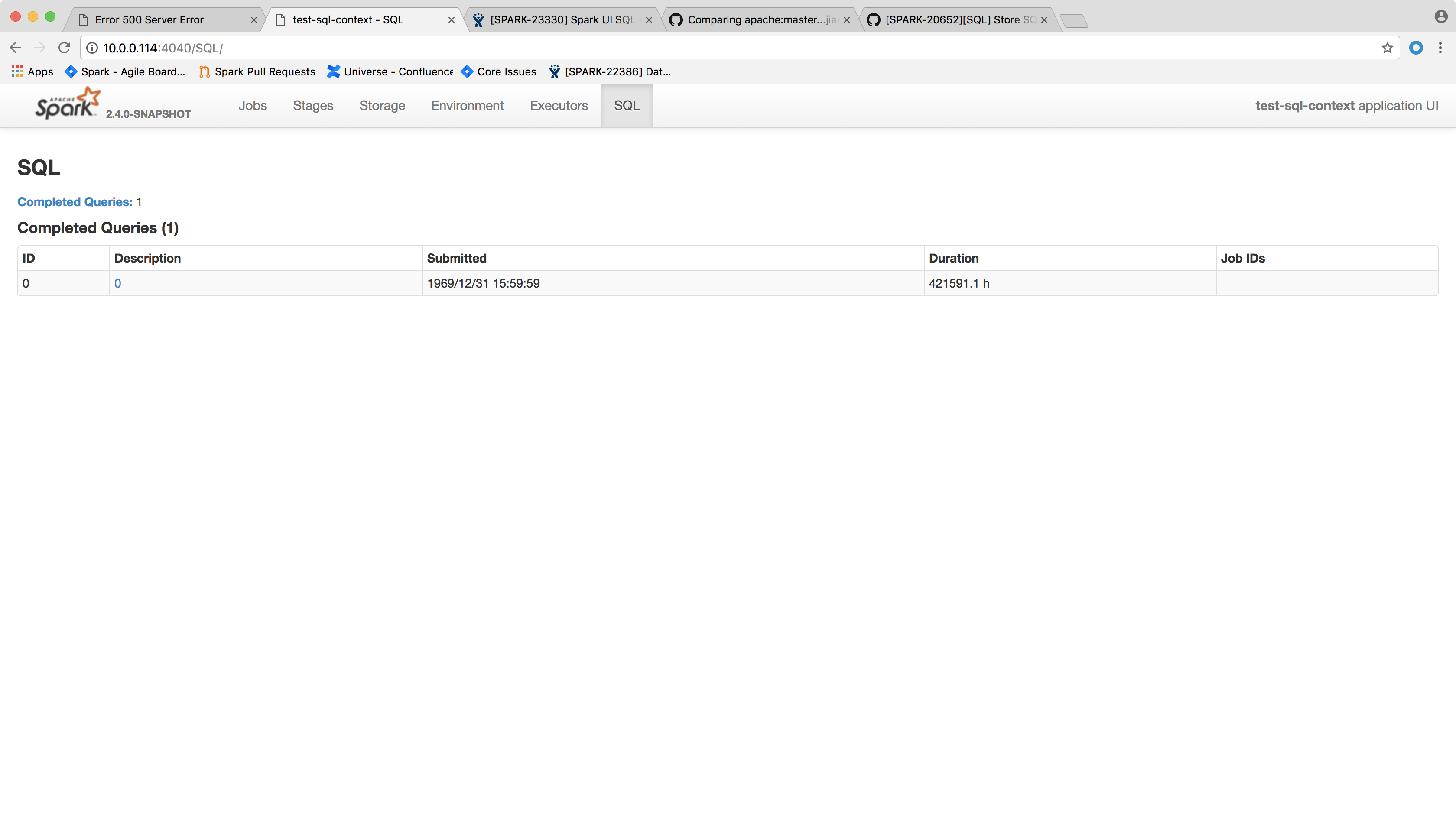
Author: Xingbo Jiang <xi...@databricks.com>
Closes #20502 from jiangxb1987/executionPage.
(cherry picked from commit c2766b07b4b9ed976931966a79c65043e81cf694)
Signed-off-by: Marcelo Vanzin <va...@cloudera.com>
commit 521494d7bdcbb6699e0b12cd3ff60fc27908938f
Author: Shixiong Zhu <zs...@...>
Date: 2018-02-06T06:42:42Z
[SPARK-23326][WEBUI] schedulerDelay should return 0 when the task is running
## What changes were proposed in this pull request?
When a task is still running, metrics like executorRunTime are not available. Then `schedulerDelay` will be almost the same as `duration` and that's confusing.
This PR makes `schedulerDelay` return 0 when the task is running which is the same behavior as 2.2.
## How was this patch tested?
`AppStatusUtilsSuite.schedulerDelay`
Author: Shixiong Zhu <zs...@gmail.com>
Closes #20493 from zsxwing/SPARK-23326.
(cherry picked from commit f3f1e14bb73dfdd2927d95b12d7d61d22de8a0ac)
Signed-off-by: Wenchen Fan <we...@databricks.com>
commit 44933033e9216ccb2e533b9dc6e6cb03cce39817
Author: Takuya UESHIN <ue...@...>
Date: 2018-02-06T09:29:37Z
[SPARK-23290][SQL][PYTHON][BACKPORT-2.3] Use datetime.date for date type when converting Spark DataFrame to Pandas DataFrame.
## What changes were proposed in this pull request?
This is a backport of #20506.
In #18664, there was a change in how `DateType` is being returned to users ([line 1968 in dataframe.py](https://github.com/apache/spark/pull/18664/files#diff-6fc344560230bf0ef711bb9b5573f1faR1968)). This can cause client code which works in Spark 2.2 to fail.
See [SPARK-23290](https://issues.apache.org/jira/browse/SPARK-23290?focusedCommentId=16350917&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-16350917) for an example.
This pr modifies to use `datetime.date` for date type as Spark 2.2 does.
## How was this patch tested?
Tests modified to fit the new behavior and existing tests.
Author: Takuya UESHIN <ue...@databricks.com>
Closes #20515 from ueshin/issues/SPARK-23290_2.3.
commit a511544822be6e3fc9c6bb5080a163b9acbb41f2
Author: Takuya UESHIN <ue...@...>
Date: 2018-02-06T09:30:50Z
[SPARK-23334][SQL][PYTHON] Fix pandas_udf with return type StringType() to handle str type properly in Python 2.
## What changes were proposed in this pull request?
In Python 2, when `pandas_udf` tries to return string type value created in the udf with `".."`, the execution fails. E.g.,
```python
from pyspark.sql.functions import pandas_udf, col
import pandas as pd
df = spark.range(10)
str_f = pandas_udf(lambda x: pd.Series(["%s" % i for i in x]), "string")
df.select(str_f(col('id'))).show()
```
raises the following exception:
```
...
java.lang.AssertionError: assertion failed: Invalid schema from pandas_udf: expected StringType, got BinaryType
at scala.Predef$.assert(Predef.scala:170)
at org.apache.spark.sql.execution.python.ArrowEvalPythonExec$$anon$2.<init>(ArrowEvalPythonExec.scala:93)
...
```
Seems like pyarrow ignores `type` parameter for `pa.Array.from_pandas()` and consider it as binary type when the type is string type and the string values are `str` instead of `unicode` in Python 2.
This pr adds a workaround for the case.
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN <ue...@databricks.com>
Closes #20507 from ueshin/issues/SPARK-23334.
(cherry picked from commit 63c5bf13ce5cd3b8d7e7fb88de881ed207fde720)
Signed-off-by: hyukjinkwon <gu...@gmail.com>
----
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #21444: Branch 2.3
Posted by asfgit <gi...@git.apache.org>.
Github user asfgit closed the pull request at:
https://github.com/apache/spark/pull/21444
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21444: Branch 2.3
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on the issue:
https://github.com/apache/spark/pull/21444
@mozammal mind closing this please?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21444: Branch 2.3
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21444
Can one of the admins verify this patch?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21444: Branch 2.3
Posted by TomaszGaweda <gi...@git.apache.org>.
Github user TomaszGaweda commented on the issue:
https://github.com/apache/spark/pull/21444
Please close this PR
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #21444: Branch 2.3
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/21444
Can one of the admins verify this patch?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org