You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@tvm.apache.org by GitBox <gi...@apache.org> on 2020/10/12 19:45:20 UTC
[GitHub] [incubator-tvm] tkonolige opened a new pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
tkonolige opened a new pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671
This PR fixes autotvm and the autoscheduler when using multiprocessing's spawn start method. I had to remove all nested function declarations, property serialize auto_scheduler's `SearchTask`, and propagate registries to subprocesses. Unfortunately, the registry propagation does not work correctly when running under pytest. I've disable those tests for now (`tests/python/unittest/test_runtime_rpc.py`), but they work if run directly. Maybe someone else can take a look at this.
See #6650
@merrymercy
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tkonolige commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tkonolige commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-708649133
The problem with using fork is that it is unsafe on macOS or when using the CUDA api. The pytorch developers recommend not using fork with CUDA: https://pytorch.org/docs/master/notes/multiprocessing.html#cuda-in-multiprocessing. It looks like we have to choose something that works over something that is fast.
I also don't think it really matters that spawning is slower than forking. We are not spawning that many processes. And if the overhead from spawning is big enough to cause a significant slowdown, then we shouldn't have been using processes/threads in the first place.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717506384
I tested your autotvm implementation and found it is significantly slower.
To do the test, you can run this tutorial (https://github.com/apache/incubator-tvm/blob/main/tutorials/autotvm/tune_conv2d_cuda.py) and replace the n_trial=20 with n_trial=100
The number we care about is the time spent on simulated annealing which actually uses the xgboost_cost_model.py modified by you.
This is the screenshot before your PR. You can see elapsed: 63.40 in the last line, which means it takes 63.40 ms to do simulated annealing.
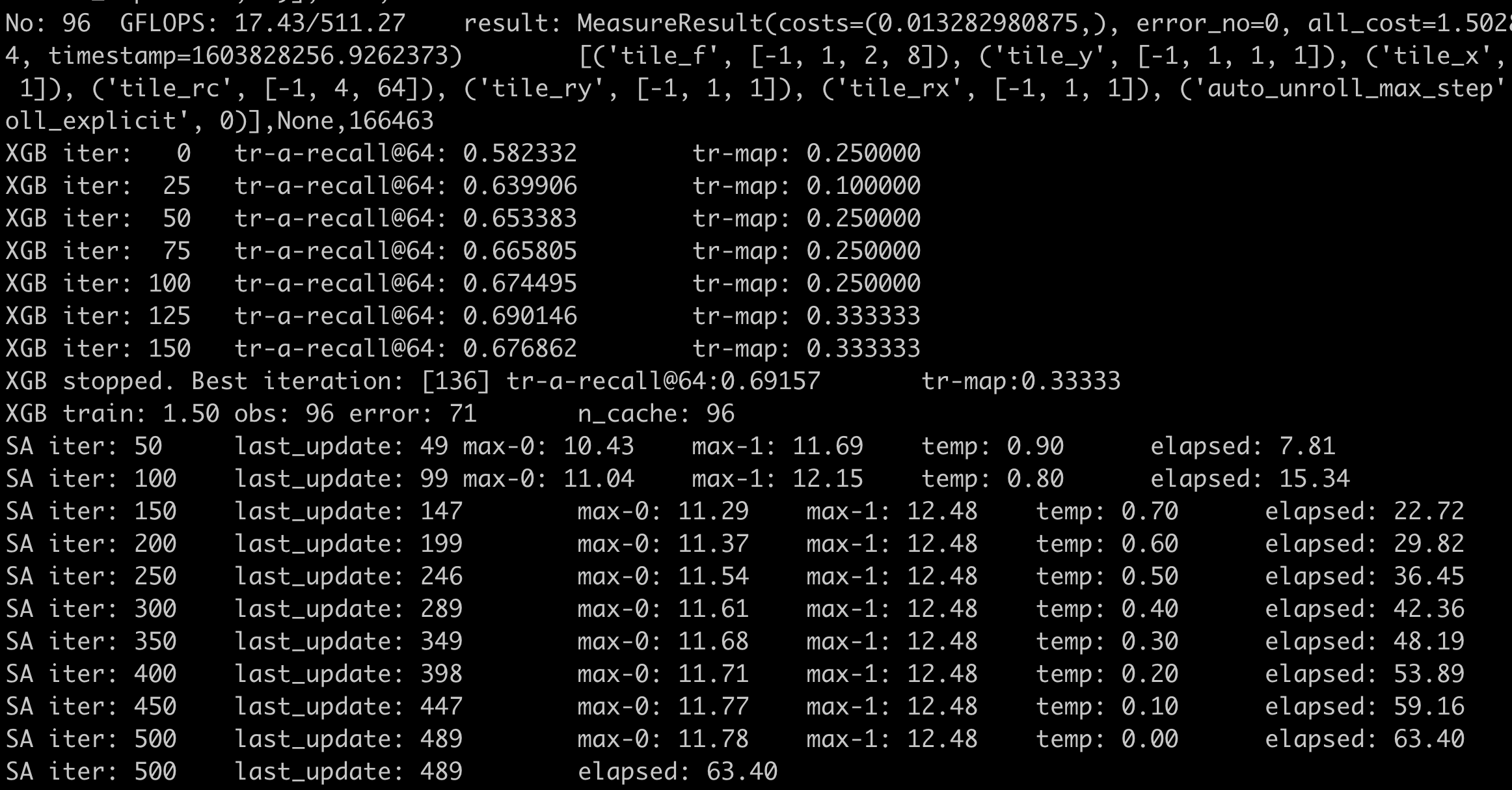
However, with your PR, the number becomes 194.67
<img width="1152" alt="Screen Shot 2020-10-27 at 12 47 15 PM" src="https://user-images.githubusercontent.com/15100009/97355886-cff21380-1854-11eb-9058-72eb1ac9f844.png">
I don’t understand why the autotvm part is required for that PR, because autotvm and auto-scheduler are totally independent. Can you delete autotvm files in that PR?
The test machine is a 24-core Intel E5
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716905146
The auto-scheduler part looks good to me. I believe this PR solves the problem while not bringing any performance regression.
But I am not sure about the autotvm part. Your test case is not correct. With `n-trials=16`, the code modified by you will not even be executed. Because the cost model only starts to work after getting enough training samples (n-trials > 64). To do the benchmark correctly, you should use a larger matrix size (n=1024), run the autotvm with n-trials > 64 and `XGBTuner`, and report the time used in simulated annealing (i.e., the part modified by you).
Could you delete the autotvm part in this PR so we can merge this?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tkonolige edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tkonolige edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717560438
I was thinking it was cloud pickle reloading the main module, but I took off the `__name__ == "__main__"` lines and it performs the same. `__name__ == "__main__"` is still required for non-linux machines (i.e. the tutorials are buggy on non linux machines), but it isn't causing the issue here. The only difference I can see then is that your machine has so many threads. Can you reproduce your results on a different machine?
Also, did you remove the tuning logs between runs?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-708845921
Autotvm uses a lot of python multiprocessing and I expect it will be much slower when using spawn. AutoTVM uses multiprocessing for feature extraction. So it needs to launch about 50,000 tasks every measurement batch.
The situation for Ansor is better as Ansor does not rely on multiprocessing as heavily as AutoTVM does.
However, I'd like to see benchmark numbers about fork vs. spawn.
i.e. Run a search with `n-trials=64` with (Ansor, AutoTVM) x (fork, spawn) X (CPU, GPU) (Optional).
The requirement from my side is that I don't want to see any performance regression.
I prefer to only use the slower and safer fallback mechanism when the fast approach does not work.
Removing all multiprocessing requires huge engineering effort.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tkonolige commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tkonolige commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717392440
Here are the autotvm times you requested. 1024x1024 with 100 trials.
```
This PR
autotvm llvm 297.038928
autotvm cuda 15.138037
main
autotvm llvm 297.375458
autotvm cuda 14.163432
```
Results are very similar.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-708845921
Autotvm uses a lot of python multiprocessing and I expect it will be much slower when using spawn. AutoTVM uses multiprocessing for feature extraction. So it needs to launch about 50,000 tasks every measurement batch.
The situation for Ansor is better as Ansor does not rely on multiprocessing as heavily as AutoTVM does.
However, I'd like to see benchmark numbers about fork vs. spawn.
i.e. Run a search with `n_trials=64` with (Ansor, AutoTVM) x (fork, spawn).
The requirement from my side is that I don't want to see any performance regression.
I prefer to only use the slower and safer fallback mechanism when the fast approach does not work.
Removing all multiprocessing requires huge engineering effort.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tkonolige commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tkonolige commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717369426
@merrymercy The autotvm changes are required for things to work.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716905146
The auto-scheduler part looks good to me. I believe this PR solves the problem while not bringing any performance regression.
But I am not sure about the autotvm part. Your test case is not correct. With `n-trials=16`, the code modified by you will not even be executed. Because the cost model only starts to work after getting enough training data (n-trials > 64). To do the benchmark correctly, you should use a larger matrix size, run the autotvm with n-trials > 64 and `XGBTuner`, and report the time used in simulated annealing (i.e., the part modified by you).
Could you delete the autotvm part in this PR so we can merge this?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tqchen edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tqchen edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717620222
the sphinx gallery will run all tutorials together, and it would still be useful to keep the tutorials in the form of ipynb style(no main)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717588164
I added `__name__ == "__main__"` but the results are the same.
Can you delete all autotvm related code and tutorials in this PR? We can investigate later. In the meanwhile, can you try on a machine with more cores?
Can you check whether your modifications to the tutorial break its format?
I don't think the tutorial scripts can generate correct rst files after adding indentation to the text block.
You can build the tutorials locally and check the generated HTML files.
This PR and #6710 are conflicting. I want to merge this first so I can do merge and clean up on my PR. Otherwise, you have to do more work by yourself.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tkonolige commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tkonolige commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-718075660
Maybe we should at least leave a comment that they are broken when using the spawn method?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tkonolige edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tkonolige edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717560438
I was thinking it was cloud pickle reloading the main module, but I took off the `__name__ == "__main__"` lines and it performs the same. `__name__ == "__main__"` is still required for non-linux machines (i.e. the tutorials are buggy on non linux machines), but it isn't causing the issue here. The only difference I can see then is that your machine has so many threads. Can you reproduce your results on a different machine?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tqchen commented on a change in pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tqchen commented on a change in pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#discussion_r511931651
##########
File path: python/tvm/autotvm/task/task.py
##########
@@ -173,6 +172,8 @@ def __getstate__(self):
# some unpickable local task functions.
# So we only pickle the name of the function
# and restore the function by name when unpickling it.
+ import cloudpickle # pylint: disable=import-outside-toplevel
Review comment:
in this case I asked @tkonolige to import here for now since cloudpickle is an optional dep introduced by autotuning atm,
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717506384
I tested your autotvm implementation and found it is significantly slower.
To do the test, you can run this tutorial (https://github.com/apache/incubator-tvm/blob/main/tutorials/autotvm/tune_conv2d_cuda.py) and replace the n_trial=20 with n_trial=100
The number we care about is the time spent on simulated annealing which actually uses the xgboost_cost_model.py modified by you.
This is the screenshot before your PR. You can see `elapsed: 63.40` in the last line, which means it takes 63.40 ms to do simulated annealing.

However, with your PR, the number becomes 194.67
<img width="1152" alt="Screen Shot 2020-10-27 at 12 47 15 PM" src="https://user-images.githubusercontent.com/15100009/97355886-cff21380-1854-11eb-9058-72eb1ac9f844.png">
I don’t understand why the autotvm part is required for that PR, because autotvm and auto-scheduler are totally independent. Can you delete autotvm files in that PR?
The test machine is a 24-core Intel E5
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tkonolige commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tkonolige commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-714820720
@merrymercy @tqchen A review on this would be great.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716905146
The auto-scheduler part looks good to me.
But I am also not sure about the autotvm part.
If you don't mind, I suggest deleting the autotvm part in this PR.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717588164
I added `__name__ == "__main__"` but the results are the same.
Can you delete all autotvm related code and tutorials in this PR? We can investigate later. In the meanwhile, can you try on a machine with more cores?
Can you check whether your modifications to the tutorial break its format?
I don't think the tutorials can generate correct rst files after adding indentation to the text block.
This PR and #6710 are conflicting. I want to merge this first so I can do merge and clean up on my PR. Otherwise, you have to do more work by yourself.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on a change in pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy commented on a change in pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#discussion_r511923166
##########
File path: python/tvm/auto_scheduler/measure.py
##########
@@ -590,14 +634,20 @@ def local_builder_build(inputs, timeout, n_parallel, build_func="default", verbo
res : List[BuildResult]
The build results of these MeasureInputs.
"""
- # We use fork and a global variable to copy arguments between processes.
- # This can avoid expensive serialization of TVM IR when using multiprocessing.Pool
- global GLOBAL_BUILD_ARGUMENTS
-
- GLOBAL_BUILD_ARGUMENTS = (inputs, build_func, timeout, verbose)
-
- pool = NoDaemonPool(n_parallel)
- tuple_res = pool.map(local_build_worker, range(len(inputs)))
+ # This pool is not doing computationally intensive work, so we can use threads
+ pool = multiprocessing.pool.ThreadPool(n_parallel)
Review comment:
Do we still need serialization with `ThreadPool`?
I guess all these arguments will be shared in memory and will be passed as references.
If this is true, then we don't need to change any other part of the code in this file.
In addition, we can choose to use `ProcessingPool` and `ThreadPool` here according to the OS.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716534539
Another concern is that I introduced a new kind of workload in this PR (#6710, https://github.com/apache/incubator-tvm/blob/5d93c61896acafe5d0b76b70615f2e2823cbf3b2/python/tvm/auto_scheduler/workload_registry.py#L158) for relay integration.
When using auto-scheduler in Relay, we don't serialize a ComputeDAG by function + arguments.
We save a copy of the TE expressions generated by relay as the workload.
So we have to support serializing TE expressions after this PR. But I am not sure whether it works because there are pointers in TE expressions.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716534539
Another concern is that I introduced a new kind of workload in this PR (#6710) for relay integration.
When using auto-scheduler in Relay, we don't serialize a ComputeDAG by function + arguments.
We save a copy of the TE expressions generated by relay as the workload.
So we have to support serializing TE expressions after this PR. I am not sure if it works because there are pointers in TE expressions.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-708845921
Autotvm uses a lot of python multiprocessing and I expect it will be much slower when using spawn. AutoTVM uses multiprocessing for feature extraction. So it needs to launch about 50,000 tasks every measurement batch.
Ansor does not rely on multiprocessing too much. So the situation for Ansor is better.
However, I'd like to see benchmark numbers about fork vs. spawn.
i.e. Run a search with `n-trials=64` with (Ansor, AutoTVM) x (fork, spawn) X (CPU, GPU) (Optional)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-708845921
Autotvm uses a lot of python multiprocessing and I expect it will be much slower when using spawn. AutoTVM uses multiprocessing for feature extraction. So it needs to launch about 50,000 tasks every measurement batch.
Ansor does not rely on multiprocessing too much. So the situation for Ansor is better.
However, I'd like to see benchmark numbers about fork vs. spawn.
i.e. Run a search with `n-trials=64` with (Ansor, AutoTVM) x (fork, spawn) X (CPU, GPU) (Optional).
The requirement from my side is that I don't want to see any performance regression.
I prefer to only use the slower and safer fallback mechanism when the fast approach does not work.
Removing all multiprocessing requires huge engineering effort.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tkonolige commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tkonolige commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-713161790
@merrymercy spawn is definitely slower. With autotvm, spawn is about 50% slower. I figured out where the CUDA drivers were being called in forked threads and fixed it. Now fork should be used on linux.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-708845921
Autotvm uses a lot of python multiprocessing and I expect it will be much slower when using spawn. AutoTVM uses multiprocessing for feature extraction. So it needs to launch about 50,000 tasks every measurement batch.
The situation for Ansor is better as Ansor does not rely on multiprocessing as heavily as AutoTVM does.
However, I'd like to see benchmark numbers about fork vs. spawn.
i.e. Run a search with `n_trials=64` with (Ansor, AutoTVM) x (fork, spawn).
The requirement from my side is that I don't want to see any performance regression.
I prefer to only use the slower and safer fallback mechanism when the fast approach does not work.
On the other hand, removing all multiprocessing requires some engineering effort. But this is not on my agenda for now.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716534539
Another concern is that I introduced a new kind of workload in this PR (#6710, https://github.com/apache/incubator-tvm/blob/5d93c61896acafe5d0b76b70615f2e2823cbf3b2/python/tvm/auto_scheduler/workload_registry.py#L158) for relay integration.
When using auto-scheduler in Relay, we don't serialize a ComputeDAG by function + arguments.
We save a copy of the TE expressions generated by relay as the workload.
So we have to support serializing TE expressions after this PR. But I am not sure if it works because there are pointers in TE expressions.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717540915
What's your testing environment?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717550912
Sorry, could you point me to the related lines? I only see you rename some variables in `python/tvm/autotvm/measure/local_executor.py`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717540915
What's your testing environment (python version, CPU, OS, ...)?
Why is the tutorial broken? I can run it successfully.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-708845921
Autotvm uses a lot of python multiprocessing and I expect it will be much slower when using spawn. AutoTVM uses multiprocessing for feature extraction. So it needs to launch about 50,000 tasks every measurement batch.
The situation for Ansor is better as Ansor does not rely on multiprocessing as heavily as AutoTVM does.
However, I'd like to see benchmark numbers about fork vs. spawn.
i.e. Run a search with `n_trials=64` with (Ansor, AutoTVM) x (fork, spawn).
The requirement from my side is that I don't want to see any performance regression.
I prefer to only use the slower and safer fallback mechanism when the fast approach does not work.
On the other size, removing all multiprocessing requires some engineering effort. But this is not on my agenda for now.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on a change in pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy commented on a change in pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#discussion_r511899520
##########
File path: python/tvm/auto_scheduler/measure.py
##########
@@ -51,19 +51,52 @@
from .loop_state import StateObject
from .utils import (
get_const_tuple,
- NoDaemonPool,
call_func_with_timeout,
request_remote,
check_remote,
)
+from .compute_dag import ComputeDAG
+from .search_task import SearchTask
+from .workload_registry import workload_name, get_workload
# The maximum length of error message
MAX_ERROR_MSG_LEN = 512
-# We use fork and a global variable to copy arguments between processes.
-# This can avoid expensive serialization of TVM IR when using multiprocessing.Pool
-GLOBAL_BUILD_ARGUMENTS = None
-GLOBAL_RUN_ARGUMENTS = None
+
+def recover_measure_input(inp, rebuild_state=False):
+ """
+ Recover a deserialized MeasureInput by rebuilding the missing fields.
+ 1. Rebuid the compute_dag in inp.task
+ 2. (Optional) Rebuild the stages in inp.state
+
+ Parameters
+ ----------
+ inp: MeasureInput
+ The deserialized MeasureInput
+ rebuild_state: bool = False
+ Whether rebuild the stages in MeasureInput.State
+
+ Returns
+ -------
+ new_input: MeasureInput
+ The fully recovered MeasureInput with all fields rebuilt.
+ """
+ task = inp.task
+ print(task.hardware_params)
Review comment:
delete this
##########
File path: python/tvm/auto_scheduler/measure.py
##########
@@ -950,26 +1017,30 @@ def rpc_runner_run(
res : List[MeasureResult]
The measure results of these MeasureInputs.
"""
- global GLOBAL_RUN_ARGUMENTS
- GLOBAL_RUN_ARGUMENTS = (
- inputs,
- build_results,
- key,
- host,
- port,
- priority,
- timeout,
- number,
- repeat,
- min_repeat_ms,
- cooldown_interval,
- enable_cpu_cache_flush,
- verbose,
- )
-
assert len(inputs) == len(build_results), "Measure input size should be equal to build results"
- pool = NoDaemonPool(n_parallel)
- tuple_res = pool.map(rpc_run_worker, range(len(build_results)))
+ # This pool is not doing computationally intensive work, so we can use threads
Review comment:
Did you benchmark the speed of ProcessingPool vs. ThreadPool?
For the comment, is it "not doing computational intensive work" or "not doing computational intensive work in python"?
##########
File path: python/tvm/auto_scheduler/utils.py
##########
@@ -169,17 +143,18 @@ def kill_child_processes(parent_pid, sig=signal.SIGTERM):
return
+def _func_wrapper(que, func, args, kwargs):
Review comment:
document it?
##########
File path: python/tvm/auto_scheduler/measure.py
##########
@@ -590,14 +634,20 @@ def local_builder_build(inputs, timeout, n_parallel, build_func="default", verbo
res : List[BuildResult]
The build results of these MeasureInputs.
"""
- # We use fork and a global variable to copy arguments between processes.
- # This can avoid expensive serialization of TVM IR when using multiprocessing.Pool
- global GLOBAL_BUILD_ARGUMENTS
-
- GLOBAL_BUILD_ARGUMENTS = (inputs, build_func, timeout, verbose)
-
- pool = NoDaemonPool(n_parallel)
- tuple_res = pool.map(local_build_worker, range(len(inputs)))
+ # This pool is not doing computationally intensive work, so we can use threads
+ pool = multiprocessing.pool.ThreadPool(n_parallel)
Review comment:
Do we still need serialization with `ThreadPool`?
I guess all these arguments will be shared in memory and will be passed as references.
##########
File path: python/tvm/auto_scheduler/measure.py
##########
@@ -87,6 +120,24 @@ def __init__(self, task, state):
state = state if isinstance(state, StateObject) else state.state_object
self.__init_handle_by_constructor__(_ffi_api.MeasureInput, task, state)
+ def serialize(self):
Review comment:
Can we use `__getstate__`?
##########
File path: python/tvm/autotvm/task/task.py
##########
@@ -173,6 +172,8 @@ def __getstate__(self):
# some unpickable local task functions.
# So we only pickle the name of the function
# and restore the function by name when unpickling it.
+ import cloudpickle # pylint: disable=import-outside-toplevel
Review comment:
Why not import on the top-level?
##########
File path: python/tvm/autotvm/tuner/xgboost_cost_model.py
##########
@@ -321,10 +316,11 @@ def _get_feature(self, indexes):
indexes = np.array(indexes)
need_extract = [x for x in indexes if x not in fea_cache]
+ args = [(self.space.get(x), self.target, self.task) for x in need_extract]
Review comment:
Doing this still needs serializing a lot of things. Did you test the performance before vs. after?
##########
File path: src/auto_scheduler/measure_record.cc
##########
@@ -107,18 +107,68 @@ struct Handler<::tvm::auto_scheduler::StateNode> {
}
};
+template <>
+struct Handler<::tvm::auto_scheduler::HardwareParamsNode> {
+ inline static void Write(dmlc::JSONWriter* writer,
+ const ::tvm::auto_scheduler::HardwareParamsNode& data) {
+ writer->BeginArray(false);
+ writer->WriteArrayItem(data.num_cores);
+ writer->WriteArrayItem(data.vector_unit_bytes);
+ writer->WriteArrayItem(data.cache_line_bytes);
+ writer->WriteArrayItem(data.max_shared_memory_per_block);
+ writer->WriteArrayItem(data.max_registers_per_block);
+ writer->WriteArrayItem(data.max_threads_per_block);
+ writer->WriteArrayItem(data.max_vthread_extent);
+ writer->WriteArrayItem(data.warp_size);
+ writer->EndArray();
+ }
+ inline static void Read(dmlc::JSONReader* reader,
+ ::tvm::auto_scheduler::HardwareParamsNode* data) {
+ bool s;
+ reader->BeginArray();
+ s = reader->NextArrayItem();
+ CHECK(s);
+ reader->Read(&data->num_cores);
+ s = reader->NextArrayItem();
+ CHECK(s);
+ reader->Read(&data->vector_unit_bytes);
+ s = reader->NextArrayItem();
+ CHECK(s);
+ reader->Read(&data->cache_line_bytes);
+ s = reader->NextArrayItem();
+ CHECK(s);
+ reader->Read(&data->max_shared_memory_per_block);
+ s = reader->NextArrayItem();
+ CHECK(s);
+ reader->Read(&data->max_registers_per_block);
+ s = reader->NextArrayItem();
+ CHECK(s);
+ reader->Read(&data->max_threads_per_block);
+ s = reader->NextArrayItem();
+ CHECK(s);
+ reader->Read(&data->max_vthread_extent);
+ s = reader->NextArrayItem();
+ CHECK(s);
+ reader->Read(&data->warp_size);
+ s = reader->NextArrayItem();
+ CHECK(!s);
+ }
+};
+
template <>
struct Handler<::tvm::auto_scheduler::SearchTaskNode> {
inline static void Write(dmlc::JSONWriter* writer,
const ::tvm::auto_scheduler::SearchTaskNode& data) {
writer->BeginArray(false);
writer->WriteArrayItem(std::string(data.workload_key));
writer->WriteArrayItem(data.target->str());
+ writer->WriteArrayItem(*data.hardware_params.get());
Review comment:
Since you changed the format, please update the version number to `v0.3`
https://github.com/apache/incubator-tvm/blob/c6f18250e176a0f107481d489651f6abdfe00976/src/auto_scheduler/measure_record.cc#L219
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717506384
I tested your autotvm implementation and found it is significantly slower.
To do the test, you can run this tutorial (https://github.com/apache/incubator-tvm/blob/main/tutorials/autotvm/tune_conv2d_cuda.py) and replace the n_trial=20 with n_trial=100
The number we care about is the time spent on simulated annealing which actually uses the xgboost_cost_model.py modified by you.
This is the screenshot before your PR. You can see `elapsed: 63.40` in the last line, which means it takes 63.40 seconds to do simulated annealing.

However, with your PR, the number becomes 194.67
<img width="1152" alt="Screen Shot 2020-10-27 at 12 47 15 PM" src="https://user-images.githubusercontent.com/15100009/97355886-cff21380-1854-11eb-9058-72eb1ac9f844.png">
I don’t understand why the autotvm part is required for that PR, because autotvm and auto-scheduler are totally independent. Can you delete autotvm files in that PR?
The test machine is a 24-core Intel E5
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717540915
What's your testing environment?
Why is the tutorial broken? I can run it successfully.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tkonolige commented on a change in pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tkonolige commented on a change in pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#discussion_r512090033
##########
File path: python/tvm/auto_scheduler/measure.py
##########
@@ -87,6 +120,24 @@ def __init__(self, task, state):
state = state if isinstance(state, StateObject) else state.state_object
self.__init_handle_by_constructor__(_ffi_api.MeasureInput, task, state)
+ def serialize(self):
Review comment:
There was some weird initialization bug with `__getstate__` that I could not figure out. I'll add a comment about this.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tkonolige commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tkonolige commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717536336
@merrymercy The goal of this pr is to make autotuning and auto scheduling work on macOS and windows. Currently autotvm does not work on macOS, so that is why I have been touching it.
The tutorial you are using is broken. All code that needs to be run should be within an `if __name__ == "__main__":` statement. With this statement, and changing n_trials to 100, I get these results:
On main
```
SA iter: 50 last_update: 49 max-0: 5.05 max-1: 5.32 temp: 0.90 elapsed: 22.72
SA iter: 100 last_update: 98 max-0: 5.19 max-1: 5.43 temp: 0.80 elapsed: 44.25
SA iter: 150 last_update: 147 max-0: 5.19 max-1: 5.43 temp: 0.70 elapsed: 65.84
SA iter: 200 last_update: 198 max-0: 5.29 max-1: 5.43 temp: 0.60 elapsed: 87.38
SA iter: 250 last_update: 248 max-0: 5.29 max-1: 5.43 temp: 0.50 elapsed: 108.47
SA iter: 300 last_update: 299 max-0: 5.31 max-1: 5.43 temp: 0.40 elapsed: 129.17
SA iter: 350 last_update: 331 max-0: 5.32 max-1: 5.43 temp: 0.30 elapsed: 149.26
SA iter: 400 last_update: 396 max-0: 5.32 max-1: 5.43 temp: 0.20 elapsed: 168.95
SA iter: 450 last_update: 448 max-0: 5.32 max-1: 5.43 temp: 0.10 elapsed: 187.60
SA iter: 500 last_update: 499 max-0: 5.32 max-1: 5.43 temp: 0.00 elapsed: 204.33
SA iter: 500 last_update: 499 elapsed: 204.33
```
On this PR
```
SA iter: 50 last_update: 49 max-0: 6.39 max-1: 6.87 temp: 0.90 elapsed: 23.53
SA iter: 100 last_update: 97 max-0: 6.56 max-1: 7.05 temp: 0.80 elapsed: 46.57
SA iter: 150 last_update: 149 max-0: 6.68 max-1: 7.05 temp: 0.70 elapsed: 69.27
SA iter: 200 last_update: 192 max-0: 6.69 max-1: 7.05 temp: 0.60 elapsed: 91.90
SA iter: 250 last_update: 238 max-0: 6.71 max-1: 7.05 temp: 0.50 elapsed: 114.53
SA iter: 300 last_update: 294 max-0: 6.77 max-1: 7.05 temp: 0.40 elapsed: 136.67
SA iter: 350 last_update: 348 max-0: 6.77 max-1: 7.05 temp: 0.30 elapsed: 158.47
SA iter: 400 last_update: 398 max-0: 6.87 max-1: 7.05 temp: 0.20 elapsed: 179.36
SA iter: 450 last_update: 447 max-0: 6.87 max-1: 7.05 temp: 0.10 elapsed: 198.81
SA iter: 500 last_update: 497 max-0: 6.87 max-1: 7.05 temp: 0.00 elapsed: 216.06
SA iter: 500 last_update: 497 elapsed: 216.06
```
Which has the runtime pretty close (I'm not sure what the variance on times is here).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tkonolige commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tkonolige commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717548491
They are broken with respect to the multiprocessing changes I have introduced in this PR. Technically speaking they were never correct as the script to be executed should be wrapped in `__name__ == "__main__"`.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716516782
Thanks for the refactoring! I would like to see benchmark results for both autotvm and auto-scheduler, so we don't get performance regression.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716534539
Another concern is that I introduced a new kind of workload in this PR (#6710) for relay integration.
When using auto-scheduler in Relay, we don't serialize a ComputeDAG by function + arguments.
We save a copy of the TE expressions generated by relay as the workload.
So we have to support serializing TE expressions after this PR. But I am not sure if it works because there are pointers in TE expressions.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717588164
I added `__name__ == "__main__"` but the results are the same.
Can you delete all autotvm related code and tutorials in this PR? We can investigate later. In the meanwhile, can you try on a machine with more cores?
Can you check whether your modifications to the tutorials break their format?
I don't think the tutorial scripts can generate correct RST files after adding indentation to the text block.
You can build the tutorials locally and check the generated HTML files.
This PR and #6710 are conflicting. I want to merge this first so I can do merge and clean up on my PR. Otherwise, you have to do more work by yourself.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tkonolige commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tkonolige commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717560438
I took off the `__name__ == "__main__"` lines and it performs the same. `__name__ == "__main__"` is still required for non-linux machines (i.e. the tutorials are buggy on non linux machines), but it isn't causing the issue here. The only difference I can see then is that your machine has so many threads. Can you reproduce your results on a different machine?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717550912
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716905146
The auto-scheduler part looks good to me. I believe this PR solves the problem while not bringing any performance regression.
But I am not sure about the autotvm part. Your test case is not correct. With `n-trials=16`, the code modified by you will not even be executed. Because the cost model only starts to work after getting enough training samples (n-trials > 64). To do the benchmark correctly, you should use a larger matrix size (n=1024), run the autotvm with n-trials > 64 and `XGBTuner`, and report the time used in simulated annealing (which actually runs the modified `xgboost_cost_model.py`).
Could you delete the autotvm part in this PR (files : `python/tvm/autotvm/task/task.py`, `python/tvm/autotvm/tuner/xgboost_cost_model.py`) so we can merge this?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717619470
How about also undoing the tutorials? I guess their format will be wrong because you add indentation to text blocks.
For the autotvm problem, I am okay to accept the following solution:
provide two versions of the code and pick the version of code according to OS.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717619470
How about also undoing the tutorials? I guess their format will be wrong because you add indentation to text blocks.
For the autotvm problem, I am okay to accept the following solution:
1. provide two versions of the code.
2. pick the version of code according to OS.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tkonolige commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tkonolige commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717601781
Here is the tests I've run on a 64-core machine:
```
This PR
XGB iter: 0 tr-a-recall@64: 0.598716 tr-map: 0.142857
XGB iter: 25 tr-a-recall@64: 0.667324 tr-map: 0.500000
XGB stopped. Best iteration: [13] tr-a-recall@64:0.67690 tr-map:0.50000
XGB train: 1.24 obs: 64 error: 50 n_cache: 64
SA iter: 50 last_update: 49 max-0: 4.42 max-1: 4.71 temp: 0.90 elapsed: 16.14
SA iter: 100 last_update: 97 max-0: 4.55 max-1: 4.71 temp: 0.80 elapsed: 30.59
SA iter: 150 last_update: 145 max-0: 4.56 max-1: 4.74 temp: 0.70 elapsed: 45.74
SA iter: 200 last_update: 197 max-0: 4.58 max-1: 4.83 temp: 0.60 elapsed: 60.61
SA iter: 250 last_update: 249 max-0: 4.67 max-1: 4.84 temp: 0.50 elapsed: 76.09
SA iter: 300 last_update: 299 max-0: 4.69 max-1: 4.84 temp: 0.40 elapsed: 90.07
SA iter: 350 last_update: 349 max-0: 4.71 max-1: 4.84 temp: 0.30 elapsed: 104.27
SA iter: 400 last_update: 377 max-0: 4.71 max-1: 4.84 temp: 0.20 elapsed: 118.12
SA iter: 450 last_update: 448 max-0: 4.72 max-1: 4.84 temp: 0.10 elapsed: 130.86
SA iter: 500 last_update: 498 max-0: 4.76 max-1: 4.84 temp: 0.00 elapsed: 143.39
SA iter: 500 last_update: 498 elapsed: 143.39
main
XGB iter: 0 tr-a-recall@64: 0.641594 tr-map: 0.500000
XGB iter: 25 tr-a-recall@64: 0.716034 tr-map: 0.500000
XGB iter: 50 tr-a-recall@64: 0.728245 tr-map: 1.000000
XGB stopped. Best iteration: [38] tr-a-recall@64:0.73020 tr-map:0.50000
XGB train: 1.10 obs: 64 error: 46 n_cache: 64
SA iter: 50 last_update: 49 max-0: 6.21 max-1: 6.94 temp: 0.90 elapsed: 3.40
SA iter: 100 last_update: 99 max-0: 6.50 max-1: 7.16 temp: 0.80 elapsed: 6.68
SA iter: 150 last_update: 149 max-0: 6.74 max-1: 7.38 temp: 0.70 elapsed: 10.24
SA iter: 200 last_update: 199 max-0: 6.86 max-1: 7.39 temp: 0.60 elapsed: 13.91
SA iter: 250 last_update: 249 max-0: 6.97 max-1: 7.39 temp: 0.50 elapsed: 17.68
SA iter: 300 last_update: 294 max-0: 7.07 max-1: 7.56 temp: 0.40 elapsed: 21.29
SA iter: 350 last_update: 348 max-0: 7.11 max-1: 7.56 temp: 0.30 elapsed: 24.52
SA iter: 400 last_update: 399 max-0: 7.15 max-1: 7.56 temp: 0.20 elapsed: 27.68
SA iter: 450 last_update: 449 max-0: 7.16 max-1: 7.56 temp: 0.10 elapsed: 30.63
SA iter: 500 last_update: 499 max-0: 7.17 max-1: 7.56 temp: 0.00 elapsed: 33.48
SA iter: 500 last_update: 499 elapsed: 33.48
```
Seems like the issue is hit when there are a lot of cores.
I've pulled out the autotvm parts and will send another pr when I figure out those.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-708845921
Autotvm uses a lot of python multiprocessing and I expect it will be much slower when using spawn. AutoTVM uses multiprocessing for feature extraction. So it needs to launch about 50,000 processes every measurement batch.
Ansor does not rely on multiprocessing too much. So the situation for Ansor is better.
However, I'd like to see benchmark numbers about fork vs. spawn.
i.e. Run a search with `n-trials=64` with (Ansor, AutoTVM) x (fork, spawn) X (CPU, GPU) (Optional)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716905146
The auto-scheduler part looks good to me. I believe this PR solves the problem while not bringing any performance regression.
But I am not sure about the autotvm part. Your test case is not correct. With `n-trials=16`, the code modified by you will not even be executed. Because the cost model only starts to work after getting enough training samples (n-trials > 64). To do the benchmark correctly, you should use a larger matrix size (n=1024), run the autotvm with n-trials > 64 and `XGBTuner`, and report the time used in simulated annealing (which actually uses the modified cost model)).
Could you delete the autotvm part in this PR so we can merge this?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716905146
The auto-scheduler part looks good to me. I believe this PR solves the problem while not bringing any performance regression.
But I am not sure about the autotvm part. Could you delete the autotvm part in this PR so we can merge this?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717588164
I added `__name__ == "__main__"` but the results are the same.
Can you delete all autotvm related code and tutorials in this PR? We can investigate later. In the meanwhile, can you try on a machine with more cores?
Can you check whether your modifications to the tutorial break its format?
I don't think the tutorial scripts can generate correct rst files after adding indentation to the text block.
You can build the tutorials locally and check the built HTML files.
This PR and #6710 are conflicting. I want to merge this first so I can do merge and clean up on my PR. Otherwise, you have to do more work by yourself.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717547728
Which PR introduced the changes that broke the tutorials? I don't find related changes in your PR.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716905146
The auto-scheduler part looks good to me. I believe this PR solves the problem while not bringing any performance regression.
But I am not sure about the autotvm part. Your test case is not correct. With `n-trials=16`, the code modified by you will not even be executed.
Could you delete the autotvm part in this PR so we can merge this?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on a change in pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy commented on a change in pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#discussion_r511923166
##########
File path: python/tvm/auto_scheduler/measure.py
##########
@@ -590,14 +634,20 @@ def local_builder_build(inputs, timeout, n_parallel, build_func="default", verbo
res : List[BuildResult]
The build results of these MeasureInputs.
"""
- # We use fork and a global variable to copy arguments between processes.
- # This can avoid expensive serialization of TVM IR when using multiprocessing.Pool
- global GLOBAL_BUILD_ARGUMENTS
-
- GLOBAL_BUILD_ARGUMENTS = (inputs, build_func, timeout, verbose)
-
- pool = NoDaemonPool(n_parallel)
- tuple_res = pool.map(local_build_worker, range(len(inputs)))
+ # This pool is not doing computationally intensive work, so we can use threads
+ pool = multiprocessing.pool.ThreadPool(n_parallel)
Review comment:
Do we still need serialization with `ThreadPool`?
I guess all these arguments will be shared in memory and will be passed as references.
If this is true, then we don't need to change any other part of the code in this file.
In addition, we can choose to use `ProcessingPool` and `ThreadPool` here according to the OS.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tkonolige commented on a change in pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tkonolige commented on a change in pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#discussion_r512097091
##########
File path: python/tvm/auto_scheduler/measure.py
##########
@@ -950,26 +1017,30 @@ def rpc_runner_run(
res : List[MeasureResult]
The measure results of these MeasureInputs.
"""
- global GLOBAL_RUN_ARGUMENTS
- GLOBAL_RUN_ARGUMENTS = (
- inputs,
- build_results,
- key,
- host,
- port,
- priority,
- timeout,
- number,
- repeat,
- min_repeat_ms,
- cooldown_interval,
- enable_cpu_cache_flush,
- verbose,
- )
-
assert len(inputs) == len(build_results), "Measure input size should be equal to build results"
- pool = NoDaemonPool(n_parallel)
- tuple_res = pool.map(rpc_run_worker, range(len(build_results)))
+ # This pool is not doing computationally intensive work, so we can use threads
Review comment:
The pool is doing basically no work. Each thread in the pool spawns a process and then waits till it times out.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716905146
The auto-scheduler part looks good to me. I believe this PR solves the problem while not bringing any performance regression.
But I am not sure about the autotvm part. Your test case is not correct. With `n-trials=16`, the code modified by you will not even be executed. Because the cost model only starts to work after getting enough training samples (n-trials > 64). To do the benchmark correctly, you should use a larger matrix size (n=1024), run the autotvm with n-trials > 64 and `XGBTuner`, and report the time used in simulated annealing (which actually uses the modified cost model)).
Could you delete the autotvm part in this PR (`python/tvm/autotvm/task/task.py`, `python/tvm/autotvm/tuner/xgboost_cost_model.py`) so we can merge this?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tqchen commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tqchen commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-715919654
cc @jcf94 @comaniac @yzhliu please also help to take a look
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tkonolige commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tkonolige commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717543079
If you don't have the `if __name__ == "__main__":`, then the the whole body of the module may be run on every sub process. Could you test on your machine with this change?
My environment is archlinux with a Intel(R) Core(TM) i5-3570K CPU @ 3.40GHz and 1080. Python 3.8.6.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy merged pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy merged pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717547728
Which PR introduced the changes that broke the tutorials? I don't find related thing in your PR.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on a change in pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy commented on a change in pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#discussion_r511903881
##########
File path: python/tvm/auto_scheduler/measure.py
##########
@@ -950,26 +1017,30 @@ def rpc_runner_run(
res : List[MeasureResult]
The measure results of these MeasureInputs.
"""
- global GLOBAL_RUN_ARGUMENTS
- GLOBAL_RUN_ARGUMENTS = (
- inputs,
- build_results,
- key,
- host,
- port,
- priority,
- timeout,
- number,
- repeat,
- min_repeat_ms,
- cooldown_interval,
- enable_cpu_cache_flush,
- verbose,
- )
-
assert len(inputs) == len(build_results), "Measure input size should be equal to build results"
- pool = NoDaemonPool(n_parallel)
- tuple_res = pool.map(rpc_run_worker, range(len(build_results)))
+ # This pool is not doing computationally intensive work, so we can use threads
Review comment:
Did you benchmark the speed of ProcessingPool vs. ThreadPool?
For the comment, is this pool "not doing computational intensive work" or "not doing computational intensive work in python"?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717619470
How about also undoing the tutorials? I guess their format will be wrong because you add indentation to text blocks.
For the autotvm problem, I am okay to accept the following solution:
1. provide two versions of the code.
2. pick the version according to OS.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-708845921
Autotvm uses a lot of python multiprocessing and I expect it will be much slower when using spawn. AutoTVM uses multiprocessing for feature extraction. So it needs to launch about 50,000 tasks every measurement batch.
The situation for Ansor is better as Ansor does not rely on multiprocessing as heavily as AutoTVM does.
However, I'd like to see benchmark numbers about fork vs. spawn.
i.e. Run a search with `n_trials=64` with (Ansor, AutoTVM) x (fork, spawn) X (CPU, GPU) (Optional).
The requirement from my side is that I don't want to see any performance regression.
I prefer to only use the slower and safer fallback mechanism when the fast approach does not work.
Removing all multiprocessing requires huge engineering effort.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on a change in pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy commented on a change in pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#discussion_r511923166
##########
File path: python/tvm/auto_scheduler/measure.py
##########
@@ -590,14 +634,20 @@ def local_builder_build(inputs, timeout, n_parallel, build_func="default", verbo
res : List[BuildResult]
The build results of these MeasureInputs.
"""
- # We use fork and a global variable to copy arguments between processes.
- # This can avoid expensive serialization of TVM IR when using multiprocessing.Pool
- global GLOBAL_BUILD_ARGUMENTS
-
- GLOBAL_BUILD_ARGUMENTS = (inputs, build_func, timeout, verbose)
-
- pool = NoDaemonPool(n_parallel)
- tuple_res = pool.map(local_build_worker, range(len(inputs)))
+ # This pool is not doing computationally intensive work, so we can use threads
+ pool = multiprocessing.pool.ThreadPool(n_parallel)
Review comment:
Do we still need serialization with `ThreadPool`?
I guess all these arguments will be shared in memory and will be passed as references.
If this is true, then we don't need to change any other part of the code in this file.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tqchen commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tqchen commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717620222
I agree that the sphinx gallery will run all tutorials together, and it would still be useful to keep the tutorials in the form of ipynb style(no main)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716905146
The auto-scheduler part looks good to me. I believe this PR solves the problem while not bringing any performance regression.
But I am not sure about the autotvm part. Your test case is not correct. With `n-trials=16`, the code modified by you will not be executed.
Could you delete the autotvm part in this PR so we can merge this?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716905146
The auto-scheduler part looks good to me.
But I am not sure about the autotvm part.
If you don't mind, I suggest deleting the autotvm part in this PR.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717550912
Sorry, could you point me to the related lines? I only see you rename some variables in the `python/tvm/autotvm/measure/local_executor.py`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717506384
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on a change in pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy commented on a change in pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#discussion_r511940229
##########
File path: python/tvm/auto_scheduler/workload_registry.py
##########
@@ -175,6 +175,41 @@ def workload_key_to_tensors(workload_key):
return lookup(*args)
+def get_workload(task):
+ """Get the workload function for a given task
+
+ Parameters
+ ----------
+ task : SearchTask
+ Task to get workload of.
+
+ Returns
+ -------
+ workload : callable
+ The registered workload function.
+ """
+ name = workload_name(task.workload_key)
+ lookup = WORKLOAD_FUNC_REGISTRY[name]
+ assert callable(lookup)
+ return lookup
+
+
+def workload_name(workload_key):
Review comment:
```suggestion
def workload_func_name(workload_key):
```
##########
File path: python/tvm/auto_scheduler/workload_registry.py
##########
@@ -175,6 +175,41 @@ def workload_key_to_tensors(workload_key):
return lookup(*args)
+def get_workload(task):
Review comment:
```suggestion
def get_workload_func(task):
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] tkonolige commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
tkonolige commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716780203
Here are benchmark results on linux using forking. This is `dense` with 64 x 64 matrices. ntrials=16, 5 bencmarking iterations.
| Branch | Auto-what | Target | Mean Time | STD |
| ------ | --------- | ------ | --------- | --- |
| main | autotvm | llvm | 20.429478 | 1.914881 |
| PR | autotvm | llvm | 26.400752 | 9.013005 |
| main | autotvm | cuda | 7.010600 | 0.080864 |
| PR | autotvm | cuda | 7.001349 | 0.017357 |
| main | autoscheduler | llvm | 16.711073 | 2.572820 |
| PR | autoscheduler | llvm | 14.752735 | 0.757895 |
| main | autoscheduler | cuda | 32.981713 | 0.072185 |
| PR | autoscheduler | cuda | 32.283536 | 0.054209 |
Looks pretty similar except for high standard deviation in runtime. Not sure what's causing this. I still think we should merge this as it fixes users not being able to run auto scheduling on Macs.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716905146
The auto-scheduler part looks good to me. I believe this PR won't bring any performance regression.
But I am not sure about the autotvm part. Could you delete the autotvm part in this PR so we can merge this?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717588164
I added `__name__ == "__main__"` but the results are the same.
Can you delete all autotvm related code and tutorials in this PR? We can investigate later. In the meanwhile, can you try on a machine with more cores?
This PR and #6710 are conflicting. I want to merge this first so I can do merge and clean up on my PR. Otherwise, you have to do more work by yourself.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716905146
The auto-scheduler part looks good to me. I believe this PR solves the problem while not bringing any performance regression.
But I am not sure about the autotvm part. Your test case is not correct. With `n-trials=16`, the code modified by you will not even be executed. Because the cost model only starts to work after getting enough training samples (n-trials > 64). To do the benchmark correctly, you should use a larger matrix size, run the autotvm with n-trials > 64 and `XGBTuner`, and report the time used in simulated annealing (i.e., the part modified by you).
Could you delete the autotvm part in this PR so we can merge this?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-708103769
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716905146
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy commented on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-708103769
Note that "spawn" is slower than "fork" (https://docs.python.org/3/library/multiprocessing.html#contexts-and-start-methods).
We should not change all default settings to "spawn".
We should prefer "fork" as the default setting when it is possible.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6671: [FIX,AUTOSCHEDULER] Fix auto_scheduler to run with multiprocessing's spawn start method
Posted by GitBox <gi...@apache.org>.
merrymercy edited a comment on pull request #6671:
URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-716905146
The auto-scheduler part looks good to me. I believe this PR solves the problem while not bringing any performance regression.
But I am not sure about the autotvm part. Your test case is not correct. With `n-trials=16`, the code modified by you will not even be executed. Because the cost model only starts to work after getting enough training data (n-trials > 64). To do the benchmark correctly, you should use a larger matrix size, run the autotvm with n-trials > 64, and report the time used in simulated annealing.
Could you delete the autotvm part in this PR so we can merge this?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org