You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2021/12/16 02:47:07 UTC
[GitHub] [spark] yikf opened a new pull request #34916: Avoid shuffle in some scenes with CollectLimitExec
yikf opened a new pull request #34916:
URL: https://github.com/apache/spark/pull/34916
### What changes were proposed in this pull request?
Currently, Some scenes retain the combination of GlobalLimitExec - LocalLimitExec, which can actually be optimized to CollectLimitExec, like: `INSERT INTO t2 SELECT c1 FROM t1 LIMIT 1`
The PR aims to 2 points:
- Improve `INSERT INTO t2 SELECT c1 FROM t1 LIMIT 1` to `CollectLimitExec`
- Add a flag that identifies `CollectLimitExec` without shuffle and scan all data.
Example:
> CREATE TABLE t1(id STRING) USING parquet
CREATE TABLE t2(id STRING) USING parquet
INSERT INTO t1 SELECT * FROM t2 LIMIT 5
Before:
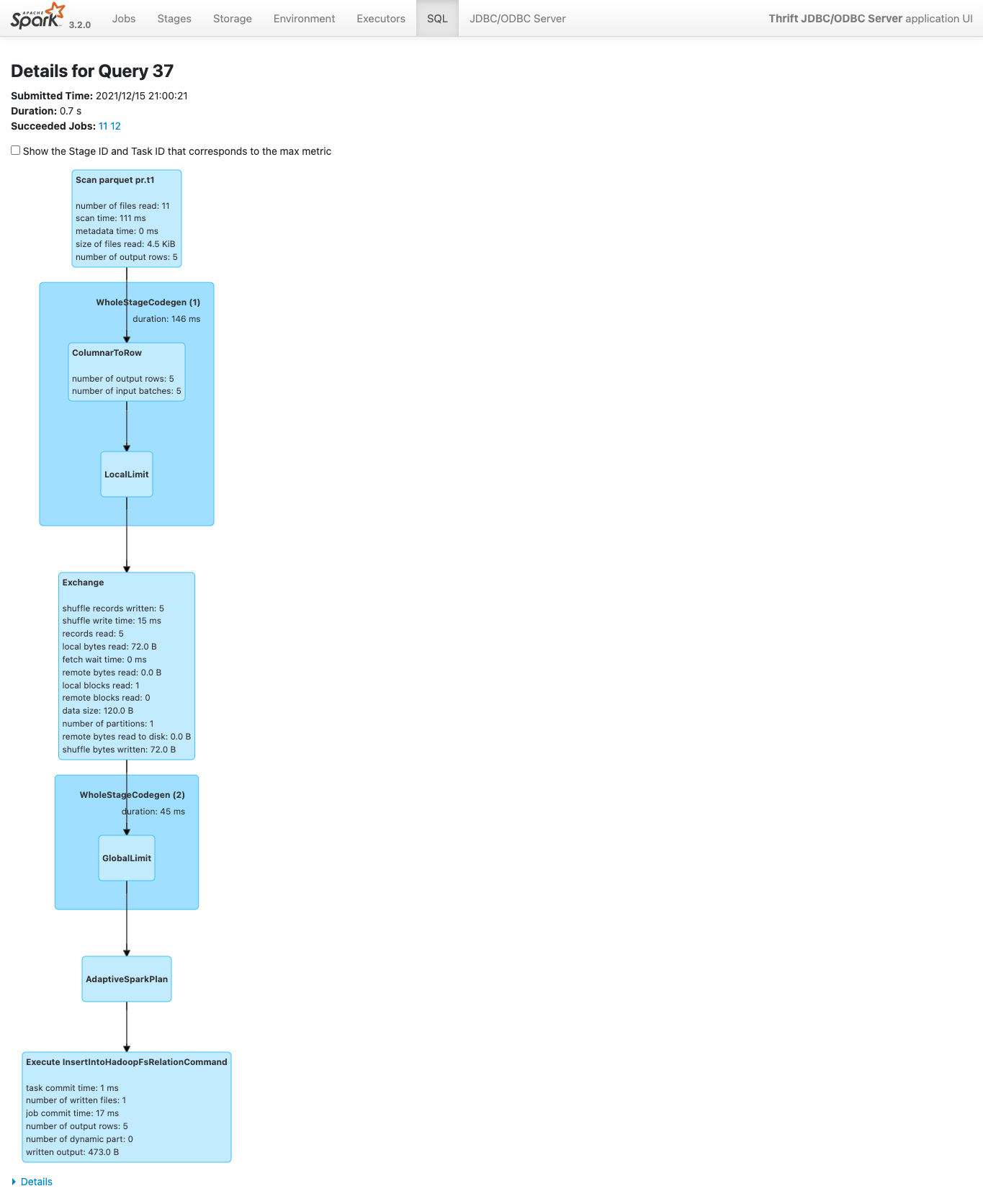
After:
<img width="669" alt="After PR" src="https://user-images.githubusercontent.com/51110188/146298706-78ef867d-8342-4340-8ad5-7a648c597e50.png">
### Why are the changes needed?
Optimize logic
### Does this PR introduce _any_ user-facing change?
No, optimize only
### How was this patch tested?
Unit Test and manually test.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34916: [SPARK-35355][SQL] Avoid shuffle in some scenes with CollectLimitExec
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34916:
URL: https://github.com/apache/spark/pull/34916#issuecomment-995404679
Can one of the admins verify this patch?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] yikf commented on pull request #34916: [SPARK-35355][SQL] Avoid shuffle in some scenes with CollectLimitExec
Posted by GitBox <gi...@apache.org>.
yikf commented on pull request #34916:
URL: https://github.com/apache/spark/pull/34916#issuecomment-995393068
@zhengruifeng @cloud-fan Could you take a look when you have a time?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] yikf commented on pull request #34916: [SPARK-35355][SQL] Avoid shuffle in some scenes with CollectLimitExec
Posted by GitBox <gi...@apache.org>.
yikf commented on pull request #34916:
URL: https://github.com/apache/spark/pull/34916#issuecomment-995586845
> I'm not sure if this is a good idea. Yes, you save one shuffle, but you also need to collect data to the driver side and distribute it later to run table insertion, which I don't think is cheaper than a shuffle, and is probably more fragile (causes driver OOM)
1. limit scene which data is less is not prone occur OOM, and CollectLimitExec's outputPartitioning is `SinglePartition`, It is similar to Driver collect limit.
2. If collectExec's shuffle reader node and insert are on the same node, it does reduce exactly the cost of distribution, but if it is not on the same node, it also needs to be distributed. However, the cost of distribution should be less than that of the shuffle operator.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #34916: [SPARK-35355][SQL] Avoid shuffle in some scenes with CollectLimitExec
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on pull request #34916:
URL: https://github.com/apache/spark/pull/34916#issuecomment-995567705
I'm not sure if this is a good idea. Yes, you save one shuffle, but you also need to collect data to the driver side and distribute it later to run table insertion, which I don't think is cheaper than a shuffle, and is probably more fragile (causes driver OOM)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #34916: [SPARK-35355][SQL] Avoid shuffle in some scenes with CollectLimitExec
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on pull request #34916:
URL: https://github.com/apache/spark/pull/34916#issuecomment-995638178
> limit scene which data is less is not prone occur OOM
We can't rely on assumptions. Technically the limit can be arbitrarily big. So I think writing to disk and reading back (shuffle) is better than collecting to memory and re-distribute. BTW AQE can optimize shuffles much better.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org