You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by "soumilshah1995 (via GitHub)" <gi...@apache.org> on 2023/04/07 16:42:53 UTC
[GitHub] [hudi] soumilshah1995 opened a new issue, #8406: [SUPPORT] Hudi Async Indexing for Column Stats for Video Content for Community
soumilshah1995 opened a new issue, #8406:
URL: https://github.com/apache/hudi/issues/8406
Hello
i made sample hudi MOR table using glue job
# Glue Job
```
"""
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.sql.hive.convertMetastoreParquet=false --conf spark.sql.hive.convertMetastoreParquet=false --conf spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog --conf spark.sql.legacy.pathOptionBehavior.enabled=true
"""
try:
import sys
import os
from pyspark.context import SparkContext
from pyspark.sql.session import SparkSession
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import col, to_timestamp, monotonically_increasing_id, to_date, when
from pyspark.sql.functions import *
from awsglue.utils import getResolvedOptions
from pyspark.sql.types import *
from datetime import datetime, date
import boto3
from functools import reduce
from pyspark.sql import Row
import uuid
from faker import Faker
except Exception as e:
print("Modules are missing : {} ".format(e))
spark = (SparkSession.builder.config('spark.serializer', 'org.apache.spark.serializer.KryoSerializer') \
.config('spark.sql.hive.convertMetastoreParquet', 'false') \
.config('spark.sql.catalog.spark_catalog', 'org.apache.spark.sql.hudi.catalog.HoodieCatalog') \
.config('spark.sql.extensions', 'org.apache.spark.sql.hudi.HoodieSparkSessionExtension') \
.config('spark.sql.legacy.pathOptionBehavior.enabled', 'true').getOrCreate())
sc = spark.sparkContext
glueContext = GlueContext(sc)
job = Job(glueContext)
logger = glueContext.get_logger()
# =================================INSERTING DATA =====================================
global faker
faker = Faker()
class DataGenerator(object):
@staticmethod
def get_data():
return [
(
uuid.uuid4().__str__(),
faker.name(),
faker.random_element(elements=('IT', 'HR', 'Sales', 'Marketing')),
faker.random_element(elements=('CA', 'NY', 'TX', 'FL', 'IL', 'RJ')),
str(faker.random_int(min=10000, max=150000)),
str(faker.random_int(min=18, max=60)),
str(faker.random_int(min=0, max=100000)),
str(faker.unix_time()),
faker.email(),
faker.credit_card_number(card_type='amex'),
) for x in range(10000)
]
# ============================== Settings =======================================
db_name = "hudidb"
table_name = "employees"
recordkey = 'emp_id'
precombine = "ts"
PARTITION_FIELD = 'state'
path = "s3://delta-streamer-demo-hudi/hudi/"
method = 'upsert'
table_type = "MERGE_ON_READ"
# ====================================================================================
hudi_part_write_config = {
'className': 'org.apache.hudi',
'hoodie.table.name': table_name,
'hoodie.datasource.write.table.type': table_type,
'hoodie.datasource.write.operation': method,
'hoodie.datasource.write.recordkey.field': recordkey,
'hoodie.datasource.write.precombine.field': precombine,
"hoodie.schema.on.read.enable": "true",
"hoodie.datasource.write.reconcile.schema": "true",
'hoodie.datasource.hive_sync.mode': 'hms',
'hoodie.datasource.hive_sync.enable': 'true',
'hoodie.datasource.hive_sync.use_jdbc': 'false',
'hoodie.datasource.hive_sync.support_timestamp': 'false',
'hoodie.datasource.hive_sync.database': db_name,
'hoodie.datasource.hive_sync.table': table_name
, "hoodie.clean.automatic": "false"
, "hoodie.clean.async": "false"
, "hoodie.clustering.async.enabled": "false"
, "hoodie.metadata.enable": "true"
, "hoodie.metadata.index.async": "true"
, "hoodie.metadata.index.column.stats.enable": "true"
,"hoodie.metadata.index.check.timeout.seconds":"60"
,"hoodie.write.concurrency.mode":"optimistic_concurrency_control"
,"hoodie.write.lock.provider":"org.apache.hudi.client.transaction.lock.InProcessLockProvider"
}
for i in range(0, 5):
data = DataGenerator.get_data()
columns = ["emp_id", "employee_name", "department", "state", "salary", "age", "bonus", "ts", "email", "credit_card"]
spark_df = spark.createDataFrame(data=data, schema=columns)
spark_df.write.format("hudi").options(**hudi_part_write_config).mode("append").save(path)
```
# Schedule Indexing
```
try:
import json
import uuid
import os
import boto3
from dotenv import load_dotenv
load_dotenv("../.env")
except Exception as e:
pass
global AWS_ACCESS_KEY
global AWS_SECRET_KEY
global AWS_REGION_NAME
AWS_ACCESS_KEY = os.getenv("DEV_ACCESS_KEY")
AWS_SECRET_KEY = os.getenv("DEV_SECRET_KEY")
AWS_REGION_NAME = "us-east-1"
client = boto3.client("emr-serverless",
aws_access_key_id=AWS_ACCESS_KEY,
aws_secret_access_key=AWS_SECRET_KEY,
region_name=AWS_REGION_NAME)
def lambda_handler_test_emr(event, context):
# ------------------Hudi settings ---------------------------------------------
db_name = "hudidb"
table_name = "employees"
recordkey = 'emp_id'
precombine = "ts"
PARTITION_FIELD = 'state'
path = "s3://delta-streamer-demo-hudi/hudi/"
method = 'upsert'
table_type = "MERGE_ON_READ"
# ---------------------------------------------------------------------------------
# EMR
# --------------------------------------------------------------------------------
ApplicationId = os.getenv("ApplicationId")
ExecutionTime = 600
ExecutionArn = os.getenv("ExecutionArn")
JobName = 'hudi_async_indexing_columns_{}'.format(table_name)
# --------------------------------------------------------------------------------
spark_submit_parameters = ' --conf spark.jars=/usr/lib/hudi/hudi-utilities-bundle.jar'
spark_submit_parameters += ' --class org.apache.hudi.utilities.HoodieIndexer'
arguments = [
'--spark-memory', '1g',
'--parallelism', '2',
"--mode", "schedule",
"--base-path", path,
"--table-name", table_name,
"--index-types", "COLUMN_STATS",
"--hoodie-conf", "hoodie.metadata.enable=true",
"--hoodie-conf", "hoodie.metadata.index.async=true",
"--hoodie-conf", "hoodie.metadata.index.column.stats.enable=true",
"--hoodie-conf", "hoodie.metadata.index.check.timeout.seconds=60",
"--hoodie-conf", "hoodie.write.concurrency.mode=optimistic_concurrency_control",
"--hoodie-conf", "hoodie.write.lock.provider=org.apache.hudi.client.transaction.lock.InProcessLockProvider",
]
response = client.start_job_run(
applicationId=ApplicationId,
clientToken=uuid.uuid4().__str__(),
executionRoleArn=ExecutionArn,
jobDriver={
'sparkSubmit': {
'entryPoint': "command-runner.jar",
'entryPointArguments': arguments,
'sparkSubmitParameters': spark_submit_parameters
},
},
executionTimeoutMinutes=ExecutionTime,
name=JobName,
)
print("response", end="\n")
print(response)
lambda_handler_test_emr(context=None, event=None)
```
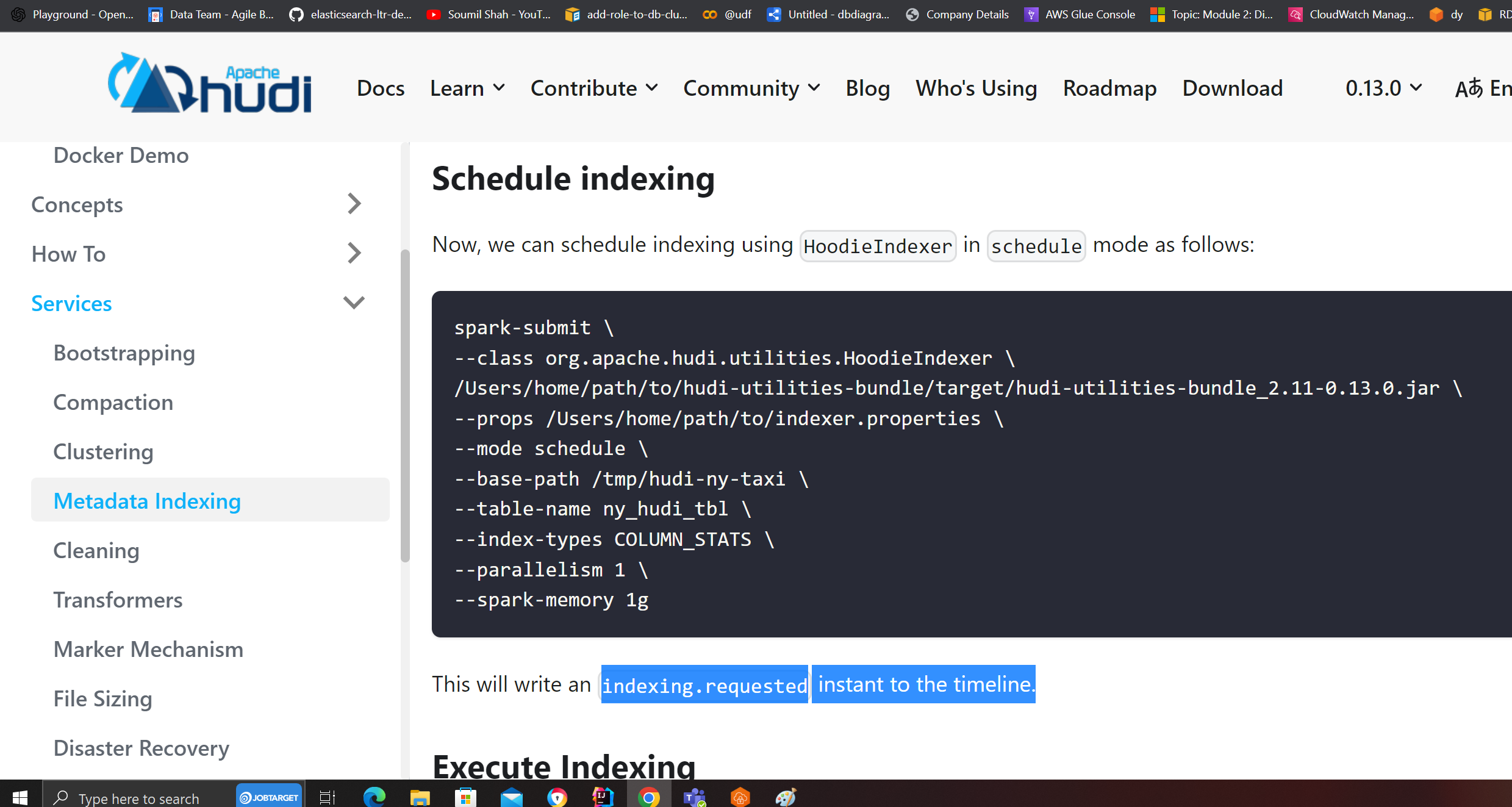
Website says i should be seeing indexing.requested files i dont see these files
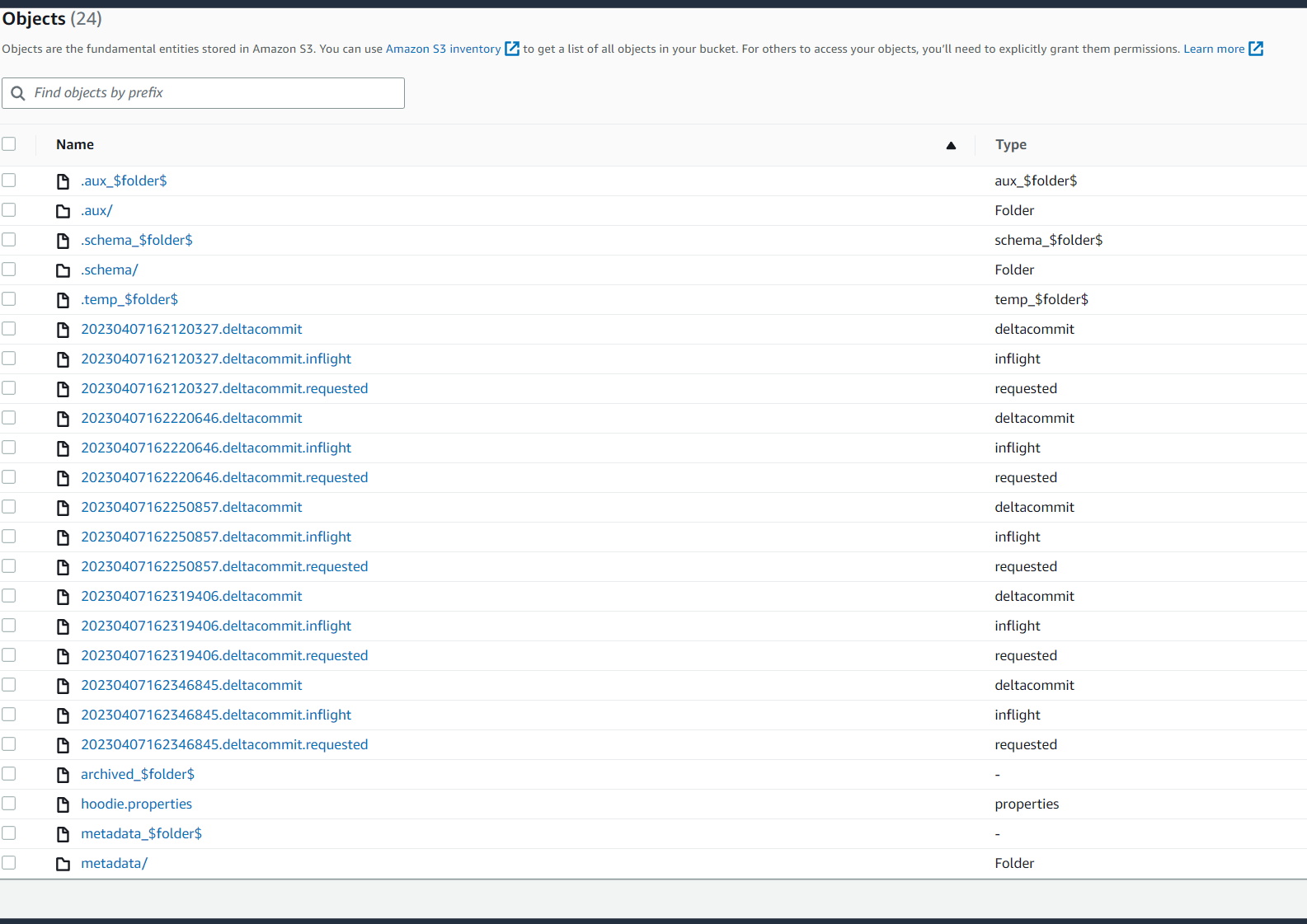
if i am missing anything would seek your advice and help
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 closed issue #8406: [SUPPORT] Hudi Async Indexing for Column Stats for Video Content for Community
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 closed issue #8406: [SUPPORT] Hudi Async Indexing for Column Stats for Video Content for Community
URL: https://github.com/apache/hudi/issues/8406
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8406: [SUPPORT] Hudi Async Indexing for Column Stats for Video Content for Community
Posted by "soumilshah1995 (via GitHub)" <gi...@apache.org>.
soumilshah1995 commented on issue #8406:
URL: https://github.com/apache/hudi/issues/8406#issuecomment-1500453377
issue resolved
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org