You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@liminal.apache.org by av...@apache.org on 2021/12/15 13:36:23 UTC
[incubator-liminal] branch master updated: [LIMINAL-87] Enable PreCommit Hooks isort yamllints pyupgrade
This is an automated email from the ASF dual-hosted git repository.
aviemzur pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/incubator-liminal.git
The following commit(s) were added to refs/heads/master by this push:
new a63c609 [LIMINAL-87] Enable PreCommit Hooks isort yamllints pyupgrade
a63c609 is described below
commit a63c60959be6186727d8b25d7b8fa035802609cd
Author: ChethanUK <ch...@outlook.com>
AuthorDate: Wed Dec 15 19:06:17 2021 +0530
[LIMINAL-87] Enable PreCommit Hooks isort yamllints pyupgrade
---
.asf.yaml | 14 +-
.github/PULL_REQUEST_TEMPLATE.md | 1 -
.github/workflows/pre_commits.yml | 5 +-
.github/workflows/unittest.yml | 38 ++---
.github/workflows/versioning.yml | 7 +-
.pre-commit-config.yaml | 173 ++++++++++++++++++++-
CONTRIBUTING.md | 14 +-
DISCLAIMER-WIP | 2 -
MANIFEST.in | 2 +-
docs/liminal/services.md => dev/LICENSE.txt | 22 ---
dev/RELEASE.md | 12 +-
docs/Makefile | 2 +-
docs/README.md | 2 +-
docs/architecture.md | 12 +-
docs/getting-started/hello_world.md | 6 +-
docs/getting-started/iris_classification.md | 6 +-
docs/getting-started/spark_app_demo.md | 2 +-
docs/liminal/advanced.liminal.yml.md | 2 +-
docs/liminal/executors/README.md | 2 +-
docs/liminal/images/README.md | 4 +-
docs/liminal/liminal.yml.md | 16 +-
docs/liminal/metrics_backends/README.md | 2 +-
docs/liminal/metrics_backends/index.rst | 2 +-
docs/liminal/monitoring.md | 2 +-
docs/liminal/pipelines.md | 6 +-
docs/liminal/services.md | 4 +-
docs/liminal/tasks/create_cloudformation_stack.md | 1 -
docs/liminal/tasks/delete_cloudformation_stack.md | 1 -
docs/liminal/tasks/python.md | 2 +-
..._to_install_liminal_in_airflow_on_kubernetes.md | 10 +-
examples/aws-ml-app-demo/liminal.yml | 2 +-
.../aws-ml-app-demo/manifests/aws-ml-app-demo.yaml | 10 +-
examples/aws-ml-app-demo/model_store.py | 7 +-
examples/liminal-getting-started/liminal.yml | 14 +-
examples/spark-app-demo/k8s/archetype/liminal.yml | 5 +-
examples/spark-app-demo/k8s/data/iris.csv | 1 -
examples/spark-app-demo/k8s/data_cleanup.py | 2 +-
examples/spark-app-demo/k8s/liminal.yml | 8 +-
.../k8s/manifests/spark-app-demo.yaml | 8 +-
examples/spark-app-demo/k8s/model_store.py | 7 +-
examples/spark-app-demo/k8s/training.py | 16 +-
liminal-arch.md | 16 +-
.../image/python_server/liminal_python_server.py | 12 +-
liminal/build/image/spark/Dockerfile | 2 +-
liminal/build/liminal_apps_builder.py | 2 +-
liminal/core/config/config.py | 3 +-
liminal/core/config/defaults/base/liminal.yml | 4 +-
liminal/core/util/class_util.py | 2 +-
liminal/core/util/files_util.py | 2 +-
liminal/kubernetes/volume_util.py | 2 +-
liminal/runners/airflow/dag/__init__.py | 1 +
liminal/runners/airflow/dag/liminal_dags.py | 6 +-
liminal/runners/airflow/executors/kubernetes.py | 7 +-
liminal/runners/airflow/model/executor.py | 4 +-
.../runners/airflow/operators/cloudformation.py | 2 +-
.../airflow/operators/job_status_operator.py | 2 +-
liminal/runners/airflow/tasks/containerable.py | 2 +-
.../airflow/tasks/create_cloudformation_stack.py | 4 +-
liminal/runners/airflow/tasks/spark.py | 4 +-
scripts/docker-compose.yml | 102 ++++++------
scripts/requirements-airflow.txt | 2 +-
setup.py | 2 +-
tests/liminal/kubernetes/test_volume_util.py | 1 +
.../python/test_python_server_image_builder.py | 2 +-
tests/runners/airflow/dag/test_liminal_dags.py | 5 +-
tests/runners/airflow/executors/test_emr.py | 4 +-
tests/runners/airflow/liminal/liminal.yml | 10 +-
tests/runners/airflow/liminal/requirements.txt | 2 +-
.../test_operator_with_variable_resolving.py | 8 +-
.../tasks/test_create_cloudformation_stack.py | 8 +-
.../tasks/test_delete_cloudformation_stack.py | 8 +-
tests/runners/apps/test/liminal.yml | 1 -
tests/runners/apps/test_app/defaults/liminal.yml | 4 +-
tests/runners/apps/test_app/extra/liminal.yml | 14 +-
tests/runners/apps/test_app/liminal.yml | 8 +-
tests/runners/apps/test_spark_app/liminal.yml | 6 +-
.../apps/test_spark_app/wordcount/wordcount.py | 4 +-
.../apps/test_spark_app/wordcount/words.txt | 2 +-
tests/test_licenses.py | 14 +-
.../archetype/liminal.yml => yamllint-config.yml | 59 +++----
80 files changed, 495 insertions(+), 302 deletions(-)
diff --git a/.asf.yaml b/.asf.yaml
index bffe4fe..7797bda 100644
--- a/.asf.yaml
+++ b/.asf.yaml
@@ -1,3 +1,4 @@
+---
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
@@ -17,7 +18,9 @@
# under the License.
github:
- description: "Apache Liminals goal is to operationalise the machine learning process, allowing data scientists to quickly transition from a successful experiment to an automated pipeline of model training, validation, deployment and inference in production. Liminal provides a Domain Specific Language to build ML workflows on top of Apache Airflow."
+ description: Apache Liminals goal is to operationalise the machine learning process, allowing data scientists to quickly transition from a successful
+ experiment to an automated pipeline of model training, validation, deployment and inference in production. Liminal provides a Domain Specific Language
+ to build ML workflows on top of Apache Airflow.
homepage: https://liminal.apache.org
labels:
- data-science
@@ -25,12 +28,11 @@ github:
- machine-learning
- airflow
- ai
- - ml
+ - ml
- workflows
-
+
notifications:
- commits: commits@liminal.apache.org
- issues: issues@liminal.apache.org
+ commits: commits@liminal.apache.org
+ issues: issues@liminal.apache.org
pullrequests: dev@liminal.apache.org
jira_options: link label worklog
-
diff --git a/.github/PULL_REQUEST_TEMPLATE.md b/.github/PULL_REQUEST_TEMPLATE.md
index 4e9c4ef..75e078f 100644
--- a/.github/PULL_REQUEST_TEMPLATE.md
+++ b/.github/PULL_REQUEST_TEMPLATE.md
@@ -20,4 +20,3 @@ Replace this: describe the PR status. Examples:
- [ ] [PreCommitChecks - Code linting](../CONTRIBUTING.md#InstallRunPreCommit) (required)
- [ ] [Tests](../CONTRIBUTING.md#RunningTests)
-
diff --git a/.github/workflows/pre_commits.yml b/.github/workflows/pre_commits.yml
index 42d064c..8a18a15 100644
--- a/.github/workflows/pre_commits.yml
+++ b/.github/workflows/pre_commits.yml
@@ -1,3 +1,4 @@
+---
name: PreCommitChecks
on:
@@ -11,7 +12,7 @@ on:
# - '!release*'
jobs:
linting:
- name: "Run pre-commit hooks on py3.6"
+ name: Run pre-commit hooks on py3.6
runs-on: ubuntu-latest
steps:
#----------------------------------------------
@@ -24,7 +25,7 @@ jobs:
# Install Python
- uses: actions/setup-python@v2
with:
- python-version: 3.6
+ python-version: 3.6
- name: Check Python ${{ matrix.python-version }} version
run: python -V
diff --git a/.github/workflows/unittest.yml b/.github/workflows/unittest.yml
index 18d4e9b..d2f05a2 100644
--- a/.github/workflows/unittest.yml
+++ b/.github/workflows/unittest.yml
@@ -1,3 +1,4 @@
+---
name: Running unittest
on:
@@ -11,26 +12,27 @@ on:
# Trigger the workflow on cron schedule
schedule:
- cron: '7 0 * * *'
+
jobs:
unittest:
runs-on: ubuntu-latest
timeout-minutes: 10
steps:
- - name: Checkout
- uses: actions/checkout@v1
- - name: Setup Minikube
- uses: manusa/actions-setup-minikube@v2.3.0
- with:
- minikube version: 'v1.16.0'
- kubernetes version: 'v1.19.2'
- github token: ${{ secrets.GITHUB_TOKEN }}
- - name: Set up Python
- uses: actions/setup-python@v1
- with:
- python-version: '3.6'
- - name: Install python requirements
- run: |
- python -m pip install --upgrade pip
- pip install -r requirements.txt
- - name: Run unittest
- run: ./run_tests.sh
+ - name: Checkout
+ uses: actions/checkout@v1
+ - name: Setup Minikube
+ uses: manusa/actions-setup-minikube@v2.3.0
+ with:
+ minikube version: v1.16.0
+ kubernetes version: v1.19.2
+ github token: ${{ secrets.GITHUB_TOKEN }}
+ - name: Set up Python
+ uses: actions/setup-python@v1
+ with:
+ python-version: '3.6'
+ - name: Install python requirements
+ run: |
+ python -m pip install --upgrade pip
+ pip install -r requirements.txt
+ - name: Run unittest
+ run: ./run_tests.sh
diff --git a/.github/workflows/versioning.yml b/.github/workflows/versioning.yml
index d49a83b..b3157e5 100644
--- a/.github/workflows/versioning.yml
+++ b/.github/workflows/versioning.yml
@@ -1,10 +1,11 @@
+---
name: Versioning RC
on:
workflow_run:
- workflows: ["Running unittest"]
+ workflows: [Running unittest]
branches: [master]
- types:
+ types:
- completed
jobs:
@@ -28,4 +29,4 @@ jobs:
run: |
git config --global user.name 'Liminal Bot'
git commit -am "Increment version"
- git push
\ No newline at end of file
+ git push
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index bc7cac5..bb6e2aa 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -14,8 +14,9 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+
---
-minimum_pre_commit_version: "2.16.0"
+minimum_pre_commit_version: 2.16.0
exclude: >
(?x)^(
.+/.venv/.+|.+/dist/.+|.+/.autovenv|.+/docs/|.github
@@ -29,12 +30,178 @@ default_stages:
# - push
repos:
+ - repo: https://github.com/pre-commit/pre-commit-hooks
+ rev: v4.0.1
+ hooks:
+ - id: check-case-conflict
+ - id: check-merge-conflict
+ stages:
+ - commit
+ - id: check-added-large-files
+ args: [--maxkb=1000]
+ stages:
+ - commit
+ - id: detect-aws-credentials
+ args:
+ - --allow-missing-credentials
+ - id: fix-encoding-pragma
+ args:
+ - --remove
+ - id: detect-private-key
+ - id: destroyed-symlinks
+ - id: mixed-line-ending
+ - id: trailing-whitespace
+ - id: check-toml
+ # To match test*.py instead
+ # - id: name-tests-test
+ # args: [--django]
+ # exclude: |
+ # - tests/test_licenses
+ - id: end-of-file-fixer
+ description: Ensures that a file is either empty, or ends with one newline.
+ exclude_types: [sql]
+ # types: [text]
+ - id: pretty-format-json
+ args:
+ - --autofix
+ - --no-sort-keys
+ - --indent
+ - '2'
+ # files:
+ pass_filenames: true
+
+ - repo: https://github.com/Lucas-C/pre-commit-hooks
+ rev: v1.1.10
+ hooks:
+ - id: insert-license
+ name: Add license for all md files
+ files: \.md$
+ exclude: ^\.github/.*$
+ args:
+ - --comment-style
+ - <!--|| -->
+ - --license-filepath
+ - dev/LICENSE.txt
+ - --fuzzy-match-generates-todo
+ - id: insert-license
+ name: Add license for all SQL files
+ files: \.sql$
+ exclude: ^\.github/.*$|^airflow/_vendor/
+ args:
+ - --comment-style
+ - /*||*/
+ - --license-filepath
+ - dev/LICENSE.txt
+ - --fuzzy-match-generates-todo
+ - id: insert-license
+ name: Add license for all other files
+ exclude: ^\.github/.*$|^airflow/_vendor/
+ args:
+ - --comment-style
+ - '|#|'
+ - --license-filepath
+ - dev/LICENSE.txt
+ - --fuzzy-match-generates-todo
+ files: >
+ \.properties$|\.cfg$|\.conf$|\.ini$|\.ldif$|\.readthedocs$|\.service$|\.tf$|Dockerfile.*$
+ - id: insert-license
+ name: Add license for all JINJA template files
+ files: ^airflow/www/templates/.*\.html$|^docs/templates/.*\.html$.*\.jinja2
+ exclude: ^\.github/.*$^airflow/_vendor/
+ args:
+ - --comment-style
+ - '{#||#}'
+ - --license-filepath
+ - dev/LICENSE.txt
+ - --fuzzy-match-generates-todo
+ - id: insert-license
+ name: Add license for all shell files
+ exclude: ^\.github/.*$|^airflow/_vendor/
+ files: ^breeze$|^breeze-complete$|\.sh$|\.bash$|\.bats$
+ args:
+ - --comment-style
+ - '|#|'
+ - --license-filepath
+ - dev/LICENSE.txt
+ - --fuzzy-match-generates-todo
+ - id: insert-license
+ name: Add license for all Python files
+ exclude: ^\.github/.*$|^airflow/_vendor/
+ types: [python]
+ args:
+ - --comment-style
+ - '|#|'
+ - --license-filepath
+ - dev/LICENSE.txt
+ - --fuzzy-match-generates-todo
+ - id: insert-license
+ name: Add license for all YAML files
+ exclude: ^\.github/.*$|^airflow/_vendor/
+ types: [yaml]
+ files: \.yml$|\.yaml$
+ args:
+ - --comment-style
+ - '|#|'
+ - --license-filepath
+ - dev/LICENSE.txt
+ - --fuzzy-match-generates-todo
+
+ # Python: Black formatter
- repo: https://github.com/psf/black
rev: 21.12b0
hooks:
- id: black
- args: [ --safe, --quiet ]
+ args: [--safe, --quiet, --config=./pyproject.toml]
files: \.pyi?$
exclude: .github/
# override until resolved: https://github.com/psf/black/issues/402
- types: [ ]
+ types: []
+
+ # - repo: https://github.com/jumanjihouse/pre-commit-hook-yamlfmt
+ # rev: 0.1.0
+ # hooks:
+ # - id: yamlfmt
+ # args: [--mapping, '2', --sequence, '4', --offset, '2']
+
+ # Yaml: lint
+ - repo: https://github.com/adrienverge/yamllint
+ rev: v1.26.3
+ hooks:
+ - id: yamllint
+ name: Check YAML files with yamllint
+ entry: yamllint -c yamllint-config.yml # --strict
+ types: [yaml]
+
+ # Python - isort to sort imports in Python files
+ - repo: https://github.com/timothycrosley/isort
+ rev: 5.10.1
+ hooks:
+ - id: isort
+ name: Run isort to sort imports in Python files
+ args: [--profile, black]
+ files: \.py$
+ # To keep consistent with the global isort skip config defined in setup.cfg
+ exclude: ^build/.*$|^.tox/.*$|^venv/.*$
+
+ # PyUpgrade - 3.6
+ - repo: https://github.com/asottile/pyupgrade
+ rev: v2.29.1
+ hooks:
+ - id: pyupgrade
+ args: [--py36-plus]
+ exclude: ^scripts/|^docs
+
+ - repo: https://github.com/asottile/blacken-docs
+ rev: v1.12.0
+ hooks:
+ - id: blacken-docs
+ alias: black
+ additional_dependencies: [black==21.9b0]
+
+ # - repo: https://github.com/PyCQA/bandit
+ # rev: 1.7.1
+ # hooks:
+ # - id: bandit
+ # args: [-ll, -r, liminal]
+ # files: .py$
+ # exclude: tests/test_licenses.py|^tests/runners
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 9683595..8a05523 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -94,8 +94,20 @@ Now on every commit, `pre-commit` will use a git hook to run the tools.
### Resolving failed commits
-* If `black` fail, they have reformatted your code. `git add` and `git commit` the changes.
+* If `black` fail, they have reformatted your code.
+* You should check the changes made. Then simply "git add --update ." and re-commit or `git add` and `git commit` the changes.
Example:

+
+### EnabledHooks
+
+1. [black](https://black.readthedocs.io/en/stable/): a Python automatic code formatter
+1. [yamllint](https://yamllint.readthedocs.io/): A linter for YAML files.
+ yamllint does not only check for syntax validity, but for weirdnesses like key repetition and cosmetic problems such as lines length, trailing spaces, indentation, etc.
+1. [OutOfBoxHooks](https://github.com/pre-commit/pre-commit-hooks) - Out-of-the-box hooks for pre-commit like Check for files that contain merge conflict strings
+1. [Bandit](https://bandit.readthedocs.io/en/latest/) is a tool designed to find common security issues in Python code.
+1. [blacken-docs](https://github.com/asottile/blacken-docs) Run `black` on python code blocks in documentation files
+1. [pyupgrade](https://github.com/asottile/pyupgrade) A tool (and pre-commit hook) to automatically upgrade syntax for newer versions of the language.
+1. [isort](https://pycqa.github.io/isort/) A Python utility / library to sort imports.
diff --git a/DISCLAIMER-WIP b/DISCLAIMER-WIP
index 6911ba3..b632bb7 100644
--- a/DISCLAIMER-WIP
+++ b/DISCLAIMER-WIP
@@ -20,5 +20,3 @@ building Liminal requires using a transitive required library chardet V 4.0.0, w
If you are planning to incorporate this work into your product/project,
please be aware that you will need to conduct a thorough licensing review
to determine the overall implications of including this work.
-
-
diff --git a/MANIFEST.in b/MANIFEST.in
index 662861a..8adfd16 100644
--- a/MANIFEST.in
+++ b/MANIFEST.in
@@ -18,4 +18,4 @@
include scripts/* requirements.txt requirements-airflow.txt
-recursive-include liminal/build/ *
\ No newline at end of file
+recursive-include liminal/build/ *
diff --git a/docs/liminal/services.md b/dev/LICENSE.txt
similarity index 64%
copy from docs/liminal/services.md
copy to dev/LICENSE.txt
index 9e5ca11..60b675e 100644
--- a/docs/liminal/services.md
+++ b/dev/LICENSE.txt
@@ -1,4 +1,3 @@
-<!--
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
@@ -15,24 +14,3 @@ software distributed under the License is distributed on an
KIND, either express or implied. See the License for the
specific language governing permissions and limitations
under the License.
--->
-
-# Services
-
-In the `services` section you can configure constantly running applications such as
-servers.
-
-```yaml
-services:
- - service: my_server
- image: myorg/myrepo:myserver
-```
-
-`services` is a section in the root lof your liminal.yml file and is a list of `service`s, defined
-by the following attributes:
-
-## service attributes
-
-`service`: name of your service.
-
-`image`: the service's docker image.
diff --git a/dev/RELEASE.md b/dev/RELEASE.md
index f47bffa..edf0cf3 100644
--- a/dev/RELEASE.md
+++ b/dev/RELEASE.md
@@ -118,7 +118,7 @@ This can be any string which results in a legal call to:
pip install ${LIMINAL_VERSION}
```
-This includes
+This includes
- A standard pip version like apache-liminal==0.0.1dev1 avail from pypi
- A URL for git e.g. git+https://github.com/apache/incubator-liminal.git
- A string indicating where to get the package from like --index <url> apache-liminal==xyz
@@ -128,16 +128,16 @@ in the scripts/ folder)
This is useful if you are making changes in liminal locally and want to test them.
If you don't specify this variable, liminal attempts to discover how to install itself
-by running a pip freeze and looking at the result.
+by running a pip freeze and looking at the result.
This covers pip repositories, files and installtion from URL.
-The fallback in case no string is found, is simply 'apache-liminal' assuming your .pypirc contains an
+The fallback in case no string is found, is simply 'apache-liminal' assuming your .pypirc contains an
index which has this package.
## Testing a version from testpypi:
-Installing liminal locally:
+Installing liminal locally:
pip install --index-url https://test.pypi.org/simple/ --extra-index-url https://pypi.org/simple apache-liminal
Tell liminal where to take the version to put inside the airflow docker:
@@ -240,7 +240,7 @@ The Release Candidate artifacts we vote upon should be the exact ones we vote ag
export LIMINAL_BUILD_VERSION=0.0.1rc1-incubating
# Example after cloning
-git clone https://github.com/apache/incubating-liminal.git
+git clone https://github.com/apache/incubating-liminal.git
cd incubating-liminal
```
@@ -249,7 +249,7 @@ cd incubating-liminal
# Set Version
sed -i '/^current_version /s/=.*$/= '"$LIMINAL_BUILD_VERSION"'/' .bumpversion.cfg
```
-
+
- Tag your release
```bash
diff --git a/docs/Makefile b/docs/Makefile
index 26a8d56..31def38 100644
--- a/docs/Makefile
+++ b/docs/Makefile
@@ -33,4 +33,4 @@ help:
# Catch-all target: route all unknown targets to Sphinx using the new
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
%: Makefile
- @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
\ No newline at end of file
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/docs/README.md b/docs/README.md
index c5aa8ed..74165ff 100644
--- a/docs/README.md
+++ b/docs/README.md
@@ -42,4 +42,4 @@ A more advanced example which demonstrates a simple data-science workflow can be
Full documentation of Apache Liminal can be found [here](liminal)
## High Level Architecture
-High level architecture documentation can be found [here](architecture.md)
\ No newline at end of file
+High level architecture documentation can be found [here](architecture.md)
diff --git a/docs/architecture.md b/docs/architecture.md
index d1567c2..1ee5337 100644
--- a/docs/architecture.md
+++ b/docs/architecture.md
@@ -26,12 +26,12 @@ The process involves automating and orchestrating multiple steps which run on he
There are no mature standards for this workflow, and most organizations do not have the experience to build it in-house. In the best case, dev-ds-devops teams form in order to accomplish this task together; in many cases, it's the data scientists who try to deal with this themselves without the knowledge or the inclination to become infrastructure experts.
As a result, many projects never make it through the cycle. Those who do suffer from a very long lead time from a successful experiment to an operational, refreshable, deployed and monitored model in production.
-
+
The goal of Apache Liminal is to simplify the creation and management of machine learning pipelines by data engineers & scientists. The platform provides declarative building blocks which define the workflow, orchestrate the underlying infrastructure, take care of non functional concerns, enabling focus in business logic / algorithm code.
Some Commercial E2E solutions have started to emerge in the last few years, however, they are limited to specific parts of the workflow, such as Databricks MLFlow. Other solutions are tied to specific environments (e.g. SageMaker on AWS).
## High Level Architecture
-The platform is aimed to provide data engineers & scientists with a solution for end to end flows from model training to real time inference in production. It’s architecture enables and promotes adoption of specific components in existing (non-Liminal) frameworks, as well as seamless integration with other open source projects. Liminal was created to enable scalability in ML efforts and after a thorough review of available solutions and frameworks, which did not meet our main KPIs:
+The platform is aimed to provide data engineers & scientists with a solution for end to end flows from model training to real time inference in production. It’s architecture enables and promotes adoption of specific components in existing (non-Liminal) frameworks, as well as seamless integration with other open source projects. Liminal was created to enable scalability in ML efforts and after a thorough review of available solutions and frameworks, which did not meet our main KPIs:
- Provide an opinionated but customizable end-to-end workflow
- Abstract away the complexity of underlying infrastructure
- Support major open source tools and cloud-native infrastructure to carry out many of the steps
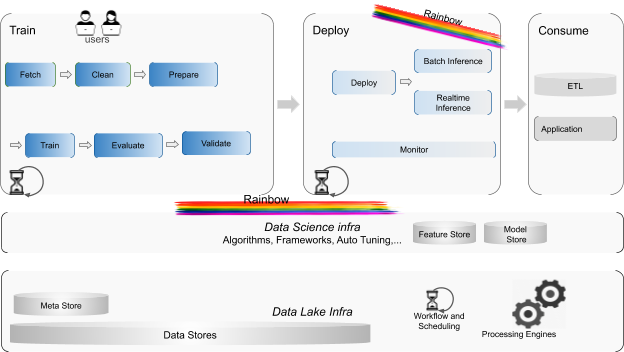
@@ -42,14 +42,14 @@ The following diagram depicts these main components and where Apache Liminal com

-A classical data scientist workflow includes some base phases:
+A classical data scientist workflow includes some base phases:
_Train, Deploy and Consume._
**The Train phase includes the following tasks:**
1. Fetch - get the data needed to build a model - usually using SQL
-1. Clean - make sure the data is useful for building the model
-1. Prepare - split data and encode features from the data according to model needs
+1. Clean - make sure the data is useful for building the model
+1. Prepare - split data and encode features from the data according to model needs
1. Train - Build the model and tune it
1. Evaluate - make sure the model is correct - run it on a test set, etc…
1. Validate - make sure the model is up to the standards you need
@@ -58,7 +58,7 @@ _Train, Deploy and Consume._
1. Deploy - make it available for usage in production
1. Inference - Batch or Real-time - use the model to evaluate data by your offline or online by your applications
1. Consume - The actual use of the models created by applications and ETLs, usually through APIs to the batch or real-time inference that usually rely on Model and Feature stores.
-
+
Liminal provides its users a declarative composition capabilities to materialize these steps in a robust way, while exploiting existing frameworks and tools. e.g. Data science frameworks such as scikit-learn, Tensor flow, Keras and such, for running core data science algorithms; as numerous core mechanisms as data stores, processing engines, parallelism, schedulers, code deployment as well as batch and real-time inference.
Liminal allows the creation and wiring of these kinds of functional and non functional tasks while making the underlying infrastructure used by these tasks very easy to use and even abstracted away entirely. While handling the non-functional aspects as monitoring (in a standard fashion) deployment, scheduling, resource management and execution.
diff --git a/docs/getting-started/hello_world.md b/docs/getting-started/hello_world.md
index f036d5a..b259d55 100644
--- a/docs/getting-started/hello_world.md
+++ b/docs/getting-started/hello_world.md
@@ -74,7 +74,7 @@ Create a kubernetes local volume:
liminal create
```
```BASH
-liminal deploy --clean
+liminal deploy --clean
```
The deploy command deploys a liminal server and deploys any liminal.yml files in your working
directory or any of its subdirectories to your liminal home directory.
@@ -89,7 +89,7 @@ liminal start
```
The start command spins up the liminal server containers which will run pipelines based on your
deployed liminal.yml files.
-It runs the following three containers:
+It runs the following three containers:
* liminal-postgress
* liminal-webserver
* liminal-scheduler
@@ -103,7 +103,7 @@ By default liminal server starts Apache Airflow servers and admin UI will be tha
***Important:** Set off/on toggle to activate your pipeline (DAG), nothing will happen otherwise!*
-You can go to graph view to see all the tasks configured in the liminal.yml file:
+You can go to graph view to see all the tasks configured in the liminal.yml file:
[http://localhost:8080/admin/airflow/graph?dag_id=example_pipeline](
http://localhost:8080/admin/airflow/graph?dag_id=example_pipeline
)
diff --git a/docs/getting-started/iris_classification.md b/docs/getting-started/iris_classification.md
index 1e9ce74..69fdff9 100644
--- a/docs/getting-started/iris_classification.md
+++ b/docs/getting-started/iris_classification.md
@@ -97,7 +97,7 @@ liminal create
### Liminal deploy
The deploy command deploys a liminal server and deploys any liminal.yml files in your working directory or any of its subdirectories to your liminal home directory.
```BASH
-liminal deploy --clean
+liminal deploy --clean
```
*Note: liminal home directory is located in the path defined in LIMINAL_HOME env variable.
@@ -110,7 +110,7 @@ The start command spins up 3 containers that load the Apache Airflow stack. Limi
liminal start
```
-It runs the following three containers:
+It runs the following three containers:
* liminal-postgress
* liminal-webserver
* liminal-scheduler
@@ -123,7 +123,7 @@ Once liminal server has completed starting up, you can navigate to admin UI in y
***Important:** Set off/on toggle to activate your pipeline (DAG), nothing will happen otherwise!*
-You can go to graph view to see all the tasks configured in the liminal.yml file:
+You can go to graph view to see all the tasks configured in the liminal.yml file:
[http://localhost:8080/admin/airflow/graph?dag_id=my_datascience_pipeline](
http://localhost:8080/admin/airflow/graph?dag_id=my_datascience_pipeline
)
diff --git a/docs/getting-started/spark_app_demo.md b/docs/getting-started/spark_app_demo.md
index 229f400..3b4192f 100644
--- a/docs/getting-started/spark_app_demo.md
+++ b/docs/getting-started/spark_app_demo.md
@@ -117,7 +117,7 @@ The deploy command deploys a liminal server and deploys any liminal.yml files in
directory or any of its subdirectories to your liminal home directory.
```BASH
-liminal deploy --clean
+liminal deploy --clean
```
*Note: liminal home directory is located in the path defined in LIMINAL_HOME env variable. If the
diff --git a/docs/liminal/advanced.liminal.yml.md b/docs/liminal/advanced.liminal.yml.md
index 95f3ed3..d056863 100644
--- a/docs/liminal/advanced.liminal.yml.md
+++ b/docs/liminal/advanced.liminal.yml.md
@@ -227,7 +227,7 @@ pipeline_defaults:
type: python
image: myorg/myrepo:mypythonapp
cmd: python -u my_teardown_module2.py
-```
+```
In the example above we set a list of `tasks` in `pipeline_defaults` which leads to each pipeline
defined in our liminal.yml file will have `my_common_setup_task` run before its tasks and
diff --git a/docs/liminal/executors/README.md b/docs/liminal/executors/README.md
index 5ddbeb8..a570686 100644
--- a/docs/liminal/executors/README.md
+++ b/docs/liminal/executors/README.md
@@ -41,7 +41,7 @@ pipelines:
In the example above we define an `executor` of type `kubernetes` with custom resources
configuration.
-`executors` is a section in the root of your liminal.yml file and is a list of `executor`s defined
+`executors` is a section in the root of your liminal.yml file and is a list of `executor`s defined
by the following attributes:
## executor attributes
diff --git a/docs/liminal/images/README.md b/docs/liminal/images/README.md
index bee8a22..c3ab5f8 100644
--- a/docs/liminal/images/README.md
+++ b/docs/liminal/images/README.md
@@ -29,13 +29,13 @@ images:
source: .
- image: myorg/myrepo:myserver
type: python_server
- source: path/to/my/server/code
+ source: path/to/my/server/code
endpoints:
- endpoint: /myendpoint
module: my_module
```
-`images` is a section in the root lof your liminal.yml file and is a list of `image`s, defined
+`images` is a section in the root lof your liminal.yml file and is a list of `image`s, defined
by the following attributes:
## image attributes
diff --git a/docs/liminal/liminal.yml.md b/docs/liminal/liminal.yml.md
index 91b3f4a..9fbacf8 100644
--- a/docs/liminal/liminal.yml.md
+++ b/docs/liminal/liminal.yml.md
@@ -48,14 +48,14 @@ images:
source: .
- image: myorg/myrepo:myserver
type: python_server
- source: path/to/my/server/code
+ source: path/to/my/server/code
endpoints:
- endpoint: /myendpoint
module: my_module
function: my_function
```
-`images` is a section in the root lof your liminal.yml file and is a list of `image`s, defined
+`images` is a section in the root lof your liminal.yml file and is a list of `image`s, defined
by the following attributes:
#### image attributes
@@ -94,9 +94,9 @@ pipelines:
type: sql
query: "SELECT * FROM
{{my_database_name}}.{{my_table_name}}
- WHERE event_date_prt >=
+ WHERE event_date_prt >=
'{{yesterday_ds}}'"
- AND cms_platform = 'xsite'
+ AND cms_platform = 'xsite'
output_table: my_db.my_out_table
output_path: s3://my_bky/{{env}}/mydir
- task: my_python_task
@@ -115,7 +115,7 @@ pipelines:
fizz: buzz
```
-`pipelines` is a section in the root lof your liminal.yml file and is a list of `pipeline`s defined
+`pipelines` is a section in the root lof your liminal.yml file and is a list of `pipeline`s defined
by the following attributes:
#### pipeline attributes
@@ -149,7 +149,7 @@ Different task types require their own additional configuration. For example, `p
For fully detailed information on services see: [services](services.md).
In the `services` section you can configure constantly running applications such as
-servers.
+servers.
```yaml
services:
@@ -157,7 +157,7 @@ services:
image: myorg/myrepo:myserver
```
-`services` is a section in the root lof your liminal.yml file and is a list of `service`s, defined
+`services` is a section in the root lof your liminal.yml file and is a list of `service`s, defined
by the following attributes:
#### service attributes
@@ -170,7 +170,7 @@ by the following attributes:
For fully detailed information on monitoring see: [monitoring](monitoring.md).
-In the `monitoring` section you can configure monitoring for your pipelines and services.
+In the `monitoring` section you can configure monitoring for your pipelines and services.
```yaml
monitoring:
diff --git a/docs/liminal/metrics_backends/README.md b/docs/liminal/metrics_backends/README.md
index fc6f3ba..64d3d06 100644
--- a/docs/liminal/metrics_backends/README.md
+++ b/docs/liminal/metrics_backends/README.md
@@ -21,7 +21,7 @@ under the License.
`metrics_backend` is the definition of a metrics backend to which all automatically
generated metrics from your pipeline are sent to and is part of the `metrics_backends` list in the
-`monitoring` section of your liminal.yml
+`monitoring` section of your liminal.yml
```yaml
- metrics_backend: cloudwatch_metrics
diff --git a/docs/liminal/metrics_backends/index.rst b/docs/liminal/metrics_backends/index.rst
index c32772f..e9b29df 100644
--- a/docs/liminal/metrics_backends/index.rst
+++ b/docs/liminal/metrics_backends/index.rst
@@ -29,7 +29,7 @@ Metrics Backends
``metrics_backend`` is the definition of a metrics backend to which all automatically
generated metrics from your pipeline are sent to and is part of the ``metrics_backends`` list in the
-``monitoring`` section of your liminal.yml
+``monitoring`` section of your liminal.yml
.. code-block:: yaml
diff --git a/docs/liminal/monitoring.md b/docs/liminal/monitoring.md
index fa73705..423264a 100644
--- a/docs/liminal/monitoring.md
+++ b/docs/liminal/monitoring.md
@@ -19,7 +19,7 @@ under the License.
# Monitoring
-In the `monitoring` section you can configure monitoring for your pipelines and services.
+In the `monitoring` section you can configure monitoring for your pipelines and services.
```yaml
monitoring:
diff --git a/docs/liminal/pipelines.md b/docs/liminal/pipelines.md
index 070a8ed..e59752a 100644
--- a/docs/liminal/pipelines.md
+++ b/docs/liminal/pipelines.md
@@ -33,9 +33,9 @@ pipelines:
type: sql
query: "SELECT * FROM
{{my_database_name}}.{{my_table_name}}
- WHERE event_date_prt >=
+ WHERE event_date_prt >=
'{{yesterday_ds}}'"
- AND cms_platform = 'xsite'
+ AND cms_platform = 'xsite'
output_table: my_db.my_out_table
output_path: s3://my_bky/{{env}}/mydir
- task: my_python_task
@@ -47,7 +47,7 @@ pipelines:
fizz: buzz
```
-`pipelines` is a section in the root lof your liminal.yml file and is a list of `pipeline`s defined
+`pipelines` is a section in the root lof your liminal.yml file and is a list of `pipeline`s defined
by the following attributes:
## pipeline attributes
diff --git a/docs/liminal/services.md b/docs/liminal/services.md
index 9e5ca11..2718b77 100644
--- a/docs/liminal/services.md
+++ b/docs/liminal/services.md
@@ -20,7 +20,7 @@ under the License.
# Services
In the `services` section you can configure constantly running applications such as
-servers.
+servers.
```yaml
services:
@@ -28,7 +28,7 @@ services:
image: myorg/myrepo:myserver
```
-`services` is a section in the root lof your liminal.yml file and is a list of `service`s, defined
+`services` is a section in the root lof your liminal.yml file and is a list of `service`s, defined
by the following attributes:
## service attributes
diff --git a/docs/liminal/tasks/create_cloudformation_stack.md b/docs/liminal/tasks/create_cloudformation_stack.md
index 4a393f9..2cd56d7 100644
--- a/docs/liminal/tasks/create_cloudformation_stack.md
+++ b/docs/liminal/tasks/create_cloudformation_stack.md
@@ -43,4 +43,3 @@ The `create_cloudformation_stack` task allows you to create cloudformation stack
`properties`: any attribute of [aws-create-stack-request-parameters](
https://docs.aws.amazon.com/AWSCloudFormation/latest/APIReference/API_CreateStack.html#API_CreateStack_RequestParameters)
-
diff --git a/docs/liminal/tasks/delete_cloudformation_stack.md b/docs/liminal/tasks/delete_cloudformation_stack.md
index 462c5c7..335c3a3 100644
--- a/docs/liminal/tasks/delete_cloudformation_stack.md
+++ b/docs/liminal/tasks/delete_cloudformation_stack.md
@@ -33,4 +33,3 @@ The `delete_cloudformation_stack` task allows you to delete stack
`task`: name of your task (must be made of alphanumeric, dash and/or underscore characters only).
`stack_name`: the name of the stack to delete
-
diff --git a/docs/liminal/tasks/python.md b/docs/liminal/tasks/python.md
index 34a439f..b7b62ad 100644
--- a/docs/liminal/tasks/python.md
+++ b/docs/liminal/tasks/python.md
@@ -25,7 +25,7 @@ The `python` task allows you to run python code packaged as docker images.
- task: my_python_task
type: python
image: myorg/myrepo:mypythonapp
- cmd: python my_python_app.py
+ cmd: python my_python_app.py
env_vars:
env: '{{env}}'
fizz: buzz
diff --git a/docs/source/How_to_install_liminal_in_airflow_on_kubernetes.md b/docs/source/How_to_install_liminal_in_airflow_on_kubernetes.md
index 383d24e..ec1137d 100644
--- a/docs/source/How_to_install_liminal_in_airflow_on_kubernetes.md
+++ b/docs/source/How_to_install_liminal_in_airflow_on_kubernetes.md
@@ -62,12 +62,12 @@ You can read up about EFS [here](https://aws.amazon.com/efs/features/) and set i
There are multiple ways to install liminal into the Airflow pods, depending on how you deployed Airflow on Kubernetes. \
In principle, it requires the package to be pip-installed into the Airflow docker - either during build time or in run time.
-1. If you are rolling out your own Airflow Docker images based on the [official docker image](https://github.com/apache/airflow),
-you can add apache-liminal installation during the build:
+1. If you are rolling out your own Airflow Docker images based on the [official docker image](https://github.com/apache/airflow),
+you can add apache-liminal installation during the build:
```docker build --build-arg ADDITIONAL_PYTHON_DEPS="apache-liminal"```
-2. If you already have a running Airflow on Kubernetes, you can run a command which iterates over Airflow pods and executes a ```pip install apache-liminal```
-on each of the pods.
+2. If you already have a running Airflow on Kubernetes, you can run a command which iterates over Airflow pods and executes a ```pip install apache-liminal```
+on each of the pods.
3. If you used the [airflow-helm-chart-7.16.0], you just need to specifiy apache-liminal inside the ```requirements.txt``` file as per the instructions [here][airflow-helm-chart-7.16.0]
@@ -110,7 +110,7 @@ Finally, the one time setup is done, and by this point, you should have:
1. A deployment box which can deploy Liminal to an EFS folder
2. Airflow pods which will pick up the Yamls from that folder automatically.
-Deploying the actual Yaml files is the simple part.
+Deploying the actual Yaml files is the simple part.
Each time you want to deploy the Liminal Yamls from the deployment box:
```
diff --git a/examples/aws-ml-app-demo/liminal.yml b/examples/aws-ml-app-demo/liminal.yml
index 3284529..4670334 100644
--- a/examples/aws-ml-app-demo/liminal.yml
+++ b/examples/aws-ml-app-demo/liminal.yml
@@ -1,4 +1,3 @@
-#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
@@ -15,6 +14,7 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+
---
name: MyDataScienceApp
owner: Bosco Albert Baracus
diff --git a/examples/aws-ml-app-demo/manifests/aws-ml-app-demo.yaml b/examples/aws-ml-app-demo/manifests/aws-ml-app-demo.yaml
index 180df8a..aee5f08 100644
--- a/examples/aws-ml-app-demo/manifests/aws-ml-app-demo.yaml
+++ b/examples/aws-ml-app-demo/manifests/aws-ml-app-demo.yaml
@@ -1,4 +1,3 @@
-#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
@@ -15,6 +14,7 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+
---
apiVersion: v1
@@ -33,10 +33,10 @@ spec:
lifecycle:
postStart:
exec:
- command: [ "/bin/bash", "-c", "apt update && apt install curl -y" ]
+ command: [/bin/bash, -c, apt update && apt install curl -y]
ports:
- containerPort: 80
- name: "http-server"
+ name: http-server
volumeMounts:
- - mountPath: "/mnt/gettingstartedvol"
- name: task-pv-storage
\ No newline at end of file
+ - mountPath: /mnt/gettingstartedvol
+ name: task-pv-storage
diff --git a/examples/aws-ml-app-demo/model_store.py b/examples/aws-ml-app-demo/model_store.py
index 1f23270..684b5ec 100644
--- a/examples/aws-ml-app-demo/model_store.py
+++ b/examples/aws-ml-app-demo/model_store.py
@@ -16,11 +16,10 @@
# specific language governing permissions and limitations
# under the License.
-import pickle
-import time
import glob
-
import os
+import pickle
+import time
MOUNT_PATH = os.environ.get('MOUNT_PATH', '/mnt/gettingstartedvol')
PRODUCTION = 'production'
@@ -51,7 +50,7 @@ class ModelStore:
def _download_latest_model(self):
objects = glob.glob(f'{MOUNT_PATH}/{self.env}/**/*')
- models = list(reversed(sorted([obj for obj in objects if obj.endswith('.p')])))
+ models = list(reversed(sorted(obj for obj in objects if obj.endswith('.p'))))
latest_key = models[0]
version = latest_key.rsplit('/')[-2]
print(f'Loading model version {version}')
diff --git a/examples/liminal-getting-started/liminal.yml b/examples/liminal-getting-started/liminal.yml
index 5521841..d280577 100644
--- a/examples/liminal-getting-started/liminal.yml
+++ b/examples/liminal-getting-started/liminal.yml
@@ -1,4 +1,3 @@
-#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
@@ -15,6 +14,7 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+
---
name: GettingStartedPipeline
volumes:
@@ -48,28 +48,28 @@ pipelines:
key2: val2
metrics:
namespace: TestNamespace
- backends: [ ]
+ backends: []
tasks:
- task: python_hello_world_example
type: python
image: python_hello_world_example_image
env_vars:
- env1: "{{myvar}}"
- env2: "foo"
+ env1: '{{myvar}}'
+ env2: foo
mounts:
- mount: mymount
volume: gettingstartedvol
path: /mnt/gettingstartedvol
cmd: python -u hello_world.py
executors: 2
- cmd: python -u hello_world.py
+ # cmd: python -u hello_world.py
- task: python_hello_world_output_task
type: python
description: task with input from other task's output
image: python_hello_world_example_image
env_vars:
- env1: "a"
- env2: "b"
+ env1: a
+ env2: b
mounts:
- mount: mymount
volume: gettingstartedvol
diff --git a/examples/spark-app-demo/k8s/archetype/liminal.yml b/examples/spark-app-demo/k8s/archetype/liminal.yml
index e863e5d..f08ac03 100644
--- a/examples/spark-app-demo/k8s/archetype/liminal.yml
+++ b/examples/spark-app-demo/k8s/archetype/liminal.yml
@@ -1,4 +1,3 @@
-#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
@@ -15,6 +14,7 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+
---
# superliminal for local development
name: InfraSpark
@@ -30,7 +30,7 @@ images:
- image: my_spark_image
source: .
type: spark
- no_cache: True
+ no_cache: true
task_defaults:
spark:
executor: k8s
@@ -41,4 +41,3 @@ task_defaults:
- mount: mymount
volume: gettingstartedvol
path: /mnt/gettingstartedvol
-
diff --git a/examples/spark-app-demo/k8s/data/iris.csv b/examples/spark-app-demo/k8s/data/iris.csv
index c413d1e..9781000 100644
--- a/examples/spark-app-demo/k8s/data/iris.csv
+++ b/examples/spark-app-demo/k8s/data/iris.csv
@@ -168,4 +168,3 @@ sepallength,sepalwidth,petallength,petalwidth,class
6.5,3.0,5.2,2.0,Iris-virginica
6.2,3.4,5.4,2.3,Iris-virginica
5.9,3.0,5.1,1.8,Iris-virginica
-
diff --git a/examples/spark-app-demo/k8s/data_cleanup.py b/examples/spark-app-demo/k8s/data_cleanup.py
index c78d0aa..9d0c5d0 100644
--- a/examples/spark-app-demo/k8s/data_cleanup.py
+++ b/examples/spark-app-demo/k8s/data_cleanup.py
@@ -20,7 +20,7 @@ import argparse
import pyspark.sql.functions as F
from pyspark.ml import Pipeline
-from pyspark.ml.feature import StringIndexer, VectorAssembler, StandardScaler
+from pyspark.ml.feature import StandardScaler, StringIndexer, VectorAssembler
from pyspark.ml.functions import vector_to_array
from pyspark.sql import SparkSession
diff --git a/examples/spark-app-demo/k8s/liminal.yml b/examples/spark-app-demo/k8s/liminal.yml
index 301e321..c7d6b14 100644
--- a/examples/spark-app-demo/k8s/liminal.yml
+++ b/examples/spark-app-demo/k8s/liminal.yml
@@ -1,4 +1,3 @@
-#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
@@ -15,6 +14,7 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+
---
name: MyFirstLiminalSparkApp
super: InfraSpark
@@ -52,9 +52,9 @@ pipelines:
type: spark
description: prepare the data for training
application_arguments:
- - '--input_uri'
+ - --input_uri
- '{{input_root_dir}}data/iris.csv'
- - '--output_uri'
+ - --output_uri
- '{{training_data_path}}'
- task: train
type: python
@@ -88,4 +88,4 @@ services:
function: predict
- endpoint: /healthcheck
module: serving
- function: healthcheck
\ No newline at end of file
+ function: healthcheck
diff --git a/examples/spark-app-demo/k8s/manifests/spark-app-demo.yaml b/examples/spark-app-demo/k8s/manifests/spark-app-demo.yaml
index d2bc32d..c67c7eb 100644
--- a/examples/spark-app-demo/k8s/manifests/spark-app-demo.yaml
+++ b/examples/spark-app-demo/k8s/manifests/spark-app-demo.yaml
@@ -1,4 +1,3 @@
-#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
@@ -15,6 +14,7 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+
---
apiVersion: v1
@@ -33,10 +33,10 @@ spec:
lifecycle:
postStart:
exec:
- command: [ "/bin/bash", "-c", "apt update && apt install curl -y" ]
+ command: [/bin/bash, -c, apt update && apt install curl -y]
ports:
- containerPort: 80
- name: "http-server"
+ name: http-server
volumeMounts:
- - mountPath: "/mnt/gettingstartedvol"
+ - mountPath: /mnt/gettingstartedvol
name: task-pv-storage
diff --git a/examples/spark-app-demo/k8s/model_store.py b/examples/spark-app-demo/k8s/model_store.py
index 1f23270..684b5ec 100644
--- a/examples/spark-app-demo/k8s/model_store.py
+++ b/examples/spark-app-demo/k8s/model_store.py
@@ -16,11 +16,10 @@
# specific language governing permissions and limitations
# under the License.
-import pickle
-import time
import glob
-
import os
+import pickle
+import time
MOUNT_PATH = os.environ.get('MOUNT_PATH', '/mnt/gettingstartedvol')
PRODUCTION = 'production'
@@ -51,7 +50,7 @@ class ModelStore:
def _download_latest_model(self):
objects = glob.glob(f'{MOUNT_PATH}/{self.env}/**/*')
- models = list(reversed(sorted([obj for obj in objects if obj.endswith('.p')])))
+ models = list(reversed(sorted(obj for obj in objects if obj.endswith('.p'))))
latest_key = models[0]
version = latest_key.rsplit('/')[-2]
print(f'Loading model version {version}')
diff --git a/examples/spark-app-demo/k8s/training.py b/examples/spark-app-demo/k8s/training.py
index 2857c95..b70aa20 100644
--- a/examples/spark-app-demo/k8s/training.py
+++ b/examples/spark-app-demo/k8s/training.py
@@ -15,25 +15,25 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+import os
import sys
import time
import model_store
-import pandas as pd
import numpy as np
+import pandas as pd
from model_store import ModelStore
-from sklearn import datasets
+from sklearn import datasets, model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
-from sklearn import model_selection
-import os
_CANDIDATE_MODEL_STORE = ModelStore(model_store.CANDIDATE)
_PRODUCTION_MODEL_STORE = ModelStore(model_store.PRODUCTION)
-import numpy as np
-import csv
import argparse
+import csv
+
+import numpy as np
def load_iris_from_csv_file(f):
@@ -45,7 +45,7 @@ def load_iris_from_csv_file(f):
def get_dataset(d):
- print("searching for csv files in {}".format(d))
+ print(f"searching for csv files in {d}")
for root, dirs, files in os.walk(d):
for file in files:
@@ -57,7 +57,7 @@ def get_dataset(d):
def load_and_split(input_uri):
csv_file = get_dataset(input_uri)
if csv_file:
- print("found {} dataset".format(csv_file))
+ print(f"found {csv_file} dataset")
iris = load_iris_from_csv_file(csv_file)
return train_test_split(iris, test_size=0.2, random_state=8)
diff --git a/liminal-arch.md b/liminal-arch.md
index 9906430..095e16a 100644
--- a/liminal-arch.md
+++ b/liminal-arch.md
@@ -17,18 +17,20 @@ specific language governing permissions and limitations
under the License.
-->
# Liminal
+
Liminal is an end-to-end platform for data engineers & scientists, allowing them to build, train and deploy machine learning models in a robust and agile way. The platform provides the abstractions and declarative capabilities for data extraction & feature engineering followed by model training and serving. Apache Liminal's goal is to operationalise the machine learning process, allowing data scientists to quickly transition from a successful experiment to an automated pipeline of model [...]
## Motivation
+
The challenges involved in operationalizing machine learning models are one of the main reasons why many machine learning projects never make it to production.
The process involves automating and orchestrating multiple steps which run on heterogeneous infrastructure - different compute environments, data processing platforms, ML frameworks, notebooks, containers and monitoring tools.
There are no mature standards for this workflow, and most organizations do not have the experience to build it in-house. In the best case, dev-ds-devops teams form in order to accomplish this task together; in many cases, it's the data scientists who try to deal with this themselves without the knowledge or the inclination to become infrastructure experts.
-As a result, many projects never make it through the cycle. Those who do suffer from a very long lead time from a successful experiment to an operational, refreshable, deployed and monitored model in production.
+As a result, many projects never make it through the cycle. Those who do suffer from a very long lead time from a successful experiment to an operational, refreshable, deployed and monitored model in production.
The goal of Apache Liminal is to simplify the creation and management of machine learning pipelines by data engineers & scientists. The platform provides declarative building blocks which define the workflow, orchestrate the underlying infrastructure, take care of non functional concerns, enabling focus in business logic / algorithm code.
Some Commercial E2E solutions have started to emerge in the last few years, however, they are limited to specific parts of the workflow, such as Databricks MLFlow. Other solutions are tied to specific environments (e.g. SageMaker on AWS).
## High Level Architecture
-The platform is aimed to provide data engineers & scientists with a solution for end to end flows from model training to real time inference in production. It’s architecture enables and promotes adoption of specific components in existing (non-Liminal) frameworks, as well as seamless integration with other open source projects. Liminal was created to enable scalability in ML efforts and after a thorough review of available solutions and frameworks, which did not meet our main KPIs:
+The platform is aimed to provide data engineers & scientists with a solution for end to end flows from model training to real time inference in production. It’s architecture enables and promotes adoption of specific components in existing (non-Liminal) frameworks, as well as seamless integration with other open source projects. Liminal was created to enable scalability in ML efforts and after a thorough review of available solutions and frameworks, which did not meet our main KPIs:
Provide an opinionated but customizable end-to-end workflow
Abstract away the complexity of underlying infrastructure
Support major open source tools and cloud-native infrastructure to carry out many of the steps
@@ -38,14 +40,14 @@ The following diagram depicts these main components and where Apache Liminal com
-A classical data scientist workflow includes some base phases:
+A classical data scientist workflow includes some base phases:
_Train, Deploy and Consume._
**The Train phase includes the following tasks:**
1. Fetch - get the data needed to build a model - usually using SQL
-1. Clean - make sure the data is useful for building the model
-1. Prepare - split data and encode features from the data according to model needs
+1. Clean - make sure the data is useful for building the model
+1. Prepare - split data and encode features from the data according to model needs
1. Train - Build the model and tune it
1. Evaluate - make sure the model is correct - run it on a test set, etc…
1. Validate - make sure the model is up to the standards you need
@@ -54,8 +56,8 @@ _Train, Deploy and Consume._
1. Deploy - make it available for usage in production
1. Inference - Batch or Real-time - use the model to evaluate data by your offline or online by your applications
1. Consume - The actual use of the models created by applications and ETLs, usually through APIs to the batch or real-time inference that usually rely on Model and Feature stores.
-
+
Liminal provides its users a declarative composition capabilities to materialize these steps in a robust way, while exploiting existing frameworks and tools. e.g. Data science frameworks such as scikit-learn, Tensor flow, Keras and such, for running core data science algorithms; as numerous core mechanisms as data stores, processing engines, parallelism, schedulers, code deployment as well as batch and real-time inference.
Liminal allows the creation and wiring of these kinds of functional and non functional tasks while making the underlying infrastructure used by these tasks very easy to use and even abstracted away entirely. While handling the non-functional aspects as monitoring (in a standard fashion) deployment, scheduling, resource management and execution.
-
\ No newline at end of file
+
diff --git a/liminal/build/image/python_server/liminal_python_server.py b/liminal/build/image/python_server/liminal_python_server.py
index 2099fd3..52708c6 100644
--- a/liminal/build/image/python_server/liminal_python_server.py
+++ b/liminal/build/image/python_server/liminal_python_server.py
@@ -17,7 +17,7 @@
# under the License.
import yaml
-from flask import Flask, request, Blueprint
+from flask import Blueprint, Flask, request
def __get_module(kls):
@@ -38,12 +38,10 @@ if __name__ == '__main__':
with open('service.yml') as stream:
config = yaml.safe_load(stream)
- endpoints = dict(
- [
- (endpoint_config['endpoint'][1:], __get_endpoint_function(endpoint_config))
- for endpoint_config in config['endpoints']
- ]
- )
+ endpoints = {
+ endpoint_config['endpoint'][1:]: __get_endpoint_function(endpoint_config)
+ for endpoint_config in config['endpoints']
+ }
blueprint = Blueprint('liminal_python_server_blueprint', __name__)
diff --git a/liminal/build/image/spark/Dockerfile b/liminal/build/image/spark/Dockerfile
index db93f5b..e691419 100644
--- a/liminal/build/image/spark/Dockerfile
+++ b/liminal/build/image/spark/Dockerfile
@@ -23,4 +23,4 @@ WORKDIR /app
COPY . /app/
-RUN {{mount}} pip install -r requirements.txt
\ No newline at end of file
+RUN {{mount}} pip install -r requirements.txt
diff --git a/liminal/build/liminal_apps_builder.py b/liminal/build/liminal_apps_builder.py
index 49ebf21..a31390f 100644
--- a/liminal/build/liminal_apps_builder.py
+++ b/liminal/build/liminal_apps_builder.py
@@ -21,7 +21,7 @@ import os
from liminal.build.image_builder import ImageBuilder
from liminal.core.config.config import ConfigUtil
-from liminal.core.util import files_util, class_util
+from liminal.core.util import class_util, files_util
def build_liminal_apps(path):
diff --git a/liminal/core/config/config.py b/liminal/core/config/config.py
index a559278..a233d18 100644
--- a/liminal/core/config/config.py
+++ b/liminal/core/config/config.py
@@ -22,8 +22,7 @@ import traceback
from liminal.core import environment
from liminal.core.config.defaults import base, default_configs
-from liminal.core.util import dict_util
-from liminal.core.util import files_util
+from liminal.core.util import dict_util, files_util
class ConfigUtil:
diff --git a/liminal/core/config/defaults/base/liminal.yml b/liminal/core/config/defaults/base/liminal.yml
index 41682a2..14b0982 100644
--- a/liminal/core/config/defaults/base/liminal.yml
+++ b/liminal/core/config/defaults/base/liminal.yml
@@ -1,4 +1,3 @@
-#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
@@ -15,6 +14,7 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+
---
name: base
type: super
@@ -42,4 +42,4 @@ pipeline_defaults:
type: job_start
after_tasks:
- task: end
- type: job_end
\ No newline at end of file
+ type: job_end
diff --git a/liminal/core/util/class_util.py b/liminal/core/util/class_util.py
index a34f4a2..98eba27 100644
--- a/liminal/core/util/class_util.py
+++ b/liminal/core/util/class_util.py
@@ -42,7 +42,7 @@ def find_subclasses_in_packages(packages, parent_class):
subclasses.add(child)
break
- return dict([(sc.__module__.split(".")[-1], sc) for sc in subclasses])
+ return {sc.__module__.split(".")[-1]: sc for sc in subclasses}
def import_module(package, recursive=True):
diff --git a/liminal/core/util/files_util.py b/liminal/core/util/files_util.py
index 798e468..8aead3e 100644
--- a/liminal/core/util/files_util.py
+++ b/liminal/core/util/files_util.py
@@ -45,7 +45,7 @@ def load(path):
config_entities = {}
for file_data in find_config_files(path):
- with open(file_data, 'r') as data:
+ with open(file_data) as data:
config_file = yaml.safe_load(data)
config_entities[config_file['name']] = config_file
cached_source_files[config_file['name']] = file_data
diff --git a/liminal/kubernetes/volume_util.py b/liminal/kubernetes/volume_util.py
index 18de4e9..d1e085a 100644
--- a/liminal/kubernetes/volume_util.py
+++ b/liminal/kubernetes/volume_util.py
@@ -32,7 +32,7 @@ except Exception:
sys.stdout.write(f"INFO: {msg}")
_LOG = logging.getLogger('volume_util')
-_LOCAL_VOLUMES = set([])
+_LOCAL_VOLUMES = set()
_kubernetes = client.CoreV1Api()
diff --git a/liminal/runners/airflow/dag/__init__.py b/liminal/runners/airflow/dag/__init__.py
index 8d028e2..3e6452b 100644
--- a/liminal/runners/airflow/dag/__init__.py
+++ b/liminal/runners/airflow/dag/__init__.py
@@ -16,6 +16,7 @@
# specific language governing permissions and limitations
# under the License.
import os
+
from liminal.core import environment as env
from liminal.runners.airflow.dag import liminal_register_dags
diff --git a/liminal/runners/airflow/dag/liminal_dags.py b/liminal/runners/airflow/dag/liminal_dags.py
index c89c9fe..8e728fc 100644
--- a/liminal/runners/airflow/dag/liminal_dags.py
+++ b/liminal/runners/airflow/dag/liminal_dags.py
@@ -15,10 +15,12 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
-import liminal.runners.airflow.dag as liminal
-from airflow import DAG
import traceback
+from airflow import DAG
+
+import liminal.runners.airflow.dag as liminal
+
pipelines = liminal.register_dags()
for pipeline, dag in pipelines:
diff --git a/liminal/runners/airflow/executors/kubernetes.py b/liminal/runners/airflow/executors/kubernetes.py
index ca386cb..14fddb2 100644
--- a/liminal/runners/airflow/executors/kubernetes.py
+++ b/liminal/runners/airflow/executors/kubernetes.py
@@ -21,8 +21,11 @@ import datetime
import logging
import os
-from airflow.providers.cncf.kubernetes.operators.kubernetes_pod import KubernetesPodOperator
-from kubernetes.client import models as k8s, V1Volume, V1VolumeMount
+from airflow.providers.cncf.kubernetes.operators.kubernetes_pod import (
+ KubernetesPodOperator,
+)
+from kubernetes.client import V1Volume, V1VolumeMount
+from kubernetes.client import models as k8s
from liminal.core.util import env_util
from liminal.runners.airflow.config.standalone_variable_backend import get_variable
diff --git a/liminal/runners/airflow/model/executor.py b/liminal/runners/airflow/model/executor.py
index 2af3a2d..b7f31ac 100644
--- a/liminal/runners/airflow/model/executor.py
+++ b/liminal/runners/airflow/model/executor.py
@@ -20,7 +20,9 @@ from abc import ABC, abstractmethod
from airflow.models import BaseOperator
-from liminal.runners.airflow.operators.operator_with_variable_resolving import OperatorWithVariableResolving
+from liminal.runners.airflow.operators.operator_with_variable_resolving import (
+ OperatorWithVariableResolving,
+)
def add_variables_to_operator(operator, task) -> BaseOperator:
diff --git a/liminal/runners/airflow/operators/cloudformation.py b/liminal/runners/airflow/operators/cloudformation.py
index b846ef0..8ea1e87 100644
--- a/liminal/runners/airflow/operators/cloudformation.py
+++ b/liminal/runners/airflow/operators/cloudformation.py
@@ -22,8 +22,8 @@ Can be removed when Airflow 2.0.0 is released.
"""
from typing import List
-from airflow.providers.amazon.aws.hooks.base_aws import AwsBaseHook
from airflow.models import BaseOperator
+from airflow.providers.amazon.aws.hooks.base_aws import AwsBaseHook
from airflow.sensors.base import BaseSensorOperator
from botocore.exceptions import ClientError
diff --git a/liminal/runners/airflow/operators/job_status_operator.py b/liminal/runners/airflow/operators/job_status_operator.py
index 60ecce9..b6cae53 100644
--- a/liminal/runners/airflow/operators/job_status_operator.py
+++ b/liminal/runners/airflow/operators/job_status_operator.py
@@ -48,7 +48,7 @@ class JobStatusOperator(BaseOperator):
for metric in self.metrics(context):
self.report_functions[backend](self, metric)
else:
- raise AirflowException('No such metrics backend: {}'.format(backend))
+ raise AirflowException(f'No such metrics backend: {backend}')
def metrics(self, context):
raise NotImplementedError
diff --git a/liminal/runners/airflow/tasks/containerable.py b/liminal/runners/airflow/tasks/containerable.py
index 46028e3..3a70fb3 100644
--- a/liminal/runners/airflow/tasks/containerable.py
+++ b/liminal/runners/airflow/tasks/containerable.py
@@ -87,4 +87,4 @@ class ContainerTask(task.Task, ABC):
if ENV not in env_vars:
env_vars[ENV] = env
- return dict([(k, str(v)) for k, v in env_vars.items()])
+ return {k: str(v) for k, v in env_vars.items()}
diff --git a/liminal/runners/airflow/tasks/create_cloudformation_stack.py b/liminal/runners/airflow/tasks/create_cloudformation_stack.py
index cbc457d..125947d 100644
--- a/liminal/runners/airflow/tasks/create_cloudformation_stack.py
+++ b/liminal/runners/airflow/tasks/create_cloudformation_stack.py
@@ -25,7 +25,9 @@ from liminal.runners.airflow.operators.cloudformation import (
CloudFormationCreateStackSensor,
CloudFormationHook,
)
-from liminal.runners.airflow.operators.operator_with_variable_resolving import OperatorWithVariableResolving
+from liminal.runners.airflow.operators.operator_with_variable_resolving import (
+ OperatorWithVariableResolving,
+)
from liminal.runners.airflow.tasks import airflow
diff --git a/liminal/runners/airflow/tasks/spark.py b/liminal/runners/airflow/tasks/spark.py
index d490bfd..77ff69a 100644
--- a/liminal/runners/airflow/tasks/spark.py
+++ b/liminal/runners/airflow/tasks/spark.py
@@ -20,7 +20,7 @@ from itertools import chain
from flatdict import FlatDict
-from liminal.runners.airflow.tasks import hadoop, containerable
+from liminal.runners.airflow.tasks import containerable, hadoop
class SparkTask(hadoop.HadoopTask, containerable.ContainerTask):
@@ -64,7 +64,7 @@ class SparkTask(hadoop.HadoopTask, containerable.ContainerTask):
source_code = self.task_config.get("application_source")
- for conf_arg in ['{}={}'.format(k, v) for (k, v) in FlatDict(self.task_config.get('conf', {})).items()]:
+ for conf_arg in [f'{k}={v}' for (k, v) in FlatDict(self.task_config.get('conf', {})).items()]:
flat_conf_args.append('--conf')
flat_conf_args.append(conf_arg)
diff --git a/scripts/docker-compose.yml b/scripts/docker-compose.yml
index 2098362..b987537 100644
--- a/scripts/docker-compose.yml
+++ b/scripts/docker-compose.yml
@@ -1,4 +1,3 @@
-#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
@@ -15,20 +14,19 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+
---
version: '3'
-x-airflow-common:
- &airflow-common
+x-airflow-common: &airflow-common
image: liminal-airflow
build:
context: .
dockerfile: scripts/Dockerfile-airflow
args:
- LIMINAL_VERSION: ${LIMINAL_VERSION}
- environment:
- &airflow-common-env
- LOAD_EX: 'n'
- AIRFLOW__CORE__EXECUTOR: 'LocalExecutor'
+ LIMINAL_VERSION: ${LIMINAL_VERSION}
+ environment: &airflow-common-env
+ LOAD_EX: n
+ AIRFLOW__CORE__EXECUTOR: LocalExecutor
KUBECONFIG: /home/airflow/kube/config
AIRFLOW__CORE__LOAD_EXAMPLES: 'False'
AIRFLOW__WEBSERVER__WORKERS: '1'
@@ -47,53 +45,53 @@ x-airflow-common:
postgres:
condition: service_healthy
healthcheck:
- test: ["CMD-SHELL", "[ -f /usr/local/airflow/airflow-webserver.pid ]"]
- interval: 30s
- timeout: 30s
- retries: 3
+ test: [CMD-SHELL, '[ -f /usr/local/airflow/airflow-webserver.pid ]']
+ interval: 30s
+ timeout: 30s
+ retries: 3
logging:
- options:
- max-size: 10m
- max-file: "3"
+ options:
+ max-size: 10m
+ max-file: '3'
restart: always
services:
- postgres:
- image: postgres:13
- container_name: liminal-postgress
- environment:
- POSTGRES_USER: airflow
- POSTGRES_PASSWORD: airflow
- POSTGRES_DB: ""
- ports:
- - "5432:5432"
- volumes:
- - ${LIMINAL_HOME}/db:/var/lib/postgresql/data
- logging:
- options:
- max-size: 10m
- max-file: "3"
- healthcheck:
- test: ["CMD", "pg_isready", "-U", "airflow"]
- interval: 30s
- timeout: 30s
- retries: 3
- restart: always
+ postgres:
+ image: postgres:13
+ container_name: liminal-postgress
+ environment:
+ POSTGRES_USER: airflow
+ POSTGRES_PASSWORD: airflow
+ POSTGRES_DB: ''
+ ports:
+ - 5432:5432
+ volumes:
+ - ${LIMINAL_HOME}/db:/var/lib/postgresql/data
+ logging:
+ options:
+ max-size: 10m
+ max-file: '3'
+ healthcheck:
+ test: [CMD, pg_isready, -U, airflow]
+ interval: 30s
+ timeout: 30s
+ retries: 3
+ restart: always
- webserver:
- <<: *airflow-common
- container_name: liminal-webserver
- environment:
- <<: *airflow-common-env
- ports:
- - "8080:8080"
- command: "webserver"
+ webserver:
+ <<: *airflow-common
+ container_name: liminal-webserver
+ environment:
+ <<: *airflow-common-env
+ ports:
+ - 8080:8080
+ command: webserver
- scheduler:
- <<: *airflow-common
- container_name: liminal-scheduler
- environment:
- <<: *airflow-common-env
- ports:
- - "8793:8793"
- command: "scheduler"
+ scheduler:
+ <<: *airflow-common
+ container_name: liminal-scheduler
+ environment:
+ <<: *airflow-common-env
+ ports:
+ - 8793:8793
+ command: scheduler
diff --git a/scripts/requirements-airflow.txt b/scripts/requirements-airflow.txt
index a9bf995..268e785 100644
--- a/scripts/requirements-airflow.txt
+++ b/scripts/requirements-airflow.txt
@@ -24,4 +24,4 @@ kubernetes
diskcache==3.1.1
flatdict==4.0.1
kafka-python==2.0.2
-influxdb-client
\ No newline at end of file
+influxdb-client
diff --git a/setup.py b/setup.py
index 11b0105..242c747 100644
--- a/setup.py
+++ b/setup.py
@@ -22,7 +22,7 @@ import os
import setuptools
-with open("README.md", "r") as fh:
+with open("README.md") as fh:
long_description = fh.read()
with open('requirements.txt') as f:
diff --git a/tests/liminal/kubernetes/test_volume_util.py b/tests/liminal/kubernetes/test_volume_util.py
index 36f6b8f..8e3a0d0 100644
--- a/tests/liminal/kubernetes/test_volume_util.py
+++ b/tests/liminal/kubernetes/test_volume_util.py
@@ -20,6 +20,7 @@ import sys
import unittest
from kubernetes import config
+
from liminal.kubernetes import volume_util
try:
diff --git a/tests/runners/airflow/build/http/python/test_python_server_image_builder.py b/tests/runners/airflow/build/http/python/test_python_server_image_builder.py
index c82ca01..78e9ad0 100644
--- a/tests/runners/airflow/build/http/python/test_python_server_image_builder.py
+++ b/tests/runners/airflow/build/http/python/test_python_server_image_builder.py
@@ -27,8 +27,8 @@ from unittest import TestCase
import docker
-from liminal.build.python import PythonImageVersions
from liminal.build.image.python_server.python_server import PythonServerImageBuilder
+from liminal.build.python import PythonImageVersions
IMAGE_NAME = 'liminal_server_image'
diff --git a/tests/runners/airflow/dag/test_liminal_dags.py b/tests/runners/airflow/dag/test_liminal_dags.py
index 4dcf7a6..bb320ff 100644
--- a/tests/runners/airflow/dag/test_liminal_dags.py
+++ b/tests/runners/airflow/dag/test_liminal_dags.py
@@ -22,7 +22,10 @@ from unittest import TestCase, mock
from liminal.core.config.config import ConfigUtil
from liminal.runners.airflow.dag import liminal_register_dags
-from liminal.runners.airflow.operators.job_status_operator import JobEndOperator, JobStartOperator
+from liminal.runners.airflow.operators.job_status_operator import (
+ JobEndOperator,
+ JobStartOperator,
+)
class Test(TestCase):
diff --git a/tests/runners/airflow/executors/test_emr.py b/tests/runners/airflow/executors/test_emr.py
index e530783..ac2ce1d 100644
--- a/tests/runners/airflow/executors/test_emr.py
+++ b/tests/runners/airflow/executors/test_emr.py
@@ -28,7 +28,9 @@ from moto import mock_emr
from liminal.runners.airflow import DummyDag
from liminal.runners.airflow.executors.emr import EMRExecutor
-from liminal.runners.airflow.operators.operator_with_variable_resolving import OperatorWithVariableResolving
+from liminal.runners.airflow.operators.operator_with_variable_resolving import (
+ OperatorWithVariableResolving,
+)
from liminal.runners.airflow.tasks import hadoop
from tests.util import dag_test_utils
diff --git a/tests/runners/airflow/liminal/liminal.yml b/tests/runners/airflow/liminal/liminal.yml
index 48a9907..f6e32c9 100644
--- a/tests/runners/airflow/liminal/liminal.yml
+++ b/tests/runners/airflow/liminal/liminal.yml
@@ -1,4 +1,3 @@
-#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
@@ -15,6 +14,7 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+
---
name: MyPipeline
volumes:
@@ -25,15 +25,15 @@ images:
- image: my_python_task_img
type: python
source: write_inputs
- no_cache: True
+ no_cache: true
- image: my_parallelized_python_task_img
type: python
source: write_outputs
- no_cache: True
+ no_cache: true
- image: my_server_image
type: python_server
source: myserver
- no_cache: True
+ no_cache: true
endpoints:
- endpoint: /myendpoint1
module: my_server
@@ -51,7 +51,7 @@ pipelines:
key2: val2
metrics:
namespace: TestNamespace
- backends: [ ]
+ backends: []
tasks:
- task: my_python_task
type: python
diff --git a/tests/runners/airflow/liminal/requirements.txt b/tests/runners/airflow/liminal/requirements.txt
index d41765d..2045d74 100644
--- a/tests/runners/airflow/liminal/requirements.txt
+++ b/tests/runners/airflow/liminal/requirements.txt
@@ -16,4 +16,4 @@
# specific language governing permissions and limitations
# under the License.
-pillow
\ No newline at end of file
+pillow
diff --git a/tests/runners/airflow/operators/test_operator_with_variable_resolving.py b/tests/runners/airflow/operators/test_operator_with_variable_resolving.py
index 1207feb..5acfd21 100644
--- a/tests/runners/airflow/operators/test_operator_with_variable_resolving.py
+++ b/tests/runners/airflow/operators/test_operator_with_variable_resolving.py
@@ -18,11 +18,13 @@
import os
from unittest import TestCase
-from unittest.mock import patch, MagicMock
+from unittest.mock import MagicMock, patch
from airflow.models import BaseOperator
-from liminal.runners.airflow.operators.operator_with_variable_resolving import OperatorWithVariableResolving
+from liminal.runners.airflow.operators.operator_with_variable_resolving import (
+ OperatorWithVariableResolving,
+)
class TestKubernetesPodOperatorWithAutoImage(TestCase):
@@ -165,7 +167,7 @@ class BaseTestOperator(BaseOperator):
class TestOperator(BaseTestOperator):
def __init__(self, *args, **kwargs):
- super(TestOperator, self).__init__(*args, **kwargs)
+ super().__init__(*args, **kwargs)
def execute(self, context):
return self.expected
diff --git a/tests/runners/airflow/tasks/test_create_cloudformation_stack.py b/tests/runners/airflow/tasks/test_create_cloudformation_stack.py
index 63557d9..ec638be 100644
--- a/tests/runners/airflow/tasks/test_create_cloudformation_stack.py
+++ b/tests/runners/airflow/tasks/test_create_cloudformation_stack.py
@@ -29,8 +29,12 @@ from liminal.runners.airflow.operators.cloudformation import (
CloudFormationCreateStackSensor,
CloudFormationHook,
)
-from liminal.runners.airflow.operators.operator_with_variable_resolving import OperatorWithVariableResolving
-from liminal.runners.airflow.tasks.create_cloudformation_stack import CreateCloudFormationStackTask
+from liminal.runners.airflow.operators.operator_with_variable_resolving import (
+ OperatorWithVariableResolving,
+)
+from liminal.runners.airflow.tasks.create_cloudformation_stack import (
+ CreateCloudFormationStackTask,
+)
from tests.util import dag_test_utils
diff --git a/tests/runners/airflow/tasks/test_delete_cloudformation_stack.py b/tests/runners/airflow/tasks/test_delete_cloudformation_stack.py
index 7594ff6..08b2978 100644
--- a/tests/runners/airflow/tasks/test_delete_cloudformation_stack.py
+++ b/tests/runners/airflow/tasks/test_delete_cloudformation_stack.py
@@ -29,8 +29,12 @@ from liminal.runners.airflow.operators.cloudformation import (
CloudFormationDeleteStackOperator,
CloudFormationDeleteStackSensor,
)
-from liminal.runners.airflow.operators.operator_with_variable_resolving import OperatorWithVariableResolving
-from liminal.runners.airflow.tasks.delete_cloudformation_stack import DeleteCloudFormationStackTask
+from liminal.runners.airflow.operators.operator_with_variable_resolving import (
+ OperatorWithVariableResolving,
+)
+from liminal.runners.airflow.tasks.delete_cloudformation_stack import (
+ DeleteCloudFormationStackTask,
+)
from tests.util import dag_test_utils
diff --git a/tests/runners/apps/test/liminal.yml b/tests/runners/apps/test/liminal.yml
index 217e5db..13a8339 100644
--- a/tests/runners/apps/test/liminal.yml
+++ b/tests/runners/apps/test/liminal.yml
@@ -1,4 +1,3 @@
-#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
diff --git a/tests/runners/apps/test_app/defaults/liminal.yml b/tests/runners/apps/test_app/defaults/liminal.yml
index ef4c3c5..b46431f 100644
--- a/tests/runners/apps/test_app/defaults/liminal.yml
+++ b/tests/runners/apps/test_app/defaults/liminal.yml
@@ -1,4 +1,3 @@
-#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
@@ -15,6 +14,7 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+
---
name: default_liminal
type: super
@@ -25,4 +25,4 @@ task_defaults:
env1: a
pipeline_defaults:
one: one
- two: twoww
\ No newline at end of file
+ two: twoww
diff --git a/tests/runners/apps/test_app/extra/liminal.yml b/tests/runners/apps/test_app/extra/liminal.yml
index 3bf8489..f5e287e 100644
--- a/tests/runners/apps/test_app/extra/liminal.yml
+++ b/tests/runners/apps/test_app/extra/liminal.yml
@@ -1,4 +1,3 @@
-#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
@@ -15,6 +14,7 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+
---
name: extra_liminal
type: super
@@ -28,11 +28,11 @@ images:
- image: my_static_input_task_image
type: python
source: helloworld
- no_cache: True
+ no_cache: true
- image: my_task_output_input_task_image
type: python
source: helloworld
- no_cache: True
+ no_cache: true
pipeline_defaults:
tasks:
- task: my_static_input_task
@@ -40,17 +40,17 @@ pipeline_defaults:
description: static input task
image: my_static_input_task_image
env_vars:
- env2: "b"
+ env2: b
cmd: python -u hello_world.py
- task: extenable
type: pipeline
description: optional sub tasks
- task: my_task_output_input_task
type: python
- no_cache: True
+ no_cache: true
description: task with input from other task's output
image: my_task_output_input_task_image
env_vars:
- env1: "c"
- env2: "b"
+ env1: c
+ env2: b
cmd: python -u hello_world.py
diff --git a/tests/runners/apps/test_app/liminal.yml b/tests/runners/apps/test_app/liminal.yml
index 5a63b0f..25aafbe 100644
--- a/tests/runners/apps/test_app/liminal.yml
+++ b/tests/runners/apps/test_app/liminal.yml
@@ -1,4 +1,3 @@
-#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
@@ -15,6 +14,7 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+
---
name: MyPipeline
super: extra_liminal
@@ -22,11 +22,11 @@ images:
- image: my_static_input_task_image
type: python
source: helloworld
- no_cache: True
+ no_cache: true
- image: my_server_image
type: python_server
source: myserver
- no_cache: True
+ no_cache: true
pipelines:
- pipeline: my_pipeline
owner: Bosco Albert Baracus
@@ -34,7 +34,7 @@ pipelines:
timeout_minutes: 45
schedule: 0 * 1 * *
default_arg_loaded: check
- default_array_loaded: [ 2, 3, 4 ]
+ default_array_loaded: [2, 3, 4]
default_object_loaded:
key1: val1
key2: val2
diff --git a/tests/runners/apps/test_spark_app/liminal.yml b/tests/runners/apps/test_spark_app/liminal.yml
index ff3071a..e285099 100644
--- a/tests/runners/apps/test_spark_app/liminal.yml
+++ b/tests/runners/apps/test_spark_app/liminal.yml
@@ -1,4 +1,3 @@
-#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
@@ -15,13 +14,14 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+
---
name: MyPipeline
images:
- image: my_spark_image
type: spark
source: wordcount
- no_cache: True
+ no_cache: true
pipelines:
- pipeline: my_pipeline
owner: Bosco Albert Baracus
@@ -36,4 +36,4 @@ pipelines:
executors: 2
application_source: wordcount.py
application_arguments:
- - "words.txt"
+ - words.txt
diff --git a/tests/runners/apps/test_spark_app/wordcount/wordcount.py b/tests/runners/apps/test_spark_app/wordcount/wordcount.py
index d678cfe..8829616 100644
--- a/tests/runners/apps/test_spark_app/wordcount/wordcount.py
+++ b/tests/runners/apps/test_spark_app/wordcount/wordcount.py
@@ -19,8 +19,8 @@
import sys
from operator import add
-from pyspark.sql import SparkSession
import yaml
+from pyspark.sql import SparkSession
if __name__ == "__main__":
if len(sys.argv) != 3:
@@ -35,7 +35,7 @@ if __name__ == "__main__":
for (word, count) in output:
print("%s: %i" % (word, count))
- print("writing the results to {}".format(sys.argv[2]))
+ print(f"writing the results to {sys.argv[2]}")
counts.toDF(["word", "count"]).coalesce(1).write.mode("overwrite").json(sys.argv[2])
spark.stop()
diff --git a/tests/runners/apps/test_spark_app/wordcount/words.txt b/tests/runners/apps/test_spark_app/wordcount/words.txt
index 0a4b90b..6b1300c 100644
--- a/tests/runners/apps/test_spark_app/wordcount/words.txt
+++ b/tests/runners/apps/test_spark_app/wordcount/words.txt
@@ -15,4 +15,4 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
-my first liminal spark task
\ No newline at end of file
+my first liminal spark task
diff --git a/tests/test_licenses.py b/tests/test_licenses.py
index b30194a..d5c597a 100644
--- a/tests/test_licenses.py
+++ b/tests/test_licenses.py
@@ -23,8 +23,18 @@ from unittest import TestCase
from termcolor import colored
EXCLUDED_EXTENSIONS = ['.gif', '.png', '.pyc', 'LICENSE', 'DISCLAIMER', 'DISCLAIMER-WIP', 'NOTICE', '.whl']
-EXCLUDED_DIRS = ['docs/build', 'build', 'dist', '.git', '.idea', 'venv', 'apache_liminal.egg-info']
-EXCLUDED_FILES = ['DISCLAIMER-WIP']
+EXCLUDED_DIRS = [
+ 'docs/build',
+ 'build',
+ 'dist',
+ '.git',
+ '.idea',
+ 'venv',
+ '.venv',
+ 'apache_liminal.egg-info',
+ '.pytest_cache',
+]
+EXCLUDED_FILES = ['DISCLAIMER-WIP', 'LICENSE.txt', '.autovenv']
PYTHON_LICENSE_HEADER = """
#
diff --git a/examples/spark-app-demo/k8s/archetype/liminal.yml b/yamllint-config.yml
similarity index 58%
copy from examples/spark-app-demo/k8s/archetype/liminal.yml
copy to yamllint-config.yml
index e863e5d..ea52231 100644
--- a/examples/spark-app-demo/k8s/archetype/liminal.yml
+++ b/yamllint-config.yml
@@ -1,4 +1,3 @@
-#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
@@ -15,30 +14,38 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+
---
-# superliminal for local development
-name: InfraSpark
-owner: Bosco Albert Baracus
-type: super
-executors:
- - executor: k8s
- type: kubernetes
-variables:
- output_root_dir: /mnt/gettingstartedvol
- input_root_dir: ''
-images:
- - image: my_spark_image
- source: .
- type: spark
- no_cache: True
-task_defaults:
- spark:
- executor: k8s
- image: my_spark_image
- executors: 2
- application_source: '{{application}}'
- mounts:
- - mount: mymount
- volume: gettingstartedvol
- path: /mnt/gettingstartedvol
+# https://yamllint.readthedocs.io/en/stable/
+extends: default
+
+locale: en_US.UTF-8
+
+yaml-files:
+ - '*.yaml'
+ - '*.yml'
+ - .yamllint
+rules:
+ line-length:
+ max: 110
+ # level: warning
+ brackets: enable
+ colons: enable
+ commas: enable
+ empty-lines: enable
+ empty-values: disable
+ key-duplicates: disable
+ hyphens: enable
+ key-ordering: disable
+ new-line-at-end-of-file: enable
+ new-lines: enable
+ # quoted-strings: disable
+ truthy:
+ level: warning
+ indentation:
+ spaces: 2
+ indent-sequences: true
+ignore: |
+ docs/
+ .asf.yaml