You are viewing a plain text version of this content. The canonical link for it is here.
Posted to github@arrow.apache.org by GitBox <gi...@apache.org> on 2022/10/14 02:48:38 UTC
[GitHub] [arrow] h928725721 opened a new issue, #14411: java parse data performance optimization
h928725721 opened a new issue, #14411:
URL: https://github.com/apache/arrow/issues/14411
First of all, thank you for your technical support
I have a question about data parsing,for example:
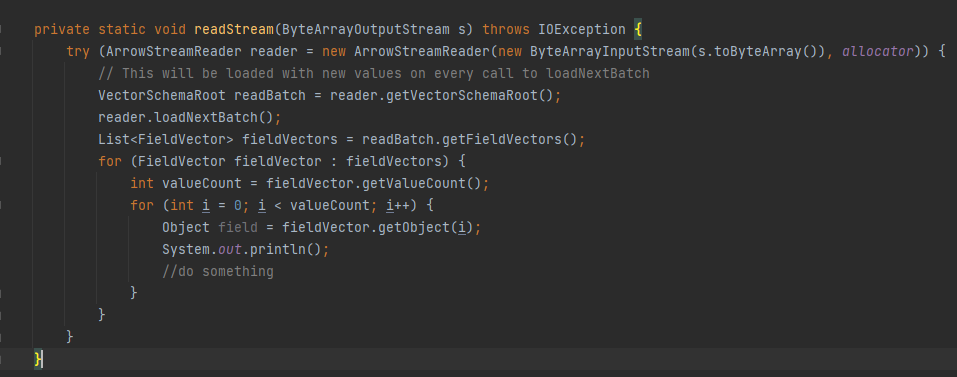
for (FieldVector fieldVector : fieldVectors) {
int valueCount = fieldVector.getValueCount();
for (int i = 0; i < valueCount; i++) {
}
}
Two for loops are required to parse the data,If there's a lot of data,The performance is very poor.
If there's a better way to parse the data which can help speed up parsing?
Looking forward to hearing from you,Thank you very much.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] h928725721 commented on issue #14411: java parse data performance optimization
Posted by GitBox <gi...@apache.org>.
h928725721 commented on issue #14411:
URL: https://github.com/apache/arrow/issues/14411#issuecomment-1280240597
`
@Slf4j
public class ValueVectorTest {
static BufferAllocator allocator = new RootAllocator();
public static void main(String[] args) {
getSchema();
}
@SneakyThrows
public static Schema getSchema() {
ByteArrayOutputStream out = writeStream();
readStream(out);
return null;
}
private static void readStream(ByteArrayOutputStream s) throws IOException {
try (ArrowStreamReader reader = new ArrowStreamReader(new ByteArrayInputStream(s.toByteArray()), allocator)) {
VectorSchemaRoot schemaRoot = reader.getVectorSchemaRoot();
reader.loadNextBatch();
List<FieldVector> fieldVectors = schemaRoot.getFieldVectors();
long start = System.currentTimeMillis();
fieldVectors.forEach(fieldVector -> {
long start1 = System.currentTimeMillis();
typeHandler(fieldVector);
long end1 = System.currentTimeMillis();
log.info("each time -------------------------> {}",end1 - start1);
});
long end = System.currentTimeMillis();
log.info("total time -------------------------> {}",end - start);
}
}
private static void typeHandler(FieldVector fieldVector) {
Types.MinorType minorType = fieldVector.getMinorType();
switch (minorType) {
case BIT:
BitVector b = (BitVector) fieldVector;
int bCount = b.getValueCount();
for (int i = 0; i < bCount; i++) {
Boolean i1 = b.getObject(i);
//do something
}
break;
case VARCHAR:
VarCharVector v = (VarCharVector) fieldVector;
int vCount = v.getValueCount();
for (int i = 0; i < vCount; i++) {
Text bytes = v.getObject(i);
//do something
}
break;
}
}
private static ByteArrayOutputStream writeStream() throws IOException {
BitVector bitVector = new BitVector("boolean", allocator);
VarCharVector varCharVector = new VarCharVector("varchar", allocator);
for (int i = 0; i < 100000000; i++) {
bitVector.setSafe(i, i % 2 == 0 ? 0 : 1);
varCharVector.setSafe(i, ("test" + i).getBytes(StandardCharsets.UTF_8));
}
bitVector.setValueCount(100000000);
varCharVector.setValueCount(100000000);
List<Field> fields = Arrays.asList(bitVector.getField(), varCharVector.getField());
List<FieldVector> vectors = Arrays.asList(bitVector, varCharVector);
VectorSchemaRoot root = new VectorSchemaRoot(fields, vectors);
ByteArrayOutputStream out = new ByteArrayOutputStream();
ArrowStreamWriter writer = new ArrowStreamWriter(root, /*DictionaryProvider=*/null, Channels.newChannel(out));
writer.start();
writer.writeBatch();
for (int i = 0; i < 4; i++) {
BitVector childVector1 = (BitVector) root.getVector(0);
VarCharVector childVector2 = (VarCharVector) root.getVector(1);
childVector1.reset();
childVector2.reset();
writer.writeBatch();
}
writer.end();
return out;
}
}
`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] h928725721 commented on issue #14411: java parse data performance optimization
Posted by GitBox <gi...@apache.org>.
h928725721 commented on issue #14411:
URL: https://github.com/apache/arrow/issues/14411#issuecomment-1281892659
Ok,I see
Thank you very much.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] h928725721 commented on issue #14411: java parse data performance optimization
Posted by GitBox <gi...@apache.org>.
h928725721 commented on issue #14411:
URL: https://github.com/apache/arrow/issues/14411#issuecomment-1280243677
The above is a simple example that I wrote.
In that example,I've written vectors of two categories with 100000000 pieces of data each ,It's going to loop 2X100000000 times,
And if I have ten vectors,then it will be loop 10X100000000 times.This is where I get confused.
So I want to konw how can I shorten the parsing time.
Thanks
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] lwhite1 commented on issue #14411: java parse data performance optimization
Posted by GitBox <gi...@apache.org>.
lwhite1 commented on issue #14411:
URL: https://github.com/apache/arrow/issues/14411#issuecomment-1279060711
It's hard to see what would make performance poor here. Could you provide more detail about what you are seeing.
One thing that will impact performance is using getObject() as opposed to get(). Again, it's hard to know what the impact of that will be without knowing the vector types, but you might find memory performance (and time performance also, if there's a lot of data), is improved by switching on vector type and using a reader that gets the value as a primitive. Getting objects every time can lead to a lot of GC overhead.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] lwhite1 commented on issue #14411: java parse data performance optimization
Posted by GitBox <gi...@apache.org>.
lwhite1 commented on issue #14411:
URL: https://github.com/apache/arrow/issues/14411#issuecomment-1280922513
All you can do is read the vectors in separate threads, which should speed things up considerably if you have enough cores available. Ultimately, there is no support in the Arrow java code for vectorizing the reads so if you want to read 100 million values you have to read 100 million values individually.
OTOH, what is "slow" depends on your requirements. I wouldn't expect it to take very long to read 100 million primitive values from memory.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] h928725721 closed issue #14411: java parse data performance optimization
Posted by GitBox <gi...@apache.org>.
h928725721 closed issue #14411: java parse data performance optimization
URL: https://github.com/apache/arrow/issues/14411
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org