You are viewing a plain text version of this content. The canonical link for it is here.
Posted to dev@zeppelin.apache.org by GitBox <gi...@apache.org> on 2021/07/09 09:59:57 UTC
[GitHub] [zeppelin] zjffdu opened a new pull request #4169: [ZEPPELIN-5454] Explain output should be in text format
zjffdu opened a new pull request #4169:
URL: https://github.com/apache/zeppelin/pull/4169
### What is this PR for?
Use text format instead of table format for the spark sql explain statement. Because the table format is not readable. See the following screenshot.
### What type of PR is it?
[Improvement ]
### Todos
* [ ] - Task
### What is the Jira issue?
* https://issues.apache.org/jira/browse/ZEPPELIN-5454
### How should this be tested?
* UT is added and Manually tested
### Screenshots (if appropriate)
Before

After

### Questions:
* Does the licenses files need update? No
* Is there breaking changes for older versions? No
* Does this needs documentation? No
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@zeppelin.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [zeppelin] zjffdu commented on a change in pull request #4169: [ZEPPELIN-5454] Explain output should be in text format
Posted by GitBox <gi...@apache.org>.
zjffdu commented on a change in pull request #4169:
URL: https://github.com/apache/zeppelin/pull/4169#discussion_r667613020
##########
File path: spark/spark1-shims/src/main/scala/org/apache/zeppelin/spark/Spark1Shims.java
##########
@@ -81,17 +82,28 @@ public String showDataFrame(Object obj, int maxResult, InterpreterContext contex
}
}
+ InterpreterResult.Type outputType = InterpreterResult.Type.TABLE;
+ String sql = context.getLocalProperties().get("sql");
+ if (StringUtils.isNotBlank(sql) && sql.trim().toLowerCase().startsWith("explain")) {
+ outputType = InterpreterResult.Type.TEXT;
+ }
+
StringBuilder msg = new StringBuilder();
- msg.append("\n%table ");
+ msg.append("\n%" + outputType.toString().toLowerCase() + " ");
Review comment:
I think JVM will optimize it via StringBuilder, I write in this way just for readability purpose.
https://stackoverflow.com/questions/1532461/stringbuilder-vs-string-concatenation-in-tostring-in-java
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@zeppelin.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [zeppelin] Reamer commented on a change in pull request #4169: [ZEPPELIN-5454] Explain output should be in text format
Posted by GitBox <gi...@apache.org>.
Reamer commented on a change in pull request #4169:
URL: https://github.com/apache/zeppelin/pull/4169#discussion_r667428363
##########
File path: spark/spark1-shims/src/main/scala/org/apache/zeppelin/spark/Spark1Shims.java
##########
@@ -81,17 +82,28 @@ public String showDataFrame(Object obj, int maxResult, InterpreterContext contex
}
}
+ InterpreterResult.Type outputType = InterpreterResult.Type.TABLE;
+ String sql = context.getLocalProperties().get("sql");
+ if (StringUtils.isNotBlank(sql) && sql.trim().toLowerCase().startsWith("explain")) {
+ outputType = InterpreterResult.Type.TEXT;
+ }
+
StringBuilder msg = new StringBuilder();
- msg.append("\n%table ");
+ msg.append("\n%" + outputType.toString().toLowerCase() + " ");
Review comment:
Use the StringBuilder to concatenate the string.
##########
File path: spark/spark3-shims/src/main/scala/org/apache/zeppelin/spark/Spark3Shims.java
##########
@@ -80,18 +82,28 @@ public String showDataFrame(Object obj, int maxResult, InterpreterContext contex
return "";
}
}
+ InterpreterResult.Type outputType = InterpreterResult.Type.TABLE;
+ String sql = context.getLocalProperties().get("sql");
+ if (StringUtils.isNotBlank(sql) && sql.trim().toLowerCase().startsWith("explain")) {
+ outputType = InterpreterResult.Type.TEXT;
+ }
StringBuilder msg = new StringBuilder();
- msg.append("%table ");
+ msg.append("\n%" + outputType.toString().toLowerCase() + " ");
Review comment:
Same as above.
##########
File path: spark/spark2-shims/src/main/scala/org/apache/zeppelin/spark/Spark2Shims.java
##########
@@ -81,17 +82,28 @@ public String showDataFrame(Object obj, int maxResult, InterpreterContext contex
}
}
+ InterpreterResult.Type outputType = InterpreterResult.Type.TABLE;
+ String sql = context.getLocalProperties().get("sql");
+ if (StringUtils.isNotBlank(sql) && sql.trim().toLowerCase().startsWith("explain")) {
+ outputType = InterpreterResult.Type.TEXT;
+ }
+
StringBuilder msg = new StringBuilder();
- msg.append("\n%table ");
+ msg.append("\n%" + outputType.toString().toLowerCase() + " ");
Review comment:
Same as above.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@zeppelin.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [zeppelin] Reamer commented on a change in pull request #4169: [ZEPPELIN-5454] Explain output should be in text format
Posted by GitBox <gi...@apache.org>.
Reamer commented on a change in pull request #4169:
URL: https://github.com/apache/zeppelin/pull/4169#discussion_r667951650
##########
File path: spark/spark1-shims/src/main/scala/org/apache/zeppelin/spark/Spark1Shims.java
##########
@@ -81,17 +82,28 @@ public String showDataFrame(Object obj, int maxResult, InterpreterContext contex
}
}
+ InterpreterResult.Type outputType = InterpreterResult.Type.TABLE;
+ String sql = context.getLocalProperties().get("sql");
+ if (StringUtils.isNotBlank(sql) && sql.trim().toLowerCase().startsWith("explain")) {
+ outputType = InterpreterResult.Type.TEXT;
+ }
+
StringBuilder msg = new StringBuilder();
- msg.append("\n%table ");
+ msg.append("\n%" + outputType.toString().toLowerCase() + " ");
Review comment:
You may be right, but I get the following suggestion in intellij when using StringBuilder and normal string concatenation.
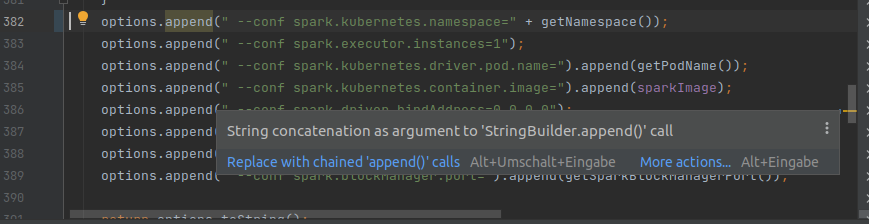
##########
File path: spark/spark1-shims/src/main/scala/org/apache/zeppelin/spark/Spark1Shims.java
##########
@@ -81,17 +82,28 @@ public String showDataFrame(Object obj, int maxResult, InterpreterContext contex
}
}
+ InterpreterResult.Type outputType = InterpreterResult.Type.TABLE;
+ String sql = context.getLocalProperties().get("sql");
+ if (StringUtils.isNotBlank(sql) && sql.trim().toLowerCase().startsWith("explain")) {
+ outputType = InterpreterResult.Type.TEXT;
+ }
+
StringBuilder msg = new StringBuilder();
- msg.append("\n%table ");
+ msg.append("\n%" + outputType.toString().toLowerCase() + " ");
Review comment:
I thought you were also using Intellij. Don't you get the comment in your IDE?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@zeppelin.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [zeppelin] zjffdu commented on a change in pull request #4169: [ZEPPELIN-5454] Explain output should be in text format
Posted by GitBox <gi...@apache.org>.
zjffdu commented on a change in pull request #4169:
URL: https://github.com/apache/zeppelin/pull/4169#discussion_r667966841
##########
File path: spark/spark1-shims/src/main/scala/org/apache/zeppelin/spark/Spark1Shims.java
##########
@@ -81,17 +82,28 @@ public String showDataFrame(Object obj, int maxResult, InterpreterContext contex
}
}
+ InterpreterResult.Type outputType = InterpreterResult.Type.TABLE;
+ String sql = context.getLocalProperties().get("sql");
+ if (StringUtils.isNotBlank(sql) && sql.trim().toLowerCase().startsWith("explain")) {
+ outputType = InterpreterResult.Type.TEXT;
+ }
+
StringBuilder msg = new StringBuilder();
- msg.append("\n%table ");
+ msg.append("\n%" + outputType.toString().toLowerCase() + " ");
Review comment:
I check the bytecode, jvm indeed do optimization here.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@zeppelin.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org