You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2020/10/14 10:05:22 UTC
[GitHub] [hudi] spyzzz opened a new issue #2175: [SUPPORT] HUDI MOR tuning with spark structured streamiung
spyzzz opened a new issue #2175:
URL: https://github.com/apache/hudi/issues/2175
Hello,
Quick explanation of the situation, i've multiples kafka topics (one for each table) containing CDC events sent by debezium.
I need to read in streaming thoses changes, and update corresponding table in HIVE (1.2).
Tables could be huge (200M+ events) but CDC are not very huge, lets says maximum few thousands per day per table.
so the first sync could be painful, but once its done, CDC could be pretty ''light''.
I first tried DeltaStream but i need to do specific operation, such as filtering data, converting date so i'd rather do it in custom spark code to get more flexibility.
I decided to use structured streaming to connect to all my topics (two choice here: one stream connected to severeals topics, or on stream per topic)
1 -> this solution need a groupby topic to be able to save data in corresponding table (not simple)
```
spark.readStream.format("kafka").options(xxxxx).option("subscribe","all-topics")
```
2 ->
This solution is easier to manage but its create lots of stream (more vcpu)
```
for (table <- tables ) {
spark.readStream.format("kafka").options(xxxxx).option("subscribe",table)
}
```
After this, i use writeStream in hudi format every 2min to write received data to corresponding table :
```
writeStream
.trigger(Trigger.ProcessingTime("120 seconds"))
.foreachBatch((df,id) => {
df.write.format("org.apache.hudi")
.options(HudiUtils.getHudiOptions(table))
.options(HudiUtils.getHiveSyncOptions(table.name))
.options(HudiUtils.getCompactionOptions)
.mode(SaveMode.Append)
.save(config.pathConf.outputPath + "/out/" + table.name )
})
.option("checkpointLocation",config.pathConf.outputPath + "/checkpoint/" + table.name)
.start()
```
Here are my configuration :
For HUDI :
```
Map(
TABLE_TYPE_OPT_KEY -> "COPY_ON_WRITE",
PRECOMBINE_FIELD_OPT_KEY -> "ts_ms",
RECORDKEY_FIELD_OPT_KEY -> table.pk,
OPERATION_OPT_KEY -> "upsert",
KEYGENERATOR_CLASS_OPT_KEY-> "org.apache.hudi.keygen.NonpartitionedKeyGenerator",
TABLE_NAME_OPT_KEY -> ("hudi_" + table.name),
"hoodie.table.name" -> ("hudi_" + table.name),
"hoodie.upsert.shuffle.parallelism" -> "2",
```
For Compaction :
```
Map(
"hoodie.compact.inline" -> "true",
"hoodie.compact.inline.max.delta.commits" -> "1",
"hoodie.cleaner.commits.retained" -> "1",
"hoodie.cleaner.fileversions.retained" -> "1",
"hoodie.clean.async" -> "false",
"hoodie.clean.automatic" ->"true",
"hoodie.parquet.compression.codec" -> "snappy"
)
```
For Spark :
```
.config("spark.executor.cores", "3")
.config("spark.executor.instances","5")
.config("spark.executor.memory", "2g")
.config("spark.rdd.compress","true")
.config("spark.shuffle.service.enabled","true")
.config("spark.sql.hive.convertMetastoreParquet","false")
.config("spark.kryoserializer.buffer.max","512m")
.config("spark.driver.memoryOverhead","1024")
.config("spark.executor.memoryOverhead","3072")
.config("spark.max.executor.failures","100")
```
**Expected behavior**
I tried this code with a unique topic with 24K records, and its takes more than 5min to write to HDFS.
with multiple topics its hangs and can be pretty long...


**Environment Description**
* Hudi version : 0.6.0
* Spark version : 2.4.6
* Hive version : 1.2
* Hadoop version : 2.7
* Storage (HDFS/S3/GCS..) : HDFS
* Running on Docker? (yes/no) : no
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz closed issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
spyzzz closed issue #2175:
URL: https://github.com/apache/hudi/issues/2175
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] naka13 edited a comment on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
naka13 edited a comment on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-709208973
One obvious bottleneck is the sequential processing. Since you are already creating multiple streams, you can increase concurrency using `spark.streaming.concurrentJobs`. You can set it as `sparkConf.set("spark.streaming.concurrentJobs", "4");` [Check this](https://stackoverflow.com/questions/34430636/spark-processing-multiple-kafka-topic-in-parallel)
On a side note, how are you handling deletes? Or you don't have deletes in your DB? Also, are you using a custom de-serializer for avro?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz commented on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
spyzzz commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-710000914
@naka13 Yes i'll, but i'd like to make something cleaner first. Yet its really Q&D.
Still, my avro deserialisation is take 80% of my spark time jobs ...
Dunno yet if there is a wait to make it faster ??
Not many information for structured streaming with confluent schema registry
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] naka13 commented on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
naka13 commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-709208973
One obvious bottleneck is the sequential processing. Since you are already creating multiple streams, you can increase concurrency using `spark.streaming.concurrentJobs`. You can set it as `sparkConf.set("spark.streaming.concurrentJobs", "4");`
On a side note, how are you handling deletes? Or you don't have deletes in your DB?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz edited a comment on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
spyzzz edited a comment on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-708505801
Actually i need around 5min to get 100K events from Kafka and write it to HDFS (5mo parquet file)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] parisni commented on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
parisni commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-925750020
thanks ! I am also considering [kafka-connect-hudi](https://github.com/apache/hudi/pull/3592) for this use case
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] parisni commented on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
parisni commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-924992418
@spyzzz you finally choosed to run one spark streaming per table instead of grouping all topics ?
```
for (table <- tables ) {
spark.readStream.format("kafka").options(xxxxx).option("subscribe",table)
}
```
and not
```
spark.readStream.format("kafka").options(xxxxx).option("subscribe","all-topics")
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz edited a comment on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
spyzzz edited a comment on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-709238060
@naka13 I'm already using spark.streaming.concurrentJobs with 5.
For delete i handle this by adding _hoodie_is_deleted when the field op = d (for delete) in debezium :
```
.withColumn("_hoodie_is_deleted",when(col("op") === 'd' , true).otherwise(false))
```
And for avro i'm using a schema registry yo deserialise data in flight
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] naka13 commented on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
naka13 commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-708992777
Do you think you could do the _"specific operation, such as filtering data, converting date"_ using SMTs in kafka connect? Then you could directly use multi table deltastreamer
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] naka13 edited a comment on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
naka13 edited a comment on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-709208973
One obvious bottleneck is the sequential processing. Since you are already creating multiple streams, you can increase concurrency using `spark.streaming.concurrentJobs`. You can set it as `sparkConf.set("spark.streaming.concurrentJobs", "4");` [Check this](https://stackoverflow.com/questions/34430636/spark-processing-multiple-kafka-topic-in-parallel)
On a side note, how are you handling deletes? Or you don't have deletes in your DB?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz edited a comment on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
spyzzz edited a comment on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-708505801
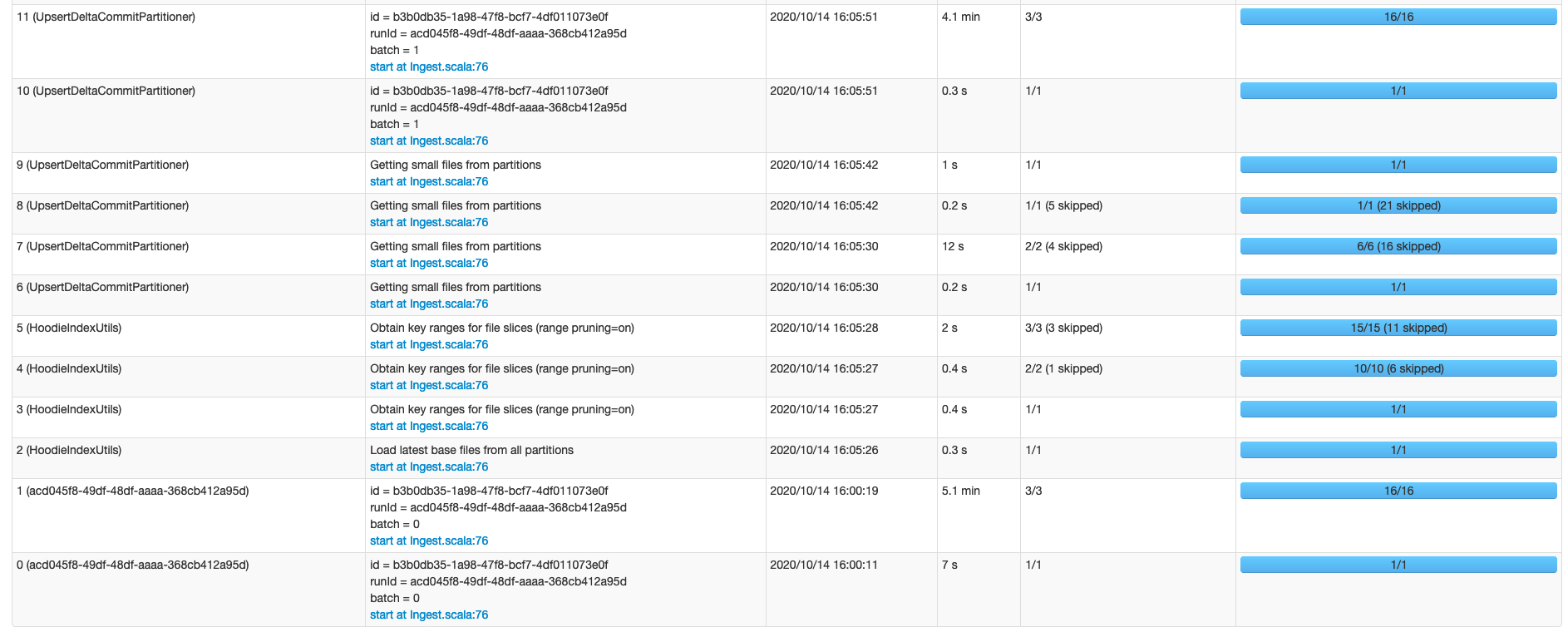
Actually i need around 5min to get 100K events from Kafka and write it to HDFS (5mo parquet file)

OUTPUT :

----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz edited a comment on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
spyzzz edited a comment on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-713434086
sorry for delay;
Here some tips about what i did :
```
val df = SparkUtils.getStream(sparkSession,config).option("subscribe", table.name).load()
val df2 = df
.withColumn("deser_value",Deserializer.deser(table.name,config.getRegistryProps)(col("value")))
.withColumn("parsed_value",from_json(col("deser_value"),sru.getLastestSchema(table.name).dataType))
val df_upsert = df2.select("parsed_value")
.select(
col("parsed_value.after.*"),
col("parsed_value.ts_ms"),
col("parsed_value.op"),
col("parsed_value.before."+table.pk).as("id_before")
)
.withColumn(table.pk,when(col("op") === 'd',col("id_before")).otherwise(col(table.pk))).drop("id_before")
.filter(col(table.pk).isNotNull)
.withColumn("_hoodie_is_deleted",when(col("op") === 'd' , true).otherwise(false))
df_upsert.writeStream
.trigger(Trigger.ProcessingTime("120 seconds"))
.foreachBatch((df,id) => {
df.write.format("org.apache.hudi")
.options(HudiUtils.getHudiOptions(table))
.options(HudiUtils.getHiveSyncOptions(table.name))
.options(HudiUtils.getCompactionOptions)
.mode(SaveMode.Append)
.save(config.pathConf.outputPath + "/out/" + table.name )
})
.option("checkpointLocation",config.pathConf.outputPath + "/checkpoint/" + table.name)
.start()
```
```
object HudiUtils {
def getHudiOptions(table:Table) : Map[String,String] ={
Map(
TABLE_TYPE_OPT_KEY -> "MERGE_ON_READ",
PRECOMBINE_FIELD_OPT_KEY -> "ts_ms",
RECORDKEY_FIELD_OPT_KEY -> table.pk,
OPERATION_OPT_KEY -> "upsert",
KEYGENERATOR_CLASS_OPT_KEY-> "org.apache.hudi.keygen.NonpartitionedKeyGenerator",
TABLE_NAME_OPT_KEY -> ("hudi_" + table.name),
"hoodie.table.name" -> ("hudi_" + table.name),
"hoodie.upsert.shuffle.parallelism"-> "6",
"hoodie.insert.shuffle.parallelism"-> "6",
"hoodie.bulkinsert.shuffle.parallelism"-> "6",
"hoodie.parquet.small.file.limit" -> "4194304"
)
}
def getCompactionOptions : Map[String,String] = {
Map(
"hoodie.compact.inline" -> "true",
"hoodie.compact.inline.max.delta.commits" -> "10",
"hoodie.cleaner.commits.retained" -> "10",
"hoodie.cleaner.fileversions.retained" -> "10",
"hoodie.keep.min.commits" -> "12",
"hoodie.keep.max.commits" -> "13"
//"hoodie.clean.async" -> "false",
//"hoodie.clean.automatic" ->"true",
//"hoodie.parquet.compression.codec" -> "snappy"
)
}
def getHiveSyncOptions(tableName:String) : Map[String,String] = {
Map(
HIVE_SYNC_ENABLED_OPT_KEY -> "true",
HIVE_USE_JDBC_OPT_KEY -> "false",
HIVE_DATABASE_OPT_KEY -> "raw_eu_hudi",
HIVE_URL_OPT_KEY -> "thrift://x",
HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY-> "org.apache.hudi.hive.NonPartitionedExtractor",
HIVE_TABLE_OPT_KEY -> tableName.split("\\.").drop(1).mkString("_")
)
}
}
```
```
object Deserializer extends Serializable {
def deser(topic:String,props:Map[String,String]) = udf((input: Array[Byte]) => deserializeMessage(props,topic,input))
val valueDeserializer = new KafkaAvroDeserializer()
private def deserializeMessage(props:Map[String,String],topic:String,input: Array[Byte]): String = {
try {
valueDeserializer.configure(props.asJava,false)
valueDeserializer.deserialize(topic, input).asInstanceOf[GenericRecord].toString
} catch {
case e: Exception => {
e.printStackTrace()
null
}
}
}
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] naka13 commented on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
naka13 commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-709882868
@spyzzz Would it be possible for you to share the complete code? It'll be really helpful for others
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz commented on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
spyzzz commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-709876261
After some deep research i finally found something. I first try to do only a read and write without any transformation and its was way faster (around 500K in 30s) so i tried step by step to find what was the bottleneck and in fact it was my avro deserialisation :
```
xxx.readStream.selectExpr("deserialize(value) as message")
```
So i manage to find a better solution to deserialise avro message with io confluent schema registry
```
xxx.readStream.select(from_avro(col("value"), schema))
```
And now i can read and write 500K messages in HUDI in 1.5min. That's way better ...
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz commented on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
spyzzz commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-708998405
Actually Deltasteamer can't handle key in avro desirialiser that's why i wasnt able to test it.
Its hardcoded (String Deserializer) for KEY and Avro for value.
In my case both are serialized in avro
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz commented on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
spyzzz commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-925079262
Hello @parisni ,
Yes , I havent worked on this poc since a while but i was still using a stream per table because I had really specific treament on each. And its really not easy to handle with a group topics.
didn't tested hudi v0.7 or v0.8 or v0.9
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz commented on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
spyzzz commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-713434086
sorry for delay;
Here some tips about what i did :
```
val df = SparkUtils.getStream(sparkSession,config).option("subscribe", table.name).load()
val df2 = df
.withColumn("deser_value",Deserializer.deser(table.name,config.getRegistryProps)(col("value")))
.withColumn("parsed_value",from_json(col("deser_value"),sru.getLastestSchema(table.name).dataType))
val df_upsert = df2.select("parsed_value")
.select(
col("parsed_value.after.*"),
col("parsed_value.ts_ms"),
col("parsed_value.op"),
col("parsed_value.before."+table.pk).as("id_before")
)
.withColumn(table.pk,when(col("op") === 'd',col("id_before")).otherwise(col(table.pk))).drop("id_before")
.filter(col(table.pk).isNotNull)
.withColumn("_hoodie_is_deleted",when(col("op") === 'd' , true).otherwise(false))
df_upsert.writeStream
.trigger(Trigger.ProcessingTime("120 seconds"))
.foreachBatch((df,id) => {
df.write.format("org.apache.hudi")
.options(HudiUtils.getHudiOptions(table))
.options(HudiUtils.getHiveSyncOptions(table.name))
.options(HudiUtils.getCompactionOptions)
.mode(SaveMode.Append)
.save(config.pathConf.outputPath + "/out/" + table.name )
})
.option("checkpointLocation",config.pathConf.outputPath + "/checkpoint/" + table.name)
.start()
```
```
object HudiUtils {
def getHudiOptions(table:Table) : Map[String,String] ={
Map(
TABLE_TYPE_OPT_KEY -> "MERGE_ON_READ",
PRECOMBINE_FIELD_OPT_KEY -> "ts_ms",
RECORDKEY_FIELD_OPT_KEY -> table.pk,
OPERATION_OPT_KEY -> "upsert",
KEYGENERATOR_CLASS_OPT_KEY-> "org.apache.hudi.keygen.NonpartitionedKeyGenerator",
TABLE_NAME_OPT_KEY -> ("hudi_" + table.name),
"hoodie.table.name" -> ("hudi_" + table.name),
"hoodie.upsert.shuffle.parallelism"-> "6",
"hoodie.insert.shuffle.parallelism"-> "6",
"hoodie.bulkinsert.shuffle.parallelism"-> "6",
"hoodie.parquet.small.file.limit" -> "4194304"
)
}
def getCompactionOptions : Map[String,String] = {
Map(
"hoodie.compact.inline" -> "true",
"hoodie.compact.inline.max.delta.commits" -> "10",
"hoodie.cleaner.commits.retained" -> "10",
"hoodie.cleaner.fileversions.retained" -> "10",
"hoodie.keep.min.commits" -> "12",
"hoodie.keep.max.commits" -> "13"
//"hoodie.clean.async" -> "false",
//"hoodie.clean.automatic" ->"true",
//"hoodie.parquet.compression.codec" -> "snappy"
)
}
def getHiveSyncOptions(tableName:String) : Map[String,String] = {
Map(
HIVE_SYNC_ENABLED_OPT_KEY -> "true",
HIVE_USE_JDBC_OPT_KEY -> "false",
HIVE_DATABASE_OPT_KEY -> "raw_eu_hudi",
HIVE_URL_OPT_KEY -> "thrift://ovh-mnode1.26f5de01-5e40-4d8a-98bd-a4353b7bf5e3.datalake.ovh:9083",
HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY-> "org.apache.hudi.hive.NonPartitionedExtractor",
HIVE_TABLE_OPT_KEY -> tableName.split("\\.").drop(1).mkString("_")
)
}
}
```
```
object Deserializer extends Serializable {
def deser(topic:String,props:Map[String,String]) = udf((input: Array[Byte]) => deserializeMessage(props,topic,input))
val valueDeserializer = new KafkaAvroDeserializer()
private def deserializeMessage(props:Map[String,String],topic:String,input: Array[Byte]): String = {
try {
valueDeserializer.configure(props.asJava,false)
valueDeserializer.deserialize(topic, input).asInstanceOf[GenericRecord].toString
} catch {
case e: Exception => {
e.printStackTrace()
null
}
}
}
}
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz commented on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
spyzzz commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-708505801
Actually i need around 5min to get 100K events from Kafka and write it to HDFS (5mo parquet file)
![Uploading Capture d’écran 2020-10-14 à 18.10.43.png…]()
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz commented on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
spyzzz commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-709293656
I seems that the pulling from kafka is veryyyy slow ...
```
20/10/15 12:33:48 INFO memory.MemoryStore: Block broadcast_17 stored as values in memory (estimated size 29.4 KB, free 3.0 GB)
20/10/15 12:33:49 INFO consumer.KafkaConsumer: [Consumer clientId=consumer-spark-kafka-source-6d40b7a1-e6f9-4f86-95c3-3f875be5984f-1049685671-executor-1, groupId=spark-kafka-source-6d40b7a1-e6f9-4f86-95c3-3f875be5984f-1049685671-executor] Seeking to offset 16750 for partition xxx
20/10/15 12:33:53 INFO consumer.KafkaConsumer: [Consumer clientId=consumer-spark-kafka-source-6d40b7a1-e6f9-4f86-95c3-3f875be5984f-1049685671-executor-1, groupId=spark-kafka-source-6d40b7a1-e6f9-4f86-95c3-3f875be5984f-1049685671-executor] Seeking to offset 17250 for partition xxx
20/10/15 12:33:57 INFO consumer.KafkaConsumer: [Consumer clientId=consumer-spark-kafka-source-6d40b7a1-e6f9-4f86-95c3-3f875be5984f-1049685671-executor-1, groupId=spark-kafka-source-6d40b7a1-e6f9-4f86-95c3-3f875be5984f-1049685671-executor] Seeking to offset 17750 for partition xxx
20/10/15 12:34:01 INFO consumer.KafkaConsumer: [Consumer clientId=consumer-spark-kafka-source-6d40b7a1-e6f9-4f86-95c3-3f875be5984f-1049685671-executor-1, groupId=spark-kafka-source-6d40b7a1-e6f9-4f86-95c3-3f875be5984f-1049685671-executor] Seeking to offset 18250 for partition xxx
20/10/15 12:34:06 INFO consumer.KafkaConsumer: [Consumer clientId=consumer-spark-kafka-source-6d40b7a1-e6f9-4f86-95c3-3f875be5984f-1049685671-executor-1, groupId=spark-kafka-source-6d40b7a1-e6f9-4f86-95c3-3f875be5984f-1049685671-executor] Seeking to offset 18750 for partition xxx
20/10/15 12:34:10 INFO consumer.KafkaConsumer: [Consumer clientId=consumer-spark-kafka-source-6d40b7a1-e6f9-4f86-95c3-3f875be5984f-1049685671-executor-1, groupId=spark-kafka-source-6d40b7a1-e6f9-4f86-95c3-3f875be5984f-1049685671-executor] Seeking to offset 19250 for partition xxx
```
Only 500 messages per 5/10s :s
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz commented on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
spyzzz commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-709238060
@naka13 I'm already using spark.streaming.concurrentJobs with 5.
For delete i handle this by adding _hoodie_is_deleted when the field op = d (for delete) in debezium :
```
.withColumn("_hoodie_is_deleted",when(col("op") === 'd' , true).otherwise(false))
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz commented on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
spyzzz commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-713435043
i'm able now to read around 500K message per sec. I need to optimise the hudi write part now. I'll open a new issue for that.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #2175: [SUPPORT] HUDI MOR/COW tuning with spark structured streaming
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-709445492
Yeah, I think this is a bottleneck. Is this a setup issue (are they located across dcs) ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org